
Better Spacial Hashing with Linear Memory Usage and Parallelism
Mykola Zhyhallo
a
and Bo
˙
zena Wo´zna-Szcze
´
sniak
b
Department of Mathematics and Computer Science, Jan Długosz University in Cze¸stochowa, Armii Krajowej 13/15, 42-200
Cze¸stochowa, Poland
Keywords:
Spatial Hashing, Collision Detection, Proximity Queries.
Abstract:
Spatial hashing is an efficient approach for performing proximity queries on objects in collision detection,
crowd simulations, and navigation in 3D space. It can also be used to enhance other proximity-related tasks,
particularly in virtual realities. This paper describes a fast approach for creating a 1D hash table that handles
proximity maps with fixed-size vectors and pivots. Because it allows for linear memory iteration and quick
proximity detection, this method is suitable for reaching interactive frame rates with a high number of sim-
ulating objects. The technique we propose outperforms previous algorithms based on fixed-size vectors and
pivots. Furthermore, our algorithm significantly reduces the memory usage of the pivots table, resulting in de-
creased dependency on the size of the scene. This improvement allows for more efficient memory utilization,
irrespective of the scene’s dimensions.
1 INTRODUCTION
Larger and more complicated simulations become
possible as computers get more powerful. However,
quicker algorithms are necessary to ensure appropri-
ate reaction times in applications where real-time re-
sponse is critical.
Rendering, collision detection, decision-making
or AI processes are the most prominent areas where
performance might suffer for a high number of ob-
jects. When rendering, objects that are not visible to
the camera must be immediately excluded from con-
sideration to maintain an acceptable frame rate. Col-
lision detection often involves comparing each object
in the scene to every other object in the scene, result-
ing in a O(N
2
) method that can significantly decrease
application performance as the number of objects in-
creases. Similarly, AI or autonomous agent decisions
can be exponential, requiring each object to be aware
of its distance from every other object.
Spatial hashing is a widely used method for speed-
ing up proximity searches in large-entity simulations
(Hastings and Mesit, 2005). This technique uses a
hash function to map the positions of 2D or 3D ob-
jects to a 1D hash table. Additionally, the environ-
ment is organized into interconnected cells, forming
a spatial grid. This organization minimizes the num-
a
https://orcid.org/0009-0008-3131-7701
b
https://orcid.org/0000-0002-1486-6572
ber of necessary comparisons between objects, lead-
ing to faster proximity queries. By utilizing the spa-
tial grid, the method optimizes the search process and
improves the overall efficiency of proximity-related
operations.
Spatial hashing has been extensively applied in
a variety of domains to address different challenges,
such as real-time collision detection for simula-
tions (Knievel et al., 2023) or games involving a sig-
nificant number of mobile objects (Hastings et al.,
2004). It has also proven valuable in handling colli-
sions among flexible or deformable models (Teschner
et al., 2003; Mesit et al., 2004), and dense mesh ani-
mations (Kondo and Kanai, 2004).
Beyond the realm of graphics and simulations,
spatial hashing methods have found applications in
other contexts as well. They have been utilized in
tasks such as nearest-neighbor detection in spatial
databases (Zhang et al., 2004), and spatial hash-joins
in relational databases (Lo and Ravishankar, 1996).
These diverse applications highlight the versatility
and effectiveness of spatial hashing algorithms in ad-
dressing spatial data processing requirements across
different fields.
The construction of hash tables can be approached
in various ways, taking into account the changing
number of objects during a simulation. In (Pozzer
et al., 2014) Cesar T. Pozzer et al. have introduced a
spatial hashing algorithm, which employs fixed-size
Zhyhallo, M. and WoÅžna-Szcze
´
sniak, B.
Better Spacial Hashing with Linear Memory Usage and Parallelism.
DOI: 10.5220/0012415700003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 1, pages 351-358
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
351

vectors and pivots to address collisions within the
hash table. This algorithm facilitates upfront com-
putation of the memory requirements for storing the
algorithm’s output. The usage of pivots allows for ef-
ficient updates and queries for the number of elements
within each cell. Moreover, it simplifies the linear it-
eration through entities and cells in memory, enabling
the effective execution of proximity queries. Further-
more, the approach presented in (Pozzer et al., 2014)
demonstrates superior performance (3-10 times) and
improved linear scalability compared to the hash table
implementations proposed in (Buckland, 2005) and
(Hastings and Mesit, 2005).
The algorithm described in (Pozzer et al., 2014)
adopts a 3-step approach, which involves the creation
of two tables: one for pivots and another for data.
This implementation utilizes a space complexity of
O(T
2
) + O(N), where T represents the size of the
scene in cells and N denotes the number of objects.
However, this approach results in significant memory
consumption, particularly in large simulations where
the number of objects is relatively smaller than the
size of the scene.
In this paper, we present a novel method for the
efficient creation of a 1D hash table, specifically de-
signed to handle proximity maps using fixed-size vec-
tors and pivots. Our approach allows for efficient lin-
ear memory iteration and rapid proximity detection,
making it suitable for achieving interactive frame
rates even with a high number of simulating objects.
The proposed solution addresses the issue of
memory consumption by reducing its dependency
on scene size. Moreover, it introduces a new stor-
age structure that enables parallelized implementa-
tion with relaxed memory management, leveraging
the processing resources offered by modern hardware.
As a result, our solution exhibits significantly im-
proved performance for large-scale simulations.
To validate the effectiveness of our approach, we
will first implement and utilize a novel memory stor-
age strategy for pivot tables. Next, we will introduce
parallelization to the solution, capitalizing on the ben-
efits of concurrent processing. Finally, we will com-
pare our results against a basic implementation utiliz-
ing a hash map from the standard library and the algo-
rithm described in the work of C. Pozzer et al ((Pozzer
et al., 2014)).
Overall, our proposed solution offers a more ef-
ficient and scalable approach to spatial hashing for
large-scale simulations, reducing memory consump-
tion and enabling parallelized implementation.
2 PROPOSED SOLUTION
The method we propose extends the method presented
in (Pozzer et al., 2014), which introduced a 3-step ap-
proach for constructing a hash table:
1. for each object, compute its cell ID, and locate
this cell in the pivots table. Increment the object
counter for this cell by 1;
2. traverse the pivots table from the beginning to the
end. Determine the index where all objects within
the cell specified by the pivot will be positioned in
the data table, taking into account the number of
objects in each pivot;
3. move the information of each object to the data
table based on the stored index position in the cor-
responding pivot.
Our method changes the order of the statements
inside each step, utilizes a modified data structure to
store results, and introduces several new steps to syn-
chronize concurrent work.
2.1 Parallelized Algorithm
Our primary aim is to optimize the (Pozzer et al.,
2014) construction of the spatial hash table by har-
nessing the computational power of multiple CPU
cores. The (Pozzer et al., 2014) algorithm encom-
passes three distinct steps, ultimately yielding two es-
sential tables: pivots and data. The pivots table in-
dicates the precise number of objects within each as-
sociated cell. Additionally, it provides the necessary
offset within the data table, facilitating efficient re-
trieval of pertinent information about these objects.
2.1.1 Step 1. Pivots Calculation
As the initial step, a pivots table is allocated, compris-
ing objects characterized by two atomic fields: count
(representing the number of objects in the cell) and
index (indicating the specific offset in the data ta-
ble). In contrast to (Pozzer et al., 2014) algorithm,
our method does not utilize columns named Initial
and Final, thereby reducing the overall size of the
pivots table by 33%. The dimension of this table is
determined by T ∗ T , where T corresponds to the size
of the simulation world measured in cells. Prior to
the commencement of the algorithm, it is crucial to
ensure the proper initialization of objects within this
table, ensuring their values are set to zero.
All the objects are divided into chunks, with
the number of chunks determined by the available
threads. Alternatively, a thread pool data structure can
be employed to partition the objects table into chunks
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
352

of a pre-defined size. The start and end indexes of
the chunk will be used in the algorithm to determine
the bounds of the thread operation. Next, for each ob-
ject (as demonstrated in Listing 1), the cell is calcu-
lated, and the counter for that cell in the pivots table is
incremented by one. In order to reduce synchroniza-
tion overhead, relaxed memory ordering can be used
for atomic operations.
Listing 1: Pivots calculation algorithm.
procedure CalculatePivots(Objects, Pivots, start, end)
for i := start, i < end, i += 1:
c := CalculateCellIndex(Objects[i])
// Please, note that this operation is
// an ATOMIC increment
Pivots[c].count += 1
end procedure
The pivots table will be filled in a manner simi-
lar to the depiction shown in Figure 1. In contrast to
(Pozzer et al., 2014) algorithm, our method employs
atomic counters for pivots and runs in parallel for all
objects.
Figure 1: Building pivots table.
2.1.2 Step 2. Calculating Data Offsets
In this step, we will calculate offsets for the objects
within the data table. Leveraging the pivots table, we
will set the index to the value offset + count to
each cell where the count exceeds 0. To prevent off-
set overlap, an atomic counter will be defined to indi-
cate the subsequently available offset within the data
table. The algorithm for filling the table with offsets
is outlined in Listing 2, and the ultimate outcome can
be observed in Figure 2.
To understand where indexes came from, we have
to compare our solution to (Pozzer et al., 2014) algo-
rithm. The crucial difference is that we are using an
atomic counter that is shared between all the threads
working simultaneously. That means that for every
pivot, the index is calculated by atomic increment and
fetch counter, thus the values in the indexes appear to
be random. And in the end, the counter is equal to the
number of elements in the pivots table.
Listing 2: Offsets calculation algorithm.
procedure CalculateOffsets(Pivots, start, end, Counter)
for p := start, p < end, p += 1:
count := Pivots[p].count
if count != 0:
offset := Counter.FetchAdd(count)
Pivots[c].index = offset + count
end procedure
As stated before, in contrast to the (Pozzer
et al., 2014) algorithm, our method employs a global
counter with a FetchAdd operation, which is an
atomic operation that retrieves the current value and
simultaneously adds another value to it. This ensures
that other threads searching for the index do not over-
lap. Notably, our approach does not utilize the Initial
and Final fields in the pivots table, as we solely rely
on the Index field.
Figure 2: Precalculating data offsets.
2.1.3 Step 3. Copy Objects into Hash Table
Utilizing the offsets contained within the pivots table,
we can proceed to copy the object information to the
designated data table. This data migration process is
executed concurrently for each individual object, as
shown in Listing 3. First of all, for each object, we are
calculating its cell. Then we get the next available po-
sition in the data table by leveraging FetchAdd opera-
tion on the pivots index value. By utilizing this opera-
tion, we can guarantee the selection of a unique index
in the data table for each object, even when multiple
threads are involved. The final step involves transfer-
ring the object information to the data table.
Listing 3: Data migration algorithm.
procedure MigrateData(Objects, Pivots, Data, start, end)
for i := start, i < end, i += 1:
c := CalculateCellIndex(Objects[i])
// FetchAdd returns the value stored before
// operation,
// "−1" is required to actually subtract it
index := Pivots[c].index.FetchAdd(−1) − 1
Data[index] = Objects[i]
end procedure
As a result, we will have a properly constructed
pivots table with offsets pointing to the filled regions
Better Spacial Hashing with Linear Memory Usage and Parallelism
353
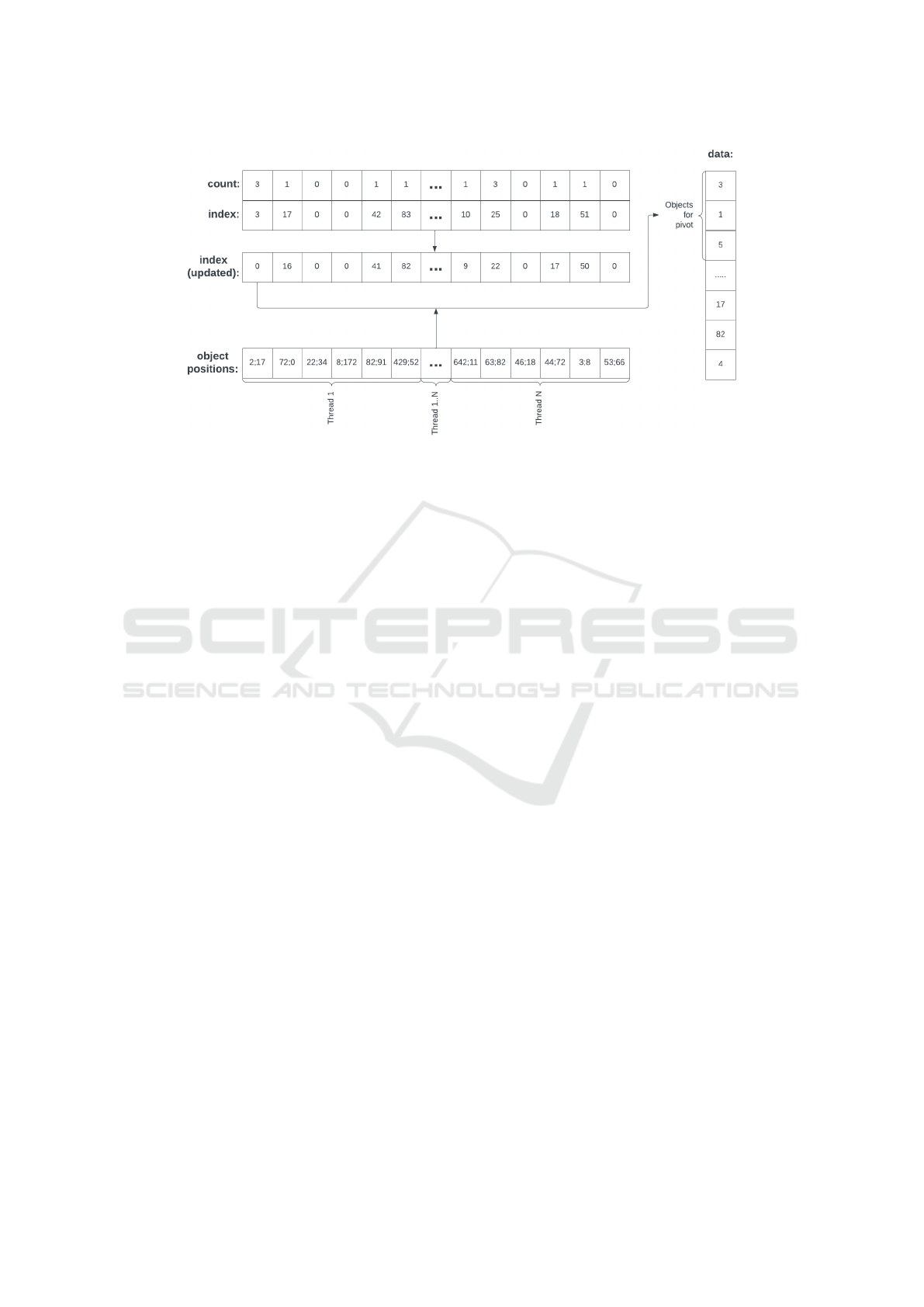
Figure 3: Building the final pivots and data tables.
in the data table, as depicted in Figure 3.
2.2 Parallelization with Better Pivots
Storage. Chunked Algorithm
To effectively handle collisions within the hash table,
the approach described in (Pozzer et al., 2014) uti-
lizes a methodology centered around fixed-sized vec-
tors and pivots. This technique enables the precompu-
tation of the memory needed to store the algorithm’s
output, thereby facilitating efficient resource alloca-
tion. Regarding the storage of pivots, the (Pozzer
et al., 2014) method always uses a table of dimensions
T ∗ T , where T represents the size of the scene mea-
sured in cells. In cases where the scene is relatively
small, the corresponding table size is also small, en-
suring that all entries within the table are used. How-
ever, in situations where the scene is considerably
larger and consists of only a few objects, a significant
portion of the table becomes redundant or unused.
This observation prompts a fundamental ques-
tion: How can we avoid the allocation of memory
for the nonessential portions of the scene? The most
straightforward solution relies on the implementation
of memory paging. By partitioning the scene into uni-
formly sized chunks, we can allocate memory solely
for the chunks that encompass objects of interest.
It is essential to select an appropriate strategy for
splitting space into chunks:
• when performing computations that do not neces-
sitate the utilization of floating-point arithmetic,
particularly in scenarios involving stable physics
simulations, it is wise to partition the space into
chunks with a size that aligns with a power of two.
In this case, the calculation of the chunk index
for an object can be achieved efficiently without
utilizing division, but rather by leveraging binary
shift operations;
• it is recommended that the size of the table stor-
ing chunk pivots be padded and aligned to accom-
modate the CPU cache line size. This alignment
optimization helps facilitate improved cache uti-
lization and subsequently enhances overall perfor-
mance;
• the precise determination of the chunk size ought
to be deduced through a comprehensive assess-
ment of performance metrics and the specific re-
quirements of the application at hand.
The aforementioned optimizations are crucial as
they introduce an additional step in the application’s
workflow, which involves calculating the cell chunk
index to select a chunk from the chunks table, and
then using the pivots table from the specific chunk.
Since this operation is executed frequently, optimiz-
ing the underlying data structure becomes essential to
ensure efficient performance.
We shall proceed with a step-by-step reconstruc-
tion of the algorithm proposed in (Pozzer et al., 2014),
meticulously revisiting each step while incorporat-
ing necessary adaptations and refinements. Also, we
will leverage our work on parallelization and show it
working with this new data structure.
2.2.1 Step 0. Clear
This particular step was omitted from the work con-
ducted by C. Pozzer et al. ((Pozzer et al., 2014))
due to its minimal time requirement when dealing
with small-scale scenes. However, for larger scenes,
despite the operation’s swift execution on contem-
porary computers that leverage the full potential of
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
354

SIMD (Single Instruction, Multiple Data), it can still
consume multiple milliseconds. Such time intervals
prove to be excessive for certain real-time applica-
tions, such as video game physics simulations.
In this step, the pivots table necessitates zeroing.
This step is performed on every iteration of the algo-
rithm. The current approach significantly enhances its
efficiency by exclusively zeroing the allocated space.
Furthermore, when the chunk count is substantial, the
operation can be distributed among multiple threads.
In such cases, each thread is assigned a distinct set of
chunks to zero, thereby enabling parallel processing
and optimization of the zeroing process.
2.2.2 Step 1. Pivots Calculation
As we stated earlier, we assume that the objects in
the pivots table will have only two fields: an atomic
counter for objects and an atomic counter for indices.
This modification will result in a reduction of the
pivot table’s size by 33% compared to the original so-
lution.
Our algorithm presented in Listing 4 utilizes
atomic incrementation (i.e., the AtimicInc(1)
method) and compare-and-swap (i.e., the
CAS(whereToSwap, oldValue, newValue)
method) operations to allocate memory for chunks,
increment the counter in the pivot, and increment
total objects counter for each chunk.
Listing 4: Pivots calculation algorithm.
procedure CalculatePivots(Objects, start, end, Chunks)
for i := start, i < end, i += 1:
c := CalculateChunkIndex(Objects[i])
if Chunks[c] == NULL:
newChunk := AllocateChunk()
if not CAS(Chunk[c], newChunk, NULL):
DeallocateChunk(newChunk)
p := CalculatePivotIndex(Objects[i])
Chunks[c].pivots[p].count.AtomicInc(1)
Chunks[c].objectsCount.AtomicInc(1)
end procedure
The object list is partitioned into slices, with each
slice allocated to an individual thread. This enables
parallel processing, with each thread independently
operating on its assigned slice of objects.
The utilization of a memory pool data struc-
ture for chunk allocation and deallocation opera-
tions is essential at this stage. The absence of a
memory pool would hinder the algorithm’s perfor-
mance compared to alternative solutions, as the re-
peated allocation of all the chunks in each itera-
tion would be excessively time-consuming. That’s
why under the methods AllocateChunk() and
DeallocateChunk(newChunk) we use the memory
pool and not just a simple allocator.
2.2.3 Step 2. Synchronization of the Chunks
Starting Indexes
The original approach employs a single large vector
with a static size to store all object data. In our solu-
tion, all the data can still be stored in a single vector,
but an additional step is required to synchronize the
pivots tables across all chunks. This involves iterating
through all the chunks and assigning a starting index
based on the total objects count within each chunk, as
outlined in Listing 5.
Listing 5: Indexes calculation algorithm.
procedure SyncPivotTables(Chunks)
accum := 0
for i := 0, i < SizeOf(Chunks), i += 1:
Chunks[i].startIndex = accum
accum += Chunks[i].objectsCount.Get()
end procedure
This step can be parallelized; however, since it
involves iterating through a small list of initialized
chunks, the operation is expected to be very fast;
2.2.4 Step 3. Calculation of Indexes Inside
Chunks
In this step, we will calculate offsets for the chunk ob-
jects within the data table. Leveraging the chunk piv-
ots table, we will initially set the index to the chunk
startIndex value for each chunk. To prevent off-
set overlap, a counter will indicate the subsequently
available offset within the data table. The algorithm
for filling the table with offsets is outlined in Listing 6
Listing 6: Indexes calculation algorithm.
procedure CalculateIndexes(Chunk)
if Chunk == NULL:
return
counter := Chunk.startIndex
for p := 0, p < SizeOf(Chunk.pivots), p += 1:
counter += Chunk.pivots[p].count.Get()
Chunk.pivots[p].index.Set(counter)
end procedure
As in the previous step, the chunks can be dis-
tributed among multiple threads. It is noteworthy that
we only operate on the allocated chunks, skipping the
unallocated ones. This significantly reduces the over-
all execution time.
2.2.5 Step 4. Assign Objects in Data Tables
Once the data and pivots tables are prepared, the final
step involves adding each object to the data tables us-
Better Spacial Hashing with Linear Memory Usage and Parallelism
355
ing the corresponding indexes from the pivots tables,
as demonstrated in Listing 7.
Listing 7: Indexes calculation algorithm.
procedure AssignObjects(Objects, Chunks)
for i := 0, i < SizeOf(Objects), i += 1:
c := CalculateChunkIndex(Objects[i])
p := CalculatePivotIndex(Objects[i])
// Calculating index in the data table.
// FetchAdd returns the value stored before
// operation,
// "−1" is required to actually subtract it
d := Chunks[c].pivots[p].index.FetchAdd(−1) − 1
Chunks[c].data[d] = Objects[i]
end procedure
The object list is partitioned into chunks, and each
chunk is allocated to a separate thread. This enables
parallel processing, allowing each thread to operate
independently on its assigned chunk of objects.
3 EXPERIMENTS AND RESULTS
To assess the performance of the proposed algorithm,
a series of experiments were conducted. These ex-
periments involved varying the number of objects and
the size of the simulation scene. The simulation scene
size has ranged from 2048x2048 up to 14336x14336
cells. All experiments were performed on a note-
book PC with an AMD Ryzen 7 5000 CPU, 32 GB
of RAM, running on 16 threads. The following two
testing scenarios were considered:
• Real world - where the distribution of objects in
the simulation space is non-uniform, resulting in
regions with a significantly higher concentration
of objects and regions with no objects at all.
• Worst case - objects are uniformly distributed
across the simulation space.
3.1 Parallelism
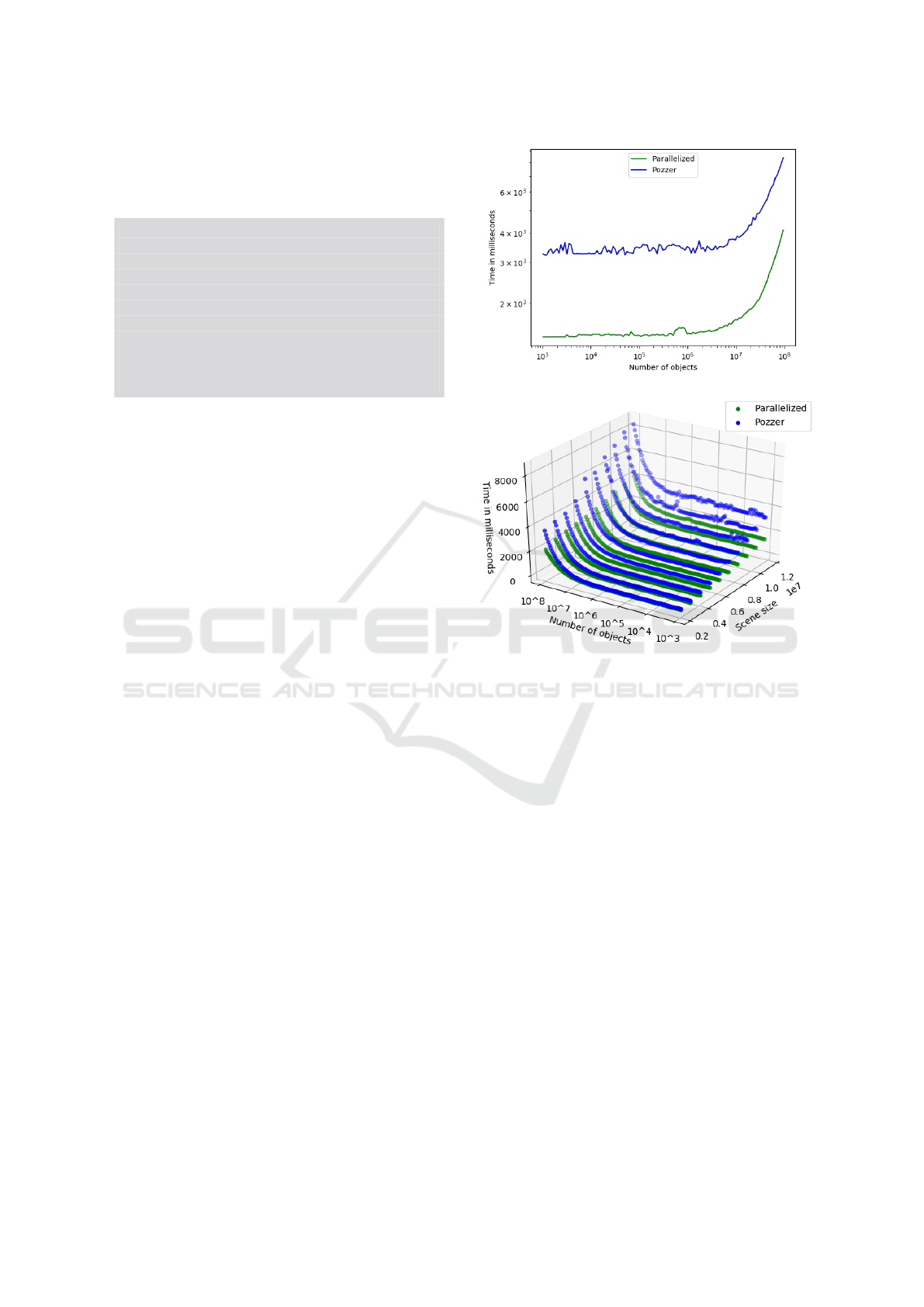
We present a comparison between our newly devel-
oped parallelized method and the method proposed
in (Pozzer et al., 2014), focusing on scene size, ob-
ject count, and simulation runtime. Our parallelized
method, as illustrated in Figure 4a, demonstrates a
significant reduction in simulation time, ranging from
2-4 times faster. In this simulation, objects are uni-
formly distributed across the simulation space. In or-
der to create Figure 4a, the algorithm was run for dif-
ferent scene sizes and object counts, resulting in 1200
simulations.
The algorithm implemented in our method ex-
hibits random memory access, causing a bottleneck in
(a) Fixed scene size.
(b) Different scene sizes.
Figure 4: Results of the parallelized algorithm.
RAM input/output (I/O) operations rather than CPU
power. Consequently, increasing the number of CPU
cores does not guarantee a decrease in simulation
time, even with our algorithm’s lock-free design and
utilization of relaxed memory access.
To reinforce this observation, we refer to Fig-
ure 4b, which shows the simulation time increase
as the simulation space expands, resulting in higher
RAM allocation. Simulation time rises due to the
CPU’s inability to cache memory regions for ex-
tended periods, given the constant loading of new re-
gions. Thus, the necessity for an improved data struc-
ture is evident, as demonstrated in this study.
In cases where the simulation space is extremely
small, parallelization may not yield significant ben-
efits. Additionally, the implementation of our algo-
rithm may introduce unnecessary complexity, poten-
tially leading to increased simulation time and CPU
usage.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
356
3.2 Better Data Structure
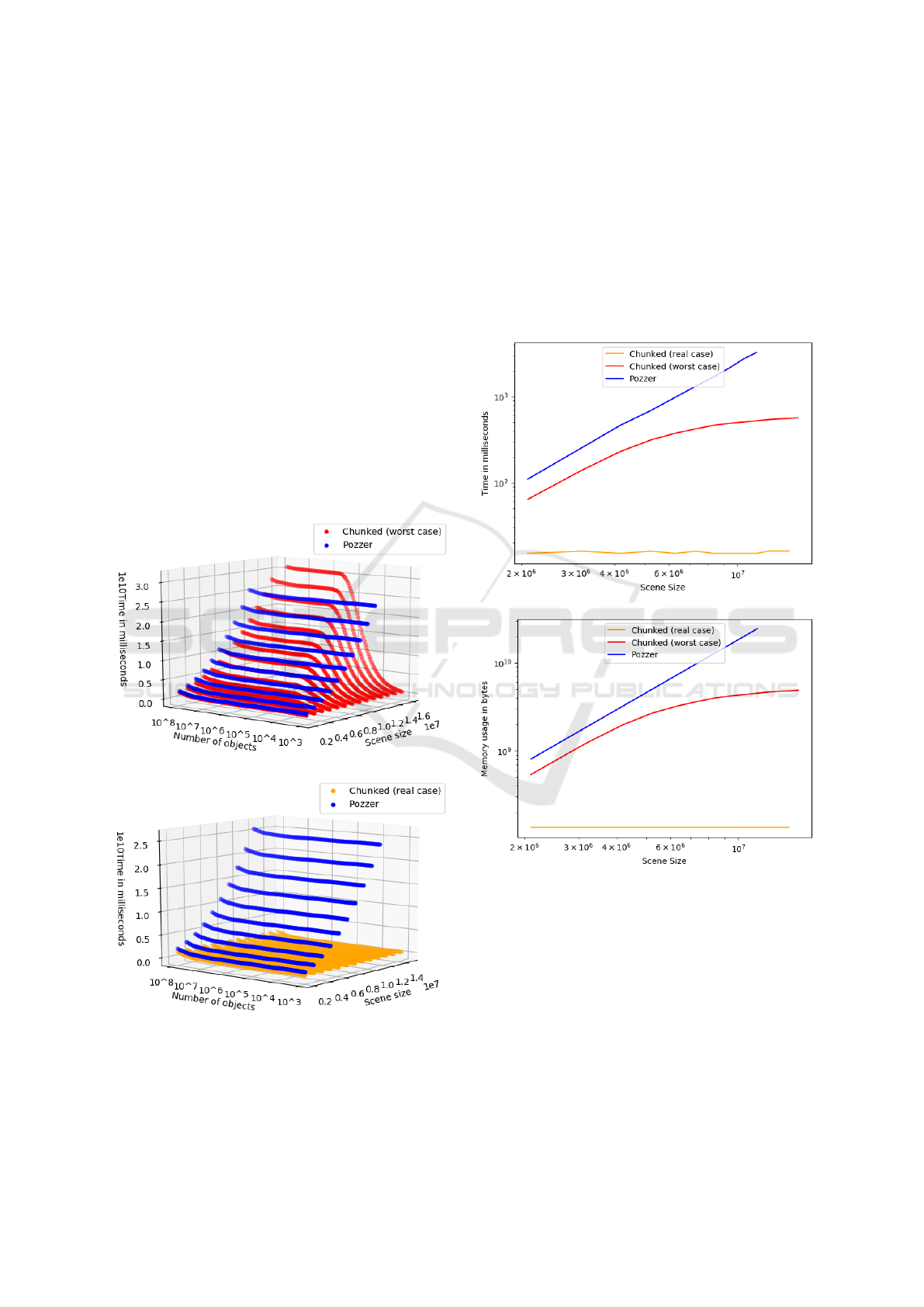
Let’s analyze the worst-case scenario for the chunked
algorithm, where objects are uniformly distributed in
the simulation space, and storage allocation optimiza-
tion is not feasible. Consequently, all regions must
be allocated without the possibility of achieving ef-
ficiency gains. This is evident in Figure 5a, where
regions exhibit a gradual increase in memory usage.
In real-world simulations and tasks, where sim-
ulation spaces typically contain concentrated groups
of objects, memory usage tends to vary significantly.
In this case, as an example of real-world usage, we
selected a physics engine for a 2D game. Figure 5b
demonstrates that the memory usage is no longer de-
pendent on the simulation space but rather linearly de-
pends on the number of objects. This indicates that
our chunked algorithm achieves efficient memory al-
location by effectively managing the concentrated ob-
ject groups within the simulation space.
(a) The worst case scenario.
(b) A real-world scenario.
Figure 5: Memory usage of the chunking algorithm.
A comparative analysis of simulation time (Fig-
ure 6a) and memory usage (Figure 6b) is provided for
various scene sizes and algorithms, focusing on a spe-
cific scenario with a small, predetermined number of
objects (10000 objects). On the charts, we compared
the algorithm from (Pozzer et al., 2014) work (named
Pozzer), with the algorithm from section 2.2 working
in worst case scenario (Chunked (worst case)) and
real-world scenario (Chunked (real case)). We
can see, that memory and CPU usage for the proposed
Chunked algorithm, in contrast to Pozzer, don’t di-
rectly depend on the simulation size in real-world sce-
narios.
(a) Simulation time for 10000 objects.
(b) Memory usage for 10000 objects.
Figure 6: Resource usage comparison for fixed objects
count.
4 RESULTS SUMMARY
In this study, we have introduced a novel spatial hash
algorithm that employs fixed-size vectors and piv-
ots to handle collisions within the hash table. The
proposed approach offers several advantages, includ-
ing reduced memory consumption, support for par-
allelization, and enhanced performance in large-scale
simulations. Our algorithm is designed to leverage
Better Spacial Hashing with Linear Memory Usage and Parallelism
357

modern hardware resources, resulting in improved ef-
ficiency and scalability for spatial hashing tasks.
To validate the effectiveness of our approach, we
implemented a new memory storage strategy for pivot
tables, introduced parallelization techniques, and con-
ducted a comparative analysis against existing imple-
mentations. Our findings highlight the need for a
more efficient data structure, as we identified RAM
I/O operations rather than CPU power as the primary
bottleneck of the algorithm.
Additionally, our study presents observations re-
lated to simulation time increases with the expansion
of the simulation space and memory allocation. We
discuss the worst-case scenario for the chunked algo-
rithm and emphasize that memory usage varies sig-
nificantly in real-world simulations, particularly when
dealing with concentrated groups of objects.
Overall, this research addresses the limitations of
current spatial hashing techniques and proposes an ef-
ficient solution for large-scale simulations by mitigat-
ing memory consumption, facilitating parallelization,
and optimizing proximity queries.
Nevertheless, there are potential ways for further
improvements in our algorithm. For instance, explor-
ing the possibility of leveraging GPU computations,
because the algorithm is designed in a way to sup-
port GPU integration. Additionally, making slight
modifications to enable the utilization of SIMD op-
erations could also enhance performance. These im-
provements could be explored in future research en-
deavors.
REFERENCES
Buckland (2005). Programming Game AI by Example.
Wordware game developer’s library.
Hastings, E. and Mesit, J. (2005). Optimization of large-
scale, real-time simulations by spatial hashing. In
Proceedings of Summer Computer Simulation Confer-
ence, volume 37(4) of SCSC’05, pages 9–17. Society
for Modeling & Simulation International (SCS).
Hastings, E., Mesit, J., and Guha, R. K. (2004). T-
collide: A temporal, real-time collision detection
technique for bounded objects. In Proceedings of
the 5th Game-On International Conference on Com-
puter Games: Artificial Intelligence, Design and Ed-
ucation (CGAIDE), pages 41–48. The University of
Wolverhampton, School of Computing and Informa-
tion Technology Printed in Wolverhampton, UK.
Knievel, C., Pejic, A., Krüger, L., Ziegler, C., and Adamy, J.
(2023). Boids flocking algorithm for situation assess-
ment of driver assistance systems. IEEE Open Journal
of Intelligent Transportation Systems, 4:71–82.
Kondo, R. and Kanai, T. (2004). Interactive physically-
based animation system for dense meshes. In Pro-
ceedings of Eurographics 2004, pages 93–96. The Eu-
rographics Association.
Lo, M.-L. and Ravishankar, C. V. (1996). Spatial hash-
joins. In Proceedings of the 1996 ACM SIGMOD In-
ternational Conference on Management of Data, vol-
ume 25 of SIGMOD’96, page 247–258. ACM.
Mesit, J., Guha, R. K., and Hastings, E. (2004). Optimized
collision detection for flexible objects in a large envi-
ronment. In Proceedings of the 5th Game-On Inter-
national Conference on Computer Games: Artificial
Intelligence, Design and Education (CGAIDE), pages
49–54. The University of Wolverhampton, School of
Computing and Information Technology Printed in
Wolverhampton, UK.
Pozzer, C., De, C., Pahins, C., Heldal, I., Mellin, J.,
and Gustavsson, P. (2014). A hash table construc-
tion algorithm for spatial hashing based on linear
memory. In Proceedings of the 11th Conference
on Advances in Computer Entertainment Technology
(ACE’14), ACE’14. Association for Computing Ma-
chinery.
Teschner, M., Heidelberger, B., Müller, M., Pomerantes, D.,
and Gross, M. H. (2003). Optimized spatial hashing
for collision detection of deformable objects. In The
8th International Fall Workshop on Vision, Modeling,
and Visualization, VMV, pages 47–54. Aka GmbH.
Zhang, J., Mamoulis, N., Papadias, D., and Tao, Y. (2004).
All-nearest-neighbors queries in spatial databases. In
Proceedings of the 16th International Conference on
Scientific and Statistical Database Management (SS-
DBM’04). IEEE Computer Society.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
358
