
Enhancing Surgical Visualization: Feasibility Study on GAN-Based
Image Generation for Post Operative Cleft Palate Images
Daniel Anojan Atputharuban
1
, Christoph Theopold
2
and Aonghus Lawlor
1
1
The Insight Centre for Data Analytics, School of Computer Science, University College Dublin, Dublin, Ireland
2
Children’s Health Ireland at Temple Street, Dublin, Ireland
Keywords:
Deep Learning, Medical Image Generation, Generative Adversarial Networks, Image Inpainting, Cleft Lips,
Siamese Network.
Abstract:
Cleft Lip/Palate (CL/P) is a prevalent maxillofacial congenital anomaly arising from the failure of fusion in
the frontonasal and maxillary processes. Currently, no internationally agreed gold standard procedures for
cleft lip repair exists, and surgical approaches are frequently selected based on the surgeon’s past experiences
and the specific characteristics of individual patient cases. The Asher-McDade score, a widely employed tool
in assessing unilateral cleft lip surgeries, relies on criteria related to aesthetics and symmetry of maxillofacial
region. However, no objective metric has been developed for assessing surgical success. This study aims to
incorporate deep learning and Generative Adversarial Network (GAN) methods to construct an image gener-
ation framework to produce post-operative lip images that can serve as a standardized reference for assessing
surgical success. We introduce an image similarity score based on the image embeddings which we use to
validate the generated images. Our method paves the way to a set of techniques for the generation of synthetic
faces which can guide surgeons in assessing the outcomes of CL/P surgery.
1 INTRODUCTION
Cleft lip/Palate(CL/P) stands as the most common
maxillofacial birth defect, resulting from the failure
of fusion in frontonasal and maxillary processes. This
failure leads to the physical separation of either one
side, termed a unilateral cleft or both sides, referred to
as a bilateral cleft, in the upper lip (Agrawal, 2009).
On a global scale,1 in 600-800 children are born with
this condition, leading to an annual occurrence of
nearly 220,000 cases (Vyas et al., 2020; Cobourne,
2004; Yilmaz et al., 2019). Children born with the
cleft lip condition experience speech and hearing is-
sues, high susceptibility to dental cavities, difficulty
in feeding and they often undergo social and men-
tal development disorders (Chaudhari et al., 2021).
It also causes significant psychological and socioeco-
nomic effects on parents as well as caretakers.
Cleft lip is treated with surgical procedures fol-
lowed by rehabilitation starting as early as 10-12
weeks of age and follow up surgeries from the age
of 1 year (Shkoukani et al., 2013). Most of the cases
undergo at least two surgeries where more follow up
surgeries are required for complex conditions. Ide-
ally cleft lip repair surgeries should result in symmet-
ric and naturally looking upper lips (Mosmuller et al.,
2016). But in most of the patients, surgical scars can
be noticed in upper lip and philtrum which is the area
between upper lip and nose. Cleft lip surgeries re-
store or repair speech, appearance and normal feed-
ing. Cleft lip surgical procedures are complex and
rely on the collective expertise drawn from multiple
clinical domains (Yilmaz et al., 2019).
Machine learning and deep learning methods to
model the face have experienced a surge of interest in
recent years. In particular, facial GANs have emerged
as an active research topic and poses a number of in-
teresting challenges, largely due to the fact that the
human face is a very complex object which can be
represented in 2D or 3D and we often need to ac-
count for dynamic poses and facial expression which
modify the features considerably (Kammoun et al.,
2022). There are some recent efforts to develop meth-
ods to assist and guide clinicians performing CL/P
surgical repairs. (Li et al., 2019) have trained a
model to locate surgical markers and incisions which
helps surgeons prepare for the procedure particularly
in circumstances where they may lack experience. In
(Chen et al., 2022) GAN inpainting methods are pro-
posed to generate non-cleft lips from images with
Atputharuban, D., Theopold, C. and Lawlor, A.
Enhancing Surgical Visualization: Feasibility Study on GAN-Based Image Generation for Post Operative Cleft Palate Images.
DOI: 10.5220/0012576900003654
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 13th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2024), pages 939-945
ISBN: 978-989-758-684-2; ISSN: 2184-4313
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
939

cleft lip. Despite the advances in facial recognition
and modelling, the application of these methods in
plastic surgery is still very limited. In part, this is due
to the lack of good quality datasets for training and in
our case to a particular lack of datasets with faces of
children.
At present, there is no established standard surgi-
cal procedure for restoring cleft lip and palate. As
a result, a diverse range of surgical approaches ex-
ists for CL/P repair (Wadde et al., 2022). (Asher-
Mcdade et al., 1991) introduced a standardised rat-
ing method for evaluating different cleft lip treatment
approaches. This widely used index serves as a com-
mon measure to evaluate the success of cleft lip surg-
eries, focusing on the aesthetics of the nasolabial re-
gion. More recently, the Cleft Aesthetic Rating Scale
(CARS) (Mosmuller et al., 2016) has been developed,
but the Asher-McDade scale is considered superior
and is still the most widely used. One of the major
issues with both of the scales is the subjectivity in-
volved, whereby the assessments by clinicians do not
accord well with those of the cleft patients and other
lay people (Duggal et al., 2023).
In light of this, we intend to develop methods
which can be used to provide an automated and stan-
dardised scoring scale for cleft lip patients based on
objective and explainable analysis. The method relies
on generation of synthetic facial features including
the upper lip and philtrum (groove between the base
of the nose and the upper lip) and detailed compari-
son of the generated features with the original faces
to provide an objective and reliable score for post-
operative assessment.
The main contributions of this study are therefore:
• KidsLips. A curated dataset of lips and philtrum
of children suitable for training image generation
models.
• Lip Image Inpainting. This is the first study of
image inpainting with a specific focus on details
of lips and philtrum.
• We propose a pipeline for post surgical assess-
ment of cleft palate repair.
The code
1
and dataset
2
for training the gan-
inpainting model are available online.
1
https://github.com/danielanojan/Cleft Inpainting.git
2
https://doi.org/10.5281/zenodo.10498842
2 RELATED WORK
2.1 ML Applications on CL/P
Despite the widespread applications of machine
learning and deep learning in the medical domain in
recent years, it is noteworthy that only a limited vol-
ume of research has been directed towards address-
ing issues associated with the cleft lip condition. (Lin
et al., 2021) worked on predicting the need for cleft
lip repair surgery at a later age from cephalometric
features based on the radiographic images taken at
an early stage. (Li et al., 2019) developed a CNN
based algorithm to automate the localisation of sur-
gical markers for cleft lip surgeries. (Agarwal et al.,
2018) worked on classifying unilateral and bilateral
cleft lips from healthy lips. To our knowledge, there is
no machine learning research to date has investigated
the success of the cleft lip surgical procedures with
the goal of assisting surgeons in choosing the best-
fit surgical procedure. For CL/P repair, (Chen et al.,
2022) proposed an image inpainting on pre-op CL/P
images to predict the post-op repaired CL/P images
which would guide surgeons on surgical planning and
educate patients and caretakers on surgical outcomes.
In particular, this work used images of faces with a
resolution of 224x224 pixels, at which size it is dif-
ficult to discern the relevant features on the lip and
philtrum. In addition, the model is trained on the
CelebA (Liu et al., 2015) dataset which consists of
mid age to old age celebrity faces.
2.2 GAN Inpainting
Image generation has been studied in detail over the
years and with the development of GAN, VAE re-
alistic images can be generated. StyleGAN (Karras
et al., 2020) succeeded in generating high resolution
realistic looking human faces. In medical imaging,
skin lesion images, brain MRI images and lung cancer
nodule images are generated using GANs (Ali et al.,
2022; Wang et al., 2022). These methods pave the
way for better analysis by generating realistic train-
ing images for data hungry deep learning modalities.
Image Inpainting is used to synthesize missing parts
of an image maintaining the semantic meaning. Gen-
erative models are proven to be the state of the art in
Image inpainting. In medical imaging, inpainting is
used to remove occlusions such as metallic implants
(Armanious et al., 2018) and reconstructing distorted
portions in CT (Tran et al., 2021) and removing light
distortions caused by endoscopes (Daher et al., 2022).
Face inpainting is complex task due to the unique and
complex facial structures and generative models are
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
940
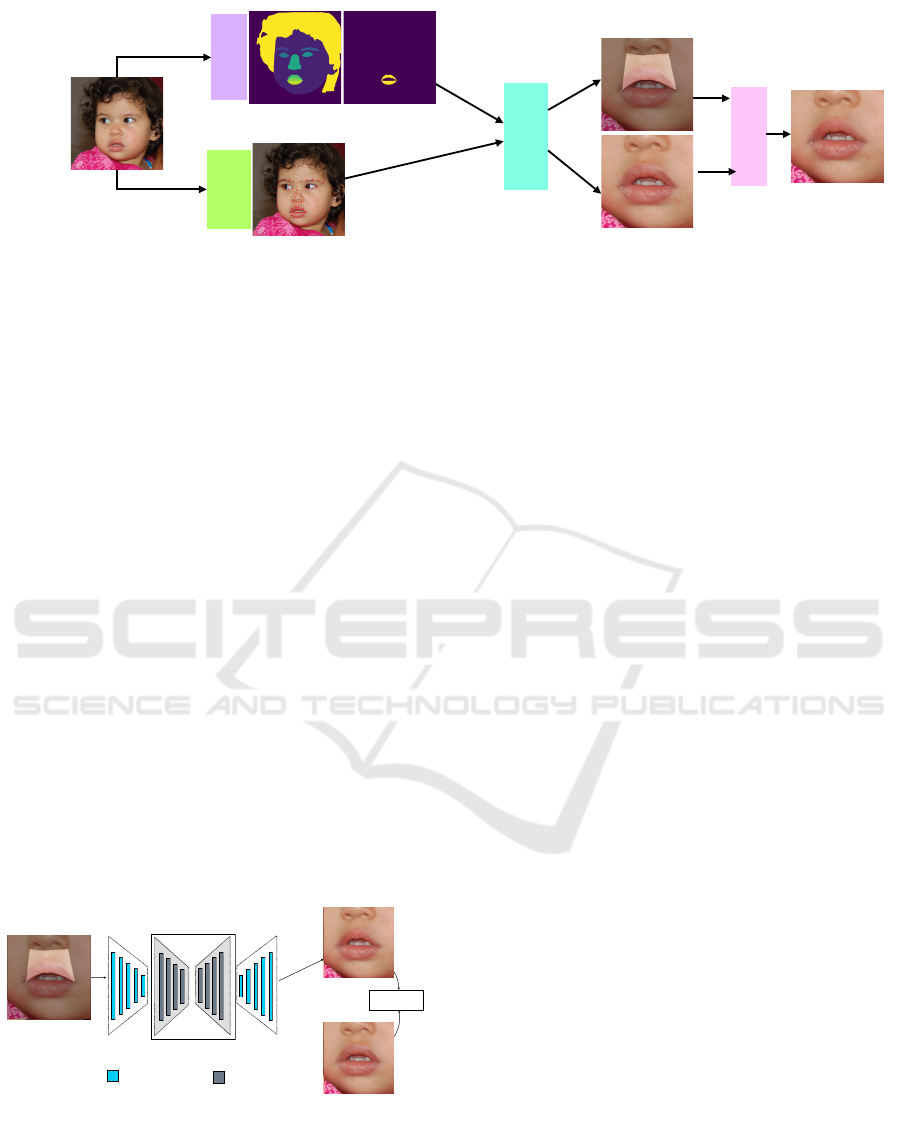
Segmentation
Model
Dlib Key point
Detection
Model
Mask Generation,
Cropping and
Resizing
GAN-Inpainting
Model
Mask for GAN-
Inpainting
Cropped Lip
Area
Segmentation !
Mask
Segmentation
Mask for Upper
and Lower Lip
256x256
GAN Generated
Image
Facial Keypoints
Input Image
from ChildLips
Dataset
1024x1024
Input Image
from KidsLips
Dataset
Figure 1: KidsLips Dataset preparation Pipeline. We obtain lip area and corresponding masks from high-res faces. For this
purpose, use LaPa (Liu et al., 2020) segmentation of Upper lip and nose keypoints detected by Dlib (King, 2009) to guide the
region selection.
coupled with transformers to reduce the inductive bias
and learn semantically appealing features (Deng et al.,
2022).
2.3 Siamese Network
Siamese networks (Koch et al., 2015) are a subclass of
neural networks, in which two identical sub-networks
learn a similarity function from the input pairs by
comparing feature embeddings. With the ability of
the network to learn with image pairs which resemble
a one-shot learning process, Siamese networks can
handle imbalanced classes which usually cause seri-
ous problems for traditional CNNs. Also as the net-
work learns the distance between image embeddings,
it can learn features resembling semantic similarity
and this helps in this study, as we want to quantify
the similarity between image pairs. (Pei et al., 2023)
have used Siamese network to identify face spoofing.
We use contrastive loss, due to its ability to reduce
inter-class variance and and increase intra-class vari-
ance.
Hourglass shaped attention
CNN Residual
block
Attention block
Generated
Masked Input
Loss
Ground Truth
CNN
Encoder
CNN
Decoder
Figure 2: Hourglass Attention Network for Generation of
Upper Lip Area.
3 METHODOLOGY
3.1 Dataset Acquisition
An overview of the data preparation pipeline is shown
in Figure 1. We start with high quality images of chil-
dren’s faces from our curated KidsLips dataset. We
extract the facial keypoints using standard methods,
but the keypoints alone are not sufficient to locate
the regions of interest. We also apply a segmenta-
tion model to identify precise masks for the upper and
lower lips regions. Using the masks and keypoints,
we mask, crop and resize the image in preparation for
GAN-inpainting. The GAN-inpainting model is ap-
plied to the cleft-lip images to inpaint the upper lip
and philtrum regions and generate faces without cleft.
The fully anonymised post-op Cleft lip surgery
dataset was collected in Childrens’s Health Ireland at
Temple Street between 2009-2012 and obtained under
a research agreement between Children’s Health Ire-
land at Temple Street and University College Dublin.
The cleft repair surgery had been performed when
the children were between 6 months to 1 year old but
the actual images have been taken by surgeons during
follow ups when the children reached the age of 5.
Due to GDPR constraints, the images are anonymised
and have been cropped to lip and surrounding area
only. The images were not taken in a controlled envi-
ronment and the variations in lighting, angle and res-
olution are apparent. The original dataset consists of
174 images. Subsequently due to insufficient light-
ing or blurring, the poor quality images had to be ex-
cluded. This resulted in the final dataset containing
147 images with a combination of both unilateral and
bilateral clefts which was used in the study. For the
purposes of this study, these images are used only for
inference and do not appear in any training dataset.
Deep learning models are data hungry and they
Enhancing Surgical Visualization: Feasibility Study on GAN-Based Image Generation for Post Operative Cleft Palate Images
941
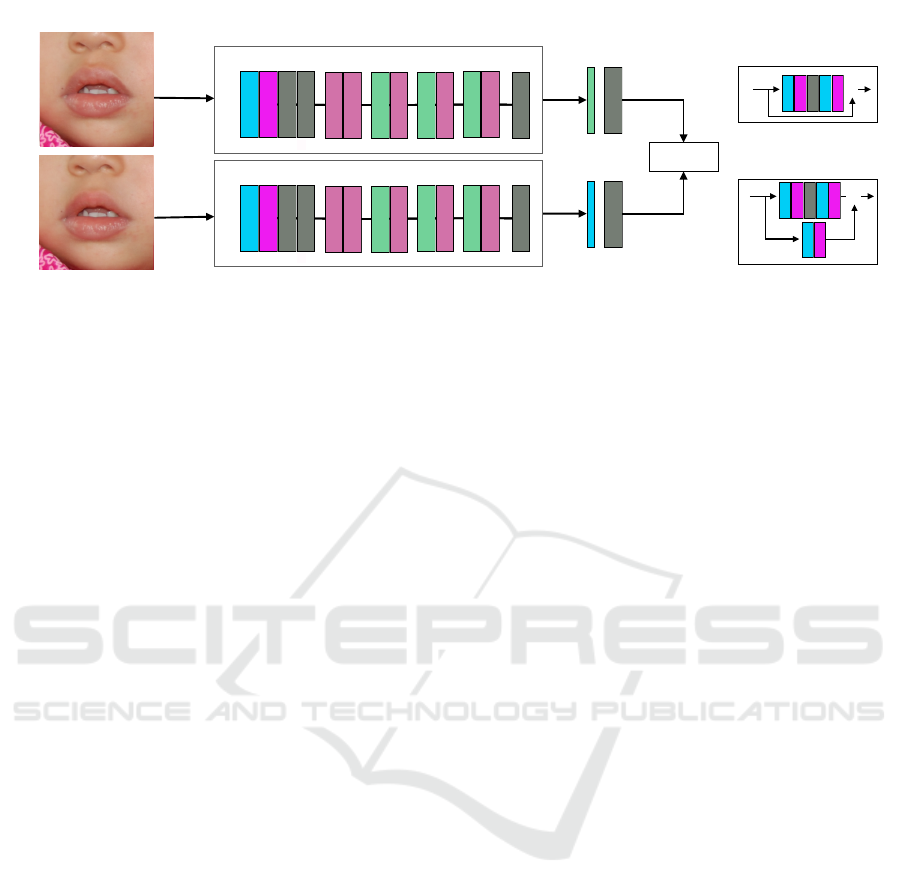
FC
FC
Contrastive
Loss
Conv
Batch Norm
ReLU
Conv
Batch Norm
⊕
Resblock1
Conv
Batch Norm
ReLU
Conv
Batch Norm
Resblock2
Conv
Batch Norm
3x256x256
GAN generated
Lip Image
3x256x256
Real Lip
Image
ResBlock1
Stage1
Stage2
Stage3
Stage4
Resnet1
7x7,64
3
1
Avgpool
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock1
Conv
Batch
ReLU
Maxpool
ResBlock1
Stage1
Stage2
Stage3
Stage4
Resnet1
7x7,64
3
1
Avgpool
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock1
Conv
Batch
ReLU
Maxpool
ResBlock1
Stage1
Stage2
Stage3
Stage4
Resnet1
7x7,64
3
1
Avgpool
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock1
Conv
Batch
ReLU
Maxpool
ResBlock1
Stage1
Stage2
Stage3
Stage4
Resnet1
7x7,64
3
1
Avgpool
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock2
ResBlock1
ResBlock1
Conv
Batch
ReLU
Maxpool
1000
⊕
1000
3
3
Figure 3: Siamese Network architecture for image similarity prediction. The GAN-inpainted image and the real image are
fed as inputs to the Siamese network which is trained with contrastive loss. The distance between the image embeddings is
used to compute a similarity score.
require significant amounts of labelled data of sim-
ilar distribution of that of target domain for train-
ing. In the context of this study, we require 256x256
pixel regions of the cropped area as shown in Fig-
ure 1. This requirement is challenging as there are
no publicly available image datasets specifically tai-
lored to children’s lips or faces. Though YLFW
(Medvedev et al., 2023) contains a substantial num-
ber of children’s faces, the images are low-resolution
and not suitable for this study. Consequently, we
address this gap by mining existing high resolution
face datasets as sources for extracting lip images rele-
vant for this study. We use the FFHQ dataset (Karras
et al., 2018) for this purpose. FFHQ consists of 70000
faces sourced from Flickr.com with a resolution of
1024x2024, and includes a variety of ages, ethnicities
and image backgrounds. For this study we manually
scrape children’s faces in the age range 0-10. We are
releasing this curated dataset as KidsLips and hope it
will be of use to the community for future research
and development.
We use keypoints in association with a segmenta-
tion model to build masks of the facial region of in-
terest. Our GAN-inpainting model is used to generate
synthesised upper lips and philtrum and we condition
the generation of these regions on the lower lip. The
lower lip is suitable for conditioning the GAN gener-
ation, as it is usually unaffected by the cleft. We find
the exact boundary of the upper lip by joining key-
points. We leverage the segmentation model of LaPa
(Liu et al., 2020) to get the lip boundaries at pixel
level and fuse it with the nose keypoints extracted by
Dlib (King, 2009) to form a polygon and generate the
mask region, as show in Figure 1. This mask genera-
tion is different from other state of the art inpainting
methods where random masks are commonly used. In
contrast, we condition the mask on the lower lip for all
cases.
As shown in Figure 1 images are then cropped to
include lip and philtrum area based on keypoints from
the nose and lip areas. Subsequently, both the cropped
images and their corresponding masks are reshaped
to 256x256 pixels. The dataset is then manually in-
spected, and images featuring occluded or blurry lip
regions are excluded. The resulting dataset comprises
of 6,508 high-quality images of healthy children’s lips
of diverse ethnicity. We refer to this curated dataset as
KidsLips dataset. Within this KidsLips dataset, 5,900
images are randomly assigned for training the GAN
inpainting model, while the remaining 608 images are
further partitioned in an 80:20 ratio to facilitate the
training and validation of a Siamese similarity model.
The face keypoint models cannot be used on par-
tial face images as they are trained on full faces. Due
to this limitation, we manually annotate the masks
on the cleft lip dataset to generate the upper lip and
philtrum area.
3.2 GAN Inpainting Network for Upper
Lip Generation
We use the Hourglass Attention network(Deng et al.,
2022) for GAN inpainting to generate the upper lip
and philtrum area. The network is constructed with
symmetric structure similar to the UNet model (Ron-
neberger et al., 2015). The base building blocks
are constructed from CNN encoder and decoder and
hourglass-shaped attention modules as shown in Fig-
ure 2. The encoder captures contextual information
as hierarchical features and passes it to the attention
module. The hourglass attention block is similar to a
multi-head self attention module with laplacian prior
referred to as laplacian attention module. This prior
calculates the distance between feature maps and con-
stitutes the spatial locations as a laplacian distribu-
tion. The model generates esthetically appealing im-
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
942

ages well-suited for this study. The GAN inpainting
model is trained with our KidsLips dataset along with
the corresponding generated masks.
3.3 Training Siamese Network to
Identify Image Similarity
We use pairs of images to train a Siamese network to
determine if the pair of images are from same, or dif-
ferent child. This training process is chosen to train
the baseline network weights to capture the similar-
ities in images while penalising defects for example
post operative scaring. During training, we present
the networks with different pairs of images, which
could be real and GAN-inpainted images of the same
child or real and GAN-inpainted images of different
children. If both the images are of same child, this is
a positive pair otherwise they it is a negative pair.
We use the ResNet18 (He et al., 2015) architec-
ture, pretrained on ImageNet as the backbone network
for the Siamese network which is shown in Figure 3.
The embeddings from the fully connected layer are
trained with contrastive loss to optimize the network.
We use the contrastive loss function due to its ability
to reduce inter-class variance and increase intra-class
variance (Shorfuzzaman and Hossain, 2021).
The contrastive loss is defined as
L =
1
2
(1 −Y )(D
e
)
2
+ (Y )
1
2
max(0,m − D
e
)
2
(1)
where Y is the label, D
e
is the euclidean distance be-
tween the feature embeddings of the image pair de-
fined below and m is the margin.
∥D
e
( f
1
, f
2
)∥
2
=
n
∑
i=1
|( f
1
− f
2
)|
2
!
1/2
(2)
Here f
1
and f
2
are image embeddings obtained from
Siamese network. The threshold value for contrastive
loss is updated after each epoch based on the updated
mean values between two classes.
3.4 Similarity Between Post-Op Cleft
Lip Images and Generated Images
We use images of cleft lip patients and the corre-
sponding GAN-inpainted images with the pre-trained
Siamese network to calculate the euclidean distance
between embeddings. Finally, we determine the sim-
ilarity score as the inverse of the distance.
4 EXPERIMENTS
We use the hyperparameters from (Deng et al., 2022)
and the GAN-inpainting model is trained for 1000000
iterations. No image augmentation is used. A learn-
ing rate of 1x10-5 is applied with learning rate decay.
The model is trained with Adam optimizer and the
batch size is 4. For training the Siamese network, im-
ages are augmented with Random Flip and Random
Rotation with an angle of 0-10 degrees. Grid search is
used for hyper parameter tuning. We used a batch size
of 1, the learning rate is 0.001 and the model is trained
with the Adam optimizer. The initial contrastive loss
threshold was chosen to be 2.4 and updated after each
epoch. The accuracy is calculated if the euclidean dis-
tance between image embeddings are smaller than a
predefined distance threshold of 1.5. The validation
accuracy was reported as 0.972. We implement both
networks using PyTorch (Paszke et al., 2017) Frame-
work.
5 RESULTS & DISCUSSION
Figure 5 shows the similarity scores between post-
operative CL/P images and GAN-generated images.
We use euclidean distance of 1.5 as the threshold for
GAN-generated image to be classified as a match and
the results show that 80% of the generated post-op
cleft upper lips have the euclidean distance less than
1.5. We observe that the network trained on healthy
children’s images generates highly realistic images of
post-operative faces, preserving the large scale fea-
tures of the faces while removing the post-surgical
scars. The model shows great ability to adapt to the
domain of cleft lip images, even though these images
are not used in training. The similarity score captures
the differences in images and coincides well with a
visual assessment. It should be noted that the visible
scars in the post-op images are captured by the simi-
larity score. For example, Figure 5(c) and Figure 5(d)
have a high similarity score and we do indeed see that
the generated images have upper lip structure which is
visually similar to the ground truth upper lips. How-
ever, Figure 5(c) contains noticeable scars, resulting
in a lower score compared to Figure 5(d), which has
much less noticeable post-operative scarring.
The GAN-inpainting model fails to generate im-
ages of vertically asymmetric lips where the upper
lips are vertically elongated compared to the lower
lips. In those cases, flat lips are generated and it
is penalized while calculating the similarity score as
shown in Figure 5(a) and Figure 5(b). This is due
to the fact that the KidsLips training dataset contains
Enhancing Surgical Visualization: Feasibility Study on GAN-Based Image Generation for Post Operative Cleft Palate Images
943
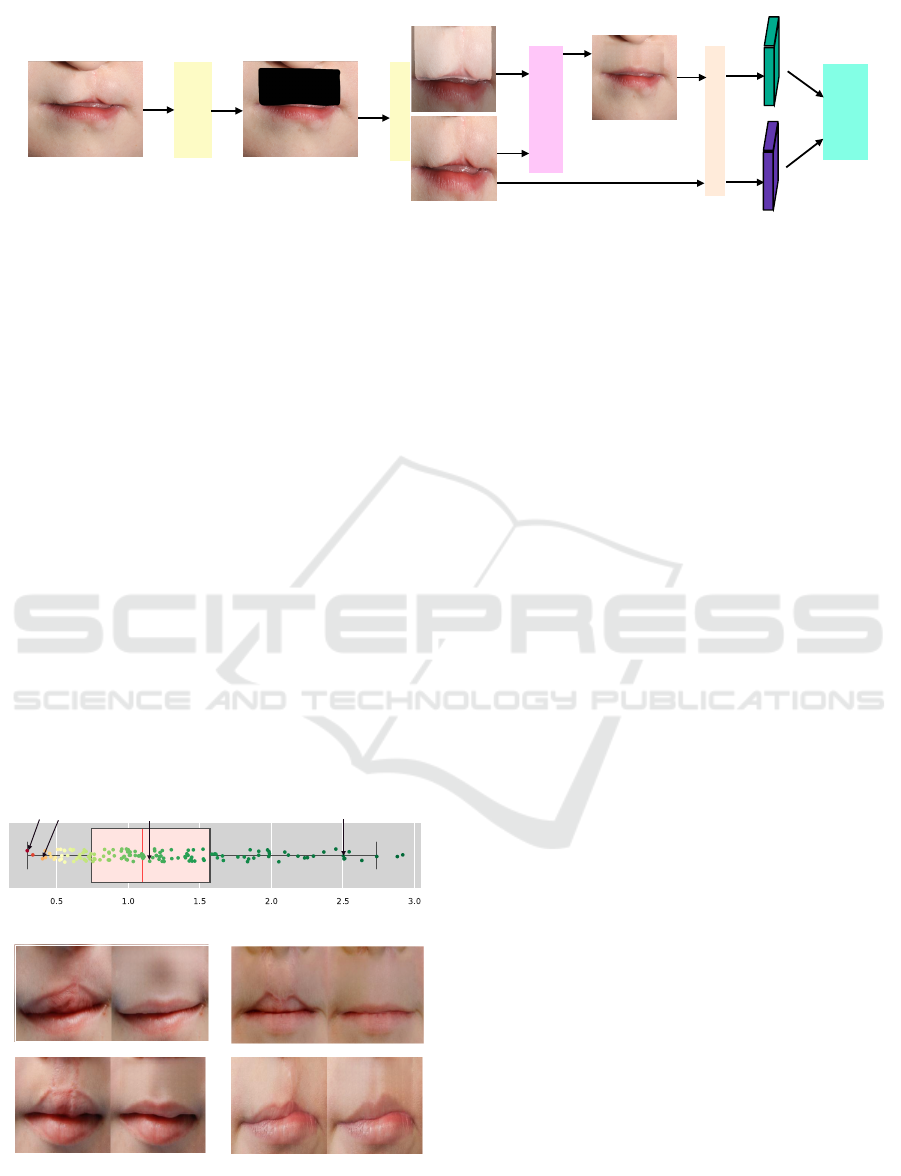
Manual Mask
Annotation
Resizing
GAN-Inpainting
Model
Siamese Network
Predict Similarity
Score
Post-op Cleft Lip Img
Manually Annotated
Mask
Resized Img
256x256
GAN Generated
Image
Image Embedding
Image Embedding
Mask for GAN-
Inpainting
Figure 4: Inference Pipeline for post-op CL/P. Images are annotated and reshaped to 256x256 and passed to the pretrained
GAN inpainting model to generate corresponding lip image. Then the similarity score is calculated between GAN generated
image and real image using pretrained Siamese Network.
mostly lips with a flat shape. It is also noted that the
model fails to capture the texture of the philtrum for a
small proportion of cases, resulting in blurry regions
or the region with patches as shows in Figure 5(a)(b).
For the cases with low similarity score, the GAN-
inpainting model is unable to produce a realistic syn-
thetic image and these cases are not suitable for use
in surgical assessment.
6 CONCLUSION AND FUTURE
WORK
Our goal in this work is to develop an image inpaint-
ing method tailored for post-op cleft lip generation
in children to be used as a ground truth automated
scoring method for assessing the success of cleft lip
surgery. It is evident that the GAN-inpainting models
can generate visually appealing images, it can be used
as the reference to score the success of the surgery.
Similarity Score
(a) (b)
Ground Truth Generated
Ground Truth Generated
(a) (b)
(c)
(c)
(d)
(d)
Figure 5: Similarity score distribution calculated using
Siamese Network. Image pairs with high similarity scores
have a strong visual resemblance.
The Siamese-based image similarity distance calcu-
lation is proven to be a good measure in validating
the image generation. We make the KidsLips dataset
available to facilitate further research in this area. In
our future work, we will perform assesements with
the clincians and surgeons and ask them to validate
the scoring methods detailed in this work.
ACKNOWLEDGEMENTS
This work was supported by the Science Foundation
Ireland through the Insight Centre for Data Analytics
under grant number SFI/12/RC/2289P2.
REFERENCES
Agarwal, S., Hallac, R. R., Mishra, R., Li, C., Daescu, O.,
and Kane, A. (2018). Image based detection of cran-
iofacial abnormalities using feature extraction by clas-
sical convolutional neural network. In 2018 IEEE 8th
International Conference on Computational Advances
in Bio and Medical Sciences (ICCABS), pages 1–6.
Agrawal, K. (2009). Cleft palate repair and variations. In-
dian journal of plastic surgery : official publication
of the Association of Plastic Surgeons of India, 42
Suppl:S102–9.
Ali, H., Biswas, M., Mohsin, F., Shah, U., Alamgir, A.,
Mousa, O., and Shah, Z. (2022). Correction: The
role of generative adversarial networks in brain mri:
a scoping review. Insights into Imaging, 13.
Armanious, K., Mecky, Y., Gatidis, S., and Yang, B. (2018).
Adversarial inpainting of medical image modalities.
CoRR, abs/1810.06621.
Asher-Mcdade, C., Roberts, C., Shaw, W. C., and Gallager,
C. (1991). Development of a method for rating na-
solabial appearance in patients with clefts of the lip
and palate. Cleft Palate Craniofac. J., 28(4):385–391.
Chaudhari, P. K., Kharbanda, O. P., Chaudhry, R., Pandey,
R. M., Chauhan, S., Bansal, K., and Sokhi, R. K.
(2021). Factors affecting high caries risk in children
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
944

with and without cleft lip and/or palate: A cross-
sectional study. The Cleft palate-craniofacial jour-
nal : official publication of the American Cleft Palate-
Craniofacial Association, 58(9):1150—1159.
Chen, S., Atapour-Abarghouei, A., Kerby, J., Ho, E. S. L.,
Sainsbury, D. C. G., Butterworth, S., and Shum, H.
P. H. (2022). A feasibility study on image inpaint-
ing for non-cleft lip generation from patients with cleft
lip. In 2022 IEEE-EMBS International Conference on
Biomedical and Health Informatics (BHI), pages 01–
04.
Cobourne, M. T. (2004). The complex genetics of cleft
lip and palate. European Journal of Orthodontics,
26(1):7–16.
Daher, R., Vasconcelos, F., and Stoyanov, D. (2022). A
temporal learning approach to inpainting endoscopic
specularities and its effect on image correspondence.
Deng, Y., Hui, S., Meng, R., Zhou, S., and Wang, J. (2022).
Hourglass attention network for image inpainting. In
Computer Vision – ECCV 2022: 17th European Con-
ference, Tel Aviv, Israel, October 23–27, 2022, Pro-
ceedings, Part XVIII, page 483–501, Berlin, Heidel-
berg. Springer-Verlag.
Duggal, I., Talwar, A., Duggal, R., Chaudhari, P. K., and
Samrit, V. (2023). Comparative evaluation of na-
solabial appearance of unilateral cleft lip and palate
patients by professional, patient and layperson using
2 aesthetic scoring systems: A cross sectional study.
Orthodontics & Craniofacial Research, 26(4):660–
666.
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Deep resid-
ual learning for image recognition.
Kammoun, A., Slama, R., Tabia, H., Ouni, T., and Abid,
M. (2022). Generative Adversarial Networks for Face
Generation: A Survey. ACM Computing Surveys,
55(5):1–37.
Karras, T., Laine, S., and Aila, T. (2018). A style-based
generator architecture for generative adversarial net-
works. CoRR, abs/1812.04948.
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J.,
and Aila, T. (2020). Analyzing and improving the im-
age quality of stylegan.
King, D. E. (2009). Dlib-ml: A machine learning toolkit.
The Journal of Machine Learning Research, 10:1755–
1758.
Koch, G., Zemel, R., and Salakhutdinov, R. (2015).
Siamese neural networks for one-shot image recogni-
tion.
Li, Y., Cheng, J., Mei, H., Ma, H., Chen, Z., and Li, Y.
(2019). Clpnet: Cleft lip and palate surgery support
with deep learning. In 2019 41st Annual International
Conference of the IEEE Engineering in Medicine and
Biology Society (EMBC), pages 3666–3672.
Lin, G., Kim, P.-J., Baek, S.-H., Kim, H.-G., Kim, S.-W.,
and Chung, J.-H. (2021). Early prediction of the need
for orthognathic surgery in patients with repaired uni-
lateral cleft lip and palate using machine learning and
longitudinal lateral cephalometric analysis data. Jour-
nal of Craniofacial Surgery, 32(2):616–620.
Liu, Y., Shi, H., Shen, H., Si, Y., Wang, X., and Mei, T.
(2020). A new dataset and boundary-attention se-
mantic segmentation for face parsing. In AAAI, pages
11637–11644.
Liu, Z., Luo, P., Wang, X., and Tang, X. (2015). Deep learn-
ing face attributes in the wild. In Proceedings of In-
ternational Conference on Computer Vision (ICCV).
Medvedev, I., Shadmand, F., and Gonc¸alves, N. (2023).
Young labeled faces in the wild (ylfw): A dataset for
children faces recognition.
Mosmuller, D. G., Mennes, L. M., Prahl, C., Kramer, G. J.,
Disse, M. A., Couwelaar, G. M. V., Frank, B. N., and
Griot, J. D. (2016). The Development of the Cleft
Aesthetic Rating Scale: A New Rating Scale for the
Assessment of Nasolabial Appearance in Complete
Unilateral Cleft Lip and Palate Patients. The Cleft
Palate-Craniofacial Journal, 54(5):555–561.
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E.,
DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., and
Lerer, A. (2017). Automatic differentiation in Py-
Torch. NIPS.
Pei, M., Yan, B., Hao, H., and Zhao, M. (2023). Person-
specific face spoofing detection based on a siamese
network. Pattern Recognition, 135:109148.
Ronneberger, O., P.Fischer, and Brox, T. (2015). U-
net: Convolutional networks for biomedical image
segmentation. In Medical Image Computing and
Computer-Assisted Intervention (MICCAI), volume
9351 of LNCS, pages 234–241. Springer. (available
on arXiv:1505.04597 [cs.CV]).
Shkoukani, M., Chen, M., and Vong, A. (2013). Cleft lip –
a comprehensive review. Frontiers in pediatrics, 1:53.
Shorfuzzaman, M. and Hossain, M. S. (2021). Metacovid:
A siamese neural network framework with contrastive
loss for n-shot diagnosis of covid-19 patients. Pattern
recognition, 113:107700.
Tran, M.-T., Kim, S.-H., Yang, H.-J., and Lee, G.-S.
(2021). Multi-task learning for medical image inpaint-
ing based on organ boundary awareness. Applied Sci-
ences, 11(9).
Vyas, T., Gupta, P., Kumar, S., Gupta, R., Gupta, T., and
Singh, H. (2020). Cleft of lip and palate: A re-
view. Journal of Family Medicine and Primary Care,
9(6):2621.
Wadde, D., Chowdhar, D., Venkatakrishnan, D., Ghodake,
D., Sachdev, S., and Chhapane, D. (2022). Protocols
in the management of cleft lip and palate: A system-
atic review. Journal of Stomatology, Oral and Max-
illofacial Surgery, 124.
Wang, X., Yu, Z., Wang, L., and Zheng, P. (2022). An
enhanced priori knowledge gan for ct images gener-
ation of early lung nodules with small-size labelled
samples. Oxid Med Cell Longev, 2022:2129303.
Yilmaz, H. N., Ozbilen, E. O., and and, T. U. (2019). The
prevalence of cleft lip and palate patients: A single-
center experience for 17 years. Turkish Journal of Or-
thodontics, 32(3):139–144.
Enhancing Surgical Visualization: Feasibility Study on GAN-Based Image Generation for Post Operative Cleft Palate Images
945
