
Clustering-Based Approach to Strategy Selection for Meta-Strategy in
Automated Negotiation
Hiroyasu Yoshino and Katsuhide Fujita
Department of Electrical Engineering and Computer Science, Institute of Engineering, Tokyo University of Agriculture and
Technology, Tokyo, Japan
Keywords:
Automated Negotiation, Negotiation Strategy, Meta-Strategy, Multiagent System, Reinforcement Learning,
Clustering.
Abstract:
This study aims to develop an automated negotiation meta-strategy and proposes an approach that automati-
cally selects a strategy based on the opponent from a range of available strategies using clustering techniques.
The proposed method groups the possible negotiation strategies into clusters and employs deep reinforcement
learning to determine an effective bidding strategy for the representative point of each cluster. This strategy
is optimized for the average agent within each cluster, consistently outperforming other agents in the same
cluster. An analysis of the number of strategy clusters identified using the proposed method indicates that in-
dividual utility tends to increase when the number of clusters is limited. Notably, the highest utility is achieved
when there are three clusters. In addition, negotiation simulation experiments demonstrate that the proposed
approach yields higher individual utility compared to the previous studies.
1 INTRODUCTION
In recent years, consensus building and interest ad-
justment techniques among multiple agents with dif-
ferent interests have garnered interest in the study of
multiagent systems. In the case of agents acting au-
tonomously according to their own preferences, it is
difficult to achieve consensus building by centralized
agent management when it is necessary to coordinate
interests while maintaining confidential information
or when a large number of agents are involved. In
such cases, there is a growing interest in automated
negotiation as a technology that allows agents to reach
a consensus while maintaining their autonomy. Sup-
ply chain management and drone delivery are attract-
ing attention as examples of real-world applications
of automated negotiation (van der Putten et al., 2006)
(Ho et al., 2022). One of the advantages of applying
automated negotiation to the real world is that it is ex-
pected to reduce the cost and time required for negoti-
ation compared to human negotiation. However, there
are various problems in applying automated negotia-
tion to the real world, one of which is that, in reality,
there are a wide variety of negotiation scenarios and
strategies of negotiation opponents. Therefore, there
is a need to develop a general-purpose automated ne-
gotiation agent that can handle not only specific ne-
gotiation strategies and scenarios but also a variety of
negotiation strategies and scenarios.
Since it is dificult to deal with various negotia-
tion opponents and scenarios with only a single strat-
egy, a meta-strategy approach has been proposed as
a method to develop a general-purpose automated ne-
gotiation agent, in which the agent maintains multiple
strategies and switches strategies according to negoti-
ation opponents and scenarios (Ilany and Gal, 2016).
In this case, it is imperative to consider how to select
an appropriate set of multiple strategies and how to
employ them effectively in negotiations.
Recently, in the field of automated negotiation,
many methods have been proposed to train agents’
strategies using reinforcement learning (Razeghi
et al., 2020) (Bagga et al., 2021). Moreover, a
novel method that integrates this reinforcement learn-
ing methodology combined with the aforementioned
meta-strategy has been proposed (Sengupta et al.,
2021). In this method, the bidding strategy is learned
against each of the multiple negotiating agents using
reinforcement learning, and the choice of which strat-
egy should be employed is determined based on the
history of offers extended by the other agents. How-
ever, it is important to note that newly-learned strate-
gies for emerging agents may either be added to or
replace the existing set of retained bidding strategies.
256
Yoshino, H. and Fujita, K.
Clustering-Based Approach to Strategy Selection for Meta-Strategy in Automated Negotiation.
DOI: 10.5220/0012349300003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 1, pages 256-263
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

This can reduce the number of strategies retained and
may limit the system’s ability to respond to unknown
agents and scenarios. Furthermore, since the selec-
tion of the bidding strategy for a negotiation is pri-
marily based on the utility obtained by the opponent’s
offer, the characteristics of the other agent might not
be sufficiently captured. Therefore, developing an al-
gorithm that selects strategies according to the oppo-
nent characteristics while preserving a diverse array
of strategies is crucial.
This study proposes a strategy selection method
using clustering in meta-negotiation strategies. The
objective is to develop a general-purpose negotiation
agent that is capable of effectively responding to var-
ious negotiation strategies and scenarios. In addition,
we examine and clarify the optimal number of clus-
ters for effective strategy selection by assessing them
in terms of individual utility and social welfare.
Our approach in this study involves an algorithm
that divides existing negotiating agents into multiple
clusters through clustering techniques and switches
the effective bidding strategy for the agent positioned
at the representative point of each cluster, a strategy
learned through deep reinforcement learning. The
number of clusters was assessed by conducting sim-
ulation experiments with various cluster quantities.
We also conducted a comparative experiment with the
methodology of a previous study to demonstrate that
the proposed strategy selection method can achieve a
better utility value. The following is a summary of the
contributions of this study.
• Proposal of a strategy selection algorithm using
clustering for meta-strategy in automatic negotia-
tion
• Investigation of the number of clusters for strategy
selection using clustering
• Confirmation of the effectiveness of the proposed
method and its applied negotiation agents for var-
ious negotiation strategies and scenarios through
simulation experiments
The rest of the paper is organized as follows: Sec-
tion 2 provides some related works. Section 3 pro-
vides a detailed explanation of negotiation settings.
In Section 4, we describe the proposed strategy selec-
tion algorithm. Section 5 provides the results of the
experimental evaluations of negotiation agents apply-
ing the proposed method. Finally, we conclude this
paper in Section 6.
2 RELATED WORK
2.1 Opponent Features for Automated
Negotiation
Opponent features are information consisting of four
features derived from the negotiation history (Renting
et al., 2020). Renting et al. proposed these features
for automatically determining the best configuration
of the agent. However, we use these to create groups
of strategies with clustering. We provide a detailed
description of each feature below.
2.1.1 Concession Rate
Concession Rate is the metric that represents the de-
gree of concession by the opponent agent (Baarslag
et al., 2011), denoted by
CR(x
−
o
) =
(
1 if u
o
(x
−
o
) ≤ u
o
(ω
+
)
1−u
o
(x
−
o
)
1−u
o
(ω
+
)
otherwise
(1)
where x
−
o
is the bid that gives the minimum utility to
the opponent during the negotiation, and u
o
(x
−
o
) is the
minimum utility that the opponent can obtain. Also,
ω
+
is the bid that gives the maximum utility to our
agent. If CR = 1, then the opponent is fully conceded.
2.1.2 Average Rate
Average Rate expresses the average utility value de-
manded by the opponent agent as a ratio according to
the negotiation scenario. The definition is as follows:
AR( ¯x) =
(
1 if u
o
( ¯x) ≤ u
o
(ω
+
)
1−u
o
( ¯x)
1−u
o
(ω
+
)
otherwise
(2)
2.1.3 Default Configuration Performance
Default Configuration Performance is the index that
normalizes the utility value obtained by our agent in
reaching an agreement according to the negotiation
scenario. The DCP value is defined as
DCP(ω
a
) =
(
0 if u(ω
a
) ≤ u(ω
−
)
u(ω
a
)−u(ω
−
)
1−u(ω
−
)
otherwise
(3)
where ω
a
is the final agreement bid, and ω
−
is the bid
that gives the maximum utility to the opponent.
2.2 Autonomous Negotiating Agent
Framework with Deep
Learning-Based Strategy Selection
Ayan et al. proposed an automated negotiating agent
framework that consists of base negotiators, a classi-
Clustering-Based Approach to Strategy Selection for Meta-Strategy in Automated Negotiation
257
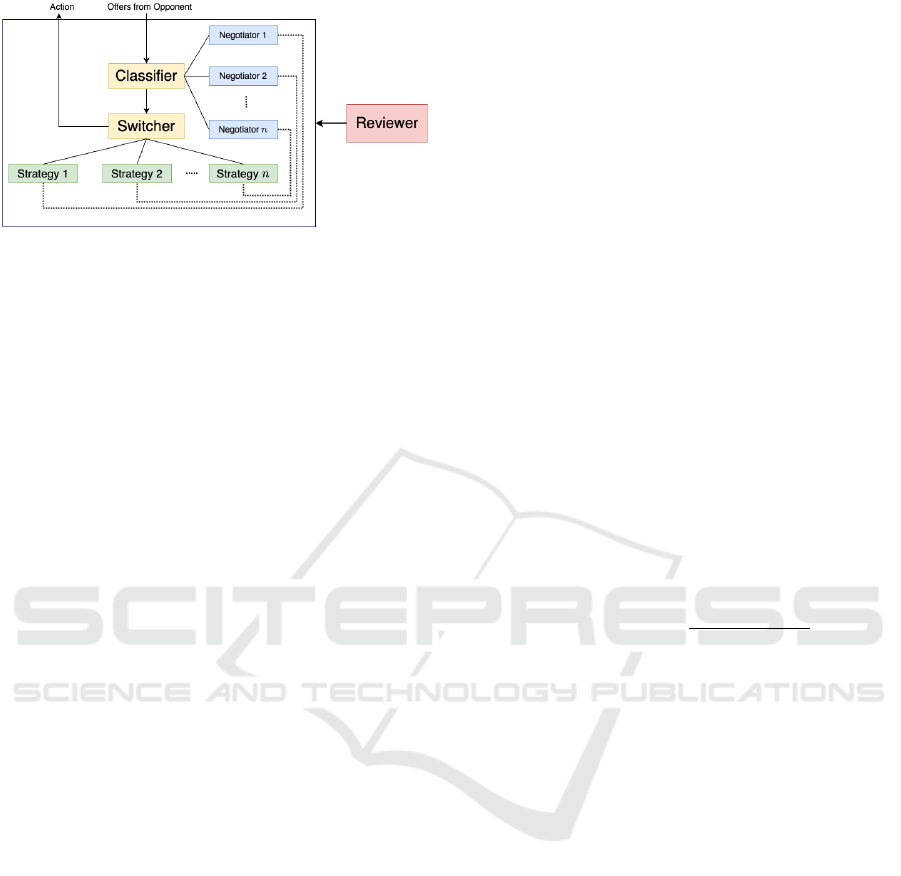
Figure 1: Overview of the negotiating agent framework of
the previous study. The classifier (yellow block) predicts
the probability that the opponent behaves as each base ne-
gotiator (blue and green blocks), and the switcher selects
the next action based on the output of the classfier. The re-
viewer (red block) are used between a negotiation session.
fier, a switcher, and a reviewer (Sengupta et al., 2021).
An overview of this framework is shown in Figure 1.
Base negotiator is the pair of negotiating agents
and the bidding strategies effective for each. The
classifier is based on a one-dimensional convolutional
neural network. The input to the classifier is the his-
tory of the utility value U
s
(ω
i
) that the agent can ob-
tain. The output is the estimated probability that the
offer history of the opponent is that of each base ne-
gotiating agent.
The switcher is a strategy-switching mechanism
based on the classifier for classifying the behavior of
an unknown negotiating agent without using an oppo-
nent model. The next offer ω
t
is selected as follos:
ω
t
= U
−1
s
(u
s
i
) where s
i
∈ S
b
= {s
1
,s
2
,··· ,s
n
} (4)
where S
b
is the set of base strategies corresponding to
the set of base negotiators and u
s
i
is the utility value
based on the strategy s
i
The reviewer is a mechanism that decides whether
to add or update new agents and strategies to the set of
base negotiators. When a new negotiation agent N
new
is introduced into the reviewer, it first learns a bid-
ding strategy S
train
that is effective against it. Then,
the agent with the learned S
train
and the current agent
negotiates with N
new
, and the evaluation value is ob-
tained using the Eval function. The evaluation value
of strategy s for agent N, Eval(N,s), is defined as the
average utility obtained by the agent using strategy s
for agent N. The reviewer gives permission to add a
new agent and a new strategy to the set of base ne-
gotiators if the evaluation value for N
new
is higher for
S
train
than for its own current agent, and the classi-
fier is trained on the new set of base negotiators. It
then compares the newly trained strategy S
train
with
the base strategies and updates the base strategies with
S
train
and the evaluation value, where the base strate-
gies are the strategies that are effective for each agent
in the base negotiator.
3 BILATERAL MULTI-ISSUE
NEGOTIATION
Bilateral multi-issue negotiation deals with negoti-
ations conducted by two agents in a common ne-
gotiation domain. The negotiation domain defines
the issues and the options for each issue in nego-
tiations, which is determined by the set of issues
I = {I
1
,I
2
,··· ,I
n
} consisting of n issues, and the set
of options V
i
consisting of m options for each issue
I
i
. A bid that the agent proposes during negotiations
is a set of options, one from each issue, written as
ω = {v
1
,v
2
,··· ,v
n
}.
Each negotiating agent has a preference profile
and a utility function. The preference profile com-
prises the weights of the issues and the evaluations of
the options on each issue, and the utility function out-
puts the utility value of each bid based on the utility
information. The preference profile and utility func-
tion of each agent are private and not available to
other agents. The utility function U
s
(ω) for a bid ω
is expressed as
U
s
(ω) =
n
∑
i=1
w
i
·
eval(v
i
k
i
)
max
j
(eval(v
i
j
))
(5)
where w
i
is the weight of issue I
i
and eval(v
i
) is
the evaluation value of the option v
i
. w
i
satisfies
∑
n
i=1
w
i
= 1 and w
i
≥ 0, and the evaluation value sat-
isfies eval(v
i
j
) ≥ 0. The value obtained according to
the utility function U
s
(ω) for the agreed-upon bid ω is
called the utility value, which is represented by a real
number in the range [0, 1]. The goal of this negotiation
problem is to maximize the utility value as much as
possible. In this study, we use the Alternating Offers
Protocol (Rubinstein, 1982), which is widely used in
bilateral negotiations, as the negotiation protocol. In
this protocol, both agents take turns performing their
actions until the time limit is reached or the negotia-
tion is terminated. When selecting their own actions,
the agents choose one of the following three actions.
• Accept: The agent accepts and agrees to the last
bid offered by the opponent and terminates the ne-
gotiation.
• Offer: The agent rejects the opponent’s offer and
proposes a new bid to the opponent. Negotiations
continue.
• End Negotiation: End the negotiation without
reaching an agreement.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
258
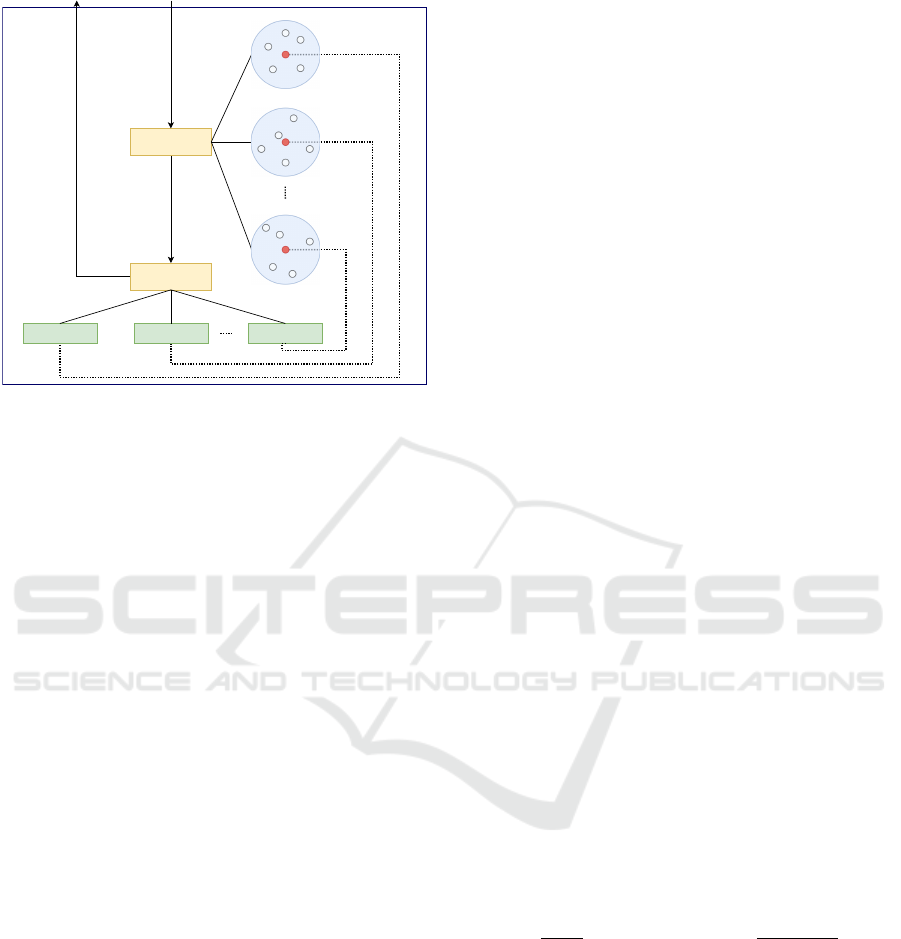
Classifier
Switcher
Strategy 1 Strategy 2 Strategy `n`
Action Offers from Opponent
Cluster 1
Cluster 2
Cluster `n`
Figure 2: Relationship between each component of the pro-
posed model. The existing negotiating agents are divided
into n clusters (blue blocks), and the red point is the repre-
sentative point of each cluster.
After the negotiation, the agents obtain the utility
value for the last bid if an agreement is reached. Oth-
erwise, they obtain the reservation value.
4 STRATEGY SELECTING
ALGORITHM BY CLUSTERING
In this section, we propose a new strategy selecting
algorithm using clustering for meta-strategy in auto-
mated negotiation. Our proposed method consists of
three main components: base negotiator, classifier,
and switcher, based on the previous study (Sengupta
et al., 2021). Figure 2 shows the relationship between
each component of the proposed model. As in the pre-
vious study (Sengupta et al., 2021), the state space,
action space, and reward function for training each
effective bidding strategy are defined as
s
t
= {t
r
,U
s
(ω
t−2
s
),U
s
(ω
t−2
o
),U
s
(ω
t−1
s
),
U
s
(ω
t−1
o
),U
s
(ω
t
s
),U
s
(ω
t
o
)}
(6)
a
t
= u
t+1
s
such that u
r
< u
t+1
s
≤ 1 (7)
R(s
t
,a
t
,s
t+1
) =
U
s
(ω
a
)
if there is
an agreement ω
a
−1
for no agreement and
s
t+1
is terminal state
0 otherwise
(8)
where t
r
is the relative progress time, and U
s
is the
self-utility function. ω
t
o
and ω
t
s
represent the pro-
posed and counter offers, respectively. u
r
is the self-
reservation value, and u
t+1
s
represents the utility value
of the counter offer at the next time step. The clas-
sifier calculates the probabilities that the opponent is
behaving as each agent of the base negotiator based
on the history of the opponent’s offer. The switcher
determines an action based on the strategy that seems
most appropriate from the output probabilities of the
classifier.
Our approach improves the classifier model from
the previous study and proposes a new method for se-
lection of the base negotiator using clustering.
4.1 Classifier with Opponent Features
The input to the classifier is the history of three
features from the opponent features (Renting et al.,
2020): concession rate (CR), average rate (AR), and
default configuration performance (DCP). Each fea-
ture is calculated at every time step, and the input vec-
tor to classifier is defined as follows:
I
t
c
= { f
i
o
}
i=t−1
i=t−k
where
f
t
o
= (CR
t
o
,AR
t
o
,DCP
t
o
), k ∈ Z
+
, and k > 1
(9)
where CR
t
o
, AR
t
o
, and DCP
t
o
are the features of the
opponent agent at time step t. The opponent’s utility
function is required to obtain the exact value of each
feature, but since the preference profiles are usually
kept private, we estimate the opponent’s preferences
using the opponent model. In addition, to obtain the
DCP value, the self-utility value obtained when reach-
ing an agreement is needed. However, as it is im-
possible to obtain this value while negotiations are in
progress, we approximate it by the utility value of the
last opponent’s offer.
The output of the classifier is the estimated proba-
bilities of behaving as each agent, defined as
p
i
=
d
i
∑
j
d
j
where d
i
=
t−1
∑
l=t−k
f
l
o
· f
l
N
i
∥ f
l
o
∥∥ f
l
N
i
∥
(10)
where N
i
represents the ith base negotiator.
4.2 Selection of Base Negotiator with
Clustering
We create groups of possible negotiation agents and
select the pair of representative points of each cluster
and an effective bidding strategy corresponding to it
as the base negotiator. CR, AR, and DCP are used for
clustering along with the classifier. Let us denote the
Clustering-Based Approach to Strategy Selection for Meta-Strategy in Automated Negotiation
259

set of negotiation agents as A and the feature vector
on agent a ∈ A at time step t as f
t
a
. Then,
f
t
a
=
1
|A|
∑
b∈A
f
t
b×a
where
f
t
b×a
= (CR
t
b×a
,AR
t
b×a
,DCP
t
b×a
)
(11)
where f
t
b×a
represents the feature vector on agent a at
time step t when negotiating with agent b. In contrast
to the classifier model, the utility function of existing
negotiation agents is known. Therefore, the opponent
model is not used but the actual utility values are used
to compute the features. For clustering, the feature
vectors at the time step when reaching an agreement
are used, and those are calculated while the negotia-
tion is ongoing as they are required in the classifier.
In addition, DCP for clustering is calculated with the
utility value of the last opponent’s offer initially as in
the classifier model and with that of the final agreed
offer once agreement is reached. Furthermore, we de-
fine the feature vector at time step t
′
after agreement
is reached in Equation (12) in order to allow compari-
son of the feature vectors at any time step, because the
number of time steps required to reach an agreement
differs depending on the combination of negotiating
agents.
f
t
′
a
= f
t
a
a
∀
t
′
∈ {t
a
+ 1,t
a
+ 2,· ·· , T } (12)
where t
a
is the time step when agreement is reached,
and T is the deadline, maximum time step.
5 EXPERIMENTAL RESULTS
5.1 Negotiation Settings
5.1.1 Negotiation Agents
For training, we used an agent that makes random ac-
tion choices (Random Negotiator), Boulware agent
(Faratin et al., 1998), and Naive tit-for-tat agent
(Baarslag et al., 2013) for the method of the previ-
ous study. For our proposed method, in addition to
the above three agents, we used agents available in
Genius platform (Lin et al., 2014), including agents
from ANAC 2015-2017 shown in Table 1, because
it is desirable to have a certain number of agents for
proper clustering.
5.1.2 Negotiation Domain
To compare our proposed method with the one used
in the previous study, the same domain should be used
for learning of effective bidding strategies. There-
fore, we train the strategies in the Lunch domain used
in ANAC 2013 in common, in which the reservation
value is kept zero and the discount factor for the utility
value δ = 1. When the reservation value is zero, the
utility value the agent obtains when the negotiation
fails is 0, and when the discount factor is 1, the util-
ity value does not decrease over time. The self-utility
function is fixed, and the opponent’s utility function
is randomly generated for training strategies.
For evaluations, we used 12 domains of ANAC
2013 including the Lunch domain, as shown in Ta-
ble 2. We selected these domains as a diverse set of
domains based on two metrics: domain size and op-
position.
5.1.3 Opponent Model
Our proposed method estimates the opponent’s pref-
erence with Smith Frequency Model (van Galen Last,
2012).This method relies on the analysis of the fre-
quency of occurrence of each option within the bids
presented by the opponent. In the estimation of
weights, issues with frequently appearing options are
expected to be important to the opponent; therefore,
the weight of the issue is estimated as the ratio of the
occurrence frequency of the option with the largest
frequency at each issue. The evaluation score for
each option is estimated as the ratio of occurrence fre-
quency of each option at each issue.These are denoted
as follows:
ˆw
i
=
max
j
(freq(v
i
j
))
∑
j
freq(v
i
j
)
,
d
eval(v
i
j
) =
freq(v
i
j
)
∑
k
freq(v
i
k
)
(13)
where v
i
j
is the jth option of the ith issue, and freq()
represents the number of the occurrence frequency of
each option.
5.2 Experimental Settings
In the experiments, we examine the number of clus-
ters maintained by an automated negotiating agent
using our proposed method, which we call Meta-
Strategy with Clustering agent (MSC-agent), and
compare its performance with that of a replicated im-
plementation of a prior method, RL-agent.
For training the bidding strategies, we used Soft
Actor-Critic (SAC) (Haarnoja et al., 2018) as a re-
inforcement learning algorithm and OpenAI gym
(Brockman et al., 2016) as a training environment.
Table 3 shows the hyperparameters for training with
SAC. The negotiation simulations were conducted on
NegMAS (Mohammad et al., 2021), an automated ne-
gotiation platform. In addition, the fuzzy c-means
method (Bezdek et al., 1984), one of the soft clus-
tering methods, was used for clustering the agents.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
260
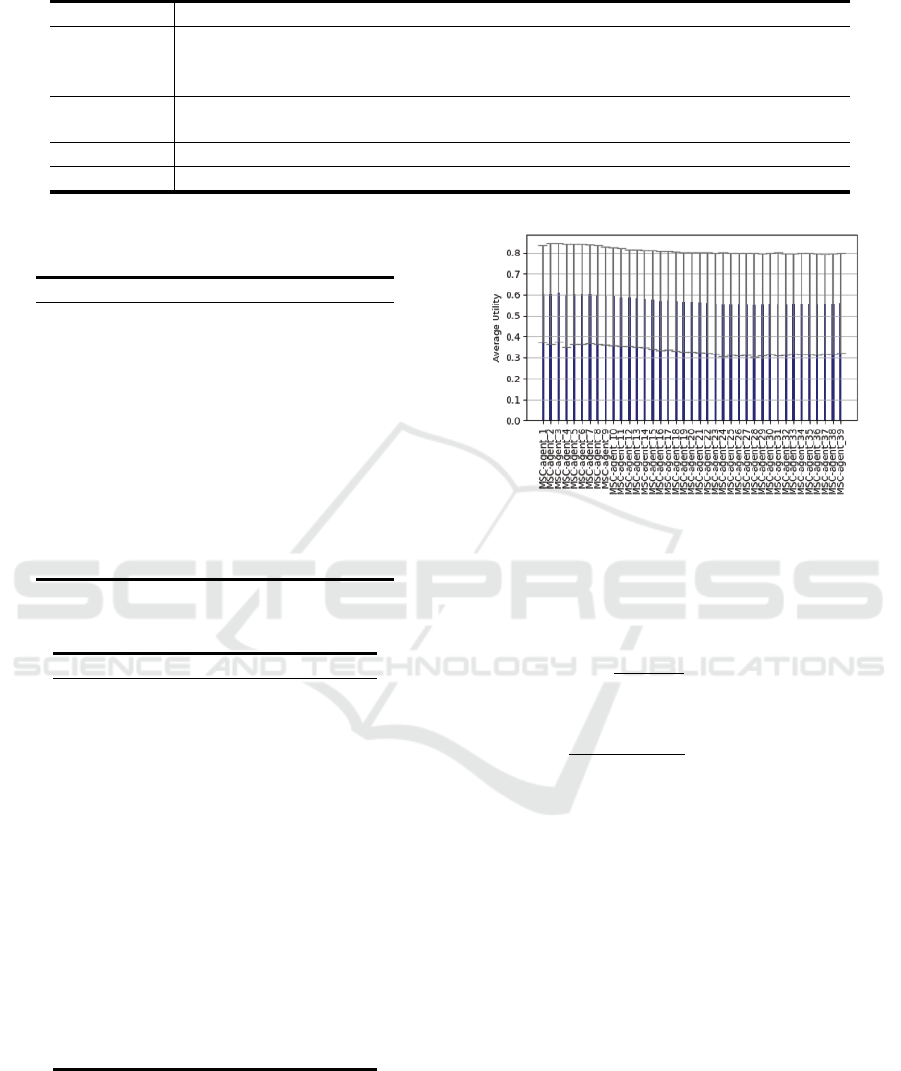
Table 1: Agents available on Genius used for learning.
Agents
ANAC 2015 AgentNeo, AgentX, AresParty, Atlas3, DrageKnight, JonnyBlack, ParsAgent,
RandomDance, SENGOKU, TUDMixedStrategyAgent, AgentBuyooMain,
AgentH, CUHKAgent2015, kawaii, MeanBot, PokerFace
ANAC 2016 AgentSmith2016, Caduceus, ClockworkAgent, Farma, GrandmaAgent, MyAgent,
Ngent, SYAgent, Terra,
ANAC 2017 AgentF, Farma17, PonPokoAgent, TucAgent
Other Group2, Group3, Group5, Group6, Group7, Group9, Group10, Group11
Table 2: ANAC 2013 domains used for our experimental
evaluations.
Domains Opposition Size
Acquisition 0.104 384
Animal 0.15 1152
Coffee 0.279 112
Defensive Charms 0.193 36
Dog Choosing 0.002 270
Fifty-Fifty 0.498 11
House Keeping 0.13 384
Kitchen 0.219 15625
Lunch 0.246 3840
Planes 0.606 27
Ultimatum 0.319 9
Wholesaler 0.128 56700
Table 3: Hyperparameters for Training Bidding Strategy us-
ing Soft Actor-Critic Algorithm.
Parameter Value
Epochs 1000∼5000
Initial collect steps 500
Replay buffer capacity 1000000
Batch size 128
activation fn relu
Optimizer Adam
Actor learning rate 3e-5
Actor loss weight 1
Critic learning rate 3e-2
Critic loss weight 0.5
α learning rate 3e-3
α loss weight 1
Initial α 1.0
Target update τ 0.005
Target update period 1
TD error loss function MSE
γ 0.99
The time limit per negotiation session is 100
rounds, and the agents negotiate only on a single do-
main when learning the bidding strategy and on all
domains in the evaluation. The Self Utility Bench-
mark and the Utility Against Opponent Benchmark
(Sengupta et al., 2021) are used as evaluation mea-
Figure 3: Comparison of benchmark scores for individual
utility when the number of clusters n is 1 to 39.
sures to compare the benchmark scores of individual
utility and social welfare. Each benchmark is denoted
as follows:
S
a
=
1
|A| × |D|
∑
d∈D
∑
b∈A
U
a×b:d
a
(14)
O
a
=
1
(|A| − 1) × |D|
∑
d∈D
∑
b∈A/a
U
a×b:d
b
(15)
where U
a×b:d
a
represents the average utility obtained
by agent a against b in domain d over 100 runs. A and
D is the set of agents and domains respectively.
5.3 Experimental Results
5.3.1 Comparison of Number of Clusters
We first compared the number of clusters in nego-
tiation simulations, varying the number of clusters
maintained by the agents to determine the appropriate
number of clusters. Figure 3 shows the comparison
of benchmark scores for individual utility when the
number of clusters n is 1 to 39. The mean score of in-
dividual utility is higher when the number of clusters
is smaller. In particular, the number of clusters n = 3
has the highest mean individual utility score.
Clustering-Based Approach to Strategy Selection for Meta-Strategy in Automated Negotiation
261
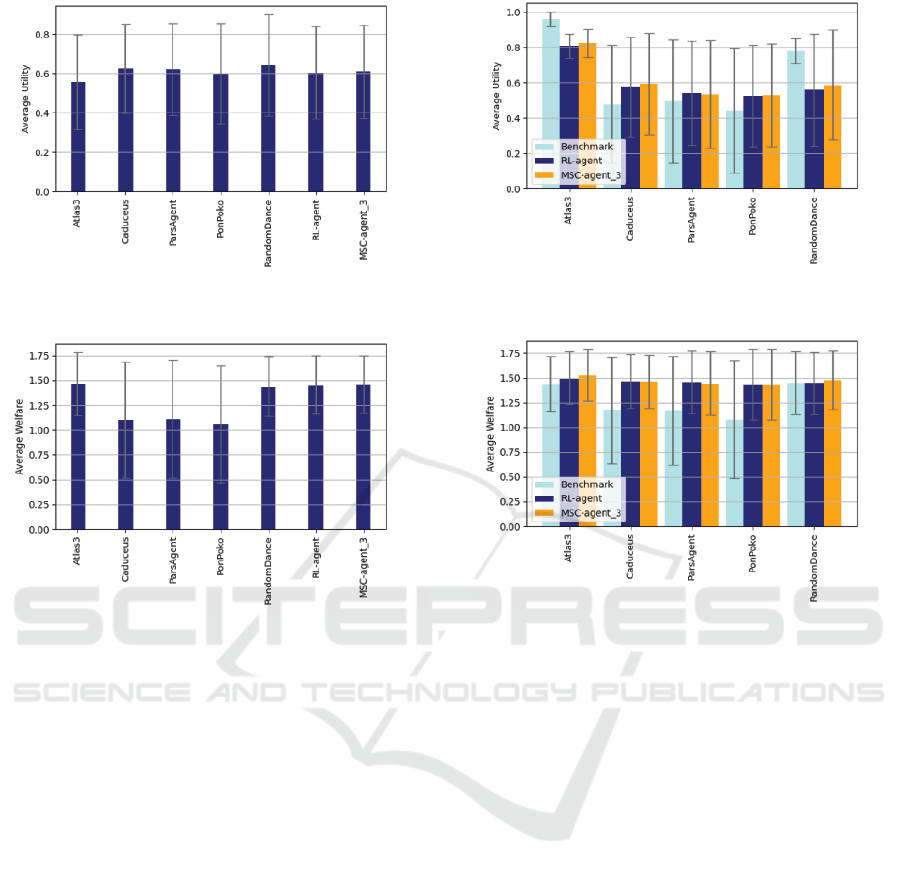
Figure 4: Comparison of MSC-agent with RL-agent and 5
ANAC agents in benchmark scores of individual utility.
Figure 5: Comparison of MSC-agent with RL-agent and 5
ANAC agents in benchmark scores of social welfare.
5.3.2 Comparison of MSC-Agent with
RL-Agent and ANAC Winning Agent
To demonstrate the effectiveness of our proposed
method, we compared the best performing MSC-
agent (the number of clusters n = 3) with the RL-
agent, which uses the prior method (Sengupta et al.,
2021) and the agents that achieved excellent results
in ANAC. The results are shown in Figure 4 and Fig-
ure 5. The MSC-agent outperforms the RL-agent in
both individual utility and social welfare. In addi-
tion, in comparison with the ANAC winning agents,
its individual utility score is comparable to that of
ParsAgent, Caduceus, and RandomDance, and out-
performs the other agents. The standard deviation of
social welfare is smaller than that of Atlas3 and Ran-
domDance, which have the same level of utility, indi-
cating that high social welfare is obtained regardless
of the domain.
5.3.3 Comparison of Utility Against Opponent
Benchmark
We compared the Utility Against Opponent Bench-
mark for each agent with the individual utility gained
Figure 6: Comparison of Utility Against Opponent Bench-
mark of individual utility.
Figure 7: Comparison of Utility Against Opponent Bench-
mark of social welfare.
by the RL-agent and the MSC-agent for each agent.
Figure 6 shows that the MSC-agent achieved higher
individual utility for four out of five agents compared
to the RL-agent. The MSC-agent also obtained higher
individual utility for the three agents compared to the
benchmark scores.
Figure 7 shows that the MSC-agent received
higher social welfare than the RL-agent against At-
las3 and RandomDance, and compared with the
benchmarks, the MSC-agent outperformed all the
ANAC winning agents.
6 CONCLUSION
In this study, we proposed a clustering-based strategy
selection algorithm for meta-strategy in automated
negotiation. For strategy selection, we proposed an
algorithm that selects an appropriate strategy based
on the opponent features each time during the nego-
tiation with clustering techniques. We trained a bid-
ding strategy effective for each agent positioned at the
representative point of each cluster using a deep rein-
forcement learning algorithm, SAC. Upon analyzing
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
262

the number of strategy clusters identified by our pro-
posed method, it is evident that the individual util-
ity tends to increase when the number of clusters is
limited, with the highest utility achieved when there
are three clusters. In addition, negotiation simulation
experiments demonstrated that our approach yields
higher individual utility than those of previous stud-
ies.
Although this study provides valuable insights
into meta-strategy for automated negotiation, there re-
main several avenues for future studies. One potential
direction could be the development of new features
for agent clustering. In our proposed method, three
features from the existing opponent features are used
for clustering to group the opponent agents. How-
ever, these features focus on the distribution of of-
fers at the end of the negotiation or at specific time
points, thereby not sufficiently considering the transi-
tion of offers. Therefore, for precise classification of
the behavior of the opponent agent, the incorporation
of new features that can reflect the negotiation process
will be essential.
REFERENCES
Baarslag, T., Hindriks, K., and Jonker, C. (2011). Towards
a quantitative concession-based classification method
of negotiation strategies. In Kinny, D., Hsu, J. Y.-j.,
Governatori, G., and Ghose, A. K., editors, Agents in
Principle, Agents in Practice, pages 143–158, Berlin,
Heidelberg. Springer Berlin Heidelberg.
Baarslag, T., Hindriks, K., and Jonker, C. (2013). A tit
for tat negotiation strategy for real-time bilateral ne-
gotiations. Studies in Computational Intelligence,
435:229–233.
Bagga, P., Paoletti, N., Alrayes, B., and Stathis, K. (2021).
A deep reinforcement learning approach to concurrent
bilateral negotiation. In Proceedings of the Twenty-
Ninth International Joint Conference on Artificial In-
telligence, IJCAI’20.
Bezdek, J. C., Ehrlich, R., and Full, W. (1984). Fcm: The
fuzzy c-means clustering algorithm. Computers &
Geosciences, 10(2):191–203.
Brockman, G., Cheung, V., Pettersson, L., Schneider, J.,
Schulman, J., Tang, J., and Zaremba, W. (2016). Ope-
nAI Gym. arXiv e-prints arXiv:1606.01540.
Faratin, P., Sierra, C., and Jennings, N. R. (1998). Ne-
gotiation decision functions for autonomous agents.
Robotics and Autonomous Systems, 24(3):159–182.
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S.
(2018). Soft Actor-Critic: Off-Policy Maximum En-
tropy Deep Reinforcement Learning with a Stochastic
Actor. arXiv e-prints arXiv:1801.01290.
Ho, F., Geraldes, R., Gonc¸alves, A., Rigault, B., Sportich,
B., Kubo, D., Cavazza, M., and Prendinger, H. (2022).
Decentralized multi-agent path finding for uav traffic
management. IEEE Transactions on Intelligent Trans-
portation Systems, 23(2):997–1008.
Ilany, L. and Gal, Y. (2016). Algorithm selection in bilat-
eral negotiation. Autonomous Agents and Multi-Agent
Systems, 30(4):697–723.
Lin, R., Kraus, S., Baarslag, T., Tykhonov, D., Hindriks,
K., and Jonker, C. (2014). Genius: An integrated en-
vironment for supporting the design of generic auto-
mated negotiators. Computational Intelligence: an in-
ternational journal, 30(1):48–70. Online verschenen
september 2012; hard copy februari 2014.
Mohammad, Y., Nakadai, S., and Greenwald, A. (2021).
Negmas: A platform for situated negotiations. In
Aydo
˘
gan, R., Ito, T., Moustafa, A., Otsuka, T., and
Zhang, M., editors, Recent Advances in Agent-based
Negotiation, pages 57–75, Singapore. Springer Singa-
pore.
Razeghi, Y., Yavuz, C. O. B., and Aydo
˘
gan, R. (2020). Deep
reinforcement learning for acceptance strategy in bi-
lateral negotiations. Turkish J. Electr. Eng. Comput.
Sci., 28:1824–1840.
Renting, B. M., Hoos, H. H., and Jonker, C. M. (2020).
Automated configuration of negotiation strategies. In
Proceedings of the 19th International Conference on
Autonomous Agents and MultiAgent Systems, AA-
MAS ’20, page 1116–1124, Richland, SC. Interna-
tional Foundation for Autonomous Agents and Mul-
tiagent Systems.
Rubinstein, A. (1982). Perfect equilibrium in a bargaining
model. Econometrica, 50:97–109.
Sengupta, A., Mohammad, Y., and Nakadai, S. (2021).
An autonomous negotiating agent framework with re-
inforcement learning based strategies and adaptive
strategy switching mechanism. In Proceedings of
the 20th International Conference on Autonomous
Agents and MultiAgent Systems, AAMAS ’21, page
1163–1172, Richland, SC. International Foundation
for Autonomous Agents and Multiagent Systems.
van der Putten, S., Robu, V., La Poutr
´
e, H., Jorritsma, A.,
and Gal, M. (2006). Automating supply chain negotia-
tions using autonomous agents: A case study in trans-
portation logistics. In Proceedings of the Fifth Inter-
national Joint Conference on Autonomous Agents and
Multiagent Systems, AAMAS ’06, page 1506–1513,
New York, NY, USA. Association for Computing Ma-
chinery.
van Galen Last, N. (2012). Agent smith: Opponent model
estimation in bilateral multi-issue negotiation. In Ito,
T., Zhang, M., Robu, V., Fatima, S., and Matsuo, T.,
editors, New Trends in Agent-Based Complex Auto-
mated Negotiations, pages 167–174, Berlin, Heidel-
berg. Springer Berlin Heidelberg.
Clustering-Based Approach to Strategy Selection for Meta-Strategy in Automated Negotiation
263
