
Learning End-to-End Deep Learning Based Image Signal Processing
Pipeline Using a Few-Shot Domain Adaptation
Georgy Perevozchikov
1,2 a
and Egor Ershov
2 b
1
Moscow Institute of Physics and Technology (National Research University), Dolgoprudny, Russia
2
Institute for Information Transmission Problems, Moscow, Russia
Keywords:
Computational Photography, Image Signal Processing Pipeline, Domain Adaptation, Image Processing.
Abstract:
Nowadays the quality of mobile phone cameras plays one of the most important roles in modern smartphones,
as a result, more attention is being paid to the camera Image Signal Processing (ISP) pipeline. The current
goal of the scientific community is to develop a neural-based end-to-end pipeline to remove the expensive
and exhausting process of classical ISP tuning for each next device. The main drawback of the neural-based
approach is the necessity of preparing large-scale datasets each time a new smartphone is designed. In this
paper, we address this problem and propose a new method for few-shot domain adaptation of the existing
neural ISP to a new domain. We show that it is sufficient to have 10 labeled images of the target domain to
achieve state-of-the-art performance on the real camera benchmark datasets. We also provide a comparative
analysis of our proposed approach with other existing ISP domain adaptation methods and show that our
approach allows us to achieve better results. Our proposed method exhibits notably comparable performance,
with only a marginal 2% drop in performance compared to the learned from scratch in the whole dataset
baseline. We believe that this solution will significantly reduce the cost of neural-based ISP production for
each new device.
1 INTRODUCTION
Deep CNNs have made tremendous progress in high-
level computer vision applications including object
identification, segmentation, and picture classification
(Medioni and Dickinson, 2016). The availability of
large-scale datasets with thousands of tagged pictures
is a significant contributor to the generalizing ability
and performance of CNNs. But on the reverse side of
the coin, gathering large-scale datasets for each new
device sensor is a time-consuming and expensive pro-
cess.
For instance, the data acquisition procedure for the
image processing pipeline is fraught with great diffi-
culties, since it is necessary not only to collect large-
scale dataset but also reconstruct its spectral sensitiv-
ities (Karaimer and Brown, 2016), which also may
differ for two separate pixels of the same sensor. In
practice, obtaining such data pairs often requires ad-
ditional complex equipment such as a color checker,
integration sphere, stable light sources, and specially
equipped rooms. Moreover, the collection of such
a
https://orcid.org/0009-0009-7176-6242
b
https://orcid.org/0000-0001-6797-6284
10-shot domain adaptation from S to T
(proposed solution)
Ground Truth
Trained ISP on same domain (T)
Trained ISP on other domain (S)
Figure 1: Visualization of the various ISP training ap-
proaches. Our few-shot domain adaptation approach is ef-
fective in RAW image enhancement tasks. Here are S is
Zurich RAW-to-RGB dataset and T is Mobile AIM21.
samples should contain a wide variety of frames with
different scene parameters, illumination levels, etc.
Another part of the problem is the strong sensi-
tivity of convolutional neural networks to the dataset
distribution (Deng et al., 2009). Differences in color
Perevozchikov, G. and Ershov, E.
Learning End-to-End Deep Learning Based Image Signal Processing Pipeline Using a Few-Shot Domain Adaptation.
DOI: 10.5220/0012268900003660
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 3: VISAPP, pages
255-263
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Copyright © 2024 by Paper published under CC license (CC BY-NC-ND 4.0)
255

spaces, noise characteristics, and camera spectral
sensitivities for different camera manufacturers cre-
ate a huge domain gap between different sensors.
Even more, the difference in color reproduction exists
among the same sensor’s instances, which is caused
by the production inaccuracy. Consequently, a model
trained on the raw data of one camera performs sub-
optimally on the raw data of another camera (fig.
1). The quality of the currently existing photography
pipeline drops significantly when the pipeline is ap-
plied directly to a new camera sensor. In addition, ex-
isting non-machine learning-based algorithms do not
have an exact solution and depend on many free vari-
ables (Karaimer and Brown, 2016), which also com-
plicates their usage.
Inspired by several unsupervised and few-shot
domain adaptation approaches (Ganin and Lempit-
sky, 2015), (Ganin et al., 2016), (Prabhakar et al.,
2023) in learning domain-invariant features we pro-
pose a paradigm shift for the raw image enhance-
ment task using a few-shot domain adaptation to ad-
dress the above-mentioned challenges. The primary
distinguishing factors of our proposed method are
its use of inverse gradient utilization, the employ-
ment of an AW-Net architecture as a base pipeline,
and the utilization of marginally distinct loss func-
tions to achieve state-of-the-art performance. In this
work, we consider each camera as a separate do-
main. The main idea is to apply a domain adapta-
tion method based on the reverse gradient to the U-
Net-like deep learning-based image signal processing
pipeline (Ronneberger et al., 2015). We improve the
performance of our approach by using a large existing
data collection from the source domain and transfer-
ring the task onto a new target domain with only 10
labeled samples. We anticipate that this domain adap-
tation method can make the development of the im-
age processing pipelines easier (both for a new device
and for different sensor instances of the same model),
which can bring benefits to the related digital camera
industries.
In summary, our contributions are as follows:
• We propose a new domain adaptation method for
learning the image signal processing pipeline;
• We show that with a few labeled samples (10
images) from the target domain our approach
can reach the comparable quality of the model
trained from scratch with a complete target do-
main dataset;
• We present the results of the experiments illustrat-
ing the blazing performance of our method and
compare it with other methods such as existing
domain adaptation techniques, transfer learning,
and projective transformation.
Figure 2: The main network architecture of the AWNet.
2 RELATED WORK
Domain Adaptation: Domain adaptation is a branch
of transfer learning where the goal adapt a model
learned on a source domain to perform with a high
quality on an other (target) domain. A popular prac-
tice for domain adaptation is to use the reverse gra-
dient to obtain domain-invariant data representations.
The pioneer of this practice was V. Lempitsky et al.,
authors propose to use unsupervised domain adapta-
tion by backpropagation (DANN) (Ganin and Lem-
pitsky, 2015) for a handwritten digit classifier. After
that, a number of break through papers have been pub-
lished. The MADA technique (Pei et al., 2018), for
instance, uses captured multi-mode structures to align
various data distributions more effectively. There is
also a few-shot (Motiian et al., 2017) domain adap-
tation work that uses a few labeled samples with
many unlabeled samples in the target domain for im-
age classification. Currently, mixed approaches are
becoming increasingly common, including both ele-
ments of unsupervised and a few-shot domain adap-
tation (Shang et al., 2022), (Yue et al., 2021). The do-
main adaptation technique, which is gaining popular-
ity, has found its application in RAW-to-RAW image
signal processing. M. Afifi et al., used domain adapta-
tion to learn RAW-to-RAW transformations between
different cameras (Afifi and Abuolaim, 2021). An ar-
ticle of particular significance was also presented, pi-
oneering the application of domain adaptation tech-
niques to RAW-to-RGB image processing pipelines
using only a few images (Prabhakar et al., 2023). The
central premise of this research involves the employ-
ment of a common ISP pipeline to extract domain-
invariant features.
Image Signal Processing Pipeline: The classic
pipeline was described by M. Brown et al. (Ramanath
et al., 2005). Such ISP often consists of many stages
such as black level offset, normalization, bad pixel
mask, demosaicing, white balance, noise reduction,
color transform and etc. Each of these steps depends
on a large number of parameters and may have a large
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
256

computational complexity, which complicates its us-
age.
Contrariwise, the recent increase in the process-
ing capacity of smartphones and embedded devices
has also contributed to the rise in popularity of deep
learning for RAW-to-RGB image mapping during the
past few years. This led to the appearance of various
open RAW-to-RGB datasets, competitions, and scien-
tific researches around deep learning-based ISP.
First RAW-to-RGB datasets were Samsung S7
ISP (Schwartz et al., 2018) and Zurich RAW-to-RGB
(Ignatov et al., 2019). In 2021, the eponymous dataset
was presented at the Mobile AIM challenge, one of
the major image signal processing competition (Igna-
tov et al., 2021) which is running for 4 years now.
In addition, Cube++ dataset made by E. Ershov et al.
(Ershov et al., 2020) can also be used for learning ISP
models.
There are also a number of publications devoted
to neural-based ISP. In fact, nearly all of the proposed
solutions are based on U-Net (Ronneberger et al.,
2015): it is true as for the first approaches, namely
proposed in 2018 DeepISP (Schwartz et al., 2018) and
in 2019 PyNET (Ignatov et al., 2020b), as for the re-
cently presented MW-ISPNet (Ignatov et al., 2020a)
and AW-Net (Dai et al., 2020). A new state-of-the-art
neural network called dh isp was presented at Mobile
AIM 2021 challenge (Ignatov et al., 2021).
Nowadays the two primary research goals are to
improve image quality by discovering an effective
network architecture and training method and to mod-
ify the network to perform within the computational
limits of smartphones.
3 PROPOSED METHOD
We present an image processing pipeline based on
AW-Net and determine the way of applying domain
adaptation to it. In our approach, we combine the
ideas of using a common ISP pipeline with separated
pre-encoders (Prabhakar et al., 2023) and an inverse
gradient (Ganin and Lempitsky, 2015) to obtain a
domain-invariant representation. Since the output is
an RGB image but the input is a RAW image, the net-
work has to learn camera hardware-specific enhance-
ment in addition to its entire ISP pipeline. The do-
main gap results from the fact that a model developed
using data from a single camera (the source domain)
does not perform similarly when applied to data from
another camera (the target domain). Specifically, not
only spectral sensitivities of the sensors usually are
different but also the ISP itself. The situation is even
more challenging because of the fact that ISP is usu-
ally a proprietary software and it is almost impossible
to perform its reverse engineering. To cope with these
limitations, we propose a domain adaptation method
to move the ISP task from a large-scale labeled source
dataset to a small set of labeled target data in order to
produce output in the target domain.
Here and after we will denote a source dataset as
a large enough for training neural-based ISP with a
good quality, while the target domain will be consid-
ered as a small one (about 10 images). Our goal is
to adapt a neural-based ISP pipeline train on a source
domain to a target domain without noticeable quality
loss. To achieve this goal we train our model to gener-
ate RGB images with both source and target domains
as input. Our method is illustrated in Fig. 3 with the
source and target training pipelines. It is an end-to-
end trainable deep network that takes the RAW image
as input and performs image reconstruction utilizing
the source data for domain adaptation to the target do-
main using a few target-labeled samples.
3.1 Model Architecture
The neural network is a small AW-Net with additional
blocks such as a domain classifier with a reverse gra-
dient layer and pre-encoders for the possibility of ap-
plying domain adaptation to it. The description of
each of the blocks is described below.
Pre-Encoders: The pre-encoder is a small convolu-
tional network made up of three Convolution2D lay-
ers with 3x3 kernels and a number of filters - 8, 16,
32. Pre-encoders are needed in order to reduce the
significant domain gap between different cameras by
extracting individual and independent features from
each of them. It takes a 4-channel GRGB RAW (be-
fore debayering) image as an input and produces a
32-channel output.
Common AW-Net: A lightweight U-Net-like autoen-
coder with 3 downsampling and 4 upsampling blocks.
It takes a 32-channel image from each pre-encoder
as input and produces two outputs: a 3-channel RGB
image and a 256-dimensional vector from the bottle-
neck.
Domain Classifier: To reduce the gap between do-
mains and increase the performance we add a binary
domain classifier (Ganin et al., 2016) with an inverse
gradient (Ganin and Lempitsky, 2015) using a con-
volutional neural network with GlobalAveragePool-
ing2D and two Dense layers at the end. It takes a
256-dimensional vector as input from AW-Net.
Learning End-to-End Deep Learning Based Image Signal Processing Pipeline Using a Few-Shot Domain Adaptation
257
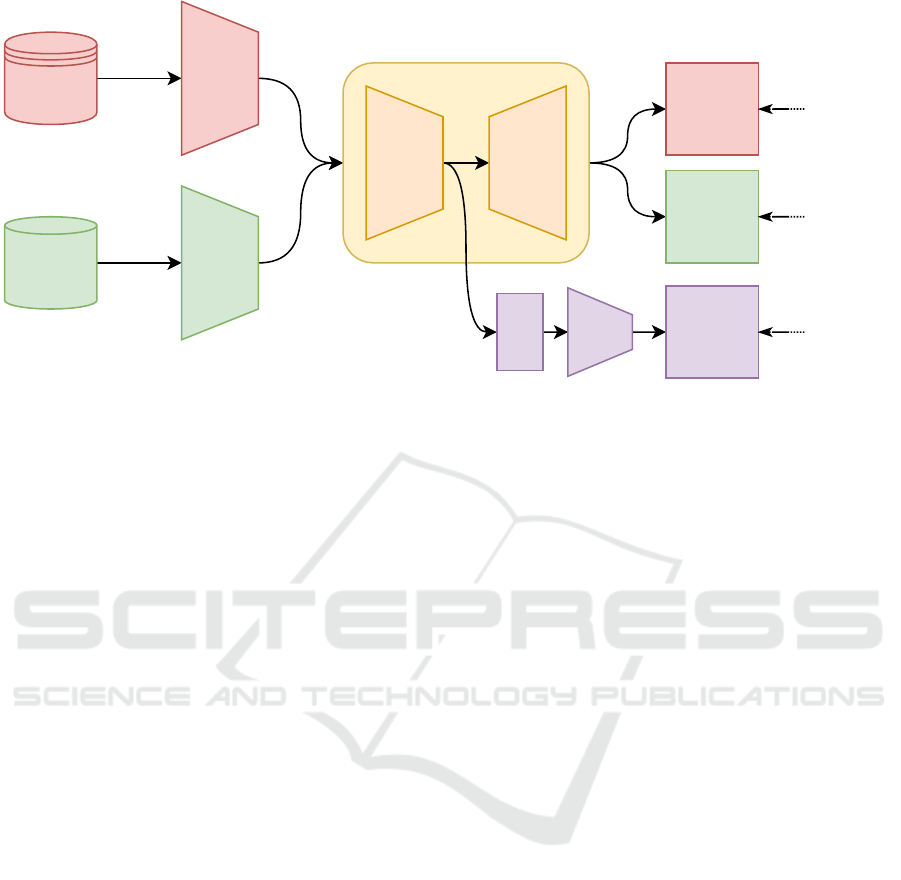
Source
dataset
Target
dataset
Source pre-
encoder
Target pre-
encoder
RGL
Classi-
fier
AW-Net
Source
Image
Target
Image
Domain
Class
Source
Loss
Target
Loss
BCE
Figure 3: Illustration of the proposed few-shot domain adaptation approach. We use separate pre-encoders from each domain
to extract camera-specific features. We use AW-Net as a common ISP pipeline and domain classifier with reverse gradient
layer (RGL) to midimase domain gap and learn domain-invariant features.
3.2 Training Process
To achieve a good performance of domain adaptation,
the network is trained in two stages:
1. Perform pipeline pre-training on the source do-
main. At this stage, we use only the source do-
main pre-encoder and AW-Net’s RGB output; the
outputs of the domain classifier are not considered
and the target domain pre-encoder is not used.
2. Initialize the initial weights of the target pre-
encoder by the weights from the source pre-
encoder to preserve structural integrity while
transmitting the signal through the pre-encoder
specific to the target domain.
3. Start the domain adaptation stage training the
whole network and using the entire source domain
and a small part of the target domain. During this
stage at each training step, we sequentially feed
image crops from the target and source domains to
the corresponding pre-encoder and calculate the
corresponding loss functions. In addition, we take
into account the predictions of the domain classi-
fier and its inverse gradient.
3.3 Loss Functions
Within this section, we expound upon the loss func-
tions pertinent to both the pre-training and domain
adaptation phases. It is imperative to underscore
that all the enumerated loss functions are composed
as amalgamations encompassing perceptual loss, L
1
loss, MS-SSIM loss, as well as additional compo-
nents, namely, color loss and exposure fusion loss,
the latter of which will be elucidated in subsequent
discussions. The nomenclature employed herein des-
ignates the predicted image as
ˆ
I and the ground truth
RGB image as I.
Perceptual Loss. To mitigate pixel misalignment dis-
crepancies, we employ the perceptual loss derived
from the output of the pre-trained VGG19 network
(Simonyan and Zisserman, 2014). The loss function
is defined as follows:
L
vgg
= L
2
(V GG(I) −V GG(
ˆ
I)). (1)
Here, V GG represents the output from the final
convolutional layer of the pre-trained VGG-19 net-
work, and L
2
denotes the mean squared error, facil-
itating the minimization of discrepancies between the
reconstructed image (
ˆ
I) and the ground truth image
(I). This approach effectively accounts for perceptual
qualities and pixel-level fidelity.
L1 Loss. We use L
1
loss as strong supervision to op-
timize pixel values during the training of the network.
We also do not use this loss during training the target
domain on a few data samples to avoid overfitting the
neural network.
MS-SSIM Loss. The multi-scale structural similar-
ity loss L
MSSSIM
is used to enhance the reconstructed
RGB images by the structural similarity index. The
loss function can be defined as:
L
MSSSIM
= 1 − MSSSIM(I,
ˆ
I), (2)
where MSSSIM is a multi-scale structural similarity
(Wang et al., 2003). This approach facilitates the
preservation of structural characteristics and percep-
tual quality in the reconstructed images.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
258

Color Loss. This loss is measured as the cosine
similarity between the RGB vectors to minimize the
color difference between the predicted image and the
ground truth. We denote it as L
rgb
.
Exposure Fusion Loss. Exposure fusion technique
(Mertens et al., 2009) is used for fusing a bracketed
exposure sequence into a high-quality image, without
converting to HDR first. Exposure fusion computes a
target image by identifying the best parts of multiple
exposures. We use a set of quality measures to guide
the process, which we consolidate into a scalar-valued
weight map. The exposure fusion loss function min-
imizes the difference of these maps between the pre-
dicted and the ground truth images, which helps to
build a more accurate exposure, avoiding overexpo-
sure and darkening. The loss function can be defined
as:
L
exp
= L
1
(Exp(I), Exp(
ˆ
I)), (3)
where Exp is an exposure fusion technique.
Pre-Training Stage. In the beginning, we pre-train
the pipeline using only source domain data. At this
stage, we use the following loss function:
L
pretrain
= L
1
+ L
vgg
+ L
MSSSIM
+ L
rgb
+ L
exp
. (4)
Domain Adaptation Stage. In the second stage, we
make domain adaptation using source and target do-
main data together. In this case, we minimize three
losses:
• Loss for source domain: L
source
= L
1
;
• Loss for target domain: L
target
= L
vgg
+L
MSSSIM
+
L
rgb
+ L
exp
;
• Loss for domain classifier: L
classi f ier
= BCE (bi-
nary cross-entropy).
4 EXPERIMENTS
We used TensorFlow 2.9.0 and Python 3.9 to imple-
ment the proposed neural network and then trained
the model with the following server environment:
Ubuntu 21.10, AMD Ryzen 7 5800X, 64G RAM, and
NVIDIA GeForce RTX 2080 Ti GPU x1. It should
be noted that each experiment was run 5 times and
quality measurements were averaged. We also used
Adam optimiser with default parameters: lr = 0.001,
β
1
= 0.9, β
2
= 0.9, ε = 1 · 10
−7
.
4.1 Datasets
In our experimentation involving domain adaptation,
we employed three open datasets: the Zurich RAW-
to-RGB dataset, the Samsung S7 ISP dataset, and the
Mobile AIM21 dataset. It is essential to underscore
that each training experiment for domain adaptation
incorporated 10 pairs of RAW-RGB images, each at
full resolution. A comprehensive description of each
of these datasets can be found in Table 1. Further-
more, we conducted color checker photographs using
two distinct devices to establish a projective transfor-
mation between the color spaces of their respective
cameras.
Table 1: The datasets comparison.
Dataset Crops
per
image
Train
size
(Crops)
Domain
adap-
tation
size
(Crops)
Valida-
tion
size
(Crops)
Zurich
RAW-
to-RGB
60 32000 600 8043
Samsung
S7 ISP
46 4000 460 1060
Mobile
AIM21
700 19200 7000 4961
Zurich RAW-to-RGB Dataset. This dataset was
submitted for the Mobile AIM19 challenge in 2021
and is the largest dataset to date. The dataset contains
more than 20K pairs of outdoor images taken syn-
chronously by a Canon 5D Mark IV DSLR camera
and a Huawei P20 smartphone with a Sony IMX380
mobile sensor (12M pixel) capturing images in the
RAW format. The images were taken during the day-
time in a wide variety of places and in various illu-
mination and weather conditions. Since training deep
learning models on high-resolution images is infea-
sible, the patches of size 224×224 pixels were ex-
tracted from the P20-RAW / Canon image pairs pre-
liminary aligned. As a result, 48043 crops were se-
lected, where about 60 patches come to one full-size
image.
Samsung S7 ISP Dataset. This dataset consists of
the RAW and JPEG image pairs captured using the
Samsung S7 smartphone. For each scene, both nor-
mally lit and low light are captured (low light is sim-
ulated by shorter exposure). A total of 110 scenes
are captured in full resolution (12M pixels). For our
experiments, images with standard lighting were se-
lected that were cut into crops of 512×512 without
overlap.
Mobile AIM21 Dataset. The dataset was gener-
ated using a Sony IMX586 quad Bayer mobile sen-
sor (48M pixel), and a Fujifilm GFX100 DSLR. Since
the captured RAW-RGB image pairs are not perfectly
aligned, they were matched using an advanced dense
correspondence algorithm (Truong et al., 2021), and
Learning End-to-End Deep Learning Based Image Signal Processing Pipeline Using a Few-Shot Domain Adaptation
259

then smaller patches of size 256×256 pixels were ex-
tracted. We obtained 24K training RAW-RGB image
pairs 256×256, where about 700 patches come to one
full-size image.
Samsung S7 Colors
Huawei P20 Colors
sRGB Colors
Figure 4: Visualization of color pairs from ColorChecker
and sRGB representations. A set of 24 color pairs was ob-
tained by capturing images with Samsung S7 and Huawei
P20 devices under standardized D50 lighting conditions.
ColorChecker Dataset. Data acquisition involved
the deployment of two devices, namely the Samsung
S7 and Huawei P20, to capture a scene featuring
a ColorChecker under D50 illumination conditions.
These specific devices align with Samsung S7 ISP and
Zurich RAW-to-RGB datasets. Subsequently, the tar-
get color information was extracted from each RAW
image for every color pitch on the ColorChecker. This
process yielded a total of 24 pairs of colors, repre-
sented in the RGGB format as 4-dimensional vectors.
4.2 Training Description and Results
In the investigation of domain adaptation, we har-
nessed a triad of datasets, such as Zurich RAW-to-
RGB, Samsung S7 ISP, and Mobile AIM21, in di-
verse source and target domain combinations. Fur-
thermore, for the sake of comparative analysis with
established methodologies, such as the color space
transform (CST), transfer learning, and Prabhakar’s
domain adaptation (PDA) approach (Prabhakar et al.,
2023), we selected the Samsung S7 ISP dataset as the
source domain and the Zurich RAW-to-RGB dataset
as the target domain (Table 4, Figure 7). It is impera-
tive to highlight that, within the framework of our ex-
periments, we restricted the utilization of merely ten
images for the target domain.
Pre-Training. Our initial phase entails pipeline pre-
training on the source domain data. During this stage,
exclusively the source domain pre-encoder and AW-
Net RGB output are utilized. Training of the neural
network commences from a pristine state, encompass-
ing the entire dataset sourced from Zurich RAW-to-
RGB, Mobile AIM21, and Samsung S7 ISP, spanning
four training epochs. This pre-training endeavor cul-
minated in our model’s attainment of noteworthy out-
comes, as elaborated in Table 2, and visually repre-
sented in Figure 6.
Domain Adaptation. Subsequently, we embarked on
domain adaptation by exploring all feasible dataset
combinations, resulting in six distinct instances. In
this phase, a modest subset of ten images, each at
full resolution, was exclusively employed. The neu-
ral network underwent a two-epoch training process,
resulting in the outcomes detailed in Table 2 and vi-
sually depicted in Figure 5. Notably, our approach to
domain adaptation demonstrated a commendable per-
formance, achieving a mere 2% reduction in efficacy
compared to learning from scratch.
Furthermore, we engaged in a detailed compara-
tive study to evaluate the impact of different combi-
nations of loss function components. The loss func-
tion under scrutiny was defined as L
target
= L
vgg
+
L
MSSSIM
+ L
rgb
+ L
exp
. This analysis aimed to eluci-
date the individual contribution of each term to the
overall performance. Additionally, our methodol-
ogy was juxtaposed with existing domain adaptation
techniques, including Color Space Transform (CST),
Transfer Learning, and Prabhakar Domain Adaptation
(PDA) as delineated in (Prabhakar et al., 2023). The
comparative results of these techniques are systemat-
ically presented in Table 4 and Figure 7. The empiri-
cal evidence substantiates that our proposed approach
outperforms other domain adaptation methodologies
in terms of effectiveness.
Table 2: The validation scores (PSNR and SSIM), were
computed across various datasets. The diagonal of the ma-
trix represents scores when learning from scratch. Our pro-
posed 10-shot domain adaptation method exhibits notably
comparable performance, with only a marginal 2% drop in
performance compared to the learned from scratch in the
whole dataset baseline.
Target Domain
Domain
Adaptation
Zurich
RAW-
to-RGB
Mobile
AIM21
Samsung
S7 ISP
Source Domain
Zurich
RAW-to-
RGB
19.46,
0.73
23.15,
0.86
22.07,
0.79
Mobile
AIM21
18.92,
0.71
23.48,
0.87
22.03,
0.79
Samsung S7
ISP
18.85,
0.71
23.08,
0.85
22.16,
0.81
Furthermore, we conducted experiments to evalu-
ate domain adaptation from Zurich RAW-to-RGB to
Mobile AIM21 using varying numbers of images: 1,
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
260

Ground
Truth
Trained
from
Scratch
Zurich to
AIM21
S7 to
AIM21
Ground
Trough
Trained
from
Scratch
AIM21 to
Zurich
S7 to
Zurich
Figure 5: Predictions visualization for Domain adaptation from source domains to Zurich RAW-to-RGB and Mobile AIM21.
Training from scratch – an AW-Net ISP pipeline trained from scratch on the corresponding dataset (Mobile AIM21 on top,
Zurich RAW-to-RGB on bottom). Zurich to AIM21, AIM21 to Zurich, etc. – a demonstration of the work of our domain
adaptation approach on 10 images for the corresponding datasets.
5, 10, 20, 40, and 80 (Table 3, Figure 6). The findings
indicate that our current approach yields near state-
of-the-art quality, specifically, with five images, the
quality decrement is 8%, surpassing the efficacy of
conventional transfer learning, and for a single image,
it stands at 19%. Performance close to trained from
scratch ISP is achieved with 10 images. A further in-
crease in the number of images does not provide a
significant increase in performance.
Table 3: Validation scores (using the validation set) for
domain adaptation from Zurich RAW-to-RGB to Mobile
AIM21 using k = 1, 5, 10, 20, 40, 80 images.
k images PSNR ↑ SSIM ↑
1 19.05 0.77
5 21.70 0.79
10 23.15 0.86
20 23.31 0.86
40 23.39 0.87
80 23.43 0.87
Color Space Transform (CST). In addressing the
fundamental challenge of domain transfer, we ini-
tially explored a rudimentary yet pragmatic solution,
involving color space transformations from the Zurich
RAW-to-RGB domain to the Samsung S7 ISP do-
main. To implement this approach, we conducted the
linear regression training with polynomial features of
Figure 6: Visualisation of predictions for domain adapta-
tion from Zurich RAW-to-RGB to Mobile AIM21 using
k = 1, 5, 10 images.
the third degree, extracted from our ColorChecker
dataset corresponding to each camera:
P
3,3
=
{
r, g, b
}
∪
r
2
, g
2
, b
2
, rg, rb, gr
∪
r
3
, g
3
, b
3
, r
2
g, r
2
b, g
2
r, g
2
b, b
2
r, b
2
g, rgb
(5)
The selection of the polynomial degree was de-
termined through a systematic grid-search proce-
Learning End-to-End Deep Learning Based Image Signal Processing Pipeline Using a Few-Shot Domain Adaptation
261

dure. Subsequently, we applied the trained regres-
sion model to transform the RAW images within
the Zurich RAW-to-RGB dataset. Following this
transformation, we employed the image processing
pipeline, which had been trained from scratch on the
Samsung S7 ISP dataset, to process the transformed
data.
Transfer Learning. To facilitate comparative anal-
ysis, we pursued the strategy of transferring learning
acquired by a pre-trained model from the Samsung S7
ISP domain to the Zurich RAW-to-RGB domain. The
training process for this transfer involved two epochs
and encompassed the complete dataset. The same loss
function employed during training from scratch was
used for transfer learning.
Prabhakar Domain Adaptation (PDA). In our eval-
uation, we conducted a comparative analysis between
our proposed approach and what, to the best of our
knowledge, stands as the sole third-party method out-
lined in (Prabhakar et al., 2023). The primary distin-
guishing factors of our proposed method are its use
of inverse gradient utilization, the employment of an
AW-Net architecture instead of U-Net, and the utiliza-
tion of marginally distinct loss functions.
To rigorously assess this adaptation approach, re-
ferred to as PDA, we conducted experiments involv-
ing 10 images sourced from the Samsung S7 ISP do-
main, adapted to the Zurich RAW-to-RGB domain.
The comparative evaluation reveals that, in compar-
ison to our approach, the PDA method exhibits a
slightly inferior performance, as delineated in Table
4 and Figure 7.
Table 4: Validation scores (using the validation set) for
domain adaptation approaches from Samsung S7 ISP to
Zurich RAW-to-RGB. Our domain adaptation approach
with only ten images showcases superior performance com-
pared to existing methods and achieves performance com-
parable to training from scratch on the entire dataset.
Method PSNR ↑ SSIM ↑
Learning from scratch 19.46 0.73
Domain adaptation (ours) 18.85 0.71
Domain adaptation (ours)
L
V GG
+ L
MSSIM
+ L
rgb
18.02 0.70
Domain adaptation (ours)
L
V GG
+ L
MSSIM
17.21 0.67
CST 15.16 0.73
Transfer learning 16.74 0.67
PDA 17.12 0.69
Ground
Truth
Trained
from
Scratch
Domain
Adaptation
(ours)
CST
Transfer
Learning
PDA
Figure 7: Visualisation of predictions for domain adapta-
tion of different approaches from Samsung S7 ISP to Zurich
RAW-to-RGB. Our approach has the best performance that
is closest to the result of an ISP trained from scratch.
5 CONCLUSION
Using only a small number of labeled samples from
the target domain and a large number of samples from
the source domain, we demonstrated the SoTA (state-
of-the-art) domain adaptation approach for the RAW
to RGB image signal processing pipeline that can be
very useful for manufacturers of digital cameras and
smartphones, as it can significantly reduce financial
and time production costs. We first obtain camera-
specific information using pre-encoders, followed by
domain invariant characteristics that are extracted us-
ing the AW-Net network. We apply domain adapta-
tion using the back-propagation approach to decrease
the domain gap. Our findings demonstrate that, com-
pared to training with huge target domain data, using
our approach with even very few (about a dozen) la-
beled samples from the target domain is enough to
provide a comparable performance level. We believe
that our approach will stimulate more explorations in
these fields and will be applied in the production of
digital cameras.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
262

REFERENCES
Afifi, M. and Abuolaim, A. (2021). Semi-supervised raw-
to-raw mapping. arXiv preprint arXiv:2106.13883.
Dai, L., Liu, X., Li, C., and Chen, J. (2020). Awnet: Atten-
tive wavelet network for image isp. In European Con-
ference on Computer Vision, pages 185–201. Springer.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). Imagenet: A large-scale hierarchical
image database. In 2009 IEEE conference on com-
puter vision and pattern recognition, pages 248–255.
Ieee.
Ershov, E., Savchik, A., Semenkov, I., Bani
´
c, N., Belokopy-
tov, A., Senshina, D., Ko
ˇ
s
ˇ
cevi
´
c, K., Suba
ˇ
si
´
c, M., and
Lon
ˇ
cari
´
c, S. (2020). The cube++ illumination estima-
tion dataset. IEEE Access, 8:227511–227527.
Ganin, Y. and Lempitsky, V. (2015). Unsupervised do-
main adaptation by backpropagation. In International
conference on machine learning, pages 1180–1189.
PMLR.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P.,
Larochelle, H., Laviolette, F., Marchand, M., and
Lempitsky, V. (2016). Domain-adversarial training of
neural networks. The journal of machine learning re-
search, 17(1):2096–2030.
Ignatov, A., Chiang, C.-M., Kuo, H.-K., Sycheva, A., and
Timofte, R. (2021). Learned smartphone isp on mo-
bile npus with deep learning, mobile ai 2021 chal-
lenge: Report. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR) Workshops, pages 2503–2514.
Ignatov, A., Timofte, R., Ko, S.-J., Kim, S.-W., Uhm, K.-H.,
Ji, S.-W., Cho, S.-J., Hong, J.-P., Mei, K., Li, J., et al.
(2019). Aim 2019 challenge on raw to rgb mapping:
Methods and results. In 2019 IEEE/CVF International
Conference on Computer Vision Workshop (ICCVW),
pages 3584–3590. IEEE.
Ignatov, A., Timofte, R., Zhang, Z., Liu, M., Wang, H.,
Zuo, W., Zhang, J., Zhang, R., Peng, Z., Ren, S., et al.
(2020a). Aim 2020 challenge on learned image sig-
nal processing pipeline. In European Conference on
Computer Vision, pages 152–170. Springer.
Ignatov, A., Van Gool, L., and Timofte, R. (2020b). Re-
placing mobile camera isp with a single deep learning
model. In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition Work-
shops, pages 536–537.
Karaimer, H. C. and Brown, M. S. (2016). A software plat-
form for manipulating the camera imaging pipeline.
In European Conference on Computer Vision, pages
429–444. Springer.
Medioni, G. and Dickinson, S. (2016). Synthesis lectures
on computer vision.
Mertens, T., Kautz, J., and Van Reeth, F. (2009). Expo-
sure fusion: A simple and practical alternative to high
dynamic range photography. In Computer graphics
forum, volume 28, pages 161–171. Wiley Online Li-
brary.
Motiian, S., Jones, Q., Iranmanesh, S., and Doretto, G.
(2017). Few-shot adversarial domain adaptation. Ad-
vances in neural information processing systems, 30.
Pei, Z., Cao, Z., Long, M., and Wang, J. (2018). Multi-
adversarial domain adaptation. In Thirty-second AAAI
conference on artificial intelligence.
Prabhakar, K. R., Vinod, V., Sahoo, N. R., and Babu,
R. V. (2023). Few-shot domain adaptation for
low light raw image enhancement. arXiv preprint
arXiv:2303.15528.
Ramanath, R., Snyder, W. E., Yoo, Y., and Drew, M. S.
(2005). Color image processing pipeline. IEEE Signal
Processing Magazine, 22(1):34–43.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net:
Convolutional networks for biomedical image seg-
mentation. In International Conference on Medical
image computing and computer-assisted intervention,
pages 234–241. Springer.
Schwartz, E., Giryes, R., and Bronstein, A. M. (2018).
Deepisp: Toward learning an end-to-end image pro-
cessing pipeline. IEEE Transactions on Image Pro-
cessing, 28(2):912–923.
Shang, J., Niu, C., Huang, J., Zhou, Z., Yang, J., Xu, S., and
Yang, L. (2022). Few-shot domain adaptation through
compensation-guided progressive alignment and bias
reduction. Applied Intelligence, pages 1–17.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556.
Truong, P., Danelljan, M., Van Gool, L., and Timofte, R.
(2021). Learning accurate dense correspondences and
when to trust them. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 5714–5724.
Wang, Z., Simoncelli, E. P., and Bovik, A. C. (2003). Mul-
tiscale structural similarity for image quality assess-
ment. In The Thrity-Seventh Asilomar Conference on
Signals, Systems & Computers, 2003, volume 2, pages
1398–1402. Ieee.
Yue, X., Zheng, Z., Zhang, S., Gao, Y., Darrell, T., Keutzer,
K., and Vincentelli, A. S. (2021). Prototypical cross-
domain self-supervised learning for few-shot unsu-
pervised domain adaptation. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 13834–13844.
Learning End-to-End Deep Learning Based Image Signal Processing Pipeline Using a Few-Shot Domain Adaptation
263
