
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
Simon Thomine
1,2 a
and Hichem Snoussi
1
1
University of Technology Troyes, Troyes, France
2
AQUILAE, Troyes, France
Keywords:
Unsupervised, Anomaly, Pattern, Contrastive, Autoencoder, Feature Extraction.
Abstract:
Detecting surface anomalies of industrial materials poses a significant challenge within a myriad of industrial
manufacturing processes. In recent times, various methodologies have emerged, capitalizing on the advan-
tages of employing a network pre-trained on natural images for the extraction of representative features. Sub-
sequently, these features are subjected to processing through a diverse range of techniques including memory
banks, normalizing flow, and knowledge distillation, which have exhibited exceptional accuracy. This paper
revisits approaches based on pre-trained features by introducing a novel method centered on target-specific
embedding. To capture the most representative features of the texture under consideration, we employ a
variant of a contrastive training procedure that incorporates both artificially generated defective samples and
anomaly-free samples during training. Exploiting the intrinsic properties of surfaces, we derived a meaningful
representation from the defect-free samples during training, facilitating a straightforward yet effective calcu-
lation of anomaly scores. The experiments conducted on the MVTEC AD and TILDA datasets demonstrate
the competitiveness of our approach compared to state-of-the-art methods.
1 INTRODUCTION
The unsupervised anomaly detection domain, espe-
cially in industrial applications, has attracted con-
siderable attention in the past few years. Convolu-
tional Neural Networks (CNNs) have emerged as a
significant breakthrough in this field by introducing
effective mechanisms for anomaly detection. The ef-
ficacy of CNNs resides in their capacity to analyze
and process visual data, including images and sur-
faces, through the capture of spatial features and pat-
terns. Deep learning has gained increasing momen-
tum in the industry owing to its capacity to derive in-
tricate representations from extensive datasets, adapt
to diverse domains, and execute real-time process-
ing. Harnessing the potential of deep learning enables
industries to attain heightened accuracy, automation,
and efficiency across diverse applications, including
the detection of anomalies in quality control.
In the industrial setting, where precision and accuracy
are of paramount importance, it is imperative to em-
ploy specialized and faultless methods that adhere to
stringent standards, minimizing errors and ensuring
flawless performance tailored to the specific require-
ments of the environment.
a
https://orcid.org/0009-0001-8989-8720
Recently, there has been a proliferation of approaches
capitalizing on extracted features derived from pre-
trained classifiers. These classifiers, trained on ex-
tensive databases like ImageNet (Krizhevsky et al.,
2012), encapsulate a wealth of informative features
at various levels, encompassing both low-level details
such as contours and color, as well as higher-level fea-
tures that are more contextual and abstract in nature.
These approaches regroups mainly memory banks,
normalizing flows and knowledge distillation that all
offers impressive results while guaranteeing a decent
inference time. The purpose of this paper is to intro-
duce a new method based on pre-trained features that
broadens the possibilities in terms of approaches to
handle this specific problem while concurrently min-
imizing inference time.
The primary objective of feature extraction from pre-
trained models is to compile the most representa-
tive features of the object, emphasizing those that
exhibit differences in the presence of an anomaly.
Conventional approaches employ various strategies
for feature extraction, including sub-sampling of fea-
tures, normalizing flows, or reconstruction-based ap-
proaches. Our conviction lies in the idea that, for ef-
fective anomaly detection, guiding the model toward
features with optimal ”anomaly detection” capabili-
280
Thomine, S. and Snoussi, H.
CSE: Surface Anomaly Detection with Contrastively Selected Embedding.
DOI: 10.5220/0012546700003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 2: VISAPP, pages
280-289
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

ties for our target texture is crucial. To this end, we
employ a defect generation method, such as the one
introduced in DRAEM (Zavrtanik et al., 2021), to as-
sist the model in extracting features that are respon-
sive to defects. Our model comprises three primary
components: a pre-trained feature extractor, an em-
bedder/encoder responsible for aggregating the most
representative features, and a decoder designed to
avoid a trivial embedded representation. In the pro-
cess of training the model, two samples are subjected
to processing: one being anomaly-free, and the other
exhibiting either an absence of anomalies or the pres-
ence of an artificially generated defect with a speci-
fied probability. Subsequently, the cosine similarity
measure is employed as a contrastive loss function,
with the objective of minimizing the embedding dis-
tance between the two samples if both are anomaly-
free, or increasing it otherwise. The anomaly-free em-
bedding of the defect-free sample is then subjected
to the decoder to minimize the reconstruction loss,
thereby enhancing the diversity of the embedding rep-
resentation. Following the completion of the train-
ing process, a k-means clustering procedure is imple-
mented to extract a predetermined number of clusters,
which subsequently functions as a feature bank. In
the testing phase, the anomaly score is computed ef-
ficiently and accurately by comparing these clusters
with the embedding of the test sample. Figure 1 de-
scribed our proposed score calculation approach com-
pared to other embedding-based approaches.
The primary contributions of this paper are outlined
as follows:
• An embedder capturing the most representative
features of a target surface through the applica-
tion of a contrastive training approach, showcas-
ing exceptional performance in the domain of tex-
ture defect detection and achieving state-of-the-
art capabilities.
• A contrastive cosine loss formulated with the in-
tention of amplifying the difference in embed-
ding representation between defective samples
and anomaly-free samples, while simultaneously
diminishing this difference between two anomaly-
free samples.
• A comprehensive training design incorporating a
decoder to augment the variability of the embed-
ded features, thereby preventing a trivial represen-
tation.
• A k-means clustering approach extracting the
most significant clusters for anomaly scoring.
Subsequent to the introductory section, the following
segment of this manuscript is devoted to a compre-
hensive review of existing literature concerning deep
learning methodologies utilized in unsupervised in-
dustrial anomaly detection. Section 3 presents our in-
novative approach with a precise description of each
components. Section 4 is dedicated to a series of
experiments to evaluate the efficacy of our proposed
model. In section 5, an ablation study is conducted to
present the benefits of each components from the con-
trastive approach relevance to a comparison between
training methods for the decoder along with an expla-
nation of the choice of features. A conclusive section
offers a summary of the paper’s findings, outlines the
limitations and proposes potential avenues for future
research.
2 RELATED WORK
In the realm of industrial applications, the compre-
hensive compilation of data pertaining to every po-
tential defect in an object or texture poses a challeng-
ing and time-intensive task where neglecting to ac-
count for all types of defects can result in sub-optimal
performance outcomes (Han et al., 2022). This sec-
tion provides a thorough overview of methodologies
for unsupervised anomaly detection, placing specific
emphasis on recent advancements that leverage deep
learning techniques.
In early literature, generative models like auto-
encoders (Mei et al., 2018; Nguyen et al., 2019; Za-
vrtanik et al., 2021), generative adversarial networks
(Goodfellow et al., ) , and their variations (Schlegl
et al., 2019; Pourreza et al., 2021; Liang et al., 2022)
were employed to reconstruct normal images from
anomalous ones. Notwithstanding their utility, these
methods encountered difficulties in accurately recon-
structing complex objects or surfaces, occasionally
leading to the generation of faulty samples.
In recent times, there has been a growing convic-
tion that exploiting fine-grained visual features can
contribute significantly to advancements in anomaly
detection. Responding to this conjecture, emerging
methodologies prioritize the extraction of representa-
tions from normal samples, and a prevailing approach
in anomaly detection involves utilizing models pre-
trained of external images datasets to comprehend the
distribution of normal features.
The utilization of features extracted from pre-trained
networks, especially those trained on extensive
datasets such as ImageNet (Deng et al., ), has been
observed to confer superior anomaly detection accu-
racy when compared to the direct processing of the
image itself.
Within this framework, three predominant methods
have emerged to exploit the extracted features.
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
281
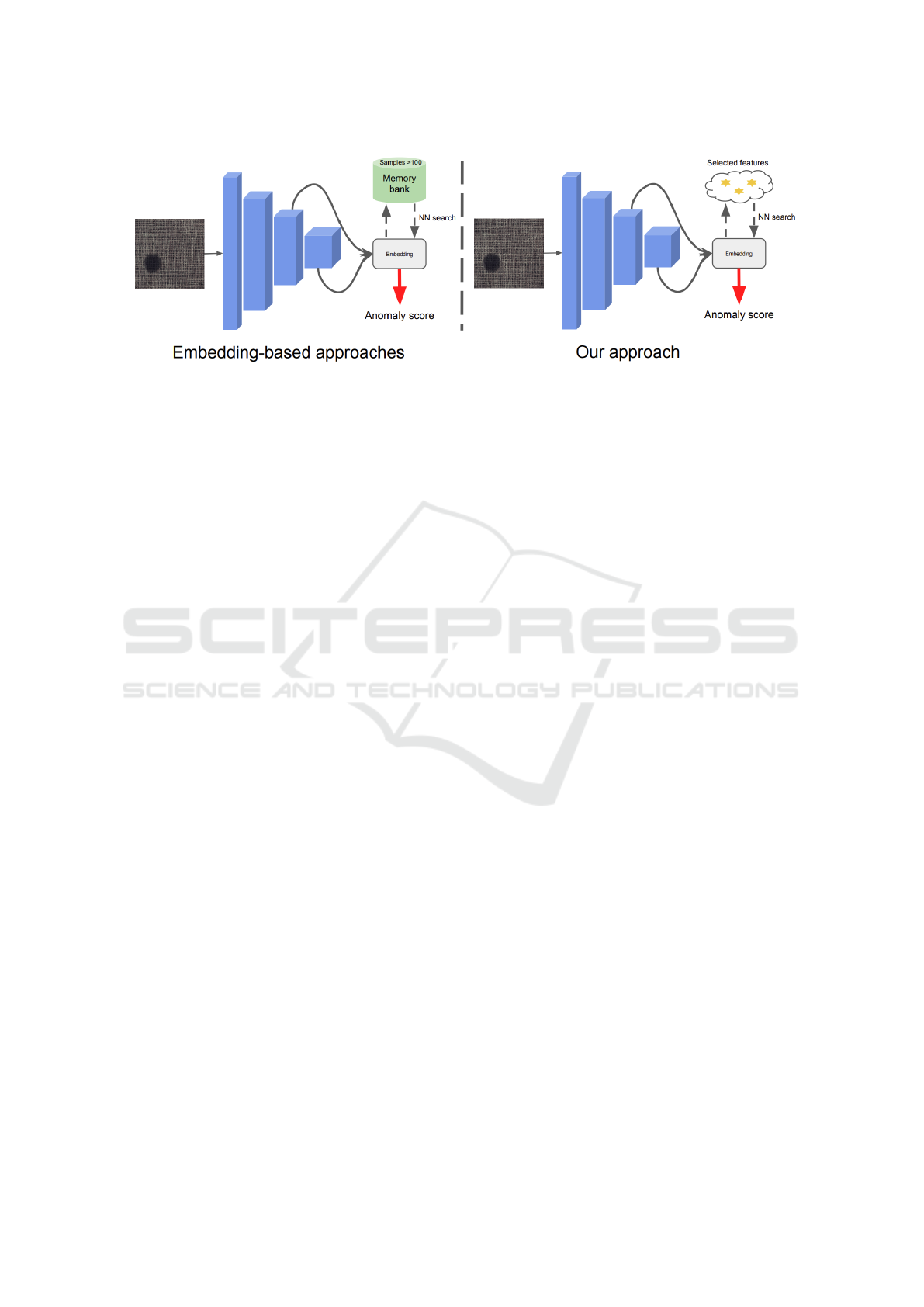
Figure 1: A comprehensive examination of the distinctions between our methodology and alternative embedding-based ap-
proaches during the inference phase. Limiting the comparison to a few specifically chosen samples, instead of encompassing
the entire set of features, results in a considerable reduction in inference time.
One method focuses on estimating the distribution
of the normal pattern within a parametric frame-
work, particularly by employing normalizing flows
(Rezende and Mohamed, 2016). In the training phase,
flow-based models aim to minimize the negative log-
likelihood loss associated with normal images, align-
ing their features with the target distribution to en-
hance the performance of the anomaly detection sys-
tem. Various strategies were employed to improve
performance, including the utilization of a 2D flow
(Yu et al., 2021) or the adoption of a cross-scale flow
(Rudolph et al., 2021).
Alternative approaches employed the concept of
knowledge distillation (Hinton et al., 2015) adapted
to unsupervised anomaly detection. In this approach,
a student network is trained on normal samples, em-
ploying the output features of a pre-trained teacher
network initially designed for classification tasks. In
the testing phase, the objective of the student net-
work is to emulate the output features of the teacher
network when given defect-free samples. Neverthe-
less, its accuracy declines when confronted with de-
fective samples, facilitating the derivation of a mean-
ingful anomaly score. Diverse methods have emerged
based on this paradigm such as a multi-layer feature
selection (Wang et al., 2021), a reverse distillation ap-
proach (Deng and Li, 2022) (Tien et al., 2023) or a
mixed-teacher approach (Thomine et al., 2023).
Memory banks approaches rely on diverse defect-free
samples to accumulate pertinent features, thereby es-
tablishing a bank of features dedicated to the compar-
ison with new samples. PatchCore (Roth et al., 2021)
uses a pre-trained classifier to extract specific layers
and then gathers features based on their awareness
and sub-samples these features. Subsequently, these
features are deposited in a memory bank, and the de-
tection of anomalies is accomplished by comparing
patch-level distances between the core set and a given
sample. Nonetheless, it is crucial to acknowledge that
these methods face limitations when trained on ex-
tensive datasets, as they demand significant compu-
tational resources for the establishment of memory
banks and necessitate intricate architectural consider-
ations.
Other approaches rely on the generation of custom de-
fects. Significantly, the DRAEM method (Zavrtanik
et al., 2021), introduces a discriminatively trained au-
toencoder to generate textural defects using the DTD
(Describable Textures Dataset) dataset (Cimpoi et al.,
2014) and Perlin noise. The CutPaste (Li et al., 2021)
and MemSeg (Yang et al., 2022) approaches have
also suggested the generation of structural defects to
introduce diversity into the defect pool. The em-
ployed methodologies demonstrate exceptional out-
comes and hold promise for textural anomaly detec-
tion, given the inherent properties of surfaces that
render the generation of defects comparatively more
straightforward.
3 PROPOSED METHOD
This section is devoted to delineating our proposed
methodology, which capitalizes on distinct subcom-
ponents to achieve efficient training and precise out-
comes. Our approach relies on a contrastive training
process that exploits synthesized anomalies and uti-
lizes deep features extracted from a pre-trained model
to derive a precise embedding. The complete archi-
tecture is shown in Figure 2.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
282
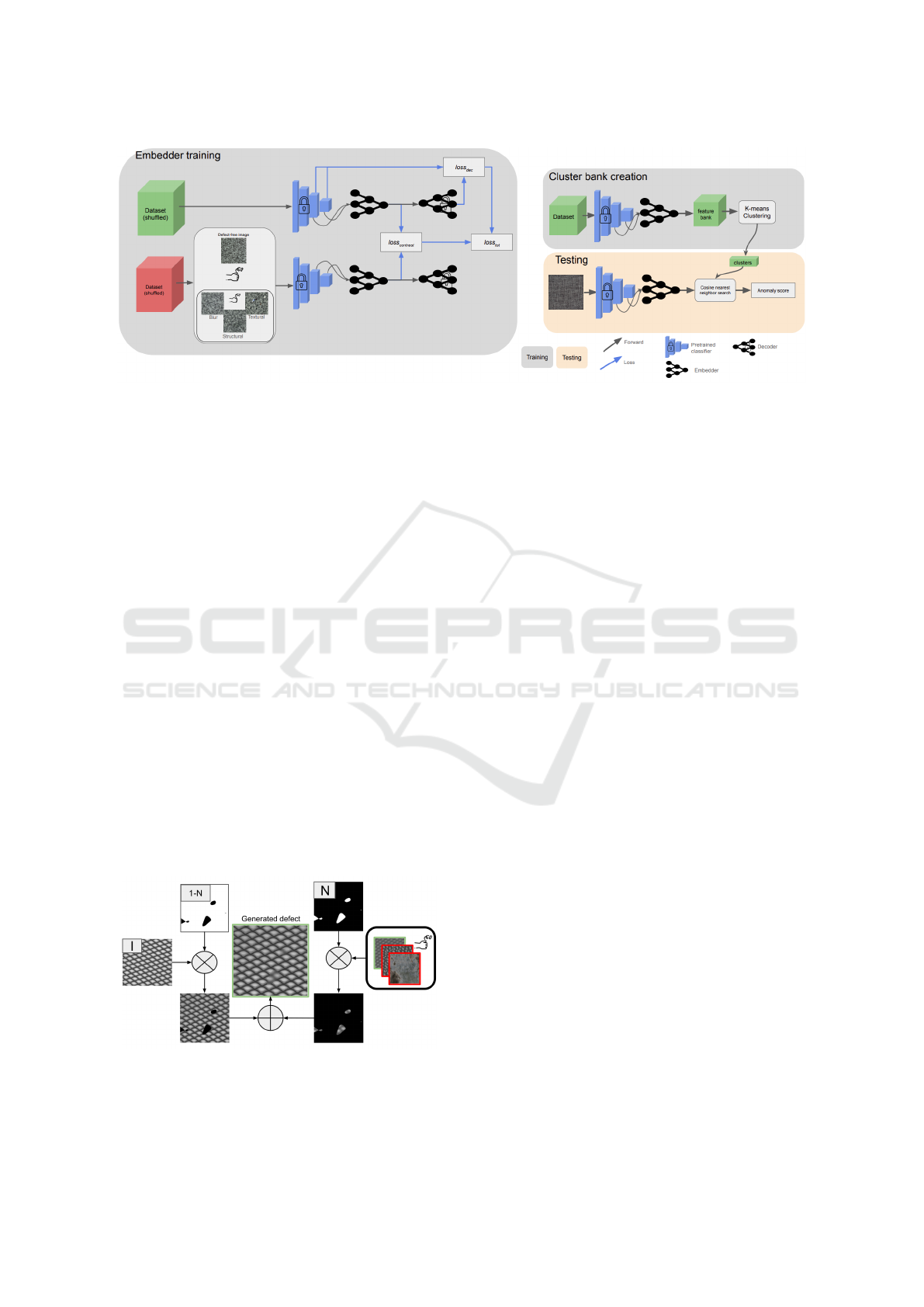
Figure 2: The complete training process. The training of the embedder constitutes the initial step, followed by the computation
of clusters derived from the embedding representations.
3.1 Image Corruption with Synthesized
Anomalies
To conduct contrastive training, it is imperative to
generate anomalies. In alignment with contempo-
rary literature, our anomaly detection process is based
on Perlin Noise generation and encompasses various
types of anomalies, including structural anomalies
(Yang et al., 2022), textural anomalies utilizing the
DTD dataset (Zavrtanik et al., 2021) (Cimpoi et al.,
2014), and a novel blurry noise introduced through a
straightforward application of Gaussian noise with a
randomly generated kernel applied to the original im-
age. The complete process of defect generation is de-
tailed in Figure 3. Every category of defect manifests
with equal probability during the training process to
ensure a balanced training regimen and prevent bias
towards any particular anomaly type. It is crucial to
note that defects are randomly generated during the
training process rather than pre-existing before train-
ing. This approach aims to mitigate overfitting and
enhance the model’s capacity to effectively address a
diverse range of defects.
Figure 3: The defect generation process. N is the mask
generated by thresholding a Perlin noise and (1-N) denote
its negation. I is the original image.
3.2 Anomaly Detection Specific
Embedding
To achieve efficient defect detection, the embedding
is trained through a contrastive process, wherein the
embedder is presented with pairs of images. These
pairs consist of either two defect-free samples or one
anomalous sample paired with one defect-free sam-
ple. Each scenario occurs with equal probability.
Subsequently, the embedder is trained to augment the
dissimilarity between features for antagonistic sam-
ples, while reducing it for correct samples.
In the context of surfaces, conducting contrastive
training poses challenges, as a texture with a minor
defect remains highly similar to a defect-free texture.
To alleviate this issue, we opted to train our feature
embedder using deep features extracted from a pre-
trained model. Deep features offer the advantage of
possessing a substantial receptive field and a rela-
tively low resolution. Consequently, the features of
a defective sample are highly likely to encompass a
substantial portion of the image.
To retain spatial information and simplify the embed-
der architecture, we opted to exclusively employ con-
volutions with a kernel size of one. For enhanced ca-
pabilities, the embedder possesses the capacity to uti-
lize features from various deep layers and efficiently
fuse them without incurring any additional inference
time cost.
Given a training dataset of images without anomaly
D = [I
1
, I
2
, ..., I
n
], our goal is to extract the relevant
feature from the L top layers of a pre-trained model.
For an image I
k
∈ R
w×h×c
where w is the width, h the
height, c the number of channels and l the l
th
bot-
tom layer, the output features are noted as F
l
(I
k
) ∈
R
w
l
×h
l
×c
l
. The embedded feature is denoted as E(I
k
),
signifying the embedding of the features extracted
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
283

from the image I
k
by the pre-trained model. When
presented with another image I
m
, our aim is to en-
hance the disparity between E(I
k
) and E(I
m
) in the
case of a defective I
m
, while reducing this difference
if I
m
is non-defective.
The design of the embedder is straightforward, featur-
ing a sequence of pointwise convolution layers, com-
plemented by a ReLU layer, a batch normalization
layer, and culminating in an average pooling layer that
acts as a smoothing component. In the event of input
features from multiple layers, the features are initially
upscaled to match the size of the largest features and
subsequently concatenated before being fed into the
embedder.
3.3 Contrastive Cosine Loss
Our contrastive loss relies on cosine similarity, as op-
posed to the conventional mean square error. This
choice is driven by the superior results observed and
the absence of a margin parameter, which can be chal-
lenging to optimize. The cosine similarity is defined
as:
CosSim(E(I
k
), E(I
m
)) =
E(I
k
) · E(I
m
)
kE(I
k
))kkE(I
m
)k
(1)
The cosine contrastive loss function is defined as:
loss
contr
=
(
1 +CosSim(E(I
k
), E(I
m
)) if I
m
is defective
1 −CosSim(E(I
k
), E(I
m
)) otherwise
(2)
where CosineSim(E(I
k
), E(I
m
)) ∈ [−1; 1]. The ob-
jective of this loss function is to enhance the similarity
of features from defect-free samples and amplify the
discrepancy between features otherwise.
3.4 Decoder Loss
During the training of our model using only the
contrastive loss, we encountered an issue of trivial
representation in our embedding. This manifested as
all embedded features being identical to each other.
This phenomenon is attributed to the absence of
diversity requirements in the training objective. To
mitigate this phenomenon, we introduced a decoder
designed to reconstruct features from the embedder
dimension to the original dimension. The objective
was to ensure diversity, as the decoder would be
unable to reconstruct the original dimension from a
trivial representation. Significant to note is that the
decoder remains untrained throughout the training
process and is initialized with random weights.
Further details on this aspect are elaborated in the
ablation study. This decoder process is done only on
the defect-free image I
k
and the reconstruction of the
layer l is noted as R
l
(I
k
).
The pixel-loss function is defined as :
ploss
l
(I
k
)
i j
=
1
2
kF
l
(I
k
)
i j
− R
l
(I
k
)
i j
k (3)
with ploss
l
∈ R
H
l
×W
l
,the layer l loss function as :
loss
l
(I
k
) =
1
w
l
h
l
w
l
∑
i=1
h
l
∑
j=1
ploss
l
(I
k
)
i j
(4)
and the decoder loss is written as:
loss
dec
(I
k
) =
l
∑
loss
l
(I
k
) (5)
The decoder process is described in Figure 4.
Ultimately, the total loss can be expressed as:
loss
tot
(I
k
) = loss
dec
(I
k
) + α · loss
contr
(I
k
) (6)
with α the weighting factor. In our experimental
setup, α is configured to 10.
A description of the decoder architecture for multiple
layers can be seen in Figure 4.
3.5 Anomaly Scoring and Memory
Bank
Cutting-edge memory bank methodologies necessi-
tate the utilization of a memory bank whose scale
aligns with that of the training dataset, thereby max-
imizing accuracy. By depending on shallow and
mid-level features, these methodologies necessitate a
larger number of defect-free samples to enhance the
likelihood of aligning with the features of a defect-
free sample during the inference process. In con-
trast, leveraging deep features and concentrating on
surfaces obviates the requirement for a comprehen-
sive memory bank, as features characterized by a high
level of abstraction lack fine-grained details such as
edges and contours. To obtain computable features
for deriving an anomaly score, we employed the k-
means algorithm on the embeddings of all elements
within the defect-free training dataset, utilizing a vari-
able number of clusters based on the texture’s diver-
sity. In pursuit of a domain-generalized approach, a
greater number of clusters may be employed com-
pared to a texture characterized by regular samples.
In our experiments with public datasets, we config-
ured the number of clusters to one, thereby rendering
our cluster equivalent to the computation of the mean
of defect-free training samples. The anomaly score
is subsequently determined by calculating the cosine
similarity with all clusters and selecting the minimum
distance. The process is described in Figure 2.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
284

Figure 4: The decoder process for multi-layer embedder. Throughout the training process, both the pre-trained classifier and
the decoder remain in a frozen state.
4 EXPERIMENTS
4.1 Implementation Details
We used the deep layers of an EfficientNet-b3 (Tan
and Le, 2020) pre-trained on ImageNet as pre-trained
extractor. The training and inference processes were
conducted on an RTX 3090ti. In order to maintain
consistency with other unsupervised approaches dur-
ing the evaluation process, either the images were re-
sized to 256x256 pixels and then further processed
through center-cropping to a final size of 224x224
pixels for the dataset MVTEC AD, or conducted
the evaluation under identical conditions using the
anomalib library (Akcay et al., 2022) for the TILDA
(DFG, 1996) dataset. During training, the dataset
was split into a training set, comprising 70% of the
data, and a validation set, containing the remaining
30%. Throughout the training phase, we systemati-
cally tracked the validation loss, preserving the check-
point corresponding to the minimum recorded loss
value. To optimize the model’s parameters, we uti-
lized the ADAM optimizer (Kingma and Ba, 2017)
with a learning rate of 0.0004. To expedite con-
vergence, we implemented a one-cycle learning rate
scheduler (Smith, 2018) and conducted training over
100 epochs, utilizing a batch size of 8.
All experiments presented were conducted utilizing
the deep layers of EfficientNet-B3, employing input
sizes of 136x14x14 and 384x7x7, along with an em-
bedding dimension set at 64x7x7.
4.2 Experiments on Surface Datasets
We used the area under the receiver operating char-
acteristic curve (AUROC) to assess the image-level
anomaly detection performance.
Our evaluation was conducted in different surfaces
datasets namely the MVTEC AD dataset (Bergmann
et al., 2019) and the TILDA dataset (Xie et al., 2021).
These datasets compile a substantial amount of textu-
ral samples representing various conceivable scenar-
ios.
4.2.1 MVTEC AD Surfaces
The widely recognized and demanding benchmark
MVTEC dataset gathers 5 surfaces and 10 objects in
the realm of industrial inspection. Since our method
is designed for unsupervised surface defect detection,
we evaluate only on the 5 surfaces. An overview of
the dataset is shown in 5. The results of our evalua-
tion are depicted in Table 1.
Figure 5: An overview of MVTEC AD surfaces. The fig-
ure’s upper section contains defect-free samples, whereas
defective samples are situated in the lower part. Red encir-
clement highlights the defects.
Table 1 illustrates the competitive efficacy of our
methodology relative to contemporary approaches,
exhibiting a mean Area Under the Receiver Operating
Characteristic (AUROC) comparable to leading mod-
els and demonstrating state-of-the-art performance on
wood surface.
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
285

Table 1: Anomaly detection results with AUROC on MVTEC surfaces.
Category CFA (Lee et al., ) PatchCore (Roth et al., 2021) FastFlow (Yu et al., 2021) RD++ (Tien et al., 2023) MixedTeacher (Thomine et al., 2023) Ours
carpet 97.3 98.7 99.4 100 99.8 100
tile 99.4 98.7 100 99.7 100 99.3
wood 99.7 99.2 99.2 99.3 99.6 100
leather 100 100 99.9 100 100 100
grid 99.2 98.2 100 100 99.7 99.6
Mean 99.1 99.0 99.7 99.8 99.8 99.8
4.2.2 TILDA Dataset
Our methodology was additionally evaluated on the
TILDA (Xie et al., 2021) textile datasets encompass-
ing a diverse collection of 8 distinct textile types from
plain fabric to patterned fabric. Various examples
from defective samples are illustrated in Figure 6. Re-
sults are depicted in Table 2.
Figure 6: An overview of defective samples from the
TILDA dataset. Red encirclement highlights the defects.
The outcomes presented in Table 2 exemplify the
competitiveness of our approach in comparison to
other state-of-the-art methods. Our methodology
showcases a mean Area Under the Receiver Operating
Characteristic (AUROC) superior to alternative tested
methods, and notably, it achieves a superior AUROC
for 4 out of the 8 fabric types considered in the evalu-
ation.
4.3 Inference Speed
An essential advantage of our approach lies in its in-
ference speed, which is primarily constrained by the
selection of the pre-trained model employed for fea-
ture extraction. The architecture of the embedder,
coupled with the straightforward comparison with
one or a few clusters during inference, does not sub-
stantially increase the inference time. This critical ad-
vantage establishes our method as the fastest among
counterparts employing the same pre-trained model.
Furthermore, it stands out as a comparably swift so-
lution even when compared to methods utilizing a
smaller pre-trained model for feature extraction. This
distinction is particularly noteworthy as such methods
often incorporate a secondary model to extract perti-
nent anomaly detection information, thereby poten-
tially introducing additional computational overhead.
An inference speed comparison is shown in Table 3.
5 ABLATION STUDY
5.1 Comparison with a Simple Classifier
To evaluate the effectiveness of our contrastive train-
ing approach, we conducted a comparative analy-
sis with a traditional binary classifier. This classi-
fier was trained on defect-free samples and artificially
generated anomalous samples. We maintained con-
sistency by extracting the same deep features from
EfficientNet-B3. In contrast to our contrastive train-
ing methodology, the binary classifier was trained us-
ing standard binary classification techniques rather
than adopting a contrastive learning framework.
The results obtained not only showcase the descrip-
tive capability of the deep layers of EfficientNet but
also affirm the superiority of our approach when com-
pared to a straightforward classifier. It is noteworthy
to highlight that the results achieved by the classifier
remain highly impressive and are comparable to state-
of-the-art methods from two years ago in the context
of surface defect detection. Results are shown in Ta-
ble 4 for the surfaces of the MVTEC AD dataset.
5.2 Decoder Initialization and Training
As outlined in Section 3, we employ a decoder with
frozen weights initialized randomly during the train-
ing process. While unconventional, we present our re-
sults with varying decoder initialization approaches: a
decoder trained prior to embedder training, a decoder
trained concurrently with the embedder, and a frozen
decoder with random weights. Additionally, we offer
an explanation for this unconventional methodology.
The results of the first aforementioned approach are
presented in Table 5.
Our conjecture posits that confining the decoder’s
training exclusively to defect-free samples could in-
duce a bias towards features crucial for reconstruc-
tion, potentially overlooking those essential for de-
fect detection. This phenomenon results in a form
of ”concurrent” training between the embedder and
the decoder. On the other hand, the random weight
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
286
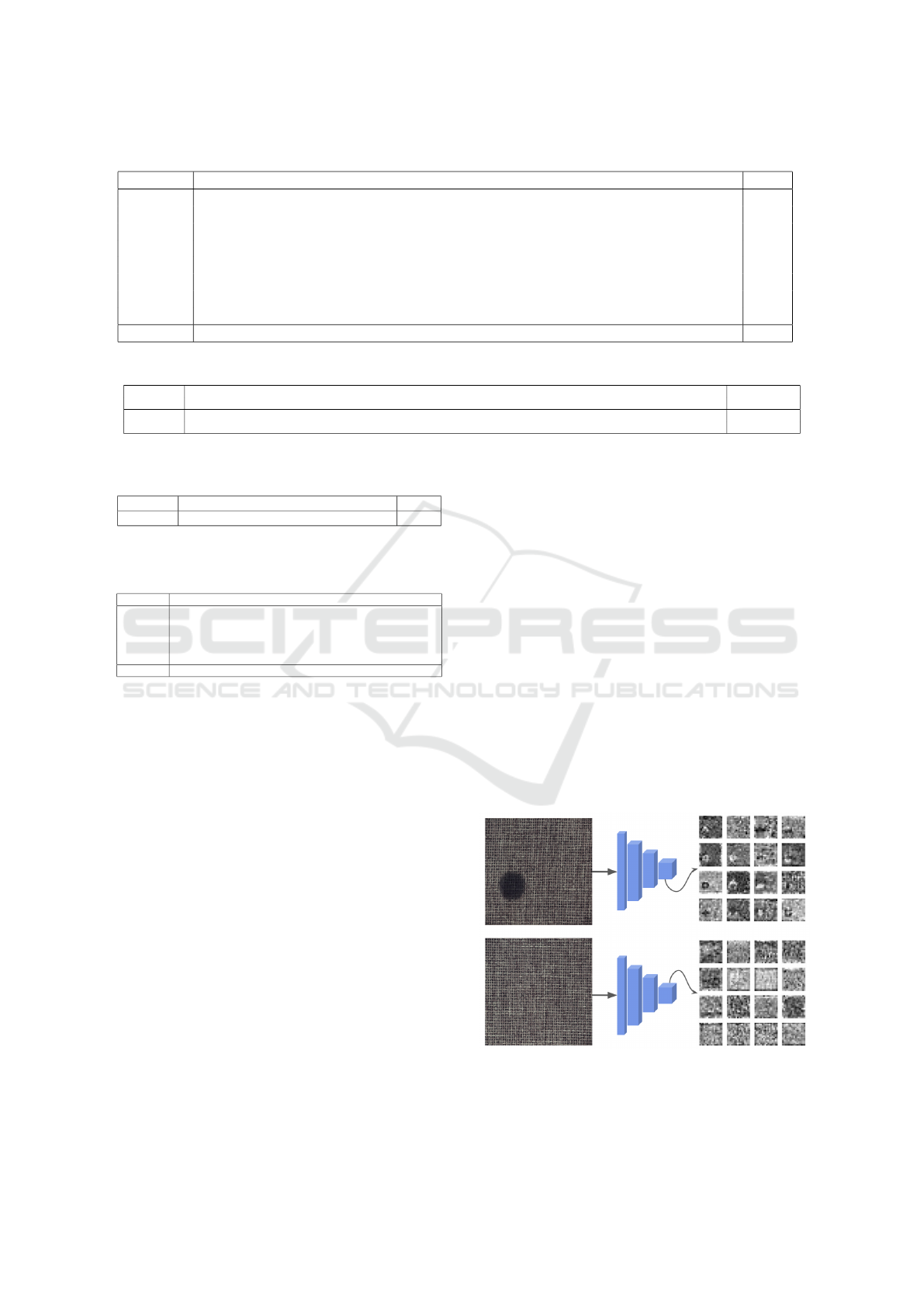
Table 2: Anomaly detection results with AUROC on TILDA surfaces.
Category PaDiM (Defard et al., ) CFA (Lee et al., ) Reverse distillation (Deng and Li, 2022) Ours
tilda1 89.1 88.4 94.8 90.2
tilda2 88.4 86.5 88.2 92.0
tilda3 80.1 89.7 91.4 84.8
tilda4 45.9 83.6 59.6 80.0
tilda5 61.2 83.2 67.4 88.2
tilda6 79.1 85.7 78.7 93.0
tilda7 81.1 82.4 78.6 79.7
tilda8 45.8 48.1 84.5 68.2
Mean 71.3 80.9 80.4 84.5
Table 3: Comparison of pre-trained based approach in terms of inference time and frame per second.
Category PatchCore (Roth et al., 2021) FastFlow (Yu et al., 2021) RD(Deng and Li, 2022) RD (Deng and Li, 2022) Ours
Extractor WideResnet50 (Zagoruyko and Komodakis, ) WideResnet50 WideResnet50 Resnet18 (He et al., ) EfficientNet-b3
FPS 5.8 21.8 33 62 56
Latency (ms) 172 45.9 30 16 18
Table 4: AUROC obtained a simple classifier trained on
efficientNet-b3 deep features on MVTEC surfaces.
category carpet wood tile leather grid mean
classifier 99.2 99.1 98.0 100 94.5 98.2
Table 5: Anomaly detection results with AUROC on
MVTEC surfaces.
Category No decoder Trained before Trained together Random
carpet 99.5 99.7 99.6 100
tile 98.4 98.4 98.7 99.3
wood 99.9 100 99.9 100
leather 100 100 99.9 100
grid 99.3 99.6 98.4 99.6
Mean 99.4 99.5 99.3 99.8
initialization provides a reconstruction with a statisti-
cally balanced mix of both representative features and
those pertinent to defect detection. This randomness
in reconstruction aligns optimally with our training
objective. An alternative option could have involved
training the decoder on a combination of generated
defective samples and defect-free samples. However,
this approach yielded unsatisfactory results due to the
limited training capacity of the decoder and the imper-
ative for a compact architecture to ensure expeditious
inference.
5.3 Relevance of Deep Features
In contrast to prevailing methodologies that utilize
shallow and mid-level features from pre-trained mod-
els to mitigate bias towards specific classification
tasks, our approach relies on deep features. These
deep features, characterized by a lower resolution and
a considerable number of filters, exhibit a pronounced
bias toward classification making them unusable for
object defect defection. This unconventional choice
is elucidated by various considerations, encompass-
ing the utilization of the contrastive loss function and
the inherent characteristics of surface defect detec-
tion. In the context of a surface, a defect typically
affects only a small portion while leaving the remain-
der unaffected. To optimize the effectiveness of the
contrastive loss, it is advantageous to extract deep
features where the defect, if discernible, occupies a
more substantial portion of the feature space. This
is achieved by employing deep features with a larger
receptive field and lower resolution. Given that the
defect constitutes a significant portion of the image,
the contrastive loss methodology becomes particu-
larly beneficial. In contrast to objects, surfaces exhibit
regularity, and the bias towards classification does not
introduce misleading information. Indeed, as illus-
trated in Figure 7, the features extracted from surfaces
primarily capture regular patterns. However, when a
defect emerges, it becomes readily discernible. These
two considerations have been instrumental in guiding
our decision regarding the selection of features.
Figure 7: A sample of features extracted from the layer of
size 136x14x14 from EfficientNet-b3 .
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
287

6 CONCLUSION
In this article, we introduced a novel method for unsu-
pervised surface anomaly detection, centered around
a contrastively selected embedding designed to ag-
gregate the most pertinent features for the task of
defect detection. Leveraging the representational
capabilities of deep features extracted from a pre-
trained model, our approach achieves state-of-the-art
performance in surface defect detection on both the
MVTEC AD dataset and the TILDA dataset. Through
the employment of a compact network comprised of
pointwise convolutions and a judicious selection of
samples for inference comparison, our method en-
sures that inference speed is solely contingent on
the chosen pre-trained classifier for deep feature ex-
traction. This design leads to state-of-the-art perfor-
mance in terms of model latency. However, it is cru-
cial to acknowledge the potential limitations of our
method. The primary constraint is associated with the
choice of the feature extractor and our substantial re-
liance on its representational power. As we focus on
deep features, it becomes challenging to unbias the
extracted features if the anomaly is not discernible
within them. Another constraint lies in the process of
defect generation during training, which significantly
slows down model training, resulting in a relatively
extended training duration compared to other state-
of-the-art approaches. In conclusion, we posit that
this methodology holds considerable promise in the
field of surface defect detection, and we earnestly en-
courage researchers to explore and further investigate
such approaches.
REFERENCES
Akcay, S., Ameln, D., Vaidya, A., Lakshmanan, B., Ahuja,
N., and Genc, U. (2022). Anomalib: A deep learning
library for anomaly detection.
Bergmann, P., Fauser, M., Sattlegger, D., and Steger, C.
(2019). MVTec AD — a comprehensive real-world
dataset for unsupervised anomaly detection. In 2019
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 9584–9592. IEEE.
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., and
Vedaldi, A. (2014). Describing textures in the wild. In
2014 IEEE Conference on Computer Vision and Pat-
tern Recognition, pages 3606–3613. IEEE.
Defard, T., Setkov, A., Loesch, A., and Audigier, R. PaDiM:
a patch distribution modeling framework for anomaly
detection and localization. In 2021 ICPR Interna-
tional Workshops and Challenges.
Deng, H. and Li, X. (2022). Anomaly detection via reverse
distillation from one-class embedding. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR), pages 9737–9746.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. ImageNet: A large-scale hierarchical image
database. In 2009 IEEE Conference on Computer Vi-
sion and Pattern Recognition, pages 248–255. ISSN:
1063-6919.
DFG (1996). TILDA textile texture-database.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A., and Ben-
gio, Y. Generative adversarial networks. In Advances
in neural information processing systems. 2014.
Han, S., Hu, X., Huang, H., Jiang, M., and Zhao, Y. (2022).
ADBench: Anomaly detection benchmark.
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learn-
ing for image recognition. In 2016 IEEE Conference
on Computer Vision and Pattern Recognition (CVPR.
Hinton, G., Vinyals, O., and Dean, J. (2015). Distilling the
knowledge in a neural network. In NIPS 2014 Deep
Learning Workshop.
Kingma, D. P. and Ba, J. (2017). Adam: A method for
stochastic optimization. In 2015 International Con-
ference on Learning Representations (ICLR).
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
ageNet classification with deep convolutional neural
networks. In NIPS’12: Proceedings of the 25th Inter-
national Conference on Neural Information Process-
ing Systems, volume 60, pages 84–90.
Lee, S., Lee, S., and Song, B. C. CFA: Coupled-
hypersphere-based feature adaptation for target-
oriented anomaly localization. In IEEE Access Vol-
ume 10 Pages 78446-78454 2022.
Li, C.-L., Sohn, K., Yoon, J., and Pfister, T. (2021). Cut-
Paste: Self-supervised learning for anomaly detection
and localization. In 2021 IEEE Conference on Com-
puter Vision and Pattern Recognition.
Liang, Y., Zhang, J., Zhao, S., Wu, R., Liu, Y., and Pan, S.
(2022). Omni-frequency channel-selection represen-
tations for unsupervised anomaly detection. In IEEE
Transactions on Image Processing 2022.
Mei, S., Wang, Y., and Wen, G. (2018). Automatic fabric
defect detection with a multi-scale convolutional de-
noising autoencoder network model. In Sensors 2018,
volume 18, page 1064.
Nguyen, Q. P., Lim, K. W., Divakaran, D. M., Low,
K. H., and Chan, M. C. (2019). GEE: A gradient-
based explainable variational autoencoder for network
anomaly detection. In IEEE Conference on Commu-
nications and Network Security (CNS) 2019.
Pourreza, M., Mohammadi, B., Khaki, M., Bouindour, S.,
Snoussi, H., and Sabokrou, M. (2021). G2d: Generate
to detect anomaly. In 2021 IEEE Winter Conference
on Applications of Computer Vision (WACV), pages
2002–2011. IEEE. event-place: Waikoloa, HI, USA.
Rezende, D. J. and Mohamed, S. (2016). Variational infer-
ence with normalizing flows. In Proceedings of the
32nd International Conference on Machine Learning
2016.
Roth, K., Pemula, L., Zepeda, J., Sch
¨
olkopf, B., Brox, T.,
and Gehler, P. (2021). Towards total recall in in-
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
288

dustrial anomaly detection. In 2022 IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
Rudolph, M., Wehrbein, T., Rosenhahn, B., and Wandt,
B. (2021). Fully convolutional cross-scale-flows for
image-based defect detection. In Winter Conference
on Applications of Computer Vision (WACV) 2022.
Schlegl, T., Seeb
¨
ock, P., Waldstein, S. M., Langs, G., and
Schmidt-Erfurth, U. (2019). f-AnoGAN: Fast unsu-
pervised anomaly detection with generative adversar-
ial networks. In Medical Image Analysis 54, vol-
ume 54, pages 30–44.
Smith, L. N. (2018). A disciplined approach to neural net-
work hyper-parameters: Part 1 – learning rate, batch
size, momentum, and weight decay.
Tan, M. and Le, Q. V. (2020). EfficientNet: Rethinking
model scaling for convolutional neural networks. In
Proceedings of the 36th International Conference on
Machine Learning 2019.
Thomine, S., Snoussi, H., and Soua, M. (2023).
MixedTeacher: Knowledge distillation for fast infer-
ence textural anomaly detection. In 2023 Interna-
tional Conference on Computer Vision Theory and
Applications (VISAPP 2023), pages 487–494.
Tien, T. D., Nguyen, A. T., Tran, N. H., Huy, T. D., Duong,
S. T. M., Nguyen, C. D. T., and Truong, S. Q. H.
(2023). Revisiting reverse distillation for anomaly de-
tection. In 2023 IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR).
Wang, G., Han, S., Ding, E., and Huang, D.
(2021). Student-teacher feature pyramid matching for
anomaly detection. In The British Machine Vision
Conference (BMVC)2021.
Xie, H., Zhang, Y., and Wu, Z. (2021). An improved fabric
defect detection method based on SSD. In AATCC
Journal of Research Volume 8. 2021, volume 8, pages
181–190.
Yang, M., Wu, P., Liu, J., and Feng, H. (2022). MemSeg: A
semi-supervised method for image surface defect de-
tection using differences and commonalities. In Engi-
neering Applications of Artificial Intelligence Volume
119, page 15.
Yu, J., Zheng, Y., Wang, X., Li, W., Wu, Y., Zhao, R., and
Wu, L. (2021). FastFlow: Unsupervised anomaly de-
tection and localization via 2d normalizing flows.
Zagoruyko, S. and Komodakis, N. Wide residual networks.
Zavrtanik, V., Kristan, M., and Sko
ˇ
caj, D. (2021). DRAEM
– a discriminatively trained reconstruction embedding
for surface anomaly detection. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion (ICCV).2021.
CSE: Surface Anomaly Detection with Contrastively Selected Embedding
289
