
Modification of DDIM Encoding for Generating Counterfactual
Pathology Images of Malignant Lymphoma
Ryoichi Koga
1
, Mauricio Kugler
1
, Tatsuya Yokota
1
, Kouichi Ohshima
2,3
, Hiroaki Miyoshi
2,3
,
Miharu Nagaishi
2
, Noriaki Hashimoto
4
, Ichiro Takeuchi
4,5
and Hidekata Hontani
1
1
Nagoya Institute of Technology, Gokiso-cho, Showa-ku, Nagoya-shi, Aichi, 466-8555, Japan
2
Kurume University Department of Pathology, 67 Asahi-cho, Kurume-shi, Fukuoka, 830-0011, Japan
3
The Japanese Society of Pathology, 1-2-5 Yushima, Bunkyo-ku, Tokyo, 113-0034, Japan
4
RIKEN Center for Advanced Intelligence Project, 1-4-1 Nihonbashi, Chuo-ku, Tokyo, 103-0027, Japan
5
Nagoya University, Furo-cho, Chikusa-ku, Nagoya-shi, Aichi, 464-8601, Japan
{ohshima kouichi, miyoshi hiroaki, nagaishi miharu}@med.kurume-u.ac.jp,
noriaki.hashimoto.jv@riken.ac.jp, ichiro.takeuchi@mae.nagoya-u.ac.jp
Keywords:
Counterfactual Images, Diffusion Models, Pathological Images, Malignant Lymphoma, Causal Inference.
Abstract:
We propose a method that modifies encoding in DDIM (Denoising Diffusion Implicit Model) to improve the
quality of counterfactual histopathological images of malignant lymphoma. Counterfactual medical images are
widely employed for analyzing the changes in images accompanying disease. For the analysis of pathological
images, it is desired to accurately represent the types of individual cells in the tissue. We employ DDIM
because it can refer to exogenous variables in causal models and can generate counterfactual images. Here,
one problem of DDIM is that it does not always generate accurate images due to approximations in the forward
process. In this paper, we propose a method that reduces the errors in the encoded images obtained in the
forward process. Since the computation in the backward process of DDIM does not include any approximation,
the accurate encoding in the forward process can improve the accuracy of the image generation. Our proposed
method improves the accuracy of encoding by explicitly referring to the given original image. Experiments
demonstrate that our proposed method accurately reconstructs original images, including microstructures such
as cell nuclei, and outperforms the conventional DDIM in several measures of image generation.
1 INTRODUCTION
Malignant lymphoma has more than 70 subtypes, and
pathologists identify the subtype from a set of tissue
slides of a specimen that is invasively extracted from
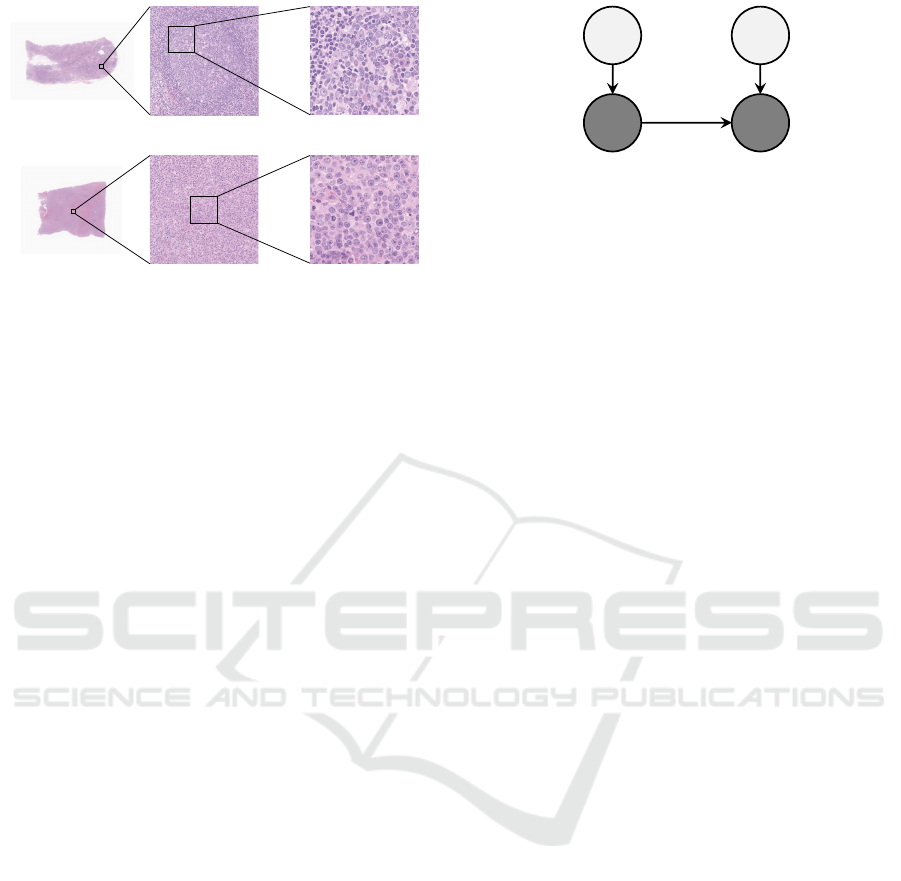
a patient (Swerdlow SH et al., 2017). Some examples
of tissue microscopic images of malignant lymphoma
are shown in Fig.1. The top panel shows images of a
non-cancerous tissue and the bottom panel images of
a cancerous tissue. In the weakly magnified image (a-
2) of Fig.1, a circular structure can be observed. This
is a cross-section of a spherical microtissue structure
called the follicle. On the other hand, the follicle can-
not be observed in (b-2) because the degree of cell
differentiation decreases in cancerous tissues and the
structure of the follicle collapses. In the strong mag-
nified image (a-3) of Fig.1, a greater variety of cells
are observed in the non-cancerous tissue than in (b-3)
of cancerous tissue. Non-cancerous tissues are com-
posed of a wide variety of cells that differ from each
other in the morphology and texture of their cell nu-
clei than the cancerous tissues. In the cancerous tis-
sues, the ratio of self-replicated cancer cells increases,
and the diversity of cell types constituting the tissues
tends to decrease. Changes in the tissue structure in
cancerous tissues can be observed both in the global
tissue structures and in the local cell structures.
Pathologists identify the subtypes by observing
the morphology of tissue and cell structures. Cur-
rently, the diagnosis is largely qualitative based on the
pathologists’ experience and intuition. This makes it
difficult for pathologists to explain the basis for their
diagnosis, and there is room for improvement in diag-
nostic reproducibility. To achieve the improvement,
it is desired to quantitatively evaluate the morphology
of tissue and cell structures. To construct quantitative
Koga, R., Kugler, M., Yokota, T., Ohshima, K., Miyoshi, H., Nagaishi, M., Hashimoto, N., Takeuchi, I. and Hontani, H.
Modification of DDIM Encoding for Generating Counterfactual Pathology Images of Malignant Lymphoma.
DOI: 10.5220/0012366100003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 2: VISAPP, pages
519-527
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
519
(a-2)
(b-2)
(a-1)
(b-1)
(a-3)
(b-3)
Figure 1: The examples of pathology images. In this fig-
ure, (a-1) and (b-1) are a non-cancerous tissue image and
a cancerous one, respectively. (a-2) and (b-2) are weakly
magnified images. (a-3) and (b-3) are strongly magnified
images.
criteria for the changes in the morphology of these
structures, we employ an approach of constructing
a subtype classifier and then approximating the dis-
criminant function by an explainable function at post-
hoc. For example, decision trees are used to approx-
imate the discriminant function of a neural network-
based classifier for improving the interpretability of
the classifier and constructing a quantitative criterion
useful for the classification (Singla et al., 2021). In
such approaches, counterfactual images are used to
select image features that are interpretable and use-
ful for classification. In this paper, we propose a
method that generates counterfactual pathology im-
ages of malignant lymphoma.
A counterfactual image is a hypothetical image
obtained when one factor changes in the causal model
of a given image. A causal model consists of endoge-
nous variables and exogenous ones. The causal model
represents the causal relationships between factors
represented by the endogenous variables, of which
values are observable. The exogenous variables rep-
resent unobservable stochastic factors that are not af-
fected by other ones. Here, we consider a simple
causal model with only two endogenous variables:
One represents the subtype and the other represents
the pathological image. Fig.2 shows the causal model
considered in this study. In this causal model, the
pathological image x
(2)
is modeled with the corre-
sponding exogenous variable u
(2)
and the subtype x
(1)
as follows:
x
(2)
= f (x
(1)
, u
(2)
), (1)
where the image x
(2)
is deterministically computed
by the function f from x
(1)
and u
(2)
. The counter-
factual images generated in this study are the images
obtained when only the endogenous variable x
(1)
rep-
resenting the subtype changes and the exogenous vari-
𝒖
(1)
𝒖
(2)
𝒙
(1)
𝒙
(2)
Figure 2: The causal model considered in this study. In this
figure, x
(1)
and x
(2)
are endogenous variables, indicating
the subtype and the pathology image, respectively. u
(1)
and
u
(2)
are exogenous variables corresponding to x
(1)
and x
(2)
,
respectively.
able u
(2)
is fixed. Counterfactual images are obtained
by the disentanglement of tissue morphological fea-
tures specific to the subtype difference from other fea-
tures representing individual differences.
Several methods for generating counterfactual
images have been proposed (Singla et al., 2020),
(Sanchez and Tsaftaris, 2022). In this study, we em-
ploy a method that uses a diffusion model. A diffu-
sion model is one of the most popular generative mod-
els and is capable of generating higher-quality data
than other methods. In addition, the generation of
counterfactual images using denoising diffusion im-
plicit models (DDIMs) (Song et al., 2021), which was
proposed to alleviate the problem of high computa-
tional cost of denoising diffusion probabilistic mod-
els (DDPMs) (Ho et al., 2020), one of the most pop-
ular diffusion models, is easier to interpret based on a
causal model than other methods. In DDIM, the for-
ward process to the noise image is deterministic, and
the image obtained with the backward process is de-
termined only by the initial noise image. This deter-
ministic property is consistent with the causal model
in Eq.(1) and the obtained noise image can be em-
ployed as a representation of the exogenous variables
(Sanchez and Tsaftaris, 2022). We employ DDIM and
generate images of the different subtype correspond-
ing to the same exogenous variable from the noise im-
age by guiding on the different subtype.
When a pathological microscopic image is first
encoded into a noise image using DDIM and then the
noise image is restored to the original image by the
backward process, the details of the restored image
may not match the original image. Fig.3 shows exam-
ples of the original image and the corresponding im-
age reconstructed by a conventional DDIM. As shown
in Fig.3, some cell nuclei are reconstructed with a dif-
ferent shape from those of the original image. This
is because the computation of the forward process
in DDIM includes some approximations, which de-
grades the accuracy of the encoding. As mentioned
above, when one has malignant lymphoma, tissue
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
520

Input Image
Reconstructed Image
Input Image
Reconstructed Image
Figure 3: The result of reconstructed images using the con-
ventional DDIM. The conventional DDIM fails to accu-
rately reconstruct the input image in the region highlighted
with a red rectangle.
structure changes not only in its global structure but
also in the microcell structures. To quantitatively
evaluate the changes in tissue structures, it is desired
to be able to accurately reconstruct the microstruc-
tures such as individual cell nuclei.
In this study, we propose a method that removes
errors added to the series of diffused images in the
forward process of DDIM by referring to the original
image. Since the computation of the backward pro-
cess of DDIM does not include any approximation,
making the encoding in the forward process accurate
can improve the accuracy of the reconstruction. By
utilizing the same noise estimator used in the back-
ward process of a conventional DDIM, our method
can accurately reconstruct the original image.
Our main contributions are as follows: (1) To im-
prove the accuracy of encoding in the forward process
of DDIM, we propose a method that determines opti-
mal modification vectors to obtain a better noise im-
age that accurately reconstructs the original input im-
age, and (2) We evaluate the effectiveness of modified
DDIM encoding and the quality of generated counter-
factual images visually and quantitatively.
2 GENERATION OF
COUNTERFACTUAL IMAGES
USING DIFFUSION MODELS
In this section, we first describe DDPMs. Thereafter,
we introduce a denoising diffusion implicit model
(DDIM) that can deterministically encode an input
image. Then we describe the generation of counter-
factual images with the classifier-guidance.
2.1 Denoising Diffusion Probabilistic
Models
Diffusion models are latent variable models of the
form p
θ
(x
0
) :=
R
p
θ
(x
0:T
)dx
1:T
, where x
0
is an ob-
served variable and x
1
, ..., x
T
are latent representation
and indices of x are timesteps of forward process.
The observed variable x
0
follows the data distribu-
tion q(x
0
) and the latent variables x
1
, ..., x
T
are the
same dimensions as the observed variable x
0
. The
joint distribution p
θ
(x
0:T
) is defined as the following
equations:
p
θ
(x
0:T
) := p(x
T
)
T
∏
t=1
p
θ
(x
t−1
|x
t
), (2)
p
θ
(x
t−1
|x
t
) := N (x
t−1
;µ
θ
(x
t
,t), Σ
θ
(x
t
,t)), (3)
where p(x
T
) = N (x
T
;0, I) and θ is model param-
eters. Sampling from the distribution p
θ
(x
0
) that
is parametrized with θ, we can compute the back-
ward process of the diffusion model. For the forward
process or diffusion process in DDPM, the posterior
q(x
1:T
|x
0
) comes from Markovian process that gradu-
ally adds Gaussian noise to the data according to noise
schedulers β
1
, ..., β
T
:
q(x
1:T
|x
0
) :=
T
∏
t=1
q(x
t
|x
t−1
), (4)
q(x
t
|x
t−1
) := N (x
t
;
p
1 −β
t
x
t−1
, β
t
I). (5)
When the distribution q(x
t
|x
t−1
) of Eq.(5) is Gaus-
sian distribution, if β
t
is small, then the distribution
p
θ
(x
t−1
|x
t
) of Eq.(3) is also Gaussian distribution
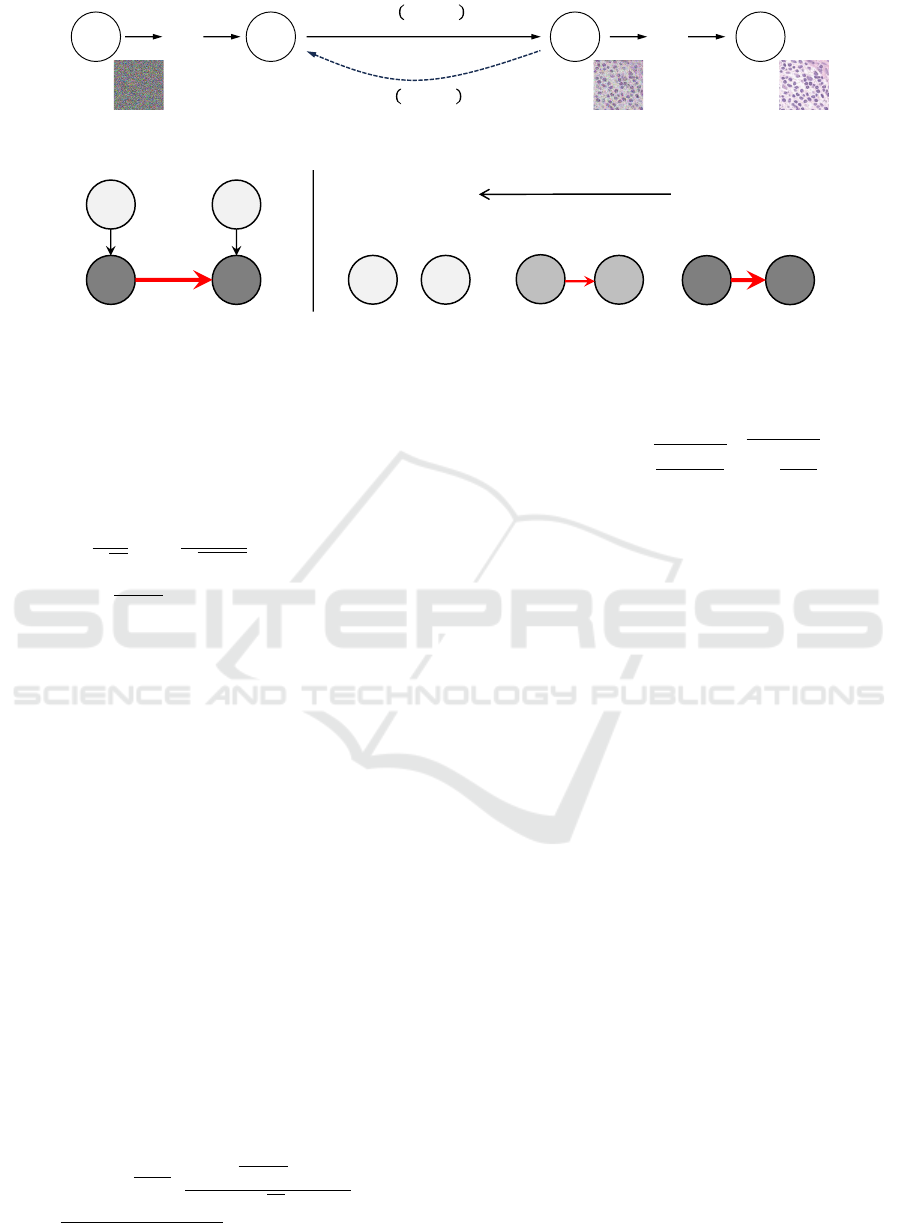
(Sohl-Dickstein et al., 2015). Fig.4 illustrates the di-
rected graphical model based on Eq.(3) and Eq.(5).
This forward process have a notable property that ad-
mits sampling x
t
at an arbitrary timestep t in closed
form:
q(x
t
|x
0
) = N (x
t
;
√
¯
α
t
x
0
, (1 −
¯
α
t
)I), (6)
where α
t
:= 1 −β
t
and
¯
α
t
:=
∏
t
s=1
α
s
. Training of
the DDPM is performed by optimizing the usual vari-
ational inference bound on negative log likelihood.
Consequently, as described in (Ho et al., 2020), the
objective function of DDPM is expressed as:
min
θ
E
t,x
0
,ε
∥ε −ε
θ
(
√
¯
α
t
x
0
+
p
1 −
¯
α
t
ε,t)∥
2
2
, (7)
where ε ∼ N (0, I) and ε
θ
is a function that predicts ε
from x
t
and t.
Modification of DDIM Encoding for Generating Counterfactual Pathology Images of Malignant Lymphoma
521
𝒙
𝑇
𝒙
𝑡
𝒙
𝑡−1
𝒙
0
⋯ ⋯
𝑝
𝜃
𝒙
𝑡−1
|𝒙
𝑡
𝑞 𝒙
𝑡
|𝒙
𝑡−1
Figure 4: The directed graphical model considered in diffusion models.
Figure 5: Illustration of the forward process of diffusion model as weakening of causal relationship considered in this study.
Arrows in this figure indicate the causal relationships between variables and direction, and the thickness of red arrows express
strength of the relation.
After training of the DDPM, a sample x
0
is
produced by repeating the sampling of x
t−1
∼
p
θ
(x
t−1
|x
t
) with t = T,..., 1. The sampling of x
t−1
∼
p
θ
(x
t−1
|x
t
) can be realized by computing Eq.(8) as
described in (Ho et al., 2020):
x
t−1
=
1
√
α
t
x
t
−
1 −α
t
√
1 −
¯
α
t
ε
θ
(x
t
,t)
+ σ
t
z, (8)
where σ
t
:=
1−
¯
α
t−1
1−
¯
α
t
βt and z ∼ N (0, I). Since the
DDPM is constructed under the small noise sched-
ulers β
t
and the large timestep T , such as T = 1, 000,
it is known that the generation of samples with the
DDPM takes much time.
2.2 Denoising Diffusion Implicit Models
In the DDPM, iterative noise addition in the forward
process is formulated as Markovian process and an
original image is encoded into a series of noise im-
ages. In the backward process, the estimation and re-
moval of the noise must be repeated the same number
of times as the number of the noise addition, which
is computationally inefficient. DDIM can reduce the
number of times to estimate and remove noise com-
ponents in the backward process compared to the for-
ward process (Song et al., 2021). This efficiency im-
provement is achieved by making the forward pro-
cess non-Markovian while using the same objective
function of DDPMs (Eq.(7)). The update equation in
the backward process of DDIM is derived so that the
marginal distribution q(x
t
|x
0
) at a timestep t in the
forward process matches that in the forward process
of the DDPM, and is expressed as:
x
t−1
=
p
¯
α
t−1
x
t
−
√
1 −
¯
α
t
ε
θ
(x
t
,t)
√
¯
α
t
+
q
1 −
¯
α
t−1
−{
ˆ
σ
t
(η)}
2
ε
θ
(x
t
,t)+
ˆ
σ
t
(η)z, (9)
where
ˆ
σ
t
(η) := η
r
1 −
¯
α
t−1
1 −
¯
α
t
s
1 −
¯
α
t
¯
α
t−1
. (10)
On the other hand, the forward process of DDIM is
derived from Bayes’ rule using Eq.(9). When η = 1
for all t, Eq.(9) reduces to Eq.(8). When η = 0 for
all t, the coefficient of the random noise z in Eq.(9)
becomes zero, and a sample is deterministically pro-
duced. When η > 0 at least one t, random noise z
in the Eq.(9) is added during sampling, and a sample
stochastically produced.
DDIMs are utilized in order not only to acceler-
ate the backward process but also to encode an input
image x
0
. The authors of (Song et al., 2021) demon-
strate that the original input image can be efficiently
reconstructed from the corresponding final noise im-
age, x
T
, encoded using the DDIM.
2.3 Generation with
Classifier-Guidance
In our study, we generate counterfactual images us-
ing classifier-guidance. In the classifier-guidance, the
backward process of the trained diffusion model is
conditioned with a gradient of the classifier (Dhari-
wal and Nichol, 2021). The classifier p
φ
(y|x
t
,t) is
trained from noise images x
t
, where φ is the classi-
fier’s parameters and y is a class label. After training
of the classifier, we generate counterfactual images
from an encoded representation by guiding the back-
ward process of diffusion models based on the gradi-
ent ∇
x
t
p
φ
(y|x
t
,t).
Given a causal model, counterfactual images are
generated by changing only the endogenous variable
of interest under deleting the directed edges toward
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
522
(a) Conventional DDIM encoding
(b) Modified DDIM encoding (Proposed)
𝒙
𝑇
ෝ
𝒙
0
ෝ
𝒙
1
𝒙
1
ෝ
𝒙
1
ෝ
𝒙
2
𝒙
1
∗
ෝ
𝒙
0
𝒙
1
∗
ෝ
𝒙
1
𝒙
2
∗
𝒙
𝑇
∗
𝒙
0
backward
backward
𝒙
𝑇
𝒙
1
𝒙
0
ෝ
𝒙
0
ෝ
𝒙
1
ෝ
𝒙
1
ෝ
𝒙
2
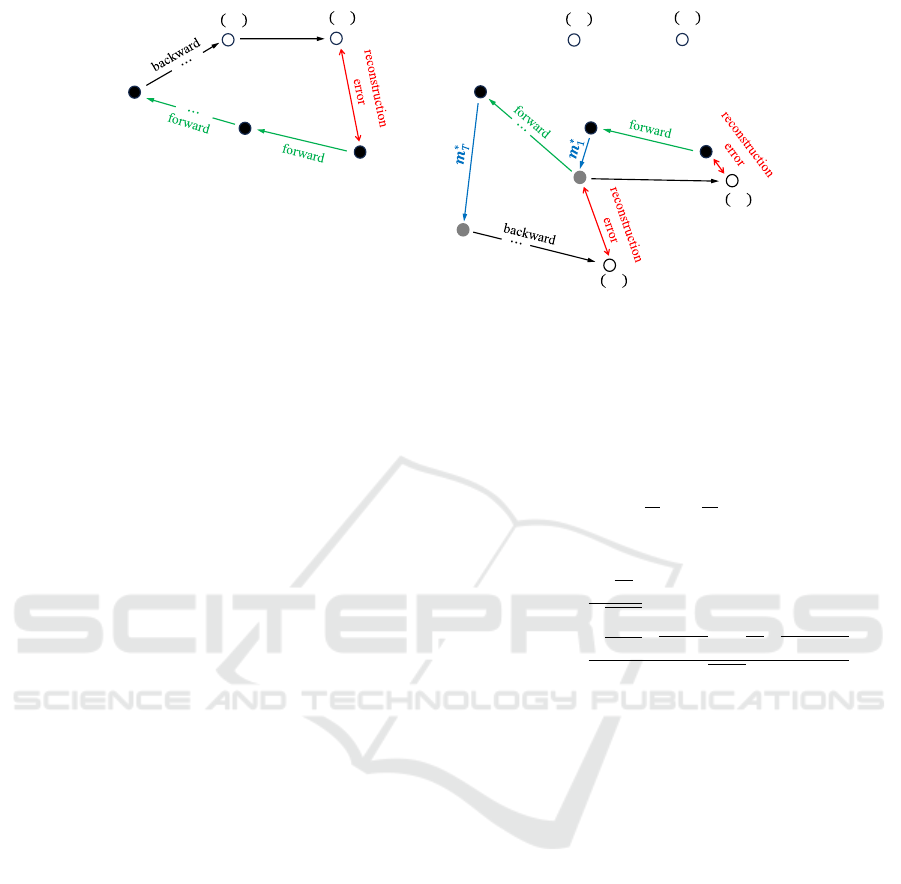
Figure 6: The comparison of conventional DDIM encoding and modified DDIM encoding. The left panel illustrates the
conventional DDIM encoding and the right panel illustrates our proposed modified DDIM encoding. Green arrows show the
forward process using Eq.(14). Black arrows show the backward process using Eq.(11). Red arrows indicate the reconstruction
error. Blue arrows show the modification vector.
the endogenous variable of interest and fixing all
other variables except for that variable. According to
(Sanchez and Tsaftaris, 2022), the forward process of
the diffusion model weakens the causal relationships
between variables, as illustrated in Fig.5, where x
(k)
t
are k-th endogenous variables and u
(k)
are respective
exogenous variables. In this study, x
(1)
denotes the
subtype of malignant lymphoma and x
(2)
denotes the
pathological image. In the right panel of Fig.5, the
forward process weakens the relationships between
endogenous variables until these variables are com-
pletely independent at t = T . By computing the for-
ward process of DDIM until t = T , the exogenous
variables u
(2)
of pathological image x
(2)
can be in-
ferred deterministically.
3 PROPOSED METHOD
In the generation of counterfactual images, it is de-
sired that we can uniquely reconstruct the original
images from the exogenous variables. This is one of
the main reasons that we employ the DDIM. As men-
tioned in Sec.2.3, in counterfactual image generation
using the DDIM, the noise image, x
T
, obtained by
encoding the given image with the forward process
is considered as an exogenous variable. For this rea-
son, high accuracy is desired in the computation of the
forward process. The computation of the forward pro-
cess in the DDIM includes approximations, and there
is room for the improvement of accuracy. The reason
including the approximation is shown below. The for-
ward process that computes x
t
from x
t−1
is obtained
from Eq.(9). At first, Eq.(9) is rewritten as:
x
t−1
=
1
a
t
x
t
−
b
t
a
t
ε
θ
(x
t
,t), (11)
where η = 0 in Eq.(9) and
a
t
=
√
¯
α
t
√
¯
α
t−1
, (12)
b
t
=
√
¯
α
t−1
√
1 −
¯
α
t
−
√
¯
α
t
√
1 −
¯
α
t−1
√
¯
α
t−1
. (13)
By solving Eq.(11) for x
t
under the assumption of
ε
θ
(x
t
,t) ≈ ε
θ
(x
t−1
,t) (Song et al., 2021), we obtain
the equation that is used in a conventional DDIM:
x
t
≈ a
t
x
t−1
+ b
t
ε
θ
(x
t−1
,t). (14)
Here, it should be noted that the approximation of
ε
θ
(x
t
,t) ≈ε
θ
(x
t−1
,t) causes an encoded error for each
x
t
(t = 1, 2, ..., T ) in the forward process. When one
reconstructs the sample x
t−1
from the x
t
that includes
noise, the reconstructed sample would have a non-
negligible reconstruction error. This error would be
added at each timestep in the backward process and
it is known that the propagation of the error leads to
incorrect image reconstruction (Wallace et al., 2023).
This inaccuracy should be corrected for the genera-
tion of counterfactual pathology images. We propose
a method that corrects the inaccuracy of the conven-
tional DDIM.
3.1 Modified DDIM Encoding
Our proposed method modifies the series of the noise
images, x
1
, ..., x
T
, obtained in the forward process so
that the backward process accurately reconstructs the
Modification of DDIM Encoding for Generating Counterfactual Pathology Images of Malignant Lymphoma
523

Table 1: The settings for training the models. The diffusion models and the classifiers are trained with two image sizes. In
this table, “DDPM” refers to the diffusion model, and “CLS” refers to the classifier.
256 × 256 256 × 256 512 × 512 512 × 512
(DDPM) (CLS) (DDPM) (CLS)
Batch size 16 128 4 32
Epoch 100 80 100 80
Timesteps T = 1, 000 T = 1, 000 T = 2, 000 T = 2, 000
original image. The modification method is shown
below. Fig.6 illustrates the comparison of conven-
tional DDIM encoding and our proposed modified
DDIM encoding. Let x
t
denote a sample obtained
by applying DDIM encoding to the sample x
t−1
.
Let
ˆ
x
t−1
(x
t
) denote a sample reconstructed from the
sample x
t
using Eq.(11). The reconstructed sample
ˆ
x
t−1
(x
t
) would have the reconstruction error and the
error strength at each timestep t is evaluated as:
E
t
:= ∥x
t−1
−
ˆ
x
t−1
(x
t
)∥
2
. (15)
This error comes from the inaccuracy of the encod-
ing due to the approximation in the forward process.
To reduce this error, we introduce a modification vec-
tor m
t
for the compensation of reconstructed error
as shown in Fig.6, that is,
ˆ
x
t−1
is not reconstructed
from x
t
but from (x
t
+ m
t
). This compensation by m
t
makes the series of encodes, x
1
, ..., x
T
, more consis-
tent with the theoretical non-Markovian forward pro-
cess.
Let
ˆ
x
t−1
(x
t
+ m
t
) denote a reconstructed sample
from (x
t
+ m
t
) using Eq.(11). By adding a modifica-
tion vector m
t
, the reconstruction error of Eq.(15) can
be written as:
E
t
(m
t
) = ∥x
t−1
−
ˆ
x
t−1
(x
t
+ m
t
)∥
2
. (16)
The objective here is to reduce the errors included in
each x
t
by inferring m
t
for t = 1, ..., T . We start the
inference of m
t
from t = 1: We compute the optimal
m
∗
1
by solving the optimization problem:
m
∗
1
:= argmin
m
1
∥x
0
−
ˆ
x
0
(x
1
+ m
1
)∥
2
, (17)
where
ˆ
x
0
(x
1
+ m
1
) is obtained by applying the back-
ward process of the conventional DDIM. Once we
obtain m
∗
1
that minimizes the reconstruction error
(Eq.(17)), we update x
1
as x
∗
1
= x
1
+m
∗
1
and apply the
forward process of the conventional DDIM to obtain
x
2
from x
∗
1
. Then, the m
2
is obtained by minimizing
∥x
∗
1
−
ˆ
x
1
(x
2
+ m
2
)∥
2
. Incrementing t from 1 to T , we
estimate m
∗
t
for t = 1, ..., T by minimizing the recon-
struction error (Eq.(16)) at each timestep and obtain
the series of encoded images, x
∗
1
, ..., x
∗
T
.
The proposed method is summarized in Algo-
rithm 1. Procedure FORWARD(·) refers to apply-
ing the forward process of the conventional DDIM
and BACKWARD(·) refers to applying the backward
process of the conventional DDIM. To determine the
modification vectors, we utilize the trained diffusion
model used in the conventional method and require no
retraining of the diffusion model. We use the modified
DDIM encoding denoted above to obtain the series of
the noise images that can accurately reconstruct the
input image x
0
.
Data: a given original image x
0
Result: a series of modified noise images,
x
∗
1
, ..., x
∗
T
x
∗
0
= x
0
for t = 1, 2..., T do
x
t
= FORWARD(x
∗
t−1
)
m
t
← 0
ˆ
x
t−1
(x
t
+ m
t
) = BACKWARD(x
t
+ m
t
)
m
∗
t
= argmin
m
t
∥x
∗
t−1
−
ˆ
x
t−1
(x
t
+ m
t
)∥
2
x
∗
t
= x
t
+ m
∗
t
end
Algorithm 1: Modified DDIM encoding.
4 EXPERIMENTAL RESULTS
In this section, we first describe the training of dif-
fusion models and classifiers for guidance. There-
after, we demonstrate the performance of the modi-
fied DDIM encoding. Finally, we illustrate the result
of generating counterfactual images.
4.1 Training of DDPMs and Classifiers
Our database for the experiments in this paper com-
prises the WSIs of 10 reactive cases, non-cancerous,
and 10 DLBCL cases, one of the subtypes. DDPMs
and classifiers for guidance are trained with the set-
tings shown in Table 1 using the AdamW (Loshchilov
and Hutter, 2019) optimizer with a learning rate 7.0 ×
10
−4
from 128,000 patch images cropped in two type
sizes, 256 × 256 and 512 × 512, from the WSIs.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
524
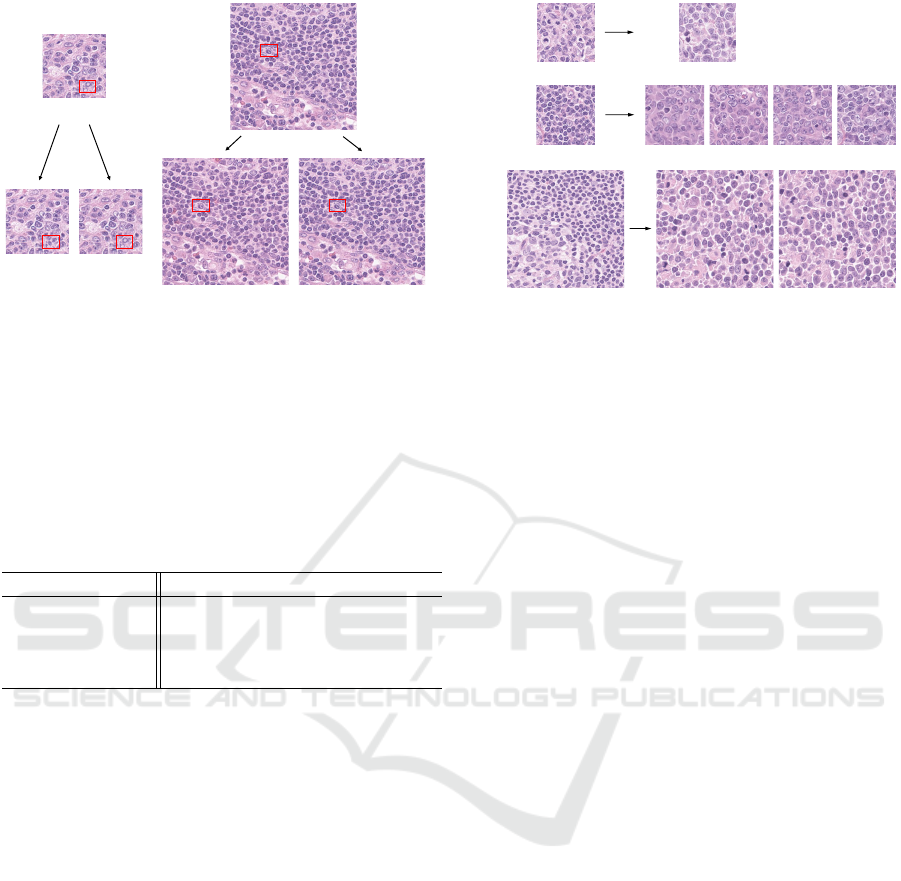
(a)
(b)
(a-1) (a-2)
(b-1) (b-2)
Figure 7: Visual comparison of the conventional method
and the proposed one. The input images of (a) and (b) are
the size of 256 × 256 and 512 × 512, respectively. (a-1)
and (b-1) are the reconstructed images based on the con-
ventional DDIM encoding. (a-2) and (b-2) are the recon-
structed images based on the modified DDIM encoding.
Table 2: Quantitative comparison of the conventional and
proposed methods. For each method, the reconstruction er-
ror between the input image x
0
and reconstructed image
ˆ
x
0
is evaluated with the l
1
distance. The best result is marked
in bold.
Patch size 256 × 256 512 × 512
Conventional
0.025 ± 0.012 0.021 ± 0.004
DDIM encoding
Modified
0.009 ± 0.010 0.006 ± 0.004
DDIM encoding
4.2 Performance of Modified DDIM
Encoding
We evaluate the effect of introducing modification
vectors in DDIM encoding. For the models con-
structed with two type patch sizes, the images that are
reconstructed based on the conventional DDIM en-
coding and the modified DDIM encoding are shown
in Fig.7 and Table 2. The number of iterative pro-
cesses required to solve the optimization problem of
m
t
at each timestep is set to 10. Evidently from Fig.7,
whereas the conventional method fails to accurately
reconstruct the input images, our proposed method is
successful in accurately reconstructing the input im-
ages. Specifically, our proposed method accurately
reconstructs the input image in the region highlighted
by the red rectangle in Fig.7. This visual evaluation is
consistent with the results of quantitative evaluation,
as shown in Table 2. This result demonstrates that
our proposed method reduces the approximation er-
ror derived from the conventional DDIM encoding to
obtain the series of noise images that can accurately
reconstruct the input image.
(C)
(B)
Counterfactual Images
Input Image
Input Image
Counterfactual Images
Counterfactual Image
Input Image
(A)
Figure 8: Result of generating counterfactual images. A
row of (A) is the result with the existing method based on
the cGAN. Rows of (B) and (C) are the results with the
DDPM using the classifier-guidance.
4.3 Generation of Counterfactual
Images
From the intermediate representation obtained by
DDIM encoding, we generate counterfactual images
when the patient changes from reactive to DLBCL. In
image generation, η in Eq.(10) is set to 0.5 and a guid-
ance scale for the classifier-guidance is set to 20. The
generated counterfactual images are shown in Fig.8.
The row of (A) in Fig.8 includes the counterfactual
images generated using the existing method based
on the conditional GAN (Singla et al., 2020). This
method deterministically generates a single counter-
factual image from a given input image and can-
not stochastically generate many counterfactual im-
ages. In addition, unfortunately, pathologists have
commented that if the counterfactual image of a row
of (A) was generated as DLBCL, the cell nuclei were
too dense to be real. By contrast, counterfactual im-
ages in rows of (B) and (C) are stochastically gener-
ated from a given input image and are good in terms
of the ability to render microstructures such as nucle-
oli. Moreover, whereas the cGAN-based method has
failed to learn the counterfactual image generator of
512 × 512, the diffusion-based method is successful
in generating images of 512 × 512.
We quantitatively evaluate the quality of generated
counterfactual images. FID scores are known as in-
dicators evaluating the quality of images generated
using generative models (Heusel et al., 2017). Ta-
ble 3 shows the computed FID scores. The cGAN-
based method failed to learn the counterfactual image
generator of 512 × 512. The diffusion-based method
demonstrates better performance than the GAN-based
one and this assessment is consistent with the visual
evaluation in Fig.8.
Modification of DDIM Encoding for Generating Counterfactual Pathology Images of Malignant Lymphoma
525
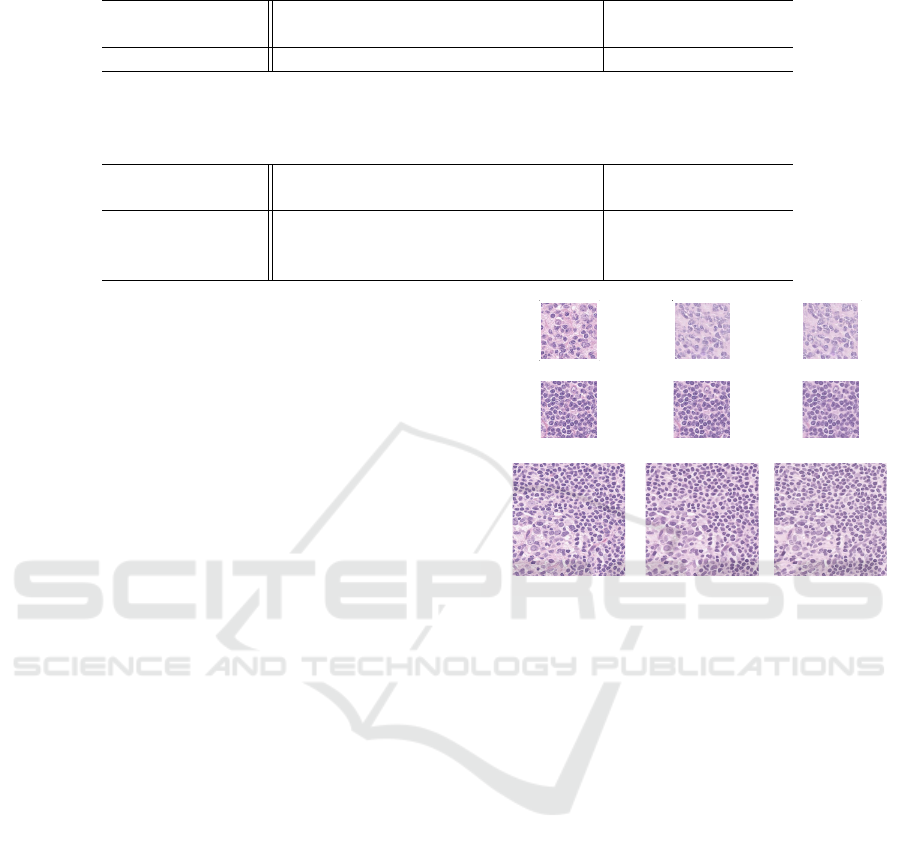
Table 3: The FID scores of generated images. The best result is marked in bold.
256 × 256 256 × 256 512 × 512
(cGAN) (DDPM) (DDPM)
FID scores (↓) 15.061 14.304 7.264
Table 4: The quantitative evaluation of generated counterfactual images. Lower values for the composition and the reversibil-
ity measured with the l
1
distance indicate higher performance. Higher values for the effectiveness measured with the accuracy
of the classifier indicate higher performance. The best result is marked in bold.
256 × 256 256 × 256 512 × 512
(cGAN) (DDPM) (DDPM)
Composition (↓) 0.209 0.049 0.041
Reversibility (↓) 0.215 0.087 0.069
Effectiveness (↑) 0.678 0.965 0.677
Furthermore, we evaluate the quality of generated
images in terms of counterfactuals. The authors of
(Monteiro et al., 2023) provide three indicators based
on Pearl’s axiomatic definition (Pearl, 2009) to eval-
uate the quality of counterfactual images; these in-
dicators are composed of composition, reversibility,
and effectiveness. Briefly, the composition implies
that the generated image
ˆ
x
0
is consistent with the in-
put image x
0
under the case without any interven-
tion, and this is often measured with the l
1
distance.
The reversibility implies cycle-consistency in a cycle-
backed transformation from the generated counterfac-
tual image to the original input image, and this is also
often measured with the l
1
distance. The effective-
ness implies the effect of intervention on the genera-
tion of counterfactual images. For instance, when the
generated counterfactual image is fed into a different
subtype classifier from the classifier constructed for
the classifier-guidance, its effectiveness is computed
as whether the classifier can accurately classify it into
the class specified in the generation of the counterfac-
tual image.
We evaluate the quality of counterfactual images
based on the three indicators. Fig.9 shows the re-
constructed images to visually evaluate the compo-
sition and the reversibility of these indicators. Evi-
dently from Fig.9, we can see that the diffusion-based
method accurately reconstructs the input image than
the cGAN-based one. Moreover, these three indica-
tors are shown in Table 4. Since the diffusion-based
method is superior in all the indicators, it is expected
that the diffusion-based method is a better counterfac-
tual image generator than the GAN-based one in most
cases.
5 RELATED WORKS
There have been several studies that generate counter-
factual images using diffusion models. The authors of
(C)
Input Image Reconstructed Image
Cycle-backed Image
(B)
Input Image Reconstructed Image Cycle-backed Image
(A)
Input Image
Reconstructed Image
Cycle-backed Image
Figure 9: Result of reconstructed images and cycle-backed
transformed ones. A row of (A) is the result with the exist-
ing method using the cGAN. Rows of (B) and (C) are the
results with the DDPM using the classifier-guidance.
(Jeanneret et al., 2022) proposed a method for gener-
ating counterfactual images using a DDPM and a per-
ceptual loss (Johnson et al., 2016), and were success-
ful in manipulating such as emotion and age of facial
images. Since this method uses the DDPM, the orig-
inal image cannot always be reconstructed from the
noise image obtained with the forward process. Ow-
ing to this property, it is not easy to consider causal
models for counterfactuals. Thus, we conduct the
counterfactual image generation based on the DDIM
encoding with the deterministic forward process, as
proposed in (Sanchez and Tsaftaris, 2022).
6 SUMMARY AND FUTURE
WORKS
In this paper, we propose a method that modifies en-
coding in DDIM to improve the quality of counter-
factual histopathological images of malignant lym-
phoma. DDIM encoding is employed as an encoder
for generating counterfactual images. DDIM encod-
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
526

ing generates non-negligible reconstruction error for
pathological image analysis and it is not easy to ob-
tain an intermediate representation that accurately re-
constructs the original input image. To alleviate this
problem, we propose a method that reduces the errors
in DDIM encoding. Experimental results demonstrate
that our proposed method is successful in obtaining
better intermediate representations that accurately re-
construct the original input image. In addition, we
generate multiple counterfactual images from the en-
coded representation and demonstrate that the quality
of these images is good based on the visual and quan-
titative evaluation.
The final goal of our study is to construct quan-
titative criteria for the changes in the morphology of
tissue structures for malignant lymphoma. To achieve
this, we first generated counterfactual pathology im-
ages of DLBCL using diffusion models. Future works
also include the construction of an explainable func-
tion that approximates a subtype classifier using the
generated counterfactual images.
ACKNOWLEDGEMENTS
This work was supported by JSPS KAKENHI Grant
Numbers JP22H03613 to H.H. and JP23KJ1141 to
R.K.
REFERENCES
Dhariwal, P. and Nichol, A. (2021). Diffusion models beat
gans on image synthesis. In Advances in Neural Infor-
mation Processing Systems, volume 34, pages 8780–
8794.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and
Hochreiter, S. (2017). Gans trained by a two time-
scale update rule converge to a local nash equilibrium.
In Advances in Neural Information Processing Sys-
tems, volume 30.
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffu-
sion probabilistic models. In Larochelle, H., Ran-
zato, M., Hadsell, R., Balcan, M., and Lin, H., editors,
Advances in Neural Information Processing Systems,
volume 33, pages 6840–6851.
Jeanneret, G., Simon, L., and Jurie, F. (2022). Diffu-
sion models for counterfactual explanations. In Pro-
ceedings of the Asian Conference on Computer Vision
(ACCV), pages 858–876.
Johnson, J., Alahi, A., and Fei-Fei, L. (2016). Perceptual
losses for real-time style transfer and super-resolution.
CoRR, abs/1603.08155.
Loshchilov, I. and Hutter, F. (2019). Decoupled weight
decay regularization. In International Conference on
Learning Representations.
Monteiro, M., Ribeiro, F. D. S., Pawlowski, N., Castro,
D. C., and Glocker, B. (2023). Measuring axiomatic
soundness of counterfactual image models. In The
Eleventh International Conference on Learning Rep-
resentations.
Pearl, J. (2009). Causality. Cambridge University Press.
Sanchez, P. and Tsaftaris, S. A. (2022). Diffusion causal
models for counterfactual estimation. volume 177
of Proceedings of Machine Learning Research, pages
647–668. PMLR.
Singla, S., Pollack, B., Chen, J., and Batmanghelich, K.
(2020). Explanation by progressive exaggeration.
In International Conference on Learning Representa-
tions.
Singla, S., Wallace, S., Triantafillou, S., and Batmanghe-
lich, K. (2021). Using causal analysis for conceptual
deep learning explanation. Med Image Comput Com-
put Assist Interv, 12903:pp. 519–528.
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and
Ganguli, S. (2015). Deep unsupervised learning using
nonequilibrium thermodynamics. In Proceedings of
the 32nd International Conference on Machine Learn-
ing, volume 37 of Proceedings of Machine Learning
Research, pages 2256–2265. PMLR.
Song, J., Meng, C., and Ermon, S. (2021). Denoising diffu-
sion implicit models. In International Conference on
Learning Representations.
Swerdlow SH, Campo E, H. N., Jaffe ES, P. S., and Stein H,
T. J., editors (2017). World Health Organization clas-
sification of tumours of haematopoietic and lymphoid
tissues. Revised 4th ed. Lyon. IARC Press.
Wallace, B., Gokul, A., and Naik, N. (2023). Edict: Exact
diffusion inversion via coupled transformations. In
Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
22532–22541.
Modification of DDIM Encoding for Generating Counterfactual Pathology Images of Malignant Lymphoma
527
