
QEBB: A Query-Efficient Black-Box Adversarial Attack on Video
Recognition Models Based on Unsupervised Key Frame Selection
Kimia Haghjooei
a
and Mansoor Rezghi
b
Department of Computer Science, Tarbiat Modares University, Tehran, Iran
Keywords:
Adversarial Examples, Adversarial Attack, Video Recognition, Black-Box Attack.
Abstract:
Despite the success of deep learning models, they remain vulnerable to adversarial attacks introducing slight
perturbations to inputs, resulting in adversarial examples. Black-box attacks, where model details are hidden
from the attacker, gain attention for their real-world applications. Although studying adversarial attacks on
video models is crucial due to their surveillance importance and security applications, most works on adversar-
ial examples mainly focus on images, and videos are rarely studied since attacking videos is more challenging.
Recent black-box video attacks involve selecting key frames to reduce video’s dimensionality. This addresses
the high costs of attacking the entire video but may require numerous queries, making the attack noticeable.
Our work introduces QEBB, a query-efficient black-box video attack. We employ an unsupervised key frame
selection method to choose frames with vital representative information. Using saliency maps, we focus on
key frame salient regions. QEBB successfully attacks UCF-101 and HMDB-51 datasets with 100% success
and reducing query numbers by nearly 90% in comparison to state-of-the-art methods.
1 INTRODUCTION
Deep Neural Networks have demonstrated a lot of
power and success across various computer vision
tasks such as image classification (Jiang et al., 2023;
Mittal et al., 2022; Paymode and Malode, 2022),
video recognition (Surek et al., 2023; Pham et al.,
2022; Wu et al., 2023), face recognition (Boussaad
and Boucetta, 2022; Kurakin et al., 2018; Li et al.,
2022) and object detection (Ajagbe et al., 2022; Zaidi
et al., 2022). Despite their success, deep neural net-
works have shown vulnerability to adversarial exam-
ples (Goodfellow et al., 2014). Recent studies have
shown that adding a slight perturbation to a clean
input can fool a DNN and lead to incorrect out-
put. Therefore, studying adversarial attacks is crit-
ical, especially since deep learning models are used
in security-critical applications (Nasir et al., 2022;
Arunnehru et al., 2023).
Adversarial examples can be generated by an ad-
versarial attack in either a white-box manner (Wang
et al., 2022; Agnihotri and Keuper, 2023; Carlini
and Wagner, 2017; Moosavi-Dezfooli et al., 2016),
where the attacker has full knowledge of the model’s
a
https://orcid.org/0009-0001-1722-9739
b
https://orcid.org/0000-0003-4214-5008
structure or a in a black-box manner (Cheng et al.,
2018; Carlini and Wagner, 2018; Zhang et al., 2022;
Wan et al., 2023), where the attacker has no infor-
mation about the model and can only query predic-
tions for specific inputs. Therefore, black-box attacks
seem to make more realistic assumptions. However,
it is worth mentioning that a high number of queries
would make the attack visible to defence mechanisms.
Furthermore, adversarial attacks can be catego-
rized as targeted attacks (Sadrizadeh et al., 2023),
where the goal is to make the model predict a specific
adversarial label or untargeted attacks (Zhou et al.,
2022), where the output of model after attack is not
important as long as it differs from the original label.
Most of the recent research on adversarial exam-
ples have been considered on image models and ad-
versarial attacks on video recognition models have
been rarely studied. Since video classification models
are used in surveillance applications (Sultani et al.,
2018), it is necessary to assess their robustness to-
wards adversarial attacks. Although several white-
box (Wei et al., 2019; Li et al., 2018; Pony et al.,
2021; Lo and Patel, 2021) adversarial attacks have
been proposed for video recognition models, black-
box attacks on these models have been rarely studied.
PATCHATTACK (V-BAD) (Jiang et al., 2019) repre-
sents the first attempt to design a black-box attack on
288
Haghjooei, K. and Rezghi, M.
QEBB: A Query-Efficient Black-Box Adversarial Attack on Video Recognition Models Based on Unsupervised Key Frame Selection.
DOI: 10.5220/0012359900003654
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 13th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2024), pages 288-295
ISBN: 978-989-758-684-2; ISSN: 2184-4313
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

video recognition models. It initially uses a local im-
age classifier to generate perturbations for each video
frame, and then updates the perturbations by query-
ing the target model. To design adversarial attacks
for video recognition models, one approach involves
treating videos as sets of images and apply existing at-
tacks proposed for image models. Nevertheless, this
method can be significantly time-consuming due to
the higher dimensionality of videos compared to im-
ages. To address this issue, a potential solution in-
volves reevaluating the approach for designing black-
box adversarial attacks on video recognition models.
A novel aspect of this approach is to leverage the spa-
tial and temporal redundancies present in video data
to reduce the complexity of generating adversarial
video examples. One potential method is to reduce
the dimensionality of video data by selecting a subset
of frames as key frames and performing the adver-
sarial attack on this specific set of frames rather than
on all frames. Key frames are defined as frames that
contribute the most to representing the actual video
and play a crucial role in the classification task. Re-
cent black-box adversarial attacks on video recogni-
tion models have introduced innovative attacks that
include key frame selection before the attack phase.
For example, the Heuristic attack by Zhang et al. (Wei
et al., 2020) estimates the importance of each frame
based on its role in the classification task, although
it requires a high number of queries. Furthermore,
they utilize a saliency map to target the important re-
gions of key frames during the attack process. Despite
its effectiveness, this method is still time-consuming
and demands a significant number of queries, which
is an important criterion when evaluating black-box
adversarial attacks, as a high number of queries can
make the attack more visible. Additionally, Wei et al.
introduced the SVA attack (Wei et al., 2022), which
employs reinforcement learning to select key frames.
Despite its novelty, this attack also requires a substan-
tial number of queries during the key frame selection
phase.
Therefore, recent advancements in black-box ad-
versarial examples have effectively addressed the
challenge posed by high-dimensional video data
through the introduction of a key frame selection pro-
cess (Wei et al., 2020; Wei et al., 2022). How-
ever, it’s important to note that their key frame se-
lection methods (Wei et al., 2020; Wei et al., 2022)
heavily rely on the classifier model, determining a
frame’s importance based on its impact on the clas-
sification outcome. This approach presents two major
issues: Firstly, these selection processes necessitate
a substantial number of queries to compute individ-
ual scores for each frame, indicating its influence on
the classification result. Secondly, these methods as-
sess the importance of each frame independently and
select those with the highest classification scores as
key frames. Consequently, these methods do not ex-
plore potential sets of frames, potentially missing out
on possible candidates for key frames that could be
crucial.
To tackle this issue, we propose a novel approach
for designing a black-box adversarial attack on video
recognition models, based on the Heuristic attack
(Wei et al., 2020). In our method, we introduce an un-
supervised key frame selection process and redefine
what constitutes key frames. We define key frames
as the set of frames containing the most informative
details about a video. These frames contribute signif-
icantly to the classification process, as they signify
essential representative characteristics of the video.
Moreover, these key frames represent the entire video
data, encapsulating its overall information. To select
such frames in an unsupervised manner, we employ
k-means, a simple clustering technique. Our work
results in a significantly reduced number of queries
while achieving a 100% fooling rate on two bench-
mark datasets. In summary, our main contributions
are as follows:
• We study the problem of black-box adversar-
ial attacks on video recognition models and pro-
posed an untargeted query-efficient black-box at-
tack called QEBB.
• For each clean video, we define a subset of frames
as key frames using an unsupervised selection
method. We generate video adversarial examples
by perturbing key frames only.
• We conducted a series of comprehensive exper-
iments on two benchmark video datasets and
a video recognition model indicating that our
method not only requires a significantly smaller
number of queries, but also generates more real-
istic adversarial examples closely resembling real
videos.
2 RELATED WORK
In this section we review popular adversarial attacks
on both image and video models.
2.1 Adversarial Attack on Image
Models
Recent studies on adversarial examples are mainly fo-
cused on image classification models. Various attacks
QEBB: A Query-Efficient Black-Box Adversarial Attack on Video Recognition Models Based on Unsupervised Key Frame Selection
289
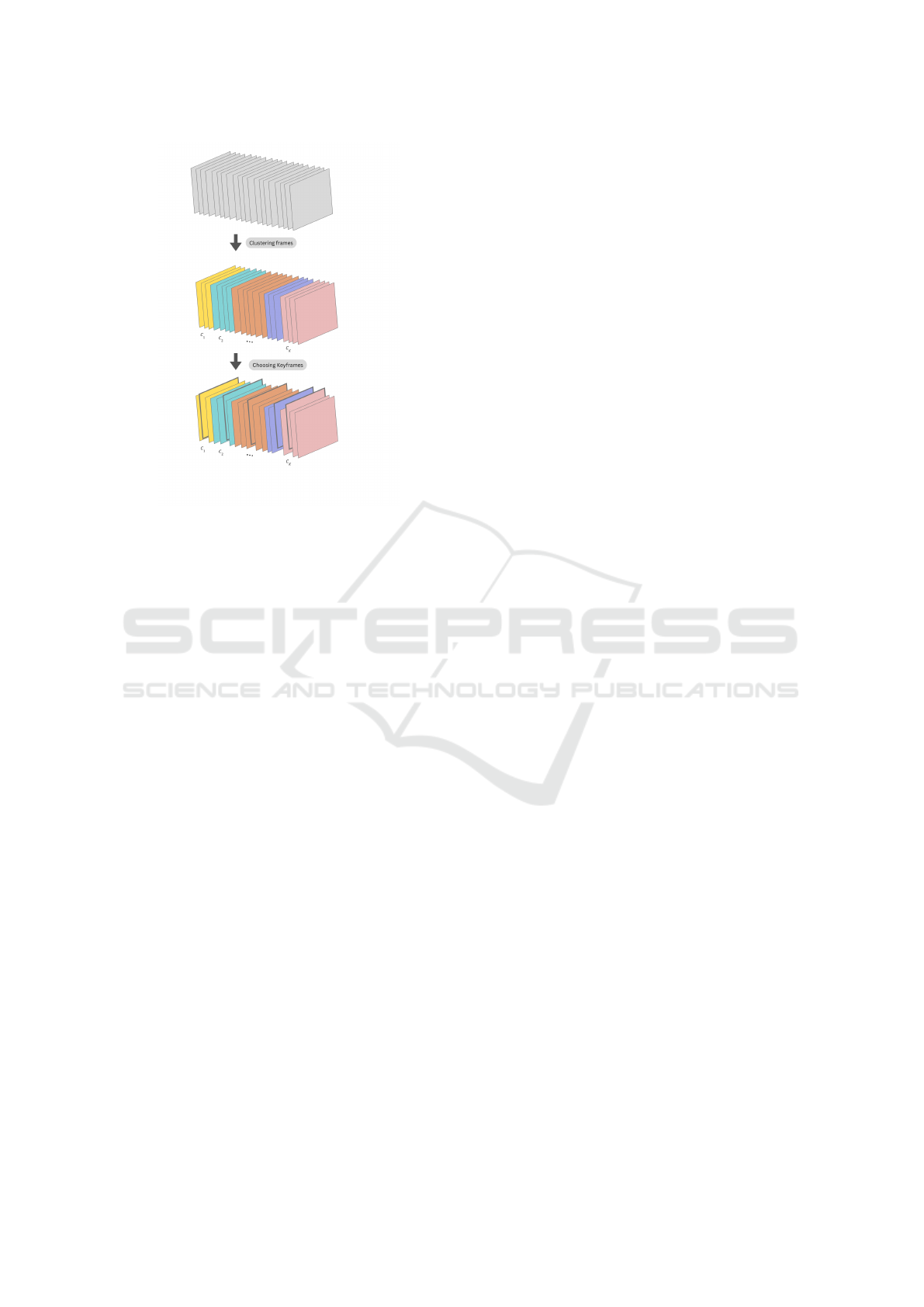
Figure 1: Selecting key frames using a clustering algorithm.
After collecting frames into K clusters, the nearest frames
to the cluster center are chosen as key frame candidates.
are designed in both white-box attacks (Wang et al.,
2022; Agnihotri and Keuper, 2023; Carlini and Wag-
ner, 2017; Moosavi-Dezfooli et al., 2016) and black-
box (Cheng et al., 2018; Carlini and Wagner, 2018;
Zhang et al., 2022; Wan et al., 2023) manners. In
the Opt-attack (Cheng et al., 2018), θ represents the
search direction, and the distance from a clean image
x to the decision boundry along θ is defined by g (θ).
The goal in Opt-attack (Cheng et al., 2018)is to mini-
mize g(θ).
2.2 Adversarial Attack on Video Models
The number of existing adversarial attacks on video
models is significantly lower than the efforts made for
image models duo for several reasons. Firstly, videos
consist of high-dimensional data making them more
complex. Secondly, applying existing adversarial at-
tacks designed for image models to video models con-
sumes a lot of time, resources and a large amount of
queries, making the attack more detectable from a se-
curity standpoint. Hence, it is crucial to design attacks
for video models specifically.
Recent adversarial attacks on video recognition
models are mainly in a white-box manner. For in-
stance, (Wei et al., 2019) discusses the sparsity of ad-
versarial perturbations through frames. Li et al. (Li
et al., 2018) proposed a novel approach to produce
perturbation clips in order to achieve higher attack
success rate. Pony et al. (Pony et al., 2021) proposed
Flickering attack that is generalized to make universal
perturbations. Lo et al. (Lo and Patel, 2021) proposed
MultAV which generates perturbations on videos by
using multiplication.
Whilst several white-box adversarial attacks have
been proposed on video recognition models, attacks
in a black-box setting have been rarely studied. Jiang
et al. (Jiang et al., 2019) claimed to be the first at-
tempt to design a black-box attack on video models
called V-BAD which generates initial perturbations
for each video frame utilizing a local image classi-
fier, and then updates the perturbations by querying
the target model. Compared to V-BAD, our work
doesn’t require a local image classifier and requires
significantly lower number of queries. One of the
state-of-art methods in this field is the Heuristic at-
tack (Wei et al., 2020), which introduces an innova-
tive approach to tackle the challenges associated with
high-dimensional video data. This method involves
selecting a small subset of key frames for each input
video. Specifically, Heuristic ranks frames based on
their classification scores and chooses those with the
highest scores. Subsequently, salient regions within
these selected key frames are targeted with perturba-
tions. In fact, Heuristic attack (Wei et al., 2020) de-
fines frames as key frames based on their impact on
the discrimination task. Despite its success in deceiv-
ing video models, Heuristic attack (Wei et al., 2020)
still demands a substantial number of queries to iden-
tify suitable key frames, potentially making the attack
more noticeable in a black-box setting. Another novel
attack, SVA (Wei et al., 2022), employs reinforcement
learning to select key frames. While effective in at-
tacking video classification models, this method also
requires a significant number of queries for its frame
selection process.
In this work, we approach the key frame selection
process differently. Specifically, we look for frames
that can best represent the video and its features in an
unsupervised manner. We choose the most represen-
tative and important frames, which make the most sig-
nificant contribution to the classification process due
to their rich informational content about the video.
Our approach achieves far fewer queries compared to
state-of-the-art black-box attacks.
3 PROPOSED METHOD
We indicate a video recognition model as a function f .
Specially, f (x) takes a clean video X ∈ R
T ×W ×H×C
as
an input and outputs ˆy as its top-1 class and the corre-
sponding probability P ( ˆy|X) where T,W,H,C denote
the number of frames, width, height and the num-
ber of channels respectively. The true class y ∈ Y =
{1, 2, ··· ,V } where V is the number of classes. The
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
290

adversarial example X
adv
is resulted by perturbing the
original video X. In the untargeted setting we aim to
make f (X
adv
) ̸= y. Recent black-box attacks (Wei
et al., 2020; Wei et al., 2022) have introduced var-
ious key frame selection methods to generate more
efficient video adversarial examples by targeting key
frames rather than all frames of a video. Although
they managed to produce adversarial examples with
higher qualities, they require a substantial number of
queries to select key frames. Therefore, we propose
an unsupervised key frame selection approach which
enhances attack efficiency bu eliminating the need for
a high number of queries, making it more practical
for real-world scenarios. In fact, we select a subset
of key frames and conduct the QEBB attack, inspired
by Opt-attack (Cheng et al., 2018), on these specific
frames rather than on all frames. Specifically, if we
indicate the selected key frames as
ˆ
X and other frames
as X
′
, we can represent video X = (
ˆ
X, X
′
). Therefore,
we define the following function to indicate the output
of the model:
h(
ˆ
X) = f (X) = y (1)
There are multiple methods to define and select key
frames. In this paper, we propose a novel key
frame selection method from a different point of view.
Specifically, if we consider a video X as a collection
of frames followed by a time dimension which are
temporally related, frames that are temporally close
to each other share a high degree of similarity. In
fact, we can categorize all of the frames based on their
similarities into some groups so that frames within
a group would be highly similar, and frames from
different groups would be different. Therefore, by
choosing some frames from each group as the indi-
cator of the frames of that group, we would be able
to find a key frame set that has the most represen-
tative details of the video while demonstrating the
overall flow of the video. For this manner, we have
used k-means, a simple clustering algorithm. Specif-
ically, consider Ψ = {x
i
= X(i, :, :, :)|i = 1,2,...,T}
(Ψ =
ˆ
X
S
X
′
) as the frame set of video X where x
i
demonstrates the ith frame of video X. Consequently,
after performing k-means on Ψ, we obtain K clusters
C = {C
1
,C
2
, ...,C
K
}. We select a subset of frames for
each cluster that are closer to the center of the clus-
ter and represent the members of that cluster in the
best possible way. Therefore, such a statement can be
formulated as follows:
χ
j
= argmin
x∈C
j
∥x − µ
j
∥
2
F
(2)
where χ
j
is the set of representative frames for C
j
,
indicating the jth cluster, and µ
j
denotes the center of
it. Hence, we choose a set of frames for each cluster
as the representative of the members of that cluster.
Therefore, we construct the key frames set as follows:
ˆ
X =
k
[
j=1
{χ
j
} (3)
Figure1 indicates a schema of our key frame selec-
tion.
Opt-attack (Cheng et al., 2018) defines a direction
θ and searches for the closest distance g(θ) where an
adversarial example can be found. For further effi-
ciency, Opt-attack (Cheng et al., 2018) improves θ
iteratively. In this paper, we extend the Opt-attack
(Cheng et al., 2018) to video recognition models.
Specially, same as Opt-attack (Cheng et al., 2018),
our objective is to find
min
θ
g(θ) (4)
where g(θ) is defined as
g(θ) = min
λ
h(
ˆ
X +
θ
||θ||
.λ) ̸= y
(5)
meaning that we perform attack on key frames only.
Therefore, we conduct our attack on
ˆ
X. Moreover,
as in (Wei et al., 2020), we used a saliency map (Lee
et al., 2012) for further efficiency. Hence, if we con-
sider the salient region mask as M, X
adv
is generated
as below:
X
adv
=
ˆ
X +θ
⋆
.g(θ)
⋆
∗ M, X
′
(6)
Moreover, same as Heuristic attack (Wei et al., 2020),
we initialize direction θ =
p
||p||
where p = Z −X and Z
is an input video which comes from a different class.
Finally, we obtain the adversarial example X
adv
=
X +g (θ
⋆
) ×θ
⋆
where θ
⋆
is the optimal solution in an
iterative manner by updating θ. For this aim, we use
Zero-Order-Optimizatin method (Chen et al., 2017), a
method that defines the estimated gradient as follows:
g
′
=
g(θ + βu) − g(θ)
β
.u (7)
Here, u represents a random Gaussian vector with
same dimensions as θ. Moreover, β > 0 indicates a
smoothing parameter which is subjected to a tenfold
reduction if the estimated gradients fail to offer mean-
ingful insights for the updating of θ (Wei et al., 2020).
Hence, we update θ in each iteration as follows:
θ ← θ − α.g
′
(8)
where α indicates the step size of each iteration. In
conclusion, we tackle the challenges of generating ef-
ficient video adversarial examples using an unsuper-
vised manner which results in a significant reduction
of number of queries required for this process while
selecting the best potential candidates for key frames
containing the overall informative details of a video.
QEBB: A Query-Efficient Black-Box Adversarial Attack on Video Recognition Models Based on Unsupervised Key Frame Selection
291

Table 1: Numerical evaluation of our framework, QEBB(including its two variations N-QEBB and α-QEBB), compared to
state-of-art black-box attacks.
Model Dataset Attack MQ MT MAP MSSIM FR(%)
C3D
N-QEBB 349.21 10.255 95.776 0.097 100
α-QEBB 349.82 9.225 90.213 0.1036 100
Heuristic(Wei et al., 2020) 5947.9 11.05 94.32 0.101 100
HMDB51 SVA(Wei et al., 2022) 3328.9 4.67 56.84 17e-5 100
VBAD(Jiang et al., 2019) 68584.2 32.24 59.59 76e-6 95
N-QEBB 352.21 10.657 96.22 0.0423 100
α-QEBB 357.79 11.45 96.23 0.0381 100
Heuristic(Wei et al., 2020) 53596.4 55.54 96.15 0.022 100
UCF101 SVA(Wei et al., 2022) 4473.8 7.11 53.24 12e-5 89
VBAD(Jiang et al., 2019) 71480.8 31.68 56.5 52e-6 87
Figure 2: Examples of adversarial frames generated by N-QEBB and α-QEBB under the untargeted setting.
4 EXPERIMENTS
In this section, we provide a comprehensive evalua-
tion to test the performance of our proposed quarry-
efficient, untargeted, black-box adversarial attack on
two benchmark video datasets. Our evaluation con-
tains various aspects, including the reduction in over-
all perturbation, significant decrease in query num-
bers required for the attack, resulting in adversarial
examples that are highly imperceptible to the human
eye. Furthermore, we offer a detailed assessment of
our method, showcasing its efficiency and effective-
ness among state-of-art black-box attacks on video
recognition models.
4.1 Experiment Setting
Datasets. We used two common video datasets for
our evaluation: UCF-101 (Soomro et al., 2012) and
HMDB-51 (Kuehne et al., 2011). UCF-101 is an
action recognition datasets derived from YouTube
that contains 13,320 videos with 101 action classes.
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
292

HMDB-51 is a large human motion dataset which
contains 7000 videos with 51 action categories. For
both datasets, we used 70% of videos for training set
and the rest of 30% for test set as in (Wei et al., 2020).
In (Wei et al., 2020) for each video, 16-frame snip-
pets are extracted using uniform sampling. In our set-
ting, we then perform our novel key frame selection
method on these 16 frames.
Video Recognition Models. We used C3D (Hara
et al., 2018), a popular video recognition model as
our target models. Moreover, we consider that the at-
tacker can only access top-1 class and its correspond-
ing probability.
Parameter Setting. As in (Wei et al., 2020), the pa-
rameter tuning is done on 30 videos that are randomly
sampled from the test set. We set the area ratio of
salient region φ to 0.6. We also set the step size for up-
dating the gradient to 0.2 on UCF-101. On the other
hand, we set a larger step size for some samples on
HMDB-51. Moreover, we set the number of cluster
to K = 5. Furthermore, after clustering frames, we
choose the representative frames for each cluster as
either N-nearest frame (N-QEBB) or to the α% near-
est frames (α-QEBB) to the cluster center. In our
evaluation, we set α = 20% and N = 1.
4.2 Evaluation Metrics
We employ five metrics to comprehensively assess
our method’s performance:
Fooling Rate (FR). This metric represents the ratio
of successfully misclassified adversarial videos.
MT (Average Running Time). It denotes the average
time in minutes required to execute the attack on test
samples.
MQ (Average Query Number). This metric signifies
the average number of queries necessary to generate
each adversarial example.
MAP (Mean Absolute Perturbation). This metric
indicates the mean perturbation in each pixel through-
out the entire video:
MAP =
1
N
N
∑
i
||x
i,adv
− x
i
||
|P
i
|
(9)
where N denotes the number of test samples and P
i
represents the total number of pixels existing in x
i
.
MSSIM (Mean Structural Similarity Index
Measure). It quantifies the average SSIM sim-
ilarity between each adversarial example and its
corresponding clean video:
SSIM(x
j
, x
j
adv
) =
(2µ
x
j
adv
µ
x
j
adv
+C
1
)(2σ
x
j
,x
j
adv
+C
2
)
(µ
2
x
j
+ µ
2
x
j
adv
+C
1
)(σ
2
x
j
+ σ
2
x
j
adv
+C
2
)
(10)
where x
j
indicates the jth frame of the video x while
µ
x
j
and σ
2
x
j
are showing the mean and the variance
of the jth frame of x respectively. Furthermore,
σ
x
j
,x
j
adv
shows the correlation coefficient between the
jth frame of x
adv
and x. Moreover, C
1
and C
2
are nu-
meric parameters.
These metrics collectively provide a comprehen-
sive evaluation of our method’s effectiveness and ef-
ficiency.
4.3 Performance Evaluation
In our comprehensive evaluation, we achieved a com-
parative analysis between our proposed methods,
namely N-QEBB and α-QEBB, and three state-of-
the-art black-box attacks: Heuristic (Wei et al., 2020),
SVA (Wei et al., 2022), and VBAD (Jiang et al.,
2019). Our assessments were carried out using a
single video recognition model on two benchmark
datasets, UCF-101 (Soomro et al., 2012) and HMDB-
51 (Kuehne et al., 2011). The results, presented in Ta-
ble 1 and visually illustrated in Figure 2, provide com-
pelling evidence of the effectiveness and efficiency of
our framework.
Table 1 indicates the superior performance of both
variations of our method. N-QEBB and α-QEBB
both achieve a 100% fooling rate on both datasets,
outperforming other approaches. particularly, they
achieve this with significantly fewer queries, a crucial
factor when evaluating the stealthiness of black-box
attacks from a security perspective.
Moreover, while we achieve a significant reduc-
tion in the number of queries on both datasets, both N-
QEBB and α-QEBB succeed in generating adversar-
ial examples with higher Mean Structural Similarity
Index Measure (MSSIM). This indicates that our ad-
versarial examples closely resemble the clean videos
compared to other attacks.
In terms of computational time, both of our frame-
works require less time compared to Heuristic (Wei
et al., 2020) and VBAD (Jiang et al., 2019). Although
N-QEBB and α-QEBB are more time-consuming
compared to SVA (Wei et al., 2022) attack, they
achieve fully successful attacks on both datasets.
Furthermore, it is worth mentioning that α-QEBB
generates adversarial examples with lower Mean Ab-
solute Perturbation (MAP) compared to Heuristic
(Wei et al., 2020) attack on HMDB. However, MAP
is not necessarily the most suitable metric for assess-
ing video adversarial examples since it does not ac-
count for the spatial and temporal relations within
video data. In contrast, other criteria such as MSSIM
are more suitable for comparing video examples since
they consider the spatial relations of video frames.
QEBB: A Query-Efficient Black-Box Adversarial Attack on Video Recognition Models Based on Unsupervised Key Frame Selection
293

Both of our frameworks on UCF and α-QEBB on
HMDB achieve higher MSSIM compared to the other
attacks, indicating that our frameworks generate more
similar adversarial examples to clean videos.
Moreover, even though SVA (Wei et al., 2022)
stands out as one of the most effective existing at-
tacks with faster execution and superior Mean Abso-
lute Perturbation (MAP) scores, our framework out-
performs SVA (Wei et al., 2022) by requiring signif-
icantly lower number of queries, along with achiev-
ing 100% successful adversarial examples and higher
Mean Structural Similarity Index Measure (MSSIM).
Figure 2 visually indicates examples of adversar-
ial examples generated by both N-QUEFB and α-
QUEFB. As shown in this figure, our frameworks can
produce adversarial examples that closely resemble
the original videos, supporting the quality of our ap-
proach.
In conclusion, our proposed unsupervised key
frame selection method combined with saliency-
based perturbations, significantly enhances attack ef-
ficiency. This method reduces the need for queries,
making our framework less detectable from a security
standpoint, while generating high-quality adversarial
examples. These findings emphasize the potential of
our approach in the black-box adversarial attacks on
video recognition models.
5 CONCLUSIONS
Generating video adversarial examples poses a signif-
icant challenge due to their high-dimensional nature.
To enhance efficiency, recent black-box attacks tar-
get only a subset of the video frames as keyframes.
This approach, while more efficient, often requires
many queries, making attacks detectable by defense
mechanisms, as keyframes are chosen based on their
impact on recognition tasks. In this paper, we in-
troduce an innovative, unsupervised keyframe selec-
tion method using simple clustering, where we group
frames and select representative frames from each
group as keyframes. This method significantly re-
duces the number of required queries, enabling the
generation of imperceptible adversarial examples by
focusing on representativeness rather than influence
on recognition tasks. Future work may explore vari-
ous video summarization techniques for more effec-
tive keyframe selection.
REFERENCES
Agnihotri, S. and Keuper, M. (2023). Cospgd: a unified
white-box adversarial attack for pixel-wise prediction
tasks. arXiv preprint arXiv:2302.02213.
Ajagbe, S. A., Oki, O. A., Oladipupo, M. A., and
Nwanakwaugwu, A. (2022). Investigating the effi-
ciency of deep learning models in bioinspired object
detection. In 2022 International conference on elec-
trical, computer and energy technologies (ICECET),
pages 1–6. IEEE.
Arunnehru, J. et al. (2023). Deep learning-based real-world
object detection and improved anomaly detection for
surveillance videos. Materials Today: Proceedings,
80:2911–2916.
Boussaad, L. and Boucetta, A. (2022). Deep-learning
based descriptors in application to aging problem in
face recognition. Journal of King Saud University-
Computer and Information Sciences, 34(6):2975–
2981.
Carlini, N. and Wagner, D. (2017). Towards evaluating the
robustness of neural networks. In 2017 ieee sympo-
sium on security and privacy (sp), pages 39–57. Ieee.
Carlini, N. and Wagner, D. (2018). Audio adversarial ex-
amples: Targeted attacks on speech-to-text. In 2018
IEEE security and privacy workshops (SPW), pages
1–7. IEEE.
Chen, P.-Y., Zhang, H., Sharma, Y., Yi, J., and Hsieh, C.-J.
(2017). Zoo: Zeroth order optimization based black-
box attacks to deep neural networks without training
substitute models. In Proceedings of the 10th ACM
workshop on artificial intelligence and security, pages
15–26.
Cheng, M., Le, T., Chen, P.-Y., Yi, J., Zhang, H., and Hsieh,
C.-J. (2018). Query-efficient hard-label black-box at-
tack: An optimization-based approach. arXiv preprint
arXiv:1807.04457.
Goodfellow, I. J., Shlens, J., and Szegedy, C. (2014). Ex-
plaining and harnessing adversarial examples. arXiv
preprint arXiv:1412.6572.
Hara, K., Kataoka, H., and Satoh, Y. (2018). Can spa-
tiotemporal 3d cnns retrace the history of 2d cnns and
imagenet? In Proceedings of the IEEE conference
on Computer Vision and Pattern Recognition, pages
6546–6555.
Jiang, H., Diao, Z., Shi, T., Zhou, Y., Wang, F., Hu, W.,
Zhu, X., Luo, S., Tong, G., and Yao, Y.-D. (2023). A
review of deep learning-based multiple-lesion recog-
nition from medical images: classification, detec-
tion and segmentation. Computers in Biology and
Medicine, page 106726.
Jiang, L., Ma, X., Chen, S., Bailey, J., and Jiang, Y.-G.
(2019). Black-box adversarial attacks on video recog-
nition models. In Proceedings of the 27th ACM Inter-
national Conference on Multimedia, pages 864–872.
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., and Serre,
T. (2011). Hmdb: a large video database for human
motion recognition. In 2011 International conference
on computer vision, pages 2556–2563. IEEE.
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
294

Kurakin, A., Goodfellow, I. J., and Bengio, S. ((2018)). Ad-
versarial examples in the physical world. In Artificial
intelligence safety and security, pages 99–112. Chap-
man and Hall/CRC.
Lee, Y. J., Ghosh, J., and Grauman, K. (2012). Discover-
ing important people and objects for egocentric video
summarization. In 2012 IEEE conference on com-
puter vision and pattern recognition, pages 1346–
1353. IEEE.
Li, M., Huang, B., and Tian, G. (2022). A comprehensive
survey on 3d face recognition methods. Engineering
Applications of Artificial Intelligence, 110:104669.
Li, S., Neupane, A., Paul, S., Song, C., Krishnamurthy,
S. V., Chowdhury, A. K. R., and Swami, A. (2018).
Adversarial perturbations against real-time video clas-
sification systems. arXiv preprint arXiv:1807.00458.
Lo, S.-Y. and Patel, V. M. (2021). Multav: Multiplica-
tive adversarial videos. In 2021 17th IEEE Inter-
national Conference on Advanced Video and Signal
Based Surveillance (AVSS), pages 1–6. IEEE.
Mittal, S., Srivastava, S., and Jayanth, J. P. (2022). A sur-
vey of deep learning techniques for underwater image
classification. IEEE Transactions on Neural Networks
and Learning Systems.
Moosavi-Dezfooli, S.-M., Fawzi, A., and Frossard, P.
(2016). Deepfool: a simple and accurate method to
fool deep neural networks. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 2574–2582.
Nasir, I. M., Raza, M., Shah, J. H., Wang, S.-H., Tariq, U.,
and Khan, M. A. (2022). Harednet: A deep learning
based architecture for autonomous video surveillance
by recognizing human actions. Computers and Elec-
trical Engineering, 99:107805.
Paymode, A. S. and Malode, V. B. (2022). Transfer learning
for multi-crop leaf disease image classification using
convolutional neural network vgg. Artificial Intelli-
gence in Agriculture, 6:23–33.
Pham, H. H., Khoudour, L., Crouzil, A., Zegers, P., and Ve-
lastin, S. A. (2022). Video-based human action recog-
nition using deep learning: a review. arXiv preprint
arXiv:2208.03775.
Pony, R., Naeh, I., and Mannor, S. (2021). Over-the-air
adversarial flickering attacks against video recogni-
tion networks. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 515–524.
Sadrizadeh, S., Aghdam, A. D., Dolamic, L., and Frossard,
P. (2023). Targeted adversarial attacks against neural
machine translation. In ICASSP 2023-2023 IEEE In-
ternational Conference on Acoustics, Speech and Sig-
nal Processing (ICASSP), pages 1–5. IEEE.
Soomro, K., Zamir, A. R., and Shah, M. (2012). Ucf101:
A dataset of 101 human actions classes from videos in
the wild. arXiv preprint arXiv:1212.0402.
Sultani, W., Chen, C., and Shah, M. (2018). Real-world
anomaly detection in surveillance videos. In Proceed-
ings of the IEEE conference on computer vision and
pattern recognition, pages 6479–6488.
Surek, G. A. S., Seman, L. O., Stefenon, S. F., Mariani,
V. C., and Coelho, L. d. S. (2023). Video-based human
activity recognition using deep learning approaches.
Sensors, 23(14):6384.
Wan, J., Fu, J., Wang, L., and Yang, Z. (2023). Bounceat-
tack: A query-efficient decision-based adversarial at-
tack by bouncing into the wild. In 2024 IEEE Sym-
posium on Security and Privacy (SP), pages 68–68.
IEEE Computer Society.
Wang, Y., Liu, J., Chang, X., Rodr
´
ıguez, R. J., and Wang, J.
(2022). Di-aa: An interpretable white-box attack for
fooling deep neural networks. Information Sciences,
610:14–32.
Wei, X., Yan, H., and Li, B. (2022). Sparse black-box video
attack with reinforcement learning. International
Journal of Computer Vision, 130(6):1459–1473.
Wei, X., Zhu, J., Yuan, S., and Su, H. (2019). Sparse ad-
versarial perturbations for videos. In Proceedings of
the AAAI Conference on Artificial Intelligence, vol-
ume 33, pages 8973–8980.
Wei, Z., Chen, J., Wei, X., Jiang, L., Chua, T.-S., Zhou, F.,
and Jiang, Y.-G. (2020). Heuristic black-box adversar-
ial attacks on video recognition models. In Proceed-
ings of the AAAI Conference on Artificial Intelligence,
volume 34, pages 12338–12345.
Wu, W., Sun, Z., and Ouyang, W. (2023). Revisiting clas-
sifier: Transferring vision-language models for video
recognition. In Proceedings of the AAAI conference on
artificial intelligence, volume 37, pages 2847–2855.
Zaidi, S. S. A., Ansari, M. S., Aslam, A., Kanwal, N., As-
ghar, M., and Lee, B. (2022). A survey of modern
deep learning based object detection models. Digital
Signal Processing, 126:103514.
Zhang, J., Li, B., Xu, J., Wu, S., Ding, S., Zhang, L., and
Wu, C. (2022). Towards efficient data free black-box
adversarial attack. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 15115–15125.
Zhou, C., Wang, Y.-G., and Zhu, G. (2022). Object-
attentional untargeted adversarial attack. arXiv
preprint arXiv:2210.08472.
QEBB: A Query-Efficient Black-Box Adversarial Attack on Video Recognition Models Based on Unsupervised Key Frame Selection
295
