
AccidentGPT: Large Multi-Modal Foundation Model for Traffic
Accident Analysis
Kebin Wu
a
, Wenbin Li
b
and Xiaofei Xiao
Technology Innovation Institute, Abu Dhabi, U.A.E.
Keywords:
Traffic Accident Analysis, Multi-Modal Model, Video Reconstruction, Vehicle Dynamics, Multi-Task,
Multi-Modality.
Abstract:
Traffic accident analysis is pivotal for enhancing public safety and developing road regulations. Traditional
approaches, although widely used, are often constrained by manual analysis processes, subjective decisions,
uni-modal outputs, as well as privacy issues related to sensitive data. This paper introduces the idea of Ac-
cidentGPT, a foundation model of traffic accident analysis, which incorporates multi-modal input data to
automatically reconstruct the accident process video with dynamics details, and furthermore provide multi-
task analysis with multi-modal outputs. The design of the AccidentGPT is empowered with a multi-modality
prompt with feedback for task-oriented adaptability, a hybrid training schema to leverage labelled and unla-
belled data, and a edge-cloud split configuration for data privacy. To fully realize the functionalities of this
model, we proposes several research opportunities. This paper serves as the stepping stone to fill the gaps in
traditional approaches of traffic accident analysis and attract the research community’s attention for automatic,
objective, and privacy-preserving traffic accident analysis.
1 INTRODUCTION
The rapid and accurate traffic accident analysis is crit-
ical in enhancing public safety and shaping effective
road regulations. The tasks of the traffic accident
analysis, varying from accident process reconstruc-
tion, responsibility attribution to traffic management
and emergency response, are multifaceted and com-
plex. Conventional approaches (Mohammed et al.,
2019), relying on eyewitness testimonies, official po-
lice documentation, and footage from surveillance
cameras (if any), have been the core of the accident
analysis for decades. However, these approaches are
constrained by intensive manual labor nature, suscep-
tibility to subjective biases, restricted uni-modal out-
puts, and the privacy concerns emerging from the han-
dling of sensitive data (Al-ani et al., 2023).
The advent of machine learning techniques have
begun to boost the field of the traffic accident analy-
sis, presenting enhanced precision and insights. Mod-
els are built by learning vast datasets including video
footage, sensor data, and textual reports to achieve
specific tasks such as accident detection (Ali et al.,
a
https://orcid.org/0000-0003-4492-4152
b
https://orcid.org/0000-0002-7836-0052
2021), accident prediction (Chand et al., 2021), cause
identification (Najafi Moghaddam Gilani et al., 2021).
Focusing on the accident process reconstruction, from
numerical modelling to software simulations of the
collisions (Duma et al., 2022) are applied to deter-
mine sliced elements (e.g., pre-collision speed, trav-
eled distance, trajectory) during the accident process.
Nevertheless, these works are often uni-modal pro-
viding useful but fragmented information, while lack-
ing the capacity to integrate and interpret diverse data
sources cohesively to reconstruct all details (e.g., pro-
cess video, vehicles’ dynamics) of the accident and
automate the post-accident management such as in-
jury assessment, emergency response, report gener-
ation, and insurance claim. Furthermore, these traf-
fic applications have been limited in their adaptabil-
ity, often requiring extensive customization for each
specific use case.
As a step further, the recent emergence of the large
language models (LLMs) such as LLaMa2 (Touvron
et al., 2023) and large multi-modal models (LMMs)
such as GPT-4V (Wu et al., 2023b) not only demon-
strate the capability to handle multi-modal inputs and
outputs, but also underscores a paradigm shift towards
task-agnostic learning frameworks, which generate
insights across a myriad of tasks without the necessity
Wu, K., Li, W. and Xiao, X.
AccidentGPT: Large Multi-Modal Foundation Model for Traffic Accident Analysis.
DOI: 10.5220/0012422100003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 943-950
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
943

for task-specific training. The intrinsic versatility of
these models is manifested in their capability to gen-
eralize learned knowledge and skills across complex
multi-task output scenarios. Although most of LMMs
focus on dealing with image and text inputs and out-
puts, recent work (Zhang et al., 2023), (Wu et al.,
2023b) shows the possibility to bridge extended list of
modalities (e.g., image, text, video, audio, video, etc.)
as inputs and produce corresponding outputs of multi-
modalities as a response to the prompt. In the context
of traffic accident analysis, the technical foundation
of such LMM models and techniques brings forward
the possibility to build a foundation model to take into
account multi-modal inputs and generate outputs for
a multiplicity of traffic accident analysis tasks.
However, while the incorporation of multi-
modality in traffic analysis presents a promising fron-
tier, it also brings to light significant challenges that
have yet to be fully addressed specific to the field:
• Quality and Integrity of Data from Various
Sources: In traffic analysis, data can come from
a variety of sources, including dashcams, traffic
cameras, eyewitness reports, vehicle sensors, and
more. The quality and integrity of this data can
vary greatly, impacting the accuracy and reliabil-
ity of the analysis. The quality and integrity of
the data from various sources are to be ensured
for desired model performance;
• Complexities with Seamless Interpreting and Rea-
soning: The complexities associated with seam-
less interpreting and reasoning from diverse traffic
accident data and modalities are substantial;
• Model Training and Task-Specific Outputs with
Multi-Modal Inputs: The model training and the
alignment of task-specific outputs with multi-
modal inputs are challenging, which often require
intricate customization and tuning;
• Ethical and Privacy Concerns: Ethical and privacy
concerns, especially related to the handling and
processing of sensitive and personal data, have
also been inadequately addressed.
In this work, we propose the idea of Accident-
GPT - a foundation model to transform the domain
of traffic accident analysis by integrating multi-modal
inputs not only to automatically reconstruct acci-
dent scenario details but also delivers comprehensive
multi-task analysis with a variety of output modali-
ties. The idea extends the existing LLM and LMM
solutions with a multi-modality prompt coupled with
a feedback mechanism for adaptive task optimization,
a hybrid training schema leveraging both labelled and
unlabelled data for enhanced model generalization
and performance, and a edge-cloud split configura-
tion for data privacy. This paper seeks to tackles the
gaps in conventional solutions and unveil the poten-
tial of an automated, fast responding, objective, and
privacy-preserving traffic accident analysis solution.
The rest of the paper is organized as follows: sec-
tion 2 discusses the gaps inherent in existing traffic
accident analysis approaches. Section 3 outlines our
idea of AccidentGPT, highlighting its multi-modal in-
puts and outputs and multi-task features. Section
4 presents the corresponding research opportunities.
Section 5 concludes the paper.
2 GAPS IN CURRENT TRAFFIC
ACCIDENT ANALYSIS
The traditional approaches and contemporary ma-
chine learning techniques, while contributory, present
several gaps and challenges that limit their applicabil-
ity. These gaps highlight the urgent need for a sys-
tematic approach to traffic accident analysis.
2.1 Data Integration and Analysis
Manual Efforts: The traditional approaches (Mo-
hammed et al., 2019) involve substantial manual ef-
forts in post-accident data collection, processing, and
analysis. This labor-intensive process is prone to
bias of human judgment and thus can lead to incon-
sistencies and errors impacting the reliability of the
analysis. Furthermore, the manual process is time-
consuming and the lag in analysis undermines the im-
mediacy of response, impacting emergency services,
traffic management, and subsequent investigative pro-
cesses. Automate the process with timeliness and sys-
tematic analysis is one of the key challenge to tackle.
Privacy Concerns: Machine learning based ap-
proaches (Najafi Moghaddam Gilani et al., 2021) in-
tegrates sensitive data sources (e.g., dashcam footage
and bystander videos) and raise corresponding pri-
vacy and ethical concerns (Butt et al., 2019). These
challenges have constrained the scope and depth of
accident analysis, leaving a wealth of potentially in-
sightful data untapped. Ensuring the privacy of sen-
sitive data directly improves the effectiveness of the
traffic accident analysis.
2.2 Model Modality and Generalization
Model Specialization: Current machine learning
models in the filed of traffic accident analysis are of-
ten specialized and task-specific (Chand et al., 2021).
These models excel in their designated tasks but face
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
944

challenges when exposed to scenarios or data that are
different from their training environments. The gen-
eralization capability of these models is limited, and
this specialization hinders their adaptability and flex-
ibility, reducing their applicability to a diverse range
of accident scenarios and conditions. There exists a
significant gap in developing models endowed with
task-agnostic learning mechanisms that can seam-
lessly adapt and perform across a variety of tasks and
conditions without the need for retraining or extensive
customization.
Uni-Modal Analysis: Automatic traffic accident
analysis on specific tasks (Ali et al., 2021) predomi-
nantly relies on uni-modal data sources, such as tex-
tual reports or image evidence. These uni-modal ap-
proaches lack the capacity to provide a holistic view
of accident scenarios, often missing out on crucial
contextual and dynamic information that multi-modal
data can offer. The lack of versatility to adapt to dif-
ferent data types and analysis requirements leads to a
fragmented and compartmentalized understanding of
accident scenarios. There is a pressing need for mod-
els that can assimilate diverse data sources, under-
stand the intricate interplay of dynamic factors, and
provide a comprehensive analysis.
Output Limitations: The outputs of existing
models (Duma et al., 2022) for traffic accident analy-
sis is typically limited in solo modality (e.g., respon-
sibility, text report) as well. The uni-modality re-
stricts the detailed insights that stakeholders, includ-
ing investigators, traffic planners, and victims, can ex-
tract from the outputs. Furthermore, the lack of in-
teroperability between different analysis systems and
technologies can hinder comprehensiveness and intu-
itiveness of accident analysis across machine learning
models. Models are expected to produce multi-modal
outputs (e.g., visual representation, numerical dynam-
ics, text reports and news) especially in a multi-task
scenario in order to meet diverse stakeholders’ re-
quirements (e.g., responsibility attribution, video re-
construction) for a traffic accident analysis system.
In the light of these gaps and challenges, this pa-
per introduces AccidentGPT as a multi-modal foun-
dation model capable of automatically interpreting a
diverse range of data modalities and delivering com-
prehensive, multi-faceted outputs on multiple traffic
accident analysis tasks.
3 AccidentGPT OVERVIEW
The general idea of the AccidentGPT is depicted in
Figure 1, and the model core follows a preprocess-
ing&encoding, alignment&fusion, and decoding pro-
cess. To revolutionize the field of traffic accident anal-
ysis, the joint of use of data from diverse sources is
critical to provide robust and insightful analyses. The
model inputs can include a) pre- and post-accident
site photos, b) CCTV camera recordings, c) dash-
cam footage, d) statements about the accident process
from the involving parties (e.g., drivers, witness) , e)
information from Inertial Measurement Units (IMUs)
of the movement dynamics during the accident, f) the
contextual data containing the accident’s related GPS
location, time, road signal and condition (e.g., wet,
dry, icy), historical traffic data of the traffic sites, and
the details related to vehicles and their insurances, and
g) most importantly, the task-oriented prompt to in-
struct AccidentGPT on the desired analysis and out-
puts. AccidentGPT does not expect the comprehen-
sive set of the input data in every accident analy-
sis, but dynamically adapt to the available data for
analysis with partial inputs as similar to the work
(Moon et al., 2023). The statements, context and
the prompt can be described in a multi-modal fash-
ion (e.g., speech, text, image, etc.), leveraging both
textual and non-textual data for a more holistic inter-
pretation.
The model inputs encompass a variety of modal-
ities, including audio, image, video, text, spatial
and/or temporal tabular data, and other modali-
ties such as remote sensing spectrum. Each in-
put modality is subject to modality-specific prepro-
cessing steps and encoders (e.g., CLAP (Wu et al.,
2023c) for audio, DinoV2 (Oquab et al., 2023) for im-
age, AnyMAL-Video (Moon et al., 2023) for video,
IMU2CLIP (Moon et al., 2022) for spatial/temporal
series). During the model inference, the preprocess-
ing and encoding process is to be carried out on the
users’ edge devices for the sake of privacy, and the
decoding process is to be performed by the Acci-
dentGPT model on cloud server. The edge machine
learning techniques (Li et al., 2023) can be applied to
the encoders for computational efficiency and perfor-
mance; in the case that specific encoders remain sig-
nificantly demanding in computational resources after
model compression, split learning (Vepakomma et al.,
2018) can be leveraged by executing only the initial
layers of the encoder on the edge devices, while the
remaining layers can be offloaded and ran in the cloud
environment.
The alignment among different modalities (Gird-
har et al., 2023) harmonizes different data sources and
ensures diverse modalities are properly integrated and
correlated for accurate and cohesive analysis. In this
edge-cloud split configuration, the alignment can be
flexibly executed in the edge devices and/or the cloud
environment. This provides adaptability based on the
AccidentGPT: Large Multi-Modal Foundation Model for Traffic Accident Analysis
945
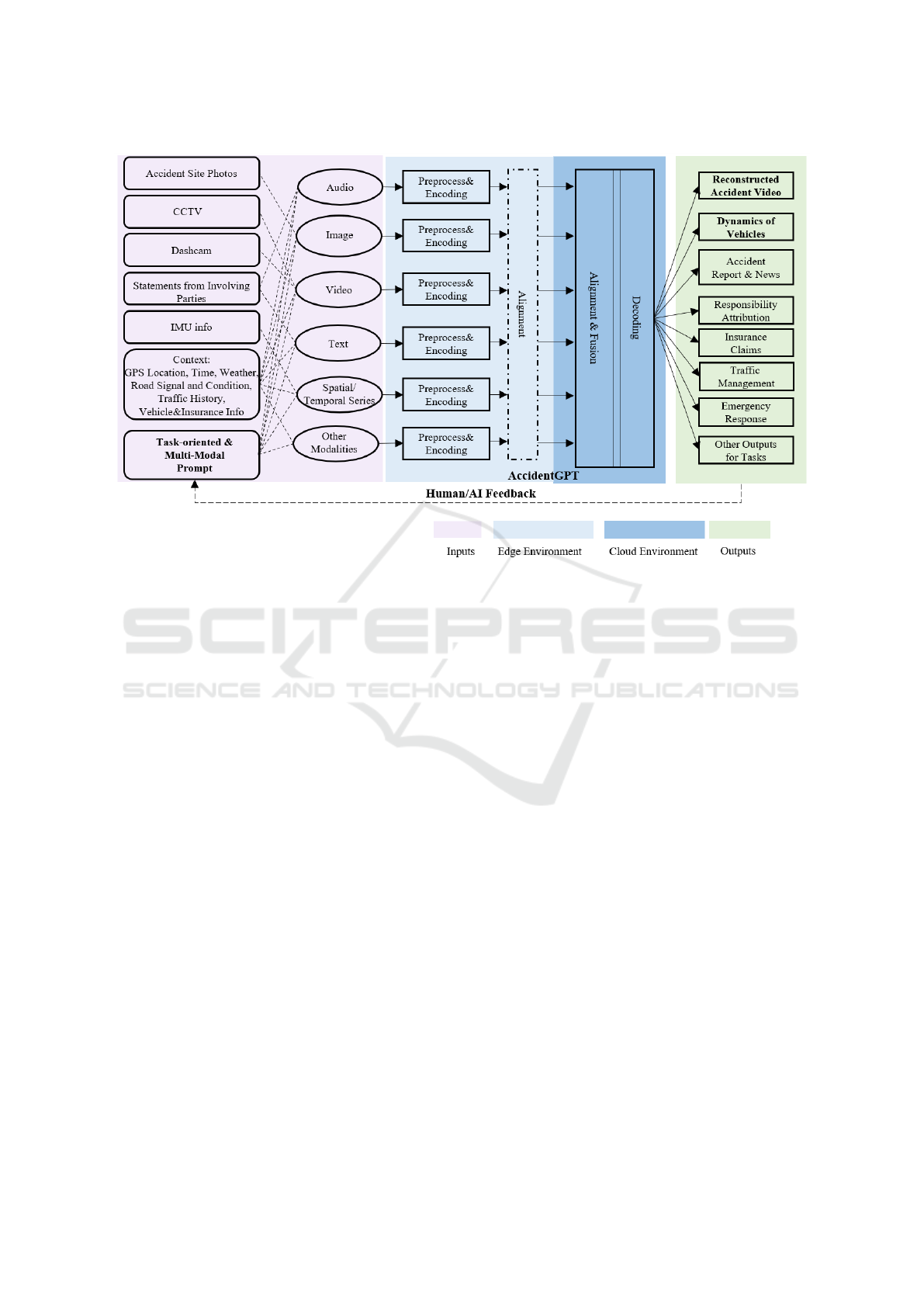
Figure 1: AccidentGPT Overview.
specific requirements of tasks, the computational re-
sources available at the edge, and the desired response
time. For simpler alignments on edge, the involving
parties can quickly access the data and indicate the
temporal and spatial properties of each data item (e.g.,
pre-accident, in-accident, post-accident). Conversely,
for precise alignments involving multiple modalities
and the complete input data, the cloud environment
can be leveraged with superior computational capa-
bilities to encapsulate the intricate cross-modal inter-
actions among individual components spanning vari-
ous modalities via representation fusion, coordination
and fission (Liang et al., 2023).
After preprocessing, encoding and alignment, the
data are fed into the AccidentGPT for modality-
specific decoding to automatically generate outputs
corresponding to multiple tasks. AccidentGPT targets
the following outputs of traffic accident analysis:
• Reconstructed Video: this output creates a vi-
sual 2D or 3D representation of the complete acci-
dent process. The resulting representation offers a
temporal and spatially accurate depiction, provid-
ing investigators with a sequential understanding
of the events leading up to, during, and after the
accident.
• Dynamics of Vehicles: The dynamics of vehicles
are associated with each video frame containing
the following information of the involved vehi-
cles: coordinates, velocity, direction, actions of
each vehicle involved (i.e., braking, acceleration,
turning, no action) and the point of impact and the
damage descriptions.
• Accident Report & News: The accident report
servers as the official documentation and details
the sequence of events, involved parties, identified
causes, and potential preventive measures. Based
on the report, an accident news is tailored for dis-
semination to news agencies for public awareness.
• Responsibility Attribution: This output method-
ically identifies and attributes responsibilities to
involved parties.
• Insurance Claims: This output automates the in-
surance claim assessments by providing a data-
driven breakdown of the accident, which high-
lights damages, identifies potential policy viola-
tions, and offers estimations of repair costs based
on the severity and nature of the damages.
• Traffic Management: This output primarily fo-
cuses on the immediate and long-term implica-
tions of traffic flow and infrastructure. Post-
accident, the output provides real-time recom-
mendations on traffic rerouting, crowd control,
and area isolation to ensure minimal disruption
and prevent secondary accidents. In the long term,
based on recurrent patterns, the output identifies
weaknesses in current infrastructure and traffic
regulations, and suggest interventions to ensure
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
946

smoother and safer traffic flow in the future.
• Emergency Response: Emphasizing immediate
post-accident actions, this output assists in de-
termining the severity of injuries, potential haz-
ards (e.g., fuel leaks), and the requirement of
specialized resources such as medical teams, fire
brigades, or specialized rescue units. Addition-
ally, the output provides essential information to
first responders, like the number of vehicles in-
volved, hazards, and the access to the accident
site. This ensures that the response is not only
swift but also tailored to the specific needs of the
incident, minimizing harm and damage.
• Other Tasks: The adaptability and expansive-
ness of the AccidentGPT’s design based on multi-
modality and multi-task modelling makes the
model suited for additional task-specific outputs
not covered in the primary list. Such flexibility
ensures that the model remains relevant and scal-
able, accommodating evolving traffic safety needs
and technology advancements.
Furthermore, the model provides avenues for
multi-modal prompt based on reinforcement learn-
ing with human feedback (RLHF) (Christiano et al.,
2017) or AI feedback (RLAIF) (Bai et al., 2022),
ensuring a continuous loop of learning and refine-
ment to improve the model performance with the task-
oriented and multi-modal prompt.
4 RESEARCH OPPORTUNITIES
4.1 Opportunity 1: Multi-Modal Traffic
Data Collection and Integration
Gathering and integrating a comprehensive dataset for
traffic accident analysis is essential for pretraining.
Collection and Standardization: Similar to the
paradigm shift in the computer vision domain with
the introduction of ImageNet (Deng et al., 2009), the
traffic accident analysis field expects a transforma-
tion through the establishment of a comprehensive
and standardized multi-modal dataset. However, the
complexity and multifaceted nature of traffic acci-
dents, along with the discrepancies in data collection
methods across regions, make this endeavor challeng-
ing. The collaboration and standardization of the data
gathering to consolidate such data require synchro-
nized efforts from various stakeholders, in order to
ensure the analysis uniformity and solution scalabil-
ity. Alternatively, leveraging simulation software for
autonomous driving such as (Cognata, 2023) can pro-
duce standardized datasets with controlled variables,
which can act as a base for model training across dif-
ferent scenarios and conditions.
Data Preprocessing: Real-world traffic data can
be noisy due to various interference sources like
weather conditions affecting sensors or low-quality
traffic cameras, and thus necessitate extensive propro-
cessing efforts (e.g., cleaning, filtering). On the other
hand, collecting high-quality supervised data can be
expensive and, at times, unfeasible. Although semi-
supervised learning approaches resort to leveraging
unlabeled or weakly labeled data, they still demand
specialized filtering procedures (Radenovic et al.,
2023). In a multi-modal scenario, the challenges com-
pound even more, as each modality has its own inher-
ent noise and discrepancies. The integration of varied
data streams necessitates not only modality-specific
preprocessing but also meticulous alignment and syn-
chronization. This is essential to guarantee that inputs
from disparate sources accurately represent a singular
event. Additionally, an inter-modality harmonization
mechanism (Wu et al., 2023a) is crucial to ensure that
the composite representation holistically encapsulates
the phenomenon under study, with no single modality
disproportionately influencing the analysis.
4.2 Opportunity 2: Multi-Modal Model
Structure and Core Components
Although the general idea of the AccidentGPT fol-
lows the encoding, alignment, fusion, and decoding
process to generate multi-task multi-modal outputs,
no dominant design of model structure exists yet ei-
ther in existing vision-language pretraining (Liu et al.,
2023; Alayrac et al., 2022; Zhu et al., 2023a; Zhu
et al., 2023b) or the multi-modality works (Zhang
et al., 2023; Wu et al., 2023b), and no singular struc-
ture has been conclusively demonstrated to signifi-
cantly outperform others. In addition to the model
structure, the large multi-modal and multi-task model
for traffic accident analysis involves four fundamental
components that require further research innovations:
Alignment: Alignment deals with the synchro-
nization of data from various modalities to ensure that
they represent the same event or phenomenon. Al-
though emerging works (Girdhar et al., 2023) demon-
strate promising results, the extent and dimensions
where the traffic accident data are shared across
modalities can lead to: a) non-uniformity across
modality alignment (e.g., one-to-one, one-to-many, or
not exist at all), and b) long-range dependencies that a
particular element from one modality corresponds to
an element in another modality that is temporally or
spatially distant. Effective alignment methods are ex-
pected for temporal matching, spatial calibration and
AccidentGPT: Large Multi-Modal Foundation Model for Traffic Accident Analysis
947

semantic bridging across modalities.
Fusion: Once aligned, the fusion component form
a unified representation of the data from different
modalities and learn representations that capture the
interactions between individual elements spanning
various modalities (Man et al., 2023). Due to the
fact that multi-modal data are heterogeneous in char-
acteristics, distribution, carried information and rel-
evance toward specific tasks, this component is in-
trinsically challenging. In the filed of traffic accident
analysis, the fusion process becomes even more im-
portant due to the critical spatial-temporal relations
of the sequencing, timing, and positioning of events
and actions that lead up to, occur during, and follow
an accident.
Decoding: The decoding process produces
human-understandable outputs that reflect cross-
modal interactions and coherence. While certain
modality-specific decoders (e.g., text) are mature and
widely used, the AccidentGPT decoding components
do not merely construct raw outputs from model’s
internal representation, but also involves summariza-
tion of contents, translation between modalities and
creation of new contents (i.e., reconstruction of acci-
dent process video). Video generation, as a modality,
poses multiple challenges, especially when aiming for
high fidelity and temporally coherent sequences. This
is yet one of the most challenging but popular re-
search direction. Recent advances (Xu et al., 2023)
offer potential solutions, but further research is es-
sential to enhance the granularity, accuracy, and re-
alism of generated video content, particularly in the
nuanced domain of traffic accident analysis due to its
dynamics complexity, physical consistency and multi-
modal integration.
4.3 Opportunity 3: Multi-Modal
Reasoning
During the AccidentGPT’s entire process of traffic ac-
cident analysis, reasoning with the fused represen-
tation is the key capability of to reconstruct the ac-
cident sequence, derive critical insights, and formu-
late logical conclusions about the incident’s dynam-
ics. The reasoning dimension is vast and complex for
AccidentGPT involving the culmination of a series of
events and interactions among multiple entities. The
reasoning function is expected to: a) determine and
learn the relationships and interactions within the ac-
cident scene, b) understand the contribution of each
multi-modal data within the reasoning sequence, c)
extrapolate increasingly abstract ideas from the in-
dividual pieces of multi-modal evidence. Existing
works show contradicting results (Stechly et al., 2023;
Figure 2: Framework for Pretraining.
Huang and Chang, 2023) on how well multi-modal
models can perform on reasoning tasks, and yet a fur-
ther step on the reasoning leveraging external large-
scale knowledge and components can yield significant
advancements in accurate accident reconstruction and
understanding.
4.4 Opportunity 4: Data Efficient
Training Paradigm
Data from different sources for traffic accident analy-
sis can be categorized into three types: labeled, unla-
beled data, and weakly-labeled noisy data (even af-
ter preprocessing). Since the data related to traffic
accident is scarce in general, it is worthwhile to in-
vestigate how to maximize the utilization of (pseudo)
supervision or priors in the multi-modal data.
One potential solution is to adopt a combined
loss that enables supervised learning for labeled data
(Dosovitskiy et al., 2020), self-supervised learning for
unlabeled data (He et al., 2022; Chen et al., 2020) and
weakly-supervised learning for weakly-labeled noisy
data (Radford et al., 2021). Without losing gener-
alization, illustrative examples are shown in Figure
2. In contrast to single strategy training, the hybrid
training paradigm is another research opportunity al-
lowing for the comprehensive exploitation of valuable
and diverse data information, offering a flexible trade-
off between the cost of data collection and the perfor-
mance of the model.
4.5 Opportunity 5: Task-Oriented
Multi-Modal Prompt with Feedback
The concept of ”prompting” has demonstrated re-
markable utility in LLMs (Brown et al., 2020) and
LMMs (Lyu et al., 2023). By managing various
tasks with task-specific descriptive prompts, attach-
ing them to the input for downstream processing, and
then jointly feeding them into a pre-trained, frozen
foundational model, this approach offers a unified so-
lution for diverse tasks. However, the full poten-
tial of prompting within the realm of large multi-
modal models has yet to be fully explored. One of
the paramount challenges lies in the vast complex-
ity and diversity of multi-modal data. Unlike textual
data where prompts can be relatively straightforward,
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
948

defining an ideal prompt in multi-modal scenarios be-
comes intricate. And the alignment of task objectives
with the modality specifics make the process non-
trivial, as the misinterpretations or biases can have
significant real-world consequences in the traffic acci-
dent analysis, ensuring the accuracy, interpretability,
and contextual relevance of multi-modal prompts be-
comes absolutely critical.
Further, the process of feedback plays a vital role
in shaping the effectiveness of the prompt. While
RLHF (OpenAI, 2023) can provide nuanced insights
and guide the model towards desired outcomes, re-
lying solely on it can be costly and time-consuming.
On the other hand, recent work on RLAIF (Bai et al.,
2022) demonstrates that AI systems can potentially
self-regulate, refine, and provide feedback only with
the help of human oversight in terms of a list of rules
or principles. This presents an intriguing paradigm
where multi-modal prompts can be self-optimized
and critiqued by a balance between human and AI
feedback. The potential evolution of a feedback-
driven prompting mechanism could pave the way for
more granular and context-aware prompts, thereby
enhancing the model’s efficacy and responsiveness.
4.6 Opportunity 6: Validation Methods
and Reliability Metrics
The evolution of multi-modal models in traffic acci-
dent analysis opens new avenues for research, partic-
ularly in the development of sophisticated validation
techniques. Future studies should focus on creating
methodologies that can accurately assess and ensure
the reliability of outputs from complex systems like
AccidentGPT. Another critical area of research is the
formulation of robust metrics tailored to multi-modal,
multi-task models in high-stake scenarios. These met-
rics would serve as benchmarks for evaluating the
trustworthiness of the model’s interpretations, which
is paramount in traffic accident analysis.
5 CONCLUSION
In this paper, we have introduced AccidentGPT, an
innovative foundation model tailored for the intricate
domain of traffic accident analysis, leveraging multi-
modal data streams and a multi-tasking paradigm.
AccidentGPT synthesizes these varied data streams
and processes them seamlessly through a unified an-
alytical framework, thereby enabling comprehensive
and insightful outputs that span multiple modalities
and tasks. The potential of this approach represents
a significant paradigm shift, promising to revolution-
ize the methodologies and tools available for traffic
accident analysis.
Our work marks a first step towards an auto-
matic, systematic and privacy preserving traffic acci-
dent analysis solution. Research efforts are required
to refine these opportunities, fully realize their poten-
tial, and rigorously evaluate their performance in real-
world scenarios. Future work will focus on exploring
the related research opportunities and enhancing the
effectiveness of the proposed approach.
REFERENCES
Al-ani, R., Baker, T., Zhou, B., and Shi, Q. (2023). Pri-
vacy and safety improvement of VANET data via a
safety-related privacy scheme. International Journal
of Information Security, 22(4):763–783.
Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr,
I., Hasson, Y., Lenc, K., Mensch, A., Millican, K.,
Reynolds, M., et al. (2022). Flamingo: a visual
language model for few-shot learning. Advances in
Neural Information Processing Systems, 35:23716–
23736.
Ali, F., Ali, A., Imran, M., Naqvi, R. A., Siddiqi, M. H., and
Kwak, K.-S. (2021). Traffic accident detection and
condition analysis based on social networking data.
Accident Analysis & Prevention, 151:105973.
Bai, Y., Kadavath, S., and et al. (2022). Constitutional ai:
Harmlessness from ai feedback.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D.,
Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G.,
Askell, A., et al. (2020). Language models are few-
shot learners. Advances in neural information pro-
cessing systems, 33:1877–1901.
Butt, T. A., Iqbal, R., Salah, K., Aloqaily, M., and Jarar-
weh, Y. (2019). Privacy management in social internet
of vehicles: Review, challenges and blockchain based
solutions. IEEE Access, 7:79694–79713.
Chand, A., Jayesh, S., and Bhasi, A. (2021). Road traf-
fic accidents: An overview of data sources, analysis
techniques and contributing factors. Materials To-
day: Proceedings, 47:5135–5141. International Con-
ference on Sustainable materials, Manufacturing and
Renewable Technologies 2021.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. (2020).
A simple framework for contrastive learning of visual
representations. In International conference on ma-
chine learning, pages 1597–1607. PMLR.
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S.,
and Amodei, D. (2017). Deep reinforcement learning
from human preferences. In Guyon, I., Luxburg, U. V.,
Bengio, S., Wallach, H., Fergus, R., Vishwanathan,
S., and Garnett, R., editors, Advances in Neural Infor-
mation Processing Systems, volume 30. Curran Asso-
ciates, Inc.
Cognata (2023). Cognata — Autonomous and ADAS Vehi-
cles Simulation Software.
AccidentGPT: Large Multi-Modal Foundation Model for Traffic Accident Analysis
949

Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). Imagenet: A large-scale hierarchical
image database. In 2009 IEEE Conference on Com-
puter Vision and Pattern Recognition, pages 248–255.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., et al. (2020). An image is
worth 16x16 words: Transformers for image recogni-
tion at scale. arXiv preprint arXiv:2010.11929.
Duma, I., Burnete, N., and Todorut, A. (2022). A review of
road traffic accidents reconstruction methods and their
limitations with respect to the national legal frame-
works. IOP Conference Series: Materials Science and
Engineering, 1220(1):012055.
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala,
K. V., Joulin, A., and Misra, I. (2023). Imagebind:
One embedding space to bind them all.
He, K., Chen, X., Xie, S., Li, Y., Doll
´
ar, P., and Girshick,
R. (2022). Masked autoencoders are scalable vision
learners. In Proceedings of the IEEE/CVF conference
on computer vision and pattern recognition, pages
16000–16009.
Huang, J. and Chang, K. C.-C. (2023). Towards reasoning
in large language models: A survey. In Findings of
the Association for Computational Linguistics: ACL
2023, pages 1049–1065, Toronto, Canada. Associa-
tion for Computational Linguistics.
Li, W., Hacid, H., Almazrouei, E., and Debbah, M. (2023).
A comprehensive review and a taxonomy of edge ma-
chine learning: Requirements, paradigms, and tech-
niques. AI, 4(3):729–786.
Liang, P. P., Zadeh, A., and Morency, L.-P. (2023). Foun-
dations and trends in multimodal machine learning:
Principles, challenges, and open questions.
Liu, H., Li, C., Wu, Q., and Lee, Y. J. (2023). Visual in-
struction tuning. arXiv preprint arXiv:2304.08485.
Lyu, C., Wu, M., Wang, L., Huang, X., Liu, B., Du, Z.,
Shi, S., and Tu, Z. (2023). Macaw-llm: Multi-modal
language modeling with image, audio, video, and text
integration.
Man, Y., Gui, L.-Y., and Wang, Y.-X. (2023). Bev-
guided multi-modality fusion for driving perception.
In Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
21960–21969.
Mohammed, A. A., Ambak, K., Mosa, A. M., and Syam-
sunur, D. (2019). A Review of the Traffic Accidents
and Related Practices Worldwide. The Open Trans-
portation Journal, 13(1):65–83.
Moon, S., Madotto, A., Lin, Z., Dirafzoon, A., Saraf, A.,
Bearman, A., and Damavandi, B. (2022). Imu2clip:
Multimodal contrastive learning for imu motion sen-
sors from egocentric videos and text.
Moon, S., Madotto, A., Lin, Z., Nagarajan, T., Smith, M.,
Jain, S., Yeh, C.-F., Murugesan, P., Heidari, P., Liu,
Y., Srinet, K., Damavandi, B., and Kumar, A. (2023).
Anymal: An efficient and scalable any-modality aug-
mented language model.
Najafi Moghaddam Gilani, V., Hosseinian, S. M., Ghasedi,
M., and Nikookar, M. (2021). Data-Driven Ur-
ban Traffic Accident Analysis and Prediction Using
Logit and Machine Learning-Based Pattern Recogni-
tion Models. Mathematical Problems in Engineering,
2021:9974219.
OpenAI (2023). Gpt-4 technical report.
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec,
M., Khalidov, V., Fernandez, P., Haziza, D., Massa,
F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W.,
Howes, R., Huang, P.-Y., Li, S.-W., Misra, I., Rab-
bat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H.,
Mairal, J., Labatut, P., Joulin, A., and Bojanowski, P.
(2023). Dinov2: Learning robust visual features with-
out supervision.
Radenovic, F., Dubey, A., Kadian, A., Mihaylov, T., Van-
denhende, S., Patel, Y., Wen, Y., Ramanathan, V., and
Mahajan, D. (2023). Filtering, distillation, and hard
negatives for vision-language pre-training. In Pro-
ceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition, pages 6967–6977.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G.,
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark,
J., et al. (2021). Learning transferable visual models
from natural language supervision. In International
conference on machine learning, pages 8748–8763.
PMLR.
Stechly, K., Marquez, M., and Kambhampati, S. (2023).
Gpt-4 doesn’t know it’s wrong: An analysis of iter-
ative prompting for reasoning problems.
Touvron, H., Martin, L., and et al. (2023). Llama 2: Open
foundation and fine-tuned chat models.
Vepakomma, P., Gupta, O., Swedish, T., and Raskar, R.
(2018). Split learning for health: Distributed deep
learning without sharing raw patient data.
Wu, P., Wang, Z., Zheng, B., Li, H., Alsaadi, F. E., and
Zeng, N. (2023a). Aggn: Attention-based glioma
grading network with multi-scale feature extraction
and multi-modal information fusion. Computers in Bi-
ology and Medicine, 152:106457.
Wu, S., Fei, H., Qu, L., Ji, W., and Chua, T.-S. (2023b).
Next-gpt: Any-to-any multimodal llm.
Wu, Y., Chen, K., Zhang, T., Hui, Y., Berg-Kirkpatrick,
T., and Dubnov, S. (2023c). Large-scale contrastive
language-audio pretraining with feature fusion and
keyword-to-caption augmentation. In ICASSP 2023
- 2023 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP), pages 1–5.
Xu, Z., Peng, S., Lin, H., He, G., Sun, J., Shen, Y., Bao,
H., and Zhou, X. (2023). 4k4d: Real-time 4d view
synthesis at 4k resolution.
Zhang, Y., Gong, K., Zhang, K., Li, H., Qiao, Y., Ouyang,
W., and Yue, X. (2023). Meta-transformer: A unified
framework for multimodal learning.
Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M.
(2023a). Minigpt-4: Enhancing vision-language un-
derstanding with advanced large language models.
arXiv preprint arXiv:2304.10592.
Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M.
(2023b). Minigpt-4: Enhancing vision-language un-
derstanding with advanced large language models.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
950
