
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting
Action
Javier Tor
´
on Artiles
a
, Daniel Hern
´
andez-Sosa
b
, Oliverio J. Santana
c
,
Javier Lorenzo-Navarro
d
and David Freire-Obreg
´
on
e
SIANI, Universidad de Las Palmas de Gran Canaria, Las Palmas de Gran Canaria, Spain
Keywords:
Computer Vision, Soccer, Free Kick, Human Action Recognition, Dataset.
Abstract:
This research addresses whether the ball’s direction after a soccer free-kick can be accurately predicted solely
by observing the shooter’s kicking technique. To investigate this, we meticulously curated a dataset of soccer
players executing free kicks and conducted manual temporal segmentation to identify the moment of the kick
precisely. Our approach involves utilizing neural networks to develop a model that integrates Human Action
Recognition (HAR) embeddings with contextual information, predicting the ball-on-goal position (BoGP)
based on two temporal states: the kicker’s run-up and the instant of the kick. The study encompasses a
performance evaluation for eleven distinct HAR backbones, shedding light on their effectiveness in BoGP
estimation during free-kick situations. An extra tabular metadata input is introduced, leading to an interesting
model enhancement without introducing bias. The promising results reveal 69.1% accuracy when considering
two primary BoGP classes: right and left. This underscores the model’s proficiency in predicting the ball’s
destination towards the goal with high accuracy, offering promising implications for understanding free-kick
dynamics in soccer.
1 INTRODUCTION
In the 2021/22 season, the top 20 revenue-generating
clubs collectively made a profit of C9.2 billion, mark-
ing a 13% increase from the previous season and
nearly reaching the pre-pandemic levels of 2018/19.
This resurgence was driven by the return of fans
to stadiums, resulting in a significant increase in
matchday revenue, which rose from C111 million to
C1.4 billion. The revenue composition of clubs in
2021/22 returned to pre-pandemic levels, with 15%
from matchday activities, 44% from broadcasting,
and 41% from commercial sources (Deloitte, 2023).
Furthermore, the data indicates that the 2022 FIFA
World Cup, held in Qatar, garnered the highest view-
ership in the tournament’s history, with over five bil-
lion spectators tuning in through diverse platforms,
surpassing more than half of the global population
(FIFA, 2022).
a
https://orcid.org/0009-0000-5082-310X
b
https://orcid.org/0000-0003-3022-7698
c
https://orcid.org/0000-0001-7511-5783
d
https://orcid.org/0000-0002-2834-2067
e
https://orcid.org/0000-0003-2378-4277
This remarkable financial, as well as the
widespread global viewership of soccer events, under-
score the tremendous potential and impact of soccer
as a mass sport. Furthermore, the evolution of soccer
continues after these outstanding statistics. The intro-
duction of technology into the sport is emerging as a
pivotal factor, shaping both its on-field dynamics and
off-field engagement. According to Microsoft, dur-
ing a match, players navigate the entire field at high
speed, necessitating the deployment of up to 16 fixed
cameras for optical tracking positioned around the
perimeter of each stadium, capturing a staggering 3.5
million data points per game (Microsoft, 2023). This
data is subsequently processed through the Media-
coach platform, making it accessible to clubs and fans
through match broadcasts and digital content. Mi-
crosoft also remarks that the data strategy is designed
to give clubs invaluable insights for adapting training
schedules, scrutinizing opponents, and preparing for
match days.
In this context, the integration of technology into
soccer has brought about a significant transformation
in how the sport is played, assessed, and enjoyed.
Several studies and technological innovations have
highlighted the potential of technology to enhance
Artiles, J., Hernández-Sosa, D., Santana, O., Lorenzo-Navarro, J. and Freire-Obregón, D.
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting Action.
DOI: 10.5220/0012417100003654
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 13th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2024), pages 79-90
ISBN: 978-989-758-684-2; ISSN: 2184-4313
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
79

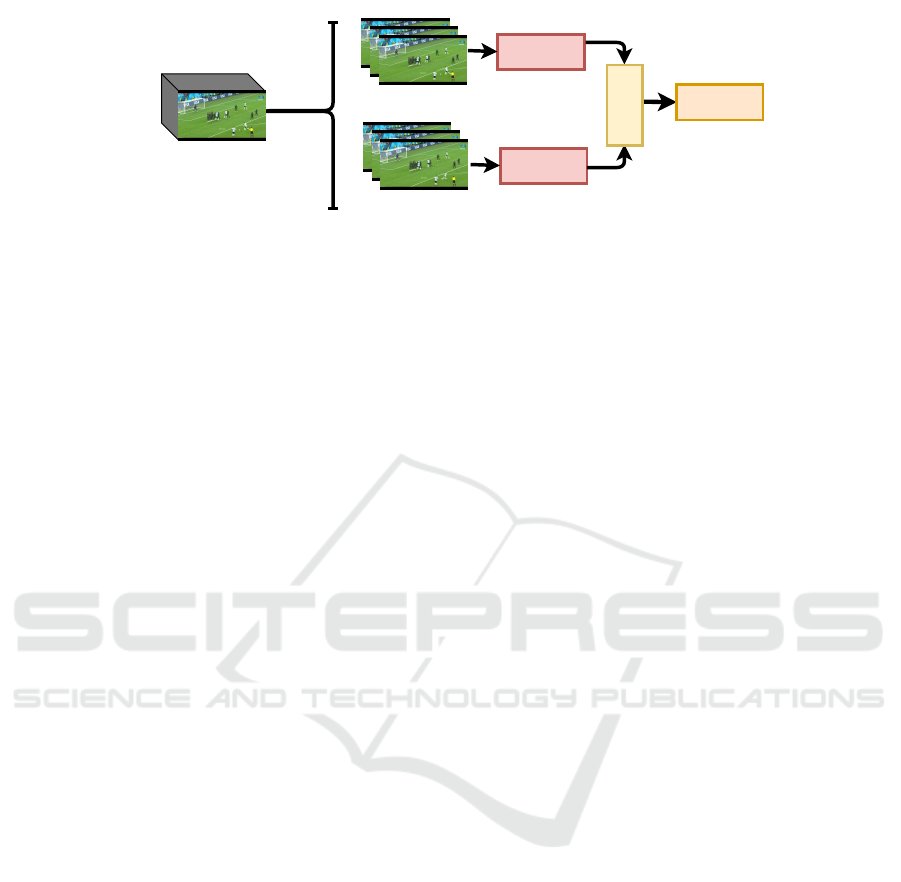
Analyzed Outputs
Running Stage
Kicking Stage
Footage Sequence
Figure 1: Free-Kick BoGP Classification. Our proposal involves a thorough analysis of free-kick actions by integrating
data from various sources, including free-kick metadata and HAR embeddings. Critically, our classifier combines contextual
information with the two-stream action recognition embeddings to make accurate predictions regarding the ball’s placement
concerning the goal. It is important to note that these experiments relied solely on visual observations of the kicker during the
shot without factoring in any ball trajectory data.
various aspects of soccer. Notably, some studies in-
troduced a visual analytic system that combines video
recordings with abstract visualizations of trajectory
data, enabling analysts to delve deep into ball, player,
or team behavior (Stein et al., 2018; Kamble et al.,
2019; He, 2022). Furthermore, some comprehensive
datasets have been introduced to facilitate the local-
ization of crucial events within extended soccer video
footage (Giancola et al., 2018; Deli
`
ege et al., 2021).
In addition, an automatic method was proposed to lo-
calize sports fields in broadcast images, eliminating
the need for manual annotation or specialized cam-
eras (Homayounfar et al., 2017). Lastly, some ana-
lytic systems were developed to visually represent the
spatiotemporal evolution of team formations, aiding
analysts in understanding and tracking the dynamic
aspects of soccer strategies (Wu et al., 2019; Li et al.,
2023). These technological advancements have no-
tably transformed sports analysis and enhanced the
fan experience in soccer, revealing new insights and
engagement opportunities. Nevertheless, unexplored
possibilities persist. While previous studies have en-
riched our understanding of the game, untapped areas
exist where technology can drive substantial advance-
ments in soccer. For instance, incorporating predic-
tive analytics in free-kick actions could lead to the
creation of advanced algorithms that account for fac-
tors like goal distance, angle, kicker skills, defensive
wall positioning, and even the goalkeeper’s historical
performance in stopping free kicks.
This work represents a significant step in ad-
vancing our understanding of ball-on-goal position
(BoGP) in the context of free kicks directed toward
the opponent’s goal. Utilizing HAR backbones, we
have crafted a BoGP classifier, benchmarking our
models against a novel and extensive collection of
free-kicks. To accomplish this, we have gathered
and processed free-kick footage from various sources
on the Internet. Building upon this dataset, multiple
models that integrated contextual information and uti-
lized pre-trained HAR encoders (commonly referred
to as backbones) were tested to predict the final des-
tination of the kicked ball into the goal. Notably, our
methodology incorporates two crucial stages as inputs
to the model: the running and the kicking stages, both
depicted in Figure 1.
The significance of this approach lies in the fact
that it captures the dynamic nature of a free-kick, al-
lowing our classifier to consider the player’s approach
and the moment of impact. This nuanced perspective
is pivotal for a more accurate and comprehensive un-
derstanding of BoGP in free kicks. Furthermore, we
conducted two distinct analyses. The first analysis in-
volved categorizing the goal into three classes (left,
center, and right), providing a fine-grained BoGP as-
sessment. The second analysis simplified the catego-
rization into two classes (left and right), allowing for
a broader perspective on BoGP accuracy. This dual
approach enabled a deeper exploration of free-kick
complexities; please refer to Figure 1.
Our contributions can be summarized as follows:
• We introduce a novel soccer free-kick dataset
comprising 603 short clips from actual matches.
This dataset has been curated from online sources
and is readily accessible to the public.
• Through a series of experiments, we empirically
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
80

showcase the feasibility of addressing the BoGP
challenge by employing a classifier that combines
contextual data with a two-stream approach. Each
stream offers a distinct embedding path, encom-
passing the running stage and the kicking stage of
the free-kick process.
• Within the scope of this study, we conduct a com-
parative analysis of eleven different HAR back-
bone architectures, assessing their respective per-
formance in BoGP classification.
• An in-depth error analysis study was undertaken
to evaluate how the various classes influence the
performance of the top-performing model.
The subsequent sections of this paper are struc-
tured as follows. Section 2 discusses previous related
work. Section 3 outlines the proposed pipeline. Sec-
tion 4 details the experimental setup and presents the
results. Section 5 offers an analysis of errors. Lastly,
Section 6 draws our conclusions.
2 RELATED WORK
Sports analysis has consistently captured the commu-
nity’s attention, leading to a substantial surge in pub-
lished research over the past decade. In this sporting
domain, technology has become an integral and trans-
formative force, significantly shaping our understand-
ing of sports, as well as how athletes train and com-
pete. This section offers a comprehensive examina-
tion of two specific elements addressed in this study:
datasets in sports and their computing application.
The available sports video datasets can be cate-
gorized into two main groups: still-image and video-
sequence datasets. The first group encompasses
datasets primarily designed for image classification.
For instance, the UIUC Sports Event Dataset com-
prises 1,579 images spanning eight sports event cat-
egories (Li and Li Fei-Fei, 2007). Each category may
contain subsets of images ranging from 180 to 205,
categorized as easy or medium based on human sub-
ject judgments. Another noteworthy collection is the
Leeds Sports Pose Dataset (Johnson and Everingham,
2010), featuring 2.000 pose-annotated images of ath-
letes gathered from the Internet. Each image includes
annotations for 14 joint locations. More recently,
ultra-distance runners competitions have also been
captured in wild conditions (Penate-Sanchez et al.,
2020).
In contrast, the video-sequence datasets offer time
series information about the actions occurring within
the scene. These sequences are typically captured us-
ing stationary cameras. Sequences from individual
sports provide a suitable context for activity recog-
nition, while sequences from team sports can be used
for player tracking and event detection. In this con-
text, many sports datasets have been assembled from
international competitions to advance research in au-
tomatic quality assessment for sports. Some of the
most recent datasets include the MTL-AQA diving
dataset (Parmar and Morris, 2019b), the UNLV AQA-
7 dataset, which includes diving, gymnastic vaulting,
skiing, snowboarding, and trampoline (Parmar and
Morris, 2019a), and the Fis-V skating dataset (Xu
et al., 2020). These datasets have been collected in
controlled, non-obstructed environments, with excep-
tions like the UNLV AQA-7 snowboarding and skiing
subsets, gathered in quiet conditions with a dark sky
(night) and snowy ground.
The semantic structure of sports video content can
be categorized into four layers: raw video, object,
event, and semantic layers (Shih, 2018). The foun-
dation of this pyramid consists of raw video input,
from which objects are identified in the higher layers.
Specifically, critical objects featured in video clips are
recognized through object extraction, such as players
(Guo et al., 2020) and object tracking, including the
ball (Wang et al., 2019) and players (Lee et al., 2020).
The event layer signifies the actions of critical objects.
Various actions, combined with scene information,
generate event labels that depict the related actions
and interactions among multiple objects. Research in
areas like action recognition (Freire-Obreg
´
on et al.,
2022), re-identification (Akan and Varli, 2023; Freire-
Obreg
´
on et al., 2023), facial expression recognition
(Brick et al., 2018; Santana et al., 2023), trajectory
prediction (Teranishi et al., 2020), and highlight de-
tection (Gao et al., 2020) falls within the scope of
this layer. The topmost layer, the semantic layer, is
responsible for summarizing the semantic content of
the footage (Cioppa et al., 2018). As our objective is
BoGP, we seek to classify the outcome of a free-kick
action. Furthermore, the mentioned collections pre-
dominantly feature professional athletes. In this con-
text, our work does not address the team dimension,
as it specifically focuses on a particular action. Never-
theless, several pivotal individuals are visible during
this action, including the kicker, the referee, the other
players, especially those forming the defensive wall,
and the goalkeeper.
3 DESCRIPTION OF THE
PROPOSAL
This paper introduces and assesses a sequential
pipeline consisting of two core modules, where video
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting Action
81

Original Frame Frame Detections Context-Constrained Frame
Figure 2: Context Removal. For every frame at time t, the process entails isolating the kicker’s bounding box, which is then
superimposed onto a stable background derived from the mean of τ frames.
Stages split
Footage Context Constraint
Running
Kicking
Figure 3: Video Pre-Processing Module. The initial
video material undergoes a pre-processing phase wherein
the kicker is separated from a dynamic background. Follow-
ing this, two sets of frames are manually chosen to delineate
the running and kicking stages. The remaining frames are
excluded.
pre-processing is performed manually before enter-
ing the pipeline. The core modules include a video
pre-processing module, a stage-embeddings extrac-
tion module, and a classifier. Figures 4, and 5 depict
visual representations of these modules, while Figure
3 illustrates the executed video pre-processing. The
following subsections comprehensively describe the
video pre-processing step and each module.
3.1 Context Constraint
In order to optimize the quality of the embeddings
generated by the backbone, it is imperative to ensure
that the input footage provided to the action recogni-
tion networks is devoid of extraneous elements, as in-
dicated in a prior study (Freire-Obreg
´
on et al., 2022).
Within the context of the dataset utilized for the ex-
periments detailed in this research, as described in
Section 4.1, these extraneous elements encompass un-
related players, staff, supporters, and referees. Given
their lack of relevance within the purpose of this work,
an initial pre-processing phase is conducted to refine
the raw input data by isolating the primary subject,
i.e., the kicker. This task is accomplished by lever-
aging ByteTrack (Zhang et al., 2021), a multi-object
tracking network that can precisely track the kicker
within each video footage, see Figure 2. Following
this, a context-constrained pre-processing technique
is applied to establish an ideal setting for conducting
the experiments.
In the context of acquiring context-constrained
video frames for a specific kicker (k) at a given time
(t) within a specified time interval ([0, T]), the bound-
ing box (BB
k
(t)) plays a crucial role. This bound-
ing box outlines the area occupied by kicker k within
the frame recorded at time t. To facilitate this pro-
cess, two primary factors are considered: the bound-
ing box area of the kicker (BB
k
(t)) and the average
number of frames required (τ) to establish a static
background against which the isolated kicker (k) ap-
pears in the pre-processed video frame. The resulting
pre-processed frame (F
′
k
(t)) is generated through the
following equation:
F
′
k
= BB
k
(t) ∪ τ
Here, the ∪ operation involves aligning and superim-
posing the bounding box of kicker k onto the aver-
age of the selected τ frames. This sequence of pre-
processed frames constitutes the new video footage,
with the kicker as the sole moving element.
Lastly, as depicted in Figure 3, the resultant
footage is temporally segmented. This manual seg-
mentation identifies two distinct moments aligned
with the kicker’s actions: the running stage and the
kicking stage. Any elements in the video, such as
the free-kick outcome or the kicker’s reaction, have
been excluded from the analyzed stages. This study
focuses exclusively on the running stage (the phase in
which the kicker approaches the ball) and the kick-
ing stage (comprising the 16 frames before and the 16
frames after the ball is kicked).
3.2 Stage-Embeddings Extraction
The preprocessed input footage for each stage, con-
sisting of m frames, undergoes a twofold procedure.
Initially, the footage is downsampled, which results in
its division into n video clips, represented as v
1
, ..., v
n
,
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
82
...
Features ExtractionStage Input
Backbone
Action
Embeddings
Backbone
v
1
v
n
Pooling
...
Figure 4: Embeddings Extraction Module. Each stage footage undergoes downsampling, dividing it into n smaller clips.
A pre-trained human-action model is then applied to extract features from these clips. These features are combined using a
pooling technique, resulting in a final tensor that serves as input to the classifier. This work examines two pooling methods,
average pooling and max pooling.
where each clip comprises a sequence of q consecu-
tive frames that encapsulate a snapshot of the activity,
see Figure 4. In practical terms, the n clips exhibit
partial overlap, spaced one frame apart from the pre-
ceding one. These video clips traverse a pre-trained
HAR encoder (backbone), producing r-dimensional
feature vectors. It is worth noting that these encoder
models have undergone prior training on the Kinet-
ics 400 dataset, which encompasses a broad spectrum
of 400 action categories (Kay et al., 2017). Follow-
ing the acquisition of feature vectors for all n video
clips, a pooling layer ensures the contribution from
each clip. In this regard, we have evaluated both av-
erage and max pooling layers, as seen in Section 4.
We have chosen eleven backbones to test our ap-
proach to tackle the BoGP problem. Some are more
complex backbones (Slowfast or I3D) than others
(the X3D instances and C2D). This section offers
an overview of the HAR models considered for this
study. The C2D (Convolutional 2D) model, designed
for video action classification (Simonyan and Zisser-
man, 2014), exploits the power of 2D Convolutional
Neural Networks (CNN) for spatial feature extraction
from video frames. Its architecture comprises con-
volutional layers, pooling layers, and fully connected
layers. Convolutional layers extract spatial features
while pooling layers reduce dimensionality to prevent
overfitting. The C2D model processes each frame in-
dependently, employing CNNs to extract spatial fea-
tures, which are combined to capture temporal action
dynamics.
In contrast to the C2D model, the SlowFast model
is conceived based on the principle that different
video segments possess diverse temporal resolutions
and contain crucial information for action recognition
(Feichtenhofer et al., 2018). For example, some ac-
tions occur swiftly and necessitate high temporal res-
olution for detection, while others unfold more slowly
and can be recognized with a lower temporal resolu-
tion. To address this variability, the SlowFast model
adopts a dual-pathway approach, comprising fast and
slow pathways that operate on video data at varying
temporal resolutions.
Similarly, Slow adopts a two-stream architecture
to capture both short-term and long-term temporal
dynamics in videos (Feichtenhofer et al., 2021). Its
slow pathway processes high-resolution frames but at
a lower frame rate, similar to the C2D model. Addi-
tionally, Slow incorporates a temporal-downsampling
layer to capture longer-term temporal dynamics. The
Inflated 3D ConvNet (I3D) model is designed to han-
dle short video clips as 3D spatiotemporal volumes,
enabling the capture of both appearance and mo-
tion cues using a two-stream approach (Carreira and
Zisserman, 2017). In this design, the first stream
deals with RGB images, utilizing weights that are
pre-trained on extensive image classification datasets.
Simultaneously, the second stream processes optical
flow images and undergoes fine-tuning in conjunction
with the RGB stream.
A revised variant of the I3D model, I3D NLN, in-
corporates non-local operations to enhance spatiotem-
poral dependency modeling in videos (Wang et al.,
2017). I3D NLN retains the two-stream architecture
involving RGB and optical flow streams, processing
3D spatiotemporal volumes. In contrast to the Incep-
tion module, I3D NLN employs non-local blocks ca-
pable of learning long-range dependencies across fea-
ture map positions. By computing weighted sums of
input features from all positions based on the sim-
ilarity between these positions in the feature maps,
I3D NLN captures global context information and im-
proves the modeling of temporal dynamics.
Finally, we have leveraged four X3D model varia-
tions, distinguished by their sizes: extra small (X3D-
XS), small (X3D-S), medium (X3D-M), and large
(X3D-L). Each expansion incrementally transforms
X2D from a compact spatial network to a spatiotem-
poral X3D network (Feichtenhofer, 2020) by modi-
fying temporal (frame rate and sampling rate), spa-
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting Action
83
Running
Embeddings
Dense/16u
Sigmoid
or
Softmax
BatchNorm
Concat
Kicking
Embeddings
Free-Kick
Metadata
Dense/128u
Dense/128u BatchNorm
Dense/128u
Dense/64u
BatchNorm
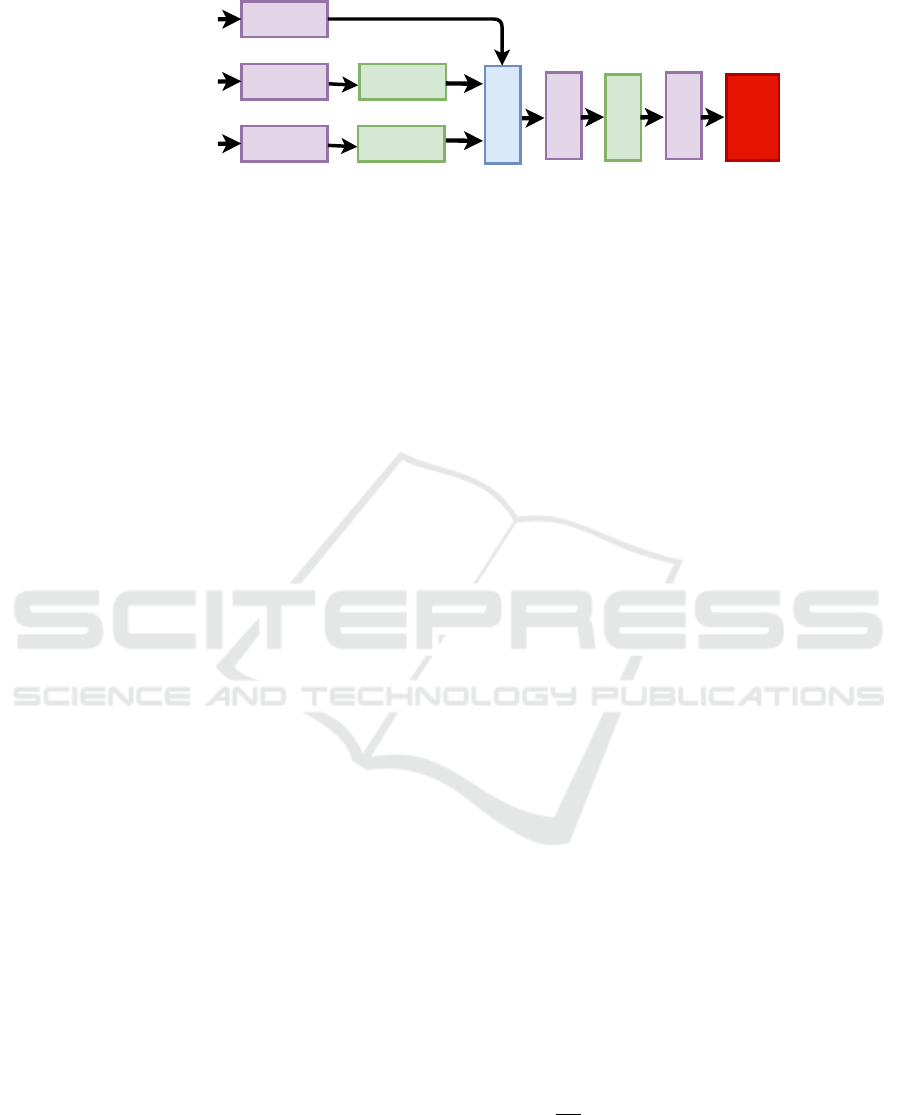
Figure 5: The proposed classifier. Features from the HAR backbones for running and kicking stages are processed alongside
free-kick metadata, combining information from various sources to contribute to the model’s decision-making process. The
features extracted from the HAR backbone offer a fine-grained understanding of the kicker’s movements. At the same time,
free-kick metadata provides valuable context, influencing the classification outcome, particularly in diverse free-kick scenar-
ios.
tial (footage resolution), width (network depth), and
depth dimensions (number of layers and units). X3D-
XS results from five expansion steps, followed by
X3D-S, which includes one backward contraction
step after the seventh expansion. X3D-M and X3D-L
are generated by the eighth and tenth expansions, re-
spectively. X3D-M augments the spatial resolution by
elevating the spatial sampling resolution of the input
video. At the same time, X3D-L expands the spatial
resolution and network depth by increasing the num-
ber of layers in each residual stage.
3.3 Classifier
The proposed classifier involves feature extraction
from the identical HAR backbone for both the run-
ning and kicking stages, as well as the inclusion of
free-kick metadata, see Figure 5.
This three-input approach combines information
from various sources, each contributing unique and
complementary insights to the model’s decision-
making process. The features extracted from the
HAR backbone offer a fine-grained understanding of
the kicker’s movements and actions during the free
kick. Simultaneously, free-kick metadata provides
valuable context and situational information that can
significantly influence the classification outcome, es-
pecially when dealing with various free-kick scenar-
ios. In this regard, the free-kick metadata encom-
passes four distinct input variables, each contributing
specific information to the model’s decision-making
process. These variables include pitch side, free-kick
side, free-kick distance, and kicker foot. The pitch
side variable operates as a binary indicator, distin-
guishing between left and right. In contrast, the free-
kick side variable offers a more detailed classification,
representing three distinct values related to the shoot-
ing point: left to the goal, center to the goal, and right
to the goal. Similarly, free-kick distance, another bi-
nary variable, provides insight into whether the free
kick occurs near or far from the penalty box. Lastly,
the kicker foot variable, also binary, characterizes the
preferred kicking foot as either left or right.
As a result, the model receives three distinct in-
puts, each of which undergoes processing via dedi-
cated fully connected layers with varying units (16
and 128) based on the nature of the input. The run-
ning and kicking paths also include batch normaliza-
tion layers. Subsequently, all paths are concatenated,
followed by two fully connected layers (128 and 64
units, respectively), separated by a batch normaliza-
tion layer. Finally, the model’s output, denoting the
ball’s position on the goal, is determined by either a
Sigmoid or a Softmax layer, depending on whether
the output comprises two or three classes.
In the conventional classification framework, the
primary objective is to assign a sample to its appro-
priate class. In this context, we have conducted two
experiments on the ball’s positioning within the goal.
The first experiment considers three distinct classes
(left, right, and center), while the second experiment
operates as a binary classifier, explicitly distinguish-
ing between left and right placements. Consequently,
we employ the categorical cross-entropy loss function
for the first experiment:
Loss
1
= −
C
∑
i=1
y
i
log(p
i
) (1)
Where C is the number of classes, y
i
is the true
probability distribution (one-hot encoded vector) of
the ground truth class, and p
i
is the predicted proba-
bility for class i. For the second experiment, the con-
sidered loss function to tackle the problem is the bi-
nary cross-entropy:
Loss
2
=
−1
N
N
∑
i=1
−(y
i
log(p
i
) + (1 − y
i
)log(1 − p
i
))
(2)
Where p
i
is the i-th scalar value in the model out-
put, y
i
is the corresponding target value, and N is the
number of scalar values in the model output.
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
84

Time
Figure 6: Free-kick Dataset Sequences. The video dataset used in this study was gathered from the Internet without any
imposed usage restrictions. Due to this unrestricted collection approach, the dataset exhibits notable pose, scale, and lighting
conditions variability. Video clips were carefully edited to retain frames from just before the running stage until the moment
of the free-kick outcome.
4 EXPERIMENTAL SETUP
This section is divided into three subsections re-
lated to the dataset acquisition, experimental setup,
and achieved results of the designed experiments.
The first subsection provides technical details regard-
ing the dataset, including its acquisition and data-
cleaning processes. The second subsection outlines
the technical aspects of our proposal, such as the data
split. Finally, the third subsection summarizes the
achieved results.
4.1 Dataset
To our knowledge, there is no publicly available soc-
cer free-kick dataset. Our data collection approach
hinges on generality, intending to construct robust de-
tection models for practical use. This compilation of
videos was sourced from the Internet without any us-
age restrictions, resulting in considerable variations in
pose, scale, and lighting conditions, see Figure 6. The
data collection process encompasses three steps:
1. Web Scraping: an extensive search was con-
ducted to gather relevant images using keywords
like ”free-kick soccer,” ”free-kick compilation”,
and the names of various soccer players well
known for frequently shooting free kicks.
2. Shot Labeling: labeling involves carefully edit-
ing each video clip. These clips are trimmed to
cover the period from just before the kicker ini-
tiates the run to the occurrence of the shot out-
come. This stage results in a subset of 603 free-
kick clips.
3. Manual Annotation: each free-kick clip is man-
ually reviewed and annotated. Annotations en-
compass various variables, including pitch side,
free-kick side, free-kick distance, kicker foot (left
or right), kick outcome, barrier configuration,
gender, goalkeeper zone, and the specific frame in
which the ball is kicked. The resolution of these
clips is 1920 × 1080 pixels.
Despite the initial inclusion of 603 free-kick clips
in the dataset, several factors reduced this number. A
critical consideration was the camera viewpoint, as
it played a substantial role in the selection process.
To maintain shooting action stability, clips where the
camera perspective was positioned behind the goal-
keeper or the kicker were excluded. As described in
Section 3.1, the remaining 584 videos underwent peo-
ple detection using ByteTrack. Unfortunately, some
videos exhibited low image quality, resulting in sub-
par detection performance. As a consequence, the
dataset was further reduced to 539 clips.
Subsequently, the duration of the videos became
a focal point, as clips that were excessively short
in length were found to be inadequate for extract-
ing meaningful information. For instance, videos
commencing precisely as the player initiated the kick
(without a preceding running stage) were omitted
from consideration due to the need for a minimum
frame count to extract pertinent information. All clips
containing fewer than 32 frames were accordingly ex-
cluded, ultimately reducing the dataset to 451 clips.
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting Action
85
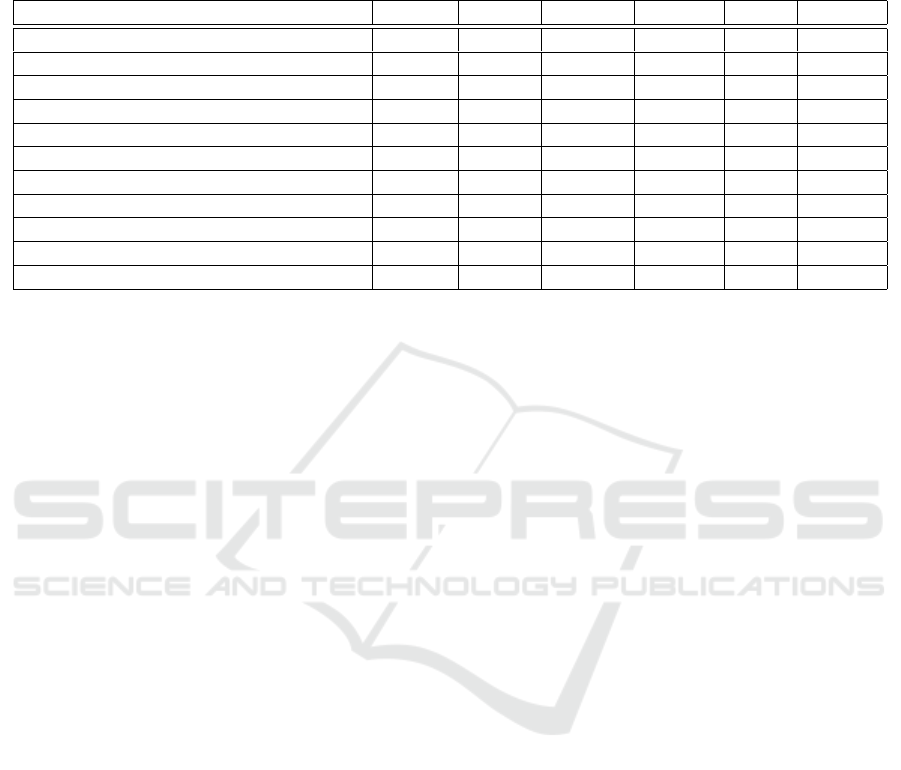
Table 1: Comparative Performance Analysis of HAR Architectures for BoGP Estimation when Considering Three
Classes. This table compares different backbone architectures used to detect BoGP during free-kick shots. The first column
lists the backbone models, while the second column specifies the number of frames the model utilizes for generating HAR
embeddings. The table includes crucial performance metrics such as the number of frames per embedding backbone, the
applied pooling method, and the values of the performance metrics: accuracy, precision, recall, and F1-Score.
Backbone #Frames Pooling Accuracy Precision Recall F1-Score
C2D (Simonyan and Zisserman, 2014) 8 Average 52.9% 49.4% 43.1% 46.1%
I3D (Carreira and Zisserman, 2017) 8 Average 51.4% 42.7% 39.6% 41.1%
I3D NLN (Wang et al., 2017) 8 Average 51.9% 44.6% 41.2% 42.8%
Slow4x16 (Feichtenhofer et al., 2021) 4 Average 55.0% 49.4% 44.6% 46.9%
Slow8x8 (Feichtenhofer et al., 2021) 8 Average 55.3% 46.1% 41.5% 43.7%
SlowFast4x16 (Feichtenhofer et al., 2018) 32 Max 55.0% 47.1% 43.9% 45.4%
SlowFast8x8 (Feichtenhofer et al., 2018) 32 Average 53.4% 47.4% 45.2% 46.2%
X3D-XS (Feichtenhofer, 2020) 4 Max 51.2% 46.3% 43.9% 45.1%
X3D-S (Feichtenhofer, 2020) 4 Max 53.4% 44.9% 43.5% 44.2%
X3D-M (Feichtenhofer, 2020) 13 Max 53.6% 47.9% 43.0% 45.3%
X3D-L (Feichtenhofer, 2020) 16 Average 57.2% 50.0% 48.5% 49.3%
The problem’s intrinsic nature also emerged as a
significant determining factor during clip selection.
Specifically, any clips in which the kick did not suc-
cessfully reach the goal, such as instances where the
ball failed to surpass the defensive barrier, were omit-
ted. In such cases, it was infeasible to ascertain the
target location within the goal, rendering these clips
inapplicable. Therefore, a refined subset of 418 clips
was designated for inclusion in this study.
4.2 Experimental Setup
The results presented in this section refer to the av-
erage accuracy on five repetitions of 10-fold cross-
validation for each experiment. Significantly, the
class distribution within the dataset is characterized
as follows: 187 free-kick shots are directed towards
the left side of the goal, 181 are aimed at the right
side, and 50 target the center area of the goal. The
class distribution exhibits a notable imbalance, par-
ticularly in the case of the center-side shots. We have
implemented a class weighting strategy during the
model training phase to address this issue. The adjust-
ment of class weights in the training process serves
to amplify the model’s sensitivity to minority classes,
effectively mitigating the inherent challenge of dis-
parate class distributions. This approach serves as a
valuable mechanism to rectify any potential bias aris-
ing from the overrepresentation of majority classes,
thereby ensuring equitable model performance across
all classes.
4.3 Results
Table 1 presents a comparative performance analysis
of various HAR backbone architectures utilized to es-
timate the BoGP during free-kick shots, specifically
when considering three different target classes: left,
center, and right. The table highlights the number
of frames used for each embedding backbone (de-
noted as q in Section 3.2), the pooling method em-
ployed, and key performance metrics including accu-
racy, precision, recall, and F1-Score. The presented
HAR backbone architectures encompass a range of
models described in Section 3.2. Each model is eval-
uated based on the aforementioned metrics, providing
valuable insights into their effectiveness in BoGP es-
timation during free-kick situations.
A noteworthy observation pertains to the choice of
pooling layers for the HAR embeddings (see Figure
4). The data presented in Table 1 reveals an intrigu-
ing trend: lighter models, exemplified by the X3D in-
stances, tend to favor the utilization of the MaxPool
layer, while heavier models typically demonstrate a
preference for the AveragePool layer. This distinction
in pooling layer selection reflects these models’ di-
verse architectural considerations and requirements,
underscoring the need to suit the pooling method to
the specific characteristics and demands of a given
HAR model.
The table prominently illustrates the distinct per-
formance levels exhibited by various models. X3D-L,
in particular, stands out as the top performer, boast-
ing the highest accuracy (57.2%), precision (50.0%),
recall (48.5%), and F1-Score (49.3%). Following
closely in classification performance are the SlowFast
and Slow instances, although they lag by a margin of
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
86
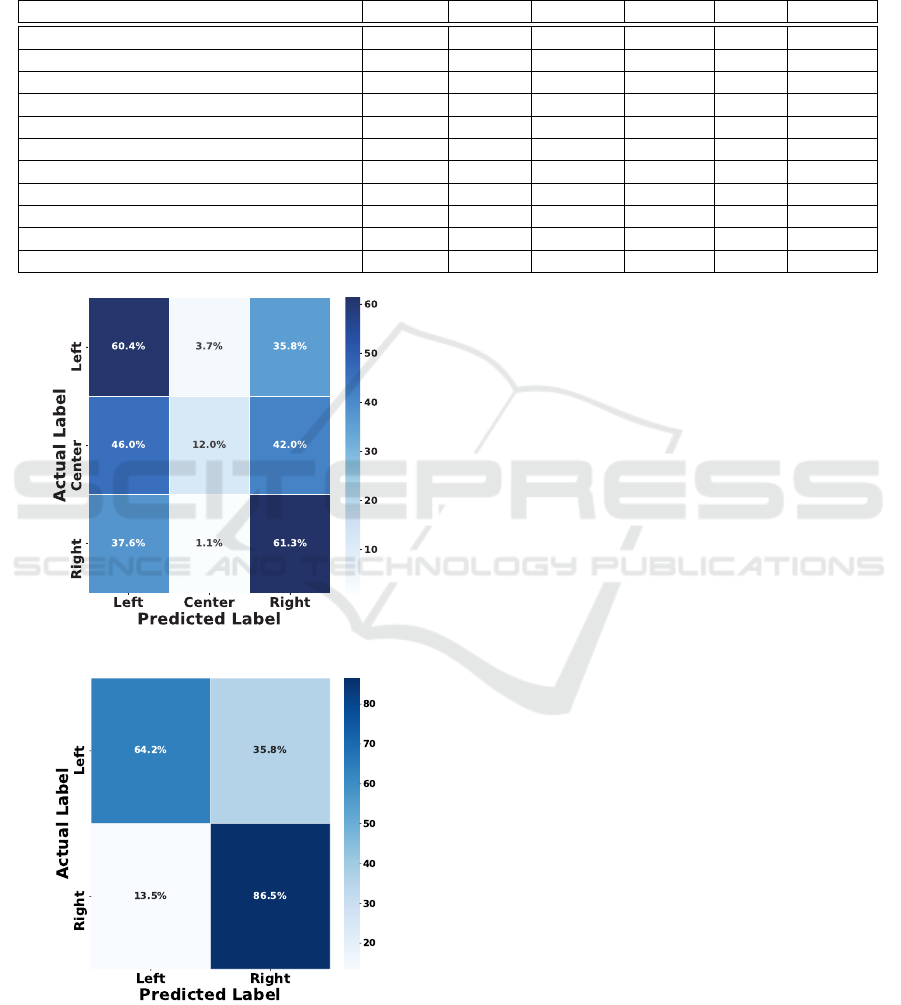
Table 2: Comparative Performance Analysis of HAR Architectures for Soccer Player Free-Kick Shoot Zone Estimation
when Considering Two Classes. This table compares different backbone architectures used to detect soccer player shoot
zones during free-kick shots. The first column lists the backbone models, while the second column specifies the number of
frames the model utilizes for generating HAR embeddings. The table includes crucial performance metrics such as the number
of frames utilized, the pooling method applied, accuracy, precision, recall, and F1-Score. These metrics offer valuable insights
into the effectiveness of each backbone architecture for this specific task.
Backbone #Frames Pooling Accuracy Precision Recall F1-Score
C2D (Simonyan and Zisserman, 2014) 8 Max 67.4% 56.5% 60.2% 58.3%
I3D (Carreira and Zisserman, 2017) 8 Average 63.1% 51.3% 56.4% 53.7%
I3D NLN (Wang et al., 2017) 8 Max 62.8% 52.6% 51.7% 52.2%
Slow4x16 (Feichtenhofer et al., 2021) 4 Average 66.9% 60.0% 68.3% 63.9%
Slow8x8 (Feichtenhofer et al., 2021) 8 Max 65.8% 57.6% 67.7% 62.2%
SlowFast4x16 (Feichtenhofer et al., 2018) 32 Average 69.1% 57.7% 76.1% 65.7%
SlowFast8x8 (Feichtenhofer et al., 2018) 32 Max 63.6% 56.6% 69.9% 62.5%
X3D-XS (Feichtenhofer, 2020) 4 Max 61.9% 47.2% 48.3% 47.7%
X3D-S (Feichtenhofer, 2020) 4 Average 64.4% 50.9% 74.3% 60.4%
X3D-M (Feichtenhofer, 2020) 13 Max 66.0% 58.4% 51.4% 54.7%
X3D-L (Feichtenhofer, 2020) 16 Max 65.8% 59.7% 56.6% 58.1%
Figure 7: Three-class SlowFast4x16 confusion matrix.
Figure 8: Two-class SlowFast4x16 confusion matrix.
2.2% in accuracy. It is worth noting that the overall
performance in the context of three-class classifica-
tion remains relatively modest, as evidenced by the
F1-Score, though exceeding that of a random classi-
fier. Section 5 provides a comprehensive error analy-
sis.
To complete our evaluation, Table 2 presents a
comparative performance analysis of various HAR
backbone architectures used in soccer player free-
kick shoot zone estimation when considering two
classes: left and right. Once again, the models are
evaluated in this scenario based on details about the
number of frames used, the pooling method applied,
and the four key performance metrics: accuracy, pre-
cision, recall, and F1-Score. Comparing this table
with the previously discussed Table 1, we observe an
interesting transition regarding the number of classes
considered. The simplification of the classification
task has a notable impact on model performance.
Despite the reduced complexity of the classification
problem, there are variations in the performance of
the backbone architectures, indicating that the choice
of backbone remains critical. Performance-wise, sev-
eral observations can be made. For instance, Slow-
Fast4x16 exhibits the highest accuracy (69.1%) in this
two-class classification scenario, outperforming other
models. Additionally, Slow4x16 achieves a remark-
able 60.0% precision, indicating its ability to accu-
rately classify instances. The F1-Score, which com-
bines precision and recall, is also noteworthy, with
SlowFast4x16 leading the way with a score of 65.7%.
These metrics provide valuable insights into the effec-
tiveness of the backbone architectures for the specific
task of soccer player free-kick shoot zone estimation.
In contrast to the outcomes in the three-class scenario,
the utilization of MaxPool and AveragePool layers is
evenly distributed in this table.
The architecture of the classifier described in Sec-
tion 3.3 poses an intriguing question: how does the
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting Action
87

Label: Left - Prediction: CenterLabel: Rigth - Prediction: Center
Figure 9: SlowFast4x16 Misclassified Clips. These frames represent the ultimate phase of two distinct samples. It is
important to note that the proposed model exclusively examines the actions of the kicker, meaning it does not consider any
frames beyond the 16 post-kicking frames, and the background remains static. Consequently, the frames presented in this
figure were never seen by the models; they are included solely to exemplify the intricacies associated with the center class.
Notably, the classifier erroneously categorizes these clips as center when labeled as right and left, respectively.
incorporation of free-kick metadata impact perfor-
mance? Upon calculating the mean accuracy across
all scrutinized models, the obtained outcome indi-
cates that without consideration for free-kick meta-
data, the accuracy diminishes by 3%, and the F1-
Score experiences a 4% decline. This signifies that
metadata enhances contextual information regarding
free-kick embeddings, yet it does not introduce bias
to the proposed model.
In summary, as shown in this table, the transi-
tion from a three-class to a two-class problem empha-
sizes the consequences of simplifying the classifica-
tion task. It underscores the performance differences
among various HAR backbone architectures and their
potential suitability for specific sports action recogni-
tion tasks. However, these findings have raised sev-
eral questions, including the influence of the center
class on classification, the distribution of error pre-
dictions, and the examination of confusion matrices
for the top-performing models. These questions will
be addressed in the following section.
5 ERROR ANALYSIS
In this section, our primary focus is on the top-
performing model, which employs the SlowFast4x16
backbone. It is crucial to comprehensively analyze its
performance under scenarios involving two and three
classes. As a case in point, Figures 7 and 8 visually
represent the confusion matrices for both experimen-
tal settings.
Our analysis presents the confusion matrix for our
classification model, designed to categorize free-kick
soccer actions into one of three classes: left, center,
or right. As illustrated in Figure 7, this matrix pro-
vides valuable insight into the model’s performance
and ability to classify BoGP correctly. The diagonal
elements of the matrix represent instances where the
model’s predictions align with the actual classes. For
instance, the model achieved an accuracy of approxi-
mately 60.4% in identifying left shots, 12.0% for cen-
ter, and 61.3% for right. These values indicate the
model’s proficiency in correctly classifying shots into
their respective categories. However, the off-diagonal
elements reveal cases of misclassification. Notably,
there is some confusion between the center and the
other two classes. The model often misclassifies cen-
ter shots as left (46.0%) or right (42.0%), suggesting
improvement in distinguishing center shots from the
others. Additionally, left shots are occasionally mis-
classified as right (35.8%), and right shots are occa-
sionally mislabeled as left (37.6%) or center (1.1%).
Our analysis suggests that the classifier faces chal-
lenges in accurately distinguishing the center cate-
gory, as illustrated in Figure 9. The intricacies of this
classification become apparent, even for human anno-
tators, as the camera perspective can sometimes ob-
scure the goal’s position. This issue is compounded
by the limited number of center samples, coupled
with the wide range of camera angles in the dataset.
Consequently, achieving a fine-grained classification
for center may not be practically feasible given these
constraints.
The confusion matrix shown in Figure 8 suggests
a notable accuracy in classifying instances, particu-
larly on the diagonal elements. The top-left quadrant
indicates a correct classification rate of 64.2% for the
left category, while the bottom-right quadrant signi-
fies an 86.5% accuracy in classifying the right cate-
gory. However, there is some misclassification, as ev-
idenced by the off-diagonal elements, with 35.8% of
left instances being erroneously classified as right and
13.5% of right instances being misclassified as left.
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
88

6 CONCLUSIONS
In conclusion, this study extensively examined the
performance of various HAR backbone architectures
in estimating the BoGP during free-kick shots. The
investigation covered three-class (left, center, and
right) and two-class (left and right) classification sce-
narios, providing valuable insights into the effective-
ness of different models.
X3D-L emerged as the top performer for the three-
class classification with notable accuracy, precision,
recall, and F1-Score. However, the overall perfor-
mance in this context remained modest, prompting a
comprehensive error analysis in Section 5. In con-
trast, the two-class scenario revealed a transition in
the number of classes and demonstrated that despite
the reduced complexity, the choice of backbone archi-
tecture remains critical. SlowFast4x16 exhibited the
highest accuracy and noteworthy precision and F1-
Score, highlighting its effectiveness in soccer player
free-kick shoot zone estimation. The inclusion of
Free-kick metadata in the analysis showcased its im-
pact on performance, revealing a 3% accuracy drop
and a 4% decline in F1-Score when not considered.
Importantly, this decline signifies the role of meta-
data in enhancing contextual information without in-
troducing bias to the model.
The focus on the top-performing model, Slow-
Fast4x16, included a detailed examination of confu-
sion matrices for the three-class and the two-class sce-
narios. While the model demonstrated proficiency in
classifying instances, challenges were identified, par-
ticularly in distinguishing the center category. The
limited number of samples and diverse camera angles
posed practical challenges in achieving fine-grained
classification for center.
These findings highlight the complexity of sports
action recognition tasks, emphasizing the need for
careful consideration of the model architecture and
task simplification’s influence. Further questions
were raised, including the impact of the center class
on classification, the distribution of error predictions,
and the exploration of confusion matrices for top-
performing models, providing avenues for future re-
search and improvement.
ACKNOWLEDGEMENTS
This work is partially funded by the Spanish Ministry
of Science and Innovation under project PID2021-
122402OB-C22 and by the ACIISI-Gobierno de Ca-
narias and European FEDER funds under project
ULPGC Facilities Net and Grant EIS 2021 04.
REFERENCES
Akan, S. and Varli, S. (2023). Reidentifying soccer play-
ers in broadcast videos using body feature alignment
based on pose. In Proceedings of the 2023 4th Inter-
national Conference on Computing, Networks and In-
ternet of Things, page 440–444, New York, NY, USA.
Association for Computing Machinery.
Brick, N. E., McElhinney, M. J., and Metcalfe, R. S. (2018).
The effects of facial expression and relaxation cues
on movement economy, physiological, and perceptual
responses during running. Psychology of Sport and
Exercise, 34:20–28.
Carreira, J. and Zisserman, A. (2017). Quo Vadis, Action
Recognition? A New Model and the Kinetics Dataset.
In 2017 IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), pages 4724–4733.
Cioppa, A., Deli
`
ege, A., and Van Droogenbroeck, M.
(2018). A bottom-up approach based on semantics for
the interpretation of the main camera stream in soccer
games. In 2018 IEEE/CVF Conference on Computer
Vision and Pattern Recognition Workshops (CVPRW),
pages 1846–184609.
Deli
`
ege, A., Cioppa, A., Giancola, S., Seikavandi, M. J.,
Dueholm, J. V., Nasrollahi, K., Ghanem, B., Moes-
lund, T. B., and Droogenbroeck, M. V. (2021).
Soccernet-v2 : A dataset and benchmarks for holis-
tic understanding of broadcast soccer videos. In The
IEEE Conference on Computer Vision and Pattern
Recognition (CVPR) Workshops.
Deloitte (2023). Deloitte football money league 2023. Ac-
cessed on November 3, 2023.
Feichtenhofer, C. (2020). X3D: Expanding Architectures
for Efficient Video Recognition. 2020 IEEE/CVF
Conf. on Computer Vision and Pattern Recognition
(CVPR), pages 200–210.
Feichtenhofer, C., Fan, H., Malik, J., and He, K. (2018).
Slowfast networks for video recognition. 2019
IEEE/CVF International Conference on Computer Vi-
sion (ICCV), pages 6201–6210.
Feichtenhofer, C., Fan, H., Xiong, B., Girshick, R. B.,
and He, K. (2021). A large-scale study on unsuper-
vised spatiotemporal representation learning. 2021
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 3298–3308.
FIFA (2022). 2019-2022 revenue. Accessed on November
3, 2023.
Freire-Obreg
´
on, D., Lorenzo-Navarro, J., Santana, O. J.,
Hern
´
andez-Sosa, D., and Castrill
´
on-Santana, M.
(2022). Towards cumulative race time regression
in sports: I3D ConvNet transfer learning in ultra-
distance running events. In International Conference
on Pattern Recognition (ICPR), pages 805–811.
Freire-Obreg
´
on, D., Lorenzo-Navarro, J., Santana, O. J.,
Hern
´
andez-Sosa, D., and Castrill
´
on-Santana, M.
(2023). A Large-Scale Re-identification Analysis in
Sporting Scenarios: the Betrayal of Reaching a Crit-
ical Point. In International Joint Conference on Bio-
metrics (IJCB).
Classifying Soccer Ball-on-Goal Position Through Kicker Shooting Action
89

Gao, X., Liu, X., Yang, T., Deng, G., Peng, H., Zhang, Q.,
Li, H., and Liu, J. (2020). Automatic key moment ex-
traction and highlights generation based on compre-
hensive soccer video understanding. In 2020 IEEE
International Conference on Multimedia Expo Work-
shops (ICMEW), pages 1–6.
Giancola, S., Amine, M., Dghaily, T., and Ghanem, B.
(2018). Soccernet: A scalable dataset for action spot-
ting in soccer videos. In 2018 IEEE/CVF Conference
on Computer Vision and Pattern Recognition Work-
shops (CVPRW), pages 1792–1810.
Guo, T., Tao, K., Hu, Q., and Shen, Y. (2020). Detection
of ice hockey players and teams via a two-phase cas-
caded cnn model. IEEE Access, 8:195062–195073.
He, X. (2022). Application of deep learning in video
target tracking of soccer players. Soft Computing,
26(20):10971–10979.
Homayounfar, N., Fidler, S., and Urtasun, R. (2017). Sports
field localization via deep structured models. In 2017
IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 4012–4020.
Johnson, S. and Everingham, M. (2010). Clustered pose
and nonlinear appearance models for human pose es-
timation. In Proc. BMVC, pages 12.1–11.
Kamble, P., Keskar, A., and Bhurchandi, K. (2019). A deep
learning ball tracking system in soccer videos. Opto-
Electronics Review, 27(1):58–69.
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C.,
Vijayanarasimhan, S., Viola, F., Green, T., Back, T.,
Natsev, P., Suleyman, M., and Zisserman, A. (2017).
The Kinetics Human Action Video Dataset. CoRR.
Lee, J., Moon, S., Nam, D.-W., Lee, J., Oh, A. R., and Yoo,
W. (2020). A study on sports player tracking based
on video using deep learning. In 2020 International
Conference on Information and Communication Tech-
nology Convergence (ICTC), pages 1161–1163.
Li, L. and Li Fei-Fei (2007). What, where and who? classi-
fying events by scene and object recognition. In 2007
IEEE 11th International Conference on Computer Vi-
sion, pages 1–8.
Li, L., Zhang, T., Kang, Z., and Zhang, W.-H. (2023).
Design and implementation of a soccer ball de-
tection system with multiple cameras. ArXiv,
abs/2302.00123.
Microsoft (2023). Shaping the future of the game. Accessed
on November 3, 2023.
Parmar, P. and Morris, B. (2019a). Action quality assess-
ment across multiple actions. In IEEE Winter Con-
ference on Applications of Computer Vision, WACV
2019, Waikoloa Village, HI, USA, January 7-11, 2019,
pages 1468–1476. IEEE.
Parmar, P. and Morris, B. T. (2019b). What and how well
you performed? A multitask learning approach to ac-
tion quality assessment. In IEEE Conference on Com-
puter Vision and Pattern Recognition, CVPR 2019,
Long Beach, CA, USA, June 16-20, 2019, pages 304–
313. Computer Vision Foundation / IEEE.
Penate-Sanchez, A., Freire-Obreg
´
on, D., Lorenzo-Meli
´
an,
A., Lorenzo-Navarro, J., and Castrill
´
on-Santana, M.
(2020). TGC20ReId: A dataset for sport event re-
identification in the wild. Pattern Recognition Letters,
138:355–361.
Santana, O. J., Freire-Obreg
´
on, D., Hern
´
andez-Sosa, D.,
Lorenzo-Navarro, J., S
´
anchez-Nielsen, E., and Cas-
trill
´
on-Santana, M. (2023). Facial expression analysis
in a wild sporting environment. Multimedia Tools and
Applications, 82(8):11395–11415.
Shih, H.-C. (2018). A survey of content-aware video anal-
ysis for sports. IEEE Transactions on Circuits and
Systems for Video Technology, 28(5):1212–1231.
Simonyan, K. and Zisserman, A. (2014). Two-stream con-
volutional networks for action recognition in videos.
ArXiv, abs/1406.2199.
Stein, M., Janetzko, H., Lamprecht, A., Breitkreutz, T.,
Zimmermann, P., Goldl
¨
ucke, B., Schreck, T., An-
drienko, G., Grossniklaus, M., and Keim, D. A.
(2018). Bring it to the pitch: Combining video and
movement data to enhance team sport analysis. IEEE
Transactions on Visualization and Computer Graph-
ics, 24(1):13–22.
Teranishi, M., Fujii, K., and Takeda, K. (2020). Trajectory
prediction with imitation learning reflecting defensive
evaluation in team sports. In 2020 IEEE 9th Global
Conference on Consumer Electronics (GCCE), pages
124–125.
Wang, S., Xu, Y., Zheng, Y., Zhu, M., Yao, H., and Xiao,
Z. (2019). Tracking a golf ball with high-speed stereo
vision system. IEEE Transactions on Instrumentation
and Measurement, 68(8):2742–2754.
Wang, X., Girshick, R. B., Gupta, A. K., and He, K. (2017).
Non-local neural networks. 2018 IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 7794–7803.
Wu, Y., Xie, X., Wang, J., Deng, D., Liang, H., Zhang, H.,
Cheng, S., and Chen, W. (2019). Forvizor: Visualiz-
ing spatio-temporal team formations in soccer. IEEE
Transactions on Visualization and Computer Graph-
ics, 25(1):65–75.
Xu, C., Fu, Y., Zhang, B., Chen, Z., Jiang, Y.-G., and
Xue, X. (2020). Learning to score figure skating sport
videos. IEEE Transactions on Circuits and Systems
for Video Technology, 30(12):4578–4590.
Zhang, Y., Sun, P., Jiang, Y., Yu, D., Yuan, Z., Luo, P., Liu,
W., and Wang, X. (2021). ByteTrack: Multi-Object
Tracking by Associating Every Detection Box. In Eu-
ropean Conference on Computer Vision.
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
90
