
A Model-Based Framework for News Content Analysis
Fazle Rabbi
1 a
, Bahareh Fatemi
1 b
, Yngve Lamo
2 c
and Andreas L. Opdahl
1 d
1
Information Science and Media Studies, University of Bergen, Norway
2
Department of Computer science, Electrical Engineering and Mathematical Sciences,
Western Norway University of Applied Sciences, Bergen, Norway
Keywords:
Category Theory, Content Analysis, Model-Based Framework, Knowledge Graph, Natural Language
Processing, Computational Journalism.
Abstract:
News articles are published all over the world to cover important events. Journalists need to keep track of
ongoing events in a fair and accountable manner and analyze them for newsworthiness. It requires an enor-
mous amount of time and effort for journalists to process information coming from mainstream news media,
social media from all over the world, as well as policy and law circulated by governments and international
organizations. News articles published by different news providers and reporters may also be subjective due
to the influence of reporters’ backgrounds, world views and opinions. In today’s journalistic practice there is a
lack of computational methods to support journalists to investigate fairness and monitor and analyze massive
information streams. In this paper we present a model-based approach to analyze the perspectives of news
publishers and monitor the progression of news events from various perspectives. The key concepts in the
news domain such as the news events and their contextual information is represented across various dimen-
sions in a knowledge graph. We presented a multi dimensional and comparative news event analysis method
for analyzing news article variants and for uncovering underlying storylines. To show the applicability of
the proposed method in real life, we also demonstrate a running example. The utilization of a model-based
approach ensures the adaptability of our proposed method for representing a wide array of domain concepts
within the news domain.
1 INTRODUCTION
In every human community, individuals bring news
to one another. News has an important role in hu-
mankind and journalists are involved in carrying out
the task in a professional way. While reporting about
real life events through news articles, journalists turn
facts into stories and analyses that engage an audience
(Schudson, 2020). While crafting news, good jour-
nalists put reality first and they follow the core princi-
ples of ethical journalism (EJN, 2023), which include
trust and accuracy; independence; fairness and im-
partiality; humanity; accountability. However there
is no bias-free journalism (Schudson, 2020) in real-
ity. The problem of bias in media has been an impor-
tant topic and it requires sophisticated techniques to
analyze the media bias in a systematic way. Journal-
a
https://orcid.org/0000-0001-5626-0598
b
https://orcid.org/0000-0002-8944-5051
c
https://orcid.org/0000-0001-9196-1779
d
https://orcid.org/0000-0002-3141-1385
ists also need to keep track of the ongoing events all
around the world and analyze the events carefully as
they need to inform their audience about the chang-
ing world. Since there is an abundance of news ar-
ticles being published all over the world by several
news media outlets, journalists would benefit from
techniques for systematically analyzing events from
news publications. Sociologists, historians, politi-
cal scientists, information scientists are involved in
gathering information from news articles and extract
insightful information. In this paper we present a
model-based framework that employs a diverse range
of models to represent knowledge from news articles
and uses computational methods for the analysis of
news events. The framework integrates the following
components:
• state-of-the-art natural language processing tech-
nique for parsing content from news articles;
• a multi dimensional meta-model allowing data to
be arranged into hierarchical groups and a knowl-
edge graph schema for structuring event related
Rabbi, F., Fatemi, B., Lamo, Y. and Opdahl, A.
A Model-Based Framework for News Content Analysis.
DOI: 10.5220/0012306800003645
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 12th International Conference on Model-Based Software and Systems Engineering (MODELSWARD 2024), pages 99-107
ISBN: 978-989-758-682-8; ISSN: 2184-4348
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
99
information;
• a content comparison method based on category
theory; and
• a statistical analysis method for analyzing news
article variants.
The knowledge graph represents news events with
relevant information e.g., source article, publication
date, involved persons, involved countries, and type
of event. We annotate news events with IPTC (In-
ternational Press Telecommunications Council) Me-
dia Topics. IPTC is a global standardization organi-
zation that provides metadata standards for the news
industry. The terms in the IPTC Media Topics are
represented in a hierarchical structure which allows
us to extract news events from different abstraction
levels. By combining different attributes and relation-
ships of news events along with the domain ontology
in IPTC Media Topics, the framework allows users to
extract different views of news events from a knowl-
edge graph. The framework integrates a computa-
tional model based on category theory which allows
us to analyze news events at a higher abstraction level,
for example, to compare and categorize events and
to analyze flow of progression of events. We present
novel application areas of category theory for analyz-
ing events stored in a knowledge graph. We assume
the reader is comfortable with the basics of category
theory (Barr and Wells, 1990).
In section 2, we present a method for extracting
structured information about news events from news
articles using large language models (LLMs). We
present a running example while describing the pro-
posed method. In section 3, we present a model-based
framework for content analysis. In section 4, we pro-
vide a discussion about the proposed method and pro-
vide a comparison with existing works.
2 HARVESTING NEWS EVENTS
KNOWLEDGE GRAPH WITH A
PRE-TRAINED LLMs
Harvesting news events into a knowledge graph is an
important topic and it has been investigated in several
other projects to support various tasks in the news do-
main. Opdahl et al. (Opdahl et al., 2022) provides a
review of using semantic knowledge graphs in news
production, distribution, and consumption, emphasiz-
ing their potential for integrating heterogeneous infor-
mation in the news industry. The Global Database of
Events, Language, and Tone (GDELT) is a Google-
sponsored project that monitors news media from all
over the world and provides a real-time update of
events in every 15 minutes (Gde, 2023).
Rospocher et al. present a method to automat-
ically build Event-Centric Knowledge Graphs from
news articles using NLP techniques, such as En-
tity Linking and Semantic Role Labeling (Rospocher
et al., 2016). Liu et al. introduces a domain-specific
knowledge graph called the “news graph” that incor-
porates collaborative relations between entities and
topic context information for news recommendations
(Liu et al., 2019).
Harvesting news events into a knowledge graph
has been studied by Berven et al. in (Berven et al.,
2020) where they presented a knowledge graph plat-
form for a newsroom. They propose an event de-
tection technique that identifies potentially newswor-
thy events from clusters of news items according to
named entities, topics, and location.
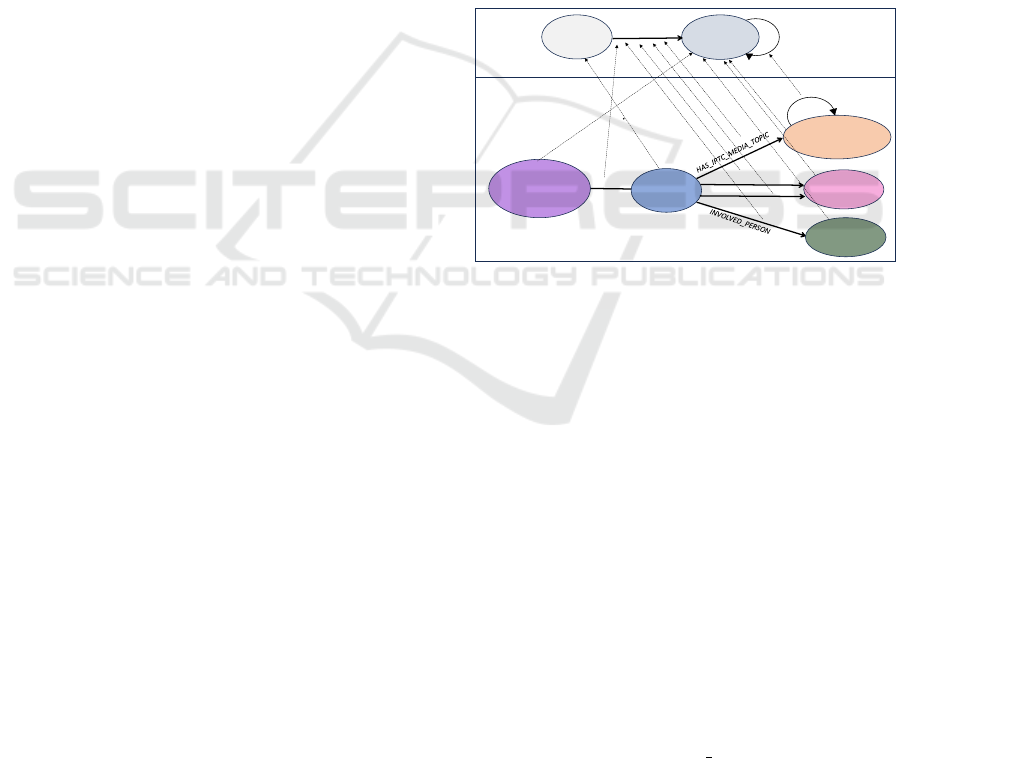
Event
- name
Location
- name
SOURCE
HAPPENED_IN
Person
- name
Article
- title
- url
- publisher
- publicationDate
IPTC_MediaTopic
- name
- level
HAS_PARENT
INVOLVED_COUNTRY
Subject
- attribute
Dimension
- attribute
HAS_RELATION
IS_A
Figure 1: Dimensional meta-model (top) and Knowledge
Graph Schema (bottom) for structuring event related infor-
mation.
In our proposed technique, we take input from
GDELT in every 15 minutes. The input includes
web addresses to news article texts. The news arti-
cle texts are parsed for analysis using a pre-trained
LLMs. We use GPT-Turbo 3.5 for extracting in-
formation from news article texts and harvest news
event related information. To structure the informa-
tion about news events we propose to use a dimen-
sional meta-model (Figure 1 top) which allows stor-
ing events with contexts along various dimensions in
a hierarchical model. The bottom of Figure 1 shows
a knowledge graph schema for structuring an event
and its contextual information such as event location,
event type and involved countries. The knowledge
graph is also enriched with IPTC Media Topics. The
knowledge graph allows us to access the hierarchi-
cal information from the IPTC Media Topics ontol-
ogy by traversing over :HAS PARENT relationships.
A Neo4j graph database has been used to store news
events and their relationships with other entities. The
information model is centered around Event and it
MODELSWARD 2024 - 12th International Conference on Model-Based Software and Systems Engineering
100

also allows us to preserve the epistemic view of in-
dividual publishers. For example, if two publishers
publish 2 news articles about a certain event, we will
be storing 2 instances of Event (along with their con-
textual information) in our knowledge graph.
Table 1 illustrates the prompt we have used to ex-
tract structured information from news article texts.
The temperature is set to 0 to limit the creativity of
the LLMs. The prompt includes an instruction about
producing output in JSON format. It also includes in-
structions to classify events using IPTC Media topic
names. However, the GPT 3.5 Turbo model gener-
ates slightly different names from what we have in
the knowledge graph. For example, in our knowl-
edge graph we have ’arts, culture and entertainment’
but the output of the prompt may include the follow-
ing name: ’Cultural, Arts and Entertainment’. It is
therefore necessary to perform a similarity analysis
of the media topic names. To find out the most sim-
ilar topic name we calculated cosine-similarity using
Python and the Spacy library.
Table 1: Prompt for extracting event related information.
prompt = ”’Write the name of the event, type of the event,
involved person, involved countries and the location of the
event from the following news. Use IPTC media topic name
while writing values for ’Event type’. Write full name while
mentioning involved persons and locations. Write only name
of persons if they are known. No need to include any
unknown person. Also do not need to write the designation
or position of the persons. While returning the location,
mention the country where the event took place. While
returning the iptc media topic names, please return the
output for which you are significantly confident about.
If there are more values, include all of them in comma
separated format. Format your answer as a JSON object
with the following key-values:
{“Event”: “event-name”,
“Event Type”: “iptc-media-topic-name”,
“Involved Countries”: “country-name”,
“Location of Event”: “country-name”,
“Involved-Person”: “Person-name”, } ”’
response = openai.ChatCompletion.create(
model=”gpt-3.5-turbo”,
messages=[
”role”: ”system”, ”content”: prompt,
”role”: ”user”, ”content”: articleText ],
temperature=0, max
tokens=256, top p=1,
frequency penalty=0, presence penalty=0 )
{ ’Event’: ”Closure of Niger’s Airspace”,
’Event Type’: ’Civil Unrest’,
’Involved Countries’: ’Niger, United Kingdom,
South Africa’,
’Location of Event’: ’Niger’,
’Involved-Person’: ’President Mohamed Bazoum,
General Abdourahmane Tchiani’ }
The proposed method in this paper is demon-
strated with a running example which includes a
knowledge graph of news events about Niger and
Gabon extracted from the news articles published
by 6 media outlets (aljazeera.com, theguardian.com,
reuters.com, independent.co.uk, nytimes.com, wash-
ingtontimes.com) from July 28th, 2023 to September
2nd, 2023. The knowledge graph consists of news
events in Niger and Gabon about two coups that took
place during the above-mentioned period.
3 MODEL-BASED FRAMEWORK
FOR CONTENT ANALYSIS
We propose a new model-based framework for news
content analysis that includes techniques for multi di-
mensional comparative analysis. The framework al-
lows us to analyze different perspectives on news con-
tents; progression of events from a variety of abstrac-
tion levels with various perspectives. The framework
allows the user to select an appropriate dimension and
abstraction level. For instance, a user might be inter-
ested in comparing the perspectives of different pub-
lishers over a certain period of time or the progression
of events at a certain level of abstraction. The knowl-
edge graph includes events and their contextual in-
formation along various hierarchically organized di-
mensions. For example, the IPTC Media topic ontol-
ogy organizes topic names in a hierarchy. The highest
level of abstraction in the IPTC Media topic ontol-
ogy (i.e., level 1 of the ontology) includes 17 media
topic names. The selection of dimension and abstrac-
tion level is used for extracting information from the
knowledge graph. The information is then used for
comparative analysis. The analysis results are used
for extracting patterns of variants. We propose a semi-
automated approach where humans are involved in
the process of variant analysis. Figure 2 illustrates
the model-based framework which employs models
for representing computational methods for the analy-
sis of news events. Graph patterns are used to specify
search criteria. We propose to use categorial opera-
tions to perform comparative analysis over the search
results (i.e., subgraphs). Category theory allows us
to deal with abstract structures and relationships be-
tween them. It allows us to study the news content
from high levels of abstraction and thereby enables us
to gain deeper insights into media contents. In this
paper we focus on the perspective comparison, pro-
gression of events, and variant analysis. The model-
based framework is adaptive to new dimensions with
more contextual information, for example numbers of
casualties, sentiments, proximity, news angles, etc.
A Model-Based Framework for News Content Analysis
101
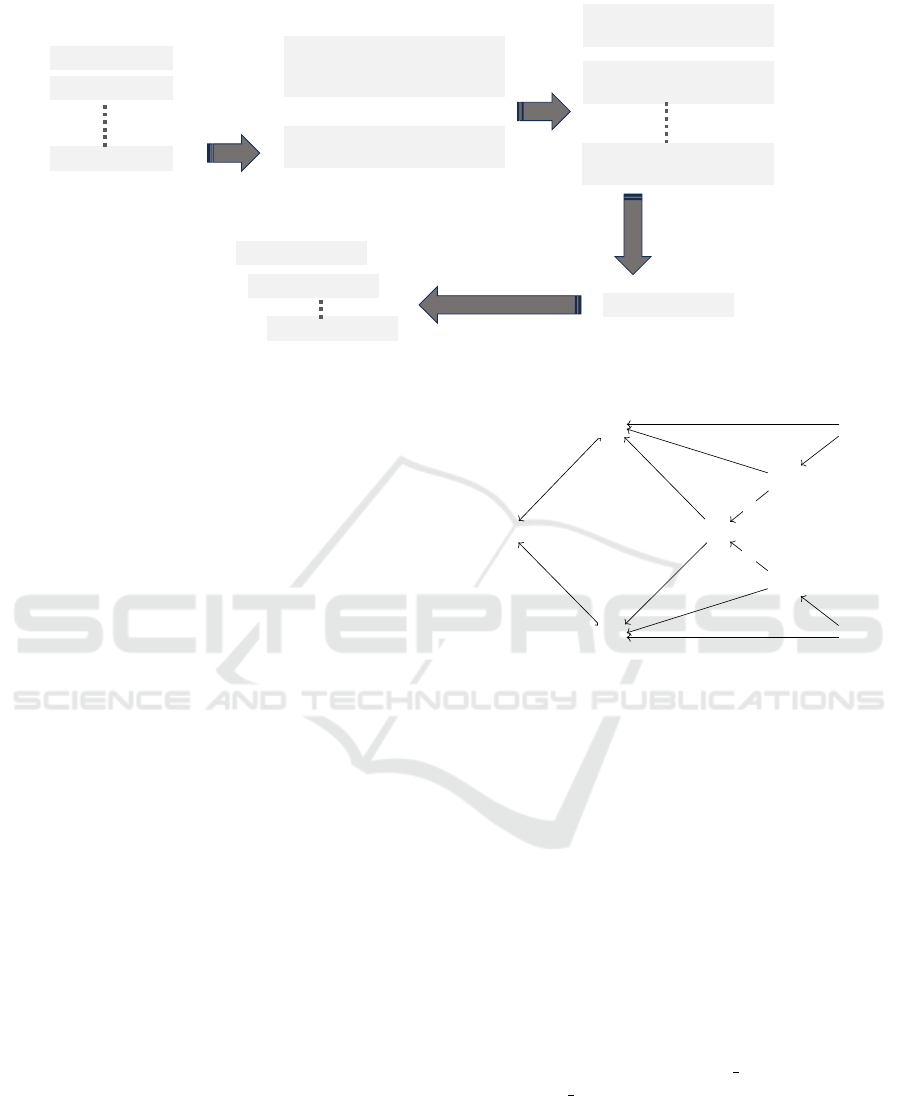
Extracting Patterns
(statistical analysis)
Graph pattern(s)
(includes requirement of
dimension and abstraction level)
Knowledge Graph
(Enriched with domain ontology)
Subgraph s1
(representing Situation 1)
Subgraph 2
(representing Situation 2)
Subgraph m
(representing Situation m)
Analysis results
News Article 1
News Article 2
News Article n
Variant x
Variant y
Variant z
Multi-dimensional comparative
analysis
(w.r.t. Correct abstraction level)
Extracting structured
information
Figure 2: Model-based framework for multi dimensional comparative analysis of news contents.
3.1 Perspective Comparison
We store contextual information about news events,
such as event location, event type, involved countries
and individuals, in the knowledge graph. When re-
porting on specific events and their subsequent de-
velopments, different publishers may have reported
them differently. In our proposed method, we com-
pare the perspectives across various dimensions of
these events. For instance, we examine the types of
events that were reported by different publishers dur-
ing a specific time period while they were covering a
particular event and its subsequent development.
To compare the perspectives of different publish-
ers, we propose employing category theory opera-
tions, including pullback and commutative diagrams.
Figure 3 gives an overview of the proposed method
for perspective analysis. All the news article related
information in the graph database is represented as I
in the figure. S
1
and S
2
represent the reports from two
different publishers. S
1
and S
2
can be computed by
querying the graph database. Cypher queries (Cyp,
2023) may be used to extract the fragments of graphs
(i.e., subgraphs) from I which represents the local per-
spective of individual publishers. For instance, we
may be interested to know the extent to which the
media topics used by different publishers match and
differ while they report about some events in their
published news articles. The figure shows pullback
object C which is computed from the following two
morphisms: S
1
m
1
−→ I and S
2
m
2
−→ I. From the pullback
object, we can figure out the perspectives of different
publishers as shown in Figure 3 by object D
1
and D
2
.
Here we explain the proposed method with a run-
ning example. We compute the perspectives from
two publishers about their news stories that cover
S
1
X
1
D
1
I PB C
D
2
S
2
X
2
m
1
∃!k
1
/
n
1
n
2
/
m
2
∃!k
2
Figure 3: Pullback object (C) computes the commonality
between S
1
and S
2
; D
1
and D
2
objects are used to compute
the dissimilarities between S
1
and S
2
.
events in Niger from July 28th to September 2nd.
We use Cypher queries to get data from the Neo4j
graph database. Cypher queries can be expressed as
graph patterns which include variables. The results of
these queries would be subgraphs of the whole graph
database. One can compute the pullback object by
writing a program using a general purpose program-
ming language (e.g., Python using the Neo4j library)
but in this paper we present a Cypher query (Fig-
ure 4) which computes the pullback object of two
subgraphs from a graph database by combining two
Cypher queries as shown above. We ensure that the
diagram commutes by specifying t1 = t2 as a condi-
tion in the query. Since the two subgraphs S
1
and S
2
include only nodes of type IPTC MediaTopic, we in-
clude IPTC MediaTopic nodes in the result pullback
object. Figure 4 shows a cypher query expression to
compute the pullback object of S
1
→ I and S
2
→ I.
The perspectives of the publishers are computed
from the difference of the subgraphs S
1
and S
2
with
the pullback object. Here we have demonstrated the
perspective analysis with respect to IPTC media top-
MODELSWARD 2024 - 12th International Conference on Model-Based Software and Systems Engineering
102
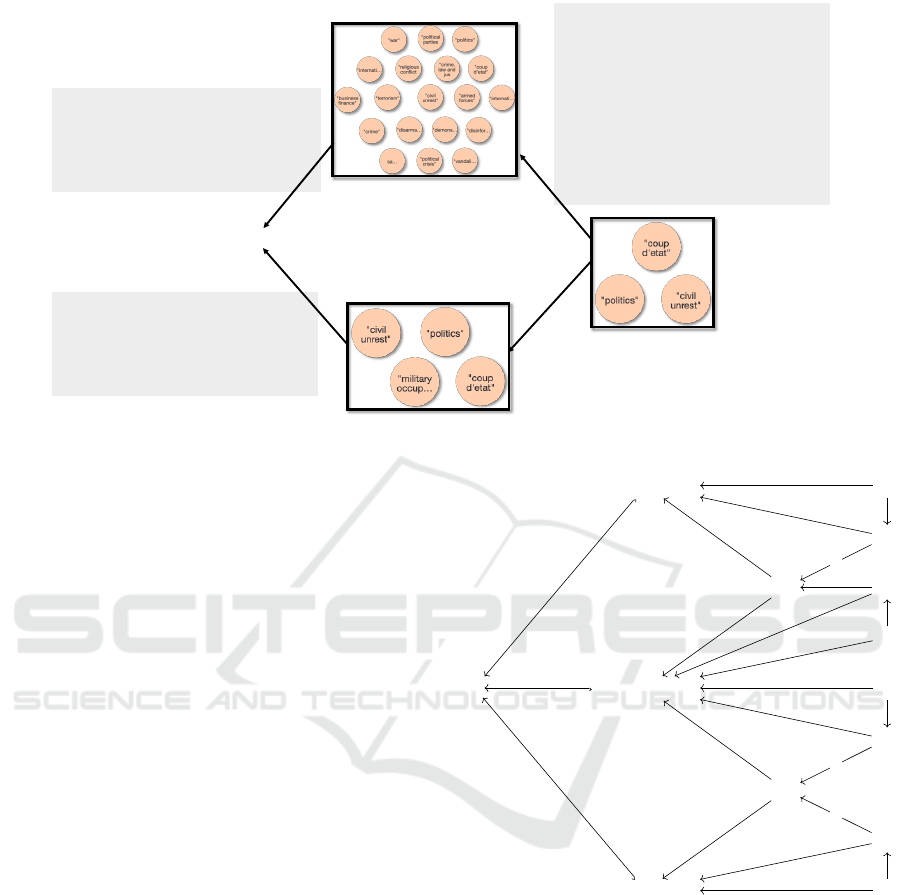
Cypher query 1:
-----------------------------------------------------
match (e1:Event)-[r1]->(a1:Article)
match (e1:Event)-[r2:HAPPENED_IN]->(loc1:Location)
match (e1:Event)-[r3]->(t1:IPTC_Media_Topic)
where loc1.name = "Niger" and a1.publisher =
"aljazeera.com"
return t1;
I
Cypher query 2:
----------------------------------------------------
match (e2:Event)-[r1]->(a2:Article)
match (e2:Event)-[r2:HAPPENED_IN]->(loc2:Location)
match (e2:Event)-[r3]->(t2:IPTC_Media_Topic)
where loc2.name = "Niger" and a2.publisher =
"nytimes.com"
return t2;
Cypher query for getting pullback of s
1
and s
2
:
------------------------------------------------------
match (e1:Event)-[r1]->(a1:Article)
match (e1:Event)-[r2:HAPPENED_IN]->(loc1:Location)
match (e1:Event)-[r3]->(t1:IPTC_Media_Topic)
where loc1.name = "Niger" and a1.publisher =
"aljazeera.com"
match (e2:Event)-[r4]->(a2:Article)
match (e2:Event)- [r5:HAPPENED_IN]->(loc2:Location)
match (e2:Event)- [r6]->(t2:IPTC_Media_Topic)
whe re loc2.name = "Niger" and a2.publisher = "nytimes.com"
and t1 = t2
return t1;
s
1
s
2
Figure 4: Computing pullback with Cypher query.
ics but the other dimensions can also be used for per-
spective analysis.
3.2 Analyzing the Progression of Events
To analyze the progression of events in computational
journalism is a complex task as there is an abundance
of information. Numerous publishers from all around
the world publish about ongoing events. There is a
lack of tool support in computational journalism to
keep record of the events and systematically analyze
them to extract insightful information about the pro-
gression of events. We propose (1) to use features
such as names, locations and IPTC topics to group
news articles covering stories about closely related
topics and, then, (2) to use category theory to analyze
the progression of events by means of analyzing con-
tents in news articles. We reuse the concept presented
in Figure 3 where we adapt S
1
and S
2
with a selection
of events capturing situations from time
x1
− time
y1
and time
x2
− time
y2
respectively. From S
1
and S
2
we
systematically compare the evolution of events from
time
x1
− time
y1
to time
x2
− time
y2
. For example, S
1
and S
2
may represent the IPTC media topics being
used to cover the news events about Niger from July
31st-August 6th and August 7th-August 13th respec-
tively. From these subgraphs we compute the emerg-
ing IPTC media topics in the reports published during
August 7th-August 13th. This comparative analysis
allows journalists to get an overview of the progres-
sion of events.
The progression of events can be represented
as a transformation of IPTC media topics being
covered by the publishers. Let us consider that
Niger
28.07−30.07
X
1
D
1
PB1 C
1
D
2
X
2
I Niger
30.07−06.08
X
3
D
3
PB2 C
2
D
4
Niger
07.08−13.08
X
4
m
1
∃!k
1
/
n
1
n
2
∃!k
2
m
2
∃!k
3
/
n
3
n
4
/
m
3
∃!k
4
Figure 5: Capturing the progression of events with pullback
operation.
in Figure 5, Niger
28.07−30.08
, Niger
31.08−06.08
and
Niger
07.08−13.08
are representing the IPTC media top-
ics being used to cover the news events in Niger
for periods July 28th-July 30th, July 31st-August
6th and August 7th-August 13th respectively. The
pullback object C
1
and C
2
represents the com-
monality of the events (with respect to IPTC me-
dia topics) in Niger
28.07−30.08
, Niger
31.08−06.08
and
Niger
31.08−06.08
, Niger
07.08−13.08
respectively. The
object D
1
would capture the media topics being re-
moved from the reporting during July 30th-August
6th; D
2
would capture the media topics being newly
A Model-Based Framework for News Content Analysis
103

X
AB11
D
AB11
C
AB1
D
AB2
X
AB12
X
B1
Country − B
w1
Country − A
w1
X
A1
D
B1
D
A1
D
B2
C
B1
PB3 PB1 C
A1
D
A2
X
B2
X
A2
X
B3
Country − B
w2
I Country − A
w2
X
A3
D
B3
D
A3
C
B2
PB4 PB2 C
A2
D
B4
D
A4
X
B4
Country − B
w3
Country − A
w3
X
A4
X
AB31
D
AB31
C
AB3
D
AB32
X
AB32
∃!k
AB11
/
n
AB12
n
AB11
/
∃!k
AB12
∃!k
B1
m
B1
m
A1
∃!k
A1
/ /
/
n
B2
n
B1
n
A1
n
A2
/
∃!k
B2
∃!k
A2
∃!k
B3
m
B2
m
A2
∃!k
A3
/ /
n
B3
n
B4
n
A3
n
A4
/ /
∃!k
B4
m
B3
m
A3
∃!k
A4
∃!k
AB31
/
n
AB31
n
AB32
/
∃!k
AB32
Figure 6: Comparison of progression of events.
added during July 30th-August 6th. Similarly, D
3
would capture the media topics being removed from
the reporting during August 7th-August 13th and D
4
would capture the media topics being added during
August 7th-August 13th.
Similar categorical operations can also be used
to analyze the progression of events in two different
countries. Let us consider that we want to analyze
the weekly progression of events in Niger and Gabon
since the coup started in those two countries. Fig-
ure 6 illustrates a computational model for such anal-
ysis. The pullback object C
AB1
is the commonality
between the progression of events in the two coun-
tries Country − A and Country − B in the first week
where Country − A
w1
and Country − B
w1
represents
contextual information of events (such as IPTC me-
dia topics or involved countries or individuals) re-
ported in the first week. For brevity we did not show
C
AB2
(pullback object between Country − A
w2
and
Country − B
w2
) in the diagram. Common develop-
ment between the two countries progression can be
found from the pullback objects C
AB1
, C
AB2
, C
AB3
, etc.
Figure 7 illustrates a computation model for the
comparison of progression of events at a higher level
of abstraction. α
1
,α
2
,β
1
,β
2
represents contextual in-
formation of events specified at a certain abstraction
level j; In our running example we only have a hier-
archical data model for IPTC Media topics, therefore,
all the IPTC Media topics in α
1
,α
2
,β
1
,β
2
are at level
j in the IPTC Media topic ontology. α
′
1
,α
′
2
,β1
′
,β2
′
represents contextual information of events specified
at a higher level of abstraction. The pullback objects
C
αβi
(where i = 1,2) in the bottom layer represent the
commonality of the progression of events. The arrows
between layers represent graph homomorphisms be-
tween corresponding elements from lower to higher
levels of abstraction in the knowledge graph I.
Theorem: For any non-empty pullback object C
αβi
(where i = 1,2) at level j, the corresponding pullback
objects C
′
αβi
at level k < j is non-empty.
Proof Sketch: Consider a non-empty pullback ob-
ject C
αβi
(where i = 1, 2) at level j; this would require
at least one element n
a
∈ α
i
and one element n
b
∈ β
i
where n
a
and n
b
are mapped to the same element in
the knowledge graph. If n
′
a
(with level k) is a par-
ent of n
a
, and n
′
b
(with level k) is a parent of n
b
, then
n
′
a
and n
′
b
must also map to the same element in the
knowledge graph. The pullback objects C
′
αβi
should
at least contain an element that maps to n
′
a
and n
′
b
and
therefore cannot be empty.
3.3 Variant Analysis
In this section we present a technique for vari-
ant analysis over the computation results from sec-
tion.3.2. We present an application of statistical anal-
ysis method for detecting news article variants. In
section 3.2 we presented techniques to retrieve data
from a knowledge graph across various dimensions
and on various abstraction levels. This selection of
data from knowledge graphs are used for identifying
variants by applying statistical methods. In this sec-
tion we present Exploratory data analysis for identi-
MODELSWARD 2024 - 12th International Conference on Model-Based Software and Systems Engineering
104
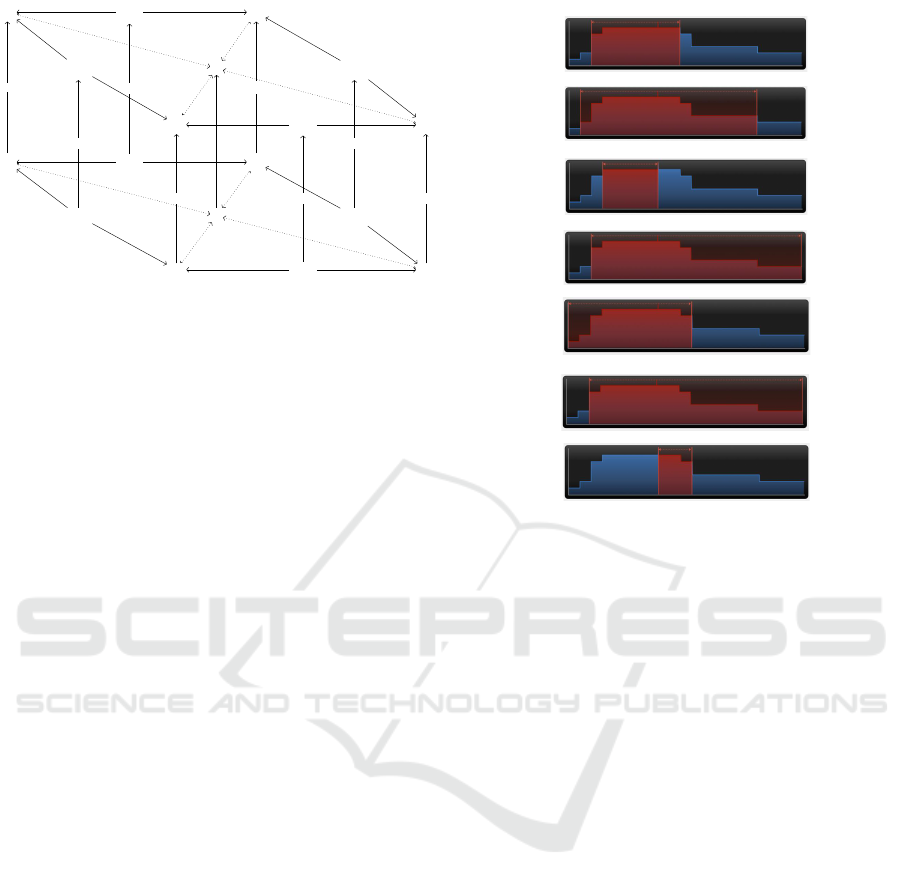
β
′
2
C
′
β12
β
′
1
C
′
αβ2
I C
′
αβ1
α
′
2
C
′
α
1
2
α
′
1
β
2
C
β12
β
1
C
αβ2
I C
αβ1
α
2
C
α
1
2
α
1
g
22
h
3
g
′
11
h
4
id
I
h
1
f
22
h
2
f
11
Figure 7: Comparison of progression of events at a higher
level of abstraction.
fying trends in time and space and use them for vari-
ant analysis.
In order to identify trends in reporting across dif-
ferent topics, we need to select a dimension and ab-
straction level and extract data from the knowledge
graph. Suppose we would like to identify trends of
publishers reporting about civil unrest in Niger from
August 1st, 2023-August 20th, 2023, we retrieve the
events from the knowledge graph that matches with
the civil unrest IPTC media topic. The results are
therefore used for statistical analysis e.g., frequency
distribution and for visualization of trends in a time-
line. Visualizing the events in a timeline allows us to
depict types of events being reported by different pub-
lishers and their engagement in reporting throughout
a selected period of time.
Figure 8 highlights the duration of engage-
ment of individual publishers among al jazeera.com,
theguardian.com, reuters.com, independent.co.uk,
nytimes.com, washingtontimes.com, cnn.com for
their reporting about civil unrest in Niger. The
background in the figure indicates the co − limit
(i.e., a categorical representation of union) of all the
events from these publishers about civil unrest in
Niger. From the figure we can extract variants e.g.,
independent.co.uk and washingtontime.com’s simi-
larity during the time of publishing about civil un-
rest in Niger. However, one might be interested to
explore the dataset for identifying trends in other di-
mensions e.g., the involvement of certain countries in
a conflict. Such requirements can be adapted by the
proposed method as we can retrieve events that are
about any kind of conflict and that involve any coun-
tries. We exploit the use of ontological hierarchies for
the retrieval of events at the correct abstraction level.
For instance, we can identify common trends in the
involvement of foreign countries in coups that have
taken place in African nations.
aljazeera.com's coverage
01.08 20.08
theguardian.com's coverage
reuters.com's coverage
Independent.co.uk's coverage
nytimes.com's coverage
washingtontimes.com's coverage
cnn.com's coverage about 'civil unrest'
Figure 8: Timeframe showing the engagement of news pub-
lishers in reporting about civil unrest in Niger.
4 DISCUSSION AND FUTURE
WORK
The proposed method allows us to analyze the per-
spective of publishers across different dimensions and
abstraction levels, and we have presented how per-
spective of publishers covering the types of events can
be captured. However, there are many other aspects
that might be important to capture such as presenta-
tions, opinions, etc. In the landscape of news content
analysis, various systems such as GDELT(Leetaru
and Schrodt, 2013) have been developed for iden-
tifying and organizing news events from vast data
streams in structured formats. While GDELT ef-
ficiently aggregates and quantitatively analyzes vast
volumes of news data, offering an overview of the dy-
namics within the media landscape, a new approach
is needed to enable researchers to dive deeper into in-
dividual news events.
We presented a model-based framework for con-
tent analysis that deviates from traditional news anal-
ysis methods that mostly rely on text mining and se-
mantic technologies (Leban et al., 2014; Rudnik et al.,
2019). Our proposed method introduces a compre-
hensive framework that holds the potential to address
critical challenges within the media domain. One
limitation in the previous research lies in the limited
A Model-Based Framework for News Content Analysis
105

ability to effectively compare news items with one
another. Our model fills this gap by offering a ro-
bust mechanism for comparative analysis. As a re-
sult, our model empowers users to explore and solve
open problems in the field of media with a holistic ap-
proach, leading to enhanced insights and deeper un-
derstanding of the complex media landscape.
In this paper, our primary focus has been on the
analysis of various reports pertaining to a specific
event, particularly in terms of perspectives. By fo-
cusing into the perspective of reports, we aim to un-
cover the nuances encapsulated within the media dis-
course surrounding the event. We can furthermore in-
clude the intricacies of reporting angles, tones, and
the framing of articles, enriching our understanding
of news narratives. Additionally, we have employed a
systematic approach to track the evolution and pro-
gression of these events over time which provides
valuable insights into how events unfold and trans-
form over time, enriching our understanding of their
dynamics and implications.
Large language models (LLMs) have demon-
strated exceptional performance in specific language-
related tasks. However, they also fall short in deliver-
ing the structured approach and transparency neces-
sary for conducting in-depth multi-dimensional anal-
yses. Our proposed framework, on the other hand,
provides a holistic structure for exploring news, en-
suring transparency and facilitating a deeper under-
standing of news content from various dimensions
and abstractions. Moreover, our approach distin-
guishes itself by offering a high level of abstraction
combined with the flexibility for users to select differ-
ent dimensions for exploration. In contrast to LLMs,
our approach goes beyond natural language under-
standing to incorporate statistical analysis, enriching
our capacity to uncover nuanced patterns and insights
in news content.
While we have presented some analysis technique
using category theory, there is much more to explore
and develop in this field. We believe that the integra-
tion of generative AI and category theory can con-
tribute to the evolution of journalism in the digital
age, fostering transparency, accountability, and en-
riched news content for both journalists and readers.
Particularly, our approach has the capacity to assist
in tasks that involve the comparison of news items.
For instance, it can be particularly useful in multilin-
gual news comparison, where it can facilitate cross-
cultural analysis of news events by overcoming lan-
guage barriers. Moreover, our model can play a valu-
able role in fact-checking and verification, aiding in
the assessment of news source credibility. Addition-
ally, it is well-suited for bias and framing analysis,
enabling the exploration of different perspectives pre-
sented in the media. In (Fatemi et al., 2023) we en-
hanced an existing automated journalism framework
by incorporating an awareness of fairness concerns.
The integration of a comparative analysis technique
into automated journalism processes would be use-
ful for systematically evaluating bias and ensuring the
fairness of automatically generated content.
ACKNOWLEDGEMENTS
This research is funded by SFI MediaFutures partners
and the Research Council of Norway (grant number
309339).
REFERENCES
(2023). Cypher query language. https://neo4j.com/
developer/cypher/. Accessed: 2023-09-25.
(2023). Ethical journalism network. https:
//ethicaljournalismnetwork.org/who-we-are. Ac-
cessed: 2023-09-26.
(2023). GDELT. https://www.gdeltproject.org/data.html.
Accessed: 2023-09-12.
Barr, M. and Wells, C. (1990). Category Theory for Com-
puting Science. Prentice-Hall, Inc., USA.
Berven, A., Christensen, O. A., Moldeklev, S., Opdahl,
A. L., and Villanger, K. J. (2020). A knowledge-
graph platform for newsrooms. Computers in Indus-
try, 123:103321.
Fatemi, B., Rabbi, F., and Tessem, B. (2023). Fairness in
automated data journalism systems. NIKT: Norsk IKT-
konferanse for forskning og utdanning.
Leban, G., Fortuna, B., Brank, J., and Grobelnik, M. (2014).
Event registry: Learning about world events from
news. In Proceedings of the 23rd International Con-
ference on World Wide Web, page 107–110. ACM.
Leetaru, K. and Schrodt, P. A. (2013). Gdelt: Global data on
events, location, and tone, 1979–2012. In ISA annual
convention, volume 2, pages 1–49. Citeseer.
Liu, D., Bai, T., Lian, J., Zhao, X., Sun, G., Wen, J.-R., and
Xie, X. (2019). News graph: An enhanced knowledge
graph for news recommendation. In KaRS@ CIKM,
pages 1–7.
Opdahl, A. L., Al-Moslmi, T., Dang-Nguyen, D.-T.,
Gallofr
´
e Oca
˜
na, M., Tessem, B., and Veres, C. (2022).
Semantic knowledge graphs for the news: A review.
ACM Computing Surveys, 55(7):1–38.
Rospocher, M., Van Erp, M., Vossen, P., Fokkens, A., Ald-
abe, I., Rigau, G., Soroa, A., Ploeger, T., and Bogaard,
T. (2016). Building event-centric knowledge graphs
from news. Journal of Web Semantics, 37:132–151.
Rudnik, C., Ehrhart, T., Ferret, O., Teyssou, D., Troncy, R.,
and Tannier, X. (2019). Searching news articles using
an event knowledge graph leveraged by wikidata. In
MODELSWARD 2024 - 12th International Conference on Model-Based Software and Systems Engineering
106

Companion proceedings of the 2019 world wide web
conference, pages 1232–1239.
Schudson, M. (2020). Journalism: why it matters. Polity
Press, United Kingdom.
A Model-Based Framework for News Content Analysis
107
