
Semantic Segmentation for Moon Rock Recognition Using U-Net with
Pyramid-Pooling-Based SE Attention Blocks
Antoni Jaszcz
a
and Dawid Połap
b
Faculty of Applied Mathematics, Silesian University of Technology,
Kaszubska 23, 44-100 Gliwice, Poland
Keywords:
Segmentation, U-Net, Semantic Analysis, Image Processing, Moonstones.
Abstract:
Analysis of data from the rover’s camera is an important element in the proper operation of unmanned vehicles.
This is important because of the ability to move, avoid obstacles and even collect samples. In this paper, we
propose a new U-Net architecture for rock/boulder recognition on the surface of the moon. For this purpose,
architecture is composed of Squeeze and Excitation blocks extended with Pyramid Pooling and Convolution.
As a result, such a network can pay attention to individual channels and give them weights based on global
data. Moreover, the network analyzes contextual information in terms of local/global features in individual
channels which allows for more accurate object segmentation. The proposed solution was tested on a publicly
available database, achieving an accuracy of 97.23% and IoU of 0.7905.
1 INTRODUCTION
Analysis of the moon and other planets is made with
rovers, which are often operated remotely or even au-
tonomously (Liu et al., 2023b; Chen et al., 2023b).
These are unmanned vehicles moving on wheels.
They have various sensors installed for data analysis.
An example is a camera that records images around
the rover. This is an important issue from a practical
point of view. The rover’s movement will be based on
moving on an unknown surface. The recorded image
can enable obtaining information about the environ-
ment and, above all, the location of obstacles that may
cause problems with movement or even damage.
The recorded image will most often include part
of the surface and sky. Under ideal conditions, the
surface will be flat, but it doesn’t have to be. Vari-
ous stones or rocks may appear and should be avoided
while moving. During sample collection, small rocks
can even be picked up by the rover. Hence, the
analysis of the image taken from the camera should
be based not only on the location of the stones but
also on their properties. In computer science, ana-
lyzing images and processing them for precise loca-
tion and shape is called segmentation (Wu and Castle-
man, 2023). The incoming image is processed and
the output is an image with selected objects. If we
a
https://orcid.org/0000-0002-8997-0331
b
https://orcid.org/0000-0003-1972-5979
only locate stones, the result will be a two-color im-
age, where one color will be the background and the
other will represent the found objects. When analyz-
ing a larger number of classes, the located objects are
marked with different colors due to other characteris-
tic features (Qureshi et al., 2023).
Semantic segmentation is based on the analysis
of various objects within a single class, which auto-
matically makes it a much more difficult task than
classic segmentation. The most popular solution in
this area are U-Net networks (Chen et al., 2023a),
which are based on the architecture of convolutional
neural networks. The idea of processing consists of
encoding and decoding, i.e. the image is downsam-
pled, which extracts the most important image fea-
tures while reducing the dimension. Then upsam-
pling is performed which restores the original size.
Of course, both mechanisms include layers that pro-
cess images and reduce/enlarge the size. Additionally,
other techniques are introduced, such as context con-
catenation, which allows for the analysis of various
image features, or skip connections, which allow the
transfer of information between layers. It is impor-
tant to note here that there is no single architecture
that would allow segmentation for each task. Hence,
new models and techniques within these networks are
constantly being modeled.
TransAttUnet (Chen et al., 2023a) proposes a seg-
mentation tool based on transformers that use long-
distance contextual dependencies. The authors pro-
Jaszcz, A. and Połap, D.
Semantic Segmentation for Moon Rock Recognition Using U-Net with Pyramid-Pooling-Based SE Attention Blocks.
DOI: 10.5220/0012424600003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 965-971
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
965

Figure 1: The proposed U-Net model with PPS-CE blocks.
posed this model for image segmentation, where var-
ious attention modules were implemented, includ-
ing the spatial attention module. Another approach
is to model an architecture based on transfer learn-
ing or even change the color model from RGB to
LAB (Zhang and Zhang, 2023). An interesting so-
lution is the fusion of thermal and visual images,
as demonstrated by the U-Net segmentation problem
(Shojaiee and Baleghi, 2023). The researcher com-
bined the U-Net model with the Fused Atrous Spa-
tial Pyramid Pooling encoder, i.e. the network is
adapted to analyze such data through classical lay-
ers and atrous convolutional layers. Attention is also
paid to the possibility of focusing the network’s at-
tention on the importance of selected regions in the
image (Zhang et al., 2023). Augmentation is used for
extending the datasets, but it can be also used as aug-
mentation in the bottleneck of the u-net model, where
attention-augmented convolution was introduced (Ra-
jamani et al., 2023). Recent years have shown that at-
tention modules are an important element of segmen-
tation networks, an example of which is the modeling
of new modules or implementation in specific places
in the network. Position attention module can be used
for feature enhancement (Jiang et al., 2023). Atten-
tion allows to direction of the network to specific fea-
tures or elements, which is crucial when modeling an
architecture tailored to a specific problem.
Segmentation analysis of stones was undertaken
by building a segmentation network that uses a pre-
trained model named VGG16 (Li et al., 2023). The
research included analysis with other segmentation
methods, although neural networks allow for much
more accurate results. Segmentation analysis on Mars
was processed by the U-Net network with a feature
enhancement module and window transformer block
(Xiong et al., 2023). This model allowed for the
analysis of features at various scales. Again, (Pan
et al., 2023) focused on tiny and fracture features.
An additional technique was the use of dilated con-
volution, which focuses on a much larger number of
pixels during processing. The results of the research
showed that the method can allow for feature extrac-
tion even with a complex background. Another solu-
tion is the model that will process long-range spatial
context (Liu et al., 2023a), which was achieved by
introducing a feature refining module between the en-
coder and decoder.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
966

Based on literature analyses, attention can be
drawn to the need for newer models that will enable
better data segmentation. In this work, we propose a
new solution based on the U-Net network model, in-
cluding the squeeze and excitation mechanism, which
enables the analysis of dependencies between features
in feature maps. Additionally, we introduce Pyramid-
Pooling to these blocks to take into account informa-
tion from different scales or sizes of objects and to
increase the importance of image context for analysis
of the moon’s surface. The main contributions of this
research are:
• a new U-net model for boulder/rock segmenta-
tion,
• a novel block type that combines Pyramid-
Pooling with Squeeze and Excitation.
2 METHODOLOGY
In this section, we propose a modified U-Net model
enhanced with PPS-CE blocks for multi-class seman-
tic segmentation tasks. The overview illustration of
the model is presented in Fig. 1. The contraction
path consists of 5 doubled 3 × 3 convolutional lay-
ers with (ReLU activation functions) and dropout be-
tween them. These are followed by 2 × 2 MaxPool-
ing layers. In the expansive path, to enhance the per-
formance of the model, we propose utilizing PPS-
SE blocks after each transpose convolution and copy
path. The final output is obtained using 1 × 1 convo-
lution with Softmax activation function (to obtain the
probabilistic distribution of the classes).
2.1 Pyramid Pooling
Pyramid pooling is a unique pooling technique that al-
lows the model to gather more contextual information
by capturing information at multiple scales. The prin-
ciple of this method is based on dividing the input fea-
ture map into regions of different sizes. Then, for each
divided feature map obtained this way, average pool-
ing is performed. The result of each pooling segment
is then concatenated, creating a unified representation
that carries multi-scale information. Mathematically,
this can be presented as processing the input feature
map X = (x
h,w,c
) where values h, w, c are accordingly
height, width and number of channels of the feature
map X. Given the set of scales L, for each l scale in
the set, a divided feature map is created according to
the following equation:
X
l
= (x
h
1
,w
1
,c
), (1)
where h
1
=
h
l
and w
1
=
j
w
l
k
. For each ob-
tained X
l
, the average pooling operation is performed.
Lastly, the pooling results at all scales are concate-
nated, resulting in the final feature map Y, whose di-
mensionality is presented as:
dim(Y ) =
|L|
∑
i=1
h
l
i
×
|L|
∑
i=1
w
l
i
× c
!
. (2)
As previously mentioned, pyramid-pooling allows
the model to gather extended contextual informa-
tion by utilizing many different perception field sizes.
This provides better robustness regarding object scale,
which is especially important in semantic segmenta-
tion tasks.
2.2 Pyramid-Pooling Squeeze and
Convolutional Excitation Blocks
Squeeze-and-excitation (SE) blocks are a mechanism
that improves the representational power of the con-
volutional layers by analyzing the dependencies be-
tween various channels in feature maps passed from
the convolutional layer and assigning them weights
based on the impact they have on the further assess-
ment of the model. This is one of many types of
attention mechanisms used in neural networks, high-
lighting the more influential channels, while also sup-
pressing less informative ones. This process improves
the overall feature representation. The basic SE block
first performs average global pooling as the squeeze
operation, obtaining 1 × 1 × c (c indicating the num-
ber of channels in the input feature map) vector. In
the excitation operation, the vector is then passed onto
two dense layers with the former having ReLU (in-
troducing non-linearity) and the ladder having a Sig-
moid activation function. The output of these lay-
ers is then scaled and applied to the original fea-
ture map. In this paper, we propose Pyramid-Pooling
Squeeze and Convolutional Excitation blocks (PPS-
CE), utilizing Pyramid-Pooling in Squeeze operation
and double 1 × 1 convolution instead of dense layers
in Excitation operation. The main advantages of this
approach are the benefits of using Pyramid-Pooling
and convolutional layers having less trainable param-
eters than dense layers. In squeeze operation, each di-
vided X
l
feature map is processed using 1×1 convolu-
tion with ReLU activation function. In this paper, we
propose that each convolution has the number of out-
put channels equal to c
conv
= b
c
r
c, with r parameter set
to 16. The output of each convolutional layer is then
concatenated along the channel axis. Next, concate-
nated feature maps from Pyramid Pooling are passed
through two 1 × 1 convolutional layers, the first of
Semantic Segmentation for Moon Rock Recognition Using U-Net with Pyramid-Pooling-Based SE Attention Blocks
967

Figure 2: The proposed PPS-CE blocks overview.
which has the number of channels equal to c
conv
and
ReLU activation function, while the other has c chan-
nels (same as the input) and Sigmoid activation func-
tion. Ending the excitation operation, the global aver-
age pooling is applied, ensuring that its shape matches
the shape of the inputs and then reshaped into a vec-
tor of length c. Lastly, the input tensor is multiplied
element-wise by the reshaped output of the excitation
operation. The above-described PPS-CE blocks are
presented visually in Fig. 2.
2.3 Loss Function
The proposed loss function is based on The Dice co-
efficient and categorical cross-entropy. The Dice co-
efficient is a statistic used to measure the similarity
between two sets. Given a ground-truth segmentation
mask Y and predicted segmentation mask Y
0
with C
classes, a Dice coefficient for i-th class can be calcu-
lated as:
Dice
i
=
2|Y
0
i
∩Y
i
|
|Y
0
| + |Y |
. (3)
Then, Dice loss is calculated by the following for-
mula:
DiceLoss
i
= 1 − Dice
i
,
DiceLoss =
1
C
C
∑
i=1
DiceLoss
i
.
(4)
The second one is categorical cross-entropy (CCE),
a reliable function loss for multi-class classification
tasks, including semantic segmentation. For each cor-
responding pair of pixels y and y
0
in the ground truth
and predicted masks, CCE is calculated according to
the following formula:
CCE = −
C
∑
i=i
y
i
· log(y
0
i
). (5)
It is worth mentioning, that the labels must be en-
coded using the one-hot-encoding technique, to re-
semble probabilistic distribution, for the CCE to work
properly. The final loss for classification is the mean
CCE of all pixels in the image and DiceLoss. This
can be described as:
L = CCE + DiceLoss. (6)
3 EXPERIMENTS
In this section, we describe the dataset used in the
experiments and show the results. In the context of
evaluation, classic measures such as accuracy, Dice
coefficient and IoU were selected.
3.1 Moon Rocks Dataset and
Experimental Settings
The data used for the training and validation of the
model are available publicly at Kaggle. The dataset
consists of nearly 10 thousand artificially created lu-
nar landscape RGB images along with the corre-
sponding segmentation masks. The ground truth im-
ages from the realistic renders were created using
Planetside Software’s Terragen. The dataset consists
of 4 classes: sky, ground, small rocks and large rocks.
The training, test and validation sets were created
in a ratio of 90:5:5. The training set consisted of 8790
images, while the test and validation ones had 488
samples each. Before training, each sample was re-
sized to 224x244 pixels. The model was trained for
50 epochs using mini-batches consisting of 32 sam-
ples. As a training algorithm, ADAM was selected
with the loss function described in Eq. (6).
3.2 Results
The graph of training the network for 50 epochs is
presented in Fig. 4. It shows that the model’s ac-
curacy quickly increased to over 94%. Exceeding
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
968
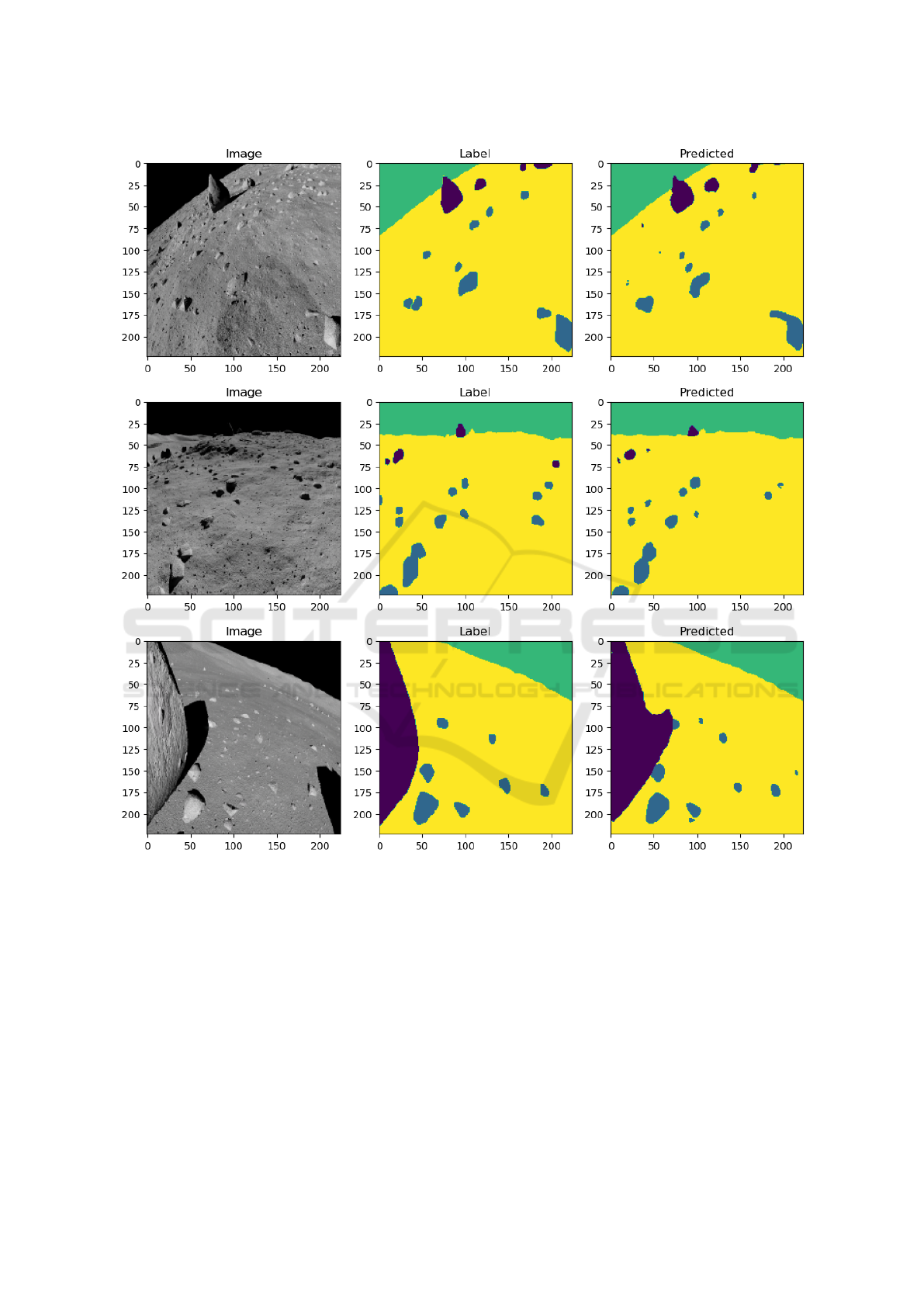
Figure 3: Sample data with masks and the result returned by the proposed network model.
96% was possible after 13 training iterations. With
subsequent epochs, the accuracy was distributed on a
training and testing basis. There were small spikes
in accuracy during the training process, but they were
within 1% point. After epoch 45, accuracy increased
linearly, reaching an accuracy of 97.23%. As part of
the analysis, other evaluation coefficients were also
determined, such as the Dice coefficient, which was
0.8763. This is a measure that determines the qual-
ity of image segmentation, the closer to 1, the more
accurate the result. The obtained result of 0.8763
indicates that the algorithm maps objects to masks
very well, and the differences are minimal. In addi-
tion, small objects are also detected by the network,
which is an important advantage of the proposed ap-
proach due to its potential practical application. The
IoU (Intersection over Union) on the validation ba-
sis reached 0.7905. This result shows that the seg-
mentation relative to the masks is quite accurate, al-
though there are small areas where the mask does not
match the segmentation result. The reason may be
shadows or details of objects. Fig. 5 shows the loss
value during the training process. The values decrease
with subsequent epochs with single value jumps be-
Semantic Segmentation for Moon Rock Recognition Using U-Net with Pyramid-Pooling-Based SE Attention Blocks
969
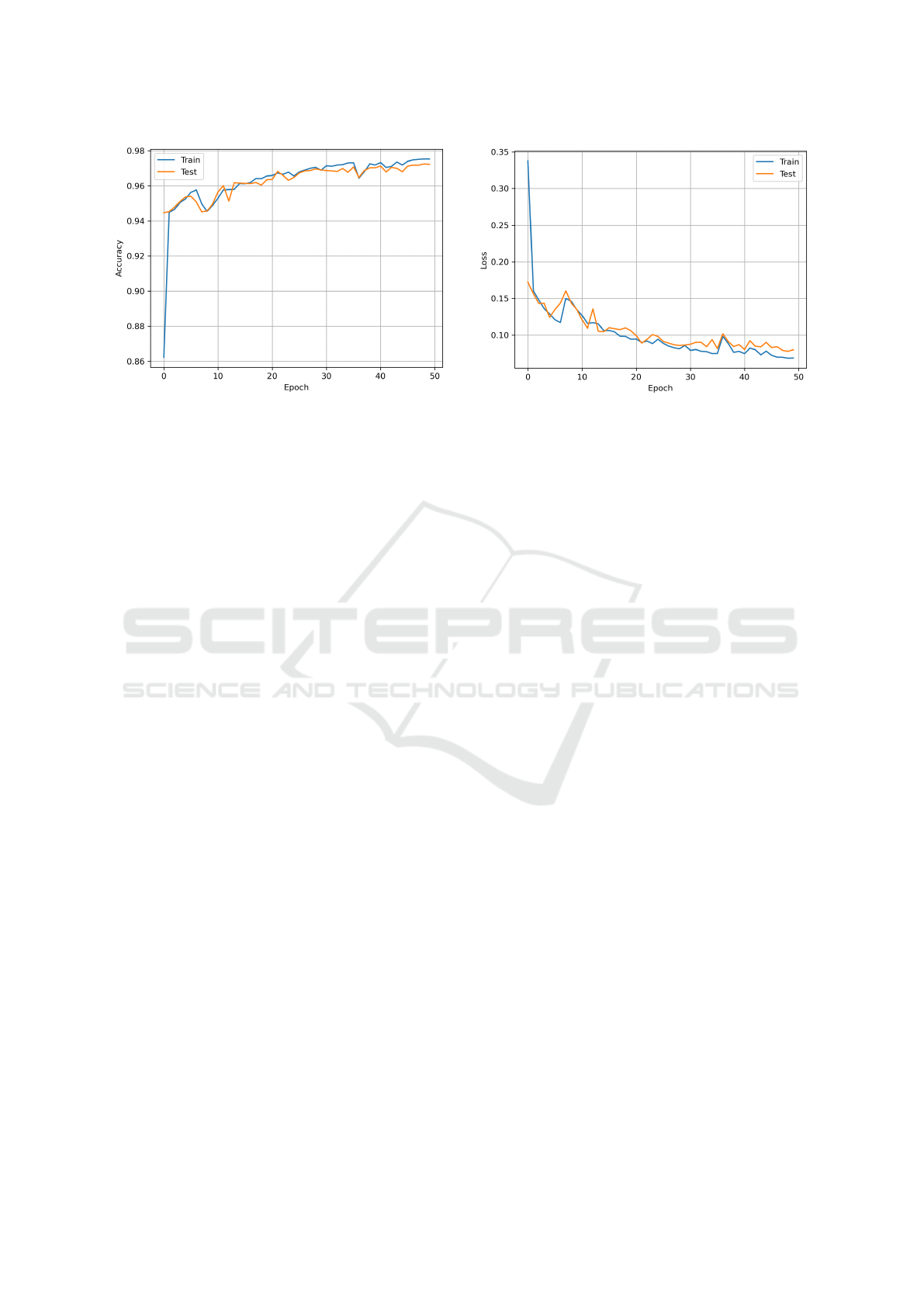
Figure 4: Accuracy plot on the training and test sets during
training.
low 0.05 (which is visible primarily after the 35th
training epoch).
The original images with masks and segmentation
results by the proposed method are shown in Fig. 3.
On the presented samples, it can be seen that the net-
work processed a shadow that was not on the mask,
or very small stones did not always appear. It is worth
noting that in the first row of images, the network de-
tected stones that are in the image but not in the orig-
inal mask. This shows that the masks themselves are
not perfect either. In (Fan et al., 2023), the authors
presented the possibility of Combining a Convolu-
tional Neural Network (based on ResNet) and Trans-
former, where the network achieved an IoU of 78.90%
while having nearly 8 million parameters. It should be
noted that the model proposed in this paper is based
on the extraction of features other than classical so-
lutions. During the analysis, we noticed that the in-
troduced SaE with Pyramid-Pooling blocks allowed
for quick achievement of good results, which were
improved with the increase in the number of epochs
while keeping the number of trained parameters rela-
tively low – less than 2 million.
4 CONCLUSION
Analyzing data from the rover’s camera is one of the
basic elements when moving to avoid hitting an obsta-
cle. In this work, we proposed a new U-Net model ar-
chitecture for semantic image segmentation. This op-
eration enables the segmentation of stones with high
accuracy, which was 97.23% and an IoU coefficient
of 0.7905. The results were made possible by intro-
ducing blocks based on the Squeeze and Excitation
technique combined with Pyramid Pooling into the U-
Net network. As a consequence, this action allowed
the network to analyze individual channels and as-
Figure 5: Loss value plot on the training and test sets during
training.
sign them weights. Attention should also be paid to
the possibility of analyzing contextual information by
processing and focusing on local and global features.
In future work, we plan to analyze the possibility
of extending the network model to spatial attention
modules, which could allow for the analysis of addi-
tional features.
ACKNOWLEDGEMENTS
This work was supported by the Rector’s mentoring
project ”Spread your wings” at the Silesian University
of Technology.
REFERENCES
Chen, B., Liu, Y., Zhang, Z., Lu, G., and Kong, A. W. K.
(2023a). Transattunet: Multi-level attention-guided u-
net with transformer for medical image segmentation.
IEEE Transactions on Emerging Topics in Computa-
tional Intelligence.
Chen, Z., Zou, M., Pan, D., Chen, L., Liu, Y., Yuan, B., and
Zhang, Q. (2023b). Study on climbing strategy and
analysis of mars rover. Journal of Field Robotics.
Fan, L., Yuan, J., Niu, X., Zha, K., and Ma, W. (2023).
Rockseg: A novel semantic segmentation network
based on a hybrid framework combining a convolu-
tional neural network and transformer for deep space
rock images. Remote Sensing, 15(16).
Jiang, J., Feng, X., Ye, Q., Hu, Z., Gu, Z., and Huang, H.
(2023). Semantic segmentation of remote sensing im-
ages combined with attention mechanism and feature
enhancement u-net. International Journal of Remote
Sensing, 44(19):6219–6232.
Li, M., Zhang, P., and Hai, T. (2023). Pore extraction
method of rock thin section based on attention u-net.
In Journal of Physics: Conference Series, volume
2467, page 012016. IOP Publishing.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
970

Liu, H., Yao, M., Xiao, X., and Xiong, Y. (2023a). Rock-
former: A u-shaped transformer network for martian
rock segmentation. IEEE Transactions on Geoscience
and Remote Sensing, 61:1–16.
Liu, S., Su, Y., Zhou, B., Dai, S., Yan, W., Li, Y., Zhang, Z.,
Du, W., and Li, C. (2023b). Data pre-processing and
signal analysis of tianwen-1 rover penetrating radar.
Remote Sensing, 15(4):966.
Pan, D., Li, Y., Lin, C., Wang, X., and Xu, Z. (2023). In-
telligent rock fracture identification based on image
semantic segmentation: methodology and application.
Environmental Earth Sciences, 82(3):71.
Qureshi, I., Yan, J., Abbas, Q., Shaheed, K., Riaz, A. B.,
Wahid, A., Khan, M. W. J., and Szczuko, P. (2023).
Medical image segmentation using deep semantic-
based methods: A review of techniques, applications
and emerging trends. Information Fusion, 90:316–
352.
Rajamani, K. T., Rani, P., Siebert, H., ElagiriRamalingam,
R., and Heinrich, M. P. (2023). Attention-augmented
u-net (aa-u-net) for semantic segmentation. Signal,
image and video processing, 17(4):981–989.
Shojaiee, F. and Baleghi, Y. (2023). Efaspp u-net for seman-
tic segmentation of night traffic scenes using fusion of
visible and thermal images. Engineering Applications
of Artificial Intelligence, 117:105627.
Wu, Q. and Castleman, K. R. (2023). Image segmentation.
In Microscope Image Processing, pages 119–152. El-
sevier.
Xiong, Y., Xiao, X., Yao, M., Liu, H., Yang, H., and Fu, Y.
(2023). Marsformer: Martian rock semantic segmen-
tation with transformer. IEEE Transactions on Geo-
science and Remote Sensing.
Zhang, J., Qin, Q., Ye, Q., and Ruan, T. (2023). St-unet:
Swin transformer boosted u-net with cross-layer fea-
ture enhancement for medical image segmentation.
Computers in Biology and Medicine, 153:106516.
Zhang, S. and Zhang, C. (2023). Modified u-net for plant
diseased leaf image segmentation. Computers and
Electronics in Agriculture, 204:107511.
Semantic Segmentation for Moon Rock Recognition Using U-Net with Pyramid-Pooling-Based SE Attention Blocks
971
