
Towards Modelling and Verification of Social Explainable AI
Damian Kurpiewski
1,2 a
, Wojciech Jamroga
1,3 b
and Teofil Sidoruk
1,4 c
1
Institute of Computer Science, Polish Academy of Sciences, Warsaw, Poland
2
Faculty of Mathematics and Computer Science, Nicolaus Copernicus University, Toru
´
n, Poland
3
Interdisciplinary Centre for Security, Reliability, and Trust, SnT, University of Luxembourg, Luxembourg
4
Faculty of Mathematics and Information Science, Warsaw University of Technology, Warsaw, Poland
Keywords:
Multi-Agent Systems, Formal Verification, Social Explainable AI, Strategic Ability, Model Checking.
Abstract:
Social Explainable AI (SAI) is a new direction in artificial intelligence that emphasises decentralisation, trans-
parency, social context, and focus on the human users. SAI research is still at an early stage. Consequently,
it concentrates on delivering the intended functionalities, but largely ignores the possibility of unwelcome be-
haviours due to malicious or erroneous activity. We propose that, in order to capture the breadth of relevant
aspects, one can use models and logics of strategic ability, that have been developed in multi-agent systems.
Using the STV model checker, we take the first step towards the formal modelling and verification of SAI
environments, in particular of their resistance to various types of attacks by compromised AI modules.
1 INTRODUCTION
Elements of artificial intelligence have become ubiq-
uitous in daily life, being involved in social media,
car navigation, recommender algorithms for music
and films, and so on. They also provide back-end
solutions to many business processes, resulting in a
huge societal and economical impact. The idea of
Social Explainable AI (SAI) represents an interesting
new direction in artificial intelligence, which empha-
sises decentralisation, human-centricity, and explain-
ability (Social Explainable AI, CHIST-ERA, 24; Con-
tucci et al., 2022). This is in line with the trend to
move away from classical, centralised machine learn-
ing, not only for purely technical reasons such as scal-
ability constraints, but also to meet the growing ethi-
cal expectations regarding transparency and trustwor-
thiness of data storage and computation (Drainakis
et al., 2020; Ottun et al., 2022). The aim is also to
put the human again in the spotlight, rather than con-
centrate on the technological infrastructure (Conti and
Passarella, 2018; Toprak et al., 2021; Fuchs et al.,
2022).
SAI is a new concept, and a subject of ongoing
research. It still remains to be seen if it delivers AI
solutions that are effective, transparent, and mindful
of the user. To this end, it should be extensively
a
https://orcid.org/0000-0002-9427-2909
b
https://orcid.org/0000-0001-6340-8845
c
https://orcid.org/0000-0002-4393-3447
studied not only in the context of its intended prop-
erties, but also the possible side effects of interaction
that involves AI components and human users in a
complex environment. In particular, we should care-
fully analyse the possibilities of adversarial misuse
and abuse of the interaction, e.g., by means of im-
personation or man-in-the-middle attacks (Dolev and
Yao, 1983; Gollmann, 2011). In those scenarios, one
or more nodes of the interaction network are taken
over by a malicious party that tries to disrupt com-
munication, corrupt data, and/or spread false infor-
mation. Clearly, the design of Social AI must be re-
sistant to such abuse; otherwise it will be sooner or
later exploited. While the topic of adversarial attacks
on machine learning algorithms has recently become
popular (Goodfellow et al., 2018; Kianpour and Wen,
2019; Kumar et al., 2020), the research on SAI has so
far focused only on its expected functionalities. This
is probably because SAI communities are bound to be
conceptually, computationally, and socially complex.
A comprehensive study of their possible unintended
behaviors is a highly challenging task.
Here, we propose that formal methods for multi-
agent systems (Weiss, 1999; Shoham and Leyton-
Brown, 2009) provide a good framework for multi-
faceted analysis of Social Explainable AI. Moreover,
we put forward a new methodology for such studies,
based on the following hypotheses:
1. It is essential to formalise and evaluate multi-
agent properties of SAI environments. In particu-
396
Kurpiewski, D., Jamroga, W. and Sidoruk, T.
Towards Modelling and Verification of Social Explainable AI.
DOI: 10.5220/0011799900003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 1, pages 396-403
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

lar, we must look at the properties of interaction
between SAI components that go beyond joint,
fully orchestrated action towards a common pre-
defined goal. This may include various relevant
functionality and safety requirements. In partic-
ular, we should assess the impact of adversarial
play on these requirements.
2. Many of those properties are underpinned by
strategic ability of agents and their groups to
achieve their goals (Pauly, 2002; Alur et al., 2002;
Bulling et al., 2015). In particular, many func-
tionality properties refer to the ability of legiti-
mate users to complete their selected tasks. Con-
versely, safety and security requirements can be
often phrased in terms of the inability of the “bad
guys” to disrupt the behavior of the system.
3. Model checking (Clarke et al., 2018) provides
a well-defined formal framework for the analy-
sis. Moreover, existing model checking tools for
multi-agent systems, such as MCMAS (Lomuscio
et al., 2017) and STV (Kurpiewski et al., 2021)
can be used to formally model, visualise, and
analyse SAI designs with respect to the relevant
properties.
4. Conversely, SAI can be used as a testbed for
cutting-edge methods of model checking and their
implementations.
In the rest of this paper, we make the first step
towards formal modelling, specification, and verifi-
cation of SAI. We model SAI by means of asyn-
chronous multi-agent systems (AMAS) (Jamroga et al.,
2020), and formalise their properties using formulas
of temporal-strategic logic ATL
∗
(Alur et al., 2002;
Schobbens, 2004). For instance, one can specify that
a malicious AI component can ensure that the remain-
ing components will never be able to build a global
model of desired quality, even if they all work to-
gether against the rogue component. Alternatively,
strategies of the “good” modules can be considered,
in order to check whether a certain threshold of non-
compromised agents is sufficient to prevent a spe-
cific type of attack. Finally, we use the STV model
checker (Kurpiewski et al., 2021) to verify the for-
malised properties against the constructed models.
The verification is done by means of the technique of
fixpoint approximation, proposed and studied in (Jam-
roga et al., 2019).
Note that this study does not aim at focused in-
depth verification of a specific machine learning pro-
cedure, like in (Wu et al., 2020; Batten et al., 2021;
Kouvaros and Lomuscio, 2021; Akintunde et al.,
2022). Our goal is to represent and analyse a broad
spectrum of interactions, possibly at the price of ab-
straction that leaves many details out of the formal
model.
The ideas, reported here, are still work in progress,
and the results should be treated as preliminary.
2 SOCIAL EXPLAINABLE AI
The framework of Social Explainable AI or SAI (So-
cial Explainable AI, CHIST-ERA, 24; Contucci et al.,
2022; Fuchs et al., 2022) aims to address several
drawbacks inherent to the currently dominant AI
paradigm. In particular, state of the art machine learn-
ing (ML)-based AI systems are typically centralised.
The sheer scale of Big Data collections, as well as
the complexity of deep neural networks that process
them, mean that effectively these AI systems act as
opaque black boxes, non-interpretable even for ex-
perts. This naturally raises issues of privacy and trust-
worthiness, further exacerbated by the fact that stor-
ing an ever-increasing amount of sensitive data in a
single, central location might eventually become un-
feasible, also for non-technical reasons such as local
regulations regarding data ownership.
In contrast, SAI envisions novel ML-based AI sys-
tems with a focus on the following aspects:
• Individuation: a “Personal AI Valet” (PAIV) asso-
ciated with each individual, acting as their proxy
in a complex ecosystem of interacting PAIVs;
• Personalisation: processing data by PAIVs via ex-
plainable AI models tailored to the specific char-
acteristics of individuals;
• Purposeful interaction: PAIVs build global AI
models or make collective decisions starting from
the local models by interacting with one another;
• Human-centricity: AI algorithms and PAIV inter-
actions driven by quantifiable models of the indi-
vidual and social behaviour of their human users;
• Explainability by design: extending ML tech-
niques through quantifiable human behavioural
models and network science analysis.
The current attempts at building SAI use gossip
learning as the ML regime for PAIVs (Social AI
gossiping. Micro-project in Humane-AI-Net, 2022;
Heged
¨
us et al., 2019; Heged
¨
us et al., 2021). An exper-
imental simulation tool to assess the effectiveness of
the process and functionality of the resulting AI com-
ponents is available in (Lorenzo et al., 2022). In this
paper, we take a different path, and focus on the multi-
agent interaction in the learning process. We model
the network of PAIVs as an asynchronous multi-agent
system (AMAS), and formalise its properties as formu-
las of alternating-time temporal logic (ATL
∗
). The
Towards Modelling and Verification of Social Explainable AI
397

formal framework is introduced in Section 3. In Sec-
tion 4, we present preliminary multi-agent models of
SAI, and show several attacks that can be modelled
that way. In Section 5, we formalise several proper-
ties and conduct model checking experiments.
3 WHAT AGENTS CAN ACHIEVE
In this section, we introduce the formalism of Asyn-
chronous Multi-agent Systems (AMAS) (Jamroga
et al., 2020; Jamroga et al., 2021), as well as the
syntax and semantics of Alternating-time Temporal
Logic ATL
∗
(Alur et al., 2002; Schobbens, 2004),
which allows for specifying relevant properties of SAI
models, in particular the strategic ability of agents to
enforce a goal.
3.1 Asynchronous MAS
AMAS can be thought of as networks of automata,
where each component corresponds to a single agent.
Definition 1 (AMAS (Jamroga et al., 2021)). An
asynchronous multi-agent system (AMAS) consists of
n agents A = {1, . . . , n}, each associated with a 7-
tuple A
i
= (L
i
, ι
i
, Evt
i
, R
i
, T
i
, PV
i
,V
i
), where:
• L
i
= {l
1
i
, . . . , l
n
i
i
} 6=
/
0 is a finite set of local states;
• ι
i
∈ L
i
is an initial local state;
• Evt
i
= {e
1
i
, . . . , e
m
i
i
} 6=
/
0 a finite set of events;
• R
i
: L
i
→ 2
Evt
i
\ {
/
0} is a repertoire of choices, as-
signing available subsets of events to local states;
• T
i
: L
i
× Evt
i
* L
i
is a (partial) local transi-
tion function that indicates the result of executing
event e in state l from the perspective of agent i.
T
i
(l
i
, e) is defined iff e ∈
S
R
i
(l
i
);
• PV
i
is a set of the agent’s local propositions, with
PV
j
, PV
k
(for j 6= k ∈ A ) assumed to be disjoint;
• V
i
: L
i
→ P (PV
i
) is a valuation function.
Furthermore, we denote:
• by Evt =
S
i∈A
Evt
i
, the set of all events;
• by L =
S
i∈A
L
i
, the set of all local states;
• by Agent(e) = {i ∈ A | e ∈ Evt
i
}, the set of all
agents which have event e in their repertoires;
• by PV =
S
i∈A
PV
i
the set of all local propositions.
The model of an AMAS provides its execution
semantics with asynchronous interleaving of private
events and synchronisation on shared ones.
Definition 2 (Model (Jamroga et al., 2021)). The
model of an AMAS is a 5-tuple M = (A , S, ι,T,V ),
where:
• A is the set of agents;
• S ⊆ L
1
×. .. ×L
n
is the set of global states, includ-
ing all states reachable from ι by T (see below);
• ι = (ι
1
, . . . , ι
n
) ∈ S is the initial global state;
• T : S × Evt ∪ {ε} * S is the (partial) global
transition function, defined by T (s
1
, e) = s
2
iff
T
i
(s
i
1
, e) = s
i
2
for all i ∈ Agent(e) and s
i
1
= s
i
2
for
all i ∈ A \ Agent(e), where s
i
j
∈ L
i
is agent i’s
local component of s
j
. Moreover, T (s, ε) = s iff
there are events e
1
, . . . , e
n
st. T
i
(s
i
, e
i
) is defined
but none of e
1
, . . . , e
n
is selected by all its owners;
• V : S → 2
PV
is the global valuation function, de-
fined as V (l
1
, . . . , l
n
) =
S
i∈A
V
i
(l
i
).
3.2 Strategic Ability
Linear and branching-time temporal logics, such as
LTL and CTL
?
(Emerson, 1990), have long been
used in formal verification. They enable to express
properties about how the state of the system will (or
should) evolve over time. However, in systems that
involve autonomous agents, whether representing hu-
man users or AI components it is usually of interest
who can direct its evolution a particular way.
ATL
∗
(Alur et al., 2002) extends temporal log-
ics with strategic modalities that allow for reasoning
about such properties. The operator hhAiiγ says that
agents in group (coalition) A have a strategy to en-
force property γ. That is, as long as agents in A select
events according to the strategy, γ will hold no matter
what the other agents do. ATL
∗
has been one of the
most important and popular agent logics in the last 25
years.
Definition 3 (Syntax of ATL
∗
). The language of
ATL
∗
is defined by the grammar:
ϕ ::= p | ¬ϕ | ϕ ∧ ϕ | hhAiiγ,
γ ::= ϕ | ¬γ | γ ∧ γ | X γ | γ U γ,
where p ∈ PV and A ⊆ A. The definitions of Boolean
connectives and temporal operators X (“next”) and
U (“strong until”) are standard; remaining operators
R (“release”), G (“always”), and F (“sometime”)
can be derived as usual.
Various types of strategies can be defined, based
on the state information and memory of past states
available to agents (Schobbens, 2004). In this work,
we focus on imperfect information, imperfect recall
strategies.
Definition 4 (Strategy). A memoryless imperfect in-
formation strategy for agent i ∈ A is a function
σ
i
: L
i
→ 2
Evt
i
\
/
0 such that σ
i
(l) ∈ R
i
(l) for each local
state l ∈ L
i
. A joint strategy σ
A
of coalition A ⊆ A is
a tuple of strategies σ
i
, one for each agent i ∈ A.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
398

The outcome set of a strategy collects all the
execution paths consistent with the strategy. For-
mally, out
M
(s, σ
A
) collects all the infinite sequences
of states, starting from s, that may occur when the
coalition follows strategy σ
A
while the opponents
choose freely from their repertoires. We use the so
called opponent-reactive outcome, where the oppo-
nents are assumed to respond with matching synchro-
nization events if such responses are available. The
interested reader is referred to (Jamroga et al., 2021;
Kurpiewski et al., 2022) for the discussion and tech-
nical details.
Definition 5 (Asynchronous semantics of ATL
∗
(Jamroga et al., 2020)). The asynchronous semantics
of the strategic modality in ATL
∗
is defined by the
following clause:
M, s |= hhAiiγ iff there is a strategy σ
A
such that
out
M
(s, σ
A
) 6=
/
0 and, for each path π ∈ out
M
(s, σ
A
),
we have M, π |= γ.
The remaining clauses for temporal operators and
Boolean connectives are standard, see (Emerson,
1990).
4 MODELS
The first step towards the verification of the interac-
tion between agents in Social Explainable AI is a thor-
ough and detailed analysis of the underlying protocol.
We begin by looking into the actions performed and
the messages exchanged by the machines that take
part in the learning phase. Then, we can start design-
ing multi-agent models. Usually, such systems are too
complex to be modelled as they are. In that case, we
create an abstract view of the system.
4.1 Agents
In this work, we focus on the learning phase of the
SAI protocol. We model each machine equipped with
an AI module as a separate agent. The local model of
an AI agent consists of three phases: the data gather-
ing phase, the learning phase and the sharing phase.
Data Gathering Phase. In this phase, the agent is
able to gather the data required for the learning phase.
The corresponding action can be performed multiple
times, each time increasing the local variable that rep-
resents the amount of gathered data. At the end of the
phase, the amount of gathered data is analysed and,
depending on the exact value, the agent’s prepara-
tion is marked as incomplete, complete, or excessive.
From this, the agent proceeds to the learning phase.
Learning Phase. Here, the agent can use the previ-
ously gathered data to train its local AI model. The
effectiveness of the training depends on the amount
of gathered data. Excessive data means that the model
can be easily overtrained, while insufficient data may
lead to more iterations required to properly train the
model. The training action can be performed multiple
times each time increasing the local variable related
to the quality of the model. At the end of this phase
the internal AI model can be overtrained, undertrained
or properly trained. After this phase, the agent is re-
quired to share its model with other agents.
Sharing Phase. Agents share their local AI mod-
els with each other following a simple sharing pro-
tocol. The protocol is based on packet traversal in the
ring topology. Each agent receives the model from
the agent with previous ID and sends its model to
the agent with next ID, while the last agent shares its
model with the first agent to close the ring. In order
to avoid any deadlocks, each agent with odd ID first
receives the model and then sends its own, and each
agent with even ID first sends its own model and then
receives the model from the agent before him.
When receiving the model, the agent can either
accept it or reject it, and its decision is based on the
quality of the model being shared. After accepting
the model, the agent merges it with its own and the
resulting model quality is the maximum of the two.
After the sharing phase, the agent can go back to
the learning phase to further train its model.
To formalize the details of the procedure, we have
utilised the open-source experimental model checker
STV (Kurpiewski et al., 2021), which was used, e.g.,
to model and verify the real-world voting protocol Se-
lene (Kurpiewski et al., 2022). Figure 1 presents a
detailed representation of an honest AI component as
an AMAS (left) and the STV code specifying its be-
havior (right). Figure 2 shows the visualization of the
component, produced by the tool.
4.2 Attacks
The model described in Section 4.1 reflects the ideal
scenario in which each agent is honest and directly
follows the protocol. Of course, it is not always the
case. A machine can malfunction, and take actions
not permitted by the protocol. Also, an agent can be
infected by malicious software, and function improp-
erly. This leads to two possible attack scenarios: the
man in the middle attack and the impersonator attack.
Man in The Middle. Assume the existence of an-
other, dishonest agent, called the intruder. This agent
does not participate in the data gathering and learning
phases, but it is particularly interested in the sharing
Towards Modelling and Verification of Social Explainable AI
399
q
0
q
1
q
2
q
3
q
4
q
5
q
6
q
7
q
8
start gathering
[AI1 data < 1] stop gathering
AI1 data = 0, AI1 completion = 1
[1 <= AI1 data < 2] sto p gathering
AI1 data = 0, AI1 completion = 2
[2 <= AI1 data] stop gathering
AI1 data = 0, AI1 completion = 3
skip gathering
start learning
[AI1 info < 1 ∧ AI1 mqual > 0] stop learning
AI1 info = 0, AI1 mstatus = 1, AI1 mqual− = 1
[AI1 info < 1 ∧ AI1 mqual ≤ 0] stop learning
AI1 info = 0, AI1 mstatus = 1
[1 ≤ AI1 info < 2 ∧ AI1 mqual < 2] stop learning
AI1 info = 0, AI1 mstatus = 2, AI1 mqual+ = 1
[1 ≤ AI1 info < 2 ∧ AI1 mqual ≥ 2] stop learning
AI1 info = 0, AI1 mstatus = 2
[2 ≤ AI1 info ∧ AI1 mqual > 0] stop learning
AI1 info = 0, AI1 mstatus = 3, AI1 mqual− = 1
[2 ≤ AI1 info ∧ AI1 mqual ≤ 0] stop learning
AI1 info = 0, AI1 mstatus = 3
skip learning
start sharing
share 3 with 1
AI1 mqual = %AI3 mqual
share 1 with 2 end sharing
repeat
[AI1 data < 2] gather data
AI1 data+ = 1
[AI1 info < 2] keep learning
AI1 info+ = AI1 completion
wait
Ag ent AI1 :
i n i t : s t a r t
%% −−−Phase1 : G a t h e ri n g d a t a −−−
s t a r t g a t h e r i n g d a t a : s t a r t −> g a t h e r
g a t h e r d a t a : g a t h e r −[ AI 1 d a ta <2]> g a t h e r
[ A I 1 d a ta += 1]
%% 1: I n co m pl e t e d a t a
s t o p g a t h e r i n g d a t a : g a t h e r −[ AI 1 d a ta < 1]> d a t a r e a d y
[ A I 1 d a ta = 0 , A I 1 d a t a c o m p l et i o n = 1]
%% 2: C omp l e te d a t a
s t o p g a t h e r i n g d a t a : g a t h e r −[1 <= A I1 d a t a < 2]> d a t a r e a d y
[ A I 1 d a ta = 0 , A I 1 d a t a c o m p l et i o n = 2]
%% 3: Too much d at a
s t o p g a t h e r i n g d a t a : g a t h e r −[2 <= A I1 d a t a]> d a t a r e a d y
[ A I 1 d a ta = 0 , A I 1 d a t a c o m p l et i o n = 3]
s k i p g a t h e r i n g d a t a : s t a r t −> d a t a r e a d y
%% −−−Phase2 : L ea r n in g ( b u i l d i n g l o c a l model)−−−
s t a r t l e a r n i n g : d a t a r e a d y −> l e a r n
k e e p l e a r n i n g : l e a r n −[ AI 1 i n f or m a t i o n < 2]> l e a r n
[ A I 1 i nf o r m a t io n += A I 1 d a t a c o m p l e t i on ]
%% 1: I n co m pl e t e model
s t o p l e a r n i n g : l e a r n
−[ A I 1 i n f or m a t i o n < 1 and A I 1 m o d el q u a l i ty > 0]> e d u c a t e d
[ A I 1 i nf o r m a t io n = 0 , A I 1 m o d e l s ta t u s = 1 , A I1 m od e l q u a l i t y −=1]
s t o p l e a r n i n g : l e a r n
−[ A I 1 i n f or m a t i o n < 1 and A I 1 m o d el q u a l i ty <= 0]> e du c at e d
[ A I 1 i nf o r m a t io n = 0 , A I 1 m o d e l s ta t u s = 1 ]
%% 2: C omp l e te model
s t o p l e a r n i n g : l e a r n
−[1 <= A I 1 i nf o r m a t i o n < 2 and A I 1 m o d e l q ua l i t y < 2]> e d u c a te d
[ A I 1 i nf o r m a t io n = 0 , A I 1 m o d e l s ta t u s = 2 , A I 1 m od e l q u a li t y +=1 ]
s t o p l e a r n i n g : l e a r n
−[1 <= A I 1 i nf o r m a t i o n < 2 and A I 1 m o d e l q ua l i t y >= 2]> e d u c a t ed
[ A I 1 i nf o r m a t io n = 0 , A I 1 m o d e l s ta t u s = 2 ]
%% 3: O v e r t r a i n e d mo de l
s t o p l e a r n i n g : l e a r n
−[2 <= A I 1 i nf o r m a t i o n a nd A I1 m o d e l q u a l i t y > 0]> e du c at e d
[ A I 1 i nf o r m a t io n = 0 , A I 1 m o d e l s ta t u s = 3 , A I1 m od e l q u a l i t y −=1]
s t o p l e a r n i n g : l e a r n
−[2 <= A I 1 i nf o r m a t i o n a nd A I1 m o d e l q u a l i t y <= 0]> e d u c at e d
[ A I 1 i nf o r m a t io n = 0 , A I 1 m o d e l s ta t u s = 3 ]
s k i p l e a r n i n g : d a t a r e a d y −> s h a r i n g
%% −−−Phase3 : S h ar i n g l o c a l m od els−−−
s t a r t s h a r i n g : e du c at e d −> s h a r i n g
%% S h a re l o c a l mo del an d g e t a ve r a g e q u a l i t y o f b o t h m odel s
%% r e c e i v e l e f t
s h a r e d s h a r e 3 w i t h 1 : s h a r i n g −> s ha r i n g 2
[ A I 1 m od e l q u a li t y=%A I 3 m od e l q u a li t y ]
%% s e n d r i g h t
s h a r e d s h a r e
1 w i t h 2 : s h a r i n g 2 −> s h a r i n g 3
e n d s h a r i n g : s h a r i n g 3 −> e nd
%% −−−Phase4 : End−−−
w a it : end −> en d
r e p e a t : end −> l e a r n
Figure 1: Honest AI agent: AMAS (left) and its specification in STV (right).
Figure 2: Visualization of honest AI in STV.
phase. The intruder can intercept any model that is
being sent by one of the honest agents and then pass
it to any other agent. The STV code for the man-in-
the-middle attacker is presented in Figure 3, and its
graphical representation in Figure 4.
Agen t Mim :
i n i t : s t a r t
s h a r ed s h a r e 1 w i t h m i m : s t a r t −> s t a r t
[ M im m o de l q ua l i t y = A I 1 m o d e l q u a l i t y ]
s h a r ed s h a r e m im w i th 1 : s t a r t −> s t a r t
s h a r ed s h a r e 2 w i t h m i m : s t a r t −> s t a r t
[ M im m o de l q ua l i t y = A I 2 m o d e l q u a l i t y ]
s h a r ed s h a r e m im w i th 2 : s t a r t −> s t a r t
Figure 3: Specification of the Man in the Middle agent.
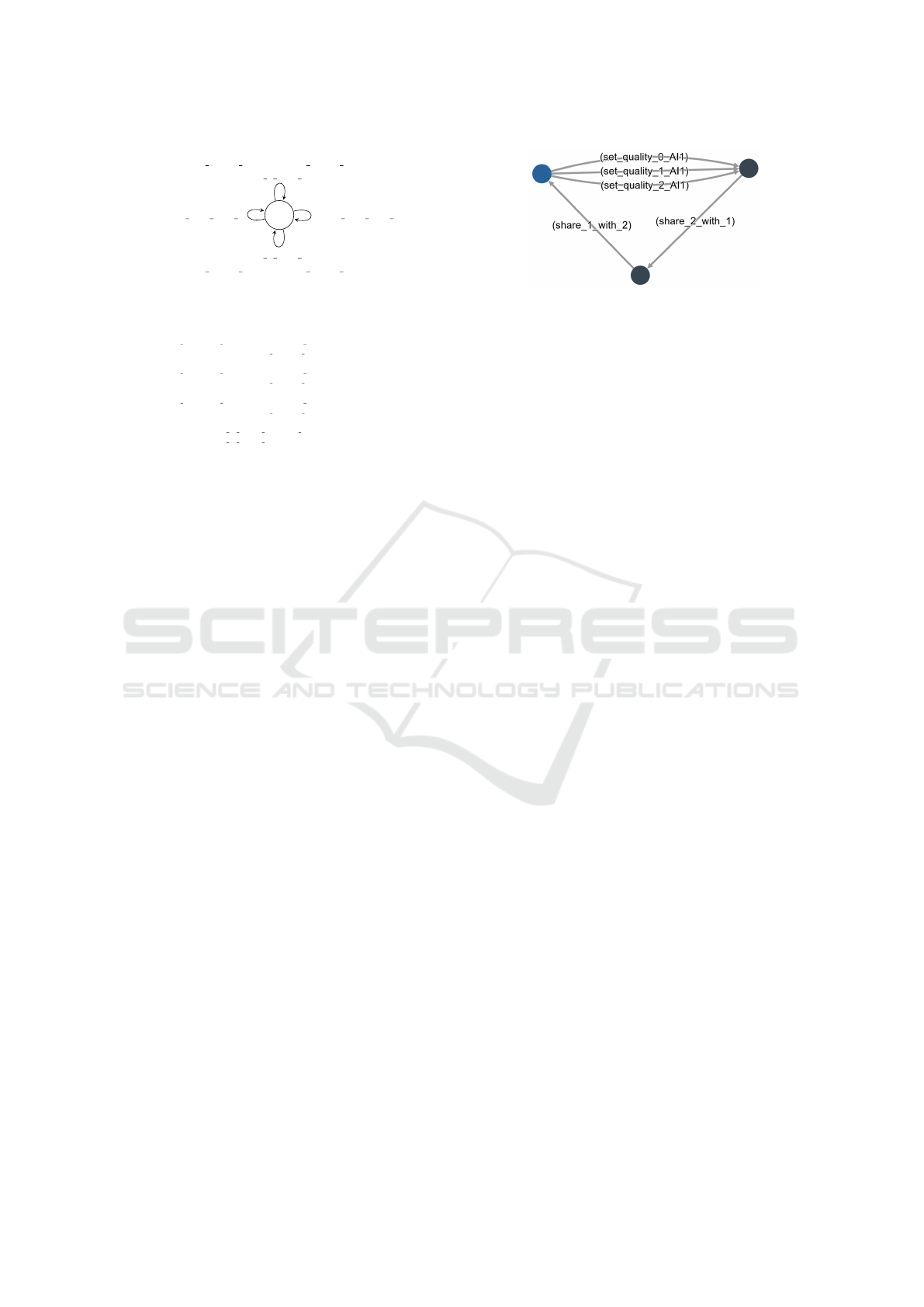
Impersonator. In this scenario, one of the AI agents
is infected with malicious code that results in un-
wanted behavior. The agent cannot participate in the
data gathering or learning phases, but can share its
model with others following the sharing protocol. The
difference between the honest agent and the imper-
sonator is that the latter can fake the quality of its local
AI model, hence tricking the next agent into accepting
it. The STV code and its visualization for Imperson-
ator are presented in Figures 5 and 6.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
400
q
0
Mim model quality = AI1 model quality
share 1 with mim
share 2 with mim
Mim model quality = AI2 model quality
share mim with 1 share mim with 2
Figure 4: Graphical representation of Man in the Middle.
Ag en t AI2 :
i n i t : s t a r t
s e t q u a l i t y 0 : s t a r t −> s e t q u a l i t y
[ A I 2 m o d e l q u a l i ty = 0 ]
s e t q u a l i t y 1 : s t a r t −> s e t q u a l i t y
[ A I 2 m o d e l q u a l i ty = 1 ]
s e t q u a l i t y 2 : s t a r t −> s e t q u a l i t y
[ A I 2 m o d e l q u a l i ty = 2 ]
s h a r e d s h a r e 2 w i t h 3 : s e t q u a l i t y −> s h a r i n g
s h a r e d s h a r e 1 w i t h 2 : s h a r i n g −> s t a r t
Figure 5: Specification of the Impersonator agent.
5 EXPERIMENTS
The STV tool can be used to combine the modules
presented in Figures 1–6, and generate the global
model of interaction. We present the output in Fig-
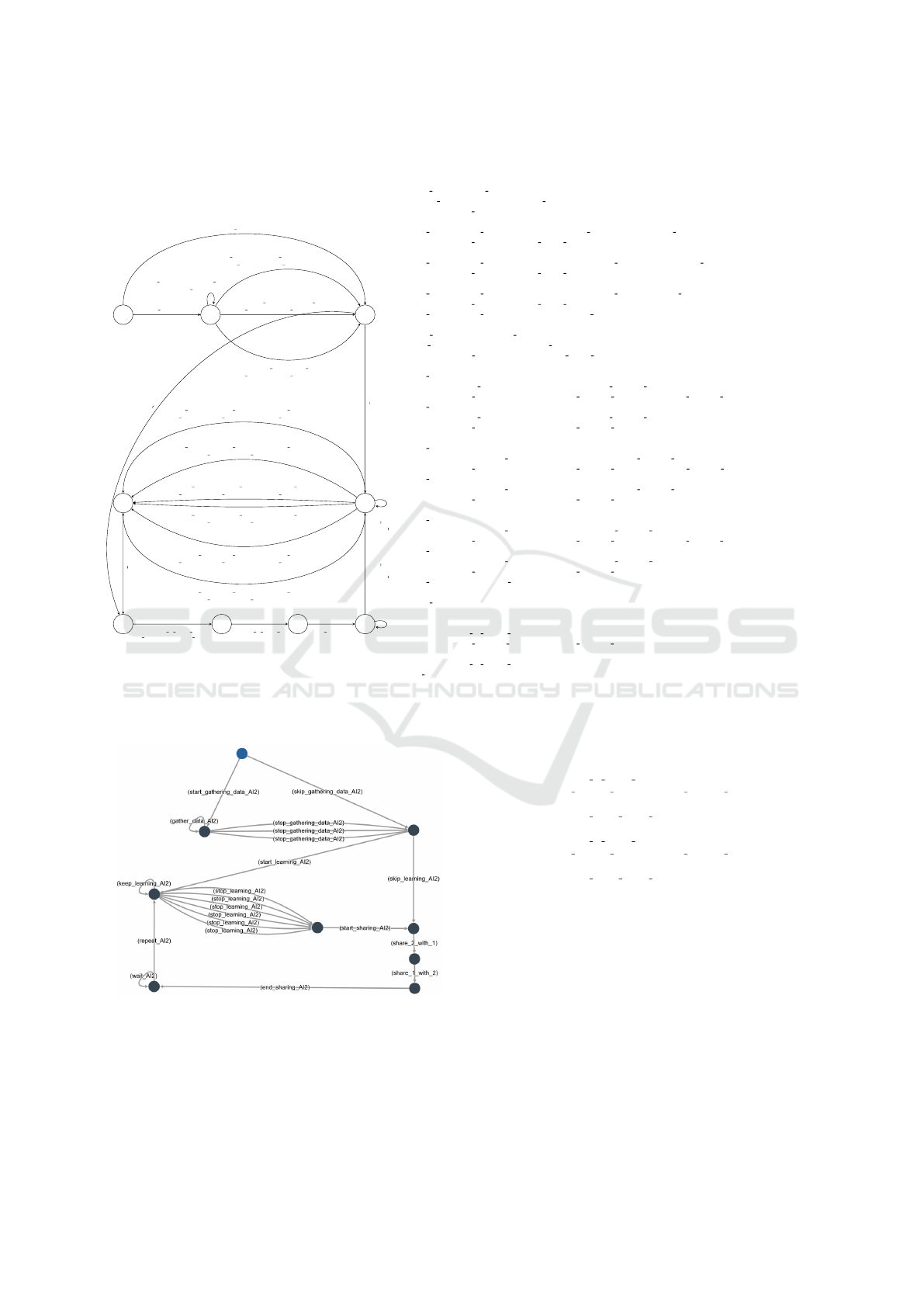
ures 7 (for the system with one honest AI agent) and 8
(for two honest agents). The models provide invalu-
able insights into the structure of possible interac-
tions. Still, a visual scrutiny is possible only in the
simplest cases due to the state-space explosion.
In more complex instances, we can use STV to
attempt an automated verification of strategic require-
ments. Since model checking of strategic ability is
hard for scenarios with partial observability (NP-hard
to undecidable, depending on the precise syntax and
semantics of the specification language (Bulling et al.,
2010)), exact verification is infeasible. Instead, we
use the technique of fixpoint approximation, proposed
in (Jamroga et al., 2019), and implemented in STV. In
what follows, we summarise the experimental results
obtained that way.
Models and Formulas. The scalable class of mod-
els has been described in detail in Section 4. In the
model checking experiments, we have used two vari-
ants of the system specification, one with a possible
impersonation attack, and the other one with the pos-
sibility of a man-in-the-middle attack. In each case,
we verified the following formulas:
• φ
1
≡ hhIiiG (shared
p
→ (
V
i∈[1,n]
mqual
i
≤ k))
• φ
2
≡ hhIiiG (shared
p
→ (
W
i∈[1,n]
mqual
i
≤ k))
Formula φ
1
checks whether the Intruder has a strat-
egy to ensure that all honest agents will not achieve
quality greater than k. Formula φ
2
checks whether the
Figure 6: Graphical representation of Impersonator in STV.
same is possible for at least one agent.
Configuration of The Experiments. The experi-
ments have been conducted with the latest version
of STV (Kurpiewski, 2022). The test platform was
a server equipped with ninety-six 2.40 GHz Intel
Xeon Platinum 8260 CPUs, 991 GB RAM, and 64-
bit Linux.
Results. We present the verification results in Fig-
ures 9 and 10. #Ag specifies the scalability factor,
namely the number of agents in the system. #st and
#tr report the number of global states and transitions
in the resulting model of the system, and Gen gives
the time of model generation. Verif φ
1
and Verif φ
2
present the verification time and its output for formu-
las φ
1
and φ
2
, respectively. All times are given in sec-
onds. The timeout was set to 8 hours.
Discussion. We were able to verify models of SAI
for up to 5 agents. The verification outcome was con-
clusive in all cases, i.e., the model checker always re-
turned either True or False. This means that we suc-
cessfully model-checked systems for up to almost a
billion transitions, which is a serious achievement for
an NP-hard verification problem. In all cases, formula
φ
2
turned out to be true. That is, both impersonation
and man-in-the-middle attacks can disrupt the learn-
ing process and prevent some agents from obtaining
good quality PAIVs. At the same time, φ
1
was false in
all cases. Thus, the intruder cannot disrupt all PAIVs,
even with its best attack.
6 CONCLUSIONS
In this paper, we present our work in progress on for-
mal analysis of Social Explainable AI. We propose
that formal methods for multi-agent systems provide
a good framework for multifaceted analysis of SAI
environments. As a proof of concept, we demonstrate
simple multi-agent models of SAI, prepared with the
model checker STV. Then, we use STV to formalize
and verify two variants of resistance to impersonation
and man-in-the-middle attacks, with very promising
results. Notably, we have been able to successfully
Towards Modelling and Verification of Social Explainable AI
401

Figure 7: Model of SAI with one honest agent.
Figure 8: Model of SAI with two honest agents.
#Ag #st #tr Gen Verif φ
1
Verif φ
2
2 886 2007 < 0.1 < 0.1/False < 0.1/True
3 79806 273548 28 151/False 202/True
4 6538103 29471247 1284 5061/False 5102/True
5 93581930 623680431 7845 25828/False 25916/True
6 timeout
Figure 9: Verification results for the Impersonator attack.
#Ag #st #tr Gen Verif φ
1
Verif φ
2
3 23966 67666 12 21/False 33/True
4 4798302 20257664 875 3810/False 3882/True
5 71529973 503249452 5688 19074/False 20103/True
6 timeout
Figure 10: Verification results for Man in the Middle.
model-check models of systems for up to almost a
billion transitions – a considerable achievement for
an NP-hard verification problem.
ACKNOWLEDGEMENTS
The work has been supported by NCBR Poland
and FNR Luxembourg under the PolLux/FNR-CORE
project STV (POLLUX-VII/1/2019), by NCN Poland
under the CHIST-ERA grant CHIST-ERA-19-XAI-
010 (2020/02/Y/ST6/00064), and by the CNRS IEA
project MoSART.
REFERENCES
Akintunde, M. E., Botoeva, E., Kouvaros, P., and Lomus-
cio, A. (2022). Formal verification of neural agents in
non-deterministic environments. Auton. Agents Multi
Agent Syst., 36(1):6.
Alur, R., Henzinger, T. A., and Kupferman, O. (2002).
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
402

Alternating-time Temporal Logic. Journal of the
ACM, 49:672–713.
Batten, B., Kouvaros, P., Lomuscio, A., and Zheng, Y.
(2021). Efficient neural network verification via layer-
based semidefinite relaxations and linear cuts. In Pro-
ceedings of IJCAI, pages 2184–2190. ijcai.org.
Bulling, N., Dix, J., and Jamroga, W. (2010). Model check-
ing logics of strategic ability: Complexity. In Dastani,
M., Hindriks, K., and Meyer, J.-J., editors, Specifi-
cation and Verification of Multi-Agent Systems, pages
125–159. Springer.
Bulling, N., Goranko, V., and Jamroga, W. (2015). Logics
for reasoning about strategic abilities in multi-player
games. In van Benthem, J., Ghosh, S., and Verbrugge,
R., editors, Models of Strategic Reasoning. Logics,
Games, and Communities, volume 8972 of Lecture
Notes in Computer Science, pages 93–136. Springer.
Clarke, E., Henzinger, T., Veith, H., and Bloem, R., editors
(2018). Handbook of Model Checking. Springer.
Conti, M. and Passarella, A. (2018). The internet of peo-
ple: A human and data-centric paradigm for the next
generation internet. Comput. Commun., 131:51–65.
Contucci, P., Kertesz, J., and Osabutey, G. (2022). Human-
ai ecosystem with abrupt changes as a function of the
composition. PLOS ONE, 17(5):1–12.
Dolev, D. and Yao, A. C. (1983). On the security of public
key protocols. IEEE Trans. Inf. Theory, 29(2):198–
207.
Drainakis, G., Katsaros, K. V., Pantazopoulos, P., Sourlas,
V., and Amditis, A. (2020). Federated vs. centralized
machine learning under privacy-elastic users: A com-
parative analysis. In Proceedings of NCA, pages 1–8.
IEEE.
Emerson, E. (1990). Temporal and modal logic. In van
Leeuwen, J., editor, Handbook of Theoretical Com-
puter Science, volume B, pages 995–1072. Elsevier.
Fuchs, A., Passarella, A., and Conti, M. (2022). Model-
ing human behavior part I - learning and belief ap-
proaches. CoRR, abs/2205.06485.
Gollmann, D. (2011). Computer Security (3. ed.). Wiley.
Goodfellow, I. J., McDaniel, P. D., and Papernot, N. (2018).
Making machine learning robust against adversarial
inputs. Commun. ACM, 61(7):56–66.
Heged
¨
us, I., Danner, G., and Jelasity, M. (2019). Gos-
sip learning as a decentralized alternative to federated
learning. In Proceedings of IFIP DAIS, volume 11534
of Lecture Notes in Computer Science, pages 74–90.
Springer.
Heged
¨
us, I., Danner, G., and Jelasity, M. (2021). Decen-
tralized learning works: An empirical comparison of
gossip learning and federated learning. J. Parallel Dis-
tributed Comput., 148:109–124.
Jamroga, W., Knapik, M., Kurpiewski, D., and Mikulski, Ł.
(2019). Approximate verification of strategic abilities
under imperfect information. Artificial Intelligence,
277.
Jamroga, W., Penczek, W., and Sidoruk, T. (2021). Strate-
gic abilities of asynchronous agents: Semantic side
effects and how to tame them. In Proceedings of KR
2021, pages 368–378.
Jamroga, W., Penczek, W., Sidoruk, T., Dembi
´
nski, P., and
Mazurkiewicz, A. (2020). Towards partial order re-
ductions for strategic ability. Journal of Artificial In-
telligence Research, 68:817–850.
Kianpour, M. and Wen, S. (2019). Timing attacks on ma-
chine learning: State of the art. In IntelliSys Volume 1,
volume 1037 of Advances in Intelligent Systems and
Computing, pages 111–125. Springer.
Kouvaros, P. and Lomuscio, A. (2021). Towards scal-
able complete verification of relu neural networks via
dependency-based branching. In Proceedings of IJ-
CAI, pages 2643–2650. ijcai.org.
Kumar, R. S. S., Nystr
¨
om, M., Lambert, J., Marshall, A.,
Goertzel, M., Comissoneru, A., Swann, M., and Xia,
S. (2020). Adversarial machine learning-industry per-
spectives. In IEEE Security and Privacy Workshops,
pages 69–75. IEEE.
Kurpiewski, D. (2022). STV – StraTegic Verifier. code
repository. https://github.com/blackbat13/stv.
Kurpiewski, D., Jamroga, W., Masko, L., Mikulski, L.,
Pazderski, W., Penczek, W., and Sidoruk, T. (2022).
Verification of Multi-agent Properties in Electronic
Voting: A Case Study. In Proceedings of AiML 2022.
Kurpiewski, D., Pazderski, W., Jamroga, W., and Kim, Y.
(2021). STV+Reductions: Towards practical verifi-
cation of strategic ability using model reductions. In
Proceedings of AAMAS, pages 1770–1772. ACM.
Lomuscio, A., Qu, H., and Raimondi, F. (2017). MCMAS:
An open-source model checker for the verification of
multi-agent systems. International Journal on Soft-
ware Tools for Technology Transfer, 19(1):9–30.
Lorenzo, V., Boldrini, C., and Passarella, A. (2022). SAI
simulator for social AI gossiping. https://zenodo.org/
record/5780042.
Ottun, A.-R., Mane, P. C., Yin, Z., Paul, S., Liyanage,
M., Pridmore, J., Ding, A. Y., Sharma, R., Nurmi,
P., and Flores, H. (2022). Social-aware federated
learning: Challenges and opportunities in collabora-
tive data training. IEEE Internet Computing, pages
1–7.
Pauly, M. (2002). A modal logic for coalitional power
in games. Journal of Logic and Computation,
12(1):149–166.
Schobbens, P. (2004). Alternating-time logic with imper-
fect recall. Electronic Notes in Theoretical Computer
Science, 85(2):82–93.
Shoham, Y. and Leyton-Brown, K. (2009). Multiagent
Systems - Algorithmic, Game-Theoretic, and Logical
Foundations. Cambridge University Press.
Social AI gossiping. Micro-project in Humane-AI-Net
(2022). Project website. https://www.ai4europe.eu/
research/research-bundles/social-ai-gossiping.
Social Explainable AI, CHIST-ERA (2021–24). Project
website. http://www.sai-project.eu/.
Toprak, M., Boldrini, C., Passarella, A., and Conti, M.
(2021). Harnessing the power of ego network layers
for link prediction in online social networks. CoRR,
abs/2109.09190.
Weiss, G., editor (1999). Multiagent Systems. A Modern
Approach to Distributed Artificial Intelligence. MIT
Press: Cambridge, Mass.
Wu, M., Wicker, M., Ruan, W., Huang, X., and
Kwiatkowska, M. (2020). A game-based approxi-
mate verification of deep neural networks with prov-
able guarantees. Theor. Comput. Sci., 807:298–329.
Towards Modelling and Verification of Social Explainable AI
403
