
Module of Contrastive Analysis for a Phonological Assessment Software
in Development
Jo
˜
ao V
´
ıctor B. Marques
1 a
, Jo
˜
ao Carlos D. Lima
1 b
, M
´
arcia Keske-Soares
2 c
and Fabr
´
ıcio Andr
´
e Rubin
3 d
1
Centro de Tecnologia, Universidade Federal de Santa Maria, Santa Maria, Brazil
2
Centro de Ci
ˆ
encias da Sa
´
ude, Universidade Federal de Santa Maria, Santa Maria, Brazil
3
Petroleo Brasileiro S.A., Rio de Janeiro, Brazil
Keywords:
Speech Therapy Software, Phonological Assessments, Digital Platforms, Contrastive Analysis.
Abstract:
The interest in software as tools to assist speech therapy has grown in recent years, with proposed features
primarily focused on the analysis of children’s speech. However, there is still a gap in tools to apply phono-
logical assessments that are suitable to collect data. In this context, our research group is working on a digital
platform called “e-Fono”, which consists of a mobile application, a REST API, and a web service where the
speech therapist has access to the assessments. However, despite the existence of robust tools for data analysis,
predominantly used in academic contexts, no software was found with a module for phonological contrastive
analysis in Brazilian Portuguese. In the contrastive analysis, the speech therapist compares and identifies the
contrasts between the child’s speech and that of an adult, providing a detailed report on which phonemes and
in which positions of the words the child experiences greater difficulties. Through this process, currently car-
ried out manually by the speech therapists in our group, the child’s phonetic inventory is also obtained – a
list of all phonemes the child can articulate. This paper proposes the development of a contrastive analysis
module, which has been implemented in the e-Fono digital platform. In our implementation, the module was
able to perform an automatic contrastive analysis by comparing the child’s phonetic transcriptions with known
correct transcriptions from our database. The results can be reviewed by the speech therapist, who can replace
and submit information of this analysis in case of wrong or incomplete results. With these information on the
platform, it will be possible to identify speech difficulties in children and guide the speech therapist toward
a specific treatment for them. Finally, in this paper we also present screens from the implemented prototype,
which may be available to the general public after validation and adjustments with specialists from our group.
1 INTRODUCTION
In the process of language acquisition, it is expected
that a child will attempt to approximate their speech
to that of an adult, by substituting or omitting sounds
they are not yet capable of producing (Ceron et al.,
2017). In speech therapy, these approximations are
referred to as “phonological processes”, and their ap-
plication results in incorrect pronunciation. In the lit-
erature, such processes are already mapped, and a nat-
ural overcoming age limit is defined (Yavas and Lam-
precht, 1988) – an expected age limit by which a child
a
https://orcid.org/0009-0007-3206-725X
b
https://orcid.org/0000-0001-9719-3205
c
https://orcid.org/0000-0002-5678-8429
d
https://orcid.org/0009-0009-5154-7843
should naturally articulate a word correctly without
substituting or omitting phonemes.
The integration of computational systems in
speech therapy has assisted in the early identification
of phonological processes (Franciscatto et al., 2021),
the application of phonological assessments through
software (Ceron et al., 2020), and the analysis of chil-
dren’s speech (Rose and Hedlund, 2021; Ramalho
et al., 2022) for the identification and treatment of
phonological deviations (Sotero and Pagliarin, 2018;
Jesus et al., 2019; Uberti et al., 2020). Each as-
sessment involves presenting a set of images to the
child, who must pronounce the represented object
(target word) in the image (Ceron et al., 2020). In
this context, the Contrastive Analysis aims to com-
pare the child’s phonological system with an adult
system (Storkel, 2022), identifying contrasts between
Marques, J., Lima, J., Keske-Soares, M. and Rubin, F.
Module of Contrastive Analysis for a Phonological Assessment Software in Development.
DOI: 10.5220/0012584000003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 973-980
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
973

both and detailing exactly which phonemes the child
struggles to articulate and in which part of the word
this difficulty occurs.
In the southern region of Brazil, where this work
was developed, phonological assessments containing
words familiar to the socio-economic context of in-
dividuals. This work is based on the phonological
assessment software from the study by (Ceron et al.,
2020).
Up until the writing of this article, no phono-
logical assessment system containing a contrastive
analysis module was found to support Brazilian Por-
tuguese. Given the importance of this functional-
ity for a comprehensive and detailed identification of
phonological deviations, this work proposes an ar-
chitecture for the operation of contrastive analysis in
a virtual environment, utilizing technologies such as
React and MongoDB, in addition to implementing
functions in a REST API.
To validate the presented modeling, we imple-
mented the prototype of the introduced module and
demonstrated how the system behaves with real data.
After implementing this module, it was possible to
determine the indication of phonological deviation
in the evaluated child according to the PCC-R (Per-
cent of Consonants Correct-Revised) (Shriberg et al.,
1997). This index is widely used in the field of pe-
diatric speech therapy, associating the percentage of
correct consonants in the assessment with an indica-
tion of phonological deviation present in the child’s
speech (Ceron et al., 2017; McCabe et al., 2023).
Lastly, the child’s phonetic inventory—the set of
phonemes the child can correctly articulate—was also
presented at the end of the assessment through the
module introduced by this study.
The paper is organized as follows. In Section 2,
the reader is introduced to the context in which this
study was produced. In Section 3, the operation of
Contrastive Analysis is presented, followed by its im-
plementation in Section 4 where the screens devel-
oped in this study are presented. Finally, in Section 5,
we conclude the work with our final considerations.
2 BACKGROUND AND CONTEXT
In (Franciscatto et al., 2021), a tool was proposed
to predict phonological processes, aiming to as-
sist speech therapists in identifying weaknesses in a
child’s speech. It is normal that mispronunciations
occurs while the language acquisition process (Ceron
et al., 2017) However, if the child do not overcome
her speak difficulties, they can evolve into a more seri-
ous phonological disorder, persisting into adolescence
and adulthood if not treated early. Hence, the impor-
tance of early identification.
The software introduced by (Ceron et al., 2020)
presented a set of 84 target words for phonologi-
cal assessment. The children were exposed to a set
of images representing the word they should pro-
nounce spontaneously, without reading or hearing the
word beforehand. The mobile application discussed
in (Franciscatto et al., 2021) is based on Brazilian Por-
tuguese words and was developed to assist a team of
speech therapy experts in collecting phonological as-
sessment data.
Cavalo [horse]
Listen PlayRecord
Back Next
Figure 1: Target word that must be spoken by the subject.
Adapted from (Franciscatto et al., 2021).
The software “Phon” (Rose and Hedlund, 2020)
already has functionalities such as calculating the
PCC-R, also implemented in our platform. Al-
though suitable for clinical evaluation (Byun and
Rose, 2016), it is primarily used for academic re-
search (Rose and Stoel-Gammon, 2015). Addition-
ally, it is an open-source software maintained and fre-
quently updated, and it has plugins like AutoPATT
by (Combiths et al., 2022). This plugin is capable of
automatically generating the phonetic inventory, also
generated in our implementation. One of the differ-
ences between our studies is the application of these
functionalities in Brazilian Portuguese, and also the
integration between a mobile application for data col-
lection and a web service for analysis, allowing the
workflow to be carried out by different professionals,
regardless of their location.
2.1 e-Fono Platform
The e-Fono Platform is a prototype of a product de-
veloped by our research group, providing speech ther-
apists with the capability to conduct phonological as-
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
974
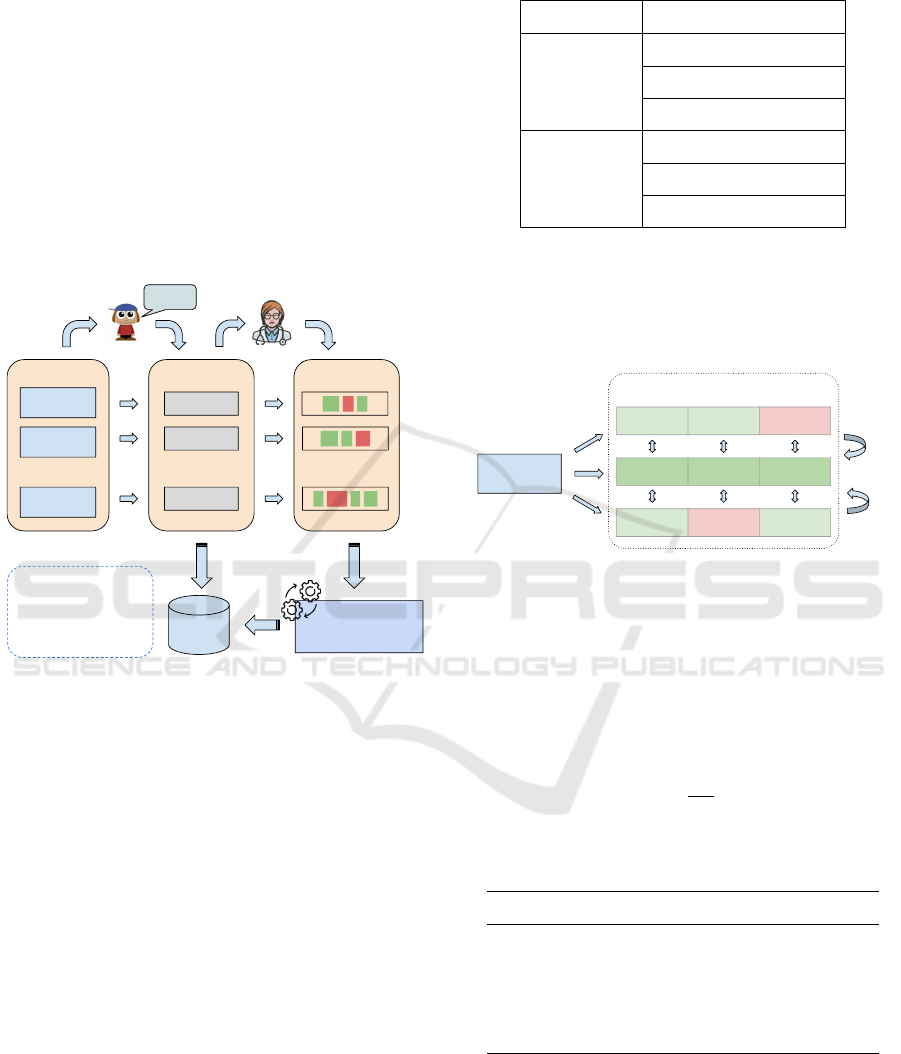
sessments online. It stores audio recordings and pho-
netic transcriptions in a database, as illustrated in
Figure 2. All stored data have been the subject of
previous studies (Franciscatto et al., 2019a; Francis-
catto et al., 2019b; Franciscatto et al., 2021; Mar-
ques. et al., 2023). Currently, our database contains
132,031 phonetic transcriptions entered by a team of
speech therapists from the Federal University of Santa
Maria (Brazil). Additionally, the data is associated
with over 1,200 phonological assessments conducted
on 1,357 children aged 3–7 in the southern region of
Brazil, encompassing approximately 130,000 audio
samples.
Phonological
Assessment
Speech Data Collection and
Internal Processing
cavalo
[horse]
pateta
[goofy]
biblioteca
[library]
●
●
●
Speak
audio
audio
audio
●
●
●
[‘ka.fa.lo]
[‘pa.te.pa]
[bi.bio’.tɛ.kə]
●
●
●
Internal Processing
Data
word-audio-transcription
Target Words
Pronunciations
Transcriptions
Figure 2: Model for implementing Digital Phonological As-
sessment.
Each phonological assessment comprises a set of
target words that the child is expected to pronounce
spontaneously. In a digital environment, the speech
therapist records the child’s speech in audios, which
are stored on the platform. Following this initial col-
lection, the professional enters the phonetic transcrip-
tion of each word, including phoneme omissions and
substitutions. All data undergo internal processing,
involving the extraction of regions of interest and
noise removal (Franciscatto et al., 2019a). It is at
this stage that our module integrates into the plat-
form, automatically analyzing the phonetic transcrip-
tions from the assessment.
3 CONTRASTIVE ANALYSIS
The Contrastive Analysis is a process that compares
the phonological system of the child with the standard
adult system (Storkel, 2022). The Figure 3 presents
Table 1: Examples of Phonetic Transcriptions.
Palavra Transcric¸
˜
ao Fon
´
etica
Bi.blio.te.ca
bi.bli.o.’te.ka
bi.o.’te.ka
bi.bi.o.’te.ka
Ca.va.lo
ka.’va.lo
ka.’va.lu
ka’falu
this process in a simplified manner, where the speech
therapist compares each phonetic syllable individu-
ally, noting differences in the child’s pronunciation
based on an acceptable outcome, indicated in dark
green.
cavalo
[horse]
ka va lo
ka va jo
ka fa lo
compare
Phonetic Transcription
Figure 3: Comparison between a child’s Phonetic Tran-
scription and that of an adult (dark green).
In this analysis, concerning cases of phonological
disorder and also considering the PCC-R index, only
the consonantal phonemes are observed (Shriberg
et al., 1997). This value is calculated according to
Equation 1 and is associated with an indication of
phonological deviation shown in Table 2.
PCC-R =
PC
T P
× 100 (1)
Table 2: Indication of speech disorder according with PCC-
R value. (Shriberg et al., 1997).
PCC-R Value Indication of Disorder
Less than 50% High
Between 50% e 65% Moderate-High
Between 65% e 85% Low-Moderate
Greater than 85% Low
So far, no freely available software with the func-
tionality of contrastive analysis has been found in
Brazilian Portuguese. It is up to the speech thera-
pist to do manually this process with paper and pen,
including counting correct productions and the total
number of phoneme productions in an assessment.
For this reason, the contrastive analysis module for
Module of Contrastive Analysis for a Phonological Assessment Software in Development
975
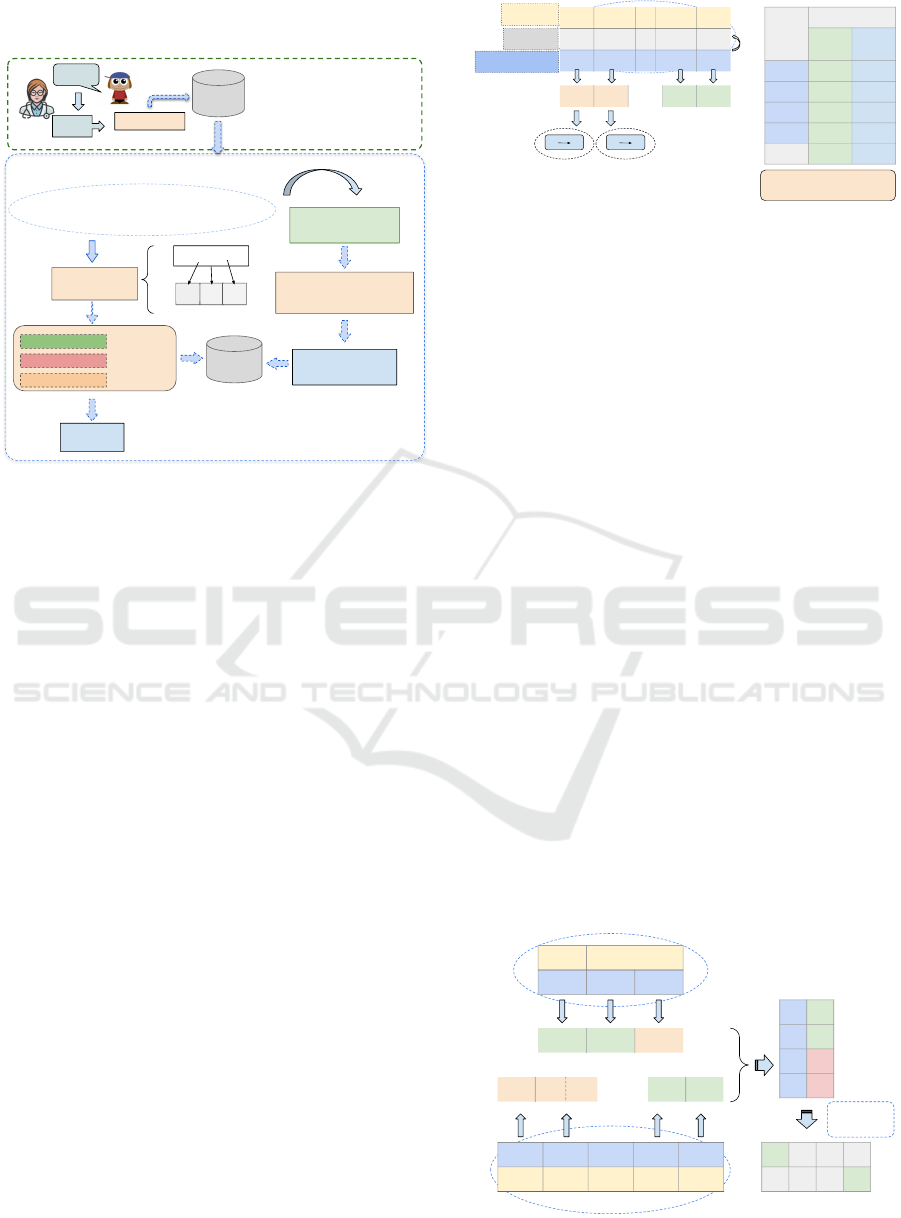
the e-Fono software is the subject of this study, and
its flowchart can be viewed in Figure 4.
Phonemes and
Consonant Clusters Productions
Obtaining the
Phonetic Inventory
Speak
Phonological Assessment
Speech Data Collection and
Internal Processing
Audio
Processing
C (Correct)
∅ (Omission)
S (Substitution)
Classification
of phoneme
productions
Split Phonemes
Database
Recording the sounds
the child can produce
Phonetic
Inventory
Generates
PCC-R
Data
Obtaining the PCC-R and
Phonetic Inventory
Contrastive Analysis
[‘ka.fa.lo]
k
f l
Figure 4: Contrastive Analysis Flowchart.
The implemented Contrastive Analysis separately
analyzes the productions of phonemes and conso-
nant clusters to obtain the phonetic inventory, i.e., the
list of phonemes that the child can articulate. With
the classification of each production, it is possible to
calculate the PCC-R by tallying all correct produc-
tions in the assessment. This classification is auto-
matically implemented by the module following the
logic shown in Figure 3, comparing the transcriptions
from the assessment with similar correct transcrip-
tions in our database. This allows the identification
of phonemes with correct productions, substitutions,
and omissions. Next, we will see the details of each
of these steps.
3.1 Phonemes and Consonant Clusters
Productions
This step involves receiving the data from the phono-
logical assessment, including the phonetic transcrip-
tion of the word pronounced by the child. This al-
lows the analysis of phonemes in different syllabic
and word positions, classified as correct productions,
substitutions, or omissions. In the case of an omis-
sion, the platform records the frequency with which
it occurred for each phoneme. Occurrences of substi-
tution of one phoneme for another are also recorded.
The analysis details which phoneme was replaced in
the child’s pronunciation, the phoneme used in the
substitution, and the frequency of this event. An ex-
ample of this process is illustrated in Figure 5.
PCC-R = 2/4
(Moderate-High)
OI OCM OM OM
bi bli o tƐ ka
pi pli o tƐ ka
b p
Positions
Template
Productions
Substitution
[b] by [p]
p pl t k
bl pl
Substitution
[bl] by [pl]
Transcription
Compare
Phon.
Productions
Correct
(PC)
Total
(TP)
p 0 1
pl 0 1
t 1 1
k 1 1
Total 2 4
Figure 5: Example of Phoneme and Consonant Cluster
Analysis and PCC-R calculation.
In the example, using the phonemes of the word
“biblioteca” [library in English], from left to right:
there was a substitution of the [b] phoneme with [p]
in the Initial Onset (OI) and a substitution of the con-
sonant cluster [bl] with [pl] in the Medial Complex
Onset (OCM). Finally, in the last two Medial Onsets,
there was a correct production of the [t] phoneme and
the [k] phoneme.
At the end of this step, the necessary records are
obtained to automatically generate the child’s pho-
netic inventory, i.e., all the phonemes in certain po-
sitions of the word that the child can articulate at
least twice (Stoel-gammon, 1985). It is sufficient to
consider the number of correct productions for each
phoneme and add it to the number of times that the
phoneme was used to substitute other phonemes. This
step will be discussed in more detail in the next sec-
tion.
3.2 Phonetic Inventory
To determine the presence or absence of a sound in the
phonetic inventory, a minimum of two occurrences
of the segment can be considered, regardless of its
position in the word (Stoel-gammon, 1985). In the
example shown in Figure 6, even the phonemes that
were articulated in an incorrect pronunciation (or-
ange) are considered in the production count, as the
OI OM
pa te pa
Productions
p t p
p p l t k
p 4
t 2
k 1
l 1
Total of Productions
pi pli o tƐ ka
OI OCM OM OM
p b l d
f k … t
Phonetic
Inventory
Figure 6: Example of the generation the Phonetic Inventory.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
976
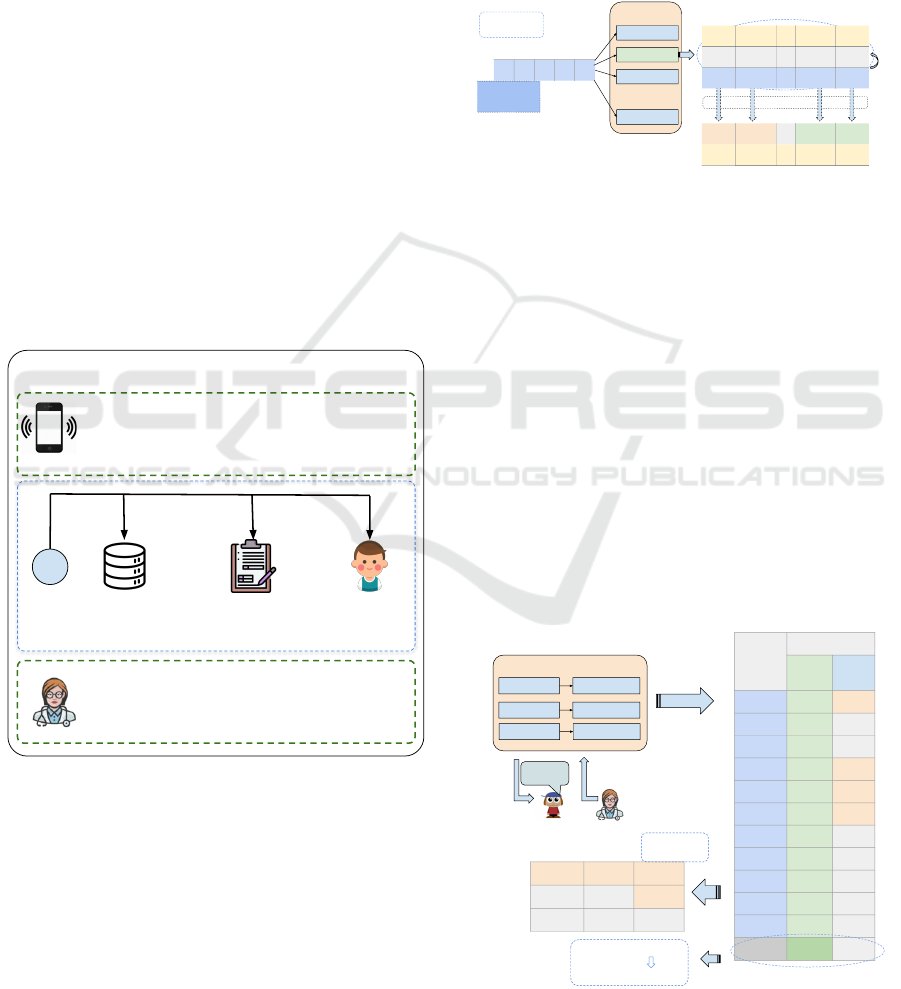
child was able to articulate them through the appli-
cation of a phonological process. Also in the exam-
ple, the phonemes [k] and [l] are not considered in
the phonetic inventory, as they had fewer than two
productions. In the table in the lower right corner,
containing the phonetic inventory, only the phonemes
with two or more productions were considered ac-
quired by the child (green).
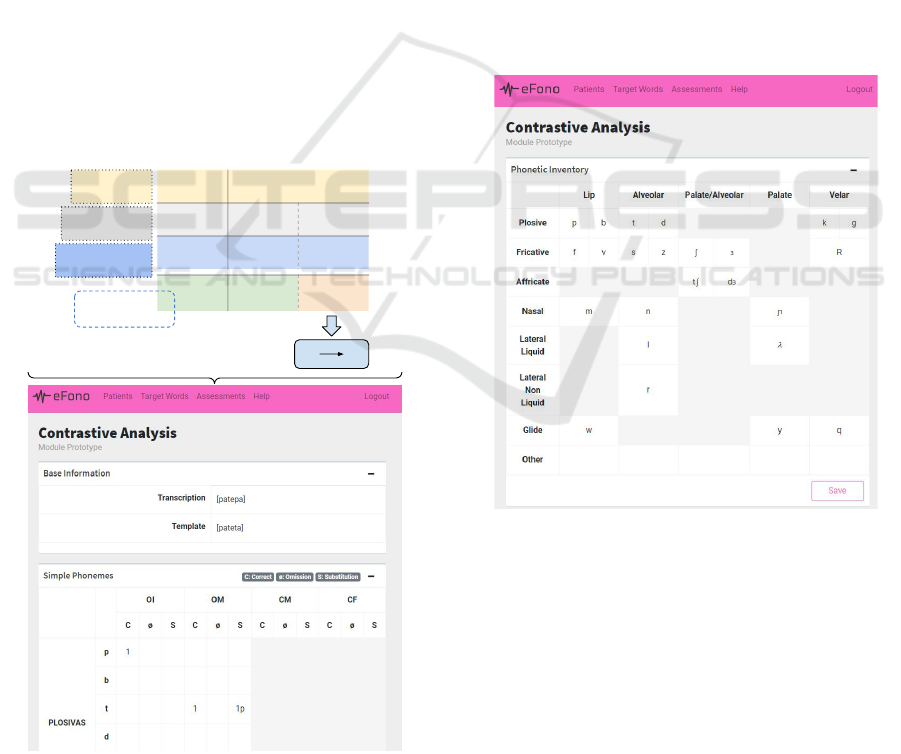
4 IMPLEMENTATION
A basic architecture of the e-Fono Platform is pre-
sented in Figure 7. It consists of a REST API that
connects the mobile application used for phonologi-
cal assessments and the web service for data analy-
sis. In this model, the mobile application could be
used by family members or early childhood educators
to assess children’s speech. It would be useful for a
screening process where children with results below
the expected level for their age would be referred to
a speech therapist for professional follow-up, similar
to the concept presented in the study by (Franciscatto
et al., 2021).
Audio Records
Storage
Phonological
Assessments
Management
Patients
Management
REST
API
MOBILE APP
● Perform Phonological Assessments
● Send Records Data to Server for classification and
screening
WEB SERVICE
● Phonological Assessments Tool Creation
● Validation of generated data from API
e-Fono Platform Model
Figure 7: Presenting the Model of e-Fono Plataform with
REST API.
The implementation of the present study occurred
in the REST API and the web service since the con-
trastive analysis is a process that occurs after the
phonological assessment. The main challenge was
determining a way to recognize the positions (OI,
OM, OCI, etc.) of each phoneme in the transcrip-
tions, so that the therapist could have detailed infor-
mation about which phonemes and in which positions
the child faced the most difficulty.
To address this situation, the algorithm presented
in Figure 8 compares the input transcription with a set
of known transcriptions for the word, already contain-
ing the correct positions of the phonemes. In this step,
the Levenshtein distance algorithm, previously used
in works in the field of computational systems for
speech therapy (Martinez-Quezada et al., 2022), was
employed to identify which known case were most
similar to the provided transcription.
Remove vowels
pi pli o tƐ ka
Entry
Transcription
[bibio’tɛkə]
[biblio’tɛkə]
[bibilo’tɛkə]
●
●
●
Known Correct
Cases
[biøo’tɛkə]
Look for
most similar
transcription
p pl o t k
OI OCM OM OM
Biblioteca
[library]
OI OCM OM OM
bi bli o tƐ ka
pi pli o tƐ ka
Compare
Now we have the positions
for the Entry Transcription
Figure 8: Algorithm for recognizing phoneme positions
given an unknown transcription.
With the result provided by this algorithm, each
phoneme can be analyzed separately, and it is suffi-
cient to observe the differences between the correct
transcription (gray) and the input transcription to ob-
tain the contrastive analysis automatically. Thus, the
classification of each phoneme in each word position
is obtained, tallying productions as correct, omitted,
or substituted.
For the automatic construction of the phonetic
inventory and PCC-R, it is enough to consider the
data from the entire assessment and count the num-
ber of correct productions for each phoneme. Fig-
ure 9 presents the obtention of the phonetic inventory
and the indication of phonological deviation based on
PCC-R, considering a minimum of two correct occur-
rences in each word position (Stoel-gammon, 1985).
[transcript]
[transcript]
Assessment Data
[transcript]
word 1
word 2
word 3
p(OI) t(OM) l(OM)
b(OI) f(OM) k(OI)
pl(OCM) … …
Phonetic
Inventory
Phon.
Productions
Correct
(PC)
Total
(TP)
p(OI) 1 2
p(OM) 0 1
pl(OCM) 0 1
t(OM) 2 2
l(OM) 2 2
k(OI) 2 2
k(OM) 1 1
f(OM) 0 1
b(OI) 1 1
b(OM) 1 1
ʒ(OM) 1 1
Total 11 15
11 / 15 = 0.73
73%
PCC-R
Speaks
Transcribes
(Low-Moderate)
Figure 9: Method for obtaining the Phonetic Inventory and
PCC-R.
Module of Contrastive Analysis for a Phonological Assessment Software in Development
977
Finally, since the data from the contrastive analy-
sis are generated automatically by the proposed mod-
ule, we implemented a mechanism in the records that
distinguishes the information generated by the system
from the data coming from user corrections or inser-
tions. For this purpose, a variable “createdBySystem”
stores all records generated by the module, so that
they can be validated later by the speech therapist in
the web service.
4.1 Prototype
The e-Fono Platform, currently in development, is a
prototype of a tool to assist speech therapists in the
screening process of patients with possible phonolog-
ical disorders. With the implementation of the module
proposed by this work, the platform gains functional-
ities for data analysis that occur after the screening
performed by the phonological assessment.
The contrastive analysis module was implemented
in the layers of the REST API and WEB SERVICE,
using MongoDB for data storage and React on the
web platform. Figure 10 shows how the Contrastive
Analysis information is presented to the user on the
web platform.
t p
Substitution [t] by [p]
p t p
Productions
OI OM
pa te ta
pa te pa
Positions
Template
Transcription
Figure 10: Screen of the Contrastive Analysis Module on
the e-Fono Platform detailing the Production of Phonemes
in a Transcription.
The visualization of the phonetic inventory is
shown in Figure 11, where the speech therapist has
access to all phonemes that the child produced in the
assessments at least twice. However, in the current
version, the module does not specify in which word
position the phoneme can be considered acquired, ac-
cording to the table in Figure 9. Therefore, the speech
therapist has access to the child’s phonetic inventory
regardless of the word position, and this gap could be
filled in future versions.
We implemented this prototype with the assis-
tance of speech therapists from our group, and the
graphical interface resembles the spreadsheets cur-
rently used in a manual process of contrastive analy-
sis by paper and pencil. Compared to this method, our
proposal tends to significantly reduce the time profes-
sionals spend from applying the assessment to diag-
nosis, given the automatic nature of data generation
in our implementation. It is noteworthy that this tool
has not yet been officially launched and its field vali-
dation should take place in the next months.
Figure 11: Contrastive Analysis Module screen showing the
Phonetic Inventory of a fictional child.
Finally, the PCC-R is available on the main screen
containing the patient’s assessment data, as shown in
Figure 12. This value is calculated automatically by
the system and can be recalculated if the speech ther-
apist identifies and corrects errors generated by the
platform.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
978
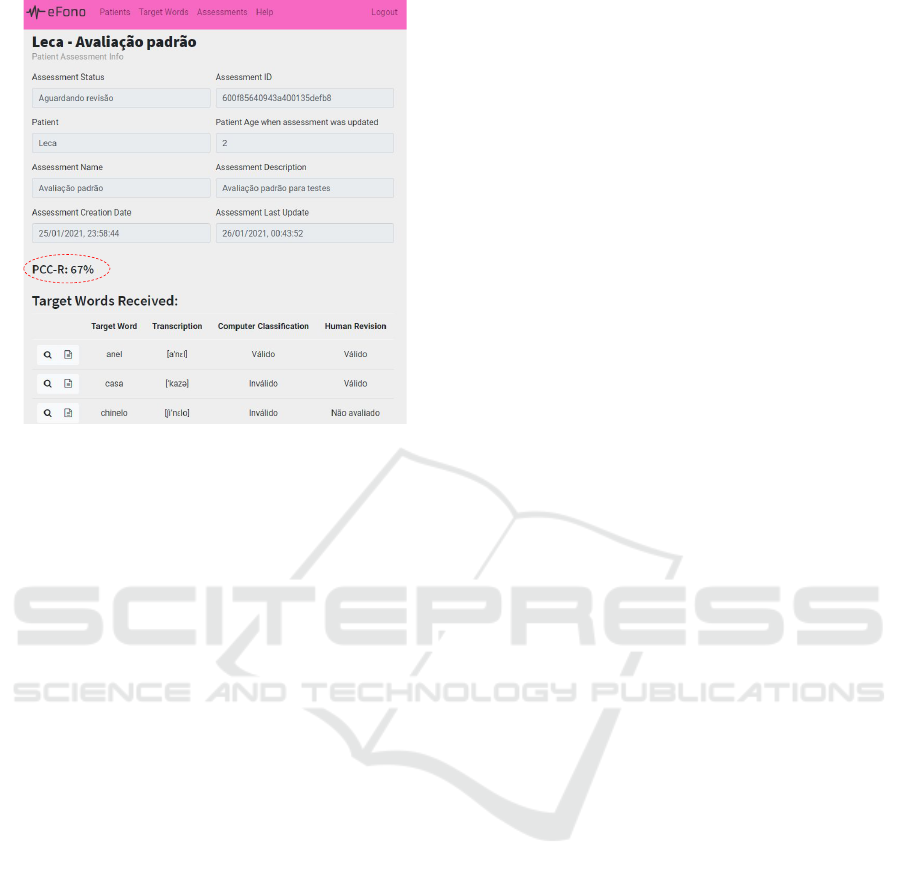
Figure 12: Screen showing the PCC-R value automatically
calculated by the Contrastive Analysis Module.
5 CONCLUSIONS
In the Southern Brazil, where this study was devel-
oped, phonological assessments are used to identify
potential phonological deviations in school-age chil-
dren. Despite the increasing adoption of computa-
tional systems in speech therapy (Ceron et al., 2020;
Rose and Hedlund, 2021; Ramalho et al., 2022), there
is currently no literature on a phonological assess-
ment system containing a contrastive analysis mod-
ule in Brazilian Portuguese. This module aims to
compare the child’s phonological system with that
of an adult (Storkel, 2022), identifying contrasts be-
tween them and detailing the difficulties present in the
child’s speech.
Through this analysis, the speech therapist not
only obtains a detailed report on the phonemes and
positions in which the child experiences difficulties,
but also acquires the child’s phonetic inventory. This
refers to the list of all phonemes that the child can ar-
ticulate according to the position in the word where
they are observed. Additionally, it is possible to de-
termine the PCC-R (Percent of Consonants Correct-
Revised) value (Shriberg et al., 1997), widely used in
speech therapy as an indicator of phonological disor-
der based on the percentage of correct consonants in
the assessment.
Given the importance of this functionality, our
study proposed the Contrastive Analysis Module in a
digital platform called e-Fono, which is under devel-
opment by our research group. In this platform, data
generated in phonological assessments via a mobile
application were automatically processed by the mod-
ule, separating and identifying precisely which word
positions and phonemes the child struggled with. It
was also possible to automatically obtain the child’s
phonetic inventory and determine the PCC-R value
using the phonological assessment data. As this value
is associated with the level of phonological disorder
in the child, a more targeted treatment could be ap-
plied, focusing on phonemes not yet acquired by the
child, which can be observed in the platform.
The module was implemented in the API REST
and web service layers of the e-Fono Platform.
Through it, the speech therapist can have a more de-
tailed understanding of the child’s speech, isolating
the phonemes that require special attention. The mod-
ule was capable of generating the information of the
contrastive analysis, phonetic inventory, and PCC-R
automatically and displaying them in user interfaces
for the speech therapist. We discussed the logic used
in the implementation, and screens of the current pro-
totype were presented in Section 4.1. Finally, it is
worth noting that the system allows for a review by
the specialist, enabling correction and insertion of
new data. However, all corrected and user-inserted
data are stored separately from the system-generated
data, just to maintain control over the origin of the
information.
For future work, the automatically generated in-
formation and those inserted by the speech therapist
could be compared to identify gaps in the proposed
logic and implement improvements and adaptations
to the system. Also, with adjustments to the interface
and a thorough review from our speech specialists, the
platform could be made available to the general public
in Brazil, and we are open to the possibility of contri-
butions to larger projects. Given the continental size
of a country like Brazil with its socio-economic lim-
itations, the application of phonological assessment
could, for example, be carried out by a teacher in a
rural school and later accessed by a speech therapist
in an urban center, democratizing access to phonolog-
ical assessments.
REFERENCES
Byun, T. M. and Rose, Y. (2016). Analyzing clinical phono-
logical data using phon. Seminars in Speech and Lan-
guage, 37:85–105.
Ceron, M. I., Gubiani, M. B., Oliveira, C. R. d., and Keske-
Soares, M. (2017). Factors influencing consonant ac-
quisition in brazilian portuguese–speaking children.
Journal of Speech, Language, and Hearing Research,
60(4):759–771.
Module of Contrastive Analysis for a Phonological Assessment Software in Development
979

Ceron, M. I., Gubiani, M. B., Oliveira, C. R. d., and Keske-
Soares, M. (2020). Phonological assessment instru-
ment (infono): A pilot study. CoDAS, 32(4).
Combiths, P., Amberg, R., Hedlund, G., Rose, Y., and Bar-
low, J. A. (2022). Automated phonological analysis
and treatment target selection using autopatt. Clini-
cal Linguistics & Phonetics, 36(2-3):203–218. PMID:
34085574.
Franciscatto, M. H., Fabro, M. D. D., Lima, J. C. D.,
Trois, C., Moro, A., Maran, V., and Keske-Soares,
M. (2021). Towards a speech therapy support sys-
tem based on phonological processes early detection.
Computer Speech & Language, 65:101130.
Franciscatto, M. H., Lima, J. a. C. D., Trois, C., Maran, V.,
Soares, M. K., and Rocha, C. C. d. (2019a). Apply-
ing situation-awareness for recommending phonolog-
ical processes in the children’s speech. In Proceed-
ings of the 34th ACM/SIGAPP Symposium on Applied
Computing, SAC ’19, page 739–746, New York, NY,
USA. Association for Computing Machinery.
Franciscatto, M. H., Lima, J. a. C. D., Trois, C., Maran,
V., Soares, M. K., and Rocha, C. C. d. (2019b). A
case-based approach using phonological knowledge
for identifying error patterns in children’s speech. In
Proceedings of the 34th ACM/SIGAPP Symposium on
Applied Computing, SAC ’19, page 968–975, New
York, NY, USA. Association for Computing Machin-
ery.
Jesus, L. M. T., Martinez, J., Santos, J., Hall, A., and Joffe,
V. (2019). Comparing traditional and tablet-based in-
tervention for children with speech sound disorders: A
randomized controlled trial. Journal of Speech, Lan-
guage, and Hearing Research, 62(11):4045–4061.
Marques., J., Lima., J., Keske-Soares., M., Rocha., C., Ru-
bin., F., and Miollo., R. (2023). Algorithm for select-
ing words to compose phonological assessments. In
Proceedings of the 25th International Conference on
Enterprise Information Systems - Volume 1: ICEIS,,
pages 80–88. INSTICC, SciTePress.
Martinez-Quezada, M. E., S
´
anchez-Sol
´
ıs, J. P., Rivera, G.,
Florencia, R., and L
´
opez-Orozco, F. (2022). English
mispronunciation detection module using a trans-
former network integrated into a chatbot. Interna-
tional Journal of Combinatorial Optimization Prob-
lems and Informatics, 13(2):65–75.
McCabe, P., Preston, J. L., Evans, P., and Heard, R. (2023).
A pilot randomized control trial of motor-based treat-
ments for childhood apraxia of speech: Rapid sylla-
ble transition treatment and ultrasound biofeedback.
American Journal of Speech-Language Pathology,
32(2):629–644.
Ramalho, A. M., Bernhardt, B. M., and Freitas, M. J.
(2022). Protracted phonological development of a por-
tuguese six-year-old from the perspective of nonlin-
ear phonology. Clinical Linguistics and Phonetics,
36:708–720.
Rose, Y. and Hedlund, G. (2020). Phon 3.1 [computer soft-
ware]. https://phon.ca.
Rose, Y. and Hedlund, G. (2021). The Phonbank Database
within Talkbank, and a Practical Overview of the
Phon Program, pages 228–246. Taylor & Francis.
Rose, Y. and Stoel-Gammon, C. (2015). Using phonbank
and phon in studies of phonological development and
disorders. Clinical Linguistics & Phonetics, 29(8-
10):686–700. PMID: 26035223.
Shriberg, L. D. et al. (1997). The speech disorders classi-
fication system (sdcs). Journal of Speech, Language
and Hearing Research, 40(4):723–740.
Sotero, L. K. B. and Pagliarin, K. C. (2018). The use of
software in cases of speech sound disorders. CoDAS,
30(6).
Stoel-gammon, C. (1985). Phonetic inventories, 15–24
months. Journal of Speech, Language, and Hearing
Research, 28(4):505–512.
Storkel, H. L. (2022). Minimal, maximal, or multiple:
Which contrastive intervention approach to use with
children with speech sound disorders? Language,
Speech, and Hearing Services in Schools, 53(3):632–
645.
Uberti, L., Rodrigues Portalete, C., Pagliarin, K., and
Keske-Soares, M. (2020). Speech articulation assess-
ment tools: a systematic review. Journal of Speech
Sciences, 8:01–35.
Yavas, M. and Lamprecht, R. (1988). Processes and intelli-
gibility in disordered phonology. Clinical Linguistics
& Phonetics, 2(4):329–345.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
980
