
Machine Learning-Based Customer Segmentation: A Comprehensive
Investigation of Techniques, Challenges and Applications
Yazhi Zhang
a
Steinhardt School of Culture, Education, and Human Development, New York University, New York, U.S.A.
Keywords: Customer Segmentation, Machine Learning, Deep Learning.
Abstract: Customer segmentation is vital for optimizing targeted marketing strategies, improving customer experiences,
and driving profitability across various industries. This study proposes to provide a comprehensive analysis
of how machine learning can improve segmentation accuracy and offer deeper insights into customer
behaviours. To achieve this, this paper conducted a detailed examination of machine learning methods used
in customer segmentation across banking, telecommunications, and healthcare industries. The methods
reviewed include decision trees, random forests, k-means clustering, hierarchical clustering, auto machine
learning (AutoML) tools like H2O, and deep learning models. The study also involved analyzing specific
machine learning workflows, including problem definition, data collection, preprocessing with techniques
like Local Outlier Factor (LOF) and Principal Component Analysis (PCA), model selection, training,
evaluation, and deployment. Each industry-specific case study was scrutinized to emphasize the effectiveness
and risks of these methods in real-world applications. The results demonstrate that while machine learning
significantly enhances customer segmentation, it also introduces challenges related to model interpretability,
domain applicability, and privacy concerns. The study supports the hypothesis that incorporating
interpretability tools like SHAP and LIME, leveraging transfer learning, and adopting federated learning are
crucial for overcoming these challenges.
1 INTRODUCTION
Customer segmentation entails categorizing a
customer base into several different groups depended
on common characteristics like reactions,
requirements, and predilections. (Monil et al., 2020).
In the context of machine learning, this process
utilizes advanced algorithms to analyze vast datasets,
uncovering patterns that traditional methods might
miss. Employing machine learning techniques in
customer segmentation helps to strengthen the
advantages of targeted marketing strategies, upgrade
customer experiences, optimize marketing efforts,
and increase profitability for businesses across
various sectors, particularly in the highly competitive
landscape of modern commerce.
Machine learning can be generally divided into
two main categories: supervised learning and
unsupervised learning. Supervised learning is
commonly utilized for addressing classification and
regression problems, where the data includes an
a
https://orcid.org/0009-0001-8080-1451
objective standard that the model aims to predict in
future scenarios, such as estimating a student’s grade
or forecasting the number of current transactions
(Narayana et al., 2022). In contrast, unsupervised
learning does not involve predicting a specific label
or target variable. Instead, it focuses on identifying
patterns and grouping data based on similarities, such
as categorizing students according to their purchasing
behavior or learning patterns, without predefined
labels (Narayana et al., 2022). Previous studies on
customer segmentation in the industries have
predominantly focused on traditional statistical
methods, such as cluster analysis and regression
models. These methods, while useful, often lack the
ability to handle large and complex datasets
effectively. Recent research has started to explore the
use of machine learning techniques, including k-
means clustering, auto machine learning, and neural
networks, to enhance segmentation accuracy and
provide deeper insights. For instance, Narayana and
other researchers utilized methods of K-means,
Zhang, Y.
Machine Learning-Based Customer Segmentation: A Comprehensive Investigation of Techniques, Challenges and Applications.
DOI: 10.5220/0013207200004568
In Proceedings of the 1st International Conference on E-commerce and Artificial Intelligence (ECAI 2024), pages 97-101
ISBN: 978-989-758-726-9
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
97
Agglomerative, and Mean Shift to identify possible
customer segments in the mall, depended on their
gender, age, yearly income, and consuming score
(Narayana et al., 2022); Turkmen investigated k-
means, Hierarchical clustering, and Density-Based
Spatial Clustering of Applications with Noise
(DBSCAN) for online retail industry (Turkmen,
2022); Yadegaridehkordi et al. scholars researched
the k-means, Technique for Order of Preference by
Similarity to Ideal Solution (TOPSIS) , and
Classification and Regression Trees (CART) method
to analyze travelers for eco-friendly hotel
(Yadegaridehkordi et al., 2021).
The primary aim of the article is to investigate the
latest trends in customer segmentation in various
industries using machine learning within the context
of an omnichannel world. Initially, this paper
examines the current state and innovations in
customer segmentation. The methods utilized in
different industries are then recapitulated. Subsequent
sections discuss the advantages and disadvantages of
implementing these models for customer
segmentation, offering valuable insights for
practitioners and researchers alike. The final part
summarizes the theoretical and practical conclusions.
2 METHODS
2.1 Introduction of Machine Learning
Workflow
The focus of machine learning is on developing
algorithms that enable computers to learn and make
decisions or predictions based on data, which is a
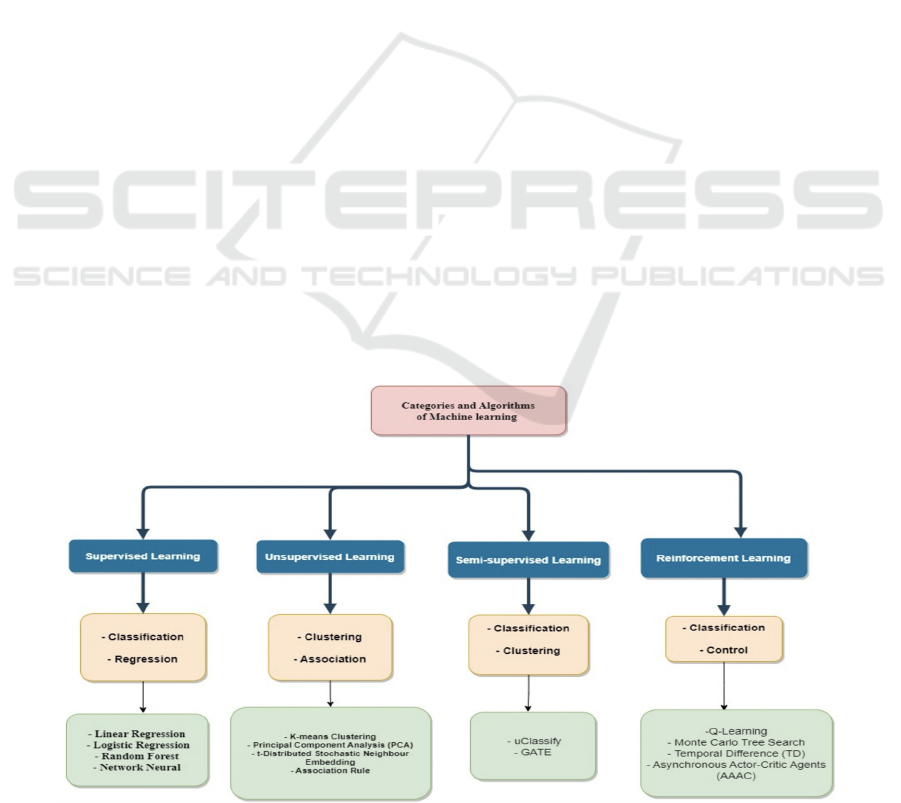
branch of artificial intelligence. Figure 1 shows that
machine learning can be divided into four categories:
Supervised Learning, Unsupervised Learning, Semi-
supervised Learning, and Reinforcement Learning
(Taye, 2023). Supervised learning involves the
progress of classification and regression, a traditional
method of fitting the data into a pre-existing structure
and types. It usually utilizes the knowledge of Linear
Regression, Logistic Regression, Random Forest, and
Network Neutral. Unsupervised learning, on the other
hand, consists of clustering and association. It often
includes K-means clustering, principal component
analysis, t-distributed stochastic neighbor
embedding, and association rule. Semi-supervised
Learning contains the step of classification and
clustering, with the algorithm of uClassify and
GATE. And reinforcement learning requires
classification and control, having the methods such as
Q-learning, Monte Carlo Tree Search, Temporal
Difference, and Asynchronous Actor-Critic Agents.
A machine learning workflow shown in Figure 2
encompasses several key stages, each crucial for
creating effective and reliable models. The first stage
in the machine learning workflow is problem
regression, or clustering. The second step is data
preparation and preprocessing, which involves data
cleaning, data transformation, and data splitting. The
third step might be Model selection and training. The
selection of appropriate machine learning algorithms
is made during this phase according to the type of
problem and the nature of the data. After training, the
model’s performance must be evaluated and
validated. Visualizing the results and interpreting
Figure 1: Different Categories and Algorithms of Machine Learning (Taye, 2023).
ECAI 2024 - International Conference on E-commerce and Artificial Intelligence
98

Figure 2: Workflow of the Machine Learning Procedure
(Monge, 2021).
the mode’s predictions are crucial for understanding
the insights generated and communicating them to
stakeholders. The final stage in the machine learning
workflow is model deployment and monitoring,
where it can be used for real-world applications. This
often involves integrating the model into existing
systems through APIs or user interfaces, making it
accessible and functional. Detecting any degradation
or drift over time requires continuous monitoring of
the model’s performance.
2.2 Customer Segmentation in Bank
Yuping et al. researchers explore the changing
landscape of customer behavior and payment
methods, especially in an omnichannel world where
physical money is becoming obsolete (Yuping et al.,
2020). Commercial banks face challenges when
evaluating personal credit using traditional methods
due to this shift. During the procedure of personal
credit evaluation, the Local Outlier Factor (LOF) test
method is used to identify and remove outliers from
the sample data. Afterward, any missing values in the
original sample data, as well as those that result from
removing outliers, are filled in using a random forest
model. This approach replaces the traditional
statistical methods of filling in missing values with
averages or most frequent values, thereby enhancing
the accuracy of the predictions. The key variables that
impact individual credit evaluation are identified
using a gradient boosting decision tree model.
Following this, utilizing either logistic regression or a
Backpropagation (BP) neural network, a scorecard
model is established to assess and forecast using the
selected key variables, resulting in a personal credit
score. This approach compensates for inaccuracies in
credit scoring that may arise from relying solely on
credit data and the traditional model for generating
the personal credit score.
Examining the machine learning methods in
predicting bank crises, Buetel et al. highlight that
neural networks, especially with a single hidden
layer, can offer greater flexibility than traditional
logit models (Buetel et al., 2019). However, they also
note the risk of overfitting, particularly with more
complex architectures like deep neural networks. The
potential for neural networks to outperform simpler
models like the logit model depends heavily on
controlling this overfitting risk and effectively
managing the network’s complexity. However,
authors consider that in some circumstances, machine
learning methods can’t perform better than the
traditional methods.
2.3 Customer Segmentation in
Telecommunication
The challenge of risk management within the
telecommunications industry includes the need for
efficient handling of large datasets, ensuring the
scalability of the ML models, and enabling non-
expert users to deploy and maintain these models
(Ferreira et al., 2020). Specifically, it focuses on
automating and scaling ML applications for tasks
such as churn detection, event forecasting, and fraud
detection. The AutoML tools, particularly H2O
AutoML, were considered a robust solution for
developing machine-learning models with minimal
human intervention. This tool is noted for its ability
to handle large datasets and integrate various machine
learning algorithms, such as Gradient Boosting
Machine (GBM), Generalized Linear Model (GLM),
XGBoost, Random Forest, and Deep Learning
models. The choice of H2O AutoML by the project’s
stakeholders suggests a strong endorsement of its
capabilities in efficiently managing complex
machine-learning tasks.
To deal with the problem of understanding and
segmenting telecom customers based on their
behavior and tailoring services more effectively, PCA
was used to reduce the dimensionality of the dataset,
and the elbow method helped to figure out the most
favorable number of clusters before conducting
clustering (Sharaf et al., 2022). K-means clustering
was the primary approach emploted to segment
telecom customers based on various attributes such as
demographic, behavioral, and regional aspects.
Subsequently, an interactive web-based dashboard
called INSIGHT has been created to help telecom
managers in obtaining a thorough comprehension of
Machine Learning-Based Customer Segmentation: A Comprehensive Investigation of Techniques, Challenges and Applications
99

their customers and creating more informed business
decisions.
2.4 Customer Segmentation in Healthcare
K-means clustering and hierarchical clustering are
identified as the most prevalent and useful techniques
in addressing the issue of understanding healthcare
consumer behaviors and attitudes, which is crucial in
the shift towards patient-centered care (Swenson,
2018). While both machine learning methods are
significant, K-means clustering is highlighted as
particularly useful due to its ease of use, ability to
handle large datasets, and widespread application in
healthcare market segmentation, compared to
hierarchical clustering. The method’s capability to
form well-defined clusters based on similarity
measures makes it a preferred choice for segmenting
healthcare data into actionable groups, which can
inform targeted healthcare services and marketing
strategies.
With the advent of big data in healthcare,
customized segmentation can be utilized in web-
based healthcare content (Guni et al., 2021). Deep
learning used in advanced recommender systems like
YouTube’s processes a rich set of user and content
features to generate and rank candidate items. It is
highlighted for its ability to handle and integrate a
wide variety of content features, both high-level
(semantic features like tags, genre, and actors) and
low-level (stylistic features like colors, texture, and
lighting). And deep learning outperforms traditional
methods by providing more accurate and
personalized content recommendations, making it a
powerful tool for processing large and complex
datasets in healthcare industry.
3 DISCUSSIONS
3.1 Limitations and Challenges
Interpretability is a significant challenge in target
marketing, particularly when complex machine
learning models are used. These models often
function as “black boxes”, making it difficult to
understand which factors are influencing the
outcomes. In business contexts where trust and
compliance depend on understanding the decision-
making process, a lack of transparency can be
problematic. For example, if a marketing model
predicts customer behavior but doesn't provide clear
reasoning behind these predictions, it may be difficult
for marketers to explain or justify the strategies to
stakeholders, potentially leading to skepticism and
reduced confidence in the model’s results.
Another challenge is the limited applicability of
specific models across different scenarios. Many
models are tailored to specific datasets or marketing
environments, which means they might not generalize
well to other cases. This limitation is especially
problematic in target marketing, where consumer
behavior can vary significantly across different
industries, regions, and time periods. The inability to
generalize can reduce the effectiveness of the model
when applied outside its initial context, requiring
extensive retraining or adjustments that can be
resource-intensive.
Privacy concerns are another significant
limitation in target marketing, particularly with the
increasing amount of customer data being used for
personalized marketing strategies. The use of
sensitive customer data raises the risk of privacy
breaches, which can lead to significant legal and
reputational consequences. If customer data is not
handled securely, there is a high likelihood of privacy
leaks, which can result in the loss of customer trust
and, subsequently, customers themselves. This
challenge underscores the need for rigorous data
protection measures and accordance with privacy
rules, such as GDPR, to mitigate the risks associated
with customer data usage in marketing.
3.2 Future Prospects
To address the challenge of interpretability in target
marketing models, future efforts could focus on
integrating expert systems and advanced
interpretability tools such as SHapley Additive
exPlanations (SHAP) and Local Interpretable Model-
agnostic Explanations (LIME). These methods offer
knowledge about how different characteristics impact
the model’s predictions, providing a easier way to
understand and explain the decisions made by
complex models. SHAP, for instance, can supply a
unified method of feature significance across
different models, while LIME offers a way to
understand individual predictions by approximating
the model locally. By incorporating these tools,
marketers can gain greater transparency and trust in
the AI-driven decisions, ultimately leading to better-
informed marketing strategies.
To overcome the limitations of applicability,
transfer learning and domain adaptation techniques
could be employed. For instance, transfer learning
enables models to transfer comprehension learned
from one realm to another realm, lessening the
requirement for substantial retraining when models
ECAI 2024 - International Conference on E-commerce and Artificial Intelligence
100

are applied to new datasets or scenarios. Domain
adaptation, on the other hand, focuses on adjusting
models to perform well in different but related
domains. These techniques can significantly improve
the generalizability of target marketing models,
allowing them to be more flexible and effective
across various contexts and industries. This would
reduce the resource-intensive process of building new
models from scratch for different applications.
Privacy concerns in target marketing can be
addressed by adopting federated learning approaches.
Federated learning makes it possible to train models
on multiple decentralized devices or servers that
contain local data samples, without having to
exchange the data itself. This method ensures that
customer data remains on their devices, reducing the
risk of privacy breaches. Federated learning also
complies with stringent data privacy regulations, such
as GDPR, by enabling secure, decentralized learning
processes. By implementing federated learning,
organizations can enhance customer trust while still
benefiting from personalized marketing strategies
that leverage large-scale data insights.
4 CONCLUSIONS
The investigation into the latest trends in customer
segmentation reaffirms the critical role that machine
learning plays in enhancing targeted marketing
strategies. As highlighted in the introduction, the
transition from traditional methods to advanced
algorithms offers businesses a competitive edge in
understanding customer behavior and optimizing
marketing efforts. This review’s main contribution
lies in synthesizing the current state of machine
learning applications across various industries,
providing a comprehensive analysis of their strengths
and challenges. By examining case studies from
banking, telecommunications, and healthcare, this
paper demonstrates the effectiveness of machine
learning models like k-means clustering, auto
machine learning, decision trees, and neural networks
in improving segmentation accuracy and customer
insights. However, the review also identifies
significant limitations, including the challenges of
model interpretability, domain applicability, and
privacy concerns. Addressing these issues will
require future research focused on integrating
interpretability tools like SHAP and LIME, exploring
transfer learning and domain adaptation, and adopting
federated learning to enhance privacy. These
advancements are essential for ensuring that machine
learning continues to provide valuable and
trustworthy insights in customer segmentation.
REFERENCES
Beutel, J., List, S., & von Schweinitz, G. 2019. Does
machine learning help us predict banking crises?.
Journal of Financial Stability, 45, 100693.
Ferreira, L., Pilastri, A. L., Martins, C., Santos, P., &
Cortez, P. 2020. An Automated and Distributed
Machine Learning Framework for Telecommunications
Risk Management. In ICAART (2) (pp. 99-107).
Guni, A., Normahani, P., Davies, A., & Jaffer, U. 2021.
Harnessing machine learning to personalize web-based
health care content. Journal of medical Internet
research, 23(10), e25497.
Monge, M., Quesada-López, C., Martínez, A., & Jenkins,
M. 2021. Data mining and machine learning techniques
for bank customers segmentation: A systematic
mapping study. In Intelligent Systems and Applications:
Proceedings of the 2020 Intelligent Systems Conference
(IntelliSys) Volume 2 (pp. 666-684). Springer
International Publishing.
Monil, P., Darshan, P., Jecky, R., Vimarsh, C., & Bhatt, B.
R. 2020. Customer segmentation using machine
learning. International Journal for Research in Applied
Science and Engineering Technology (IJRASET), 8(6),
2104-2108.
Narayana, V. L., Sirisha, S., Divya, G., Pooja, N. L. S., &
Nouf, S. A. 2022. Mall customer segmentation using
machine learning. In 2022 International Conference on
Electronics and Renewable Systems (ICEARS) (pp.
1280-1288). IEEE.
Sharaf Addin, E. H., Admodisastro, N., Mohd Ashri, S. N.
S., Kamaruddin, A., & Chong, Y. C. 2022. Customer
Mobile Behavioral Segmentation and Analysis in
Telecom Using Machine Learning. Applied Artificial
Intelligence, 36(1).
Swenson, E. R., Bastian, N. D., & Nembhard, H. B. 2018.
Healthcare market segmentation and data mining: A
systematic review. Health Marketing Quarterly, 35(3),
186-208.
Taye, M. M. 2023. Understanding of machine learning with
deep learning: architectures, workflow, applications
and future directions. Computers, 12(5), 91.
Turkmen, B. 2022. Customer Segmentation with machine
learning for online retail industry. The European
Journal of Social & Behavioural Sciences.
Yadegaridehkordi, E., Nilashi, M., Nasir, M. H. N. B. M.,
Momtazi, S., Samad, S., Supriyanto, E., & Ghabban, F.
2021. Customers segmentation in eco-friendly hotels
using multi-criteria and machine learning techniques.
Technology in Society, 65, 101528.
Yuping, Z., Jílková, P., Guanyu, C., & Weisl, D. 2020. New
methods of customer segmentation and individual
credit evaluation based on machine learning. In “New
Silk Road: Business Cooperation and Prospective of
Economic Development” (NSRBCPED 2019) (pp. 925-
931) Atlantis Press.
Machine Learning-Based Customer Segmentation: A Comprehensive Investigation of Techniques, Challenges and Applications
101
