
Learning to Participate Through Trading of Reward Shares
Michael K
¨
olle, Tim Matheis, Philipp Altmann and Kyrill Schmid
Institute of Informatics, LMU Munich, Oettingenstraße 67, Munich, Germany
Keywords:
Multi-Agent Systems, Reinforcement Learning, Social Dilemma.
Abstract:
Enabling autonomous agents to act cooperatively is an important step to integrate artificial intelligence in our
daily lives. While some methods seek to stimulate cooperation by letting agents give rewards to others, in
this paper we propose a method inspired by the stock market, where agents have the opportunity to participate
in other agents’ returns by acquiring reward shares. Intuitively, an agent may learn to act according to the
common interest when being directly affected by the other agents’ rewards. The empirical results of the tested
general-sum Markov games show that this mechanism promotes cooperative policies among independently
trained agents in social dilemma situations. Moreover, as demonstrated in a temporally and spatially extended
domain, participation can lead to the development of roles and the division of subtasks between the agents.
1 INTRODUCTION
The field of cooperative AI seeks to explore methods
which establish cooperative behavior among indepen-
dent and autonomous agents (Dafoe et al., 2020). The
ability to act cooperatively is a mandatory step in
order to integrate artificial intelligence in our daily
lives especially in applications where different deci-
sion makers interact like autonomous driving. Vari-
ous breakthroughs in the field of single agent domains
(Mnih et al., 2015; Silver et al., 2017) have also led to
the successful application of reinforcement learning
in the field of multi-agent systems (Leibo et al., 2017;
Phan et al., 2018; Vinyals et al., 2019). However,
while purely cooperative scenarios, where all agents
receive the same reward and thus pursue the same
goal, can be addressed with centralized training tech-
niques, this is not the case if agents have individual re-
wards and goals. Moreover, if agents share resources
it is likely that undesired behaviors are learned, espe-
cially when resources are getting scarce (Leibo et al.,
2017). Independent optimization may lead to sub-
optimal outcomes such as for the Prisoner’s dilemma
or public good games. In more complex games, the
agents’ risk-aversion as well as information asymme-
try additionally deteriorate the likelihood of a desired
outcome (Schmid et al., 2020).
In recent years, various approaches have been
proposed to promote cooperation among independent
agents, such as learning proven game theoretic strate-
gies like tit-for-tat (Lerer and Peysakhovich, 2018),
C D
C (-1, -1)
(-3, 0)
D (-3, 0) (-2, -2)
(a) PD without particpation
C D
C (-1, -1)
(
-1.5,-1.5
)
D
(
-1.5,-
1.5)
(-2, -2)
(b) PD with 50% particpation
Figure 1: By enabling agents to trade shares in their payoffs,
a socially optimal outcome may be achieved.
the possibility for agents to incentivize each other to
be more cooperative (Schmid et al., 2018; Lupu and
Precup, 2020; Yang et al., 2020), or the integration of
markets to let agents trade for increased overall wel-
fare (Schmid et al., 2021b). In this work, we adopt the
market concept in order to generate increased coop-
eration between independent decision makers. More
specifically, we propose a method that allows agents
to trade shares of their own rewards. In the presence
of such a participation market, we argue that a bet-
ter equilibrium can be reached by letting agents di-
rectly participate in other agents’ rewards. A socially
optimal equilibrium may be established due to the di-
rect incorporation of all global rewards instead of only
incorporating individual rewards. Enabling agents to
trade their shares at a fair price, while at the same time
creating a trading path that in fact leads to a beneficial
distribution of shares, represents the hardest challenge
when implementing this model.
To motivate the effectiveness of participation,
consider the Prisoner’s dilemma (PD) as depicted in
Figure 1. In the standard version of the Prisoner’s
Kölle, M., Matheis, T., Altmann, P. and Schmid, K.
Learning to Participate Through Trading of Reward Shares.
DOI: 10.5220/0011781600003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 1, pages 355-362
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
355

dilemma, each agent receives its individual reward.
For two rational decision makers, the only Nash equi-
librium lies in mutual defection (DD), which is so-
cially undesirable. However, if we introduce the abil-
ity of reward trading and each agent holds shares in
the other agent’s return (say 50% participation), then
the overall dynamic changes and mutual cooperation
becomes a dominant strategy.
In order to train agents to participate, we apply
different methods of reinforcement learning, so that
the agents autonomously find strategies. Thus, par-
ticipation in other agents’ returns is realized over the
course of many training episodes. To that end, differ-
ent variants of the market for participation are tested
in this work, which differ in the way the participa-
tion mechanism is implemented. More specifically,
the following contributions are made:
• A theoretical motivation is given why market par-
ticipation is beneficial.
• The participation mechanism is empirically eval-
uated in the Prisoner’s dilemma as well as in a
complex multi-agent scenario, called the clean-up
game (Yang et al., 2020).
All code for the experiments can be found here
1
.
2 RELATED WORK
Despite the increasing success of reinforcement learn-
ing on an expanding set of tasks, most effort has been
devoted to single-agent environments as well as fully
cooperative multi-agent environments (Mnih et al.,
2015; Silver et al., 2017; Vinyals et al., 2019; Ope-
nAI et al., 2019). However, with multiple agents in-
volved their goals are often not (perfectly) aligned,
which renders centralized training techniques in gen-
eral unfeasible. The drawback of fully decentralized
models is that agents focus only on their individual
rewards, which therefore might result in undesirable
collective performance especially in situations of so-
cial dilemmas or with common pool resources (Leibo
et al., 2017; Perolat et al., 2017).
Previously, one way of tackling this problem has
been to give independent agents intrinsic rewards (Ec-
cles et al., 2019; Hughes et al., 2018; Wang et al.,
2019). The concept of intrinsic rewards draws from
concepts in behavioral economics such as altruistic
behavior, reciprocity, inequity aversion, social influ-
ence, and peer evaluations. These intrinsic rewards
are usually either predefined or they evolve based on
the other agents’ performance over the game. Other
1
https://github.com/TimMatheis/Learning-to-participate
works suggest that reward mechanisms (Yang et al.,
2020) or penalty mechanisms (Schmid et al., 2021a)
may lead to cooperation in sequential social dilem-
mas. The literature distinguishes between selective
incentives and sanctioning mechanisms which incen-
tivize cooperative behavior in social dilemmas (Kol-
lock, 1998). Selective incentives describe methods
that attempt to positively promote cooperation. For
instance, this could occur by giving monetary rewards
to reduce the consumption of common pool goods,
such as water or electricity (Maki et al., 1978). Con-
trarily, penalties could be a method to reduce defec-
tive behavior. In fact, experiments with humans sug-
gest that penalties are effective in reducing defective
behavior (Komorita, 1987).
In LIO (Yang et al., 2020), a reward-giver’s in-
centive function is learned on the same timescale as
policy learning. Adding an incentive function is a de-
viation from classical reinforcement learning, where
the reward function is the exclusive property of the
environment, and is only altered by external factors.
As shown by empirical research (Lupu and Precup,
2020), augmenting an agent’s action space with a
“give-reward” action can improve cooperation during
certain training phases. Through opponent shaping,
an agent can influence the learning update of other
agents for its own benefit. A different attempt at op-
ponent shaping is to account for the impact of one
agent’s policy on the anticipated parameter update
of the other agents (Foerster et al., 2018). Through
this additional learning component in LOLA, strate-
gies like tit-for-tat can emerge in the iterated Pris-
oner’s dilemma, whereby cooperation can be main-
tained.
Other work in the field suggests markets as vehi-
cles for cooperativeness (Schmid et al., 2018; Schmid
et al., 2021b). Usually, agents only receive their in-
dividual rewards. As they are not affected by the
other agents’ individual rewards, they only act in their
own interest. However, by only receiving individual
rewards, the agents are exposed to substantial risk.
According to economic theory, it is usually benefi-
cial to be diversified. In portfolio theory, there is a
common agreement that diversification increases ex-
pected returns. Although people do not seem to diver-
sify enough, which is called the diversification puzzle
(Statman, 2004), a rational agent should be perfectly
diversified and should only hold a combination of the
market portfolio and a risk-free asset (such as a safe
government bond). When applying this to games such
as the Prisoner’s dilemma, the agents should be inter-
ested in receiving a combination of their individual
rewards and the other agents’ individual rewards to
minimize their risk exposure.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
356

3 LEARNING TO PARTICIPATE
Multi-agent systems consist of multiple agents that
share a common environment. An agent is an au-
tonomous entity with two main capabilities: perceiv-
ing and acting. The perception of the current state of
the environment allows the agent to choose an appro-
priate action out of an action set. The chosen action
depends on an agent’s policy. Reinforcement learning
methods are often applied to teach an agent a good
policy in multi-agent reinforcement learning.
Since cooperative strategies can be difficult to find
and maintain, we suggest a participation mechanism.
The idea is to let agents participate in other agents’
environmental rewards directly in order to align their
formerly conflicting goals. In the following, we use
the trading of participation shares as an instrument to
make cooperation possible. If the agents are willing
to hold a significant amount of shares in all agents’
rewards, they may act in the “society’s interest”.
Namely, the difference of the individual interest of a
single agent and the common interest of the collective
of all agents could vanish. In our implementation, two
agents only trade shares whenever both choose to in-
crease or decrease the amount of their own shares. In
the initial state, agents hold 100% of their own shares.
If the agents want to be perfectly diversified, each
agent could have
100%
n
shares, with n denoting the
number of agents in the environment, of every agent’s
rewards after some trading steps.
4 EXPERIMENTS
In this section, we examine our theoretical considera-
tions in the iterated prisoner’s dilemma and the clean-
up game experimentally.
4.1 The Iterated Prisoner’s Dilemma
The prisoner’s dilemma can be thought of as the
action of two burglars. When they get caught,
they can decide between a
0
= admitting and a
1
=
notadmitting a crime. If both admit the crime, they
receive a high punishment. If none of them admits
the crime, they only receive a low punishment. The
dilemma evolves from the case in which only one of
them admits the crime. Then, the admitter is not pun-
ished due to its status as a principal witness, whereas
the denier receives a very high punishment. Admit-
ting is the defective (D) action and not admitting is
the cooperative (C) action in Figure 1. By definition,
none of the agents can put itself in a better position by
changing its strategy in a Nash equilibrium. Agent 1
knows that agent 2 can defect and cooperate. When
agent 2 defects, agent 1 is better off by defecting as
well. If agent 2 cooperates instead, agent 1 is again
better off by defecting. Thus, agent 1 should defect in
any case, which makes defecting a dominant strategy
in a one-shot game. By symmetry, agent 2 faces the
same problem and should also defect. The tragedy is
that this outcome is not desirable, as mutual coopera-
tion leads to a better payoff for both agents. When the
game is iterated multiple times, defecting is in theory
not necessarily dominant.
Although the agents could defect in every itera-
tion based on backward induction, the agents could
develop strategies to incentivize cooperation.
4.2 Participation in the Iterated
Prisoner’s Dilemma
For testing different implementations of the iterated
prisoner’s dilemma, we use an actor-critic method.
We adapt Algorithm 1 from LIO ((Yang et al., 2020)
page 5) by replacing the incentive function and its pa-
rameter η with a greater action space during the whole
episode or a preliminary trade action. Hence, either
the actions specify an environment action as well as a
trade action during the whole episode, or there is one
additional step at the start of each episode in which
the participation is determined, or both.
We use the same fully-connected neural network
for function approximation as LIO. However, we only
use the policy network, as we do not make use of the
incentive function, for which LIO uses another neu-
ral network. The policy network has a softmax output
for discrete actions in all environments. For all ex-
periments, we use the same architecture and the same
hyperparameters: β = 0.1, ε
start
= 1.0, ε
end
= 0.01,
α
θ
= 1.00E − 03. As the agents do not participate in
the other agent’s rewards at the start, max steps is set
to 40 instead of 5 in the implementations with trading.
Hence, they have enough steps for trading. We test the
following implementations of the iterated Prisoner’s
dilemma with two agents.
(i) No Participation. The possible environment ac-
tions of each agent are cooperation and defection. In
the implementation, these two actions are encoded as
0 and 1. There are four possible states: (cooperation,
cooperation), (cooperation, defection), (defection, co-
operation), (defection, defection). If the agents chose
their actions randomly, the average individual reward
would be (−1 + 0 − 3 − 2)/4 = −1.5. If instead the
agents learned to maintain a cooperative equilibrium
in which both choose cooperation, the individual re-
wards would converge to −1. But according to theory,
defection is a dominant action in the “classical” Pris-
Learning to Participate Through Trading of Reward Shares
357

oner’s dilemma. In that case, the individual rewards
would converge to −2. Indeed, in the implementa-
tion without participation shares, a stable equilibrium
evolves in which both agents defect. The accumulated
reward converges to −2 + (−2) = −4 (Figure 2).
(ii) Equal Distribution of Individual Rewards. In
this implementation, the agents always receive the av-
erage reward of all individual shares. Mathematically
speaking, this means that all individual rewards are
aggregated and then divided by the number of agents:
1
n
×
∑
n
i
reward
i
for n agents. The action space and ev-
erything else stays the same. An agent cannot choose
between sharing the rewards or receiving the individ-
ual reward. Each agent learns to cooperate, which
leads to an accumulated reward of −1 + (−1) = −2.
In this implementation, cooperating is a dominant ac-
tion. This implementation demonstrates that the shar-
ing of rewards can lead to cooperation. However, it
does not demonstrate whether the agents can actively
find and maintain such an equilibrium, when they can
freely trade (Figure 2).
(iii) Choosing Whether to Share Rewards. The
agents can decide to share their individual rewards.
The action space is extended. In addition to the
two environment actions, an agent can choose be-
tween sharing the rewards or receiving the individ-
ual reward. The action space is defined by an ac-
tion tuple: the environment action and the trade ac-
tion. Hence, there are now 2 × 2 = 4 possible actions
per agent. Importantly, an individual agent cannot
determine whether the combined rewards are evenly
divided between both agents. Instead, this is only
the case if both agents decide to share their rewards.
The state space is extended to eight states: sharing ×
env. action 1 × env. action 2 = 2 × 2 × 2 = 8. Both
agents learn to defect, which leads to an accumulated
reward of −2 + (−2) = −4 (Figure 2). In this im-
plementation, defecting without sharing is a dominant
action. Hence, the sole opportunity to share rewards
is not enough.
(iv) Trading 50% Shares. Initially, both agents do
not hold participation shares of the other agent. In
every step, they can choose between six actions. An
action can be regarded as a 3-tuple: the environment
action, whether to increase the shares of the own re-
wards, and whether to increase the shares of the other
agent’s rewards. When an agent decides to cooper-
ate, there are three possible actions: (cooperate, not
buy own shares, not buy other agent’s shares), (coop-
erate, buy own shares, not buy other agent’s shares),
(cooperate, not buy own shares, buy other agent’s
shares). Symmetrically, there are three possible ac-
tions for defection. Again, a trade of shares is only
executed if both agents intend to do so. For instance,
if both choose to buy own shares and they hold 50%
in each agent’s rewards, they exchange shares and
now hold 100% of their own shares. This would
mean that there is no participation anymore. How-
ever, if they now choose to buy own shares again,
this trade cannot occur, as they already hold all of
their own shares. As a consequence, only the envi-
ronment action has an effect. The implication is that
all shares are valued at the same price, they are just
exchanged in the same proportions, and the sum of
shares per agent is always 100%. There are 36 states:
env. actions×portion own shares × trade = 4 ×3 ×3.
The portion of own shares can be 0, 0.5, or 1. The
“trade” variable represents whether there is no trade,
a trade which leads to an increasing amount of own
shares, or a trade which leads to a decreasing amount
of own shares. This implementation is successful in
establishing cooperation. The accumulated rewards
converge to −1 + (−1) = −2 (Figure 2b). However,
the learning process takes rather long. Additionally,
the actions and rewards first drift off to the previous
inefficient equilibrium.
(v) Trading 10% Shares. Compared to the trading of
50% shares, the state space increases to 4 × 11 × 3 =
132 because the proportion of own shares can now be
0, 0.1, 0.2, ..., 1. Again, a socially optimal equilibrium
can be established. A proportion of around 40% own
shares and 60% other shares seems to be efficient to
make the agents not deviate to defection (Figure 2).
4.3 The Clean-Up Game
In the clean-up game, multiple agents simultaneously
attempt to collect apples in the same environment. An
agent gets rewarded +1 for each apple that they col-
lect. The apples spawn randomly on the right side
of a quadratic 7x7 or 10x10 map. On the left side
of the map, there is a river that gets increasingly pol-
luted with waste. As the waste level increases and ap-
proaches a depletion threshold, the apple spawn rate
decreases linearly to zero. To avoid a quick end of
the game, an agent can fire a cleaning beam to clear
waste. But an agent can only do so when being in
the river. The cleaning beam then clears all the waste
upwards from the agent. Each agent’s observation is
an egocentric RGB image of the whole map. The
dilemma is that clearing waste by staying in the river
and firing cleaning beams is less attractive than re-
ceiving rewards by collecting apples. However, if all
agents focus on only collecting apples, the game is
quickly over and the total reward of the agents re-
mains very low. Hence, the game is an intertemporal
social dilemma, in which there is a trade-off between
short-term individual incentives and long-term collec-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
358
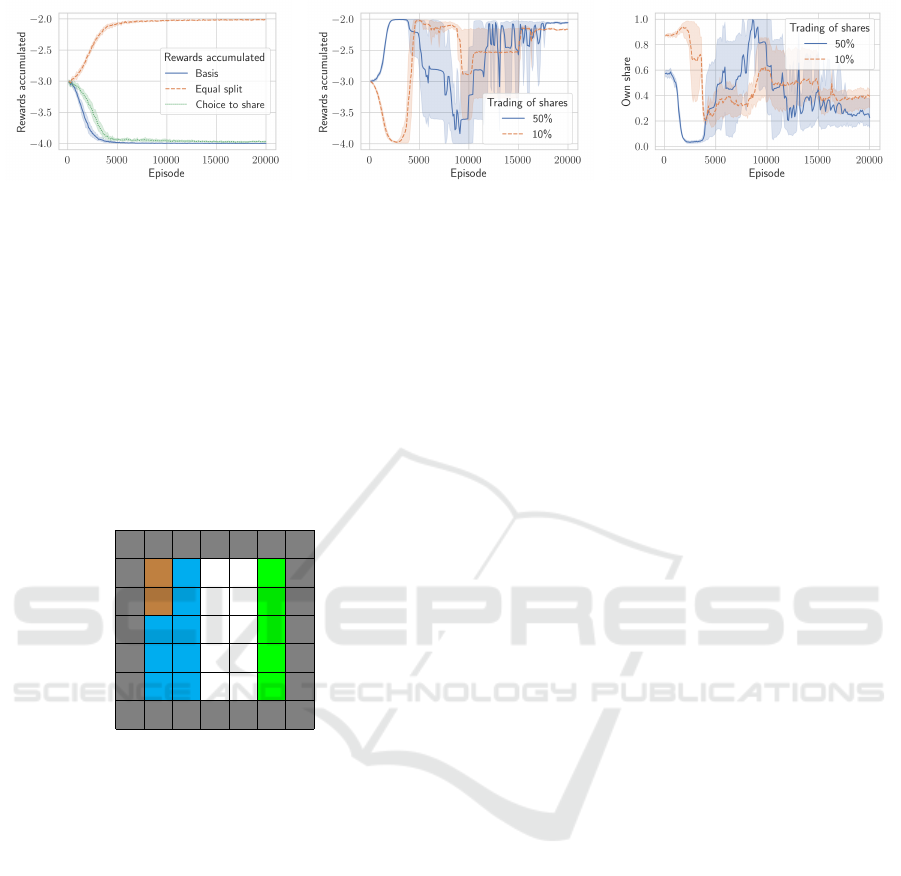
(a) Rewards (b) Rewards with trading of 10% or 50%
shares
(c) Shares in own reward
Figure 2: Results from the iterated Prisoner’s dilemma with and without participation.
tive interest (Hughes et al., 2018). This domain is
especially interesting as models based on behavioral
economics can only explain cooperation in simple,
unrealistic, stateless matrix games. In contrast, the
cleanup game is a temporally and spatially extended
Markov game.
4.4 Participation in the Clean-Up Game
with Two Agents
A2
A1
Figure 3: Small 7x7 map with two agents. Agent 1 gets
spawned by the river, whereas agent 2 gets spawned close
to the apples. If they do not divide their tasks, the game is
likely to stop soon, as the waste expands downwards if it is
not cleared by the agents.
The smaller 7x7 map is used as described in (Yang
et al., 2020). The initial state of the game is displayed
in Figure 3. The blue cells on the left side of the map
represent the river, the green cells indicate the area
where apples are randomly spawned, and the brown
cells represent the waste. Agent 1 gets spawned in the
river, which enables it to clear the waste. Agent 2 gets
spawned close to the green area on the right where
apples are randomly spawned. This already gives a
hint at one possible strategy, which consists of agent
1 clearing the waste, and agent 2 collecting the apples.
However, there is no justifying reason for agent 1 to
clear waste as long as it does not get the chance to col-
lect apples or profits from agent 2’s rewards. Agent 2
is in a similar dilemma. If it attempts to collect apples
by being in the green area, it cannot fire the cleaning
beam. Without a division of work between the agents,
the game must stop early, as the blue and green area
are too far away. The possible environment actions of
each agent are move left, move right, move up, move
down, no operation, and cleaning. In all implemen-
tations of the clean-up domain, an actor-critic method
is used. The optimization is decentralized.
We use the same convolutional networks to pro-
cess image observations in Cleanup as LIO. The pol-
icy network has a softmax output for discrete actions
in all environments. For all experiments, We use the
same neural architecture. We test the following im-
plementations of the clean-up game with two agents.
(i) No Participation. Without any additional incen-
tive structures, the social dilemma seems unsolvable.
As depicted in Figure 4a, the accumulated reward re-
mains at a very low level. Cooperation is not attrac-
tive for any of the agents. It is difficult to learn that
clearing waste is creating value since the apples are
spawned far away from the river. If the agent moves
back from the river to the apples, the game is likely to
stop before it even collects an apple.
(ii) LIO. The baseline scenario is augmented with
the possibility for each agent to give rewards to the
other agent as an additional channel for cooperation.
Importantly, the additional reward payments r
j
η
i
from
agent i to agent j is learned via direct gradient as-
cent on the agent’s own extrinsic objective, involv-
ing its effect on all other agents’ policies. Hence, the
payments are not part of the reinforcement learning,
leaving the action space of the reinforcement learner
unaffected (instead of augmenting it). The agents suc-
cessfully divide their tasks. The one that is closer to
the river and waste becomes the cleaner, whereas the
one that is closer to the apples specializes in collect-
ing apples. See (Yang et al., 2020) for implementation
details.
(iii) Equal Distribution of Individual Rewards. In
this scenario, the baseline scenario is augmented with
the equal distribution of the joint rewards between the
agents after each step. This additional computation
does not affect the state or action space. Similar to
LIO, the one that is closer to the river turns into the
Learning to Participate Through Trading of Reward Shares
359
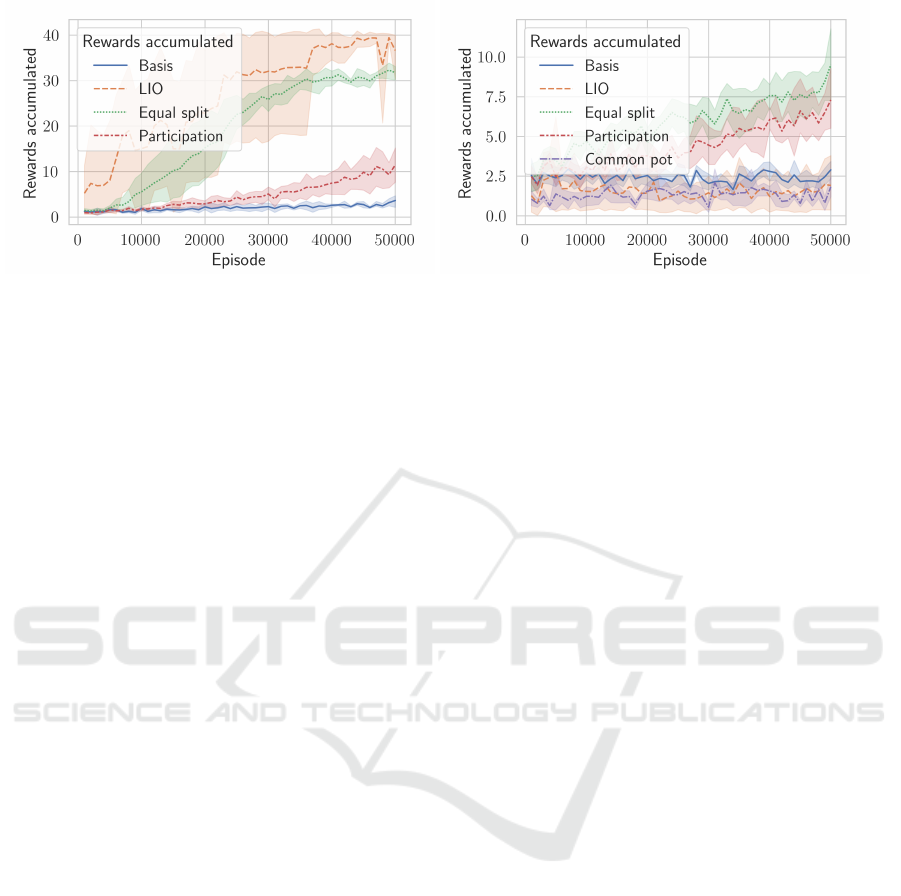
(a) Two agents (b) Three agents
Figure 4: Results from the clean-up game.
cleaner, whereas the one that is closer to the apples
specializes in collecting apples. Both profit from this
task division, as both are evenly rewarded for any ap-
ple being collected by anyone. In comparison with
LIO, the learning process looks less volatile.
(iv) Pre-Trade of Participation Rights. In this sce-
nario, there is an additional first step added to each
episode of the baseline scenario. In this first step,
both agents can choose between six actions (0-5),
representing 0%, 20%, 40%, 60%, 80%, and 100%.
The maximum of both agents’ chosen number deter-
mines the participation in their own rewards over the
episode. The remaining portion is the participation in
the other agent’s individual rewards. For instance, if
agent 1 chooses 40%, and agent 2 prefers 80%, they
will receive 80% of their individual rewards and 20%
of the other agent’s individual rewards. The additional
first step is part of the reinforcement learning, but
no rewards are distributed in this step. The idea be-
hind the additional trade step is that both agents can
avoid cooperation by choosing 100%. By taking the
maximum, the more conservative action is executed.
Again, the agents successfully divide their tasks. The
amount of waste cleared by agent 1 moves in parallel
with the accumulated rewards. However, the magni-
tude of the joint rewards only reaches around 11, and
it is unclear whether this is a stable level.
5 CONCLUSION
By introducing the idea of participating in other
agents’ rewards, we suggest a new method for co-
ordination and cooperation in shared multi-agent en-
vironments. Agents learn that direct participation in
other agents’ rewards reinforces policies that opti-
mize a global objective. Through this mechanism,
no additional extrinsic incentive structures are needed
such as in LIO (Yang et al., 2020). Other previous
works focused on intrinsic incentives (Eccles et al.,
2019; Hughes et al., 2018; Wang et al., 2019) which
would not be needed either. Especially the simplis-
tic and graspable extension of standard models makes
the participation appealing. In the two tested social
dilemma problems, the Iterated Prisoner’s dilemma
and Cleanup, the opportunity to participate via shares
is used by the agents to discover cooperative behav-
iors. In fact, the division of labor in Cleanup is
effectively enabled. Without the participation, the
agents cannot learn to divide their task into sub-
tasks, as clearing waste does not directly lead to re-
wards. But through the participation, the positive im-
pact of clearing waste is directly observed through the
other agents’ rewards from collecting apples. Impor-
tantly, the other agent can only collect apples thanks
to the clearing of the waste beforehand. The intro-
duced method of participation can achieve optimal
collective performance in the Prisoner’s dilemma. In
Cleanup, the improvement in the collective perfor-
mance through participation is clearly visible. Al-
though it is not clear whether the agents exhaustively
learn the perfect participation allocation, the agents
manage to coordinate and enhance their performance
over time.
Our approach attempts to answer some open ques-
tions regarding cooperation in a decentralized multi-
agent population. Firstly, although the agents must
simultaneously learn how to participate via shares in
addition to learning their environment actions, learn-
ing to keep shares of other agents may be a simpler
task than punishing other agents whenever they act
only in their own interest. Secondly, punishments or
other incentivizing rewards should be earned before-
hand. When working with shares, they can be directly
traded without costs. Thirdly, a share market can be
implemented in various ways. We are certain that a
suitable market structure can be found in most social
dilemmas. Furthermore, LIO assumes that recipients
cannot reject an incentive, but an agent may accept
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
360
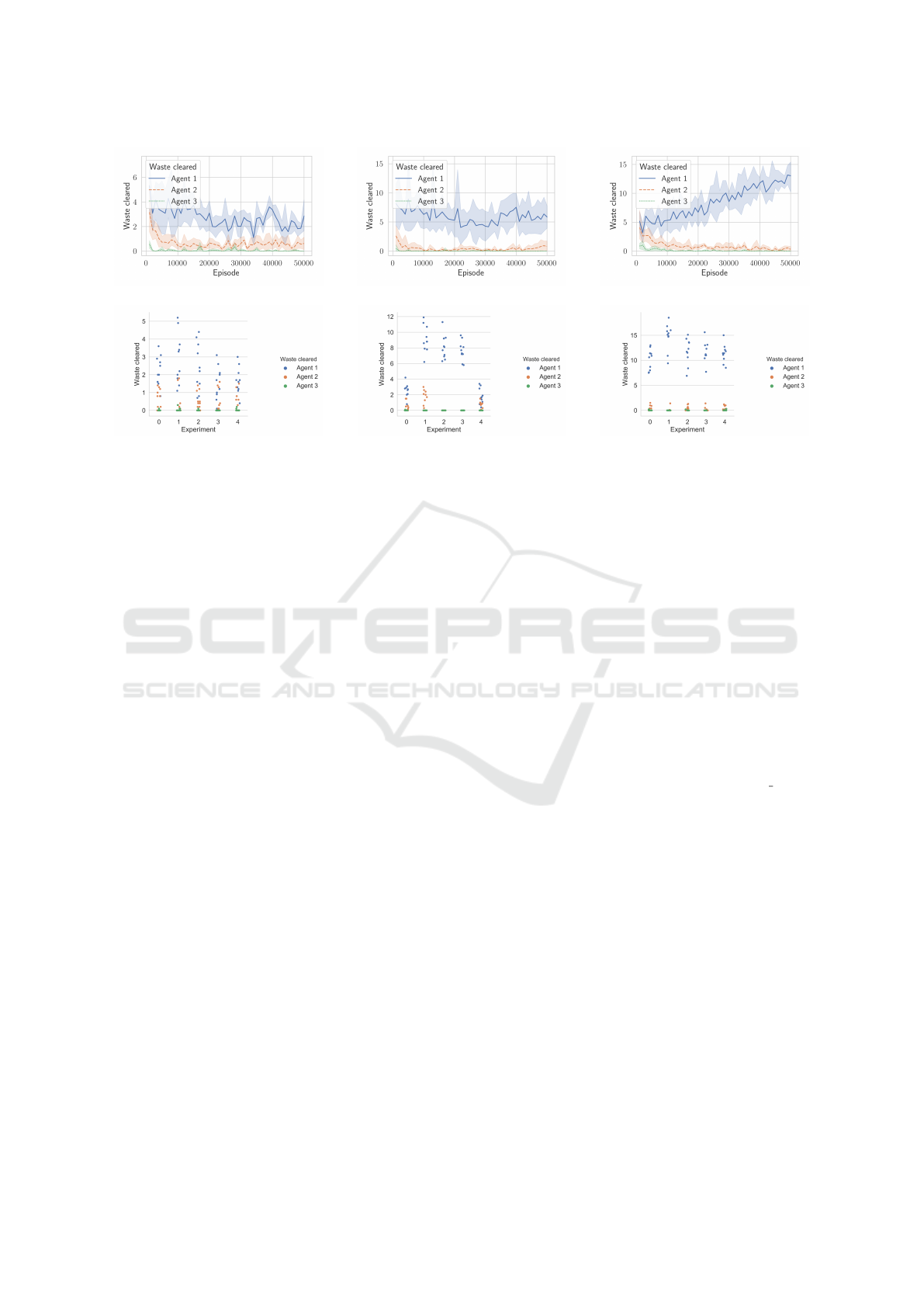
(a) In the basic implementation, none
of the agents learns to clear waste.
(b) In the LIO implementation, no
clear strategy evolves.
(c) With participation, one of the
agents learns to clear waste.
Figure 5: Waste cleared in clean-up with three agents for the basic implementation, LIO, and participation.
only some incentives. In the case of shares, this is
not a problem as the respective rewards are just dis-
tributed according to the owned shares. Another ben-
efit of the participation approach is that there is no
clear strategy for the agents to misuse the additional
market feature to exploit the other agents. There is
an emerging literature on reward tampering (Everitt
et al., 2021), and a participation market could be a
step in the right direction of deploying safe applica-
tions.
Our work contributes to the aim of ensuring
the common good in environments with independent
agents. Although the participation approach works
well in the tested social dilemmas, it remains unclear
whether this is also the case in other environments.
Another open question is if the agents can always find
a stable allocation of shares. We suggest experiments
with a broker that sets prices in combination with a
limit order book for matching demand and supply.
Additionally, participation needs to be tested in other
environments with more agents as well as other game
structures.
REFERENCES
Dafoe, A., Hughes, E., Bachrach, Y., Collins, T., Mc-
Kee, K. R., Leibo, J. Z., Larson, K., and Graepel,
T. (2020). Open problems in cooperative AI. CoRR,
abs/2012.08630.
Eccles, T., Hughes, E., Kram
´
ar, J., Wheelwright, S., and
Leibo, J. Z. (2019). Learning Reciprocity in Complex
Sequential Social Dilemmas. arXiv:1903.08082 [cs].
arXiv: 1903.08082.
Everitt, T., Hutter, M., Kumar, R., and Krakovna, V. (2021).
Reward tampering problems and solutions in rein-
forcement learning: a causal influence diagram per-
spective. Synthese, 198(27):6435–6467.
Foerster, J. N., Chen, R. Y., Al-Shedivat, M., Whiteson, S.,
Abbeel, P., and Mordatch, I. (2018). Learning with
Opponent-Learning Awareness. arXiv:1709.04326
[cs]. arXiv: 1709.04326.
Hughes, E., Leibo, J. Z., Phillips, M. G., Tuyls, K., Du
´
e
˜
nez-
Guzm
´
an, E. A., Casta
˜
neda, A. G., Dunning, I., Zhu,
T., McKee, K. R., Koster, R., Roff, H., and Graepel,
T. (2018). Inequity aversion improves cooperation in
intertemporal social dilemmas. arXiv:1803.08884 [cs,
q-bio]. arXiv: 1803.08884.
Kollock, P. (1998). Social Dilemmas: The
Anatomy of Cooperation. Annual Re-
view of Sociology, 24(1):183–214.
eprint:
https://doi.org/10.1146/annurev.soc.24.1.183.
Komorita, S. S. (1987). Cooperative Choice in Decomposed
Social Dilemmas. Personality and Social Psychology
Bulletin, 13(1):53–63. Publisher: SAGE Publications
Inc.
Leibo, J. Z., Zambaldi, V., Lanctot, M., Marecki, J., and
Graepel, T. (2017). Multi-agent Reinforcement Learn-
ing in Sequential Social Dilemmas. arXiv:1702.03037
[cs]. arXiv: 1702.03037.
Lerer, A. and Peysakhovich, A. (2018). Maintaining coop-
eration in complex social dilemmas using deep rein-
forcement learning. arXiv:1707.01068 [cs]. arXiv:
1707.01068.
Lupu, A. and Precup, D. (2020). Gifting in Multi-Agent
Reinforcement Learning. New Zealand, page 9.
Maki, J. E., Hoffman, D. M., and Berk, R. A. (1978). A time
series analysis of the impact of a water conservation
campaign. Evaluation Quarterly, 2(1):107–118. Pub-
lisher: Sage Publications Sage CA: Thousand Oaks,
CA.
Learning to Participate Through Trading of Reward Shares
361

Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Ve-
ness, J., Bellemare, M. G., Graves, A., Riedmiller,
M., Fidjeland, A. K., Ostrovski, G., Petersen, S.,
Beattie, C., Sadik, A., Antonoglou, I., King, H., Ku-
maran, D., Wierstra, D., Legg, S., and Hassabis,
D. (2015). Human-level control through deep re-
inforcement learning. Nature, 518(7540):529–533.
Bandiera abtest: a Cg type: Nature Research Jour-
nals Number: 7540 Primary atype: Research Pub-
lisher: Nature Publishing Group Subject term: Com-
puter science Subject term id: computer-science.
OpenAI, Berner, C., Brockman, G., Chan, B., Cheung,
V., Debiak, P., Dennison, C., Farhi, D., Fischer, Q.,
Hashme, S., Hesse, C., J
´
ozefowicz, R., Gray, S., Ols-
son, C., Pachocki, J., Petrov, M., Pinto, H. P. d. O.,
Raiman, J., Salimans, T., Schlatter, J., Schneider, J.,
Sidor, S., Sutskever, I., Tang, J., Wolski, F., and
Zhang, S. (2019). Dota 2 with Large Scale Deep Re-
inforcement Learning. arXiv:1912.06680 [cs, stat].
arXiv: 1912.06680.
Perolat, J., Leibo, J. Z., Zambaldi, V., Beattie, C., Tuyls,
K., and Graepel, T. (2017). A multi-agent reinforce-
ment learning model of common-pool resource ap-
propriation. arXiv:1707.06600 [cs, q-bio]. arXiv:
1707.06600.
Phan, T., Belzner, L., Gabor, T., and Schmid, K.
(2018). Leveraging Statistical Multi-Agent Online
Planning with Emergent Value Function Approxima-
tion. arXiv:1804.06311 [cs]. arXiv: 1804.06311.
Schmid, K., Belzner, L., Gabor, T., and Phan, T. (2018).
Action Markets in Deep Multi-Agent Reinforcement
Learning. In K
˚
urkov
´
a, V., Manolopoulos, Y., Ham-
mer, B., Iliadis, L., and Maglogiannis, I., editors,
Artificial Neural Networks and Machine Learning –
ICANN 2018, Lecture Notes in Computer Science,
pages 240–249, Cham. Springer International Pub-
lishing.
Schmid, K., Belzner, L., and Linnhoff-Popien, C. (2021a).
Learning to penalize other learning agents. MIT Press.
Schmid, K., Belzner, L., M
¨
uller, R., Tochtermann, J.,
and Linnhoff-Popien, C. (2021b). Stochastic Market
Games. In Zhou, Z.-H., editor, Proceedings of the
Thirtieth International Joint Conference on Artificial
Intelligence, IJCAI-21, pages 384–390. International
Joint Conferences on Artificial Intelligence Organiza-
tion.
Schmid, K., Belzner, L., Phan, T., Gabor, T., and Linnhoff-
Popien, C. (2020). Multi-agent Reinforcement Learn-
ing for Bargaining under Risk and Asymmetric Infor-
mation. Pages: 151.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I.,
Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M.,
Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L.,
van den Driessche, G., Graepel, T., and Hassabis, D.
(2017). Mastering the game of Go without human
knowledge. Nature, 550(7676):354–359. Bandiera -
abtest: a Cg type: Nature Research Journals Num-
ber: 7676 Primary atype: Research Publisher: Na-
ture Publishing Group Subject term: Computational
science;Computer science;Reward Subject term id:
computational-science;computer-science;reward.
Statman, M. (2004). The Diversification Puzzle. Financial
Analysts Journal, 60(4):44–53. Publisher: Routledge
eprint: https://doi.org/10.2469/faj.v60.n4.2636.
Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu,
M., Dudzik, A., Chung, J., Choi, D. H., Powell, R.,
Ewalds, T., Georgiev, P., Oh, J., Horgan, D., Kroiss,
M., Danihelka, I., Huang, A., Sifre, L., Cai, T., Aga-
piou, J. P., Jaderberg, M., Vezhnevets, A. S., Leblond,
R., Pohlen, T., Dalibard, V., Budden, D., Sulsky, Y.,
Molloy, J., Paine, T. L., Gulcehre, C., Wang, Z.,
Pfaff, T., Wu, Y., Ring, R., Yogatama, D., W
¨
unsch,
D., McKinney, K., Smith, O., Schaul, T., Lillicrap,
T., Kavukcuoglu, K., Hassabis, D., Apps, C., and
Silver, D. (2019). Grandmaster level in StarCraft
II using multi-agent reinforcement learning. Nature,
575(7782):350–354. Bandiera abtest: a Cg type: Na-
ture Research Journals Number: 7782 Primary atype:
Research Publisher: Nature Publishing Group Sub-
ject term: Computer science;Statistics Subject term -
id: computer-science;statistics.
Wang, J. X., Hughes, E., Fernando, C., Czarnecki, W. M.,
Duenez-Guzman, E. A., and Leibo, J. Z. (2019).
Evolving intrinsic motivations for altruistic behavior.
arXiv:1811.05931 [cs]. arXiv: 1811.05931.
Yang, J., Li, A., Farajtabar, M., Sunehag, P., Hughes, E.,
and Zha, H. (2020). Learning to Incentivize Other
Learning Agents. arXiv:2006.06051 [cs, stat]. arXiv:
2006.06051.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
362
