
ALISE: An Automated Literature Screening Engine for Research
Hendrik Roth
1 a
and Carsten Lanquillon
2 b
1
Artificial Intelligence (M.Sc.), Johannes Kepler University Linz, Austria
2
Business Information Systems, Heilbronn University of Applied Sciences, Heilbronn, Germany
Keywords:
Literature Review, Screening, Automation.
Abstract:
The screening process needs the most time of a literature review. An automated approach saves a lot of time,
making it easier for researchers to review literature. Most current approaches do not consider the full text for
screening, which can cause the exclusion of relevant papers. The Automated LIterature Screening Engine
(ALISE) performs full-text screening based on a research question about the retrieved papers of the literature
search. With an average of 61.87% nWSS and a median of 74.38% nWSS, ALISE can save time for reviewers
but cannot be used without human screening afterwards. Furthermore, ALISE is sensitive to the given research
question(s).
1 INTRODUCTION
A literature review is a widely used research method
intended to provide an overview of previous research,
identify new research opportunities, or draw new con-
clusions from previously unrecognised correlations
(Rowe, 2014; Okoli, 2015). However, conducting a
literature review with an increasing amount of litera-
ture is impractical due to the time-consuming search
and screening process (van Dinter et al., 2021). This
is primarily because extensive screening is required
(van Dinter et al., 2021). Researchers initially retrieve
many publications, e.g., from a keyword search of-
ten numbering in the hundreds or thousands, making
thorough review impractical (Kitchenham and Char-
ters, 2007). Hence, researchers typically rely on ti-
tles and abstracts for preliminary screening, adapted
from established review frameworks (Kitchenham
and Charters, 2007; Page et al., 2021). While this
title and abstract screening saves time, it comes with
limitations. The shortness of titles and abstracts can
lead to the omission of relevant publications and thus
excluding papers that address the research questions
of researchers (Blake, 2010; Penning de Vries et al.,
2020; Wang et al., 2020). This problem is reduced
by full-text screening (Penning de Vries et al., 2020).
However, it has become more difficult as the litera-
ture volume increases continuously. In response, re-
a
https://orcid.org/0009-0007-2602-9679
b
https://orcid.org/0000-0002-9319-1437
searchers have explored automation to aid literature
reviews, employing machine learning algorithms for
screening and categorization (Noroozi et al., 2023;
van Dinter et al., 2021). Many automated methods
still hinge on title and abstract screening (van Din-
ter et al., 2021), perpetuating the risk of overlooking
relevant literature. Large language models (LLMs)
can effectively comprehend and respond to text-based
queries, even rivaling human performance in some
tasks (Ouyang et al., 2022; Liu et al., 2023). This
makes them suitable for automating the screening of
full-text papers. Especially chaining an LLM can
achieve higher results on a downstream task rather
than using only one standard prompt (Yu et al., 2023;
Haji et al., 2023). Despite the possible benefits, there
are currently no studies on applying LLM chains to
automated literature reviews. For this reason, this
paper addresses this gap, aiming to develop an auto-
mated full-text literature screening engine based on a
given research question while following established
literature review protocol guidelines like (Kitchen-
ham and Charters, 2007). To reach this goal, the pa-
per seeks to answer the following research question:
How can the full-text screening process of a literature
review be automated using an LLM chain?
2 RELATED WORK
There are several studies on automated screening pro-
cesses for literature reviews. (van Dinter et al., 2021)
Roth, H. and Lanquillon, C.
ALISE: An Automated Literature Screening Engine for Research.
DOI: 10.5220/0012415200003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 2, pages 453-461
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
453

provide an overview of automated literature review
approaches, identifying various studies, which focus
on title and abstract screening. Yet, only a few ap-
proaches focus on full-text screening. This is be-
cause several challenges come with screening over
full-texts, e.g., PDF files have to be converted to ac-
cessible text (Cohen et al., 2010). However, as also
stated by (Portenoy and West, 2020), it is question-
able if the returned papers by these methods are ac-
tually relevant, or only show strong topic similari-
ties. While considering only keywords or topics to
identify relevant studies, full-text screening seems to
be worse than only screening abstract and title (Di-
este and Padua, 2007). Nevertheless, when defin-
ing a relevant paper for a literature review as a pa-
per that addresses a research question (Templier and
Par
´
e, 2015), this conclusion cannot be made because,
logically, a research question of a reviewer may not
necessarily be answered directly by the abstract or ti-
tle, but instead by paragraphs or sentences of a paper
(Blake, 2010; Penning de Vries et al., 2020). Hence,
(La Quatra et al., 2021) use a text summarizer and
correlation calculations to classify if a cited paper
contains relevant information in its full text. (Wil-
son et al., 2023) compare the effectiveness of regu-
lar expression matching and a machine learning clas-
sifier that was trained particularly for human screen-
ing categorization when it came to automated full-text
screening. By employing language models as phrase
embeddings, (Alchokr et al., 2022) suggested a differ-
ent method that involved weighting and clustering the
literature according to its relevance. Although the au-
thors’ approach is conducted on assessing titles and
abstracts, they recognized the potential relevance of
this method to full-text analysis, highlighting the need
for more research in this field. In a different study,
(Noroozi et al., 2023) iteratively classified relevant
and irrelevant literature during the systematic search
process using a random forest classifier based on full-
text feature similarity. The goal of this iterative clas-
sification strategy was to enhance the accuracy of the
screening process and improve the selection of per-
tinent publications. There is no study yet that uses
LLMs for automating the screening process respect-
ing the full text of a paper and a given research ques-
tion.
3 BACKGROUND
3.1 Conducting a Literature Review
There are several common literature review method-
ologies for various domains. For the information sys-
tems domain, the methodology proposed by (Brocke
et al., 2009) is a frequently used methodological
framework, whereas the framework of (Kitchenham
and Charters, 2007) is often utilized in the software
engineering domain. PRIMSA by (Page et al., 2021)
is often applied in the biomedical domain, and the
methodology by (Snyder, 2019) is common for busi-
ness research. However, they all basically consist of
the same general steps, the differences are mainly ref-
erences to domain-specific journals and quality as-
sessments or more detailed descriptions of some steps
(Templier and Par
´
e, 2015). Therefore, (Templier and
Par
´
e, 2015) as well as (Okoli, 2015) modeled general
steps for a literature review based on these common
methodology frameworks. The only difference be-
tween (Okoli, 2015) and (Templier and Par
´
e, 2015)
is that they switch the general steps 5 and 6 and, fur-
thermore, split the screening process into two steps
(an initial title and abstract screening, which is fol-
lowed by full-text screening). The last step of (Okoli,
2015) can be ignored because it is about writing the
review, not conducting the review. Hence, there are 6
general steps for conducting a literature review based
on (Okoli, 2015) and (Templier and Par
´
e, 2015). The
steps are iterative and can lead to refinement of the
previous steps (Brocke et al., 2009; Templier and
Par
´
e, 2015). Figure 1 visualises these six general
steps.
Figure 1: General literature review methodology based on
(Templier and Par
´
e, 2015) and (Okoli, 2015).
Step 1 - The first step consists of defining the
problem inclusive the research question(s) (Okoli,
2015). (Kitchenham and Charters, 2007) noted, that
each literature review must have a research question
for guidance of the review. Therefore, this step also
includes the definition of the general conditions based
on this research question(s) and problem conception,
such as the definition of the search terms (Brocke
et al., 2009).
Step 2 - After the conceptualisation of the prob-
lem and research questions, a search is performed
with the defined search terms and filter criteria with
the goal to get a literature collection of various litera-
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
454

ture databases (Templier and Par
´
e, 2015).
Step 3 - When various papers are retrieved by the
search in databases, the literature has to be checked
for relevance, also called screening, where the goal
is to find papers which helps answer the defined
research question (Templier and Par
´
e, 2015). The
Screening Process consists typically of initial ab-
stract/title screening to shorten the large volume of re-
trieved papers, followed by a full-text screening pro-
cess on the reduced paper corpus (Okoli, 2015; Tem-
plier and Par
´
e, 2015).
Step 4 - For each relevant literature, the quality
must be assessed (Brocke et al., 2009; Templier and
Par
´
e, 2015; Okoli, 2015). Even if a paper is relevant,
it can have a low quality and hence must be rejected
for inclusion due to quality standards (Okoli, 2015).
There are several techniques to assess the quality of a
paper (Templier and Par
´
e, 2015).
Step 5 - With the completion of step 4, the review-
ers have now a literature corpus for the data extraction
related to their research question(s), which represents
then the actual findings of the review (Templier and
Par
´
e, 2015; Okoli, 2015). The extracted data depends
on the study and research question, which then also
defines the method which can be used for extracting
(Templier and Par
´
e, 2015).
Step 6 - The last step is to analyze and synthe-
size the extracted data (Okoli, 2015; Templier and
Par
´
e, 2015). Typical methods are a concept matrix
by (Webster and Watson, 2002) or a table/forest plot
as indicated by (Kitchenham and Charters, 2007).
3.2 Explainability
As (Kitchenham and Charters, 2007) and PRISMA
by (Page et al., 2021) stated in their methodology, the
point of the literature review protocol is to record ev-
erything in such a way that it is comprehensible and
explainable. For this reason, notes should also be
made on relevant papers while screening (Kitchen-
ham and Charters, 2007). By taking notes, re-
searchers can keep track of their thought processes,
criteria, and justifications for including or excluding
specific papers (Okoli, 2015). Most automated meth-
ods do not indicate why a paper is relevant, but just
return a corpus labelled as relevant without justifica-
tion (Portenoy and West, 2020). Thus, ALISE must
be able to explain why a paper is relevant, as it can
also be done when screened manually.
4 APPROACH
4.1 Problem Definition
As ALISE aims to be integrated into commonly used
literature review methodology processes, the screen-
ing process can be described similar to the gen-
eral literature review methodology by (Okoli, 2015)
or (Templier and Par
´
e, 2015) and thus covers the
methodology processes of (Kitchenham and Char-
ters, 2007), (Brocke et al., 2009), (Snyder, 2019),
and (Page et al., 2021). Given our study’s focus
on full-text screening, we omit the initial abstract
and title screening step. Furthermore, this task can
be seen as a classification task determining as rele-
vant or not relevant paper (Olorisade et al., 2019),
which is also respected by the definitions. Typi-
cally, the screening process involves the application
of inclusion and exclusion criteria (Templier and Par
´
e,
2015). Exclusion criteria, used to apply automatic fil-
ters (e.g., language, article type, date), can be applied
during the initial literature database search (Brocke
et al., 2009). Quality-related exclusion criteria are
assessed during the quality assessment step follow-
ing the screening process (Kitchenham and Charters,
2007). For this reason, the inclusion criteria consid-
ered are only from the content perspective as men-
tioned by (Okoli, 2015), which is to review if the pa-
per addresses the specific research question(s) (Tem-
plier and Par
´
e, 2015). With this context, we describe
the screening process as follows:
Let RQ be the given research question. Given
an initial set P = {p
1
, p
2
, . . . , p
n
} of n papers p
i
and
RQ, retrieved from an initial search (keyword search,
snowballing, etc.), the screening process in a litera-
ture review involves checking if a paper addresses the
research question and documenting the reasons why
a paper is considered relevant. Hereby, ∀p
i
∈ P, the
relevance labelling function is defined as follows:
f (p
i
) =
(
1, if p
i
addresses RQ
0, otherwise
(1)
Thus, the relevance labels l
i
∈ {0, 1} resulting
from f are used for each paper p
i
∈ P. Addition-
ally, there is a need for the review protocol to cap-
ture the reasons why each paper is considered rel-
evant (Kitchenham and Charters, 2007). This is
defined as a set R consisting of paper-specific rea-
sons r
i
∀p
i
∈ P. Hence, for each paper p
i
that ad-
dresses the research question, t paper specific reasons
r
i
= {reason
1
, reason
2
, . . . , reason
t
} are assigned to
explain its relevance.
To conclude, the screening process involves evalu-
ating each paper p
i
and documenting the correspond-
ALISE: An Automated Literature Screening Engine for Research
455
ing relevance reasons r
i
if it is relevant. Hence,
the results of the screening process are two sets
S = {p
i
| l
i
= 1, p
i
∈ P} and R = {(p
i
, r
i
) | l
i
=
1, r
i
explains relevance of p
i
}. The set S represents
the subset of papers from P that are relevant, hence
which address the given research question RQ (label
l is equal to 1). The set R contains pairs of papers p
i
and their corresponding relevance reasons r
i
. Conse-
quently, during the automated screening process, each
paper p
i
of P is examined, and if it is found to ad-
dress the research question RQ, l is set to 1, and a
relevance reason r
i
is documented in R. By selecting
papers based on the value of f and documenting the
relevance reasons in R, the review protocol ensures
transparency and provides a record of the justification
behind the inclusion of each relevant paper that ad-
dresses the research question in the literature review.
If there are multiple research questions, this proce-
dure will be logically performed for all research ques-
tions. As output, S can be used for the quality assess-
ment, which is the next step in the general literature
review methodology (Templier and Par
´
e, 2015).
4.2 Technical Details
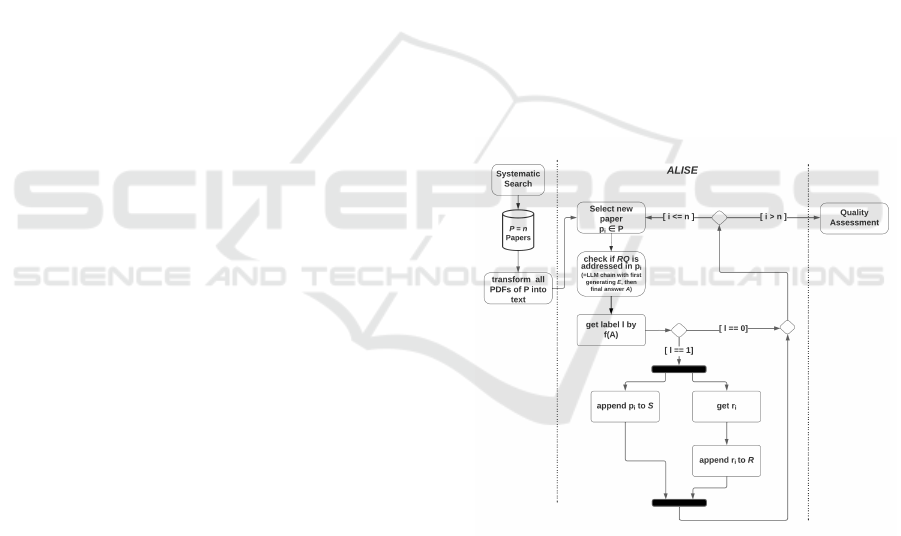
To assess whether a paper addresses a given RQ, we
utilize an LLM chain as described by (Wu et al.,
2022), since it has the potential to outperform vari-
ous classical retriever-reader architectures (Yu et al.,
2023). Our chain is inspired by the generate-read
chain of (Yu et al., 2023) and the multi-hop QA chain
of (Haji et al., 2023) using Flan-t5-XL due to hard-
ware limitations. Thus, the LLM chain with manual
prompt templates first generates the evidence E based
on the chunks C which serve as an answer to RQ and,
then, generates the final answer A using E as con-
text. Here, the chunks C were created by an straight-
forward approach. The template length was sub-
tracted from the maximum input token length of 512
to determine the chunk size l
chunk
= 512 − l
template
.
For each sentence, it was checked whether adding the
sentence to the current chunk would exceed the token
limit in order to avoid truncated sentences. Chunk-
ing by logical sections of the paper also seemed in-
tuitive, but handling long sections was challenging
and kind of arbitrary in some cases, so we chose the
simpler and more straight-forward approach of cut-
ting right before reaching the token limit. The us-
age of the evidence-answer chain also enables simul-
taneously getting the reason r
i
for a paper when con-
ducting MRC because it generates the evidence for
the answers and the answer itself as a reason. This
also implicates the labelling function because if the
RQ is not answerable by a paper p
i
, the LLM chain
returns unanswerable. If the answer is not unanswer-
able, l = f (p
i
) = 1, otherwise l = f (p
i
) = 0. When
l = 1, the reason r
i
can be returned by referring to the
extracted pieces of evidence related to that question.
However, most retrieved papers P from the search are
in PDF format (van Dinter et al., 2021), necessitating
a PDF-to-text conversion before being used as textual
input for the evidence-answer chain. This is a chal-
lenge due to the diverse layouts of scientific texts, in-
cluding multiple columns, different headers and foot-
ers, variable abstract positions, and figures and tables
affecting text flow (Bast and Korzen, 2017). Address-
ing these issues, (Tauchert et al., 2020) employed op-
tical character recognition (OCR) to convert scientific
PDFs into plain text format. While they used OCR-
tesseract, better libraries have emerged, with Grobid
being a notable choice as evaluated by (Miah et al.,
2022). Grobid is also utilized by the Semantic Scholar
Open Research Corpus (Lo et al., 2020), offering both
effectiveness and scalability for handling large vol-
umes of scientific papers. For this reason, we chose
the s2orc json converter of the Semantic Scholar Open
Research Corpus (Lo et al., 2020). Figure 2 visualises
the flow of ALISE.
Figure 2: Implementation of ALISE.
5 EVALUATION
5.1 Metrics
ALISEs goal is to assist scientists in the screening
process and reduce the time and effort of reviewers.
To evaluate its performance, we follow the precedent
set by other automated screening approaches against
human performance, like (Cohen et al., 2006; Kusa
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
456

et al., 2023). We use standard NLP metrics based
on the confusion matrix: true positives (TP) for cor-
rectly classified papers, false positives (FP) for pa-
pers ALISE incorrectly labels as relevant, true neg-
atives (TN) for correctly classified irrelevant papers,
and false negatives (FN) for papers ALISE misses.
The evaluation metrics equations are provided below:
Accuracy (Acc) =
T P + T N
T P + T N + FP + FN
(2)
Precision(Pr) =
T P
T P + FP
(3)
Recall (Re) =
T P
T P + FN
(4)
F1 = 2 ×
Pr × Re
Pr + Re
(5)
W SS =
T N + FN
N
− (1.0 − Re) (6)
The WSS metric measures the work saved over
sampling (Cohen et al., 2006). It represents the ra-
tio of articles initially identified through a literature
search that researchers can skip reading because they
have already been screened out by ALISE.
nW SS =
T N
T N + FP
(7)
The nWSS metric by (Kusa et al., 2023) is the nor-
malized WSS metric to enable better comparisons be-
tween different literature reviews, hence not the same
reviews must be evaluated as a baseline. Furthermore,
the nWSS is equal to the true negative rate (Kusa
et al., 2023).
5.2 Dataset
The common dataset of (Cohen et al., 2006) for eval-
uating automated screening was not used due to its
limitation on titles and abstracts, whereas ALISE uses
full-texts. In the evaluation of automated screening
approaches, researchers often contend with the chal-
lenge of manual annotation. Some studies evaluate
these approaches based on a single literature review
(Noroozi et al., 2023), while others consider two dif-
ferent reviews (Alchokr et al., 2022). Our selec-
tion of three literature reviews from random searches
on ACM, IEEE, and SpringerLink due to the labor-
intensive nature of manual annotation, followed spe-
cific criteria. We considered reviews that were peer-
reviewed, reproducible (yielding consistent search re-
sults with the provided searches), accessible (in lit-
erature databases to which we had access), well-
documented (with relevant papers clearly listed, such
as in a table), and comprehensible (with well-defined
inclusion and exclusion criteria to minimize FP dur-
ing manual annotation). The following reviews met
our specified criteria, while many others were unsuit-
able due to factors such as irreproducibility, inaccessi-
ble databases, or the impracticality of manually down-
loading thousands of papers. Consequently, our eval-
uation baseline comprises three literature reviews: lit-
erature review 1 (LR1) (Jakob, 2022), literature re-
view 2 (LR2) (da Silva Junior et al., 2022), and lit-
erature review 3 (LR3) (Omran and Treude, 2017).
Table 1 provides an overview of the evaluated litera-
ture reviews regarding the number of papers screened
(n) and how many papers are actually relevant.
Table 1: Overview of LRs used for evaluation.
Literature Review n relevant
LR1 (Jakob, 2022) 101 60
LR2 (da Silva Junior et al., 2022) 262 6
LR3 (Omran and Treude, 2017) 232 33
5.3 Setup
Manually downloading all papers from the three se-
lected literature reviews was necessary since there are
no open API accesses available for obtaining full-text
content from SpringerLink, IEEE, and ACM Digital
Library or the automation of this task was longer than
manually downloading. To save time, and considering
that automated downloading was solely for evaluation
purposes and not part of the screening process, we
opted for manual downloads. The automated screen-
ing process ran on an NVIDIA Tesla T4, with no mod-
ifications to the quantization of Flan-t5-XL. Where
the literature reviews had multiple research questions,
one search was performed for each research question,
and duplicate results were removed. Each iteration
took approximately 45 minutes to two hours, result-
ing in a total evaluation time ranging from 2.5 to 6
hours, depending on the number of papers evaluated.
5.4 Results
This section presents the evaluation results for each
literature review. In the evaluation of the literature
Table 2: Confusion matrix of all literature reviews.
LR TP FP FN TN
LR1 57 17 1 23
LR2 6 61 0 192
LR2* 10 57 0 192
LR3 33 197 0 2
LR3* 21 54 12 145
LR3** 53 22 12 145
ALISE: An Automated Literature Screening Engine for Research
457

review by (Jakob, 2022) (LR1), out of an initial popu-
lation of 101 papers, 98 were evaluated due to limited
full-text access. ALISE achieved 57 TPs, 17 FPs, 1
FNs, and 23 TNs. See table 2 for the confusion ma-
trix values. For the literature review by (da Silva Ju-
nior et al., 2022) (LR2), which initially screened on
title and abstracts, 67 papers were classified as rel-
evant by ALISE. Subsequently, two independent re-
viewers of the related domain manually reviewed the
FPs of the first evaluation LR2, leading to 10 TPs
and 57 FPs. The final confusion matrix values are
listed in table 2 as LR2*. The third literature review
by (Omran and Treude, 2017) (LR3), initially evalu-
ated with the same research questions, has a gold stan-
dard of 33 relevant papers. However, ALISE classi-
fied 230 papers as relevant out of 232. An error analy-
sis revealed several issues causing this misclassifica-
tion, including sensitivity to certain keywords. Due
to the search by keyword with ”natural language” in
several major high-ranked software engineering con-
ferences, this results in all papers mentioning natural
language and additionally in 226 out of 232 also ”pro-
cess”, causing ALISE to classify nearly all papers as
relevant to the first RQ of (Omran and Treude, 2017).
Whereas RQ two and three of LR3 results in lower
relevant papers, we identified that Flan-t5-XL also
classified NLP algorithms like latent Dirichlet alloca-
tion as NLP library, which is not the library used for
implementation, but an algorithm. The fourth ques-
tion ”If so, how was the choice justified?” makes no
sense when iterating over each question because it is
related to the third question as a follow-up. However,
this completely failed evaluation shows two valuable
conclusions: Follow-up research questions currently
cannot be handled when iterating over the questions
and Flan-t5-XL requires some more input rather than
just buzzwords, e.g. an example what an NLP li-
brary is or what is covered under natural language
processing. The evaluation of LR3 was repeated with
a new research question, yielding 32 TPs and 22 FPs.
The confusion matrix for this evaluation is in table
2 as LR3*. After reevaluation regarding the new re-
search question, we encountered the same issue of
FPs as in the evaluation of LR2. Two independent
reviewers, both research engineers in NLP, followed
the same procedure as in LR2: conducting individ-
ual assessments followed by a final comparison and
discussion. Of the initial 54 FPs, the reviewers iden-
tified 32 as genuinely relevant due to their mention of
NLP libraries used in research implementation. This
significant disparity in the number of relevant papers
not identified by (Omran and Treude, 2017) can be
explained by their screening strategy. This evalua-
tion is referred to as LR3** based on the indepen-
dent reviewers’ annotations. Based on these confu-
Table 3: Evaluation results of ALISE.
Acc Re Pr F1 WSS nWSS
LR1 81.63 98.28 77.03 86.36 22.77 57.50
LR2 76.45 100.00 08.96 16.44 74.13 75.89
LR2* 78.00 100.00 14.93 25.97 74.13 77.11
LR3 15.09 100.00 14.35 25.10 00.87 01.05
LR3* 71.55 63.64 28.00 38.89 31.31 72.86
LR3** 85.34 81.54 70.67 75.71 49.21 86.83
sion matrices, table 3 provides a summary of evalu-
ation metrics for all literature reviews. The accuracy
ranges from 15.09% to 85.34%, with perfect recalls
for LR2, LR2*, and LR3. Precision varies between
8.96% (LR2) and 77.03% (LR1). The F1 score ranges
from 16.44% to 86.36%. WSS metrics vary widely,
with some in the intermediate range, while the nWSS
has only one outlier LR3.
5.5 Result Analysis
(Cohen et al., 2006) noted that the goal of automated
screening tools should be at least having a 95.00% re-
call compared to the human baseline and a WSS as
high as possible. (Kusa et al., 2023) adapted this goal
also with the nWSS. The evaluation metrics show (ta-
ble 3), that ALISE can surpass this goal by reach-
ing 98.28% and 100.00% for LR1 and LR2. ALISE
also reached 100.00% recall for the first evaluation
of LR3. Yet, this must be taken with caution be-
cause nearly every paper was classified as relevant
for LR3 (see table 3). This is also then represented
by the low WSS and nWSS of 00.87% and 1.05%
indicating that nearly no work was saved by manu-
ally screening the literature. In contrast, exceeding
72.86% nWSS for the majority of literature reviews,
this is a strong indication that, in general, ALISE is
capable of saving a lot of time for human reviewers.
Nevertheless, ALISE cannot be used without manual
human evaluation after classification due to the clas-
sification of some FPs in each evaluated literature re-
view. Otherwise, the nWSS would have also been per-
fect 100.00%. Furthermore, the outlier of LR3 and the
following evaluation LR3** shows the sensitivity for
the research question used as input since there is an
improvement of 85,78% nWSS score. Consequently,
the results mark the validation of ALISE being used
for automated screening over full-texts, but having
some limitations. The nWSS also makes it possible
to compare these results with other automated tools.
In this study, ALISE has an average nWSS score of
61.87%, which is better than the best method in av-
erage evaluated by (Kusa et al., 2023) with 57.21%.
Without evaluation LR3 being an outlier due to the
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
458

wrong research questions needed for the LLM, the
average is even 74.04% nWSS which clearly outper-
forms the best method stated in (Kusa et al., 2023).
Except for model E evaluated by (Kusa et al., 2023)
with an average nWSS of 55.50%, all other five eval-
uated models are below an average of 41.41%. How-
ever, a user of ALISE may also not initially define
the research question(s) as well as required for the
model and would then have to iteratively adjust that,
so the average without the outlier should be viewed
with caution. For this reason, the average with outlier
and the median of 74.38% is more meaningful. The
median of the best model D evaluated by (Kusa et al.,
2023) is 60.9%. This also indicates a strong proof that
ALISE can be used as an automated screening method
when considering its limitations.
6 CONCLUSION
ALISE can be used as an automated screening tool
over full-texts for literature reviews. Not only is rele-
vant literature classified as relevant, ALISE also pro-
vides reasons for the review protocol why a paper is
relevant. An evaluation of three different literature
reviews was conducted to measure the performance
of ALISE. The highest nWSS score is 86.83%, indi-
cating a large time saving for the reviewers after the
literature search. With an average of 61.87% nWSS
considering all evaluated literature reviews, and a me-
dian of 74.38% nWSS, ALISE can save a lot of time
but cannot be used without a followed human screen-
ing iteration over the literature classified as relevant
by ALISE. However, there are some limitations when
using ALISE regarding RQ sensitivity and hardware.
LIMITATIONS
ALISE shares LLM limitations, making it sensitive
to the RQ and the chain prompts. In addition, fast
inference requires a GPU, which makes it costly. Fur-
thermore, the PDF conversion may introduce errors,
potentially affecting the results. Two of the three LRs
evaluated initially screened titles and abstracts before
full-text, introducing the possibility of FNs not identi-
fied by either reviewers or ALISE. Utilizing LRs with
full-text screening from the start could have mitigated
this issue. An inadequately defined research question
can lead to suboptimal results, negating the time sav-
ings and potentially requiring significant refinement.
Even if subsequent iterations were error-free, the cu-
mulative computation time may exceed the manual
screening.
REFERENCES
Alchokr, R., Borkar, M., Thotadarya, S., Saake, G., and
Leich, T. (2022). Supporting systematic literature re-
views using deep-learning-based language models. In
Proceedings of the 1st International Workshop on Nat-
ural Language-Based Software Engineering, NLBSE
’22, page 67–74, New York, NY, USA. Association
for Computing Machinery.
Bast, H. and Korzen, C. (2017). A benchmark and evalua-
tion for text extraction from pdf. In 2017 ACM/IEEE
Joint Conference on Digital Libraries (JCDL), pages
1–10.
Blake, C. (2010). Beyond genes, proteins, and abstracts:
Identifying scientific claims from full-text biomed-
ical articles. Journal of Biomedical Informatics,
43(2):173–189.
Brocke, J. v., Simons, A., Niehaves, B., Riemer, K., Plat-
tfaut, R., and Cleven, A. (2009). Reconstructing the
giant: On the importance of rigour in documenting the
literature search process. In European Conference on
Information Systems.
Cohen, A. M., Hersh, W. R., Peterson, K., and Yen, P.-
Y. (2006). Reducing workload in systematic review
preparation using automated citation classification.
Journal of the American Medical Informatics Associ-
ation, 13(2):206–219.
Cohen, K. B., Johnson, H. L., Verspoor, K., Roeder, C.,
and Hunter, L. E. (2010). The structural and content
aspects of abstracts versus bodies of full text journal
articles are different. BMC bioinformatics, 11(1):492.
da Silva Junior, B. A., Silva, J., Cavalheiro, S., and Foss, L.
(2022). Pattern recognition in computing education:
A systematic review. In Anais do XXXIII Simp
´
osio
Brasileiro de Inform
´
atica na Educac¸
˜
ao, pages 232–
243, Porto Alegre, RS, Brasil. SBC.
Dieste, O. and Padua, A. G. (2007). Developing search
strategies for detecting relevant experiments for sys-
tematic reviews. In First International Symposium
on Empirical Software Engineering and Measurement
(ESEM 2007), pages 215–224.
Haji, S., Suekane, K., Sano, H., and Takagi, T. (2023).
Exploratory inference chain: Exploratorily chaining
multi-hop inferences with large language models for
question-answering. In 2023 IEEE 17th International
Conference on Semantic Computing (ICSC), pages
175–182.
Jakob, D. (2022). Voice controlled devices and older adults
– a systematic literature review. In Gao, Q. and Zhou,
J., editors, Human Aspects of IT for the Aged Pop-
ulation. Design, Interaction and Technology Accep-
tance, pages 175–200, Cham. Springer International
Publishing.
Kitchenham, B. A. and Charters, S. (2007). Guidelines
for performing systematic literature reviews in soft-
ware engineering. Technical Report EBSE-2007-01,
School of Computer Science and Mathematics, Keele
University.
Kusa, W., Lipani, A., Knoth, P., and Hanbury, A. (2023).
An analysis of work saved over sampling in the eval-
uation of automated citation screening in systematic
ALISE: An Automated Literature Screening Engine for Research
459

literature reviews. Intelligent Systems with Applica-
tions, 18:200193.
La Quatra, M., Cagliero, L., and Baralis, E. (2021). Lever-
aging full-text article exploration for citation analysis.
Scientometrics, 126(10):8275–8293.
Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., and Neubig,
G. (2023). Pre-train, prompt, and predict: A system-
atic survey of prompting methods in natural language
processing. ACM Comput. Surv., 55(9).
Lo, K., Wang, L. L., Neumann, M., Kinney, R., and Weld,
D. (2020). S2ORC: The semantic scholar open re-
search corpus. In Proceedings of the 58th Annual
Meeting of the Association for Computational Lin-
guistics, pages 4969–4983, Online. Association for
Computational Linguistics.
Miah, M. S. U., Sulaiman, J., Sarwar, T. B., Naseer, A.,
Ashraf, F., Zamli, K. Z., and Jose, R. (2022). Sentence
boundary extraction from scientific literature of elec-
tric double layer capacitor domain: Tools and tech-
niques. Applied Sciences, 12(3).
Noroozi, M., Moghaddam, H. R., Shah, A., Charkhgard,
H., Sarkar, S., Das, T. K., and Pohland, T. (2023). An
ai-assisted systematic literature review of the impact
of vehicle automation on energy consumption. IEEE
Transactions on Intelligent Vehicles, pages 1–22.
Okoli, C. (2015). A guide to conducting a standalone sys-
tematic literature review. Commun. Assoc. Inf. Syst.,
37:43.
Olorisade, B. K., Brereton, P., and Andras, P. (2019). The
use of bibliography enriched features for automatic ci-
tation screening. Journal of Biomedical Informatics,
94:103202.
Omran, F. N. A. A. and Treude, C. (2017). Choosing an
nlp library for analyzing software documentation: A
systematic literature review and a series of experi-
ments. In Proceedings of the 14th International Con-
ference on Mining Software Repositories, MSR ’17,
page 187–197. IEEE Press.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright,
C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K.,
Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L.,
Simens, M., Askell, A., Welinder, P., Christiano, P. F.,
Leike, J., and Lowe, R. (2022). Training language
models to follow instructions with human feedback.
In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave,
K. Cho, and A. Oh, editors, Advances in Neural Infor-
mation Processing Systems, volume 35, pages 27730–
27744. Curran Associates, Inc.
Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron,
I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L.,
Tetzlaff, J. M., Akl, E. A., Brennan, S. E., Chou,
R., Glanville, J., Grimshaw, J. M., Hr
´
objartsson, A.,
Lalu, M. M., Li, T., Loder, E. W., Mayo-Wilson, E.,
McDonald, S., McGuinness, L. A., Stewart, L. A.,
Thomas, J., Tricco, A. C., Welch, V. A., Whiting,
P., and Moher, D. (2021). The prisma 2020 state-
ment: An updated guideline for reporting systematic
reviews. Journal of Clinical Epidemiology, 134:178–
189.
Penning de Vries, B. B., van Smeden, M., Rosendaal, F. R.,
and Groenwold, R. H. (2020). Title, abstract, and key-
word searching resulted in poor recovery of articles in
systematic reviews of epidemiologic practice. Journal
of Clinical Epidemiology, 121:55–61.
Portenoy, J. and West, J. D. (2020). Constructing and eval-
uating automated literature review systems. Sciento-
metrics, 125(3):3233–3251.
Rowe, F. (2014). What literature review is not: diversity,
boundaries and recommendations. European Journal
of Information Systems, 23(3):241–255.
Snyder, H. (2019). Literature review as a research method-
ology: An overview and guidelines. Journal of Busi-
ness Research, 104:333–339.
Tauchert, C., Bender, M., Mesbah, N., and Buxmann, P.
(2020). Towards an integrative approach for auto-
mated literature reviews using machine learning. In
Hawaii International Conference on System Sciences.
Templier, M. and Par
´
e, G. (2015). A framework for guiding
and evaluating literature reviews. Commun. Assoc. Inf.
Syst., 37:6.
van Dinter, R., Tekinerdogan, B., and Catal, C. (2021). Au-
tomation of systematic literature reviews: A system-
atic literature review. Information and Software Tech-
nology, 136:106589.
Wang, Z., Nayfeh, T., Tetzlaff, J., O’Blenis, P., and Murad,
M. H. (2020). Error rates of human reviewers during
abstract screening in systematic reviews. PLOS ONE,
15(1):1–8.
Webster, J. and Watson, R. T. (2002). Analyzing the past
to prepare for the future: Writing a literature review.
MIS Quarterly, 26(2):xiii–xxiii.
Wilson, E., Cruz, F., Maclean, D., Ghanawi, J., McCann,
S. K., Brennan, P. M., Liao, J., Sena, E. S., and
Macleod, M. (2023). Screening for in vitro system-
atic reviews: a comparison of screening methods and
training of a machine learning classifier. Clinical Sci-
ence, 137(2):181–193.
Wu, T., Terry, M., and Cai, C. J. (2022). Ai chains: Trans-
parent and controllable human-ai interaction by chain-
ing large language model prompts. In Proceedings of
the 2022 CHI Conference on Human Factors in Com-
puting Systems, CHI ’22, New York, NY, USA. Asso-
ciation for Computing Machinery.
Yu, W., Iter, D., Wang, S., Xu, Y., Ju, M., Sanyal, S., Zhu,
C., Zeng, M., and Jiang, M. (2023). Generate rather
than retrieve: Large language models are strong con-
text generators. In The Eleventh International Confer-
ence on Learning Representations.
APPENDIX
In this appendix, we list some implementation details
of ALISE.
Libraries
• Langchain (https://python.langchain.com)
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
460

• s2orc-doc2json (https://github.com/allenai/s2orc-
doc2json)
• Transformers
(https://github.com/huggingface/transformers)
Langchain was used for the evidence-answer LLM
chain with Flan-t5-XL coming with transformers and
hugging face hub. To transform the pdf papers into
strings, we used the s2orc-doc2json converter.
Prompt Templates
Figure 3 contains the evidence and answer prompt
templates used. These templates performed best
in the evidence-response chain evaluation with the
QASPER dataset.
Figure 3: Prompt templates.
ALISE: An Automated Literature Screening Engine for Research
461
