
Parameter-Free Undersampling for Multi-Label Data
Sarbani Palit
1 a
and Payel Sadhukhan
2 b
1
Computer Vision and Pattern Recognition Unit, Indian Statistical Institute, Kolkata, India
2
Institute for Advancing Intelligence, TCG CREST, Kolkata, India
Keywords:
Multi-Label, Natural Nearest Neighborhood, Class Imbalance, Undersampling.
Abstract:
This work presents a novel undersampling scheme to tackle the imbalance problem in multi-label datasets.
We use the principles of the natural nearest neighborhood and follow a paradigm of label-specific undersam-
pling. Natural-nearest neighborhood is a parameter-free principle. Our scheme’s novelty lies in exploring the
parameter-optimization-free natural nearest neighborhood principles. The class imbalance problem is partic-
ularly challenging in a multi-label context, as the imbalance ratio and the majority-minority distributions vary
from label to label. Consequently, the majority-minority class overlaps also vary across the labels. Working
on this aspect, we propose a framework where a single natural neighbor search is sufficient to identify all the
label-specific overlaps. Natural neighbor information is also used to find the key lattices of the majority class
(which we do not undersample). The performance of the proposed method, NaNUML, indicates its ability to
mitigate the class-imbalance issue in multi-label datasets to a considerable extent. We could also establish a
statistically superior performance over other competing methods several times. An empirical study involving
twelve real-world multi-label datasets, seven competing methods, and four evaluating metrics - shows that
the proposed method effectively handles the class-imbalance issue in multi-label datasets. In this work, we
have presented a novel label-specific undersampling scheme, NaNUML, for multi-label datasets. NaNUML
is based on the parameter-free natural neighbor search and the key factor, neighborhood size ’k’ is determined
without invoking any parameter optimization.
1 INTRODUCTION
Class imbalance is a note-worthy characteristic of
data obtained from several real-world domains. The
naturally occurring biases in the real world give rise
to varying numbers of points in different classes of a
dataset. Multi-label datasets – mostly obtained from
real-world sources (Li et al., 2014; Katakis et al.,
2008) is no exception to this. In a multi-label dataset,
an instance is associated with more than one possi-
ble label. Let D be a multi-label dataset with L la-
bels. D = {(x
i
, Y
i
), 1 ≤ i ≤ n}. x
i
’s denote the fea-
ture vectors and Y
i
denotes its membership to L la-
bels. Y
i
= {y
i1
, y
i2
, . . . , y
iL
} and for binary classifica-
tion, y
i j
can be either 0 (negative class) or 1 (positive
class). The task is to correctly predict the class (0
or 1) for L labels of a test instance. In a two-class
dataset, we term the class with a higher number of in-
stances and the class with a lower number of instances
as the majority class and the minority class respec-
a
https://orcid.org/0000-0002-4105-6452
b
https://orcid.org/0000-0001-7795-3385
tively. In yeast dataset (Elisseeff and Weston, 2001),
the imbalance ratio (ratio of majority set cardinality
to that of minority set cardinality) is greater than 1.5
for 12 out of 14 labels. Alternatively, we can say that,
for 12 out of 14 labels in yeast dataset, one class has
50% more points than the other class. It is also ob-
served that the different labels of a multi-label dataset
possess differing degrees of imbalances. This aspect
further intricates the issue and calls for dedicated and
label-specific handling of the class imbalance issue in
a multi-label context.
Data preprocessing is a popular technique for han-
dling the class imbalance of the datasets. This par-
ticular technique is motivated to reduce the difference
in cardinalities of the classes in a dataset by i] either
removing the points from the majority class (under-
sampling the majority class) or ii] by adding synthetic
points to the minority class (oversampling the minor-
ity class). This helps mitigate the bias of the major-
ity class in the classifier modeling phase and helps
detect minority instances. In undersampling of data,
points are removed from the majority class to reduce
Palit, S. and Sadhukhan, P.
Parameter-Free Undersampling for Multi-Label Data.
DOI: 10.5220/0012401400003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 2, pages 397-406
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
397

the difference in the majority and the minority class
cardinalities. It also reduces the overall training data
volume, thereby reducing the computation of the clas-
sifier modeling. Undersampling is a convenient op-
tion for multi-label datasets as their dimensionality is
high concerning the number of points and features.
We should also remember that — the positive and
negative class memberships vary across labels in a
multi-label dataset. Even though the feature vectors
reside in the same locations of the feature space (for
all labels), their changing memberships lead to differ-
ent majority and minority point configurations.
In this work, we propose a natural neighborhood-
based undersampling scheme (NaNUML) to deal
with the class imbalance of multi-label datasets. Due
to disparate ranges of imbalance ratios and the diver-
sified distributions of majority and minority points
across the labels, we resort to a label-specific un-
dersampling. We look at the mutual co-locations of
the majority and the minority points within a neigh-
borhood to find the majority candidates to be under-
sampled. Our principal aim is to find and remove
the majority points that overlap with many minority
points. Removing the majority points from the over-
lapped space will increase the cognition of the minor-
ity points in those regions.
To find the majority points overlapping in the minor-
ity spaces, we employ the technique of natural nearest
neighborhood (Zhu et al., 2016). Two points p and
q are natural neighbors of each other if i] p is a k-
nearest neighbor of q and also ii] q is also a k-nearest
neighbor of p. Unlike the identification of the neigh-
bors via a directional and one-sided nearness (like that
in the k-nearest neighborhood), natural neighbors are
computed based on the mutual nearness of two points
(hence, commutative). The relative nearness of two
points (relative to their neighborhood) is instrumental
in chalking out the neighborhood relation. The mu-
tual nearness protocol of natural neighborhoods aids
in the efficient identification of the majority and mi-
nority class overlaps. The other significant advantage
of the natural neighborhood scheme is computing the
neighborhood size ’k’ without human intervention or
a parameter optimization phase. This characteristic
is helpful in any machine learning context, and our
scheme enjoys the advantage. In NaNUML, a single
natural nearest neighbor search is sufficient to com-
pute all labels’ label-specific natural neighbor infor-
mation.
For each label, we compute the minority natural
neighbor count of the majority points. A high minor-
ity neighbor count for a majority point indicates its
increased overlap with the minority space (as well as
the minority points). Hence, the majority points with
higher minority natural neighbor counts are potential
candidates for undersampling. Accordingly, we re-
move the majority points in order of their decreasing
minority neighbor count. The majority point with the
highest minority neighbor count is removed first. The
undersampled majority set and the original minority
set form the augmented training set and are used to
learn a set of label-specific classifiers.
The major highlights of our work are as follows:
• We undersample the label-specific majority points
to obtain an augmented yet reduced training set
for each label.
• We employ a parameter-optimization-free tech-
nique to compute the neighbors of the points. The
computation of the neighbors is based on a mutual
nearness calculation, which helps in an enhanced
identification of the majority-minority overlaps.
• This is the first work to introduce the paradigm of
natural neighborhoods in multi-label learning.
• While undersampling the majority class, we also
preserve the key lattice points of the majority class
by preserving (and not allowing the undersam-
pling of) the majority points (top 10%) with the
highest majority natural neighbor count.
• The natural neighborhood search is not label-
dependent and depends on the distribution of the
points in the feature space. Hence, only one natu-
ral neighbor search is required (for all labels).
• The outcomes from an experimental study in-
volving twelve real-world multi-label datasets,
seven competing methods (multi-label learners
and generic class-imbalance focused learning
paradigms), and four evaluating metrics indicate
the proposed method’s competence over other
competing learners.
2 RELATED WORKS
This work is focused on the class-imbalance aspect of
multi-label learning. The study of the extant works
will be devoted to both these aspects – i] class imbal-
ance learning and ii] multi-label learning in general.
Several diversified approaches are followed in the
domain of class-imbalance learning to mitigate the
bias of the majority class (He and Garcia, 2009).
Algorithm-based methods are one of the earliest
methods in this field. The methods mostly function
in one of two ways – i] by shifting the boundary
away from the minority class to add more region in
their favor, or ii] by employing a cost-sensitive learn-
ing framework where the misclassification of minor-
ity instances incur a higher penalty. Other approaches
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
398

like kernel-based methods, multi-objective optimiza-
tion methods, and ensemble-based learners also focus
on achieving the same goal.
Data preprocessing is a popular technique of handling
the class-imbalance problem (Ali et al., 2019). Here,
the schemes are motivated to balance the cardinali-
ties of the majority and the minority classes. This
can be done in the following ways – i] undersampling
or removing points from the majority class (Pereira
et al., 2020a; Tahir et al., 2012), ii] oversampling or
adding synthetic points to the minority class (Charte
et al., 2015a; Chawla et al., 2002), iii] hybrid sam-
pling where both undersampling and oversampling
are involved (Choirunnisa and Lianto, 2018; Ludera,
2021). This step of data sampling occurs before the
classification step, and the classifier modeling is done
on the augmented data (obtained through preprocess-
ing).
The focus of the researchers on multi-label learning
dates back to the beginning of this century (Joachims,
1998; Godbole and Sarawagi, 2004). The commu-
nity’s ongoing efforts have provided several ways of
handling this issue (Moyano et al., 2018).
Multi-label methods are principally classified into
i] |Problem Transformation approaches: in which
several classifiers are modeled and learned to facili-
tate an overall multi-label learning of the data at var-
ious levels of label association (they are further clas-
sified into first-order, second-order and higher or-
der according to the degree of label associations in
the classifiers (Zhang and Wu, 2015; Sadhukhan and
Palit, 2020; Tsoumakas et al., 2011; Fürnkranz et al.,
2008), and ii] Algorithm Adaptation approaches:
which consider tweaking of an existing classifier like
Support Vector Machine, nearest-neighborhood based
classifier, random forest to accommodate the multi-
label learning (Gonzalez-Lopez et al., 2018; Nam
et al., 2014; Liu et al., 2018; Siblini et al., 2018).
The researchers in multi-label were quick to notice
the issue of class imbalance in multi-label datasets
(Tahir et al., 2012). We should note that handling
the class-imbalance issue in multi-label datasets is
way more knotty than single-label traditional datasets.
The principal causes are i] the multi-output nature
where the degree of imbalance in each output varies
from the others and ii] a set of imbalance ratios, one
for each label. Data pre-processing, being a popular
choice, is explored in multi-label contexts. MLeNN
(Charte et al., 2014) uses the edited Nearest Neigh-
bor rule principles to undersample the majority points
with similar label sets of its neighbors in a multi-
label dataset. In a hybrid sampling technique, ML-
RUS deletes the instances belonging to the major-
ity classes of a multi-label dataset. ML-ROS deletes
the clone examples with minority labels to facilitate
better learning of the imbalanced multi-label datasets
(Pereira et al., 2020b). ML-SMOTE resorts to the
oversampling of minority classes to balance the car-
dinalities of the majority and the minority classes of
the labels (Charte et al., 2015b). (Liu and Tsoumakas,
2020) couples the majority class undersampling with
the classifier chain scheme’s ensembles to tackle the
class imbalance issue. COCOA (Zhang et al., 2020)
presents a scheme where the asymmetric distribution
of classes and the pair-wise label correlations are con-
sidered, and a three-way learner is produced for each
pair of labels. (Daniels and Metaxas, 2017) exploits
the Hellinger forests to design an imbalance-aware
multi-label classifier. In LIIML (Sadhukhan and Palit,
2019), an imbalance-informed label-specific feature
set is constructed for the labels, followed by a cost-
sensitive learning scheme to learn the multi-label
datasets.
In the next section, we briefly describe the intuition
and working principles of the natural nearest neigh-
borhood.
3 PRINCIPLES OF NATURAL
NEAREST NEIGHBORHOOD
Let us have a set of points x
1
, x
2
, . . . , x
n
and we want
to find the natural neighbors of x
i
from the given
search space (excluding itself). For some k = α,
(α >= 1), we say that x
i
is a natural neighbor of x
j
(at k = α), if x
i
is a α-nearest neighbor of x
j
and x
j
is
also a α-nearest neighbor of x
i
(Zhu et al., 2016). Let
NN(x
j
) be a natural neighbor of x
i
and KNN
α
(x
j
) be
a α-nearest neighbor of x
i
.
x
j
∈ NN(x
i
) ⇐⇒ (x
i
∈ KNN
α
(x
j
)) ∩ (x
j
∈ KNN
α
(x
i
)) (1)
The authors of this work have also stated the pro-
cedure for selecting a natural neighbor eigenvalue (λ)
(the neighborhood size). In a dataset, the minimum k-
value at which all points get at least one natural neigh-
bor is to be noted. Let this critical k-value be β. The
natural neighbor eigenvalue, λ is computed from β.
According to the authors,
λ =
p
β
Unlike k-nearest neighborhood search or reverse
nearest neighborhood search, natural neighborhood
search retrieves a symmetric neighborhood configu-
ration of a dataset. We can identify the true majority
and minority class overlaps via the symmetric neigh-
borhood or hand-shake configurations. In this work,
NaNUML, the nearest neighbor eigenvalue for each
dataset, is computed and used in the subsequent stages
for undersampling the majority class. The proposed
approach is described in the next section.
Parameter-Free Undersampling for Multi-Label Data
399

4 NaNUML APPROACH
Algorithm 1: NaNUML.
Input: D = {(x
i
, Y
i
), 1 ≤ i ≤ n}, α
Output: Augmented dataset, UD
( j)
for 1 ≤ j ≤
L
1: Find λ from the feature space information of D ▷
It is calculated irrespective of the class informa-
tion.
2: Find the natural neighbors of x
i
, x
i
∈ D acc. to
(Equation 1). ▷ It is calculated irrespective of the
class information.
3: for j do=1 to L do
4: Segregate D into D
M( j)
and D
m( j)
(Equation
2). ▷ According to their majority and minority
memberships w.r.t. label j
5: Compute u
j
acc. to (Equation 3) ▷ Number
of points to be undersampled for label j
6: Compute count
M(i)( j)
and count
m(i)( j)
acc.
(Equation 4). ▷ Number of majority and
minority neighbors of instance i w.r.t. label j
7: Mark the points in D
M( j)
with highest
count
M(i)( j)
values and do not undersample them.
8: Sort the points in D
M( j)
in descending order
of their count
m(i)( j)
values and select the first u
j
points in U
( j)
.
9: Undersample U
( j)
from D
M( j)
to get the un-
dersampled majority set, UM
( j)
(Equation 5).
10: UD
( j)
is obtained by taking the union of
D
m( j)
and UM
( j)
(Equation 6).
11: end for
Let a multi-label dataset be denoted D, and the num-
ber of labels be L.
D = {(x
i
, y
i
), 1 ≤ i ≤ n}. x
i
denote the i
th
feature vec-
tor and y
i
denotes its class information corresponding
to L labels. y
i
= {y
i1
, y
i2
, . . . , y
iL
} and each y
i j
can be
either 0 (negative membership) or 1 (positive mem-
bership). Example, y
14
=1 signifies that x
1
belongs to
(has) the positive class of the 4
th
label. Our primary
task is to predict the correct membership of the test
points for all the labels.
1. Finding the natural neighbors of points in D:
Following the natural neighbor principles, we find
the natural neighbors of all points in D for k = λ
(where λ is the natural neighbor eigenvalue). λ
is specific to a dataset. Let N(x
i
) be the natural
neighbor set of x
i
.
N (x
i
) = {x
j
;(x
i
∈ KNN
λ
(x
j
))∩ (x
j
∈ KNN
λ
(x
i
))}, i = 1, 2,. . ., n
(2)
This step is common for all labels as the labels
share the same feature points.
2. Imbalance ratios of the labels and the number
of points removed: For each label, the points be-
longing to the positive and negative classes are
segregated into two mutually exclusive sets. In
a multi-label dataset, usually, the positive class
qualifies as the minority class, and the negative
class becomes the majority class. Class inversion
can indeed occur, where the negative and posi-
tive classes change their roles. But, for clarity and
synchronization, we denote the positive and neg-
ative classes as the minority and majority classes,
respectively. Let D
M( j)
and D
m( j)
be the majority
and the minority classes of label j, respectively.
D
M( j)
= {x
i
;1 ≤ i ≤ n and y
i j
= 0}
D
m( j)
= {x
i
;1 ≤ i ≤ n and y
i j
= 1}
D = D
M( j)
∪ D
m( j)
(3)
For each label, we compute the cardinality of
the undersampled set from the difference between
the cardinalities of the majority and the minority
classes. Let u
j
be the number of points to be re-
moved from D
M( j)
. Let α be a number such that
0 < α ≤ 1.
u
j
= max(α ×(|D
M( j)
| −|D
m( j)
|), 0), j = 1, 2, .. . , L (4)
α allows us to choose the number of points to
be removed from the majority point set. When
α = 1, we equate the cardinality of the undersam-
pled majority point set with that of the minority
point set. After the undersampling, the difference
in cardinalities of the undersampled majority class
and the minority class is equal to the (1 − α)% of
the original difference between the two sets.
Note that: When there is an inversion of the pos-
itive and the negative class for a label, (majority
class (class 0) has lesser number of points than the
minority class (class 1)), (|D
M( j)
| − |D
m( j)
|) will
be negative and u
j
will be 0. We will not remove
any point for that label.
3. Finding the majority points to be undersam-
pled for each label and generating the aug-
mented dataset: For each label, we find the nat-
ural neighbor count of the majority points. The
majority point set and the minority point set vary
across the labels depending on the label-specific
membership of the points. Additionally, we segre-
gate this count into two mutually exclusive counts
– i] majority natural neighbor count and ii] mi-
nority natural neighbor count. Let count
Mi( j)
and
count
mi( j)
denote the majority natural neighbor
count and minority natural neighbor count, re-
spectively, of an instance x
i
for label j.
count
M(i)( j)
= |{x
k
: (x
k
∈ N
i
) and (x
k
, x
i
) ∈ D
M( j)
}|
count
m(i)( j)
= |{x
k
: (x
k
∈ N
i
) and (x
k
∈ D
m( j)
) and (x
i
∈ D
M( j)
)}|
(5)
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
400

• Finding the label-specific majority points,
which are the key structural components and
preserving them from undersampling: We ex-
plore the majority natural neighbor counts to
find the key structural points of the majority
set. The points with the higher majority natural
neighbor counts are selected as the key struc-
tural points, and the top 10% points are kept
away from the undersampling in the next phase
(even if their minority counts are higher).
• Finding the majority points to be removed from
the remaining set of points: For a label j, we
look at the minority natural neighbor count of
the remaining majority points. The majority
point with the highest minority natural neigh-
bor count is removed (undersampled) first from
the majority set. This procedure of undersam-
pling is continued (according to the decreasing
order of the minority natural neighbor counts of
the majority points) till u
j
points are removed.
A majority point in a majority class-minority
class overlapped region will have a high minor-
ity natural neighbor count and is a good candi-
date for removal.
Let U
( j)
be the set of removed points from the
majority set D
M( j)
. The undersampled majority
set for label j, UM
j
is obtained by taking the dif-
ference of U
( j)
from D
M( j)
.
UM
( j)
= D
M( j)
\ U
( j)
, j = 1, 2, . . . , L (6)
The undersampled training set for label j, UD
( j)
is obtained by taking the union of UM
( j)
and
D
m( j)
.
UD
( j)
= UM
M( j)
∪ D
m( j)
, j = 1, 2, . . . , L
(7)
UD
( j)
is used to train the label-specific classifier
for label j, and the classifier is subsequently used
to make the predictions for label j.
Remarks: In this work, we suggest preserving
10% majority points as the key structural components
of the majority class. In datasets with an imbalance
ratio (r > 10), this will impose an upper limit on α.
α =
0.9r
r − 1
(8)
Given that, it is not possible to equate the cardinal-
ities of the minority and the undersampled majority
classes when r > 10. The experimental results on ex-
ploring α manifest that it is a fair trade-off. Too much
removal of majority points can lead to the distortion
of the majority class. If it is of utmost necessity to
balance the cardinalities of the majority and minority
classes, it has to be done by lessening the degree of
preservation.
In order, we present the Experimental Setup, Results
and Discussion, and Conclusion in the following three
sections.
5 EXPERIMENTAL SETUP
• Datasets: We have performed the experiments on
12 real-world multi-label datasets enlisted in Ta-
ble 1
1
. Here, instances, inputs, and labels indi-
cate the cardinality, features, and the number of
labels respectively in each dataset. Type indicates
the nominal or numeric nature of the features. The
number of unique label combinations present in a
dataset is indicated by Distinct label sets. Cardi-
nality is the average number of labels per instance,
and Density is Cardinality weighted by the num-
ber of labels.
We have pre-processed the datasets according to
the recommendations in (Zhang et al., 2020; He
and Garcia, 2009). Labels having a very high
degree of imbalance (50 or greater) or having
too few positive samples (20 in this case) are re-
moved. For text datasets (medical, enron, rcv1-s1,
rcv1-s2), only the input space features with a high
degree of document frequencies are retained.
• Comparing Algorithms: Seven schemes, com-
prising of, i] six multi-label learning schemes
and ii] one generic class-imbalance focused learn-
ers are employed in the empirical study. The
multi-label learners involved in the study are
COCOA (Zhang et al., 2020), THRESHL(Pillai
et al., 2013), IRUS (Tahir et al., 2012), CLR
(Fürnkranz et al., 2008), RAKEL (Tsoumakas
et al., 2011) and ECC (Read et al., 2011). In
COCOA, several imbalance-focused multi-class
learners are implemented in the Weka platform
using the J48 decision tree with undersampling,
where the number of coupling class labels is set
as K = min(L − 1, 10). IRUS is a label-specific
undersampling scheme like the proposed method,
NaNUML where L are trained, one for each label.
Each label-specific classifier is trained using the
label-specific undersampled training data. IRUS
is an ensemble method and the random undersam-
pling is repeated several times to produce a clas-
sifier ensemble. THRESHL also learns in a label-
specific setting with one classifier for each label.
The scheme of THRESHL is to maximize the F-
scores in a hold-out setting to find the threshold
for classification. CLR is a second-order learning
1
http://mulan.sourceforge.net/datasets-mlc.html
Parameter-Free Undersampling for Multi-Label Data
401

Table 1: Description of datasets.
Dataset Instances Inputs Labels Type Cardinality Density Distinct Proportion of Imbalance Ratio
Labelsets Distinct min max avg
Labelsets
CAL500 502 68 124 numeric 25.058 0.202 502 1.000 1.040 24.390 3.846
Emotions 593 72 6 numeric 1.869 0.311 27 0.046 1.247 3.003 2.146
Scene 2407 294 6 numeric 1.074 0.179 15 0.006 3.521 5.618 4.566
Yeast 2417 103 13 numeric 4.233 0.325 189 0.078 1.328 12.500 2.778
Image 2000 294 5 numeric 1.236 0.247 20 0.010 2.448 3.890 3.117
Rcv1-s1 6000 472 42 numeric 2.458 0.059 574 0.096 3.342 49.000 24.966
Rcv1-s2 6000 472 39 numeric 2.170 0.056 489 0.082 3.216 47.780 26.370
medical 978 144 14 nominal 1.075 0.077 42 0.043 2.674 43.478 11.236
Llog 1460 100 18 nominal 0.851 0.047 109 0.075 7.538 46.097 24.981
Enron 1702 50 24 nominal 3.113 0.130 547 0.321 1.000 43.478 5.348
Slashdot 3782 53 14 nominal 1.134 0.081 118 0.031 5.464 35.714 10.989
Corel5k 5000 499 44 nominal 2.241 0.050 1037 0.207 3.460 50.000 17.857
scheme that exploits pair-wise label correlations
to obtain a multi-label learning performance. In
ECC, the classification outputs of a label are used
as an input feature for predicting the succeeding
labels, thereby involving the correlations of the
labels. RAKEL is also a higher-order learning
approach where the set of overlapping and non-
overlapping subsets of labels are considered, and
multi-class classifiers are learned on the power set
of the labels. RML (Tahir et al., 2012) is a generic
class-imbalance learner used in the comparative
study. In RML, the macro-averaging F measure
is used as the optimization metric while modeling
the classifier. In IRUS, the C4.5 decision tree is
used as the base learner. In RAKEL, the recom-
mended settings of k = 3 and the number of sub-
sets m = 2q are employed. In ECC, an ensemble
size of 100 is chosen. In CLR, a synthetic label is
used to differentiate between the relevant and the
irrelevant labels.
In NaNUML, we have used Support Vector Ma-
chine Classifier with linear kernel and the regular-
ization parameter is set to 1.
• Evaluating metrics: Four multi-label domain-
specific metrics, namely – macro averaging F
1
,
macro-averaging AUC, average precision, and
ranking loss are used to compute the performance
of the proposed and the competing methods. They
are briefly described as follows:
– Macro-averaging F
1
: It is the average of all the
label-specific F
1
scores. Let F
1 j
be the F
1
score
for label j. The higher the macro averaging F
1
score, the better the performance.
Macro F
1
=
1
L
L
∑
j=1
F
1 j
(9)
– Macro-averaging AUC: It is the sum of the
label-specific AUC scores, weighted by the
number of labels L. Let AUC
j
be the AUC
score for label j. The higher the macro aver-
aging AUC score, the better the learner’s per-
formance.
Macro AUC =
1
L
L
∑
j=1
AUC
j
(10)
– Average Precision: Average precision evaluates
the average fraction of relevant labels ranked
higher than a particular label. It is desirable
that, for instance, the relevant labels will
be predicted with higher scores (more confi-
dence) than that of the irrelevant or absent ones.
Let R (x
i
, l
k
) = {l
j
|rank(x
i
, l
j
) ≤
rank(x
i
, l
k
), l
j
∈ Y
i
}
Average Precision =
1
n
t
∑
1
1
|Y
i
|
∑
|R (x
i
, l
k
)|
rank(x
i
, l
k
)
(11)
– Ranking loss: is used to evaluate the percent-
age of misordered label pairs. Let R (x
i
, l
k
) =
{l
j
|rank(x
i
, l
j
) ≤ rank(x
i
, l
k
), l
j
∈ Y
i
}. Y
′
i
de-
notes the labels not belonging to x
i
. The lower
the value, the better the performance.
Ranking loss =
1
n
t
∑
1
1
|Y
i
||Y
′
i
|
(y
ik
, y
i j)| f
k
(x
i
))≤ f
j
(x
i
),(y
k
,y
j
)∈(Y
i
× Y
′
i
)
rank(x
i
, l
k
)
(12)
• Statistical Significance Test: We have conducted
Wilcoxon Signed Rank Test to evaluate the dif-
ference in the methods’ performance statistically.
We have conducted the tests for a pair of methods
— (NaNUML-50% or NaNUML-100% or Best
of two) and each competing method on the re-
sults obtained from all four evaluating metrics.
We have made the evaluations at p = 0.05 signif-
icance level.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
402

Table 2: Macro F
1
results. Higher the score ↑, better is the performance.
Datasets NaNUML-50% NaNUML-100% COCOA THRESHL IRUS RML CLR ECC RAKEL
CAL500 0.152 0.292* 0.210 0.252 0.277 0.209 0.081 0.092 0.193
Emotions 0.646 0.669* 0.660 0.562 0.622 0.645 0.595 0.638 0.613
Scene 0.692 0.649 0.729 0.627 0.632 0.682 0.630 0.715 0.687
Yeast 0.388 0.503* 0.462 0.427 0.428 0.471 0.414 0.392 0.421
Image 0.613 0.618 0.640 0.526 0.573 0.512 0.546 0.616 0.613
RCV1 0.171 0.364 0.364 0.294 0.262 0.385 0.228 0.192 0.227
RCV2 0.161 0.393* 0.339 0.273 0.226 0.370 0.212 0.164 0.229
Medical 0.780* 0.671 0.759 0.733 0.537 0.707 0.724 0.733 0.672
Llog 0.200 0.207* 0.085 0.095 0.124 0.095 0.024 0.024 0.022
Enron 0.368* 0.345 0.341 0.292 0.293 0.308 0.244 0.268 0.267
Slashdot 0.442* 0.382 0.372 0.335 0.258 0.342 0.288 0.305 0.296
Corel5k 0.217* 0.185 0.196 0.144 0.106 0.215 0.48 0.054 0.083
Table 3: Macro AUC results. Higher the score ↑, better is the performance.
Datasets NaNUML-50% NaNUML-100% COCOA THRESHL IRUS CLR ECC RAKEL
CAL500 0.532 0.528 0.558 0.509 0.545 0.561 0.554 0.528
Emotions 0.819 0.824 0.844 0.687 0.804 0.797 0.851 0.797
Scene 0.909 0.902 0.942 0.759 0.922 0.894 0.941 0.893
Yeast 0.648 0.666 0.712 0.574 0.653 0.651 0.704 0.652
Image 0.817 0.822 0.864 0.681 0.824 0.798 0.865 0.812
RCV1 0.898* 0.920* 0.889 0.642 0.881 0.882 0.876 0.742
RCV2 0.902* 0.917* 0.881 0.643 0.880 0.880 0.874 0.701
Medical 0.970* 0.967* 0.964 0.870 0.963 0.954 0.952 0.860
Enron 0.736 0.748 0.752 0.597 0.737 0.722 0.750 0.654
Llog 0.730* 0.741* 0.664 0.518 0.678 0.613 0.674 0.519
Slashdot 0.817* 0.817* 0.774 0.635 0.752 0.740 0.765 0.632
Corel5k 0.698 0.706 0.716 0.597 0.684 0.741 0.722 0.553
Table 4: Average precision results. Higher the score ↑, better is the performance.
Datasets NaNUML-50% NaNUML-100% COCOA THRESHL IRUS CLR ECC RAKEL
CAL500 0.512* 0.377 0.478 0.333 0.276 0.506 0.511 0.401
Emotions 0.788 0.806 0.801 0.683 0.756 0.767 0.809 0.766
Scene 0.839 0.830 0.865 0.707 0.844 0.809 0.871 0.822
Yeast 0.767* 0.729 0.762 0.596 0.543 0.742 0.766 0.717
Image 0.793 0.782 0.819 0.671 0.780 0.766 0.821 0.775
RCV1 0.630* 0.628 0.601 0.427 0.556 0.596 0.626 0.501
RCV2 0.678* 0.676* 0.612 0.457 0.569 0.611 0.632 0.516
Medical 0.934* 0.926* 0.922 0.870 0.882 0.913 0.920 0.829
Enron 0.669 0.606 0.712 0.595 0.532 0.704 0.717 0.654
Llog 0.618* 0.612* 0.346 0.306 0.308 0.342 0.353 0.218
Slashdot 0.672* 0.680* 0.605 0.565 0.507 0.593 0.598 0.486
Corel5k 0.396 0.360 0.396 0.343 0.190 0.387 0.406 0.213
6 RESULTS AND DISCUSSION
We have randomly partitioned each dataset into two
equal (or nearly equal), mutually exclusive halves to
construct a training set and a test set for a single
run. For each run, we have obtained the results on
three metrics. The values in the table are the mean
scores obtained from ten experiment runs. The scores
obtained on macro-averaging F
1
, macro-averaging
AUC, average precision and ranking loss are shown
in Table 2, 3, 4, and 5 respectively. NaNUML
(NaNUML-50% and NaNUML-100%) has obtained
the best scores on macro-averaging F
1
in 9 out of 12
datasets. Of the nine best scores obtained, NaNUML-
50% obtains four, and NaNUML-100% obtains five.
COCOA (two) and RML (one) obtain the remaining
three best performances. This feat by NaNUML indi-
cates its appropriateness in handling class-imbalance
problems in a multi-label context. The performance
of NaNUML on macro-averaging AUC is a bit sub-
Parameter-Free Undersampling for Multi-Label Data
403
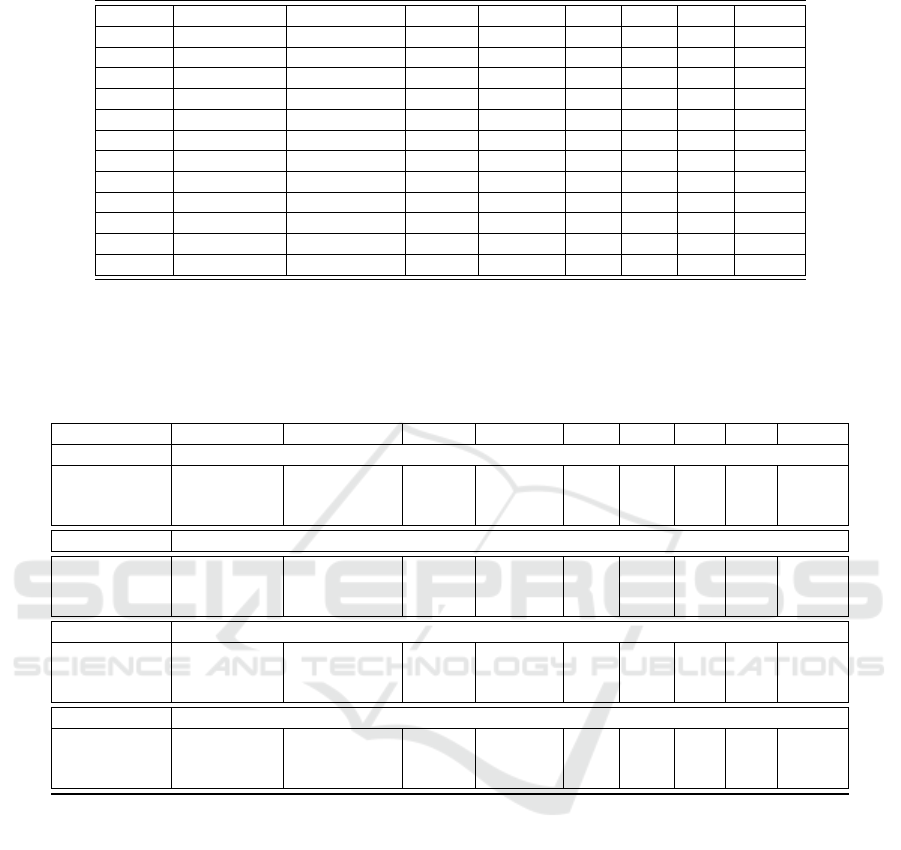
Table 5: Ranking Loss results. Lower the score ↓, better is the performance.
Datasets NaNUML-50% NaNUML-100% COCOA THRESHL IRUS CLR ECC RAKEL
CAL500 0.233* 0.332 0.265 0.383 0.482 0.241 0.237 0.340
Emotions 0.159 0.162 0.159 0.306 0.202 0.193 0.151 0.200
Scene 0.085 0.096 0.073 0.248 0.089 0.111 0.073 0.112
Yeast 0.180* 0.233 0.186 0.348 0.439 0.204 0.182 0.230
Image 0.168 0.182 0.149 0.312 0.182 0.199 0.147 0.198
RCV1 0.073* 0.062* 0.078 0.287 0.104 0.077 0.074 0.187
RCV2 0.068* 0.061* 0.081 0.269 0.108 0.079 0.079 0.194
Medical 0.018* 0.016 0.023 0.052 0.030 0.027 0.022 0.087
Enron 0.121 0.168 0.116 0.230 0.250 0.121 0.112 0.200
Llog 0.173* 0.177* 0.221 0.265 0.258 0.228 0.223 0.356
Slashdot 0.138* 0.140* 0.189 0.217 0.246 0.183 0.186 0.330
Corel5k 0.200 0.207 0.201 0.256 0.362 0.186 0.189 0.570
Table 6: Results of Wilcoxon Signed Rank Test (two-tailed) at p = 0.05. ↑ in (i, j)
th
cell signifies that the performance of the
method in i
th
row is better and statistically significant than that of the method present in j
th
column. ↓ in (i, j)
th
cell signifies
that the performance of the method in i
th
row is poor and statistically significant than that of the method present in j
th
column.
−− in (i, j)
th
cell signifies that there is no statistical significance in the difference in the performance of the method in i
th
row
and the method in j
th
column. * indicates evaluation was not performed.
Methods NaNUML-50% NaNUML-100% COCOA THRESHL IRUS RML CLR ECC RAKEL
Macro-averaging F
1
Best – – ↑ ↑ ↑ ↑ ↑ ↑ ↑
NaNUML-50% – – – – – – – – –
NaNUML-100% – - – ↑ ↑ – – ↑ ↑
Macro-averaging AUC
Best – - – ↑ ↑ * – – ↑
NaNUML-50% – ↓ – ↑ – * – – ↑
NaNUML-100% ↑ – – ↑ ↑ * – – ↑
Averaging Precision
Best – – – ↑ ↑ * ↑ – ↑
NaNUML-50% – – – ↑ ↑ * ↑ – ↑
NaNUML-100% – - ↓ ↑ ↑ * – – ↑
Ranking Loss
Best – – – ↑ ↑ * ↑ – ↑
NaNUML-50% – – – ↑ ↑ * ↑ – ↑
NaNUML-100% – - – ↑ ↑ * – – ↑
dued as compared to that of macro-averaging F
1
.
NaNUML has obtained the best scores in 6 out of 12
datasets only. The remaining best scores are shared
by COCOA (3 out of 6), CLR (2 out of 6), and ECC
(3 out of 6). Between NaNUML-50% and NaNUML-
100%, the latter has attained a relatively better per-
formance. NaNUML has attained the best scores on
average precision in 7 out of 12 datasets. We may also
note that NANUML-50% achieves six out of those
cases, and only one is achieved by NaNUML-100%.
ECC has attained the remaining five best scores. The
probable reason regarding the loss of performance by
NaNUML-100% is due to the deletion of some ma-
jority instances, which leads to the loss of some perti-
nent information. On ranking loss, NaNUML has the
lowest loss values in 7 out of 12 cases. Out of these,
NaNUML-50% and NANUML-100% have achieved
4 and 3, respectively. ECC and CLR have achieved
four and one of the best scores, respectively.
We report the statistical significance of the improve-
ment achieved by NaNUML. We have presented
the results of the statistical significance test in Ta-
ble 6. On macro-averaging F
1
, the performance of
NaNUML (best of NaNUML-50% and NaNUML-
100% ) is better and statistically superior to all com-
peting methods. Concerning macro-averaging AUC,
NaNUML has delivered a statistically significant im-
provement against three competing methods and has
failed to do so against three. The three methods are
COCOA, CLR, and ECC. This finding is in congru-
ence with the data presented in Table 3. On average
precision and ranking loss, NaNUML has obtained
statistically superior performance against four com-
peting methods, and NaNUML’s performance is sta-
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
404

tistically comparable to that of COCOA and ECC. We
should also note that, only in one case, NaNUML-
100% has achieved a statistically inferior perfor-
mance (against COCOA, on average precision). The
above-summarized results ascertain the appropriate-
ness of the proposed method, NaNUML, over existing
schemes dedicated to multi-label learning and class-
imbalance mitigation. It is to be noted that, being an
undersampling scheme, NaNUML reduces the com-
plexity associated with the classifier modeling.
7 CONCLUSION
In this work, we have presented a novel label-specific
undersampling scheme, NaNUML, for multi-label
datasets. NaNUML is based on the parameter-free
natural neighbor search, and the critical factor, neigh-
borhood size ’k’, is determined without invoking any
parameter optimization. In our scheme, we eliminate
the majority instances closer to the minority class. In
addition, we preserve the critical lattices of the major-
ity class by looking at the majority natural neighbor
count of the majority class. The other advantage of
the scheme is that we require only one natural neigh-
bor search for all labels. Undersampling schema has
the intrinsic characteristic of reducing the complex-
ity in the classifier modeling phase (through the re-
duction in training data), and NaNUML is no excep-
tion. The performance of NaNUML indicates its abil-
ity to mitigate the class-imbalance issue in multi-label
datasets to a considerable extent.
In our future work, we would like to design
a natural-neighborhood-based oversampling scheme
for class-imbalanced datasets. We would also like to
explore if we can incorporate label correlations in our
undersampling scheme.
REFERENCES
Ali, H., Salleh, M. N. M., Hussain, K., Ahmad, A., Ul-
lah, A., Muhammad, A., Naseem, R., and Khan, M.
(2019). A review on data preprocessing methods for
class imbalance problem. International Journal of En-
gineering & Technology, 8:390–397.
Charte, F., Rivera, A. J., del Jesus, M. J., and Herrera, F.
(2014). Mlenn: a first approach to heuristic multil-
abel undersampling. In International Conference on
Intelligent Data Engineering and Automated Learn-
ing, pages 1–9. Springer.
Charte, F., Rivera, A. J., del Jesus, M. J., and Herrera, F.
(2015a). MLSMOTE: approaching imbalanced mul-
tilabel learning through synthetic instance generation.
Knowledge-Based Systems, 89:385–397.
Charte, F., Rivera, A. J., del Jesus, M. J., and Herrera, F.
(2015b). Mlsmote: Approaching imbalanced multi-
label learning through synthetic instance generation.
Knowledge-Based Systems, 89:385–397.
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer,
W. P. (2002). SMOTE: synthetic minority over-
sampling technique. J. Artif. Int. Res., 16(1):321–357.
Choirunnisa, S. and Lianto, J. (2018). Hybrid method of
undersampling and oversampling for handling imbal-
anced data. In 2018 International Seminar on Re-
search of Information Technology and Intelligent Sys-
tems (ISRITI), pages 276–280. IEEE.
Daniels, Z. and Metaxas, D. (2017). Addressing imbalance
in multi-label classification using structured hellinger
forests. In Proceedings of the AAAI Conference on
Artificial Intelligence, volume 31.
Elisseeff, A. and Weston, J. (2001). A kernel method for
multi-labelled classification. In Proceedings of the
14th International Conference on Neural Information
Processing Systems: Natural and Synthetic, NIPS’01,
pages 681–687, Cambridge, MA, USA. MIT Press.
Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., and
Brinker, K. (2008). Multilabel classification via cali-
brated label ranking. Mach. Learn., 73(2):133–153.
Godbole, S. and Sarawagi, S. (2004). Discriminative meth-
ods for multi-labeled classification. In Proceedings
of the 8th Pacific-Asia Conference on Knowledge Dis-
covery and Data Mining, pages 22–30.
Gonzalez-Lopez, J., Ventura, S., and Cano, A. (2018). Dis-
tributed nearest neighbor classification for large-scale
multi-label data on spark. Future Generation Com-
puter Systems, 87:66–82.
He, H. and Garcia, E. A. (2009). Learning from imbal-
anced data. IEEE Trans. on Knowl. and Data Eng.,
21(9):1263–1284.
Joachims, T. (1998). Text categorization with support vec-
tor machines: Learning with many relevant features.
In European conference on machine learning, pages
137–142. Springer.
Katakis, I., Tsoumakas, G., and Vlahavas, I. (2008). Multi-
label text classification for automated tag suggestion.
In: Proceedings of the ECML/PKDD-08 Workshop on
Discovery Challenge.
Li, X., Zhao, F., and Guo, Y. (2014). Multi-label image
classification with a probabilistic label enhancement
model. In Uncertainty in Artificial Intelligence.
Liu, B. and Tsoumakas, G. (2020). Dealing with class
imbalance in classifier chains via random undersam-
pling. Knowledge-Based Systems, 192:105292.
Liu, Y., Wen, K., Gao, Q., Gao, X., and Nie, F. (2018). Svm
based multi-label learning with missing labels for im-
age annotation. Pattern Recognition, 78:307–317.
Ludera, D. T. (2021). Credit card fraud detection
by combining synthetic minority oversampling and
edited nearest neighbours. In Future of Informa-
tion and Communication Conference, pages 735–743.
Springer.
Moyano, J. M., Gibaja, E. L., Cios, K. J., and Ventura, S.
(2018). Review of ensembles of multi-label classi-
Parameter-Free Undersampling for Multi-Label Data
405

fiers: Models, experimental study and prospects. In-
formation Fusion, 44:33 – 45.
Nam, J., Kim, J., Mencía, E. L., Gurevych, I., and
Fürnkranz, J. (2014). Large-scale multi-label
text classification—revisiting neural networks. In
Joint european conference on machine learning and
knowledge discovery in databases, pages 437–452.
Springer.
Pereira, R. M., Costa, Y. M., and Silla Jr., C. N. (2020a).
MLTL: A multi-label approach for the tomek link
undersampling algorithm. Neurocomputing, 383:95–
105.
Pereira, R. M., Costa, Y. M., and Silla Jr, C. N. (2020b).
Mltl: A multi-label approach for the tomek link under-
sampling algorithm. Neurocomputing, 383:95–105.
Pillai, I., Fumera, G., and Roli, F. (2013). Threshold opti-
misation for multi-label classifiers. Pattern Recogn.,
46(7):2055–2065.
Read, J., Pfahringer, B., Holmes, G., and Frank, E. (2011).
Classifier chains for multi-label classification. Ma-
chine learning, 85(3):333.
Sadhukhan, P. and Palit, S. (2019). Lattice and imbalance
informed multi-label learning. IEEE Access, 8:7394–
7407.
Sadhukhan, P. and Palit, S. (2020). Multi-label learning on
principles of reverse k-nearest neighbourhood. Expert
Systems, page e12615.
Siblini, W., Kuntz, P., and Meyer, F. (2018). Craftml, an
efficient clustering-based random forest for extreme
multi-label learning. In International Conference on
Machine Learning, pages 4664–4673. PMLR.
Tahir, M. A., Kittler, J., and Yan, F. (2012). Inverse
random under sampling for class imbalance prob-
lem and its application to multi-label classification.
45(10):3738–3750.
Tsoumakas, G., Katakis, I., and Vlahavas, I. (2011). Ran-
dom k-labelsets for multilabel classification. IEEE
Transactions on Knowledge and Data Engineering,
23(7):1079–1089.
Zhang, M.-L., Li, Y.-K., Yang, H., and Liu, X.-Y. (2020).
Towards class-imbalance aware multi-label learning.
IEEE Transactions on Cybernetics.
Zhang, M.-L. and Wu, L. (2015). Lift: Multi-label learning
with label-specific features. Pattern Analysis and Ma-
chine Intelligence, IEEE Transactions on, 37(1):107–
120.
Zhu, Q., Feng, J., and Huang, J. (2016). Natural neighbor:
A self-adaptive neighborhood method without param-
eter k. Pattern Recognition Letters, 80:30–36.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
406
