
Event-Based Semantic-Aided Motion Segmentation
Chenao Jiang
a
, Julien Moreau
b
and Franck Davoine
c
Universit
´
e de Technologie de Compi
`
egne, CNRS, Heudiasyc (Heuristics and Diagnosis of Complex Systems),
CS 60319 - 60203 Compi
`
egne Cedex, France
Keywords:
Event Cameras, Unconventional Vision, Semantic and Motion Segmentation.
Abstract:
Event cameras are emerging visual sensors inspired by biological systems. They capture intensity changes
asynchronously with a temporal precision of up to µs, in contrast to traditional frame imaging techniques
running at a fixed frequency of tens of Hz. However, effectively utilizing the data generated by these sensors
requires the development of new algorithms and processing.
In light of event cameras’ significant advantages in capturing high-speed motion, researchers have turned
their attention to event-based motion segmentation. Building upon (Mitrokhin et al., 2019) framework, we
propose leveraging semantic segmentation enable the end-to-end network not only to segment moving objects
from background motion, but also to achieve semantic segmentation of distinct moving objects. Remarkably,
these capabilities are achieved while maintaining the network’s low parameter count of 2.5M. To validate
the effectiveness of our approach, we conduct experiments using the EVIMO dataset and the new and more
challenging EVIMO2 dataset (Burner et al., 2022). The results demonstrate improvements attained by our
method, showcasing its potential in event-based multi-objects motion segmentation.
1 INTRODUCTION
Motion segmentation plays a vital role in enabling au-
tonomous robots to navigate dynamic scenes. How-
ever, this has always been a challenging problem due
to the presence of dual motion originating from both
the camera and moving objects.
Traditional imaging cameras often struggle in dy-
namic scenarios with moving objects due to motion
blur and low-light conditions. Inspired by the spiking
nature of biological visual pathways, neuromorphic
engineers have developed a sensor called event cam-
era, or Dynamic Vision Sensor (DVS) (Lichtsteiner
et al., 2008). Unlike conventional image frames, the
DVS captures asynchronous temporal changes in the
scene as a stream of events. When a change in log
light intensity is detected in a pixel, the camera im-
mediately returns an event, e = {x, y,t, p}, consisting
of the position of the pixel (x, y), timestamp of the
change t, accurate to microseconds, and the polarity
of the change p, corresponding to whether the pixel
became brighter or darker.
a
https://orcid.org/0009-0005-6283-4064
b
https://orcid.org/0000-0001-5008-9232
c
https://orcid.org/0000-0002-8587-6997
Event slice (input) Grayscale + mask
Ground truth mask with labels Predicted mask with labels
Figure 1: Motion and semantic segmentation with a monoc-
ular event camera on an EVIMO dataset sequence. Event
slice will be explained in Sec. 3.1. Grayscale images are
only provided for visualization, and bounding boxes on the
images are only used for computing the evaluation metrics.
Best viewed in color.
Event cameras provide benefits in terms of tem-
poral resolution, low latency, and low-bandwidth sig-
nals. However, due to the unconventional output
and underlying principles of operation, algorithms de-
signed for traditional cameras cannot be directly ap-
plicable. To fully harness the potential of event cam-
eras, novel algorithms are required. A recent survey
Jiang, C., Moreau, J. and Davoine, F.
Event-Based Semantic-Aided Motion Segmentation.
DOI: 10.5220/0012308100003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 4: VISAPP, pages
159-171
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
159

(Gallego et al., 2022) offers a overview of event cam-
eras, algorithms, and their applications.
Our work focuses on the motion segmentation es-
timation by leveraging the exceptional temporal reso-
lution and high dynamic range of event cameras. We
deal with dynamic scenes observed by moving event
cameras, and containing Independently Moving Ob-
jects (IMOs). This scenario poses greater difficulties
than with static cameras, as events are influenced not
only by moving objects but also by the background.
To address this problem, we build upon the neu-
ral network framework proposed by (Mitrokhin et al.,
2019), which estimates 3D motion field using event
data. Expanding on this architecture, we introduce
the task of supervised semantic segmentation to the
network. By doing so, we empower the network to
effectively segment IMOs in dynamic scenes captured
by event cameras. Fig. 1 displays visual results, pro-
viding a sample of the output from our work.
Our contributions can be summarized as follows:
• A neural network inferring camera and object mo-
tion, and semantic segmentation, from event data.
• A comprehensive evaluation, qualitative and
quantitative, conducted on available datasets,
showing better performance compared to compet-
ing baseline methods.
• Introducing more complete metrics to assess per-
formance in event-based IMOs segmentation and
detection.
The rest of the paper is organized as follows:
Sec. 2 discusses the related works on event-based mo-
tion segmentation and semantic segmentation prob-
lems. Sec. 3 provides a detailed presentation of our
network, followed by a comprehensive evaluation on
different datasets in Sec. 4. Finally, the study is sum-
marized in Sec. 5.
2 RELATED WORK
2.1 Event-Based Motion Segmentation
Motion segmentation for a static event-based cam-
era is relatively straightforward since events in this
scenario are exclusively caused by moving objects
(assuming no changes in illumination) (Litzenberger
et al., 2006). For example, (Piatkowska et al., 2012)
apply Gaussian mixture models to detect, describe
and track objects in the case of static event cameras.
More challenges arise when dealing with a mov-
ing camera, as events are triggered across the entire
image plane, originating from both moving objects
and the apparent motion of the static scene induced
by the camera’s ego motion. In early works on event-
based motion segmentation, it was necessary to have
prior knowledge about the shape of IMOs: (Glover
and Bartolozzi, 2016) detect and track circular ob-
jects (such as a ball) in the presence of clutter caused
by camera ego-motion by extending the Hough-based
circle detection algorithm using optical flow infor-
mation from the spatio-temporal event space. Alter-
natively, prior knowledge about the correlation be-
tween tracked geometric primitives and the motion of
the event camera was also used, e.g. (Vasco et al.,
2017) detect and track corners in the event stream and
learn the statistics of their motion as a function of the
robot’s joint velocities when no IMOs are present.
In more recent works, such prior knowledge is no
longer necessary. There are some model-based meth-
ods like (Stoffregen and Kleeman, 2018), that works
by collecting events up to a threshold and applying fo-
cus maximisation with a 2-Degree of Freedom (DoF)
optic flow motion model. The events belonging to
the dominant motion (e.g., background) were then re-
moved to analyze the remaining events in a greedy
manner with the same process. (Mitrokhin et al.,
2018) use a similar scheme, whereby focus optimi-
sation with a 4-DoF motion model is applied to a set
of events to find the dominant motion, which is as-
sumed to be the camera ego-motion. However it fails
to achieve accurate segmentation in densely textured
environments or in the presence of overlapping mov-
ing objects. (Stoffregen et al., 2019) improve on these
results, which uses focus optimisation on multiple
motion models together with a probabilistic model.
The motion parameters and the event probabilities are
then updated in a combined optimisation in an Expec-
tation Maximisation (EM) approach. (Parameshwara
et al., 2021) present a model based approach similar
to (Stoffregen et al., 2019), apply a global motion-
compensation, resulting in a sharp background and
blurry object boundaries. They then apply motion
tracking to the residual events and use K-means clus-
tering to group the resulting track lets (K is set to a
large value), the clusters are then merged using a con-
trast and distance function. Recently, (Zhou et al.,
2023) propose to cast the motion segmentation prob-
lem as an energy minimization one involving the fit-
ting of multiple motion models. They jointly solve
two sub-problems, namely event cluster assignment
(labeling) and motion model fitting, in an iterative
manner by exploiting the structure of the input event
data in the form of a spatio-temporal graph.
More related to our approach are the machine
learning-based methods. (Mitrokhin et al., 2020)
use a Graph Convolutional Neural Network (GCNN)
architecture in which the nodes are the events.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
160

(Mitrokhin et al., 2019) propose a pipeline that incor-
porates a depth prediction and a pose prediction net-
works to estimate depth, per-pixel pose, and motion
segmentation mask in supervised mode. The outputs
are used to generate the optical flow, associated with
a two-stage loss to evaluate the warping quality.
2.2 Event-Based Semantic Segmentation
Semantic segmentation is a visual recognition task
that involves assigning a semantic label to each pixel
in an image. Deep learning addresses this problem
with state-of-the-art solutions predominantly relying
on encoder-decoder CNN architectures using RGB
images, such as (He et al., 2016), (Chollet, 2017),
(Chen et al., 2018).
The pioneering work in event-based semantic seg-
mentation was (Alonso and Murillo, 2019), with an
Xception-type network (Chollet, 2017).
Novel sensors like event cameras often face a
common challenge of limited labeled datasets for se-
mantic segmentation. To address this issue, several
approaches try to leverage labeled conventional im-
ages to train networks for event cameras. This trans-
fer from a labeled source domain (images) to an un-
labeled target domain (events) is generally defined as
Unsupervised Domain Adaption (UDA). In this con-
text, (Sun et al., 2022) explores the utilization of UDA
for event-based semantic segmentation.
Current motion segmentation methods can detect
and segment moving objects but lack semantic infor-
mation. We believe that semantic information is valu-
able for motion segmentation, as it not only includes
class labels but also relates to the dynamics and ex-
pected motion of objects. Moreover, both motion and
semantic segmentation tasks can be achieved through
encoder-decoder network. Therefore, in this work, we
propose a multi-task network that estimate jointly mo-
tion and semantic segmentation, and demonstrating
that these two tasks can mutually benefit each other.
3 PROPOSED ARCHITECTURE
3.1 Event Representation
The raw data of the Dynamic Vision Sensor (DVS)
consists of a continuous stream of events, the repre-
sentation of the event stream is the form of a sparse
three-dimensional point cloud. For this unconven-
tional data, various representation methods currently
exist: event frame or 2D histogram, time surface,
voxel grid, 3D point set, etc (Gallego et al., 2022).
Red channel Green channel Blue channel
Figure 2: Example of the event slice represented in RGB
mapping with a scene from EVIMO dataset. The R and
B color channels represent the positive and negative event
counts and the G color channel represents the aggregation
of timestamps within the δt. Best viewed in color.
To enhance the efficiency of our convolutional neu-
ral network and maximize the utilization of the event
stream, we aim to represent it in a 2D form and parti-
tion it into continuous time slices of size δt (25ms in
our network). The event information within each time
slice is projected onto a generated frame referred to as
event slices, akin to the approach in (Mitrokhin et al.,
2018) and (Mitrokhin et al., 2019). An example of
such event slice can be seen in Fig. 2. This frame-
like representation encompasses three channel map-
pings: one is the aggregation of timestamps within
the δt time slice, while the other two correspond to
the count of positive and negative events.
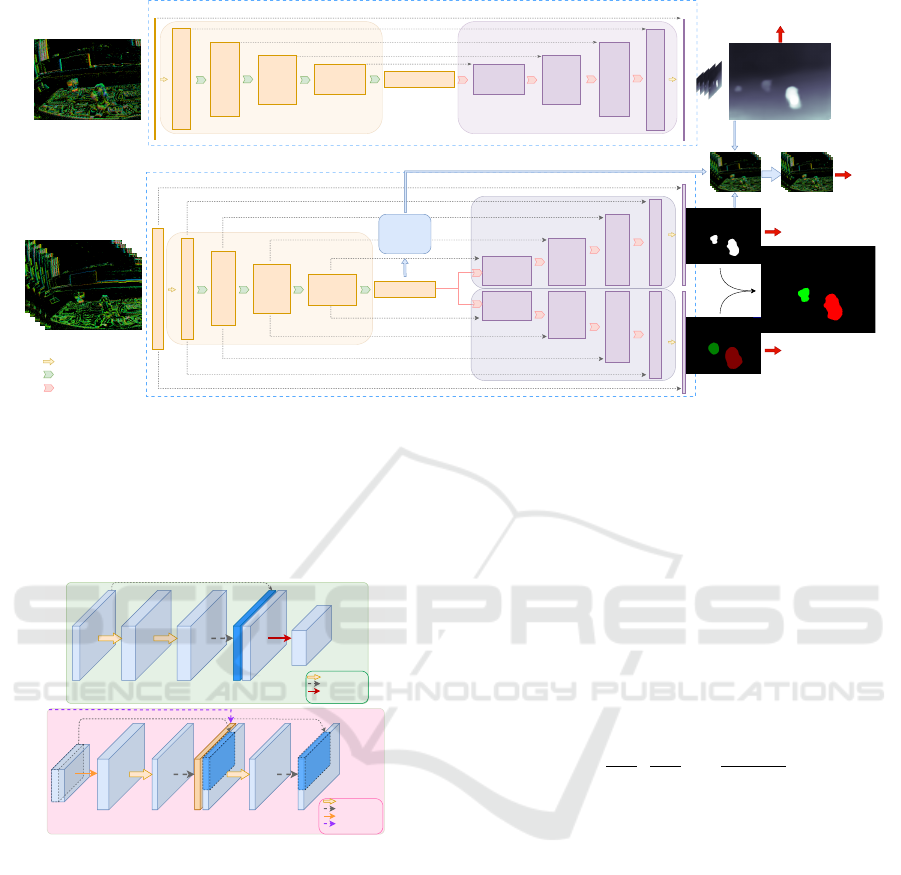
3.2 Overview of the Architecture
Our pipeline, Fig. 3, inherits from (Mitrokhin
et al., 2019) principle. It comprises a depth pre-
diction network and a semantic-aided motion seg-
mentation network, both designed as low-parameter
encoder-decoder networks (Ronneberger et al., 2015).
The depth prediction network is similar to that
in (Mitrokhin et al., 2019) and is summarized in
Sec. 3.3. Proposed semantic and motion segmentation
network shares a common encoder and split into two
decoding branches, for simultaneous semantic seg-
mentation and motion segmentation. This way we in-
troduce a lightweight semantic-aided motion segmen-
tation network, which is detailed in Sec. 3.4.
Both networks are based on CascadeLayer and In-
vertedCascadeLayer, introduced in (Ye et al., 2018)
and shown in Fig. 4. These two blocks aims to
fuse multi-level features through concatenation oper-
ations. In our network, the output dimension of the
CascadeLayer is half of the input, while the output
dimension of the InvertedCascadeLayer is twice that
of the input. Channel numbers of the features are con-
trolled by the growth rate hyper-parameter. This con-
Event-Based Semantic-Aided Motion Segmentation
161
8015
16 32 48
64
160
3
3264
96
128
Decoder
3
32
64
96
128
Encoder
Depth Prediction Network
4
16
32
48
64
Decoder (Motion Segmentation Task)
4
16
32
48
64
3D Motion
Model
Decoder (Semantic Segmentation Task)
Encoder
Semantic-aided Motion Prediction Network
Conv3*3
CascadeLayer
InvertedCascadeLayer
Warp
∩
L
depth
L
warp
L
mask
L
semantic
Figure 3: Network architecture for our depth and semantic-aided motion segmentation model. Top: the Depth Prediction
Network uses an encoder-decoder architecture and is trained in supervised mode to estimate multi-scale depths. Bottom:
the Semantic-aided Motion Segmentation Network and 3D Motion Model share the encoder and then branch out to predict
3D motion vector, multi-scale motion masks, and semantic segmentation. During training, the outputs (depth, 3D motion
vector, motion mask) are combined to generate the optical flow and then to inversely warp the inputs and back-propagate the
error. The final result is a motion mask with semantic labels. The number of channels before and after each CascadeLayer
corresponds to C and C+gr in Fig. 4, and the InvertedCascadeLayer corresponds to C and C-gr.
C
W * H
2W * 2H
2W * 2H
2W * 2H
2W * 2H
2W * 2H
InvertedCascadeLayer
C
C C-gr C-gr C-gr C-gr
Conv3x3+Relu
Cascade (add)
Up Sampling
Skip Connection
gr: growth rate
CascadeLayer
W * H
C C+gr C gr
C+gr
W * H
W * H
W * H
W/2 * H/2
C+gr
Conv3x3+Relu
Cascade (add)
AveragePooling
gr: growth rate
Figure 4: Design of the CascadeLayer and InvertedCas-
cadeLayer.
figuration allows our network to correspond in the en-
coding and decoding layers and introduce skip con-
nections to integrate features from different levels.
3.3 Depth Prediction Network
The depth prediction network estimates scaled inverse
depth from a single event slice (representation out-
lined in Sec. 3.1). As in (Mitrokhin et al., 2019), the
network is supervised by ground-truth depth image,
and its output is used as depth information in the sub-
sequent process of calculating optical flow.
During the decoding phase, different levels of fea-
tures are predicted, a bi-linear interpolation is applied
to up-sample and refine the depth map, and introduce
residuals to integrate different levels of features into
the backbone prediction. For each level of predicted
depth pred, the corresponding ground truth gt is gen-
erated through average pooling for supervision, with
penalties applied to their deviations as follows, while
also applying a smoothness constraint to the second-
order gradient of depth prediction:
L
depth
= max
gt
pred
,
pred
gt
+
|pred−gt|
gt
+ ||∆pred||
1
(1)
3.4 Semantic-Aided Motion
Segmentation Network
Semantic-aided Motion Segmentation Network
shares an encoder and has a motion module and
two decoders for motion segmentation and semantic
segmentation tasks. The outputs’ contributions to
loss functions for training are shown in Fig. 3.
3.4.1 Motion Segmentation Task
The Semantic-aided Motion Segmentation Network
takes 5 consecutive event slices as input, so that it can
explain the motion from the original input event data.
Similar to (Mitrokhin et al., 2019), after an encoder
composed of CascadeLayer (see Fig. 4), and under the
assumption that both camera and objects are rigid mo-
tions, Semantic-aided Motion Segmentation Network
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
162

uses the 3D motion model to estimate pixel-wise 3D
motion (including camera ego-motion and object mo-
tion) from continuous event slices.
In the decoding phase, multi-scale prediction and
residual fusion are performed under the supervision of
ground truth, and finally the pixel-wise motion mask
weight is predicted for the background and moving
objects. This weight is weighted to the camera ego-
motion and object 3D motion to obtain the final pixel-
wise 3D motion vector denoted as p which is the can-
didate velocities of objects relative to the camera. As
show in the middle of Fig. 3.
Then, utilizing the Image Jacobian (Hutchinson
et al., 1996) which relates image-plane velocity of a
point to the relative velocity of the point with respect
to the camera, we leverage the predicted 3D motion
vector to predict the motion field, thereby effectively
compensating for motion:
˙x
˙y
=
−1
Z
0
x
Z
xy −(1 +x
2
) y
0
−1
Z
x
Z
1 +y
2
−xy −x
| {z }
J
img
v
ω
|{z}
p
(2)
where p = (v, ω)
T
is 3D motion vector with a trans-
lational velocity v = (v
x
, v
y
, v
z
)
T
and a rotational ve-
locity ω = (ω
x
, ω
y
, ω
z
)
T
, J
img
denotes the 2x6 Image
Jacobian matrix. x = (x, y)
T
is the point image co-
ordinates and its velocity ( ˙x, ˙y). Thus, for each pixel,
there is a linear relation between the optical flow and
the 3D motion vector.
In the training process, we calculate the optical
flow (Eq. 2) in order to inversely warp events to com-
pensate for the motion, as show in the right of Fig. 3.
This optical flow, along with depth (output of the
Depth Prediction Network), is then utilized to calcu-
late the warp loss (Sec. 3.4.3), which is employed for
training optimization through back-propagation.
3.4.2 Semantic Segmentation Task
In the previous section, we compute motion compen-
sation to achieve the background and moving object
segmentation (background and foreground). How-
ever, the segmentation between moving objects is also
crucial in the field of autonomous robots, and this can
be aided by semantic segmentation.
Currently, for traditional cameras, most of state-
of-the-art on semantic segmentation solutions based
on deep learning are based on different variants of
the encoder-decoder CNN architecture (Ronneberger
et al., 2015) (Chen et al., 2018). Similarly, for
event-based cameras, they also adhere to an encoder-
decoder framework (Alonso and Murillo, 2019). To
minimize network parameters and complexity, we
propose a method that shares the encoder with the mo-
tion mask prediction task, while introducing an auxil-
iary decoder for semantic segmentation task. Within
this network, this decoder also is built upon the
lightweight and trainable InvertedCascadeLayer (re-
fer to Fig. 4) for multi-scale per-pixel classification.
Additionally, our architecture employs skip connec-
tions (Ronneberger et al., 2015) to integrate shallow-
level features, aiding in optimizing the deep structure
and mitigating gradient vanishing issues. As shown
below in Fig. 3.
Semantic-aided Motion Segmentation Network
outputs are as follows. The output of the motion seg-
mentation task is the pixel-wise motion mask weight.
To get the binary motion mask, we apply a threshold
to these weights. In the semantic segmentation task,
we generate a mask containing the labels for each
pixel. However, to reduce noise effects, we apply a
median filter to the semantic mask before combining
the outputs of these two tasks. Values of these filters
are given in Sec. 4.2. The final network output is a
semantically labeled motion mask, which is the inter-
section of the outputs from the two tasks.
3.4.3 Loss Functions
Here we describe the loss function used in Semantic-
aided Motion Segmentation Network. Similarly to
the Depth Prediction Network (Sec. 3.3), the output
of our network is multi-scale. The loss functions de-
scribed in this section are also computed at different
scales and use residual structures to integrate features
at different levels into backbone predictions. They are
weighted by the number of pixels.
Warp Loss: From estimated optical flow, we per-
form an inverse warp of 4 adjacent event slices onto
the central event slice. The warp loss is defined by the
absolute difference in event counts after warping:
L
warp
=
∑
−2≤n≤2,n̸=0
|I
warped
n
− I
0
|
(3)
where I
warped
n
and I
0
denote the warped adjacent event
slices and the central event slice respectively.
Mask Loss: We apply a binary cross-entropy loss to
constrain that our model applies the ego motion in the
background region, while also applying a smoothing
loss on their first-order gradients:
L
mask
= −
∑
log(mask
i
bg
) + ||∇mask||
1
(4)
where mask
i
bg
are the motion mask weights for i
th
pixel and this pixel is the background.
Event-Based Semantic-Aided Motion Segmentation
163

Semantic Loss: With supervision form ground-
truth labels at every scale, we employ the common
softmax cross-entropy loss function to compute the
cumulative pixel-wise loss:
L
semantic
= −
1
N
∑
N
j=1
∑
C
c=1
w
c
y
c, j
log( ˆy
c, j
)
(5)
where N is the number of labeled pixels and C is the
number of classes. y
c, j
is a binary indicator of pixel j
belonging to class c (ground truth). ˆy
c, j
is the network
predicted probability of pixel j belonging to class c.
In order to solve the problem of uneven number of
category samples (generally speaking, the number of
pixels in the background class far exceeds those in a
specific moving object class), we add weights to each
category in the cross-entropy loss:
w
c
=
max(n
1
, n
2
, · ·· , n
C
)
n
c
(6)
where w
c
is the weight to c
th
class, and n
c
is the
number pixels belonging to c
th
class. This way,
larger weights are assigned to classes with fewer pixel
counts.
Total Loss: Finally, we aggregate the above loss
functions through weighted summation to obtain our
total loss (weights are defined by λ
i
):
L
total
= λ
1
L
depth
+ λ
2
L
warp
+ λ
3
L
mask
+ λ
4
L
semantic
(7)
The Semantic-aided Motion Segmentation Network
predicts both motion masks and semantic labels,
which we take the intersection to obtain the final mask
of different motion objects.
4 EVALUATION
4.1 Setup and Training
We conducted experiments using the two networks
explained in Sec. 3, along with the applicable datasets
introduced in Sec. 4.2. We trained our networks from
scratch using the following configuration: Adam opti-
mizer with β
1
= 0.9, β
2
= 0.999; initial learning rate
of 0.01 with a cosine annealing learning rate sched-
ule. We trained for 50 epochs with a batch size of
32, applying data augmentation steps during training,
including random zoom scales and crops as well as
horizontal flips. We set growth rate (see Sec. 3.2) to
32 for the Depth Prediction Network and 16 for the
Semantic-aided Motion Segmentation Network, and
use the batch normalization. For the weights in Eq. 7,
we set λ
1
= λ
2
= λ
3
= λ
4
= 1. Our baseline architec-
ture consists of approximately 2.5 million parameters
and each epoch takes about 25 minutes to train on an
Nvidia Tesla V100-SXM2-32GB GPU. We save the
model parameters of the epoch with the lowest vali-
dation loss as the best model for use.
4.2 Datasets
Literature in event-based motion detection provides
following datasets: EED (Mitrokhin et al., 2018),
MOD (Sanket et al., 2019) , MOD++ (Paramesh-
wara et al., 2021), EVIMO (Mitrokhin et al., 2019),
EVIMO2 (Burner et al., 2022). Since the training of
our network is supervised, it needs depth ground truth
frames and motion truth masks with semantic labels.
Tab. 1 lists the characteristics of event-based motion
detection datasets and whether they are applicable.
Therefore, during the experimental phase, we con-
ducted quantitative evaluations on the EVIMO and
EVIMO2 datasets in Sec. 4.4 and 4.5, applying mo-
tion weight thresholds of 0.7 and 0.8, and median fil-
ter with sizes of 7 × 7 and 15 × 15, respectively.
4.3 Evaluation Metrics
For the quantitative evaluation of our network, we
employ two commonly used metrics in research on
event-based motion segmentation: Detection Rate
and Intersection over Union (IoU). In addition, to
conduct a comprehensive evaluation of IMOs seg-
mentation and detection from events, we adopt the
use of the standards mIoU, Precision, Recall, and F1-
score to this application.
All these metrics, except IoU and mIoU, need
bounding boxes representation. We compute them to
fit the boundaries of the motion mask of each class.
4.3.1 Detection Rate
We assess the performance of moving object detec-
tion using the detection rate. Detection rate was in-
troduced in (Mitrokhin et al., 2018) and used ever
since. Motion detection is considered successful
when the estimated bounding box satisfies the follow-
ing two conditions: 1) The overlapping area with the
ground truth bounding box is greater than 50%; 2)
The area intersected with the ground truth bounding
box is greater than the area intersected with the out-
side world. We can express the metric as:
Success if B
p
∩B
gt
>0.5 and (B
p
∩B
gt
)>(B
p
∩B
gt
)
where B
p
refers to the predicted bounding box, B
gt
refers to the ground truth bounding box, and · de-
notes the complement of a set. The detection rate is
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
164

Table 1: Summary of characteristics of the event datasets for moving objects detection.
Dataset
EED
(Mitrokhin et al., 2018)
MOD
(Sanket et al., 2019)
MOD++
(Parameshwara et al., 2021)
EVIMO
(Mitrokhin et al., 2019)
EVIMO2
(Burner et al., 2022)
Data-type Real Simulated Simulated Real Real
Camera type DAVIS 240B
Sim. DAVIS 346C
ESIM (Rebecq et al., 2018)
Sim. DAVIS 346C
ESIM (Rebecq et al., 2018)
DAVIS 346C Samsung DVS Gen3
Resolution 240 x 180 346 x 240 346 x 240 346 x 240 640 x 480
Data
Events
Grayscale Images
IMO Bounding Boxes
Events
RGB Images
6-DoF Camera + IMO Pose
IMO Masks + Bounding Boxes
Events
RGB Images
6-DoF Camera + IMO Pose
IMO Masks + Bounding Boxes
Optical Flow
Depth
Events
Grayscale Images
6-DoF Camera + IMO Pose
IMO Masks
Depth
Events
RGB Images
6-DoF Camera + IMO Pose
IMO Masks
Depth
Scene Type Indoor Sim. Indoor + Outdoor Sim. Indoor + Outdoor Indoor Indoor
Suitability for
Our Network
No (Lack of Depth
and IMO Mask)
No
(Lack of Depth)
No (Without
training sequences)
Yes Yes
only used to evaluate the detection of moving objects,
without checking their categories.
4.3.2 Intersection over Union (IoU) and mIoU
IoU: IoU is a standard metrics used to evaluate the
performance of binary segmentation. It is used in this
work and in related literature to show the accuracy of
the segmented motion mask. IoU is expressed as:
IoU =
S
p
∩ S
gt
S
p
∪ S
gt
where S
p
refers to the predicted motion mask and S
gt
the ground truth mask.
Similar to the detection rate, IoU also doesn’t take
into account the classes of moving objects.
mIoU: Since the above evaluation metrics are only
for binary motion segmentation, we introduce mean
Intersection over Union (mIoU) to evaluate joint se-
mantic and motion segmentation results, which in-
volves calculating IoU for each class of moving ob-
jects and then taking the average.
4.3.3 Precision, Recall and F1-Score
Precision and Recall are the main metrics in object
detection problem. We aim to employ them for a
more comprehensive evaluation of IMOs detection.
Therefore, slightly different from the detection rate
which is blind to object classes, we extract bound-
ing boxes and calculate precision and recall for each
class of the moving objects, and take the average to
assess the performance of our network. We consider
a predicted bounding box to be a True Positive (TP) if
its IoU with the ground truth bounding box is greater
than 0.5. In following formulas, C is the number of
classes, T P
i
is the number of TP bounding box to i
th
class. N predicted
i
and Ngt
i
refer to the total number
of predicted and ground truth bounding boxes to i
th
class.
Precision. Precision is the ratio between the num-
ber of correctly predicted bounding boxes to the total
number of predicted bounding boxes:
Precision =
1
C
C
∑
i=1
T P
i
N predicted
i
Recall. Recall is the ratio between the number of
correctly predicted bounding boxes to the total num-
ber of ground truth bounding boxes:
Recall =
1
C
C
∑
i=1
T P
i
Ngt
i
F1-Score. F1-score is the harmonic mean of preci-
sion and recall, while considering both wrong predic-
tion and missed detection:
F1 − score =
2 ∗ (Precision ∗ Recall)
(Precision + Recall)
All these metrics are inspired by classical detec-
tion metrics, using bounding boxes.
We propose to adopt these metrics for a more thor-
ough evaluation of the moving objects detection from
events. Precision is similar to the detection rate, but
it takes into account IMO separation and association
with the ground truth objects. For example, when
a wrong class is predicted to a moving object, it is
a positive sample for the detection rate, but a nega-
tive sample for the precision. Hence, precision cri-
teria is more severe than the detection rate. Recall
is complementary to precision, and together, they in-
form whether evaluated algorithm is conservative or
loose in its predictions. F1-score gives a criteria to
compare the methods as a trade-off between Precision
and Recall.
4.4 Evaluation on the EVIMO Dataset
EVIMO (Mitrokhin et al., 2019) is a challenging
dataset for event-based IMO segmentation. Se-
Event-Based Semantic-Aided Motion Segmentation
165

quences are recorded in an indoor real-world envi-
ronment with five different backgrounds (box, floor,
table, tabletop, wall). They include objects moving at
high speed with random trajectories. It was collected
using a fast-moving handheld DAVIS 346 camera.
We trained on the EVIMO dataset training set,
and evaluated on sequences box, table, wall and fast-
motion using detection rate (Tab. 2) and IoU (Tab. 3).
In relative terms, wall and fast-motion sequences are
more challenging due to their high number of objects
and fast motion. As a result, their outcomes are not as
favorable as those of other sequences. To compare
with state-of-the-art methods, EVIMO (Mitrokhin
et al., 2019), 0-MMS (Parameshwara et al., 2021) and
EMSGC (Zhou et al., 2023), our method has a slight
improvement in detection rate and IoU score. Up to
now, 0-MMS had the best scores. It uses an iterative
model fitting and merging approach. However, it re-
quires manual parameter selection for each sequence
and cannot automatically select parameter.
For the IoU evaluation, our network achieved a
1% improvement over the original method we are
based on, EVIMO, further demonstrating the value of
semantic information.
Table 2: Comparison of proposed method on EVIMO using
detection rate with available state-of-the-art data.
Detection rate for sequence (%)
Method box table wall fast motion
avg. of
box+wall
0-MMS - - - - 81.06
Ours
*
91.28 83.79 74.00 65.07 82.64
*
Learning-based Method
Table 3: Comparison of proposed method on EVIMO using
IoU with available state-of-the-art data.
IoU for sequence (%)
Method box table wall fast motion
avg. of
box+wall
avg. of
table+wall
+fast motion
EMSGC - - - - 76.81 -
0-MMS - - - - 80.37 -
EVIMO
*
- 83 75 73 - 77.00
Ours
*
84.67 83.18 77.65 73.67 81.16 78.17
*
Learning-based method.
Table 4: Evaluation of proposed method on EVIMO using
mIoU for semantic segmentation, as well as Precision, Re-
call and F1-score for separated moving objects detection.
Sequence
Metrics box table wall fast motion
avg. of
box+wall
mIoU (%) 77.97 71.50 58.98 57.00 68.47
Precision 0.87 0.80 0.55 0.36 0.71
Recall 0.83 0.81 0.68 0.58 0.76
F1-score 0.85 0.80 0.61 0.45 0.73
Meanwhile, we conducted quantitative evalua-
tions of semantic segmentation using mIoU, Preci-
sion, Recall, and F1-score in Tab. 4. Average on box
plus wall sequences is given for comparison with the
metrics given in Tab. 2 and 3. As expected, reach-
ing high scores with proposed metrics is harder than
with the previous metrics used in event-based motion
literature, giving more reliable measurements to com-
pare best-performing methods. However, there is cur-
rently a lack of state-of-the-art methods that combine
motion segmentation with semantic segmentation for
comparison against our approach.
Furthermore, qualitative evaluation is also pro-
vided in Fig. 5. Our method is robust to scenes with
multiple fast-moving IMOs as well as scenes with fast
camera movements. In addition to showcasing suc-
cessful cases, we have included instances of failure to
better help future research work in Fig. 6.
4.5 Evaluation on the EVIMO2 Dataset
EVIMO2 (Burner et al., 2022) improves on the
EVIMO dataset by providing data from cameras with
higher resolution, in more complex scenarios, with
more rotations and more objects.
In order to be able to conduct experiments on
EVIMO2, specific processing have been mandatory:
IMO Masks Labelling. EVIMO2 provides per-
pixel ground truth depth, semantic segmentation, as
well as camera and object poses. EVIMO2 involves
multiple independently moving objects, but the IMO
masks are not provided separately in the ground truth
mask. We calculate the object velocities in world co-
ordinates using camera and object poses, then gener-
ate the IMOs ground truth masks from moving ob-
jects. For our networks supervision, generated IMOs
ground truth masks are used with the motion segmen-
tation output, while the provided ground truth labels
are used with the semantic segmentation output (they
are simplified, details in next paragraph). Since the
objects classes in the EVIMO2 dataset are different
from EVIMO, we cannot train them together.
Semantic Classes Restructuring. In EVIMO2,
there are 26 instance labels (including the back-
ground), while there are only 4 labels in EVIMO.
Since EVIMO2 dataset contain only 21 training se-
quences, having 26 labels is too many.
Therefore, we performed semantic classification
on the 26 instance labels, and finally divided them
into 7 classes (including background) for training, as
shown in Tab. 5.
Figure 7 provides examples after reorganizing the
labels, with used color scheme. The “others” class is
composed of objects with different shapes, so the net-
work cannot effectively treat them as a same seman-
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
166
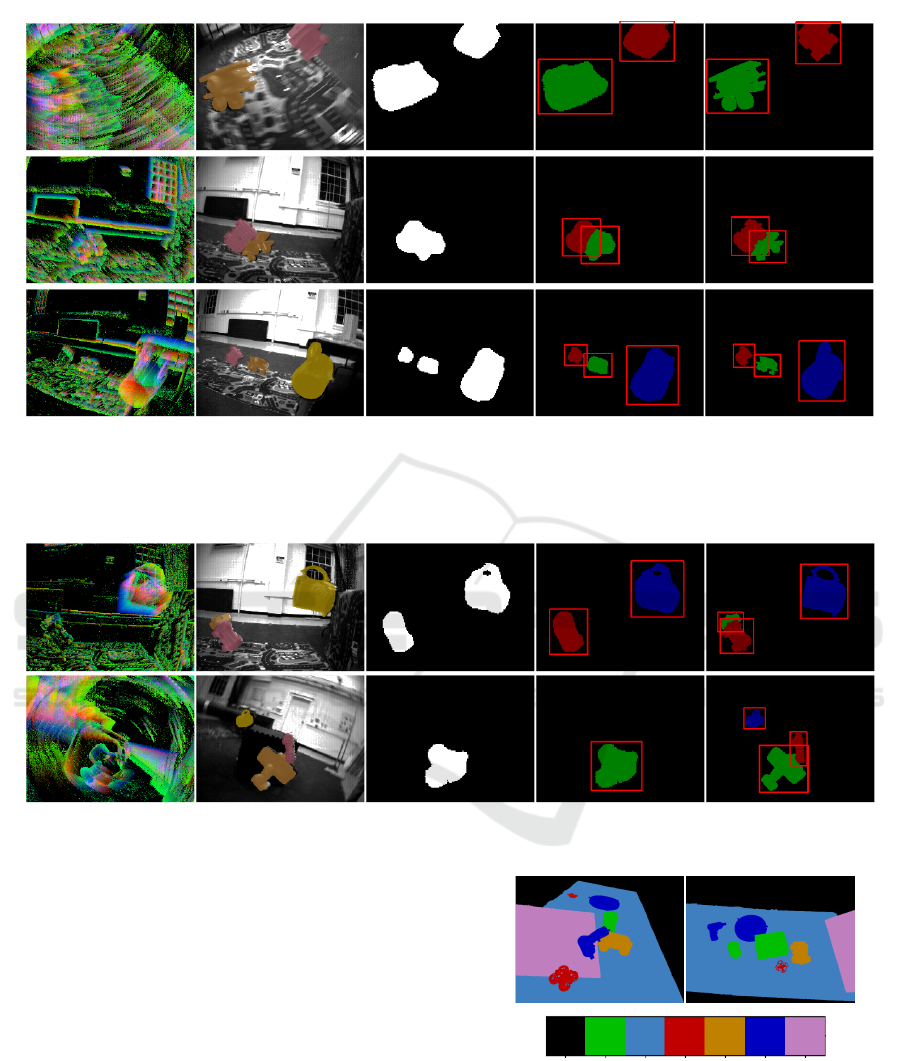
Event slice (input) Grayscale + mask Predicted motion mask Predicted motion ∩ semantic Ground truth mask
Figure 5: Qualitative Evaluation on EVIMO dataset. The table entries from left to right: event slice input, gray-scale image
with ground truth mask, predicted motion mask, predicted motion mask with semantic labels, ground truth mask with semantic
labels. There are three complex scenarios, from top to bottom: rapid camera rotations (row 1), overlapping IMOs (row 2),
multiple objects at different distances (row 3).
Event slice (input) Grayscale + mask Predicted motion mask Predicted motion ∩ semantic Ground truth mask
Figure 6: Two failure cases on EVIMO, from top to bottom: inability to separate overlapping objects with severe occlusion
(row 1), missed detection of a small object with fast camera rotation (row 2).
tic object. In fact, each object in “others” class has a
small number of samples in the dataset and cannot be
associated to a class in a way to imbalance well the
restructured classes.
Despite us adding weights to address the sample
imbalance issue in the semantic loss, training them
as individual semantic labels remain challenging. For
classes other than “others”, our network can learn rel-
atively well, as shown in Fig. 8. However, for the
“others” class, our network struggles to predict their
labels accurately, as shown in first row in Fig. 9.
Bounding Box Conversion. As explained in
Sec. 4.3, we extract the boundary of the motion mask
of each class to get the bounding box. The problem
is that EVIMO2 has far more classes than EVIMO,
some small errors in semantic labels generate a lot
0.background 1.boxes 2.markers 3.drones 4.cars 5.others 6.checkerboard
Figure 7: Reorganization of EVIMO2 labels. Segmentation
examples and proposed labels and colors scheme.
of wrong bounding boxes, which greatly affects
the results of detection rate, precision and recall.
We adopted the method of suppressing bounding
boxes with an area smaller than the parameter area
threshold to avoid it as much as possible. According
Event-Based Semantic-Aided Motion Segmentation
167
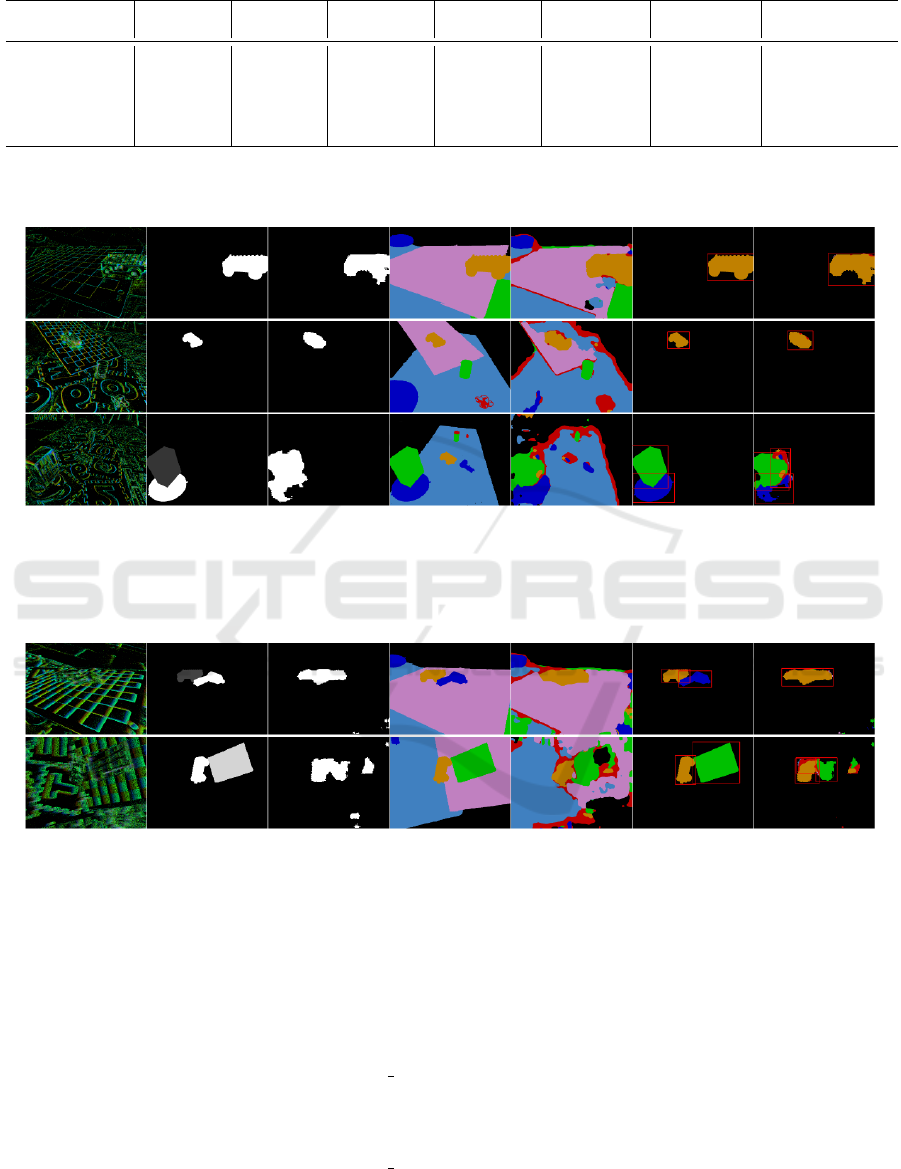
Table 5: Restructured semantic labels for EVIMO2.
Restructured labels 0.background
1.boxes
(16228)
2.tabletop
(12549)
3.drones
(13658)
4.cars
(19014)
5.others
(14643)
6.checkerboard
(8557)
Original labels
*
background box00 (267) tabletop (9841) drone00 (6829) car00 (2437) knife00 (308) checkerboard (8557)
box01 (5443) marker00 (677) drone01(6829) car01 (6829) plane00 (677)
box02 (677) marker01 (677) wheel00 (2437) plane01 (0)
box03 (3012) marker02 (677) wheel01 (2437) toy00 (6829)
can00 (6829) marker03 (677) wheel02 (2437) turntable (6829)
wheel03 (2437)
*
From the objects.txt file in dataset EVIMO2.
( )
represents the number of images containing this label in EVIMO2 training set.
Event slice (input) GT motion mask Predicted motion mask GT semantic labels Predicted semantic labels GT labeled motion mask Predicted labeled motion mask
Figure 8: Qualitative Evaluation on EVIMO2 dataset. The table entries from left to right: event slice input, ground truth
motion mask, predicted motion mask (output of motion task), ground truth semantic labels (7 classes introduced in Fig. 7),
predicted semantic labels (output of semantic task), ground truth motion mask with labels, predicted motion mask with labels
(intersection of two tasks). Three complex scenarios from top to bottom: object slowly accelerates from rest (row 1), distant
IMO plus static objects (row 2), two objects suddenly accelerate (row 3).
Event slice (input) GT motion mask Predicted motion mask GT semantic labels Predicted semantic labels GT labeled motion mask Predicted labeled motion mask
Figure 9: Two failure cases on EVIMO2, from top to bottom: wrong predicted semantic label for class “others” (row 1), less
accurate prediction of motion at high changing motion speed (row 2).
to the size of the object in the EVIMO2 dataset,
we define the area threshold as 3000 pixels. For
example, in the last mask in the second row of Fig. 8,
some pixels are mistakenly classified as drones (red),
which would generate two small wrong bounding
boxes if not applying this procedure.
The final quantitative evaluation results are shown
in Tab. 6. We observe that in the sequences “test 13”,
most of moving objects fall under the “others” cat-
egory. Consequently, the semantic segmentation re-
sults for these sequences are less satisfactory, leading
to a relatively low mIoU. In the sequences “test 14”,
there are objects that exhibit rapid speed changes. As
a result, the predictions tend to capture only the edges
of these objects, which has a greater negative impact
on detection rate, precision and recall, which require
bounding box estimation.
EMSGC (Zhou et al., 2023) provides the IoU
score of their method on the EVIMO2 dataset and
this is the only score we found that was evaluated
on the EVIMO2 dataset. Since there are more fre-
quent 3D rotations than EVIMO, the 2D appearance
of the object on the image plane is constantly chang-
ing, resulting the IoU score of their method compared
to EVIMO not good enough. The IoU score of our
method is almost the same as that of EVIMO, which
proves that our method has strong generalization abil-
ity for different motions.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
168

Biggest difficulty in EVIMO2 are the two states of
IMOs: fast and slow motion. The more challenging
scenario involves a significant change in speed, while
the camera only moves slightly. In this case, when a
moving object occupies a large portion of the frame,
the network predict the object’s outline. Events are
not triggered inside the object’s shape, leading to pos-
sible mis-prediction of multiple objects (as shown in
the second row of Fig. 9). Although in EVIMO, IMOs
are in a state of rapid motion with low speed change,
and the camera is also moving at high speed. As a re-
sult, all objects generate a significant amount of event
information as input to the network, enabling the net-
work to learn and predict more effectively.
In summary, the EVIMO2 dataset is more chal-
lenging than EVIMO. Through our qualitative and
quantitative evaluations, we have demonstrated that
our network is able to perform well when confronted
with this highly challenging dataset.
Table 6: Comparison of proposed method on EVIMO2 us-
ing all proposed metrics with available state-of-the-art data.
Method Sequence
Detection
rate (%)
IoU (%) mIoU (%) Precision Recall F1-score
Ours
test13 00 80.71 77.94 41.93 0.85 0.76 0.80
test13 05 46.38 62.81 37.02 0.67 0.32 0.43
test14 03 54.88 87.53 84.25 0.96 0.51 0.67
test14 05 34.67 85.97 72.82 0.45 0.32 0.37
test14 05 46.40 83.97 74.13 0.50 0.36 0.42
test15
01 83.60 81.84 52.96 0.46 0.48 0.47
test15 02 73.04 81.21 59.51 0.89 0.59 0.71
test15 05 71.75 78.04 70.43 0.40 0.51 0.45
Average 61.43 79.82 61.63 0.65 0.48 0.55
EMSGC Average - 64.38 - - - -
4.6 Ablation Study
In this section, we trained EVIMO and EVIMO2 sep-
arately using the same configuration, on different net-
works: “task 1” network with only motion segmenta-
tion, “task 2” network with only semantic segmen-
tation, and proposed network with both tasks (all
of these networks include depth prediction network).
They are evaluated on all available metrics, in Tab. 7
and 8. For “task 1” network (motion seg.), only detec-
tion rate and IoU can be used to evaluate since there
is no semantic information. For “task 2” network (se-
mantic seg.), evaluation with proposed metrics is not
straightforward as they aim at evaluating the semantic
classification of moving objects. In EVIMO, all seen
objects are moving, allowing to measure meaningful
scores in Tab. 7. We also fuse object semantics to
obtain a binary object masks generalized as a motion
mask to measure detection rate and IoU. However, in
the case of the EVIMO2, where multiple objects are
stationary, we can not evaluate semantic segmentation
task only with proposed metrics in Tab. 8.
The results show that the network trained for the
two tasks together has the best effect, further verifying
the beneficial contribution of semantic information to
motion segmentation.
Table 7: Ablation study results of proposed motion and se-
mantic segmentation network on EVIMO.
Depth Prediction
Network
+Motion Seg.
(task 1)
+
+Semantic Seg.
(task 2)
+ Motion Seg.
+ Semantic Seg.
Params (M) 2.26 2.26 2.5
Detection rate (%) 81.75 70.71 82.64
IoU (%) 79.33 73.22 81.16
mIoU (%) - 56.83 68.47
Precision - 0.53 0.71
Recall - 0.67 0.76
F1-score - 0.59 0.73
Table 8: Ablation study results of proposed motion and se-
mantic segmentation network on EVIMO2. All the scores
of the network with both tasks can be retrieved in Tab. 6.
Depth Prediction
Network
+Motion Seg.
(task 1)
+ Motion Seg.
+ Semantic Seg.
Params (M) 2.26 2.5
Detection rate (%) 50.94 61.38
IoU (%) 77.92 79.88
5 CONCLUSIONS
We propose a network architecture for multi-motion
and semantic segmentation using monocular event
data. Our approach is built upon a binary motion seg-
mentation state-of-the-art framework. Thanks to the
help of added semantic segmentation task, it offers
following improvements: better moving objects seg-
mentation, ability to extract multiple IMOs of differ-
ent classes. It learns in a supervised mode, can accu-
rately predict motion masks and semantic information
for multiple objects, and surpasses the state-of-the-
art. We conducted qualitative and quantitative eval-
uations on two highly challenging datasets, EVIMO
and EVIMO2, demonstrating the robustness of our
method across various real scenes, multiple types of
motion of IMOs and camera, and different semantics.
However, further improvements are needed in predict-
ing the shape of IMOs, such as enhancing the dataset
and optimizing the motion prediction module.
The design of multi-task neural networks to share
encoding layers is promising. Specifically, the net-
work could be extended to include heads for depth
and direct optical flow inference, while simplifying
the dataset requirements by adding self-supervised
losses such as in (Ye et al., 2020) and (Stoffregen
et al., 2020). Some perspectives can be to extend the
multi object segmentation to multi object tracking, to
test adaptive time windows for event accumulation in
order to adapt to different IMOs speeds, or to focus
Event-Based Semantic-Aided Motion Segmentation
169

on richer event representation methods for the inputs
to improve the network. Our next goal would be to
study other types of datasets, such as the road scene
DSEC dataset (Gehrig et al., 2021), by adding static
and moving status to objects in the annotations, to
explore broader applications of event cameras in the
field of motion segmentation.
ACKNOWLEDGMENT
This work has been carried out within SIVALab, joint
laboratory between Renault and Heudiasyc UMR
UTC/CNRS.
REFERENCES
Alonso, I. and Murillo, A. C. (2019). Ev-segnet: Semantic
segmentation for event-based cameras. In IEEE Inter-
national Conference on Computer Vision and Pattern
Recognition Workshops (CVPRW).
Burner, L., Mitrokhin, A., Fermuller, C., and Aloimonos, Y.
(2022). Evimo2: An event camera dataset for motion
segmentation, optical flow, structure from motion, and
visual inertial odometry in indoor scenes with monoc-
ular or stereo algorithms. ArXiv, abs/2205.03467.
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., and
Adam, H. (2018). Encoder-decoder with atrous sepa-
rable convolution for semantic image segmentation. In
Proceedings of the European conference on computer
vision (ECCV).
Chollet, F. (2017). Xception: Deep learning with depthwise
separable convolutions. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion.
Gallego, G., Delbr
¨
uck, T., Orchard, G., Bartolozzi, C.,
Taba, B., Censi, A., Leutenegger, S., Davison, A. J.,
Conradt, J., Daniilidis, K., and Scaramuzza, D.
(2022). Event-based vision: A survey. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence.
Gehrig, M., Aarents, W., Gehrig, D., and Scaramuzza, D.
(2021). Dsec: A stereo event camera dataset for driv-
ing scenarios. IEEE Robotics and Automation Letters.
Glover, A. and Bartolozzi, C. (2016). Event-driven ball de-
tection and gaze fixation in clutter. In IEEE/RSJ In-
ternational Conference on Intelligent Robots and Sys-
tems (IROS).
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep
residual learning for image recognition. In IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
Hutchinson, S., Hager, G., and Corke, P. (1996). A tuto-
rial on visual servo control. IEEE Transactions on
Robotics and Automation.
Lichtsteiner, P., Posch, C., and Delbruck, T. (2008). A 128×
128 120 db 15 µs latency asynchronous temporal con-
trast vision sensor. IEEE Journal of Solid-State Cir-
cuits.
Litzenberger, M., Posch, C., Bauer, D., Belbachir, A.,
Schon, P., Kohn, B., and Garn, H. (2006). Embed-
ded vision system for real-time object tracking using
an asynchronous transient vision sensor. In IEEE 12th
Digital Signal Processing Workshop & 4th IEEE Sig-
nal Processing Education Workshop.
Mitrokhin, A., Ferm
¨
uller, C., Parameshwara, C., and Aloi-
monos, Y. (2018). Event-based moving object detec-
tion and tracking. In IEEE/RSJ International Confer-
ence on Intelligent Robots and Systems (IROS).
Mitrokhin, A., Hua, Z., Ferm
¨
uller, C., and Aloimonos, Y.
(2020). Learning visual motion segmentation using
event surfaces. In IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR).
Mitrokhin, A., Ye, C., Ferm
¨
uller, C., Aloimonos, Y., and
Delbruck, T. (2019). Ev-imo: Motion segmenta-
tion dataset and learning pipeline for event cameras.
In IEEE/RSJ International Conference on Intelligent
Robots and Systems (IROS).
Parameshwara, C. M., Sanket, N. J., Singh, C. D.,
Ferm
¨
uller, C., and Aloimonos, Y. (2021). 0-mms:
Zero-shot multi-motion segmentation with a monoc-
ular event camera. In IEEE International Conference
on Robotics and Automation (ICRA). IEEE.
Piatkowska, E., Belbachir, A. N., Schraml, S., and Gelautz,
M. (2012). Spatiotemporal multiple persons track-
ing using dynamic vision sensor. In IEEE Computer
Society Conference on Computer Vision and Pattern
Recognition Workshops.
Rebecq, H., Gehrig, D., and Scaramuzza, D. (2018). Esim:
an open event camera simulator. In Conference on
robot learning. PMLR.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net:
Convolutional networks for biomedical image seg-
mentation. In International Conference on Medical
Image Computing and Computer (MICCAI). Springer.
Sanket, N. J., Parameshwara, C. M., Singh, C. D., Kurut-
tukulam, A. V., Ferm
¨
uller, C., Scaramuzza, D., and
Aloimonos, Y. (2019). Evdodge: Embodied AI for
high-speed dodging on A quadrotor using event cam-
eras. CoRR, abs/1906.02919.
Stoffregen, T., Gallego, G., Drummond, T., Kleeman, L.,
and Scaramuzza, D. (2019). Event-based motion seg-
mentation by motion compensation. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision.
Stoffregen, T. and Kleeman, L. (2018). Simultaneous op-
tical flow and segmentation (sofas) using dynamic vi-
sion sensor. arXiv preprint arXiv:1805.12326.
Stoffregen, T., Scheerlinck, C., Scaramuzza, D., Drum-
mond, T., Barnes, N., Kleeman, L., and Mahony,
R. (2020). Reducing the sim-to-real gap for event
cameras. In Vedaldi, A., Bischof, H., Brox, T., and
Frahm, J.-M., editors, Computer Vision – ECCV 2020.
Springer International Publishing.
Sun, Z., Messikommer, N., Gehrig, D., and Scaramuzza, D.
(2022). Ess: Learning event-based semantic segmen-
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
170

tation from still images. In European Conference on
Computer Vision. Springer.
Vasco, V., Glover, A., Mueggler, E., Scaramuzza, D.,
Natale, L., and Bartolozzi, C. (2017). Indepen-
dent motion detection with event-driven cameras. In
18th International Conference on Advanced Robotics
(ICAR).
Ye, C., Devaraj, C., Maynord, M., Ferm
¨
uller, C., and Aloi-
monos, Y. (2018). Evenly cascaded convolutional net-
works. In IEEE International Conference on Big Data
(Big Data).
Ye, C., Mitrokhin, A., Ferm
¨
uller, C., Yorke, J. A., and Aloi-
monos, Y. (2020). Unsupervised learning of dense
optical flow, depth and egomotion with event-based
sensors. In IEEE/RSJ International Conference on In-
telligent Robots and Systems (IROS).
Zhou, Y., Gallego, G., Lu, X., Liu, S., and Shen, S.
(2023). Event-based motion segmentation with spatio-
temporal graph cuts. IEEE Transactions on Neural
Networks and Learning Systems.
Event-Based Semantic-Aided Motion Segmentation
171
