
Harnessing LLM Conversations for Goal Model Generation
from User Reviews
Shuaicai Ren, Hiroyuki Nakagawa and Tatsuhiro Tsuchiya
Graduate School of Information Science and Technology, Osaka University, Suita, Japan
Keywords:
LLM, Goal Modeling, User Reviews.
Abstract:
User reviews are a valuable resource for developers, as the reviews contain requests for new features and bug
reports. By conducting the requirements analysis of user reviews, developers can gain timely insights for the
application, which is crucial for continuously enhancing user satisfaction. The goal model is a commonly
used model during requirements analysis. Utilizing reviews to generate goal models can assist developers in
understanding user requirements comprehensively. However, given the vast number of reviews, manually col-
lecting reviews and creating goal models is a significant challenge. A method for clustering user reviews and
automatically generating goal models has been proposed. Nevertheless, the accuracy of the goal models gen-
erated by this method is limited. To address these limitations of the existing method and enhance precision of
goal model generation, we propose a goal-generation process based on Large Language Models (LLMs). This
process does not directly generate goal models from user reviews; instead, it treats goal model generation as a
clustering problem, allowing for the visualization of the relationship between reviews and goals. Experiments
demonstrate that compared to the existing method, our LLM-based goal model generation process enhance
the precision of goal model generation.
1 INTRODUCTION
In modern society, mobile applications (Apps) are
playing an increasingly important role in our daily
lives. Mobile application platforms, represented
by the App Store and Google Play, not only al-
low users to download apps but also offer a plat-
form for interaction between users and developers.
On these platforms, users draft reviews, which in-
clude new feature requirements and bug reports (Oriol
et al., 2018) (Maalej and Pagano, 2011) (Seyff et al.,
2010) (Ma et al., 2015). User reviews are a valu-
able resource for developers, as reviews offer invalu-
able insights (Pagano and Maalej, 2013) (Hofmann
and Lehner, 2001) (Zowghi, 2018). By conducting
the requirements analysis of user reviews, develop-
ers deepen their understanding of user requirements,
thereby offering version updates that better match
user requirements. In the field of requirements analy-
sis, the goal model is one of the most commonly used
models, and it can be employed to analyze require-
ments from user reviews.
The goal model is a basic model in the field
of requirements engineering, providing a structured
framework to describe what functions a system needs
and how to implement these functions. Within the
goal model, goals are arranged in a hierarchical struc-
ture, where the root goal is refined into sub-goals,
ultimately forming a comprehensive goal structure.
This layered structure helps in deeply understand-
ing the interdependencies among goals. The goal
model contains multiple elements, such as conflicts
and soft goals. Conflicts refer to situations where
achieving one goal may obstruct the realization of an-
other, while soft goals aim to capture non-functional
requirements. The primary advantage of the goal
model is that it allows developers to define and under-
stand requirements with clarity. When goals conflict,
the goal model can support crucial decision-making.
Compared to directly analyzing user reviews, making
goal models ensures that user reviews match the app’s
goals. By connecting reviews with goals, it is easier to
figure out what goals users care about and if the new
features they want might conflict with current goals.
This helps developers know which user requirements
are most urgent and helps them make better updates.
While there are numerous advantages to employ-
ing a goal model for the analysis of user reviews, the
manual construction of a goal model presents a signif-
icant challenge. This challenge mainly arises from the
Ren, S., Nakagawa, H. and Tsuchiya, T.
Harnessing LLM Conversations for Goal Model Generation from User Reviews.
DOI: 10.5220/0012352200003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 385-392
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
385

vast number of reviews and only a small proportion
of them contain requirements or bug reports (Licorish
et al., 2015) (Pagano and Maalej, 2013) (Chen et al.,
2014). Consequently, the process of manually reading
and summarizing reviews becomes a labor-intensive
and time-consuming task. To automate the process of
utilizing user reviews for goal model generation, we
proposed a method for clustering reviews (Ren et al.,
2022). This clustering method consists of two com-
ponents: the Latent Dirichlet Allocation (LDA) topic
model (Blei et al., 2003) and a distance-based clus-
tering algorithm. The method defines the root goal as
containing all user reviews, and the topics generated
by the LDA topic model are treated as sub-goals under
the root goal. To refine sub-goals from the generated
topics, a distance-based clustering algorithm is intro-
duced. This method simplifies the process of gen-
erating goal models from user reviews, significantly
reducing the required manpower. However, it must
be acknowledged that this method has certain limita-
tions. For instance, its accuracy is suboptimal, and
the generated goals do not have a one-to-one corre-
spondence with the requirements. To enhance the pre-
cision of goal model generation from user reviews,
we explore the potential of leveraging large language
models (LLMs) for goal model generation. By har-
nessing the capabilities of LLMs, our objective is to
enhance the precision and efficacy of the goal model-
ing process, providing a more accurate representation
of user requirements and preferences.
This technology holds the potential to make con-
tributions to agents. The application of LLMs in goal
model generation has several impacts. LLMs help
agents better understand and pull key information
from a wide range of user reviews. These reviews,
coming from many users, provide valuable informa-
tion and preferences that, when processed effectively,
can significantly contribute to agent development. By
grouping and refining user reviews, agents can get a
deeper understanding of what users really want and
their main concerns. This deeper understanding al-
lows them to give more relevant and personalized re-
sponses, making the user experience better.
LLMs represent an advanced class of natural lan-
guage processing (NLP) models, notable for their ex-
tensive size and parametric complexity. In this re-
search, we harnessed GPT-4 (OpenAI, 2023), recog-
nized as a state-of-the-art LLM, for the purpose of
clustering user reviews and generating goal models.
The goal model generated by GPT-4 has higher ac-
curacy than the goal model generated by the exist-
ing method. However, using GPT-4 to directly gener-
ate goal models comes with certain drawbacks, such
as producing repetitive or incorrect goals and failing
to describe the relationships between generated goals
and reviews. To address these issues, we propose a
novel goal model generation process. This process
does not involve the direct use of GPT-4 to gener-
ate goal models; instead, it begins with clustering
and analyzing user reviews before generating the goal
models. The experimental results demonstrate that,
compared to the existing method, the use of the pro-
posed process with the GPT-4 method gains higher-
precision goal models. This not only saves time but
also enhances developers’ understanding of the im-
portance of each goal.
The contributions of this study are as follows:
First, we introduce a goal model generation method
based on LLMs, offering an alternative method for
the automation of goal model generation. Second,
the proposed method treats goal model generation as
a clustering problem, allowing developers to under-
stand the relationship between user reviews and goals.
Third, compared to the existing method, the proposed
method enhances the precision of goal model genera-
tion.
The following sections of this paper are organized
as: Section 2 introduces related work relevant to our
research. Section 3 presents the existing method for
goal model generation. Section 4 introduces GPT-4
and the proposed process for generating goal mod-
els utilizing GPT-4. Section 5 showcases compara-
tive experiments between different goal model gener-
ation methods. Section 6 evaluates the proposed goal
model generation process. Finally, in Section 7, we
summarize this study and outline future work.
2 RELATED STUDIES
In a recent development, Jiang et al. (Jiang et al.,
2019) introduced SAFER, a novel approach that en-
ables the automatic extraction of features from ap-
plication descriptions and the identification of anal-
ogous applications based on API names and extracted
features. SAFER further undertakes the aggregation
and recommendation of features from identified anal-
ogous applications. On a related note, Dkabrowski
et al. (D ˛abrowski et al., 2023) conducted empirical
research into three distinct opinion mining methods:
GuMa (Guzman and Maalej, 2014), SAFE (Johann
et al., 2017), and ReUS (Dragoni et al., 2019). These
methods underwent evaluation through two distinct
tasks encompassing feature extraction and sentiment
analysis. The research outcomes proffered valuable
insights by suggesting that the efficacy of these meth-
ods might be lower than originally reported. More-
over, Malik et al. (Malik et al., 2020) proposed a
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
386

comprehensive approach for the extraction of opin-
ions from user reviews. Their approach is particu-
larly geared towards assisting developers and users in
the automated extraction and comparison of features
across a spectrum of mobile applications. It is im-
portant to emphasize that the aforementioned studies
primarily pivot around the domain of review analy-
sis, and their primary focus does not lie in goal model
identification.
It is important to note that several researchers
believe that LLMs have the potential to revolution-
ize existing software development processes. This
has led to the proposal of numerous methods that
leverage LLMs for software modeling. Nakagawa
et al. (Nakagawa and Honiden, 2023) introduced a
semi-automated process for goal model generation
that employs generative AI founded on the MAPE-
K loop mechanism. Their two case studies demon-
strate that this process, based on the MAPE-K loop
mechanism, is efficacious in goal model construction
without omitting any goal descriptions. Additionally,
Cámara et al. (Cámara et al., 2023) conducted a com-
prehensive investigation into GPT-4’s performance in
modeling tasks and its utility to modeling personnel,
while simultaneously identifying its principal limi-
tations. Their research findings underscore that the
current iteration of GPT-4 exhibits limited efficacy
in software modeling, especially when compared to
its capabilities in code generation. It exhibits var-
iegated syntax and semantic defects, lacks response
consistency, and faces scalability challenges. Ding
et al. (Ding and Ito, 2023) introduced the ’Self-
Agreement’ framework, aimed at autonomously seek-
ing consensus among diverse opinions using data gen-
erated by large language models (LLMs), without the
need for extensive manual annotation. They utilized
GPT-3 to generate multiple opinions for each ques-
tion in a question dataset and subsequently employed
a BERT model to evaluate the consistency of each
opinion, selecting the most consistent one. Their re-
search focused on finding consensus among diverse
opinions, whereas our method centers on analyzing
the consistency of reviews and generating goal mod-
els.
Chen et al. (Chen et al., 2023) reported the pre-
liminary experimental results of goal model genera-
tion using GPT-4. They first explored GPT-4’s under-
standing of the Goal-oriented Requirement Language
(GRL) and then employed four prompt combinations
to guide the generation of GRL models in two case
studies. One case was a well-documented topic in the
goal modeling domain, while the other was the op-
posite. The experimental results indicate that GPT-4
possesses extensive knowledge related to goal mod-
els and that the generated goal models are valuable.
Notably, all three methods employ LLMs to generate
goal models. However, it is crucial to point out that,
unlike our method, they do not leverage user reviews
in the goal model generation process.
3 EXISTING METHOD
We proposed a method for creating a goal model
by clustering user reviews (Ren et al., 2022). This
method involves two key components: the LDA topic
model and a distance-based clustering algorithm. The
LDA topic model is responsible for generating goals
from all reviews, while the distance-based clustering
algorithm refines these goals. The LDA model is
a widely utilized probabilistic topic modeling tech-
nique for the analysis of extensive unstructured tex-
tual data in academic research (Papadimitriou et al.,
2000) (Blei et al., 2003). The goal representing all
reviews is regarded as the root goal, while the topics
generated by the LDA model are considered as sub-
goals of the root goal. While it’s possible to refine and
create the goal model further by applying LDA mod-
eling to reviews within each topic, this method may
not be reliable when dealing with a limited number of
reviews (Hajjem and Latiri, 2017).
Given the limitations of LDA topic modeling in
such scenarios, a distance-based clustering algorithm
is proposed to facilitate further refinement. For each
topic, the reviews are vectorized, and Ward’s method
is employed to calculate distances between vectors,
resulting in the creation of compact, evenly sized
clusters (Szmrecsanyi, 2012). These clusters are visu-
ally represented by a dendrogram. Clusters with simi-
lar distance values are assigned as sub-goals under the
same parent goal. This method follows a top-down
approach, creating boundary lines. Clusters above the
boundary line become parent goals, while those be-
low it become sub-goals. The boundary line’s value
is determined by the cluster distances and manually
selected parameters. This automated method of gen-
erating goal models from user reviews aids in a deeper
understanding of user requirements. By combining
LDA and the distance-based clustering algorithm, this
clustering method addresses the challenges of ana-
lyzing numerous reviews and automatically identifies
main topics and their hierarchical relationships, sim-
plifying the goal model generation process. Never-
theless, this method still faces specific limitations,
primarily accuracy issues. Current methods employ
Ward’s method for review clustering, where reviews
are first converted into vectors, and review similar-
ity is determined based on vector distance. Neverthe-
Harnessing LLM Conversations for Goal Model Generation from User Reviews
387
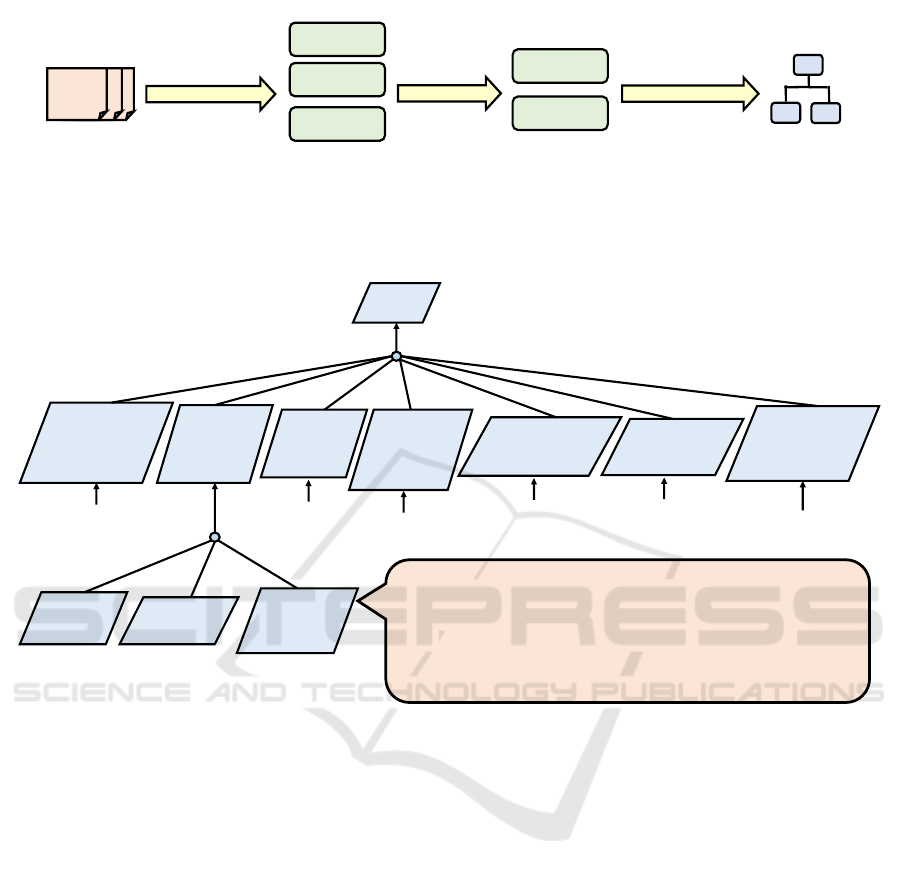
User reviews
Review clustering
(Prompt 1)
Cluster 1
Cluster 2
Cluster 3
Clusters
Cluster
selected
Cluster 1
Cluster 3
Clusters requiring
refinement
Refining clusters
and generating goals
(Prompt 2)
Goal model
Figure 1: Overview of the proposed process for generating goal models using GPT-4.
Root
Account
transfer and
device
upgrades
Chat
history
and data
backup
Multi-
device
support
Account
security
and
recovery
Chat and
media
management
User-
friendly
experience
Sticker
suggestions
and user
experience
…
…
…
… …
…
Backup
issues
Data
recovery
Cross-
platform
issues
"chat log transfer absolutely terribleit sense keep upload drive
icloud old new phone auto transfer since account "
"lose phone lock account everytime log tell account transfer phone
lose completely stupid system even send report without verify
phone lose "
…
Figure 2: Goal model generated by the proposed process.
less, research indicates that vector similarity does not
always reflect the similarity of the requirements de-
scribed in the reviews (Devine et al., 2022). Within
the same cluster, reviews may share common aspects,
but these shared aspects do not necessarily indicate
identical requirements.
To enhance goal model generation precision and
improve developers’ understanding of the generated
goal model, we explore the possibility of utilizing
GPT-4 to cluster reviews and generate goal models.
4 LLM-BASED GOAL MODEL
GENERATION METHOD
GPT-4, which stands for "Generative Pre-trained
Transformer 4," is a state-of-the-art language model
developed by OpenAI. GPT-4’s primary objective is
to facilitate interactive conversations with users, of-
fering responses that are contextually coherent across
a wide spectrum of prompts and inquiries. While
there are many advantages to generating goal mod-
els directly using GPT-4, several challenges also ex-
ist. For example, the relationship between user re-
views and the goals cannot be visualized. Sometimes,
the information developers obtain from the goals is
insufficient to fully understand user requirements. In
cases like this, if the goal model is generated using
review clustering methods, developers can check re-
views related to the goals to gather additional insights.
However, in goal models generated using GPT-4, re-
views related to the goals are not presented compre-
hensively. Even if you ask GPT-4 to display all the re-
views, it provides only a limited set of reviews, mak-
ing it challenging for developers to understand user
requirements. Additionally, the prioritization of goals
is based on the frequency of corresponding require-
ments mentioned in the reviews. The lack of visual-
ization for the relationship between goals and the as-
sociated reviews decreases the credibility of goal pri-
oritization.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
388

To address the issue of the lack of visualized re-
lationships between goals and reviews in the goal
model directly generated using GPT-4, we propose a
novel process for generating goal models using GPT-
4. This process frames the task of generating goal
models as a clustering problem, where clusters repre-
sent the goals. GPT-4 provides the cluster to which
each review belongs, thus visualizing the relationship
between goals and reviews. Subsequently, developers
can refine some or all of the goals based on factors
such as the number of reviews or the content of re-
views. Figure 1 shows the overview of the proposed
process.
This process consists of two steps. The first step
involves clustering reviews using GPT-4, in this step,
the generated clusters are regarded as goals. The
prompt for this step are as follows:
Prompt 1: Can you cluster the following re-
views?
The second step occurs after developers analyze the
generated goals and decide which goals to refine.
GPT-4 is then employed to refine the selected goals,
with prompts for this step as follows:
Prompt 2: Can the first category be refined, and
if so, what would the relevant reviews in the
subdivided categories look like? By "relevant
reviews," I mean the reviews I provided earlier.
There is no need to generate relevant reviews;
all reviews should belong to the first category
classified earlier. Each comment should belong
to only one subcategory, and each subcategory
should be akin to a goal in the goal model in the
requirement model.
It is crucial to include the statement "Cannot generate
reviews" in the prompt for the second step to prevent
generation errors by GPT-4. Additionally, it should be
specified that each review can belong to only one goal
to ensure that redundant reviews do not influence de-
velopers’ assessments of goal importance. By adopt-
ing the proposed process, developers can maintain the
advantages of using GPT-4 to generate goal models
while visualizing the relationships between reviews
and goals. Furthermore, it provides a more detailed
and time-efficient approach for developers to analyze
and refine goals.
In summary, utilizing the proposed process for
generating goal models from user reviews offers nu-
merous benefits, including high goal coverage, selec-
tive refinement of goals, and streamlined data pro-
cessing. These advantages position the proposed
process as a valuable tool for extracting and com-
prehending user requirements, facilitating effective
decision-making, and enhancing the development of
user-centric applications.
5 EXPERIMENT
The purpose of the experiment is to assess which of
the two, the existing method and the GPT-4 method
with the proposed process, is more similar to the man-
ually created goal model, including both structural
and content similarities. We have collected 150 user
reviews from the App Store. These reviews are from
Line, Google Docs, and YouTube, with each app con-
tributing 50 reviews. For each set of user reviews
for these apps, we used three different methods for
goal model generation: the existing method, the GPT-
4 method with the proposed process, and the man-
ual method. Figure 2 illustrates a portion of the goal
model generated using the GPT-4 with the proposed
process, with user reviews sourced from Line. To cre-
ate the manual model, we manually examined each
review and determined which goal it should belong
to.
We initially focus on evaluating the structure of
the generated goal models. Since goal models have
a tree-like structure, we utilize Tree-Edit-Distance-
based Similarity (TEDS) (Zhong et al., 2020) to as-
sess the similarity between the models generated by
the two methods and the manually created model.
TEDS is a normalized variant of the Tree-Edit-
Distance (TED), and its calculation is as follows:
TEDS(G,G_m) = 100 − (
EditDist(G,G_m))
max(|G|,|G_m|)
× 100),
(1)
where EditDist(G,G_m) is computed as the minimum
number of operations, comprising both Move and Join
operations, necessary to transform the generated goal
model G into the goal model G_m, which is manually
created. The value of EditDist(G,G_m) is determined
through manual computation. max(|G|,|G_m|) repre-
sents the maximum number of goals present within
goal models G and G_m. Consequently, the higher
the degree of similarity between the goal model G and
the goal model G_m, the larger the resulting TEDS
value. In the case of complete equivalence between
G and G_m, TEDS returns a value of 100. Table 1
demonstrates the TEDS values for three apps. The av-
erage TEDS value of the GPT-4 method is 26 points
higher than the existing method, indicating that the
goal model generated by GPT-4 is more similar to the
manually created goal model.
In terms of evaluating the content of the gener-
ated goals, we employ precision and recall to assess
both the existing method and the GPT-4 method. For
Harnessing LLM Conversations for Goal Model Generation from User Reviews
389

Table 1: Results of TEDS.
Line YouTube Google Docs Avg
Existing method 70 56 67 62
GPT-4 with proposed process 100 89 75 88
a goal A generated by the existing method or the GPT-
4 method, we found a goal A’ identified by the man-
ual goal model that allows the best precision to be
achieved for the goal A. Table 2 lists the precision and
recall for each goal.
6 DISCUSSION
From Table 2, we observe that the goal model gen-
erated by the GPT-4 method exhibits higher precision
and recall. In contrast to the LDA topic model, GPT-4
does not require the prior specification of the number
of topics and eliminates the need for extensive prepro-
cessing steps. Even when dealing with a limited num-
ber of reviews, the GPT-4 method does not experience
a decline in accuracy. For the LDA method, having
too many uninformative reviews or too few reviews
can reduce the clustering accuracy. Another com-
ponent of the existing method is the distance-based
clustering method, where distances are computed us-
ing Ward’s method. This method involves first trans-
forming reviews into vectors and subsequently deter-
mining the similarity between reviews based on the
vector distances. Nevertheless, studies have demon-
strated that the similarity of vectors may not always
correspond to the likeness of requirements articulated
within the reviews (Devine et al., 2022). While re-
views grouped within the same cluster may exhibit
shared elements, the presence of these commonal-
ities does not invariably signify congruent require-
ments. Owing to its robust performance, GPT-4 can
clearly understand the requirements described in user
reviews. GPT-4 underwent extensive pre-training on
a vast corpus of textual data. As a result, GPT-4
can comprehend intricate content within user reviews,
which often contain colloquialisms, domain-specific
jargon, and various forms of expression. Even if user
reviews are incomplete, use slang, or unconventional
punctuation, GPT-4 can filter potential intent and in-
formation from the noise.
By comparing the direct generation of goal mod-
els using GPT-4 with the goal models generated
through our proposed process, we identify several ad-
vantages of the proposed process, which include:
• By clustering reviews, the workload of GPT-4’s
generation process can be significantly reduced.
Developers have the option to refine only the most
critical goals, instead of diving into the fine de-
tails of every single objective. This method be-
comes especially advantageous when dealing with
a large volume of user reviews, as clustering aids
in efficiently managing and analyzing extensive
datasets, thereby reducing the complexity associ-
ated with processing substantial amounts of data.
For developers dealing with significant quantities
of user-generated content, such as product or ser-
vice reviews, this reduction in complexity is in-
valuable. It not only accelerates the goal model
generation process but also aids in maintaining the
quality of the analysis. As a result, developers can
gain meaningful insights from a vast dataset with-
out being overwhelmed by its scale.
• The proposed process can enhance the consis-
tency of the generated goal models. Cluster-
ing can aid in ensuring that the generated goal
model remains consistent within similar clusters
of reviews, thereby enhancing user experience and
comprehension. A noteworthy advantage of this
clustering process is its ability to scrutinize the
generated goals alongside their related reviews.
This critical examination phase serves as a quality
control mechanism, allowing for the identification
and correction of ambiguous or erroneous goals.
Such corrections significantly reduce the likeli-
hood of potential errors during the goal model
generation phase.
• Clustering can serve as an intermediary step,
greatly facilitating developers in iteratively im-
proving the generated goal model. Based on the
outcomes of clustering, developers can fine-tune
and optimize the generated goal model progres-
sively to enhance its quality. By examining the
clustered goals and the feedback derived from
these clusters, developers can make data-driven
decisions to prioritize certain requirements over
others. This iterative approach fosters a respon-
sive development environment where the gener-
ated goal model evolves alongside user feedback.
As a result, the goal model becomes increasingly
aligned with the users’ expectations, ensuring that
the final product or service is more user-centric
and attuned to their needs.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
390
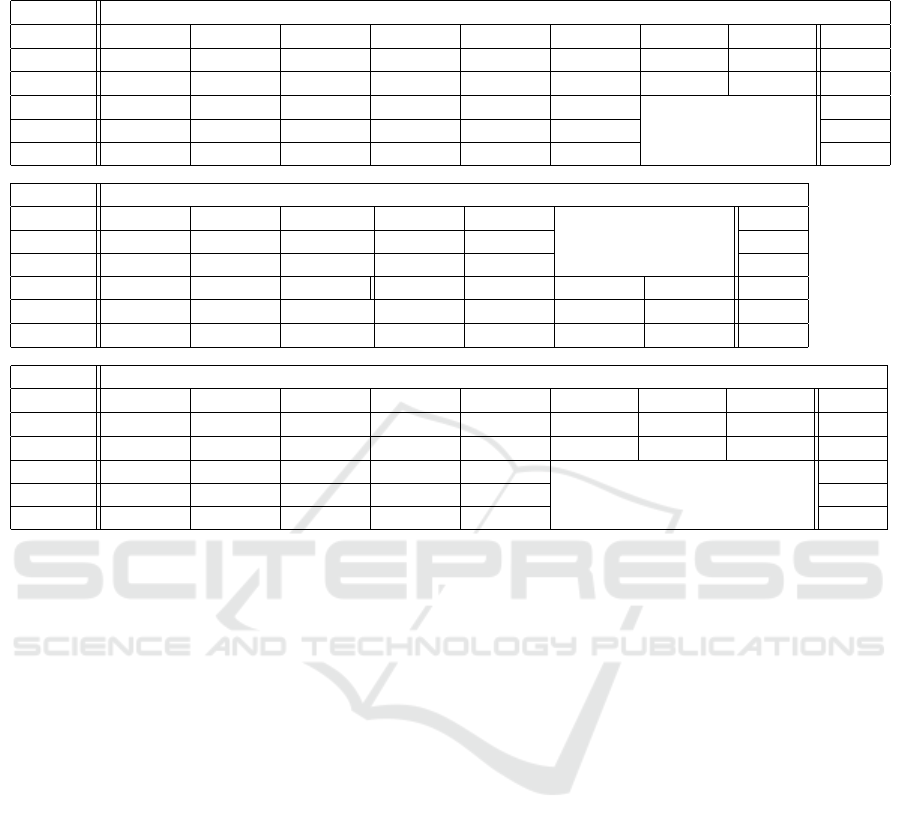
Table 2: Precision and recall of generated goals. E_Goals are generated by the existing method, and G_Goals are generated
by GPT-4 with the proposed process. Avg means the average value of the precision or recall for generated goals.
App Line
Goal E_Goal 1 E_Goal 2 E_Goal 3 E_Goal 4 E_Goal 5 E_Goal 6 E_Goal 7 E_Goal 8 E_Avg
Precision 0.56 1 0.33 0.67 0.5 0.2 0.5 0.25 0.5
Recall 0.45 0.89 0.2 0.25 0.57 0.33 0.17 0.67 0.44
Goal G_Goal 1 G_Goal 2 G_Goal 3 G_Goal 4 G_Goal 5 G_Goal 6 G_Avg
Precision 0.8 1 0.67 0.83 0.5 0.88 0.78
Recall 1 0.9 0.75 0.86 0.33 0.71 0.76
App YouTube
Goal E_Goal 1 E_Goal 2 E_Goal 3 E_Goal 4 E_Goal 5 E_Avg
Precision 0.5 0.5 0.33 0.5 0.6 0.49
Recall 0.25 0.33 0.17 0.67 0.43 0.37
Goal G_Goal 1 G_Goal 2 G_Goal 3 G_Goal 4 G_Goal 5 G_Goal 6 G_Goal 7 G_Avg
Precision 0.8 0.67 0.67 0.5 0.8 0.67 0.65 0.68
Recall 0.75 1 0.5 0.85 0.86 0.75 0.45 0.74
App GoogleDocs
Goal E_Goal 1 E_Goal 2 E_Goal 3 E_Goal 4 E_Goal 5 E_Goal 6 E_Goal 7 E_Goal 8 E_Avg
Precision 0.43 1 0.5 0.42 0.67 0.25 0.5 0.4 0.52
Recall 0.75 0.66 0.18 0.6 0.4 0.13 0.33 0.25 0.41
Goal G_Goal 1 G_Goal 2 G_Goal 3 G_Goal 4 G_Goal 5 G_Avg
Precision 0.71 0.57 0.6 0.75 1 0.73
Recall 0.63 0.67 0.43 0.71 0.2 0.53
7 CONCLUSIONS
In this study, we explored the potential of utilizing
GPT-4 to generate goal models and proposed a novel
goal model generation process. To improve the gener-
ation accuracy of the goal model, we employed GPT-4
to generate goal models. However, a limitation of the
method that directly generates goal models from user
reviews is that the relationship between goals and re-
views is not visualized. To address this limitation, we
introduced a new process that treats goal model gen-
eration as a clustering problem. This process signifi-
cantly saves developers’ time and enhances their un-
derstanding of the goal content. Experimental results
indicate that the accuracy of generating goal mod-
els using the proposed process is higher than that of
the existing method. Regarding future research direc-
tions, we have outlined the following objectives:
Enhancing stability in goal model generation:
When utilizing GPT-4 for the classification of user re-
views, it is important to consider that the outcomes
generated may not always be consistent. Specifically,
the results might exhibit variations, such as a classifi-
cation not based on requirements but rather influenced
by emotional content. This phenomenon highlights an
essential aspect of working with AI-based language
models, where several factors contribute to the unpre-
dictability of the results. GPT-4 does not possess the
ability to discern the "correct" method of classifica-
tion a priori. Its responses are determined by patterns
and information gleaned from its training data. As
a result, the quality of the responses depends on the
quality and specificity of the training data and the for-
mulation of the user’s query. To enhance the stabil-
ity and reliability of user review classification using
GPT-4, strategies such as fine-tuning the model on
domain-specific data, providing clear instructions to
the model, or post-processing its outputs may be con-
sidered. These strategies can help align the model’s
responses more closely with the specific goals of the
task, reducing the variability in outcomes, and mini-
mizing the impact of emotional content on classifica-
tion results.
Time complexity reduction: Although GPT-4 ex-
hibits the capability to generate goal models from user
reviews, it is essential to acknowledge the substantial
time investments linked to the current implementation
of this process. Even when dealing with a relatively
modest review dataset, comprising fewer than 100 re-
views, a noteworthy amount of time and computa-
tional resources is imperative. This temporal over-
head may potentially impede the practical applicabil-
ity of the approach. In response to this concern, our
Harnessing LLM Conversations for Goal Model Generation from User Reviews
391

future research initiatives are dedicated to the refine-
ment of GPT-4’s capabilities, encompassing strategies
such as fine-tuning and few-shot learning. Our ulti-
mate goal is the reduction of time complexity while
upholding the precision of the generated goal models.
REFERENCES
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent
dirichlet allocation. Journal of machine Learning re-
search, 3(Jan):993–1022.
Cámara, J., Troya, J., Burgueño, L., and Vallecillo, A.
(2023). On the assessment of generative ai in model-
ing tasks: an experience report with chatgpt and uml.
Software and Systems Modeling, pages 1–13.
Chen, B., Chen, K., Hassani, S., Yang, Y., Amyot, D.,
Lessard, L., Mussbacher, G., Sabetzadeh, M., and
Varró, D. (2023). On the use of GPT-4 for creating
goal models: An exploratory study. In 2023 IEEE
31st International Requirements Engineering Confer-
ence Workshops (REW), pages 262–271. IEEE.
Chen, N., Lin, J., Hoi, S. C., Xiao, X., and Zhang, B.
(2014). AR-miner: mining informative reviews for
developers from mobile app marketplace. In Proc. of
the 36th International Conference on Software Engi-
neering, pages 767–778. ACM.
D ˛abrowski, J., Letier, E., Perini, A., and Susi, A. (2023).
Mining and searching app reviews for requirements
engineering: Evaluation and replication studies. In-
formation Systems, page 102181.
Devine, P., Tizard, J., Wang, H., Koh, Y. S., and Blin-
coe, K. (2022). What’s inside a cluster of software
user feedback: A study of characterisation methods.
In 2022 IEEE 30th International Requirements Engi-
neering Conference (RE), pages 189–200. IEEE.
Ding, S. and Ito, T. (2023). Self-agreement: A frame-
work for fine-tuning language models to find agree-
ment among diverse opinions. arXiv preprint
arXiv:2305.11460.
Dragoni, M., Federici, M., and Rexha, A. (2019). An un-
supervised aspect extraction strategy for monitoring
real-time reviews stream. Information processing &
management, 56(3):1103–1118.
Guzman, E. and Maalej, W. (2014). How do users like this
feature? a fine grained sentiment analysis of app re-
views. In 2014 IEEE 22nd international requirements
engineering conference (RE), pages 153–162.
Hajjem, M. and Latiri, C. (2017). Combining ir and lda
topic modeling for filtering microblogs. Procedia
Computer Science, 112:761–770.
Hofmann, H. F. and Lehner, F. (2001). Requirements engi-
neering as a success factor in software projects. IEEE
software, 18(4):58–66.
Jiang, H., Zhang, J., Li, X., Ren, Z., Lo, D., Wu, X.,
and Luo, Z. (2019). Recommending new features
from mobile app descriptions. ACM Transactions
on Software Engineering and Methodology (TOSEM),
28(4):1–29.
Johann, T., Stanik, C., Maalej, W., et al. (2017). SAFE: A
simple approach for feature extraction from app de-
scriptions and app reviews. In Proc. of the 2017 IEEE
25th international requirements engineering confer-
ence (RE), pages 21–30. IEEE.
Licorish, S. A., Tahir, A., Bosu, M. F., and MacDonell,
S. G. (2015). On satisfying the android os commu-
nity: User feedback still central to developers’ portfo-
lios. In Proc. of the 2015 24th Australasian Software
Engineering Conference, pages 78–87. IEEE.
Ma, S., Wang, S., Lo, D., Deng, R. H., and Sun, C. (2015).
Active semi-supervised approach for checking app be-
havior against its description. In Proc. of the 2015
IEEE 39Th annual computer software and applica-
tions conference, volume 2, pages 179–184. IEEE.
Maalej, W. and Pagano, D. (2011). On the socialness of
software. In Proc. of the 2011 IEEE Ninth Interna-
tional Conference on Dependable, Autonomic and Se-
cure Computing, pages 864–871. IEEE.
Malik, H., Shakshuki, E. M., and Yoo, W.-S. (2020). Com-
paring mobile apps by identifying ‘hot’features. Fu-
ture Generation Computer Systems, 107:659–669.
Nakagawa, H. and Honiden, S. (2023). MAPE-K loop-
based goal model generation using generative ai. In
13th International Workshop on Model-Driven Re-
quirements Engineering (MoDRE). IEEE.
OpenAI (2023). Chatgpt. https://chat.openai.com/
chat.
Oriol, M., Stade, M., Fotrousi, F., Nadal, S., Varga, J., Seyff,
N., Abello, A., Franch, X., Marco, J., and Schmidt, O.
(2018). FAME: supporting continuous requirements
elicitation by combining user feedback and monitor-
ing. In Proc. of the 2018 ieee 26th international re-
quirements engineering conference (re), pages 217–
227. IEEE.
Pagano, D. and Maalej, W. (2013). User feedback in
the appstore: An empirical study. In Proc. of the
2013 21st IEEE international requirements engineer-
ing conference (RE), pages 125–134. IEEE.
Papadimitriou, C. H., Raghavan, P., Tamaki, H., and Vem-
pala, S. (2000). Latent semantic indexing: A prob-
abilistic analysis. Journal of Computer and System
Sciences, 61(2):217–235.
Ren, S., Nakagawa, H., and Tsuchiya, T. (2022). Goal
model structuring based on semantic correlation of
user reviews. Intelligent Decision Technologies,
16(4):737–748.
Seyff, N., Graf, F., and Maiden, N. (2010). Using mobile
re tools to give end-users their own voice. In Proc. of
the 2010 18th IEEE International Requirements Engi-
neering Conference, pages 37–46. IEEE.
Szmrecsanyi, B. (2012). Grammatical variation in British
English dialects: A study in corpus-based dialectom-
etry. Cambridge University Press.
Zhong, X., ShafieiBavani, E., and Jimeno Yepes, A. (2020).
Image-based table recognition: data, model, and eval-
uation. In Proc. of the European Conference on Com-
puter Vision, pages 564–580. Springer.
Zowghi, D. (2018). "Affects" of user involvement in soft-
ware development. In Proc. of the 2018 1st Interna-
tional Workshop on Affective Computing for Require-
ments Engineering (AffectRE), pages 13–13. IEEE.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
392
