
Transformer-Based Two-level Approach for Music-driven
Dance Choreography
Yanbo Cheng
a
and Yingying Wang
b
Department of Computing and Software, McMaster University, Hamilton, Canada
Keywords:
Deep Learning, Character Animation, Motion Synthesis, Motion Stylization, Multimodal Synchronization.
Abstract:
Human dance motions are complex, creative, and artistic expressions. Synthesizing high-quality dance mo-
tions and synchronizing them to music has always been a challenge in animation research. Three problems
in synthesizing dance motions are presented: 1) dance movements are complex non-linear motions that fol-
low high-level structures of the dance genre over a long horizon, yet must maintain a stylistic consistency; 2)
even for the same genre, dance movements require diversity, expressiveness, and nuances to appear natural
and realistic; 3) spatial-temporal features of dance movements can be influenced by music. In this paper, we
address these issues using a novel two-level transformer-based dance generation system that can synthesize
dance motions to match the audio input. Our high-level transformer network performs the choreography and
generates dance movements with consistent long-term structure, and our low-level implementer infuses diver-
sity and realizes actual dance performances. This two-level approach not only allows us to generate dances
that are consistent in structure, but also enables us to effectively add styles learnt from a wide range of dance
datasets. When training the choreography model, our approach fully utilizes existing dance datasets, even
those without musical accompaniment, and thus differs from previous research that requires dance training
data to be accompanied by music. Results in this work demonstrate that our two-level system generates high-
quality dance motions that flexibly adapt to varying musical conditions trained on a dataset of dance sequences
without accompanying music.
1 INTRODUCTION
Dance movements are complex artistic human expres-
sions. Automatic generation of dance motions that
synchronize to musical beats and match a musical
style, can assist an artist’s manual choreography, and
can provide automatically synthesized dance for vir-
tual concert, augmented reality, and other forms of
digital entertainment. Further, by combining audio
integration in platforms like the metaverse, artistic hu-
man composition and expression can be fully realized
and can benefit from automatic dance choreography.
In this work, we choreograph dance motions by
using a novel two-level transformer-based approach,
where the high-level choreographer learns to model
the long-term movement structure of the dance genre
and the low-level implementer incorporates the mu-
sic influence and realizes the actual dance motions
with fine details and nuances. The advantages of us-
ing the two-level system are that 1) the dance mo-
a
https://orcid.org/0009-0009-1684-0585
b
https://orcid.org/0000-0002-5680-1929
tions are decoupled from the music and thus have
less restrictive training data requirements which make
learning a model possible by fully utilizing standalone
dance datasets without musical accompaniment; 2)
the dance structure learning is separate from the mo-
tion implementation, which allows variations in dif-
ferent granularity levels, i.e. output dance can either
be structurally different or stylistically different given
input music; 3) the choreograph is greatly accelerated
as the automated choreographer focuses on captur-
ing high-level core structure of the dance genre; 4)
and lastly, the music rhythm and energy can be cus-
tomized in the low-level implementation, which al-
lows for better user control.
Synthesizing high-quality dance motion is a great
challenge in animation research. Unlike locomotion
which has cyclic movement with well-defined phase
patterns, dance motions have more complex time sig-
natures with expressive, creative, and artistic compo-
sitions. On the one hand, dance movements of any
genre follow their high-level dance structure. On the
other hand, performances from different dancers, or
Cheng, Y. and Wang, Y.
Transformer-Based Two-level Approach for Music-driven Dance Choreography.
DOI: 10.5220/0012434500003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 1: GRAPP, HUCAPP
and IVAPP, pages 127-139
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
127

Figure 1: Two-level dance choreography approach decouples dance structure learning from its diverse implementation. The
high-level choreographer predicts the next dance segment, and the low-level implementer fills in expressive variations given
audio input.
from the same dancer but in different takes, or influ-
enced by different music can have stylistic variations.
Data-driven motion synthesis becomes even harder, if
not entirely intractable, due to the vast combination of
motion content and motion styles (Smith et al., 2019;
Xia et al., 2015; Yumer and Mitra, 2016). Further-
more, the influence of audio channels makes dance
synthesis a multi-modal problem. Advanced deep-
learning models have been widely used in predict-
ing language sequences. However, training sequence
prediction models for dance choreography has been
restricted because of scarce 3D dance data, most of
which is unpaired with music.
We regard dance as a highly complex form com-
posed of unique body language signatures. Dance
movements follow a specific high-level motion syn-
tax, have independent expressions, and can be in-
fluenced by music during a performance, but not a
byproduct of music. Our research fully utilizes ex-
isting dance datasets (Morro Motion, 2017), to learn
a dance syntax without the need for paired accom-
panying music. During data processing, long se-
quences of dance motions are split into segments,
where each segment represents a dance word that
contains either a motion stroke emphasis or connec-
tion for a dance composition. Dance segments are
further passed through pre-trained autoencoder net-
works to extract their embeddings and cluster into
synonym groups based on the similarity of embed-
dings. To predict the long-horizontal structure of the
dance genre, a transformer-based model is trained
as the high-level choreographer. The choreographer
takes the previous dance segments’ embeddings as in-
put and predicts the next dance segment embedding.
The predicted embedding is further passed to the low-
level dance implementer to incorporate the influence
of music and infuse variations into the dance perfor-
mance. The low-level dance implementer consists of
a feature matcher which is responsible for finding a
dance segment that matches the music style; and a
dance synchronizer which is responsible for synchro-
nizing the dance segment to the music beat. The fea-
ture matcher takes the dance segment embedding pre-
dicted by the high-level choreographer, identifies the
nearest synonym cluster, and within the cluster selects
the dance segment that best matches the music rhythm
and energy features. The synchronizer takes the se-
lected dance segment and the detected musical beats
as input, adjusts the dance segment timing to align its
motion emphasis with the music beat, and blends it
into the final performance.
We summarize the main contribution of our work
as follows:
• We demonstrate a novel transformer-based se-
quence model to solve dance choreography as a
body language composition problem;
• We present a two-level approach to decouple the
high-level dance structure from its low-level re-
alization to ensure structure consistency and real-
ization diversity;
• We propose a strategy that separates motion learn-
ing from multi-modal synchronization, and thus
can take full advantage of existing dance datasets,
even unpaired with accompanying music.
2 RELATED WORK
Deep Learning for Human Motion. With the rapid
development of deep learning, researchers have suc-
cessfully applied deep neural network architectures
to human motion learning, control, and synthesis.
Early work (Taylor and Hinton, 2009) uses a factored
Conditional Restricted Boltzmann Machine (CRBM)
to model human motions. To better understand hu-
man motions, deep autoencoders (Holden et al., 2015;
Wang and Neff, 2015) have been used to extract high-
level motion features. By stacking task-specific net-
works on top of autoencoder networks, Holden et
al. (Holden et al., 2016) proposed a deep learning
framework that is capable of performing motion edit-
GRAPP 2024 - 19th International Conference on Computer Graphics Theory and Applications
128

ing, control, and stylization. Based on fully con-
nected feed-forward network structures with gating
control, Phase-Functioned Neural Networks (PFNN)
(Holden et al., 2017) successfully synthesized human
locomotion in real-time adapting to the different ter-
rains and following users’ instructions. The follow-up
work Mode-Adaptive Neural Networks (Zhang et al.,
2018a) can even handle more complicated foot pat-
terns and synthesize varied quadruped locomotion.
Regarding human motion as temporal sequences,
researchers have explored Recurrent Neural Network
(RNN) structures to model human motions. Li et al.
(Li et al., 2017) proposed a novel auto-conditioned
Long Short-Term Memory (LSTM) structure. To pre-
dict long-horizon human motions, Wang et al. (Wang
et al., 2019) used Spatio-Temporal Recurrent Neu-
ral Networks (STRNN) to model spatial and tempo-
ral variances in human motions and disambiguate the
pose prediction. Deep reinforcement learning (DRL)
has been applied to motion skill learning, includ-
ing locomotion (Peng et al., 2017), balancing skills
(Liu and Hodgins, 2017), basketball dribbling (Liu
and Hodgins, 2018), and acrobat stunts (Peng et al.,
2018). Researchers have also explored DRL to sim-
ulate physical styles, by considering muscle strength,
body proportions, and environmental conditions (Lee
et al., 2021). Based on the generative adversarial net-
work (GAN), Peng et al. (Peng et al., 2021) inte-
grated Adversarial Motion Priors (AMP) into DRL
as the discriminator for generating a wider range of
physics-based human motions. Aberman et al. (Aber-
man et al., 2020) proposed a generative model that is
capable of extracting motion styles from videos and
generating stylized human motions accordingly.
Audio-Driven Motion Synthesis. Researchers
have explored approaches to utilize audio input to
drive, disambiguate, and stylize motion generation.
By using rule-based methods or statistical methods
like Hidden Markov Models (HMMs) and Condi-
tional Random Fields (CRFs), early research extracts
prosody or verbal features to predict body language
(Levine et al., 2009), gestures(Levine et al., 2010),
head orientation (Sargin et al., 2007), lip movement
(Englebienne et al., 2007; Park and Ko, 2008) and
facial expressions (Albrecht et al., 2002; Chuang
and Bregler, 2005). In recent years, deep learning
methods have been successfully applied to predict
multi-modal behaviors. Ferstl et al. (Ferstl et al.,
2019) used LSTM-based networks as a phase classi-
fier and Gated Recurrent Unit (GRU)-based networks
as a gesture generator. Yoon et al. (Yoon et al.,
2020) proposed a multi-layered bidirectional GRU
network with an adversarial discriminator to predict
gestures from audio, text, and speaker identity. A
bidirectional LSTM model is used in (Hasegawa
et al., 2018) to learn the speech-gesture relationships
for gesture synthesis. Habibie et al. (Habibie et al.,
2022) proposed a motion matching-based framework
that selects clips using a Nearest Neighbor-based
algorithm and further synthesizes gestures through a
conditional GAN in a controllable way. In addition
to conversational human motions, music spectral
features have been used to drive arm and finger
animations playing musical instruments. Given a
piece of music or a midi file, optimization-based
procedural methods are developed to generate finger
movements performing piano (Zhu et al., 2013) and
guitar (ElKoura and Singh, 2003). An LSTM-model
(Shlizerman et al., 2018) is trained on piano and
violin videos, which takes audio input, and predicts
the performance animations for virtual avatars.
Dance Motion Choreography. Dance motions,
different from playing musical instruments or per-
forming multi-modal gestures, have much more com-
plicated movement flow and patterns and thus have
been a great challenge in computer animation re-
search. Early research (Okamoto et al., 2010) tem-
porally scales leg motions during dancing to match
the tempo of music. Shiratori et al. (Shiratori et al.,
2006) synthesizes dance motions by selecting dance
segments that match the music rhythms and inten-
sity. Aristidou et al. (Aristidou et al., 2017) uses
Gaussian Radial Basis Function (RBF) to model the
correlation between dance motion features and emo-
tion coordinates. Aristidou et al. (Aristidou et al.,
2021) samples the probability distribution of dance
motifs to maintain a consistent global dance struc-
ture, and further infuses styles using AdaIn layers and
implements motions through an acLSTM network.
Other researchers put more emphasis on choreogra-
phy controllability by proposing a dance show au-
thoring platform (Schulz and Velho, 2011), develop-
ing a body-part motion synthesis system (Soga et al.,
2016) or Disk Jockeys (DJ) user interface (Iwamoto
et al., 2017) to incorporate human input during chore-
ograph.
In recent years, many deep learning models have
been proposed to solve dance choreography prob-
lems. Alemi et al. (Alemi et al., 2017) trained
Factored Conditional Restricted Boltzmann Machines
(FCRBM) to predict dance motions frame by frame
while synchronizing to musical input. Li et al. (Li
et al., 2020) developed a two-stream transformer gen-
erative model which takes the motion and audio as
input and fuses their features to synthesize diverse
dance motions. Li et al. (Li et al., 2021) uses three
Transformer-Based Two-level Approach for Music-driven Dance Choreography
129
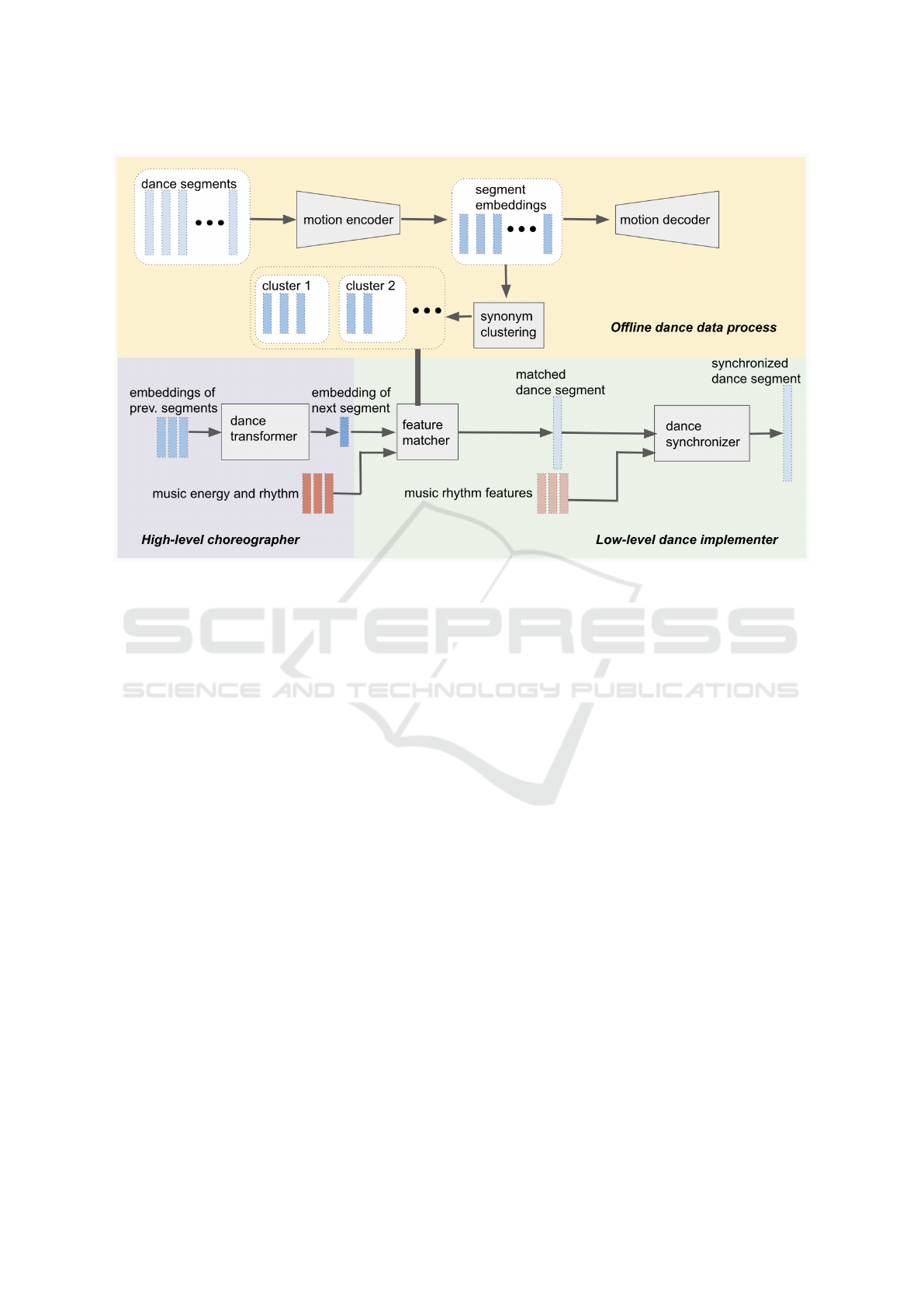
Figure 2: System Overview.
transformers for extracting motion, music, and cross-
modal features, and auto-regressively generates long-
horizon dance motions. To model the relationship
between music and dance, Chen et al. (Chen et al.,
2021) extracts choreomusical style and rhythm em-
beddings, maps them together with motion embed-
dings to a unified space, and generates the dance
motions through graph-based optimization. Lee et
al. (Lee et al., 2019) models dance variations using
a Dance Unit Variational Auto Encoder (DU-VAE)
and generates a sequence of dance movements given
music input using a Music-to-Movement GAN dur-
ing composition. Siyao et al. (Siyao et al., 2022)
trained an actor-critic Generative Pre-trained Trans-
former (GPT) model using dance poses in a large
dance motion dataset (Li et al., 2021). Alexander-
son et al. (Alexanderson et al., 2023) trained a model
using diffusion methods, which adapts the DiffWave
architecture to represent three-dimensional pose se-
quences, incorporating Conformers for enhanced per-
formance.
3 OVERVIEW
Our dance synthesis workflow is illustrated in Figure
2. Given a dance dataset, we preprocess the motions
offline. Long sequences of dance motions are first
cut into shorter dance segments where each segment
maximally contains one motion emphasis. Temporal
phase information is then labelled in a semi-automatic
way for the dance segments. We regard dance seg-
ments as the basic words of body language. Seg-
ments are then passed to an autoencoder network pre-
trained on a large 3D human motion dataset (Holden
et al., 2016) to extract the corresponding dance word
embeddings. Based on the similarity of word em-
beddings, dance segments are grouped into synonym
clusters, where within each cluster, segments are cat-
egorized as the same content but with performance
variations. While between different clusters, dance
segments have different semantic meanings.
The high-level choreographer is a transformer-
based sequence model trained on the preprocessed
dance dataset. It takes the previous dance segments’
embeddings as input and predicts the embedding of
the next segment. Though dance implementations and
styles can be influenced by music and individual per-
formers, dance itself is a form of expression in the
body language channel. Thus, the high-level chore-
ographer is trained only on motion data, to focus on
the learning of syntactic structure of a dance genre
without over-fitting to variations in the actual imple-
mentation.
The low-level dance implementer, which consists
of a motion feature matcher and a dance synchronizer,
is responsible for infusing variations into the perfor-
mance. The feature matcher takes the predicted em-
GRAPP 2024 - 19th International Conference on Computer Graphics Theory and Applications
130

bedding from the high-level choreographer and finds
its nearest synonym cluster to have a rich pool of
dance segments for motion implementation. Within
the synonym cluster, the feature matcher selects the
dance segment that best matches the input music en-
ergy and rhythm. The feature matcher is decoupled
from the high-level dance structure prediction and
helps generate diverse dance motions under musical
influence, yet still respects the global structure of the
dance genre. The dance synchronizer further synchro-
nizes the motion emphasis in the selected dance seg-
ment to the music beat, based on the segment’s tem-
poral phase information and the music’s rhythmic fea-
tures.
4 METHOD
4.1 Data Processing
Our approach requires three-dimensional dance mo-
tion datasets to train the two-level choreographer
model. Compared to previous work, training of
the two-level choreographer works with silent mo-
tions, i.e. dance motions without accompanying mu-
sic. This relaxation in data requirements qualifies a
great amount of motion capture resources available as
training-sets, and thus significantly reduces the work-
load for motion collection. While many public dance
motion capture databases suffice the requirement, for
this study, we acquired a dance dataset (Morro Mo-
tion, 2017), consisting of 61 long sequences and to-
talling 37,983 frames of dance motions (with no mu-
sic). Basic data augmentation was performed by mir-
roring the motions, which doubles the data size.
4.1.1 Motion Segmentation and Phase Labelling
In the original dataset, motions are in long continu-
ous performances with connected dance moves. We
cut the long motion sequences into smaller dance seg-
ments, where each segment is a base unit for compos-
ing longer sequences. Regarding dance as a form of
body language, we adopted a similar concept of ges-
ture phrase segmentation based on previous gesture
synthesis work (Neff et al., 2008; Levine et al., 2009;
Smith and Neff, 2017; Levine et al., 2010; McNeill,
2008). Specifically, we followed the motion segmen-
tation routine such that each segment has at most
one motion emphasis, e.g. arm stroke or footstep.
The temporal phase of each segment follows the gen-
eral pattern [preparation,emphasis,retraction], and
is denoted by p ∈ [0,1]. A time function T (p) is de-
fined as below to map the input phase p to the index
of corresponding frame in the dance segment:
T (p) =
(
2p ∗t
e
, if p ∈ [0,
1
2
]
t
e
+ 2(p −
1
2
) ∗ (t −t
e
) ifp ∈ (
1
2
,1]
(1)
When p = 0, it indicates the beginning of each dance
segment, and p keeps increasing with the progress of
motion until p =
1
2
i.e. it reaches the motion emphasis
and T (p) returns the frame index of motion emphasis
t
e
; when p ∈ (
1
2
,1], it corresponds to motion retrac-
tion to the end of the segment. Dance segments that
do not have an emphasis are regarded as connection
motions, and their phase increases from 0 to 1, and
maps to a frame index linearly. Motion segmenta-
tion and emphasis annotation were performed manu-
ally, and p values were computed automatically based
on segment boundary and emphasis. The street dance
dataset produced 1522 dance segments in total.
4.1.2 Embedding Extraction
Instead of directly using dance segments for choreog-
rapher training, we regard each segment as a word in
a body language and thus perform a similar word em-
bedding extraction process to that found in the Natural
Language Process (NLP) domain.
Each motion segment is represented by X =
[x
1
,...x
i
,x
i+1
,...,x
t
], where x
i
the full body pose
at frame i, and t indicates the number of frames
of the motion segment. For each frame, x =
[p,
˙
p
root
,
˙
r
root
,c] ∈ R
d
describes the full body pose,
and thus X is in R
t×d
space. Specifically, p ∈ R
63
are
the three-dimensional positions for 21 essential joints,
˙
p
root
∈ R
2
are the root joint’s linear velocity in x and
z directions,
˙
r
root
∈ R
3
are the root joint’s angular ve-
locity around xyz axes, c ∈ R
2
are left and right foot
contact information respectively, and thus the dimen-
sion of full body pose is d = 70.
Segment embeddings are extracted using the au-
toencoder architecture proposed in the previous work
by (Holden et al., 2016), and pre-trained on a large
combined human motion dataset, including CMU
Mocap (CMU, 2000), HDM05 (M
¨
uller et al., 2007),
MHAD (Ofli et al., 2013), and Xia-Style (Xia et al.,
2015). The forward pass of the autoencoder, i.e. the
encoder, takes a segment X of t-frame long as input
(t = 240 is used in the pre-training), performs the op-
eration Φ, and projects X to high-level embeddings H
in the hidden motion manifold:
H = Φ(X) = ReLU(MaxPool(X ∗W
0
+ b
0
)) (2)
With temporal max pooling, H ∈ R
t
2
×h
includes
t
2
frames of projected h-dimensional hidden units. W
0
is a d × h × w weight matrix that converts each frame
from d-dimensional motion space to h-dimensional
Transformer-Based Two-level Approach for Music-driven Dance Choreography
131
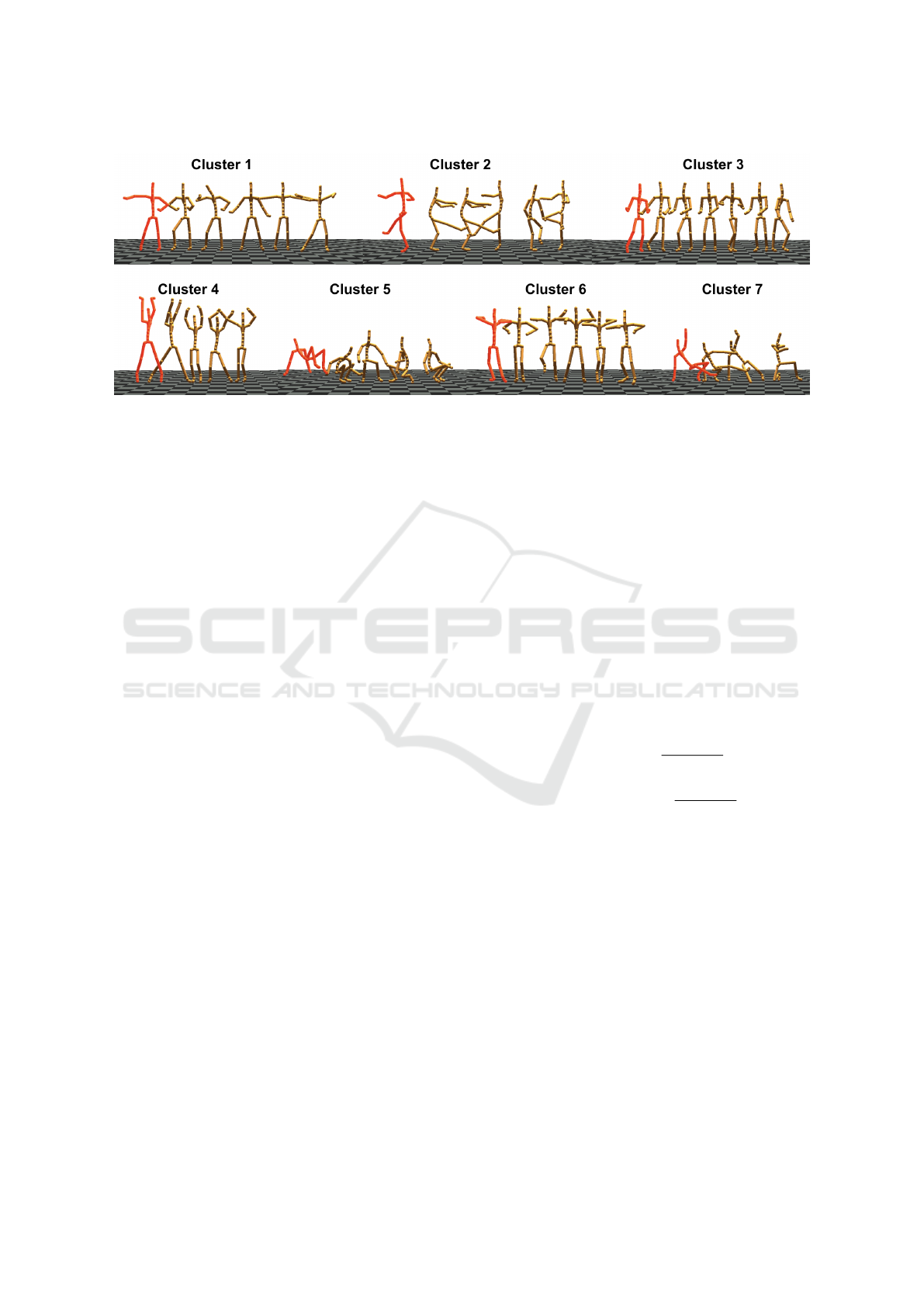
Figure 3: Dance segments clustered based on their extracted embeddings.
hidden space using temporal convolutional filters of
size w = 25. b
0
is the h-dimensional bias vector.
h = 256 is used in the pre-trained network.
The backward pass of the autoencoder, i.e. the de-
coder, performs operation Φ
+
, and maps the embed-
ding H back to
ˆ
X in observation motion space.
ˆ
X = Φ
+
(H) = (InversePool(H) − b
0
) ∗
˜
W
0
(3)
The autoencoder was trained with both a forward and
a backward pass, to minimize the reconstruction error
between X and
ˆ
X. In this work, we use the forward
encoder pass to extract motion segment embeddings.
To fully utilize the pretrained autoencoder, we renor-
malized each dance segment to 240-frame length so
that X ∈ R
240×70
fits in one pass and generates one
consolidated embedding H ∈ R
120×256
for each seg-
ment. The extracted embeddings capture the spatial
features of dance movements, and we leave the tem-
poral synchronization to the synchronizer.
4.1.3 Synonym Clustering
For all the dance segments, we employed Gaussian
Mixture Models (GMMs) to cluster similar segments
based on their embeddings H on the hidden manifold
and applied the Expectation-Maximization (EM) al-
gorithm to estimate the model parameters so that the
likelihood of the data is maximized. 1522 dance seg-
ments, represented by their embeddings, produced 21
clusters of various sizes, with large clusters typically
containing around 100 segments, and small clusters
containing about 10 ∼ 20 segments. Though dance
segments were clustered based on their embeddings,
visually each cluster covers a set of similar dance
movements with unique characteristics and diverse
implementation (illustrated in Figure 3). We compute
the mean embeddings of all segments included in one
cluster as the cluster embedding
¯
H
c
, to represent each
cluster.
4.2 High-Level Dance Choreographer
4.2.1 Model Architecture
High-level choreographer learns the long-horizon
structure of dance movement and is implemented us-
ing a transformer-based network, originally proposed
by (Vaswani et al., 2017) and (Wu et al., 2020). The
network includes three encoder layers and decoder
layers respectively (illustrated in Figure 4).
The encoder is made up of a positional encoding
layer and three identical encoder layers. Compared
with the original transformer structure in (Vaswani
et al., 2017), we removed the input layer and directly
plugged in the extracted h-dimensional hidden fea-
tures. The positional encoding layer employs the two
operations below
PE(i,2 j) = sin
i
10000
2 j/h
(4)
PE(i,2 j + 1) = cos
i
10000
2 j/h
(5)
to inform the network about the relative position of
the segment in the input sequence, where i, j are the
position index and dimension index in the hidden
space respectively. The output of the positional en-
coding layer is fed into the encoder, which includes
a self-attention sub-layer and a fully connected feed-
forward sub-layer.
The decoder is made up of three identical decoder
layers and a linear mapping layer. Compared with the
three encoder layers, in the three decoder layers, there
are similar encoder-decoder attention sub-layers per-
forming the multi-head attention to the output of the
encoder stack. It allows every position in the decoder
to attend to all positions in the input sequence. Out-
puts from the top decoder layer are passed to the lin-
ear mapping layer and converted to the target dance
segment embedding.
GRAPP 2024 - 19th International Conference on Computer Graphics Theory and Applications
132
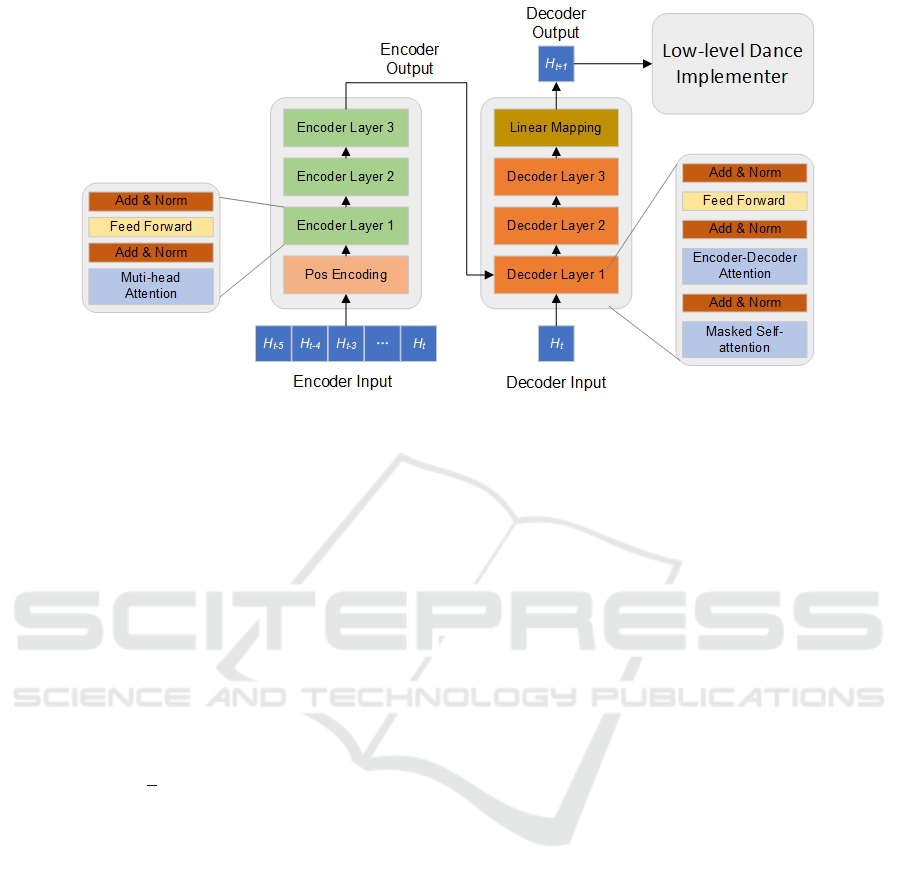
Figure 4: High-level choreographer implemented in a transformer-based network architecture.
4.2.2 Training
The input to the encoder is
[H
t−5
,H
t−4
,H
t−3
,H
t−2
,H
t−1
,H
t
], i.e. the em-
beddings of the current dance segment H
t
, and its five
previous dance segments. The input to the decoder
begins with H
t
and it learns to output H
t+1
through
supervised training. The dance segments’ original
order in the motion captured dataset is used as the
ground truth. The loss function L is defined as the
Mean Squared Error (MSE) between the ground
truth dance segment embedding H
t+1
and segment
embedding
ˆ
H
t+1
predicted by the decoder:
L =
1
h
h
∑
d=1
H
d
t+1
−
ˆ
H
d
t+1
2
(6)
During training, Adam optimizer (Kingma and Ba,
2014) with parameters β
1
= 0.9, β
2
= 0.999, ε = 10
−8
and batch size 32 is used. The learning rate is initially
set as 0.003, and scheduled to decay by the coefficient
e
−0.05
each epoch. We trained the model for a total of
50 epochs.
4.3 Low-Level Dance Implementer
The goal of the low-level dance implementer is to re-
alize various dance performances that match the ac-
companying music, given the dance segment embed-
ding
ˆ
H
t+1
output from the high-level choreographer.
It takes music and dance segment embedding
ˆ
H
t+1
as
input, finds the best dance segment, and incorporates
it into the long dance sequence.
4.3.1 Music Features
To generate a diverse dance performance that matches
the music, we first extract two key features from mu-
sic, i.e. beat and energy.
Music Beat Detection. We use Librosa (McFee
et al., 2015) for detecting beats from music input.
Librosa first computes the onset strength envelope
(OSE) and estimates the music tempo. Music beats
are tracked using a dynamic programming approach
(Ellis, 2007) that seeks to maximize the alignment
between the estimated tempo, the observed onset
strengths, and the temporal consistency of inter-beat
intervals. The algorithm iteratively refines beat tim-
ing, ensuring that the detected beats correspond to sig-
nificant onsets and adhere to a consistent tempo.
To speed up beat detection in an online fashion
for real-time application, we implemented a simpli-
fied and faster approach without using Librosa. In a
real-time application, at each refresh time, a window
of music signals streams in and is first converted from
time domain to frequency domain through Fourier
Transform. High amplitudes summed across the
low frequency band are recognized as candidates for
beats, where the low frequency threshold is set to
125Hz and the high amplitude threshold is set to 1.5
times the mean amplitudes of all frequency bands. We
maintain the running average of inter-beat intervals
to help identify the incoming beats among the candi-
dates. From the detected beats, the general (Beats Per
Minute) BPM of the music is computed accordingly.
Music Energy Computation. Librosa divides the
continuous music input into a sequence of overlap-
Transformer-Based Two-level Approach for Music-driven Dance Choreography
133

ping windows, where each window has 2048 audio
samples. Root Mean Square (RMS) value of the am-
plitudes is computed from the window spectrogram
and is defined as the energy E
t
of the music window
at time t. The sequence of RMS values across all win-
dows constitutes a time-varying representation of the
entire music’s energy.
4.3.2 Feature Matcher
Feature matcher receives the computed music features
and the
ˆ
H
t+1
embedding predicted from the high-level
choreographer as input, and its goal is to find the best
dance segment that matches the music.
Cluster Identification. We compute the mean
squared distance between each cluster embedding
¯
H
c
and the predicted segment embedding
ˆ
H
t+1
and
identified the target cluster with the nearest distance.
Cluster identification finds the structurally most prob-
able synonym group of dance segments, where seg-
ments perform similar motions in various ways.
Segment Selection. Music BPM helps estimate the
preferred frame length of the dance segment, based
on which we filtered out too long (≥ 125%) or short
(≤ 70%) segments in the nearest cluster, to avoid
drastic temporal warping during synchronization. To
further identify the best dance segment among the re-
maining segments in the cluster, we followed the style
matching practice proposed in (Aristidou et al., 2017),
where music energy computed from audio amplitudes
is linked to motion amplitudes features derived from
Laban Movement Analysis (LMA) (Laban and Ull-
mann, 1971). Specifically, eight LMA features con-
sistently related to motion amplitude are computed for
each dance segment in the nearest cluster. Grouped by
LMA component, i.e. BODY and EFFORT, the eight
LMA features { f
1
∼ f
8
} are listed in Table 1.
The preferred LMA features of the dance segment
at time t + 1 are computed using the following energy
mapping function f
LMA
:
f
LMA
(E
t+1
) =
∑
5
i=0
∑
8
j=1
f
j
t−i
∑
5
i=0
E
t−i
E
t+1
(7)
f
LMA
takes the incoming music’s energy E
t+1
as input
and computes the expected LMA features of dance
segment at time t + 1, based on previous dance seg-
ments’ LMA features within the range [t − 5,t] and
their corresponding music energy E
t−5
∼ E
t
. Dance
segment in the cluster with LMA features nearest to
the computed f
LMA
(E
t+1
) is selected, and energetic
music input is mapped to the dance segment with
a larger range of motions and sharper movements.
Our segment identification process ensures that the
selected dance segment is consistent with the music
general rhythm and matches the music energy.
Table 1: LMA features associated with motion amplitude.
Basic Definition Derived Feature
Discription max mean
BODY
f
1
hands distance ✓
f
2
left hand-hip distance ✓
f
3
right hand-hip distance ✓
f
4
feet distance ✓
EFFORT
f
5
left hand acceleration ✓
f
6
right hand acceleration ✓
f
7
left foot acceleration ✓
f
8
right foot acceleration ✓
4.3.3 Synchronizer
Dance synchronizer takes the selected dance segment
as input, aligns its motion emphasis with the musical
beat, and blends the segment smoothly into the long
sequence of dance performance.
According to segment phase discussed in 4.1.1,
p =
1
2
corresponds to the motion emphasis of the
dance segment; p ∈ [0,
1
2
) includes the preparation
movement reaching to the emphasis; and during p ∈
(
1
2
,1] dance retracts to the end of the segment. Thus
we align dance emphasis frame at T (p =
1
2
) with
the detected music beat at time T
beat
. Once aligned,
in most cases the preparation phase of the current
dance segment overlaps with the retraction phase of
its previous segment to a reasonable extent, and we
performed spherical linear interpolation (SLERP) on
the overlapping part, to splice the current dance seg-
ment smoothly with the previous one. In the case
of dense music beats, previous segment’s retraction
could overlap more than p =
1
2
with the current seg-
ment and cover the current emphasis. Then the cur-
rent segment is dropped, to avoid modifying dance
emphasis and packing too many motions within a
short period of time. In the case of disjoint previ-
ous retraction and current preparation, we performed
SLERP transitioning from the last frame of previous
retraction to the beginning of current preparation. The
dance synchronization process is illustrated in Figure
5.
5 EXPERIMENTS AND RESULTS
To fully evaluate our two-level approach for dance
choreography, we assessed the motion qualities of
the synthesized dance under three musical condi-
tions: 1) non-professional singers’ vocalizing through
GRAPP 2024 - 19th International Conference on Computer Graphics Theory and Applications
134
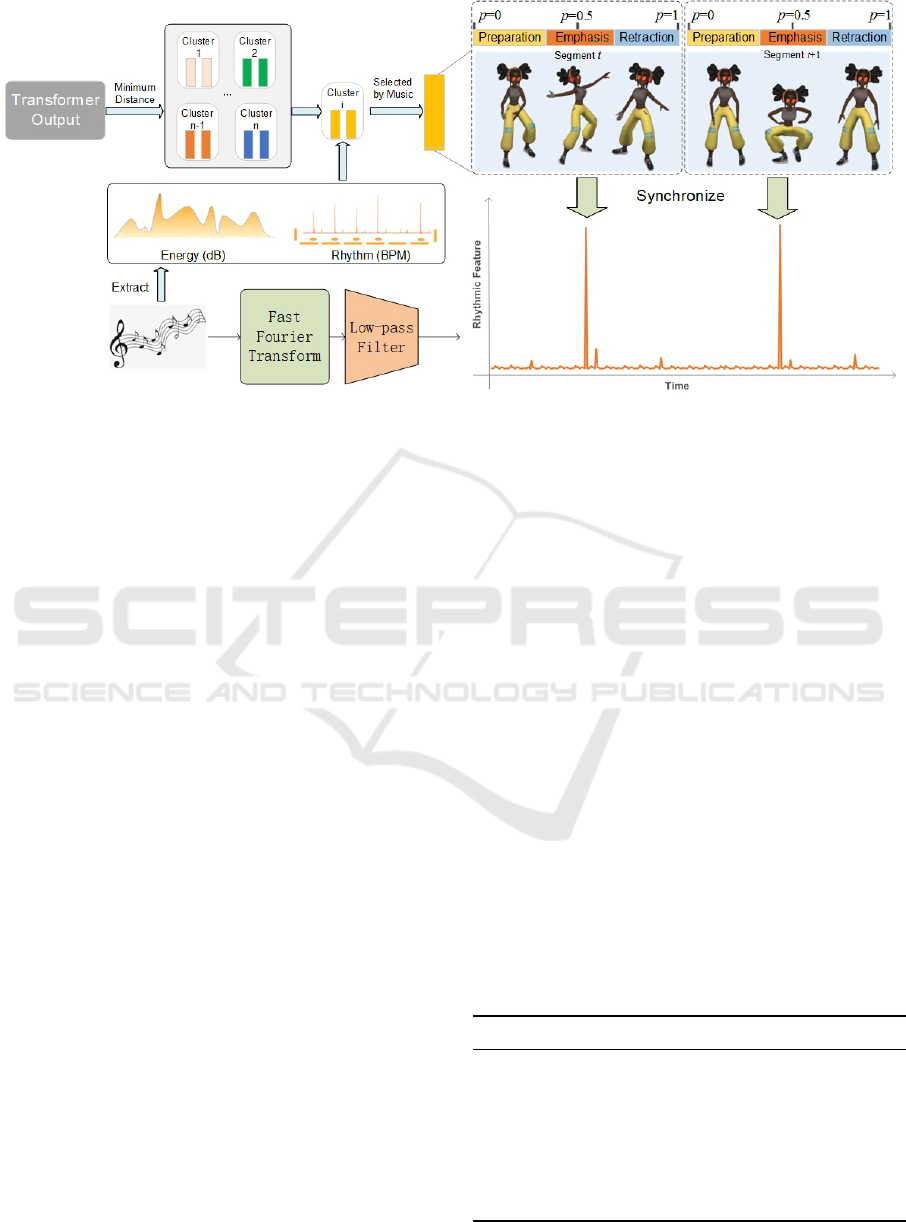
Figure 5: Low-level dance implementer.
a microphone; 2) professional singing with instru-
mental music playback from the album through a
microphone; 3) pure music playback from the al-
bum through a microphone. Visual results of chore-
ographed dance motions from our approach are illus-
trated in the Figure 1 and the supplementary video
(https://youtu.be/PkYDOr-JJDo). Perceptually our
synthesized dance results are not differentiable from
the original dance motions in the dataset. To demon-
strate the advantages of our two-level approach, we
further quantitatively evaluated dance-music synchro-
nization and dance motion diversity of the output mo-
tions.
5.1 Quantitative Evaluation
5.1.1 Dance-music Synchronization
We adopted the evaluation practice proposed in (Aris-
tidou et al., 2022) and (Lee et al., 2019) to assess
dance-music synchronization. The labelled dance
phases were not used when evaluating synchroniza-
tion, and dance emphasis was derived directly from
the result motions using a velocity-based method pro-
posed in (Aristidou et al., 2022), to make fair compar-
isons with previous work. Music beats were detected
based on the method presented in 4.3.1. For each
of the three musical conditions, we prepared two 30-
second long audio inputs and fed the audio input to
our two-level choreographer to synthesize the dance
results.
Two dance-music synchronization metrics, Beat
Coverage and Beat Hit Rate, are computed from the
music input and the result dance motions. The num-
ber of total musical beats is denoted by B
m
, the num-
ber of total motion emphasis is denoted by B
k
and
the number of motion emphasis that are aligned with
musical beats is denoted by B
a
. According to (Lee
et al., 2019), Beat Coverage is defined as B
k
/B
m
,
which measures the ratio of motion emphasis to mu-
sical beats; Beat Hit Rate is defined as B
a
/B
k
, which
is the ratio of aligned motion emphasis to total motion
emphasis.
Figure 6 illustrates a section of the choreographed
dance sequence given the song ”Gangnam Style” as
the music input. As proposed in (Aristidou et al.,
2022), the local minima in the kinematic velocity are
candidates for motion emphasis. The detected mu-
sic beats and motion emphasis are highlighted in red
dashed lines. Table 2 shows the beat score for differ-
ent music conditions. The average beat coverage and
beat hit rate of our approach are 67.3% and 65.3%
respectively across all the music conditions, which
outperforms baseline sequence model LSTM and pre-
vious work Aud-MoCoGAN (Tulyakov et al., 2018),
and Dance2Music (Lee et al., 2019).
Table 2: Comparison of beat coverage and beat hit rate.
Method Beat Coverage Hit Rate
LSTM 1.4% 51.6%
Aud-MoCoGAN 23.9% 54.8%
Dance2Music 39.4% 65.1%
Ours (professional) 62.1% 66.5%
Ours (non-fessional) 51.3% 64.5%
Ours (pure music) 88.6% 64.8%
Ours (on average) 67.3% 65.3%
Transformer-Based Two-level Approach for Music-driven Dance Choreography
135

Figure 6: Choreographed dance sequence in Gangnam Style.
5.1.2 Dance Motion Diversity
We evaluated motion diversity of the result dances
given the audio input under the three musical condi-
tions that are introduced in 5.1.1. We used the aver-
age feature distance similar to (Zhang et al., 2018b)
as measurement. The dance hidden features are ex-
tracted by the autoencoder presented in 4.1.2, which
can better measure the richness and diversity of the
motions in the observation space. Diversity results
are listed in Table 3. Compared with previous work
DeepDance (Sun et al., 2020), Dance2Music (Lee
et al., 2019) and ConvSeqGen (Yan et al., 2019), our
method achieves the highest diversity score in all mu-
sical conditions.
Table 3: Comparison of Motion Diversity.
Method Motion Diversity
ConvSeqGen 38.7
DeepDance 34.4
Dance2Music 53.2
Ours (professional) 62.9
Ours (non-professional) 59.9
Ours (pure music) 69.1
Ours (on average) 63.9
5.2 Run-Time Performance
We assessed the performance of our two-level ap-
proach, and reported the individual run-time speed per
dance segment of three major components: 1) high-
level choreographer, 2) low-level feature matcher, 3)
low-level dance synchronizer. Performance tests are
run on a machine with Intel Core i7-12700 Processor
16 GB DDR5. The results are listed in Table 4.
Table 4: Average Run-time Speed per Segment.
Component Runtime
high-level choreographer 59 ms
low-level feature matcher 14 ms
low-level dance synchronizer 7 ms
5.3 Ablation Study
To better understand the contribution of individual
components in our two-level approach, we conducted
an ablation study. Each time, we removed one com-
ponent from the complete workflow and evaluated the
system’s performance based on the three critical met-
rics: Motion Diversity, Beat Coverage, and Beat
Hit Rate. From the results listed in Table 5, we
can see that the low-level synchronizer primarily en-
sures alignment between dance emphasis and musi-
cal beats, and thus contributes to the high Beat Hit
Rate of our result motions. Both the high-level chore-
ographer and the low-level feature matcher play piv-
otal roles in enhancing Motion Diversity. The fea-
ture matcher is crucial in achieving Beat Coverage,
as it predominantly selects dance segments that match
well with the general rhythm of the music.
6 CONCLUSION AND FUTURE
WORK
In this work, we present a novel two-level genera-
tion system for choreographing dance motions that
are synchronized and compatible with the music in-
put. Our approach decouples the high-level dance
structure from its low-level implementation, allowing
for the synthesis of expressive dance motions that are
both coherent in their genre and varied in their perfor-
mance. In our results, we have demonstrated the sig-
GRAPP 2024 - 19th International Conference on Computer Graphics Theory and Applications
136

Table 5: Ablation Analysis on Algorithm’s Performance.
Component (Removed) Motion Diversity Beats Coverage Beat Hit Rate
high-level choreographer 38.7 64.1% 62.5%
low-level feature matcher 34.4 32.1% 61.7%
low-level dance synchronizer 61.3 44.6% 37.4%
Complete Workflow 63.9 67.3% 65.3%
nificance of each component of our system and evalu-
ated the performance of our system in terms of dance-
music synchronization and motion diversity.
The present dataset primarily encompasses fast-
paced dance, which offers rich movements tied
closely to rhythmic patterns. Restricted by the
dataset, our current work has limitations in chore-
ographing for relaxing low-rhythmic music. As we
continue to evolve our research, we aim to incorpo-
rate more dance styles, and adapt our algorithm to
synthesize dances for diverse genres of music. This
expansion will also enable a more comprehensive un-
derstanding of the relationship between dance mo-
tions and musical elements across genres. Our cur-
rent framework mainly focuses on music energy and
rhythmic features, reflecting the pulsating beats in-
trinsic to street dance. However, as we diversify our
dance dataset and incorporate other dance forms, we
recognize the significance of music spectral features
in dance choreography. For example, the tonal qual-
ity, timbre, and pitch contours in music can also res-
onate with different dance styles. Therefore, in the
future, in addition to music energy and rhythm, we
will investigate more on other spectral features. In
our subsequent work, we will also transition our sys-
tem to operate in real time. Such kind of work will not
only promote its applicability but will be helpful for
on-device deployment, allowing dancers and chore-
ographers to use our system directly in their practice
environments.
ACKNOWLEDGEMENTS
We would like to thank Dr. Scott Bishop for providing
constructive feedback to the work, and Yichen Jiang
for annotating the dance dataset. Financial support
for this work is provided by the McMaster University
Startup Fund.
REFERENCES
Aberman, K., Weng, Y., Lischinski, D., Cohen-Or, D., and
Chen, B. (2020). Unpaired motion style transfer from
video to animation. ACM Transactions on Graphics
(TOG), 39(4):64–1.
Albrecht, I., Haber, J., and Seidel, H.-P. (2002). Au-
tomatic generation of non-verbal facial expressions
from speech. In Advances in Modelling, Animation
and Rendering, pages 283–293. Springer.
Alemi, O., Franc¸oise, J., and Pasquier, P. (2017).
Groovenet: Real-time music-driven dance movement
generation using artificial neural networks. networks,
8(17):26.
Alexanderson, S., Nagy, R., Beskow, J., and Henter, G. E.
(2023). Listen, denoise, action! audio-driven motion
synthesis with diffusion models. ACM Transactions
on Graphics (TOG), 42(4):1–20.
Aristidou, A., Yiannakidis, A., Aberman, K., Cohen-Or, D.,
Shamir, A., and Chrysanthou, Y. (2021). Rhythm is
a dancer: Music-driven motion synthesis with global
structure. arXiv preprint arXiv:2111.12159.
Aristidou, A., Yiannakidis, A., Aberman, K., Cohen-Or, D.,
Shamir, A., and Chrysanthou, Y. (2022). Rhythm is
a dancer: Music-driven motion synthesis with global
structure. IEEE Transactions on Visualization and
Computer Graphics.
Aristidou, A., Zeng, Q., Stavrakis, E., Yin, K., Cohen-Or,
D., Chrysanthou, Y., and Chen, B. (2017). Emotion
control of unstructured dance movements. In Proceed-
ings of the ACM SIGGRAPH / Eurographics Sympo-
sium on Computer Animation, SCA ’17, pages 9:1–
9:10, New York, NY, USA. ACM.
Chen, K., Tan, Z., Lei, J., Zhang, S.-H., Guo, Y.-C.,
Zhang, W., and Hu, S.-M. (2021). Choreomaster:
choreography-oriented music-driven dance synthesis.
ACM Transactions on Graphics (TOG), 40(4):1–13.
Chuang, E. and Bregler, C. (2005). Mood swings: expres-
sive speech animation. ACM Transactions on Graph-
ics (TOG), 24(2):331–347.
CMU (2000). Carnegie mellon university mocap database.
ElKoura, G. and Singh, K. (2003). Handrix: animating the
human hand. In Proceedings of the 2003 ACM SIG-
GRAPH/Eurographics symposium on Computer ani-
mation, pages 110–119.
Ellis, D. P. (2007). Beat tracking by dynamic programming.
Journal of New Music Research, 36(1):51–60.
Englebienne, G., Cootes, T., and Rattray, M. (2007). A
probabilistic model for generating realistic lip move-
Transformer-Based Two-level Approach for Music-driven Dance Choreography
137

ments from speech. Advances in neural information
processing systems, 20.
Ferstl, Y., Neff, M., and McDonnell, R. (2019). Multi-
objective adversarial gesture generation. In Motion,
Interaction and Games, pages 1–10.
Habibie, I., Elgharib, M., Sarkar, K., Abdullah, A., Nyat-
sanga, S., Neff, M., and Theobalt, C. (2022). A mo-
tion matching-based framework for controllable ges-
ture synthesis from speech. In ACM SIGGRAPH 2022
Conference Proceedings, pages 1–9.
Hasegawa, D., Kaneko, N., Shirakawa, S., Sakuta, H., and
Sumi, K. (2018). Evaluation of speech-to-gesture gen-
eration using bi-directional lstm network. In Proceed-
ings of the 18th International Conference on Intelli-
gent Virtual Agents, pages 79–86.
Holden, D., Komura, T., and Saito, J. (2017). Phase-
functioned neural networks for character control.
ACM Transactions on Graphics (TOG), 36(4):42.
Holden, D., Saito, J., and Komura, T. (2016). A deep
learning framework for character motion synthesis
and editing. ACM Transactions on Graphics (TOG),
35(4):138.
Holden, D., Saito, J., Komura, T., and Joyce, T. (2015).
Learning motion manifolds with convolutional au-
toencoders. In SIGGRAPH Asia 2015 Technical
Briefs, SA ’15, pages 18:1–18:4, New York, NY,
USA. ACM.
Iwamoto, N., Kato, T., Shum, H. P., Kakitsuka, R., Hara,
K., and Morishima, S. (2017). Dancedj: A 3d dance
animation authoring system for live performance. In
International Conference on Advances in Computer
Entertainment, pages 653–670. Springer.
Kingma, D. P. and Ba, J. (2014). Adam: A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Laban, R. and Ullmann, L. (1971). The mastery of move-
ment.
Lee, H.-Y., Yang, X., Liu, M.-Y., Wang, T.-C., Lu, Y.-D.,
Yang, M.-H., and Kautz, J. (2019). Dancing to music.
Advances in neural information processing systems,
32.
Lee, S., Lee, S., Lee, Y., and Lee, J. (2021). Learning a
family of motor skills from a single motion clip. ACM
Transactions on Graphics (TOG), 40(4):1–13.
Levine, S., Kr
¨
ahenb
¨
uhl, P., Thrun, S., and Koltun, V.
(2010). Gesture controllers. In ACM SIGGRAPH
2010 papers, pages 1–11.
Levine, S., Theobalt, C., and Koltun, V. (2009). Real-time
prosody-driven synthesis of body language. In ACM
SIGGRAPH Asia 2009 papers, pages 1–10.
Li, J., Yin, Y., Chu, H., Zhou, Y., Wang, T., Fidler,
S., and Li, H. (2020). Learning to generate di-
verse dance motions with transformer. arXiv preprint
arXiv:2008.08171.
Li, R., Yang, S., Ross, D. A., and Kanazawa, A. (2021).
Ai choreographer: Music conditioned 3d dance gen-
eration with aist++. In Proceedings of the IEEE/CVF
International Conference on Computer Vision, pages
13401–13412.
Li, Z., Zhou, Y., Xiao, S., He, C., and Li, H. (2017). Auto-
conditioned LSTM network for extended complex hu-
man motion synthesis. CoRR, abs/1707.05363.
Liu, L. and Hodgins, J. (2017). Learning to schedule con-
trol fragments for physics-based characters using deep
q-learning. ACM Transactions on Graphics (TOG),
36(3):29.
Liu, L. and Hodgins, J. (2018). Learning basketball
dribbling skills using trajectory optimization and
deep reinforcement learning. ACM Trans. Graph.,
37(4):142:1–142:14.
McFee, B., Raffel, C., Liang, D., Ellis, D. P., McVicar, M.,
Battenberg, E., and Nieto, O. (2015). librosa: Audio
and music signal analysis in python. In Proceedings
of the 14th python in science conference, volume 8,
pages 18–25.
McNeill, D. (2008). Gesture and thought. In Gesture and
Thought. University of Chicago press.
Morro Motion (2017). Dance mocap collection.
https://assetstore.unity.com/packages/3d/animations/
dance-mocap-collection-102966.
M
¨
uller, M., R
¨
oder, T., Clausen, M., Eberhardt, B., Kr
¨
uger,
B., and Weber, A. (2007). Documentation mocap
database hdm05.
Neff, M., Kipp, M., Albrecht, I., and Seidel, H.-P. (2008).
Gesture modeling and animation based on a proba-
bilistic re-creation of speaker style. ACM Transactions
On Graphics (TOG), 27(1):1–24.
Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., and Bajcsy, R.
(2013). Berkeley mhad: A comprehensive multimodal
human action database. In 2013 IEEE workshop on
applications of computer vision (WACV), pages 53–
60. IEEE.
Okamoto, T., Shiratori, T., Kudoh, S., and Ikeuchi, K.
(2010). Temporal scaling of leg motion for music
feedback system of a dancing humanoid robot. In
2010 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems, pages 2256–2263. IEEE.
Park, J. and Ko, H. (2008). Real-time continuous
phoneme recognition system using class-dependent
tied-mixture hmm with hbt structure for speech-
driven lip-sync. IEEE Transactions on Multimedia,
10(7):1299–1306.
Peng, X. B., Abbeel, P., Levine, S., and van de Panne,
M. (2018). Deepmimic: Example-guided deep rein-
forcement learning of physics-based character skills.
CoRR, abs/1804.02717.
Peng, X. B., Berseth, G., Yin, K., and Van De Panne, M.
(2017). Deeploco: Dynamic locomotion skills using
hierarchical deep reinforcement learning. ACM Trans-
actions on Graphics (TOG), 36(4):41.
Peng, X. B., Ma, Z., Abbeel, P., Levine, S., and Kanazawa,
A. (2021). Amp: Adversarial motion priors for styl-
ized physics-based character control. ACM Transac-
tions on Graphics (TOG), 40(4):1–20.
Sargin, M. E., Erzin, E., Yemez, Y., Tekalp, A. M., Erdem,
A. T., Erdem, C., and Ozkan, M. (2007). Prosody-
driven head-gesture animation. In 2007 IEEE Inter-
national Conference on Acoustics, Speech and Sig-
GRAPP 2024 - 19th International Conference on Computer Graphics Theory and Applications
138

nal Processing-ICASSP’07, volume 2, pages II–677.
IEEE.
Schulz, A. and Velho, L. (2011). Choreographics: an au-
thoring environment for dance shows. In ACM SIG-
GRAPH 2011 Posters, pages 1–1.
Shiratori, T., Nakazawa, A., and Ikeuchi, K. (2006).
Dancing-to-music character animation. In Computer
Graphics Forum, volume 25, pages 449–458. Wiley
Online Library.
Shlizerman, E., Dery, L., Schoen, H., and Kemelmacher-
Shlizerman, I. (2018). Audio to body dynamics. In
Proceedings of the IEEE conference on computer vi-
sion and pattern recognition, pages 7574–7583.
Siyao, L., Yu, W., Gu, T., Lin, C., Wang, Q., Qian, C., Loy,
C. C., and Liu, Z. (2022). Bailando: 3d dance gener-
ation by actor-critic gpt with choreographic memory.
In Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition, pages 11050–
11059.
Smith, H. J., Cao, C., Neff, M., and Wang, Y. (2019). Effi-
cient neural networks for real-time motion style trans-
fer. Proceedings of the ACM on Computer Graphics
and Interactive Techniques, 2(2):1–17.
Smith, H. J. and Neff, M. (2017). Understanding the im-
pact of animated gesture performance on personality
perceptions. ACM Transactions on Graphics (TOG),
36(4):49.
Soga, A., Yazaki, Y., Umino, B., and Hirayama, M. (2016).
Body-part motion synthesis system for contemporary
dance creation. In ACM SIGGRAPH 2016 Posters,
pages 1–2.
Sun, G., Wong, Y., Cheng, Z., Kankanhalli, M. S., Geng,
W., and Li, X. (2020). Deepdance: music-to-dance
motion choreography with adversarial learning. IEEE
Transactions on Multimedia, 23:497–509.
Taylor, G. W. and Hinton, G. E. (2009). Factored con-
ditional restricted boltzmann machines for modeling
motion style. In Proceedings of the 26th Annual In-
ternational Conference on Machine Learning, ICML
’09, pages 1025–1032, New York, NY, USA. ACM.
Tulyakov, S., Liu, M.-Y., Yang, X., and Kautz, J. (2018).
Mocogan: Decomposing motion and content for video
generation. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 1526–
1535.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I.
(2017). Attention is all you need. Advances in neural
information processing systems, 30.
Wang, H., Ho, E. S., Shum, H. P., and Zhu, Z. (2019).
Spatio-temporal manifold learning for human motions
via long-horizon modeling. IEEE transactions on vi-
sualization and computer graphics, 27(1):216–227.
Wang, Y. and Neff, M. (2015). Deep signatures for index-
ing and retrieval in large motion databases. In Pro-
ceedings of the 8th ACM SIGGRAPH Conference on
Motion in Games, MIG ’15, pages 37–45, New York,
NY, USA. ACM.
Wu, N., Green, B., Ben, X., and O’Banion, S. (2020).
Deep transformer models for time series forecast-
ing: The influenza prevalence case. arXiv preprint
arXiv:2001.08317.
Xia, S., Wang, C., Chai, J., and Hodgins, J. (2015). Re-
altime style transfer for unlabeled heterogeneous hu-
man motion. ACM Transactions on Graphics (TOG),
34(4):119.
Yan, S., Li, Z., Xiong, Y., Yan, H., and Lin, D. (2019).
Convolutional sequence generation for skeleton-based
action synthesis. In Proceedings of the IEEE/CVF
International Conference on Computer Vision, pages
4394–4402.
Yoon, Y., Cha, B., Lee, J.-H., Jang, M., Lee, J., Kim, J., and
Lee, G. (2020). Speech gesture generation from the
trimodal context of text, audio, and speaker identity.
ACM Transactions on Graphics (TOG), 39(6):1–16.
Yumer, M. E. and Mitra, N. J. (2016). Spectral style transfer
for human motion between independent actions. ACM
Transactions on Graphics (TOG), 35(4):137.
Zhang, H., Starke, S., Komura, T., and Saito, J. (2018a).
Mode-adaptive neural networks for quadruped mo-
tion control. ACM Transactions on Graphics (TOG),
37(4):145.
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang,
O. (2018b). The unreasonable effectiveness of deep
features as a perceptual metric. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 586–595.
Zhu, Y., Ramakrishnan, A. S., Hamann, B., and Neff, M.
(2013). A system for automatic animation of pi-
ano performances. Computer Animation and Virtual
Worlds, 24(5):445–457.
Transformer-Based Two-level Approach for Music-driven Dance Choreography
139
