
The Application of Machine Learning to Algorithmic Trading in
Financial Markets
Kehan Feng
a
School of Business, McMaster University, Hamilton, Canada
Keywords: Algorithmic Trading; Artificial Intelligence; Predictive Modelling; Market Forecasting.
Abstract: The surge in global digitalization has propelled stock market forecasting into a new era of advanced
technology, transforming traditional trading models. This paper explores the use of Artificial Intelligence (AI)
in algorithmic trading, highlighting its potential to optimize trading strategies, improve forecasting accuracy,
and manage risk. By utilizing the AI techniques such as the deep learning, machine learning and reinforcement
learning algorithms, this study examines how these methods can improve the market forecasting by analysing
the structured and unstructured data. Artificial intelligence-driven trading systems, while promising, face
significant challenges, including model interpretability, applicability in volatile markets, and. To address these
challenges, this paper discusses the importance of integrating interpretable AI tools, as well as the potential
of emerging technologies such as the transfer learning and federated learning. These innovations aim to
improve model transparency, adaptability, and privacy, paving the way for more robust and reliable AI
applications in financial markets.
1 INTRODUCTION
The rise of the global digitalization wave has ushered
stock market forecasting into a new era of high
technology, revolutionizing traditional trading
models. The World Bank reported in 2018 that the
global stock market capitalization has exceeded
$68.654 trillion (WorldBank, 2021). The rising tide
of global digitization has brought stock market
forecasting into a new era of high technology,
revolutionizing traditional trading models. As market
capitalization continues to grow, stock trading has
become a focal point for many financial investors
seeking to optimize their portfolios and maximize
returns. Advanced trading models now enable
researchers to leverage non-traditional text data from
social platforms to predict market trends and
behavior. For example, Frank and Sanai used the
comprehensive news set of S&P 500 corporations
(Murray et al., 2018). By applying sophisticated
machine learning techniques such as text data
analytics and integration methods, the accuracy of
market predictions has improved significantly,
providing investors with deeper insights into potential
market movements.
a
https://orcid.org/0009-0004-2837-3519
Despite these advances, stock market analysis and
forecasting remain one of the most challenging
research topics in finance due to the inherent
dynamics, instability, and complexity of market data.
Due to its nonlinear, dynamic, stochastic and
unreliable nature of Stock Market Prediction (SMP)
(Tan et al., 2007), traditional algorithmic trading
systems rely heavily on structured market data such
as stock prices and trading volumes, often ignoring
unstructured data that can have a significant impact
on the market. These characteristics require
researchers to constantly innovate and develop new
methods to adapt to the changing market
environment.
Algorithmic trading is a key area of focus in the
evolution of this technology, which relies on complex
mathematical models and high-performance
computer programs to execute trade orders in
milliseconds, thereby capturing fleeting market
opportunities. This approach has shown great
potential to improve trading efficiency, reduce costs
and optimize portfolios. However, the practical
application of algorithmic trading poses unresolved
challenges, particularly in terms of the accuracy and
reliability of Artificial Intelligence (AI) algorithms
when processing market data, identifying trading
Feng, K.
The Application of Machine Learning to Algorithmic Trading in Financial Markets.
DOI: 10.5220/0013264200004568
In Proceedings of the 1st International Conference on E-commerce and Artificial Intelligence (ECAI 2024), pages 407-411
ISBN: 978-989-758-726-9
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
407
patterns and managing risk. Traditional algorithmic
trading systems rely heavily on structured market data
such as stock prices and trading volumes. While
effective, this approach tends to ignore unstructured
data such as news sentiment, social media activity,
and other external information that can have a
significant impact on market dynamics. The omission
of unstructured data limits the effectiveness of
existing forecasting models, especially given the
inherent volatility and complexity of financial
markets. As these markets evolve and attract more
attention, there is a growing need for systematic
approaches that integrate a variety of data sources,
including traditional and unconventional inputs.
Research has extensively explored high-
frequency trading and quantitative investing, using
artificial intelligence algorithms to accelerate trading
and optimize portfolio management. Despite this,
most existing algorithmic trading systems continue to
rely heavily on structured market data, with limited
consolidation of unstructured data that can provide
valuable insights. This gap in integrating different
data sources is a key area for future research, as
merging unstructured data can improve the
robustness and accuracy of predictive models. In
addition, existing research highlights the importance
of applying AI to multi-asset class trading. By
examining how to optimize portfolios across different
markets and asset classes, researchers aim to diversify
risk and improve overall returns. Expansion into
multi-asset class trading involves developing
algorithms that can manage complex relationships
and correlations between various assets, a task that
requires sophisticated AI and machine learning
models.
This study aims to explore the application of (AI)
in algorithmic trading, especially how AI technology
can be used to optimize trading strategies, improve
prediction accuracy and reduce risks.
2 METHOD
This section explains conducted literature collection
through various search engines, digital libraries, and
databases, including Google Scholar, ResearchGate,
and Scopus, among others. In the process of literature
collection, keywords and phrases such as "stock
market forecasting method", "quantitative
investment" and "structured market data and
unstructured data" were used to obtain relevant
research results. Through this literature, existing
predictive models and algorithmic trading strategies
can be identified, and their strengths and weaknesses
can be evaluated.
2.1 Introduction of Machine Learning
Workflow
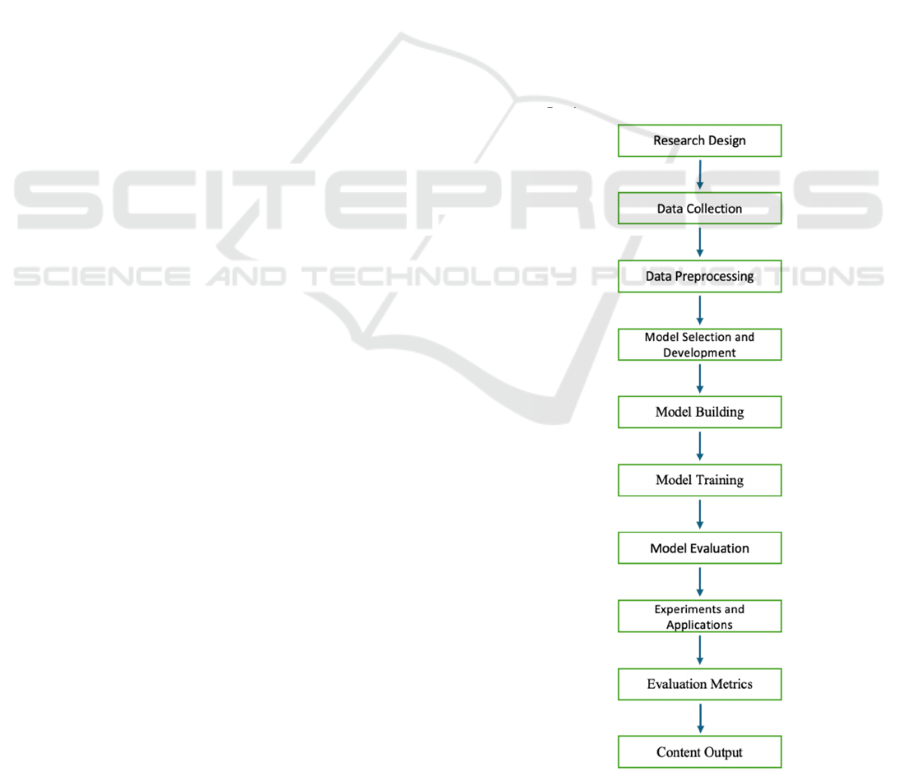
A machine learning workflow shown in Figure 1
involves several critical stages, each essential for
developing effective predictive models. It begins
with Data Collection, where structured and
unstructured data relevant to the problem is gathered
from various sources. This data is then subjected
to Data Pre-processing, which includes cleaning,
normalization, and feature engineering to ensure it is
suitable for model input. The next step is Model
Selection and Development, where appropriate
algorithms are chosen based on the problem's nature
and data characteristics. This is followed by Model
Building, where the selected algorithms are
implemented and designed for training. Model
Training involves feeding the prepared data into the
model, allowing it to learn and optimize its
parameters. Finally, Model Testing evaluates the
model’s performance using a separate dataset,
ensuring its accuracy and generalization ability
before deployment.
Figure 1: The typical machine learning workflow (Photo/
Picture credit: Original).
ECAI 2024 - International Conference on E-commerce and Artificial Intelligence
408

2.2 Quantitative Investment
2.2.1 PPO Algorithm
Proximal Strategy Optimization (PPO) is a
reinforcement learning algorithm that optimizes
trading strategies by directly adjusting them to
maximize expected returns while maintaining
stability through restricted updates. It is particularly
useful in algorithmic trading and portfolio
management, where strategies can be dynamically
adjusted according to market conditions. The
shearing mechanism of PPO ensures the
controllability of strategy changes and reduces the
risk of instability during training, making it an
effective tool for developing risk-aware and profit-
optimizing trading agents. Therefore, this study
chooses the model-free algorithm that learns under
the assumption that the transition probabilities are
unknown. Among the model-free algorithms, the
policy optimization algorithm that performs better
than the Q-learning algorithm for continuous
behavior and high dimensional data is selected
(Brockman et al., 2016; Duan et al., 2016). Finally,
among the policy optimization algorithms, the PPO
algorithm, which outperforms the other algorithms in
terms of implementation, simplicity and
performance, is selected (Schulman et al., 2017).
2.2.2 Risk Management and Hedging
In quantitative investing, risk management and
hedging strategies are central to ensuring portfolio
stability and optimizing returns. Quantitative
investing relies on mathematical models and
algorithms to identify, assess and control risk through
a variety of tools. Among them, volatility
management and value-at-risk (VaR) are commonly
used risk management methodologies. var is widely
used by most trading organizations to track the risk of
their market portfolios and to help supply chain
managers quantify the potential risk of "what-if"
scenarios (Saita, 2007). Volatility management helps
investors reduce risk exposure when market volatility
rises, or increase return potential when volatility falls,
by measuring how much asset prices or portfolio
returns move. Historical volatility provides a picture
of past market volatility, while implied volatility
reflects the market's expectation of future uncertainty.
VaR, on the other hand, is used to estimate the
maximum potential loss that could occur in each time
period, providing a basis for investors to set stop-loss
points or adjust their investment strategies.
Hedging strategies also play an important role in
quantitative investing. Through derivatives such as
futures and options, investors can effectively hedge
the risk of a particular asset or the market. For
example, market-neutral strategies reduce the impact
of market volatility on investment portfolios by
simultaneously going long and short the underlying
assets; statistical arbitrage utilizes historical
relationships between assets to conduct hedging
transactions.
The dynamic risk-adjustment capability of
quantitative investing is one of its significant
advantages. By automating the adjustment of risk
exposures, quantitative investment strategies can
respond in a timely manner to changes in market
conditions, reducing risk exposure or capturing more
return opportunities. These methods not only enhance
the science of investment decision-making, but also
strengthen the resilience of investment portfolios in
complex market environments, ensuring that
investors effectively control risks while pursuing
returns.
2.3 Stock Price Prediction
2.3.1 Deep Neural Network-Based
Prediction
The method utilizes deep learning techniques to
extract complex patterns from large amounts of
historical data to predict future stock prices. Deep
neural networks are constructed through multiple
layers of neurons with strong nonlinear mapping
capabilities. Commonly used network architectures
include fully connected networks, convolutional
neural networks (CNN), and recurrent neural
networks (RNNs), of which long short-term memory
networks (LSTMs) and gated recurrent units (GRUs)
are particularly suited for processing time series data.
The process of stock price prediction usually includes
data preprocessing, model training and prediction
evaluation. Data preprocessing includes
normalization, standardization and feature extraction
to improve model training. The model training stage
uses a large amount of historical data to adjust the
model parameters and minimize the prediction error
by selecting appropriate loss functions and
optimization algorithms. The trained model can be
used to predict future stock prices, and the results
need to be post-processed (e.g., inverse
normalization) to obtain the actual stock prices.
DNN-based stock price prediction offers
significant advantages, including capturing complex
nonlinear patterns and automatic feature learning
without the need for manually designed features.
However, these approaches also face challenges, such
as the need for large amounts of data, the risk of
overfitting, poor model interpretability, and high
computational resource requirements. The “black
box” nature of deep neural networks makes their
The Application of Machine Learning to Algorithmic Trading in Financial Markets
409

decision-making process difficult to interpret, which
may pose difficulties in financial decision-making.
Therefore, although DNNs perform well in stock
price prediction, these challenges need to be
addressed to improve the accuracy and stability of
predictions.
2.3.2 LSTM-Based Prediction
Stock price prediction based on Long Short-Term
Memory Networks utilizes the LSTM model in deep
learning to analyses and predict the future movements
of stock prices. LSTM is a special type of recurrent
neural network (RNN) designed to process and learn
long-term dependencies in time-series data, which
overcomes the problems of gradient vanishing and
gradient explosion faced by traditional RNNs in long-
series data. LSTM is able to effectively capture
complex patterns in stock price data, including
seasonal and long-term trends, which makes it
particularly suitable for time series forecasting. Its
memory mechanism allows the network to maintain
and update information over a longer period of time,
thus enhancing the prediction of stock price
movements. By stacking multiple LSTM layers, the
model can learn deeper features in the data to further
improve prediction accuracy.
When applying LSTM for stock price prediction,
it usually includes the following steps: first, the data
preparation stage requires collecting and cleaning
historical stock price data, including processing
missing values and normalization. Next, the LSTM
model is constructed, the network structure is
designed, and appropriate hyperparameters are
selected. When training the model, the network
weights are optimized by historical data to minimize
the prediction error. The trained model needs to be
evaluated to verify its prediction performance using
metrics such as Mean Square Error (MSE) and to
check the generalization ability of the model through
cross-validation. Finally, the model is deployed for
real-time forecasting with continuous monitoring and
retraining to adapt to market changes.
3 DISCUSSIONS
In the current research on stock market forecasting
and algorithmic trading, AI technologies still face
many challenges and limitations despite
demonstrating their potential. First, model
interpretability is a notable issue. Complex AI
models, especially deep learning networks such as
LSTM, are often viewed as "black boxes," making it
difficult for investors and regulators to understand
their decision-making process. This lack of
transparency not only reduces trust in AI-driven
strategies but may also pose challenges in terms of
regulatory compliance. In addition, AI models excel
in laboratory environments, but uncertainty remains
about their applicability in real, highly volatile
financial markets. Models that rely on historical data
for training often perform poorly in the face of
unprecedented market events or volatility, leading to
a lack of model generalization capabilities, thus
limiting their practical application value. While AI
models show promise in controlled environments,
their applicability in real-world, highly volatile
financial markets remains uncertain. Models trained
on historical data may perform poorly in the face of
unprecedented market events or changes. On the
other hand, relying on historical data to train AI
models may lead to overfitting, in which case the
model performs very well on past data but fails to
generalize to new, unseen scenarios. This limitation
hinders the practical application of AI in dynamic
market conditions.
Quantitative Investment (QI) has demonstrated
unique advantages in relying on mathematical models
and algorithms to make investment decisions in a
data-driven manner. However, these models also face
multiple limitations and challenges. Firstly, model
overfitting is a major issue, especially when relying
too much on historical data during training, leading to
unsatisfactory performance in real markets. In
addition, the effectiveness of quantitative investing
relies on the quality of the data, and any errors or
noise in the data may trigger wrong investment
decisions. The changing dynamics of financial
markets also pose a challenge to quantitative models,
as sudden market events or policy changes may
invalidate models based on past data.
Another key challenge is the transparency and
explanatory nature of models, especially when
complex machine learning algorithms are used, which
can make it difficult for investors and regulators to
understand the model's decision-making process.
The popularity of algorithmic trading could also lead
to increased market volatility and even trigger
phenomena such as flash crashes. The high demand
for technological infrastructure, on the other hand,
means that building and maintaining these models
requires powerful computing power and high costs,
which can be challenging for small investment
organizations or individual investors. In addition, as
regulators increase their focus on algorithmic trading,
compliance issues may limit the use of certain
strategies or increase the complexity of
implementation. Finally, quantitative models may
perform well at small scales, but market impact and
ECAI 2024 - International Conference on E-commerce and Artificial Intelligence
410

slippage issues may erode their returns when
operating with large-scale capital.
In the future development of AI technology,
several emerging approaches are expected to
significantly improve the limitations of current
algorithmic trading systems. First of all, Expert
systems, SHAPLE Additive explanations (SHAP)
and Local Interpretable Model-agnostic Explanatory
AI tools such as Explanations (LIME) will play an
important role in improving model transparency and
explainability. By shedding light on the basis on
which model decisions are made, these tools can help
not only bolster investor and regulator trust in AI-
driven strategies, but also help identify potential
model biases and risks (Linardatos et al., 2020). This
will lead to the evolution of AI models from "black
boxes" to more explanatory and transparent, allowing
them to be more widely used in practical financial
decisions.
In addition, transfer learning and domain
adaptation techniques can enhance the adaptability of
AI models (Ma et al., 2024; Weiss et al., 2016). These
approaches accelerate model deployment in new
markets by reusing knowledge from existing models
in new domains and reducing reliance on large-scale
data and computing resources. This is particularly
critical for dealing with dynamic changes and
unpredictability in financial markets, as models can
quickly adapt to new market characteristics,
improving their robustness and extensiveness for
practical applications. These future directions not
only provide potential solutions to the current
challenges of AI technology, but also lay the
foundation for innovation in algorithmic trading
systems
4 CONCLUSIONS
This paper explores the use of AI in algorithmic
trading, revealing its potential to optimize trading
strategies, improve forecast accuracy, and reduce
risk. However, despite the demonstrated power of AI
technology in financial markets, its widespread use
still faces many challenges, such as model
interpretability, applicability. Through an in-depth
analysis of these challenges, this study emphasizes
the need to develop more explanatory and transparent
AI tools, such as SHAP and LIME, to enhance the
confidence of investors and regulators. These
approaches not only extend the application scope of
AI models, but also improve their adaptability and
security in complex financial environments. In the
future, with the further development and application
of these technologies, AI is expected to play a more
important role in algorithmic trading and drive the
digital transformation of financial markets.
REFERENCES
Brockman, G., Cheung, V., Pettersson, L., Schneider, J.,
Schulman, J., Tang, J., et al. 2016. OpenAI gym. arXiv,
arXiv:1606.01540.
Duan, Y., Chen, X., Houthooft, R., Schulman, J., & Abbeel,
P. 2016. Benchmarking deep reinforcement learning for
continuous control. In Proceedings of the International
Conference on Machine Learning (pp. 1329-1338).
Frand, M. Z., & Sanati, A. 2018. How Does the Stock
Market Absorb Shocks. Journal of Financial
Economics, 136-153.
Linardatos, P., Papastefanopoulos, V., & Kotsiantis, S.
2020. Explainable ai: A review of machine learning
interpretability methods. Entropy, 23(1), 18.
Ma, Y., Chen, S., Ermon, S., & Lobell, D. B. 2024. Transfer
learning in environmental remote sensing. Remote
Sensing of Environment, 301, 113924.
Saita, F. 2007. Value at Risk and Bank Capital Management
(pp. 1-5). Boston: Academic Press.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., &
Klimov, O. 2017. Proximal policy optimization
algorithms. arXiv, arXiv:1707.06347.
Tan, T. Z., Quek, C., & Ng, G. S. 2007. Biological Brain-
Inspired Genetic Complementary Learning for Stock
Market and Bank Failure Prediction. Computational
Intelligence, 23, 236-261.
Weiss, K., Khoshgoftaar, T. M., & Wang, D. 2016. A
survey of transfer learning. Journal of Big data, 3, 1-40.
World Bank. 2021. Market Capitalization of Listed
Domestic Companies (Current US$) Data. Retrieved
May 19, 2021, from https://data.worldbank.org/
indicator/CM.MKT.LCAP.CD
The Application of Machine Learning to Algorithmic Trading in Financial Markets
411
