
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework
Maria Hartmann
1 a
, Gr
´
egoire Danoy
1,2 b
, Mohammed Alswaitti
1 c
and Pascal Bouvry
1,2 d
1
SnT, University of Luxembourg, Luxembourg, Esch-sur-Alzette, Luxembourg
2
FSTM/DCS, University of Luxembourg, Esch-sur-Alzette, Luxembourg
Keywords:
Machine Learning, Distributed Machine Learning, Federated Learning, Vertical Federated Learning.
Abstract:
Federated learning is a particular type of distributed machine learning, designed to permit the joint training of
a single machine learning model by multiple participants that each possess a local dataset. A characteristic
feature of federated learning strategies is the avoidance of any disclosure of client data to other participants
of the learning scheme. While a wealth of well-performing solutions for different scenarios exists for Hor-
izontal Federated Learning (HFL), to date little attention has been devoted to Vertical Federated Learning
(VFL). Existing approaches are limited to narrow application scenarios where few clients participate, privacy
is a main concern and the vertical distribution of client data is well-understood. In this article, we first argue
that VFL is naturally applicable to another, much broader application context where sharing of data is mainly
limited by technological instead of privacy constraints, such as in sensor networks or satellite swarms. A VFL
scheme applied to such a setting could unlock previously inaccessible on-device machine learning potential.
We then propose the Joint-embedding Vertical Federated Learning framework (JoVe-FL), a first VFL frame-
work designed for such settings. JoVe-FL is based on the idea of transforming the vertical federated learning
problem to a horizontal one by learning a joint embedding space, allowing us to leverage existing HFL solu-
tions. Finally, we empirically demonstrate the feasibility of the approach on instances consisting of different
partitionings of the CIFAR10 dataset.
1 INTRODUCTION
Federated learning is a co-operative machine learn-
ing strategy that allows distributed devices to compute
a joint machine learning model, combining locally
available information, without actually sharing their
individual data sets with each other. This is gener-
ally accomplished by training local machine learning
models on the separate data sets owned by each par-
ticipant and intermittently sharing information about
the resulting models (most commonly weights of
neural networks) with other participants. These lo-
cal models can be aggregated mathematically to ob-
tain a more accurate global model. There has been
widespread interest in the field of federated learning
since it was first proposed by McMahan et al. in 2016
(McMahan et al., 2016), but the overwhelming ma-
jority of research contributions (Kairouz et al., 2019)
have focused on improving applications to the class
of scenarios for which the framework was first de-
a
https://orcid.org/0000-0002-2179-3703
b
https://orcid.org/0000-0001-9419-4210
c
https://orcid.org/0000-0003-0580-6954
d
https://orcid.org/0000-0001-9338-2834
signed: performing joint machine learning in a con-
text where participants’ datasets may not be transmit-
ted for reasons such as privacy and confidentiality of
client information. Indeed, this focus is reflected in a
commonly accepted definition of the federated learn-
ing concept (Yang et al., 2019) : “A federated learning
system is a learning process in which the data owners
collaboratively train a model M
FED
, in which pro-
cess any data owner F
i
does not expose its data D
i
to
others”.
However, the same solution approach lends it-
self naturally to another type of application scenarios:
those where data cannot be transmitted for external
reasons like technological constraints. Examples of
such applications include on-line learning for an au-
tonomous swarm of unmanned aerial vehicles (UAVs)
(Brik et al., 2020) carrying out a survey as part of a
search-and-rescue mission. In such a context UAVs
must limit the amount of information they transmit
in order to conserve battery charge and maximise fly-
ing range. Using federated learning, a swarm of such
devices could train a simple machine learning model
predicting the efficiency of particular flying manoeu-
vres in the specific, potentially difficult, conditions it
416
Hartmann, M., Danoy, G., Alswaitti, M. and Bouvry, P.
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework.
DOI: 10.5220/0011802600003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 2, pages 416-426
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
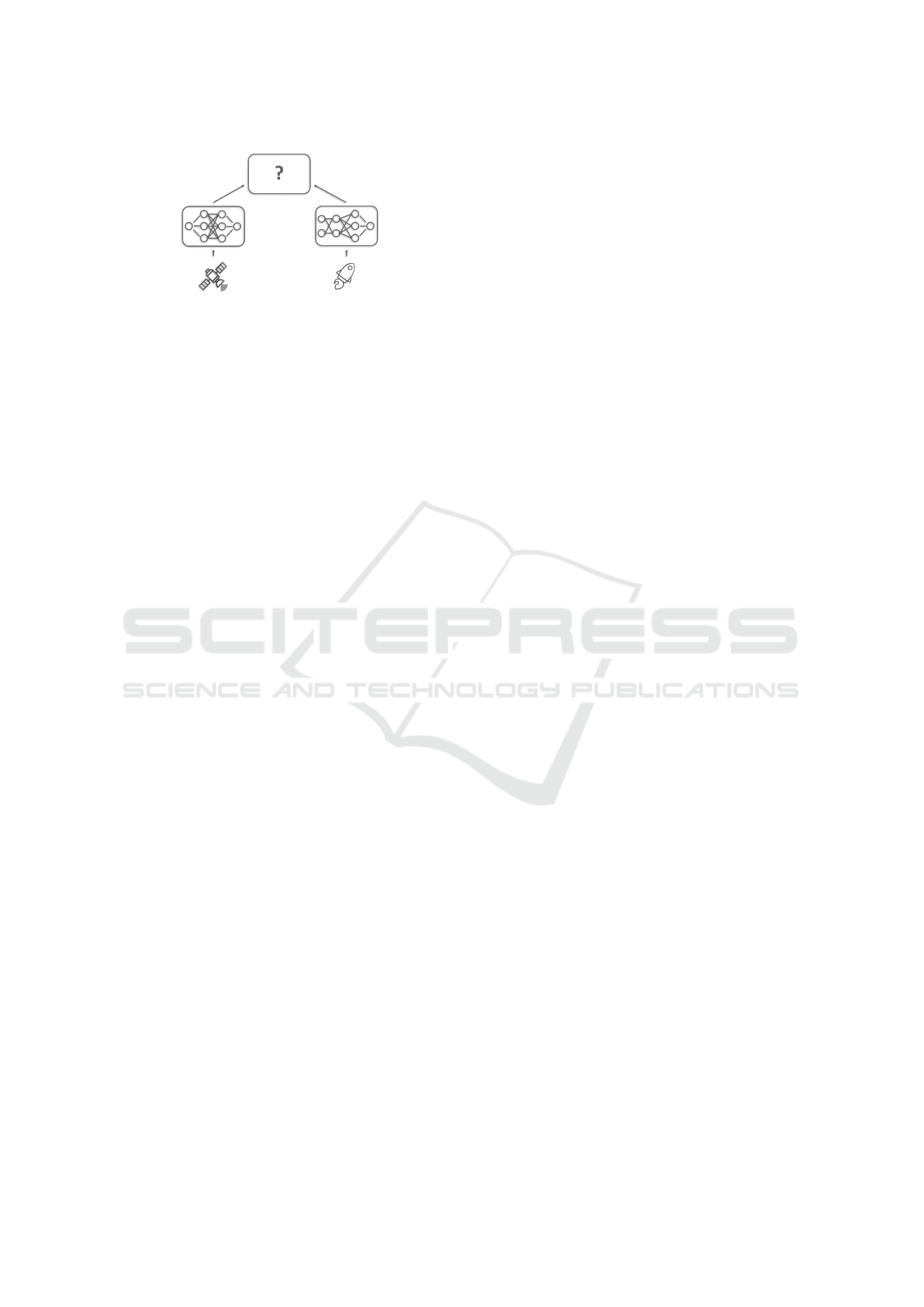
Figure 1: The central challenge of vertical federated learn-
ing is the aggregation of client models with heterogeneous
architectures trained on different types of data.
is deployed in. In another example, a constellation
of Earth observation satellites in different orbits that
pass each other only intermittently in communication
range could exchange model information during those
short intervals to train a federated machine learning
model assisting in simple autonomous navigation pro-
cedures such as self-correcting for tumbling motions.
Leveraging Federated Learning in such contexts
could enable joint machine learning training on each
device even across severely limited communication
channels, allowing participants to share information
much more efficiently. Learning in a way that main-
tains a current model on each agent (i.e. device such
as a UAV) means that swarming agents may still
operate successfully in unstable communications en-
vironments, exiting and rejoining the learning pro-
cess without interruption to the wider system. Fur-
thermore, federated learning can conceivably be per-
formed across networks where not all agents are fully
connected, e.g. in large-scale or ad-hoc networks, by
propagating what is learned across the network.
Such types of application scenarios call for feder-
ated learning solutions with a focus on different chal-
lenges that have been addressed less in existing re-
search - this includes e.g. handling unstable connec-
tions, limited computational (server) resources or on-
line learning. By far the least studied challenge, how-
ever, concerns the integration of multiple different in-
put data and models into one such federated system.
The type of applications discussed here extends natu-
rally to include sets of different types of devices with
different capabilities, such as UAVs each carrying dif-
ferent sensor equipment.
The pool of existing solutions to this type of fed-
erated learning problem (known as vertical federated
learning or VFL; see Figure 1 for an illustration) is
in general quite sparse, and existing research can-
not easily be applied to this context, as many VFL
approaches are designed for narrow use cases (Feng
and Yu, 2020) or require extensive pre-processing
and preliminary exchange of information (Liu et al.,
2020). Others propose a more centralised approach
that produces a global model only on a central server
(Chen et al., 2020).
We present here a federated learning framework
that is designed to address the type of application
scenario where participants are sufficiently limited in
computational and communication capacity that clas-
sical machine learning is not an attractive option. In
particular, our framework has been developed to al-
low participants observing different types of data to
train heterogeneous machine learning models while
still exchanging information with each other in a fed-
erated manner.
The remainder of this article is structured as fol-
lows: we first recapture and discuss related work in
Section 2, then in Section 3 introduce the JoVe-FL
framework in detail. We present a first experimental
demonstration of the framework in Section 4. Section
5 contains our conclusions and perspectives.
2 RELATED WORK
On a high level, federated learning schemes are
commonly classified as horizontal federated learning
(HFL), vertical federated learning (VFL), or feder-
ated transfer learning (FTL) based on the distribu-
tion of client data sets (Yang et al., 2019). Accord-
ing to a strict definition of these terms, clients in HFL
models share the same feature space, but data is par-
titioned between clients in the sample space (it may
be unevenly distributed among clients, i.e. non-iid).
In VFL, clients are partitioned in the feature space,
but share the same sample space. When clients share
neither the feature space nor the sample space, this
is referred to as Federated Transfer Learning (FTL).
In practical applications, these categories may be less
clear-cut, particularly with respect to the boundary
between VFL and FTL (Saha and Ahmad, 2020).
Clients are likely to overlap in both the feature space
and the sample space to some degree, and in this case
the classification of the problem may depend on the
size of the overlap or the target of the particular learn-
ing problem.
Much progress has been made in various direc-
tions in the classical HFL scenario, where all clients
possess samples from the same feature space and train
the same type of model (Kairouz et al., 2019). Less
work exists on the VFL and FTL scenario (Kairouz
et al., 2019), where the feature space is subdivided
among clients and clients may thus train different
model architectures. Of the existing solutions, most
strictly consider either the case where clients’ feature
spaces are guaranteed to overlap (Feng and Yu, 2020),
(Zhang and Jiang, 2022) – e.g. each client possesses
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework
417

part of an image, – or the case where the feature space
is fully partitioned. In some cases, it is additionally
assumed that labels are also private to a subset of par-
ticipants, e.g. in (Xia et al., 2021). Approaches to
the former generally rely on pre-processing to match
partial samples; some utilise data augmentation meth-
ods to exploit shared features between clients. Exam-
ples include an expansion of multi-view learning into
the Multi-Participant Multi-View Federated Learning
(MMVFL) framework (Feng and Yu, 2020), as well
as a method to artificially extend client samples to
a common feature space using generative adversar-
ial networks (Zhang and Jiang, 2022). (Liu et al.,
2020) consider the notion of asymmetry in federated
learning, where some participants have a significantly
stronger interest than others in protecting their sam-
ple identities during data-matching. The requirement
to perform pre-processing or additional model train-
ing makes these approaches fairly computationally
expensive and thus ill-suited to scenarios that involve
restricted computational resources, e.g. edge devices
or satellite networks.
For clients with non-overlapping feature spaces,
the SplitNN approach (Gupta and Raskar, 2018) to
distributed learning has been adapted for the fed-
erated scenario, both for horizontal federated learn-
ing(Yuan et al., 2020) and for vertical federated learn-
ing (Vepakomma et al., 2018), (Cai et al., 2022). The
central insight of the SplitNN architecture is to have
each client train a separate network model up to a cer-
tain layer known as the cut layer. The output of the
cut layer – an embedding of the original input data
– is then transferred to a joint model that is trained
on the collected output of all clients. In existing
federated learning adaptations this generally involves
concatenation of all client outputs (Ceballos et al.,
2020), thereby binding the server to a fixed number
of client inputs that may be subject to communication
delays. The Virtual Asynchronous Federated Learn-
ing (VAFL) framework (Chen et al., 2020) mitigates
such issues by dealing with asynchronicity of client
messages.
The Cascade Vertical Federated Learning (CVFL)
framework (Xia et al., 2021) extends the concept fur-
ther to address the asynchronous setting, including
the straggler problem, where the label space is also
partitioned among clients. CVFL employs bottom-up
cascade training, training an embedding model on all
participants and an additional top (prediction) model
on those participants that possess labels. Each client
that owns labels collects the embedding vectors of the
clients that do not and concatenates those vectors – as
in SplitNN and VAFL – before feeding them into the
prediction model. The resulting prediction models are
aggregated using a horizontal federated learning strat-
egy. However, another shortcoming of these methods
remains: the joint model is incompatible with indi-
vidual clients. A single client cannot use the results
of the joint training, and in return the joint model is
only functional while the required number of clients
participate reliably.
JoVe-FL overcomes this inflexibility without re-
quiring any concatenation of results. No data match-
ing is required and no constraints are placed on the
mutual overlap of client datasets.
3 DESCRIPTION OF
FRAMEWORK
This section provides a detailed description of the
proposed vertical federated learning framework. We
consider a scenario in which constraints are dictated
primarily by technological limitations instead of pri-
vacy concerns. In particular, we make the follow-
ing assumptions: (1) Each participant knows the la-
bels associated with its own samples. We assume that
clients are capable of independent action and learn-
ing, and this requires clients to know the labels to
their observations. Furthermore, all clients are aware
of the full label space; (2) No information is known
about the relation between different clients’ datasets,
i.e. matching of samples or whether the respective
feature spaces overlap; (3) Clients do not share raw
data with each other or a server; (4) No server with
significantly more computing power than any client is
available.
3.1 Application Scenario
As the framework presented in this paper is intended
to solve a class of application scenarios that differs
fundamentally from those considered in previous re-
search, it appears worthwhile to first outline these dif-
ferences. We shall do so with the aid of two examples.
For a classical example of vertical federated learn-
ing scenarios, consider the case of several hospitals
located in the same geographical region. Each hos-
pital maintains confidential patient files. Different
hospitals may have different specialisations, so may
be visited by the same patient for different medical
needs and thus collect different types of data, such
as the results of blood or imaging tests, differential
diagnoses or the duration and outcome of hospital
admissions. These hospitals could perform machine
learning on these data sets to better predict patient
outcomes based on symptoms and test results, prefer-
ably on the combined data of all regional hospitals
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
418
since a larger and broader data set would give a more
precise model. However, due to the confidential na-
ture of health data, pooling patient data into one large
data set accessible to all participants is not a feasible
option. This is a typical example of a scenario that
can be solved using federated learning. Using VFL
solutions, hospitals can jointly train a global model
that includes all information possessed by any one
hospital without disclosing patient data. In this sce-
nario, a federated learning scheme typically involves
few (probably much less than 100) participants that
consolidate large data sets (also known as data si-
los). There are stable communication channels be-
tween participants with few limitations on transmis-
sion size or frequency, and little constraint on comput-
ing power available to clients and servers. The main
concern is the privacy and confidentiality of the train-
ing data.
As an example of the type of application problem
targeted by JoVe-FL, consider a hypothetical constel-
lation of CubeSats – a class of small research satellites
– orbiting Mars on a mapping mission. Each satel-
lite is equipped with onboard imaging sensors and
observes a slice of the planetary surface. To obtain
maximum coverage, the orbits of individual satellites
are arranged such that there is little overlap between
their respective observation areas. The objective of
each satellite is to classify observed geological fea-
tures. Note that in fixed orbits satellites may each
consistently observe only some of the features occur-
ring on the surface, but this is difficult to predict in
advance due to the exploratory nature of the mission.
Owing to their limited size, CubeSats are limited in
the solar charging equipment they can carry, and so
all onboard electronics are necessarily subject to strict
energy budgeting to extend the lifespan of the satel-
lite (Arnold et al., 2012). These constraints reduce
the available downlink transmission bandwidth such
that it is infeasible to simply transmit all observations
from the satellites to Earth or a more powerful inter-
mediary for processing. However, on-board comput-
ing power is also necessarily limited; therefore a strat-
egy for efficient on-board classification is required.
This scenario exhibits some markedly different char-
acteristics to the previously discussed hospital setting,
most importantly:
• No powerful server is available, hence any aggre-
gation strategy cannot be too computationally tax-
ing to be carried out by a limited participant.
• The distribution of features between participants
may be unknown - a federated learning solution
cannot rely on exploiting a particular relation be-
tween participants’ data sets.
• Participants need to be able to use the trained
model locally and independently at any time in the
learning process, since satellites may temporarily
lose connection or experience technical faults un-
expectedly and drop out of the learning process.
As a consequence, the global model cannot re-
quire the concatenated input of multiple partici-
pants to function.
• The main objective in applying a federated learn-
ing strategy is to enable efficient information shar-
ing. Data confidentiality is a secondary concern,
particularly in deep space missions.
In conclusion, this application scenario – and so
also this framework we propose as a first solution ap-
proach – is fundamentally client-oriented as opposed
to the server-oriented scenario in existing VFL ap-
proaches, e.g. (Chen et al., 2020). In existing re-
search, the main aim of vertical federated learning is
to obtain an accurate centralised model, with the sep-
arate clients as participants but not direct beneficiaries
of the solution. In the setting considered here, these
aims are reversed: we seek to find accurate models
for each client, with the server only used as a means
of enabling the learning of more accurate client mod-
els.
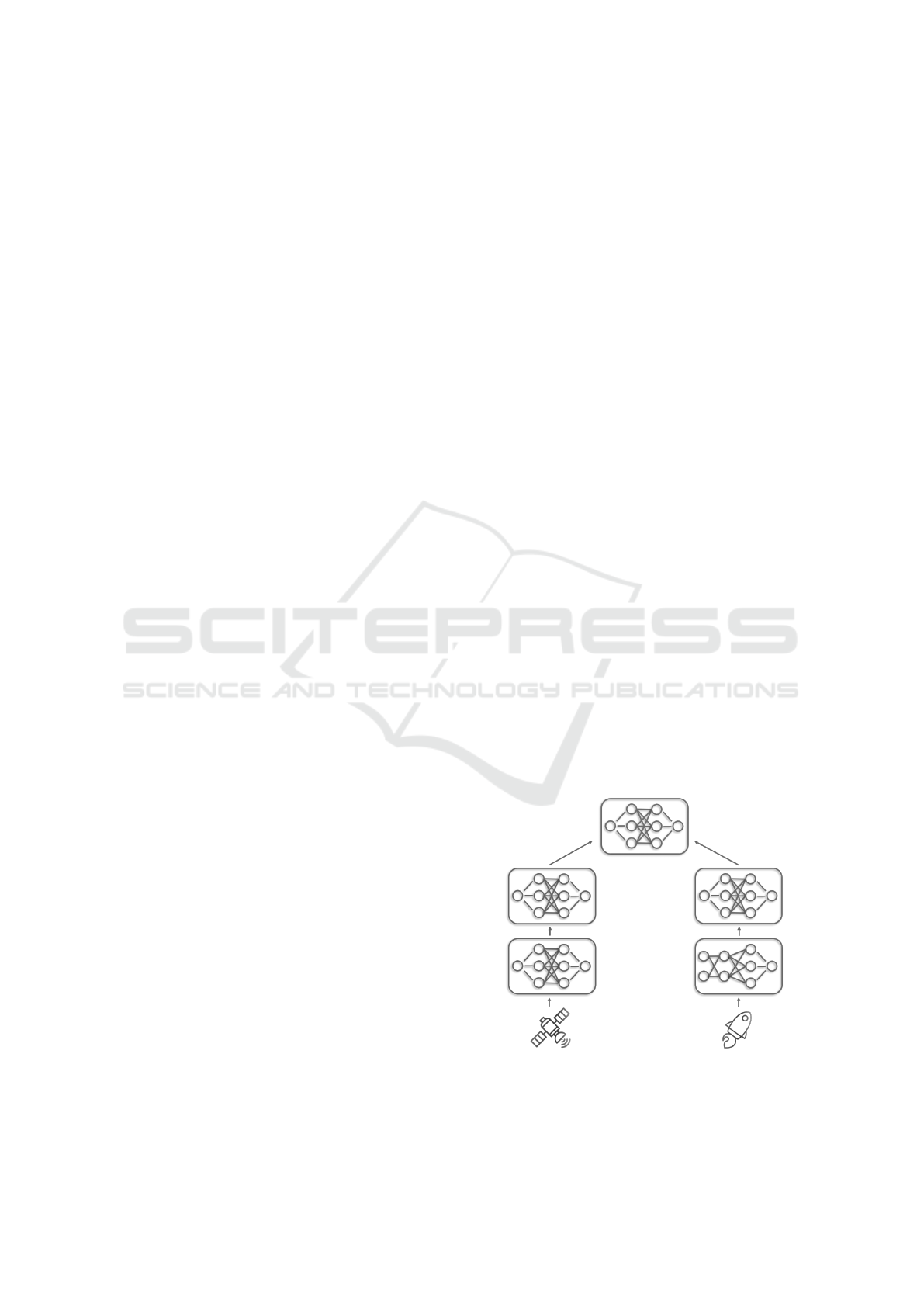
3.2 Concept
The fundamental idea of JoVe-FL, illustrated in Fig-
ure 2, is to transform a vertical federated learning
problem into a horizontal one, as the concept of hor-
izontal federated learning has been far more well-
studied and offers a wide variety of well-performing
solution approaches. This transformation is accom-
plished by training individual local models to map in-
Figure 2: Concept of the framework - Each client maintains
a two-level local model. Horizontal federated learning is
performed on the top-level models only; the architecture of
bottom-level models may be heterogeneous.
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework
419
put data to a common feature space. On this common
feature space a second local model is trained to pre-
dict final results. Since the second model operates on
a common feature space across all clients, it can be
aggregated using a HFL strategy. To the best of our
knowledge, JoVe-FL is the first framework to propose
handling vertically distributed data implicitly by such
a mapping, giving newfound flexibility both regard-
ing client participation and aggregation approaches,
and for the first time opening the VFL setting to the
existing approaches in the horizontal setting.
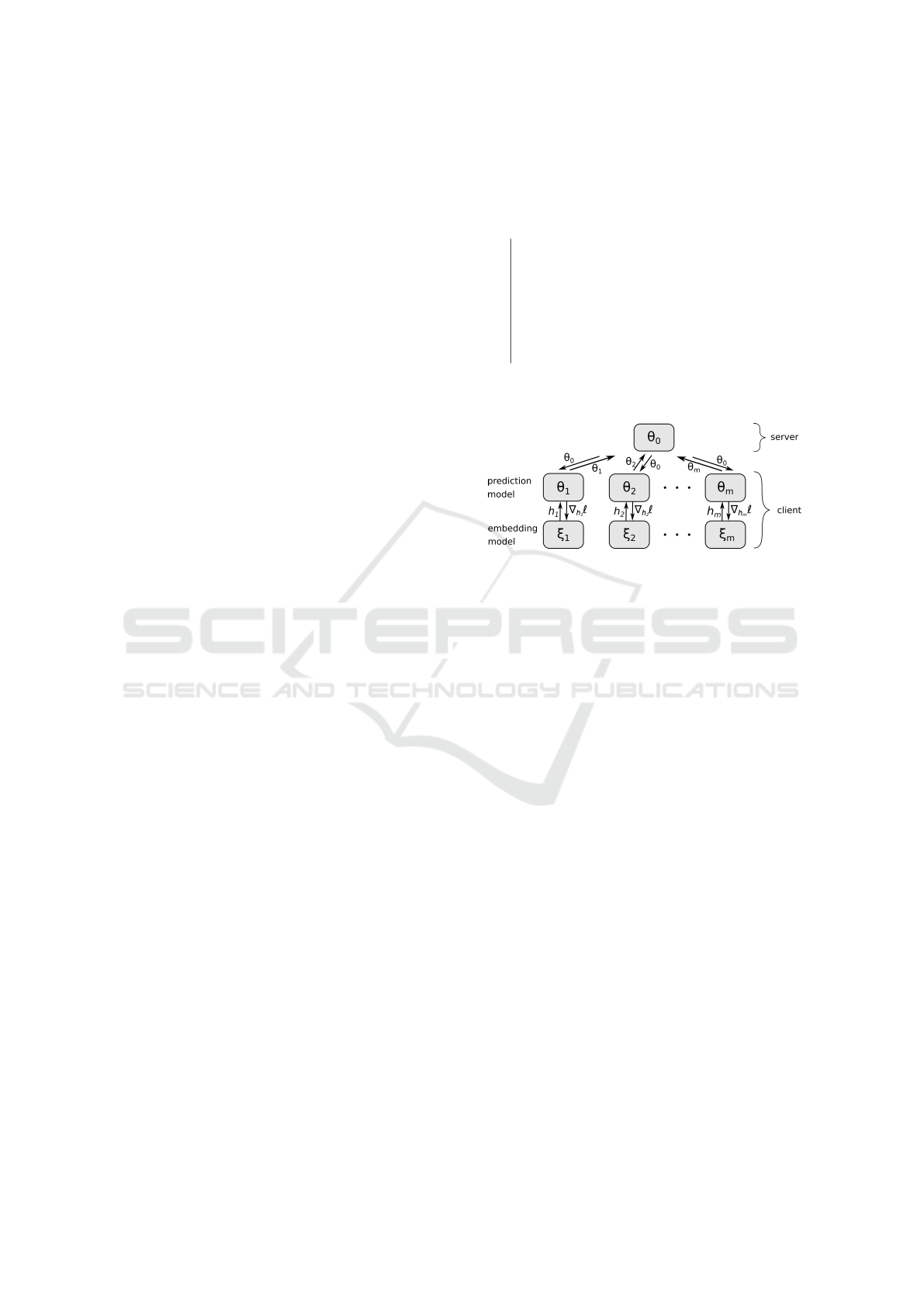
3.3 Client
Each client locally maintains a model that consists of
two chained submodels: an embedding model ξ
i
and
a prediction model θ
i
as illustrated in Figure 3. The
embedding model first maps the client’s input to an
embedding vector of fixed size that is passed to the
prediction model. This embedding is then mapped to
the final output by the prediction model. The choice
of model architecture for the embedding model is free
for each individual client, with the exception of some
constraints on output size that will be detailed be-
low. The architecture of the prediction model is fixed
across all clients.
Consider m clients C
1
, . . . ,C
m
. Each client C
i
pos-
sesses a dataset X
i
with samples x
i, j
, |x
i, j
| = n
i
and as-
sociated labels Y
i
, where Y
i
consists of elements of the
full label space Y that is known to all clients. Each
client defines an embedding model ξ
i
, with architec-
tures of these models bound only by the constraint
that the respective output tensors must have the same
dimensions:
∀i∀ j ξ
i
(x
i, j
) =: h
i, j
s.t. |h
i, j
| = k. (1)
Furthermore, each client has a prediction model
θ
i
, whose architecture – unlike that of the embedding
models – is fixed across all clients. Concatenated the
two local models produce a prediction label ˆy
i, j
for
each sample, i.e. θ
i
◦ ξ
i
= θ
i
(h
i, j
) = ˆy
i, j
. The mod-
els are trained using classical gradient descent, with
the loss gradient passed through accordingly to the
embedding model. Locally, this training is function-
ally and mathematically equivalent to training a single
complete model Ξ
i
:= θ
i
◦ξ
i
. To illustrate the concept,
an example instantiation of a JoVe-FL client is shown
in Algorithm 1; the corresponding server instantiation
follows in Section 3.4. A more detailed discussion of
instantiation choices follows in Section 4.2.
3.4 Server
The role of the server in JoVe-FL is to aggregate
only the prediction models, i.e. the top model layer
Init: current learning rate η
c
,
local embedding model ξ
i
local prediction model θ
i
,
last top-1 accuracy acc
i
← 0
while server is active do
send θ
i
, acc
i
to server;
wait for server update;
θ
0
, η
c
← receive global model from
server;
θ
i
← θ
0
;
ξ
i
, θ
i
← train θ
i
◦ ξ
i
for one epoch;
acc
i
← test θ
i
◦ ξ
i
;
end
Algorithm 1: JoVe-FL algorithm instance on client i.
Figure 3: Formal architecture of the framework - Each
client maintains an embedding model ξ
i
and a prediction
model θ
i
. HFL is performed on the prediction models θ
i
to
obtain a global model θ
0
. The training loss is passed back
to the embedding model as in a classical neural network.
θ
i
of each client C
i
(see Figure 3). By design of the
client architecture, the embedding models are each in-
stances of the same model architecture. We strate-
gically exploit this setup in the design of the server
by treating the aggregation problem as equivalent to
a horizontal federated learning (HFL) problem. As
previously noted, in HFL the clients are assumed to
share the same feature space, which is not necessarily
true for the input that is fed into the prediction models
in this setting. However, by treating the aggregation
as if this were the case, we aim to force the clients
to compensate by each training the individual bottom-
layer embedding models to map their local input to an
embedding in a common feature space. JoVe-FL per-
mits considerable freedom of choice regarding server
behaviour. By design of the clients, the server can
essentially use any aggregation strategy known from
classical horizontal federated learning.
Algorithm 2 shows the server instantiation of the
framework corresponding to the client intantiation in
Algorithm 1.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
420

Init: Number of clients m,
learning rate η, current learning rate η
c
learning rate factor ε
global prediction model θ
0
,
patience p
approximate global accuracy acc
g
while η
c
> ε
4
· η do
Wait for all clients to update;
θ
1
, . . . θ
m
← read client updates;
acc
1
, . . . , acc
m
← read client updates;
θ
0
← mean(θ
1
, . . . , θ
m
);
acc
g
← min(acc
1
, . . . , acc
m
);
η
c
←
recomputeLearningRate(η
c
, acc
g
, ε, p);
Send θ
0
, η
c
to all clients;
end
Send termination command to all clients.
Algorithm 2: JoVe-FL algorithm instance on the server.
3.5 Full Algorithm
The full federated learning algorithm consists of two
alternating phases: the learning phase and the aggre-
gation phase. In this formulation of the framework we
describe only the case of synchronous communication
between the clients and server; this can doubtlessly be
extended in future work to include the asynchronous
setting. In the learning phase, each client trains its full
individual model on the local dataset. As detailed in
section 3.3, this involves sequential application of the
embedding model and the prediction model to gen-
erate a label prediction. Both models are trained at
once using stochastic batch gradient descent on the
local labels. This local training phase continues for
a given duration, determined by the precise instanti-
ation of the framework. Possible termination condi-
tions include e.g. passage of a given time threshold
on the server side or completion of a given number of
training iterations or epochs on all clients. The aggre-
gation phase is initiated by the server once a training
phase has concluded. During this phase, local clients
pause their training process – independently or upon
request of the server – and the server collects the cur-
rent prediction models of participating clients. A HFL
aggregation strategy is performed on the collected
prediction models, and gradients are passed back to
the clients to update the local embedding models de-
pending on the choice of aggregation strategy. Once
this is completed, the next local learning phase begins.
This process continues until a termination condition
on the server is satisfied. Choices of termination con-
dition might include all clients reaching a certain pre-
diction accuracy, completion of a predefined number
of aggregation rounds or plateauing of the loss func-
tion across all clients.
Init: Number of clients m,
learning rate η
learning rate factor ε
global prediction model θ
0
,
patience p
approximate global accuracy acc
g
Initialise server S(m,η, η, ε, θ
0
, p, 0) for i ← 1
to m do
Initialise client C
i
(η, ξ
i
, θ
i
)
end
Algorithm 3: Full JoVe-FL algorithm instance.
4 EXPERIMENTS
Due to the relative novelty of the sub-field of verti-
cal federated learning, there exists, to the best of our
knowledge, no VFL algorithm that addresses a com-
parable setting. The most closely related work has
been explored in the eponymous Section 2, but targets
very different application scenarios, as discussed in
Sections 2 and 3.1. Consequently, different assump-
tions about data distribution and available resources
are made in the design of these algorithms, which
makes a direct comparison with JoVe-FL fruitless.
Therefore, in line with other works on different VFL
scenarios (Chen et al., 2020), (Xia et al., 2021), we
compare the performance of JoVe-FL to 1) the perfor-
mances of individual clients without cooperation as a
lower bound and 2) the state-of-the-art results on the
centralised dataset as an upper bound, where avail-
able. Where the overlap of our self-generated split
datasets does not correspond to the full feature space,
no state-of-the-art results of the centralised data are
readily available. For these experiments we generate
upper bounds using the centralised data and the same
model as is used on the clients for the federated learn-
ing.
For the first demonstration of the joint-embedding
vertical federated learning concept proposed in this
paper, we perform proof-of-concept experiments on
the CIFAR10 dataset (Krizhevsky and Hinton, 2009).
This and similar image classification datasets are
widely used for benchmarking in similarly fundamen-
tal machine learning experiments (Chen et al., 2020),
(Feng and Yu, 2020). Other datasets often used in fed-
erated learning research include health- and finance-
related data, such as the MIMIC-III and Parkinson
datasets. As these simulate application scenarios that
our approach is explicitly not designed for, we refrain
from using them for our demonstrations in the interest
of clarity.
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework
421

Figure 4: Image split parameters used to generate vertical
client inputs. The shaded rectangle corresponds to the pa-
rameter selection i = 16, j = 12, w = 20, h = 16.
4.1 Problem Instances
Experiments were run on different combinations of
image parameters: in general, each client observes
a slice of fixed size and location of each image, but
different sections of the image are revealed to each
client. The parameters across different experiments
are chosen such that in some cases, client views over-
lap, in others the image is fully partitioned between
clients. These choices have been designed to test the
feasibility of JoVe-FL across different types of client
data distributions. Defined precisely, the image pa-
rameters for each client are defined as follows: i, j
are the indices of the top left corner of the rectangular
image slice visible to the given client, relative to top
left corner of the full image; w, h are the width and
height of the visible slice (see Figure 4). We consider
five different experimental configurations, shown in
Figure 5 and Table 1. We run each configuration
five times and average the results across experimen-
tal runs.
4.2 JoVe-FL Instantiation and
Implementation
Experiments were implemented in python using the
MIT-licensed OARF benchmarking suite (Hu et al.,
2022a),(Hu et al., 2022b), for federated learning sys-
tems, which uses pytorch to implement its machine
learning aspects. A new server and client module
were implemented within the existing code frame-
work. The simulation framework was also modified
such that each client may be passed a separate em-
bedding model and individual data splitting parame-
ters upon launch of the simulation.
For the purpose of demonstrating the feasibility
of JoVe-FL, we choose the classical synchronous Fe-
dAvg algorithm (McMahan et al., 2016) as the ag-
gregation mechanism for the prediction model. The
server computes the global prediction model as the
true average of all submitted models, and at the be-
ginning of each round all clients replace their local
prediction model with the global parameters. This
process continues until it is ended by the server. In
accordance with the choice of aggregation algorithm,
the initial choice of hyperparameters is also modeled
on the choices made for the pre-existing implementa-
tion of the FedAvg algorithm in OARF. The learning
rate is managed on the server side using established
pytorch functionalities: a gradual warm-up sched-
uler increases the initial learning rate linearly from
a very small value to the intended starting rate over
a small number of epochs. Then, the learning rate
is multiplied by a reduction factor during the training
whenever the training loss plateaus. After the fourth
such reduction, the learning process is ended. Since
the server does not possess a complete model and so
cannot compute test losses independently, it instead
considers the minimum test loss across participating
clients.
A sensitivity analysis was carried out to determine
the optimal numerical instantiation of model parame-
ters. The parameters that were explored and the re-
sulting selection are listed in Table 2. In total, 432
candidate parameterisations were tested over five ex-
perimental runs each, leading to a total of 2160 runs.
All experiments were executed on the same type of
image input slices with five different random seeds
per parameterisation. Computations were performed
using the HPC facilities of the University of Lux-
embourg (Varrette et al., 2022), on multi-GPU nodes
with the following hardware specifications per node:
Table 1: Experimental configurations used to generate vertically distributed data for different experiments.
Exp. ID view View dimensions (top, left) idx # clients
1
smaller
larger
12 × 32
20 × 32
(0, 0)
(0, 0)
1
1
2 equal-size 16 × 32
(0, 0)
(16, 0)
1
1
3 equal-size
16 × 32
32 × 16
(0, 0)
(0, 20)
1
1
4
smaller
larger
12 × 32
32 × 20
(0, 0)
(0, 12)
1
1
5
smaller
larger
12 × 32
20 × 32
(0, 0)
(12, 0)
1
1
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
422
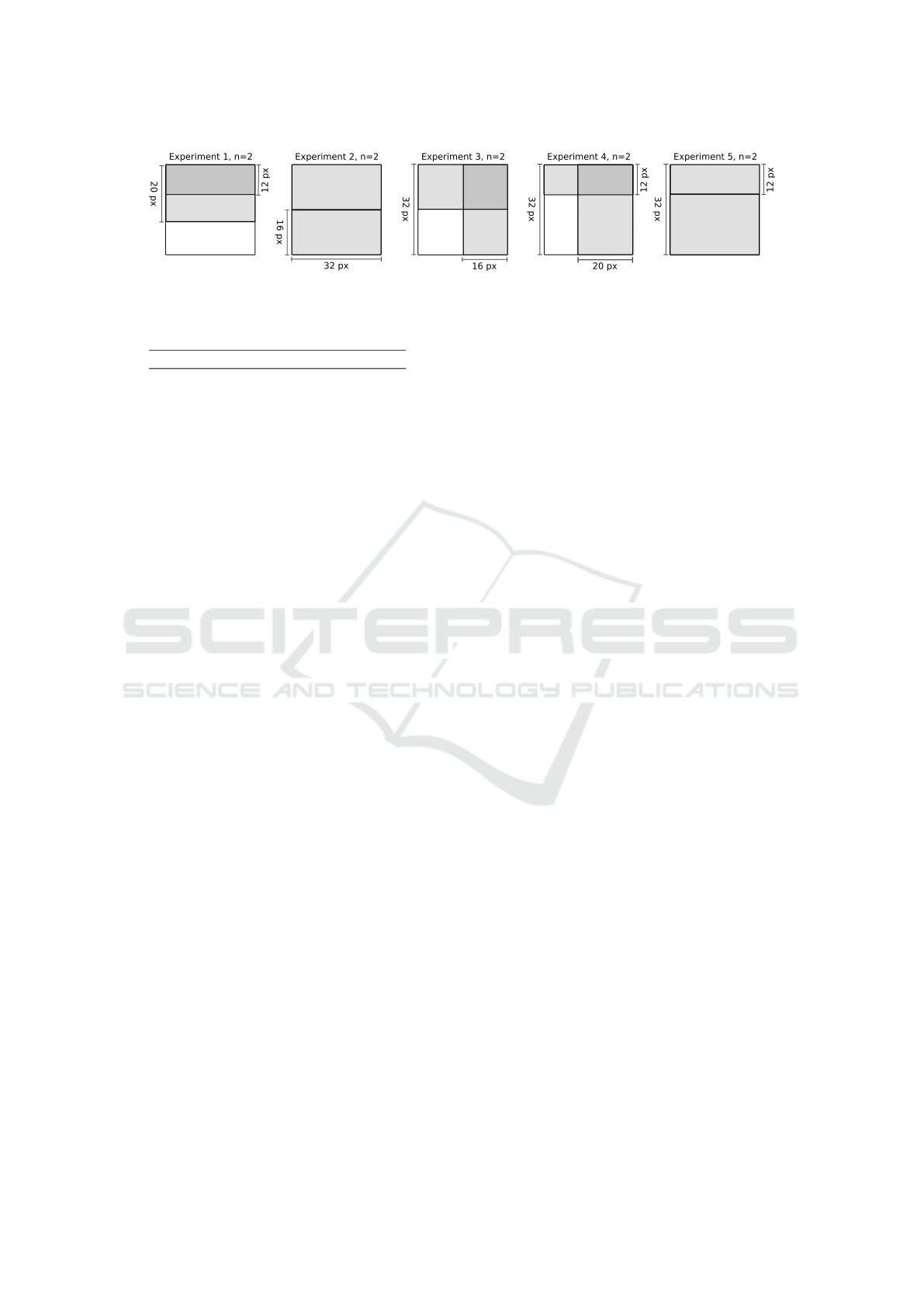
Figure 5: Image split patterns used to generate vertical client inputs. Each shaded rectangle corresponds to one slice of the
image visible to an individual client; n denotes the number of clients.
Table 2: Choice of parameters for the experimental model.
Parameter Value
Learning rate 0.1
Learning rate reduction factor 0.2
Batch size 128
Warmup epochs 15
Patience 15
Dual Intel Xeon Skylake CPU (28 cores), 4 Nvidia
Tesla V100 SXM2 GPU accelerators (16 or 32 GB),
768 GB RAM. On this hardware the experiments re-
quired for our sensitivity analysis consumed a total of
about 2000 hours of computing time.
In all experiments, each client receives the same
number of training and test sample images as all other
clients. 83.3% of images are reserved for training and
8.33% are used for testing. Aggregation of the predic-
tion model is performed once per epoch. For simplic-
ity, none of the encryption measures that the OARF
framework provides are used in our experiments.
All clients train instances of the same model archi-
tecture: the ResNet18 model, split after the second of
four block layers (i.e. the third and fourth layer form
the prediction model used for the federated aggrega-
tion). Locally, each client trains the full ResNet18
model.
As a classical and widely used dataset, the CI-
FAR10 image dataset for object classification, avail-
able under the MIT license, was chosen as the basis
for experimental validation. The full image dataset is
made available in the OARF implementation, and a
modified parameterised pre-processing approach was
implemented within the code framework to generate
vertically partitioned data. For the partitioned dataset,
each client receives a partial view of each image de-
fined by a parameterised rectangle (see Figure 4). The
views available to separate clients may overlap fully,
partially, or not at all depending on the choice of pa-
rameters.
4.3 Results and Discussion
Numerical results are presented in Table 3, showing
the minimum, average, and maximum top-1 accura-
cies achieved by clients in JoVe-FL, by clients learn-
ing separately on the same split datasets without com-
munication, and by the same model trained on the
centralised dataset. In cases where the two clients re-
ceive inputs of different sizes (i.e. experiments 1, 4
and 5), the results are presented separately for each
of the two clients. In the other cases, results are av-
eraged over both clients. The learning curves for all
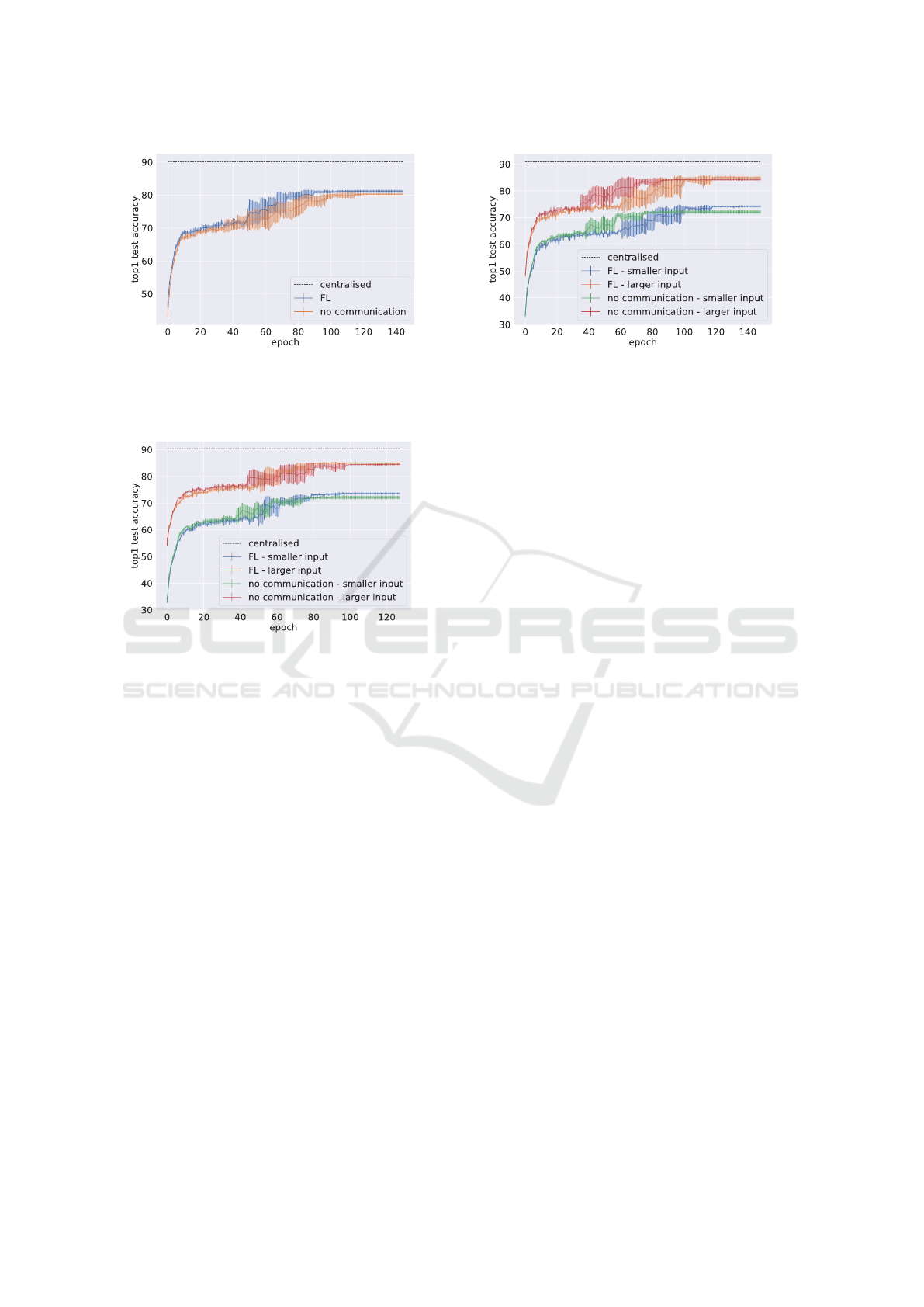
experiments are plotted in Figures 6, 7 and 8.
Across all experiments, we consistently observe
that federated clients obtain a final top-1 accuracy
that is close to or better than the one achieved by in-
dividual clients without communication. In particu-
lar, clients that have a smaller or equally-sized feature
space compared to their counterpart perform better in
federation than individually across all experiments.
The results indicate that all clients succeed in
learning a joint embedding space in all instances, ir-
regardless of whether the data available to clients is
fully partitioned or has overlapping sections. Further,
this embedding combined with the federated predic-
tion model appears to be effective in many cases at
transferring information between clients without re-
quiring a more explicit encoding of information.
In only one experiment (Experiment 2, results
shown in Figure 6b) no gains are made by the fed-
erated clients compared to the non-federated clients.
The input views passed to the clients in this experi-
ment are of equal size and do not overlap; it is possi-
ble that in this case the client models converged on an
embedding arrangement where the embedding space
is simply partitioned between the clients.
In three of our experiments, both clients learn
a more accurate classification model using JoVe-FL
than they do without communication. In experiment
3, both clients possess image slices of equal size, and
both clients benefit from the federated learning - see
Figure 7a for the detailed results. In both experiments
4 and 5, the two clients observe image slices of dif-
ferent sizes - overlapping in the case of experiment
4, separate in the case of experiment 5. It appears
that an overlap between the participants’ datasets is
not necessary to find an effective embedding, but
neither is it a barrier to information transfer. In-
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework
423
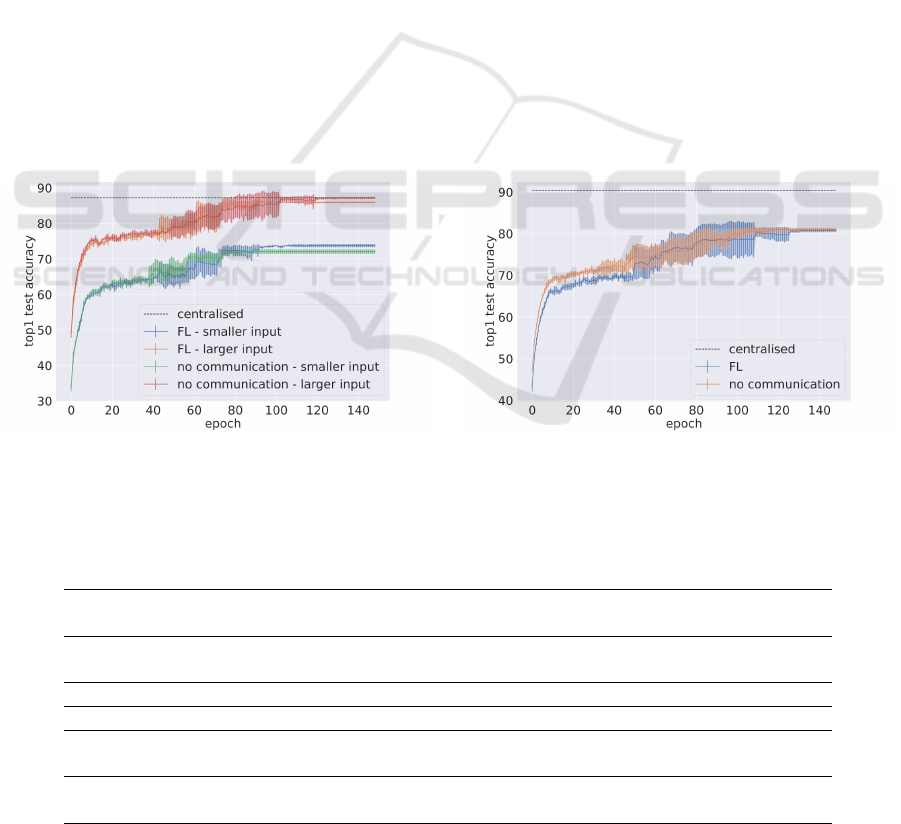
deed, both clients in experiment 4 make slightly larger
accuracy gains compared to the non-communicating
clients than those in experiment 5; so it appears pos-
sible that the overlap between datasets is recognised
while learning a joint embedding and so helps implic-
itly in aligning the embedding models.
In one case the information gain is unilateral - we
observe this in experiment 1, which represents the
edge case where one client observes a subset of the
feature space that is available to the other client. Since
both client datasets originate from the same sample
space, we cannot expect any information gain from
the client with the larger feature space; but we ob-
serve that it appears to lose accuracy in this case.
It is possible that in this case attempts at learning a
joint embedding space disturbed the learning process
of this client and so prevented it from converging to
the optimal solution achieved by the equivalent non-
federated client. However, we note that the client with
the smaller dataset does benefit from the exchange,
supporting the fundamental idea of transferring infor-
mation in this manner. It appears likely that the loss of
accuracy on the part of the first client can be avoided
by a more careful choice of model architecture; this is
an interesting edge case to explore in future work.
Importantly, these preliminary experiments con-
firm that JoVe-FL handles different vertical distribu-
tions of client data – both overlapping and fully par-
titioned feature spaces – similarly well. To the best
of our knowledge, this in itself is a novel character-
istic for a VFL framework. In addition we confirm
that, even with very little modification to a machine
learning model not developed for this purpose and on
a basic dataset, JoVe-FL is capable of transferring in-
formation between participants with little additional
overhead. Nonetheless, the upper accuracy bound
computed on the combined datasets of clients is not
reached by the federated clients in these preliminary
experiments; this requires further development.
5 CONCLUSION
This article proposed to explore the potential of apply-
ing VFL strategies to settings where machine learning
capability is not constrained by privacy concerns, but
by other factors, such as technical ones, that also limit
participants’ ability to share large amounts of data.
Different application scenarios have been discussed,
particularly in the context of vertical federated learn
(a) Accuracy results of experiment 1. (b) Accuracy results of experiment 2.
Figure 6: Average top-1 accuracy for unequally-sized views of the dataset with one client dataset a subset of the other (left;
Exp. ID 1 in Figure 5) and for equally-sized views of the dataset with no mutual overlap (Exp. ID 2 in Figure 5).
Table 3: Aggregated experimental results of federated learning scheme compared to learning without communication and
learning on the centralised dataset.
Exp. ID View
FL – top-1
min, avg, max
no communication – top-1
min, avg, max
centralised – top-1
min, avg, max
1
smaller
larger
73.0, 73.73, 74.16
85.7, 86.0, 86.3
71.5, 72.1, 73.3
86.8, 87.2, 87.6
86.8, 87.2, 87.6
2 equal-size 80.2, 80.8, 81.2 80.5, 81.0, 81.6 90.0, 90.03, 90.9
3 equal-size 80.6, 81.1, 81.91 79.9, 80.3, 80.6 89.0, 90.1, 90.3
4
smaller
larger
73.7, 74.2, 74.65
84.22, 84.9, 85.4
71.5, 72.1, 73.3
83.6, 84.2, 84.5
90.6, 91.0, 91.3
5
smaller
larger
72.9, 73.7, 74.0
84.5, 85.0, 85.2
71.5, 72.1, 73.3
84.2, 84.5, 85.1
90.0, 90.3, 90.9
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
424
(a) Accuracy results of experiment 3. (b) Accuracy results of experiment 4.
Figure 7: Average top-1 accuracy for equally-sized views of the dataset with partial mutual overlap (left; Exp. ID 3 in
Figure 5) and for unequally-sized views of the dataset with partial mutual overlap (Exp. ID 4 in Figure 5).
Figure 8: Average top-1 accuracy for unequally-sized views
of the dataset with no mutual overlap (Exp. ID 5 in Fig-
ure 5).
ing. We propose JoVe-FL, a novel vertical fed-
erated learning scheme for flexible learning tailored
to this setting. JoVe-FL is, to the best of our knowl-
edge, the first to map a VFL problem to a horizontal
one by learning a joint embedding space instead of
concatenating separate embeddings. This approach
offers remarkable flexibility regarding the partition of
data between participants, and it reduces the reliance
on consistent participation of clients that is inherent
to approaches that use a concatenated embedding
space.
We demonstrate the feasibility of our proposed
scheme by showing experimentally that clients can
implicitly learn a shared embedding space for
vertically-distributed data while ultimately achieving
a performance accuracy that is at least equal to that
of non-communicating clients, and accomplishes su-
perior performance of at least one participating client
in all but one of the experiments. Future work will
include more extensive benchmarking of JoVe-FL,
involving further experimentation on the choice of
model architecture both for embedding and prediction
models as well for the choice of horizontal aggrega-
tion strategy. In addition, further testing and develop-
ment towards deploying the framework in application
use cases such as swarms of unmanned aerial vehicles
or small satellites.
ACKNOWLEDGEMENTS
This work is partially funded by the joint research
programme UL/SnT–ILNAS on Technical Standardi-
sation for Trustworthy ICT, Aerospace, and Construc-
tion.
The experiments presented in this paper were carried
out using the HPC facilities of the University of Lux-
embourg (Varrette et al., 2022) – see https://hpc.uni.lu.
REFERENCES
Arnold, S. S., Nuzzaci, R., and Gordon-Ross, A. (2012).
Energy budgeting for cubesats with an integrated fpga.
In 2012 IEEE Aerospace Conference, pages 1–14.
Brik, B., Ksentini, A., and Bouaziz, M. (2020). Feder-
ated learning for uavs-enabled wireless networks: Use
cases, challenges, and open problems. IEEE Access,
8:53841–53849.
Cai, S., Chai, D., Yang, L., Zhang, J., Jin, Y., Wang, L.,
Guo, K., and Chen, K. (2022). Secure forward aggre-
gation for vertical federated neural networks.
Ceballos, I., Sharma, V., Mugica, E., Singh, A., Roman,
A., Vepakomma, P., and Raskar, R. (2020). SplitNN-
driven vertical partitioning. CoRR, abs/2008.04137.
Chen, T., Jin, X., Sun, Y., and Yin, W. (2020). VAFL: a
method of vertical asynchronous federated learning.
CoRR, abs/2007.06081.
Feng, S. and Yu, H. (2020). Multi-participant multi-class
vertical federated learning. CoRR, abs/2001.11154.
Gupta, O. and Raskar, R. (2018). Distributed learning of
deep neural network over multiple agents. CoRR,
abs/1810.06060.
JoVe-FL: A Joint-Embedding Vertical Federated Learning Framework
425

Hu, S., Li, Y., Liu, X., Li, Q., Wu, Z., and He, B. (2022a).
The OARF benchmark suite: Characterization and im-
plications for federated learning systems. ACM Trans.
Intell. Syst. Technol., 13(4).
Hu, S., Li, Y., Liu, X., Li, Q., Wu, Z., and He, B. (2022b).
The OARF benchmark suite: Characterization and
implications for federated learning systems [source
code], https://github.com/xtra-computing/oarf.
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Ben-
nis, M., Bhagoji, A. N., Bonawitz, K. A., Charles, Z.,
Cormode, G., Cummings, R., D’Oliveira, R. G. L.,
Rouayheb, S. E., Evans, D., Gardner, J., Garrett, Z.,
Gasc
´
on, A., Ghazi, B., Gibbons, P. B., Gruteser, M.,
Harchaoui, Z., He, C., He, L., Huo, Z., Hutchinson,
B., Hsu, J., Jaggi, M., Javidi, T., Joshi, G., Kho-
dak, M., Kone
ˇ
cn
´
y, J., Korolova, A., Koushanfar, F.,
Koyejo, S., Lepoint, T., Liu, Y., Mittal, P., Mohri, M.,
Nock, R.,
¨
Ozg
¨
ur, A., Pagh, R., Raykova, M., Qi, H.,
Ramage, D., Raskar, R., Song, D., Song, W., Stich,
S. U., Sun, Z., Suresh, A. T., Tram
`
er, F., Vepakomma,
P., Wang, J., Xiong, L., Xu, Z., Yang, Q., Yu, F. X., Yu,
H., and Zhao, S. (2019). Advances and open problems
in federated learning. CoRR, abs/1912.04977.
Krizhevsky, A. and Hinton, G. (2009). Learning multiple
layers of features from tiny images. Technical Re-
port 0, University of Toronto, Toronto, Ontario.
Liu, Y., Zhang, X., and Wang, L. (2020). Asymmetrical
vertical federated learning. CoRR, abs/2004.07427.
McMahan, H. B., Moore, E., Ramage, D., and y Arcas,
B. A. (2016). Federated learning of deep networks
using model averaging. CoRR, abs/1602.05629.
Saha, S. and Ahmad, T. (2020). Federated transfer learning:
concept and applications. CoRR, abs/2010.15561.
Varrette, S., Cartiaux, H., Peter, S., Kieffer, E., Valette, T.,
and Olloh, A. (2022). Management of an Academic
HPC & Research Computing Facility: The ULHPC
Experience 2.0. In Proc. of the 6th ACM High Per-
formance Computing and Cluster Technologies Conf.
(HPCCT 2022), Fuzhou, China. Association for Com-
puting Machinery (ACM).
Vepakomma, P., Gupta, O., Swedish, T., and Raskar, R.
(2018). Split learning for health: Distributed deep
learning without sharing raw patient data. CoRR,
abs/1812.00564.
Xia, W., Li, Y., Zhang, L., Wu, Z., and Yuan, X. (2021). A
vertical federated learning framework for horizontally
partitioned labels. CoRR, abs/2106.10056.
Yang, Q., Liu, Y., Chen, T., and Tong, Y. (2019). Federated
machine learning: Concept and applications. ACM
Trans. Intell. Syst. Technol., 10(2).
Yuan, B., Ge, S., and Xing, W. (2020). A federated learn-
ing framework for healthcare iot devices. CoRR,
abs/2005.05083.
Zhang, J. and Jiang, Y. (2022). A data augmentation method
for vertical federated learning. Wireless Communica-
tions and Mobile Computing, 2022:1–16.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
426
