
XYZ Unsupervised Network: A Robust Image Dehazing Approach
Percy Maldonado-Quispe
a
and Helio Pedrini
b
Institute of Computing, University of Campinas, Campinas, SP, 13083-852, Brazil
Keywords:
Image Dehazing, Unsupervised Network, Zero-Shot Learning, Disentanglement, Dark Channel Prior,
Atmospheric Scattering Model.
Abstract:
In this work, we examine a major less-explored topic in image dehazing neural networks, specifically how to
remove haze (natural phenomenon) in an unsupervised manner from a given image. By considering a hazy
image as the entanglement of many “simpler” layers, such as a hazy-free image layer, transmission map layer,
and atmospheric light layer, as shown in the atmospheric scattering model, we propose a method based on the
concept of layer disentanglement. Our XYZ approach presents improvements in the SSIM and PSNR metrics,
this being the combination of the XHOT, YOLY and ZID methods, in which the advantages of each of them are
maintained. The main benefits of the proposed XYZ are twofold. First, since it is an unsupervised approach,
no clean photos, including hazy-clear pairs, are used as the ground truth. In other words, it differs from the
traditional paradigm of deep model training on a large dataset. The second is to consider haze issues as being
composed of several layers.
1 INTRODUCTION
In bad weather conditions, such as fog and haze, im-
age quality is greatly degraded due to the influence of
particles in the atmosphere. The suspended particles
will scatter the light and dim the reflected light from
the scene, and the scattered atmospheric light will also
mix with the light received by the camera and change
the contrast and color of the image.
The quality of the images captured by the camera
is reduced due to absorption by particles floating in
the environment. The phenomenon of degraded im-
age quality on foggy days negatively affects photo-
graphic work. The contrast of the image will be re-
duced and the colors will change. At the same time,
the textures and boundaries of objects in the scene be-
come blurred. For vision tasks such as object detec-
tion and image segmentation, poor-quality inputs can
degrade the performance of well-designed models.
To estimate the global atmospheric light and trans-
mission coefficient per pixel from the atmospheric
scattering model, a variety of methods have been pro-
posed, which could be roughly divided into previous
assumption-based methods and learning-based meth-
ods.
Previous methods rely mainly on some back-
a
https://orcid.org/0009-0007-6391-5370
b
https://orcid.org/0000-0003-0125-630X
ground derived from the image. For example, Tan
(2008) proposed to remove haze by maximizing the
local contrast of the image, based on the assump-
tion that clean images tend to have higher contrast.
Berman et al. (2016) proposed to remove haze based
on the assumption that the colors of an image without
haze could well approximate a few hundred colors.
Although remarkable performance has been achieved
with these methods, the quality of haze removal is
highly dependent on the consistency between the data
and actual distribution.
To avoid previous assumptions, several authors
have devoted much effort to the design of methods
based on deep neural networks. This method changes,
detects and removes haze from an image by directly
learning atmospheric dispersion parameters from the
training data. For example, Cai et al. (2016) proposed
a convolutional neural network that requires a large
set of pairs of clean and haze images, so they are su-
pervised learning methods.
Although supervised learning methods (Qin et al.,
2020; Liu et al., 2019; Dong et al., 2020) have
achieved high performance in haze removal, they
have several limitations, one of which is that they
require large-scale clean and fuzzy image pairs to
train their models, and such a requirement is usu-
ally satisfied by artificially synthesizing fuzzy images,
through the physical model with the parameters made
500
Maldonado-Quispe, P. and Pedrini, H.
XYZ Unsupervised Network: A Robust Image Dehazing Approach.
DOI: 10.5220/0012383400003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 3: VISAPP, pages
500-507
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

by hand and the clean image. As pointed out by Golts
et al. (2020), synthesized databases are less informa-
tive and inconsistent than the real ones. Therefore, it
is expected that unsupervised models will be devel-
oped.
However, in practice, due to variations in the scene
and other factors such as illumination, it is difficult, if
not impossible, to collect a large scale dataset with the
desired ground truth. As a result, most methods rely
on first collecting some clean images and then syn-
thesizing the corresponding hazy images using an at-
mospheric scattering model with handcrafted param-
eters. However, when the model trained on the syn-
thetic dataset is applied to real-world haze images, the
domain shift problem will arise, as the synthetic haze
images are likely to be less informative and inconsis-
tent with the real-world haze images. For this reason,
we propose our method called XYZ, which tries to
overcome the problems mentioned above. As far as
we know, this task was not widely addressed.
As main contributions, we have that our method
does not need paired images, that is, we do not have
the dependence of having a large data set with im-
ages with haze and without haze, which was already
a problem in itself. In this work, we propose two ap-
proaches in their totality, the first of them is to obtain
a simple and lightweight unsupervised neural network
(XHOT) for the removal of haze in order to lighten the
processing time, on the other hand we have the exist-
ing neural network clustering approach for haze re-
moval. XYZ (ZHOT, YOLY and ZID) seeks an inte-
gration of the advantages of these methods present in
the state of the art, assuming that each method focuses
on different aspects such as: Dark Channel Prior ap-
proximation, HSV Color Space and the use of a deep
neural network such as U-Net.
2 RELATED WORK
As a result, many researchers are trying to recover
clean, high-quality scenes from haze images. Be-
fore the widespread use of deep learning in com-
puter vision tasks, image haze removal algorithms
were mainly based on some earlier assumptions (He
et al., 2009) and the Atmospheric Scattering Model
(ASM) (McCartney, 1978). The processing se-
quences of these rule-based statistical methods are
easy to interpret. However, they can fail when faced
with complex real-world scenarios. For example, the
popular dark channel prior (He et al., 2009) (DCP)
does not handle empty regions well.
The works (Cai et al., 2016; Liu et al., 2019;
Zheng et al., 2021) are inspired by deep learning and
combined ASM with convolutional neural networks
(CNN) to estimate physical parameters. Quantitative
and qualitative experimental results show that deep
learning can help predict physical parameters in a su-
pervised manner. Wang et al. (2022a) on the other
hand proposes the use of an attention-convolutional
module.
Following this, Liu et al. (2019) and Zheng et al.
(2021) have demonstrated that end-to-end supervised
dehazing networks can be implemented indepen-
dently of the ASM. Thanks to the powerful feature
extraction capability of CNN, these non-ASM-based
dehazing algorithms can achieve similar accuracy as
ASM-based algorithms.
ASM-based and non-ASM-based supervised al-
gorithms have shown impressive performance. How-
ever, they often require synthetic paired images that
are inconsistent with real-world hazy images. There-
fore, recent research focus on methods that are more
suitable to the real world dehazing task. Engin et al.
(2018), Li et al. (2020), Golts et al. (2020) and Li et al.
(2021) explored unsupervised algorithms that do not
require synthetic data.
In addition, Chen et al. (2022) designed a method
based on two stages, which eliminates haze using
DCP and subsequently optimizes the results using ex-
isting features between the transmission and depth
map. Wang et al. (2022b) proposes a method com-
pletely independent of real haze-free images. How-
ever, GAN-based networks have great complexity and
runtime.
Data-driven unsupervised dehazing methods have
achieved impressive performances. Unlike models
that require sufficient data to perform network train-
ing, Li et al. (2020) proposed a neural network de-
hazing process that only requires a single example.
They further reduced the dependence of the parameter
learning process on data by combining the advantages
of unsupervised learning and zero-shot learning.
Methods for unsupervised dehazing that are data-
driven have demonstrated outstanding results. In the
approaches developed by Li et al. (2020) and Li et al.
(2021), a dehazing based on neural networks uses a
single example, in contrast to methods that require
sufficient data to perform network training. By com-
bining the benefits of unsupervised learning and zero-
shot learning, the authors further decreased the depen-
dence of the parameter learning process on data.
Supervised methods of dehazing have achieved
excellent results. However, this requires paired data,
which is difficult to obtain in the real world. For out-
door scenes with moving objects, it is difficult to guar-
antee that two images taken on a clear, cloudy day
have exactly the same content. This is why other ap-
XYZ Unsupervised Network: A Robust Image Dehazing Approach
501

proaches (Engin et al., 2018; Li et al., 2020; Golts
et al., 2020; Li et al., 2021) have explored unsuper-
vised haze removal algorithms.
3 UNSUPERVISED APPROACH
In this section, we present the development of our
proposed approaches, which combines three unsuper-
vised learning methods. First, there is XHOT 3.1.1,
which is based on the fundamentals presented in pre-
vious investigations, specifically in the works of (Li
et al., 2021) and (Golts et al., 2020). Then, we ex-
plore YOLY, based on research by Li et al. (2021), and
ZID, based on research by Li et al. (2020). Both meth-
ods demonstrated outstanding performance in metrics
such as SSIM and PSNR, establishing themselves as
state-of-the-art benchmarks in the RESIDE dataset.
In addition, it is important to highlight that all the
methods described as follows do not require a set of
paired images for your training, as they address the
removal of haze individually for each image.
3.1 Methods
In the next subsections, we present the methods used
in this work, which include XHOT, YOLY and ZID.
3.1.1 XHOT
The XHOT network arises from the need to develop
an effective and efficient haze removal solution with-
out relying on paired data, as required in unsupervised
learning. Recognizing that haze removal can be bro-
ken down into simpler components, we base our strat-
egy on the combination of multiple simple layers, as
discussed in previous research (Li et al., 2020).
To address this challenge, we create three neu-
ral networks, two of which are convolutional neu-
ral networks designed to estimate the best values for
J(x) and T(x), respectively, as shown in Figure 1.
However, in the case of calculating atmospheric light,
an independent component of the image content, we
chose to maintain the methodology proposed by pre-
vious research, specifically by Li et al. (2020) and Li
et al. (2021), who employed a Variational Autoen-
coder for estimating atmospheric light.
Architectures. Three sub-networks were con-
structed to estimate the values for J(x), T (x) and
A:
• J-Net: This sub-network consists of a non de-
generative convolutional neural network, which
means that it does not alter the dimensions of
+
J(x)
T(x)
A(x)
ASM
Normalization
LeakyRelu
Sigmoid
Conv
MaxPool
Upsample
I(x)
x
Figure 1: Architecture of our proposed XHOT, in which
we have three sub-networks to calculate the variables J(x),
T (x) and A, respectively.
the input, which is composed of three convolu-
tional blocks, each one performing a convolution
with a kernel size 5, followed by normalization by
batches and finally a LeakyRelu activation func-
tion with a slope of 0.01. At the end of the third
block, we applied a convolution together with a
Sigmoid activation function, to normalize the out-
put between 0 and 1. The output of this sub-
network is an image with 3 channels that is the
haze free image J(x) and that later will be in
charge of guiding the training.
• T-Net: This sub-network uses the same neural
network as J-Net, however presents a difference
with respect to the outcome of the neural network
which is a single-channel image, representing the
transmission map T (x) within the image.
• A-Net: This sub-network consists of a Variational
Autoencoder, since the variable A is not related to
the content of the image, similar to the work by Li
et al. (2020), it is assumed that A is sampled from
a latent Gaussian distribution, and so the prob-
lem becomes a variational inference (Kingma and
Welling, 2014).
Loss Function. To train our unsupervised model,
we employ a loss function that combines the loss
functions of J-Net and A-Net, as expressed in Equa-
tion 1:
L
XHOT
= L
J
+ L
A
(1)
where L
J
is the loss function between the input x and
the result of generating haze I(x), this value is cal-
culated taking into account the 3 variables predicted
following Equation 2. Then, we can define L
J
as:
I(x) = J(x)t(x) + A(1 −t(x)) (2)
L
J
= MSELoss(I(x), x) (3)
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
502

In addition, the loss function for the A-Net sub-
network is expressed as:
L
A
= L
H
+ L
KL
(4)
where L
H
is the loss function MSELoss between A
and A
H
, A
H
is the pre-calculated value of the im-
age with haze x using Dark Channel Prior (He et al.,
2009). Finally, the function L
KL
is given following the
equation 5, where KL() denotes the Kullback-Leibler
divergence between two distributions:
L
KL
= KL(N(µ
z
, σ
2
z
)||N(0, 1))
=
1
2m
∑
i
(µ
z
i
)
2
+ (σ
z
i
)
2
− 1 − log(σ
z
i
)
2
(5)
3.1.2 YOLY
Considering a haze image, represented as x, the cen-
tral purpose is to restore the image without haze J(x)
without making use of information beyond what is
contained in the image itself. The essence of this
method is based on breaking down x into three sub-
networks, as illustrated in Figure 2. To be more pre-
cise, YOLY simultaneously channels x through three
main networks: the first is designed to estimate J(x),
the second to estimate the transmission map T (x), and
the third focuses on estimating atmospheric light A.
Subsequently, the results of these networks are further
combined to reconstruct x in the upper layer, making
use of the atmospheric dispersion model (Equation 2).
Therefore, the model as a whole learns in an unsuper-
vised way. In summary, the goal is to minimize the
following loss function:
L
rec
= ||I(x) − x|| (6)
The cleared image J(x) is obtained by combining
the outputs generated by the three sub-networks, as
expressed in Equation 2. The loss function L
rec
was
designed to regulate the performance of the system
as a whole, encompassing both the individual sub-
networks and the reconstruction of the haze image
I(x) after calculating its components. More precisely,
this loss function monitors and guides the disentan-
gling process, and this is achieved by incorporating
the haze generation process.
Loss Function. In addition, YOLY proposes a new
loss function taking into account the HSV color space,
which arises based on the observation made by Zhu
et al. (2015), which indicates that the difference be-
tween brightness and saturation is close to zero in the
haze-free zones. To make use of this previous infor-
mation, they propose the following equation regard-
ing the prediction of J(x).
L
J
= ||V (J(x)) − S(J(x))|| (7)
Figure 2: The architecture of YOLY. Extracted from the
work developed by Li et al. (2021).
In addition, YOLY proposes a set of loss functions
for training the A-Net sub-network, including a regu-
larization function to avoid overfitting.
3.1.3 ZID
The approach followed by ZID is similar to YOLY (Li
et al., 2021), in terms of deinterlacing the problem
into capable simpler ones. However, ZID differs from
YOLY in two fundamental respects. First, a distinc-
tion is made in terms of the loss function used. Specif-
ically, ZID proposes a loss similar to that used in DCP
for J-Net training, while YOLY is based on observ-
ing the HSV color space. In addition to this, ZID
introduces a smooth regularization in the outputs of
T-Net and A-Net, as opposed to YOLY, which only
applies this regularization in A-Net. Second, network
architectures vary. ZID adopts a structure analogous
to the U-Net architecture, in contrast to YOLY, which
is based on a non-degenerate architecture.
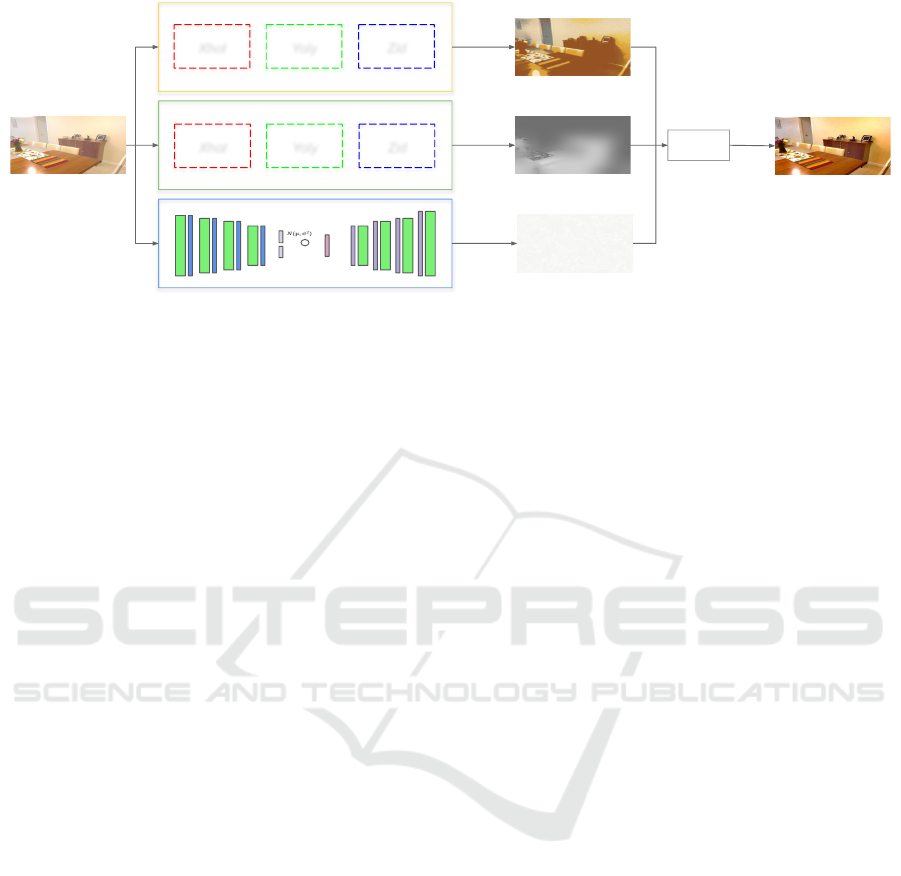
3.2 XYZ Network
In the following subsections, we present the second
proposed approach, which is characterized by the in-
tegration of the advantages offered by the XHOT,
YOLY and ZID methods. It is important to note that
the three unsupervised methods retain their respective
loss functions, which will play a fundamental role
in the training process of the robust model we are
proposing.
3.2.1 Architecture
As shown in Figure 3, our approach makes use of the
methods presented by Li et al. (2020) and Li et al.
(2021). As seen in Section 3.1, the proposed meth-
ods attempt to deinterlace the effect of haze into lay-
ers simpler to calculate, this disentanglement is possi-
ble thanks to Equation 2. The atmospheric dispersion
model is composed of 3 unknown variables, and that
is why the vast majority of dehazing techniques focus
XYZ Unsupervised Network: A Robust Image Dehazing Approach
503

on finding these values. In the same way, XYZ makes
use of this disentanglement to be able to calculate the
haze free image, that is why our approach has two
sub-network groups and one unsupervised neuronal
sub-network, the gJ-Net group to calculate the clear
image J(x) and with this to train our neural network
with its loss function, gT-Net is in charge of calcu-
lating the transmission map T (x) and finally the sub-
network A-Net which estimates the atmospheric light
within the image.
• gJ-Net. This group is the result of the combina-
tion of XHOT, YOLY and ZID methods, where
XHOT presents a non-degenerative neural net-
work such as YOLY, which helps us preserve im-
portant details for the haze-free image, as it is the
case of the object shapes within the image with
haze and also preserve the current dimensions. In
addition, YOLY makes use of the space of colors
HSV to address the training of the unsupervised
network. This is thanks to the observations made
by Zhu et al. (2015), who formulate that in haze-
free areas the difference between brightness and
saturation is close to zero. Finally, ZID proposes
the training taking into account a loss function
based on Dark Channel Prior Loss (Golts et al.,
2020), also makes use of a degenerative neural
network of the type U-Net with skip connections.
• gT-Net. As in J-Net, this sub-network is com-
posed of the three methods seen previously, only
with the difference of the output of each method.
Independent of the method, they present the trans-
mission map of the image being processed.
• A-Net. This sub-network is responsible for cal-
culating the atmospheric light present in an image
(independent of the content) so we assume that
arises apart from a latent space resulting from a
Gaussian distribution, which is why we decided
to use only a neural network, specifically a Varia-
tional Autoencoder, detailed in Section 3.1.1.
3.2.2 Loss Function
To train our model composed of three unsupervised
methods, we use together a loss function taking into
account the output of each method as described in
Equation 8:
L
XYZ
= L
XHOT
+ L
YOLY
+ L
ZID
(8)
where L
XHOT
is the loss function for our XHOT
method, L
YOLY
is the loss function for YOLY and fi-
nally L
ZID
is the loss function for ZID, we decided to
give the same weight to each loss function as the three
guide our training, taking into account the assump-
tions made, such as the case of the HSV color space,
Dark Channel Prior Loss, in addition to the XHOT
loss function, which turns out to be an improvement
of Golts et al. (2020) and Li et al. (2021).
3.3 Datasets
We conducted our experiments using the REalistic
Single Image Dehazing (RESIDE) dataset (Li et al.,
2019), a well-recognized resource for large-scale haze
removal evaluation. This dataset is composed of two
test subsets: SOTS and HSTS. The SOTS subset con-
sists of 500 indoor hazy images, which were syntheti-
cally generated using a physical model with manually
calibrated parameters. In contrast, the HSTS subset
contains 10 synthetic hazy images and 10 real-world
hazy images captured in diverse scenes. Addition-
ally, the RESIDE dataset offers training subsets: OTS
(Outdoor Training Set) comprises a total of 72,135
hazy images generated from 2,061 ground truth im-
ages. Meanwhile, ITS (Indoor Training Set) consists
of 13,990 hazy images generated from 1,399 ground
truth images.
As mentioned previously, the methods described
in Section 3.1 do not require a “training” dataset, but
only need a set of images to carry out the evaluation
of the method. These methods, based on Zero-Shot
Learning, eliminate the haze adapting according to
the number of iterations made for each image eval-
uated.
3.4 Metrics
To assess the performance of our model, as well as
other methods, we employed Structured Similarity In-
dexing Method (SSIM) and Peak-Signal-to-Noise Ra-
tio (PSNR) (Wang et al., 2004) as image quality anal-
ysis metrics, which are commonly used in haze re-
moval studies. SSIM quantifies the structural simi-
larity between the haze-free reference image and the
output image obtained from our proposed technique.
Similarly, PSNR provides a measure of the relation-
ship between the maximum possible signal power and
the noise power present in the images.
These two metrics serve as indicators of the im-
age’s fidelity to the haze-free reference. Models that
achieve higher values for these metrics indicate a
higher quality and greater similarity between the gen-
erated image and the haze-free reference.
4 RESULTS
In our experiments, we carry out both qualitative and
quantitative assessments, as detailed in Section 3.4.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
504
+
J(x)
T(x)
A(x)
ASM
Xhot
Yoly
Zid
Xhot
Yoly
Zid
gJ-Net
gT-Net
A-Net
x
I(x)
Figure 3: The architecture of our proposed XYZ approach. XYZ includes two groups of sub-networks: gJ-Net group of
sub-networks (XHOT, YOLY and ZID) for image estimation clean J(x), gT-Net group of sub-networks for transmission map
estimation T (x). In addition, XYZ maintains layer disentanglement for the estimate of A.
The test dataset includes manually generated syn-
thetic data as well as actual images provided by Li
et al. (2019). These assessments covered a variety of
aspects and metrics to provide a comprehensive view
of the performance of our imaging haze removal ap-
proach.
4.1 Quantitative Comparison
In this section, we present the results by applying our
approach of disentanglement of complex layers into
simpler layers, compared to the methods proposed
by Li et al. (2020) and Li et al. (2021). It it worth
mentioning that the methods with which we are mak-
ing the comparison make use of the disentanglement
approach of haze in simpler layers.
As can be seen in Table 1, we can see that
our XHOT network does not improve on SSIM and
PSNR metrics to ZID and YOLY methods. However,
this method still presents significant advances for the
elimination of haze. On the other hand, our XYZ net-
work manages to improve the results present in the
SOTS data set, which contains images of closed envi-
ronments in relation to the other HSTS test data set.
This still does not improve the other two methods in
the metrics. We find it important to clarify that al-
though our technique does not improve the state of
the art, this is in the second method with the best re-
sult.
4.2 Qualitative Comparison
In this section, we observe the visual results by elim-
inating haze in outdoor images and in a indoor envi-
ronment. Figures 4 and 6 show the results achieved
by the unsupervised learning-based methods XHOT,
ZID (Li et al., 2020), YOLY (Li et al., 2021) and
XYZ, respectively. The images visually show that the
results are close to the actual image in terms of color
and detail.
From Figure 4, we can observe that the XHOT
method presents better results visually in areas such
as the sky, since we do not make use directly of an
approximation by DCP that normally fails to distin-
guish the haze from the clouds. On the other hand
ZID presents the most artifacts for the same reason,
which uses an approximation by DCP. However, XYZ
attempts to make this distinction in a more coherent
manner, but still presents artifacts. Figure 5 shows
a set of real-world images of the HSTS dataset, from
which we can observe that XYZ manages to eliminate
the haze in large part of the image with haze, however
this still does not manage to eliminate the haze in its
entirety.
Figure 6 shows the elimination of haze in closed
environments, of which we can observe that the ZID
method behaves better in the third image, since it
does not lose the details of color in areas such as the
floor. However, XYZ achieves better results in images
where we have more light as is the case with the first,
second and fourth images.
5 CONCLUSIONS
In this work, we present an approach to haze re-
moval based on disentanglement of complex layers
into simpler layers. We have developed an unsu-
pervised method, called XHOT, which is simple and
lightweight. While it is important to note that, to
date, this method does not surpass the leading ap-
proaches in the state of the art in unsupervised haze
removal. Additionally, we propose a group disentan-
glement approach using three unsupervised methods:
XYZ Unsupervised Network: A Robust Image Dehazing Approach
505

Table 1: Results for XHOT, YOLY, ZID and XYZ methods applied to the SOTS and HSTS datasets. The results are shown in
relation to SSIM and PSNR metrics.
Network
SOTS Indoor HSTS Outdoor
SSIM PSNR SSIM PSNR
ZID (Li et al., 2020) 0.815 18.313 0.851 21.650
YOLY (Li et al., 2021) 0.807 17.950 0.832 22.217
XHOT 0.803 17.860 0.829 21.430
XYZ 0.818 18.530 0.846 21.680
(a) Haze (b) XHOT (c) YOLY (d) ZID (e) XYZ (f) Ground Truth
Figure 4: Qualitative comparisons on HSTS Outdoor dataset for different methods.
(a) Haze (b) XHOT (c) YOLY (d) ZID (e) XYZ
Figure 5: Qualitative comparisons on HSTS Real World for different methods.
XHOT, YOLY and ZID.
This approach, called XYZ, represents an effec-
tive strategy that combines the advantages of these
three individual methods. XYZ results show signif-
icant improvements in image quality metrics, such as
SSIM and PSNR, supporting its effectiveness in haze
removal. In other words, both approaches presented
in this study address the challenge of haze removal
in an unsupervised manner. This is especially valu-
able as we overcome the limitation of the lack of real-
world paired images and eliminate the need to train
with an extensive dataset. Our methods address the
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
506

(a) Haze (b) XHOT (c) YOLY (d) ZID (e) XYZ (f) Ground Truth
Figure 6: Qualitative comparisons on SOTS Indoor dataset for different methods.
haze problem individually for each image, which rep-
resents a significant advance in unsupervised haze re-
moval.
REFERENCES
Berman, D., Treibitz, T., and Avidan, S. (2016). Non-Local
Image Dehazing. In IEEE Conference on Computer
Vision and Pattern Recognition, pages 1674–1682.
Cai, B., Xu, X., Jia, K., Qing, C., and Tao, D. (2016).
DehazeNet: An End-to-End System for Single Image
Haze Removal. IEEE Transactions on Image Process-
ing, 25(11):5187–5198.
Chen, X., Li, Y., Kong, C., and Dai, L. (2022). Unpaired
Image Dehazing With Physical-Guided Restoration
and Depth-Guided Refinement. IEEE Signal Process-
ing Letters, 29:587–591.
Dong, H., Pan, J., Xiang, L., Hu, Z., Zhang, X., Wang,
F., and Yang, M.-H. (2020). Multi-Scale Boosted
Dehazing Network With Dense Feature Fusion. In
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 2154–2164.
Engin, D., Genc, A., and Ekenel, H. (2018). Cycle-Dehaze:
Enhanced CycleGAN for Single Image Dehazing. In
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition Workshops, pages 938–9388, Los
Alamitos, CA, USA. IEEE Computer Society.
Golts, A., Freedman, D., and Elad, M. (2020). Unsuper-
vised Single Image Dehazing Using Dark Channel
Prior Loss. IEEE Transactions on Image Processing,
29.
He, K., Sun, J., and Tang, X. (2009). Single Image Haze
Removal Using Dark Channel Prior. In IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 1956–1963.
Kingma, D. and Welling, M. (2014). Auto-Encoding Vari-
ational Bayes. arXiv preprint arXiv:1312.6114, pages
1–14.
Li, B., Gou, Y., Gu, S., Liu, J. Z., Zhou, J. T., and Peng, X.
(2021). You Only Look Yourself: Unsupervised and
Untrained Single Image Dehazing Neural Network.
International Journal of Computer Vision, pages 1–
14.
Li, B., Gou, Y., Liu, J. Z., Zhu, H., Zhou, J. T., and Peng,
X. (2020). Zero-Shot Image Dehazing. IEEE Trans-
actions on Image Processing, 29:8457–8466.
Li, B., Ren, W., Fu, D., Tao, D., Feng, D., Zeng, W., and
Wang, Z. (2019). Benchmarking Single-Image De-
hazing and Beyond. IEEE Transactions on Image Pro-
cessing, 28(1):492–505.
Liu, X., Ma, Y., Shi, Z., and Chen, J. (2019). GridDe-
hazeNet: Attention-Based Multi-Scale Network for
Image Dehazing. In International Conference on
Computer Vision.
McCartney, E. (1978). Optics of the Atmosphere – Scat-
tering by Molecules and Particles. IEEE Journal of
Quantum Electronics, 14(9):698–699.
Qin, X., Wang, Z., Bai, Y., Xie, X., and Jia, H. (2020).
FFA-Net: Feature Fusion Attention Network for Sin-
gle Image Dehazing. AAAI Conference on Artificial
Intelligence, 34(7):11908–11915.
Tan, R. T. (2008). Visibility in Bad Weather from a Single
Image. In IEEE Conference on Computer Vision and
Pattern Recognition, pages 1–8.
Wang, E., Shu, S., and Fan, C. (2022a). CNN-based Single
Image Dehazing via Attention Module. In IEEE 5th
International Conference on Automation, Electronics
and Electrical Engineering, pages 683–687.
Wang, Y., Yan, X., Guan, D., Wei, M., Chen, Y., Zhang,
X.-P., and Li, J. (2022b). Cycle-SNSPGAN: To-
wards Real-World Image Dehazing via Cycle Spectral
Normalized Soft Likelihood Estimation Patch GAN.
IEEE Transactions on Intelligent Transportation Sys-
tems, 23(11):20368–20382.
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P.
(2004). Image Quality Assessment: From Error Vis-
ibility to Structural Similarity. IEEE Transactions on
Image Processing, 13(4):600–612.
Zheng, Z., Ren, W., Cao, X., Hu, X., Wang, T., Song, F., and
Jia, X. (2021). Ultra-High-Definition Image Dehazing
via Multi-Guided Bilateral Learning. In IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 16180–16189.
Zhu, Q., Mai, J., and Shao, L. (2015). A Fast Single Im-
age Haze Removal Algorithm Using Color Attenua-
tion Prior. IEEE Transactions on Image Processing,
24(11):3522–3533.
XYZ Unsupervised Network: A Robust Image Dehazing Approach
507
