
Research on Key Technologies of Neural Machine Translation Based
on Deep Learning
Kaijie Lai
a
Informatuon and Computing Science, Xi’an Jiaotong-Liverpool University, Suzhou, Jiangsu, China
Keywords: Deep Learning, Neural Machine Translation, Recurrent Neural Network, Transformer.
Abstract: Machine Learning is a technology aiming to finish automatic translation from one language to another by
using a computer. Such a technique plays a significant role in promoting cultural communication and boosting
the economic development. Nowadays, the fast development and enormous utilization of Deep Learning and
Neural Networks in Natural Language Processing (NLP) field generate a new concept called Neural Machine
Translation (NMT). The way to integrate Neural Networks into NMT models has a promising future. And
after several years’ development, progress in NMT has been made on all fronts. Learning different Deep
Learning based Machine Translation models is meaningful to acquire a better understanding about NMT. To
show the research progress, based on the proposed time, the article discussed some famous NMT models
through their operating principle, innovation points and problems remained, highlighting the progression from
Recurrent Neural Network (RNN) Encoder-Decoder architecture in NMT to the powerful Transformer model.
The article also sorts out and compares the performance of the NMT models mentioned based on their
performances on some public corpuses. Finally, the paper discusses the future directions in NMT, such as
solving challenges for low-resource languages’ translation, developing multilingual NMT models and
increasing the models’ interpretability.
1 INTRODUCTION
Machine Translation (MT) is a technique using the
power of AI to fulfil the task of automatically
translation from one language to another (Stahlberg,
2020). As a research hotspot in Neural Language
Processing, MT technology has important application
value. It helps to promote the cultural communication
and enhance the development of economy around the
world. Famous companies such as Baidu, Google and
Microsoft have their own MT models for translation
software to increase the translation efficiency and
better fulfill their users’ needs. The rise of neural
networks has contributed to a fast development in MT
and generated a new concept: Neural Machine
Translation (NMT). Unlike the model that relies on
statistics, the neural network makes NMT provide a
much more reliable solution than Statistics Machines
Translation (SMT) which the translation results are
more acceptable to users due to the self-learning
models on huge parallel corpora for training
(Dowling et al., 2018). The translation results from
a
https://orcid.org/ 0000-0002-4663-3255
NMT might be closer to people’s usual language
habits than traditional SMT. Early attempts to
compare NMT and SMT on United Nations Parallel
Corpus v1.0 illustrated NTM’s equal or even better
performance on some translation tasks (Junczys,
Dwojak & Hoang, 2016). From then, the NMT model
gradually replaced the traditional MT relied on
statistics. The introduction of Attention Mechanism
and Transformer enormously improved NMT’s
performance and has been used in education,
healthcare, finance and many other fields for different
aspects of translation. It solved some traditional
problems in MT tasks such as long-term
dependencies problems. The performance of
Transformer is superior to all previous NMT models
in translation tasks and lays the foundation for the
subsequent NMT models.
In the past, without the help of deep learning,
SMT was the mainstream approach to for translation.
The method will use statistical models such as Hidden
Markov Models to translate texts. To translate a
sentence from one language to another, SMT will do
60
Lai, K.
Research on Key Technologies of Neural Machine Translation Based on Deep Learning.
DOI: 10.5220/0013231400004558
In Proceedings of the 1st International Conference on Modern Logistics and Supply Chain Management (MLSCM 2024), pages 60-65
ISBN: 978-989-758-738-2
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
statistical analysis to predict the most likely
translation based on the already known translations
(which are also known as given bilingual corpora)
(Hearne & Way, 2011). However, such methods will
finish the translation mission without considering the
context and contribute to less human-readable
translations (Bahdanau, Cho & Bengio, 2014). And
the statistical models also have problems in model
complexity, translation quality, etc. The introduction
of NMT helps to solve or improve some of the
problems brought by SMT. Based on the proposed
time, some of the famous NMT models are:
1) Recurrent Neural Network (RNN)
Encoder-Decoder: Introduced by Cho et al., this
framework implemented neural networks to machine
translation (Cho, Van & Gulcehre et al., 2014). To
process input and output sequence in encoder-
decoder architecture step by step, the model improved
‘long-term dependencies’ problem and could retain
context related information (Sutskever, Vinyals & Le,
2014). However, such benefits also contributed to
complexity and uncertainty in decoding.
2) Attention Mechanism: Introduced by
Bahdanau et al., the Attention Mechanism aims to
solve low translation quality on long sentence
problems (Bahdanau, Cho & Bengio, 2014). It solved
the performance bottleneck caused by the fixed-
length context vector in the traditional RNN
architecture. Such a method improves the accuracy of
long sentences translation on RNN model.
3) Transformer: Introduced by Vaswani et al.,
beyond the RNN architecture, the Transformer Model
put forward the Self-Attention Mechanism (Vaswani
et al., 2017). The model could realize parallel
computing through Multi-Head Attention mechanism
and capture different contextual information in a
sequence. Besides, the feed-forward network layer
helps to increase the model’s interpretability.
According to the famous models in NMT
mentioned above, this article will introduce and
discuss different NMT models, showing their
performance on public datasets and illustrating the
future development of NMT.
2 FAMOUS NMT MODELS
2.1 Basic RNN
Introduced by Cho et al., the basic RNN Encoder-
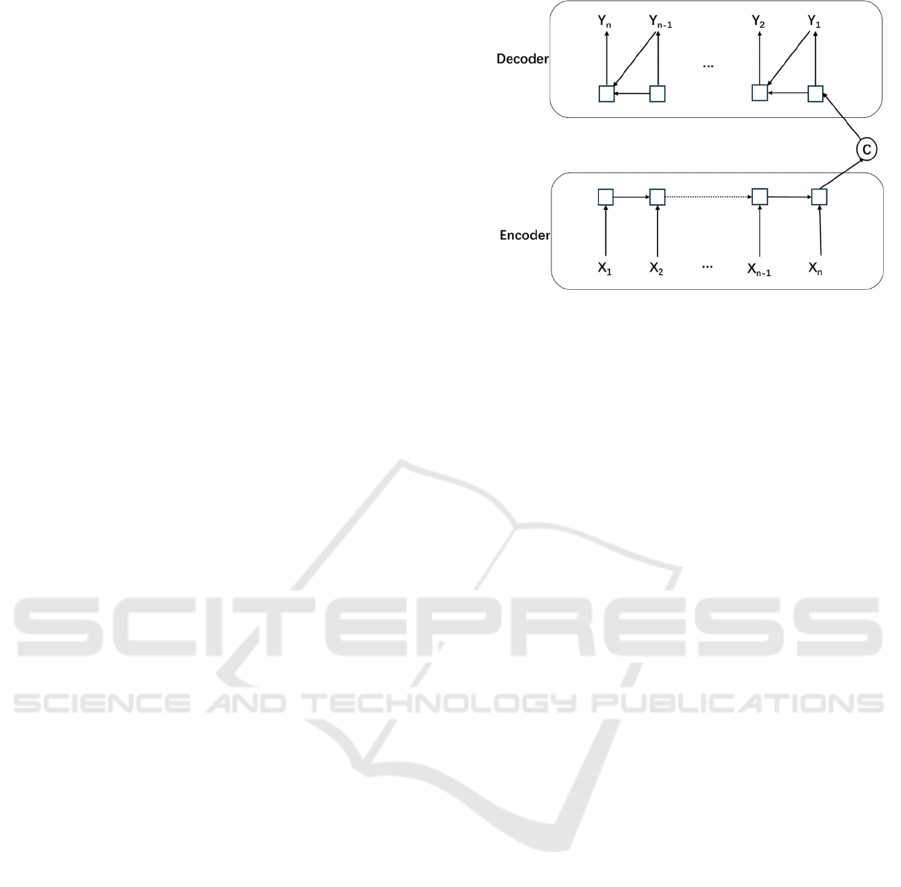
Decoder architecture lays foundation of NMT. Refer
to Figure 1, the model has two key components:
Encoder and Decoder. The encoder is constructed by
recurrent neural networks (RNNs). Each symbol in
Figure 1: Process for the basic RNN Encoder-Decoder
architecture. (Photo/Picture credit: Original).
the sequence will be read and use the output hidden
state of RNN to represent the input sequence, which
is also called the context vector. Another RNN in
decoder will generate sequence from the vector. The
main innovation of this model is that it has contextual
understanding. The updated hidden states allow the
model to acquire the context information in the
sequence. However, the basic RNN’s hidden states
are in fixed length. Therefore, if the sentences are
very long, the model might miss some context
information and performs bad on long sentences,
which is also called the long-term dependencies
problem and directly affect the model’s result.
2.2 Utilize Long Short-Term Memory
(LSTM)
Like traditional RNN architecture in Section 2.1, the
encoder and decoder part could utilize LSTM to
improve the performance on long-term dependency
problems (Refer to Figure 3). Such implementation
was proposed by Sutskever et al. (Sutskever et al.,
2014). The RNN unit was replaced by LSTM. In
order to manipulate the data flow, input gate, output
gate and forget gate were utilized (Shown in Figure
2). These three kinds of gate units could help to learn
the context information in certain sequences. And
while dealing with long sentences, the result of
utilizing LSTM is better than traditional RNN.
Nevertheless, such implementation still performs
badly on the word out of domain. And LSTM’s
architecture complexity will increase the
computational cost.
2.3 Utilize Gated Recurrent Unit
(GRU)
Introduced by Cho et al., GRU aims to simplify the
Research on Key Technologies of Neural Machine Translation Based on Deep Learning
61
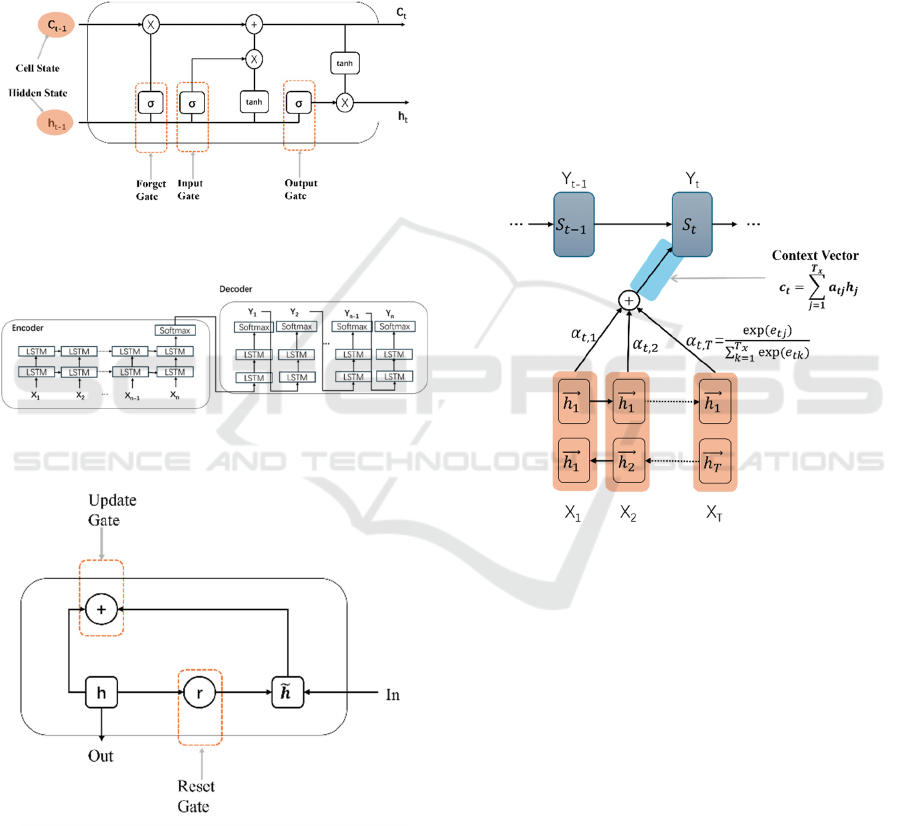
complex LSTM architecture (Refer to Figure 4) (Cho,
Van & Gulcehre et al., 2014). To optimize the model
by GRU, only two gates are needed for information
flow control. The new update gate in GRU could
replace the original forget and input gate in LSTM,
which could be simpler and reduce complexity. The
result shows that GRU is also capable of learning
contextual information as LSTM and the complexity
of the model is simpler than LSTM. GRU performs
comparably to LSTM on various tasks.
Figure 2: LSTM unit architecture. (Photo/Picture credit:
Original).
Figure 3: Process for the LSTM Encoder-Decoder
architecture. (Photo/Picture credit: Original).
Figure 4: Process for the Gated Recurrent Unit.
(Photo/Picture credit: Original).
2.4 Attention Mechanism
Introduced by Bahadanau et al., the utilization of
Attention Mechanism in NMT firstly aims to solve
the long-term dependencies problem left by the RNN
Encoder-Decoder model (Refer to Figure 5)
(Bahadanau, Cho & Bengio, 2014). As the length of
the sequence increasing, some related information for
symbols at the start of the sequence might be lost in
traditional RNN Encoder-Decoder model. The
method of utilizing LSTM might not completely
solve the problem. Unlike the fixed length hidden
state vector in the traditional RNN Encoder-Decoder
architecture, the context vector will change. Such
change makes the relation of each symbol in long
sentences be the focus. The most relevant part for the
predicting word in the input will be reflected by the
context vector. By integrated attention mechanism in
traditional RNN architecture, the model’s
performance gets boosted. However, the Domain
Mismatch problem still exists, which means that the
model performs badly on unfamiliar words.
Figure 5: Process for basic Attention Mechanism.
(Photo/Picture credit: Original).
2.5 Transformer
Introduced by Vaswani’s group, the transformer
model (Refer to Figure 6) was designed to handle
translation tasks (Vaswani et al., 2017). Unlike the
traditional RNN model mentioned before, it
completely relies on the self-attention mechanism. No
RNN will be included. The input sequence will be
firstly converted to multi-dimensional vectors after
embedding and then go through the positional
encoding process. So, the final input of the
transformer model becomes several matrices. In the
Encoder, after going through several layers of self-
attention and feed forward neural network, the output
vector. And the decoder will accept the output vector
from encoder and the target sequence. The
transformer model’s Multi-Head Attention
MLSCM 2024 - International Conference on Modern Logistics and Supply Chain Management
62
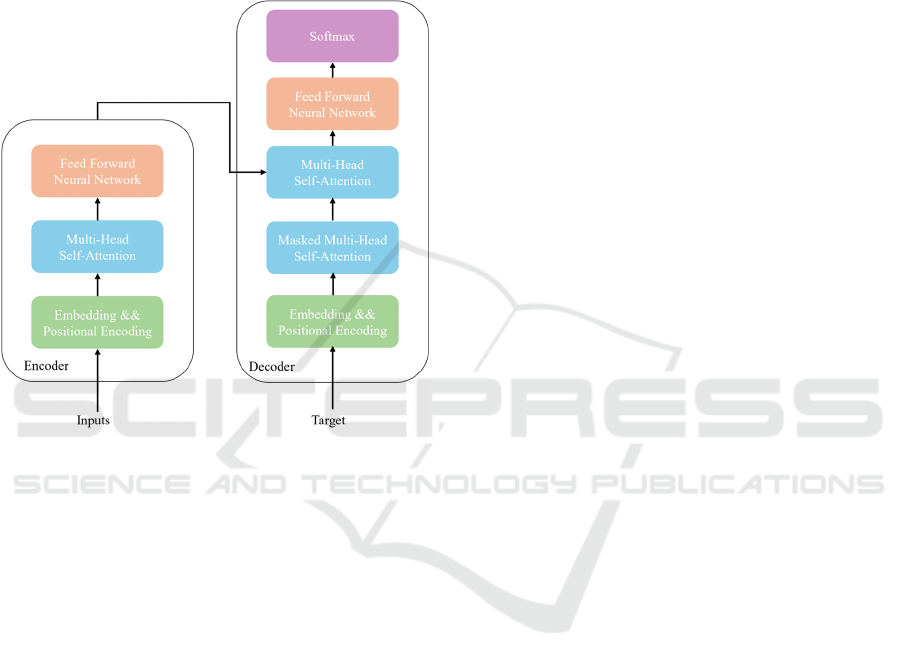
mechanism allows parallel computing which makes it
possible to acquire the dependencies in long-term.
The parallelization also reduces the training time
compared to RNN Encoder-Decoder architecture.
The Feed Forward Neural Network boosted the
model’s translation performance. The good
performance of the model in machine translation
reaches state-of-art quality and becomes the
mainstream framework nowadays.
Figure 6: Brief Process of Transformer Model.
(Photo/Picture credit: Original).
3 MODEL DISCUSSION
3.1 Evaluation Method
Understanding a model’s performance is crucial for
finding the model’s limitation and subsequent
improvement. To evaluate a model for NMT tasks,
there are two types of methods: human-based and
automated. For the human-based evaluation might be
more convincing but the evaluation results are more
subjective. For automated way, the evaluation speed
and efficiency are higher than human based. Most of
the model evaluations in NMT nowadays will use
Bilingual Evaluation Understudy (BLEU) score to
show performances on different dataset (Reiter, 2018).
It provides a fast and objective measurement.
3.2 Model Comparison
The mentioned models were tested in different
situations such as translating sentences in limited
word count or translating sentences with unknown
words. And refer to the performance of different
models in different settings, according to Table 1, it
can be concluded that:
1)For the traditional RNN Encoder-Decoder
architecture, its performance will be affected by the
translating sentences’ lengths and the out-of-domain
words’ count in translating sentences. The neural
network model shows its best performance on short
sentences with no unknown words. The fixed hidden
layer state was considered to be the cause of such
outcome
(Cho,
Van Merriënboer & Bahdanau
et al.,
2014)
.
2)By utilizing LSTM, the performance while
dealing with long sentences is improved. A little trick
to input sequences in reverse order could increase the
performance of LSTM model and manage the long-
term dependencies problem was proposed by
Sutskever et al. in 2014 (Sutskever, Vinyals & Le,
2014). And with propose of the comparable and
simplified GRU model, the whole architecture is
simpler and more intuitive than traditional SMT.
However, for the bad performance on words out of
domain, the problem is not solved yet. And the
complex structure of LSTM will increase the
computation complexity and lengthen the model’s
training time.
3)The utilization of Attention mechanism on
traditional RNN model increases the BLEU score on
WMT 2014 English-to-French test set about 9, which
indicates the feasibility of Attention mechanism. The
integration of Attention mechanism in the traditional
RNN architecture performs well while facing long-
term dependencies problem. It increases long
sentences’ translation accuracy for traditional RNN
model.
4)The transformer model’s translation quality
surpasses the performance of any other previous
NMT models in RNN architecture. Such performance
could give credit to its parallel computation capability
and better performance on context information
acquisition in the sequence.
4 DISCUSSION AND FUTURE
TREND
In the age of large language models, there are huge
differences in NMT than before. Some of the
problems like Long-term Dependencies, Word
Alignment or training data size are gradually
improved. However, there are still some challenges to
nowadays machine translation tasks.
Research on Key Technologies of Neural Machine Translation Based on Deep Learning
63
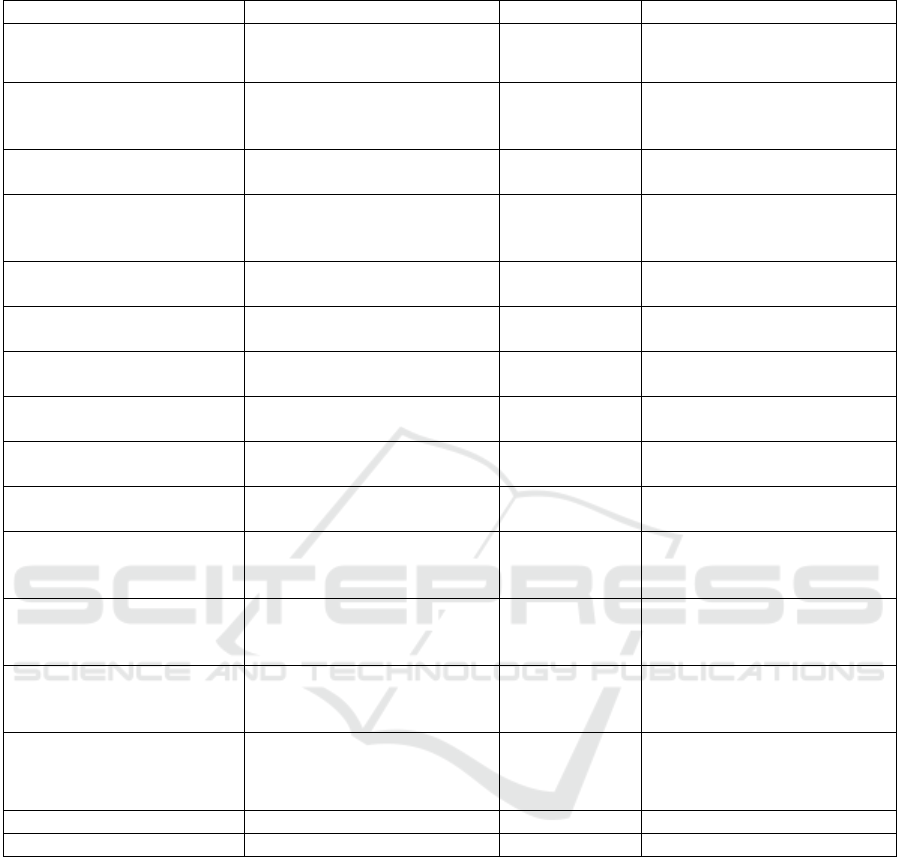
Table 1: Model comparison according to BLEU score for mentioned architecture.
Model Dataset test BLEU Score Key Paper
Basic RNN for all sentences in
all length
WMT 2014 English-to-French 13.92
(Cho, Van Merriënboe
r
&
Bahdanau
et al., 2014)
Basic RNN for sentences with
no unknown words in all
length
WMT 2014 English-to-French 23.45
(Cho, Van Merriënboe
r
&
Bahdanau
et al., 2014)
Basic RNN for all 10-20
words sentences
WMT 2014 English-to-French 20.99 (Cho, Van Merriënboe
r
&
Bahdanau
et al., 2014)
Basic RNN for all 10-20
words sentences with no
unknown words
WMT 2014 English-to-French 27.03 (Cho, Van Merriënboe
r
&
Bahdanau
et al., 2014)
Single forward LSTM, beam
size 12
WMT 2014 English-to-French 26.17 (Sutskever, Vinyals & Le,
2014
)
Single reversed LSTM, beam
size 12
WMT 2014 English-to-French 30.59 (Sutskever, Vinyals & Le,
2014
)
Ensemble of 5 reversed
LSTM, beam size 1
WMT 2014 English-to-French 33.00 (Sutskever, Vinyals & Le,
2014
)
Ensemble of 5 reversed
LSTM, beam size 2
WMT 2014 English-to-French 34.50 (Sutskever, Vinyals & Le,
2014
)
Ensemble of 5 reversed
LSTM, beam size 12
WMT 2014 English-to-French 34.81 (Sutskever, Vinyals & Le,
2014
)
Ensemble of 2 reversed
LSTM, beam size 12
WMT 2014 English-to-French 33.27 (Sutskever, Vinyals & Le,
2014
)
RNN with Atten- tion trained
on all sentences with max
length 30
WMT 2014 English-to-French 21.50
(Bahdanau, Cho & Bengio, 2014)
RNN with Attention trained
on sentences with no unknown
word and max length 30
WMT 2014 English-to-French 31.44
(Bahdanau, Cho & Bengio, 2014)
RNN with Attention trained
on all sentences with max
length 50
WMT 2014 English-to-French 28.45
(Bahdanau, Cho & Bengio, 2014)
RNN with Attention trained
on sentences with no unknown
word and max length 50
WMT 2014 English-to-French 36.15
(Bahdanau, Cho & Bengio, 2014)
Transformer WMT 2014 English-to-French 41.0 (Vaswani et al., 2017)
Transformer WMT 2014 English-to-German 28.4 (Vaswani et al., 2017)
The translation tasks for some low-resources
languages are not that good due to the unbalanced
pretraining data (Pang et al., 2014). More attention
should be given to the computational resource’s
distribution for researchers.
Another future direction for NMT is the
multilingual NMT model. It could finish the
translation task in one-to-many languages. One
multilingual NMT model (Johnson et al., 2017)
showed the possibility to improve the translation
performance on low resource language by sharing
parameters in a unified model.
Model interpretability and controllability are
crucial. Good interpretability helps to observe the
decisions made by neural models (Li, Monroe &
Jurafsky, 2016). The way to let users manipulate
certain features like translation style is also a future
direction. Translation tasks like translating sentences
containing some domain-specific vocabularies are
sometimes needed by users.
5 CONCLUSION
In this work, research about the utilization of deep
learning in Machine Translation was made to
illustrate the NMT’s development. Based on the
proposed time, some of the famous NMT models
MLSCM 2024 - International Conference on Modern Logistics and Supply Chain Management
64

were introduced: based on RNN, LSTM utilized,
GRU, Attention Mechanism and Transformer. And
comparisons among the mentioned models on some
public test set in different situations were made to
discuss the problems they solved and challenges they
met. The research found that traditional RNN
architecture was suffered from the long sentences’
translation tasks. And the integration of Attention
Mechanism in traditional RNN Encoder-Decoder
architecture could better treat the long-term
dependencies problem and showed a better
performance on translating long sentences. And the
development of transformer model made the NMT
model reach a new milestone. For the future
development of NMT models, the research on
training low-resources language models is crucial for
the unbalanced pretraining data. Besides, the
development of a multilingual NMT model is
significant to deal with some of low-resources
languages. Furthermore, the model’s interpretability
and controllability should be improved for a better
user experience.
REFERENCES
Bahdanau, D., Cho, K., & Bengio, Y. 2014. Neural machine
translation by jointly learning to align and translate.
arXiv preprint arXiv:1409.0473.
Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y.
2014. On the properties of neural machine translation:
Encoder-decoder approaches. arXiv preprint
arXiv:1409.1259.
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D.,
Bougares, F., Schwenk, H., & Bengio, Y. 2014.
Learning phrase representations using RNN encoder-
decoder for statistical machine translation. arXiv
preprint arXiv:1406.1078.
Dowling, M., Lynn, T., Poncelas, A., & Way, A. 2018.
SMT versus NMT: Preliminary comparisons for Irish.
Hearne, M., & Way, A. 2011. Statistical machine
translation: a guide for linguists and translators.
Language and Linguistics Compass, 5(5), 205-226.
Johnson, M., Schuster, M., Le, Q. V., Krikun, M., Wu, Y.,
Chen, Z., ... & Dean, J. 2017. Google’s multilingual
neural machine translation system: Enabling zero-shot
translation. Transactions of the Association for
Computational Linguistics, 5, 339-351.
Junczys-Dowmunt, M., Dwojak, T., & Hoang, H. 2016. Is
neural machine translation ready for deployment? A
case study on 30 translation directions. arXiv preprint
arXiv:1610.01108.
Li, J., Monroe, W., & Jurafsky, D. 2016. Understanding
neural networks through representation erasure. arXiv
preprint arXiv:1612.08220.
Pang, J., Ye, F., Wang, L., Yu, D., Wong, D. F., Shi, S., &
Tu, Z. 2024. Salute the classic: Revisiting challenges of
machine translation in the age of large language models.
arXiv preprint arXiv:2401.08350.
Reiter, E. 2018. A structured review of the validity of
BLEU. Computational Linguistics, 44(3), 393-401.
Sutskever, I., Vinyals, O., & Le, Q. V. 2014. Sequence to
sequence learning with neural networks. Advances in
neural information processing systems, 27.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., ... & Polosukhin, I. 2017. Attention
is all you need. Advances in neural information
processing systems, 30.
Research on Key Technologies of Neural Machine Translation Based on Deep Learning
65
