
SEALM: Semantically Enriched Attributes with Language Models for
Linkage Recommendation
Leonard Traeger
1,2 a
, Andreas Behrend
2
and George Karabatis
1 b
1
Department of Information Systems, University of Maryland, Baltimore County, U.S.A.
2
Institute of Computer and Communication Technology (ICCT), Technical University of Cologne, Germany
Keywords:
Database Integration, Schema Matching, Language Models, Semantic Enrichment.
Abstract:
Matching attributes from different repositories is an important step in the process of schema integration to con-
solidate heterogeneous data silos. In order to recommend linkages between relevant attributes, a contextually
rich representation of each attribute is quite essential, particularly when more than two database schemas are
to be integrated. This paper introduces the SEALM approach to generate a data catalog of semantically rich at-
tribute descriptions using Generative Language Models based on a new technique that employs six variations
of available metadata information. Instead of using raw attribute metadata, we generate SEALM descrip-
tions, which are used to recommend linkages with an unsupervised matching pipeline that involves a novel
multi-source Blocking algorithm. Experiments on multiple schemas yield a 5% to 20% recall improvement
in recommending linkages with SEALM-based attribute descriptions generated by the tiniest Llama3.1:8B
model compared to existing techniques. With SEALM, we only need to process the small fraction of attributes
to be integrated rather than exhaustively inspecting all combinations of potential linkages.
1 INTRODUCTION
Schema Matching is a core discipline in data man-
agement, especially when dealing with integration
tasks. Matching multiple and heterogeneous rela-
tional database schemas requires finding the semantic
linkages between the different tables and attributes in
order to query the respective records in an integrated
view, which is an important pre-processing step for
multi-source data search, query transformations, and
data fusion (Bleiholder and Naumann, 2009). Auto-
matically identifying true linkages in the large search
space of candidates is a challenging task, particularly
with more than two schemas (Saeedi et al., 2021).
Consequently, the more schemas need to be integrated
(volume), the more critical the context and represen-
tation of the tables and attributes becomes (veracity).
Motivating Example. If two attributes represent the
same semantic concept, they should be linked to-
gether since their signatures (numerical embeddings
representing the attributes) are similar. Therefore,
when computing the similarities among all potential
pairs of attribute signatures, the linkages with the
highest similarity score (lowest distance) are consid-
a
https://orcid.org/0009-0000-3039-0685
b
https://orcid.org/0000-0002-2208-0801
ered to be the true ones. We provide an example
in Figure 1 with attributes a
k
i
from three different
schemas k: 1 (red), 2 (yellow), and 3 (green) and
their signatures. On the left side of the figure, the
linkages of the attribute signatures that are based on
the shortest distances are inaccurate. The reason for
these mismatches is that textual attributes contain-
ing domain-specific abbreviations (e.g., CUST abbre-
viates CUSTOMER in schema 2) do not result in a mean-
ingful signature that represents the attribute. Cur-
rently, existing approaches use the textual descrip-
tors “as-is” to generate signatures of schema ele-
ments for linkage generation (Cappuzzo et al., 2020)
(Zeakis et al., 2023) (Peeters and Bizer, 2023) which
makes the encoding to link attributes that are seman-
tically dissimilar. Therefore, we need a solution to
this problem as meaningful attribute representations
containing relevant context are fundamental for ac-
curate linkages towards data integration (Papadakis
et al., 2020) (Zeng et al., 2024). For example, the
attributes OFFICE_CITY and CUST_CITY are textually
similar and may both contain the concept CITY, but
they should not be linked together because they have
different semantics (OFFICE ̸= CUST), as shown in
Figure 1. Therefore, name-based attribute representa-
tions are insufficient for accurate linkages. Therefore,
Traeger, L., Behrend, A. and Karabatis, G.
SEALM: Semantically Enriched Attributes with Language Models for Linkage Recommendation.
DOI: 10.5220/0013217700003929
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 1, pages 39-50
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
39
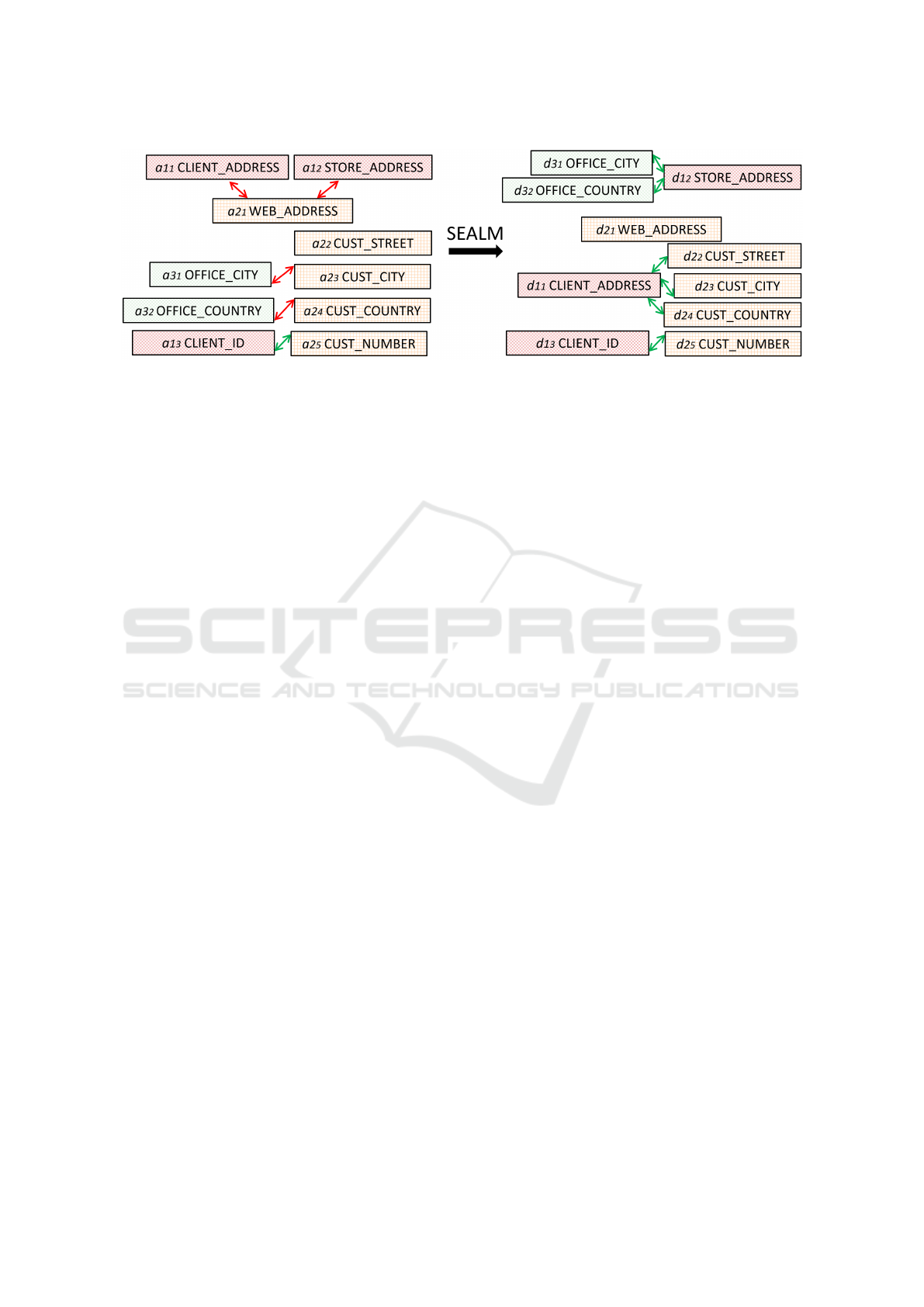
Figure 1: Attribute Signatures placed in a Metric Space with Linkages before and after SEALM based on OC3-HR Schemas.
they must be enriched with context through available
metadata such as table names, datatypes, constraints,
samples of cell values, domain names, or an expert
description in order to recommend relevant linkages.
Additionally, existing approaches explore the full
search space of linkage candidates (Narayan et al.,
2022) (Peeters and Bizer, 2023) (Remadi et al., 2024)
in an attempt to link source-to-target entities between
two databases (Zezhou Huang et al., 2024) (Sheetrit
et al., 2024). Motivated by the need for mean-
ingful representations of database entities for multi-
ple schemas, we introduce Semantic Enrichment of
Attributes using Language Models, an approach to
generate effective representations and efficient link-
ages among them. With SEALM, the attributes are
represented using semantically rich descriptions d
k
i
resulting in corresponding signatures that are more
precise, leading to true/accurate linkages as shown on
the right-hand side in Figure 1. This is achieved with
the help of Generative Language Models, which en-
rich the description of attributes and lead to higher
similarity scores between the relevant linkages (green
versus red arrow links). This paper addresses the
problem of discovering true linkages between at-
tributes, and its contributions are:
• Defining a scheme of incremental enhancements
on attribute signature quality based on metadata
information that is available, which varies from
little to full access (Section 3.2).
• Introducing SEALM, a method to generate effec-
tive attribute descriptions for relational database
schema catalogs (Section 3.3).
• Utilizing Blocking in a novel approach that
efficiently generates attribute linkages between
multi-source database schemas (Section 3.4).
• Evaluating the efficiency of SEALM descriptions
and the effectiveness of linkage recommendation
between the “OC3-HR” schemas (Section 4).
2 RELATED WORK
Database Enrichment dates back to (Castellanos and
Saltor, 1991) converting relational schemas into an
expressive object-oriented model that reflects inclu-
sion and exclusion dependencies of database enti-
ties to minimize interaction with a user towards in-
teroperability between multiple and heterogeneous
databases. Similarly, (Abdelsalam Maatuk et al.,
2010) propose to generate an enhanced Relational
Schema Representation (RSR) transposed into a
model that captures the essential database character-
istics suitable for migration. In our previous work,
we introduced Inteplato, an unsupervised linkage ap-
proach that links similar tables and attributes among
different schemas. To boost the linkage accuracy,
we enriched the database schemas by retrieving syn-
onyms for table and attribute names to overcome the
semantic ambiguity of naming choices by database
designers (Traeger et al., 2022).
With the recent advances in Language Models,
(Fernandez et al., 2023) and (Halevy and Dwivedi-Yu,
2023) envision more automation on data integration
as Language Models provide a new paradigm to chal-
lenge the underlying syntactical and semantic hetero-
geneities of data repositories. In the past, research on
Entity Resolution and Schema Matching had already
used encoder-based Language Models to create em-
beddings (signature) of schema elements or records
that can be used in supervised (Loster et al., 2021)
(Zeakis et al., 2023) and unsupervised (Cappuzzo
et al., 2020), (H
¨
attasch et al., 2022), (Zeng et al.,
2024) linkage approaches, all with the limitation of
using the data input “as-is”. In more recent work,
(Narayan et al., 2022), (Peeters and Bizer, 2023),
and (Remadi et al., 2024) delegate the pair-wise link-
age task between two databases to Generative Lan-
guage Models (GLM) via prompting all potential
pairs as a binary classification task. (Sheetrit et al.,
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
40

2024) use encoder-based Language Models to gener-
ate table and attribute signatures of source and tar-
get databases filtered on top linkage candidates sub-
sequently classified by ChatGPT. The previous work
that involved GLMs were able to effectively classify
linkages. However, in this paper we show that a more
efficient linkage candidate selection is needed to pro-
vide a scalable solution for multi-source database in-
tegration while still being able to use the language
synthesis capabilities of GLMs. In this context, (Mi-
hindukulasooriya et al., 2023) and (Zezhou Huang
et al., 2024) enrich the source database to a target
database or to a business glossary by generating “de-
scriptive table captions, tags, expanded column names
that can be mapped to concepts” with a GLM. In con-
trast, our approach systematically matches more than
two database schemas without a target schema given.
Recently, (Vogel et al., 2024) collected a corpus of
100,000 real-world databases dubbed “WikiDBs” and
renamed tables and attributes using GPT-4o to pro-
vide more context. With SEALM, we generate at-
tribute descriptions at different metadata availability
conditions and adapt algorithms that generate link-
ages between multiple (more than two) databases
without a given target ontology or schema (target-
free), or pre-annotated linkages (unsupervised), re-
flecting a real-world schema integration setting.
3 METHODOLOGY
We first define the problem of attribute linkages (Sec-
tion 3.1) and then define a scheme of information
availability of the attribute metadata that varies from
little to full access (Section 3.2). Afterwards, we
present our novel approach to Semantically Enrich
Attributes from relational database schemas with
Language Models to generate a data catalog with
meaningful textual description (Section 3.3). We con-
tinue to generate attribute linkages between schemas
by generating signatures, a novel multi-source Block-
ing algorithm, and Filtering (Section 3.4). We assume
a schema-aware, multi-source, target-free, and unsu-
pervised linkage environment. Table 1 provides an
overview of the notations used in this section.
3.1 Problem Definition
Attribute Linkages. We are given k database schemas
S
1
,S
2
,...,S
k
that each contains a heterogeneous set of
attributes S
k
= {a
k
1
,a
k
2
,...,a
k
i
}. The goal is to find
all linkages L(S) = {(a
k
i
,a
m
j
)} between the attributes
within the attribute collection of all schemas S = S
1
∪
S
2
∪...∪S
k
. The true set of attribute linkages contains
the attribute pairs that are congruent (a
k
i
∼
=
a
m
j
) ⇒ r
by representing a real-world concept with sub-typed
or identical semantics.
Given the set of attributes in Figure 1 for example,
the attributes a
1
3
CLIENT_ID and a
2
5
CUST_NUMBER
are identical, while a
1
1
CLIENT_ADDRESS are sub-
typed to a
2
2
CUST_STREET and a
2
3
CUST_CITY be-
cause the latter two contain partial semantics of a
1
1
.
In this paper, for simplicity we identify linkages
between attributes. For data integration based on
the Local-as-View paradigm, additional SQL-based
transformations are required to generate table link-
ages between schemas and joins within the schemas
(Bleiholder and Naumann, 2009). Although SEALM
is a general approach that can also be applied to gener-
ate linkages between tables, we leave these extensions
for future work.
Table 1: Notations.
Symbol Description
S
k
= {a
k
1
,a
k
2
,...,a
k
i
} Attributes in schema k.
a
k
i
= (n
k
i
,tn
k
i
,dc
k
i
,cv
k
i
,sn
k
i
)
Attribute and object-values (name, table name, data
type and constraint, record cell values, schema name).
LM(a
k
i
,c) ⇒ d
c
k
i
SEALM description where c represents the
condition on attribute metadata availability.
S = S
1
∪ S
2
∪ . . . ∪ S
k
for k schemas Attribute collection from all schemas.
E({d
c
k
i
= LM(a
k
i
,c)|∀a
k
i
∈ S}) ⇒ AS
c
= {⃗v
1
1
,...,⃗v
k
i
}
Attribute signature set conditioned on c
with |⃗v
k
i
| based on encoder E.
B(AS
c
,n) ⇒ BL = {(⃗v
k
i
,⃗v
m
j
)} where k ̸= m Blocking n linkage candidates for each attribute.
F(BL,k) ⇒ FL = {(⃗v
k
i
,⃗v
m
j
,s)} where s is similarity Filtering top-k similarity score linkages.
(a
k
i
∼
=
a
m
j
) ⇒ r where k ̸= m
Two congruent attributes representing a real-
world concept with sub-typed or identical semantic.
L(S) = {(a
k
i
,a
m
j
)} where (a
k
i
∼
=
a
m
j
) ⇒ r ∧ k ̸= m All true attribute linkages between schemas.
SEALM: Semantically Enriched Attributes with Language Models for Linkage Recommendation
41

3.2 Metadata Availability on Attributes
We define an attribute as a
k
i
containing the object val-
ues on the attribute name n
k
i
, table name tn
k
i
, data
type with relational constraints (if one exists) dc
k
i
, a
sample of maximum five cell values cv
k
i
, and schema
name sn
k
i
. Having full access to metadata within
a database environment is a desirable condition for
comprehensive data management. However, full ac-
cess to schema metadata is often impractical due to
security and operational risks. We can see this in (Mi-
hindukulasooriya et al., 2023) who observe that “most
organizations only permit semantic enrichment pro-
cesses to access to the table metadata such as column
headers and not actual data (i.e., cell values) due to
privacy and access control regulations”. Furthermore,
not all metadata information might be available, ade-
quately defined, or helpful for linkage recommenda-
tion tasks. Motivated by these observations, we create
a scheme with six conditions C = (c
1
,c
2
,c
3
,c
4
,c
5
,c
6
)
to represent different types or conditions, of available
metadata on attributes, as shown in Table 2.
• c
1
= (n
k
i
,tn
k
i
): represents a condition with min-
imal metadata information exposing only the at-
tribute name n
k
i
, and the table name tn
k
i
, e.g.,
a
c
1
2
3
= “CITY CUSTOMERS”. At this stage,
types, constraints, and data are not disclosed, lim-
iting tasks to schema maintenance and auditing.
• c
2
= (n
k
i
,tn
k
i
,dc
k
i
): extends c
1
by exposing data
types and constraints dc
k
i
of attributes, e.g., a
c
2
2
3
=
“CITY CUSTOMERS STRING”. The data con-
tent is still protected but generally less secure as
structural constraints relevant to data integrity are
revealed.
• c
3
= (n
k
i
,tn
k
i
,dc
k
i
,cv
k
i
): extends c
2
by exposing
the cell values cv
k
i
of attributes, e.g., a
c
3
2
3
= “CITY
CUSTOMERS STRING [Strasbourg, ..., Koeln]”.
This condition necessitates access control mecha-
nisms to prevent unauthorized data exposure.
• c
4
= (n
k
i
,tn
k
i
,sn
k
i
): extends c
1
basic struc-
tural metadata by revealing the schema context
sn
k
i
, e.g., a
c
4
2
3
= “CITY CUSTOMERS Order-
Customers”. This condition allows for high-level
schema documentation without data exposure.
• c
5
= (n
k
i
,tn
k
i
,cv
k
i
,sn
k
i
): represents a unique con-
dition with all available metadata except the data
type and constraints dc
k
i
of the attributes of-
ten found in Data Lakes, e.g., a
c
5
2
3
= “CITY
CUSTOMERS [Strasbourg, ..., Koeln] Order-
Customers”. Data Lakes do not enforce schema
constraints in order to handle large amounts of
data in a flexible manner.
• c
6
= (n
k
i
,tn
k
i
,dc
k
i
,cv
k
i
,sn
k
i
): represents highly
usable and least secure access to all attribute meta-
data, e.g., a
c
6
2
3
= “CITY CUSTOMERS STRING
[Strasbourg, ..., Koeln] Order-Customers”.
3.3 SEALM
Trying to solve this problem by directly prompting
a Generative Language Model to match all potential
attribute linkage candidates (e.g., “Do the attributes
‘CITY’ and ‘ADDRESS’ represent the same concept?
Answer with ‘yes’ if they do and ‘no’ if they do not.” as
proposed in (Narayan et al., 2022), (Peeters and Bizer,
2023), and (Remadi et al., 2024)) is problematic as
|S
1
| × |S
2
| × ... × |S
k
| prompts are necessary to cover
and classify the full linkage search space, which is not
scalable (Section 4). To provide a scalable solution
and still use the rich context that Generative Language
Models were trained on, we propose to use GLMs to
generate a comprehensible data catalog with mean-
ingful attribute descriptions. Adopting the SEALM
approach, the number of required prompts is signifi-
cantly reduced down to the total number of attributes
we aim to link |S
1
| + |S
2
| + ... + |S
k
|. Afterward, we
continue to efficiently recommend linkages using the
SEALM-generated descriptions (Section 3.4).
Prompt-Engineering. We generate SEALM prompts
p based on the “Prompt” column in Table 2 for each
attribute. Given the metadata availability condition
c ∈ C, we uniformly chain the contextual information
of the attribute metadata to specify the textual task
(prompt p) for a Generative Language Model. For
example, the rule-based prompt for a
k
3
at condition
c
1
and c
6
looks as follows:
• p
c
1
k
3
: “Briefly describe the attribute ‘CITY’ stored
in table ‘CUSTOMERS’.”
Table 2: Scheme of Attribute Metadata Availability Condition and SEALM Prompt Constellation.
a
k
i
Attribute Objects c
1
c
2
c
3
c
4
c
5
c
6
Prompt (with object-value inserted at *)
n
k
i
attribute name ✓ ✓ ✓ ✓ ✓ ✓ Briefly describe the attribute ‘*’
tn
k
i
table name ✓ ✓ ✓ ✓ ✓ ✓ stored in the table ‘*’
dc
k
i
data type and constraint ✓ ✓ ✓ with the data type ‘*’ and constraint ‘*’
cv
k
i
cell values ✓ ✓ ✓ with sampled record cells ‘[*]’
sn
k
i
schema name ✓ ✓ ✓
in the context of a ‘*’ database schema
and how it might be used
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
42

• p
c
6
k
3
: “Briefly describe the attribute ‘CITY’ stored
in the table ‘CUSTOMERS’ with the data type
‘STRING’ with sampled records [Strasbourg,
Saint Petersburg, Glendale, Nashua, Koeln] in
the context of a ‘Order-Customers’ database
schema and how it might be used.”
Using Generative Language Models (GLMs).
GLMs are ideal for language generation tasks where
the input is partial text that requires completion or ex-
tensive language synthesis. These models are widely
used for creative content generation and chat-bots,
which motivates this work to explore their use in au-
tomatically generating attribute descriptions in a data
catalog. Given the above two prompt examples p
c
1
k
3
and p
c
6
k
3
, GLM
1
generated attribute descriptions can
look as follows:
• LM(a
k
3
,c
1
) = d
c
1
k
3
: “(...) It seems you’re referring
to a hypothetical database table. Assuming that
‘CITY’ is indeed an attribute in the table ‘CUS-
TOMERS’, here’s a brief description: The ‘CITY’
attribute in the ‘CUSTOMERS’ table likely stores
the city where each customer resides. This could
be a string value, such as “New York”, “Los An-
geles”, or “Chicago”. The data type of this at-
tribute might be a character-based type like VAR-
CHAR or CHAR, with a fixed length or varying
lengths depending on the database management
system being used.”
• LM(a
k
3
,c
6
) = d
c
6
k
3
: “In the ‘ORDER-
CUSTOMERS’ database schema, the ‘CITY’
attribute is stored in the ‘CUSTOMERS‘ table
with a data type of ‘STRING’. This attribute rep-
resents the city where each customer is located.
Sampled records: Strasbourg, Saint Petersburg,
Glendale, Nashua, Koeln. The ‘CITY’ attribute
might be used to: 1. Geographic targeting: The
database can be queried to identify customers in
specific cities, allowing for targeted marketing
campaigns or promotions. 2. Customer cluster-
ing: By analyzing the distribution of cities among
customer records, the database can group similar
customers together based on their geographic
locations, enabling tailored sales strategies or
loyalty programs. 3. Order fulfillment and
logistics: The ‘CITY’ attribute can be used to
optimize shipping routes, delivery times, and
(...). In summary, the ‘CITY’ attribute in the
‘CUSTOMERS’ table provides valuable insights
into customers’ geographic locations, enabling
more effective marketing, sales, and logistics
strategies.”
1
Llama3.1:8B on Ollama (Version ID 365c0bd3c000)
A GLM may generate plausible yet nonfactual
content, also known as hallucination (Huang et al.,
2024). We address SEALM’s related attribute en-
richment process using GLMs based on our scheme
of metadata availability conditions. Given restricted
metadata availability (e.g. c
1
), which is an indis-
putably legitimate privacy concern, the generated at-
tribute descriptions may suffer from plausible but un-
true artifacts, that is, the GLM wrongly generates an
attribute’s data type or cell values when compared to
the actual database state (hallucinating). In such a
case, an inaccurate attribute description may be incor-
rectly identified as similar to another one. However,
as we increase the context of the GLM prompt by
supplying metadata conditions c
2
,...c
6
, the additional
context information of these conditions prevents the
GLM from synthesizing inaccurate database schema
design choices and lowers the possibility of hallucina-
tions, leading to a contextually accurate attribute de-
scription. We compare the raw attribute object value
constellation a
c
k
i
∈ S at a certain condition c ∈ C with
the corresponding SEALM generated descriptions d
c
k
i
towards generating effective linkages in Section 4.
3.4 Unsupervised Linkage
Recommendation
Our goal is to recommend a set of attribute linkages
between multiple schemas without trainable linkage
examples. Therefore, we propose a matching pipeline
with Signature, a novel multi-source LSH-Blocking
algorithm that extends the approach of (Sheetrit et al.,
2024), and Filtering in sequential order.
1. Signature. In the previous section on SEALM, we
used GLMs to generate an attribute description d
c
k
i
for
a given prompt p
c
k
i
at metadata availability condition
c. These models utilize a decoder-only transformer-
based architecture that internally represents a prompt
as an auto-regressive response task to be answered
by predicting each word based on all previously
generated words. Since we intend to compare the
attributes or SEALM descriptions, e.g., d
c
1
k
1
and d
c
1
m
1
on similarities, there is a need to transform these
back into a structured numeric embedding that can be
compared efficiently.
This is where encoder-decoder based Language
Models become necessary. The encoder component
of these models is designed to take input text and
encode it into a multi-dimensional and fixed-sized
vector (signature) that captures the semantic and
syntactic nuances of the attribute object-values a
k
1
or the SEALM descriptions d
k
1
that we define as ⃗v
k
i
.
Subsequently, the decoder’s role is to regenerate the
SEALM: Semantically Enriched Attributes with Language Models for Linkage Recommendation
43

original text with a low reconstruction error. In this
work, we mainly focus on the encoder function from
compatible Language Models that we define as E.
This function is uniformly applied to each attribute
a
c
k
i
∈ S or description d
c
k
i
∈ S given a condition
c ∈ C on metadata availability and results in a set of
attribute signatures AS
c
.
2. Multi-source LSH-Blocking. In the case of inte-
gration with multiple schemas, the computational cost
of pair-wise distances and similarities becomes im-
practical. Computing |S
1
| × |S
2
| × ... × |S
k
| compar-
isons quickly becomes infeasible to scale with large
numbers of schemas and attributes. Approximate
Nearest Neighborhood (ANN) algorithms reduce this
complexity to handle large-scale data. We focus
in this work on the ANN-related locality-sensitive
hashing (LSH) technique that hashes n most simi-
lar signatures into a “bucket” with high probability.
Various generic algorithms have been implemented
by companies such as Meta with FAISS (Facebook
AI Similarity Search)
2
and Spotify with Voyager
3
.
These methods drastically reduce the number of com-
parisons needed to efficiently provide effective rec-
ommendations in the social and audio domains.
Algorithm 1: Multi-source LSH-Blocking.
Input: AS
c
= {⃗v
1
1
,...,⃗v
k
i
},n ▷ Attribute signature
set, custom number linkage candidates
Output: BL = {(⃗v
k
i
,⃗v
m
j
)} where k ̸= m ▷ Set of n
blocked linkages per attribute signature
1: SK ←
/
0 ▷ Initialize schema key set
2: BL ←
/
0 ▷ Initialize blocked linkage set
3: for k in schemas do
4: SK ← SK ∪ {k} ▷ Add schema identifier
5: I ←LSH(|⃗v|) ▷ Initialize LSH
index with uniformed signature length predefined
by encoder-LM
6: I.set{⃗v
k
i
|∀⃗v
k
i
∈ AS
c
∧ k not in SK} ▷ Set
signatures from different schemas to LSH index
7: for i in attribute signatures do
8: BL
k
i
← I.search(v
k
i
,n) ▷ Search
for n most similar signatures through index and
set linkage candidates bucket (
⃗
b
1
,...,
⃗
b
n
)
9: for
⃗
b in BL
k
i
do
10: BL ← BL ∪ {(⃗v
k
i
,
⃗
b)} ▷ Add linkage
candidate
11: end for
12: end for
13: end for
14: return BL
2
https://ai.meta.com/tools/faiss/
3
https://spotify.github.io/voyager/
Due to the large search space of potential attribute
linkages, we adapt the LSH method in Algorithm 1
to efficiently recommend a bucket of inter-schema
linkage candidates BL = {(⃗v
k
i
,⃗v
m
j
)} and accom-
modate multiple schemas as input so that k ̸= m.
The inputs to our Blocking algorithm B are AS
c
,
the encoded set of attribute signatures, and n, the
custom number of the most similar signatures per
attribute. We begin to iterate over each schema k
(Line 3) and assign the set of signatures that do not
originate from the same schema as k to the LSH
index. This assignment task includes one or multiple
LSH functions that compress the high-dimensional
signatures into a lower dimension so that similar
ones are hashed into the same bucket with a higher
probability (Lines 4-6). Then, each attribute signature
⃗v
k
i
from schema k is set as a query item. At search,
the query item is also hashed to check for potential
neighboring signatures with similar hash keys, which,
consequently, avoids directly comparing the query
item with every other signature (Lines 7-8). The
result is a bucket set BL
k
i
= (
⃗
b
1
,...,
⃗
b
n
) of size n with
the most similar attributes as linkage candidates of
which each is added as a tuple of signature pairs
(⃗v
k
i
,
⃗
b) where
⃗
b ∈ BL
k
i
to the globally blocked linkage
set BL (Lines 9-10). We highlight that our algorithm
generates linkages with attribute pairs {(⃗v
k
i
,⃗v
m
j
)} in
the order of the iteration of the schemas as we want
to avoid recommending an identical attribute linkage
twice (e.g., (a
c
1
k
1
,a
c
1
m
1
) and (a
c
1
m
1
,a
c
1
k
1
), just in reverse
order). As a result, the attributes that have been used
as a query item do not need to be set to the LSH index.
3. Filtering. Now that we have a much more con-
densed set of n likely matching linkages for each at-
tribute, BL still contains several linkages, of which
not all are relevant or correct. For example, Blocking
does not consider that an attribute may only be linked
to a single different schema and none of the others.
Furthermore, some attributes may not be linked to any
other attributes as they represent a unique concept to
its originating schema.
To consider the above-described cases and priori-
tize recommending very similar (close distanced) at-
tribute signatures, we apply Filtering to generate a
more relevant linkage set FL that we describe in Al-
gorithm 2. The inputs to this algorithm are BL, the
blocked linkage attributes, and top-k, a custom num-
ber that cuts off irrelevant linkages. For each blocked
attribute linkage, we compute a similarity function
s (e.g. Cosine similarity ∈ [0..1]) to quantitatively
express how distant or close two attribute signatures
from different schemas are, resulting in the linkage set
FL = {(⃗v
k
i
,⃗v
m
j
,s)} (Lines 1-5). We continue to sort
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
44

Algorithm 2: Filtering top-k Attribute Linkages.
Input: BL = {(⃗v
k
i
,⃗v
m
j
)},top-k ▷ Blocked linkage
set, custom number to filter top-k scored linkages
Output: FL = {(⃗v
k
i
,⃗v
m
j
,s)} where s is similarity ▷
Set of top-k similarity filtered linkages
1: FL ←
/
0 ▷ Initialize filtered linkage set
2: for (⃗v
k
i
,⃗v
m
j
) in BL do
3: s ← similarity(⃗v
k
i
,⃗v
m
j
) ▷ Compute similarity
4: FL ← FL ∪ {(⃗v
k
i
,⃗v
m
j
,s)}
5: end for
6: FL ← {(⃗v
a
,⃗v
b
,s
y
),(⃗v
c
,⃗v
d
,s
z
),...} ∈ FL∧s
y
> s
z
▷
Sort linkage triplet descending on similarity score
7: FL ← {t
1
,t
2
,...} with t
k
∈ FL ∧ k <=top-k ▷
Filter top-k similarity scored linkages
8: return FL
the linkage triplets based on the similarity score s in
descending order (Line 6) and subsequently filter the
top-k linkages (Line 7). In a more abstract sense, Fil-
tering effectively minimizes the operational and cog-
nitive overload on a human by recommending a pre-
cise linkage set needed for data integration. We refer
the reader to the survey paper by (Papadakis et al.,
2020) for more details on Blocking and Filtering in
the context of Entity Resolution and Linkage.
4 EVALUATION
In this section, we present the evaluation of our pro-
posed research based on the experiments we con-
ducted. We first describe the experimental dataset
and then provide the configuration details of the
SEALM, Signature, Blocking, and Filtering meth-
ods. Then, we present the evaluation metrics. To
the best of our knowledge, we are the first to ap-
ply SEALM and its methods within the unsupervised,
multi-source, and target-free Schema Matching re-
search space. All experiments are conducted in a
Python Jupyter Notebook on an Intel i7-1265U CPU
with 32GB memory. The datasets and code can be
found at https://github.com/leotraeg/SEALM.
Dataset: We conduct distinct experiments with two
datasets that contain multiple schemas on Orders,
Customers, and Human Resources from the three dif-
ferent database vendors Oracle, MySQL, and SAP
HANA (Traeger et al., 2024).
• The “OC3” dataset contains a domain-
specific set of three Order-Customer schemas
(43+59+40=142 attributes) with 47 true inter-
schema linkages out of 6617 potential linkage
candidates.
• The “OC3-HR” dataset extends the domain-
specific schemas with a Human-Resources
schema, which comes from a completely different
application domain (142+35=177 attributes) that
contains 15 additional inter-schema linkages and
results in overall 62 true inter-schema linkages
out of 11587 potential linkage candidates.
Methods. We compare the effectiveness of attribute
linkages for OC3 and OC3-HR using the state-of-the-
art (SOTA) approach based on attribute signatures en-
coded on the raw object values (name, table name,
data type and constraint, record cell values, schema
name) versus linkages using description signatures
encoded on the SEALM-generated descriptions.
• SEALM: We engineer prompts at six different
conditions c ∈ C corresponding to various lev-
els of metadata availability as described in Sec-
tion 3.3. For each schema, we initialize Meta’s
tiniest open-source GLM Llama3.1:8B (Version
ID 365c0bd3c000) that we locally host via Ol-
lama
4
and prompt “Your task is to describe at-
tributes from heterogeneous relational databases
based on extracted schema metadata to improve
linkages for Data Integration.” Then, we sequen-
tially prompt and retrieve the respective attribute
descriptions d
c
k
i
.
• Signatures: We generate attribute signatures us-
ing the attribute a
c
k
i
object values (SOTA) and
compare these with the SEALM-based descrip-
tion signatures d
c
k
i
over the range of all six con-
ditions c ∈ C on metadata levels of availability.
Therefore, we use the encoder-based Sentence
Transformer Bert Language Model (Reimers and
Gurevych, 2019)
5
often used in the Entity Resolu-
tion research area (Cappuzzo et al., 2020) (Zeakis
et al., 2023) (Peeters and Bizer, 2023) to encode
the various textual attribute descriptions into fix-
sized 768-dimensional signatures. Finally, we
normalize the signatures for each conditioned set
AS
c
dimension-wisely into a [0..1] range.
• Blocking: We implement Algorithm 1 with
Meta’s LSH-based similarity-search module
(FAISS) as it has been used in recent research
on source-to-target Entity Resolution for records
(Papadakis et al., 2020), (Paulsen et al., 2023),
(Zeakis et al., 2023). Our algorithm generates the
linkage set BL with the approximate n nearest
attributes between multiple schemas.
• Filtering: We implement Algorithm 2 in order to
further reduce the linkage set BL to the top-k sim-
ilarity scored linkages FL.
4
https://ollama.com
5
https://sbert.net (gtrt5-base)
SEALM: Semantically Enriched Attributes with Language Models for Linkage Recommendation
45
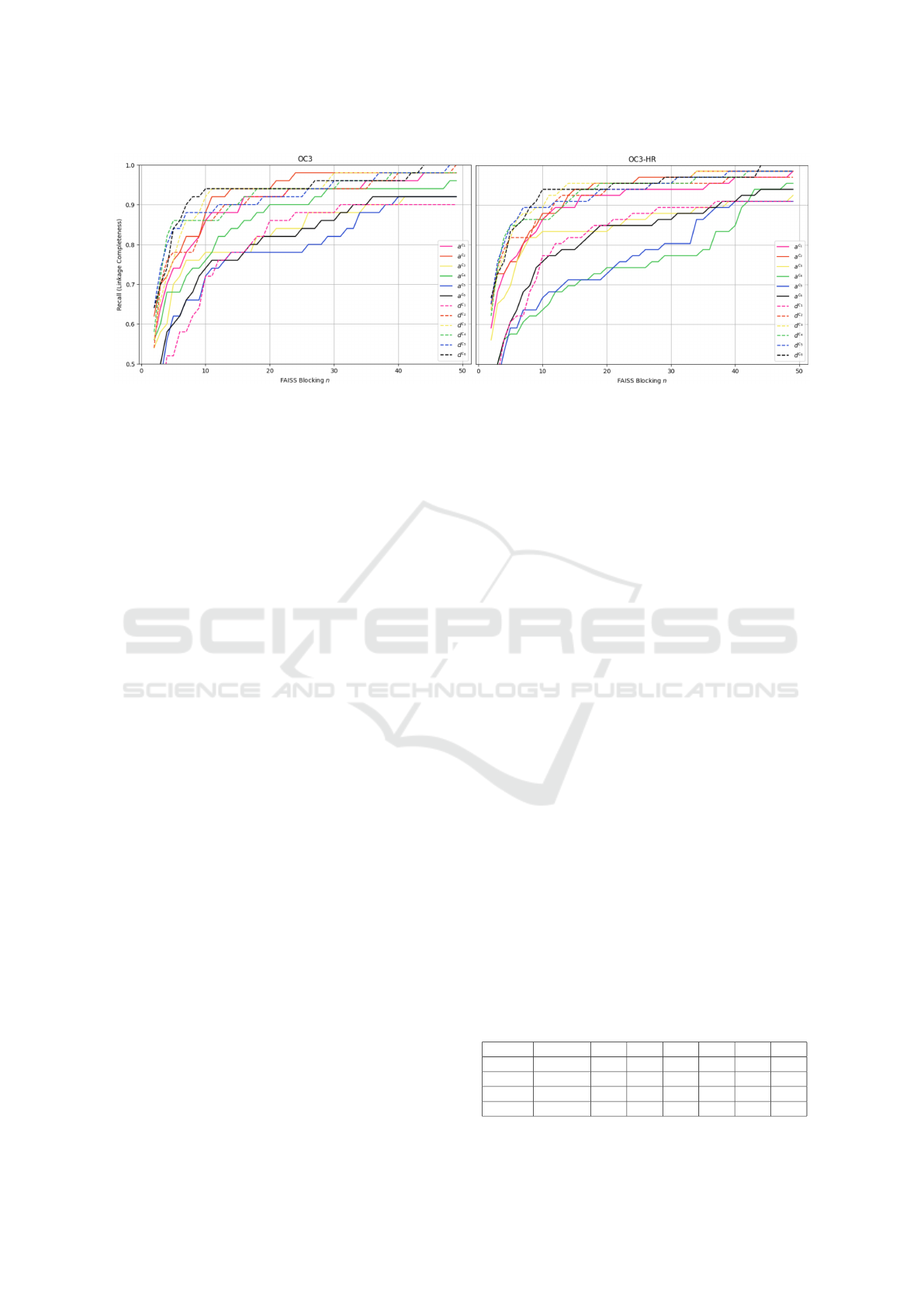
Figure 2: Evaluating Recall on Blocking n ∈ [2..50] with Attribute a
c
and SEALM d
c
Signatures in OC3-HR Schemas by
Metadata Availability Condition.
Metrics. Using OC3 and OC3-HR datasets we com-
pare the recommended set of blocked BL and subse-
quently filtered linkages FL to the set of ground truth
linkages.
• Recall (Linkage Completeness): First, we mea-
sure the recall of the generated linkages over
the range of the n nearest attributes for the
blocked linkages |BL
true
|/|L(S)
true
| and, subse-
quently, over the top-k for the filtered linkages
|FL
true
|/|L(S)
true
|.
• Precision (Linkage Quality): We measure the pre-
cision of the generated linkages over the top-k fil-
tered linkages |FL
true
|/k. We refrain from evalu-
ating the precision of blocked linkages as, without
Filtering, too many false linkages remain in the
blocked BL set.
Blocking Results. The experimental results on
Blocking attribute linkages in OC3 (left) and OC3-
HR (right) schemas are shown in Figure 2. We
measure the recall (linkage completeness) at the y-
axis for n ∈ [2..50] linkage candidates at the x-axis
for the signatures with the raw attribute values a
c
(straight lines) and SEALM-generated descriptions
d
c
(dashed lines), colored in the six different meta-
data availability conditions c
1
(pink), c
2
(orange), c
3
(yellow), c
4
(green), c
5
(blue), and c
6
(black). On
OC3 schemas (left), attribute a
c
3
, a
c
4
, a
c
5
, a
c
6
and
SEALM d
c
1
, d
c
2
signatures generate fewer true at-
tribute linkages than others over the full range of n.
The gap in recall for these signatures becomes even
more visible for the OC3-HR schemas. We con-
clude that Blocking attribute signatures yield the best
recall if they are encoded based on their name, ta-
ble name a
c
1
, and include the data type and con-
straint a
c
2
. On the contrary, Blocking SEALM sig-
natures yield the best recall when the GLM addition-
ally processes the data type and constraint with cell
values d
c
3
, the schema name d
c
4
, or in combination
with d
c
5
and d
c
6
. At n ∈ [5..10], blocking SEALM
signatures d
c
3−6
reach 85% to 95% recall while the
best performing attribute signatures a
c
1
and a
c
2
gen-
erate 10% fewer true linkages. At n = 25, block-
ing signatures a
c
1
, d
c
3
, d
c
4
, d
c
5
, d
c
6
generate 95%
recall with only the a
c
2
exceeding by approximately
4%/2% for the OC3/OC3-HR schemas. At n = 30, the
SEALM signature d
c
3
(OC3) and signatures d
c
3
,d
c
5
,
and d
c
6
(OC3-HR) align with the recall performance
of a
c
2
. Afterward, blocking d
c
6
signatures gradually
performs better in recall, reaching 100% at n = 44 for
both OC3 and OC3-HR schemas.
In real-world integration scenarios, knowing the
blocking value n beforehand would imply knowing
the ground truth of attribute linkages. To fairly com-
pare the performance of Blocking signatures and se-
lect a relevant subset between the twelve signatures
for the subsequent Filtering phase, we compute the
Area Under the Curve (AUC) Recall in Table 3. Sum-
mary: Over the range of n ∈ [2..50], the six best
AUC Recall for Blocking linkages in OC3 and OC3-
HR schemas use attribute signatures a
c
1
and a
c
2
and
SEALM signatures d
c
3
, d
c
4
, d
c
5
, and d
c
6
. Block-
ing the respective SEALM signatures over the full
range of n yields higher recall than with the attribute
signatures except at n ∈ [25...30]. At higher n with
Blocking, SEALM signatures contain all true link-
ages, while attribute signatures cut off a few ones that
we discuss in the next paragraph.
Table 3: Evaluating Area Under Curve Recall on Blocking
n ∈ [2..50] with Attribute a
c
and SEALM d
c
Signatures in
OC3-HR Schemas by Metadata Availability Condition.
Schemas Signature c
1
c
2
c
3
c
4
c
5
c
6
OC3 SOTA:a
k
i
42.51 43.82 39.19 40.90 37.38 38.39
OC3 SEALM:d
k
i
38.00 42.77 43.75 43.42 43.44 44.04
OC3-HR SOTA:a
k
i
42.73 43.73 39.97 35.42 36.13 38.83
OC3-HR SEALM:d
k
i
38.97 43.32 44.23 43.77 43.88 44.19
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
46
Figure 3: Evaluating Precision and Recall on Blocking n = 10 and Filtering top-k ∈ [1..1000] with Attribute a
c
1
and a
c
2
and
SEALM d
c
3
,d
c
4
,d
c
5
, and d
c
6
Signatures in OC3-HR Schemas by Metadata Availability Condition.
Figure 4: Evaluating Precision and Recall on Blocking n = 25 and Filtering top-k ∈ [1..1000] with Attribute a
c
1
and a
c
2
and
SEALM d
c
3
,d
c
4
,d
c
5
, and d
c
6
Signatures in OC3-HR Schemas by Metadata Availability Condition.
Filtering Results. We evaluate the precision (dotted)
and recall (straight) performance (y-axis) on Filtering
the top-k ∈ [1..1000] linkages (x-axis) using the
Cosine similarity for each of the top-performing
Blocking subset of attribute a
c
1
(pink) and a
c
2
(or-
ange) and SEALM-based d
c
3
(yellow), d
c
4
(green),
d
c
5
(blue), and d
c
6
(black) signatures. As we do not
know the ideal n value for the prior Blocking phase
for the OC3 (left) and OC3-HR (right) schemas,
we evaluate two Filtering experiments with blocked
linkage sets at n = 10 (Figure 3) and at n = 25
(Figure 4). At the start of top-k, all experiments
filter linkage sets with 100% precision. Notably, the
SEALM signatures d
c
3
and d
c
4
fluctuate and fall
below the precision performance of the signatures
a
c
1
, a
c
2
, d
c
5
, and d
c
6
. At approximately k = 44,
the precision and recall graphs of all signatures
intersect at 45-50% (OC3) and 38-43% (OC3-HR)
on the y-axis, reflecting that OC3-HR schemas are
the more challenging integration scenario. Within
the range k ∈ [44...1000], Blocking and Filtering the
SEALM signatures d
c
4
, d
c
5
, and d
c
6
yields 5% to
20% improvement in recall compared to d
c
3
and the
attribute signatures a
c
1
and a
c
2
. Even though there is
a minor recall improvement in Blocking the attribute
signatures a
c
2
at n = 25, Filtering the corresponding
top-scored linkages generates more false linkages
than with SEALM-based description signatures.
Summary: Overall, the SEALM description signa-
ture d
c
6
performs the best within the Blocking and
Filtering pipeline among both OC3 and OC3-HR
schemas with minor SEALM exceptions d
c
4
and
d
c
5
. The corresponding SEALM description of d
c
6
requires full metadata availability that includes the
attribute name, table name, data type and constraints,
cell values, and schema name. If cell values of the
attributes are not disclosed due to access control
regulations, the SEALM signature d
c
4
should be
used for representing the attributes followed by a
c
1
and a
c
2
. Overall, neither the attribute nor SEALM
signatures provide a linkage set that contains all
true linkages due to the parameters of Blocking
(n =< 26) and Filtering (top-k =< 1000) cutting off
a few ground truth linkages with low similarities.
SEALM: Semantically Enriched Attributes with Language Models for Linkage Recommendation
47
Figure 5: Processing Time for Invoked SEALM Attribute Descriptions in OC3-HR Schemas by Metadata Availability Condi-
tion with Llama3.1:8B.
Expanding the linkage search space by setting these
parameters higher would generate more linkage
candidates that cover all ground truths. The more
complex OC3-HR linkages that were cut off contain
semantically challenging attribute pairs such as
REPORTS TO and MANAGER ID or TERRITORY and
REGION NAME. With SEALM-generated descriptions,
we identify and recommend more of such sub-typed
attribute linkages that are more nuanced.
The improvement in recall for linkage recommen-
dation is attributed to the semantically rich descrip-
tions that are used for encoding the attribute signa-
tures, bringing similar attributes closer together and
distinguishing dissimilar ones more effectively. De-
spite the computational cost to invoke GLM prompts,
the resulting increase in the quality of attribute sig-
natures significantly enhances the recommendation
process. We show the time needed in seconds for
invoking SEALM prompts using the tiniest open-
source GLM by Meta (Llama3.1:8B) hosted on a lap-
top without GPU acceleration in Figure 5 as colored
boxplots of the HR-ORACLE (green), OC-ORACLE
(red), OC-MYSQL (yellow), and OC-SAP (blue)
schemas. With this experimental set-up, Llama3.1:8B
requires approximately 50 to 58 seconds to describe
attributes with SEALM prompts based on their name,
table name, data type and constraint, and cell values
at conditions c
1
, c
2
, and c
3
. By adding the schema
name with the suffix “and how it might be used”, rep-
resented with prompts at conditions c
4
, c
5
, and c
6
,
we observe that the processing time doubles to ap-
Table 4: Processing Time for SEALM Prompts in OC3-HR
Schemas by Metadata Availability Condition.
Phase/Condition c
1
c
2
c
3
c
4
c
5
c
6
SEALM Prompt(a
k
i
)
(LM=Llama3.1:8B)
µ in seconds
51.84 49.64 57.49 93.79 108.32 115.75
OC3
×142 Attributes
∑
in hours
1.96 2.05 2.28 3.72 4.29 4.58
OC3-HR
×177 Attributes
∑
in hours
2.53 2.46 2.82 4.61 5.32 5.70
proximately 93 to 115 seconds. No pattern indicates
a faster or slower generation of attribute descriptions
among the schemas, whether it is related to Orders,
Customers, or Human Resources.
Scalability: Additionally, we show the mean and
overall processing time for invoking the GLM for
SEALM attribute descriptions for the OC3 and OC3-
HR schemas in Table 4. We can see that SEALM
prompts are processed for each attribute from all the
schemas to be integrated |S
1
| + |S
2
| + ... + |S
k
|. We
show this linearity in Figure 6 with the cumulative
sum in hours for invoked SEALM descriptions by the
attributes in OC3-HR schemas.
Let us assume that we compare k different
schemas to be integrated S
1
,S
2
,...,S
k
, there is one
schema with the maximum number of attributes,
which we denote as M = |S
k
|. Then, the result-
ing number of needed SEALM prompts requires at
most linear complexity O(M · k). This becomes rele-
vant if we consider an evolving multi-database system
that needs to identify correct linkages in a reoccur-
ring integration process with k +1 newly participating
schemas. We highlight that the generated SEALM de-
scriptions of a schema k, once processed, can be con-
tinuously reused as they are unaffected by attributes
from a new schema k + 1. However, attribute de-
scriptions that were enriched with different GLMs or
signatures that were encoded with different encoder-
based Language Models may not be comparable and,
thus, may indicate a weak similarity for actually simi-
lar attributes. In addition to using the GLMs’ descrip-
tive language capabilities with SEALM, our unsu-
Figure 6: Linear Cumulative Processing Time for Invoked
SEALM Attribute Descriptions in OC3-HR Schemas by
Metadata Availability Condition with Llama3.1:8B.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
48

pervised Signature, Blocking, and Filtering approach
efficiently covers the entire attribute linkage search
space to provide relevant linkage recommendations.
Based on work by (Narayan et al., 2022), (Peeters
and Bizer, 2023), and (Remadi et al., 2024), the al-
ternative GLM approach would be to compare and
classify all potential attribute pairs that may exist,
such as with the prompt “Do the attributes ‘a
c
k
i
’ and
‘a
c
m
j
’ represent the same concept? Answer with ‘yes’
if they do and ‘no’ if they do not.” While their ap-
proach would also cover the entire linkage search
space, it represents a brute-force solution that requires
|S
1
| × |S
2
| × ... × |S
k
| comparisons in order to solve
the Attribute Linkages problem defined in Section 3.1.
The multiplicative nature of brute-force comparisons
between attributes implies exponential growth in the
order of O(M
k
). Consequently, in the context of multi-
source schema integration, a brute-force approach is
not scalable. For example, exploring all 11578 possi-
ble linkages for the relatively small OC3-HR schemas
for the condition c
6
on metadata availability would
lead to more than 100 computation hours. Also, ran-
domly selecting linkage samples does not guarantee
coverage of the entire space, leading to the loss of all
linkages that are outside of the sample.
On the contrary, our approach is quite scalable
growing in a linear fashion since we first gener-
ate semantically enriched attribute descriptions via
SEALM and then recommend relevant linkages via
Signature, Blocking, and Filtering.
5 CONCLUSIONS
This paper introduces SEALM, a new method in
the EL pipeline that generates Semantically Enriched
Attribute descriptions using Language Models based
on various levels of metadata availability ranging
from highly-secure to full-exposure access. SEALM-
generated attribute descriptions can be used as Sig-
natures to efficiently generate linkages between mul-
tiple heterogeneous schemas by taking advantage of
our novel Blocking algorithm, and Filtering. We eval-
uated the raw attribute metadata values (SOTA) with
SEALM descriptions between two different multi-
source schema matching scenarios using the OC3 and
OC3-HR schemas at different ranges of Blocking and
Filtering configurations and observed a significant 5%
to 20% recall improvement in linkage recommenda-
tions.
The SEALM methodology can be applied to ar-
bitrary data repositories, and its approach can be
adapted to generate linkages for different schema
components. Dealing with a search space of link-
ages scales problematically with the Cartesian prod-
uct size when integrating more than two database
schemas. Our SEALM approach uses Generative
Language Models that need to process only a smaller
number of attributes of the integrated schemas, thus
scaling up nicely in a linear fashion. We efficiently
combine the rich language synthesis capabilities of
Generative Language Models with scalable Schema
Matching and Entity Linkage methods, a major devi-
ation from prior research techniques.
Looking ahead, several improvements can be
made through (1) Prompt Engineering with more
powerful Generative Models. Specializing GLMs to
relational schemas on recently available real-world
database corpora, such as GitSchemas (D
¨
ohmen et al.,
2022) and WikiDBs (Vogel et al., 2024), could lead
to improved data cataloging capabilities. (2) Simi-
larly, encoding the descriptions into more effective
signatures may be achieved by fine-tuned encoder-
based Language Models on the basis of database cor-
pora. (3) Finally, additional methods such as Scoping
(Traeger et al., 2024) can improve the efficiency and
effectiveness of the linkage pipeline.
ACKNOWLEDGEMENTS
Leonard Traeger was partially supported by a Tech-
nology Catalyst Fund TCF24KAR11131049602 by
UMBC and a grant project PLan CV (reference num-
ber 03FHP109) by the German Federal Ministry of
Education and Research (BMBF) and Joint Science
Conference (GWK).
REFERENCES
Abdelsalam Maatuk, M., Ali, A., and Rossiter, N. (2010).
Semantic Enrichment: The First Phase of Relational
Database Migration. In Innovations and Advances in
Computer Sciences and Engineering, pages 373–378,
Dordrecht. Springer Netherlands.
Bleiholder, J. and Naumann, F. (2009). Data fusion. ACM
Computing Surveys, 41(1):1–41.
Cappuzzo, R., Papotti, P., and Thirumuruganathan, S.
(2020). Creating Embeddings of Heterogeneous Rela-
tional Datasets for Data Integration Tasks. SIGMOD
’20, pages 1335–1349, New York, NY, USA. ACM.
Castellanos, M. and Saltor, F. (1991). Semantic enrichment
of database schemes: an object oriented approach. In
[1991] Proceedings. First International Workshop on
Interoperability in Multidatabase Systems.
D
¨
ohmen, T., Hulsebos, M., Beecks, C., and Schelter, S.
(2022). GitSchemas: A Dataset for Automating Re-
lational Data Preparation Tasks. In 2022 IEEE 38th
SEALM: Semantically Enriched Attributes with Language Models for Linkage Recommendation
49

International Conference on Data Engineering Work-
shops (ICDEW), pages 74–78. ISSN: 2473-3490.
Fernandez, R. C., Elmore, A. J., Franklin, M. J., Krishnan,
S., and Tan, C. (2023). How Large Language Models
Will Disrupt Data Management. VLDB, 16(11):3302–
3309.
Halevy, A. and Dwivedi-Yu, J. (2023). Learnings from
Data Integration for Augmented Language Models.
arXiv:2304.04576 [cs].
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang,
H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T.
(2024). A Survey on Hallucination in Large Language
Models: Principles, Taxonomy, Challenges, and Open
Questions. ACM Transactions on Information Sys-
tems, page 3703155.
H
¨
attasch, B., Truong-Ngoc, M., Schmidt, A., and Bin-
nig, C. (2022). It’s AI Match: A Two-Step Ap-
proach for Schema Matching Using Embeddings.
arXiv:2203.04366 [cs].
Loster, M., Koumarelas, I., and Naumann, F. (2021).
Knowledge Transfer for Entity Resolution with
Siamese Neural Networks. Journal of Data and In-
formation Quality, 13(1):1–25.
Mihindukulasooriya, N., Dash, S., and Bagchi, S. (2023).
Unleashing the Potential of Data Lakes with Seman-
tic Enrichment Using Foundation Models. In ISWC
Industry Track CEURWP, Athens, Greece.
Narayan, A., Chami, I., Orr, L., Arora, S., and R
´
e, C.
(2022). Can Foundation Models Wrangle Your Data?
arXiv:2205.09911 [cs].
Papadakis, G., Skoutas, D., Thanos, E., and Palpanas, T.
(2020). Blocking and Filtering Techniques for En-
tity Resolution: A Survey. ACM Comput. Surv.,
53(2):31:1–31:42.
Paulsen, D., Govind, Y., and Doan, A. (2023). Sparkly:
A Simple yet Surprisingly Strong TF/IDF Blocker for
Entity Matching. VLDB, 16(6):1507–1519.
Peeters, R. and Bizer, C. (2023). Using ChatGPT for Entity
Matching. arXiv:2305.03423 [cs].
Reimers, N. and Gurevych, I. (2019). Sentence-bert: Sen-
tence embeddings using siamese bert-networks. In
Proceedings of the 2019 Conference on Empirical
Methods in Natural Language Processing. Associa-
tion for Computational Linguistics.
Remadi, A., El Hage, K., Hobeika, Y., and Bugiotti, F.
(2024). To prompt or not to prompt: Navigating the
use of Large Language Models for integrating and
modeling heterogeneous data. Data & Knowledge En-
gineering, 152:102313.
Saeedi, A., David, L., and Rahm, E. (2021). Matching Enti-
ties from Multiple Sources with Hierarchical Agglom-
erative Clustering:. In Proceedings of the 13th IC3K,
pages 40–50. SciTePress.
Sheetrit, E., Brief, M., Mishaeli, M., and Elisha, O. (2024).
ReMatch: Retrieval Enhanced Schema Matching with
LLMs. arXiv:2403.01567 [cs].
Traeger, L., Behrend, A., and Karabatis, G. (2022). In-
teplato: Generating mappings of heterogeneous rela-
tional schemas using unsupervised learning. In 2022
CSCI, pages 426–431.
Traeger, L., Behrend, A., and Karabatis, G. (2024).
Scoping: Towards Streamlined Entity Collections
for Multi-Sourced Entity Resolution with Self-
Supervised Agents. pages 107–115.
Vogel, L., Bodensohn, J.-M., and Binnig, C. (2024).
WikiDBs: A Large-Scale Corpus Of Relational
Databases From Wikidata.
Zeakis, A., Papadakis, G., Skoutas, D., and Koubarakis, M.
(2023). Pre-Trained Embeddings for Entity Resolu-
tion: An Experimental Analysis. VLDB, 16(9):2225–
2238.
Zeng, X., Wang, P., Mao, Y., Chen, L., Liu, X., and Gao,
Y. (2024). MultiEM: Efficient and Effective Unsuper-
vised Multi-Table Entity Matching. pages 3421–3434.
IEEE Computer Society.
Zezhou Huang, Guo, Jia, and Wu, Eugene (2024). Trans-
form Table to Database Using Large Language Mod-
els. 2nd International Workshop TaDA@VLDB.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
50
