
Towards Developing an Agent-Based Framework for Validating the
Trustworthiness of Large Language Models
Johannes Bubeck, Janick Greinacher, Yannik Langer, Tobias Roth and Carsten Lanquillon
a
Business Information Systems, Heilbronn University of Applied Sciences, Heilbronn, Germany
Keywords:
Large Language Models, ChatGPT, Prompting, Trustworthiness, Validation, Verification.
Abstract:
Large language models (LLMs) have revolutionized the field of generative artificial intelligence and strongly
affect human-computer interaction based on natural language. Yet, it is difficult for users to understand how
trustful LLM outputs are. Therefore, this paper develops an agent-based framework by exploring approaches,
methods, and the integration of external data sources. The framework contributes to AI reasearch and usage
by enabling future users to consider LLM outputs more efficiently and critically.
1 INTRODUCTION
Large Language Models (LLMs) have significantly
transformed the fields of artificial intelligence (AI)
and natural language processing (NLP), leading to the
creation of advanced conversational models. With the
increasing complexity and capabilities of these mod-
els, the necessity to ensure their outputs are trust-
worthy and verifiable becomes paramount (Ali et al.,
2023). Trust is increasingly recognized as an es-
sential element in user-AI interactions, especially as
more opaque and complex machine learning models
become widespread in AI (Jacovi et al., 2021).
Moreover, the field of LLMs is experiencing an
exponential growth in the number of papers published
each month (Zhao et al., 2023). As LLMs gain more
prominence, the validation of their outputs for trust-
worthiness becomes increasingly crucial. This trend
aligns with the strong focus on ethical considerations
in AI and machine learning, urging the need to ensure
trustworthiness in both current and future AI systems
and applications (Future of Life Institute (FLI), 2021).
A viable solution to this challenge is the valida-
tion of LLM outputs. This validation process ensures
that the models operate as intended, producing accu-
rate and reliable results. Validation, in this context,
involves verifying the trustworthiness of a model’s
outputs against established criteria or standards (Bow-
man and Dahl, 2021; Srivastava et al., 2022).
GPT-4 from OpenAI is one of the most advanced
language models currently available. It vigorously ex-
a
https://orcid.org/0000-0002-9319-1437
emplifies the critical need for validating LLM outputs.
Although ChatGPT, with its web interface that facili-
tates easy access to different GPT versions, has shown
remarkable ability in generating coherent and contex-
tually appropriate responses to user queries, instances
of the model delivering inconsistent outputs have also
been reported (Jang and Lukasiewicz, 2023).
Hence, validating the outputs of LLMs is vital to
ensure their reliability across various scenarios. This
leads to our research question:
How can we construct a framework that en-
hances LLM outputs by incorporating exist-
ing validation approaches and external data
sources to increase their trustworthiness?
To advance our research, we have identified the fol-
lowing subsidiary questions:
1. What suitable validation approaches and external
data sources already exist in the literature?
2. What are a reasonable architecture and process for
developing such a framework?
3. How can a prototype be developed based on this
framework?
The primary contribution of this paper is the devel-
opment of an agent-based framework that augments
the outputs of LLMs, providing users with feedback
on the trustworthiness of these outputs. We have de-
veloped a prototype to test and evaluate our proposed
framework. To address these research questions, we
have created the following artifacts:
• a literature review identifying suitable validation
approaches utilizing external data,
Bubeck, J., Greinacher, J., Langer, Y., Roth, T. and Lanquillon, C.
Towards Developing an Agent-Based Framework for Validating the Tr ustworthiness of Large Language Models.
DOI: 10.5220/0012364000003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 527-534
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
527

• a multi-agent validation framework,
• a prototype implementation of the framework, and
• an evaluation of the prototype.
The structure of this paper is organized as follows:
First, we discuss the scientific foundations and theo-
retical background. This is followed by a detailed pre-
sentation of our research methodology and our find-
ings. Finally, we conclude with a discussion of our
results and an exploration of potential future research
avenues.
2 THEORETICAL BACKGROUND
2.1 Large Language Models
LLMs are advanced AI models with an extensive
number of parameters. They are pre-trained on vast
text corpora using self-supervised learning methods,
and are often further refined with task-specific exam-
ples in supervised settings. Their development began
to significantly advance around 2018, with both their
parameter count and performance showing exponen-
tial growth since then (Birhane et al., 2023).
Current LLMs employ deep neural networks and
leverage sophisticated machine learning techniques,
such as the transformer model (Vaswani et al., 2017).
They utilize substantial computational resources and
large datasets, including internet content, enabling
them to develop a comprehensive understanding of
language and respond in contextually relevant and co-
herent ways (Teubner et al., 2023).
A major advantage of LLMs is their versatility
in tasks like text composition, question answering,
translation, chatbot operations, and program code
generation. They are distinguished by their scala-
bility and high parameter counts, which contribute
to their cutting-edge performance in natural language
processing. Notably, LLMs can initially learn from
unlabeled data, a self-supervised learning approach
that yields impressive outcomes and broadens their
applicability without extensive supervised training
(Vaswani et al., 2017; Huang et al., 2022).
However, there are several concerns associated
with LLMs. These include challenges in captur-
ing scientific interpretation and meaning, potential
neglect of value judgments in scientific texts, risks
of producing inaccurate content, so-called hallucina-
tions, and the potential erosion of trust in the peer re-
view process. These issues underscore the need for
cautious and critical assessment, as well as further re-
search to ensure responsible and appropriate use of
LLMs in scientific settings (Birhane et al., 2023).
2.2 Trust in Artificial Intelligence
Trust is a fundamental factor in the adoption and ef-
fective utilization of AI technologies. This is par-
ticularly true for the complex models used in natu-
ral language processing, where high levels of trust
are imperative. Trust enables researchers, develop-
ers, and users to depend on the accuracy and relia-
bility of AI-generated results. It lays the groundwork
for applying AI in diverse areas, including machine
translation, text generation, and information retrieval.
To establish trust, an AI system’s transparency, inter-
pretability, and accountability need to be thoroughly
addressed. This is essential to ensure that an AI sys-
tem is not only reliable but also ethically responsible
(Toreini et al., 2020).
However, the task of ensuring AI systems’ trust-
worthiness is fraught with challenges, primarily due
to the inherent black box nature of these systems. In
particular, LLMs with their complex deep neural net-
work architectures and extensive parameter spaces are
trained on massive datasets. The opacity of these deep
learning systems presents a significant challenge, as
their decision-making processes typically remain elu-
sive. The lack of clarity and understanding of these
processes casts doubt on the extent to which these
systems can be trusted. As such, transparency is
paramount in building trust in AI, ensuring that users
can have confidence in their outcomes (von Eschen-
bach, 2021).
3 RESEARCH METHODOLOGY
For the scientific design of our research process, we
adhere to the established methodology outlined in
(Peffers et al., 2007). Our research process is seg-
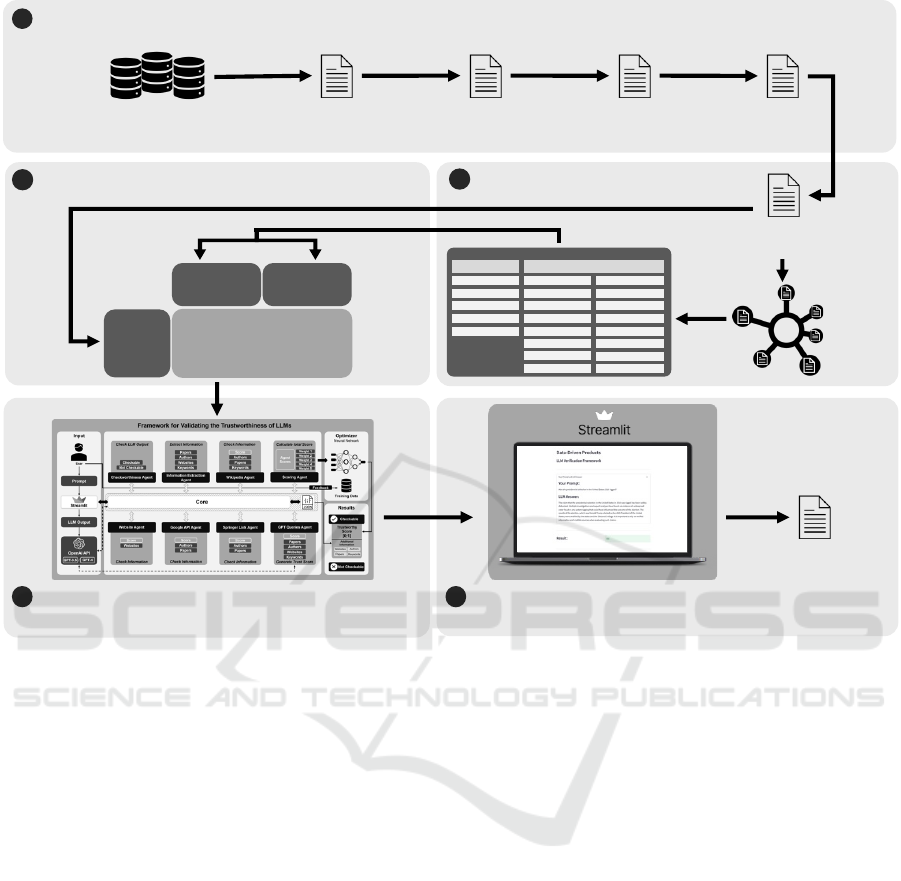
mented into five distinct steps, as depicted in Figure 1
and described in greater detail below.
Our literature review methodology is guided by
(Webster and Watson, 2002) and (vom Brocke et al.,
2009). We conducted title searches using the
terms [“fake checking” AND (“methods” OR “ap-
proaches”)] and [“fact checking” AND (“methods”
OR “approaches”)], with no date restrictions, across
several literature databases including IEEE Xplore
Digital Library, ScienceDirect, SpringerLink, and
Emerald Insight. In addition, we conduct forward and
backward searches (Webster and Watson, 2002).
In the second step, relevant papers are read thor-
oughly and, also, implemented. For the coding pro-
cess of the approaches, the procedure of qualitative
content analysis as proposed by (Mayring and Fenzl,
2010) is performed. All publications are analyzed to
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
528
Literature Search
(vom Brocke et al. 2009, Webster and Watson 2002)
4
Literature & Conference Databases
111
Identified Papers
64
Unique Papers
25
Relevant Papers
34
Final Papers
Search query
Excluding of
duplicates
Analyzing the
abstracts
Forward and
backward search
Approaches that are connected to external Data
(Mayring 2010)
Developing the Framework for Validating the
Trustworthiness of Responses from LLMs
(based on Peffers et al. 2007)
Literature Analysis
(Mayring 2010, Cruzes and Dyba 2011)
1
23
4
Implementation, Evaluation and Demonstration of
the prototype
(Peffers et al. 2007)
Assignment of
text segments
34
Papers
Clustering of 21
approaches
21
References
Identification of Approaches that are
connected to external Data
Feature
Extraction
Approaches
Modelling
Approaches
Approaches that are connected to external data
Feature Extraction
Approaches (5)
Modelling Approaches (16)
TF-IDF
Word2Vec
Fasttext
GloVe
BERT
Graph
Knowledge Graph
Logistic Regression
Linear SVM
KNN
Neural Network
RNN
CNN
LSTM
Anomaly Detection
Decision Tree/Random Forest
Naïve Bayes
XG-Boost
Question Answering
Cosine Similarity
Evidence Retrieval
5
Evaluation
Figure 1: Overview of the research process (Peffers et al., 2007).
identify approaches and external data sources. Only
text segments describing approaches connected to ex-
ternal data are considered here. Based on this, we
identify several text segments according to the the-
matic synthesis process by (Cruzes and Dyba, 2011).
These segments are condensed into various character-
istics and assigned to high-level categories (Mayring
and Fenzl, 2010). Subsequently, in the third step, we
summarize the segments and the associated publica-
tions in a concept matrix (Webster and Watson, 2002).
The fourth step is dedicated to conceptualizing the
framework. This entails analyzing the identified ap-
proaches related to external data sources and integrat-
ing them within the framework. A critical aspect of
this conceptual design is the recognition that not all
identified approaches could be considered in the ini-
tial implementation of the framework. However, the
agent-based structure that we propose will offer the
flexibility to easily incorporate additional approaches
in future iterations.
In the final step, the design and development
and, also, the demonstration and evaluation phases
are completed according to (Peffers et al., 2007).
The prototype is being implemented, evaluated, and
demonstrated based on our proposed framework. Par-
ticular emphasis is placed on the structure of the
agents, ensuring that they align well with the over-
arching framework and meet the objectives set out in
our research.
4 FINDINGS
This section delves into the detailed presentation and
discussion of the results and findings. It encompasses
the literature review, the conceptual design of the
framework, and the development of the prototype.
4.1 Literature Review
The literature search process resulted in 111 publica-
tions. After a thorough review of the abstracts and
keywords, we narrowed down to 25 publications that
were directly relevant to our research focus. The for-
ward and backward searches increased the final num-
ber of pertinent publications to 34.
We identified two main categories: feature ex-
traction and modeling approaches. These categories
Towards Developing an Agent-Based Framework for Validating the Trustworthiness of Large Language Models
529

form the foundation for conceptualizing and develop-
ing both the framework and the prototype. As de-
picted in Figure 1 (step 2), the category feature ex-
traction comprises five approaches, while modeling
approaches includes 16.
We conducted a comprehensive analysis and eval-
uation of these approaches to assess their suitability.
Some approaches are incompatible with our current
research focus, which is primarily focused on the con-
ceptualization of a prototypical framework. Thus, we
carefully selected suitable approaches and integrated
them into the initial iteration of our project. Nonethe-
less, the knowledge gained from the literature review
is expected to be extremely valuable for future re-
search and the continued development of the frame-
work in its subsequent iterations.
4.2 Framework
The development of our framework is based on the
results and analyses of approaches identified in the
literature review. We opted for an agent-based frame-
work as the foundational conceptual model because
it allows seamless integration of the approaches we
identified without the need for complex adaptations.
This ensures the framework’s modularity and scala-
bility. We consider agents as independent entities,
each with specific tasks, capable of interacting within
the framework. The analysis of the trustworthiness of
LLM outputs is facilitated by individual agents, each
calculating scores for different tasks. A neural net-
work, referred to as the scoring agent, is then used to
compute a weighted overall score.
For the frontend, we selected Streamlit due to its
ability to support the rapid development of visually
appealing prototypes. Figure 2 illustrates our frame-
work, which will be discussed in more detail in the
subsequent sections.
The OpenAI API component serves as a gateway
to the OpenAI API, enabling interaction with GPT-
3.5-Turbo or GPT-4 for text generation. This interface
facilitates sending requests to the OpenAI API and
receiving the corresponding text responses. As a part
of our research, we approached OpenAI to share our
research methodology and were subsequently granted
access to GPT-4, allowing us to test our framework
with its more sophisticated outputs.
The checkworthiness agent assesses the reliability
of statements utilizing the OpenAI API to process any
request. Its run method analyzes the model’s response
and produces a list indicating a statement’s verifiabil-
ity along with detailed explanations.
Core is the central component of the LLM valida-
tion framework. It orchestrates various agents, such
as the checkworthiness agent, information extraction
agent, website agent, Wikipedia agent, Google API
agent, GPT queries agent, and scoring agent. Trig-
gered from the Streamlit frontend after confirming a
statement’s trustworthiness, the core’s main function
orchestrates the sequence flow. This enables the inte-
gration of data from different agents and acts as the
central control point of the framework.
In the information extraction agent, an interface
connects to the OpenAI API to conduct specific
searches for papers, authors, websites, and keywords
used in the model’s outputs. This agent processes this
information with comprehensive error handling to ad-
dress potential inaccuracies or incorrect feedback.
The Wikipedia agent extracts information using
keywords from the information extraction agent as
search queries. It scans the initial articles using these
keywords to identify authors’ names and paper titles.
It then compares these details with known authors and
titles. After this comparison, a scoring mechanism is
applied to measure the level of similarity or relevance
between them.
The website agent scores a given LLM output
based on matching websites and a thorough analysis
based on their content and status. The agent sends
requests to individual websites and analyzes the re-
sulting HTTP status codes as they indicate whether
a website is functioning correctly, undergoing redi-
rection, offering informative content, or facing errors.
The final score is determined based on the number of
matching websites found and their status categoriza-
tion.
The Google API agent leverages the Google
Books API to review books and their respective au-
thors. It examines authors and book titles by dis-
patching API requests, evaluating the outcomes, and
compiles distinct lists of verified authors and books.
Finally, the agent calculates a score based on the fre-
quency of successful Google Books API queries.
The SpringerLink agent gathers information
through an advanced search on the SpringerLink web-
site, explicitly searching for certain authors and ti-
tles. The results it receives are then compared with
the data extracted by the information extraction agent,
which includes details of authors and papers. Similar
to the process in the Wikipedia agent, a score is calcu-
lated for this agent based on the number of successful
matches found between the authors and papers iden-
tified by the information extraction agent.
The GPT queries agent employs the OpenAI
model to generate trust scores. This agent initializes
the OpenAI object and uses a predefined text as a tem-
plate for evaluating trust. Unlike other agents that de-
rive their scores from external data, this agent calcu-
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
530

Figure 2: Overview of identified approaches.
lates the LLM’s trustworthiness score internally. The
LLM assesses this score using information extracted
by the information extraction agent. Therefore, its in-
puts are solely its own previously generated outputs,
without any external data.
The scoring agent and the optimizer component
are responsible for calculating the overall trustwor-
thiness score and optimizing it. To do so, the scor-
ing agent activates a neural network module with the
individual agents’ scores. The overall trustworthi-
ness score is computed as a weighted sum of the in-
dividual agent scores. A neural network optimizes
the weights by predicting the specific weight for each
agent’s score based on the available data. Users can
contribute feedback on the trustworthiness score’s ac-
curacy, which is then incorporated into the neural net-
work’s training data. This retraining occurs when the
framework is initially launched.
Currently, the overall trustworthiness score in-
cludes assessments from five agents, each determin-
ing its score individually. These individual scores
are based on how closely their findings align with the
LLM’s output, for which the trustworthiness score is
being calculated. The scores range from 0 to 1, with
0.5 indicating a neutral position. Each score reflects
the degree to which the LLM’s output is considered
trustworthy. If an agent is unable to gather useful
information, it adapts by assigning a neutral score
of 0.5. To maintain transparency and comparability,
the individual agents’ algorithms for calculating their
scores always follow a consistent pattern based on the
numbers of matches and their respective quality.
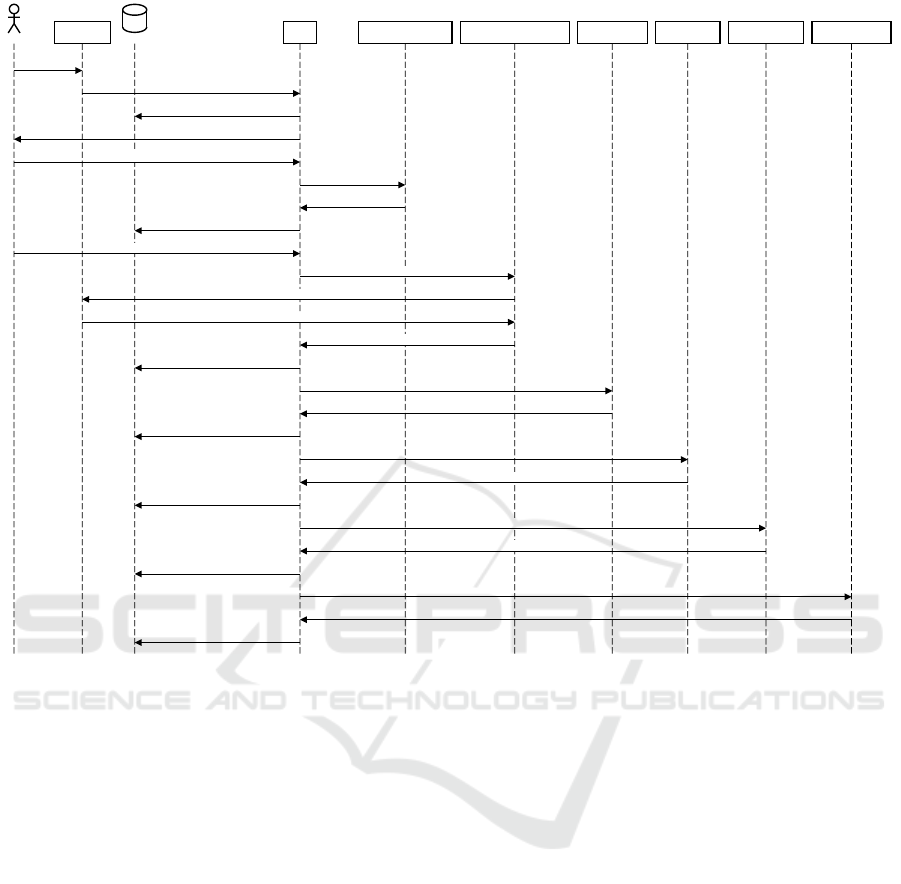
4.3 Implementation of the Prototype
The implementation of the prototype closely follows
the conceptual framework’s description. Figure 3 dis-
plays a section of our sequence diagram. Given the
prototype’s complexity, which includes a multitude of
agents and their interactions, the sequence diagram is
essential for structuring the prototype and the code
flow and enhancing its comprehensibility.
With Python being the programming language of
our choice, an object-oriented approach was adopted,
and each agent is implemented as a distinct object or
class. JSON was employed to consolidate the results
and scores, with only the core module having admin-
istrative rights. Once the framework is initialized,
the core module assumes full control over all other
modules, orchestrating the individual results from the
agents.
The validation process is initiated only if the
LLM’s statement is deemed verifiable by the check-
worthiness agent. Access to the LLM is facilitated
through the OpenAI API, where requests are sent to
the designated chat completion endpoint. Authentica-
tion to the API is secured using organization details
and API keys, which are also essential for API billing
purposes. This combination of authentication meth-
ods is crucial to ensure that the model operates within
the context of the initially provided prompt, which is
key to our prompt design strategy. As mentioned in
the previous section, we gained access to the GPT-4
model from OpenAI for this research project, follow-
ing a request and a description of our research focus.
Towards Developing an Agent-Based Framework for Validating the Trustworthiness of Large Language Models
531
LLMVerificationFramework
User
OpenAIAPI
JSON
Core CheckworthinessAgent InformationExtractionAgent WikipediaAgent WebsiteAgent GoogleAPIAgent SpringerLinkAgent GPTQueriesAgent ScoringAgent ScoreOptimizer NeuralNetwork
TrainData
Prompt
Prompt
PromptandOutput
LLMOutput
TriggerCheckworthinessScan
CheckLLMOutput
Checkable/NotCheckable
Checkable/NotCheckable
StartFramework
LLMResponse
ExtractionPrompts
DeliverextractedInformation
ReturnPapers,Authors,WebsitesandKeywords
Papers,Authors,Websites,Keywords
Keywords,Authors,Papers
WikipediaScore
Papers,Authors,Score
Websites
WebsiteScore
Websites,Score
Authors,Papers
GoogleScore
Papers,Authors,Score
Authors,Papers
SpringerlinkScore
Papers,Authors,Score
JSONData
request
SendScore
GPTQueriesScore
Score
SendAgent-Scores
SendAgent-Scores
PredictWeights
ReturnpredictedWeights
ReturnpredictedWeights
ReturncalculatedtotalScore
TotalScore
TrustworthyScoreandadditionalInformation
DisplaytrustworthyScoreandadditionalInformation
RatingAccuracyofTrustworthinessScore
AppendScores,WeightsandFeedbackScore
TrainModel
Figure 3: Part of the developed sequence diagram.
5 EVALUATION
This section focuses on evaluating the developed
framework and its prototype implementation. It aims
to determine the feasibility of successfully evaluating
the trustworthiness of LLM outputs.
The user workflow and the prototype are depicted
in Figure 4, using the example of querying whether
the 2016 U.S. presidential election was rigged. The
prototype, created in Streamlit, functions as a local
web server. Users can input any text or question into
the start screen as requests for a LLM. Once a prompt
is submitted, it is sent to the OpenAI API, and the
response from OpenAI’s GPT-4 model is displayed.
Initially, the user has the option to check if the out-
put is worthy of further scrutiny. A reasoned response
is then provided, indicating whether the output can
be checked. If the LLM’s output is deemed uncheck-
able, the user can initiate a new query. Otherwise, the
user can activate the framework, which then starts the
complex validation process in the background. This
involves the individual agents’ data processing and
information analysis. Once all agents have completed
their tasks and the overall trustworthiness score is cal-
culated, it is displayed appropriately.
Besides the output results, users can view all the
underlying information used in the agents’ calcula-
tions, as illustrated in Figure 5. The detailed results
are provided for questions such as: “Was the moon
landing real?”
Access to detailed information about the output
and the corresponding score enables users to not only
receive the LLM’s answer to their initial prompt, but
also gain additional insights about it. This approach
empowers users to delve into and scrutinize the rele-
vant sources and authors associated with the informa-
tion provided.
6 CONCLUSION
Our research methodology has been an effective foun-
dation for developing an agent-based framework to
validate the trustworthiness of LLMs. In this section,
we summarize and critically analyze the results, while
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
532
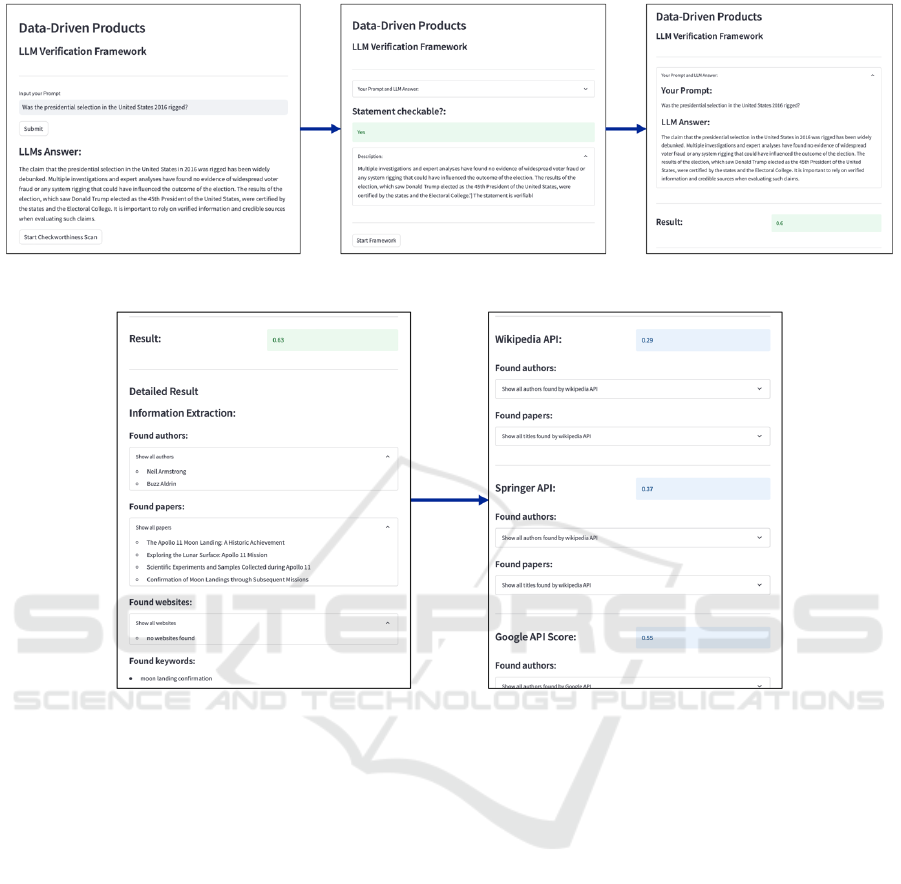
Figure 4: Interaction process of the user with the framework.
Figure 5: Detailed results of the calculated trustworthiness score.
also identifying potential avenues for future research.
In our analysis of the literature, we identified 21
potential approaches for prototypically implementing
an agent-based framework. By adopting the selected
methodologies and integrating external data sources,
our prototype framework computes a trustworthiness
score. This score is calculated based on the vary-
ing weights assigned to the evaluations from individ-
ual agents. It serves as a measure for assessing the
reliability of OpenAI’s GPT-4 model in generating
responses. The trustworthiness score, which ranges
from 0 to 1, acts as a metric to determine the de-
gree of trust that can be placed in the model’s outputs.
A score of 0 indicates a low level of trustworthiness,
whereas a score of 1 represents an exceptionally high
level of trustworthiness.
The agent-based framework we have conceptu-
alized offers a flexible and scalable architecture for
future development. Evaluating the system through
our implemented prototype has yielded valuable in-
sights into its functionality and usability. Since not
all agent approaches identified in our literature review
have been included in the prototype, there is room for
integrating additional agents in future iterations.
As stated above, our research methodology was
effective in developing the implementation of the
agent-based framework. However, this work is not
without its limitations. Additional approaches could
have been explored for use within the framework to
validate the trustworthiness of LLM outputs. While
we have successfully incorporated various approaches
in the form of agents, there is currently no scientifi-
cally robust justification for the selection of these ap-
proaches. Moreover, our framework is currently lim-
ited to six agents due to its prototype status. There-
fore, future developments could involve expanding
the framework by adding new agents, potentially de-
veloping and implementing a separate agent for each
method identified in our literature analysis.
To the best of our knowledge, this paper presents
a novel approach for validating the trustworthiness of
LLMs. The findings here lay the groundwork for sub-
sequent research. Future studies might focus on en-
hancing the proposed trustworthiness score calcula-
Towards Developing an Agent-Based Framework for Validating the Trustworthiness of Large Language Models
533

tion. For instance, our neural network could undergo
further iterations to incorporate diverse data sources,
thereby optimizing the weighting of agents in deter-
mining the score. Additionally, future work should
involve reconfiguring the architecture of the prototype
and subjecting it to empirical evaluation.
In the scope of our work, we have successfully
created a prototypical agent-based framework for as-
sessing the trustworthiness of LLMs. This prototype
establishes a robust foundation and signals promising
directions for future advancements. With this imple-
mentation, we have made a contribution in developing
a validation framework for LLM outputs, marking a
vital step towards its potential future application.
REFERENCES
Ali, S., Abuhmed, T., El-Sappagh, S., Muhammad, K.,
Alonso-Moral, J. M., Confalonieri, R., Guidotti, R.,
Del Ser, J., D
´
ıaz-Rodr
´
ıguez, N., and Herrera, F.
(2023). Explainable Artificial Intelligence (XAI):
What we know and what is left to attain Trust-
worthy Artificial Intelligence. Information Fusion,
99:101805.
Birhane, A., Kasirzadeh, A., Leslie, D., and Wachter, S.
(2023). Science in the age of large language models.
Nature Reviews Physics, 5(5):277–280. Number: 5
Publisher: Nature Publishing Group.
Bowman, S. R. and Dahl, G. (2021). What Will it Take to
Fix Benchmarking in Natural Language Understand-
ing? In Proceedings of the 2021 Conference of the
North American Chapter of the Association for Com-
putational Linguistics: Human Language Technolo-
gies, pages 4843–4855, Online. Association for Com-
putational Linguistics.
Cruzes, D. S. and Dyba, T. (2011). Recommended steps for
thematic synthesis in software engineering. In 2011
international symposium on empirical software engi-
neering and measurement, pages 275–284. IEEE.
Future of Life Institute (FLI) (2021). The Artificial Intelli-
gence Act.
Huang, J., Gu, S. S., Hou, L., Wu, Y., Wang, X., Yu, H., and
Han, J. (2022). Large Language Models Can Self-
Improve. arXiv:2210.11610 [cs].
Jacovi, A., Marasovi
´
c, A., Miller, T., and Goldberg, Y.
(2021). Formalizing Trust in Artificial Intelligence:
Prerequisites, Causes and Goals of Human Trust in
AI. In Proceedings of the 2021 ACM Conference on
Fairness, Accountability, and Transparency, FAccT
’21, pages 624–635, New York, NY, USA. Associa-
tion for Computing Machinery.
Jang, M. and Lukasiewicz, T. (2023). Consistency Analysis
of ChatGPT. arXiv:2303.06273 [cs].
Mayring, P. and Fenzl, T. (2010). Qualitative inhaltsanalyse
[qualitative content analysis]. Qualitative Forschung
Ein Handbuch (Qualitative Research: A Handbook),
pages 468–475.
Peffers, K., Tuunanen, T., Rothenberger, M. A., and
Chatterjee, S. (2007). A Design Science Re-
search Methodology for Information Systems Re-
search. Journal of Management Information Sys-
tems, 24(3):45–77. Publisher: Routledge eprint:
https://doi.org/10.2753/MIS0742-1222240302.
Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M.,
Abid, A., Fisch, A., Brown, A. R., Santoro, A.,
Gupta, A., Garriga-Alonso, A., et al. (2022). Be-
yond the imitation game: Quantifying and extrapolat-
ing the capabilities of language models. arXiv preprint
arXiv:2206.04615.
Teubner, T., Flath, C. M., Weinhardt, C., van der Aalst, W.,
and Hinz, O. (2023). Welcome to the Era of ChatGPT
et al. Business & Information Systems Engineering,
65(2):95–101.
Toreini, E., Aitken, M., Coopamootoo, K., Elliott, K., Ze-
laya, C. G., and van Moorsel, A. (2020). The rela-
tionship between trust in AI and trustworthy machine
learning technologies. In Proceedings of the 2020
Conference on Fairness, Accountability, and Trans-
parency, FAT* ’20, pages 272–283, New York, NY,
USA. Association for Computing Machinery.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2017). Attention Is All You Need. arXiv:1706.03762
[cs].
vom Brocke, J., Simons, A., Niehaves, B., and Reimer,
K. (2009). Reconstructing the Giant: On the Impor-
tance of Rigour in Documenting the Literature Search
Proess. In European Conference on Information Sys-
tems (ECIS) 2009.
von Eschenbach, W. J. (2021). Transparency and the Black
Box Problem: Why We Do Not Trust AI. Philosophy
& Technology, 34(4):1607–1622.
Webster, J. and Watson, R. T. (2002). Analyzing the Past to
Prepare for the Future: Writing a Literature Review.
MIS Quarterly, 26(2):xiii–xxiii.
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou,
Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y.,
Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li,
Y., Tang, X., Liu, Z., Liu, P., Nie, J.-Y., and Wen,
J.-R. (2023). A Survey of Large Language Models.
arXiv:2303.18223 [cs].
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
534
