
Group Privacy for Personalized Federated Learning
Filippo Galli
1 a
, Sayan Biswas
2,4 b
, Kangsoo Jung
2 c
, Tommaso Cucinotta
3 d
and Catuscia Palamidessi
2,4 e
1
Scuola Normale Superiore, Pisa, Italy
2
INRIA, Palaiseau, France
3
Scuola Superiore Sant’Anna, Pisa, Italy
4
LIX,
´
Ecole Polytechnique, Palaiseau, France
Keywords:
Federated Learning, Differential Privacy, d-Privacy, Personalized Models.
Abstract:
Federated learning (FL) is a particular type of distributed, collaborative machine learning, where participating
clients process their data locally, sharing only updates of the training process. Generally, the goal is the
privacy-aware optimization of a statistical model’s parameters by minimizing a cost function of a collection
of datasets which are stored locally by a set of clients. This process exposes the clients to two issues: leakage
of private information and lack of personalization of the model. To mitigate the former, differential privacy
and its variants serve as a standard for providing formal privacy guarantees. But often the clients represent
very heterogeneous communities and hold data which are very diverse. Therefore, aligned with the recent
focus of the FL community to build a framework of personalized models for the users representing their
diversity, it is of utmost importance to protect the clients’ sensitive and personal information against potential
threats. To address this goal we consider d-privacy, also known as metric privacy, which is a variant of local
differential privacy, using a metric-based obfuscation technique that preserves the topological distribution of
the original data. To cope with the issues of protecting the privacy of the clients and allowing for personalized
model training, we propose a method to provide group privacy guarantees exploiting some key properties of
d-privacy which enables personalized models under the framework of FL. We provide theoretical justifications
to the applicability and experimental validation on real-world datasets to illustrate the working of the proposed
method.
1 INTRODUCTION
With the modern developments in machine learning,
user data collection has become ubiquitous, often dis-
closing sensitive personal information with increasing
risks of users’ privacy violations (Le M
´
etayer and De,
2016; NIST, 2021). To try and curb such threats, Fed-
erated Learning (McMahan et al., 2017a) was intro-
duced as a collaborative machine learning paradigm
where the users’ devices, on top of harvesting user
data, directly train a global predictive model, with-
out ever sending the raw data to a central server. On
the one hand, this paradigm has received much at-
a
https://orcid.org/0000-0002-2279-3545
b
https://orcid.org/0000-0002-2115-1495
c
https://orcid.org/0000-0003-2070-1050
d
https://orcid.org/0000-0002-0362-0657
e
https://orcid.org/0000-0003-4597-7002
tention with the appealing promises of guaranteeing
user privacy and model performance. On the other
hand, given the heterogeneity of the data distributions
among clients, training convergence is not guaran-
teed and model utility may be reduced by local up-
dates. Many works have thus focused on the topic
of personalized federated learning, to tailor a set of
models to clusters of users with similar data distribu-
tions (Ghosh et al., 2020; Mansour et al., 2020; Sat-
tler et al., 2020). On a similar note, other lines of
work have also showed that relying on avoiding the
release of user’s raw data only provides a lax pro-
tection to potential attacks violating the users’ pri-
vacy (Hitaj et al., 2017), (Nasr et al., 2019), (Zhu
et al., 2019). To tackle this problem, researchers have
been exploring the application of Differential Privacy
(DP) (Dwork et al., 2006b; Dwork et al., 2006a) to
federated learning, in order to quantify and provide
252
Galli, F., Biswas, S., Jung, K., Cucinotta, T. and Palamidessi, C.
Group Privacy for Personalized Federated Learning.
DOI: 10.5220/0011885000003405
In Proceedings of the 9th International Conference on Information Systems Security and Privacy (ICISSP 2023), pages 252-263
ISBN: 978-989-758-624-8; ISSN: 2184-4356
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

privacy to users participating in the optimization. The
goal of differential privacy mechanisms is to intro-
duce randomness in the information released by the
clients, such that each user’s contribution to the final
model can be made probabilistically indistinguishable
up to a certain likelihood factor. To bound this factor,
the domain of secrets (i.e. the parameter space in FL)
is artificially bounded, be it to provide central (An-
drew et al., 2021; McMahan et al., 2017b) or local
DP guarantees (Truex et al., 2020; Zhao et al., 2020).
When users share with the central server their locally
updated models for averaging, constraining the opti-
mization to a subset of R
n
can have destructive ef-
fects, e.g. when the optimal model parameters for
a certain cluster of users may be found outside such
bounded domain. Therefore, in this work we aim to
address the problems of personalization and local pri-
vacy protection by adopting a generalization of DP,
i.e. d-privacy or metric-based privacy (Chatzikoko-
lakis et al., 2013). This notion of privacy does not re-
quire a bounded domain and provides guarantees de-
pendent on the distance between any two points in the
parameter space. Thus, under the minor assumption
that clients with similar data distributions will have
similar optimal fitting parameters, d-privacy will pro-
vide them with stronger indistinguishability guaran-
tees. Conversely, privacy guarantees degrade grace-
fully for clients whose data distributions are vastly
different. More precisely, our key contributions in this
paper are outlined as follows:
1. We provide an algorithm for the collaborative
training of machine learning models, which builds
on top of state-of-the-art strategies for model per-
sonalization.
2. We formalize the privacy guarantees in terms of d-
privacy. To the best of our knowledge, this is the
first time that d-privacy is used in the context of
machine learning for protecting user information.
3. We study the Laplace mechanism on high dimen-
sions, under Euclidean distance, based on a gener-
alization of the Laplace distribution in R, and we
give a closed form expression.
4. We provide an efficient procedure for sampling
from such
The rest of the paper is organized as follows. Sec-
tion 2 introduces fundamental notions for federated
learning and differential privacy and discusses related
work. Section 3 explains the proposed algorithm for
personalized federated learning with group privacy.
Section 4 validates the proposed procedure through
experimental results. Section 5 concludes and dis-
cusses future work.
2 BACKGROUND
2.1 Related Works
Federated optimization has shown to be under-
performing when the local datasets are samples of
non-congruent distributions, failing to minimize both
the local and global objectives at the same time. In
(Ghosh et al., 2020; Mansour et al., 2020; Sattler
et al., 2020), the authors investigate different meta-
algorithms for personalization. Claims of user pri-
vacy preservation are based solely on the clients re-
leasing updated models (or model updates) instead of
transferring the raw data to the server, with potentially
dramatic effects. To confront this issue, a number of
works have focused on the privatization of the (feder-
ated) optimization algorithm under the framework of
DP (Abadi et al., 2016; Geyer et al., 2017; McMa-
han et al., 2017b; Andrew et al., 2021) who adopt
DP to provide defenses against an honest-but-curious
adversary. Even in this setting though, no protection
is guaranteed against sample reconstruction from the
local datasets (Zhu et al., 2019), using the client up-
dates. Different strategies have been tried to provide
local privacy guarantees, either from the perspective
of cryptography (Bonawitz et al., 2016), or under the
framework of local DP (Truex et al., 2020; Agarwal
et al., 2018; Hu et al., 2020). In particular in (Hu et al.,
2020) the authors address the problem of personal-
ized and locally differentially private federated learn-
ing, but for the simple case of convex, 1-Lipschitz
cost functions of the inputs. Note that this assump-
tion is unrealistic in most machine learning models,
and it excludes many statistical modeling techniques,
notably neural networks.
2.2 Personalized Federated Learning
The problem can be cast under the framework of
stochastic optimization and we adopt the notation of
(Ghosh et al., 2020) to find the set of minimizers
θ
∗
j
∈ R
n
with j ∈
{
1,...,k
}
of the cost functions
F(θ
j
) = E
z∼D
j
[ f (θ
j
;z)], (1)
where {D
1
,...,D
k
} are the data distributions which
can only be accessed through a collection of
client datasets Z
c
=
z|z ∼ D
j
,z ∈ D
for some j ∈
{1,...,k} with c ∈ C =
{
1,...,N
}
the set of clients,
and D a generic domain of data points. C is parti-
tioned in k disjoint sets
S
∗
j
= {c ∈ C | ∀z ∈ Z
c
, z ∼ D
j
} ∀ j ∈ {1,...,k} (2)
The mapping c → j is unknown and we rely on es-
timates S
j
of the membership of Z
c
to compute the
Group Privacy for Personalized Federated Learning
253

empirical cost functions
˜
F(θ
j
) =
1
|S
j
|
∑
c∈S
j
˜
F
c
(θ
j
;Z
c
);
˜
F
c
(θ
j
;Z
c
) =
1
|Z
c
|
∑
z
i
∈Z
c
f (θ; z
i
)
(3)
The cost function f : R
n
× D 7→ R
≥0
is applied on
z ∈ D, parametrized by the vector θ
j
∈ R
n
. Thus, the
optimization aims to find, ∀ j ∈ {1, . . . , k},
˜
θ
∗
j
= argmin
θ
j
˜
F(θ
j
) (4)
2.3 Privacy
d-privacy (Chatzikokolakis et al., 2013) is a gener-
alization of DP for any domain X , representing the
space of original data, endowed with a distance mea-
sure d : X
2
7→ R
≥0
, and any space of secrets Y . A
random mechanism R : X 7→ Y is called ε-d-private
if for all x
1
,x
2
∈ X and measurable S ⊆ Y :
P [R (x
1
) ∈ S] ≤ e
εd(x
1
,x
2
)
P [R (x
2
) ∈ S] (5)
Note that when X is the domain of databases, and
d is the distance on the Hamming graph of their ad-
jacency relation, then Equation (5) results in the stan-
dard definition of DP in (Dwork et al., 2006b; Dwork
et al., 2006a). In this work we will have though that
θ ∈ R
n
= X = Y . The main motivation behind the
use of d-privacy is to preserve the topology of the pa-
rameter distributions among clients, i.e. to have that,
in expectation, clients with close model parameters in
the non-privatized space X will communicate close
model parameters in the privatized space Y .
3 AN ALGORITHM FOR
PRIVATE AND PERSONALIZED
FEDERATED LEARNING
We propose an algorithm for personalized federated
learning with local guarantees to provide group pri-
vacy (Algorithm 1). Locality refers to the sanitization
of the information released by the client to the server,
whereas group privacy refers to indistinguishability
with respect to a neighborhood of clients, defined with
respect to a certain distance metric. Thus we proceed
to define neighborhood and group.
Definition 3.1. For any model parametrized by θ
0
∈
R
n
, we define its r-neighborhood as the set of points
in the parameter space which are at a L
2
distance of at
most r from θ
0
, i.e., {θ ∈ R
n
:
k
θ
0
− θ
k
2
≤ r}. Clients
whose models are parametrized by θ ∈ R
n
in the same
r-neighborhood are said to be in the same group, or
cluster.
Algorithm 1 is motivated by the Iterative Fed-
erated Clustering Algorithm (IFCA) (Ghosh et al.,
2020) and builds on top of it to provide formal pri-
vacy guarantees. The main differences lie in the intro-
duction of the SanitizeUpdate function described in
Algorithm 2 and k-means for server-side clustering of
the updated models.
3.1 The Laplace Mechanism Under
Euclidean Distance in R
n
Algorithm 2’s SanitizeUpdate is based on a gener-
alization of the Laplace mechanism under Euclidean
distance to R
n
, introduced in (Andr
´
es et al., 2013)
for geo-indistinguishability in R
2
. The motivation to
adopt the L
2
norm as distance measure is twofold.
First, clustering is performed on θ with the k-means
algorithm under Euclidean distance. Since we de-
fine clusters or groups of users based on how close
their model parameters are under L
2
norm, we are
looking for a d-privacy mechanism that obfuscates
the reported values within a certain group and al-
lows the server to discern among users belonging to
different clusters. Second, parameters that are sani-
tized by equidistant noise vectors in L
2
norm are also
equiprobable by construction and lead to the same
bound in the increase of the cost function in first or-
der approximation, as shown in Proposition 3.2. The
Laplace mechanism under Euclidean distance in a
generic space R
n
is defined in Proposition 3.1. Proofs
of all Propositions and Theorems are included in Ap-
pendix 5.
Proposition 3.1. Let L
ε
: R
n
7→ R
n
be
the Laplace mechanism with distribution
L
x
0
,ε
(x) = P [L
ε
(x
0
) = x] = Ke
−εd(x,x
0
)
with d(.)
being the Euclidean distance. If ρ ∼ L
x
0
,ε
(x), then:
1. L
x
0
,ε
is ε-d-private and K =
ε
n
Γ(
n
2
)
2π
n
2
Γ(n)
2.
k
ρ
k
2
∼ γ
ε,n
(r) =
ε
n
e
−εr
r
n−1
Γ(n)
3. The i
th
component of ρ has variance σ
2
ρ
i
=
n+1
ε
2
where Γ(n) is the Gamma function defined for
positive reals as
R
∞
0
t
n−1
e
−t
dt which reduces to the
factorial function whenever n ∈ N.
Proposition 3.2. Let y = f (x,θ) be the fitting func-
tion of a machine learning model parameterized by θ,
and (X,Y ) = Z the dataset over which the RMSE loss
function F(Z,θ) is to be minimized, with x ∈ X and
y ∈ Y . If ρ ∼ L
0,ε
, the bound on the increase of the
cost function does not depend on the direction of ρ,
ICISSP 2023 - 9th International Conference on Information Systems Security and Privacy
254

Algorithm 1: An algorithm for personalized federated learning with formal privacy guarantees in local neighborhoods.
Input: number of clusters k; initial hypotheses θ
(0)
j
, j ∈
{
1,...,k
}
; number of rounds T ; number of users per
round U; number of local epochs E; local step size s; user batch size B
s
; noise multiplier ν; local dataset Z
c
held by user c.
for t =
{
0,1,...,T − 1
}
do Server-side loop
C
(t)
← SampleUserSubset(U)
BroadcastParameterVectors(C
(t)
; θ
(t)
j
, j ∈
{
1,...,k
}
)
for c ∈ C
(t)
do in parallel Client-side loop
¯
j = arg min
j∈
{
1,...,k
}
F
c
(θ
(t)
j
;Z
c
)
θ
(t)
¯
j,c
← LocalUpdate(θ
(t)
¯
j
;s;E; Z
c
)
ˆ
θ
(t)
¯
j,c
← SanitizeUpdate(θ
(t)
¯
j,c
; ν)
end for
{
S
1
,...,S
k
}
= k-means(
ˆ
θ
(t)
¯
j,c
, c ∈ C
(t)
; θ
(t)
j
, j ∈
{
1,...,k
}
)
θ
(t+1)
j
←
1
|S
j
|
∑
c∈S
j
ˆ
θ
(t)
¯
j,c
, ∀ j ∈
{
1,...,k
}
end for
Algorithm 2: SanitizeUpdate obfuscates a vector θ ∈ R
n
,
with a Laplacian noise tuned on the radius of a certain
neighborhood and centered in 0.
function SANITIZEUPDATE(θ
(t)
¯
j
;θ
(t)
¯
j,c
;ν)
δ
(t)
c
= θ
(t)
¯
j,c
− θ
(t)
¯
j
ε =
n
νkδ
(t)
c
k
Sample ρ ∼ L
0,ε
(x)
ˆ
θ
(t)
¯
j,c
= θ
(t)
¯
j,c
+ ρ
return
ˆ
θ
(t)
¯
j,c
end function
in first order approximation, and:
k
F(Z,θ + ρ)
k
2
−
k
F(Z,θ)
k
2
≤
J
f
(X,θ)
2
k
ρ
k
2
+ o(
J
f
(X,θ)· ρ
2
)
(6)
The results in Proposition 3.1 allow to reduce the
problem of sampling a point from Laplace to i) sam-
pling the norm of such point according to the re-
sult in Item 2 of Proposition 3.1 and then ii) sam-
ple uniformly a unit (directional) vector from the hy-
persphere in R
n
. Much like DP, d-privacy provides
a means to compute the total privacy parameters in
case of repeated queries, a result known as Composi-
tionality Theorem for d-privacy 3.1. Although it was
known as a folk result, we provide a formal proof in
Appendix 5.
Theorem 3.1. Let K
i
be (ε
i
)-d-private mechanism
for i ∈ {1,2}. Then their independent composition
is (ε
1
+ ε
2
)-d-private.
3.2 A Heuristic for Defining the
Neighborhood of a Client
At the t
th
iteration, when a user c calls the
SanitizeUpdate routine in Algorithm 2, it has al-
ready received a set of hypotheses, optimized θ
(t)
¯
j
(the one that fits best its data distribution), and got
θ
(t)
¯
j,c
. It is reasonable to assume that clients whose
datasets are sampled from the same underlying data
distribution D
¯
j
will perform an update similar to δ
(t)
c
.
Therefore, we enforce points which are within the
δ
(t)
c
-neighborhood of
ˆ
θ
(t)
¯
j,c
to be indistinguishable. To
provide this guarantee, we tune the Laplace mech-
anism such that the points within the neighborhood
are εkδ
(t)
c
k
2
differentially private. With the choice of
ε = n/(νδ
(t)
c
), one finds that εkδ
(t)
c
k
2
= n/ν, and we
call ν the noise multiplier. It is straightforward to ob-
serve that the larger the value of ν gets, the stronger
is the privacy guarantee. This results from the norm
of the noise vector sampled from the Laplace distri-
bution being distributed according to Equation (12)
whose expected value is E [γ
ε,n
(r)] = n/ε.
4 EXPERIMENTS
4.1 Synthetic Data
We generate data according to k = 2 different distribu-
tions: y = x
T
θ
∗
i
+u and u ∼ Uniform [0,1), ∀i ∈ {1,2}
and θ
∗
1
= [+5,+6]
T
, θ
∗
2
= [+4,−4.5]
T
. We then as-
Group Privacy for Personalized Federated Learning
255
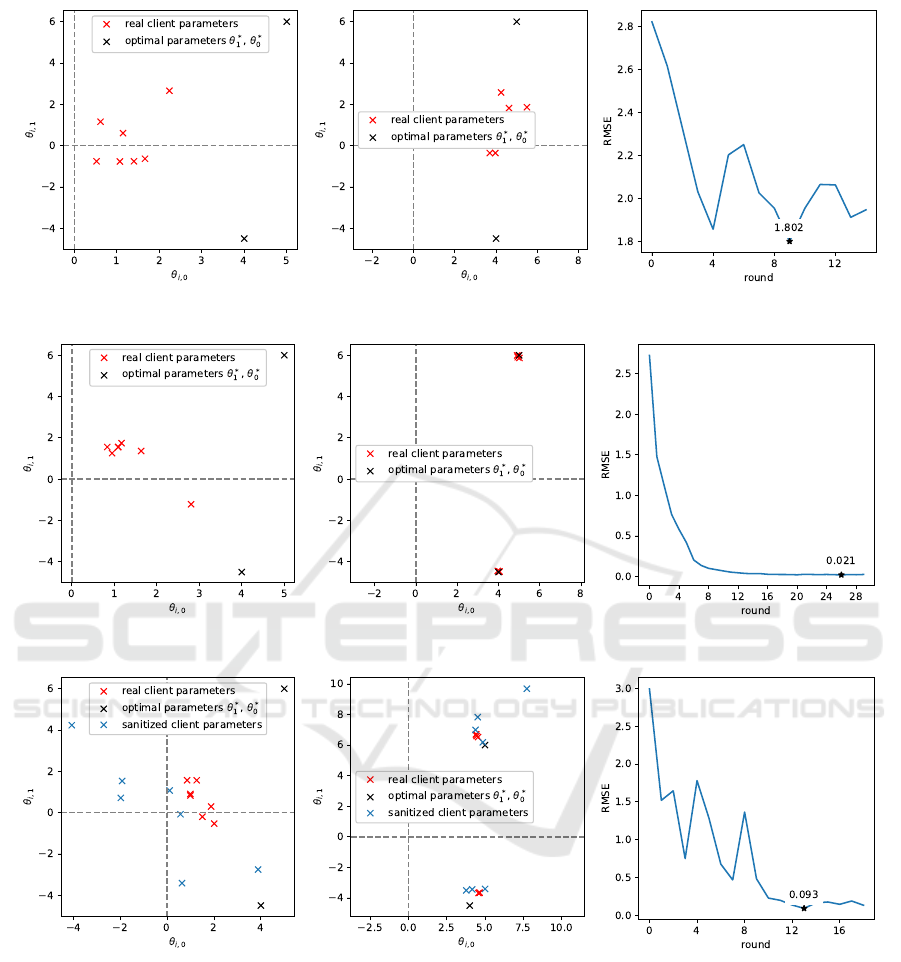
(a) First round. (b) Best round. (c) Validation loss.
(d) First round. (e) Best round. (f) Validation loss.
(g) First round. (h) Best round. (i) Validation loss.
Figure 1: Learning federated linear models with: (a, b, c) one initial hypothesis and non-sanitized communication, (d, e, f)
two initial hypotheses and non-sanitized communication, (g, h, i) two initial hypotheses and sanitized communication. The
first two figures of each row show the parameter vectors released by the clients to the server.
sess how training progresses as we move from the
Federated Averaging (Kone
ˇ
cny et al., 2016) (Figure
1a, 1b, 1c), to IFCA (Figure 1d, 1e, 1f), and finally
Algorithm 1 (Figure 1g, 1h, 1i). When using Feder-
ated Averaging, there seems to be an obvious prob-
lem, that is using one single hypothesis is not enough
to capture the diversity in the data distributions, re-
sulting in the final parameters settling somewhere in
between the optimal parameters (Figure 1b). On the
contrary using IFCA, shows that having multiple ini-
tial hypotheses helps in improving the performance
when the clients have heterogeneous data, as the op-
timized clients parameters almost overlap the opti-
mal parameters (Figure 1e). Adopting our algorithm
ICISSP 2023 - 9th International Conference on Information Systems Security and Privacy
256
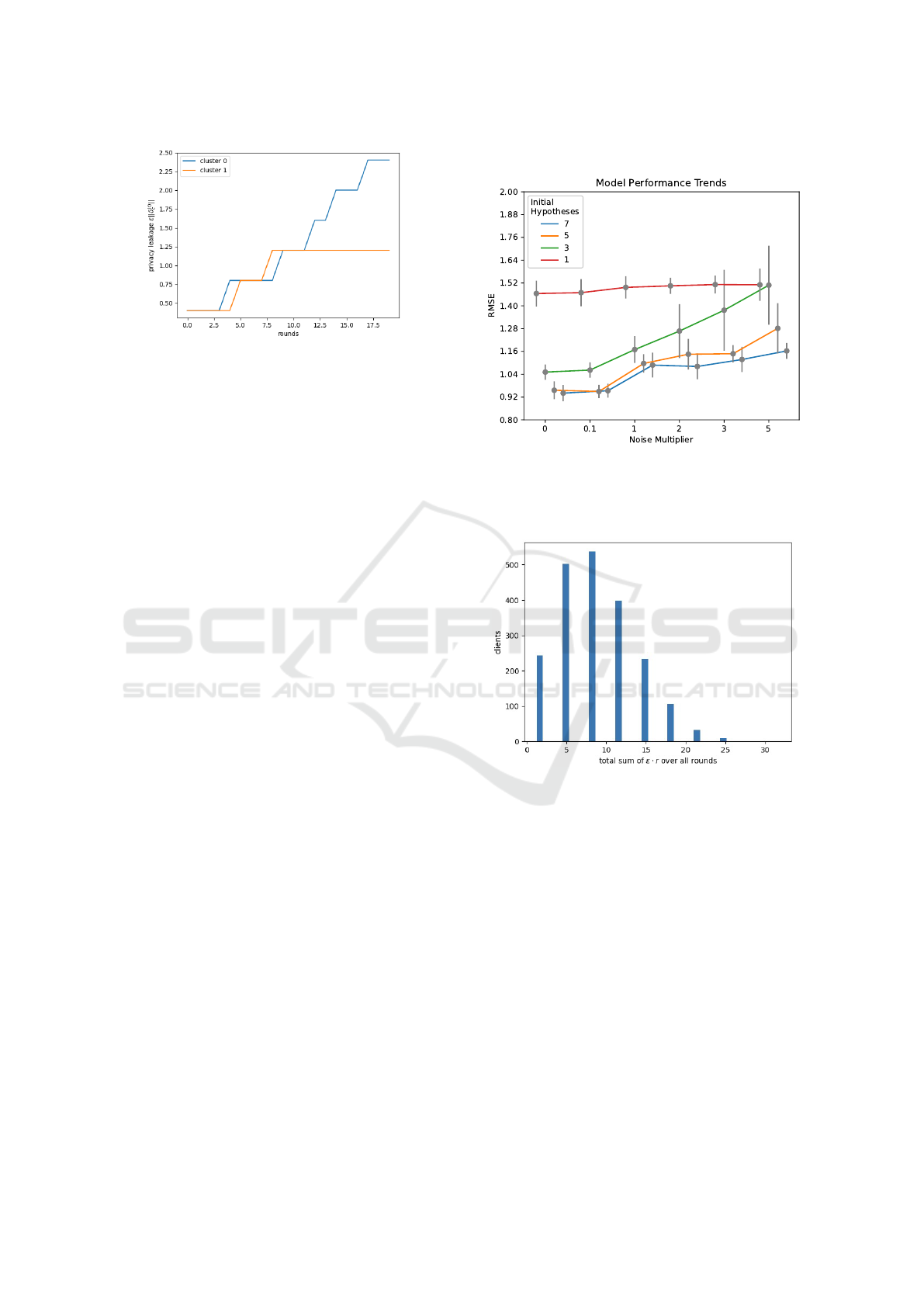
Figure 2: Synthetic data: max privacy leakage among
clients clients. Privacy leakage is constant when clients with
the largest privacy leakage are not sampled (by chance) to
participate in those rounds.
shows that on top of providing formal guarantees, we
can still achieve great results in terms of proximity to
the optimal parameters (Figure 1h) and reduction of
the loss function (Figure 1i). Figure 2 provides the
maximum value of privacy leakage clients incur into,
per cluster. Further details about the experimental set-
tings are provided in Appendix 5.
4.2 Hospital Charge Data
This experiment is performed on the Hospital Charge
Dataset by the Centers for Medicare and Medicaid
Services of the US Government (CMMS, 2021). The
healthcare providers are considered the set of clients
willing to train a machine learning model with fed-
erated learning. The goal is to predict the cost of a
service given where it is performed in the country,
and what kind of procedure it is. More details on
the preprocessing and training settings are included
in Appendix 5. To assess the trade-off between pri-
vacy, personalization and accuracy, a different num-
ber of initial hypotheses has been checked, as it is not
known a-priori how many distributions generated the
data. Accuracy has been evaluated at different levels
of the noise multiplier ν. Note that, using Algorithm 1
with 1 hypothesis results in the Federated Averaging
algorithm. Figure 3 shows that adopting multiple hy-
potheses drastically reduces the RMSE loss function.
This is especially true when moving from 1 to 3 hy-
potheses. Additionally, we highlight how increasing
the number of hypotheses also helps in curbing the ef-
fects of the noise multiplier even when it reaches high
levels, on the right hand side of the picture, making
a compelling case for adopting formal privacy guar-
antees when a slight increase in the cost function is
admissible. Figure 4 provides the empirical privacy
leakage distribution of the clients involved in a par-
ticular training configuration. Table 1 shows privacy
leakage statistics over multiple rounds and for all con-
figurations.
Figure 3: RMSE for models trained with Algorithm 1 on
the Hospital Charge Dataset. Error bars show ±σ, with σ
the empirical standard deviation. Lower RMSE values are
better for accuracy.
Figure 4: Hospital charge data: the empirical distribution
of the privacy budget over the clients for: ν = 3, 5 initial
hypotheses, seed = 3, r is the radius of the neighborhood,
the total number of clients is 2062.
4.3 FEMNIST Image Classification
This task consists of image-based character recogni-
tion on the FEMNIST dataset (Caldas et al., 2018).
Details on the experimental settings are in Appendix
5. With the choice of the range of noise multipli-
ers ν the corresponding value for the privacy leak-
age εkδ
(t)
c
k
2
= n/ν would be enormous, considering
a CNN with n = 206590 parameters, providing no
meaningful theoretical privacy guarantees. This is a
common issue for local privacy mechanisms (Bassily
et al., 2017), and it comes from the linear dependence
of the expected value of the norm of the noise vector
on n: E [γ
ε,n
(r)] = n/ε. Still, it is possible to validate,
Group Privacy for Personalized Federated Learning
257
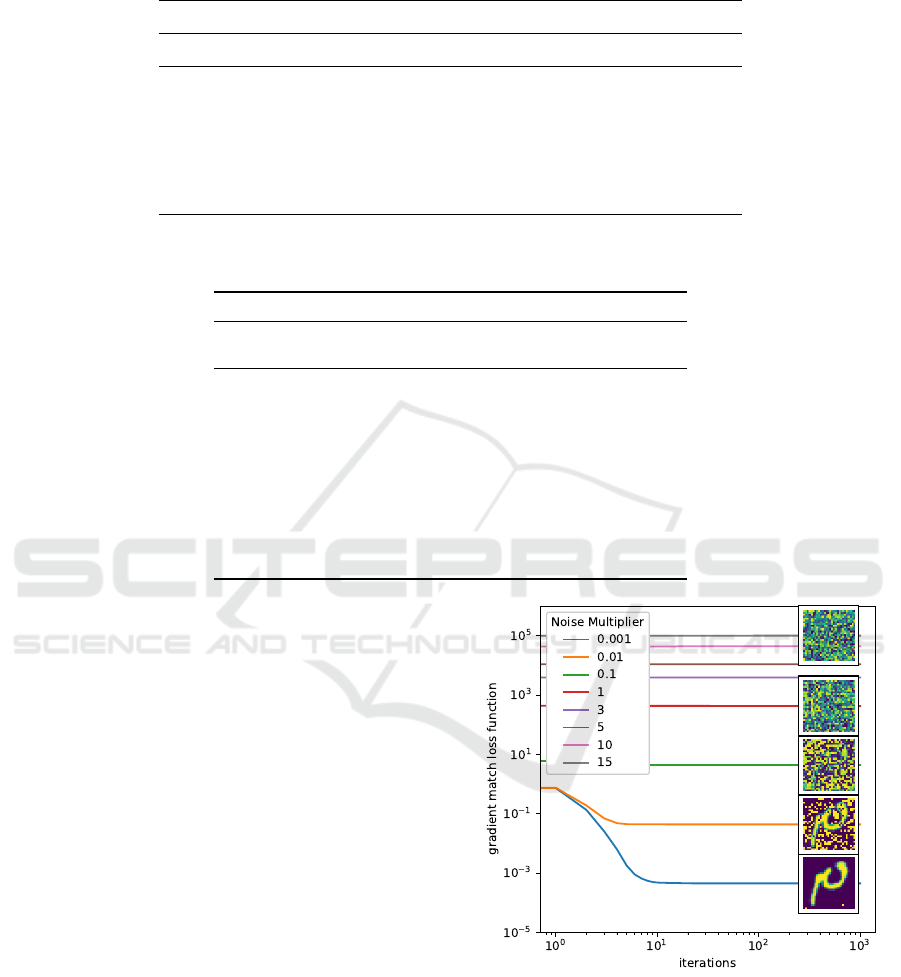
Table 1: Hospital charge data: median and maximum local privacy budgets over the whole set of clients, averaged over 10
runs with different seeds. ν = 0 means no privacy guarantee.
Hypotheses
ν 7 5 3 1
0 −,− −,− −,− −,−
0.1 517.0, 1551.0 418.0, 1342.0 473.0, 1386.0 528.0, 1540.0
1 36.3, 126.5 40.7, 127.6 44.0, 138.6 49.5, 147.4
2 15.4, 57.8 14.3, 54.5 22.0, 69.3 21.5, 66.6
3 7.7, 32.3 8.4, 36.7 12.5, 40.0 12.1, 40.0
5 5.7, 21.3 5.9, 22.0 5.5, 21.6 5.3, 20.9
Table 2: Effects of increasing the noise multiplier on the validation accuracy and standard deviation.
Cross Entropy loss RMSE loss
ν
Average
Accuracy
Standard
Deviation
Average
Accuracy
Standard
Deviation
0 0.832 ± 0.012 0.801 ± 0.001
0.001 0.843 ± 0.006 0.813 ± 0.014
0.01 0.832 ± 0.017 0.805 ± 0.008
0.1 0.834 ± 0.026 0.808 ± 0.019
1 0.834 ± 0.014 0.814 ± 0.012
3 0.835 ± 0.017 0.825 ± 0.010
5 0.812 ± 0.016 0.787 ± 0.003
10 0.692 ± 0.002 0.687 ± 0.014
15 0.561 ± 0.005 0.622 ± 0.003
in practice, whether this particular generalization of
the Laplace mechanism can protect against a specific
attack: DLG (Zhu et al., 2019). Figure 5 and Table 2
report the results of varying the noise multiplier val-
ues. When ν = 10
−3
the ground truth image is fully
reconstructed. Up to ν = 10
−1
we see that at least par-
tial reconstruction is possible. For ν ≥ 1 we see that,
experimentally, the DLG attack fails to reconstruct in-
put samples when we protect the client-server com-
munication with the mechanism in Proposition 3.1.
5 CONCLUSIONS
We use the framework of d-privacy to sanitize points
in the parameter space of machine learning models,
which are then communicated to a central server for
aggregation in order to converge to the optimal pa-
rameters and, thus, obtain the personalized models for
the diverse datasets. Given that the distribution of the
data among individuals is unknown, it is reasonable
to assume a mixture of multiple distributions. Clus-
tering the sanitized parameter vectors released by the
clients with the k-means algorithm shows to be a good
proxy for aggregating clients with similar data distri-
Figure 5: Effects of the Laplace mechanism in Proposition
3.1 with different noise multipliers as a defense strategy
against the DLG attack.
butions. This is possible because d-private mecha-
nisms preserve the topology of the domain of true val-
ues. Our mechanism shows to be promising when ma-
chine learning models have a small number of param-
eters. Although formal privacy guarantees degrade
sharply with large machine learning models, we show
ICISSP 2023 - 9th International Conference on Information Systems Security and Privacy
258

experimentally that the Laplace mechanism is effec-
tive against the DLG attack. As future work, we want
to explore other privacy mechanisms, which may be
more effective in providing a good trade-off between
privacy and accuracy in the context of machine learn-
ing. Furthermore, we are interested in studying more
complex federated learning scenarios where partici-
pants and datasets may change over time.
ACKNOWLEDGEMENTS
The work of Sayan Biswas and Catuscia Palamidessi
was supported by the European Research Council
(ERC) project HYPATIA under the European Union’s
Horizon research and innovation programme, grant
agreement n. 835294. The work of Kangsoo Jung was
supported by ELSA - The European Lighthouse on
Secure and Safe AI, a Network of Excellence funded
by the European Union under the Horizon research
and innovation programme.
REFERENCES
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B.,
Mironov, I., Talwar, K., and Zhang, L. (2016). Deep
learning with differential privacy. In Proceedings of
the 2016 ACM SIGSAC conference on computer and
communications security, pages 308–318.
Agarwal, N., Suresh, A. T., Yu, F. X. X., Kumar, S.,
and McMahan, B. (2018). cpsgd: Communication-
efficient and differentially-private distributed sgd. Ad-
vances in Neural Information Processing Systems, 31.
Andr
´
es, M. E., Bordenabe, N. E., Chatzikokolakis, K., and
Palamidessi, C. (2013). Geo-indistinguishability: Dif-
ferential privacy for location-based systems. In Pro-
ceedings of the 2013 ACM SIGSAC conference on
Computer & communications security, pages 901–
914.
Andrew, G., Thakkar, O., McMahan, B., and Ramaswamy,
S. (2021). Differentially private learning with adaptive
clipping. Advances in Neural Information Processing
Systems, 34.
Bassily, R., Nissim, K., Stemmer, U., and Guha Thakurta,
A. (2017). Practical locally private heavy hitters. In
Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H.,
Fergus, R., Vishwanathan, S., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 30. Curran Associates, Inc.
Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A.,
McMahan, H. B., Patel, S., Ramage, D., Segal, A.,
and Seth, K. (2016). Practical secure aggregation for
federated learning on user-held data. arXiv preprint
arXiv:1611.04482.
Caldas, S., Duddu, S. M. K., Wu, P., Li, T., Kone
ˇ
cn
`
y,
J., McMahan, H. B., Smith, V., and Talwalkar, A.
(2018). Leaf: A benchmark for federated settings.
arXiv preprint arXiv:1812.01097.
Chatzikokolakis, K., Andr
´
es, M. E., Bordenabe, N. E., and
Palamidessi, C. (2013). Broadening the scope of dif-
ferential privacy using metrics. In International Sym-
posium on Privacy Enhancing Technologies Sympo-
sium, pages 82–102. Springer.
CMMS (2021). Centers for medicare and medicaid ser-
vices. Accessed: 2022-09-21.
Cohen, G., Afshar, S., Tapson, J., and Van Schaik, A.
(2017). Emnist: Extending mnist to handwritten let-
ters. In 2017 international joint conference on neural
networks (IJCNN), pages 2921–2926. IEEE.
Dwork, C., Kenthapadi, K., McSherry, F., Mironov, I., and
Naor, M. (2006a). Our data, ourselves: Privacy via
distributed noise generation. In Vaudenay, S., editor,
Advances in Cryptology - EUROCRYPT 2006, pages
486–503, Berlin, Heidelberg. Springer Berlin Heidel-
berg.
Dwork, C., McSherry, F., Nissim, K., and Smith, A.
(2006b). Calibrating noise to sensitivity in private data
analysis. In Halevi, S. and Rabin, T., editors, Theory
of Cryptography, pages 265–284, Berlin, Heidelberg.
Springer Berlin Heidelberg.
Geyer, R. C., Klein, T., and Nabi, M. (2017). Differentially
private federated learning: A client level perspective.
arXiv preprint arXiv:1712.07557.
Ghosh, A., Chung, J., Yin, D., and Ramchandran, K.
(2020). An efficient framework for clustered federated
learning. Advances in Neural Information Processing
Systems, 33:19586–19597.
Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., and
Bengio, Y. (2013). An empirical investigation of
catastrophic forgetting in gradient-based neural net-
works. arXiv preprint arXiv:1312.6211.
Hitaj, B., Ateniese, G., and Perez-Cruz, F. (2017). Deep
models under the gan: information leakage from col-
laborative deep learning. In Proceedings of the 2017
ACM SIGSAC conference on computer and communi-
cations security, pages 603–618.
Hu, R., Guo, Y., Li, H., Pei, Q., and Gong, Y. (2020). Per-
sonalized federated learning with differential privacy.
IEEE Internet of Things Journal, 7(10):9530–9539.
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J.,
Desjardins, G., Rusu, A. A., Milan, K., Quan, J.,
Ramalho, T., Grabska-Barwinska, A., et al. (2017).
Overcoming catastrophic forgetting in neural net-
works. Proceedings of the national academy of sci-
ences, 114(13):3521–3526.
Kone
ˇ
cny, J., McMahan, H. B., Yu, F. X., Richt
´
arik, P.,
Suresh, A. T., and Bacon, D. (2016). Federated learn-
ing: Strategies for improving communication effi-
ciency. arXiv preprint arXiv:1610.05492.
Le M
´
etayer, D. and De, S. J. (2016). PRIAM: a Privacy
Risk Analysis Methodology. In Livraga, G., Torra, V.,
Aldini, A., Martinelli, F., and Suri, N., editors, Data
Privacy Management and Security Assurance, Herak-
lion, Greece. Springer.
Lopez-Paz, D. and Ranzato, M. (2017). Gradient episodic
Group Privacy for Personalized Federated Learning
259

memory for continual learning. Advances in neural
information processing systems, 30.
Mansour, Y., Mohri, M., Ro, J., and Suresh, A. T.
(2020). Three approaches for personalization with
applications to federated learning. arXiv preprint
arXiv:2002.10619.
McMahan, B., Moore, E., Ramage, D., Hampson, S., and
y Arcas, B. A. (2017a). Communication-efficient
learning of deep networks from decentralized data. In
Artificial intelligence and statistics, pages 1273–1282.
PMLR.
McMahan, H. B., Ramage, D., Talwar, K., and Zhang, L.
(2017b). Learning differentially private recurrent lan-
guage models. arXiv preprint arXiv:1710.06963.
Nasr, M., Shokri, R., and Houmansadr, A. (2019). Compre-
hensive privacy analysis of deep learning: Passive and
active white-box inference attacks against centralized
and federated learning. In 2019 IEEE symposium on
security and privacy (SP), pages 739–753. IEEE.
NIST (2021). Nist privacy framework core.
Sattler, F., M
¨
uller, K.-R., and Samek, W. (2020). Clustered
federated learning: Model-agnostic distributed mul-
titask optimization under privacy constraints. IEEE
transactions on neural networks and learning systems,
32(8):3710–3722.
Truex, S., Liu, L., Chow, K.-H., Gursoy, M. E., and Wei, W.
(2020). Ldp-fed: Federated learning with local differ-
ential privacy. In Proceedings of the Third ACM In-
ternational Workshop on Edge Systems, Analytics and
Networking, pages 61–66.
Zhang, Z. and Sabuncu, M. (2018). Generalized cross en-
tropy loss for training deep neural networks with noisy
labels. Advances in neural information processing
systems, 31.
Zhao, Y., Zhao, J., Yang, M., Wang, T., Wang, N., Lyu, L.,
Niyato, D., and Lam, K.-Y. (2020). Local differential
privacy-based federated learning for internet of things.
IEEE Internet of Things Journal, 8(11):8836–8853.
Zhu, L., Liu, Z., and Han, S. (2019). Deep leakage from
gradients. Advances in Neural Information Processing
Systems, 32.
APPENDIX
Proofs
Proposition 3.1. Let L
ε
: R
n
7→ R
n
be
the Laplace mechanism with distribution
L
x
0
,ε
(x) = P [L
ε
(x
0
) = x] = Ke
−εd(x,x
0
)
with d(.)
being the Euclidean distance. If ρ ∼ L
x
0
,ε
(x), then:
1. L
x
0
,ε
is ε-d-private and K =
ε
n
Γ(
n
2
)
2π
n
2
Γ(n)
2.
k
ρ
k
2
∼ γ
ε,n
(r) =
ε
n
e
−εr
r
n−1
Γ(n)
3. The i
th
component of ρ has variance σ
2
ρ
i
=
n+1
ε
2
where Γ(n) is the Gamma function defined for posi-
tive reals as
R
∞
0
t
n−1
e
−t
dt which reduces to the facto-
rial function whenever n ∈ N.
Proof. We provide proof of the three statements sep-
arately:
1. If L
x
0
,ε
(x) = Ke
−εd(x,x
0
)
is a probability density
function of a point x ∈ R
n
then K should be such that
R
R
n
L
x
0
(x)dx = 1. We note that it depends only on
the distance x and x
0
and we can write Ke
−εd(x,x
0
)
as
Ke
−εr
where r is the radius of the ball in R
n
centered
in x
0
. Without loss of generality, let us now take x
0
=
0. The probability density of the event x ∈ S
n
(r) =
{x :
k
x
k
2
= r} is then p(x ∈ S
n
(r)) = Ke
−εr
S
n
(1)r
n−1
where S
n
(1) is the surface of the unitary ball in R
n
and S
n
(r) = S
n
(1)r
n−1
is the surface of a generic ball
of radius r. Given that
S
n
(1) =
2π
n/2
Γ(
n
2
)
(7)
solving
Z
+∞
0
P [x ∈ S
n
(r)] dr =
Z
+∞
0
Ke
−εr
S
n
(1)r
n−1
dr =
K
2π
n/2
Γ(n)
ε
n
Γ(
n
2
)
= 1
(8)
results in
K =
ε
n
Γ(
n
2
)
2π
n
2
Γ(n)
(9)
where Γ(·) denotes the gamma function. By plugging
L
x
0
,ε
(x) = Ke
−εd(x,x
0
)
in Equation 5:
Ke
−εd(x,x
1
)
≤ e
εd(x
1
,x
2
)
Ke
−εd(x,x
2
)
(10)
e
ε(
k
x−x
2
k
2
−
k
x−x
1
k
2
)
≤ e
ε
k
x
1
−x
2
k
= e
εd(x
1
,x
2
)
(11)
which completes the poof of the first statement.
2. Without loss of generality, let us take x
0
= 0.
Exploiting the radial symmetry of the Laplace dis-
tribution, we note that, in order to sample a point
ρ ∼ L
x
0
,ε
(x) in R
n
, it is possible to first sample the set
of points distant d(x,0) = r from x
0
and then sample
uniformly from the resulting hypersphere. Accord-
ingly, the p.d.f. of the L
2
-norm of ρ is the p.d.f. of
the event ρ ∈ S
n
(r) = {ρ :
k
ρ
k
2
= r} which is then
P [ρ ∈ S
n
(r)] = Ke
−εr
S
n
(1)r
n−1
, where S
n
(r) is the
surface of the sphere with radius r in R
n
. Hence, we
can write
k
ρ
k
2
∼ γ
ε,n
(r) =
ε
n
e
−εr
r
n−1
Γ(n)
(12)
which completes the proof of the second statement.
ICISSP 2023 - 9th International Conference on Information Systems Security and Privacy
260

3. With ρ ∼ γ
ε,n
we have that, by construction,
E
ρ
2
= E
"
n
∑
i=1
ρ
2
i
#
= nE
ρ
2
i
= nσ
2
ρ
i
(13)
With the last equality holding since L
0,ε
is isotropic
and centered in zero. Recalling that
E
ρ
2
=
d
2
dt
2
M
ρ
(t)
t=0
(14)
with M
ρ
(t) the moment generating function of the
gamma distribution γ
ε,n
,
d
2
dt
2
1 −
t
ε
−n
t=0
=
=
n(n + 1)
ε
2
1 −
t
ε
−(n+2)
t=0
=
=
n(n + 1)
ε
2
which leads to σ
2
ρ
i
=
n+1
ε
2
, completing the proof of the
third statement and of the Proposition.
Proof. The Root Mean Square Error loss function is
defined as:
F =
v
u
u
u
t
|Z|
∑
i=1
( f (x
i
,θ) − y
i
)
2
|Z|
=
k
f (X,θ) −Y
k
2
p
|Z|
(15)
If the model parameters θ are sanitized by the addi-
tion of a random vector ρ ∼ L
0,ε
, we can evaluate how
the cost function would change with respect to the
non-sanitized parameters. Dropping the multiplica-
tive constant we find:
k
f (X,θ + ρ) −Y
k
2
−
k
f (X,θ) −Y
k
2
≤
k
f (X,θ + ρ) −Y − f (X,θ) +Y
k
2
=
k
f (X,θ + ρ) − f (X ,θ)
k
2
=
f (X,θ) + J
f
(X,θ)· ρ − f (x, θ) + o(J
f
(X,θ)· ρ)
2
=
J
f
(X,θ)· ρ + o(J
f
(X,θ)· ρ)
2
≤
J
f
(X,θ)
2
k
ρ
k
2
+ o(
J
f
(X,θ)· ρ
2
)
with J
f
(X,θ) being the Jacobian of f with respect to
X and o(.) being higher terms coming from the Tay-
lor expansion. Thus we proved that the bound on the
increase of the cost function does not depend on the
direction of the additive noise, but on its norm, in first
order approximation.
Theorem 3.1. Let K
i
be (ε
i
)-d-private mechanism
for i ∈ {1,2}. Then their independent composition
is (ε
1
+ ε
2
)-d-private.
Proof. Let us simplify the notation and denote:
P
i
= P
K
i
[y
i
∈ S
i
|x
i
]
P
0
i
= P
K
i
y
i
∈ S
i
|x
0
i
for i ∈ {1,2}. As mechanisms K
1
and K
2
are applied
independently, we have:
P
K
1
,K
2
[(y
1
,y
2
) ∈ S
1
× S
2
|(x
1
,x
2
)] = P
1
· P
2
P
K
1
,K
2
(y
1
,y
2
) ∈ S
1
× S
2
|(x
0
1
,x
0
2
)
= P
0
1
· P
0
2
Therefore, we obtain:
P
K
1
,K
2
[(y
1
,y
2
) ∈ S
1
× S
2
|(x
1
,x
2
)] = P
1
· P
2
≤
e
ε
1
d(x
1
,x
0
1
)
P
0
1
e
ε
2
d(x
2
,x
0
2
)
P
0
2
≤ e
ε
1
d(x
1
,x
0
1
)+ε
2
d(x
2
,x
0
2
)
P
K
1
,K
2
(y
1
,y
2
) ∈ S
1
× S
2
|(x
0
1
,x
0
2
)
Experimental Settings
All the following experiments are run on a local server
running Ubuntu 20.04.3 LTS with an AMD EPYC
7282 16-Core processor, 1.5TB of RAM and NVIDIA
A100 GPUs. Python and PyTorch are the main soft-
ware tools adopted for simulating the federation of
clients and their corresponding collaborative training.
Synthetic Data
A total of 100 users holding 10 samples each, drawn
from either one of the distributions, participate in a
training of two initial hypotheses which are sampled
from a Gaussian distribution centered in 0 and unit
variance at iteration t = 0. A total of U = 7 users are
asked to participate in the optimization at each round
and train locally the hypothesis that fits better their
dataset for E = 1 epochs each time. The noise mul-
tiplier is set to ν = 5. Local step size s = 0.1 and a
batch size B
s
= 10 complete the required inputs to the
algorithm. To verify the training process, another set
of users with the same characteristics is held out form
training to perform validation and stop the federated
optimization once the is no improvement in the loss
function in Equation (15) for 6 consecutive rounds.
Although at first the updates seem to be distributed
all over the domain, in just a few rounds of training
the process converges to values very close to the two
optimal parameters. With the heuristic presented in
Section 3.2 it is easy to find that whenever a user par-
ticipates in an optimization round it incurs in a privacy
leakage of at most n/ν = 2/5 = 0.4, in a differential
private sense, with respect to points in its neighbor-
hood. Using the result in Theorem 3.1 clients can
Group Privacy for Personalized Federated Learning
261

compute the overall privacy leakage of the optimiza-
tion process, should they be required to participate
multiple times. For any user, whether to participate
or not in a training round can be decided right before
releasing the updated parameters, in case that would
increase the privacy leakage above a threshold value
decided beforehand.
Hospital Charge Data
The dataset contains details about charges for the
100 most common inpatient services and the 30 most
common outpatient services. It shows a great vari-
ety of charges applied by healthcare providers with
details mostly related to the type of service and the
location of the provider. Preprocessing of the dataset
includes a number of procedures, the most important
of which are described here:
i) Selection of the 4 most widely treated conditions,
which amount to simple pneumonia; kidney and
urinary tract infections; hart failure and shock;
esophagitis and digestive system disorders.
ii) Transformation of ZIP codes into numerical coor-
dinates in terms of longitude and latitude.
iii) Setting as target the Average Total Payments, i.e.
the cost of the service averaged among the times
it was given by a certain provider.
iv) As it is a standard procedure in the context of
gradient-based optimization, dependent and inde-
pendent variables are brought to be in the range
of the units before being fed to the machine learn-
ing model. Note that this point takes the spot of
the common feature normalization and standard-
ization procedures, which we decided not to per-
form here to keep the setting as realistic as pos-
sible. In fact, both would require the knowledge
of the empirical distribution of all the data. Al-
though it is available in simulation, it would not
be available in a real scenario, as each user would
only have access to their dataset.
Given the preprocessing described above, the dataset
results in 2947 clients, randomly split in train and val-
idation subsets with 70 and 30 per cent of the total
clients each. The goal is being able to predict the
cost that a service would require given where it is
performed in the country, and what kind of proce-
dure it is. The model that was adopted in this con-
text is a fully connected neural network (NN) of two
layers, with a total of 11 parameters and Rectified
Linear Unit (ReLU) activation function. Inputs to the
model are an increasing index which uniquely defines
the healthcare service, the longitude and latitude of
the provider. Output of the model is the expected
cost. Tests have been performed to minimize the
RMSE loss on the clients selected for training (100
per round) and at each round the performance of the
model is checked against a held-out set of validation
clients, from where 200 are sampled every time. If
30 validation rounds are passed without improvement
in the cost function, the optimization process is ter-
minated. In order to decrease the variability of the
results, a total of 10 runs have been performed with
different seeds for every combination of number of
hypotheses and noise multiplier.
Table 3: NN architecture adopted in the experiments of Sec-
tion 4.3.
Layer Properties
2D Convolution
kernel size: (2,2)
stride: (1,1)
nonlinearity: ReLU
output features: 32
2D Convolution
kernel size: (2,2)
stride: (1,1)
nonlinearity: ReLU
output features: 64
2D Max Pool
kernel size: (2,2)
stride: (2,2)
nonlinearity: ReLU
Fully Connected
nonlinearity: ReLU
units: 128
Fully Connected
nonlinearity: ReLU
units: 62
FEMNIST Image Classification
The task consists in performing image classification
on the FEMNIST (Caldas et al., 2018) dataset, which
is a standard benchmark dataset for federated learn-
ing, based on EMNIST (Cohen et al., 2017) and with
the data points grouped by user. It consists of a large
number of images of handwritten digits, lower and
upper case letters of the Latin alphabet. As a pre-
processing step, images of client c are rotated 90 de-
grees counter-clockwise depending on the realization
of the random variable rot
c
∼ Bernoulli(0.5). This is a
common practice in machine learning to simulate lo-
cal datasets held by different clients being generated
by different distributions (Ghosh et al., 2020; Good-
fellow et al., 2013; Kirkpatrick et al., 2017; Lopez-
Paz and Ranzato, 2017). The chosen architecture is
described in Table 3 and yields a parameter vector
θ ∈ R
n
0
, n
0
= 1206590. Runs are performed with a
maximum of 500 rounds of federated optimization,
unless 5 consecutive validation rounds are conducted
without improvements on the validation loss. The lat-
ter is evaluated on a held out set of clients, consisting
ICISSP 2023 - 9th International Conference on Information Systems Security and Privacy
262

of 10% of the total number. Validation is performed
every 5 training rounds, thus the process terminates
after 25 rounds without the model’s performance im-
provement. The optimization process aims to mini-
mize either the RMSE loss or the Cross Entropy loss
(Zhang and Sabuncu, 2018) between model’s predic-
tions and the target class.
Group Privacy for Personalized Federated Learning
263
