
A Comprehensive Study of Art Image Style Transfer Methods Based
on Generative Adversarial Networks
Liyuan Huang
1
a
, Hanlin Liu
2
b
and Jiaqi Wen
3
c
1
Aberdeen Institute, South China Normal University, Foshan, Guangdong, 523000, China
2
Computer Science, Xu Hai College, China University of Mining and Technology, Xuzhou, Jiangsu, 221000, China
3
School of Information Science, Guangdong University of Finance & Economics, Guangzhou, Guangdong, 510000, China
Keywords: Art Image Style, Transfer Method, Generative Adversarial Networks.
Abstract: Image style transfer is a cutting-edge technique that seamlessly merges one image's content with another's
distinct style. The rapid progress of deep learning has led to significant advancements in image style transfer
technology. Nevertheless, this technology still encounters several issues, such as the inability to attain the
optimal expression effect of artistic attributes, and the mismatch between semantic and style characteristics.
Based on the generative adversarial network (GAN), this paper examines the improved algorithmic
applications of image style transfer technology in ink painting, animation, and oil painting. Additionally,
using quantification and comparative analysis of the outcomes of the improved style transfer algorithm
applied in diverse art forms, Foreseen are the obstacles to be tackled and the expected development path of
image style transfer technology in the future. The application of image style transfer technology in the domain
of art still demands more efficient algorithms and more artistic outputs. This study focuses on summarizing
popular algorithms in image style transfer technology and driving forward innovation in style transfer
techniques.
1 INTRODUCTION
Image style transfer constitutes a deep learning
technique, it can transfer the style of one image to
another, thereby generating a new image. In recent
years, image style transfer has been extensively
applied across various fields. In the transportation
sector, Lin has proposed day-night style transmission
for detection purposes of vehicles during the night, to
reduce the incidence of car accidents (Lin, Huang,
and Wu, et al, 2021). In medicine, Yin improves
medical image accuracy through a context-aware
framework (Xu and Li, 2020). Lv adds to the
authenticity of blood vessel image generation through
the application of deepnet (Tmenova, Martin, and
Duong, 2019). In art, migrating imagery is used more
frequently. By incorporating the Cantonese dialect
into the creation of porcelain patterns, the Cantonese
porcelain culture can be preserved and passed on
(Chen, Cui, Tan, et al., 2020).
a
https://orcid.org/0009-0005-7243-1963
b
https://orcid.org/0009-0005-1265-9923
c
https://orcid.org/0009-0001-9110-1039
Painting is an ancient form of artistic expression.
The most common way to create paintings with
different styles is Generative Adversarial Network
(GAN). Chinese Ink Painting with rice paper and ink.
They integrate and intermingle, creating a sense of
depth. Anime uses simple strokes to create images.
Oil paintings have rich colors and strong three-
dimensional texture. Most experiments on style
transfer employ GAN to generate new images.
Nevertheless, as time goes by, the majority of basic
GANs to doing things fail to satisfy people's
requirements for generating images. There are many
problems arising: differences in skills and styles
between ink painting and Western painting contribute
to style transfer in ink painting's suboptimal
performance. When transferring animation styles,
there exist problems regarding anime image feature
texture is missing and the generated image quality is
not good. When transferring oil painting styles, there
Huang, L., Liu, H., Wen and J.
A Comprehensive Study of Art Image Style Transfer Methods Based on Generative Adversarial Networks.
DOI: 10.5220/0013512100004619
In Proceedings of the 2nd International Conference on Data Analysis and Machine Learning (DAML 2024), pages 171-178
ISBN: 978-989-758-754-2
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
171
are often issues with image local minutiae are missing
and style area and content do not match.
To address these issues, several new models have
emerged. The purpose of this article is to discuss
some new GAN-based model for use in various types
of paintings and introduce their advantages and
disadvantages. The aim is to provide some basis for
the subsequent research on style transfer in paintings.
2 METHOD
In this section, the application of image style transfer
technology in the field of art will be elaborated,
focusing on three main categories: ink painting,
animation, and oil painting.
2.1 The Overview of GAN
GAN, which stands for Generative Adversarial
Network, is a type of deep learning model comprised
of two primary components: the generator and the
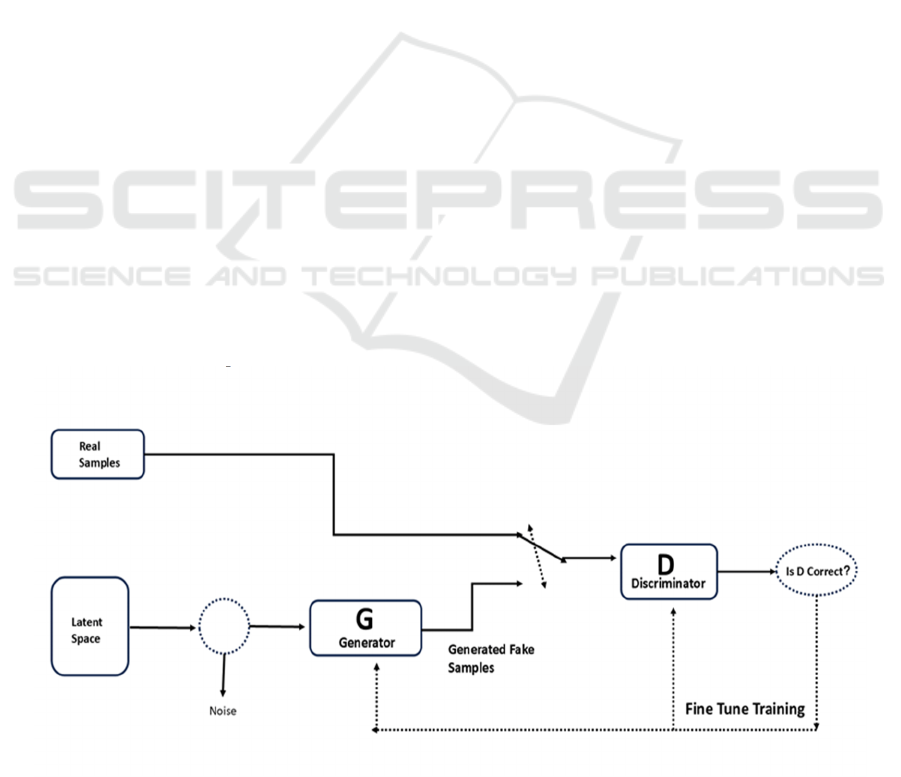
discriminator. As illustrated in Figure 1, the generator
G takes random noise Z as input and produces an
image G(z), while x represents the input image. The
discriminator D assesses whether x is a real image and
outputs D(x) as the probability of its authenticity. A
probability closer to 1 indicates higher authenticity of
the image; conversely, a probability closer to 0
suggests lower authenticity. The objective of G is to
generate images that are highly realistic to deceive D,
while D strives to differentiate real photos accurately.
They engage in a mutual game to enhance their
respective discriminative capabilities.
2.2 Ink Painting
Due to the significant differences between Chinese
ink painting and Western painting techniques, the
direct application of existing image style conversion
methods is ineffective. Hu improved on the existing
ChipGAN model to promote the standard and white
space effect related to the generated image, replacing
the ResNet residual network in the generator with a
residual dense network (RDN), which enables the
network to reuse shallow features of the image and to
extract more feature information by combining
shallow and deep features (Hu, 2023). The PatchGAN
discriminator is substituted with a multi-scale
discriminator to enhance the discriminative ability of
images at different scales. The white space loss is
added based on the original loss function, the image
background is processed by threshold segmentation,
and the background white space is constrained using
the L1 loss and the SSIM loss to generate an image
that is more in line with the ink style.
2.3 Animation
To solve the previous problem of imperfect style
migration of anime images, derived from edge
improvement and coordinated attention Hong et al.
proposed an animation translation method, called
FAEC-GAN, to help complete the task of migrating
from real photos to anime faces (Lin, Xu, Liu, 2023).
Firstly, they introduced an edge discriminative
network consisting of an edge detection module and
an edge discriminator. The edge detection module
obtains edge information from the image and sends it
Figure 1: The structure of GAN (Photo/Picture credit: Original).
DAML 2024 - International Conference on Data Analysis and Machine Learning
172

to the edge discriminator for evaluation. Next, they
designed a novel loss function that measures the
image discrepancy between the focusing frequency
loss and the spatial loss (Lin, Xu, Liu, 2023).
Zhao proposed a new image canonisation architecture
that extracts anime image features independently,
making it controllable and scalable in practical
applications (Zhao, Zhu, Huang, et al., 2024). The
architecture is a GAN model based on multiple
decompositions. The image features generated by the
generator network training are decomposed and
extracted, and the texture module takes the extracted
texture and trains the image using a discriminator to
create textures with more cartoon image features.
Such a structural module uses the pre-trained network
to efficiently extract image structural features and
preserve image content information (Zhao, Zhu,
Huang, et al., 2024).
Li proposed an improved GAN-based style
migration algorithm for anime images (Li, Zhu, Liu,
et al., 2023). Firstly, the improved inverted residual
block and the efficient attention mechanism are used
to form a feature transformation module, which
enriches the local feature attributes of the migrated
image and improves the expression ability of style
features; secondly, the style loss function is improved
to suppress the interference of colour and luminance
on texture learning. Experiments reveal that the
introduced algorithm excels in producing images with
superior quality and enhanced visual realism (Li, Zhu,
Liu, et al., 2023).
2.4 Oil Painting
To solve the detail loss and blurring that appears
locally in the generated oil painting images problem,
Han proposed a multi-feature extractor to perform
style transfer of shape, texture, color, and space in oil
painting (Han X, Wu Y, and Wan R, 2023). The
extractor contains U-net, MiDas, texture extraction
network, and chromatic histogram. Meanwhile, the
autoencoder structure is employed as the main
framework for feature extraction. After identifying
the input and style images, DE-GAN is trained using
the model architecture, generating a network that
shares style parameters with the feature extraction
module. Finally, implement the generation of realistic
photos in the oil painting style (Han, Wu, and Wan,
2023).
To address the challenges of generating and
reconstructing image details in oil painting, Liu
proposed a method that combines the LBP algorithm
with an improved loss function (Liu, 2021). Liu
initially applied the Wasserstein metric to the GAN's
objective function to enhance training stability(Liu,
2021). Then add gradient penalty to loss function
(WGAN-GP), it can deal with gradient vanishing
during training. By incorporating noise control in the
CycleGAN loss function, boundary details and
surface patterns are enhanced after oil painting style
transfer, along with the addition of LBP structural
features and total variation.
3 RESEARCH
3.1 Quantitative Results of Ink
Painting Experiments
Hu's experiments found that the ChipGAN model,
which incorporates a residual dense network and
introduces a multi-scale discriminator, can largely
improve the quality of the generated images (Hu,
2023). The quality of an image is assessed by
quantitatively analyzing the image using Peak Signal
Noise Ratio (PSNR), Structural Similarity (SSIM),
Frechette's Distance (FID), and Cosine Similarity
(CosSim) as metrics (Hu, 2023). PSNR is used to
measure the generation quality of an image, and the
higher its value, the closer the style-migrated image
is to the original content, maximizing the retention of
content information. FID is used to compute the
similarity between two images in terms of feature
vectors, the smaller its value, the more similar it
represents the distribution of the generated image and
the real image in space. CosSim is used to measure
the pixel-wise similarity of two images, with higher
values indicating a smaller angle between the two
vectors represented by the image features and a
higher degree of similarity. SSIM is a measure of the
structural similarity of the two images, where higher
values indicate that the reconstructed image is more
similar to the original image in terms of brightness,
contrast, and structural inverse.
Hu uses four methods, method 1 is ChipGAN,
method 2 is ChipGAN based on RDN, method 3 is
ChipGAN using a multi-scale discriminator, and
method 4 is ChipGAN based on RDN and multi-scale
discriminator. Among them, method 1 is for the
ChipGAN model without any improvement, which is
a variant of GAN. The basic principles include:
generative network generates IC layout according to
the input design parameters; discriminative network
accepts the generated layout and the real layout and
outputs the true-false discriminative results;
optimizing the generative network and discriminative
network through adversarial training, so that the
quality of the generated layout is continuously
A Comprehensive Study of Art Image Style Transfer Methods Based on Generative Adversarial Networks
173

improved, and at the same time, the discriminative
ability of the discriminative network is improved.
Finally, the quality of the generated plates is
gradually improved by optimizing the loss function.
For method 2, ChipGAN based on RDN is combined
with the basic principle that the generative network
utilizes a deep convolutional neural network, which,
integrated with the architecture of RDN, can enhance
the multilevel feature extraction capability to
generate accurate and high-quality plat maps. For
method 3, which introduces a multi-scale
discriminator, the basic principle is that the generated
IC layout is evaluated for multi-level and multi-scale
fidelity, and combined with the adversarial training of
the GAN, the generative network is continuously
optimized to generate a layout that is realistic at
different scales, to achieve automatic generation of IC
layouts with higher accuracy and quality. For method
4, both combines RDN and multiscale discriminators.
For the performance comparison of these four
methods (Hu, 2023), as shown in Table 1, it can be
concluded that the SSIM, PSNR, and CosSim are
greater than the base ChipGAN model when RDN or
multiscale discriminator is introduced alone. The
reconstructed image is closer to the original image in
terms of brightness, contrast, and structure, and the
generated image is of higher quality, with less
difference from the original one and higher similarity
of image or text features. At the same time, the FID is
all lower than the base ChipGAN model, representing
a closer distribution of the generated image to the real
image in the feature space. The performance data is
further improved by combining both residual dense
networks and multi-scale discriminators (Hu 2023).
Hu's experimental results demonstrate that the ink-
style images generated by the improved model have
significant improvement in both visual quality and
white space effect (Hu, 2023). As in Figure 2, it can
be seen from the examples of apples, flowers, and fish
that the ink-style images generated by the improved
model have significant improvement in visual quality
and white space effect, and have good generalization
ability on different datasets.
Table 1: Comparison of different model performance
Evaluation
metrics
Method
1
Method
2
Method
3
Method
4
SSIM 0.8064 0.8127 0.8092 0.8191
PSNR 13.9860 14.5329 14.2367 14.7879
FID 172.44 167.04 166.95 165.62
CosSi
m
0.9733
0.9825
0.9785
0.9841
Figure 2: Examples of apples, flowers, and fish in the
improved model of image generation representation (Hu,
2023)
3.2 The Result of Animation
3.2.1 FAEC-GAN
LIN used two datasets, self2anime, and ce2anime, to
propose the FAEC-GAN method, a style migration
method based on edge enhancement and coordinated
attention mechanisms (Lin, Xu, Liu, 2023).
To validate the FAEC-GAN model's
effectiveness, LIN used FID and KID measures in the
experiments. On self2anime, FAEC-GAN reduced
FID by 1.95 and KID by 0.37 compared to the best-
performing ACL-GAN in the baseline (Lin, Xu, Liu,
2023). On the ce2anime dataset, FAEC-GAN reduces
FID by 3.03 and KID by 0.61 compared to
SpatchGAN. By delivering top results on several
datasets, FAEC-GAN proves its capacity to learn
from different data distributions and generate highly
realistic anime faces. In addition, the method
achieved the lowest scores on both evaluation
metrics, which further demonstrates that FAEC-GAN
performs very well regardless of which metric is used.
Table 2: Comparison of six methods for FID and KID under
two datasets (Lin, Xu, Liu, 2023)
Dataset
Model
Self2anime Ce2anime
FID KID*100 FID KID*100
FAEC-GAN 92.92 2.91 60.28 2.71
C
y
cle-GAN 114.54 3.80 70.90 3.67
U-GAT-IT 105.78 3.93 68.28 3.21
NICE-GAN 112.62 5.41 68.04 3.61
ACL-GAN 94.87 3.28 63.69 2.81
S
p
atchGAN 98.78 3.71 63.31 3.32
3.2.2 GAN Expansion of Animation 1
Zhao proposed a GAN-based method to combine the
features used in the generator for extracting deep
networks with the attention mechanism, and in terms
of content, real-world photographs were used as test
data. Stylistically, cartoon images from the films of
DAML 2024 - International Conference on Data Analysis and Machine Learning
174

Table 3: Uses FID to assess the similarity between real and synthetic anime images and the stability of different styles of
results relative to baseline results (Zhao, Zhu, Huang, et al., 2024).
Methods Photo CycleGAN CartoonGAN GDWCT (Zhao, 2024)
FID to cartoon 165. 70 140. 37 145. 21 136. 21 110. 39
FID to photo N/A 121. 11 86. 48 100. 29 35. 79
Methods Photo Ha
y
ao St
y
le Pa
p
rika st
y
le ShinkaiSt
y
le
(
Zhao, 2024
)
FID to cartoon 165. 70 127. 35 127. 05 129. 52 110. 39
FID to
p
hoto N/A 86. 48 118. 56 37. 96 35. 79
two directors, Hayao Miyazaki and Makoto Shinkai,
are used respectively, and the proposed method is
compared with Cycle GAN, CartoonGAN, and
GDWCT (Zhao, Zhu, Huang, et al., 2024).
To find the differences between the methods more
precisely, Zhao employed FID to assess the similarity
between authentic and generated anime images, as
well as the consistency of results across various styles
compared to the baseline. As in Table 3, Zhao's
methods all have minimum errors (Zhao, Zhu, Huang,
et al., 2024).
To compare the visual quality of the images
generated by each method more objectively, TABLE
4 shows the percentage of each method selected as the
best method, with higher percentages indicating more
popularity, which is used to assess the visual quality
of the images.
Table 4: Percentage of the four methods selected as the best
method under different styles (Zhao, Zhu, Huang, et al.,
2024).
Methods Hayaostyl
e
Paprika
style
Shinkai
style
CycleGAN 16.20% 7.37% 15.24%
CartoonGAN 32.40% 39.69% 40.36%
GDWCT 10.88% 3.1% 2.3%
(Zhao, 2024) 40.50% 49.84% 49.84%
3.2.3 GAN Expansion of Animation 2
The content image set selected for Li's experiments is
from real images on the Flickr website, and the style
image set is from four sets of anime film frames
produced by Hayao Miyazaki and Makoto Shinkai
(Li, Zhu, Li, et al., 2023). The improved method uses
a channel blending operation combined with a
modified inverted residual block to form a feature
transformation module to enhance the local feature
attributes of the images, and in the meanwhile,
invokes an efficient attention mechanism to further
improve the stylistic feature expression capability.
Li combined the proposed algorithm with three
algorithms, Cycle GAN, CartoonGAN, and
AnimeGAN, to perform anime style migration on two
content images in the test set (Li, Zhu, Li, et al.,
2023). According to the experimental results, the
CycleGAN algorithm generates over-stylized images
loses the semantic content of the input images, and
cannot accurately determine the object information.
CartoonGAN algorithm generates anime images with
green artifacts and more distortions in the level of
detail; at the same time, it loses the color information
of the original images due to the lack of constraints of
the color loss function. AnimeGAN algorithm still
has image details on local areas, but it is not possible
to determine the object information accurately. local
area still exists image content detail loss and point
artifacts, and there is a problem of structural adhesion
for the portrayal of the distant region. Li's proposed
algorithm incorporates an enhanced inverted residual
block within the feature transformation module,
which focuses on emphasizing local image details
while effectively maintaining global information
through feature reuse and fusion techniques (Li, Zhu,
Li, et al., 2023). At the same time, an efficient
attention mechanism is introduced to help the model
better focus on the stylistic feature information in
anime images. In the style loss function part, the color
and luminance information of the image is erased, so
that the generated image presents obvious anime
texture and avoids color shifting.
Table 5: Stylistic and Semantic FIDs of Images Generated
by Different Algorithms (Li, Zhu, Li, et al., 2023)
algorithm Hayao style Shinkai style
Style Semantic Style Semantic
FID FID FID FID
original 179.
16
— 135.
81
—
CycleGAN 123.
03
163. 55 106.
61
107. 32
CartoonGAN 157.
72
90. 64 114.
38
79. 58
AnimeGAN 160.
90
89. 12 116.
72
87. 73
(Li, 2023) 154.
61
71. 97 115.
64
63. 48
A Comprehensive Study of Art Image Style Transfer Methods Based on Generative Adversarial Networks
175

Li also computes the FID scores for images
produced by various algorithms on the test set. This
helps assess how closely the generated images match
the content of the content image and the style of the
style image. Separate FID scores are calculated for
content and style (Li, Zhu, Li, et al., 2023).
As shown in Table 5, the initial values of the style
FID of the original image are 179. 16 and 135. 81, and
the style FID values of their proposed algorithm are
second only to the CycleGAN algorithm and
CartoonGAN algorithm in Miyazaki and Makoto
Shinkai styles, whereas there is a significant decrease
in the semantic FID values, which reaches 71. 97 and
63. 48. The CycleGAN algorithm, compared with the
others, has the style FID score the lowest, this is
because the CycleGAN algorithm only matches the
stylistic information of the target image and ignores
the semantic information of the original image, so the
generated image produces semantic distortion (Li,
Zhu, Li, et al., 2023).
3.3 Oil Paintiong
3.3.1 DE-GAN
Han and three others proposed DE-GAN, 1. a style
transfer scheme based on GAN, capable of deeply
extracting the artistic style from artistic works to
target image (Han, Wu, and Wan, 2023). For
verifying the efficacy of this approach, four indicators
are used for a single picture as an evaluation criterion.
There are feature similarity index (FSIM), mean
SSIM index (MSSIM), image average gradient, and
average reasoning time. SSIM ranges from 0 to 1,
where larger scores signify greater image similarity
(Han, Wu, and Wan, 2023). FSIM is an extension of
SSIM, its evaluation system is similar to SSIM.
MSSIM is the greater the average gradient of the
image, the sharper the image, and the better the
texture details. According to this indicator, DE-GAN
was compared with StyleGAN and CycleGAN.
StyleGAN is a GAN-based model that uses style to
influence the face and body shape in the generated
images. CycleGAN is a model based on GAN that can
transform photos into oil painting styles. The
comparison results of these three methods are shown
in Table 6.
Table 6: Evaluation and comparison of different models
(Han, Wu, and Wan, 2023)
Methods StyleGAN CycleGAN
DE-
GAN
FSIM1 0. 72 0. 68 0. 74
FSIM2 0. 62 0. 60 0. 64
FSIM3 0. 64 0. 62 0. 66
MSSIM1 0. 52 0. 52 0. 54
MSSIM2 0. 48 0. 51 0. 53
MSSIM3 0. 50 0. 52 0. 53
avera
g
e
g
radient1 0. 31 0. 23 0. 41
avera
g
e
g
radient2 0. 45 0. 41 0. 52
average gradient3 0. 52 0. 58 0. 63
Average
Reasoning Time
for a Single
Picture
(
ms
)
15. 64 26. 78 42. 63
These three methods can all effectively transfer
the painting style. However, it is clear from Table 6
that the migration images obtained by DE-GAN all
show small improvements in FSIM, MSSIM, and
average gradient. From this, it may draw such
conclusion, that the artistic images generated by this
method have better performance in structural
features, image distortion, image clarity, and texture
detail compared to others. This method is inferior to
StyleGAN and CycleGAN in speed.
3.3.2 Expansion of WGAN-GP
Liu proposed an Improved GAN for gradient
punishment to solve the difficulty of algorithm
training high, and the loss gradient of the generator
and discriminator disappears in the transfer of oil
painting style (Liu, 2021). WGAN-GP is a model that
uses Deep Convolutional Neural Network
architecture. It can solve the problem of loss gradient
disappearance of the generator and the discriminator
is difficult to train. This method is to transform a
model based on WGAN. To further assess the
efficacy of this approach., Contrast, SSIM, Entropy,
PSNR, MSE, and speed were used for evaluation.
Contrast and Entropy are two important indicators for
measuring image information in style transfer. MSE
is employed to evaluate the disparity between the
generated output and the target picture. Speed can be
seen as the algorithm efficiency. Liu uses CycleGAN
+ L1 regularization and CycleGAN to evaluate these
six indicators using this method (Liu, 2021). WGAN-
GP was only compared with this speed method. The
image quality of CycleGAN can be further improved
by CycleGAN + L1 regularization. A comparison of
these four methods is shown in Table 7.
DAML 2024 - International Conference on Data Analysis and Machine Learning
176
Table 7: Performance comparison of different methods
Methods CycleGAN CycleGAN+L1
(Liu Y, 2021) WGAN-GP
Contrast 28374.4 28736.2 29, 215. 9
SSIM 0.223 0.129 0. 251
Entropy 5.839 6.411 7. 216
PSNR 11.553 12.187 12. 638
MSE 3826.8 3769.6 3544. 7
Speed (Landscape 1) 2837.38s 2736.46 s 2637. 33 s 1384. 32 s
Speed (Landscape 2) 2365.32s 2645.56 s 2736. 73 s 1463. 23 s
S
p
eed
(
Landsca
p
e 3
)
3026.83s 2937.73 s 3173. 78 s 1183. 28 s
S
p
eed
(
Landsca
p
e 4
)
2653.43s 2736.82 s 2557. 38 s 1583. 41 s
In Table 7, most of the indicators of this approach
are better than CycleGAN + L1 regularization and
CycleGAN. This suggests that the visual quality of
this approach surpasses other methods and offers
higher practicality. In terms of efficiency, Original
WGAN-GP is more efficient than CycleGAN. The
results of time complexity for all are similar.
Therefore, to improve the speed of operation of the
law becomes a new problem.
4 CONCLUSIONS
Image style migration, as an emerging image
processing technique, has been widely used in several
fields This paper provides an overview of GAN-based
art image style translation techniques in three art
types: ink painting, animation, and oil painting, and
focuses on highlighting the significance of the
application, research implications and results of these
improved new models, as well as the advantages over
existing techniques.
In terms of ink painting, due to the special
characteristics of the style, such as white space and
other features that need to be fragmented to learn the
drawing, optimized based on ChipGAN is more
efficient in solving this problem, because it can
flexibly control the effect of the generated ink
paintings by inputting different conditional
information, such as brush strokes, ink color,
composition, etc., and perfecting the details of the ink
intensity, penetration patterns, etc. can also make the
generated ink paintings more realistic. Additionally,
the model can learn and master the characteristics of
ink drawings from ink drawing datasets, enabling it
to generate new works with strong generalization
abilities. Moreover, training ChipGAN models
requires significant computational power.
There are not many papers on anime as an image
style, and three methods are mentioned in this paper
which are applied to migrate two image styles,
landscape and people respectively. FAEC-GAN
addresses the issue of image edge distortion caused
by the migration process. In contrast, Zhao employs a
new architecture that efficiently extracts structural
features using a pre-trained network while preserving
image content. Additionally, Li's proposed algorithm
offers significant advantages in terms of quality and
visual realism in the generated images. Quality and
visual realism, Li's proposed algorithm has
significant advantages in terms of the quality and
visual realism of the generated images. Each of the
three approaches solves different problems faced by
the application, and it is a challenge to implement a
more comprehensive approach to get better results for
anime images.
AUTHORS CONTRIBUTION
All the authors contributed equally and their names
were listed in alphabetical order.
REFERENCES
Chen, S. S. C., Cui, H., Tan, P., Sun, X., Ji, Y. and Duh, H.,
2020. Cantonese porcelain image generation using
user-guided generative adversarial networks. IEEE
Computer Graphics and Applications, 40(5), pp.100-
107.
Dicke, R.H., Beringer, R., Kyhl, R.L. and Vane, A.B., 1946.
Atmospheric absorption measurements with a
microwave radiometer. Physical Review, 70(5-6),
pp.340.
Han, X., Wu, Y. and Wan, R., 2023. A method for style
transfer from artistic images based on depth extraction
generative adversarial network. Applied Sciences,
13(2), p.867.
Hong, L., Xu, C. and Liu, C., 2023. Computer animation
and virtual worlds. 2023.
Hu, B., 2023. Improvement study of ChipGAN, an image
inking style migration network. Master's thesis. Xi'an
Petroleum University.
A Comprehensive Study of Art Image Style Transfer Methods Based on Generative Adversarial Networks
177

Li, Y., Zhu, J., Liu, X., Chen, J. and Su, X., 2023. A style
translation algorithm for animation images based on
improved generative adversarial network. Journal of
Beijing University of Posts and Telecommunications,
pp.1-7.
Lin, C. T., Huang, S. W., Wu, Y. Y. and Lai, S.-H., 2021.
GAN-based day-to-night image style transfer for
nighttime vehicle detection. IEEE Transactions on
Intelligent Transportation Systems, 22(2), pp.951-963.
Liu, Y., 2021. Improved generative adversarial network and
its application in image oil painting style transfer.
Image and Vision Computing, 105, p.104087.
Tmenova, O., Martin, R. and Duong, L., 2019. CycleGAN
for style transfer in X-ray angiography. International
Journal of Computer Assisted Radiology and Surgery,
14, pp.1785-1794.
Xu, Y., Li, Y. and Shin, B.S., 2020. Medical image
processing with contextual style transfer. Human-
Centric Computing and Information Sciences, 10, p.46.
Zhao, W., Zhu, J., Huang, J., Li, P. and Sheng, B., 2024.
GAN-based multi-decomposition photo cartoonization.
Computer Animation and Virtual Worlds, 35(3),
p.e2248.
DAML 2024 - International Conference on Data Analysis and Machine Learning
178
