Emotion-Cause Pair Extraction as Question Answering
Huu-Hiep Nguyen
1
and Minh-Tien Nguyen
2a
1
Cinnamon AI, Vietnam
2
Faculty of Information Technology, Hung Yen University of Technology and Education, Vietnam
Keywords:
Sentiment Analysis, Emotion-Cause Pair Extraction, Question Answering, BERT.
Abstract:
The task of Emotion-Cause Pair Extraction (ECPE) aims to extract all potential emotion-cause pairs of a
document without any annotation of emotion or cause clauses. Previous approaches on ECPE have tried to
improve conventional two-step processing schemes by using complex architectures for modeling emotion-
cause interaction. In this paper, we cast the ECPE task to the question answering (QA) problem and propose
simple yet effective BERT-based solutions to tackle it. Given a document, our Guided-QA model first predicts
the best emotion clause using a fixed question. Then the predicted emotion is used as a question to predict the
most potential cause for the emotion. We evaluate our model on a standard ECPE corpus. The experimental
results show that despite its simplicity, our Guided-QA achieves promising results and is easy to reproduce.
The code of Guided-QA is also provided.
1 INTRODUCTION
Emotion Cause Extraction (ECE) is the task of detect-
ing the cause behind an emotion given the emotion an-
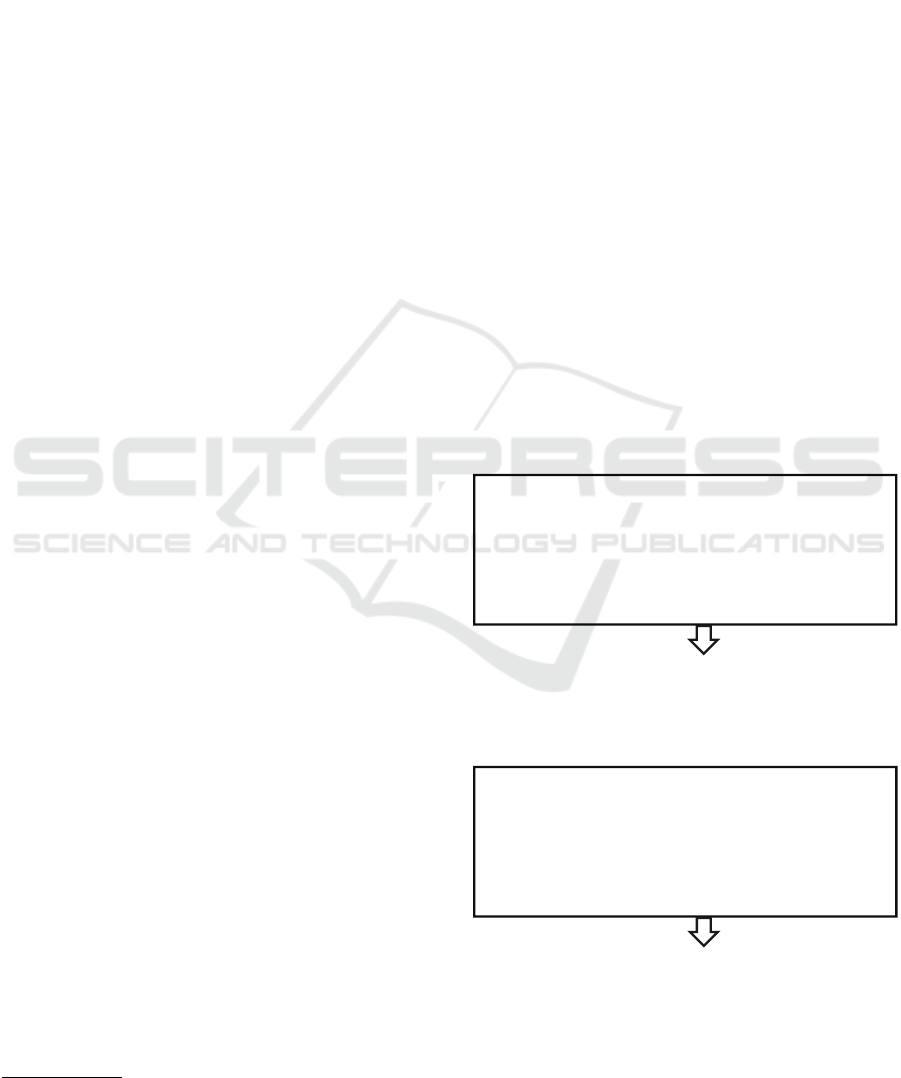
notation (Lee et al., 2010; Gui et al., 2016), see Figure
1 (Top). The text was divided into clauses and the task
was to detect the clause containing the cause, given
the clause containing the emotion. However, the ap-
plicability of ECE is limited due to the fact that emo-
tion annotations are required at test time. Recently,
(Xia and Ding, 2019) introduced the more challeng-
ing Emotion-Cause Pair Extraction (ECPE) task: ex-
tracting all possible emotion-cause clause pairs in a
document without annotations. Figure 1 (Bottom)
shows an example of the ECPE task. The input is a
document of six clauses. Clauses c4 and c5 contain
emotion with the emotion expressions “happy” and
”worried”. The emotion c4 has two causes c3 and c2,
the emotion c5 has one cause c6, so the expected out-
put is {(c4,c2), (c4,c3), (c5,c6)}.
Why cause-effect pair extraction? We argue that
independent extraction of cause and emotion may be
ineffective. For a given document, ECPE models
may predict correct cause but incorrect emotion. This
makes the output incomplete, and subsequent process-
ing steps less reliable (Ding et al., 2020; Wei et al.,
2020; Chen et al., 2020; Yan et al., 2021). We make
a toy example of two models using the document in
a
Corresponding author.
c1: Yesterday morning
c4: The old man was very happy (Emotion)
c6: as he doesn’t know how to keep so much money. (Cause)
c2: a policeman visited the old man with the lost money (Cause)
c3: and told him that the thief was caught. (Cause)
Emotion-Cause Pair Extraction (ECPE)
Input: a document
Output: emotion-cause pairs
{(c4,c2), (c4, c3),(c5,c6)}
c5: but he still feels worried, (Emotion)
c1: Yesterday morning
c4: The old man was very happy
c6: as he doesn’t know how to keep so much money. (Cause)
c2: a policeman visited the old man with the lost money
c3: and told him that the thief was caught.
Emotion-Cause Extraction (ECE)
Input: a document and annotation of emotions c5
Output: cause clause(s)
{c6}
c5: but he still feels worried, (Emotion)
Figure 1: Illustration of ECE and ECPE tasks.
Figure 1. Model-1 predicts (c4,c1) and (c6,c3) as
emotion-cause pairs. Its emotion, cause and pair ac-
988
Nguyen, H. and Nguyen, M.
Emotion-Cause Pair Extraction as Question Answering.
DOI: 10.5220/0011883100003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 988-995
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

curacy scores are 0.5, 0.33 and 0.0. Model-2 predicts
(c4, c2) and (c6, c1) as emotion-cause pairs. Its emo-
tion, cause and pair accuracy scores are 0.5, 0.33 and
0.33. From the perspective of the pair extraction task,
Model-2 is better.
Previous studies addressed the ECPE task by us-
ing sequence labeling (Lee et al., 2010; Cheng et al.,
2021), clause-level classification (Gui et al., 2016;
Ding et al., 2020; Chen et al., 2020), ranking (Wei
et al., 2020), or recurrent synchronization (Chen et al.,
2022). The methods achieved promising results, yet
the use of interaction between emotion and cause
clauses is still an open question. For example, c4 and
c2 share ”the old man” tokens, which refer to ”him”
in c3; and c5 and c6 share ”he”, which mentions ”the
old man” in c2 and c4.
Based on this observation, we introduce a
paradigm shift (Sun et al., 2022) for ECPE by us-
ing span extraction. As far as we know, (Gui et al.,
2017) is the first work that uses question answering
for emotion-cause detection. However, their work ad-
dresses the ECE task only, which requires the annota-
tion of emotion for cause prediction. In contrast, our
paradigm shift is applied to the ECPE task, which is
more challenging and does not require the annotation
of emotion for cause prediction. The paradigm bases
on two hypotheses. First, information from emotion
clauses can be used to infer cause clauses. Second,
emotion and cause clauses share implicit interaction.
The design of our model is based on these two hy-
potheses. For the first hypothesis, we form questions
based on emotional information which is used to pre-
dict emotion clauses. For the second hypothesis, we
used predicted emotion as the guided question for
cause prediction. The model is trained by using the
BERT-QA architecture (Devlin et al., 2018) in form
of SQuAD task (Rajpurkar et al., 2016).
Our paper makes three main contributions.
• We formulate the ECPE task as a QA problem and
propose a Guided-QA model to implicitly cap-
ture the relationship between emotion and cause
clauses, in which the predicted emotion is used as
a guided question for cause prediction. The model
can capture the implicit interaction between emo-
tions and causes with a simple but effective archi-
tecture. To the best of our knowledge, we are the
first to address the ECPE task by using QA for-
mulation.
• We evaluate our model on the standard ECPE cor-
pus (Xia and Ding, 2019; Fan et al., 2020). Exper-
imental results show that our approach achieves
promising results compared to previous methods.
• We promote the reproducibility (Houghton et al.,
2020) by providing the source code of our meth-
ods as well as rerunning publicly available source
codes of the compared methods.
2 RELATED WORK
ECE and ECPE Tasks. The ECE task was formu-
lated as sequence-labeling by (Lee et al., 2010) and
refined as clause-level by (Gui et al., 2016). Recently,
the more challenging ECPE task (Xia and Ding, 2019)
has attracted a lot of contributions with several strong
methods (Ding et al., 2020; Wei et al., 2020; Chen
et al., 2020; Cheng et al., 2021; Chen et al., 2022). For
example, (Ding et al., 2020) introduced ECPE-MLL,
which uses a sliding window for a multi-label learning
scheme. ECPE-MLL extracts the emotion and cause
by using the iterative synchronized multitask learn-
ing. (Chen et al., 2022) proposed a similar approach,
recurrent synchronization network (RSN), that ex-
plicitly models the interaction among different tasks.
(Wei et al., 2020) presented RankCP, a transition-
based framework, by transforming the ECPE problem
into directed graph construction, from which emo-
tions and the corresponding causes can be extracted
simultaneously based on labeled edges. The PairGCN
model (Chen et al., 2020) used Graph Convolutional
Networks to model three types of dependency rela-
tions among local neighborhood candidate pairs and
facilitate the extraction of pair-level contextual infor-
mation.
We share the purpose of addressing the ECE and
ECPE tasks with prior studies, however, instead of us-
ing classification or sequence labeling, we address the
tasks with a new paradigm shift by using span extrac-
tion. It allows us to take into account the implicit in-
teraction between emotion and cause clauses and to
design a simple but effective BERT-based model for
ECE and ECPE.
(Bi and Liu, 2020) derived a span-based dataset
and formulated a new ECSP (Emotion Cause Span
Prediction) task from (Xia and Ding, 2019) but it has
not attracted much attention. The accessibility of the
dataset and source code may be the reason. We leave
span-based ECSP evaluation as future work.
Paradigm Shift in Natural Language Processing.
A paradigm is a general modeling framework or a
family of methods to solve a class of tasks. For in-
stance, sequence labeling is a mainstream paradigm
for Part-of-speech (POS) tagging and Named en-
tity recognition (NER). The sequence-to-sequence
(Seq2Seq) paradigm is a popular tool for summariza-
tion and machine translation. Different paradigms
usually require different formats of input and output,
Emotion-Cause Pair Extraction as Question Answering
989
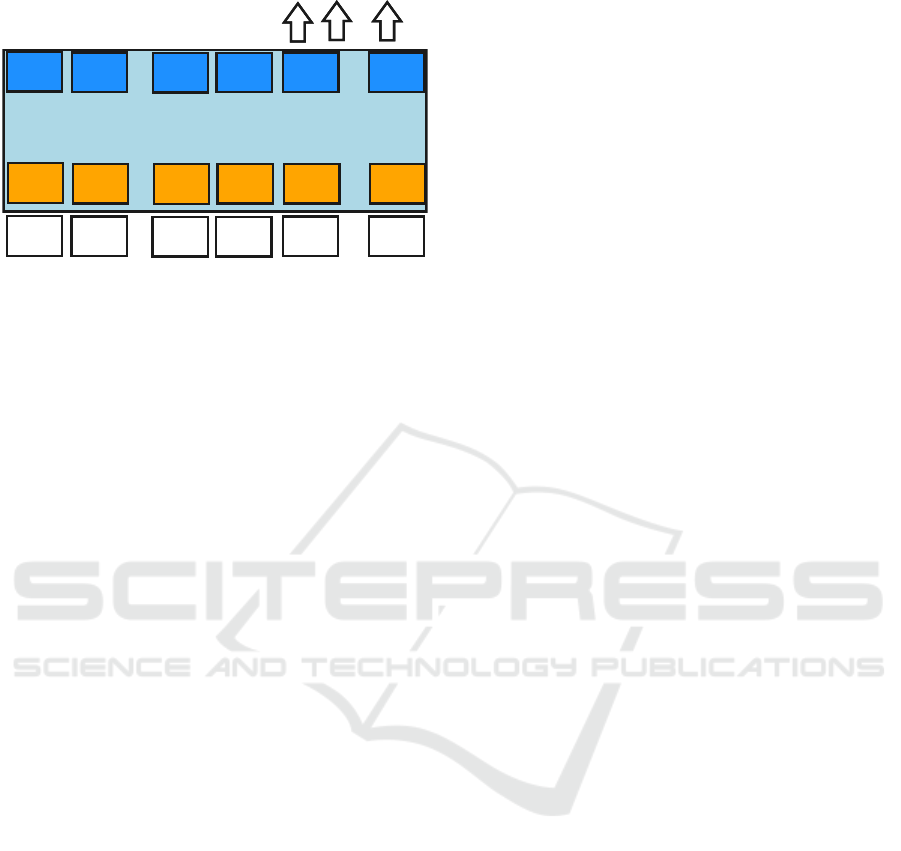
BERT
CLS
c_1
q_1
SEP
q_n
c_m
...
...
Start/End Span
T_CLS
T_c_1
T_q_1
T_SEP
T_q_n
T_c_m
...
...
E_CLS
E_c_1
E_q_1
E_SEP
E_q_n
E_c_m
...
...
Figure 2: BERT-based extractive Question Answering.
and therefore highly depend on the annotation of the
tasks.
Paradigm shift indicates the job of solving one
NLP task in a new paradigm by reformulating the
task along with changing the input-output formats.
Paradigm shift in NLP has been explored scatterringly
in recent years and with the advent of pretrained lan-
guage models, it became a rising trend (Li et al.,
2019; Khashabi et al., 2020). An excellent survey of
paradigm shifts in NLP has been done by (Sun et al.,
2022). In this work, we realize such a paradigm shift
for the ECPE task, i.e., we reformulate the clause-
based text classification task as span extraction.
Span-Based Extractive Question Answering. Our
formulation for the tasks of ECE and ECPE relates
to span-based extractive QA, which has been widely
investigated (Khashabi et al., 2020). More precisely,
we design our model based on the pretrained language
models (PLMs) such as BERT (Devlin et al., 2018) or
RoBERTa (Liu et al., 2019). This is because applying
PLMs as the backbone of QA systems has become a
standard procedure. For detailed information, please
refer to (Devlin et al., 2018).
Figure 2 reproduced from (Devlin et al., 2018)
shows how BERT is applied to the extractive QA
task. Tokens of question q = q
1
, .., q
n
and context
C = c
1
, .., c
m
are concatenated before being encoded
by BERT. The contextual representations of tokens T
i
are put into a feed-forward layer followed by a soft-
max. Each candidate span for the answer is scored as
the product of start/end probabilities. The maximum
scoring span is used as the prediction. The training
objective is the loglikelihood of the correct start and
end positions.
By casting the ECPE to QA problem, our work
leverages the powerful models of the BERT family
(Devlin et al., 2018) to detect clause-level emotions
and causes as well as emotion-cause pairs.
3 METHOD
3.1 Problem Statement
Given a document of n clauses d = (c
1
, c
2
, .., c
n
), the
goal of ECPE is to detect all potential emotion-cause
pairs P = {..(c
e
, c
c
), ..} where c
e
is an emotion clause,
and c
c
is the corresponding cause clause (Xia and
Ding, 2019). We formulated the ECPE task as a QA
problem. Given a set of questions {q
e
, q
c
} (q
e
is for
emotion and q
c
is for cause) and a context document
d with n clauses, the model learns to predict start and
end positions of each c
e
and c
c
: s
c
e
, e
c
e
= f (d, q
e
|Θ)
and s
c
c
, e
c
c
= f (d, q
c
|Θ) to form P. Θ can be learnt
by using independent or guided extraction.
3.2 Independent Emotion, Cause
Extraction
We first introduce a simple version of our model,
Indep-QA in Figure 3. Indep-QA receives a fixed
question (for emotion or cause) and then pulls out cor-
responding emotion or cause clauses independently.
Question Formulation. Because no emotion/cause
information is provided beforehand, we have to detect
them first with generic questions. It is possible to use
pre-defined questions for extraction (Mengge et al.,
2020), however, we argue that the definition of ques-
tions is time-consuming, needs domain knowledge,
and does not guarantee the semantic relationship be-
tween the questions and context documents. Instead,
we use two short questions ”emotion” and ”cause”
as an implicit indicator that provides additional infor-
mation for the model. We leave the analysis of using
generic questions such as ”What is the emotion?” and
”What is the cause?” as future work.
Learning and Prediction. Given a document d and
a question (”emotion” or ”cause”), we concatenated
all clauses of d and the question to form a single se-
quence C. The sequence was fed to a pretrained lan-
guage model (PLM) to obtain its hidden representa-
tions of tokens which were subsequently fed into a
feed-forward layer followed by a softmax layer. Each
candidate span was scored as the product of start/end
probabilities. The maximum scoring span was used
as the prediction.
Mapping Predicted Answer Span to Clauses. The
predicted answer span may overlap with one or sev-
eral clauses. We applied a span-to-clause mapping
rule to determine which clauses are predicted results:
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
990
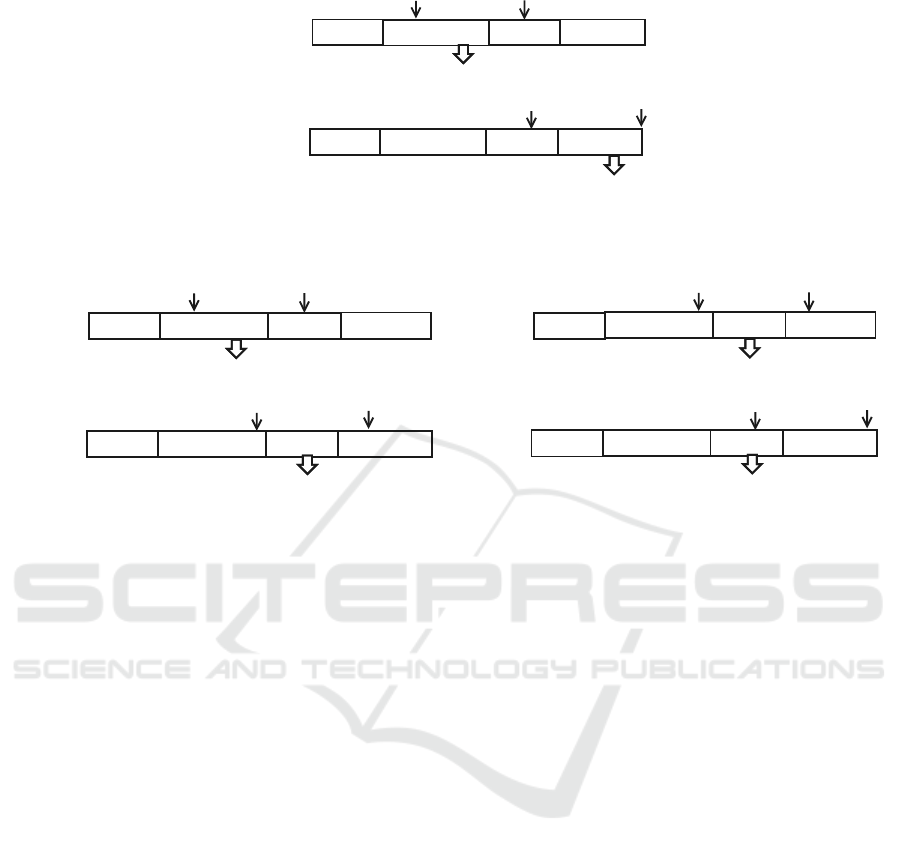
answer start
answer end
c1
c2
c3
c4
question = "emotion"
context =
predicted Emotion clause = c2
answer start
answer end
c1
c2
c3
c4
question = "cause"
context =
predicted Cause clause = c4
predicted EC-pair = (c2,c4)
Figure 3: Independent extraction Indep-QA.
c1
c2
c3
c4
question =
context =
predicted Cause clause = c3
c1
c2
c3
c4
context =
predicted Emotion clause = c4
predicted EC-pair = (c4,c3)
question =
c3
answer start
answer end
answer start
answer end
c1
c2
c3
c4
question =
context =
predicted Emotion clause = c2
c1
c2
c3
c4
context =
predicted Cause clause = c3
predicted EC-pair = (c2,c3)
question =
c2
answer start
answer end
answer start
answer end
"emotion"
"cause"
Figure 4: Guided pair extraction Guided-QA: Emotion is detected first (Left), Cause is detected first (Right).
the clause that overlaps most with the predicted span
is returned. The tie is broken arbitrarily. For instance,
In Figure 3, the predicted span for ”emotion” over-
laps with clauses c2 and c3 in which c
2
is more over-
lapped. As a result, c
2
is the predicted emotion.
EC Pair Prediction. Given predicted emo-
tion/cause clauses c
e
and c
c
, Indep-QA simply
predicts (c
e
, c
c
) as an emotion-cause pair. As
illustrated in Figure 3, (c
2
, c4) is the predicted
emotion-cause pair.
3.3 Guided Emotion-Cause Pair
Extraction
The Indep-QA model extracts emotion/clause clauses
independently but does not exploit the relationship
between emotion and cause clauses, which plays an
important role in the extraction of emotion-cause
pairs (Ding et al., 2020; Wei et al., 2020; Chen et al.,
2020; Cheng et al., 2021; Chen et al., 2022).
To better model this relationship, we introduce
Guided-QA in Figure 4. The model receives an emo-
tion question and predicts the corresponding emotion
clause. Then the predicted emotion clause is used as
a question for cause extraction. Compared to Indep-
QA, the Guided-QA takes into account an implicit re-
lationship from emotion for cause prediction.
The Guided-QA model shares the question formu-
lation, hidden representation learning, and the map-
ping process of the Indep-QA model.
EC Pair Extraction. We used the predicted (noisy)
emotion clause as the question for cause extraction.
The interaction between emotion and cause happens
here. The predicted emotion clause may or may not
be the true one but on average, it contains much more
information for the QA model than the generic ques-
tion (i.e., ”emotion”). Note that the predicted (noisy)
emotion as the question was used for the test set only.
For the training set, as the model already knows which
clauses are emotion or cause, it uses the true emotion
clause as the question.
By swapping the role, the model can detect cause
clauses first and use the noisy causes as questions
to predict the emotions. In Section 5 we compare
Emotion-first and Cause-first, the two variants of
Guided-QA and show that the gaps are tiny. In other
word, the two variants are almost equivalent on the
tested datasets.
As our QA models use the best answer span for
each question, only one emotion, one cause, and one
EC pair are predicted for each document which are
appropriate for the ECPE dataset. We also aware that
the prediction of spans should be multiple and we aim
to address this limitation in future work by using mul-
Emotion-Cause Pair Extraction as Question Answering
991

tiple span extraction methods (Nguyen et al., 2021; Fu
et al., 2021).
3.4 Discussion
Given a document of n clauses, existing schemes such
as ECPE-MLL (Ding et al., 2020), RankCP (Wei
et al., 2020) and PairGCN (Chen et al., 2020) attempt
to reduce the O(n
2
) complexity of emotion-cause
pair classification by using sliding window, transition
graph techniques. However, these techniques may
miss certain interaction between the emotion-cause
pair and the full context in the document. BERT-
based QA models with full attention between the
question and the context mitigate this issue. Through
QA models, the emotion-cause relationship between
all clauses is implicitly learned and we can leverage
the power of existing QA methods.
4 EXPERIMENTAL SETTINGS
Datasets. We followed the 10-split ECPE dataset
provided by (Xia and Ding, 2019) and the 20-split
TransECPE variant (Fan et al., 2020) to evaluate our
methods. Each split is a random partition of the 1945
documents to train/dev/test sets with ratio 8:1:1, i.e.,
the train set, dev set and test set contain approximately
1556, 194 and 195 documents. On average, each doc-
ument contains 14.8 clauses.
Table 1 shows the distribution of documents with
different number of emotion-cause pairs. Most of the
documents have only one emotion-cause pairs. This
fact makes the detection of emotion/cause clauses as
well as emotion-cause pairs challenging.
Evaluation Metrics. We used the precision, recall,
and F1 score (Xia and Ding, 2019) as evaluation met-
rics for all three tasks of ECPE: emotion extraction,
cause extraction and emotion-cause pair extraction.
Let T
e
and P
e
be the number of ground-truth and pre-
dicted emotion clauses respectively, the precision, re-
call and F1 score for emotion are as defined as fol-
lows.
P
e
=
|T
e
∩ P
e
|
|P
e
|
R
e
=
|T
e
∩ P
e
|
|T
e
|
F1
e
=
2 ∗ P
e
∗ R
e
P
e
+ R
e
Metrics for cause clauses and emotion-cause pairs
are defined similarly.
Implementation Details. Our model was imple-
mented using BERT classes provided by Hugging-
face (Wolf et al., 2020). The model was trained in 5
epochs, with the learning rate of 5e− 5, and the batch
size of 16. We used BERT (Devlin et al., 2018)
1
and
RoBERTa (Liu et al., 2019)
2
for Chinese. All models
were trained on a Tesla P100 GPU.
5 RESULTS AND DISCUSSION
Guided-QA: Emotion-First vs. Cause-First. We
first compare the two variants Emotion-first and
Cause-first of the Guided-QA method. Table 2 shows
that the two variants have almost equivalent perfor-
mance on the tested datasets except the BERT-based
results on 10-split ECPE. Also, the RoBERTa-based
results are consistently better than the BERT-based,
1.1 to 2.0 points. In the next section, we pick the
Emotion-first scores for comparing Guided-QA with
other methods.
Guided-QA vs. Indep-QA. We now compare
Guided-QA and Indep-QA. For 10-split ECPE in the
upper part of Table 3, the Guided-QA model is consis-
tently better than Indep-QA for pair extraction. This
is because Guided-QA takes into account the implicit
interaction between emotion and cause clauses. For
emotion or cause extraction, Indep-QA is competitive
with Guided-QA. This is because they share the same
formulation. The results in Table 4 also show similar
observation.
We also confirm the performance of our model by
using RoBERTa to have better analysis. The results
are consistent with the model using BERT, in which
Guided-QA outputs better F-scores than the Indep-
QA model. It also shows that our model can be im-
proved further by using stronger PLMs.
Guided-QA vs. Strong Baselines. We compare our
model with five strong methods for ECPE: ECPE-
MLL
3
(Ding et al., 2020), RankCP
4
(Wei et al., 2020),
PairGCN
5
(Chen et al., 2020), UTOS (Cheng et al.,
2021), and RSN (Chen et al., 2022). For 10-split,
our model using BERT follows ECPE-MLL, RankCP,
and RSN. It shows that with a simple architecture,
our model can output competitive results compared
1
https://huggingface.co/bert-base-chinese
2
https://huggingface.co/hfl/chinese-roberta-wwm-ext
3
https://github.com/NUSTM/ECPE-MLL
4
https://github.com/Determined22/Rank-Emotion-
Cause
5
https://github.com/chenying3176/PairGCN ECPE
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
992

Table 1: Histogram of the number of emotion-cause pairs per document.
Number Percentage
Documents with one emotion-cause pair 1746 89.77%
Documents with two emotion-cause pairs 177 9.10%
Documents with more than two emotion-cause pairs 22 1.13%
All 1945 100%
Table 2: Guided-QA Emotion-first vs. Cause-first on 10-split ECPE dataset and 20-split TransECPE dataset.
Model Emotion Extraction Cause Extraction EC Pair Extraction
P R F1 P R F1 P R F1
10-split ECPE
Emotion-first (BERT) 0.847 0.908 0.876 0.719 0.792 0.754 0.771 0.692 0.729
Cause-first (BERT) 0.831 0.891 0.860 0.714 0.787 0.749 0.763 0.685 0.722
Emotion-first (RoBERTa) 0.854 0.916 0.884 0.732 0.806 0.767 0.786 0.706 0.744
Cause-first (RoBERTa) 0.843 0.904 0.873 0.733 0.807 0.768 0.784 0.704 0.742
20-split TransECPE
Emotion-first (BERT) 0.842 0.906 0.873 0.710 0.782 0.744 0.760 0.689 0.723
Cause-first (BERT) 0.833 0.897 0.864 0.713 0.785 0.747 0.761 0.690 0.724
Emotion-first (RoBERTa) 0.844 0.909 0.875 0.723 0.796 0.757 0.772 0.700 0.734
Cause-first (RoBERTa) 0.838 0.902 0.869 0.724 0.797 0.758 0.773 0.701 0.735
to complicated methods. For 20-split TransECPE in
Table 4, the trend is consistent with Table 3, in which
the Guided-QA model is competitive for both ECE
and ECPE tasks.
Moreover, as we observe from all the compared
methods, the gaps between the reported pair-f1 scores
for 10-split ECPE and 20-split TransECPE are 0.023
(=0.745-0.722) for ECPE-MLL, 0.042 for RankCP,
0.029 for UTOS, 0.003 for Indep-QA and 0.006 for
Guided-QA, i.e., largest gap in RankCP and smallest
gaps in our models. Across the two settings, our mod-
els seem more robust than the compared methods.
Reproducibility. For fair comparison (Houghton
et al., 2020), we also rerun publicly available source
codes in the original setting. The reproduced results
confirm the gaps between reproduction and original
results. Compared to the reproduced results, Guided-
QA using BERT is the best for EC pair extraction.
Compared to the results of reproduced methods,
the Guided-QA is still better for both ECE and ECPE
tasks. This confirms our hypotheses stated in Sec-
tion 1. Compared to the results of strong baselines re-
ported in papers, the F-scores of Guided-QA are still
competitive. It shows that our simple model can out-
put promising results compared to complicated ECPE
methods (Ding et al., 2020; Wei et al., 2020; Chen
et al., 2020; Cheng et al., 2021; Chen et al., 2022).
The results from the original papers are just for ref-
erence because it seems there are gaps between the
reproduced results and original results.
6
. This is be-
6
https://github.com/Determined22/Rank-Emotion-
cause several scholars tried to reproduce the results,
but it seems there are gaps between the reproduced
results and original results.
For 20-split TransECPE in Table 4, the trend is
consistent with Table 3. The Guided-QA is competi-
tive for both ECE and ECPE tasks. The model using
RoBERTa is still the best. After rerunning the source
codes of the baselines, we found that PairGCN has the
best reproducibility.
By adopting the standardized pipeline of BERT-
based question answering, our models inherit its sim-
plicity and reproducibility which may become an is-
sue in more complex methods like RankCP.
Runtime Comparison. We also measured the run-
ning time of our model and the baselines. In Table
5, PairGCN which only uses BERT embeddings has
the best running time. The other models take longer
to run due to the fine-tuning of BERT models. Our
model is the second best, which is much faster than
ECPE-MLL. It shows that our model can balance be-
tween competitive accuracy and high speed.
6 CONCLUSION
This paper introduces a paradigm shift for the ECPE
task. Instead of treating the task as the conventional
formulation, we formulate the extraction as a QA
problem. Based on that, we design a model which
Cause/issues/3
Emotion-Cause Pair Extraction as Question Answering
993

Table 3: Experimental results of different models on 10-split ECPE dataset. * indicates reproduced results.
Model Emotion Extraction Cause Extraction EC Pair Extraction
P R F1 P R F1 P R F1
Indep-QA (BERT) 0.847 0.908 0.876 0.714 0.787 0.749 0.736 0.661 0.697
Guided-QA (BERT) 0.847 0.908 0.876 0.719 0.792 0.754 0.771 0.692 0.729
Indep-QA (RoBERTa) 0.854 0.916 0.884 0.733 0.807 0.768 0.761 0.683 0.720
Guided-QA (RoBERTa) 0.854 0.916 0.884 0.732 0.806 0.767 0.786 0.706 0.744
ECPE-MLL (BERT) 0.861 0.919 0.889 0.738 0.791 0.763 0.770 0.724 0.745
RankCP (BERT) 0.912 0.900 0.906 0.746 0.779 0.762 0.712 0.763 0.736
PairGCN (BERT) 0.886 0.796 0.838 0.791 0.693 0.738 0.769 0.679 0.720
UTOS (BERT) 0.882 0.832 0.856 0.767 0.732 0.747 0.739 0.706 0.720
RSN (BERT) 0.861 0.892 0.876 0.773 0.740 0.755 0.760 0.722 0.739
ECPE-MLL (BERT)* — — — — — — 0.688 0.752 0.718
RankCP (BERT)* 0.741 0.744 0.742 0.614 0.647 0.627 0.573 0.625 0.597
PairGCN (BERT)* 0.784 0.883 0.829 0.686 0.795 0.735 0.675 0.772 0.718
Table 4: Experimental results of different models on 20-split TransECPE dataset. * indicates reproduced results. The authors
of PairGCN and RSN did not tested their models on TransECPE.
Model Emotion Extraction Cause Extraction EC Pair Extraction
P R F1 P R F1 P R F1
Indep-QA (BERT) 0.842 0.906 0.873 0.713 0.785 0.747 0.730 0.662 0.694
Guided-QA (BERT) 0.842 0.906 0.873 0.710 0.782 0.744 0.760 0.689 0.723
Indep-QA (RoBERTa) 0.844 0.909 0.875 0.724 0.797 0.758 0.739 0.670 0.703
Guided-QA (RoBERTa) 0.844 0.909 0.875 0.723 0.796 0.757 0.772 0.700 0.734
ECPE-MLL (BERT) 0.847 0.899 0.872 0.705 0.770 0.736 0.749 0.698 0.722
RankCP (BERT) 0.894 0.895 0.894 0.694 0.747 0.719 0.658 0.731 0.692
UTOS (BERT) 0.865 0.829 0.849 0.742 0.708 0.728 0.710 0.681 0.691
ECPE-MLL (BERT)* — — — — — — 0.659 0.714 0.684
RankCP (BERT)* 0.896 0.897 0.896 0.694 0.749 0.720 0.657 0.731 0.691
PairGCN (BERT)* 0.804 0.878 0.839 0.689 0.770 0.727 0.677 0.746 0.709
Table 5: Running time (train and test) on Tesla P100.
ECPE TransECPE
ECPE-MLL 8.5h 17h
RankCP 3h 6h
PairGCN 42min 85 min
Indep-QA 2h30 5h
Guided-QA 2h30 5h
takes into account the implicit interaction between
emotion and cause clauses. Experimental results on
a benchmark Chinese dataset show that using implicit
interaction of emotions and causes can achieve com-
petitive accuracy compared to strong baselines. Fu-
ture work will consider explicit interaction between
emotion and cause clauses.
REFERENCES
Bi, H. and Liu, P. (2020). Ecsp: A new task for emotion-
cause span-pair extraction and classification. arXiv
preprint arXiv:2003.03507.
Chen, F., Shi, Z., Yang, Z., and Huang, Y. (2022). Recur-
rent synchronization network for emotion-cause pair
extraction. Knowledge-Based Systems, 238:107965.
Chen, Y., Hou, W., Li, S., Wu, C., and Zhang, X. (2020).
End-to-end emotion-cause pair extraction with graph
convolutional network. In Proceedings of the 28th In-
ternational Conference on Computational Linguistics,
pages 198–207.
Cheng, Z., Jiang, Z., Yin, Y., Li, N., and Gu, Q. (2021).
A unified target-oriented sequence-to-sequence model
for emotion-cause pair extraction. IEEE/ACM Trans-
actions on Audio, Speech, and Language Processing,
29:2779–2791.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2018). Bert: Pre-training of deep bidirectional trans-
formers for language understanding. arXiv preprint
arXiv:1810.04805.
Ding, Z., Xia, R., and Yu, J. (2020). End-to-end emotion-
cause pair extraction based on sliding window multi-
label learning. In Proceedings of the 2020 Conference
on Empirical Methods in Natural Language Process-
ing (EMNLP), pages 3574–3583.
Fan, C., Yuan, C., Du, J., Gui, L., Yang, M., and Xu, R.
(2020). Transition-based directed graph construction
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
994

for emotion-cause pair extraction. In Proceedings of
the 58th Annual Meeting of the Association for Com-
putational Linguistics, pages 3707–3717.
Fu, J., Huang, X.-J., and Liu, P. (2021). Spanner: Named
entity re-/recognition as span prediction. In Proceed-
ings of the 59th Annual Meeting of the Association
for Computational Linguistics and the 11th Interna-
tional Joint Conference on Natural Language Pro-
cessing (Volume 1: Long Papers), pages 7183–7195.
Gui, L., Hu, J., He, Y., Xu, R., Lu, Q., and Du, J. (2017).
A question answering approach for emotion cause ex-
traction. In Proceedings of the 2017 Conference on
Empirical Methods in Natural Language Processing,
pages 1593–1602.
Gui, L., Wu, D., Xu, R., Lu, Q., and Zhou, Y. (2016).
Event-driven emotion cause extraction with corpus
construction. In Proceedings of the 2016 Conference
on Empirical Methods in Natural Language Process-
ing, pages 1639–1649.
Houghton, B., Milani, S., Topin, N., Guss, W., Hofmann,
K., Perez-Liebana, D., Veloso, M., and Salakhutdinov,
R. (2020). Guaranteeing reproducibility in deep learn-
ing competitions. arXiv preprint arXiv:2005.06041.
Khashabi, D., Min, S., Khot, T., Sabharwal, A., Tafjord,
O., Clark, P., and Hajishirzi, H. (2020). Unifiedqa:
Crossing format boundaries with a single qa system.
arXiv preprint arXiv:2005.00700.
Lee, S. Y. M., Chen, Y., and Huang, C.-R. (2010). A text-
driven rule-based system for emotion cause detection.
In Proceedings of the NAACL HLT 2010 workshop on
computational approaches to analysis and generation
of emotion in text, pages 45–53.
Li, X., Feng, J., Meng, Y., Han, Q., Wu, F., and Li, J. (2019).
A unified mrc framework for named entity recogni-
tion. arXiv preprint arXiv:1910.11476.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D.,
Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov,
V. (2019). Roberta: A robustly optimized bert pre-
training approach. arXiv preprint arXiv:1907.11692.
Mengge, X., Yu, B., Zhang, Z., Liu, T., Zhang, Y., and
Wang, B. (2020). Coarse-to-fine pre-training for
named entity recognition. In Proceedings of the 2020
Conference on Empirical Methods in Natural Lan-
guage Processing (EMNLP), pages 6345–6354.
Nguyen, T.-A. D., Vu, H. M., Son, N. H., and Nguyen, M.-
T. (2021). A span extraction approach for informa-
tion extraction on visually-rich documents. In Interna-
tional Conference on Document Analysis and Recog-
nition, pages 353–363. Springer.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. (2016).
Squad: 100,000+ questions for machine comprehen-
sion of text. arXiv preprint arXiv:1606.05250.
Sun, T.-X., Liu, X.-Y., Qiu, X.-P., and Huang, X.-J. (2022).
Paradigm shift in natural language processing. Ma-
chine Intelligence Research, 19(3):169–183.
Wei, P., Zhao, J., and Mao, W. (2020). Effective inter-clause
modeling for end-to-end emotion-cause pair extrac-
tion. In Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics, pages
3171–3181.
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C.,
Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz,
M., et al. (2020). Transformers: State-of-the-art nat-
ural language processing. In Proceedings of the 2020
conference on empirical methods in natural language
processing: system demonstrations, pages 38–45.
Xia, R. and Ding, Z. (2019). Emotion-cause pair extraction:
A new task to emotion analysis in texts. In Proceed-
ings of the 57th Annual Meeting of the Association for
Computational Linguistics, pages 1003–1012.
Yan, H., Gui, L., Pergola, G., and He, Y. (2021). Posi-
tion bias mitigation: A knowledge-aware graph model
for emotion cause extraction. In Proceedings of the
59th Annual Meeting of the Association for Compu-
tational Linguistics and the 11th International Joint
Conference on Natural Language Processing (Volume
1: Long Papers), pages 3364–3375.
Emotion-Cause Pair Extraction as Question Answering
995
