
Analysis of the Principle and Algorithms for Distributed Cloud
Computing
Hongyue Yu
Jiutian Xuanyu International School, Beijing, China
Keywords: Distributed Cloud Computing, Algorithms, Task Decomposition, Communication Mechanisms, Hardware
Facilities.
Abstract: As a matter of fact, in todays’ era cloud computing has had a significant impact on how data is processed and
managed especially in these years. With the rapid development of machine learning, these techniques have
been widely adopted into handling big data issues. Among various type of approaches, distributed method
attracts lots of scholars’ insights. With this in mind, this study looks closely at the basics and algorithms
behind distributed cloud computing focusing on breaking tasks down into parts and how computations and
communication work. After examining, the latest advancements have been demonstrated as well discuss what
they mean. According to the analysis, the research shows how distributed algorithms are making cloud
systems more scalable and efficient. In addition, to that discussion of challenges faced and suggestions for
approaches are explored with an emphasis on new algorithms being introduced to the mix. These results offer
the knowledge about distributed cloud computing as well as provide useful tips, for those designing and
building systems.
1 INTRODUCTION
In the ten years or so cloud computing has
transitioned from being an idea, to a widely used
technology that has significantly changed the field of
information technology. Researchers like Surbiryala
and Rong have looked into how it all started and how
it progressed highlighting its ability to allocate
resources flexibly and process data cost effectively
(Surbiryala & Rong, 2019). The progression that
followed in the works also illustrated the shift from
centralized to decentralized cloud structures which
required improvements, in algorithms and
infrastructure (Srinivasan, 2014; Jadeja & Modi,
2012).
In the years, human beings have seen a rise, in the
use of distributed cloud computing applications in
various industries (Peng, 2012). They have shown
processing power, for data analytics. Have been
combined with edge computing to provide services.
Additionally, they are being utilized in AI and IoT
sectors to drive innovation and effectiveness (Aazam,
et al., 2014).
Driven by a desire to thoroughly examine the core
concepts and algorithms of distributed cloud
computing in a manner than just theoretically
addressing the issue at hand is the primary goal of this
papers research endeavour. To achieve this objective
effectively and efficiently the following areas are
explored in sections. Section 2 provides an overview
of aspects of cloud computing. Section 3 delves, into
the intricacies of distributed algorithms. Section 4
covers facilities and real-world applications. Section
5 scrutinizes existing limitations and future
possibilities. In Section 6 the paper is brought to a
close, with a summary.
2 DESCRIPTIONS OF CLOUD
COMPUTING
Cloud computing represents an Internet-based
computational paradigm that encapsulates computing,
storage, and network resources into an independent
virtual environment through virtualization
technology. This model provides enterprises and
individual users with convenient, on-demand network
access to a shared pool of configurable computing
resources. Users can acquire necessary resources and
services in a scalable and flexible manner via the
network. The cloud computing framework facilitates
574
Yu, H.
Analysis of the Principle and Algorithms for Distributed Cloud Computing.
DOI: 10.5220/0013270800004568
In Proceedings of the 1st International Conference on E-commerce and Artificial Intelligence (ECAI 2024), pages 574-578
ISBN: 978-989-758-726-9
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

the delivery of computing services, including servers
and storage, as services over the internet.
Fundamental concepts such as virtualization as
elucidated by (Jain & Choudhary, 2016) and resource
pooling (Wang et al., 2014) underpin this model,
enabling flexible scalability and pay-per-use pricing
options. This section examines the principles and
architecture of cloud computing to establish a
foundation for subsequent discussions on algorithms.
The core principles of cloud computing can be
distilled into several key points: Firstly, users can
access required computing, storage, and network
resources from the cloud on-demand, without the
necessity of prior hardware acquisition and
configuration. Secondly, the cloud computing
platform encapsulates these resources into an
independent virtual resource pool, serving multiple
users through a multi-tenant model. This resource
pooling mechanism facilitates efficient resource
utilization, mitigating waste. Thirdly, the platform
dynamically adjusts resource allocation based on user
requirements, enabling elastic resource expansion.
When user demand increases, the platform
automatically augments resources; conversely, it
releases excess resources when demand diminishes,
thereby optimizing user costs. Fourthly, virtualization,
a core technology in cloud computing, enables
dynamic allocation and flexible management of
resources by encapsulating computing, storage, and
network resources into independent virtual
environments. This allows users to access required
computing resources and services through software
interfaces without direct interaction with physical
hardware. Cloud computing services are typically
stratified into three tiers: Infrastructure as a Service
(IaaS), Platform as a Service (PaaS), and Software as
a Service (SaaS).
These three service layers provide users with
comprehensive support, ranging from fundamental
resources to higher-level applications. They
implementation of cloud computing relies on several
key technologies, including as following.
Virtualization technology encapsulates computing,
storage, and network resources into independent
virtual environments, facilitating dynamic resource
allocation and flexible management. Distributed
computing approach utilizes multiple computers
working in concert to execute complex computational
tasks, enhancing overall computing efficiency. Data
management technology encompasses big data
processing, data storage, and data security
technologies, ensuring efficient data processing and
secure storage.To illustrate, a large financial
institution might employ cloud computing
technology to achieve rapid deployment and elastic
expansion of its business systems. Through cloud
services, banks can flexibly respond to business peaks
caused by holidays or emergencies, enhance system
stability and security, and reduce operational and
maintenance costs
3 ALGORITHMS FOR
DISTRIBUTED CLOUD
COMPUTING
Distributed cloud computing algorithms play a
crucial role in partitioning tasks across multiple nodes
while ensuring efficient execution and inter-node
communication. Recent literature published since
2020 by researchers demonstrates advancements in
frameworks akin to MapReduce and Directed Acyclic
Graph (DAG)-based systems like Apache Spark (e.g.,
Verbraeken et al., 2020; Ageed et al., 2020; Xu et al.,
2023). These studies elucidate the process of task
decomposition into components, their distribution to
nodes for processing, and subsequent aggregation to
produce final results. Moreover, they emphasize the
analysis of communication protocols that prioritize
data locality and mitigate network congestion. The
distributed computing paradigm involves dividing
computational tasks into subtasks, executing them
concurrently on multiple compute nodes, and
synthesizing the results. This approach offers several
advantages, including the ability to dynamically scale
compute resources based on demand and maintain
system functionality even in the event of node failures.
MapReduce, a seminal distributed computing model
proposed by Google, comprises two primary phases:
the Map phase, which partitions and processes input
data, and the Reduce phase, which aggregates the
Map phase outputs. The model's strengths lie in its
simplicity and robust fault tolerance.
Apache Spark, a DAG-based distributed
computing framework, enhances performance
through in-memory computing. Compared to
MapReduce, Spark's ability to reuse data across
multiple iterative computations significantly
accelerates processing speeds.Beyond MapReduce
and Spark, the distributed computing landscape
encompasses other significant algorithms, such as
distributed deep learning algorithms and graph
computing frameworks (e.g., Apache Flink). These
algorithms optimize data processing for specific use
cases. In distributed computing, communication
efficiency is a critical factor influencing overall
performance. Researchers have proposed various
Analysis of the Principle and Algorithms for Distributed Cloud Computing
575
communication protocols aimed at optimizing data
transmission paths and alleviating network
congestion. For instance, the principle of data locality
assigns computing tasks to nodes in proximity to data
storage, thereby reducing latency and enhancing
throughput. In the realm of big data analysis,
distributed computing enables the processing of
massive datasets. Enterprises leverage frameworks
such as Hadoop and Spark for real-time data analysis
and business intelligence decision-making. In
machine learning, distributed approaches facilitate
the training of large-scale models by distributing
training tasks across multiple nodes. Frameworks like
TensorFlow and PyTorch support distributed training,
significantly accelerating model convergence.
Cloud computing platforms, such as AWS and
Azure, offer distributed computing services that allow
users to dynamically adjust computing resources
based on demand, optimizing both cost and
performance. Future research in distributed
computing is expected to focus on several key areas:
edge computing, which aims to push computation
closer to data sources to reduce latency; intelligent
scheduling, utilizing artificial intelligence to optimize
task allocation and improve resource utilization; and
enhanced security measures to strengthen data
protection and privacy in distributed environments.
4 FACILITIES AND
APPLICATIONS
Recent research, such as that conducted by Tang et al.
has comprehensively demonstrated the efficacy of
distributed cloud computing through its robust
hardware infrastructure and diverse application
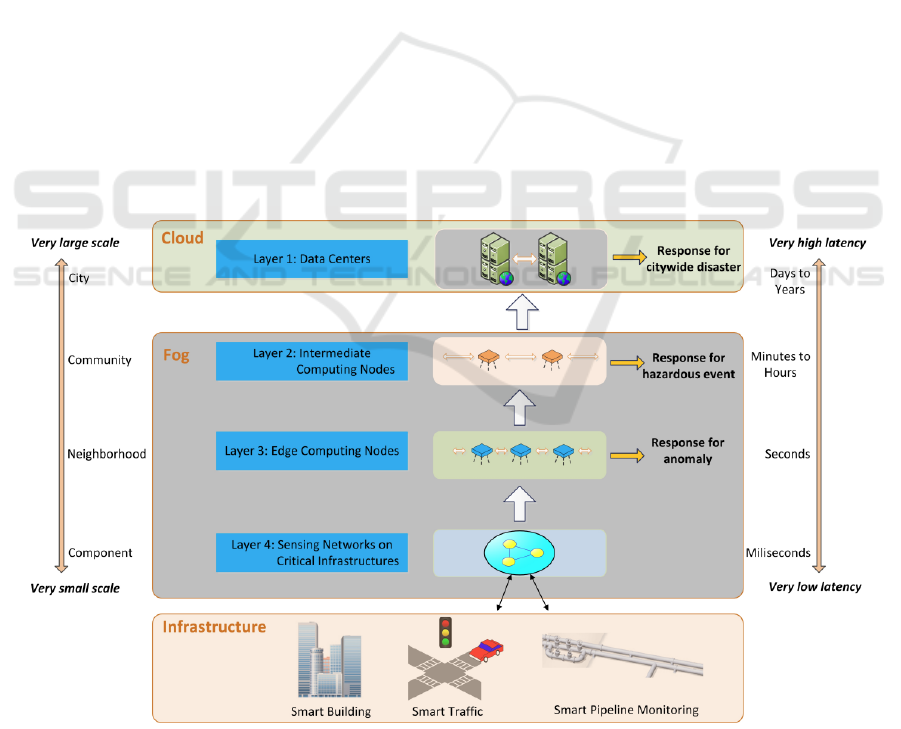
capabilities as depicted in Fig. 1 (Tang et al., 2015).
These studies have explored high-performance server
storage arrays and advanced networking technologies
that facilitate large-scale cloud deployments. This
section aims to elucidate these applications, ranging
from data analytics to real-time services, each
necessitating a tailored hardware solution.
Distributed cloud computing empowers enterprises to
efficiently manage and process vast amounts of data.
Its success is predicated on a powerful hardware
infrastructure capable of supporting a myriad of
complex applications. High-performance server
storage arrays and sophisticated networking
technologies form the cornerstone of distributed
cloud computing. Vouk et al. posits that the
implementation of high-performance computing
(HPC) servers can significantly enhance data
Figure 1: The 4-layer Fog computing architecture in smart cities, in which scale and latency sensitive applications run near
the edge. (Tang et al., 2015).
ECAI 2024 - International Conference on E-commerce and Artificial Intelligence
576

processing speeds, research indicates that
contemporary storage solutions, such as SSD arrays,
are better equipped to support big data applications
(Vouk et al., 2010). Data analysis represents a
primary application domain for distributed cloud
computing. Moreover, the demand for real-time
decision support services among enterprises is
burgeoning. Other research underscores the
advantages of cloud computing in real-time data
processing, particularly within the financial and
telecommunications sectors (Valls et al., 2012). The
diverse application requirements have precipitated
the development of customized hardware solutions.
For instance, data analytics may demand higher
memory capacity and computational power, while
real-time services prioritize low latency.
Consequently, the selection of appropriate hardware
is paramount to success. The following figure
illustrates the fundamental structure and application
scenarios of distributed cloud computing. The
practicality of distributed cloud computing is evident,
with its powerful hardware infrastructure and
extensive range of application scenarios
complementing each other synergistically. As
technology continues to advance, the future of cloud
computing promises to be increasingly efficient and
flexible, providing robust support for the
development of various industries.
5 LIMITATIONS AND
PROSPECTS
Despite significant advancements in distributed cloud
computing, numerous challenges persist in terms of
algorithmic efficiency, scalability, and security. This
research aims to elucidate key issues in current
research and propose future research directions, with
a particular emphasis on the critical roles of task
scheduling and communication protocols. Distributed
cloud computing enhances resource utilization and
computational power by distributing tasks across
multiple nodes. However, existing algorithms exhibit
limitations in efficiency and security when processing
large-scale data. Scholars conducted comprehensive
analyses of extant algorithms, underscoring the
significance of task scheduling and communication
protocols in distributed computing (Woo, et al. 1997;
Borcea et al., 2002). Their research demonstrated that
judicious task scheduling can substantially improve
overall system performance, while efficient
communication protocols are instrumental in
facilitating seamless data exchange.
Future research endeavors should prioritize the
development of algorithms capable of effectively
distributing workload and ensuring optimal
utilization of resources across all nodes, thereby
enhancing overall computational performance. Such
advancements would not only improve efficiency but
also reduce latency, consequently elevating the user
experience. As data security concerns become
increasingly prevalent, future investigations must
address the challenge of safeguarding user privacy
without compromising performance. The
development of robust encryption and access control
algorithms represents a crucial avenue for further
research. The emergence of artificial intelligence (AI)
presents novel opportunities for algorithmic
innovation. The integration of AI technologies with
distributed cloud computing has the potential to
enable more efficient computation and facilitate
intelligent decision support systems. This synergy
between AI and distributed cloud computing opens up
new frontiers for research and practical applications
in the field.
6 CONCLUSIONS
To sum up, this research studied the concepts and
methods used in distributed cloud computing and how
they play a role, in improving system performance
and scalability. One looked at studies that show how
advanced algorithms help manage tasks and
communication in distributed environments.
Additionally, discussed the hardware resources that,
back these systems and demonstrated their use in
industries. Distributed cloud computing has advanced
considerably. Still faces challenges, like optimizing
algorithms and dealing with scalability issues and
security risks which need to be tackled in research by
creating smarter algorithms that can adapt to
changing workloads and network environments
dynamically. Furthermore, collaborating emerging
technologies, like edge computing, quantum
computing and AI powered optimization might boost
the efficiency and functionality of distributed cloud
systems.
REFERENCES
Aazam, M., Khan, I., Alsaffar, A. A., Huh, E. N., 2014.
Cloud of Things: Integrating Internet of Things and
cloud computing and the issues involved. Proceedings
of 2014 11th International Bhurban Conference on
Analysis of the Principle and Algorithms for Distributed Cloud Computing
577

Applied Sciences & Technology (IBCAST) Islamabad,
Pakistan pp 414-419.
Ageed, Z. S., Ibrahim, R. K., Sadeeq, M. A., 2020. Unified
ontology implementation of cloud computing for
distributed systems. Current Journal of Applied Science
and Technology, 39(34), 82-97.
Borcea, C., Iyer, D., Kang, P., Saxena, A., Iftode, L., 2002.
Cooperative computing for distributed embedded
systems. Proceedings 22nd International Conference on
Distributed Computing Systems pp 227-236.
Ge, P., 2012. A Brief Overview on Distributed Computing
Technology. Microelectronics & Computer, 29(5), 201-
204.
Jadeja, Y., Modi, K., 2012, March. Cloud computing-
concepts, architecture and challenges. 2012
international conference on computing, electronics and
electrical technologies (ICCEET) pp 877-880.
Jain, N., Choudhary, S., 2016. Overview of virtualization in
cloud computing. Symposium on Colossal Data
Analysis and Networking (CDAN) pp 1-4.
Srinivasan, S., Srinivasan, S., 2014. Cloud computing
evolution. Cloud Computing Basics, 1-16.
Surbiryala, J., Rong, C., 2019. Cloud computing: History
and overview. IEEE Cloud Summit pp 1-7.
Tang, B., Chen, Z., Hefferman, G., Wei, T., He, H., Yang,
Q., 2015. A hierarchical distributed fog computing
architecture for big data analysis in smart cities.
Proceedings of the ASE BigData & SocialInformatics
pp 1-6.
Valls, M. G., López, I. R., Villar, L. F., 2012. iLAND: An
enhanced middleware for real-time reconfiguration of
service oriented distributed real-time systems. IEEE
Transactions on Industrial Informatics, 9(1), 228-236.
Verbraeken, J., Wolting, M., Katzy, J., Kloppenburg, J.,
Verbelen, T., Rellermeyer, J. S., 2020. A survey on
distributed machine learning. Acm computing surveys
(csur), 53(2), 1-33.
Vouk, M. A., Sills, E., Dreher, P., 2010. Integration of high-
performance computing into cloud computing services.
Handbook of cloud computing, 255-276.
Wang, W., Liang, B., Li, B., 2014. Multi-resource fair
allocation in heterogeneous cloud computing systems.
IEEE Transactions on Parallel and Distributed Systems,
26(10), 2822-2835.
Woo, S. H., Yang, S. B., Kim, S. D., Han, T. D., 1997. Task
scheduling in distributed computing systems with a
genetic algorithm. Proceedings High Performance
Computing on the Information Superhighway. HPC
Asia pp 301-305.
Xu, W., Yang, Z., Ng, D. W. K., Levorato, M., Eldar, Y. C.,
Debbah, M., 2023. Edge learning for B5G networks
with distributed signal processing: Semantic
communication, edge computing, and wireless sensing.
IEEE journal of selected topics in signal processing,
17(1), 9-39.
ECAI 2024 - International Conference on E-commerce and Artificial Intelligence
578
