
Learning 3D Human UV with Loose Clothing from Monocular Video
Meng-Yu Jennifer Kuo
1 a
, Jingfan Guo
1 b
and Ryo Kawahara
2 c
1
University of Minnesota, U.S.A.
2
Kyushu Institute of Technology, Japan
Keywords:
3D Human Reconstruction, UV Mapping, Single View.
Abstract:
We introduce a novel method for recovering a consistent and dense 3D geometry and appearance of a dressed
person from a monocular video. Existing methods mainly focus on tight clothing and recover human geome-
try as a single representation. Our key idea is to regress the holistic 3D shape and appearance as a canonical
displacement and albedo maps in the UV space, while fitting the visual observations across frames. Specif-
ically, we represent the naked body shape by a UV-space SMPL model, and represent the other geometric
details, including the clothing, as a shape displacement UV map. We obtain the temporally coherent overall
shape by leveraging a differential mask loss and a pose regularization. The surface details in UV space are
jointly learned in the course of non-rigid deformation with the differentiable neural rendering. Meanwhile, the
skinning deformation in the garment region is updated periodically to adjust its residual non-rigid motion in
each frame. We additionally enforce the temporal consistency of surface details by utilizing the optical flow.
Experimental results on monocular videos demonstrate the effectiveness of the method. Our UV representa-
tion allows for simple and accurate dense 3D correspondence tracking of a person wearing loose clothing. We
believe our work would benefit applications including VR/AR content creation.
1 INTRODUCTION
3D human shape reconstruction is crucial as it finds
applications in a wide range of domains including
3D avatars in games and metaverse, as well as vir-
tual fitting. Various approaches have been proposed
for this study. Specifically, there are methods us-
ing videos captured by a large number of perfectly
calibrated cameras (Zhao et al., 2022; Wang et al.,
2022), and methods that recover the 3D shape by re-
fining the captured depth (Newcombe et al., 2015).
Most of the images captured by surveillance cam-
eras and on the Internet, however, are monocular im-
ages. Methods that require specialized capture envi-
ronments limit the utility at the consumer level. Re-
cently, several methods have been introduced to re-
cover the 3D shape of a person from a monocular
video by optimizing a parametric human model (Guo
et al., 2023), and have achieved compelling results.
Although parametric human model such as
SCAPE (Anguelov et al., 2005) and SMPL (Loper
et al., 2015) leans a powerful means for accurate 3D
human modeling, these methods are mainly limited
in two critical ways. First, they mainly focus on the
a
https://orcid.org/0000-0002-6705-7971
b
https://orcid.org/0009-0008-6198-365X
c
https://orcid.org/0000-0002-9819-3634
Figure 1: Our method achieves holistic, temporally coher-
ent 3D dressed human reconstruction from a monocular
video. Our method also realizes dense surface correspon-
dence tracking over the sequence.
human wearing tight clothing. This assumption hin-
ders the utility especially for a person wearing skirts
or dresses. Most importantly, most of these methods
are limited to recovering the geometry as a single rep-
resentation. This could be a deal-breaker for some ap-
plications, including virtual try-on, where having 3D
human models in which the garment can be modified
with different textures and/or shapes is crucial.
In this work, we propose a novel method to cre-
ate the 3D avatar of a person wearing loose clothing
from a monocular video. Our key idea is to regress the
holistic 3D shape and appearance as canonical UV-
122
Kuo, M., Guo, J. and Kawahara, R.
Learning 3D Human UV with Loose Clothing from Monocular Video.
DOI: 10.5220/0012414500003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 4: VISAPP, pages
122-129
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

space shape displacement and albedo maps while fit-
ting the visual observations across frames. We rep-
resent the naked body shape by a standard-resolution
SMPL model (Loper et al., 2015) in the UV space
using UV mapping (Blinn and Newell, 1976), and as-
sume the model detail (including clothing and hair) is
a sub-map of the canonical UV map. Such UV repre-
sentation provides a mapping between each 3D vertex
and a predefined 2D space. The shape displacement
UV map encodes the freeform offsets. We use these
UV maps to augment the naked SMPL.
We utilize differential mask loss and a pose reg-
ularization to obtain the temporally coherent overall
shape. The details on the surface in UV space are
jointly refined with the differentiable neural render-
ing. To achieve better rendering, we decompose RGB
images to obtain the diffuse albedo, and further refine
light source and camera view directions. Meanwhile,
the skinning deformation in the garment region is up-
dated periodically to adjust its residual non-rigid mo-
tion in each frame. We also leverage optical flow to
to obtain temporally consistent representations over
the sequence, and a symmetric structure constraint is
enforced to better account for the invisibility.
We quantitatively and qualitatively evaluate our
method on both synthetic and real video datasets, as
well as on Internet videos, with a subject wearing
loose clothing. We regress the canonical UV repre-
sentation for each subject in a self-supervision man-
ner. Experimental results effectively demonstrate that
our pixel-aligned UV prediction achieves full (fuller)
and dense reconstruction of the target person. We also
show that our method realizes dense surface corre-
spondence tracking over the sequence, enabling re-
texturing and/or garment transfer. We believe that our
work would expand the application of 3D human gen-
eration in a wide range of fields.
2 RELATED WORKS
Holistic Human Reconstruction from Multi-
View/Depth. In general, 3D reconstruction requires
multi-view image data, to enable triangulation. The
number of cameras required to reconstruct fine-
grained geometries is usually very high (Joo et al.,
2015). There are several approaches using multi-view
RGB (Zhao et al., 2022; Wang et al., 2022; Hilton
and Starck, 2004) or RGBD (Dong et al., 2022) cam-
eras to capture full human body. In real-world scenar-
ios, however, sometimes it is difficult to install that
many cameras, perhaps 2 or 3 at most, or perhaps
only one camera. Requiring a multi-view capture sys-
tem greatly limits the application of these methods.
For depth-based approaches, a pioneering work by
Newcombe et al.(Newcombe et al., 2015) proposed
depth refinement through integration of 3D volumes
across time. While the aforementioned approaches
have yielded compelling results, they still require spe-
cialized setup of the capture system and are therefore
not user-friendly at the consumer level.
Holistic Human Reconstruction from Monocu-
lar Video. For single-view human reconstruction
(Alldieck et al., 2019), and synthetic data generation
(Varol et al., 2017), parametric 3D human models
such as SCAPE (Anguelov et al., 2005) and SMPL
(Loper et al., 2015) are widely used. Extending such
parametric models to generate 3D clothing or clothed
humans could be challenging (Ma et al., 2020). For
single-image approaches, Tex2Shape (Alldieck et al.,
2019) represented geometry as displacements in UV
space to the surface of the SMPL body model. How-
ever, it only estimates the shape of observed subject
and is limited to tight clothing. In our work, we also
adopt similar UV representation but go beyond it in
terms of reconstructed surface properties (albedo) and
in terms of reconstructed clothing (dresses and skirts).
Recent works on regressing 3D surfaces from im-
ages have shown promising results (Xiu et al., 2023;
Alldieck et al., 2022). These methods, however, re-
quire high-fidelity 3D data for supervision, and they
only recover the geometry at one time instance thus
cannot represent a temporally coherent shape recon-
struction over the entire sequence. Recently, several
methods proposed to obtain articulated human models
by fitting implicit neural fields to video via neural ren-
dering while requiring external segmentation methods
(Jiang et al., 2022; Weng et al., 2022). Vid2Avatar
(Guo et al., 2023), on the other hand, jointly solves
scene decomposition and 3D reconstruction. While
these methods achieve compelling results, they are
fundamentally limited to tight clothing and/or single
geometry representation.
3 METHOD
Given a monocular video of a person, our goal is to
learn its full-body model with realistic appearance
and geometry in the UV space, while enabling gar-
ment transfer and re-texturing. An overview of our
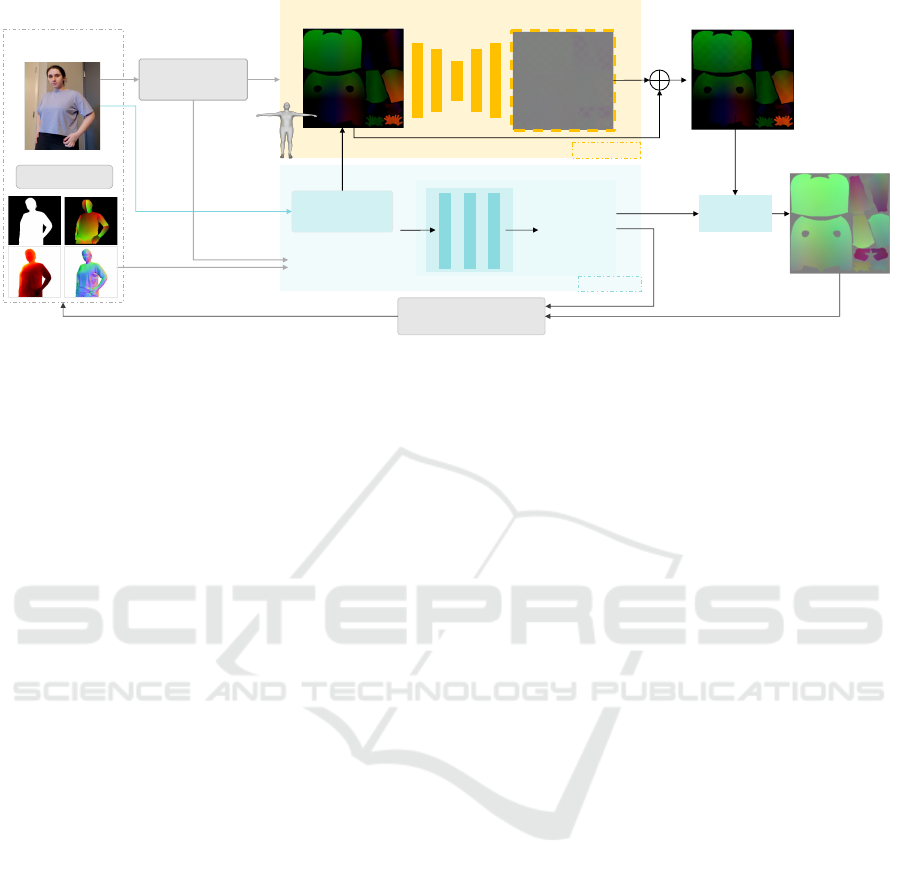
method is shown in Fig. 2 and Fig. 4.
3.1 Canonical Human Generator
We parameterize canonical human in the UV space by
leveraging a human shape prior in the form of T-posed
Learning 3D Human UV with Loose Clothing from Monocular Video
123
Offset ∆𝑑, 𝜌
SMPL UV
𝑑
𝒄
, 𝜌
"
Refined
Θ, Θ
&
, 𝑽, 𝑳
Observation
space
Forward Renderer
ℒ
#$%
ℒ
&'(
Deformer
ShapeNet
PoseNet
Light direction
𝑳
Intrinsic image
decomposition
𝐵
Video Inputs
Pre-trained Nets
Pose estimator
𝐵,Θ, 𝑽
𝜌
Figure 2: Method overview. Given a monocular video of a person, our method optimizes for the canonical albedo ρ
c
and
geometry d
c
in the UV space, light source directions L, camera viewing directions V as well as the motion field: {Θ,
ˆ
Θ}
transforming from the canonical to the observation space.
naked SMPL (Loper et al., 2015) using UV mapping
(Blinn and Newell, 1976). For each query point x in
the canonical UV space, we predict a shape displace-
ment vector ∆d(x) ∈ R
3
from the base model d
base
(x)
to model details including the clothing, as well as its
diffuse albedo ρ(x) ∈ R
3
as follows
d
c
(x) = d
base
(x) + ∆d(x),
ρ
c
(x) = ρ(x). (1)
We augment naked SMPL with geometric and ap-
pearance details using these two UV maps, including
shape and texture UV maps:
{
∆d(x),ρ(x)
}
in canon-
ical space c : R
H×W
× R
6
, where H × W is the res-
olution of UV map. Note that the details of mesh
model is proportional to the resolution of the UV map
(Alldieck et al., 2019).
3.2 Deformer
In order to learn the canonical UV model map from
posed images, we need the appearance and the 3D ge-
ometry in the observation space.
Shape Deformation. Given bone pose parameters
θ ∈ R
3×24
, we transform each canonical point x into
the observation space using Linear Blend Skinning
T (·):
ˆ
x = T (x,θ,w) =
K
∑
i=1
w
i
(x)B
i
(x,θ
i
), (2)
where B
i
and w
i
are the transformation and the canon-
ical blend weight for -i-th bone, respectively, and K is
the number of joints.
The weights are nonzero and affect each canon-
ical point x. To avoid redundant blend weights, we
represent canonical blend weight by interpolating the
weight ˆw
i
assigned to each vertex of the mesh as
w
i
(x) =
3
∑
j=1
λ
j
(x) ˆw
i
(m
j
), (3)
where m
j
denotes the j-th vertex of the face to which
the point x belongs, and λ
j
denotes the interpolation
weight of the j-th vertex in the barycentric coordinate
system (Floater, 2003).
Garment Deformation. We assume the model de-
tail (clothing, hair, and shoes) is a sub-map of the
canonical UV map, and assume each sub-map point
x
g
is associated with a body point x. That is, the de-
formation in the garment region is conditioned to the
shape deformation. We articulate each sub-map point
x
g
as:
ˆ
x
g
= T
T (x
g
,θ,w) ,
ˆ
θ, ˆw
, (4)
where
ˆ
θ and ˆw are the pose parameters and skinning
weights, respectively, that account for the residual
non-rigid motion. We compute the normals n by tak-
ing the derivative of the deformed points
ˆ
x and
ˆ
x
g
.
3.3 Learning 3D Dressed Human
In this subsection, we present our full 3D human re-
covery framework for monocular video. We start
from describing the initialization of the parameters,
followed by the optimization scheme.
3.3.1 Input Initialization
As shown in Fig. 2, given a monocular video, we
obtain Densepose (G
¨
uler et al., 2018), surface nor-
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
124

mals and depth (Jafarian and Park, 2021), optical flow
(Teed and Deng, 2020), and silhouette image (Lin
et al., 2021) for each frame from off-the-shelf net-
works. We use FrankMocap (Rong et al., 2021) to
initialize SMPL pose Θ =
{
θ
1
,.. .,θ
n
}
and shape B =
{
β
1
,.. .,β
n
}
parameters, as well as camera viewpoints
V =
{
v
1
,.. .,v
n
}
for a sequence of n frames. We aver-
age SMPL shape parameters B over the sequence and
represent it in UV space as the initial base shape d
base
for the person.
As shown in Fig. 3, Densepose only predicts UV
for the naked SMPL. We extract features of both
Densepose IUV and RGB images using Principal
Component Analysis (PCA) to segment the body
parts for the entire region of the person, including
clothing, in the image, and adopt a linear conversion
to uniformly expand UV in each part. We use this ex-
tended IUV together with depth prediction to initial-
ize shape displacement ∆d in the canonical UV space.
In order to separate illumination from reflectance
in scenes for better rendering, we decompose each
RGB image into albedo and shading images (Bell
et al., 2014). Given extended IUV and albedo images,
we initialize the diffuse albedo UV map ρ by incor-
porating bi-linear interpolation. Given shading image
and surface normals, we compute the light source di-
rection vectors L =
{
l
1
,.. .,l
n
}
at each frame using a
linear least-square solution:
l = (N
⊤
N)
−1
N
⊤
S, (5)
where N ∈ R
m×3
and S ∈ R
m×1
are the normal matrix
and the shading matrix with m sampled pixel points,
respectively. Here we assume orthographic projection
on the light source, and assume Lambertian reflection
on the target surfaces.
3.3.2 Optimization
Given the initial parameters, we augment the shape
displacement and texture UV maps to the naked
SMPL (Sec. 3.1), and then transform it from the
canonical space to the observation space using the de-
former described in Sec. 3.2. We forward render its
silhouette, normal, depth, densepose, and texture im-
ages with a differentiable renderer (Ravi et al., 2020).
We define a rendering term L
ren
to enforce the con-
sistency between the observation and the synthesized
images:
L
ren
(V,L,Θ,
ˆ
Θ, ˆw,∆d, ρ) =
L
sil
+ λ
tex
L
tex
+ λ
2D
L
2D
+ λ
n
L
n
+ λ
d
L
d
, (6)
where L
sil
and L
tex
are the sillouette loss and texture
loss, respectively, L
2D
is the sum of Densepose repro-
jection loss, and L
n
and L
d
are used to ensure geo-
metric consistency between predicted and synthesized
Input
Densepose
Part segmentation IUV Extention
Figure 3: Initialization of extended IUV.
geometry, respectively. As the visual structure is also
important for reconstructing high fidelity results, we
maximize the structural similarity by minimizing the
dissimilarity: (1−MS-SSIM)/2 (Wang et al., 2003),
(Alldieck et al., 2019). λ
tex
, λ
2D
, λ
n
, and λ
d
are
the weights that determine the relative importance of
losses.
In order to better handle the invisible areas, we
assume shape and texture are symmetric in each seg-
ment in the canonical UV space. For this, we en-
force a symmetric structure constraint to the canon-
ical shape displacement ∆d and albedo ρ UV maps
by minimizing:
L
sym
(∆d,ρ) =
10
∑
i=1
∑
x∈Ω
i
n
∆d(x) − ∆d(x
′
)
2
+λ
ρ
ρ(x) − ρ(x
′
)
2
o
, (7)
where Ω
i
denotes the area of i
th
segment in UV space,
λ
ρ
denotes the weight, and x
′
is the flipped position of
x predefined for each segment.
To obtain a temporally coherent overall shape, as
shown in Fig. 4, we define a regularization term L
reg
to enforce the temporal similarity of SMPL pose pa-
rameters Θ, camera viewpoints V, and light source
direction vectors L across frames:
L
reg
(V,L,Θ) =
∑
i, j
n
ϵ
ang
(l
i
,l
j
) + ϵ
rot
(Θ
i
,Θ
j
) + λ
v
v
i
− v
j
2
o
,
(8)
where ϵ
ang
(·) and ϵ
rot
(·) are the angular error and the
Riemannian distance (Moakher, 2002), respectively,
and λ
v
denotes the weight.
We further enforce the temporal consistency on
the surface details by leveraging the optical flow
(Teed and Deng, 2020) across frames:
L
tmp
(∆d,Θ,
ˆ
Θ, ˆw) =
∑
i, j
∑
p
i
W
i→ j
(p
i
) − p
j
2
, (9)
Learning 3D Human UV with Loose Clothing from Monocular Video
125

ShapeNet
PoseNet
𝑊
!→#
Optical flow
PoseNet
ℒ
$%&
Pose regularization ℒ
'()
𝐼
!
𝐼
#
Figure 4: Temporal coherence. We apply temporal smoothness in the pose parameters, and apply temporal consistency in the
rendered UV using optical flow.
Table 1: Quantitative Results. We report mean absolute error E
d
in cm, mean angular error E
n
in degree, image texture error
L
tex
in RGB difference, and normal consistency error L
n
in degree, respectively (mean±std).
GT dress sequence UBCFashion sequences
Method E
d
E
n
L
tex
L
n
Vid2Avatar (Guo et al., 2023) (w/ mask) 1.08 ± 0.47 50.52 ± 3.41 27.55 ± 2.36 4.68 ± 1.90
Ours 1.04 ± 0.44 18.93 ± 15.83 12.52 ± 12.41 7.55 ± 14.03
where p
i
is a pixel point of rendered UV in the i
th
frame, and W
i→ j
is the optical flow from frame i to
frame j for mapping p
i
to p
j
in j
th
frame.
Overall, the initial parameters can be further re-
fined by alternating among refining camera view-
points V and SMPL and garment pose parameters:
{Θ,
ˆ
Θ}, shape displacement map ∆d, and light source
directions L and albedo ρ until convergence:
argmin
ξ
p
or∆dor ξ
l
=
L
ren
+ λ
sym
L
sym
+ λ
reg
L
reg
+ λ
tmp
L
tmp
+ λ
p
L
p
,
(10)
where ξ
p
= {V, Θ,
ˆ
Θ, ˆw} and ξ
l
= {L, ρ}, L
p
is a L2
penalization term that prevents the pose parameters
from deviating too much from the initialization, λ
sym
,
λ
reg
, λ
tmp
and λ
p
denote loss weights.
3.4 Implementation Details
We regress a canonical UV representation consisting
of geometry and texture for each subject. As shown
in Fig. 2, our method consists of one U-Net for the
canonical UV maps (ShapeNet) and one MLP for the
motion parameters (PoseNet). We set the input RGB
images to 256 × 256 resolution, and set UV map to
512 × 512 resolution to contain most details of the
foreground while preventing from too much interpo-
lation (Alldieck et al., 2019). The ShapeNet fea-
tures each four convolution-batchnorm-ReLU down-
and up-sampling layers. The PoseNet uses 4 layers
of multi-layer perception with ReLU (Agarap, 2018)
as the activation function after each layer. We use
Adam optimizer (Kingma and Ba, 2014) with batch
size of 8 and learning rate of 10
−4
. We set λ
tex
= 0.33,
λ
2D
= 10
−4
, λ
n
= 0.03, λ
d
= 0.02, λ
sym
= 10
−2
,
λ
reg
= 0.5, λ
tmp
= 10
−4
and λ
p
= 5 × 10
−4
. We use
an NVIDIA V100 GPU and Intel(R) Xeon(R) CPU,
and our model is implemented with Pytorch (Paszke
et al., 2019).
4 EXPERIMENTS
We evaluate the effectiveness of our method on both
synthetic and real data of people wearing loose cloth-
ing. We compare our method with baseline methods
for full human 3D reconstruction from a monocular
video.
Datasets. For the synthetic data, similar to Guo
et al.(Guo et al., 2021), we generate a video se-
quence of SMPL model from the CMU motion cap-
ture database. Given shape and pose parameters of
the human body model, we use ArcSim (Narain et al.,
2012) to simulate the cloth motion of a dress from
Berkeley Garment Library (Wang et al., 2011). For
the real data, we use 3 fashion video sequences with
subjects wearing loose clothing from UBCFashion
dataset (Zablotskaia et al., 2019), as well as some In-
ternet videos.
Baseline Methods. We quantitatively and qualita-
tively compare our method with state-of-the-art that
focus on 3D reconstructing holistic human geome-
try from a single monocular video: Vid2Avatar (Guo
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
126

Inputs
Vid2Avatar (Guo et al., 2023)
GT
w/ mask
w/ mask
w/o mask
w/ maskw/o mask
Ours
0s 2.1s
0
10
0
90
0
10
0
90
Figure 5: Qualitative comparison of 3D reconstruction on synthetic (top) and real (bottom) data. For the synthetic data, we
show shape E
d
and normal E
n
error maps computed after aligning 3D reconstruction results with the ground truth. We can
observe that our method achieves more accurate and detailed surface recovery.
Table 2: Ablation study on the simulated GT dress sequence. We report mean absolute error E
d
(cm), mean angular error E
n
(degree), image texture error E
tex
(RGB), and temporal consistency error L
tmp
respectively (mean±std).
Losses E
d
E
n
E
tex
L
tmp
L
sil
+ L
2D
+ L
reg
1.44 ± 0.44 29.25 ± 15.68 - 2.88 ± 1.43
L
ren
(w/o L
tex
) + L
reg
1.41 ± 0.46 19.22 ± 15.58 - 2.60 ± 1.22
L
ren
+ L
sym
+ L
reg
1.42 ± 0.45 19.08 ± 15.89 12.10 ± 14.30 2.36 ± 0.96
Full model 1.04 ± 0.44 18.93 ± 15.83 12.02 ± 13.12 1.97 ± 0.86
Densepose
Ours
2D
3D
Figure 6: Qualitative UV results (same inputs as Fig. 5). We
show Densepose UV (G
¨
uler et al., 2018) as well as ours UV
in 2D and 3D space.
et al., 2023). Since our method can also generate re-
liable UV of dressed human observed in the video,
we also qualitatively compare our method with the
baseline method on human UV prediction: Densepose
(G
¨
uler et al., 2018).
Metrics. For the synthetic data, we report the av-
erage geometry errors in posed space computed after
aligning recovered 3D geometry with the ground truth
in Table 1. For the real data, we warp canonical 3D
model back to observation space and report the aver-
age error of two different rendering losses: L
n
and
L
tex
, between the input images and the synthesized
images (Table 1).
Ablation Studies. As reported in Table 2, we con-
duct an ablation study to analyze the impact of dif-
ferent losses. We can observe that our final model
achieves the best performance in geometry and pho-
tometric errors, as well as temporal consistency error.
Qualitative Results. We evaluate our method qual-
itatively by visualizing the results of 3D geometry re-
construction to demonstrate the performance of the
Learning 3D Human UV with Loose Clothing from Monocular Video
127

Figure 7: Results of our method on real videos. For each
subject, we show the input frames, recovered geometry, and
dense UV in 3D space from different viewpoints.
method in Fig. 5. For the synthetic data, we also show
shape and normal error maps obtained after aligning
the 3D reconstruction results with the ground truth.
These results validate the accuracy of our method for
recovering more accurate geometry of a person wear-
ing loose clothing. We also show our UV recovery
qualitatively in both 2D and 3D space in Fig. 6. This
demonstrates the effectiveness of the method in track-
ing holistic surface correspondences. Fig. 7 shows
more results on real videos.
Garment Re-Texturing and/or Transfer. As
shown in Fig. 8, we take one result of our method and
re-texture its garment by altering the albedo UV map
using standard image editing techniques. Optionally,
we can also modify the geometry UV map to apply
garment transfer in 3D space in the posed space.
Limitation. As described in Sec. 3.2, we assume
garment deformation closely follows the deformation
of the body, our method cannot handle too complex
garment non-rigid dynamics correctly. One of the
possible future directions is to incorporate (Santeste-
ban et al., 2021).
Figure 8: An example of re-texturing.
5 CONCLUSION
In this paper, we introduced a novel method for recov-
ering a consistent, dense 3D geometry and appearance
of a dressed person by observing it in a monocular
video. We reconstruct the holistic 3D surface and tex-
ture represented in a canonical UV space. Our method
jointly learns the shape displacement and albedo UV
maps, as well as pose parameters with the differential
neural rendering. In addition, we enhance the tempo-
ral coherence by utilizing a pose regularization term
and the optical flow. Experimental results on real
videos demonstrate the effectiveness of the method
and the ability to perform dense 3D correspondence
tracking of a person wearing loose clothing. We be-
lieve our work would expands the application of 3D
human generation in a wide range of domains.
REFERENCES
Agarap, A. F. (2018). Deep learning using rectified linear
units (relu). arXiv preprint arXiv:1803.08375.
Alldieck, T., Pons-Moll, G., Theobalt, C., and Magnor, M.
(2019). Tex2shape: Detailed full human body geome-
try from a single image. In IEEE/CVF Conf. Comput.
Vis. Pattern Recog., pages 2293–2303.
Alldieck, T., Zanfir, M., and Sminchisescu, C. (2022).
Photorealistic monocular 3d reconstruction of humans
wearing clothing. In IEEE/CVF Conf. Comput. Vis.
Pattern Recog.
Anguelov, D., Srinivasan, P., Koller, D., Thrun, S., Rodgers,
J., and Davis, J. (2005). Scape: shape completion and
animation of people. In ACM SIGGRAPH 2005 Pa-
pers, pages 408–416.
Bell, S., Bala, K., and Snavely, N. (2014). Intrinsic images
in the wild. ACM Trans. on Graphics (SIGGRAPH),
33(4).
Blinn, J. F. and Newell, M. E. (1976). Texture and reflection
in computer generated images. Communications of the
ACM, 19(10):542–547.
Dong, Z., Xu, K., Duan, Z., Bao, H., Xu, W., and Lau,
R. (2022). Geometry-aware two-scale pifu represen-
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
128

tation for human reconstruction. Advances in Neural
Information Processing Systems, 35:31130–31144.
Floater, M. S. (2003). Mean value coordinates. Computer
aided geometric design, 20(1):19–27.
G
¨
uler, R. A., Neverova, N., and Kokkinos, I. (2018). Dense-
pose: Dense human pose estimation in the wild. In
IEEE/CVF Conf. Comput. Vis. Pattern Recog., pages
7297–7306.
Guo, C., Jiang, T., Chen, X., Song, J., and Hilliges, O.
(2023). Vid2avatar: 3d avatar reconstruction from
videos in the wild via self-supervised scene decom-
position. In IEEE/CVF Conf. Comput. Vis. Pattern
Recog.
Guo, J., Li, J., Narain, R., and Park, H. S. (2021). In-
verse simulation: Reconstructing dynamic geometry
of clothed humans via optimal control. In IEEE/CVF
Conf. Comput. Vis. Pattern Recog.
Hilton, A. and Starck, J. (2004). Multiple view recon-
struction of people. In Proceedings. 2nd International
Symposium on 3D Data Processing, Visualization and
Transmission, 2004. 3DPVT 2004., pages 357–364.
IEEE.
Jafarian, Y. and Park, H. S. (2021). Learning high fidelity
depths of dressed humans by watching social media
dance videos. In IEEE/CVF Conf. Comput. Vis. Pat-
tern Recog., pages 12753–12762.
Jiang, W., Yi, K. M., Samei, G., Tuzel, O., and Ranjan, A.
(2022). Neuman: Neural human radiance field from
a single video. In European Conference on Computer
Vision, pages 402–418. Springer.
Joo, H., Liu, H., Tan, L., Gui, L., Nabbe, B., Matthews,
I., Kanade, T., Nobuhara, S., and Sheikh, Y. (2015).
Panoptic studio: A massively multiview system for
social motion capture. In ICCV, pages 3334–3342.
Kingma, D. P. and Ba, J. (2014). Adam: A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Lin, S., Yang, L., Saleemi, I., and Sengupta, S. (2021).
Robust high-resolution video matting with temporal
guidance.
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., and
Black, M. J. (2015). SMPL: A skinned multi-person
linear model. ACM Trans. Graphics (Proc. SIG-
GRAPH Asia), 34(6):248:1–248:16.
Ma, Q., Yang, J., Ranjan, A., Pujades, S., Pons-Moll, G.,
Tang, S., and Black, M. J. (2020). Learning to dress
3d people in generative clothing. In IEEE/CVF Conf.
Comput. Vis. Pattern Recog., pages 6469–6478.
Moakher, M. (2002). Means and averaging in the group of
rotations. SIAM J. Matrix Anal., 24(1):1–16.
Narain, R., Samii, A., and O’brien, J. F. (2012). Adap-
tive anisotropic remeshing for cloth simulation. ACM
transactions on graphics (TOG), 31(6):1–10.
Newcombe, R. A., Fox, D., and Seitz, S. M. (2015). Dy-
namicfusion: Reconstruction and tracking of non-
rigid scenes in real-time. In CVPR, pages 343–352.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J.,
Chanan, G., Killeen, T., Lin, Z., Gimelshein, N.,
Antiga, L., et al. (2019). Pytorch: An imperative style,
high-performance deep learning library. Advances in
neural information processing systems, 32.
Ravi, N., Reizenstein, J., Novotny, D., Gordon, T., Lo, W.-
Y., Johnson, J., and Gkioxari, G. (2020). Accelerating
3d deep learning with pytorch3d. arXiv:2007.08501.
Rong, Y., Shiratori, T., and Joo, H. (2021). Frankmocap:
A monocular 3d whole-body pose estimation system
via regression and integration. In IEEE/CVF Conf.
Comput. Vis. Pattern Recog., pages 1749–1759.
Santesteban, I., Thuerey, N., Otaduy, M. A., and Casas, D.
(2021). Self-supervised collision handling via gener-
ative 3d garment models for virtual try-on. ieee. In
IEEE/CVF Conf. Comput. Vis. Pattern Recog., vol-
ume 2, page 3.
Teed, Z. and Deng, J. (2020). Raft: Recurrent all-pairs
field transforms for optical flow. In Computer Vision–
ECCV 2020: 16th European Conference, Glasgow,
UK, August 23–28, 2020, Proceedings, Part II 16,
pages 402–419. Springer.
Varol, G., Romero, J., Martin, X., Mahmood, N., Black,
M. J., Laptev, I., and Schmid, C. (2017). Learning
from synthetic humans. In CVPR, pages 109–117.
Wang, H., O’Brien, J. F., and Ramamoorthi, R. (2011).
Data-driven elastic models for cloth: modeling and
measurement. ACM transactions on graphics (TOG),
30(4):1–12.
Wang, L., Zhang, J., Liu, X., Zhao, F., Zhang, Y., Zhang, Y.,
Wu, M., Yu, J., and Xu, L. (2022). Fourier plenoctrees
for dynamic radiance field rendering in real-time. In
IEEE/CVF Conf. Comput. Vis. Pattern Recog., pages
13524–13534.
Wang, Z., Simoncelli, E. P., and Bovik, A. C. (2003). Mul-
tiscale structural similarity for image quality assess-
ment. In The Thrity-Seventh Asilomar Conference on
Signals, Systems & Computers, 2003, volume 2, pages
1398–1402. Ieee.
Weng, C.-Y., Curless, B., Srinivasan, P. P., Barron, J. T.,
and Kemelmacher-Shlizerman, I. (2022). Human-
nerf: Free-viewpoint rendering of moving people
from monocular video. In IEEE/CVF Conf. Comput.
Vis. Pattern Recog., pages 16210–16220.
Xiu, Y., Yang, J., Cao, X., Tzionas, D., and Black, M. J.
(2023). ECON: Explicit Clothed humans Optimized
via Normal integration. In IEEE/CVF Conf. Comput.
Vis. Pattern Recog.
Zablotskaia, P., Siarohin, A., Zhao, B., and Sigal, L.
(2019). Dwnet: Dense warp-based network for
pose-guided human video generation. arXiv preprint
arXiv:1910.09139.
Zhao, F., Yang, W., Zhang, J., Lin, P., Zhang, Y., Yu, J., and
Xu, L. (2022). Humannerf: Efficiently generated hu-
man radiance field from sparse inputs. In IEEE/CVF
Conf. Comput. Vis. Pattern Recog., pages 7743–7753.
Learning 3D Human UV with Loose Clothing from Monocular Video
129
