
Evaluating Synthetic Data Generation Techniques for Medical Dataset
Takayuki Miura
1 a
, Eizen Kimura
2 b
, Atsunori Ichikawa
1 c
,
Masanobu Kii
1 d
and Juko Yamamoto
1
1
NTT Social Informatics Laboratories, Tokyo, Japan
2
Dept. Medical Informatics, Medical School of Ehime Univ., Ehime, Japan
Keywords:
Synthetic Data Generation, Differential Privacy, Real-World Data.
Abstract:
Anticipation surrounds the use of real-world data for data analysis in medicine and healthcare, yet handling
sensitive data demands ethical review and safety management, presenting bottlenecks in the swift progression
of research. Consequently, numerous techniques have emerged for generating synthetic data, which preserves
the features of the original data. Nonetheless, the quality of such synthetic data, particularly in the context of
real-world data, has yet to be sufficiently examined. In this paper, we conduct experiments with a Diagonosis
Procedure Combination (DPC) dataset to evaluate the quality of synthetic data generated by statistics-based,
graphical model-based, and deep neural network-based methods. Further, we implement differential privacy
for theoretical privacy protection and assess the resultant degradation of data quality. The findings indicate
that a statistics-based method called Gaussian Copula and a graphical-model-based method called AIM yield
high-quality synthetic data regarding statistical similarity and machine learning model performance. The paper
also summarizes issues pertinent to the practical application of synthetic data derived from the experimental
results.
1 INTRODUCTION
Real-world data collected from healthcare settings
has attracted attention for propelling new clinical re-
search due to its non-invasive nature for patients and
its potential to constitute big data, thereby reducing
bias. Including personal information in the data ne-
cessitates a substantial investment of person-hours for
ethical review procedures and data protection, thereby
impeding the prompt progression of medical research.
Anonymization techniques, which reduce the risk of
identifying individuals, are crucial in providing data
to third parties without patient consent and stream-
lining the research approval process. Unlike secure
computation (Cramer et al., 2015; Shan et al., 2018),
which facilitates data analysis in encrypted form,
these techniques afford analysts the advantages of
viewing anonymized data that possess similar prop-
erties to the original in a format equivalent to ac-
tual data and conducting analyses in an exploratory
manner. However, conventional anonymization meth-
a
https://orcid.org/0000-0001-8694-312X
b
https://orcid.org/0000-0002-0690-8568
c
https://orcid.org/0000-0001-8013-7071
d
https://orcid.org/0000-0003-1323-0983
Figure 1: Overview of synthetic data generation.
ods, such as k-anonymity (Sweeney, 2002), encounter
an issue where the quality of the anonymized data
significantly diminishes as the data becomes high-
dimensional (Aggarwal, 2005).
The technology of synthetic data generation has
been recognized for its ability to produce new data
while preserving the original statistical properties of
high-dimensional data (Hernandez et al., 2022; Tao
et al., 2021; Sklar, 1959; Zhang et al., 2017; McKenna
et al., 2022; McKenna et al., 2019; Xu et al., 2019).
Specifically, this technology enables the expedited
analysis of synthetic data in a relatively unrestricted
environment, potentially abbreviating the approval
process. Upon securing useful results, researchers
can directly apply them to the original data, deriv-
Miura, T., Kimura, E., Ichikawa, A., Kii, M. and Yamamoto, J.
Evaluating Synthetic Data Generation Techniques for Medical Dataset.
DOI: 10.5220/0012314500003657
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2024) - Volume 2, pages 315-322
ISBN: 978-989-758-688-0; ISSN: 2184-4305
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
315

ing final results and potentially mitigating research
costs (El Emam, 2020). Nevertheless, to the best
of our knowledge, few studies have concurrently de-
ployed various synthetic data generation techniques to
authentic medical data (Barth-Jones, 2012; Culnane
et al., 2017). Moreover, few studies have simultane-
ously applied various synthetic data generation tech-
niques to real medical data, and insufficient knowl-
edge has been accumulated on the differences among
the techniques and the quality of the generated syn-
thetic data.
In this paper, we generate synthetic data by
using statistics-based, graphical-model-based, and
deep-neural-network-based approaches and evaluate
the quality of the resultant synthetic data. Uti-
lizing the Diagnosis Procedure Combination (DPC)
dataset from Ehime University Hospital as the origi-
nal dataset, we evaluate generated synthetic data from
three critical perspectives: distribution distances, ma-
chine learning model performances, and differences
in correlation matrices. Furthermore, we incorpo-
rate differential privacy (DP) (Dwork, 2006) into each
synthetic data generation method, serving as a theo-
retical privacy framework.
Consequent to the experimental results, we ob-
tained the following conclusions:
• The incorporation of DP enhances privacy protec-
tion while concurrently diminishing the quality of
synthetic data
• The magnitude of quality degradation is contin-
gent upon the synthesis method employed. Gaus-
sian Copula (Li et al., 2014) and AIM (McKenna
et al., 2022) sustained comparatively superior
quality even after applying DP.
2 RELATED WORK
2.1 Synthetic Data Generation
Numerous methods have been proposed for generat-
ing synthetic data, especially concerning tabular for-
matted data, while ensuring DP. Synthetic data gen-
eration approaches for tabular datasets can be catego-
rized into three types. The first type is founded on
basic statistics (Li et al., 2014; Asghar et al., 2020).
The second type leverages graphical models (Zhang
et al., 2017; Zhang et al., 2021; McKenna et al., 2022;
McKenna et al., 2019). Tabular formatted data can
be regarded as features extracted by humans. Since
the graphical models learn relationships among at-
tributes, they produce high-quality synthetic data (Tao
et al., 2021). The third is the deep-neural-network-
based method (Xu et al., 2019; Fang et al., 2022;
Zhao et al., 2022; Chen et al., 2018; Lee et al., 2022;
Kotelnikov et al., 2022; Liew et al., 2022). In this
research, we evaluate one statistics-based method,
three graphical-model-based methods, and one deep-
neural-network-based method, utilizing a real medi-
cal dataset for the assessment.
2.2 Synthetic Data Generation for
Medical Data
Researchers have directed substantial interest toward
using synthetic data generation in the medical field,
mainly focusing on image data (Guibas et al., 2017;
Tajbakhsh et al., 2020). In these applications, prac-
titioners employ synthetic data for data augmenta-
tion and privacy protection. However, the predomi-
nant methods, which are image-specific, present dif-
ficulties when applied to tabular data and do not ac-
count for DP. Although Hernandez et al. investigated
a tabular healthcare dataset (Hernandez et al., 2022),
their research concentrates exclusively on deep neural
network-based synthetic data generation without con-
sidering DP. Our research evaluates several synthetic
data generation techniques in conjunction with DP.
3 METHODOLOGY
Our experiment comprises three components:
datasets, synthetic data generation algorithms, and
evaluation methods. The experiment aims to evaluate
the differences among synthesis algorithms and ana-
lyze DP’s influence. An overview of the experiment
is as follows:
• Apply a synthesis algorithm F : D → D to the
original dataset D
orig
. The generated synthetic
dataset F(D
orig
) = D
syn
is the same size as the
original dataset D
orig
.
• By using an evaluation method E : D ×D → R,
compare D
syn
with D
orig
.
3.1 Notations
In this paper, we focus on the tabular format
datasets. A tabular dataset consists of several at-
tributes A
1
, . . . , A
d
. We can express a record as an el-
ement x ∈ A := A
1
×···×A
d
. If a dataset D contains
N records, we can regard D ∈ A
N
and set a universe
of datasets as D = A
N
. We set a probabilistic simplex
∆
d
:= {x ∈ R
d
|
∑
d
i=1
x
i
= 1, x
i
≥ 0}.
HEALTHINF 2024 - 17th International Conference on Health Informatics
316

Table 1: Names and types of attributes of DPC dataset. (n)
means that the number of the attribute values is n.
Name Type
1 Gender categorical (2)
2 Type of admission categorical (7)
3 Emergency admission categorical (2)
4 Length of Stay numerical
5 Height numerical
6
Weight numerical
7 Smoking categorical (2)
8 Pregnancy categorical (2)
9 Independent eating categorical (4)
10
Independence in Activities
categorical (4)
of Daily Living
11 Independent Mobility categorical (5)
12 Major diagnostic category categorical (18)
13 Surgery categorical (9)
14 Subclassification categorical (10)
15 Secondary disease categorical (3)
3.2 Dataset
This research uses a DPC dataset from Ehime Uni-
versity Hospital. This dataset has been extracted from
the data warehouse, which encompasses DPC data
from 2010 to 2013, to analyze the impact of 15 at-
tributes on length of hospital stay: gender, type of ad-
mission, emergency admission, length of stay, height,
weight, smoking, pregnancy, independent eating, in-
dependence in activities of daily living, independent
mobility, major diagnostic category, surgery, subclas-
sification, and secondary disease. Table 1 delineates
the information for each category. All categorical data
are encoded into one-hot vectors. Records containing
missing values were excluded from the dataset, and
the number of records became 9,666.
3.3 Synthesis Algorithm
In this research, we implement five synthesis algo-
rithms, as listed in Table 2. Generally, a synthesis
algorithm F : D → D is decomposed into two steps,
as shown in Fig.1. The first step is to extract gener-
ative parameters F
ext
: D → R
p
. Generative parame-
ters are compressed information needed for the gener-
ation, such as basic statistics or trained machine learn-
ing model parameters. The second step is to generate
synthetic data from the extracted generative parame-
ters F
gen
: R
p
→ D.
Moreover, we use DP, which is known as the gold
standard of the privacy protection framework (Dwork,
2006; Dwork et al., 2014). We add intentional noise
to the generative parameter θ = F
ext
(D) to satisfy DP.
The formal definition is as follows.
Definition 3.1 (Differential privacy (Dwork, 2006;
Dwork et al., 2014)). A randomized function M :
D → Y satisfies (ε, δ)-DP ((ε, δ)-DP) if for any
neighboring D, D
′
∈ D and S ⊂ Y
Pr[M (D) ∈ S] ≤ e
ε
Pr[M (D
′
) ∈ S] + δ.
In particular, M satisfies ε-DP if it satisfies (ε, 0)-DP.
If ε is smaller, it means that the output is more se-
cure. We also interpret the case we do not add any in-
tentional noise as ε = ∞. The stronger the protection,
the worse the quality of outputs. δ can be regarded
as a permissible error. This research investigates the
case ε = ∞, 8, 4, 2, 1 and δ = 10
−5
.
3.3.1 Statistics-Based Methods
We evaluate the Gaussian Copula-based synthetic
data generation as a statistics-based method (Sklar,
1959; Li et al., 2014). The Gaussian Copula’s genera-
tive parameters are the original dataset’s mean vector
µ, the correlation matrix S, and the marginal distribu-
tion H
1
, . . . , H
d
. For the DP version, we use the im-
plementation by Li et al. (Li et al., 2014). We denote
this method by GCopula.
3.3.2 Graphical-Model-Based Methods
We evaluate PrivBayes (Zhang et al., 2017), MWEM-
PGM (McKenna et al., 2019), and AIM (McKenna
et al., 2022) as graphical-model-based methods.
PrivBayes trains important relations between at-
tributes and expresses the relation as a directed
acyclic graph. When generating data, attribute values
are sampled in accordance with the graph. AIM and
MWEM-PGM are similar methods that learn condi-
tional probability tables to satisfy DP and sample data
from them. These methods are denoted by Bayes,
MWEM, and AIM.
3.3.3 Deep-Neural-Network-Based Methods
We evaluate Conditional Tabular Gan, CTGAN (Xu
et al., 2019), as a deep-neural-network-based method.
The differentially private version of CTGAN is imple-
mented by smart-noise
1
. In this method, we train deep
neural networks with DP-SGD (Abadi et al., 2016).
This method is denoted by CTGAN.
3.4 Evaluation Methods (Quality of
Synthetic Data)
In this research, we evaluate the quality of the syn-
thetic dataset D
syn
, which is the same size as the orig-
1
https://docs.smartnoise.org/synth/index.html
Evaluating Synthetic Data Generation Techniques for Medical Dataset
317

Table 2: Synthesis algorithms in our experiment.
Synthesis algorithm Description Generative parameter
Gaussian Copula (Li et al., 2014) GCopula Statistics
PrivBayes (Zhang et al., 2017) Bayes Directed acyclic graph, conditional probability
MWEM-PGM (McKenna et al., 2019) MWEM Total joint distribution
AIM (McKenna et al., 2022) AIM Total joint distribution
CTGAN (Xu et al., 2019) CTGAN Model parameter of deep neural network
inal dataset D
orig
, from three perspectives: distribu-
tion distances, machine learning model performances,
and differences in correlations. Distribution distance
is a broad measure, and machine learning model per-
formance is a narrow measure (Drechsler and Reiter,
2009; Dankar et al., 2022). We also evaluate the ab-
solute difference in correlations to compare relations
explicitly. Let E : D ×D → R be an evaluation func-
tion.
3.4.1 Evaluation by Distribution Distances
The first evaluation is by statistical distribution dis-
tances E
dist
: D ×D → R between D
orig
and D
syn
.
For each attribute, we evaluate the statistical distance
of 1-way marginals. For the statistical distances, we
use L1 distance, L2 distance, Hellinger distance, and
Wasserstein distance. The definitions are as follows.
Definition 3.2 (L
p
norm). For x, y ∈ ∆
d
, the L
p
norm
is defined as
||x −y||
p
:= (
d
∑
i=1
|x
i
−y
i
|
p
)
1
p
.
We use the case when p = 1 or p = 2.
In a previous work, Hellinger distance was re-
garded as the best utility metric to rank synthetic data
generation algorithms (El Emam et al., 2022).
Definition 3.3 (Hellinger distance). For x, y ∈∆
d
, the
Hellinger distance is defined as
Hel(x, y) :=
d
∑
i=1
√
x
i
−
√
y
i
!
2
.
Definition 3.4 (Wasserstein distance). For x, y ∈ ∆
d
,
the Wasserstein distance or the Earth-Mover dis-
tance is defined as
Was(x, y) := inf
γ∼Γ(x,y)
E
(a,b)∼γ
[|a −b|],
where Γ(x, y) is the set of all couplings of x and y. A
coupling γ is a joint probability measure on R
d
×R
d
whose marginals are x and y on the first and second
factors, respectively.
3.4.2 Evaluation by the Difference of Machine
Learning Model Performances
The second evaluation is the differences in machine
learning model performances. Since DPC datasets
are often used to predict the length of hospital stays,
we train a regression model to predict length of stay
(fourth attribute in Table 1) with LightGBM, which
is a simple but high-performing machine learning
model. We compare machine learning models trained
by D
syn
with D
orig
.
The accuracy of models is evaluated by using the
root-mean-square error (RMSE). For a trained model
f , the error is defined by
RMSE( f , D) =
s
1
n
n
∑
i=1
(y
i
− f (x
i
))
2
,
where D = {(x
i
, y
i
)}
i=1,...,n
. We evaluate RMSE of a
trained model with a synthetic dataset D
syn
. Thus, the
evaluation function E
ml
: D ×D → R is defined as
E
ml
(D
orig
, D
syn
) = RMSE( f
syn
, D
orig
), where f
syn
is a
trained model with D
syn
.
3.4.3 Evaluation by the Difference of
Correlation Matrices
The third evaluation is the difference in correlation
matrices. The correlation matrix is defined as follows:
Definition 3.5 (Correlation matrix). For data samples
x
1
, . . . , x
m
∈ R
d
, set its mean vector as µ ∈ R
d
. Then,
a matrix R ∈ R
d×d
whose (i, j)-th component is
R
i j
=
∑
d
k=1
(x
k
i
−µ
i
)(x
k
j
−µ
j
)
q
∑
d
k=1
(x
k
i
−µ
i
)
2
q
∑
d
k=1
(x
k
j
−µ
j
)
2
is called the correlation matrix.
We calculate the correlation matrices of D
orig
and
D
syn
. We evaluate only numerical attributes and com-
pute the absolute error of each component. Thus, the
evaluation function E
cor
: D ×D → R
n×n
is defined
as (E
cor
(D
orig
, D
syn
))
i, j
= |R
orig
i j
−R
syn
i j
|, where n is the
number of numerical attributes.
HEALTHINF 2024 - 17th International Conference on Health Informatics
318
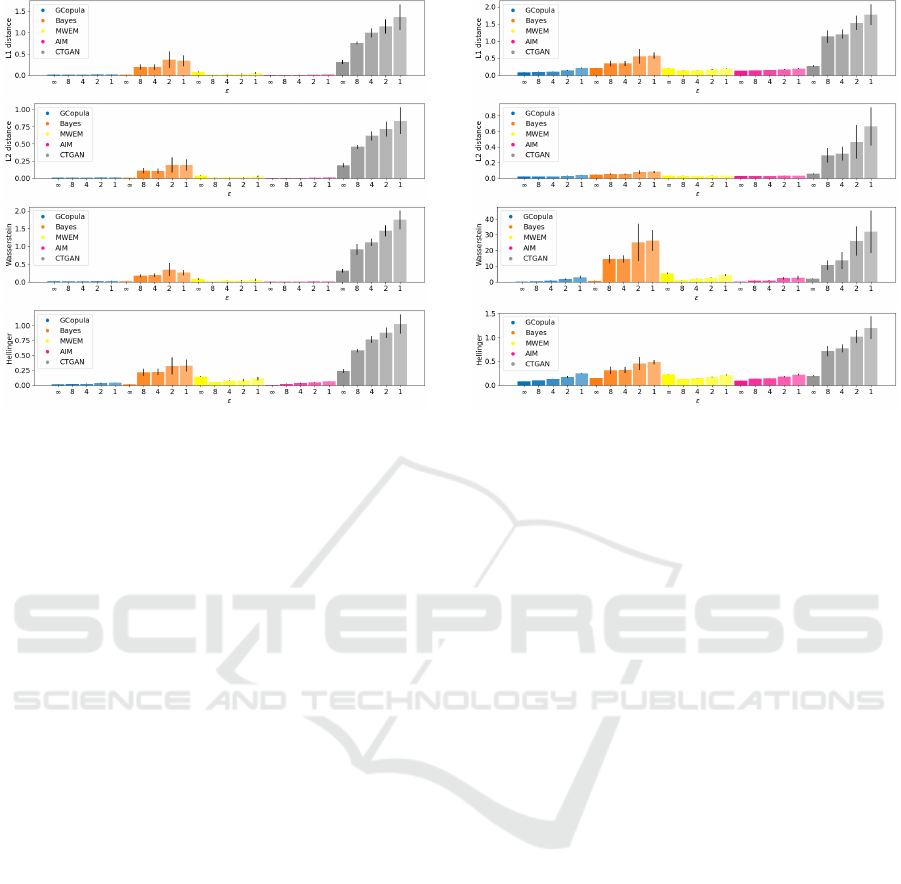
Figure 2: Result of categorical attributes distance. L1 dis-
tance, L2 distance, Hellinger distance, and Wasserstein dis-
tance from the top.
4 RESULTS
We generated synthetic data five times under the same
conditions and calculated the average of the evalua-
tion values. In this section, we report the results.
4.1 Distribution Distance Results
Figures 2 and 3 display the evaluation results by dis-
tribution distances, separating the graphs of categor-
ical and numerical attributes due to differing scales.
The results of all attributes are shown in Appendix.
Values represent the means of all categorical or nu-
merical attributes, respectively. Notably, the distance
is regarded as a loss.
First, the losses for ε = ∞, representing a non-
differentially private case, are small. Also, the losses
significantly increase as the values of ε decrease, en-
hancing the robustness of the protection by DP.
CTGAN and differentially private Bayes exhibit
more substantial losses when synthesizing algorithms
are compared, while GCopula, MWEM, and AIM demon-
strate lesser losses.
4.2 Machine Learning Model
Performance Results
Fig. 4 illustrates the results of machine learning model
performances, with the red line expressing RMSE for
the original dataset. Non-differentially private results
for each synthesis algorithm (ε = ∞) align closely
Figure 3: Result of numerical attributes distance. L1 dis-
tance, L2 distance, Hellinger distance, and Wasserstein dis-
tance from the top.
with the original. The quality of the synthetic data
discernibly declines as ε increases. Specifically, the
results from differentially private Bayes and CTGAN
are inferior, while those of GCopula and AIM remain
proximate to the original results, even when differen-
tially private.
4.3 Difference in Correlations Results
Fig. 5 presents the results in cases where ε = ∞, the
absolute losses of GCopula and Bayes are small. Ad-
ditionally, losses become more significant as ε in-
creases, resulting in differentially private CTGAN being
the worst.
5 DISCUSSION
5.1 Quality of Synthetic Data
The three evaluation methods reveal that the losses
associated with non-differentially private synthesis
remain sufficiently small, while DP diminishes the
quality of synthetic data. In differentially private
cases, the magnitude of the losses varies among syn-
thesis methods. This indicates the potential for en-
hancing the quality of synthetic data by strategi-
cally devising DP. Notably, the recently proposed
AIM achieves noteworthy experimental results consis-
tently. AIM manifests negligible deterioration in the
quality of the synthetic data when implementing DP.
Evaluating Synthetic Data Generation Techniques for Medical Dataset
319
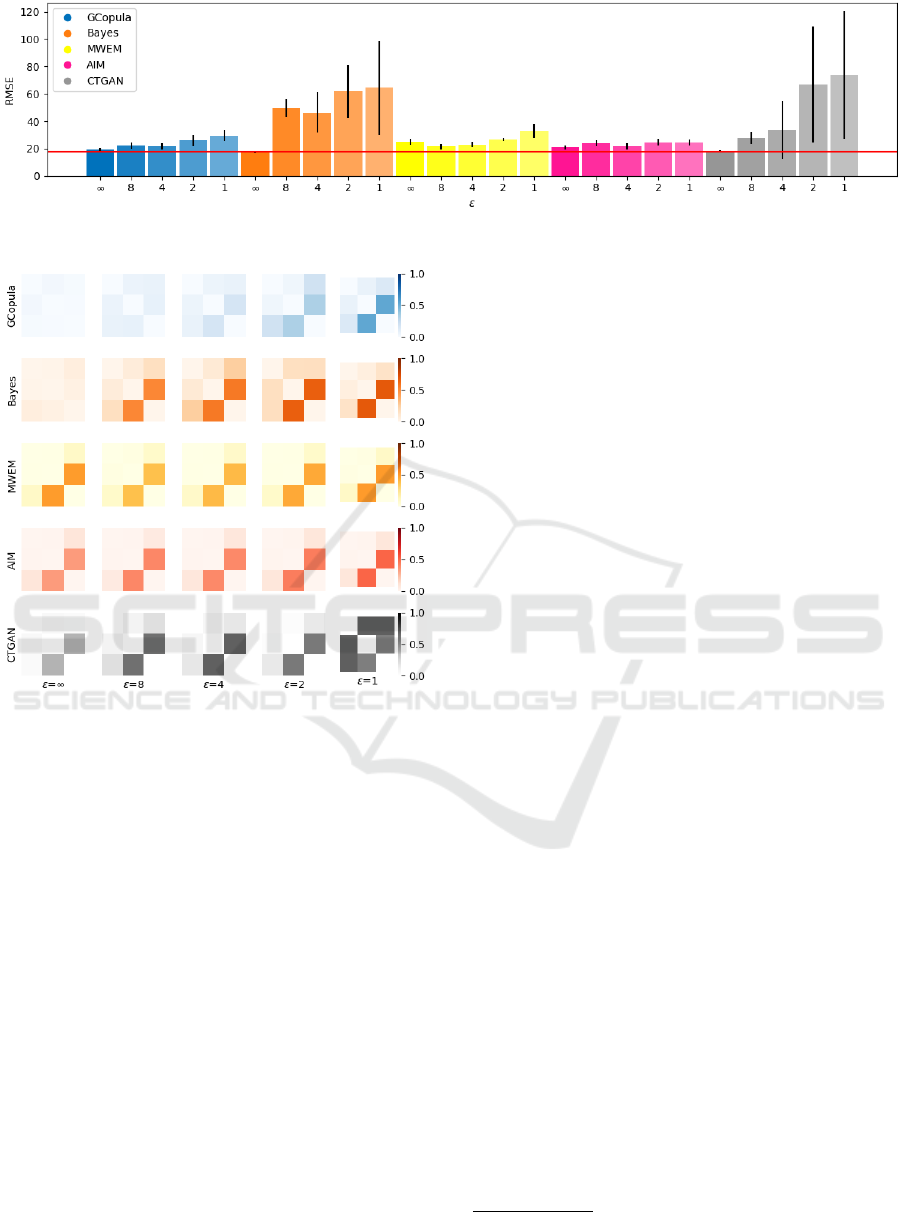
Figure 4: Results of machine learning model performances: RMSEs of a trained LightGBM regression model.
Figure 5: Results of differences in correlations
5.2 Evaluation Methods
This study employs L1 distance, L2 distance,
Hellinger distance, and Wasserstein distance as eval-
uative metrics, which are widely utilized in studies
measuring the quality of synthetic data and prove
highly useful when assessing the ”relative” quality
thereof. These metrics indicate that AIM exhibits no-
tably superior results to other methods.
Conversely, to facilitate absolute evaluations with
qualitative significance, it is necessary to assume re-
alistic use cases for evaluations by machine learning
performance and ascribe meaning to the magnitude of
errors.
5.3 Towards Practical Use
Discussion has yet to emerge regarding whether us-
ing synthetic data for personal data is subject to the
agenda of Ethics Review Committees. Conversely,
Guo et al. have reported that they did not require
an ethical review because the synthetic data contained
no information that could lead to the identification of
individual patients (Guo et al., 2020). It has been
posited that, should synthetic data gain recognition
as a viable option for privacy considerations, obtain-
ing approval from ethics committees may become un-
necessary (Azizi et al., 2021). In a case wherein an
organization inadvertently disclosed the personal in-
formation of numerous individuals online while test-
ing a cloud solution, the Norwegian Data Protection
Authority (Datatilsynet) highlighted that testing could
have been conducted by processing synthetic data or
using less personal data
2
. This ruling also implies
that synthetic data may be recognized as having the
potential to exclude information that leads to personal
identification.
Furthermore, DP can potentially enhance the se-
curity of such synthetic data. Therefore, DP is antici-
pated to minimize discussions concerning anonymous
processing and expedite the progression of research.
Nonetheless, studies have examined attacks that de-
duce the original data from synthetic data (Stadler
et al., 2022), necessitating further research to ensure
its security.
6 CONCLUSION
In this research, employing the a Diagnosis Procedure
Combination (DPC) dataset, we experimentally eval-
uated synthetic data generation techniques’ effective-
ness using statistic-based, machine-learning model-
based, and deep neural network-based methods. The
investigation clarified the differences in performance
among the methods, attributing them to variations in
the amount of source data and the degree of accuracy
degradation when implementing differential privacy.
Further, we discussed issues that must be addressed
to apply synthetic data generation techniques more ef-
fectively.
2
https://www.dataguidance.com/news/norway-datatil
synet-fines-nif-nok-12m-disclosing
HEALTHINF 2024 - 17th International Conference on Health Informatics
320

ETHICAL CONSIDERATIONS
The Ethics Review Committee of Ehime University
Hospital approved this study (“Quality evaluation of
synthetic data generation methods preserving statis-
tical characteristics,” Permission number 2012001),
and we conducted it in accordance with the commit-
tee’s guidelines.
REFERENCES
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B.,
Mironov, I., Talwar, K., and Zhang, L. (2016). Deep
learning with differential privacy. In Proceedings of
the 2016 ACM SIGSAC conference on computer and
communications security, pages 308–318.
Aggarwal, C. C. (2005). On k-anonymity and the curse of
dimensionality. In VLDB, volume 5, pages 901–909.
Asghar, H. J., Ding, M., Rakotoarivelo, T., Mrabet, S., and
Kaafar, D. (2020). Differentially private release of
datasets using gaussian copula. Journal of Privacy
and Confidentiality, 10(2).
Azizi, Z., Zheng, C., Mosquera, L., Pilote, L., and
El Emam, K. (2021). Can synthetic data be a proxy
for real clinical trial data? a validation study. BMJ
open, 11(4):e043497.
Barth-Jones, D. (2012). The’re-identification’of governor
william weld’s medical information: a critical re-
examination of health data identification risks and pri-
vacy protections, then and now. Then and Now (July
2012).
Chen, Q., Xiang, C., Xue, M., Li, B., Borisov, N., Kaarfar,
D., and Zhu, H. (2018). Differentially private data
generative models. arXiv preprint arXiv:1812.02274.
Cramer, R., Damg
˚
ard, I. B., and Nielsen, J. B. (2015).
Secure Multiparty Computation and Secret Sharing.
Cambridge University Press.
Culnane, C., Rubinstein, B. I., and Teague, V. (2017).
Health data in an open world. arXiv preprint
arXiv:1712.05627.
Dankar, F. K., Ibrahim, M. K., and Ismail, L. (2022). A
multi-dimensional evaluation of synthetic data gener-
ators. IEEE Access, 10:11147–11158.
Drechsler, J. and Reiter, J. (2009). Disclosure risk and data
utility for partially synthetic data: An empirical study
using the german iab establishment survey. Journal of
Official Statistics, 25(4):589–603.
Dwork, C. (2006). Differential privacy. In International col-
loquium on automata, languages, and programming,
pages 1–12. Springer.
Dwork, C., Roth, A., et al. (2014). The algorithmic foun-
dations of differential privacy. Found. Trends Theor.
Comput. Sci., 9(3-4):211–407.
El Emam, K. (2020). Seven ways to evaluate the utility of
synthetic data. IEEE Security & Privacy, 18(4):56–
59.
El Emam, K., Mosquera, L., Fang, X., and El-Hussuna, A.
(2022). Utility metrics for evaluating synthetic health
data generation methods: validation study. JMIR med-
ical informatics, 10(4):e35734.
Fang, M. L., Dhami, D. S., and Kersting, K. (2022).
Dp-ctgan: Differentially private medical data gen-
eration using ctgans. In Artificial Intelligence in
Medicine: 20th International Conference on Artificial
Intelligence in Medicine, AIME 2022, Halifax, NS,
Canada, June 14–17, 2022, Proceedings, pages 178–
188. Springer.
Guibas, J. T., Virdi, T. S., and Li, P. S. (2017). Synthetic
medical images from dual generative adversarial net-
works. arXiv preprint arXiv:1709.01872.
Guo, A., Foraker, R. E., MacGregor, R. M., Masood, F. M.,
Cupps, B. P., and Pasque, M. K. (2020). The use of
synthetic electronic health record data and deep learn-
ing to improve timing of high-risk heart failure sur-
gical intervention by predicting proximity to catas-
trophic decompensation. Frontiers in digital health,
2:576945.
Hernandez, M., Epelde, G., Alberdi, A., Cilla, R., and
Rankin, D. (2022). Synthetic data generation for tab-
ular health records: A systematic review. Neurocom-
puting, 493:28–45.
Kotelnikov, A., Baranchuk, D., Rubachev, I., and Babenko,
A. (2022). Tabddpm: Modelling tabular data with dif-
fusion models. arXiv preprint arXiv:2209.15421.
Lee, J., Kim, M., Jeong, Y., and Ro, Y. (2022). Differen-
tially private normalizing flows for synthetic tabular
data generation. In Proceedings of the AAAI Con-
ference on Artificial Intelligence, volume 36, pages
7345–7353.
Li, H., Xiong, L., Zhang, L., and Jiang, X. (2014). Dp-
synthesizer: Differentially private data synthesizer for
privacy preserving data sharing. In Proceedings of the
VLDB Endowment International Conference on Very
Large Data Bases, volume 7, page 1677. NIH Public
Access.
Liew, S. P., Takahashi, T., and Ueno, M. (2022). PEARL:
Data synthesis via private embeddings and adversarial
reconstruction learning. In International Conference
on Learning Representations.
McKenna, R., Mullins, B., Sheldon, D., and Miklau, G.
(2022). Aim: An adaptive and iterative mechanism
for differentially private synthetic data. arXiv preprint
arXiv:2201.12677.
McKenna, R., Sheldon, D., and Miklau, G. (2019).
Graphical-model based estimation and inference for
differential privacy. In International Conference on
Machine Learning, pages 4435–4444. PMLR.
Shan, Z., Ren, K., Blanton, M., and Wang, C. (2018). Prac-
tical secure computation outsourcing: A survey. ACM
Computing Surveys (CSUR), 51(2):1–40.
Sklar, M. (1959). Fonctions de repartition an dimensions
et leurs marges. Publ. inst. statist. univ. Paris, 8:229–
231.
Stadler, T., Oprisanu, B., and Troncoso, C. (2022). Syn-
thetic data–anonymisation groundhog day. In 31st
Evaluating Synthetic Data Generation Techniques for Medical Dataset
321

USENIX Security Symposium (USENIX Security 22),
pages 1451–1468.
Sweeney, L. (2002). k-anonymity: A model for protecting
privacy. International Journal of Uncertainty, Fuzzi-
ness and Knowledge-Based Systems, 10(05):557–570.
Tajbakhsh, N., Jeyaseelan, L., Li, Q., Chiang, J. N., Wu, Z.,
and Ding, X. (2020). Embracing imperfect datasets:
A review of deep learning solutions for medical image
segmentation. Medical Image Analysis, 63:101693.
Tao, Y., McKenna, R., Hay, M., Machanavajjhala, A.,
and Miklau, G. (2021). Benchmarking differentially
private synthetic data generation algorithms. arXiv
preprint arXiv:2112.09238.
Xu, L., Skoularidou, M., Cuesta-Infante, A., and Veera-
machaneni, K. (2019). Modeling tabular data using
conditional gan. In Advances in Neural Information
Processing Systems.
Zhang, J., Cormode, G., Procopiuc, C. M., Srivastava, D.,
and Xiao, X. (2017). Privbayes: Private data release
via bayesian networks. ACM Trans. Database Syst.,
42(4).
Zhang, Z., Wang, T., Li, N., Honorio, J., Backes, M., He, S.,
Chen, J., and Zhang, Y. (2021). {PrivSyn}: Differen-
tially private data synthesis. In 30th USENIX Security
Symposium (USENIX Security 21), pages 929–946.
Zhao, Z., Kunar, A., Birke, R., and Chen, L. Y. (2022).
Ctab-gan+: Enhancing tabular data synthesis. arXiv
preprint arXiv:2204.00401.
APPENDIX
Results of All Attributes
The results of distribution distances for each attribute
are shown in Fig. 6, 7, 8 and 9.
Figure 6: The values of L1 distance of each attribute.
Figure 7: The values of L2 distance of each attribute.
Figure 8: The values of Hel. distance of each attribute.
Figure 9: The values of Was. distance of each attribute.
HEALTHINF 2024 - 17th International Conference on Health Informatics
322
