
Generative Data Augmentation for Few-Shot Domain Adaptation
Carlos E. L
´
opez Fort
´
ın
a
and Ikuko Nishikawa
b
Graduate Department of Information Science & Engineering, Ritsumeikan University, Kusatsu, Shiga, Japan
Keywords:
Domain-Adaptation, Diffusion-Model, Few-Shot, Data-Augmentation.
Abstract:
Domain adaptation in computer vision focuses on addressing the domain gap between source and target distri-
butions, generally via adversarial methods or feature distribution alignment. However, most of them suppose
the availability of sufficient target data to properly teach the model domain-invariant representations. Few-shot
scenarios where target data is scarce pose a significant challenge for their implementation in real-world sce-
narios. Leveraging fine-tuned diffusion models for synthetic data augmentation, we present Generative Data
Augmentation for Few-shot Domain Adaptation, a model-agnostic approach to address the Few-shot problem
in domain adaptation for multi-class classification. Experimental results show that using augmented data from
fine-tuned diffusion models with open-source data sets can improve average accuracy by up to 3%, as well as
increase per-class accuracy between 3% to 30%, for state-of-the-art domain adaptation methods with respect
to their non-augmented counterparts, without requiring any major modifications to their architecture. This
provides an easy-to-implement solution for the adoption of domain adaptation methods in practical scenarios.
1 INTRODUCTION
The ability for a model to learn representations from
labeled data of a known distribution (source do-
main) and transfer that knowledge to another distri-
bution (target domain) without additional supervision
is known as Domain Adaptation (DA) (Goodfellow
et al., 2014; Long et al., 2015; Ganin and Lem-
pitsky, 2015). This has been a core challenge for
the generalization of image classification and image
segmentation models within the last few years (Liu
et al., 2022). Most state-of-the-art models rely on
techniques to partially or totally align the source and
target distributions (Saito et al., 2020; Ganin et al.,
2016; Yu et al., 2023), as well as methods to adver-
sarially learn domain-invariant representations across
domains (You et al., 2019; Yu et al., 2023). Despite
the impressive performance achieved by these meth-
ods both in closed-set and open-set scenarios, how-
ever, most of them assume that enough target data is
available during training, which is not always true in
practice due to factors such as time availability, bud-
getary constraints, or technical limitations (Liu et al.,
2022). This poses a serious obstacle for their adoption
in real-world applications.
Few-shot scenarios in DA occur when the amount
a
https://orcid.org/0000-0002-8727-7824
b
https://orcid.org/0000-0003-4780-0155
of target data available for model training is signif-
icantly less than the source data (Zhao et al., 2021;
Liu et al., 2022). This can take place both at the in-
dividual class level (i.e. only some classes have lim-
ited samples) and at a general level (e.g. all classes
from the target have limited samples). Some mod-
els have attempted to circumvent this issue by intro-
ducing prototype learning and additional adversarial
learning components to leverage limited information
from available samples (Zhao et al., 2021; Motiian
et al., 2017). Others have attempted data augmen-
tation through style-transfer from the target domain
onto source-images or through data generation by dif-
fusion models (Yang et al., 2021; Benigmim et al.,
2023).
Inspired by the results of the DATUM model
which utilized personalized diffusion models to ad-
dress the One-shot scenario for image segmentation
(Benigmim et al., 2023), we propose in this paper to
leverage fine-tuned diffusion models to generate ad-
ditional synthetic and diversified high-quality target
data for Few-shot scenarios, which can be utilized
with any DA model to improve their performance
in multi-class classification. Our proposed method,
Generative Data Augmentation for Few-Shot Domain
Adaptation, significantly contributes to improving the
model average and/or per-class accuracy of existing
DA methods, and thus offers an interesting alterna-
256
López Fortín, C. and Nishikawa, I.
Generative Data Augmentation for Few-Shot Domain Adaptation.
DOI: 10.5220/0012338000003654
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 13th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2024), pages 256-265
ISBN: 978-989-758-684-2; ISSN: 2184-4313
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

tive for the research of Few-shot domain adaptation.
In addition, it offers a simple yet innovative solu-
tion for the adoption of state-of-the-art algorithms in
real-world scenarios thanks to its model-agnostic ap-
proach, which, to our knowledge, has not been pro-
posed before for multi-class classification.
In Section 2, we introduce related work for Do-
main Adaptation, Few-shot learning, and diffusion
models for data generation. We continue Section 3 by
defining the problem and describing the method for
combining the results of fine-tuned diffusion models
with DA algorithms. We discuss our results in Sec-
tion 4 and provide a more detailed analysis in Section
5. Finally, we summarize our results in Section 6 and
propose further research directions.
2 RELATED WORKS
2.1 Domain Adaptation
When a model is trained on a certain distribution of
data, it is expected to perform similarly with new data
with similar distributions. However, when the distri-
bution is different, a domain gap is introduced, which
drastically reduces its accuracy, and thus techniques
to mitigate this difference are adopted (Liu et al.,
2022; Long et al., 2015). Domain adaptation (DA) is a
special class of transfer learning that focuses on mini-
mizing the distribution discrepancy between different
domains (You et al., 2019; Cao et al., 2019). This
is generally achieved through adversarial techniques
that allow the model to learn domain-invariant repre-
sentations of classes from the source and target do-
mains, as well as by partial or total alignment of data
distributions at different stages of the training (You
et al., 2019; Saito et al., 2020; Saito et al., 2020; Cao
et al., 2018; Yu et al., 2023). Depending on where this
alignment is carried out during training (input, latent,
or output space), different results are obtained (Ganin
and Lempitsky, 2015; Long et al., 2015; Ganin and
Lempitsky, 2015; Cao et al., 2019).
Most recent methods focus on identifying classes
shared by both source and target domains (common),
as well as classes exclusive to the source (source pri-
vate) or the target (target private) (You et al., 2019;
Saito et al., 2020; Saito et al., 2020). Scenarios
where only common classes are present are known as
closed-set DA, while variations with only source pri-
vate (partial DA), only target private (open-set DA),
and both source and target private (universal DA) ex-
ist (Cao et al., 2019). For closed-set DA, techniques to
align the source and target distributions through con-
ditional adversarial training by maximizing the intra-
class density have been implemented, while others
using progressive adaptation of the feature norm be-
tween domains have also been proposed (Long et al.,
2018; Li et al., 2021; Xu et al., 2019). For universal
DA, entropy separation techniques or auxiliary adver-
sarial discriminators have been introduced to allow
the discrimination of unknown classes (Saito et al.,
2020; Cao et al., 2018; Yu et al., 2023). In general,
universal DA methods have been shown to perform as
well or better than closed-set methods in closed DA.
Nevertheless, all of these still rely on the availabil-
ity of enough target data, which can become a major
challenge when dealing with Few-shot scenarios (Liu
et al., 2022; Zhao et al., 2021; Benigmim et al., 2023).
2.2 Few-Shot Learning
Few-shot scenarios happen when the target data avail-
able for training is very limited in comparison with
the source data (Liu et al., 2022; Bashkirova et al.,
2023; Motiian et al., 2017). In general, this means
having 2-5 images per class. A more challenging set-
ting, with only 1 image per class, is called One-shot
(Benigmim et al., 2023; Yang et al., 2021). Over-
coming both Few-shot and One-shot scenarios is a
major problem for the adoption of computer vision
techniques in practical settings, as these may incur in
cases with limited and imbalanced data, usually due
to constraints in data acquisition(Liu et al., 2022).
Few-shot learning methods have generally at-
tempted to address this problem through meta-
learning approaches. As summarized by (Zhao et al.,
2021), these can be divided into three categories:
rapid adaptation from source to target classes, proto-
typical learning through the aid of encoders, and sub-
stitution of gradient descent with novel optimization
algorithms. Some of the latest Few-shot DA methods
address both the Few-shot DA and Few-shot learning
problems by utilizing labeled target samples to build
prototypes that align with the source and target (Zhao
et al., 2021). Another method (DATUM) has used dif-
fusion models to augment data for One-shot scenarios
(Benigmim et al., 2023).
2.3 Diffusion Models
Diffusion models (DMs) have represented a major
step towards high-quality photo-realistic image gen-
eration, thanks to their combination with text en-
coders which allow for image generation through
the guidance of natural language prompts (Rom-
bach et al., 2021). Fine-grained generation has been
achieved through the use of fine-tuning methods such
as Dreambooth (Ruiz et al., 2022), Textual Inver-
Generative Data Augmentation for Few-Shot Domain Adaptation
257

sion (Gal et al., 2022), and ControlNet (Zhang and
Agrawala, 2023). In addition, recent advances have
explored the possibility of applying these fine-tuning
methods directly to the latent space of a pre-trained
autoencoder, a faster alternative to standard DMs
(Rombach et al., 2021). A recent work has success-
fully used Dreambooth to fine-tune latent DMs to ad-
dress One-shot DA for image segmentation with a
model-agnostic proposal (Benigmim et al., 2023). In-
spired by this research, here we extend the application
of fine-tuned latent DMs via Dreambooth to address
multi-class classification in Few-shot DA.
3 PROPOSED METHOD
3.1 Problem Statement
We consider a set of labeled source domain images
D
s
= {x
s
i
,y
s
i
}
N
s
i=1
, where N
s
is the total number of
source classes, as well as a set of unlabeled target im-
ages D
t
= {x
s
i
}
N
t
i=1
, where N
t
is the total number of
target classes. The label classes for the source and tar-
get are denoted by C
s
and C
t
, respectively. Here, we
consider the closed-set scenario without any private
source and target classes, e.g., C = C
s
∩C
t
= C
s
= C
t
.
Let n
k
s
and n
k
t
be the number of images of class k,
where k ∈ C.
In a Few-shot scenario, the number of images per
class for the target domain is smaller than their coun-
terparts in the source domain, e.g., n
k
t
< n
k
s
, k ∈ C.
Other works usually consider 2 ≤ n
k
≤ 5. Without los-
ing generality, here we take n
k
= 3. We want to gen-
erate new synthetic images for D
t
using a fine-tuned
latent DM model such that after data augmentation,
n
k
t
≥ n
k
s
, ∀k ∈ C.
To simulate the Few-shot scenario using standard
available data sets, we extract 3 images from each
class to construct the original Few-shot data set and
generate n additional images to build the synthetic
augmented data set. We combine both the original
3 images with the n synthetic samples to build the
total training set. The rest of the target images that
were separated for the Few-shot generation are saved
for testing.
1
. We found that this method of train-
test separation provides a better reference to simulate
a few-shot setting of a real-world scenario while us-
ing open-source data sets to benchmark model perfor-
mance.
1
For clarity: (1) Training phase: the DA model learns
from all the source data, the few-shot target data, and the
synthetic augmented target data. (2) Testing phase: the DA
model tests its results on the remaining target data only (the
one never seen during training)
3.2 Model Fine-Tuning
Image generation through diffusion models is per-
formed as an image-denoising task, where first an im-
age X
0
is sequentially degraded by the addition of
Gaussian noise at each forward iteration, X
1
,...X
T
.
Then, a convolutional network η
θ
(.) is trained to re-
construct the original image from the noisy input in
a backwards fashion (generally with U-Net). As this
is computationally expensive, research has suggested
that DMs can instead work in the latent space of a
pre-trained autoencoder (Rombach et al., 2021).
Conditioning is achieved by introducing an addi-
tional input to guide the denoising process of the net-
work. In the case of text-conditioning, the embed-
dings of a text encoder τ
θ
(y) are used to augment
the embedding of the network η
θ
(X,y) using a cross-
attention mechanism. This modifies the loss function
of the DM as described in (Ruiz et al., 2022).
For Dreambooth (Ruiz et al., 2022), a prompt with
a unique identifier (e.g. zwx) is assigned to the in-
put images to fine-tune the DM weights (e.g. p=”a
photo of zwx backpack”). Thus, the model retains the
knowledge already present in the pre-trained weights
(e.g. general appearance of a backpack), while still
capturing the specific target domain features of the
fine-tuning samples (e.g. type of the backpack present
in target domain). In particular, we use the imple-
mentation of Dreambooth with StableDiffusion 1.4 by
Shivam Shirao as provided in (Shirao, 2022).
Initially, we considered two fine-tuning methods
to generate the augmented synthetic data:
• Single Model: we fine-tune a single model for
each class using all 3 images, with a single prompt
with and a unique identifier. So, we have one fine-
tuned DM model for each class.
• Triple Model: we fine tune one model for each
one of the 3 images, using the same prompt for
each case but different unique identifiers. So, we
have 3 fine-tuned DM models for each class.
The single model approach has the advantage of
being faster and easier to implement, as only n
c
mod-
els are required for the classification task (n
c
is the
number of classes), but it may be sensitive to low-
quality image generation or lead to generation of bad
samples for DA. The triple model approach is still
easy to implement but requires 3n
c
models for the
classification task; this could help in generating more
high-fidelity images, but at the expense of a potential
lack of diversity. Detailed studies (Section 5) showed
that the single model method performs similarly to the
triple model method in most cases, so we opted for
the former when comparing the performance of our
method with different domain adaptation methods.
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
258

3.3 Synthetic Augmentation
3.3.1 Image Generation
After fine-tuning each DM model using Dreambooth,
we inputted prompts with their unique identifiers to
generate new target synthetic images and analyzed the
quality of image generation. Using simple prompts
(e.g. p=”photo of zwx backpack”) generated im-
ages that either lacked diversity or were likely to be
combined with other objects and/or background el-
ements. To address this, we repeated the process
using targeted prompts that captured the image con-
text (e.g. p=”photo of zwx backpack leaning against
wall”). The generated results had more diversity and
were more representative of the target domain for
that class. We also analyzed the effect of the num-
ber of training steps, inference steps, and guidance
scale, finding that the optimal values for all classes
were: training steps : 400, in f erence steps : 100,
guidance scale : 6.5 − 7.5. This applied both to the
single model and the triple model. We repeated this
process for each of the classes in the target domain
and constructed the full target data sets by combining
the original limited data (few-shot) with the synthetic
(augmented) data sets.
Figure 1: Good synthetic sample (a) versus bad syn-
thetic sample (b) generated with Dreambooth for Office31-
Webcam class ’backpack’, using the same prompt, (”photo
of zwx backpack against wall”, guidance scale=6.5).
3.3.2 Manual Selection
Despite our best efforts at model fine-tuning, we
noted that some of the generated samples could pro-
duce negative transfer
2
due to irrelevant objects ap-
pearing on the image (e.g., a person with a backpack),
or objects with anomalous shapes (e.g., a scissor with
more than two blades) (Figure 1). Automation was
attempted using a combination of several metrics cal-
culated between original and synthetic images (e.g.,
FSIM, RMSE, SSIM, UIQ) to filter out bad samples.
However, no effective combination that worked for all
2
Negative transfer: when the accuracy of a model after
domain adaptation is worse than the model accuracy of the
model without domain adaptation.
classes was found. To determine if these bad samples
would really incur in degraded model performance,
we manually extracted a set of good samples based
on the following criteria: (i) the object must be alone
on the image (e.g., no presence of irrelevant objects),
(ii) the object must represent the target domain (e.g.,
same background), (iii) the object must not have any
visible aberrations or deformations (e.g., backpack
with multiple handles).
We performed tests for each model using both the
manually selected samples (chosen) and all the unfil-
tered synthetic data (all).
3.4 Domain Adaptation
As the data augmentation step is independent of DA,
this approach can be implemented with any model,
with the only minor change required being the adap-
tation of the testing procedure (Section 3.1). We con-
sidered the following four universal DA models and
two closed-set DA models:
• DANCE. Domain Adaptative Neighborhood
Clustering via Entropy optimization (DANCE)
relies on learning well-clustered features from
source and target to identify common classes at
the mini-batch level, followed by entropy-based
alignment to discriminate target samples as
common classes target private classes (Saito
et al., 2020).
• (NUDA). Noisy-Universal Domain Adaptation
uses two classifiers with different initializations
trained in an adversarial manner with a genera-
tor to filter out samples with noisy labels, and the
distributions of the source and target domain are
aligned by minimizing the divergence between the
outputs of the classifiers (Yu et al., 2023). The
model is robust even for non-noisy cases, so we
consider it despite not having any noisy labels.
• ETN. Example Transfer Networks (ETN) learn
domain-invariant representations across the
source and target domains via a progressive
weighting scheme using an auxiliary domain
discriminator, which quantifies the degree of
domain transferability of source samples while
at the same time controlling the importance of
learning in the target domain (Cao et al., 2019).
• UAN. Universal Adaptation Networks (UAN) at-
tempt to learn domain-invariant representations
across domains by quantifying the sample-level
transferability to automatically identify common
samples between source and target and filter out
unknown samples (You et al., 2019).
Generative Data Augmentation for Few-Shot Domain Adaptation
259
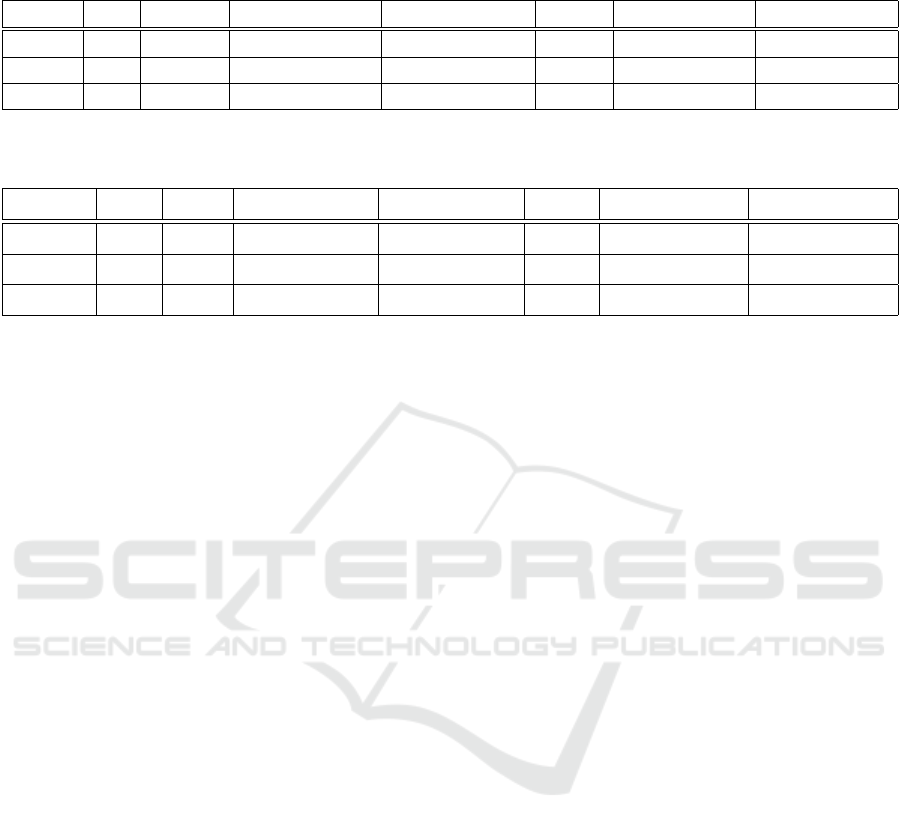
Table 1: Mean model accuracies for each universal domain adaptation model per number of classes (part 1). (a) refers to using
all synthetic augmented data, while (b) refers to using synthetic data with manual selection.
Classes SO DANCE DANCE+DB (a) DANCE+DB (b) NUDA NUDA+DB (a) NUDA+DB (b)
31 0.80 0.82 0.75 0.79 0.84 0.87 0.85
20 0.81 0.82 0.79 0.84 0.89 0.94 0.88
10 0.88 0.91 0.88 0.86 0.95 0.94 0.95
Table 2: Mean model accuracies for each universal domain adaptation model per number of classes (part 2). (a) refers to using
all synthetic augmented data, while (b) refers to using synthetic data with manual selection.
Classes SO ETN ETN+DB (a) ETN+DB (b) UAN UAN+DB (a) UAN+DB (b)
31 0.80 0.87 0.87 0.87 0.35 0.36 0.36
20 0.81 0.93 0.93 0.93 0.62 0.62 0.62
10 0.88 0.97 0.97 0.98 0.97 0.97 0.97
• CDAN. Conditional Adversarial Domain Adap-
tation (CDAN) captures cross-variance between
feature representations and classifier predictions
(multi-linear conditioning) and prioritizes the dis-
criminator on samples by using entropy-aware
weights (Long et al., 2018).
• MMD. Maximum Density Divergence (MMD) is
a distance loss that quantifies the distribution di-
vergence, which, coupled with standard adversar-
ial loss, is used to minimize inter-domain diver-
gence and maximize intra-class density to align
and compact class distributions (Li et al., 2021).
4 COMPUTER EXPERIMENTS
4.1 Experimental Set-Up
We consider a closed-set scenario using the Office31
data set for multi-class classification. We simulate the
Few-shot scenario by picking 3 representative sam-
ples for each target class: representative images must
have different poses of the object and/or display dif-
ferent variations of the class. We justify this selection
by arguing that in real-world scenarios, limited sam-
ples will try to capture at least the most representative
cases of each of the target domain classes. We then
fine-tune a single DM model for each class and use
targeted prompts to generate 32 additional synthetic
images for each class. We considered 400 training
steps, learning rate of 1e-6, with prior preservation
weight of 1.0. For manual selection, we chose 10 im-
ages for each class, following Section 3.3.2.
We randomly pick 20 (Office20) and 10 (Office10)
sets of classes from Office31 to compare the per-
formance of the models as a function of class num-
ber. For baseline, we use ResNet50 trained only on
source data, as previous works have shown it out-
performs most standard models in image classifica-
tion (Liu et al., 2022). Model-only case denotes the
performance of the base model with Few-shot target
data (3 samples for each class), Model+Dreambooth
(a) denotes its performance with all the synthetic data
augmented target samples (3+32 samples for each
class), and Model+Dreambooth (b) denotes its perfor-
mance manually chosen synthetic data augmented tar-
get samples (3+10 samples for each class). All mod-
els were trained for 5000 steps with a batch size of 32,
and results are reported at the end of the training and
rounded up to two decimal places.
Hyperparameter tuning was previously performed
for each model, and the results for the best accura-
cies of each model were considered. For DANCE and
NUDA, a margin of 0.5 and a threshold of log(N
c
)/2
were used, with N
c
being the number of classes. For
NUDA, the function to artificially introduce noisy la-
bels was removed from the original code. For ETN,
weights for adversarial augmented loss trade-off and
adversarial loss trade-off were 10.0 and 1.0, respec-
tively. For UDA, the weight for transferability trade-
off was -0.5. For CDAN and MDD, the same configu-
rations as their original works were utilized (adapting
for the number of classes).
4.2 Results
Results for the mean accuracies for each of the models
and cases considered are shown in Tables 1 and 2.
For NUDA, mean accuracy improves between 1%
and 3% when using augmented data in comparison
with model-only. In particular, not applying manual
selection (a) and instead considering all the gener-
ated images (b) yields better results. This is likely
due to the noisy label detection module as well as
the entropy separation from the target, which is able
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
260
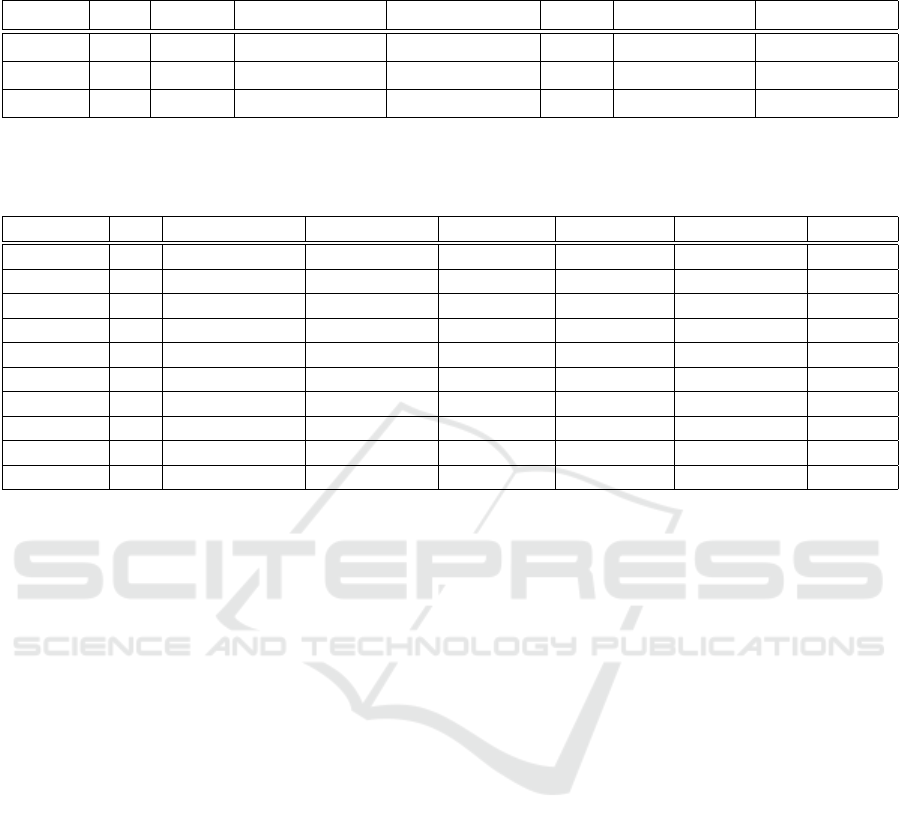
Table 3: Mean model accuracies for each closed-set adaptation model per number of classes. (a) refers to using all synthetic
augmented data, while (b) refers to using synthetic data with manual selection.
Classes SO CADN CADN+DB (a) CADN+DB (b) MDD MDD+DB (a) MDD+DB (b)
31 0.80 0.83 0.85 0.87 0.84 0.84 0.85
20 0.81 0.90 0.93 0.90 0.92 0.89 0.89
10 0.88 0.92 0.90 0.87 0.98 0.94 0.94
Table 4: Mean per-class accuracy for each model for the 10 class scenario. (a) refers to using all synthetic augmented data,
while (b) refers to using synthetic data with manual selection. We consider the best cases for each method. For NUDA,
per-class accuracy for the first classifier is reported.
Class SO DANCE+DB (b) NUDA+DB (a) ETN+DB (b) UAN+DB (a) CDAN+DB (b) MMD (a)
backpack 0.90 0.92 1.0 1.0 0.96 0.97 1.0
bike 1.0 1.0 1.0 1.0 1.0 1.0 1.0
calculator 0.47 0.5 0.82 0.82 1.0 0.43 0.71
headphones 0.82 0.96 1.0 1.0 1.0 1.0 1.0
keyboard 1.0 1.0 1.0 1.0 1.0 1.0 1.0
laptop 0.67 0.90 0.87 1.0 0.89 0.87 0.93
monitor 0.85 0.91 0.95 0.97 1.0 0.74 0.93
mouse 1.0 1.0 1.0 1.0 0.98 0.97 0.97
mug 0.99 0.95 1.0 1.0 1.0 1.0 1.0
projector 0.95 0.73 0.77 0.97 0.91 0.83 0.93
to sort the bad synthetic samples that could produce
negative transfer. For ETN and UAN, there is no
significant change in overall accuracies, so while the
augmented data does not necessarily improve model
performance, it does not hinder it either. The re-
sults are similar for all augmented data and manu-
ally selected data. This is likely thanks to the aux-
iliary discriminators in these models, which are al-
ready filtering/re-weighting potential bad synthetic
samples. For DANCE, model performance is slightly
worse for synthetic augmented data, while results for
manually chosen data are comparable to the model-
only case. This could indicate the presence of nega-
tive transfer from bad synthetic samples, as this model
does not have a module to filter out/weight out sam-
ples that may negatively affect the DA. This could
also be caused by the neighbor clustering module,
which be produce an unstable classification border for
the classes.
CDAN shows an increase in mean accuracy of up
to 4% for 31 classes when considering manual selec-
tion, while it has an increase of 2% when using all
synthetic data. In contrast, in the the other cases, there
is no significant improvement. This is likely because
of its multi-lineal conditioning, which may be sensi-
tive to the distribution of synthetic data in the latent
space when dealing with a lower number of classes
but has a positive impact as more classes are consid-
ered. MMD does not display any increase in accuracy
considering augmented data, and there is even a de-
crease in accuracy for 20 and 10 classes when com-
pared with the model trained only on Few-shot data.
This could be explained by the distribution of syn-
thetic data, which may play against the minimization
of the inter-class density of this method, in addition
to the fact that there is no technique to filter out bad
samples that may not closely align to the distribution
of the original data.
Table 3 presents the results of the mean per-class
accuracies for each model for the 10 class Few-shot
scenario. We can observe the positive effect of syn-
thetic augmented data at the per-class level, as almost
all classes have their classification accuracy improved
in the Few-shot scenario. In general, most of them
have an average increase of 3% to 10%, with the ex-
ception of the class ”calculator”, which is able to im-
prove by up to 30% when using NUDA and ETN.
Some classes in DANCE and CDAN present worse
accuracy (e.g., ”projector”), probably due to negative
transfer, but no significant negative transfer is seen
when using NUDA and ETN (sauf for ”projector”),
so these methods seem to be robust when combined
with our approach.
Generative Data Augmentation for Few-Shot Domain Adaptation
261

Table 5: Mean per-class accuracy for DANCE-only, DANCE+Dreambooth with augmented data using a single-model (I), and
DANCE+Dreambooth with augmented data using a triple-model (II).
Class DANCE-only DANCE+DB(I) DANCE+DB(II)
backpack 0.71 0.83 0.97
bike 1.0 1.0 1.0
calculator 0.78 0.43 0.50
headphones 0.82 0.94 0.99
keyboard 0.80 1.0 1.0
laptop computer 0.61 0.75 0.95
monitor 0.74 0.77 0.86
mouse 0.90 0.93 0.92
mug 0.85 0.89 0.92
projector 0.68 0.91 0.70
Figure 2: Effect of training steps in DM fine-tuning for Dreambooth image generation.
5 ABLATION ANALYSIS
5.1 Hyperparameter Tuning
We studied the effect of Dreambooth hyperparame-
ters on the quality of image generation with the fine-
tuned diffusion model. First, we considered the num-
ber of training steps and generated images with 100
inference steps using the same prompt. Increasing the
number of training steps generally leads to a better
representation of the target domain and visualization
of the object in the generated prompts (Figure 2).
We also explored the effect of the guidance rate
on the quality of image generation for fixed training
steps. Results for the class backpack are shown in
Figure 3. Both for the single-model and the triple-
model, the optimal values were in the range of 6.5-
7.5, usually with the higher end being better for ob-
jects with more complex compositions. On the other
hand, more specific prompts (e.g., p=”photo of zwx
backpack leaning against wall facing left”) did not af-
fect image diversity in comparison with already well-
targeted prompts (e.g., p=”photo of zwx backpack
leaning against wall”), so we opted for the later one.
Negative prompts did not have a significant effect on
image quality generation.
5.2 Single-Model versus Triple-Model
Considering the DANCE algorithm as a backbone for
DA, we studied the effect of using the single-model
(3 original images, 24 synthetic images) versus the
triple-model approach (11+1 original images, 8+8+8
synthetic images) on model accuracies. The results in
Table 4 differ slightly from the ones in Table 3 since
this analysis was performed with a smaller set of aug-
mented synthetic data (10 images for each case) and
calculating mean accuracy for the last 2000 iterations.
While the use of synthetic data does improve
mean performance with respect to the non-augmented
data case, there is not much difference between over-
all accuracies with the single-model (I) and triple-
model (II). Some classes like laptop computer and
monitor show an improvement for the triple-model.
In contrast, the class ”projector” shows a decrease in
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
262

Figure 3: Effect of specific prompts and guidance scale in DM fine-tuning for Dreambooth image generation.
accuracy, as the diversity from the original data set
was probably not captured by the triple-model.
Therefore, while it seems that the triple-model
yields slightly better results at the per-class level, with
small improvements in mean accuracy, it becomes
more computationally expensive when considering a
greater number of classes. For this reason, we opted
for the single-model approach for our experiments
with multiple DA methods.
5.3 Effect of Image Selection
While DANCE and CDAN have a clear improvement
when considering manual image selection, this selec-
tion becomes unnecessary for methods that are able to
filter out bad samples, such as Non-Noisy UDA and
ETN (Section 4). So, while manual selection may be
convenient for scenarios with a small class number,
in cases with time or budgetary constraints, it is not
strictly necessary to perform additional selection as
long as a proper DA method is implemented.
5.4 Effect of Number of Classes
The best results for DA are generally obtained for the
10-class case, which is expected as models are less
likely to misclassify objects in this case (Section 4).
In addition, the fewer classes considered in Few-shot
scenarios, the less likely it is that bad samples from
synthetic image generation will affect model perfor-
mance. However, the greatest improvements when
comparing the model with synthetic augmented data
with respect to the ones without augmented data can
be observed for the 31-class case, in particular for
NUDA and CDAN. This strongly suggests that num-
ber of classes, something that may be common in in-
dustries that deal with a wide variety of different prod-
ucts and objects.
6 CONCLUSIONS
We have presented an innovative approach using fine-
tuned diffusion models with Dreambooth for syn-
thetic data augmentation to address the problem of
Few-shot multi-class classification in domain adap-
tation. We have detailed the steps and considera-
Generative Data Augmentation for Few-Shot Domain Adaptation
263

tions to follow when performing fine-tuning for dif-
fusion model-assisted data augmentation and how to
combine it with state-of-the-art DA models. We ob-
serve that we can generate additional synthetic data
that captures the target domain for each class and im-
proves model accuracies over their non-augmented
counterparts. Our approach is model-agnostic and
easy-to-implement, converting the Few-shot problem
into a standard problem of DA. While not all DA
models (e.g., UAN) may benefit from this approach,
other methods do show an improvement in their av-
erage and per-class accuracy (e.g., NUDA, CDAN),
showcasing the prospective application of this tech-
nique to real-world scenarios. This is the first work
that, to our knowledge, has considered this combina-
tion of these methods to address multi-class classifi-
cation.
Future work could consider the open-set and par-
tial open-set cases for few-shot scenarios to study
how the presence of potentially bad synthetic samples
may affect the accuracy in the presence of unknown
classes, as well as a more exhaustive study on the
trade-off between the single-model and triple-model
fine tuning strategies.
ACKNOWLEDGEMENTS
The following research was financed with a fel-
lowship from the Japan International Cooperation
Agency (JICA), as part of its Japan-Mexico Training
Program for the Strategic Global Partnership 2023.
We would also like to thank the Graduate School of
Information and Engineering at Ritsumeikan Univer-
sity Campus for its kind support.
REFERENCES
Bashkirova, D., Mishra, S., Lteif, D., Teterwak, P., Kim, D.,
Alladkani, F., Akl, J., Calli, B., Bargal, S. A., Saenko,
K., Kim, D., Seo, M., Jeon, Y., Choi, D.-G., Ettedgui,
S., Giryes, R., Abu-Hussein, S., Xie, B., and Li, S.
(2023). Visda 2022 challenge: Domain adaptation for
industrial waste sorting.
Benigmim, Y., Roy, S., Essid, S., Kalogeiton, V., and Lath-
uili
`
ere, S. (2023). One-shot unsupervised domain
adaptation with personalized diffusion models. arXiv
preprint arXiv:2303.18080.
Cao, Z., Ma, L., Long, M., and Wang, J. (2018). Partial
adversarial domain adaptation. In Proceedings of the
European Conference on Computer Vision (ECCV).
Cao, Z., You, K., Long, M., Wang, J., and Yang, Q. (2019).
Learning to transfer examples for partial domain adap-
tation. In 2019 IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR), pages 2980–
2989.
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano,
A. H., Chechik, G., and Cohen-Or, D. (2022). An
image is worth one word: Personalizing text-to-image
generation using textual inversion.
Ganin, Y. and Lempitsky, V. (2015). Unsupervised do-
main adaptation by backpropagation. In Bach, F. and
Blei, D., editors, Proceedings of the 32nd Interna-
tional Conference on Machine Learning, volume 37
of Proceedings of Machine Learning Research, pages
1180–1189, Lille, France. PMLR.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P.,
Larochelle, H., Laviolette, F., Marchand, M., and
Lempitsky, V. (2016). Domain-adversarial training of
neural networks. 17(1):2096–2030.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A., and Ben-
gio, Y. (2014). Generative adversarial nets. In Ghahra-
mani, Z., Welling, M., Cortes, C., Lawrence, N., and
Weinberger, K., editors, Advances in Neural Infor-
mation Processing Systems, volume 27. Curran Asso-
ciates, Inc.
Li, J., Chen, E., Ding, Z., Zhu, L., Lu, K., and Shen,
H. T. (2021). Maximum density divergence for do-
main adaptation. IEEE Transactions on Pattern Anal-
ysis and Machine Intelligence, 43(11):3918–3930.
Liu, X., Yoo, C., Xing, F., Oh, H., Fakhri, G., Kang, J.-W.,
and Woo, J. (2022). Deep unsupervised domain adap-
tation: A review of recent advances and perspectives.
APSIPA Transactions on Signal and Information Pro-
cessing.
Long, M., Cao, Y., Wang, J., and Jordan, M. (2015). Learn-
ing transferable features with deep adaptation net-
works. In Bach, F. and Blei, D., editors, Proceed-
ings of the 32nd International Conference on Ma-
chine Learning, volume 37 of Proceedings of Machine
Learning Research, pages 97–105, Lille, France.
PMLR.
Long, M., CAO, Z., Wang, J., and Jordan, M. I. (2018).
Conditional adversarial domain adaptation. In Bengio,
S., Wallach, H., Larochelle, H., Grauman, K., Cesa-
Bianchi, N., and Garnett, R., editors, Advances in
Neural Information Processing Systems, volume 31.
Curran Associates, Inc.
Motiian, S., Jones, Q., Iranmanesh, S. M., and Doretto,
G. (2017). Few-shot adversarial domain adaptation.
In Proceedings of the 31st International Conference
on Neural Information Processing Systems, NIPS’17,
page 6673–6683, Red Hook, NY, USA. Curran Asso-
ciates Inc.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Om-
mer, B. (2021). High-resolution image synthesis with
latent diffusion models.
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., and
Aberman, K. (2022). Dreambooth: Fine tuning text-
to-image diffusion models for subject-driven genera-
tion.
Saito, K., Kim, D., Sclaroff, S., and Saenko, K. (2020). Uni-
versal domain adaptation through self supervision. In
ICPRAM 2024 - 13th International Conference on Pattern Recognition Applications and Methods
264

Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.,
and Lin, H., editors, Advances in Neural Information
Processing Systems, volume 33, pages 16282–16292.
Curran Associates, Inc.
Shirao, S. (2022). Github: Stable diffusion + dreambooth.
https://github.com/ShivamShrirao/diffusers/tree/main
/examples/dreambooth.
Xu, R., Li, G., Yang, J., and Lin, L. (2019). Larger
norm more transferable: An adaptive feature norm ap-
proach for unsupervised domain adaptation. In 2019
IEEE/CVF International Conference on Computer Vi-
sion (ICCV), pages 1426–1435.
Yang, C., Shen, Y., Zhang, Z., Xu, Y., Zhu, J., Wu, Z., and
Zhou, B. (2021). One-shot generative domain adapta-
tion.
You, K., Long, M., Cao, Z., Wang, J., and Jordan, M. I.
(2019). Universal domain adaptation. In The IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR).
Yu, Q., Hashimoto, A., and Ushiku, Y. (2023). Noisy uni-
versal domain adaptation via divergence optimization
for visual recognition.
Zhang, L. and Agrawala, M. (2023). Adding Condi-
tional Control to Text-to-Image Diffusion Models.
arXiv:2302.05543 [cs].
Zhao, A., Ding, M., Lu, Z., Xiang, T., Niu, Y., Guan, J., and
Wen, J.-R. (2021). Domain-adaptive few-shot learn-
ing. In Proceedings of the IEEE/CVF Winter Con-
ference on Applications of Computer Vision (WACV),
pages 1390–1399.
Generative Data Augmentation for Few-Shot Domain Adaptation
265
