
Deep Active Learning with Noisy Oracle in Object Detection
Marius Schubert
1,∗ a
, Tobias Riedlinger
2,∗ b
, Karsten Kahl
1 c
and Matthias Rottmann
1 d
1
School of Mathematics and Natural Sciences, IZMD, University of Wuppertal, Germany
2
Institute of Mathematics, Technical University Berlin, Germany
Keywords:
Active Learning, Label Noise, Robustness, Label Error Detection, Object Detection.
Abstract:
Obtaining annotations for complex computer vision tasks such as object detection is an expensive and time-
intense endeavor involving numerous human workers or expert opinions. Reducing the amount of annotations
required while maintaining algorithm performance is, therefore, desirable for machine learning practitioners
and has been successfully achieved by active learning. However, it is not merely the amount of annotations
which influences model performance but also the annotation quality. In practice, oracles that are queried
for new annotations frequently produce significant amounts of noise. Therefore, cleansing procedures are
oftentimes necessary to review and correct given labels. This process is subject to the same budget as the initial
annotation itself since it requires human workers or even domain experts. Here, we propose a composite active
learning framework including a label review module for deep object detection. We show that utilizing part of
the annotation budget to correct the noisy annotations partially in the active dataset leads to early improvements
in model performance, especially when coupled with uncertainty-based query strategies. The precision of the
label error proposals significantly influences the measured effect of the label review. In our experiments we
achieve improvements of up to 4.5mAP points by incorporating label reviews at equal annotation budget.
1 INTRODUCTION
In the previous decade, deep learning has revolu-
tionized computer vision models across many differ-
ent tasks like supervised object detection (Ren et al.,
2015; Redmon and Farhadi, 2018; Carion et al.,
2020). Object detection has various potential real-
world applications, many of which have not yet been
developed practically in a sense that public datasets
are oftentimes not available. When such a new field is
to be developed, there are many practical challenges
during dataset curation and creation. Oftentimes, data
can be recorded with, e.g., cameras in large amount
at acceptable cost, while acquiring corresponding la-
bels might be comparatively costly and might require
expert knowledge. Active learning aims at maintain-
ing model performance while reducing the amount of
training data by leveraging data informativeness for
the label acquisition. The model is utilized in turn to
find the data, in our case from a large pool of unla-
a
https://orcid.org/0000-0002-9410-8949
b
https://orcid.org/0000-0002-1953-8607
c
https://orcid.org/0000-0002-3510-3320
d
https://orcid.org/0000-0003-3840-0184
*
Equal contribution.
L
object detector
training
U
Q
predictions
query
R
labeling
review
Figure 1: Our active learning cycle consists of training
on labeled data L, querying and labeling informative data
points Q out of a pool of unlabeled data U by an oracle and
a review of acquired data R = L ∪ Q .
beled data, for which new labels would improve the
model performance most efficiently (Settles, 2009;
Brust et al., 2018; Riedlinger et al., 2022). The
goal is to request as few annotations with human la-
bor as possible while still receiving a well-performing
model that makes accurate predictions. When devel-
oping and simulating active learning models in a lab-
Schubert, M., Riedlinger, T., Kahl, K. and Rottmann, M.
Deep Active Learning with Noisy Oracle in Object Detection.
DOI: 10.5220/0012315800003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 2: VISAPP, pages
375-384
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
375

oratory setup, one typically assumes an oracle that
provides correct labels for queried data points (Brust
et al., 2018; Riedlinger et al., 2022). However, in
practice, such an oracle does not exist and any per-
son that labels data produces errors with some fre-
quency (Yan et al., 2014). Especially in complex
domains such as medical applications where expert
opinions are required for the annotation process, there
exists variability between different oracles (Schilling
et al., 2022). Some authors have considered active
learning with noisy oracles in image classification be-
fore (Younesian et al., 2020; Younesian et al., 2021;
Yan et al., 2016; Gupta et al., 2019). In the present
work, we consider active learning with a noisy ora-
cle, to the best of our knowledge for the first time,
in object detection. More precisely, we utilize re-
cent findings on label errors in state-of-the-art ob-
ject detection benchmarks (Schubert et al., 2023) to
simulate two types of predominantly occurring la-
bel errors in object detection oracles. On the one
hand we treat missed bounding box labels which do
not appear in the ground truth at all. On the other
hand, we consider bounding box labels with incor-
rect class assignment which are likely to induce un-
desired training feedback. We do so for the EMNIST-
Det dataset (Riedlinger et al., 2022) which is an ex-
tension of EMNIST (Cohen et al., 2017) to the ob-
ject detection and instance segmentation setting. We
complement this with the BDD100k dataset (Yu et al.,
2020) which has mostly clean bounding box annota-
tions of variable size. Both datasets have high qual-
ity bounding box labels such that we can simulate la-
bel errors without greater influence of naturally occur-
ring label noise. We introduce independent and iden-
tically distributed errors into the labels which have
been queried during the data-acquisition process. We
simulate a label reviewer as a second human in the
loop who has access to a label error detection mod-
ule (Schubert et al., 2023) which is integrated into the
active learning cycle, see fig. 1. We compare differ-
ent sources for label error proposals which are to be
considered after data acquisition. The efficiency of
the proposal method controls the frequency of jus-
tified review cases, i.e., the efficiency of the budget
utilization for label reviewing. The review oracle is
assumed to contain smaller amounts of noise since la-
bels do not have to be generated from scratch. Instead,
only individual proposals have to be reviewed.
In our experiments, we observe that a label er-
ror detection method applied to active learning with a
noisy oracle clearly outperforms active learning with
random label review and active learning without any
label review. We compare different query strategies
with and without review in terms of performance as a
function of annotation budget (split into labeling and
reviewing cost). Improvement of performance is ob-
served consistently for random queries as well as for
an uncertainty query based on the entropy of the ob-
ject detector’s softmax output. Furthermore, our find-
ings are consistent over two datasets, i.e., an artificial
one and a real world one, as well as across two dif-
ferent object detectors. We find that the success of
our method can likely be attributed to a strong perfor-
mance of the label error detection method.
Our contribution can be summarized as follows:
• We contribute the first method that performs par-
tially automated label review and active label se-
lection for object detection.
• We provide an environment for performing rapid
prototyping of methods for active learning with
noisy oracles.
• Our method outperforms manual and review-free
active learning for different queries, datasets and
underlying object detectors.
Our method can be used with humans in the loop for
labeling and label review to maximize model perfor-
mance at minimal annotation budget, thus aiding data
acquisition pipelines with partial automation.
2 RELATED WORK
Our contribution is located at the intersection of two
disciplines which both aim at reducing the tiresome
workload of repetitive image annotation by human
workers. Active learning aims at reducing the over-
all amount of annotations given while the goal of la-
bel reviewing is to control or improve the quality of
present annotations.
Label Error Detection in Object Detection. Previ-
ous work on the detection of label errors for object de-
tectors tend to make use of a model which was trained
on given, potentially error-prone data. (Hu et al.,
2022) compare a softmax probability-based measure
per prediction with the given annotations to obtain
proposals for label errors. (Schubert et al., 2023) used
an instance-wise loss computation to identify differ-
ent types of label errors. (Koksal et al., 2020), in con-
trast, use a template matching scheme to find annota-
tion errors in frame sequences for UAV detection.
Active Learning in Object Detection. Training in
the context of more refined computer vision tasks
such as object detection requires significant compu-
tational resources and the learning task itself comes
with an elevated degree of complexity. All the more
important is efficient handling when it comes to ex-
pensive data annotations which can be approached by
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
376

active learning. The following accounts for the pi-
oneering successes that were accomplished in fully
supervised active learning for deep object detection.
(Brust et al., 2018) used margin sampling by ag-
gregating probability margin scores over predicted
bounding boxes in different ways where a class-
weighting scheme addresses class imbalances. (Roy
et al., 2018) similarly utilize softmax entropy and
committee-based scoring making use of the differ-
ent detection scales of object detection architectures.
(Schmidt et al., 2020) compare different deep en-
semble consensus-based selection strategies leverag-
ing model uncertainty. (Choi et al., 2021) utilize
Monte-Carlo dropout in conjunction with a Gaussian
mixture model to estimate epistemic and aleatoric un-
certainty, respectively. The utilized scoring function
for querying takes both kinds of uncertainty into ac-
count. (Haussmann et al., 2020) compare methodi-
cally diverse scoring functions in the objectness en-
tropy, mutual information, estimated learning gradi-
ent and confidence coupled with different diversity
selection mechanisms.
Active Learning with Noisy Oracle in Classifica-
tion. The intersection between active learning and
training under label noise has been addressed in the
context of classification tasks before. While (Kim,
2022) used an active query mechanism for cleaning
up labels, the proposed training algorithm itself is not
active. (Younesian et al., 2020) consider noisy binary
and categorical oracles by assigning different label
costs to both in an online, stream-based active learn-
ing setting. (Yan et al., 2016) treat the query complex-
ity of noisy oracles with a reject option in a theoretical
manner. (Gupta et al., 2019) consider batch-based ac-
tive learning with noisy oracles under the introduction
of the QActor framework by (Younesian et al., 2021)
which has a label cleaning module in its active learn-
ing cycle is most related to our approach. One of the
proposed quality models chooses examples to clean
via the cross-entropy loss which are then re-labeled
by the oracle.
3 ACTIVE LEARNING WITH
NOISY ORACLE
In this section, we describe the task of active learning
in object detection as well as the addition of a review
module to the generic active learning cycle. While
in the active learning setting, new labels are queried
on the basis of an informativeness measure, the pres-
ence of erroneous or misleading oracle responses can
counteract the benefit of the informed data selection.
In order to account for new data containing incorrect
labels, we introduce a review module that generates
proposals for label errors to review and to potentially
correct.
3.1 Active Learning with Review in
Object Detection
Most of the commonly used datasets in object detec-
tion, e.g., MS-COCO (Lin et al., 2014) and Pascal
VOC (Everingham et al., 2010), are also the most
commonly used datasets in active learning and con-
tain label errors (Schubert et al., 2023; Rottmann and
Reese, 2023). This means that active learning meth-
ods developed on these datasets are also evaluated
based on noisy labels. To consider label errors dur-
ing active learning experiments, we introduce a re-
view module. Active learning can be viewed as an
alternating process of training a model and labeling
data based on informativeness according to the model.
Starting with an initially labeled set of images L, once
a model is trained based on L, the test performance is
measured. Object detectors are usually evaluated in
terms of mean average precision (mAP, see (Evering-
ham et al., 2010)). New images selected to be labeled
(Q ) are queried from a pool U of previously unla-
beled images. After obtaining labels for the queried
images Q by an oracle, we introduce a review step
where an oracle reviews the combined set R = L ∪Q .
The model is then trained on the reviewed data and the
cycle is repeated T times. The active learning cycle is
visualized in fig. 1 where acquisition and review of
data are two independent modules.
Queries. Active learning research usually revolves
around the development of model architectures, loss
functions or selection strategies used in the query
step. Different query approaches are then com-
pared for different annotation budgets in terms of the
achieved test performance which is often measured in
terms of mAP in object detection. In the following, we
investigate two different query strategies: random se-
lection and selection of samples with large entropy of
the softmax output of the object detector. For the for-
mer, images are randomly chosen from U. For the lat-
ter, images are selected based on the predictive clas-
sification uncertainty according to the current model
in the following sense. On a given image x, a neural
network predicts a fixed number N
0
of bounding box
predictions
ˆ
b
i
= {( ˆx
i
, ˆy
i
, ˆw
i
,
ˆ
h
i
, ˆs
i
, ˆp
i
1
,.. ., ˆp
i
C
)}, (1)
where i = 1, ... ,N
0
. Here, ˆx
i
, ˆy
i
, ˆw
i
,
ˆ
h
i
represent the
localization, ˆs
i
the objectness score and ˆp
i
1
,.. ., ˆp
i
C
the
class probabilities for all classes {1, ... ,C}. Only the
set of boxes that remain after score-thresholding (with
Deep Active Learning with Noisy Oracle in Object Detection
377

threshold s
ε
) and non-maximum suppression (NMS)
are used to compute prediction-wise entropies. The
entropy H(
ˆ
b
i
) of prediction
ˆ
b
i
is given by H(
ˆ
b
i
) =
−
∑
C
c=1
ˆp
i
c
·log( ˆp
i
c
). Moreover, we incorporate a class-
weighting (Brust et al., 2018) for computing instance-
wise uncertainty scores. Finally, the instance-wise en-
tropies of a single image are summed up to obtain an
image-wise query score and the images are sorted in
descending order by this query score. Note, that both
queries are independent of labels and, therefore, of
any label errors ( random selection is independent of
predictions and labels as well as the image-wise query
score for the entropy method is determined based on
the predictions only). Note, that query algorithms are
based on unlabeled data and oracle noise does not di-
rectly impact the selection of images. However, ora-
cle noise does influence model training.
Review Module. In order to account for noisy ora-
cles, we allow for incorrect annotations given in re-
sponse to an active learning query. To counter-act
the negative influence of noisy annotations, we intro-
duce a review module into the active learning cycle in
which proposals for label reviews are given and part
of the annotation budget can be used to clean up a
portion of annotation errors. In the following, we in-
troduce the detection of two different kinds of label
errors: missing labels (misses) and labels with incor-
rect class assignments (flips).
For one active learning cycle, we allow for the
consumption of a fixed annotation budget C . This
budget C is split up into a fraction C
Q
= (1 − λ)C
used for querying new annotations and C
R
= λC used
for reviewing data.
After the query, Q is automatically labeled and,
together with L, forms the set of active images for
the next cycle. Before the next training cycle starts,
we regard R = L ∪ Q as the set of annotations which
are potentially reviewed. Inspired by (Schubert et al.,
2023), we introduce a post-processing label error de-
tection method where the detection of misses and flips
are two independent tasks. When both types of label
errors are simultaneously present, we use a parame-
ter α ∈ [0,1] to distribute the review budget C
R
be-
tween reviewing misses (αC
R
) and flips ((1 − α)C
R
).
In the following, we introduce two different review
functions: a random review and a review (Schubert
et al., 2023) based on the computed loss function.
An illustration of our label error detection method
can be found in fig. 2. We consider the set of all
predictions on images from R and the corresponding
noisy labels
˜
Y . To detect misses, we select those pre-
dictions that are identified as false positive predictions
according to the noisy ground truth
˜
Y . To get an order
for the review, we sort the false positives in descend-
ing order by the objectness score ˆs for the highest loss
based review and in random order for the random re-
view. Large values of ˆs on false positives (where ob-
jectness is supposed to be small) amounts to a large
objectness loss.
For the flips, every label from
˜
Y is assigned to
the most overlapping prediction if the IoU of the two
boxes is greater than of equal to IoU
ε
. Then, the cross-
entropy loss of the possibly incorrect label and the
predicted probability distribution is used as a review
score for every given label. In case there is no suffi-
ciently overlapping prediction, the respective label is
not considered for review. Note, that for given label
class ˜c, the cross-entropy loss of the assigned predic-
tion
ˆ
b is CE(
ˆ
b| ˜c) = −
∑
C
c=1
δ
c ˜c
log( ˆp
c
) = −log( ˆp
˜c
),
where δ
i j
is the Kronecker symbol, i.e., δ
i j
= 1 if
i = j and δ
i j
= 0 otherwise. That is, the label with
assigned prediction that has the lowest corresponding
class probability ˆp
˜c
generates the highest loss. In case
of the random review method, we randomly select as-
signed labels for review by uniformly sampling over
all labels.
4 NUMERICAL EXPERIMENTS
In this section, we describe our active learning setup,
label noise generation and the automated data review
as well as involved hyperparameters. Afterwards, we
show results for both query functions with and with-
out review for two different datasets and object detec-
tors in terms of mAP. We also measure the perfor-
mance of the review proposal mechanism in terms of
precision.
4.1 Experimental Setup
For our active learning setup, automated labeling and
reviewing is desirable. Therefore, we simulate la-
bel errors for all training images of the underlying
datasets. We do not include evaluations of the active
learning experiments on the widely used MS-COCO
or Pascal VOC datasets for the following reasons. For
an automated review procedure, the frequently oc-
curring label errors in both datasets (Schubert et al.,
2023) would lead to strongly biased results. Evalu-
ations on either dataset would require manual anno-
tation review after each active learning cycle for sev-
eral repetitions of the same experiment. This manual
review after each cycle is necessary in practice, how-
ever, out of scope for an experimental evaluation of
the proposed method.
Datasets and Models. We make use of the EMNIST-
Det dataset (Riedlinger et al., 2022) with 20,000
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
378

O:
ˆ
s = 0.63
R:
ˆ
s = 0.97
L:
ˆs = 0.82
S:
ˆ
s = 0.95
O:
ˆ
s = 0.83
S:
ˆ
s = 0.94
M:
ˆ
s = 0.81
S: ˆs = 0.90
B:
ˆ
s = 0.63
prediction
O
T
L
O
S
M
˜
Y
S:
ˆ
s = 0.95
S: ˆs = 0.90
B:
ˆ
s = 0.63
false positive
O
T
L
O
ˆp
O
= 0.83
ˆp
T
= 0.07
ˆ
p
L
= 0.87
ˆ
p
O
= 0.97
S
M
ˆ
p
S
= 0.96
ˆ
p
M
= 0.93
has pred w/ high IoU
descending order in ˆs
(highest background loss first)
ascending order in ˆp
(highest classification loss first)
Miss Detection
Flip Detection
Figure 2: Schematic illustration of the label error detection mechanism using highest loss for missed labels (top, blue) and
label flips (bottom, green). The detection of misses considers false positive predictions of the object detector while the
detection of flips considers ground truth boxes, each of them matching at least one of the predictions in localization.
training images and 2,000 test images as well as
BDD100k (Yu et al., 2020) (short: BDD), where we
filter the training and validation split, such that we
only use daytime images with clear weather condi-
tions, resulting in 12,454 training images. Further-
more, the validation set is split into equally-sized test
and validation sets, each consisting of 882 images.
Since EMNIST-Det is a simpler task to learn com-
pared to BDD, we apply a RetinaNet (Lin et al., 2017)
and a Faster R-CNN (Ren et al., 2015) with a ResNet-
18 (He et al., 2016) backbone for EMNIST-Det, as
well as a Faster R-CNN with a ResNet-101 backbone
for BDD. Note, that this setup was introduced and
used in related work (Riedlinger et al., 2022; Schu-
bert et al., 2023).
Based on clean training data, the test performance
for EMNIST-Det in terms of mAP is 91.2% for Faster
R-CNN and 90.9% for RetinaNet. For Faster R-
CNN, the test performance decreases to 90.2% with
simulated misses in the training data and to 89.2%
with simulated flips. Simulating misses and flips si-
multaneously yields a test performance of 89.4% for
Faster R-CNN and 89.3% for RetinaNet. For BDD
and Faster R-CNN, a test performance of 50.0% is
obtained for unmodified training data and 48.9% for
training data including misses and drops.
Simulation of Label Errors. For the simulation of
misses and flips, we follow (Schubert et al., 2023). An
illustration of the label error injection scheme can be
found in fig. 3. Any dataset is equipped with a set of
G labels, i.e.,
Y = {b
i
= (x
i
,y
i
,w
i
,h
i
,c
i
) : i = 1, ...,G}. (2)
Let I = {1,. .., G} be the set of indices of all boxes
b
i
∈ Y , i = 1,.. .,G. Furthermore, we choose a pa-
O
R
L
S
O
S
M
S
I
O
R
L
O
S
M
I \ I
m
Discard
γ
l
2
· G
O
T
L
O
S
M
˜
Y
Flip
γ
l
2
· G
Figure 3: Schematic illustration of noise injection into a
clean dataset. Misses are generated by randomly discard-
ing γ
l
/2 · G of the present annotations. Afterwards, γ
l
/2 · G
of the remaining annotations receive random class flips to
one of the C − 1 incorrect classes. This results in the noisy
ground truth
˜
Y used in our experiments.
rameter γ
l
∈ [0,1] representing the relative frequency
of label errors during data acquisition.
For generating label misses, we randomly choose
a subset I
m
⊂ I of size
γ
l
2
· G, representing missed
ground truth boxes which are discarded from Y . The
number of remaining annotations that receive a class
flip is again
γ
l
2
· G, where the class flip is determined
uniformly over the C − 1 incorrect class assignments.
The potentially flipped class for each label b
i
is de-
noted by ˜c
i
. Finally, we denote the training set includ-
ing label errors by
˜
Y = {(x
i
,y
i
,w
i
,h
i
, ˜c
i
) : i ∈ I \ I
m
}.
Note, that a single label is perturbed by only one type
of label error at most. In addition, label errors are not
simulated on the test dataset to ensure an unbiased
evaluation of test performance.
Automated Review of Label Errors Since the or-
acle is noisy with error frequency γ
r
, the review is
also error-prone, i.e., misses are detected with proba-
Deep Active Learning with Noisy Oracle in Object Detection
379
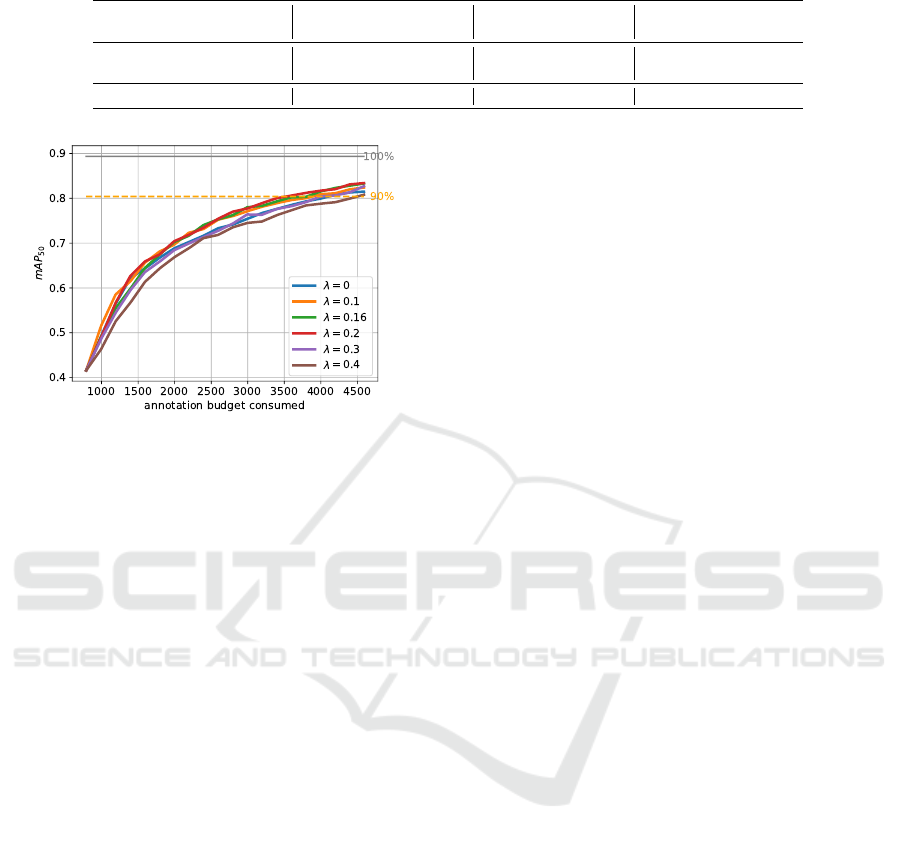
Table 1: Overview of important training, review and active learning hyperparameters for all datasets and networks.
Active Learning Review Training
|U
init
| C s
ε
T γ
l
γ
r
IoU
ε
α batch size training iters
Faster R-CNN EMNIST-Det 150 200 0.7 20 0.2 0.05 0.3 0.5 4 25,000
RetinaNet EMNIST-Det 150 200 0.5 20 0.2 0.05 0.3 0.5 4 38,000
Faster R-CNN BDD100k 625 10,000 0.7 7 0.2 0.05 0.3 0.5 4 170,000
Figure 4: EMNIST-Det ablation study of the ratio between
labeled and reviewed bounding boxes for Faster R-CNN
where both label error types are present. We compare the
random query without review with random query and high-
est loss review (RHL) with the chosen ration λ in brackets.
bility 1 − γ
r
and still overlooked with probability γ
r
.
The flips, whether the label error proposal was a false
alarm or not, are corrected with probability 1 − γ
r
and
randomly misclassified with probability γ
r
.
Implementation Details. We implemented our active
learning methods in the open source MMDetection
toolbox (Chen et al., 2019). For the label error simula-
tion, we choose the relative frequency of label errors
γ
l
= 0.2, the relative frequency of label errors dur-
ing review γ
r
= 0.05, the value for score-thresholding
s
ε
= 0.7 for Faster R-CNN and s
ε
= 0.5 for RetinaNet
as well as the IoU-value IoU
ε
= 0.3 that assigns pre-
dictions with labels. We choose γ
r
< γ
l
, assuming that
the oracle is more engaged in viewing and evaluating
single boxes during the review compared to labeling
from scratch, with all boxes having to be located and
classified on a new image. As hyperparameters for the
active learning cycle, the initially labeled set consists
of 150 randomly picked images EMNIST-Det and of
625 randomly picked images for BDD. The budget for
a single active learning step C is 200 for EMNIST-
Det and C = 10,000 for BDD. Labeling a single box
has cost 1, as does reviewing a label error proposal,
whether miss or flip and also whether a label error
was identified or not. If misses and flips are simul-
taneously present in the experiment, we set the ratio
between reviewing misses and flips α = 0.5. Finally,
the number of active learning steps for EMNIST-Det
is T = 20 and for BDD T = 7. For an overview of
training, review and active learning hyperparameters,
see table 1.
4.2 Results
In the following, we show active learning results for
EMNIST-Det and BDD. Therefore, we compare six
different methods, the random and entropy query,
both without review, as well with random review or
review by highest loss. Furthermore, we present per-
formance results for both review methods in terms of
precision over the whole active learning course.
Ablation for the Ratio of Queried and Reviewed
Bounding Boxes. For the methods with review, the
fraction λ of the amount of new data queries and the
amount of bounding box reviews plays a significant
role. Therefore, we repeat the same experiment for
EMNIST-Det and Faster R-CNN with different val-
ues for λ, see fig. 4. These results are based on train-
ing data with simulated flips and misses. The gray
and yellow lines indicate the 100% and 90% refer-
ence performance mark of the model trained with the
entire (noisy) dataset. The random query with high-
est loss review (RHL) is visually almost identical for
λ = 0.1, λ = 0.16 and λ = 0.2. All these three meth-
ods outperform the random query without review. The
random query without review performs similar to the
random query with highest loss review with λ = 0.3
and outperforms the random query with λ = 0.4, i.e.,
at about λ = 0.3 is the break-even-point, at which it is
no longer worthwhile to review more bounding boxes
instead of labeling new ones. We hypothesize that
this tipping point is strongly dependent on our cho-
sen setup with a relative frequency of label errors of
γ
l
= 0.2. Since the red curve seems to be most favor-
able, we set the fraction between queries and reviews
to λ = 0.2 in all of the following experiments.
Active Learning with Different Label Error Types.
We first investigate active learning curves for
EMNIST-Det and Faster R-CNN. We consider active
learning curves where (a) we simulated only misses,
(b) only flips, and (c) both label error types occur
equally often in the training dataset, each with noise
rate γ
l
= 0.1 (recall fig. 3). We compare both query
strategies, random and entropy, without review, with
highest loss (HL) review and with random (R) review,
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
380
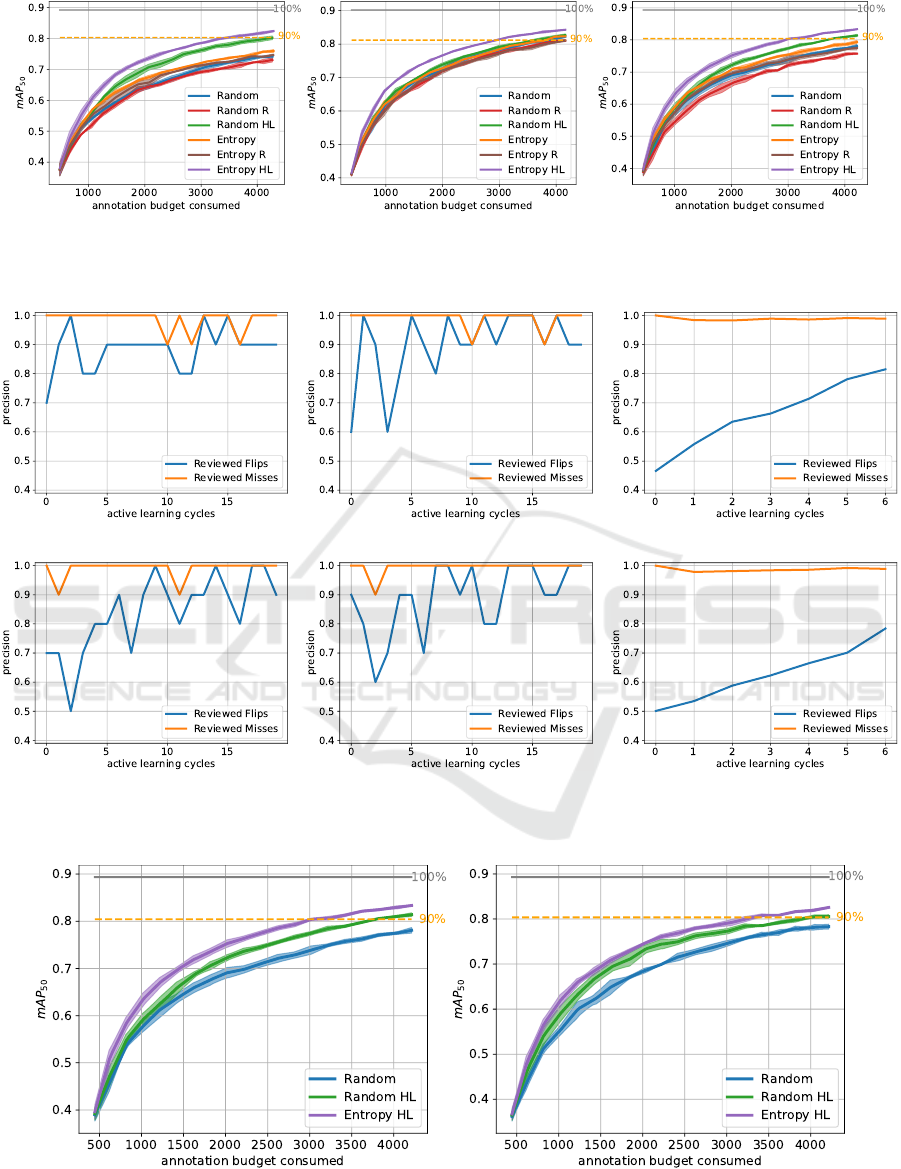
(a) Class Flips (b) Label Misses (c) Flips + Misses
Figure 5: EMNIST-Det active learning curves, where only flips are present (left), only misses (center) as well as where flips
and misses are simultaneously present (right).
(a) Faster R-CNN + EMNIST-Det (b) RetinaNet + EMNIST-Det (c) Faster R-CNN + BDD
(d) Faster R-CNN + EMNIST-Det (e) RetinaNet + EMNIST-Det (f) Faster R-CNN + BDD
Figure 6: Review quality results for random highest loss (top) and entropy highest loss (bottom). Misses and flips are
simultaneously present in all experiments.
(a) Faster R-CNN (b) RetinaNet
Figure 7: Comparison of EMNIST-Det active learning curves for Faster R-CNN (left) and RetinaNet (right) where both label
error types are present.
Deep Active Learning with Noisy Oracle in Object Detection
381

respectively. The obtained active learning curves are
averaged over four random initializations and evalu-
ated in terms of the total annotation budget consumed.
Note, that for the active learning methods without re-
view the total amount of annotation budget is equal to
the amount of (possibly incorrect) labeled bounding
boxes. For those methods incorporating a review step
the total amount of annotation budget represents the
sum of labeled and reviewed bounding boxes. Fig-
ure 5 shows active learning curves in terms of test
performance with point-wise standard deviations. For
all three active learning curves, we observe that the
entropy method outperforms random at every point.
Furthermore, the queries without review perform su-
perior to the respective query with random review.
Entropy HL and random HL, i.e., both methods with
highest loss review clearly outperform the strategies
without review and with random review. We conclude
that the success of reviewing queries strongly depends
on the performance of the review methods and that
random review is too expensive in terms of annota-
tion budget. From this we conclude that it is more
worthwhile to acquire new (noisy) labels than to ran-
domly review the active labels, at least for the given
amount of noise we studied.
All in all, the distance between the active learning
curves of the six methods is significantly larger for
label flips as compared to misses. Moreover, the max-
imum performance with simulated label errors is also
inferior for the flips compared to the misses. We hy-
pothesize that the reason for this is the sub-sampling
from the negatively associated anchors (Ren et al.,
2015) during training. This mechanism leads to only
partial learning from the misses, whereas an incorrect
foreground class induced from flips has a negative im-
pact on every gradient step.
The significant difference of the active learning
curves of the respective queries with random review
and the highest loss review can be attributed to the
high precision of the highest loss review. The ran-
dom review has an expected precision of γ
l
. Figure 6
shows the precision for the highest loss review applied
after random query in (a) and after entropy query in
(d) across the span of all active learning cycles. In
both plots, (a) and (d), flips and misses are simulta-
neously present, i.e., both plots correspond to the re-
spective method from fig. 5 (c). The blue lines vi-
sualize the precision for the review identifying a flip
and the orange lines analogously for the misses. Here,
the precision for detecting flips is always above 50%
and tends to improve as the active learning exper-
iment progresses, whereas the precision for the de-
tection of misses is even consistently above 90%. In
general, flips are more difficult to detect compared to
Table 2: Mean average precision values in % with standard
deviations in brackets for 2000 and 4000 queried and re-
viewed annotations for Faster R-CNN (top) and RetinaNet
(bottom) for EMNIST-Det. Note, that in every experiment
both label error types are present; the upper half represents
fig. 7 (a) and the bottom half fig. 7 (b).
Network Method mAP
@2000
mAP
@4000
Faster R-CNN
Random 68.97(±1.09) 77.41(±0.28)
Random HL 72.13(±0.64) 80.92(±0.23)
Entropy HL 75.13(±0.79) 82.87(±0.29)
RetinaNet
Random 68.38(±0.52) 78.04(±0.51)
Random HL 72.94(±1.06) 80.40(±0.34)
Entropy HL 74.39(±0.28) 81.86(±0.27)
misses due to the different construction of the detec-
tion methods of either label error type, recall fig. 2.
Comparing Faster R-CNN with RetinaNet on
EMNIST-Det. For the following results, we com-
pare only the random query without review with the
random and entropy query, both with highest loss re-
view. Figure 7 shows active learning curves for these
methods for Faster R-CNN in (a) and for RetinaNet
in (b). Note, that in both cases both label error types
are present. Moreover, (a) is a trimmed version of
fig. 5 (c) to make it more convenient to compare the
results from both detectors visually. We observe that
the curves for Faster R-CNN and RetinaNet look very
similar over the entire active learning course. All
curves start at just below 40% mAP and the respec-
tive methods end at similar test performances. The
ranking of the methods is always the same: entropy
HL outperforms random HL and random without re-
view. Also, random HL outperforms random without
review. For RetinaNet, random HL seems to be closer
to entropy HL as compared to Faster R-CNN.
These observations are also supported by table 2,
wherein we stated the mAP values with standard de-
viations in parentheses. We compare performance for
the total annotation budget consumed equal to 2000
and 4000 from the active learning curves shown in
fig. 7. In particular, for entropy with highest loss re-
view, the mAP
@2000
for Faster R-CNN is 0.74 per-
cent points (pp) higher and even 1.01 mAP
@4000
pp
higher. For Faster R-CNN, the difference between en-
tropy HL and random HL is 3 pp for mAP
@2000
and
1.95 for mAP
@4000
. For RetinaNet, the difference is
only 1.45 pp for mAP
@2000
and 1.46 for mAP
@4000
.
Comparing the quality of the highest loss review,
the results for RetinaNet are highly correlated to the
results of Faster R-CNN, see fig. 6. For RetinaNet,
the precision for the highest loss review in combina-
tion with random query is visualized in (b) and with
the entropy query in (e). Here, the precision for de-
tecting the misses is at or above 90%. The precision
for the detection of flips is always greater or equal to
60% and from active learning cycle 7 onward even
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
382
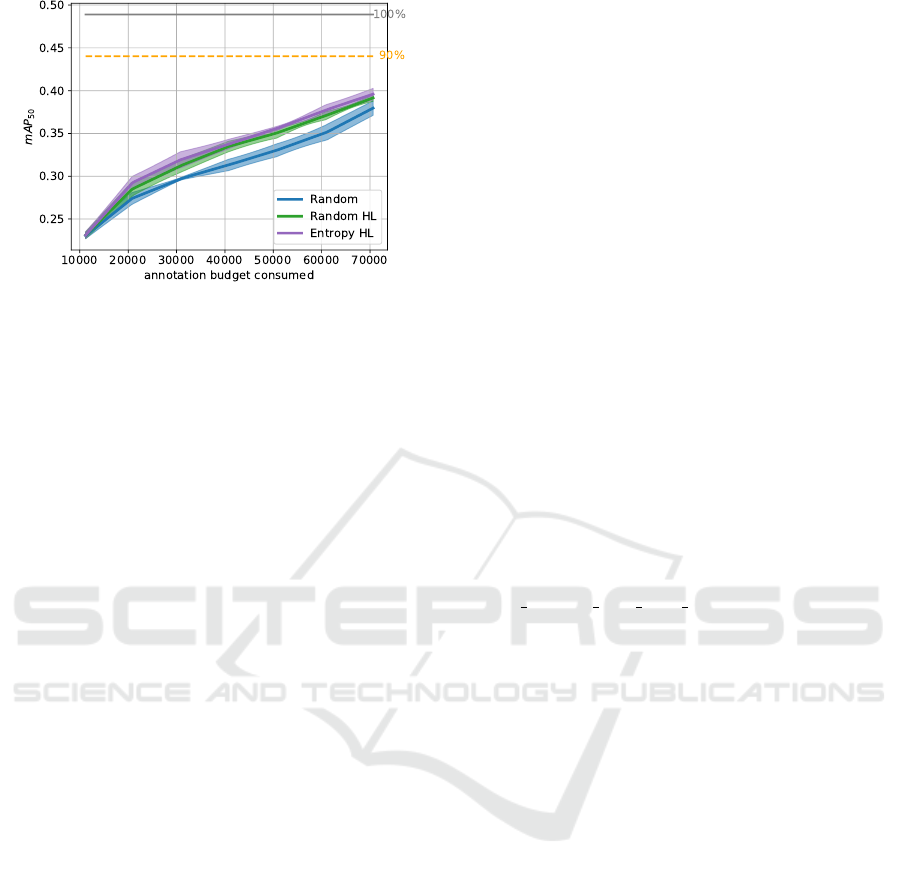
Figure 8: BDD active learning curves for Faster R-CNN
where both label error types are present.
always above 80%. We observe that the precision
of the highest loss review increases while the exper-
iments progresses, i.e., object detectors trained with
more data generate better label error proposals. We
hypothesize that with more data, overfitting can be
more effectively prevented and that the object detec-
tors will generalize better, thus label errors in the ac-
tive labels will not be as significant when sufficient
data is available.
Results for BDD with Faster R-CNN. Figure 8
shows active learning curves for the random query
without review, as well as for the random and en-
tropy query both with highest loss review. Compa-
rable to the results for EMNIST-Det, the ranking of
the methods is identical over the entire active learning
course. The random query without review is inferior
to both queries with review and entropy HL is supe-
rior to random HL. Note, that the distance between the
two queries with review is marginal. In contrast, there
is a significant difference between either one and the
random query without review.
The review quality of the highest loss review for
the random query is shown in fig. 6 (c) and for the
entropy query in (f). Again, the misses are detected at
all times with a precision of nearly 100%. Starting at
just under 50%, the precision for identifying flips in-
creases steadily over the active learning course ending
at close to 80%. We conclude that involving a label
review in the active learning cycle is also highly ben-
eficial in the more complex BDD real world dataset.
Analogous to the results for EMNIST-Det, the highest
loss review becomes more precise as the experiments
progress and the number of active labels increases.
5 CONCLUSION
In this work, we considered label errors in active
learning cycles for object detection for the first time,
where we assumed a noisy oracle during the annota-
tion process. We realized this assumption by simu-
lating two types of label errors for the training data
of datasets which are reasonably free of intrinsic la-
bel errors. These types of label errors are missing
bounding box labels as well as bounding box labels
with an incorrect class assignment. We introduce a
review module to the active learning cycle, that takes
as input the currently labeled images and the cor-
responding predictions of the most recently trained
object detector. Furthermore, we detect both types
of label errors by a random review method and a
method based on the highest loss of the model’s pre-
dictions and the corresponding noisy labels. We ob-
serve that the incorporation of random review leads to
an even worse test performance compared to the cor-
responding query without review. Nevertheless, we
show that the combination of query strategies, like
random selection or instance-wise entropy, with an
accurate review yields a significant performance in-
crease. For both query strategies, the improvement
obtained by including the highest loss review per-
sists during the whole active learning course for dif-
ferent dataset-network-combinations. We make our
code for reproducing results and further development
publicly available at https://github.com/mschubert95/
active learning with label errors.
ACKNOWLEDGEMENTS
We gratefully acknowledge financial support by the
German Federal Ministry of Education and Re-
search in the scope of project “UnrEAL”, grant no.
01IS22069. The authors gratefully acknowledge the
Gauss Centre for Supercomputing e.V. for funding
this project by providing computing time through the
Johnvon Neumann Institute for Computing on the
GCS Supercomputer JUWELS at Julich Supercom-
puting Centre.
REFERENCES
Brust, C.-A., K
¨
ading, C., and Denzler, J. (2018). Active
learning for deep object detection. arXiv preprint
arXiv:1809.09875.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov,
A., and Zagoruyko, S. (2020). End-to-end object de-
tection with transformers. In European conference on
computer vision, pages 213–229. Springer.
Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X.,
Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng,
D., Zhu, C., Cheng, T., Zhao, Q., Li, B., Lu, X., Zhu,
R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy,
Deep Active Learning with Noisy Oracle in Object Detection
383

C. C., and Lin, D. (2019). MMDetection: Open mm-
lab detection toolbox and benchmark. arXiv preprint
arXiv:1906.07155.
Choi, J., Elezi, I., Lee, H.-J., Farabet, C., and Alvarez,
J. M. (2021). Active Learning for Deep Object De-
tection via Probabilistic Modeling. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision, pages 10244–10253, Montreal, QC, Canada.
IEEE.
Cohen, G., Afshar, S., Tapson, J., and Van Schaik, A.
(2017). Emnist: Extending mnist to handwritten let-
ters. In 2017 international joint conference on neural
networks (IJCNN), pages 2921–2926. IEEE.
Everingham, M., Van Gool, L., Williams, C. K., Winn, J.,
and Zisserman, A. (2010). The pascal visual object
classes (voc) challenge. International journal of com-
puter vision, 88:303–338.
Gupta, G., Sahu, A. K., and Lin, W.-Y. (2019). Noisy Batch
Active Learning with Deterministic Annealing. arXiv
preprint arXiv:1909.12473.
Haussmann, E., Fenzi, M., Chitta, K., Ivanecky, J., Xu, H.,
Roy, D., Mittel, A., Koumchatzky, N., Farabet, C., and
Alvarez, J. M. (2020). Scalable Active Learning for
Object Detection. In 2020 IEEE Intelligent Vehicles
Symposium (IV), pages 1430–1435.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Hu, Z., Gao, K., Zhang, X., Wang, J., Wang, H., and Han,
J. (2022). Probability differential-based class label
noise purification for object detection in aerial images.
IEEE Geoscience and Remote Sensing Letters, 19:1–
5.
Kim, K. I. (2022). Active Label Correction Using Robust
Parameter Update and Entropy Propagation. In Eu-
ropean Conference on Computer Vision, pages 1–16.
Springer.
Koksal, A., Ince, K. G., and Alatan, A. (2020). Ef-
fect of annotation errors on drone detection with
YOLOv3. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
Workshops, pages 1030–1031.
Lin, T.-Y., Goyal, P., Girshick, R., He, K., and Doll
´
ar, P.
(2017). Focal loss for dense object detection. In
Proceedings of the IEEE international conference on
computer vision, pages 2980–2988.
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P.,
Ramanan, D., Doll
´
ar, P., and Zitnick, C. L. (2014).
Microsoft coco: Common objects in context. In Com-
puter Vision–ECCV 2014: 13th European Confer-
ence, Zurich, Switzerland, September 6-12, 2014, Pro-
ceedings, Part V 13, pages 740–755. Springer.
Redmon, J. and Farhadi, A. (2018). Yolov3: An incremental
improvement. arXiv preprint arXiv:1804.02767.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster
r-cnn: Towards real-time object detection with region
proposal networks. Advances in neural information
processing systems, 28.
Riedlinger, T., Schubert, M., Kahl, K., Gottschalk, H., and
Rottmann, M. (2022). Towards Rapid Prototyping
and Comparability in Active Learning for Deep Ob-
ject Detection. arXiv preprint arXiv:2212.10836.
Rottmann, M. and Reese, M. (2023). Automated detection
of label errors in semantic segmentation datasets via
deep learning and uncertainty quantification. In Pro-
ceedings of the IEEE/CVF Winter Conference on Ap-
plications of Computer Vision, pages 3214–3223.
Roy, S., Unmesh, A., and Namboodiri, V. P. (2018). Deep
active learning for object detection. In BMVC, volume
362, page 91.
Schilling, M. P., Scherr, T., Munke, F. R., Neumann, O.,
Schutera, M., Mikut, R., and Reischl, M. (2022). Au-
tomated Annotator Variability Inspection for Biomed-
ical Image Segmentation. IEEE access, 10:2753.
Schmidt, S., Rao, Q., Tatsch, J., and Knoll, A. (2020).
Advanced active learning strategies for object detec-
tion. In 2020 IEEE Intelligent Vehicles Symposium
(IV), pages 871–876. IEEE.
Schubert, M., Riedlinger, T., Kahl, K., Kr
¨
oll, D., Schoenen,
S.,
ˇ
Segvi
´
c, S., and Rottmann, M. (2023). Identifying
label errors in object detection datasets by loss inspec-
tion. arXiv preprint arXiv:2303.06999.
Settles, B. (2009). Active learning literature survey.
Yan, S., Chaudhuri, K., and Javidi, T. (2016). Active learn-
ing from imperfect labelers. Advances in Neural In-
formation Processing Systems, 29.
Yan, Y., Rosales, R., Fung, G., Subramanian, R., and Dy, J.
(2014). Learning from multiple annotators with vary-
ing expertise. Machine Learning, 95(3):291–327.
Younesian, T., Epema, D., and Chen, L. Y. (2020). Active
learning for noisy data streams using weak and strong
labelers. arXiv preprint arXiv:2010.14149.
Younesian, T., Zhao, Z., Ghiassi, A., Birke, R., and Chen,
L. Y. (2021). Qactor: Active learning on noisy la-
bels. In Asian Conference on Machine Learning,
pages 548–563. PMLR.
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F.,
Madhavan, V., and Darrell, T. (2020). Bdd100k: A
diverse driving dataset for heterogeneous multitask
learning. In Proceedings of the IEEE/CVF conference
on computer vision and pattern recognition, pages
2636–2645.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
384
