
AI Systems Trustworthiness Assessment: State of the Art
Afef Awadid
1
, Kahina Amokrane-Ferka
1
, Henri Sohier
1
, Juliette Mattioli
2
, Faouzi Adjed
1
,
Martin Gonzalez
1
and Souhaiel Khalfaoui
1,3
1
IRT SystemX, France
2
Thales, France
3
Valeo, France
juliette.mattioli@thalesgroup.com, souhaiel.khalfaoui@valeo.com
Keywords:
AI-Based Systems, Trustworthiness Assessment, Trustworthiness Attributes, Metrics, State of the Art Review.
Abstract:
Model-based System Engineering (MBSE) has been advocated as a promising approach to reduce the com-
plexity of AI-based systems development. However, given the uncertainties and risks associated with Artificial
Intelligence (AI), the successful application of MBSE requires the assessment of AI trustworthiness. To deal
with this issue, this paper provides a state of the art review of AI trustworthiness assessment in terms of trust-
worthiness attributes/ characteristics and their corresponding evaluation metrics. Examples of such attributes
include data quality, robustness, and explainability. The proposed review is based on academic and industrial
literature conducted within the Confiance.ai research program.
1 INTRODUCTION
Central to Model-based Systems Engineering
(MBSE) is ”the formalized application of modeling
to support system requirements, design, analysis,
verification, and validation activities beginning in the
conceptual design phase and continuing throughout
development and later life cycle phases” (INCOSE,
2007). MBSE, therefore, advocates ”the use of
models to perform systems engineering activities that
are traditionally performed using documents” (Mann,
2009).
This promotes the understanding of complex
systems engineering processes including Artificial
Intelligence (AI) systems engineering as a multi-
engineering process (Mattioli et al., 2023d). How-
ever, the successful application of MBSE requires
the assessment of AI trustworthiness defined by the
ISO/IEC DIS 30145-2 standard as the ”ability to meet
stakeholders’ expectations in a verifiable way”. In-
deed, without an accompanying assessment of trust-
worthiness from the early stages of development, the
deployment of an AI component within a safety crit-
ical systems such as in avionics, mobility, healthcare
and defense becomes risky (Mattioli et al., 2023b).
In view of this, it is not surprising that the quan-
tification of AI-based system trustworthiness has be-
come a hot topic (Braunschweig et al., 2022). AI
system trustworthiness is defined in terms of charac-
teristics/ attributes such as reliability, safety, and re-
siliency (AI, 2019). In this context, the paper at hand
provides a state of the art review of AI trustworthiness
assessment. Such review focuses on the main trust-
worthiness attributes as well as their evaluation met-
rics, and is based on academic and industrial literature
conducted within the Confiance.ai research program.
The rest of the paper is organized as follows. Sec-
tion 2 introduces the context and motivation of this
work. Section 3 presents the state of the art review of
AI systems trustworthiness assessment with respect
to trustworthiness attributes and their evaluation met-
rics. Finally, Section 4 concludes the paper and opens
up for future work.
2 CONTEXT AND MOTIVATION
Safety-critical systems, such as those used in avion-
ics, mobility, healthcare, and defense, are designed to
operate reliably and safely in dynamic environments
where their failure could have severe consequences.
The adoption of Artificial Intelligence (AI) de-
pends on their ability to deliver the expected service
safely, to meet user expectations, and to maintain ser-
vice continuity. Thus, such systems have to be valid,
accountable, explainable, resilient, safe and secure,
322
Awadid, A., Amokrane-Ferka, K., Sohier, H., Mattioli, J., Adjed, F., Gonzalez, M. and Khalfaoui, S.
AI Systems Trustworthiness Assessment: State of the Art.
DOI: 10.5220/0012619600003645
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 12th International Conference on Model-Based Software and Systems Engineering (MODELSWARD 2024), pages 322-333
ISBN: 978-989-758-682-8; ISSN: 2184-4348
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

Figure 1: Trustworthy AI-based critical systems (Mattioli et al., 2023a).
compliant with respect to regulation and standardiza-
tion (including ethics and sustainability).
Assessing the trustworthiness of AI becomes the cor-
nerstone of successful improvement in the design and
operation of critical systems. However, obtaining
trustworthiness measures remains a challenging task.
On the one hand, measuring trust can help identify
problems with the system before they become critical
and allow for corrective action to be taken before a
failure occurs. On the other hand, measuring trust can
help to improve the design of critical systems.
By understanding the factors that contribute to
user trust in AI systems, designers can create ones
that are more reliable, safe and secure. AI trustworthi-
ness characterization is multi-dimensional and multi-
criteria as assessed by different stakeholders (Mattioli
et al., 2023b) (regulators, developers, end-users). In
this context, (Felderer and Ramler, 2021) proposed
to consider three dimensions; the artifact type di-
mension (system, model and data perspective), the
process dimension and the quality characteristic at-
tributes, based on ISO/IEC 25023, that bear on soft-
ware product or system quality.
AI-based systems, especially those using machine
learning (ML), add a level of complexity to traditional
systems, due to their inherent stochastic nature. Thus,
to take into account the complexity of the ML-based
systems engineering process, the set of trustworthi-
ness properties illustrated in Figure 1 (Mattioli et al.,
2023a), needs to be extended. Additionally, various
experts and stakeholders are involved in the design of
such systems.
Moreover, to assess AI trustworthiness, the choice
of the relevant attributes is not easy, since the se-
lection pertains to the context of application, which
is modeled according to several elements (ODD, in-
tended domain of use, nature and roles of the stake-
holders...). The attributes can be quantitative (typi-
cally numerical values either derived from a measure
or providing a comprehensive and statistical overview
of a phenomenon) or qualitative (based on the de-
tailed analysis and interpretation of a limited number
of samples). Then once the list of relevant attributes
has been defined, the aggregation of several attributes
remains complex due to commensurability issues: in-
deed, this is equivalent with combining ”oranges and
apples”, none of the attributes having the same unit.
In addition, one aims at making trade-offs and arbitra-
tion between the attributes. This means that the value
of each attribute should be transformed into a scale
common to all attributes and representing the pref-
erences of a stakeholder, and that the values of the
scales for the different criteria should be aggregated.
These elements constitute the main steps for solving
the problem using a multi-criteria decision making
(MCDA) approach.
MCDA is a generic term for a collection of sys-
tematic approaches developed specifically to help
one or several decision makers to assess or com-
pare some alternatives on the basis of several crite-
ria (Labreuche, 2011). The difficulty is that the de-
cision criteria are frequently numerous, interdepen-
dent/overlapping and sometime conflicting. For ex-
ample, effectiveness may be conflicting with robust-
ness, explainability, or affordability. The viewpoints
are quantified through attributes.
AI Systems Trustworthiness Assessment: State of the Art
323

Aggregation functions are often used to compare
alternatives evaluated on multiple conflicting criteria
by synthesizing their performances into overall utility
values (Grabisch and Labreuche, 2010). Such func-
tions must be sufficiently expressive to fit the stake-
holder’s preferences, allowing for instance the deter-
mination of the preferred alternative or to make com-
promises among the criteria - improving a criterion
implies that one shall deteriorate on another one.
MCDA provides a tool to specify the good com-
promises (Labreuche, 2011). Our approach is based
on the following steps:
1. Step 1: Structuring attributes in a semantic tree;
2. Step 2: Identification of numerical evaluations;
3. Step 3: Adapting attributes for commensurability;
4. Step 4: Definition of an aggregation methodol-
ogy to capture operational trade-offs and evaluate
higher-level attributes.
Given this, to improve trustworthiness, assessment,
measures and processes are needed. Moreover, con-
text, usage, levels of safety and security, regulations,
(ethical) standards (including fairness, privacy), certi-
fication processes, and degrees of liability should be
considered. In addition to measures and processes,
various techniques and methodologies such as test-
ing, evaluation, and validation of the system’s per-
formance against specified criteria, expert review, and
stakeholder participation are required for trustworthi-
ness assessment in AI-based critical systems.
Such assessment should be ongoing, with regu-
lar updates and monitoring of the system’s perfor-
mance and compliant with standards and regulations.
Besides trustworthy attribute definitions (Adedjouma
et al., 2022), the current work focuses on some exam-
ples of associated metrics that help to identify poten-
tial areas for improvement. It is important to note in
this context that such attributes have a different mean-
ing depending on the stakeholder’s profile. For in-
stance, a system engineer, a safety engineer, a data
engineer, and an AI scientist may all have distinct per-
spectives on accuracy.
3 A NEW AI
TRUSTWORTHINESS
META-MODEL
A trustworthy software is defined (Wing, 2021) by
a combination of overlapping properties: reliability,
safety, security, privacy, availability and usability. For
a ML-based system, this translates and extends to
accuracy, robustness, fairness, accountability, trans-
parency, explainability and ethics. (Delseny et al.,
2021) also considers auditability.
To capture the type of considered information and
the different inter-relations needed to assess ML trust-
worthiness, we proposed a meta-model with concepts
in different abstraction levels (see Figure. 2). The red
part describes the way the tree of attributes is built. It
highlights the abstract concepts central to trustworthi-
ness assessment. An attribute which aggregates other
attributes is called a macro-attribute (e.g. robustness,
dependability, etc.). It is assessed with an aggrega-
tion method. An atomic attribute (leaf attribute) is as-
sessed with a clear and actionable observable which
can take different forms (metric, ”expected proof”).
The green part of Figure. 2 is the meta-model frag-
ment with concrete concepts. These concepts repre-
sent the different possible subjects and relations be-
tween them. For example, the product is developed
following processes as technical processes (through
which the product must go: design definition, imple-
mentation, operation, ...), agreement processes (with
external organizations: acquisition, supply), and man-
agement processes (supporting the development of
the product: quality management, risk management,
etc.). Risk and quality management ensures the com-
pliance with the specification which includes the dif-
ferent expected trustworthiness attributes. Processes
are applied with tools by people respecting a certain
governance.
The blue part summarizes systems engineer-
ing key concepts more precisely part of the non-
functional specification: they do not define what the
system ”does” or how the system works, but what
the system ”is”. The attributes are also commonly
referred to as ”-ilities” as they often have this suf-
fix. They can also be referred to as quality require-
ments. Whether a specification is functional or non-
functional, it is influenced by stakeholders such as the
user, the operator, the developer, etc.
As opposed to non-functional requirements which
define what the system is, functional requirements de-
fine what the system does: should it move? roll? roll
fast? under what conditions? From this point of view,
the Operational Design Domain (ODD), which char-
acterizes the conditions of operation of the system,
can be considered part of the functional specifica-
tion relating to trustworthiness attributes in different
ways: 1) Having transparency or clear visibility into
the ODD permits to understand the system’s capabil-
ities and limits (which is part of the AI Act’s require-
ments); 2) The ODD is the domain to consider for
the different operational trustworthiness attributes; 3)
The ODD has its own attributes (it should be com-
MBSE-AI Integration 2024 - Workshop on Model-based System Engineering and Artificial Intelligence
324
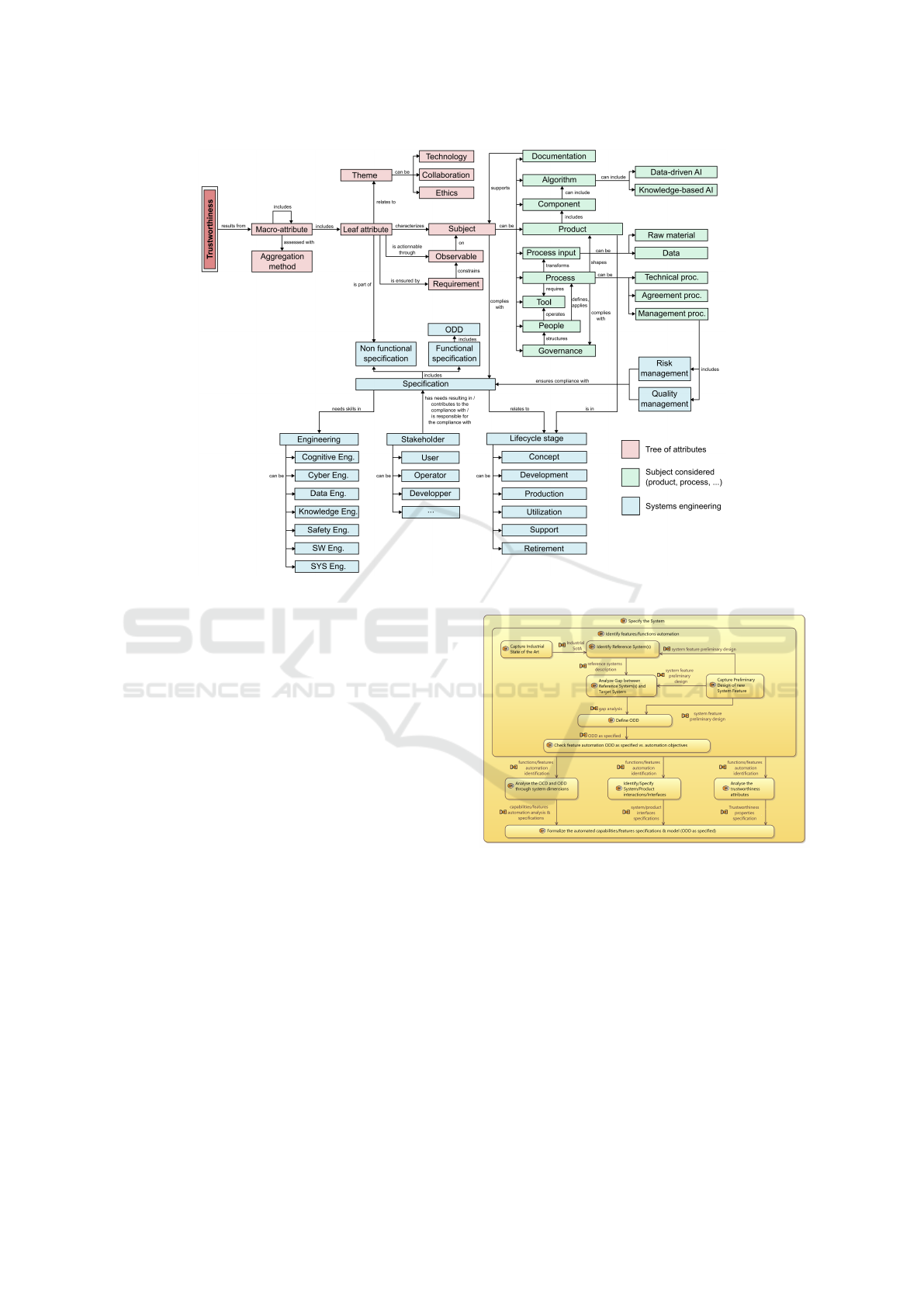
Figure 2: A new AI trustworthiness meta-model (Mattioli et al., 2023c).
plete, free of inconsistencies, human readable, etc.).
In contrast to non-functional requirements, which
define what the system is, functional requirements de-
fine what the system does: does it move? does it
roll? does it roll fast? under what conditions? From
this point of view, the Operational Design Domain
(ODD), which characterizes the operating conditions
of the system/feature of interest, can be considered as
part of the functional specification in relation to the
reliability attributes in a number of ways: 1) the trans-
parency of the ODD makes it possible to understand
the limitations of the system (a requirement of the AI
Act); 2) the ODD is the domain to be considered for
the different operational reliability attributes; 3) the
ODD has its own attributes (it should be complete,
free of inconsistencies, human readable, etc.).
Thus, the trustworthy attributes can be assessed
only if the ODD is clearly defined but many AI pro-
totypes neglect to describe their ODD or leave it
vaguely defined as the domain covered by the dis-
tribution of data used during training. In addition
to the set of Requirements applicable to the Sys-
tem, one of the results of the System Specification
phase is the ODD Definition/Specification, that aims
at specifying the sub-domain where automation fea-
tures are expected to operate according to their re-
quirements, among the whole operational domain of
the system/product. The diagram structures presented
Figure 3: Engineering Activities for “System Specification”
from AI perspective.
in fig. 3, the engineering activities needed to per-
form System Specification with AI/ML involvement
in mind.
At every stage of the system lifecycle, from en-
gineering and design to operation, trustworthiness re-
lationships must be established and maintained. Ac-
cording to the seven pillars of reliability (High-Level
Expert Group on Artificial Intelligence, 2019), Confi-
ance.ai specifies AI reliability (Mattioli et al., 2023a)
by six macro-attributes: data/information/knowledge
quality, dependability, operability, robustness, ex-
plainability/interpretability, and human control.
AI Systems Trustworthiness Assessment: State of the Art
325

Through the system development, the desired
ODD will be refined to fit the needs and constraints
from different engineering. Here comes the question
about where the ODD process stops. Figure 4 ex-
tends the ODD approaches with concepts related to
ODD limits. As an example, the ODD is an impor-
tant input for ML training, ML monitoring, etc. To
be able to address the concerns of these engineering
fields, one needs to define datasets, to define test sce-
narios, to identify the indicators to measure the al-
gorithm performance, etc. A current expectation is
that the ODD artefact must include all the features for
deriving those elements (scenario definition, robust-
ness metric, monitoring variables). However, follow-
ing the definition of the ODD, it is not the case. Be-
sides, that information is required by the engineering
fields in general, regardless if the system is AI-based
or not AI-based, which let induces that such informa-
tion may come from another source.
4 AI-BASED SYSTEMS
TRUSTWORTHINESS
ASSESSMENT
4.1 Data Quality Assessment
In ML discipline, most of the research is focus-
ing on model performance improvement more than
on datasets (Mazumder et al., 2022). In the recent
decade, ML techniques have advanced significantly
and achieved a high maturity level (Adedjouma et al.,
2022). Classical ML practices consist typically in
using the existing datasets and in leveraging perfor-
mances challenges through techniques complexity en-
hancement. In the other hand, data-driven AI takes a
broader approach by placing a greater emphasis on
the data itself (Jakubik et al., 2022; Jarrahi and Oth-
ers, 2022). Instead of simply looking for patterns and
relationships within the input features, data-driven AI
involves collecting, processing, and analyzing large
amounts of data to create more accurate and robust
models (Mattioli and other, 2022).
Moreover, a real challenge today is to associate
datasets to the Operational Design Domain (ODD)
1
from the operational level of the system definition.
Indeed, these datasets include several factors such as
user needs (Chapman et al., 2020) and related meta-
1
An ODD is concept created initially for automated
driving system (ADS) used to restrict where the ADS is
valid (Gyllenhammar et al., 2020). In the current work,
ODD is a restriction of the domain where an AI-based sys-
tem acts safely.
data. Moreover, (Mountrakis and Xi, 2013) high-
lights that dataset quality may have a more signifi-
cant impact on performance than any model design
choice. Many industrialization crisis often result from
the data used to train the models instead of the model
designs and architectures.
Without a systematic assessment of their quality,
data-driven AI risks losing control of the various steps
of data engineering such as collection, annotation and
feature engineering. Doing without data quality as-
sessment would result in assuming that data engi-
neering can not be further improved and that prob-
lems will always be detected without systematic anal-
ysis. Thus, in a given end-to-end AI-based system
process, the data quality assessment brings an evalua-
tion of some ODD description aspects. These eval-
uation goes through a set of metrics, illustrated in
Figure.1, such as data accuracy, data representative-
ness and data diversity.
Furthermore, to ensure conformity to the ODD
specifications, well-founded metrics assess the
reached data quality level. Both research and indus-
trial practices have developed relevant data quality
metrics in the AI-based system, such as accuracy and
completeness. However, many of them still lack a
sound foundation (Heinrich et al., 2018). Thereafter,
a definition and a brief technical description of five
metrics for data quality assessment are given.
Data completeness for ML datasets refers to the
degree to which it contains the necessary information
required to accurately model the underlying patterns
by the learning algorithm. Measuring dataset com-
pleteness includes evaluation of the amount of miss-
ing items, outliers and errors. Completeness met-
ric could be based on the Ge and Helfert’s ratio (Ge
and Helfert, 2006) defined as: data completeness =
∑
N
i=1
γ(d
i
)/N, where γ(d
i
) is 0 if d
i
is a missing data,
and 1 otherwise.
Data correctness refers to the accuracy of the
data items to faithfully represent the real-world phe-
nomena or objects they meant to capture. Dataset
correctness could be defined as: data correctness =
1/(1+d(ω,ω
m
)) where ω is the data value to be as-
sessed, ω
m
is the corresponding real value and d is
a domain-specific distance measure such as the Eu-
clidean or Hamming distance.
Data diversity is defined by the evaluation of
the presence of all required information and quanti-
fies how the dataset fits the environment and appli-
cation domains described in the specifications. Dur-
ing ML model design, training and testing, the level
of diversity should be equally distributed for the dif-
ferent data subsets being selected. This should en-
sure that the ML model is enough diversified so as
MBSE-AI Integration 2024 - Workshop on Model-based System Engineering and Artificial Intelligence
326
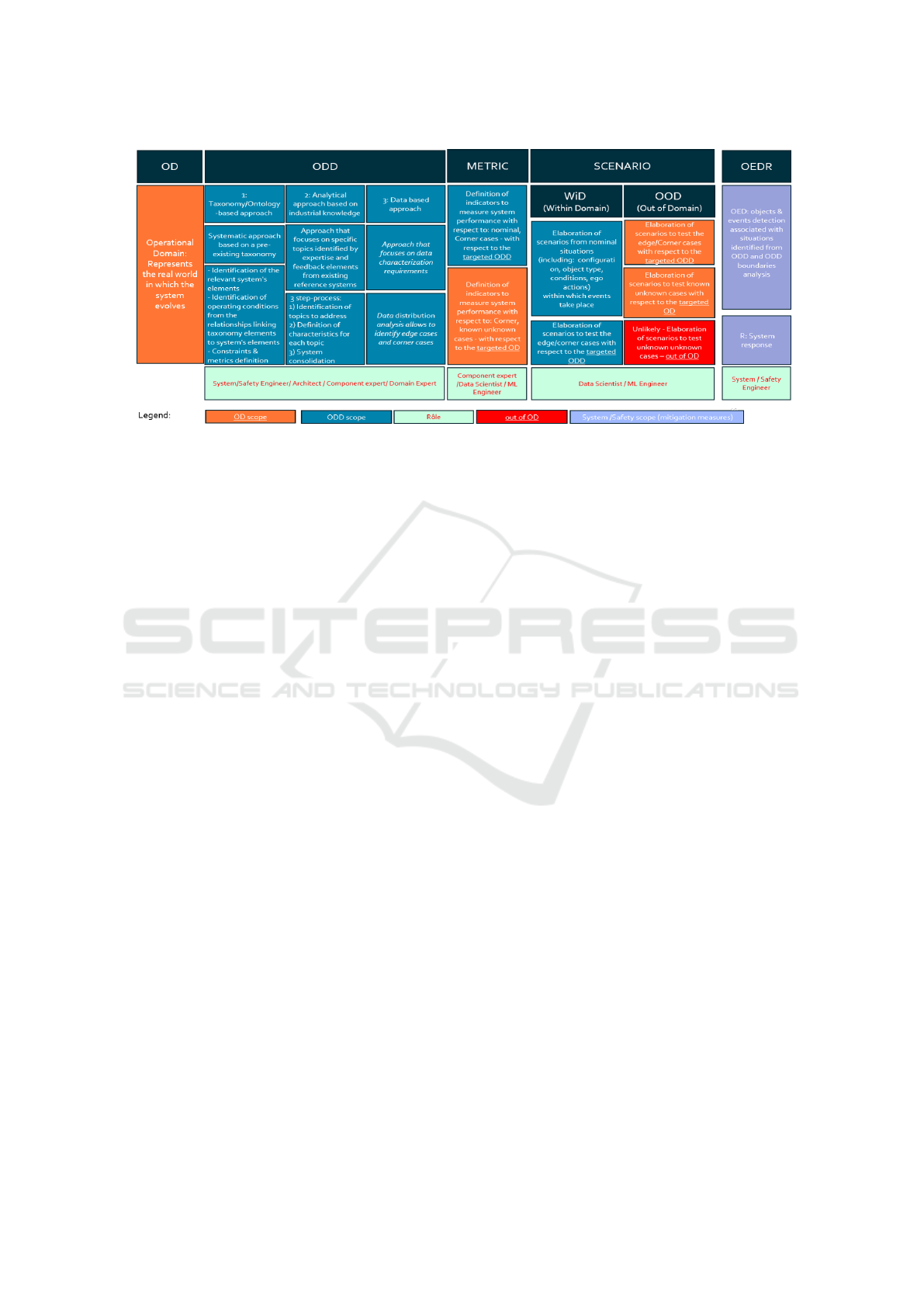
Figure 4: The ODD analysis process.
to cover its domain of possible stimuli. Accord-
ing to (Gong et al., 2019), the only metric used
for diversity for supervised ML is the Determinan-
tal Point Process (DPP) introduced by (Kulesza et al.,
2012). Then,(Derezi
´
nski, 2019) regularizes the DPP
(R-DPP) to accelerate the training process. Moreover,
other diversity indexes, used in biology and ecology,
could be adapted for ML models such as Shannon
entropy and mean proportional species abundance
(Tuomisto, 2010).
Data representativeness (Mamalet et al., 2021)
refers in statistics to the notion of sample and pop-
ulation. Transposed to AI, the sample corresponds
to the data-set available for the development of the
model (training, validation, testing), and the popula-
tion corresponds to all possible observations in the
field of application. Moreover, a dataset is representa-
tive when it describes the environment observations,
and the distribution of its key characteristics is con-
form to the specifications need, requirements and the
ODD of the targeted application. There are multiple
existing methods to quantify the representativeness of
datasets, stemming from statistics and ML fields. In-
deed, Student, Chi-square and Kolmogorov-Smirnov
tests may be applied to assess the goodness of fit of
specified distributions. Furthermore, in case of large
datasets, the confidence interval combined with the
maximum entropy probability could be used to deter-
mine, in terms of dataset size and acceptance thresh-
olds, the suitable dataset for ML need (Blatchford
et al., 2021).
4.2 Operability Assessment
By assessing operability, we can ensure that we de-
liver value to end-users and avoid problems at design-
time, where operability is the ability to keep such AI-
based system in a safe and reliable functioning con-
dition, according to predefined operational require-
ments. Thus, (AI-based system) operability is a mea-
sure of how well the system works in a produc-
tion environment, for both end users and developers.
Good operability induces diagnosis and recovery for
AI maintenance. In an operational context, it is also
defined as the degree to which a product or system
is easy to use, monitor, control and maintain and to
use. Thereby, accuracy, trueness and precision are re-
quired for AI/ML operability assessment and consid-
ered as different concepts when referring to measure-
ments.
Generally speaking, accuracy refers to how close a
measured value is in relation to a known value. How-
ever, the ISO (International Organization for Stan-
dardization) uses trueness for the above definition
while keeping the word accuracy to refer to the com-
bination of trueness and precision. On the other hand,
precision is related to how close several measure-
ments of the same quantity are to each other. Thus,
(model) accuracy is a fundamental metric for evaluat-
ing AI-based critical system, to measure how well the
system performs its intended function compared to its
ground truth or expected output.
Traditional operability metrics for regression in-
clude Mean Squared Error (MSE) or Mean Abso-
lute Error (MAE), while classification problems can
be evaluated through precision, accuracy and recall
(Davis and Goadrich, 2006). In classification, a con-
fusion matrix (depicting the distribution of true/false
negatives/positives for each class) is a practical tool
AI Systems Trustworthiness Assessment: State of the Art
327

for visualizing of the errors, and allows the compu-
tation of most metrics: precision, recall, sensitivity,
specificity, F1 score, Calibration measures how well
the AI system’s predicted probabilities match the true
probabilities of the outcomes. This can be evaluated
using various metrics, such as the Brier score or cali-
bration plot.
Let us denotes by T P (True Positive) to repre-
sent how many positive class samples your model
predicted correctly; T N (True Negative) to represent
how many negative class samples your model pre-
dicted correctly; FP (False Positive) to represent how
many positive class samples your model predicted in-
correctly and FN (False Negative) to represent how
many negative class samples your model predicted in-
correctly.
• Accuracy measures how often the Model pro-
duces correct results where Accuracy = (T P +
T N)/(T P + FP + T N + FN).
• Precision measures the proportion of true posi-
tives out of all positive predictions: Precision =
(T P)/(T P + FP).
• Recall measures the proportion of true positives
out of all actual positives: Recall = T P/(T P +
FN)
• F1 Score is a combination of precision and re-
call providing a single score to evaluate the over-
all performance of the AI system: F1 Score =
2 ∗ (Precision ∗ Recall)/(Precision + Recall).
• Specificity is the proportion of actual negatives
that the model has correctly identified as such out
of all negatives: Speci f icity = T N/(FP + T N)
• ROC Curve plots the true positive rate against the
false positive rate at various classification thresh-
olds, and can be used to evaluate the overall per-
formance of the AI system. The area under the
ROC curve is often used as a metric, with higher
area indicating better performance.
Closely related to accuracy, trueness, and precision
is correctness. Indeed, the latter is defined by ISO-
25010 as the degree to which a product or system
provides the correct results with the needed degree of
precision. In ML, correctness measures the probabil-
ity that the ML system under test ”gets things right”.
Let D be the distribution of future unknown data. Let
x be a data item belonging to D. Let h be the ML
model that we are testing. h(x) is the predicted label
of x, c(x) is the true label. (Zhang et al., 2020) defined
the model correctness E(h) as the probability that
h(x) and c(x) are identical, E(h)=Pr
x∼D
[h(x)=c(x)].
Note that there are many other metrics that can be
used to assess the operability of AI systems, and the
choice of metric(s) depends on the specific use case
and application.
4.3 Dependability Assessment
As AI becomes prevalent in critical systems, their de-
pendability takes on increasing importance. In sys-
tems engineering, dependability can be defined as the
ability of a system to deliver a service that can be jus-
tifiably trusted (Avizienis et al., 2004). But, this con-
cept has evolved to integrate other attributes: Avail-
ability readiness for correct service; Reliability conti-
nuity of correct service; Safety for absence of catas-
trophic consequences on user(s) and environment; Se-
curity availability for authorized users, confidential-
ity, and integrity; Confidentiality for absence of unau-
thorized disclosure of information; Integrity for ab-
sence of improper system alterations; and Maintain-
ability for ability to undergo modifications, and re-
pairs. Moreover, the requirements on the AI sys-
tem cannot be described completely, and the system
must function dependably in an almost infinite ap-
plication space. This is where established methods
and techniques of classical systems and software en-
gineering reach their limits and new, innovative ap-
proaches are required. A core element to assess de-
pendability is to provide assurance (Buckley and Pos-
ton, 1984) that the system as a whole is dependable,
i.e., that risk of failures is mitigate to an acceptable
level. In a data-driven AI component, the functional-
ity is not programmed in the traditional way, but cre-
ated by applying algorithms to data. One challenge
is to make this (learning) assurance case (Byun and
Rayadurgam, 2020) cleanly and to find appropriate
evidence that demonstrates the dependability of the
AI system.
• Availability and reliability are often used inter-
changeably but they actually refer to different
things. Reliability refers to the probability of
an AI-based component/system performing with-
out failure under normal operating conditions over
a given period of time. Thus, availability mea-
sure provides an indication of the percentage of
the time that the system is actually available
over the scheduled operational time. The first
step in calculating availability is deciding the pe-
riod we want to analyze. Then, it is calculated
by dividing Uptime by the total sum of Uptime
and Downtime: Availability = Uptime/(Uptime +
Downtime), where Uptime (resp. Downtime)
represents the time during the system is opera-
tional(resp. isn’t operational). Downtime has the
biggest impact on availability and is one of key
KPIs for maintenance and in service support ac-
MBSE-AI Integration 2024 - Workshop on Model-based System Engineering and Artificial Intelligence
328

tivities. Moreover, estimating AI-based software
MTBF (Mean time between failure) is a tricky
task. This interval may be estimated from the de-
fect rate of the system or can also be based on
previous experience with similar systems.
• Reliability is the probability that an asset will per-
form a required function under specified condi-
tions, without failure, for a specified period. For
AI systems, the definition of AI reliability is de-
fined as (Kaur and Bahl, 2014) “the probability
of the failure-free software operation for a spec-
ified period of time in a specified environment”.
Common measurements of reliability are MTBF
and mean time to failure (MTTF). MTBF mea-
sures the average time between two consecutive
failures, while MTTF accounts for the time elaps-
ing from the beginning of operation to the detec-
tion of the first failure. Nevertheless, the mea-
surement of the reliability of an AI algorithm is
associated to its performance. Most data-driven
AI algorithms are designed to solve problems of
classification, regression, and clustering, (Bosni
´
c
and Kononenko, 2009) used prediction accuracy
from ML algorithms as a reliability measure.
• Repeatability and reproducibility are also char-
acteristics of dependability. In the context of AI
engineering, repeatability measures the variation
in various runs of test plan under the same con-
ditions, while reproducibility measures whether
an entire experiment can be reproduced in its en-
tirety. This verification facilitates the detection,
analysis, and mitigation of potential risks in an AI
system, such as a vulnerability on specific inputs
or unintended bias. Therefore, reproducibility is
emerging as a concern among AI Engineers.
Moreover, depending on the AI methods used, func-
tional safety can still be measured and verified, inso-
far as such properties can be formally defined. For
example, ML dependability properties have to be en-
tirely verified in the field of aviation following the
”EASA Concept Paper: guidance for Level 1 & 2 ML
applications”.
4.4 Robustness Assessment and
Monitoring
AI-based critical systems should be robust, secure and
safe throughout their entire life-cycle in conditions
of normal use, foreseeable use or misuse, or other
adverse conditions, they function appropriately and
without unreasonable safety risk. To this end, robust-
ness is mandatory to ensure that an invalid input data
will not lead to an unsafe state of the system. This can
be reached “by-design” and it can also be monitored
”in operations” to enable analysis of the AI system’s
outcomes and responses appropriate to the context.
Therefore, robustness and monitoring are two
closely related topics in an AI-based system life-
cycle. Robustness and stability are defined by (Ma-
malet et al., 2021) as an AI-based system’s global ro-
bustness (out of distribution), the ability to perform its
intended function in the presence of abnormal or un-
known inputs; and local robustness (in distribution),
the extent to which the system provides equivalent re-
sponses to similar inputs.
These definitions are made more precise by (SAE
J3016, 2018) using the ODD concept. The global ro-
bustness is then called robustness and the local ro-
bustness is called stability where robustness is an AI
asset’s ability to maintain its expected/intended per-
formance under well-characterized abnormalities or
deviations in inputs and operating conditions under
its ODD; and stability is the ability of an AI asset to
maintain its expected/intended output(s) under well-
characterized and bounded perturbations to its inputs
and operating conditions within its ODD.
In addition, adversarial robustness refers to the
ability of models to maintain their performance in the
face of adversarial attacks and perturbations where
perturbations are imperceptible, non-random changes
to the input that alter a model’s prediction, thereby
maximizing its error (Kapusta et al., 2023). Some
tooled methods dedicated to local robustness assess-
ment are based on evaluation or (formal) demonstra-
tion such as:
• Non-overlapping corruption on a dataset provides
an assessment of the robustness of a given AI-
based model (Py et al., 2023);
• AI Metamorphism Observing Software (AIMOS)
(Girard-Satabin et al., 2022) assesses metamor-
phic properties on AI models such as robustness
to perturbations on the inputs but also relation be-
tween models’ inputs and outputs;
• Time-series robustness characterization focuses
and the assessment of the robustness w.r.t. pertur-
bations on the inputs of regression models applied
to time series;
• Adversarial attack characterization: (Kapusta
et al., 2023) evaluates the impact and usability of
adversarial attacks on AI models;
• Amplification methods evaluate the robustness
of models using amplification methods on the
dataset with noise functions.
Monitoring comprises methods for inspecting system
in order to analyze and predict its behavior. Enforce-
ment, on the other hand, involves designing mech-
AI Systems Trustworthiness Assessment: State of the Art
329

anisms for controlling and restricting the behavior
of systems. Once an AI systems are deployed, we
need tools to continuously monitor and adjust them.
Thus, the main objective of online monitoring of AI
models is to identify the output that does not fulfill
the expectations by detecting any deviation in oper-
ation from the specified expected behavior, or from
a predefined set of trustworthy operational properties
(Kaakai and Raffi, 2023). In Confiance.ai program,
(Adedjouma et al., 2022) addresses both concepts,
monitoring and enforcement, by combining several
monitoring timescales (Present Time, Near-Past and
Near-Future Monitoring) - with a rule-based approach
to compute the final “safe output”.
4.5 Explainability Assessment
The need to explain AI algorithms gave rise to the
field of Explainable AI. In the literature, several
studies argue that explanations positively affect user
trust (Biran and Cotton, 2017) and inappropriate trust
impairs human-machine interaction (Ribeiro et al.,
2016). For example, in data-driven AI, explainabil-
ity is a main property to bring trust to models, given
the black box nature of AI. This property is related to
the notion of explanation as an interface between hu-
mans and AI. It involves AI systems that are accurate
and understandable to people (Philippe et al., 2022).
However, explanations do not necessarily have to pro-
vide accurate information about the algorithm of the
ML process. In our study, we consider three key di-
mensions of explainability:
• Interpretability: assesses how easily human ex-
perts can understand the internal workings of an
AI system; interpretable explanations need to use
a representation that is understandable to humans,
regardless of the actual features used by the model
(Ribeiro et al., 2016). In the context of ML sys-
tems, interpretability is defined as the ability to
explain or to present in understandable terms to a
human (Doshi-Velez and Kim, 2017);
• Fidelity measures how well the explanations pro-
vided accurately reflect the AI system behavior
(Yeh et al., 2019). Fidelity metrics measure the
efficiency of the methods to explain models. Fi-
delity is also defined (Plumb et al., 2020), when
the explainer’s output space is (ε
s
, (ε
s
:= (g ∈
G|g : X → Y )), the explanation is defined as a
function g : X → Y , and it is natural to evaluate
how accurately g models f in a neighborhood N
x
:
F( f , g,N
x
) := E
x
0
∼N
x
[(g(x
0
) − f (x
0
))
2
] which re-
fer to the neighborhood-fidelity (NF) metric. This
metric is sometimes evaluated with N
x
as a point
mass on x, this version is called the point-fidelity
(PF) metric.
• Usefulness: evaluates how effectively the expla-
nations support human decision-making and ac-
tion. This last dimension is qualitative. In the
evaluation context, some questions can be asked
to the user (Tambwekar and Gombolay, 2023):
Using this explanation would be useful for me?
Using this explanation will improve my effective-
ness. Using this explanation will improve my per-
formance.
• Faithfulness: measures the degree to which an in-
terpretation method accurately reflects the reason-
ing of the model it interprets. It is important to
note that explanations provided by an unfaithful
method can conceal any biases that exist in the
model’s judgments, which may result in unwar-
ranted trust or confidence in the model’s predic-
tions. Faithfulness is calculated using the follow-
ing formula (Du et al., 2019): Faith f ulness =
1/N
∑
(y
x
i
−y
x
i
|a
), where y
x
i
is the predicted prob-
ability for a given target class using the original
inputs, and y
x
i
|a
is the predicted probability for
the target class for the input with significant sen-
tences/words removed. According to (Arya et al.,
2022), faithfulness is the inverse of the Pearson
Product-Moment correlation and ranges from -1
to 1. A negative correlation of 1 indicates a perfect
correlation, a positive correlation of -1 indicates
the inverse, and 0 indicates no correlation. Faith-
fulness is calculated as follows: Faith f ulness =
−σ
xy
/(σ
x
+ σ
y
), where σ
2
x
(resp. σ
2
xy
) represents
the variance of x (resp. the co-variance of (x, y)).
This metric can be interchangeable with Fidelity
metric in some methodes.
• Monotonicity: applies only to some explainable
methods. It consists in progressively adding the
values of x to a null vector, then looking if the
probability of predicting the correct class with it
is increasing (Ribeiro et al., 2016); The interest
in studying monotonicity in the context of MBSE
lies in its ability to enhance the understanding and
analysis of complex systems.
• Sensitivity: measures the degree of explanation
changes to subtle input perturbations using Monte
Carlo sampling-based approximation (Yeh et al.,
2019).
4.6 Human-Centered Quality & Human
Oversight Assessment
To ensure trustworthy AI, it is important to go be-
yond the AI model itself (inputs, features and out-
MBSE-AI Integration 2024 - Workshop on Model-based System Engineering and Artificial Intelligence
330

puts) and consider dynamics of the model interacting
with the overall system, including end-users. Human-
centered quality involves meeting requirements for
”usability, accessibility, user experience, and avoid-
ing harm from use”.
From such perspective, trustworthy AI should be
both usable and explainable, meaning that it should
not stop working at inappropriate times (which could
create safety risks) and should be user-friendly for in-
dividuals with diverse backgrounds. Moreover, trust-
worthy AI must allow for human explanation and
analysis to mitigate risks and empower users, as well
as transparent to promote understanding of its work-
ings mechanism. Human agency and oversight means
that AI systems shall be developed and used as a tool
that serves people, respects human dignity and per-
sonal autonomy, and being under human control and
oversight. In that context, ethics guidelines for trust-
worthy AI were written by High-Level Expert Group
on AI (High-Level Expert Group on Artificial Intel-
ligence, 2019). The guidelines have 4 ethical princi-
ples: (1) Respect for human, (2) Prevention of harm,
(3) Fairness, (4) Explainability; and seven key (ethi-
cal) requirements, among it, we can mention:
• Privacy: For IEEE-7000 privacy means that col-
lection with unsolicited surveillance, processing
with unexpected and unsolicited personal data ag-
gregation, and the dissemination of personal in-
formation is carried out in such a way that it pre-
serves the self-determination of the person with
regard to information (breach of confidentiality,
disclosure) and that any form of invasion is pre-
vented (intrusion against the will). In practice,
collection implies that data acquired are cleaned
of private information. Once stored, the cleaned
data may still fall within the scope of privacy
when crossed with other data. Privacy rules must
be explicit and respected throughout the data life
cycle. When data is crossed and processed, in-
formation must be anonymized. This implies that
data remains coherent, and that representative-
ness, diversity, and completeness are preserved.
In (Fjeld et al., 2020) eight principles of pri-
vacy are highlighted: control over the use of data,
ability to restrict data processing, right to recti-
fication, right to erasure, privacy by design, and
recommends data protection laws, and privacy
(other/general).
• Respect for fundamental rights: During human-
machine interaction, the machine is perceived as
a) attentive, by replying in a reasonable amount
of time, and b) responsive, by respecting user
privacy, with appropriate decision criteria, trans-
parency, fairness and politeness. For instance,
fairness is unsatisfied when biases were intro-
duced during model training in case of unreliable
sources or distribution shifts over the time; trans-
parency is neither met when data for learning were
suppressed nor traced. Like the other data quality
attributes, the definition of respect requirements
with their thresholds is essential to regularly as-
sess data and dataset quality - what must be con-
sidered at the beginning of the development of an
AI system (High-Level Expert Group on Artificial
Intelligence, 2019).
5 CONCLUSIONS AND
PERSPECTIVES
This paper highlights the importance of assessing AI
trustworthiness in the context of Model-based Sys-
tem Engineering (MBSE) for the development of AI-
based systems. The complexity and uncertainties as-
sociated with AI necessitate a comprehensive evalu-
ation of trustworthiness attributes and corresponding
evaluation metrics. The state of the art review pre-
sented in this paper provides insights into the various
trustworthiness attributes that need to be considered
when assessing AI systems. These attributes include
data quality, robustness, and explainability, among
others. Each attribute plays a crucial role in ensur-
ing the reliability, safety, and ethical implications of
AI systems.
The review is based on a thorough analysis of aca-
demic and industrial literature conducted within the
Confiance.ai research program. This ensures that the
findings are grounded in both theoretical and practical
perspectives, making them relevant and applicable to
real-world scenarios.
By considering the trustworthiness attributes and
evaluation metrics identified in this review, MBSE
practitioners can effectively assess the trustworthiness
of AI-based systems. This assessment is essential for
mitigating risks, addressing uncertainties, and build-
ing confidence in the deployment and utilization of AI
technologies.
However, it is important to note that the field of AI
trustworthiness assessment is rapidly evolving, and
new attributes and evaluation metrics may emerge in
the future. Therefore, future research will focus on
keeping up with the advancements in AI technology
and hence extending this work to include other trust-
worthiness attributes and metrics.
AI Systems Trustworthiness Assessment: State of the Art
331

ACKNOWLEDGEMENTS
This work has been supported by the French govern-
ment under the ”France 2030” program, as part of the
SystemX Technological Research Institute within the
Confiance.ai Program (www.confiance.ai).
REFERENCES
Adedjouma, M., Adam, J.-L., Aknin, P., Alix, C., Baril, X.,
Bernard, G., Bonhomme, Y., Braunschweig, B., Can-
tat, L., Chale-Gongora, G., et al. (2022). Towards the
engineering of trustworthy AI applications for critical
systems - the confiance.ai program.
AI, U. L. I. (2019). A plan for federal engagement in devel-
oping technical standards and related tools.
Arya, V. et al. (2022). AI Explainability 360: Impact and
design. In Proceedings of the AAAI Conf., volume 36
(11).
Avizienis, A. et al. (2004). Basic concepts and taxonomy
of dependable and secure computing. IEEE Trans. on
dependable and secure computing, 1(1):11–33.
Biran, O. and Cotton, C. (2017). Explanation and justifi-
cation in machine learning: A survey. In IJCAI-17
workshop on explainable AI (XAI), volume 8, pages
8–13.
Blatchford, M. L., Mannaerts, C. M., and Zeng, Y. (2021).
Determining representative sample size for validation
of continuous, large continental remote sensing data.
International Journal of Applied Earth Observation
and Geoinformation, 94:102235.
Bosni
´
c, Z. and Kononenko, I. (2009). An overview of ad-
vances in reliability estimation of individual predic-
tions in ML. Intelligent Data Analysis, 13(2):385–
401.
Braunschweig, B., Gelin, R., and Terrier, F. (2022). The
wall of safety for AI: approaches in the confiance.ai
program. In SafeAI@ AAAI, volume 3087 of CEUR
Workshop Proceedings. CEUR-WS.org.
Buckley, F. J. and Poston, R. (1984). Software quality assur-
ance. IEEE Trans. on Software Engineering, 1(1):36–
41.
Byun, T. and Rayadurgam, S. (2020). Manifold for machine
learning assurance. In ACM/IEEE 42nd International
Conference on Software Engineering: New Ideas and
Emerging Results, pages 97–100.
Chapman, A. et al. (2020). Dataset search: a survey. The
VLDB J., 29(1):251–272.
Davis, J. and Goadrich, M. (2006). The relationship be-
tween precision-recall and roc curves. In Proceed-
ings of the 23rd international conference on Machine
learning, pages 233–240.
Delseny, H., Gabreau, C., Gauffriau, A., Beaudouin, B.,
Ponsolle, L., Alecu, L., Bonnin, H., Beltran, B.,
Duchel, D., Ginestet, J.-B., et al. (2021). White paper
machine learning in certified systems. arXiv preprint
arXiv:2103.10529.
Derezi
´
nski, M. (2019). Fast determinantal point processes
via distortion-free intermediate sampling. In Conf. on
Learning Theory, pages 1029–1049. PMLR.
Doshi-Velez, F. and Kim, B. (2017). Towards a rigorous sci-
ence of interpretable machine learning. arXiv preprint
arXiv:1702.08608.
Du, M. et al. (2019). On attribution of recurrent neural net-
work predictions via additive decomposition. In The
WWW Conf., pages 383–393.
Felderer, M. and Ramler, R. (2021). Quality Assurance for
AI-Based Systems: Overview and Challenges (Intro-
duction to Interactive Session). In International Conf.
on Software Quality, pages 33–42. Springer.
Fjeld, J. et al. (2020). Principled artificial intelligence:
Mapping consensus in ethical and rights-based ap-
proaches to principles for AI. Berkman Klein Center
Research Publication.
Ge, M. and Helfert, M. (2006). A framework to assess deci-
sion quality using information quality dimensions. In
ICIQ, pages 455–466.
Girard-Satabin, J. et al. (2022). CAISAR: A platform for
Characterizing Artificial Intelligence Safety and Ro-
bustness. In AI Safety workshop of IJCAI-ECAI.
Gong, Z. et al. (2019). Diversity in machine learning. IEEE
Access, 7:64323–64350.
Grabisch, M. and Labreuche, C. (2010). A decade of appli-
cation of the Choquet and Sugeno integrals in multi-
criteria decision aid. Annals of Operations Research,
175(1):247–286.
Gyllenhammar, M. et al. (2020). Towards an operational
design domain that supports the safety argumentation
of an automated driving system. In 10th European
Congress on Embedded Real Time Systems (ERTS).
Heinrich, B. et al. (2018). Requirements for data quality
metrics. Journal of Data and Information Quality
(JDIQ), 9(2):1–32.
High-Level Expert Group on Artificial Intelligence (2019).
Assessment list for trustworthy artificial intelligence
(altai). Technical report, European Commission.
INCOSE, T. (2007). Systems engineering vision 2020. IN-
COSE, San Diego, CA, accessed Jan, 26(2019):2.
Jakubik, J. et al. (2022). Data-centric artificial intelligence.
arXiv 2212.11854.
Jarrahi, M. and Others (2022). The Principles of Data-
Centric AI. arXiv 2211.14611.
Kaakai, F. and Raffi, P.-M. (2023). Towards multi-timescale
online monitoring of ai models: Principles and prelim-
inary results. In SafeAI@ AAAI.
Kapusta, K., , et al. (2023). Protecting ownership rights of
ml models using watermarking in the light of adver-
sarial attacks. In AAAI Spring Symposium - AITA: AI
Trustworthiness Assessment.
Kaur, G. and Bahl, K. (2014). Software reliability, metrics,
reliability improvement using agile process. Int. J. of
Innovative Science, Engineering & Techno., 1(3):143–
147.
Kulesza, A. et al. (2012). Determinantal point processes
for machine learning. Foundations and Trends® in
Machine Learning, 5(2–3):123–286.
MBSE-AI Integration 2024 - Workshop on Model-based System Engineering and Artificial Intelligence
332

Labreuche, C. (2011). A general framework for explain-
ing the results of a multi-attribute preference model.
Artificial Intelligence, 175(7-8):1410–1448.
Mamalet, F. et al. (2021). White Paper Machine Learning
in Certified Systems. Research report, ANITI.
Mann, C. (2009). A practical guide to sysml: The systems
modeling language. Kybernetes, 38(1/2).
Mattioli, J. et al. (2023a). An overview of key trustworthi-
ness attributes and kpis for trusted ml-based systems
engineering. In AI Trustworthiness Assessment (AITA)
@ AAAI Spring Symposium.
Mattioli, J. et al. (2023b). Towards a holistic approach for ai
trustworthiness assessment based upon aids for multi-
criteria aggregation. In SafeAI @ AAAI.
Mattioli, J. et al. (2023c). Towards a holistic approach for ai
trustworthiness assessment based upon aids for multi-
criteria aggregation. In SafeAI@ AAAI.
Mattioli, J., Le Roux, X., Braunschweig, B., Cantat, L.,
Tschirhart, F., Robert, B., Gelin, R., and Nicolas, Y.
(2023d). Ai engineering to deploy reliable ai in indus-
try. In AI4I.
Mattioli, J. and other (2022). Empowering the trustworthi-
ness of ml-based critical systems through engineering
activities. arXiv preprint arXiv:2209.15438.
Mazumder, M. et al. (2022). Dataperf: Benchmarks for
data-centric ai development. arXiv:2207.10062.
Mountrakis, G. and Xi, B. (2013). Assessing reference
dataset representativeness through confidence metrics
based on information density. ISPRS journal of pho-
togrammetry and remote sensing, 78:129–147.
Philippe, D., David, V., Alice, P., Antoine, C., Antonin, P.,
Caroline, G., and Allouche, T. (2022). Explainability
benchmark v2 - the confiance.ai program.
Plumb, G., Al-Shedivat, M., Cabrera,
´
A. A., Perer, A.,
Xing, E., and Talwalkar, A. (2020). Regularizing
black-box models for improved interpretability. Ad-
vances in Neural Information Processing Systems,
33:10526–10536.
Py, E. et al. (2023). Real-time weather monitoring and
desnowification through image purification. In AAAI
Spring Symposium - AITA: AI Trustworthiness Assess-
ment.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016). ”why
should i trust you?”: Explaining the predictions of
any classifier. In Proceedings of the 22nd ACM
SIGKDD International Conf. on Knowledge Discov-
ery and Data Mining, page 1135–1144, New York,
NY, USA. Association for Computing Machinery.
SAE J3016 (2018). Taxonomy and Definitions for Terms
Related to On-Road Motor Vehicle Automated Driv-
ing Systems.
Tambwekar, P. and Gombolay, M. (2023). Towards rec-
onciling usability and usefulness of explainable ai
methodologies. arXiv preprint arXiv:2301.05347.
Tuomisto, H. (2010). A diversity of beta diversities:
straightening up a concept gone awry. part 1. defin-
ing beta diversity as a function of alpha and gamma
diversity. Ecography, 33(1):2–22.
Wing, J. M. (2021). Trustworthy ai. Communications of the
ACM, 64(10):64–71.
Yeh, C.-K., Hsieh, C.-Y., Suggala, A., Inouye, D. I., and
Ravikumar, P. K. (2019). On the (in) fidelity and sen-
sitivity of explanations. Advances in Neural Informa-
tion Processing Systems, 32.
Zhang, J. M., Harman, M., Ma, L., and Liu, Y. (2020). Ma-
chine learning testing: Survey, landscapes and hori-
zons. IEEE Transactions on Software Engineering.
AI Systems Trustworthiness Assessment: State of the Art
333
