
Improving the Accuracy of Tracker by Linearized Transformer
Thang Hoang Dinh
1 a
, Kien Thai Trung
1 b
, Thanh Nguyen Chi
1 c
and Long Tran Quoc
2,∗ d
1
Institute of Information Technology, Academy of Military Science and Technology, Hanoi, Vietnam
2
University of Engineering and Technology, Vietnam National University, Hanoi, Vietnam
Keywords:
Visual Tracking, Siamese Visual Tracking, Linearized Transformer, Attention.
Abstract:
Visual object tracking seeks to correctly estimate the target’s bounding box, which is difficult due to occlusion,
illumination variation, background clutters, and camera motion. Recently, Siamese-based approaches have
demonstrated promising visual tracking capability. However, most modern Siamese-based methods compute
target and search image features independently, then use correlation to acquire correlation information from
two feature maps. The correlation operation is a straightforward fusion technique that considers the similarity
between the template and the search region. This may be the limiting factor in the development of high-
precision tracking algorithms. This research offers a Siamese refinement network for visual tracking that
enhances and fuses template and search patch information directly without needing a correlation operation.
This approach can boost any tracker performance and produces boxes without any postprocessing. Extensive
experiments on visual tracking benchmarks such as VOT2018, UAV123, OTB100, and LaSOT with DiMP50
base tracker demonstrate that our method achieves state-of-the-art results. For example, on the VOT2018,
LaSOT, and UAV123 test sets, our method obtains a significant improvement of 5.3% (EAO), 3.5% (AUC),
and 2.9% (AUC) over the base tracker. Our network runs at approximately 30 FPS on GPU RTX 3070.
1 INTRODUCTION
Visual tracking is crucial in computer vision since it
lets us determine the status of an item inside a video
sequence. Despite significant gains in recent years, il-
lumination variations, background clutters, occlusion,
and camera motion impede visual tracking. Numer-
ous research has been published in recent years, but it
is still necessary to produce an accurate method.
The Siamese network-based tracker (Li et al.,
2019; Chen et al., 2020; Yu et al., 2020) formulate
the problem of visual object tracking as learning a
generic similarity map by cross-correlating the fea-
ture representations of the template target and search
area. However, cross-correlation is a linear matching
procedure, limiting the tracker’s capacity to capture
the complex non-linear interaction between the tem-
plate and search patch. In addition, these Siamese-
based trackers often identify the target by separately
improving the regression and classification branches,
which might result in a tracking technique mismatch.
a
https://orcid.org/0000-0002-6099-7522
b
https://orcid.org/0000-0002-3098-814X
c
https://orcid.org/0000-0003-4335-7002
d
https://orcid.org/0000-0002-4115-2890
∗
Corresponding author
DiMP (Bhat et al., 2019) and KYS (Bhat et al., 2020)
use a multiple-stage tracking technique, which incor-
porates extra tracking stages for more precise box es-
timates, to provide more robust and accurate tracking
outcomes. These trackers begin by approximating the
target’s location before refining the original result in
subsequent tracking phases for a more exact box pre-
diction.
Recently, the attention and transformer mecha-
nism was introduced to visual tracking in (Yu et al.,
2020; Wang et al., 2021; Zhao et al., 2021; Chen et al.,
2021). SiamAtnn (Yu et al., 2020) is an anchor-based
tracker that analyzes both self- and cross-attention to
enhance the discriminative ability of the template and
search features before performing depth-wise cross-
correlation. TransformerTrack (Wang et al., 2021)
utilizes a whole transformer to provide a tracking
framework with transformer assistance. TrTr (Zhao
et al., 2021) propose a tracker network based on
a powerful attention mechanism called Transformer
encoder-decoder architecture.
In addition, the majority of refinement techniques
in current trackers (Bhat et al., 2019; Bhat et al., 2020;
Cheng et al., 2021) have poor transferability since
their training is connected with other components.
And Alpha-Refine (Yan et al., 2021) continues to use
correlation. Nevertheless, a correlation technique can
Dinh, T., Trung, K., Chi, T. and Quoc, L.
Improving the Accuracy of Tracker by Linearized Transformer.
DOI: 10.5220/0011900900003411
In Proceedings of the 12th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2023), pages 607-614
ISBN: 978-989-758-626-2; ISSN: 2184-4313
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
607

only determine the link between small patches in two
feature maps. Similar Alpha-Refine and in contrast
to the abovementioned methodologies, our methodol-
ogy is independently trained. Therefore, it can be di-
rectly applied to any existing trackers in a plug-and-
play style without further training or change of the
baseline tracker.
In this study, we propose and develop a unique
Feature Enhancement module (FEM) for the enhance-
ment and a Feature Fusion module (FFM) for the fu-
sion of two Siamese branch features, therefore elim-
inating the aforementioned issue. The FEM mod-
ule repeatedly interweaves the self and cross-encoder
layers, whereas FFM is an attention-based pixel-wise
match. Moreover, as a consequence of predicting box
coordinates using a corner heatmap. These are our
most important contributions:
• We propose a new architecture that integrates fea-
ture extraction, features enhancement and fusion
(FEF), and prediction head modules to improve
tracker accuracy.
• The proposed FEF enriches and aggregates exten-
sive contextual information between the template
target and the search image. In addition, a lin-
ear transformer is utilized to lower the computing
complexity of our framework.
• We conduct extensive experiments on multi-
ple benchmark datasets, including VOT2018,
UAV123, OTB100, and LaSOT with base tracker
DiMP, demonstrating that our network achieves a
good trade-off between efficiency and precision.
On the VOT2018, LaSOT, and UAV123 test sets,
our method obtains a significant improvement of
5.3% (EAO), 3.5% (AUC), and 2.9% (AUC) over
the base tracker. Our network runs at 30 FPS on
NVIDIA GeForce RTX 3070.
2 RELATED WORK
Due to the emergence of new benchmark datasets, vi-
sual tracking has been an important area of study in
computer vision for the last several decades. This sec-
tion provides a concise overview of the three factors
most pertinent to our work.
Visual Object Tracking. Deep learning has success-
fully permeated computer vision for a variety of ap-
plications, including object tracking. Several trackers
based on deep learning train an online classifier to dif-
ferentiate the target from the backdrop and detractors.
The DiMP (Bhat et al., 2019) tracker improves the
discriminative capabilities of the learned CNN ker-
nel in an end-to-end manner. Moreover, the newly-
introduced KYS (Bhat et al., 2020) extends DiMP by
using scene information to enhance the outcomes.
Recently, Siamese-based trackers (Li et al., 2019;
Zhang et al., 2020; Chen et al., 2020; Guo et al., 2020;
Cheng et al., 2021) have garnered significant atten-
tion for their exceptional performance. SiamRPN++
(Li et al., 2019) incorporates contemporary deep net-
works into Siamese trackers, such as ResNet ResNet
(He et al., 2016). Moreover, SiamBAN (Chen et al.,
2020) and SiamCAR (Guo et al., 2020) used the
FCOS (Tian et al., 2019) idea for tracking and devel-
oped a basic yet effective anchor-free tracker. These
works still depend significantly on the correlation
operation fusion of template and search region fea-
tures. SiamRN (Cheng et al., 2021) presents a Rela-
tion Detector (RD) equipped with a contrastive train-
ing approach that is meta-trained to acquire the ca-
pacity to learn to filter the distractors from the tar-
get area by quantifying their connections. In addition,
SiamGAT (Guo et al., 2021) demonstrated a target-
aware Siamese Graph Attention network for generic
object tracking.
Attention and Transformer Mechanism. The trans-
former (Vaswani et al., 2017) receives a series as in-
put, examines each element in the sequence, and dis-
covers their relationships. This characteristic makes
the transformer capable of collecting global informa-
tion in sequential data. Attention and Transformer
mechanisms have also been investigated lately in ob-
ject tracking (Yu et al., 2020; Wang et al., 2021;
Chen et al., 2021; Zhao et al., 2021). SiamAttn (Yu
et al., 2020) explores self-attention and cross-attention
to improve the discriminative power of target fea-
tures and then fuses features derived from the template
and search images using depth-wise cross-correlation.
TransformerTrack (Wang et al., 2021) employed a
complete transformer consisting of an encoder and de-
coder that was computationally intensive, memory in-
tensive, and slow to train. TransT (Chen et al., 2021)
created a transformer-based fusion network for the in-
clusion of target-search data. However, box genera-
tion was still dependent on postprocessing using these
approaches.
Due to their quadratic complexity concerning
the input length, transformers are unacceptably slow
when processing very lengthy sequences. Recent re-
search has suggested “linear Transformers” with the
memory of constant size and time complexity propor-
tional to sequence length (Schlag et al., 2021). This
decrease in complexity is mostly due to the lineariza-
tion of the softmax.
Refinement Mechanism. Numerous state-of-the-art
trackers (Bhat et al., 2019; Bhat et al., 2020; Cheng
et al., 2021) use a multi-stage tracking method to get
precise and reliable results. This strategy begins with
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
608

Template
Search
256x256x3
256x256x3
Input
Feature Extraction
Feature Enhancement and Fusion Prediction Head
16x16x1024 8x8x64
16x16x1024 16x16x256
positional
encoding
Feature
Enhancement
and Fusion
Module
16x16x64
BBox
Pred
PrPool
BBox
16x16x256
16x16x64
Figure 1: A summary of the proposed networks. It includes an input, feature extraction, feature enhancement and fusion, and
a regression prediction head.
a coarse target location and then uses a refinement
module to refine the findings of the previous stage.
DiMP (Bhat et al., 2019) first locates the target using
an online classification module and then draws ran-
dom samples around it. Then, to offer more accurate
bounding boxes, they optimize the overlap between
these samples and the ground truth using a modified
IoU-Net (Jiang et al., 2018). This updated IoU-Net
can be trained independently of the original tracker.
Consequently, the IoU-Net has excellent transferabil-
ity, although its accuracy may still be significantly en-
hanced. SiamRN (Cheng et al., 2021) designed a re-
finement module that can perform classification and
regression concurrently to localize the target, hence
minimizing the mismatch between the two branches.
However, SiamRN is meant as a standalone tracker
and not as a refinement module; therefore, it can-
not and should not be used to improve other track-
ers. Alpha-Refine (Yan et al., 2021) is a plug-and-play
refinement module that improves the tracking perfor-
mance of many kinds of trackers. Alpha-Refine con-
tinues to employ correlation. The correlation opera-
tion is a straightforward fusion technique that takes
into account the similarity between the template and
the search area. However, the correlation operation it-
self is a local linear matching process, resulting in the
loss of semantic information and the easy occurrence
of local optimum, which may be the bottleneck in the
design of accurate tracking algorithms.
In this research, we use the core principles of lin-
earized transformer and attention to constructing a
Siamese refinement network for visual tracking that
enhances and fuses template and search patch infor-
mation directly without needing a correlation opera-
tion. In addition, as a result of employing a corner
heatmap to estimate box location, that is anchor-free.
3 PROPOSED METHOD
We describe the details of our proposed networks
(TrackerLT) in this section. As shown in Figure 1,
TrackerLT consists of three main components: a fea-
ture extraction, a feature enhancement and fusion, and
a prediction head network.
3.1 Feature Extraction
In this work, we use the fully convolutional network
to construct the Siamese subnetwork for the visual
feature extraction. The Siamese network consists of
two identical branches. For feature extraction, we em-
ploy a ResNet50 (He et al., 2016) pre-train on (Rus-
sakovsky et al., 2015) as the backbone network. We
only use the fourth stage’s (layer3) outputs as final
outputs. The backbone processes the template patch
z ∈ R
3×H
0
×W
0
and the search patch x ∈ R
3×H
0
×W
0
to
obtain their features maps F
z
∈ R
C
z
×H×W
and F
x
∈
R
C
x
×H×W
, H =
H
0
16
,W =
W
0
16
and C
z
= C
x
= 1024.
Then, we apply a neck with three stacked convolution
1 ×1, batch norm, relu to decrease the output features
channel to C=64. The output features of our network
are defined as Z ∈ R
C×H×W
and X ∈ R
C×H×W
.
With b is the bounding box of the target object in
template patch, we convert b to RoI format to get r.
Then apply Rol Pooling to Z; we get RoI feature:
Z = ψ(Z,r) ∈ R
C×h×w
(1)
where ψ is Precise RoI Pooling (Jiang et al., 2018).
3.2 Feature Enhancement Module
Transformer (Vaswani et al., 2017) adopts attention
mechanism with Query-Key-Value (QKV) model.
Given the packed matrix representations of queries
Q ∈ R
N×D
k
, keys K ∈R
M×D
v
, and values V ∈R
M×D
v
,
the scaled dot-product attention used by Transformer
is given by:
Attention(Q,K,V ) = softmax
QK
T
√
D
k
V = AV. (2)
where N and M denote the lengths of queries and
keys (or values); D
k
and D
v
denote the dimensions
Improving the Accuracy of Tracker by Linearized Transformer
609
L
Feature Enhancement Module
positional
encoding
SEL
CELSEL
Z
0
Z
X
X
0
CEL
Z
l
Z
l
X
l
X
l
Softmax
C/4 x hw
HW x C/2
HW x C/4
hw x C/2 HW x C/2
HW x hw
hxwxC
HxWxC
HxWxC
Conv(3x3)
Conv(3x3)
Conv(3x3)
Conv(3x3)
Feature Fusion Module
X
L
Z
L
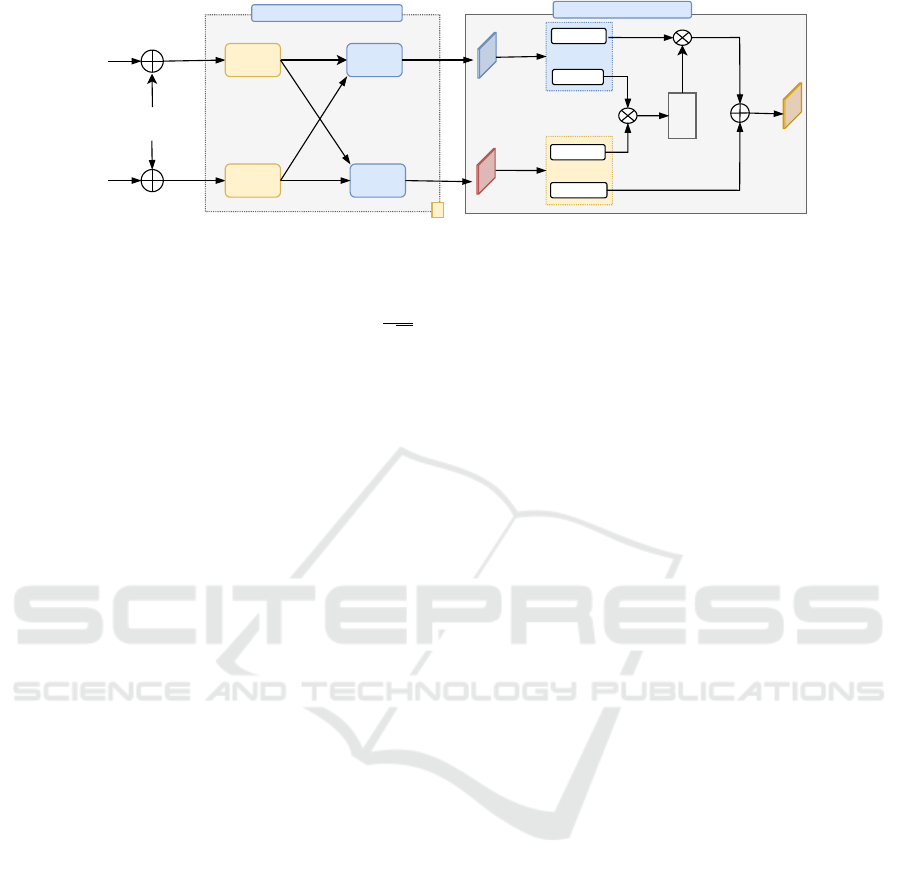
Figure 2: The proposed Feature Enhancement module (left) consists of a stack of several L Self-Encoder Layer (SEL) sub-
module and several L Cross-Encoder Layer (CEL) sub-module. The proposed Feature Fusion module (right) is a pixel-wise
match based on attention.
of keys (or queries) and values; A = softmax
QK
T
√
D
k
is often called an attention matrix. For softmax atten-
tion, the complexity of computing softmax(QK
T
)V is
quadratic O (N
2
). Following (Schlag et al., 2021), by
replacing the unnormalized attention exp(QK
T
) with
φ(Q).φ(K)
T
the computational complexity of atten-
tion can be reduced to O(N), where φ is a feature map
that is applied in a row-wise manner. Specifically,
given an input x ∈ R
D
, the feature map φ : R
D
→R
2vD
is defined by the partial function:
φ
i+2( j−1)D
(x) = ReLU([x,−x])
i
ReLU([x,−x])
i+1
for i = 1, ...,2D, j = 1, ...,v.
(3)
Hence the computation of the unnormalized atten-
tion matrix can be linearized by computing:
Attention(Q,K,V ) = φ(Q)(φ(K)
T
V ). (4)
As illustrated in Figure 2 (left), the proposed Fea-
ture Enhancement Module (FEM) takes Z and X as
inputs, and outputs the feature enhancement by apply-
ing the linearized transformer mechanism. The FEM
consists of a stacked L self-encoder layer (SEL) and
cross-encoder layer (CEL).
Following (Vaswani et al., 2017), we use 2D ex-
tension function to generate spatial position encoding
for input sequences Z and X:
Z
0
= σ
1
(Z) +P
z
∈ R
C×N
z
(5)
X
0
= σ
2
(X) + P
x
∈ R
C×N
x
(6)
where σ
1
,σ
1
, are two tensors reshape operators, P
z
,P
x
are the spatial position encodings corresponding to Z
and X, respectively, N
z
= h ×w and N
x
= H ×W
For SEL, suppose the input features are Z
l−1
and
X
l−1
, l = 1, ...,L, self-attention (SA) is formulated as:
SA(Z
l−1
) = φ(Z
l−1
W
Q
)(φ(Z
l−1
W
K
)(Z
l−1
W
V
))
(7)
SA(X
l−1
) = φ(X
l−1
W
Q
)(φ(X
l−1
W
K
)(X
l−1
W
V
))
(8)
Then, we can generate SEL features map:
Z
l
= Z
l−1
+ MPL(CAT(Z
l−1
,SA(Z
l−1
)) (9)
X
l
= X
l−1
+ MPL(CAT(X
l−1
,SA(X
l−1
)) (10)
For CEL, suppose the input features are Z
l
and X
l
,
cross-attention (CA) is formulated as:
CA(Z
l
) = φ(Z
l
W
Q
)(φ(X
l
W
K
)(X
l
W
V
)) (11)
CA(X
l
) = φ(X
l
W
Q
)(φ(Z
l
W
K
)(Z
l
W
V
)) (12)
Then, we can generate CEL features map:
Z
l
= Z
l
+ MPL(CAT(Z
l
,CA(Z
l
)) ∈ R
C×N
z
(13)
X
l
= X
l
+ MPL(CAT(X
l
,CA(X
l
)) ∈ R
C×N
x
(14)
where W
Q
,W
K
,W
V
are the learnable parameters of
three linear projection layers; MPL and CAT are
Multilayer Perceptron block and Concat, respectively.
The output of FEM are Z
L
and X
L
.
3.3 Feature Fusion Module
When appearance changes or occlusions occur, de-
tailed local features are dominant for matching the tar-
get template and search patch. Hence, instead of only
using correlation operation, we propose aa attention
fusion mechanism where template and search features
are matched at a pixel-wise level, as shown in Figure
2 (right). Key and value maps are generated from fea-
tures, which serve as a means of encoding visual se-
mantics for matching and detailed appearance infor-
mation for prediction. Given Z
L
and X
L
from FEM,
generate key and value features map by:
V
Z
= σ
1
(W
1
(Z
L
)) ∈ R
hw×C/2
K
Z
= σ
2
(W
2
(Z
L
)) ∈ R
C/4×hw
K
X
= σ
3
(W
3
(X
L
)) ∈ R
HW ×C/4
V
X
= σ
4
(W
4
(X
L
)) ∈ R
HW ×C/2
(15)
where W
1
,W
2
,W
3
, and W
4
are 3 × 3 convolution
layer, respectively, σ
1
, σ
2
, σ
3
and σ
4
are four tensors
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
610

reshape operators. Then we calculate the similarities
between key maps of template feature and search fea-
ture by:
A = K
Z
×K
X
(16)
where “×’ is the matrix dot-product operation.
Then, we perform softmax normalization as:
S = softmax(A) ∈ R
HW ×hw
(17)
Then calculate the embedding value and concat this
value with the value map of the search feature to gen-
erate attention fusion feature as:
E = S ×V
Z
∈ R
HW ×C/2
(18)
F = concat(V
X
,E) ∈ R
H×W×C
(19)
F contains massive information for prediction box.
3.4 Prediction Head Network
To improve the box estimation quality, we design
a prediction head through estimating the probabil-
ity distribution of the box corners. The fusion fea-
ture F fed into a simple fully-convolutional network
(FCN). The FCN consists of four stacked Conv-BN-
ReLU layers followed by a Conv layer predicting
two heatmaps, which represent the top-left corner
and bottom-right corner respectively. We apply soft-
argmax (Luvizon et al., 2019) to the heatmaps to out-
puts two probability maps P
tl
(x,y) and P
br
(x,y) for
the top-left and the bottom-right corners of object
bounding boxes, respectively. Finally, the predicted
box coordinates ( ˆx
tl
, ˆy
tl
) and ( ˆx
br
, ˆy
br
) are obtained by
computing the expectation of corners’ probability dis-
tribution as shown in Eq. (20).
( ˆx
tl
, ˆy
tl
) = (
H
∑
y=0
W
∑
x=0
x.P
tl
(x,y),
H
∑
y=0
W
∑
x=0
y.P
tl
(x,y)),
( ˆx
br
, ˆy
br
) = (
H
∑
y=0
W
∑
x=0
x.P
br
(x,y),
H
∑
y=0
W
∑
x=0
y.P
br
(x,y))
(20)
3.5 Loss Function
The box localization losses are calculated using the
IoU loss and are defined as follows:
L
box
= 1 −
1
N
pos
∑
i, j
1
ob j
L
IoU
(p
i, j
,g
i, j
) (21)
where N
pos
denotes the number of positive samples,
1
ob j
is the indicator function for positive samples,
L
IoU
denotes the IoU loss as UnitBox (Yu et al.,
2016), g
i, j
denotes the ground-truth box, p
i, j
denotes
the prediction bounding box.
3.6 Tracking Phase
Bhat et al. proposed DiMP (Bhat et al., 2019),
which can predict the bounding box of the ob-
ject in benchmarks datasets without finding hyper-
parameters cosine windows, penalty, and learning
rate as Siamese-based method (such as SiamRPN++,
SiamCAR, SiamBAN, SiamAttn, SiamGAT). Based
on Alpha-Refine, we crop the initial frame’s template
patch and provide it into the base tracker (DiMP)
and TrackerLT during tracking. For the following
frames, we trim the search patch p and pass via the
base tracker to get prediction bounding-box b, then
p and b process by TrackerLT again to obtain the
bounding-box regression map P
box
1×4
= [ ˆx
tl
, ˆy
tl
, ˆx
br
, ˆy
br
]
in Eq. (20)
4 EXPERIMENTS
4.1 Implementation Details
The network is trained on the COCO (Lin et al.,
2014), ImageNet DET (Russakovsky et al., 2015),
ImageNet VID (Russakovsky et al., 2015),LaSOT
(Fan et al., 2019), and GOT-10k (Huang et al., 2019)
training sets. The backbone parameters are initialized
with ImageNet-pretrained ResNet-50. Our frame-
work is trained for 50 epochs with 4000 iterations per
epoch and 64 image pairs per batch on one Nvidia
A100 GPU. The ADAM optimizer (Kingma Diederik
and Adam, 2014) is employed with an initial learning
rate of 0.001 and a decay factor of 0.5 for every eight
epochs. Our method is implemented in Python using
PyTorch.
4.2 Comparison with State-of-the-Art
Trackers
We compare our proposed method with the recent
state-of-the-art trackers published from 2019 to 2022
(SiamRPN++ (Li et al., 2019), DiMP-50 (Bhat et al.,
2019), KYS (Bhat et al., 2020), SiamBAN (Chen
et al., 2020), SiamAttn (Yu et al., 2020), Siam-
CAR (Guo et al., 2020), Ocean (Zhang et al., 2020),
TrDiMP (Wang et al., 2021), SiamRN (Cheng et al.,
2021), AR-DiMP50 (Yan et al., 2021), SiamGAT
(Guo et al., 2021), AutoMatch (Zhang et al., 2021),
TrTr (Zhao et al., 2021)), and MixFormer1K (Cui
et al., 2022) on five tracking benchmarks, including
VOT2018, UAV123, OTB100, and LaSOT.
In the VOT2018, the trackers are compared in
terms of Accuracy (A), Robustness (R), and Expected
Improving the Accuracy of Tracker by Linearized Transformer
611

Average Overlap (EAO) metrics. A is the aver-
age overlap between the predicted and ground truth
bounding boxes during successful tracking periods. R
measures how many times the tracker loses the target
(fails) during tracking. EAO is an estimator of the av-
erage overlap a tracker is expected to attain on a large
collection of short-term sequences with the same vi-
sual properties as the given dataset. The one-pass
evaluation criteria is used as defined in (Wu et al.,
2015) to measure the tracking performance in terms
of precision and success plots on OTB100, UAV123,
and LaSOT datasets.
On VOT2018. The VOT2018 (Kristan et al., 2018)
benchmark consists of sixty sequences with vary-
ing levels of difficulty, including many tiny, simi-
lar tracking objects. Detailed comparisons with the
top-performing trackers are reported in Table 1. Our
method achieves an EAO score of 0.492, significantly
outperforming state-of-the-art methods on this met-
ric. Compared with DiMP, our model achieves a per-
formance gain of 5.3%. In comparison with the AR-
DiMP50, we have a substantial improvement of 3.2%
in EAO.
Table 1: Detail comparisons on VOT2018 with the state-
of-the-art in terms of Accuracy (A), Robustness (R), Lost
Number (LN), and Expected Average Overlap (EAO). Red
and blue fonts indicate the top-2 trackers.
Method A(↑) R(↓) LN(↓) EAO(↑)
Ours 0.611 0.116 27.0 0.492
SiamAttn 0.630 0.159 34.0 0.470
SiamRN 0.595 0.131 28.0 0.466
AR-DiMP50 0.642 0.159 34.0 0.460
KYS 0.603 0.143 30.5 0.458
TrDiMP 0.595 0.141 30.0 0.457
SiamBAN 0.590 0.178 38.0 0.447
DiMP-50 0.597 0.152 32.5 0.439
TrTr-Offline 0.612 0.234 - 0.424
SiamRPN++ 0.600 0.234 50.0 0.415
In addition, we compare with state-of-the-art
trackers in terms of EAO on several visual attributes,
and the results are shown in Figure 3. Our approach
scores top in motion change and illumination change
and third in occlusion and camera motion. This
demonstrates that our approach can overcome chal-
lenges.
On UAV123. UAV123 (Mueller et al., 2016) includes
123 low altitude aerial videos captured from a UAV.
It features small objects, fast motions, occlusion, ab-
sent, and distractor objects. As demonstrated in Fig-
ure 4, the proposed method obtains 67.1% in terms
of overall AUC score, which ranks two places, bet-
ter than other trackers by a significant margin except
Overall
(0.400,0.492)
Camera motion
(0.374,0.492)
Illumination change
(0.352,0.683)
Motion Change
(0.410,0.532)
Size change
(0.428,0.562)
Occlusion
(0.305,0.388)
Unassigned
(0.123,0.193)
SiamRPN++
AR-DiMP50
SiamBAN
SiamRN
KYS
SiamAttn
Ours
DiMP-50
TrDiMP
ATOM
Figure 3: Comparison of EAO on VOT2018 for the follow-
ing visual attributes: camera motion, illumination change,
occlusion, size change, and motion change. Unassigned
frames are those that do not relate to any of the five quali-
ties. The parenthesis shows the EAO range of each tracker
characteristic and overall.
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Overlap threshold
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Success rate
Success plots of OPE on UAV123
[0.679] AR-DiMP50
[0.671] Ours
[0.659] TrDiMP
[0.650] SiamAttn
[0.646] SiamGAT
[0.644] AutoMatch
[0.643] SiamRN
[0.642] SiamRPN++
[0.642] DiMP50
[0.631] SiamBAN
[0.623] SiamCAR
[0.621] Ocean
0 5 10 15 20 25 30 35 40 45 50
Location error threshold
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Precision
Precision plots of OPE on UAV123
[0.870] AR-DiMP50
[0.863] TrDiMP
[0.861] SiamRN
[0.861] Ours
[0.849] DiMP50
[0.845] SiamAttn
[0.843] SiamGAT
[0.840] SiamRPN++
[0.838] AutoMatch
[0.833] SiamBAN
[0.823] Ocean
[0.813] SiamCAR
Figure 4: Comparisons on UAV123 in terms of success and
precision plots of OPE. In the legend, the area-under-curve
(AUC) and distance precision (DP) are reported in the left
and right figures, respectively.
for AR-DiMP50 on success score, while AR-DiMP50
train with a mask option. The proposed methodol-
ogy has a success score and a precision score higher
than that of the DiMP50 model, which is 2.9% and
1.4%, respectively. Compared with the SiamAttn,
a method developed from SiamRPN++, by adding
the box refinement and mask branch, the TrackerLT
model achieved a higher success score of 2.1% and a
precision score greater than 1.6%.
On OTB100. OTB100 (Wu et al., 2015) contains 100
sequences in total and 11 challenge attributes, includ-
ing illumination variation, out-of-plane rotation, scale
variation, occlusion, deformation, motion blur, fast
motion, in-plane rotation, out-of-view, background
clutter and low resolution. The proposed model has
a success score of 0.701, higher than the remaining
ten models, as shown in Figure 5. Compared with
DiMP50, TrackerLT achieved higher success scores
of 1.3%.
On LaSOT. LaSOT (Fan et al., 2019) is a re-
cent large-scale dataset with high-quality annotations,
which contains 280 for testing (2500 frames on aver-
age). We report the success and precision scores in the
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
612

0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Overlap threshold
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Success rate
Success plots of OPE on OTB100
[0.701] Ours
[0.701] SiamRN
[0.698] AR-DiMP50
[0.697] SiamCAR
[0.696] MixFormer1K
[0.696] SiamRPN++
[0.696] SiamBAN
[0.695] KYS
[0.691] TransT
[0.688] DiMP50
[0.684] Ocean
0 5 10 15 20 25 30 35 40 45 50
Location error threshold
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Precision
Precision plots of OPE on OTB100
[0.931] SiamRN
[0.920] Ocean
[0.915] SiamRPN++
[0.911] MixFormer1K
[0.910] SiamBAN
[0.910] SiamCAR
[0.904] KYS
[0.900] DiMP50
[0.896] Ours
[0.893] TransT
[0.881] AR-DiMP50
Figure 5: Comparison of success and precision plots on
OTB100 with state-of-the-art methods. In the legend, the
area-under-curve (AUC) and distance precision (DP) are re-
ported in the left and right figures, respectively.
Table 2. This table shows that the proposed method
obtains the best performance, better than other track-
ers by a significant margin except for AR-DiMP50,
but AR-DiMP50 train with mask head. After applying
TrackerLT to DiMP50 model, the success score im-
proved by 3.5 percent compared to DiMP50. In addi-
tion, TrackerLT outperforms the two proposed models
for 2021, AutoMatch and SiamGAT, by 2.2 percent
and 6.5 percent for success scores and by 0.9 percent
and 7.8 percent for precision ratings, respectively.
Table 2: A comparison of our method with other competi-
tive approaches on the testing set of LaSOT in terms of suc-
cess and precision metrics. The best two results are high-
lighted in red and blue, respectively.
Tracker Success(↑) Precision(↑)
Ours 0.604 0.608
AR-DiMP50 0.602 -
AutoMatch 0.582 0.599
DiMP50 0.569 -
SiamGAT 0.539 0.530
Ocean 0.516 0.526
SiamRPN++ 0.496 0.569
4.3 Ablation Study
4.3.1 Number of Transformer Layers
To compare the effect of numbers transformer layers
with evaluation datasets. We tested with L = 2 and
L = 4. As shown in Table 3, on VOT2018, when
L = 2, the approach improved the EAO score by 2.6%
compared to L = 4. Moreover, the network runs at 30
FPS, GPU Memory Usage is 3.238 GB and runs at 26
FPS, GPU Memory Usage is 3.31 GB when L = 2 and
L = 4, respectively.
4.3.2 Type of Fusion
We have experimentally compared the results for 2
types of fusion, PW-Corr (Yan et al., 2021) and FFM.
Table 3: Quantitative comparison results of our method and
its variants with different number of transformer layers on
VOT2018. The best result is highlighted in red.
Dataset L EAO(↑) FPS(↑) Memory
VOT2018
2 0.492 30 3.238 GB
4 0.466 26 3.310 GB
As shown in Table 4, on VOT 2018, FFM with L = 2
has an EAO of 0.492, 0.6% higher than PW-Corr.
Table 4: Quantitative comparison results of our method and
its variants with different type of fusion on VOT2018.
Dataset Fusion EAO(↑)
VOT2018
PW-Corr 0.486
FFM 0.492
4.4 Visualization
Figure 6 provides some representative visual results
regarding the different methods. From top to bottom
are videos from VOT2018, including nature, car1, and
basketball. We can see that our TrackerLT module fa-
cilitates the tracker obtaining more precise bounding
boxes than DiMP and AR-DiMP.
Figure 6: Visual comparison of TrackerLT and other meth-
ods. From left to right, we present the original prediction of
the DiMP base tracker and refined results obtained by AR-
DiMP, our TrackerLT. Color: Ground-Truth( GT ), DiMP
Base tracker ( DiMP ), AR-DiMP method ( AR-DiMP )
and our TrackerLT ( TrackerLT )
5 CONCLUSIONS
In this research, we introduce a new neural network
for visual tracking. We present a linear transformer
module for enhancing features and an attention-based
pixel-wise match module for combining features from
two Siamese network branches. The new network
Improving the Accuracy of Tracker by Linearized Transformer
613

can significantly improve the DiMP tracker’s robust-
ness against illumination variation, background clut-
ters, camera motion, and occlusion. Extensive test-
ing on the VOT2018, UAV123, OTB100, and LaSOT
benchmarks demonstrate that our technique provides
state-of-the-art outcomes. In future work, we will ex-
tend our network by using the new fusions module
and adding a mask branch prediction to boost the per-
formance of trackers and address the challenges of
fast motion, scale variation, and similar objects.
ACKNOWLEDGEMENTS
This research has been done under the research
project TXTCN.22.02 of Vietnam National Univer-
sity, Hanoi.
REFERENCES
Bhat, G., Danelljan, M., Gool, L. V., and Timofte, R.
(2019). Learning discriminative model prediction for
tracking. In ICCV.
Bhat, G., Danelljan, M., Gool, L. V., and Timofte, R.
(2020). Know your surroundings: Exploiting scene
information for object tracking. In ECCV.
Chen, X., Yan, B., Zhu, J., Wang, D., Yang, X., and Lu, H.
(2021). Transformer tracking. In CVPR.
Chen, Z., Zhong, B., Li, G., Zhang, S., and Ji, R. (2020).
Siamese box adaptive network for visual tracking. In
CVPR.
Cheng, S., Zhong, B., Li, G., Liu, X., Tang, Z., Li, X., and
Wang, J. (2021). Learning to filter: Siamese relation
network for robust tracking. In CVPR.
Cui, Y., Jiang, C., Wang, L., and Wu, G. (2022). Mixformer:
End-to-end tracking with iterative mixed attention. In
CVPR.
Fan, H., Lin, L., Yang, F., Chu, P., Deng, G., Yu, S., Bai,
H., Xu, Y., Liao, C., and Ling, H. (2019). Lasot: A
high-quality benchmark for large-scale single object
tracking. In CVPR.
Guo, D., Shao, Y., Cui, Y., Wang, Z., Zhang, L., and Shen,
C. (2021). Graph attention tracking. In CVPR.
Guo, D., Wang, J., Cui, Y., Wang, Z., and Chen, S. (2020).
Siamcar: Siamese fully convolutional classification
and regression for visual tracking. In CVPR.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In CVPR.
Huang, L., Zhao, X., and Huang, K. (2019). Got-10k:
A large high-diversity benchmark for generic object
tracking in the wild. In TPAML, volume 43. IEEE.
Jiang, B., Luo, R., Mao, J., Xiao, T., and Jiang, Y. (2018).
Acquisition of localization confidence for accurate ob-
ject detection. In ECCV.
Kingma Diederik, P. and Adam, J. B. (2014). A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Kristan, M., Leonardis, A., Matas, J., Felsberg, M.,
Pflugfelder, R., ˇCehovin Zajc, L., Vojir, T., Bhat, G.,
Lukezic, A., Eldesokey, A., et al. (2018). The sixth
visual object tracking vot2018 challenge results. In
ECCV Workshops.
Li, B., Wu, W., Wang, Q., Zhang, F., Xing, J., and Yan,
J. (2019). Siamrpn++: Evolution of siamese visual
tracking with very deep networks. In CVPR.
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ra-
manan, D., Doll
´
ar, P., and Zitnick, C. L. (2014). Mi-
crosoft coco: Common objects in context. In ECCV.
Luvizon, D. C., Tabia, H., and Picard, D. (2019). Human
pose regression by combining indirect part detection
and contextual information. In Computers & Graph-
ics, volume 85. Elsevier.
Mueller, M., Smith, N., and Ghanem, B. (2016). A bench-
mark and simulator for uav tracking. In ECCV.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S.,
Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bern-
stein, M., et al. (2015). Imagenet large scale visual
recognition challenge. In IJCV, volume 115. Springer.
Schlag, I., Irie, K., and Schmidhuber, J. (2021). Linear
transformers are secretly fast weight programmers. In
ICML. PMLR.
Tian, Z., Shen, C., Chen, H., and He, T. (2019). Fcos: Fully
convolutional one-stage object detection. In ICCV.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I.
(2017). Attention is all you need. In NIPS, volume 30.
Wang, N., Zhou, W., Wang, J., and Li, H. (2021). Trans-
former meets tracker: Exploiting temporal context for
robust visual tracking. In CVPR.
Wu, Y., Lim, J., and Yang, M.-H. (2015). Object tracking
benchmark. In TPAMI, volume 37.
Yan, B., Zhang, X., Wang, D., Lu, H., and Yang, X. (2021).
Alpha-refine: Boosting tracking performance by pre-
cise bounding box estimation. In CVPR.
Yu, J., Jiang, Y., Wang, Z., Cao, Z., and Huang, T. (2016).
Unitbox: An advanced object detection network. In
24th ACM international conference on Multimedia.
Yu, Y., Xiong, Y., Huang, W., and Scott, M. R. (2020). De-
formable siamese attention networks for visual object
tracking. In CVPR.
Zhang, Z., Liu, Y., Wang, X., Li, B., and Hu, W. (2021).
Learn to match: Automatic matching network design
for visual tracking. In ICCV.
Zhang, Z., Peng, H., Fu, J., Li, B., and Hu, W. (2020).
Ocean: Object-aware anchor-free tracking. In ECCV.
Zhao, M., Okada, K., and Inaba, M. (2021). Trtr:
Visual tracking with transformer. arXiv preprint
arXiv:2105.03817.
ICPRAM 2023 - 12th International Conference on Pattern Recognition Applications and Methods
614
