
BEVSeg2TP: Surround View Camera Bird’s-Eye-View Based Joint
Vehicle Segmentation and Ego Vehicle Trajectory Prediction
Sushil Sharma
1,2
, Arindam Das
1
, Ganesh Sistu
1
, Mark Halton
1
and Ciar
´
an Eising
1,2
1
Department of Electronic & Computer Engineering, University of Limerick, Ireland
2
SFI CRT Foundations in Data Science, University of Limerick, Ireland
{firstname.lastname}@ul.ie
Keywords:
Surrounded-View Camera, Encoder-Decoder Transformer, Segmentation, Trajectory Prediction.
Abstract:
Trajectory prediction is, naturally, a key task for vehicle autonomy. While the number of traffic rules is lim-
ited, the combinations and uncertainties associated with each agent’s behaviour in real-world scenarios are
nearly impossible to encode. Consequently, there is a growing interest in learning-based trajectory prediction.
The proposed method in this paper predicts trajectories by considering perception and trajectory prediction
as a unified system. In considering them as unified tasks, we show that there is the potential to improve
the performance of perception. To achieve these goals, we present BEVSeg2TP - a surround-view camera
bird’s-eye-view-based joint vehicle segmentation and ego vehicle trajectory prediction system for autonomous
vehicles. The proposed system uses a network trained on multiple camera views. The images are transformed
using several deep learning techniques to perform semantic segmentation of objects, including other vehicles,
in the scene. The segmentation outputs are fused across the camera views to obtain a comprehensive repre-
sentation of the surrounding vehicles from the bird’s-eye-view perspective. The system further predicts the
future trajectory of the ego vehicle using a spatiotemporal probabilistic network (STPN) to optimize trajectory
prediction. This network leverages information from encoder-decoder transformers and joint vehicle segmen-
tation. The predicted trajectories are projected back to the ego vehicle’s bird’s-eye-view perspective to provide
a holistic understanding of the surrounding traffic dynamics, thus achieving safe and effective driving for vehi-
cle autonomy. The present study suggests that transformer-based models that use cross-attention information
can improve the accuracy of trajectory prediction for autonomous driving perception systems. Our proposed
method outperforms existing state-of-the-art approaches on the publicly available nuScenes dataset. This link
is to be followed for the source code: https://github.com/sharmasushil/BEVSeg2TP/.
1 INTRODUCTION
Accurate trajectory prediction is a critical capabil-
ity for autonomous driving systems, playing a piv-
otal role in enhancing safety, efficiency, and driv-
ing policies. This technology is increasingly vital
as autonomous vehicles become more prevalent on
public roads, as it enables these vehicles to antic-
ipate the movements of various road users, includ-
ing pedestrians, cyclists, and other vehicles. By do-
ing so, autonomous vehicles can proactively plan and
execute safe manoeuvres, reducing the risk of po-
tential collisions (Li and Guo, 2021; Cheng et al.,
2019) and effectively navigating through complex
traffic scenarios. Moreover, trajectory prediction em-
powers autonomous vehicles to optimise their driv-
ing behaviour, enabling smoother lane changes (Chen
et al., 2020) and seamless merging to improve over-
all traffic flow and reduce congestion (Wei et al.,
2021). Furthermore, trajectory prediction also plays
a crucial role in facilitating effective communication
and interaction between autonomous vehicles, human
drivers, and pedestrians. By behaving predictably, au-
tonomous vehicles can earn the trust of other road
users (Liu et al., 2021; Yang et al., 2021) and support
other extended applications in the ADAS perception
stack, such as pedestrian detection (Das et al., 2023;
Dasgupta et al., 2022), and pose estimation (Das et al.,
2022).
In this paper, we introduce an approach called
BEVSeg2TP for joint vehicle segmentation and ego
vehicle trajectory prediction, leveraging a bird’s-
eye-view perspective from surround-view cameras.
Our proposed system employs a network trained on
Sharma, S., Das, A., Sistu, G., Halton, M. and Eising, C.
BEVSeg2TP: Surround View Camera Bird’s-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction.
DOI: 10.5220/0012321700003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 4: VISAPP, pages
25-34
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
25
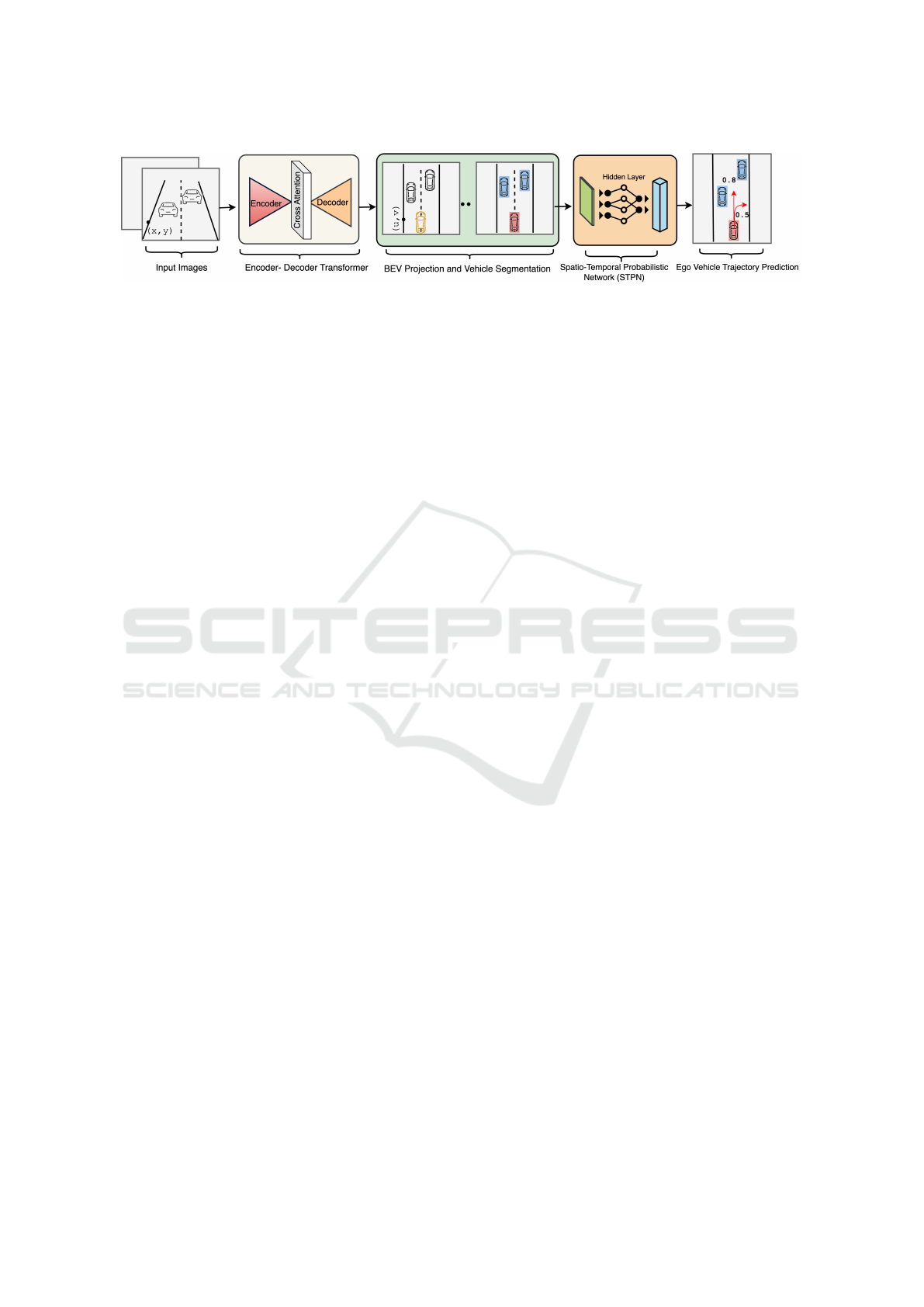
Figure 1: Our proposed BEVSeg2TP framework - surround-view camera joint vehicle segmentation and ego vehicle
trajectory prediction in bird’s-eye-view approach consists of an encoder-decoder transformer, BEV projection module
followed by segmentation outputs fed to the spatio-temporal probabilistic network to produce ego vehicle trajectory prediction.
surround-view or multi-camera view from the host
vehicle, which it transforms into bird’s-eye-view im-
agery of the surrounding context. These images un-
dergo deep learning-driven processes to perform se-
mantic segmentation on objects, including neighbor-
ing vehicles within the scene. The segmentation out-
comes are then amalgamated across camera perspec-
tives to generate a comprehensive representation of
the surrounding vehicles from a bird’s-eye-view per-
spective (Zhou and Kr
¨
ahenb
¨
uhl, 2022). Building
upon this segmented data, the proposed system also
anticipates the future trajectories of the host vehicle
using a spatio-temporal probabilistic network (STPN)
(Cui et al., 2019). The STPN learns the spatiotempo-
ral patterns of vehicle motion from historical trajec-
tory data. The predicted trajectories are then projected
back to the ego vehicle’s bird’s-eye-view perspective
to provide a holistic understanding of the surrounding
traffic dynamics. Figure 1 represents the overarch-
ing depiction of our approach. Our principal contri-
butions to the BEVSeg2TP proposal are:
• Our proposed deep architecture offers an ap-
proach to jointly accomplish vehicle segmenta-
tion and ego vehicle trajectory prediction tasks by
combining and adapting the works of (Zhou and
Kr
¨
ahenb
¨
uhl, 2022; Phan-Minh et al., 2020; Cui
et al., 2019).
• We propose enhancements to the capabilities of
the current encoder-decoder transformer used in
the spatio-temporal probabilistic network (STPN)
for optimizing trajectory prediction.
• We implemented an end-to-end trainable
surround-view camera bird’s-eye-view-based
network that achieves state-of-the-art results on
the nuScenes dataset (Caesar et al., 2020) when
jointly trained with segmentation.
2 PRIOR ART
Joint vehicle segmentation and ego vehicle trajectory
prediction using a surround or multi-camera bird’s-
eye view is currently an emerging area of research
with several motivating factors. Firstly, working on
this problem could help advance the field and con-
tribute to the development of more effective and accu-
rate autonomous driving systems. The potential uses
of precise vehicle segmentation and predictions for
ego vehicle trajectories are vast, encompassing do-
mains such as self-driving vehicles, intelligent trans-
portation systems, and automated driving systems,
among others.
Moreover, this problem is complex and challeng-
ing, requiring the integration of information from
multiple sensors and camera views. Addressing the
technical challenges of this problem, such as design-
ing effective deep learning models or developing ef-
ficient algorithms, could be a motivating factor for
researchers interested in solving complex and chal-
lenging problems. Our primary focus is on enhancing
map-view segmentation. It is undeniable that exten-
sive research has been conducted in this field, which
lies at the convergence of 3D recognition (Ma et al.,
2019; Lai et al., 2023; Manhardt et al., 2019), depth
estimation (Eigen et al., 2014; Godard et al., 2019;
Ranftl et al., 2020; Zhou et al., 2017), and mapping
(Garnett et al., 2019; Sengupta et al., 2012; Zhu et al.,
2021).
These are the key areas that can facilitate segmen-
tation construction and improvement. While trajec-
tory prediction or motion planning for autonomous
systems is crucial, we acknowledge the need to con-
sider various aspects of the vehicle state, such as cur-
rent position and velocity, road geometry (Lee and
Kim, 2016; Wiest et al., 2020; Wu et al., 2017), other
vehicles, environmental factors, and driver behaviour
(Zhang et al., 2020; Abbink et al., 2017; McDonald
and Mazumdar, 2020). The architecture previously
described by the authors (Sharma et al., 2023) ex-
plores the utilization of the CNN-LSTM model for
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
26

predicting trajectories, covering unique scenarios like
pedestrians crossing roads. While the model adeptly
comprehends these scenarios, it adheres to a model-
driven methodology, thereby carrying inherent lim-
itations. In our pursuit to address these limitations
and devise an alternative approach, we propose the
integration of a transformer-based model into our tra-
jectory prediction methodology. Our strategy entails
a partial adoption of the principles from CoverNet
(Phan-Minh et al., 2020), albeit with notable distinc-
tions. CoverNet’s trajectory prediction relies on raster
maps, whereas our model pivots towards real-time
map view representations.
3 PROPOSED METHODOLOGY
In this section, we present BEVSeg2TP - our
proposed deep architecture designed to efficiently
achieve both vehicle segmentation and ego vehicle
trajectory prediction tasks simultaneously. The pro-
posed method, as depicted in Figure 2, utilizes mul-
tiple cameras to create a comprehensive view of the
environment around the ego vehicle, improving ego
vehicle and object segmentation, based on the work
presented by (Zhou and Kr
¨
ahenb
¨
uhl, 2022). We ex-
tend this transformer technique to incorporate trajec-
tory prediction using a spatio-temporal probabilistic
network to calculate path likelihoods, as presented in
(Phan-Minh et al., 2020; Cui et al., 2019). This ap-
proach combines multiple sources of information for
more accurate future trajectory predictions, enhanc-
ing self-driving car safety and performance by jointly
learning the segmentation and the trajectory predic-
tion.
3.1 Surround-View Camera Inputs
The dataset used in this paper is nuScenes (Caesar
et al., 2020). It consists of six cameras located on
the vehicle, providing a 360
◦
field of view. All cam-
eras in each scene have extrinsic (R,t) and intrinsic K
calibration parameters provided at every timestamp;
the intrinsic parameters remain unchanged with time.
Other perception sensors in the nuScenes dataset
(radar and lidar) are not used in this work.
3.2 Image Encoder
We use the simple and effective encoder-decoder ar-
chitecture for map-view semantic segmentation from
(Zhou and Kr
¨
ahenb
¨
uhl, 2022). In summary, the au-
thors proposed an image encoder that generates a
multi-scale feature representation {φ} for each input
image, which is then combined into a shared map-
view representation using a cross-view cross-attention
mechanism. This attention mechanism utilizes a po-
sitional embedding {δ} to capture both the geomet-
ric structure of the scene, allowing for accurate spa-
tial alignment, and the sequential information be-
tween different camera views, facilitating temporal
understanding and context integration. All camera-
aware positional embeddings are presented as a sin-
gle key vector δ = [δ
1
, δ
2
......δ
6
]. Image features are
combined into a value vector φ = [φ
1
, φ
2
.....]. Both
are merged to create a comparison of attention keys
and subsequently, a softmax-cross attention is used
(Vaswani et al., 2017).
3.3 Cross Attention
As illustrated in Figure 2, the cross-view transforma-
tion component aims to establish a connection be-
tween a map view and image features, as presented
by (Zhou and Kr
¨
ahenb
¨
uhl, 2022). To summarise, pre-
cise depth estimation is not learned; rather, the trans-
former learns a depth proxy through positional em-
bedding {δ} (x
world
remains ambiguous). The cosine
similarity is used to express the geometric relation-
ship between the world and unprojected image coor-
dinates:
cos(θ) =
R
−1
k
K
−1
k
x
image
·
x
world
−t
k
∥R
−1
k
K
−1
k
x
image
∥∥x
world
−t
k
∥
(1)
where denoted as x
image
∈ P
3
is a homogeneous
image point for a given world coordinate x
world
∈ R
3
.
The cosine similarity traditionally relies on precise
world coordinates.
However, in this approach, the cosine similarity
is augmented with positional embeddings, thus hav-
ing the capability to learn both geometric and appear-
ance features (Zhou and Kr
¨
ahenb
¨
uhl, 2022). Direc-
tion vectors d
k,i
= R
−1
k
K
−1
k
x
image
i
are created for each
image coordinate x
image
i
, serving as a reference point
in world coordinates. An MLP is used to convert
the direction vector d
k,i
into a D-dimensional posi-
tional embedding denoted as δ
k,i
∈ R
D
(Per (Zhou
and Kr
¨
ahenb
¨
uhl, 2022), we have set the value of D
to 128).
3.4 Joint Vehicle Segmentation
To enhance the vehicle segmentation, we have de-
signed our segmentation head to be simple, utilizing
a series of convolutions on the bird’s-eye view (BEV)
feature. Specifically, it consists of four 3 ×3 convo-
lutions followed by a 1 ×1 convolution, resulting in
BEVSeg2TP: Surround View Camera Bird’s-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction
27

Figure 2: Our proposed BEVSeg2TP architecture: Joint vehicle segmentation and ego vehicles trajectory prediction in-
volves extracting image features {φ} at multiple scales and using a camera-aware positional embedding {δ} to account for
perspective distortion. We then use map-view positional embedding and cross-attention layers to capture contextual infor-
mation from multiple views and refine the vehicle segmentation. This segmentation information is then used as input to a
spatio-temporal probabilistic network (STPN) for trajectory prediction based on the surrounding environment.
a BEV tensor of size h ×w ×n, where n represents
the number of categories. In our case, we set n to 1,
as we focus solely on the vehicles and other agents
related to it following the approach used in the cross-
view transformer (Zhou and Kr
¨
ahenb
¨
uhl, 2022). To
enhance road and vehicle segmentation in the dataset
using an encoder-decoder transformer, we employ the
following equation:
y = f (X1,X 2)
where y is the output segmentation map, X1 is the
input image from one sensor modality (e.g., camera),
and X 2 is the input image from another sensor modal-
ity (e.g., map information). f is the cross-view trans-
former, which learns to combine the information from
the two modalities to produce a more accurate seg-
mentation map. The cross-attention mechanism can
be implemented using the following equation:
M = softmax
Q.(K
T
)
√
d
k
V (2)
where Q, K, and V are the queries, keys, and values,
respectively, for each modality. The dot product be-
tween the queries and keys is present in the form of
Q.(K
T
) is divided by the square root of the dimen-
sionality of the key vectors (d
k
) to prevent the dot
product from becoming too large. Subsequently, the
obtained attention weights are employed to weigh the
values associated with each modality. These weighted
values are then combined to generate the output fea-
ture map M.
3.5 Spatio-Temporal Probabilistic
Network (STPN)
This section describes the Spatio-temporal prob-
abilistic network for trajectory prediction of the
future states of an ego vehicle and a high-definition
map, assuming that we have access to the state
outputs of an object detection and tracking system of
sufficient quality for autonomous vehicles, based on
(Phan-Minh, 2021). The agents that an ego vehicle
interacts with at time t are denoted by the set I
t
,
and s
i
t
represents the state of agent i ∈ I
t
at time
t. The discrete-time trajectory of agent i for times
t =
m, ....., n) is denoted by s
i
m:n
=
s
i
m
, ......, s
i
n
],
where m < n and i ∈ I
t
.
Additionally, we presume that the high-definition
map, as depicted in our proposed method, will be ac-
cessible. This includes lane geometry, crosswalks,
drivable areas, and other pertinent information. The
scene context over the past m steps, which includes
the map and partial history of ego vehicles, is denoted
by C =
S
i
s
i
t−m:t
;Map Information
.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
28

Our architecture follows the trajectory prediction
layer with the approach presented in (Cui et al., 2019).
To achieve effectiveness in this domain, we employ
ResNet-50 (Table:1) (He et al., 2016), as recom-
mended by previous research (Cui et al., 2019; Chai
et al., 2019). Although our network currently gener-
ates predictions for one agent at a time, our approach
has the potential to predict for multiple agents simul-
taneously in a manner similar to (Chai et al., 2019).
However, we limit our focus to single-agent predic-
tions (as in (Cui et al., 2019)) to streamline the pa-
per and emphasize our primary contributions. To rep-
resent probabilistic trajectory predictions in multiple
modes, we utilize a classification technique that se-
lects the relevant trajectory set based on the agent of
interest and scene context C. The softmax distribution
is employed, as is typical in classification literature.
Specifically, the probability of the k-th trajectory is
expressed as follows:
p(s
k
t:t+N
|x) =
exp f
k
(x)
∑
i
exp f
i
(x)
(3)
where f
i
(x) ∈ R is the output of the network of proba-
bilistic layer. We have implemented Multi-Trajectory
Prediction (MTP) (Cui et al., 2019) with adjustments
made for our datasets. This model forecasts a set
number of trajectories (modes) and determines their
respective probabilities. Note that we are now focus-
ing on single trajectory prediction (STP)(Djuric et al.,
2020).
3.6 Loss Function
The loss function employed for vehicle segmentation
in our transformer-based model is defined as follows:
L
seg
(m,
ˆ
m) = −
1
N
N
∑
i=1
m
i
·log(p( ˆm
i
))
+ (1 −m
i
) ·log(1 − p( ˆm
i
))
(4)
where, L
seg
(m,
ˆ
m) is the binary cross-entropy loss
(Jadon, 2020) for vehicle segmentation, m is the input
tensor, and
ˆ
m is the target tensor for all N points. This
loss function is particularly valuable for binary classi-
fication challenges where our model generates logits
(unbounded real numbers) as output. It facilitates the
computation of the binary cross-entropy loss concern-
ing binary target labels
ˆ
m, ensuring effective training
and performance evaluation for vehicle segmentation
in our transformer-based approach.
In terms of trajectory prediction, the loss function
we are considering is one of the most commonly used:
the mean squared error (MSE). This loss function typ-
ically involves measuring the dissimilarity between
the predicted and the ground-truth trajectories.
L
tra j
=
1
N
N
∑
i=1
||ˆy
i
−y
i
||
2
2
(5)
Here, N is the number of training examples, ˆy
i
is
the predicted trajectory for ego vehicle i, and y
i
is the
corresponding ground truth trajectory. The squared
difference between the two trajectories is calculated
element-wise and then averaged across all elements in
the trajectory. The resulting value is the mean squared
error loss, which measures the overall performance
of the model in predicting the trajectories for the ego
vehicle.
Our final loss function L
total
constitutes two com-
ponents, as shown in the equation below.
L
total
= αL
seg
+ βL
traj
(6)
Gradients are mutually shared by both tasks till the
initial layers of the network. In the above equation,
α and β are the hyperparameters to balance between
segmentation and trajectory prediction losses.
4 EXPERIMENTAL SETUP
4.1 Dataset
Experiments are carried out on the nuScenes dataset
(Caesar et al., 2020), which comprises 1000 video
sequences gathered in Boston and Singapore. The
dataset is composed of scenes that have a duration of
20 seconds and consist of 40 frames each, resulting
in a total of 40k samples. The dataset is divided into
training, validation, and testing sets, with 700, 150,
and 150 scenes respectively. The recorded data pro-
vides a comprehensive 360
◦
view of the surrounding
area around the ego-vehicles and comprises six cam-
era perspectives. Note that we are employing iden-
tical train-test-validation splits as those used in the
previous works (Zhou and Kr
¨
ahenb
¨
uhl, 2022; Philion
and Fidler, 2020) for comparison.
4.2 Transformer Architecture and
Implementation Details
The initial step of the network involves creating a
camera-view representation for each input image. To
achieve this, we utilize EfficientNet-B4 (Tan and Le,
2019) as the feature extractor and input each im-
age I
i
to obtain a multi-resolution patch embedding
δ
1
1
, δ
2
1
, δ
3
1
, .....δ
R
n
, where R denotes the number of
resolutions that are taken into account.
BEVSeg2TP: Surround View Camera Bird’s-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction
29

According to our experimental findings, accurate
results can be achieved when using R = 1 resolution.
However, if we were to increase the value of R to 2, as
suggested by CVT in (Zhou and Kr
¨
ahenb
¨
uhl, 2022),
the camera-view representation for each input image
in the network would incorporate additional informa-
tion, such as BEV features. While this has the po-
tential to result in a more detailed representation of
the input images, it also comes with drawbacks, in-
cluding increased computational requirements and a
higher risk of overfitting.
The processing for each resolution is carried out
individually, beginning with the lowest resolution.
We employ cross-view attention to map all image fea-
tures to a map-view and refine the map-view embed-
ding, repeating this procedure for higher resolutions.
In the end, we employ three up-convolutional lay-
ers to produce the output at full resolution. Once
we obtain the full-resolution output, we input the ego
vehicle features, which have a resolution of h
bev
×
w
bev
×256, into the probabilistic function for trajec-
tory forecasting, resulting in the set of trajectories
[p
1
, p
2
, p
3
, ..., p
n
]. Subsequently, we refine and ob-
tain the probabilistic value, which represents our final
trajectory.
To implement the architecture, we employ a pre-
trained EfficientNet-B4 (Tan and Le, 2019) that we
fine-tune. The two scales, (28, 60) and (14, 30), cor-
respond to an 8× and 16× downscaling, respectively.
For the initial map view positional embedding, we
use a tensor of learned parameters with dimensions
w ×h ×D, where D is set to 128. To ensure computa-
tional efficiency, we limit the grid size to w = h = 25,
as the cross-attention function becomes quadratic in
growth with increasing grid size. The encoder com-
prises two cross-attention blocks, one for each scale
of patch features, which utilize multi-head attention
with 4 heads and an embedding size of d
head
= 64.
The decoder includes three layers of bilinear up-
sampling and convolution, each of which increases
the resolution by a factor of 2 up to the final output
resolution of 200×200, corresponding to a 100 ×100
meter area around the ego-vehicle. The map-view
representation obtained through the cross-attention
transformer is passed through the joint vehicle seg-
mentation module to accurately identify the vehicle’s
segmentation. This segmentation is then utilized as
input to the Spatial-Temporal Probabilistic Network
(STPN), which offers probabilistic predictions. In-
stead of providing a single deterministic trajectory,
the network offers a probability distribution over pos-
sible future trajectories. This information aids in
identifying the motion planning of the ego vehicle.
Precisely segmenting the pixels corresponding to the
ego vehicle enables the system to more accurately es-
timate its position, speed, and orientation in relation
to other objects in the environment. This, in turn,
facilitates improved decision-making during naviga-
tion. Figure 2 offers a comprehensive overview of this
architecture.
5 ABLATION STUDY
We perform a detailed ablation experiment to assess
the influence of several factors on the functionality
of our segmentation model. We specifically exam-
ined the impacts of various backbone models and loss
functions.
Table 1: Comparison study of different standard back-
bone models employed for trajectory prediction on
nuScenes dataset (Caesar et al., 2020).
Backbone # Params. (M) Features MSE ↓
EfficientNet-80 1.9 1280 0.3385
DenseNet-121 1.7 1024 0.2079
ResNet-50 1.4 512 0.1062
We performed an ablation on different backbone
models to investigate their impact on the performance
of our target task on the nuScenes dataset, as pre-
sented in Table 1. Notably, the ResNet-50 back-
bone, with 1.4 million trainable parameters and a
feature size of 512, demonstrated promising results,
achieving the lowest MSE of 0.1062. It is likely that
ResNet-50 works well for trajectory prediction on the
nuScenes dataset, as its model parameters align well
with the characteristics of that dataset.
Table 2: Ablation on different loss functions for segmen-
tation task on the nuScenes dataset (Caesar et al., 2020).
Loss Function No. of Class Loss ↓
Binary Cross Entropy 2 0.1848
Binary Focal Loss 2 0.2758
In our task, we utilize the binary cross-entropy
loss function, which aligns well with the inherent
characteristics of our standard binary classification
problem. Additionally, we explore and compare al-
ternative loss functions, including binary focal loss.
However, our findings indicate that the binary cross-
entropy loss function yields superior results, as pre-
sented in Table 2. This is primarily attributed to the
balanced distribution of classes within our dataset,
which favors the effectiveness of binary cross-entropy
in accurately modeling the classification problem.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
30

Table 3: Comparison of visibility-based methods for Setting 1 and Setting 2, where our method achieves the highest
visibility rate among those with visibility greater than 40%.
Visibility > 40%
Method Setting 1 Setting 2
LSS (Philion and Fidler, 2020) - 32.1
CVT (Zhou and Kr
¨
ahenb
¨
uhl, 2022) 37.5 36.0
BEVSeg2TP (Ours) 37.8 37.9
Table 4: Comparison of vehicle segmentation performance on the nuScene dataset using different methods, including LSS,
CVT, and our proposed method. Results are presented in terms of Intersection over Union (IoU) scores.
Method Resolution R Vehicle ↑
LSS (Philion and Fidler, 2020) - 32.1
CVT (Zhou and Kr
¨
ahenb
¨
uhl, 2022) 2 36.0
BEVSeg2TP (Ours) 1 37.9
Table 5: Comparison of the Minimum Average Prediction Error (MinADE) and Final Displacement Error (MinFDE)
for Competing Methods on the nuScenes Dataset, over a Prediction Horizon of 6 Seconds.
Method MinADE
5
↓ MinADE
10
↓ MinADE
15
↓ MinFDE
5
↓ MinFDE
10
↓ MinFDE
15
↓
Const Vel and Yaw 4.61 4.61 4.61 11.21 11.21 11.21
Physics oracle 3.69 3.69 3.69 9.06 9.06 9.06
CoverNet (Phan-Minh et al., 2020) 2.62 1.92 1.63 11.36 - -
Trajectron++ (Salzmann et al., 2020) 1.88 1.51 - - - -
MTP (Cui et al., 2019) 2.22 1.74 1.55 4.83 3.54 3.05
MultiPath (Chai et al., 2019) 1.78 1.55 1.52 3.62 2.93 2.89
BEVSeg2TP (Ours) 1.63 1.29 1.15 3.85 2.13 1.65
6 RESULTS
We evaluate the BEV map representation and trajec-
tory planning of the BEVSeg2TP model on the pub-
licly available nuScenes dataset. The evaluation is
conducted in two different settings - ’Setting 1’ refers
to a 100m ×50m grid with a 25cm resolution, while
’Setting 2’ refers to a 100m ×100m grid with a 50cm
resolution. During training and validation, vehicles
with a visibility level above the predefined thresh-
old of 40% are considered. Table 3 demonstrates the
comparison of our proposed approach with other ex-
isting works such as LSS (Philion and Fidler, 2020)
and CVT (Zhou and Kr
¨
ahenb
¨
uhl, 2022).
First, we compare the BEV segmentation obtained
from various methods, including LSS and CVT with
the results from our proposed BEVSeg2TP. Accu-
rately predicting the future motion of vehicles is criti-
cal, as it helps the model gain a comprehensive under-
standing of the environment by capturing the spatial
relationships among pedestrians, vehicles, and obsta-
cles. However, our second contribution focuses on
improving map-view segmentation of vehicles. Our
experimental findings show that employing a resolu-
tion of R = 1 yields promising results. However, in-
creasing the value of R to 2, as recommended by CVT,
would lead to the camera-view representation for each
input image in the network losing information, such
as BEV features. We conducted further evaluations
using various methods, as illustrated in Table 4.
As shown in Table 5, the ablation study has been
evaluated by comparing it with four baselines: (Cui
et al., 2019) (Chai et al., 2019) (Phan-Minh et al.,
2020) and (Salzmann et al., 2020) and two physics-
based approaches. These four baselines are a recently
proposed model which is considered to be the cur-
rent state-of-the-art for multimodel trajectory predic-
tion. This comparison aims to assess the effectiveness
and accuracy of our model in predicting trajectories in
comparison to existing models. The goal is to deter-
mine if our model performs better than or at least as
well as the state-of-the-art baseline model. By doing
so, we can gain insight into the strengths and weak-
nesses of our model and identify areas for further im-
provement. To evaluate the performance of our model
on the nuscenes dataset, we first obtained the output
trajectories
y
1
, y
2
, y
3
, ....y
n
. We evaluated the per-
formance of the model on this specific dataset for dif-
ferent values of K, where K was set to 5, 10, and 15
respectively.
MinADE
k
= min
i∈{1...K}
1
T
f
T
f
∑
t=1
y
gt
t
−y
(i)
t
2
(7)
To train the model, we minimized the minimum
BEVSeg2TP: Surround View Camera Bird’s-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction
31

Figure 3: Qualitative results of BEVSeg2TP model for joint vehicle segmentation and ego vehicle trajectory prediction:
Six camera views around the vehicle (top three facing forward, bottom three facing backwards) with ground truth segmentation
on the right. Our trajectory prediction with improved map-view segmentation (second from right) compared to the CVT
method (third from right).
average displacement error over K (MinADE
k
) on the
training set. In other words, we aimed to reduce the
error between the predicted trajectories and the actual
trajectories by minimizing the minimum distance be-
tween them for each of the K time steps. This method
allowed us to improve the accuracy of our model’s
predictions and ensure that it performs well on the
nuScenes dataset. Here, y
gt
t
represents the ground
truth position of the object at the final time step T,
and y
(i)
t
represents the predicted position of the object
at the final time step T for the i
th
trajectory in the set
of K trajectories.
We took the output trajectories
y
1
, y
2
, y
3
, ....y
n
and we used K = 15 for nuscenes datasets. we min-
imize the minimum over K average displacement er-
ror (MinADE
k
) over the training set. As depicted in
Figure 3, on the left-hand side of the image, there
are six camera views surrounding the vehicle. The
top three views are oriented forward, while the bot-
tom three views face backwards. On the right side
of the image, there is ground truth segmentation for
reference. Moving from right to left, the second im-
age from the right displays our trajectory prediction,
along with improved map-view segmentation for ve-
hicles. Lastly, the third image from the right illus-
trates the CVT (Zhou and Kr
¨
ahenb
¨
uhl, 2022) method,
which we use to conduct a comparison and present the
results.
The black color corresponds to the results ob-
tained using a model called CVT, the red color cor-
responds to the results obtained using our model, and
the white color corresponds to the nuScenes ground
truth, which is the true segmentation of the images.
The purpose of the comparison was to evaluate the
performance of the other model and compare it with
our model. Figure 3 reveals that our model performs
well compared to the other model in both vehicle and
road segmentation tasks. When it comes to vehicle
segmentation, our model demonstrates a high level of
accuracy in identifying the precise positions of vehi-
cles within the image. In contrast, the other model ex-
hibits a slightly lower level of accuracy in this regard.
This distinction is clearly visible in the accompany-
ing figure, where the red markings, representing the
outcomes produced by our model, closely align with
the green markings, representing the ground truth, in
comparison to the black markings, which correspond
to the results generated by the other model. Similarly,
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
32

with regard to road segmentation, our model also ex-
hibits decent performance. To gain further insights,
additional results can be explored via the following
link: https://youtu.be/FNBMEUbM3r8.
7 CONCLUSION
In this paper, we propose BEVSeg2TP - a surround-
view camera bird’s-eye-view-based joint vehicle seg-
mentation and ego vehicle trajectory prediction us-
ing encoder-decoder transformer-based techniques
that have shown promising results in achieving safe
and effective driving for autonomous vehicles. The
system processes images from multiple cameras
mounted on the vehicle, performs semantic segmen-
tation of objects in the scene, and predicts the future
ego vehicle trajectory of surrounding vehicles using a
combination of transformer and spatio-temporal prob-
abilistic network (STPN) to calculate the trajectory.
The predicted trajectories are projected back to the
ego vehicle’s bird’s-eye-view perspective, providing
a comprehensive understanding of the surrounding
traffic dynamics. Our findings underscore the poten-
tial benefits of employing transformer-based models
in conjunction with spatio-temporal networks, high-
lighting their capacity to significantly enhance trajec-
tory prediction accuracy. Ultimately, these advance-
ments contribute to the overarching goal of achieving
a safer and more efficient autonomous driving experi-
ence.
While the camera configuration of nuScenes is
important, it is not a typical commercially deployed
surround-view system. Commercial surround view
systems, used for both viewing and vehicle automa-
tion and perception tasks (Kumar et al., 2023; Eis-
ing et al., 2022), typically employ a set of four fish-
eye cameras around the vehicle. In the future, we in-
tend to apply the methods discussed here to fisheye
surround-view camera systems.
ACKNOWLEDGEMENTS
This publication has emanated from research sup-
ported in part by a grant from Science Foundation
Ireland under Grant number 18/CRT/6049. For the
purpose of Open Access, the author has applied a CC
BY public copyright licence to any Author Accepted
Manuscript version arising from this submission.
REFERENCES
Abbink, D. A., Mulder, M., and de Winter, J. C. (2017).
Driver behavior in automated driving: Results from a
field operational test. Transportation Research Part F:
Traffic Psychology and Behaviour, 45:93–106.
Caesar, H., Bankiti, V., Lang, A. H., Vora, S., Liong, V. E.,
Xu, Q., Krishnan, A., Pan, Y., Baldan, G., and Bei-
jbom, O. (2020). nuscenes: A multimodal dataset for
autonomous driving. In Proceedings of the IEEE/CVF
conference on computer vision and pattern recogni-
tion, pages 11621–11631.
Chai, Y., Sapp, B., Bansal, M., and Anguelov, D. (2019).
Multipath: Multiple probabilistic anchor trajectory
hypotheses for behavior prediction. arXiv preprint
arXiv:1910.05449.
Chen, D., Jiang, L., Wang, Y., and Li, Z. (2020). Au-
tonomous driving using safe reinforcement learning
by incorporating a regret-based human lane-changing
decision model. In 2020 American Control Confer-
ence (ACC), pages 4355–4361. IEEE.
Cheng, H., Wang, Y., and Wu, J. (2019). Research on
the design of an intelligent vehicle collision avoidance
system. In Journal of Physics: Conference Series, vol-
ume 1239, page 012096.
Cui, H., Radosavljevic, V., Chou, F.-C., Lin, T.-H., Nguyen,
T., Huang, T.-K., Schneider, J., and Djuric, N. (2019).
Multimodal trajectory predictions for autonomous
driving using deep convolutional networks. In 2019
International Conference on Robotics and Automation
(ICRA), pages 2090–2096. IEEE.
Das, A., Das, S., Sistu, G., Horgan, J., Bhattacharya, U.,
Jones, E., Glavin, M., and Eising, C. (2022). Deep
multi-task networks for occluded pedestrian pose es-
timation. Irish Machine Vision and Image Processing
Conference.
Das, A., Das, S., Sistu, G., Horgan, J., Bhattacharya, U.,
Jones, E., Glavin, M., and Eising, C. (2023). Revisit-
ing modality imbalance in multimodal pedestrian de-
tection. In 2023 IEEE International Conference on
Image Processing (ICIP), pages 1755–1759.
Dasgupta, K., Das, A., Das, S., Bhattacharya, U.,
and Yogamani, S. (2022). Spatio-contextual deep
network-based multimodal pedestrian detection for
autonomous driving. IEEE transactions on intelligent
transportation systems, 23(9):15940–15950.
Djuric, N., Radosavljevic, V., Cui, H., Nguyen, T., Chou,
F.-C., Lin, T.-H., Singh, N., and Schneider, J. (2020).
Uncertainty-aware short-term motion prediction of
traffic actors for autonomous driving. In Proceedings
of the IEEE/CVF Winter Conference on Applications
of Computer Vision, pages 2095–2104.
Eigen, D., Puhrsch, C., and Fergus, R. (2014). Depth map
prediction from a single image using a multi-scale
deep network. Advances in neural information pro-
cessing systems, 27.
Eising, C., Horgan, J., and Yogamani, S. (2022). Near-field
perception for low-speed vehicle automation using
surround-view fisheye cameras. IEEE Transactions
on Intelligent Transportation Systems, 23(9):13976–
13993.
BEVSeg2TP: Surround View Camera Bird’s-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction
33

Garnett, N., Cohen, R., Pe’er, T., Lahav, R., and Levi, D.
(2019). 3d-lanenet: end-to-end 3d multiple lane detec-
tion. In Proceedings of the IEEE/CVF International
Conference on Computer Vision, pages 2921–2930.
Godard, C., Mac Aodha, O., Firman, M., and Brostow, G. J.
(2019). Digging into self-supervised monocular depth
estimation. In Proceedings of the IEEE/CVF interna-
tional conference on computer vision.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In 2016 IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 770–778.
Jadon, S. (2020). A survey of loss functions for semantic
segmentation. In 2020 IEEE conference on compu-
tational intelligence in bioinformatics and computa-
tional biology (CIBCB), pages 1–7. IEEE.
Kumar, V. R., Eising, C., Witt, C., and Yogamani, S. K.
(2023). Surround-view fisheye camera perception for
automated driving: Overview, survey & challenges.
IEEE Transactions on Intelligent Transportation Sys-
tems, 24(4):3638–3659.
Lai, X., Chen, Y., Lu, F., Liu, J., and Jia, J. (2023). Spheri-
cal transformer for lidar-based 3d recognition. In Pro-
ceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition, pages 17545–17555.
Lee, J. and Kim, J. (2016). Road geometry recognition for
intelligent vehicles: a survey. International Journal of
Automotive Technology, 17(1):1–10.
Li, Y. and Guo, Q. (2021). Intelligent vehicle collision
avoidance technology and its applications. Journal of
Advanced Transportation, 2021:6623769.
Liu, Y., Li, X., Li, X., Li, Z., Wu, C., and Li, J. (2021).
Autonomous vehicles and human factors: A review of
the literature. IEEE Access, 9:38416–38434.
Ma, X., Wang, Z., Li, H., Zhang, P., Ouyang, W., and Fan,
X. (2019). Accurate monocular 3d object detection
via color-embedded 3d reconstruction for autonomous
driving. In Proceedings of the IEEE/CVF Interna-
tional Conference on Computer Vision.
Manhardt, F., Kehl, W., and Gaidon, A. (2019). Roi-10d:
Monocular lifting of 2d detection to 6d pose and met-
ric shape. In Proceedings of the IEEE/CVF Confer-
ence on Computer Vision and Pattern Recognition.
McDonald, M. and Mazumdar, S. (2020). Drivers’ per-
ceived benefits and barriers of advanced driver as-
sistance systems (adas) in the uk. Transportation
Research Part F: Traffic Psychology and Behaviour,
73:1–16.
Phan-Minh, T. (2021). Contract-based design: Theories
and applications. PhD thesis, California Institute of
Technology.
Phan-Minh, T., Grigore, E. C., Boulton, F. A., Beijbom, O.,
and Wolff, E. M. (2020). Covernet: Multimodal be-
havior prediction using trajectory sets. In Proceedings
of the IEEE/CVF conference on computer vision and
pattern recognition, pages 14074–14083.
Philion, J. and Fidler, S. (2020). Lift, splat, shoot: Encod-
ing images from arbitrary camera rigs by implicitly
unprojecting to 3d. In Computer Vision–ECCV 2020:
16th European Conference, Glasgow, UK, August 23–
28, 2020, Proceedings, Part XIV 16. Springer.
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., and
Koltun, V. (2020). Towards robust monocular depth
estimation: Mixing datasets for zero-shot cross-
dataset transfer. IEEE transactions on pattern anal-
ysis and machine intelligence, 44(3):1623–1637.
Salzmann, T., Ivanovic, B., Chakravarty, P., and Pavone,
M. (2020). Trajectron++: Dynamically-feasible tra-
jectory forecasting with heterogeneous data. In Com-
puter Vision–ECCV 2020: 16th European Confer-
ence, Glasgow, UK, August 23–28, 2020, Proceed-
ings, Part XVIII 16, pages 683–700. Springer.
Sengupta, S., Sturgess, P., Torr, P., et al. (2012). Automatic
dense visual semantic mapping from street-level im-
agery. in 2012 ieee. In RSJ International Conference
on Intelligent Robots and Systems, pages 857–862.
Sharma, S., Sistu, G., Yahiaoui, L., Das, A., Halton, M.,
and Eising, C. (2023). Navigating uncertainty: The
role of short-term trajectory prediction in autonomous
vehicle safety. In Proceedings of the Irish Machine
Vision and Image Processing Conference.
Tan, M. and Le, Q. (2019). Efficientnet: Rethinking model
scaling for convolutional neural networks. In Interna-
tional conference on machine learning. PMLR.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I.
(2017). Attention is all you need. Advances in neural
information processing systems, 30.
Wei, Y., Cheng, S., Wu, Y., and Liu, Y. (2021). Traffic con-
gestion prediction and control using machine learning:
A review. IEEE Transactions on Intelligent Trans-
portation Systems, 22(7):4176–4195.
Wiest, J., Omari, S., K
¨
ohler, J., L
¨
utzenberger, M., and
Ziegler, J. (2020). Learning to predict the effect of
road geometry on vehicle trajectories for autonomous
driving. IEEE Robotics and Automation Letters,
5(2):2426–2433.
Wu, C., Li, X., Li, X., and Guo, K. (2017). Road geometry
modeling and analysis for vehicle dynamics control.
Mechanical Systems and Signal Processing.
Yang, Y., Chen, Y., and Zhang, J. (2021). A survey on
human-autonomous vehicle interaction: Past, present
and future. IEEE Transactions on Intelligent Vehicles,
6(2):141–154.
Zhang, Y., Liu, H., Shen, S., and Wang, D. (2020). Multi-
modal trajectory prediction with maneuver-based mo-
tion prediction and driver behavior modeling. IEEE
Robotics and Automation Letters, 5(4):5461–5468.
Zhou, B. and Kr
¨
ahenb
¨
uhl, P. (2022). Cross-view transform-
ers for real-time map-view semantic segmentation. In
Proceedings of the IEEE/CVF conference on com-
puter vision and pattern recognition, pages 13760–
13769.
Zhou, T., Brown, M., Snavely, N., and Lowe, D. G. (2017).
Unsupervised learning of depth and ego-motion from
video. In Proceedings of the IEEE conference on com-
puter vision and pattern recognition.
Zhu, M., Zhang, S., Zhong, Y., Lu, P., Peng, H., and Lenne-
man, J. (2021). Monocular 3d vehicle detection using
uncalibrated traffic cameras through homography. In
2021 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems (IROS). IEEE.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
34
