
Japanese Word Reordering Based on Topological Sort
Peng Sun
1
, Tomohiro Ohno
2 a
and Shigeki Matsubara
1,3 b
1
Graduate School of Informatics, Nagoya University, Nagoya, Japan
2
Graduate School of Advanced Science and Technology, Tokyo Denki University, Tokyo, Japan
3
Information & Communications, Nagoya University, Nagoya, Japan
Keywords:
Writing Assistance, Elaboration Support, Paraphrasing, Readability, Sorting Algorithm.
Abstract:
In Japanese, some sentences are grammatically well-formed, but not easy to read. This paper proposes a
method for Japanese word reordering, which first adapts a Japanese BERT model to predict suitable pairwise
orderings between two words in a sentence, and then converts the predicted results into a graph. The vertices
in the graph represent the words in the sentence. The edges represent the pairwise orderings between two
words. Finally, topological sort is applied to find the correct word ordering in a sentence by visiting each
graph vertex. We conducted an evaluation experiment with uneasy-to-read Japanese sentences created from
newspaper article sentences.
1 INTRODUCTION
The Japanese language has a relatively free word or-
der, making it possible to write meaningful sentences
without paying much attention to the word order.
In practice, however, some sort of preference in the
Japanese word order exists. These preferences may
lead to the generation of some grammatically correct,
but uneasy-to-read sentences.
Word reordering is the arrangement of words in
an input sentence such that the word order can eas-
ily be read. It has been studied as a basic technique
for applications like writing assistance and sentence
generation. Several methods on Japanese word re-
ordering have been proposed (Uchimoto et al., 2000;
Yokobayashi et al., 2004; Ohno et al., 2015; Miyachi
et al., 2021). All of them are based on the depen-
dency relations between words, which are assumed to
be given as the input by preliminarily executing de-
pendency parsing or partially given by concurrently
executing dependency parsing. This is considering
the close relationship between the word order and de-
pendency relations. That is, the possible word or-
der is restricted by dependency relations. However, if
the word order of an input sentence cannot be easily
read, the accuracy of word reordering decreases under
the influence of the accuracy of dependency parsing,
a
https://orcid.org/0000-0001-7015-7714
b
https://orcid.org/0000-0003-0416-3635
which tends to decrease.
This paper proposes a Japanese word reordering
method without dependency parsing. The strategy
does not use dependency information; thus, it cannot
be affected by dependency parsing errors, which is an
advantage. By contrast, word reordering without de-
pendency information causes another problem. That
is, the possible permutation of words in an input sen-
tence may not be narrowed down based on the depen-
dency information; thus, the computational cost ex-
plosively increases. In this work, we use topological
sort (Kahn, 1962; Tarjan, 1976) to resolve the above
mentioned problem. Topological sort is an algorithm
for the linear ordering of the vertices of a directed
acyclic graph (DAG) to efficiently find the appropri-
ate word order in a sentence.
Our method first predicts the suitable pairwise or-
derings between two words in a sentence using a
Japanese BERT model. It then converts the predicted
results into a graph, where a vertex and an edge rep-
resent a word in the sentence and a pairwise ordering
between two words, respectively. Finally, it identifies
the appropriate word order by applying topological
sort to the graph. We conducted an evaluation exper-
iment and confirmed the effectiveness of our method
on Japanese word reordering.
The remainder of this paper is organized as fol-
lows: Section 2 explains the Japanese word reorder-
ing; Section3 introduces topological sort and its ap-
plication to natural language processing; Section 4
768
Sun, P., Ohno, T. and Matsubara, S.
Japanese Word Reordering Based on Topological Sort.
DOI: 10.5220/0011775000003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 768-775
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

⚾ࡣ
,
ᐙࢆ
KRPH
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
ฟࡓࠋ
OHIW
⚾ࡣ
,
ᐙࢆ
KRPH
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
ฟࡓࠋ
OHIW
6DVHQWHQFHWKDWKDVLQDSSURSULDWHZRUGRUGHU
6DVHQWHQFHWKDWKDVDSSURSULDWHZRUGRUGHU
7KH VHQWHQFH6DQG6KDYHWKHVDPHPHDQLQJWKDWLVWUDQVODWHGDV³,OHIWKRPHORQJLQJIRUWKHFLW\´LQ(QJOLVK
7KHGLIIHUHQFHEHWZHHQ6DQG6LVMXVWWKHLUZRUGRUGHUVLQ-DSDQHVH
Figure 1: Examples of inappropriate and appropriate word orders in Japanese.
presents the proposed method of Japanese word re-
ordering based on topological sort; Section 5 explains
the conducted experiment for quantitatively evaluat-
ing the proposed method; and Section 6 summarizes
this work.
2 JAPANESE WORD ORDER AND
DEPENDENCY
We propose herein a word reordering method aimed
for the elaboration support of Japanese natives. We
assumed that the input sentences were not grammat-
ically incorrect, but had an uneasy-to-read word or-
der. The reasons behind this assumption are as fol-
lows: Even Japanese natives often create such sen-
tences unless they pay attention to the Japanese word
order preference, and it is not difficult for Japanese
natives to create grammatically correct sentences due
to the relatively free word order.
Many studies have been conducted on the
Japanese word order preference in linguistics (e.g.,
(Uchimoto et al., 2000; Kuribayashi et al., 2020; Fuji-
hara et al., 2022)). Case elements have been reported
to be basically placed in the order of a nominative,
a dative, and an accusative, and that the basic order
of case elements is often changed by influence from
other factors, such as long dependencies.
Figure 1 shows two Japanese sentences, which
differ only in their word order, are grammatically cor-
rect, and have the same meaning (i.e., translated as
“I left home longing for the city.”). The box and the
arrow in the figure express a bunsetsu
1
and a depen-
1
Bunsetsu is a Japanese linguistic unit that roughly cor-
responds to a basic phrase in English. A bunsetsu consists
of one independent word and zero or more ancillary words.
dency relation, respectively. The word order of S1
is more difficult to read than that of S2 because the
distance between the bunsetsu “家を (home)” and
its modified bunsetsu “出た (left)” is large, caus-
ing the loads on the working memory to become large
(Yoshida et al., 2014). This suggests that the depen-
dency information is useful in reordering words such
that the word order becomes easier to read.
If a Japanese sentence is grammatically correct,
the sentence satisfies the following constraints on the
word order and dependency:
1. No dependency is directed from right to left.
2. Dependencies do not cross each other.
3. Each bunsetsu, except for the final one in a sen-
tence, depends on only one bunsetsu.
Therefore, if the dependencies between all words
in a sentence can be parsed before the word re-
ordering, we can narrow down the candidates of
the most appropriate word order according to the
dependencies. In Figure 1, the possible word or-
der can be narrowed down to six permutations
(i.e., “b
1
b
2
b
3
b
4
b
5
”, “b
1
b
3
b
4
b
2
b
5
”, “b
2
b
1
b
3
b
4
b
5
”,
“b
2
b
3
b
4
b
1
b
5
”, “b
3
b
4
b
1
b
2
b
5
” and “b
3
b
4
b
2
b
1
b
5
”) due
to the dependency relations. Most of the previous
methods on word reordering (Belz and Kow, 2011;
Filippova and Strube, 2007; Harbusch et al., 2006;
Kruijff et al., 2001; Ringger et al., 2004; Shaw and
Hatzivassiloglou, 1999; Yokobayashi et al., 2004)
premise that dependency parsing is preliminarily per-
formed and identify the most appropriate word order
among the possible word order candidates that satisfy
the above mentioned constraints using the preference
A dependency relation in Japanese is a modification rela-
tion, in which a modifier bunsetsu depends on a modified
bunsetsu. That is, the modifier and modified bunsetsus work
as the modifier and that which is modified, respectively.
Japanese Word Reordering Based on Topological Sort
769

between word order and dependencies. However, the
word order of S1 is thought to be more difficult to
parse than that of S2 because dependency parsers are
usually trained on syntactically annotated corpora, in
which sentences have an appropriate word order, such
as that in S2.
The above mentioned constraints between the
word order and the dependencies cannot be used in
word reordering if we choose not to use dependency
parsing in word reordering. Thus, it is necessary to se-
lect the best permutation among all possible word per-
mutations in an input sentence. If an input sentence
has n bunsetsus, the number of all possible permuta-
tions is n!, which in Figure 1 is 5! = 120. Therefore,
an efficient algorithm must be employed to explore
the best permutation among the n! candidates. It can-
not use the dependency information, which is useful
in word reordering. Hence, a model that can predict
the appropriate word order without directly using the
dependency information must be employed.
3 TOPOLOGICAL SORT
Topological sort (Kahn, 1962; Tarjan, 1976) is an
algorithm that linearly arranges all the vertices of a
DAG according to the edge directions. All vertices
are briefly linearly ordered, such that every vertex pre-
cedes its next neighbor vertices connected by the out-
going edge from the vertex. That is, for every edge
v → u directed from a vertex v to a vertex u in a DAG,
the algorithm decides the order, such that v comes be-
fore u.
Topological sort is used for some natural language
processing applications that sort something. Prabhu-
moye et al. (2000) proposed a method for identify-
ing the most appropriate sentence order in a docu-
ment using topological sort (Prabhumoye et al., 2020;
Keswani and Jhamtani, 2021). Sentence ordering is
the task of arranging all sentences in a given doc-
ument, such that the document consistency is maxi-
mized and applied (e.g., multi-document summariza-
tion (Barzilay and Elhadad, 2002; Nallapati et al.,
2017), and cooking procedure generation (Nallapati
et al., 2017)). In their work, Prabhumoye et al. pre-
dicted each relative ordering between two sentences
in a document. Each predicted result was then re-
garded as a constraint of the anteroposterior relation
of a sentence pair. A DAG was made to express a set
of constraints. They found the most appropriate or-
der of sentences by applying topological sort to the
DAG. The word reordering task is similar to the sen-
tence ordering task in terms of sorting elements in a
unit; hence, topological sort is thought to be applica-
ble to the word reordering task in the same way as in
the sentence ordering task.
The time complexity of topological sort is O(|V |+
|E|), where V and E are a set of all the vertices and
edges in a DAG, respectively. If we use topological
sort for word reordering of an input Japanese sen-
tence, a DAG has a vertex and an edge expressing a
bunsetsu in the sentence and a relative ordering be-
tween two bunsetsus, respectively. In this case, if
an input sentence has n bunsetsus, because |V | is n
and |E| is the combination
n
C
2
=
n
2
= n ∗ (n − 1)/2,
the time complexity of the topological sort is O(n
2
).
Therefore, topological sort is expected to resolve the
high computational cost problem described in Section
2.
4 PROPOSED METHOD
In our method, a grammatically correct, but uneasy-
to-read sentence is assumed as the input. Our method
reorders all bunsetsus in the input sentence such that
the reordered sentence becomes easy-to-read. Figure
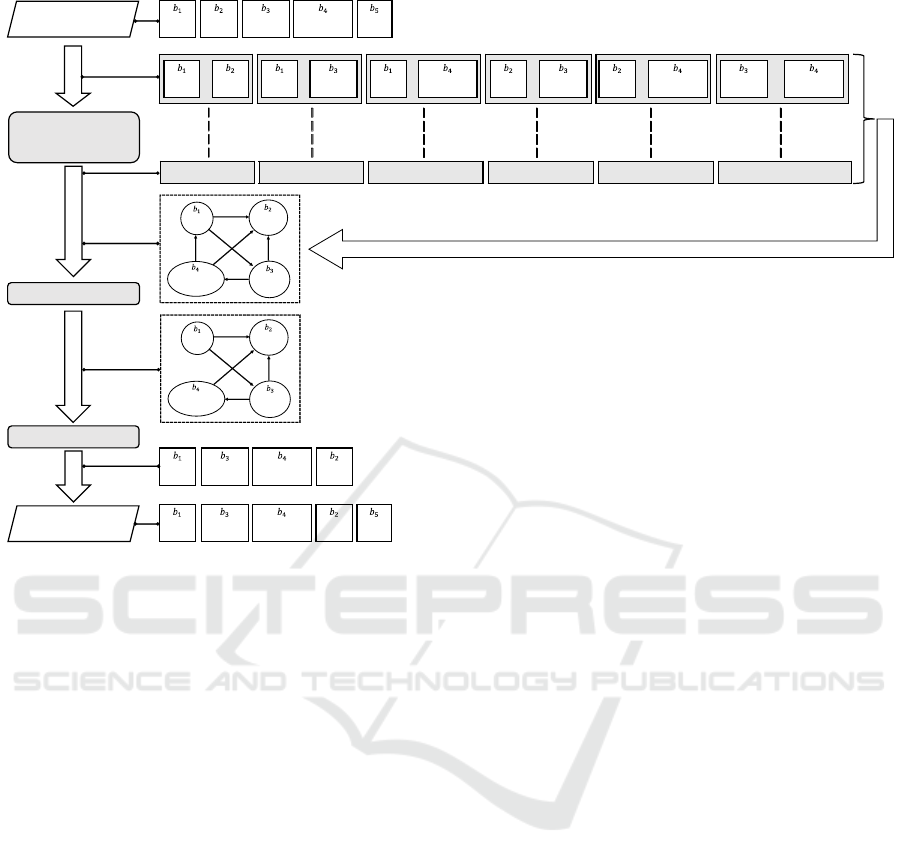
2 shows the method framework.
First, a sequence of bunsetsus of a sentence, which
has an uneasy-to-read word order, is input. In Figure
1(S1), the input sentence is “私は (I) / 家を (home)
/ 都会に (the city) / 憧れ (longing for) / 出た。
(left.)”. Our method extracts every combination of
any two bunsetsus among a set of all bunsetsus, ex-
cluding the final one in an input sentence (In Figure
1, {“私は (I),” “家を (home),” “都会に (the city),”
“憧れ (longing for)”}). It then predicts the relative
ordering of each pair, that is, the anteroposterior rela-
tion between two bunsetsus, using a Japanese BERT
model. If both an input sentence and its reordered
sentence are assumed to be grammatically correct, the
final bunsetsu of the input sentence always becomes
the final bunsetsu of the output sentence without de-
pending on the word reordering. This is why the final
bunsetsu is excluded.
Second, a set of predicted anteroposterior rela-
tions is converted into a directed graph, where a ver-
tex and an edge represent a word in the sentence and
a predicted anteroposterior relation between two bun-
setsus, respectively. If the created graph is a directed
cyclic graph (DCG), it will be converted into a DAG,
to which topological sort can be applied. The con-
version method is based on the source code of the
method proposed by Prabhumoye et al. (2000). In
the topological sort process during conversion, each
time a closed path is found, the last edge of the closed
path (i.e., the edge that returns to a visited vertex) is
deleted until no more closed paths are left.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
770
3UHGLFWDQWHURSRVWHULRU
UHODWLRQVEHWZHHQWZR
EXQVHWVXVXVLQJ%(57
,QSXWXQHDV\WR
UHDGVHQWHQFH
DQH[DPSOHRILQSXW㸸
&RQYHUWWR'$*
7RSRORJLFDOVRUW
DQH[DPSOHRIRXWSXW㸸
⚾ࡣ
,
ᐙࢆ
KRPH
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
ฟࡓࠋ
OHIW
ᐙࢆ
KRPH
࣮
⚾ࡣ
,
࣮
㒔
WKHFLW\
⚾ࡣ
,
࣮
ࢀ
ORQJLQJIRU
ᐙࢆ
KRPH
࣮
㒔
WKHFLW\
ᐙࢆ
KRPH
࣮
ࢀ
ORQJLQJIRU
㒔
WKHFLW\
࣮
ࢀ
ORQJLQJIRU
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
ᐙࢆ
KRPH
⚾ࡣ
,
⚾ࡣ
,
ᐙࢆ
KRPH
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
⚾ࡣ
,
ᐙࢆ
KRPH
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
ฟࡓࠋ
OHIW
WKHOHIWLVDQWHULRUĺ WKHOHIWLVDQWHULRUĺ WKHOHIWLVDQWHULRUĺWKHULJKWLVDQWHULRUĸ WKHULJKWLVDQWHULRUĸ WKHULJKWLVDQWHULRUĸ
㒔
WKHFLW\
ࢀ
ORQJLQJIRU
ᐙࢆ
KRPH
⚾ࡣ
,
2XWSXWHDV\WR
UHDGVHQWHQFH
⚾ࡣ
,
Figure 2: Framework of our method.
Finally, topological sort is applied to the DAG cre-
ated above. Each vertex (each bunsetsu) is then lin-
early ordered. Note that our method uses topological
sort based on the depth-first search (Tarjan, 1976).
4.1 Model
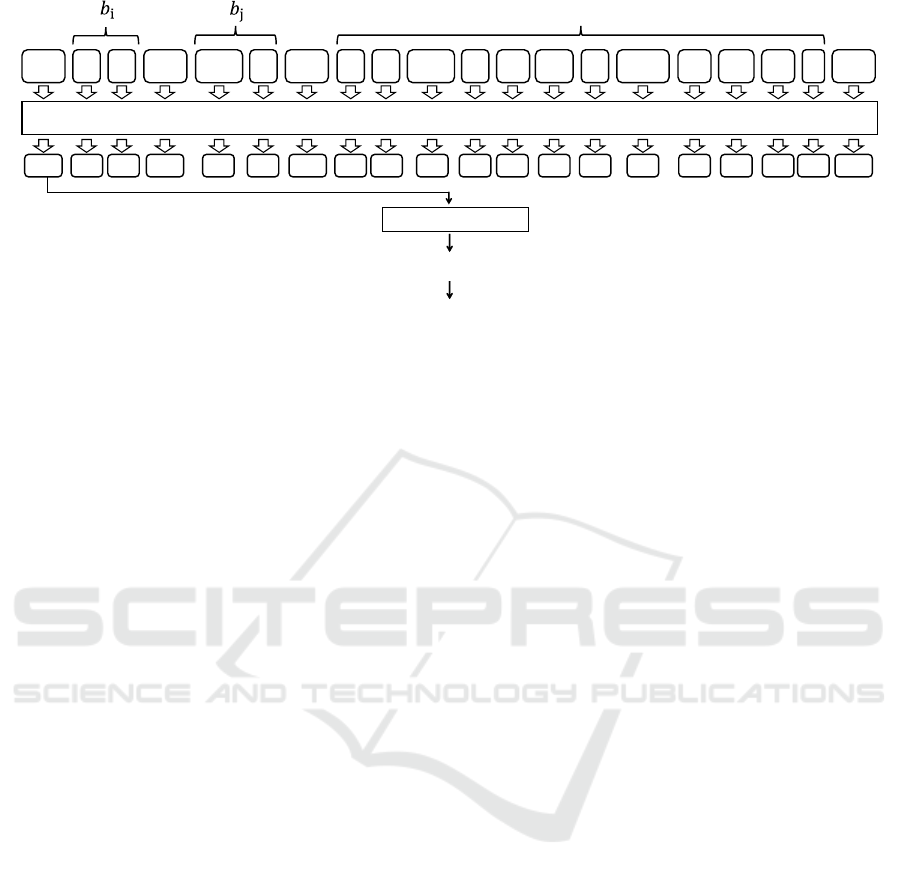
Figure 3 shows an overview of our BERT model
that predicts the anteroposterior relation between two
bunsetsus. Here, B = b
1
b
2
·· ·b
n
expresses a se-
quence of bunsetsus in an input sentence, while
b
i
, b
j
(1 ≤ i < j ≤ n − 1) expresses the two bunset-
sus, between which the anteroposterior relation is pre-
dicted by our BERT model. During this time, the in-
put to BERT is the concatenation “[CLS] b
i
[SEP] b
j
[SEP] b
1
b
2
·· ·b
n
[SEP]”, where subword division is
performed.
An input sentence, even if not easily readable,
has a partially appropriate word order because the
input sentence is grammatically correct. The relative
location of many bunsetsus after reordering tends to
be maintained in the same order as that of the input
sentence. In addition, an input sentence contains the
dependency information between bunsetsus, which is
considered to be effective for predicting the relative
ordering between two bunsetsus as described in Sec-
tion 2. These are the reasons why our method takes
the entire input sentence b
1
b
2
·· ·b
n
into the BERT
model.
The BERT model outputs a bidimensional proba-
bility distribution that expresses how appropriate the
anteroposterior relation (i.e., either b
i
or b
j
precedes
the other) is in readability. The anteroposterior rela-
tion with a higher probability becomes the predicted
result used as the constraint on the relative ordering
between the two bunsetus. The prediction by our
BERT model is performed for each combination of
any two bunsetsus created among {b
1
, b
2
, · ·· , b
n−1
}.
4.2 Creation of Training Data
The kind of data to use as the training data for our
BERT model is also important. As a simple approach,
it can use the anteroposterior relations included in
easy-to-read sentences (e.g. newspaper article sen-
tences) as the training data. This approach makes two
training events from one anteroposterior relation be-
tween two bunsetsus b
i
and b
j
(i < j) in a sentence.
One is “b
i
→ b
j
” labeled with “the left is anterior”,
and the other is “b
i
← b
j
” labeled with “the right is
anterior”. The number of labels that is “the left is an-
terior” becomes equal to that of “the right is anterior”
in these training data. However, it can be thought that
no such tendency in humans actually creates uneasy-
to-read sentences.
Japanese Word Reordering Based on Topological Sort
771
%(57
/LQHDU 6RIWPD[
>WKHLQSXWKDVDQDSSURSULDWHZRUGRUGHU@
>@
UHSUHVHQWVDQDX[LOLDU\ZRUGLQ-DSDQHVH
>SUREDELOLW\RIKDYLQJDQDSSURSULDWHZRUGRUGHU
>SUREDELOLW\RIKDYLQJDQLQDSSURSULDWHZRUGRUGHU@
>&/6@
⚾
,
ࡣ
>6(3@
ᐙ
KRPH
ࢆ
>6(3@
⚾
,
ࡣ
ᐙ
KRPH
ࢆ
㒔
WKH
FLW\
ORQJLQJ
ࢀ
IRU
ฟ
OHIW
ࡓ
ࠋ
>6(3@
DQLQSXWVHQWHQFH
9
>&/6@
9
>⚾@
9
>ࡣ@
9
>6(3@
9
>ᐙ@
9
>ࢆ@
9
>6(3@
9
>⚾@
9
>ࡣ@
9
>ᐙ@
9
>ࢆ@
9
>㒔@
9
>@
9
>@
9
>@
9
>ࢀ@
9
>ฟ@
9
>ࡓ@
9
>ࠋ@
9
>6(3@
Figure 3: Example of predicting the anteroposterior relation between two bunsetsus.
To train the tendency of humans to actually create
uneasy-to-read sentences, we must annotate the com-
bination of two bunsetsus in sentences with a label.
However, annotation costs are very high.
To solve this problem, based on the assumption
that newspaper article sentences are written in an
easy-to-read word order, we mechanically create a
pseudo-sentence with an uneasy-to-read word order
from each newspaper article sentence following the
procedure below:
1. Remove commas from the newspaper article sen-
tences.
2. Find a bunsetsu modified by multiple bunsetsus
from the sentence end.
3. Randomly change the order of sub-trees that mod-
ify this bunsetsu.
4. Iterate 2 and 3 until you reach the beginning of the
sentence.
The created pseudo-sentences satisfy the three con-
straints on word order and dependency described in
Section 2; thus, they are assumed to be grammatically
correct, but have an uneasy-to-read word order differ-
ent from that of newspaper article sentences.
With the above mentioned procedure, we can cre-
ate many training data with no cost if a corpus exists,
including newspaper article sentences annotated with
information on morphological analysis, bunsetsu seg-
mentation, and dependency analysis.
5 EXPERIMENT
We conducted an experiment on the word reorder-
ing of uneasy-to-read sentences using Japanese news-
paper articles to evaluate the effectiveness of our
method.
5.1 Experiment Outline
For the experiment, 1000 sentences with an uneasy-
to-read word order artificially created from newspa-
per articles sentences in the Kyoto Text Corpus were
used as the test and development data (Kuroashi and
Nagao, 1998), respectively, which is annotated with
information on morphological analysis, bunsetsu seg-
mentation, and dependency analysis. The creation
was based on the following procedure:
(1) Mechanically create some new sentences from a
newspaper article sentence based on the procedure
described in Section 4.2. All the sentences created
by this step have a different word order from the
original newspaper article sentence but maintain
the same dependency relations.
(2) Among the above mentioned sentences, manually
select one sentence considered as sometimes writ-
ten by Japanese native speakers.
(3) Manually add commas to make it as easy as pos-
sible to read in that word order.
We used 34,199 sentences created by the proce-
dure described in Section 4.2 as the training data.
Among which, 27,263 sentences have a different or-
der from the original newspaper article sentences, and
6936 sentences have the same order by chance. These
34,199 sentences had a more-than-equal-to 3 bunset-
sus because extremely short original sentences, whose
word order can be decided based on the constraints
described in Section 2 without using BERT, were
deleted. Note that every original newspaper article
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
772

Table 1: Experimental Results.
pair agreement sentence agreement
our method 88.49% (28,105/31,760) 40.60% (406/1,000)
[random] 50.59% (16,070/31,760) 4.60% (46/1,000)
[no reordering] 75.48% (23,973/31,760) 0.00% (0/1,000)
,QSXW
2XWSXWFRUUHFWZRUGRUGHU
7KHVHQWHQFHLVWUDQVODWHGDV³0DQ\FKLOGUHQVXIIHUIURPH\HGLVHDVHVDQGDUHPDOQRXULVKHG´LQ (QJOLVK
ᰤ㣴ኻㄪ
PDOQRXULVKHG
┠ࡢ
H\H
Ẽ
GLVHDVHV
ࡾ
VXIIHUIURP
࡞ࡗࡓ
DQGDUH
Ꮚࡀ
FKLOGUHQ
ከ࠸ࠋ
PDQ\
ᰤ㣴ኻㄪ
PDOQRXULVKHG
┠ࡢ
H\H
Ẽ
GLVHDVHV
ࡾ
VXIIHUIURP
࡞ࡗࡓ
DQGDUH
Ꮚࡀ
FKLOGUHQ
ከ࠸ࠋ
PDQ\
Figure 4: Example of sentences correctly reordered by our method.
sentence of the training data is different from that of
the test and development data.
In the evaluation, we obtained two the following
measurements are defined by Uchimoto et al. (2000)
and Miyachi et al. (2021):
• Sentence agreement: percentage of the output
sentences in which the word order entirely agrees
with that of the original sentence.
• Pair agreement: percentage of the pairs of bunset-
sus, whose word order agrees with the word order
in the original sentence.
The two following baselines were established for
comparison:
• [random]: randomly reorders all bunsetsus except
the final bunsetsu in an input sentence.
• [no reordering]: outputs an input sentence without
changing the word order.
5.2 Experimental Results
Table 1 shows the experimental results on the word
reordering of our method and each baseline. Our
method dramatically outperformed the two baselines
in both the pair and sentence agreements.
Figure 4 illustrates an example of the sentences,
in which all bunsetsus were correctly reordered by our
method. In this example, our method correctly moved
a bunsetsu “栄養失調に (malnourished)” just before
the dependent bunsetsu “なった (and are).” The dis-
tance of the two bunsetsus, where a dependency re-
lation existed, in the output sentence became shorter
than that of the input one. Moreover, the readability of
the output sentence was improved. These results con-
firmed the effectiveness of our method on Japanese
word reordering.
In Section 4, the graph became either a DCG,
which was then converted to a DAG, or a DAG when
a directed graph was created from the anteroposterior
relations predicted by BERT. We re-measured the pair
and sentence agreements separately for sentences be-
came DCGs and DAGs. Tables 2 and 3 show the pair
and sentence agreements of our method and [no re-
ordering], respectively. The results of [no reordering]
(i.e., input sentences) revealed not much of a differ-
ence between the DAGs and the DCGs. In contrast,
the results of our method showed that both agree-
ments for sentences that became DAGs were much
higher than those for sentences that became DCGs.
Some sentences were converted into a DCG because
the prediction by BERT contained some incorrect an-
teroposterior relations. Thus, even if the DCGs were
converted into DAGs, the agreements were thought
to have decreased because all incorrect edges in the
graphs were not always deleted. Resolving the agree-
ment decrease required the improvement of the pre-
diction accuracy of the anteroposterior relations by
BERT and the conversion of a DCG to a DAG by the
proper removal of incorrect edges. These issues are
to be addressed in the future.
6 CONCLUSIONS
This paper proposed a method for the word reordering
of uneasy-to-read sentences without executing depen-
dency parsing. The method used BERT to predict the
Japanese Word Reordering Based on Topological Sort
773

Table 2: Pair agreement separately for sentences that had become DCGs and sentences that had become DAGs.
DAG DCG
our method 91.51% (14,841/16,218) 85.34% (13,264/15,542)
[no reordering] 75.74% (12,284/16,218) 75.21% (11,689/15,542)
Table 3: Sentence agreement separately for sentences that had become DCGs and sentences that had become DAGs.
DAG DCG
our method 50.29% (350/696) 18.42% (56/304)
[no reordering] 0.00% (0/696) 0.00% (0/304)
anteroposterior relations between two bunsetsus and
applied topological sort to the predicted results. The
effectiveness of our method was confirmed through
the evaluation experiments using sentences with an
uneasy-to-read word order created from newspaper
article sentences.
For future works, we would like to improve the
pair and sentence agreements on word reordering. We
also intend to build an uneasy-to-read sentence corpus
that humans actually create.
ACKNOWLEDGEMENTS
This work was partially supported by JSPS KAK-
ENHI Grand Number JP19K12127.
REFERENCES
Barzilay, R. and Elhadad, N. (2002). Inferring strategies
for sentence ordering in multidocument news summa-
rization. Journal of Artificial Intelligence Research,
17(1):35–55.
Belz, A. and Kow, E. (2011). Discrete vs. continuous rat-
ing scales for language evaluation in nlp. In Proceed-
ings of the 49th Annual Meeting of the Association for
Computational Linguistics: Human Language Tech-
nologies, pages 230–235.
Filippova, K. and Strube, M. (2007). Generating constituent
order in german clauses. In Proceedings of the 45th
Annual Meeting of the Association of Computational
Linguistics, pages 320–327.
Fujihara, R., Kuribayashi, T., Abe, K., Tokuhisa, R., and
Inui, K. (2022). Topicalization in language models: A
case study on Japanese. In Proceedings of the 29th In-
ternational Conference on Computational Linguistics,
pages 851–862.
Harbusch, K., Kempen, G., Van Breugel, C., and Koch, U.
(2006). A generation-oriented workbench for perfor-
mance grammar: Capturing linear order variability in
german and dutch. In Proceedings of the 4th Inter-
national Natural Language Generation Conference,
pages 9–11.
Kahn, A. B. (1962). Topological sorting of large networks.
Communications of the ACM, 5(11):558–562.
Keswani, V. and Jhamtani, H. (2021). Formulating neural
sentence ordering as the asymmetric traveling sales-
man problem. In Proceedings of the 14th Interna-
tional Conference on Natural Language Generation,
pages 128–139.
Kruijff, G.-J. M., Kruijff-Korbayov
´
a, I., Bateman, J., and
Teich, E. (2001). Linear order as higher-level deci-
sion: Information structure in strategic and tactical
generation. In Proceedings of the 8th European Work-
shop on Natural Language Generation, pages 74–83.
Kuribayashi, T., Ito, T., Suzuki, J., and Inui, K. (2020). Lan-
guage models as an alternative evaluator of word order
hypotheses: A case study in Japanese. In Proceed-
ings of the 58th Annual Meeting of the Association for
Computational Linguistics, pages 488–504.
Kuroashi, S. and Nagao, M. (1998). Building a Japanese
parsed corpus while improving the parsing system. In
Proceedings of the 1st International Conference on
Language Resources and Evaluation, pages 719–724.
Miyachi, K., Ohno, T., and Matsubara, S. (2021). Word
reordering and comma insertion integrated with shift-
reduce dependency parsing. In Proceedings of the
13th International Conference on Agents and Artifi-
cial Intelligence - Volume 2, pages 1144–1150.
Nallapati, R., Zhai, F., and Zhou, B. (2017). Summarunner:
A recurrent neural network based sequence model for
extractive summarization of documents. In Proceed-
ings of the 31st AAAI Conference on Artificial Intelli-
gence, pages 3075–3081.
Ohno, T., Yoshida, K., Kato, K., and Matsubara, S. (2015).
Japanese word reordering executed concurrently with
dependency parsing and its evaluation. In Proceedings
of the 15th European Workshop on Natural Language
Generation, pages 61–65.
Prabhumoye, S., Salakhutdinov, R., and Black, A. W.
(2020). Topological sort for sentence ordering. In
Proceedings of the 58th Annual Meeting of the As-
sociation for Computational Linguistics, pages 2783–
2792.
Ringger, E., Gamon, M., Moore, R. C., Rojas, D. M., Smets,
M., and Corston-Oliver, S. (2004). Linguistically in-
formed statistical models of constituent structure for
ordering in sentence realization. In Proceedings of the
20th International Conference on Computational Lin-
guistics, pages 673–679.
Shaw, J. and Hatzivassiloglou, V. (1999). Ordering among
premodifiers. In Proceedings of the 37th Annual Meet-
ing of the Association for Computational Linguistics,
pages 135–143.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
774

Tarjan, R. E. (1976). Edge-disjoint spanning trees and
depth-first search. Acta Informatica, 6(2):171–185.
Uchimoto, K., Murata, M., Ma, Q., Sekine, S., and Isahara,
H. (2000). Word order acquisition from corpora. In
Proceedings of the 18th Conference on Computational
Linguistics, pages 871–877.
Yokobayashi, H., Suganuma, A., and Taniguchi, R.-i.
(2004). Generating candidates for rewriting based on
an indicator of complex dependency and it’s applica-
tion to a writing tool. Journal of Information Process-
ing Society of Japan, 45(5):1451–1459 (In Japanese).
Yoshida, K., Ohno, T., Kato, Y., and Matsubara, S. (2014).
Japanese word reordering integrated with dependency
parsing. In Proceedings of the 25th International Con-
ference on Computational Linguistics, pages 1186–
1196.
Japanese Word Reordering Based on Topological Sort
775
