
Body Part Information Additional in Multi-decoder Transformer-Based
Network for Human Object Interaction Detection
Zihao Guo
1 a
, Fei Li
1
, Rujie Liu
1
, Ryo Ishida
2
and Genta Suzuki
2
1
Fujitsu Research & Development Center Co., Ltd., Beijing, China
2
Fujitsu Research, Fujitsu Limited, Kawasaki, Japan
Keywords:
Human Object Interaction Detection, Transformer, Multi-decoder, Body Part Information, Channel Attention.
Abstract:
Human Object Interaction Detection is one of the essential branches of video understanding. However, many
complex scenes exist, such as humans interacting with multiple objects. The whole human body as the subject
of interaction in the complex interaction environment may misjudge the interaction with the wrong objects.
In this paper, we propose a Transformer based structure with the body part additional module to solve this
problem. The Transformer structure is applied to provide powerful information mining capability. Moreover,
a multi-decoder structure is adopted for solving different sub-problems, enabling models to focus on different
regions to provide more powerful performance. The most important contribution of our work is the proposed
body part additional module. It introduces the body part information for Human-Object Interaction(HOI)
detection, which refines the subject of the HOI triplet and assists the interaction detection. The body part
additional module also includes the Channel Attention module to ensure the balance between the information,
preventing the model from paying too much attention to the body part or the Human-Object pair. We got better
performance than the State-Of-The-Art model.
1 INTRODUCTION
Human Object Interaction Detection(HOID) means
detecting ‘human is doing something to the object’
from an image or a video. It has been one of the cor-
nerstones of image or video understanding. HOID in-
cludes the branches of image-based and video-based.
Many papers, such as Gkioxari et al. (2015b), Ma
et al. (2022) and Ji et al. (2021), Sunkesula et al.
(2020) have contributed to the above two aspects, re-
spectively. However, the majority of scholars pay
more attention to the case of instance-based HOID
(Gao et al., 2018; Li et al., 2020; Liao et al., 2020;
Tamura et al., 2021; Zhang et al., 2021a; Zhou et al.,
2022), which means that when given a single-frame
picture, it is not only to detect the interactive infor-
mation in the picture like the image-based HOID but
also to find the position of the Human-Object pair ac-
curately.
The instance-based HOID could be practically ap-
plied in various situations. For example, this technol-
ogy could be used to determine if an athlete is com-
mitting a foul on the field of play and could be de-
ployed at supermarket self-checkout machines to de-
tect theft. Nevertheless, all these application scenar-
a
https://orcid.org/0000-0001-9432-2227
ios have a common problem: most of the video frames
captured from the real scenes show some complex sit-
uations rather than a clear composition. The people
and multiple interactive objects always stack on top
of each other, and even multiple people and objects
interact simultaneously. These application scenarios
bring a dilemma to the application of traditional HOI
technology. It is difficult to judge the correct inter-
action pairs in two-dimensional images without depth
information. Some works also involve additional in-
formation, such as language(Yuan et al., 2022; Li
et al., 2022b) and graph(Zhang et al., 2021b), to in-
crease performance. However, the information men-
tioned above could not directly solve the problem of
the application in complex situations.
Our work aims to accurately predict the correct
HOI when a person interacts with multiple objects si-
multaneously. Considering the complex HOI situa-
tion, the whole human body is too large for the subject
to determine the interaction. Therefore, interaction
detection with the fine-grained body part could detect
interactive actions more accurately. For example, the
body part of interaction in ‘hold something’ should
be the hand, and the body part in ‘kicking the ball’
should be the foot. It is not enough to consider only
part of the human body or the Human-Object pair be-
Guo, Z., Li, F., Liu, R., Ishida, R. and Suzuki, G.
Body Part Information Additional in Multi-decoder Transformer-Based Network for Human Object Interaction Detection.
DOI: 10.5220/0011755300003417
In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2023) - Volume 5: VISAPP, pages
221-229
ISBN: 978-989-758-634-7; ISSN: 2184-4321
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
221

cause both should be used to distinguish many com-
plex actions considering the part and Human-Object
pair. Therefore, we also need to integrate the char-
acter of the interacting Human-Object pairs and con-
sider it comprehensively.
Overall, the main contributions of our works are:
• The concept of body part detection is introduced
into the detection model of human interaction to
assist HOI detection;
• While introducing the body part, the whole body
and objects are considered comprehensively with
the body part to improve the performance, keep-
ing the balance of attention between information
characteristics of the Human-Object Pair and the
body part.
2 RELATED WORKS
2.1 Review of Transformer Based HOID
Thanks to the success of Transformer models in the
object detection area, i.e. DETR(Carion et al., 2020)
and the other relative models(Zhu et al., 2020; Dai
et al., 2021), and the powerful information mining ca-
pabilities it provides, there have been a lot of HOID
models built on Transformer in recent years. The
Transformer network model can analyse the relation-
ship between all pixels in the whole image rather than
be limited to a particular part, which is more suit-
able for HOID tasks. QPIC(Tamura et al., 2021) and
HOTR(Kim et al., 2021) algorithms get good perfor-
mance by directly transforming the set prediction of
DETR into the prediction of HOI and cleverly set-
ting up the loss function. By referring to the idea of
Deformable-DETR(Zhu et al., 2020), the use of a de-
formable attention mechanism in MSTR(Kim et al.,
2022) can noticeably improve the defect of the long
training time of Transformer Based model, but the
model accuracy is not satisfactory.
Many scholars have modified the model structure
based on the characteristics of HOID tasks. AS-
Net(Chen et al., 2021) uses a Transformer struc-
ture with parallel instances and interactive branches,
achieving good performance and laying a foundation
for developing the CDN(Zhang et al., 2021a) model
with cascade structure. In addition, CDN reveals the
difference between the task in HOI and the traditional
target detection, and shows the advantages brought by
the different work of multiple decoders. On this basis,
Zhou et al. (2022) continuously increases the number
of decoders and encoders, getting some good results.
However, the performance growth can only partially
compensate for the rapid increase in algorithm com-
plexity, and compared with these models, we think
CDN is a simple and prospective algorithm.
The CDN model achieves noticeable performance
improvements with the same magnitude of parameters
as the original Transformer structure. It analyses and
excavates the advantages and disadvantages of one-
stage and two-stage structures, whose main difference
is whether the HOI is predicted once or not. CDN
has extracted the essence of both one and two-stage
model structures. The HOID task is divided into ob-
ject detection and action classification, and different
decoders are assigned to different characters for cal-
culation, thus achieving performance improvement.
In the Transformer based architecture, the de-
coders can first calculate the relationship between the
query vectors by the self-attention module and then
find the relationship between the query vectors and
the features extracted from the image by the cross-
attention module. This cross-attention weight should
be understood as the model’s attention to some spe-
cific pixels in the image, which is also visualized sev-
eral times for intuitive understanding(Carion et al.,
2020; Zhang et al., 2021a), exposing the model’s at-
tention and improvements in an explainable way. In
Section 4, we will visualise the cross-attention weight
for qualitative analysis.
2.2 Part Information Involved Models
Body part information has been introduced into the
HOID domain for a long time. Gkioxari et al. (2015a)
has verified that body parts can work on action recog-
nition effectively, and Fang et al. (2018) shows a cor-
relation between multiple body parts corresponding
to activities. The above two papers are based on the
traditional CNN network structure, which may have
a priori bias, and their information mining ability is
poor than that of the Transformer-based structures.
The model will pay more attention to the area near
the convolution kernel. However, in the HOID task,
its complex interaction background leads to the pre-
dominance of the Transformer structure model that
can mine the relationship between pixels.
Besides, Li et al. (2020) shows that the sub-actions
of each body part can be spliced into the whole per-
son’s actions, but it converts the actions of each part
into entries and then deduces the whole body actions
through language knowledge. The construction of
this algorithm is tedious, and the training time is ex-
tended. Therefore, we propose a Transformer-based
algorithm that does not require additional language
information and introduces body part information to
assist HOI detection.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
222
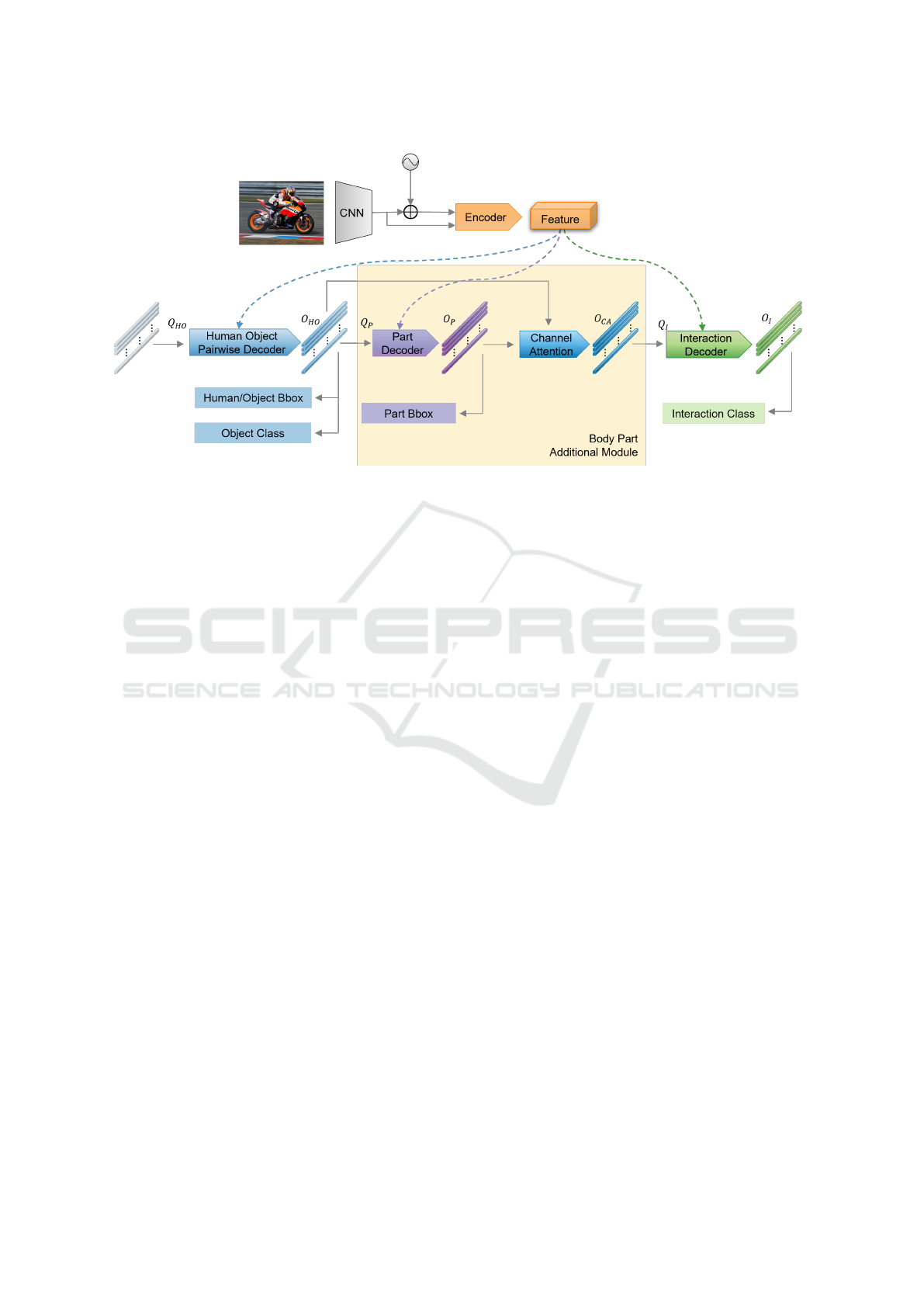
Figure 1: The framework of our model. HOI prediction is obtained by backbone, encoder and decoders from images. Different
colours represent different modules. Q
HO
, Q
P
and Q
I
mean the query vector input for HOPD, Part decoder and Interaction
decoder separately. O
HO
, O
P
and O
I
mean the output of each decoder, used to predict the HOI triplet through the Feed-
Forward Network(FFN). O
CA
is obtained by the O
HO
and O
P
processing with the Channel Attention module. Furthermore
the previous module outputs O as the input Q for the next decoder.
3 METHODS
In this section, the model structure and the details
of our method will be presented. Section 3.1 illus-
trates the frame of the model architecture. The Body
Part Additional Module, which involves the body
part information in the model to refine the subject of
HOI, and balances the attention weight of the Human-
Object pair and body part, will be revealed in Section
3.2. Moreover, the other implementation details will
be introduced in Section 3.3.
3.1 Overview
The overview of our proposed model is illustrated in
Figure 1. A CNN backbone and the Encoder model
extract the visual feature from the input images, co-
operating with the position embedding to distinguish
different pixels. Different kinds of decoders for each
task could achieve better performance than the single
decoder for all tasks(Zhang et al., 2021a). Therefore,
we apply several decoders to focus on various inter-
ested regions for mining information. The HOI pre-
diction tasks are finished by three decoders: 1) the
Human Object Pairwise Decoder(HOPD) for the hu-
man and object bounding box detection and the ob-
ject classification; 2) the Part Decoder for detecting
the part bounding box; 3) the Interaction Decoder for
classifying the interaction. Moreover, the image fea-
ture will work in each decoder for the cross-attention
module.
Under the premise of deepening the number of
model layers, it is imperative to transfer the infor-
mation between different modules. The information
transformation method among modules could connect
different modules and find more helpful information.
Therefore, in the Body Part Additional Module, we
adopt a Channel Attention(CA) module to combine
and enhance the valuable information for the final
interaction decoder. The output of the previous de-
coders will be used as the query vector input for the
next decoder.
3.2 Body Part Additional Module
One of the main contribution of our work is the Body
Part Additional Module. This module introduces in-
formation about the body part and provides guiding
concerns for HOI predictions throughout the model
architecture. It also ensures that both the character-
istics of the Human-Object pair and the body parts
will be considered through Channel Attention mech-
anisms rather than only one of them.
3.2.1 Body Part Information
The body part information is included in the model by
the additional part decoder, which refines the subject
of the HOI triplet. This decoder has the same layer
Body Part Information Additional in Multi-decoder Transformer-Based Network for Human Object Interaction Detection
223

Figure 2: Details of Channel Attention module. It shows
how to use i-th output sub-vector of HOPD(O
HO
i
) and
part decoder(O
P
i
) to calculate the Channel Attention output
O
CA
i
that takes into account both information as the input
of interaction decoder Q
I
i
. A
CA
i
represents the channel at-
tention weight. ⊙ means the multiplying the corresponding
elements. And W
CA
i
represents the weighted O
HO
i
, which
is gotten from multiplying the corresponding elements of
O
HO
i
and A
CA
i
. The vectors, O
HO
i
, W
CA
i
and O
P
i
, are listed
together to represent Concatenate. The colours used here
are the same as in Figure 1, and the colour changes show
the fusion process.
numbers and the inside architecture as the other de-
coders. As it is shown in Figure 1, the output of the
HOPD(O
HO
) will be regarded as the part decoder’s
input, and the output of this decoder(O
P
) will be sent
to the body part bounding box prediction FFN. Be-
cause the input of the Part Decoder is the informa-
tion used to predict the HO Pair, and the HOPD and
Part Decoder share the sequence number of the Query
Vector, the part location information corresponding to
each HO Pair can be predicted. O
P
and O
HO
will be
used as the input of the Channel Attention(CA) mod-
ule. The part decoder will be used primarily to predict
the location of body parts which are related to the ac-
tivities, guiding overall HOI detection.
3.2.2 Channel Attention
The primary design purpose of our Channel Atten-
tion module is to make the model balance the atten-
tion of the Human-Object pair and the body part while
adding the body part decoder. This module structure
is inspired by Zhou et al. (2022), and the details of the
Channel Attention module is shown in Figure 2.
Two ways of channel attention mechanisms are
applied in this module. Firstly, the attention weight
between HOPD and the output of the part decoder is
computed, and the former result weights the HOPD
output. Then, the weighted output between the
weighted HOPD output and the output of the two de-
coders is calculated. However, the main difference
is that Zhou et al. (2022) connects each layer of two
parallel decoders through the channel attention mod-
ule to enhance the capability of one of the decoders.
In comparison, we take the output of the last layer
of two decoders as the input and use the output for
the next decoder’s query vector. The formula of the
Channel Attention Module is shown below:
O
CA
i
= MLP (Concat (O
HO
i
,O
P
i
,W
CA
i
)) (1)
W
CA
i
= O
HO
i
· MLP (σ(Concat (O
HO
i
,O
P
i
))) (2)
where O means the output of each module, and the
subscript i represents the i-th sub-vector. W
CA
means
weighted HOPD output O
CA
. Concat (·) means con-
catenating these vectors, and MLP(·) means the vec-
tor will be calculated by the Multi-layer Perceptron.
σ (·) means the sigmoid activation function, which
could be able to limit the attention weight range be-
tween 0 and 1.
3.3 Implementation Details
3.3.1 Learning
We use ResNet-50(He et al., 2016) as the CNN back-
bone here. Only one specific body part will assist the
part-relative HOI prediction in our model. Follow-
ing the learning method of set-based prediction in ob-
ject detection task(Carion et al., 2020), we adopt the
bipartite matching before the loss calculation, which
could make the set-based prediction result match the
most relevant ground truth. The HOI loss function is
similar to the one in QPIC(Tamura et al., 2021). For
the original HOI loss, it is compute composing with
the L1 loss L
b
and GIoU loss(Rezatofighi et al., 2019)
L
u
for bounding box, cross-entropy loss L
c
for object
classification and focal loss(Lin et al., 2017) L
a
for
the activity classification. We add the bounding box
location loss L
P
for the body part during training:
L = λ
b
L
b
+ λ
u
L
u
+ λ
c
L
c
+ λ
a
L
a
+ λ
P
L
P
(3)
λ
P
L
P
=
1
|
¯
Φ|
N
q
∑
i=1
1
{i/∈Φ}
n
b
b
i
− b
b
m(i)
· λ
P
1
+
h
1 − GIoU
b
b
i
,b
b
m(i)
i
· λ
P
2
o
(4)
where the λ
b
, λ
u
, λ
c
, λ
a
and λ
P
are the hyper-
parameters for the balance of L1 loss, GIoU loss,
cross-entropy loss, focal loss and the body part loss,
respectively. λ
P
is composed by λ
P
1
,λ
P
2
for the part
bounding box L1 and GIoU loss separately. Φ repre-
sents the empty set, which means this body part does
not exist. b means the bounding box of the part,
b
b
means the prediction location result and
b
m means the
matched ground truth index. This loss function could
make the body part information location loss only cal-
culated when the specific body part exists in the image
and remain the original loss function when the body
part does not exist.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
224

Figure 3: Some examples of the HICO-Hand-DET dataset. The colourful bounding boxes show the Human, Hand and Object
ground truth in white, yellow and cyan separately. The actions shown in the figure are all ’hold’, which are not marked for
better effect. The best colour for visualisation.
3.3.2 Inference
The inference post-processing will fuse the outputs
of each FFN to form an additional HOI set, which
is composed of the location of the human and object,
the object and verb class and the confidence score, as
the following form <
b
b
h
,
b
b
o
,
b
c
o
,
b
c
v
,
b
s >. The
b
b
h
,
b
b
o
,
b
c
o
,
b
c
v
and
b
s mean the prediction of the human bounding
box, object bounding box, object classification, ac-
tion classification, confidence score separately. The
confidence score is obtained by multiplying the clas-
sification score of the object and the action.
3.3.3 Auxiliary Loss
Carion et al. (2020) has pointed out that using the out-
puts of the decoder’s each layer to predict the bound-
ing box and calculate the loss will increase the per-
formance. Recently, most of the Transformer based
HOID models, such as Tamura et al. (2021), Zhang
et al. (2021a) and Zhou et al. (2022) have followed,
extending this auxiliary loss to all of the predictions,
and we will also follow this setting.
4 EXPERIMENT
In this section, extensive experimentation will prove
the role of body part information and channel atten-
tion. We will first introduce the dataset we used in
Section 4.1. Then, the experiment setup, including
the criterion metrics and the hyper-parameters setting
situation, will be illustrated in Section 4.2. In Section
4.3, we will compare with another model, followed
by the ablation study, which reveals the detailed im-
provement of each step.
4.1 HICO-Hand-DET
In order to validate the theory that body part in-
formation will directly increase performance, we
focus on the hands and the hand-relative activi-
ties. We have conducted extensive experiments on a
sub-dataset of the widely-used open-source dataset,
HICO-DET(Chao et al., 2018).
For the hands’ location, thanks to the contribu-
tion of the HAKE(Li et al., 2022a, 2020; Lu et al.,
2018), the human keypoints detection algorithm has
been adopted to the original HICO-DET dataset as
the first step. Then, the hand location bounding
boxes are drawn based on a specific ratio of the
other body parts and the predicted wrist keypoints. If
the head and pelvis keypoints are reliable, the side
length of hand bounding box is based on the de-
tected distance between them. If not, it will base
on the distance from the wrist to the elbow. A
matching algorithm is applied to ensure that each
detected hand is correctly associated with the orig-
inal HOI triplet labels. New quadruplets, which
means ⟨Human, Hand,Ob ject,Action⟩, are labelled
as shown in Figure 3 for training.
As for the hand relative activities, we manually se-
lected 50 kinds of verbs from the original 117 verbs in
the HICO-DET dataset, which could be directly asso-
ciated with the hand in most cases, such as ‘catch,
hold’. Based on the build-up methods introduced
above, we composed the HICO-Hand-DET dataset
with 22154 images for training and 6096 images for
testing.
4.2 Setup
4.2.1 Criterion Metrics
Following the metric construction in the Chao et al.
(2018) that publishes the HICO-DET dataset, we use
the mean Average Precision(mAP) as the critical eval-
uation indicator.
Our model divides HOI into different sub-tasks in
multi-decoders for prediction. In order to distinctly
feel the performance of each sub-task, we build a new
criterion metric, the HO mAP, to quantify the detec-
tion accuracy of the Human-Object Pair. As for the
Body Part Information Additional in Multi-decoder Transformer-Based Network for Human Object Interaction Detection
225

(a)
(b) (c) (d)
Figure 4: Improvement by body part information. (a) The prediction result without body part information. (b) The original
image whose the ground truth is the older repairing the broken umbrella. (c) The cross-attention weight visualisation of the
interaction decoder’s last layer on CDN-S. (d) The cross-attention weight visualisation of the interaction decoder’s last layer
on the model involving part information.
detection accuracy of activities, since the action clas-
sification is actually based on the detection accuracy
of HO, we use the correspondence between the over-
all mAP and HO mAP to map indirectly. The HO pair
prediction will be considered positive when:
• The Intersection over Union(IoU) between the
predicted and ground truth bounding box, includ-
ing the human and object, is larger than 0.5;
• The predicted object category is the same as the
one of ground truth.
As for the whole HOI triplet, each HOI triplet
will be considered positive when the HO pair and the
predicted verb category are correct. It will be used
to calculate the overall mAP. Following the setting
in QPIC(Tamura et al., 2021), we will only consider
the HOI triplets categories introduced during training.
Pair-wise non-maximal suppression(PNMS)(Zhang
et al., 2021a) will be applied before the final evalu-
ation. In contrast to the training period, the prediction
result of the Part Bbox FFN will not be considered as
the criterion.
4.2.2 Hyper-Parameters
The learning rate is set to 10
−5
for the backbone and
10
−4
for the primary model. We train this model
for 90 epochs and the learning rate drops 10 times
after 60 epochs. The loss function balanced weight
λ
b
,λ
u
,λ
c
,λ
a
,λ
P
1
and λ
P
2
are equal to 2.5, 1, 1, 1, 1,
2.5 respectively.
4.3 Comparison and Ablation Study
In order to decrease the model structure complexity,
we use the original CDN-S model, which has only
three layers for each decoder, as the baseline in the
experiments. We train the CDN-S model on our com-
posed HICO-Hand-DET, and the result is shown in
the first row of Table 1. It is lower than the result
Table 1: Comparison and analysis the improvement of each
optimization step.
Strategy Full Rare Non-Rare
CDN-S 30.58 28.80 31.09
+Body Part 31.02 27.99 31.81
31.81
31.81
+Channel Attention 31.43
31.43
31.43 30.09
30.09
30.09 31.78
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
226

trained in HICO-DET because the hand-relative verbs
may be more challenging than the other activities.
According to the second row of Table 1, we could
find that when only adding the Part decoder after the
HOPD and summarising the outputs of the former de-
coders as the interaction decoder’s query, the over-
all performance has increased by around 0.44(1.4%)
from the baseline. When we used the Channel At-
tention(CA) to enhance the feature extracted from the
former decoder to give the interaction decoder a bet-
ter prior query, the overall performance could increase
by 0.41 again. In these ways, the Full mAP could in-
crease by 0.85, which means over 2.77% rise from
the baseline. There is a significant increase on the
Rare set, rising by 4.5% to 30.09, which is 2.1 higher
than without the Channel Attention module and 1.29
higher than the baseline.
For qualitative analysis, the benefits of involving
the part information and the channel attention into the
HOID model, we infer the images and visualise the
prediction bounding box. To find out the main at-
tention changes after the optimisation, we also visu-
alise the cross-attention weights of the last layer in
decoders.
4.3.1 Body Part Information
The visualisation result is shown in Figure 4. Accord-
ing to the images, the body part information involved
in the model structure could increase the interaction
detection performance based on hands in two ways.
Firstly, it could suppress irrelevant interactions,
solving the problem of false combining the non-
interaction Human-Object pair, especially in crowd
objects and multi-people situations. For example,
Figure 4a shows a person who stands far away from
the bicycle. Nevertheless, from the angle of the cam-
era, the person seems to be next to the bike due to the
lack of depth information. In this situation, the basic
CDN-S will detect this human-bicycle pair and pre-
dict that the human is holding the bicycle, even if it is
almost impossible in our minds. In contrast, when we
include the part decoder in the model structure, this
misleading HOI will be suppressed.
Secondly, it will also draw the attention to the re-
gions associated with hands. As we could see in Fig-
ure 4b, an old person interacts with a broken umbrella.
Suppose we visualise the attention weight of the in-
teraction decoder. In that case, we could find in Fig-
ure 4c that the model only focuses on the whole body
rather than the specific part interacting with objects,
so the correct interaction could not be detected. How-
ever, Figure 4d shows that when the part information
is involved in the model structure, hand relative area
will be paid more attention than other parts, increas-
ing the interaction detection accuracy.
4.3.2 Channel Attention
This section compares the predicted results with or
without Channel Attention. The visualisation results
are shown in Figure 5, and the quantitative analysis
result is shown in Table 2. According to the results,
the Channel Attention module could balance the at-
tention weight between the Human-Object pair and
the body part information.
Table 2: Comparison and analysis the HO mAP of each
optimization step.
Strategy HO mAP
CDN-S 34.42
+Body Part 34.08
+Channel Attention 34.43
34.43
34.43
The Channel Attention module could make the
model consider both the characteristics of the HO
pair and the hands rather than only considering one
of them. As shown in the first row of Figure 5, the
interaction prediction results and the cross-attention
weight of the interaction decoder of the model with
or without Channel Attention reveal the improvement.
As we can see in Figure 5b, the model without Chan-
nel Attention module mainly concentrates on the key-
board itself. In contrast, the model with Channel At-
tention also focuses on the relative position relation-
ship between the human, hands and objects which is
shown in Figure 5d. These attention weight differ-
ences lead to different action prediction results, which
are wrong to predict as ‘type on’ in Figure 5a and cor-
rect to predict as ‘hold, carry’ in Figure 5c, increasing
the activities’ prediction accuracy.
The Channel Attention module could make the
object’s boundaries complete. As we can see in
the second line of Figure 5, paying less attention to
the object may decrease the object’s integrity. Like
the cross-attention weight of HOPD shown here, the
model without the Channel Attention module, which
could not enhance the Human-Object pair informa-
tion, will only focus on some part of the whole ob-
ject. In contrast, the Channel Attention module could
complete the detected object bounding box. It could
also be noticed from the visualisation of the cross-
attention. The model only looks at the surface of the
umbrella in Figure 5f, while the model involves the
umbrella’s handle in Figure 5h. Therefore, the pre-
diction result of the umbrella shown in Figure 5g is
more integrated than the one in Figure 5e.
After the quantitative analysis, we found that the
Channel Attention module could increase the HO
mAP, further proving the abovementioned deduction.
Body Part Information Additional in Multi-decoder Transformer-Based Network for Human Object Interaction Detection
227

(a) (b) (c) (d)
(e) (f) (g) (h)
Figure 5: Improvement by Channel Attention module. (a)(e) The prediction result of the model w/o CA; (b) The cross
attention weight visualisation of interaction decoder’s last layer on the model w/o CA; (c)(g) The prediction result of the
model w/ CA; (d) The cross attention weight visualisation of interaction decoder’s last layer on the model w/ CA; (f) The
cross attention weight visualisation of HOPD’s last layer on the model w/o CA; (h) The cross attention weight visualisation
of HOPD’s last layer on the model w/ CA.
Table 2 illustrates that the HO mAP decreases by
about 0.34 after involving the body part information
in the model. The reduction may be due to the model
paying more attention to the body part during train-
ing and the backpropagation period. When we add
the Channel Attention module to balance the atten-
tion weight, we can find that the HO mAP rises to the
same level as the baseline model. Under the increas-
ing overall performance, it reveals that the model can
improve the performance of interactive detection on
the premise of ensuring HO accuracy.
5 CONCLUSIONS
We have proposed a Transformer based HOID model,
which involves the body part information as the assis-
tant and uses the Channel Attention module to make
the model attention balance between the Human-
Object pair and the body part. The body part infor-
mation could refine the subject of interaction detec-
tion and the balancing mechanism could dynamically
adjust the importance weight of the two kinds of fea-
ture information in the same channel. Complicated
experiments have verified that the body part infor-
mation could suppress the irrelevant interaction and
draw attention to the part’s relative area. The Channel
Attention module could complete the object’s bound-
aries and make the model consider both the character-
istics of the HO pair and the hands rather than only
considering one of them, increasing the accuracy of
the activities’ prediction. Our proposed method could
achieve a better performance comparing the State-Of-
The-Art baseline model. However, we only use the
specific body part and the relative activities for train-
ing and testing. We plan to automatically find the
most relevant body parts during HOI prediction in the
future.
REFERENCES
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov,
A., and Zagoruyko, S. (2020). End-to-end object de-
tection with transformers. In European conference on
computer vision, pages 213–229. Springer.
Chao, Y.-W., Liu, Y., Liu, X., Zeng, H., and Deng, J. (2018).
Learning to detect human-object interactions. In 2018
ieee winter conference on applications of computer vi-
sion (wacv), pages 381–389. IEEE.
Chen, M., Liao, Y., Liu, S., Chen, Z., Wang, F., and Qian,
C. (2021). Reformulating hoi detection as adaptive
set prediction. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 9004–9013.
Dai, X., Chen, Y., Yang, J., Zhang, P., Yuan, L., and Zhang,
L. (2021). Dynamic detr: End-to-end object detec-
tion with dynamic attention. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion, pages 2988–2997.
Fang, H.-S., Cao, J., Tai, Y.-W., and Lu, C. (2018). Pairwise
body-part attention for recognizing human-object in-
teractions. In Proceedings of the European conference
on computer vision (ECCV), pages 51–67.
Gao, C., Zou, Y., and Huang, J.-B. (2018). ican: Instance-
centric attention network for human-object interaction
detection. arXiv preprint arXiv:1808.10437.
Gkioxari, G., Girshick, R., and Malik, J. (2015a). Actions
and attributes from wholes and parts. In Proceedings
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
228

of the IEEE international conference on computer vi-
sion, pages 2470–2478.
Gkioxari, G., Girshick, R., and Malik, J. (2015b). Contex-
tual action recognition with r* cnn. In Proceedings
of the IEEE international conference on computer vi-
sion, pages 1080–1088.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Ji, J., Desai, R., and Niebles, J. C. (2021). Detecting human-
object relationships in videos. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion, pages 8106–8116.
Kim, B., Lee, J., Kang, J., Kim, E.-S., and Kim, H. J.
(2021). Hotr: End-to-end human-object interaction
detection with transformers. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 74–83.
Kim, B., Mun, J., On, K.-W., Shin, M., Lee, J., and Kim, E.-
S. (2022). Mstr: Multi-scale transformer for end-to-
end human-object interaction detection. In Proceed-
ings of the IEEE/CVF Conference on Computer Vision
and Pattern Recognition, pages 19578–19587.
Li, Y.-L., Liu, X., Wu, X., Li, Y., Qiu, Z., Xu, L., Xu, Y.,
Fang, H.-S., and Lu, C. (2022a). Hake: A knowledge
engine foundation for human activity understanding.
Li, Y.-L., Xu, L., Liu, X., Huang, X., Xu, Y., Wang, S.,
Fang, H.-S., Ma, Z., Chen, M., and Lu, C. (2020).
Pastanet: Toward human activity knowledge engine.
In CVPR.
Li, Z., Zou, C., Zhao, Y., Li, B., and Zhong, S. (2022b). Im-
proving human-object interaction detection via phrase
learning and label composition. In Proceedings of
the AAAI Conference on Artificial Intelligence, vol-
ume 36, pages 1509–1517.
Liao, Y., Liu, S., Wang, F., Chen, Y., Qian, C., and Feng,
J. (2020). Ppdm: Parallel point detection and match-
ing for real-time human-object interaction detection.
In Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition, pages 482–490.
Lin, T.-Y., Goyal, P., Girshick, R., He, K., and Doll
´
ar, P.
(2017). Focal loss for dense object detection. In
Proceedings of the IEEE international conference on
computer vision, pages 2980–2988.
Lu, C., Su, H., Li, Y., Lu, Y., Yi, L., Tang, C.-K., and
Guibas, L. J. (2018). Beyond holistic object recogni-
tion: Enriching image understanding with part states.
In CVPR.
Ma, X., Nie, W., Yu, Z., Jiang, H., Xiao, C., Zhu, Y., Zhu,
S.-C., and Anandkumar, A. (2022). Relvit: Concept-
guided vision transformer for visual relational reason-
ing. arXiv preprint arXiv:2204.11167.
Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I.,
and Savarese, S. (2019). Generalized intersection over
union: A metric and a loss for bounding box regres-
sion. In Proceedings of the IEEE/CVF conference on
computer vision and pattern recognition, pages 658–
666.
Sunkesula, S. P. R., Dabral, R., and Ramakrishnan, G.
(2020). Lighten: Learning interactions with graph and
hierarchical temporal networks for hoi in videos. In
Proceedings of the 28th ACM International Confer-
ence on Multimedia, pages 691–699.
Tamura, M., Ohashi, H., and Yoshinaga, T. (2021). Qpic:
Query-based pairwise human-object interaction detec-
tion with image-wide contextual information. In Pro-
ceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition, pages 10410–10419.
Yuan, H., Wang, M., Ni, D., and Xu, L. (2022). De-
tecting human-object interactions with object-guided
cross-modal calibrated semantics. arXiv preprint
arXiv:2202.00259.
Zhang, A., Liao, Y., Liu, S., Lu, M., Wang, Y., Gao, C., and
Li, X. (2021a). Mining the benefits of two-stage and
one-stage hoi detection. Advances in Neural Informa-
tion Processing Systems, 34:17209–17220.
Zhang, F. Z., Campbell, D., and Gould, S. (2021b). Spa-
tially conditioned graphs for detecting human-object
interactions. In Proceedings of the IEEE/CVF In-
ternational Conference on Computer Vision, pages
13319–13327.
Zhou, D., Liu, Z., Wang, J., Wang, L., Hu, T., Ding, E.,
and Wang, J. (2022). Human-object interaction de-
tection via disentangled transformer. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 19568–19577.
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., and Dai, J.
(2020). Deformable detr: Deformable transform-
ers for end-to-end object detection. arXiv preprint
arXiv:2010.04159.
Body Part Information Additional in Multi-decoder Transformer-Based Network for Human Object Interaction Detection
229
