
Agent Based Model for AUTODL Optimisation
Aroua Hedhili
1,2 a
and Imen Khelfa
1,2 b
1
National School of Computer Sciences, Manouba University, Manouba 2010, Tunisia
2
Research Lab: LAboratory of Research in Artificial Intelligence LARIA, ENSI, University of Manouba, Tunisia
Keywords:
Auto Deep Learning, Multi-Objective Optimization, Collective Intelligence, Agent Model.
Abstract:
Auto Deep Learning (AUTODL) has witnessed remarkable growth and advancement in recent years, sim-
plifying neural network model selection, hyperparameter tuning, and model evaluation, thereby increasing
accessibility for users with limited deep learning expertise. Nevertheless, certain performance limitations per-
sist, notably in the realm of computational resource utilization. In response, we introduce an agent-based
AUTODL methodology that leverages multi-objective optimization principles and collective intelligence to
create high-performing artificial neural networks. Our experimental results confirm the effectiveness of this
approach across various criteria, including accuracy, computational inference time, and resource consumption.
1 INTRODUCTION
In recent years, researchers have explored the fas-
cinating concept of Automated Deep Learning (Au-
toDL). AutoDL focuses on automating the process
of deep learning model design and optimization. It
aims to develop techniques and algorithms that can
automatically discover the best neural network archi-
tectures, hyperparameters, and optimization strategies
for a given task, without requiring manual interven-
tion or expert knowledge (Feurer et al., 2015). This
concept gained attention around the mid-2010s, but
its roots can be traced back to earlier work in the field
of machine learning. Since then, numerous research
papers and techniques have been proposed such as
(Ren et al., 2021), (Elsken et al., 2019), and (Jin
et al., 2019). Despite the growing interest among
researchers in Auto Deep Learning and the advance-
ments in research within the field, it is still in its early
stages of development, it also requires high compu-
tational demand(Ahmadianfar et al., 2015). Further,
theoretical guidance and experimental analysis are
necessary to fully explore its potential. Numerous re-
search works have focused on using multi-objective
optimization algorithms with AutoDL. Additionally,
some studies have explored the concept of collective
intelligence to mitigate the computational costs asso-
ciated with the search and optimization processes. In
a
https://orcid.org/0000-0002-6918-0797
b
https://orcid.org/0009-0007-2055-873X
light of these advancements, we explore an alterna-
tive angle to solve the problem. We propose an agent-
based system that exploits the collaborative contribu-
tion of agents within an evolutionary multi-objective
optimization algorithm. The primary objective of our
research is to strike a balance between achieving high
accuracy rates, minimizing inference time, and reduc-
ing memory footprint in neural network architectures.
First and foremost, we need to define the com-
ponents of our Neural Architecture Search (NAS)
framework. NAS is the process of automating the de-
sign of neural architectures for a given task. In fact,
interesting AutoDL survey (Elsken et al., 2019) con-
sider that a NAS framework is primarily composed
of three key elements: search space, search strat-
egy, and performance estimation strategy. While
the creation and selection of deep learning models
are inherently multi-objective optimization problems
where trade-offs between accuracy, complexity, and
inference speed are desired. In our case, we propose
the following composition for NAS framework:
• Search Space (S): Define a search space S, which
represents all possible neural network architec-
tures.
S =
{
Architecture
1
,...,Architecture
N
}
(1)
Each architecture in this space is defined by its el-
ements (e.g., convolutional layers, recurrent lay-
ers, pooling, skip connections) and its hyperpa-
rameters (e.g., kernel size, number of filters, acti-
vation functions).
568
Hedhili, A. and Khelfa, I.
Agent Based Model for AUTODL Optimisation.
DOI: 10.5220/0012371700003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 568-575
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

• Performance Metric (P): Define a performance
metric P, which quantifies the quality of a neural
network architecture on the task of interest. This
can be accuracy, validation loss, or any other rel-
evant metric.
P(Architecture
i
) ∈ R (2)
• Optimization Objective (O): Define an opti-
mization objective O, which specifies what we
want to achieve. For example, we might aim
to maximize the performance metric while con-
straining the computational cost.
O : Maximize P(Architecture
i
) (3)
• Search Strategy: Employ a search algorithm A
to explore the search space S and evaluate the per-
formance of different architectures using the per-
formance metric P.
A = arg max
Architecture
i
∈S
O(P(Architecture
i
)) (4)
• Evaluation Strategy: measures the performance
of the generated network architectures in terms
of accuracy, computational resource consumption
and inference time.
The remaining sections of this paper are struc-
tured as follows: Section 2 covers related works that
deal with multi-objective optimization approaches
and collective intelligence techniques for NAS. Af-
terwards, in section 3, we introduce our contribution.
Section 4 describes the experimental setup and re-
sults. Finally, we conclude the paper by summariz-
ing our findings, discussing limitations, and suggest-
ing future directions for our work.
2 RELATED WORKS
Prior works have investigated the utilization of multi-
objective optimization algorithms in NAS to enhance
its performance. These approaches aim to identify a
set of high-performing neural network architectures
that exhibit various trade-offs between accuracy, com-
putational efficiency, and memory utilization. On the
other hand, the concept of collective intelligence has
been explored to alleviate the search and to optimize
costs in NAS.
2.1 Multi-Objective Optimization with
Collective Intelligence
Multi-objective optimization is a mathematical opti-
mization technique that deals with finding the optimal
solutions to problems with multiple, often conflicting,
objectives. The task is to find a set of solutions known
as the Pareto front (or Pareto set), representing the
best compromise between these objectives.
A multi-objective optimization problem includes Ob-
jective Functions each representing a different aspect
of the problem. These objective functions can be rep-
resented as follows (Arora, 2017):
f (x) = ( f
1
(x), f
2
(x),..., f
n
(x)) (5)
where f (x) is a vector of objective function values, x
is the decision variable vector, and n is the number of
objectives.
Several works treat multi-objective optimization
problems in AutoDL context. (Dong et al., 2018),
(Elsken et al., 2018), (Lu et al., 2019), (Real et al.,
2019) and in this paper we focus on multi-objective
optimization problems with collective intelligence. In
fact, NAS often tackles the challenge of optimizing
multiple objectives concurrently, such as enhancing
model accuracy, reducing model size, and improving
inference speed. To address this, we believe that
collective intelligence techniques can be used to
handle multi-objective optimization problems effec-
tively. Actually, collective intelligence refers to the
shared intelligence and problem-solving capabilities
that emerge from the collective efforts of a group
of individuals (Bigham et al., 2015). It involves
the aggregation of diverse knowledge, perspectives,
and skills from group members to achieve better
outcomes than what could be achieved by individuals
working alone (Bigham et al., 2015). Next, we review
the most important and recent works in this context.
Cetin and Gundogmus (Cetin and Gundogmus,
2019) drew inspiration from Daniel Kahneman’s book
”Thinking, Fast and Slow” (Kahneman, 2015) for
their work. In the book, Kahneman introduces the
metaphor of two cognitive systems, System 1 and
System 2, representing fast and slow thinking, respec-
tively. System 1 operates intuitively and automati-
cally, while System 2 engages in focused and criti-
cal thinking. They represented these systems in two
agents, each agent represent Evolutionary Genetic Al-
gorithms (EGAs) with different mutation rates. The
main problem with this solution is that the algorithm’s
efficiency and computational requirements may be-
come a limitation as the dataset size and number of
features increase. Moreover, the algorithm’s hyper-
parameter settings are provided for a toy dataset and
applied to real datasets, but there is no systematic ex-
ploration of hyper-parameters for different types of
real datasets.
The work (Zoph et al., 2018) introduced a search
method based on reinforcement learning (RL). In
Agent Based Model for AUTODL Optimisation
569

their approach, they employ controllers to generate
architectural hyperparameters for neural networks.
These controllers are implemented as recurrent neu-
ral networks, and they predict various parameters like
filter height, filter width, stride height, stride width,
etc. Each instance of the controller generates m dif-
ferent child architectures, which are trained concur-
rently. Afterward, the controller collects gradients
based on the outcomes of this batch of m architectures
when they converge and sends these gradients to the
parameter server for weight updates across all con-
troller replicas. Their limitations lie in the absence of
metaheuristics in their reinforcement learning meth-
ods, as they rely on empirical predictions, resulting in
slow performance or excessively lengthy processing
times to achieve satisfactory results.
In addition, (Gupta and Raskar, 2018) propose an
agent based method. They define multiple agents for
a distributed deep learning training. This algorithm
showcased promising results for optimizing the learn-
ing process. However, as the number of agents in-
creases, so do computational resource requirements,
and managing communication between agents be-
comes more complex.
2.2 Discussion
In the following table, we emphasize the advantages
and limitations of the use of collective intelligence for
treating multi-objective problems.
In the context of addressing multi-objective opti-
mization, the use of collective intelligence principles,
where agents work collaboratively, offers several ad-
vantages. First and foremost, collaboration among
agents allows for the aggregation of diverse knowl-
edge, perspectives, and skills, as stated by Bigham
et al (Bigham et al., 2015)). This diversity can lead
to more comprehensive problem-solving approaches
and a broader exploration of the solution space, which
is particularly valuable in multi-objective optimiza-
tion scenarios where finding a diverse set of Pareto-
optimal solutions is essential. Additionally, collab-
orative agents can leverage their individual strengths,
such as different mutation rates or optimization strate-
gies, to enhance the overall optimization process.
This collaboration can lead to more efficient conver-
gence towards Pareto-optimal solutions, making the
collective intelligence approach highly promising.
However, while collaboration among agents in
multi-objective optimization has its advantages, it
also presents significant limitations. One notable lim-
itation is the increased demand for computational re-
sources as the number of agents or the complexity
of the optimization problem grows as (Gupta and
Raskar, 2018). Additionally, managing communica-
tion and coordination among a large number of agents
can become complex, potentially leading to efficiency
and scalability issues. This complexity may hinder
the practicality of collective intelligence approaches.
To address these challenges, our approach intro-
duces an agent-based AUTODL (Automated Deep
Learning) model that distributes the optimization of
neural network search across multiple agents. The
evolution of this search process leverages metaheuris-
tic search techniques, specifically genetic algorithms,
to mitigate the time required for exploration. In this
setup, each agent is responsible for optimizing a spe-
cific objective and applies genetic operators, such as
mutation and cross-over, to refine the solutions. Ad-
ditionally, agents collaboratively share learnable pa-
rameters and engage in structured interactions with
one another. This structured collaboration signifi-
cantly reduces search time and expedites the conver-
gence towards the optimal Artificial Neural Network
(ANN) model, all without incurring high computa-
tional costs.
3 OUR CONTRIBUTION
This section introduces our solution MOCA(Multi-
Objective and Collaborative Auto-DL) approach. It
describes a rapid multi-objective NAS algorithm that
employs an elitist genetic algorithm, incorporating
a collective intelligence strategy. The primary ob-
jective of MOCA is to produce neural network ar-
chitectures that are both high-performing and cost-
effective. Drawing inspiration from biological con-
cepts like natural selection and the wisdom of the
crowd, our algorithm initiates by generating a popula-
tion of networks and applies operations such as muta-
tion and cross-over, weight sharing and parameter op-
timizer to produce an offspring of candidate network
architectures. These candidates interact and exchange
knowledge through the aforementioned operators, re-
sulting in an emergent intelligence that accelerates
their learning process. Our aim is to strike a balance
between multiple objectives such as accuracy, infer-
ence time, and resource consumption. Across gener-
ations, our Neural Network Candidates (NNCs) con-
tinuously optimize their outcomes, striving towards a
shared micro architecture goal where all agents pur-
sue the aforementioned objectives individually. Each
candidate/agent acts as a single player, sharing their
acquired knowledge with others. Additionally agents
operate within a macro architecture, each focusing
on optimizing a specific goal. The top-performing
agents with different roles are subsequently com-
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
570
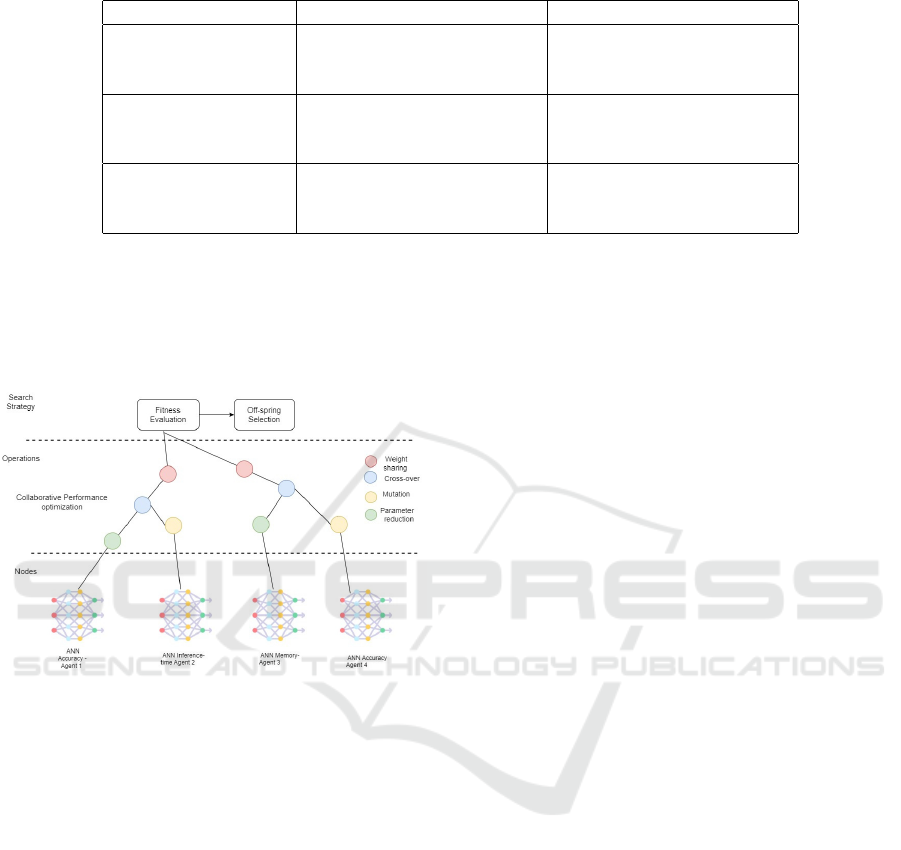
Table 1: Comparison of Collective Intelligence Methods for Multi-Objective Optimization.
Methods Advantages Limits
EGA Algorithm
(Cetin and Gundog-
mus, 2019)
Decentralized architecture High computational cost,
coordination complexity.
Reinforcement
Learning (Zoph
et al., 2018)
Controller-based architec-
ture, concurrent training
Slow convergence, sub-
stantial computational
resources.
Distributed Agents
(Gupta and Raskar,
2018)
Collaboration among
agents, robust optimization
process
Increasing computational re-
sources with more agents.
bined to align with our multiple objectives. To en-
hance the organization of our approach, we have es-
tablished a structure comprising three primary com-
ponents: Nodes,Operations and Search Strategy as
shown in the figure 1MOCA components..
Figure 1: MOCA components.
3.1 Nodes
The first component represents the agents of our
search space. It includes our candidate neural network
architectures. Since it contains a set of neural net-
works, it inherits its complexity and variation in terms
of parameters and learning algorithms. We should
also take into account additional design considera-
tions because there are multiple nodes. These in-
clude determining the degree of similarity or diversity
among nodes, deciding which input data to be passed
to each node, and defining the shared output data be-
tween nodes. Therefore, we associate each agent with
a set of features labeled PRIC (Parameters, Role,
Interaction, Contribution), we detail next each fea-
ture.
Parameters (P): This includes both the archi-
tectural and non-architectural hyperparameters of the
node, as well as the parameters acquired through
training. We encode each network as a genome, con-
sisting of a subset of genes, where each gene rep-
resents an architectural hyper-parameter, parameters
that are learned through training process and opti-
mization functions.
Role (R): This defines the objective or purpose of
the agent associated with the node. It indicates what
the agent aims to optimize such as maximizing accu-
racy, minimizing inference time.
Interactions (I): This provides insights into the
communication and information exchange among dif-
ferent agents. It describes how agents interact to-
gether. Interactions may represent mutation, cross-
over or parameter sharing.
Contribution (C): This is a score assigned to each
agent based on its level of participation and value in
the search process. It quantifies the agent’s contribu-
tion to the overall exploration and optimization.
By considering these PRIC features, we can obtain
a more comprehensive understanding of our agents
within the system and better analyse their roles, in-
teractions, and contributions.
3.2 Operations
In our proposed approach, our agents can perform the
following operations:
Mutation: The mutation process involves ran-
domly changing the parameter of the parent model to
generate the offspring network. For example, MOCA
randomly changes the parameters by random selec-
tion (the number of layers changes from 10 to 15).
Mutation mainly focuses on exploring the solution
space in the neighborhood of the original solution.
Our goal is to use Pareto-dominated models and max-
imize their performance as much as possible.
Crossover: To generate an offspring network,
we employ crossover by selecting two networks and
splitting their corresponding genomes at a random
architectural hyperparameter. One genetic fragment
from each parent model is exchanged to produce the
offspring network. In MOCA, two parent models
Agent Based Model for AUTODL Optimisation
571

are randomly chosen, and their hyper-parameters are
crossed over at a random index. For instance, the first
fragment of parent network ”i” is combined with the
second fragment of parent network ”j”, resulting in
the offspring genome with crossover. The purpose of
crossover is to increase the diversity of the population
and explore novel solutions. As the population’s per-
formance improves over generations, crossing over
random models provides an opportunity to generate
better solutions by allowing their parent models to
exchange their beneficial architectural hyperparame-
ters.
To successfully achieve agents’ behaviors, we add the
following parameters:
- Weight sharing: To reduce the training time of the
candidate network and reduce the resource con-
sumption, we use the candidate networks that give
the best performance in terms of accuracy and dis-
tribute their weights among the remaining candi-
date networks with the same topology to speed
up the divergence by obtain satisfactory accuracy.
Therefore, MOCA iteratively evaluates the per-
formance of the search space and propagates the
weights of the best performing network to the re-
maining networks to improve the overall perfor-
mance.
- Parameter reduction: It refers to techniques that
aim to reduce the number of parameters in a ma-
chine learning model. The main motivation be-
hind parameter reduction is to achieve model sim-
plification, improve model efficiency, and miti-
gate the risk of over-fitting. This process can
be guided by various approaches, the approach
we used for parameter reduction was magnitude-
based pruning (Park et al., 2020). This ap-
proach involved identifying and removing param-
eters with magnitudes below a certain threshold.
Specifically, after training the models, the weights
of the top-performing models were pruned by set-
ting small-magnitude weights to zero. This re-
sulted in a reduction in the number of non-zero
parameters, thereby reducing the overall parame-
ter count of the models.
3.3 Search Strategy
We use genetic algorithm as our optimization tech-
nique stems from its ability to provide flexibility in
determining fitness criteria and representing compu-
tational costs of models. Our primary aim is to de-
crease the search time for Neural Architecture Search
(NAS). By employing genetic algorithm, we estab-
lish a fitness criteria that ensures the preservation and
development of high-performing networks by pass-
ing all the Pareto non-dominated models from each
generation to the subsequent one. This approach al-
lows us to prioritize short-term rewards while simul-
taneously enhancing the population’s diversity, en-
abling the exploration of new solutions that could
potentially lead to better networks in future genera-
tions. MOCA starts by randomly sampling a popu-
lation of a predetermined ”N” number of networks.
These networks represent our agents (N agents). As
we mentioned, agents may have various PRIC spec-
ifications. Therefore, we can have agents with dif-
ferent architectures and different goals. We may
have agents that follow CNN architectures (let’s call
them CNN-agents), and another may follow RNN
architectures (RNN-agents). These agents may be
divided into sub-networks depending on the objec-
tive they’re trying to optimize. For instance, we
may have CNNA-agent (CNN-Accuracy-agent) and
CNNI-agent (CNN-Inference-Time-agent). Thus,
communication between these agents may take more
than one form. Within MOCA, we can have mainly
three communication forms as showcased in the fig-
ure
• Form 1: Agents that have the same architecture
and same objective (they work to optimize their
accuracy). After E epochs, these agents will oper-
ate cross-over to exchange hyper-parameters. The
top performing agent will share his weights with
his colleges.
• Form 2: Agents that have the same architecture
but different objectives. After training, the top-
performing agents in terms of accuracy will be
cloned. The resulting agents will represent a new
agent that optimizes its inference time by reduc-
ing its number of parameters.
• Form 3: Agents that have different architectures
and same objective (they work on optimizing their
accuracy). These agents will operate cross-over
by swapping the layers at a random crossover
point. Thereby, they generate new offspring and
add diversity to the search space. Moreover, in or-
der to enrich our search space, agents can operate
mutation at a random point. The mutated artifi-
cial neural network represents the child network,
which will be passed down to the next generation
along with its parent network.
3.4 MOCA Search Strategy Algorithm
The algorithm 1 outlines the search strategy used in
our solution MOCA. We start by sampling a pop-
ulation consisting of K random architectures. We
define different randomly selected hyper-parameters,
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
572

Data: Random neural network architectures
Result: Efficient artificial neural network in terms
of accuracy, inference time, and memory
footprint
Initialization;
while Generation < G do
Calculate fitness for each model;
Sort models by fitness;
Clone the top N models;
for model in top N models do
if model is original then
Reduce the parameters of the original
set;
Pass the original set to the next
generation;
end
if model is a clone then
Share weights between original and
cloned models;
Mutate the cloned models;
Perform cross-over;
Pass the generated offspring to the
next generation;
end
end
end
Select the best model;
Algorithm 1: MOCA Algorithm.
and then we run the algorithm 1 for G generations.
For every generation, we evaluate the trained mod-
els and duplicate them into two sets: the parent set
and the cloned set. We pass the parent set without
genetic modifications to allow the good solutions to
reproduce and evolve as much as possible over the
generations. For the cloned set, we generate M net-
works by crossing over two randomly selected parent
networks that achieve Top N accuracy. The goal of
this step is to enhance the diversity of the population.
We exploit the top-performing networks by mutating
the second set in an attempt to further develop their
performance. We also propagate the weights of these
parent networks to speed up the learning process for
the upcoming generations. On the other hand, these
top performing agents will be cloned and act as new
agents, trying to optimize their running time by re-
ducing their number of parameters. We repeat this
process for the G generation until a unique model is
selected.
4 EXPERIMENTAL SETUP
In preparation for our experiments, we subjected the
CIFAR-10 dataset
1
to essential preprocessing steps
1
https://www.cs.toronto.edu/ kriz/cifar.html
to ensure its compatibility with deep learning mod-
els. The dataset is organized into 10 categories. Each
category contains 6,000 images divided into 40,000
for training, 10,000 for testing, and 10,000 for valida-
tion. This division scheme ensures that the model is
trained on a substantial portion of the data and vali-
dated on a distinct subset to assess generalization per-
formance. Then, the process of data normalization
was employed to scale pixel values within a standard-
ized range of [0, 1].
For our experiments, we opted to use CNN (Convo-
lutional Neural Networks) as the underlying model
architecture. CNNs have demonstrated exceptional
performance in image classification tasks due to their
ability to capture spatial hierarchies and features.
The code and the different parameters and settings are
available.
2
4.1 Evaluation Metrics
We selected multiple evaluation metrics to align with
our research goals and provide a comprehensive as-
sessment of model quality: Accuracy, F1score, In-
ference time and Memory footprint and the Fitness
function 6.
Fitness = Accuracy × w1 − Memory Footprint × w2
−Inference Time × w3 + F1-score × w4
+Contribution × w5
(6)
where w1, w2 w3, w4 and w5 represent weights vary-
ing in the interval [0,1] that determine the priority of
each constraint; the higher the value, the more impor-
tant the constraint. These values are problem specific
and user definable.
Following each iteration, we identify the top 5 mod-
els with the highest fitness values. From the se-
lected top models, we make duplicate copies of these
5 models. This step ensures that we retain and con-
tinue to work with the best-performing architectures.
Then, we undertake weight pruning for these dupli-
cated models. This involves selectively removing un-
necessary connections or weights within the model
architecture. Weight pruning aims to simplify the
models while preserving their performance. To intro-
duce diversity and further refine the models, we ap-
ply mutation to the cloned models. Simultaneously,
we transfer weights from parent models to assist in
the learning process. This combination of mutation
and weight transfer contributes to the optimization
of model architectures. We promote knowledge ex-
change and exploration by facilitating cross-over op-
erations between models. This genetic-inspired tech-
2
https://www.kaggle.com/arouahedhili/moca-algorithm
Agent Based Model for AUTODL Optimisation
573
nique allows us to create novel architectures by com-
bining features from different high-performing mod-
els. Through these sequential steps, we iteratively ad-
vance and fine-tune our model population. This iter-
ative process leads to the discovery of architectures
that excel in terms of our chosen evaluation metrics.
In the next section, we present the results obtained
following the implementation of our solution.
4.2 Results and Comparison
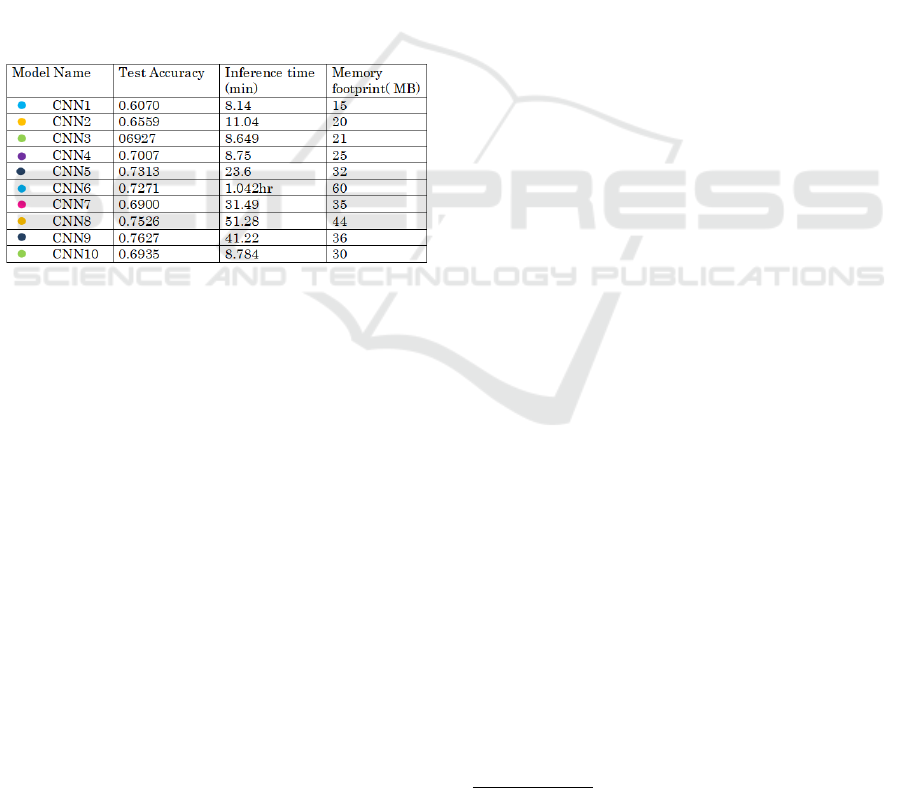
For the first generation, we randomly sampled 10
CNN models using the parameters detailed in table 2,
then we trained the models for 10 epochs. We used the
same number of epochs during our experiment so we
reduce the algorithm search time and propagate the
models that prove good performance in these epochs
to the next generation. The figure 2Initial generation
performance. represents the performance of the ini-
tial population. Over 5 generations, We evalauted the
Figure 2: Initial generation performance.
population based on accuracy, memory footprint, F1-
score, we ranked them based on the weighted sum of
these scores and assigned the rank of each model as
it’s contribution to the search process.
In our experimental findings, we observed promis-
ing outcomes when transferring weights from a more
accurate model to a less proficient counterpart. The
superior model, having demonstrated excellence in
the same image classification task on an identi-
cal dataset, provided a reservoir of learned features
aligned with our research objectives. The shared rep-
resentations within the architectures, especially in the
convolutional layers, facilitated a smooth transfer of
both low-level and high-level image features, has-
tening the convergence of the less successful model.
The success of this knowledge transfer was reinforced
by the intrinsic similarity of tasks, affirming the ef-
fectiveness of utilizing pre-trained weights to boost
overall model performance. Notably, this approach
also led to a reduction in memory consumption, as
the models required less training, thereby mitigating
computational resource demands. The table 2Per-
formance of the best 5 models on Fashion MNIST
dataset. represents the results of the best models per-
formance over the 5 iterations:
In addition, we compare in Table 3Comparai-
son of MOCA and baseline algorithms performance.
the performance of our approach with the perfor-
mance of other approaches that considered using col-
lective intelligence approach for NAS. Guerrero-Viu
et al. (Guerrero-Viu et al., 2021) propose a base-
line of collaborative multi-objective optimization al-
gorithms. These algorithms tend to evaluate their al-
gorithms on accuracy and number of parameters. So
for this comparaison we will consider the use of these
metrics. They run each algorithm 10 times on Fashion
Mnist dataset. Therefore, we also implement MOCA
algorithm with Fashion Mnist dataset
3
. They used
a maximum budget of 25 epochs for training every
model. Their search space is populated with ran-
domly sampled CNN models.
The obtained results in (Guerrero-Viu et al., 2021)
showcase that after 10 runs of tested algorithms, we
can notice that they achieve high accuracy (superior
to 0.9). This very close to our obtained results af-
ter the same number of runs. Furthermore, in their
findings, it’s notable that models achieving high ac-
curacy still retain a significant number of parameters.
As mention in the table 2Performance of the best 5
models on Fashion MNIST dataset., we could strike
a balance between producing highly accurate models
while significantly reducing the number of parameters
and mitigating computational consumption.
5 CONCLUSIONS
In this paper, we describe MOCA, an agent based
AUTODL approach based on the concept of multi-
objective optimization and collective intelligence
techniques. This solution describes a new search
strategy for neural architecture search using agents
and genetic algorithm starting from an initial ran-
domly sampled generation and ending with finding
the best model achieving high performance in term
of multiple criteria. In our experimentation, we pro-
vided a proof of concept for image classification task.
The achieved results highlight the effectiveness of the
MOCA algorithm in optimizing multiple objectives
simultaneously. We primarily explored CNN archi-
tectures due to their effectiveness in image classifica-
tion. Future research could investigate the adaptation
of the MOCA algorithm to different model types. Ad-
ditionally, we propose incorporating transfer learning
3
https://www.kaggle.com/code/imenkhelfa/moca-
fashion-mnist
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
574

Table 2: Performance of the best 5 models on Fashion MNIST dataset.
Best Model Accuracy F1-Score Memory Footprint(MB) Inference Time
Fashion MNIST
M1 0.895 0.850 28 10:22:35
M2 0.906 0.887 25 6:53:43
M3 0.914 0.890 21 7:10:12
M4 0.946 0.902 25.7 24:21:52
M5 0.961 0.941 22.3 17:15:25
Table 3: Comparaison of MOCA and baseline algorithms
performance.
Algorithm Performance
SH-EMOA ≈ 0.92 /15.3
MO-BOHB ≈ 0.93 /32.0
MS-EHVI ≈ 0.90 /9.5
MO-BANANAS-SH ≈ 0.93 /19.3
BULK & CUT ≈ 0.94 /15.3
Random Search ≈ 0.92 /38.1
MOCA 0.96/22.3
techniques into the MOCA algorithm could expedite
model convergence and boost performance.
REFERENCES
Ahmadianfar, I., Adib, A., and Taghian, M. (2015). A
multi-objective evolutionary algorithm using decom-
position (moea/d) and its application in multipurpose
multi-reservoir operations. Iran University of Science
& Technology, 5:167–187.
Arora, J. (2017). Chapter 18 – multi-objective optimum
design concepts and methods. In Multi-objective Op-
timum Design Concepts and Methods.
Bigham, J. P., Bernstein, M. S., and Adar, E. (2015).
Human-computer interaction and collective intelli-
gence. Handbook of collective intelligence, 57(4).
Cetin, U. and Gundogmus, Y. E. (2019). Feature selection
with evolving, fast and slow using two parallel genetic
algorithms. In 2019 4th International Conference on
Computer Science and Engineering (UBMK), pages
699–703. IEEE.
Dong, J.-D., Cheng, A.-C., Juan, D.-C., Wei, W., and
Sun, M. (2018). Ppp-net: Platform-aware progressive
search for pareto-optimal neural architectures. arXiv
preprint arXiv:1806.08198v2.
Elsken, T., Metzen, J. H., and Hutter, F. (2018). Efficient
multi-objective neural architecture search via lamar-
ckian evolution. arXiv preprint arXiv:1804.09081.
Elsken, T., Metzen, J. H., and Hutter, F. (2019). Neural
architecture search: A survey. The Journal of Machine
Learning Research, 20(1):1997–2017.
Feurer, M., Klein, A., Eggensperger, K., Springenberg, J.,
Blum, M., and Hutter, F. (2015). Efficient and robust
automated machine learning. Advances in neural in-
formation processing systems, 28.
Guerrero-Viu, J., Hauns, S., Izquierdo, S., Miotto, G.,
Schrodi, S., Biedenkapp, A., Elsken, T., Deng, D.,
Lindauer, M., and Hutter, F. (2021). Bag of baselines
for multi-objective joint neural architecture search
and hyperparameter optimization. arXiv preprint
arXiv:2105.01015.
Gupta, O. and Raskar, R. (2018). Distributed learning of
deep neural networks over multiple agents. Journal of
Network and Computer Applications, 116:1–8.
Jin, H., Song, Q., and Hu, X. (2019). Auto-keras: An ef-
ficient neural architecture search system. In Proceed-
ings of the 25th ACM SIGKDD international confer-
ence on knowledge discovery & data mining, pages
1946–1956.
Kahneman, D. (2015). Kahneman’s thinking fast and slow:
From bestseller to textbook: Thinking, fast and slow.
RAE Revista de Administracao de Empresas.
Lu, Z., Whalen, I., Boddeti, V., Dhebar, Y., Deb, K., Good-
man, E., and Banzhaf, W. (2019). Nsga-net: neural
architecture search using multi-objective genetic algo-
rithm. In Proceedings of the genetic and evolutionary
computation conference, pages 419–427.
Park, S., Lee, J., Mo, S., and Shin, J. (2020). Lookahead:
a far-sighted alternative of magnitude-based pruning.
CoRR, abs/2002.04809.
Real, E., Aggarwal, A., Huang, Y., and Le, Q. V. (2019).
Regularized evolution for image classifier architecture
search. In Proceedings of the aaai conference on arti-
ficial intelligence, volume 33, pages 4780–4789.
Ren, P., Xiao, Y., Chang, X., Huang, P.-Y., Li, Z., Chen,
X., and Wang, X. (2021). A comprehensive survey of
neural architecture search: Challenges and solutions.
ACM Computing Surveys (CSUR), 54(4):1–34.
Zoph, B., Vasudevan, V., Shlens, J., and Le, Q. V. (2018).
Learning transferable architectures for scalable image
recognition. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 8697–
8710.
Agent Based Model for AUTODL Optimisation
575
