
Accelerate Training of Reinforcement Learning Agent by Utilization of
Current and Previous Experience
Chenxing Li
1,3
, Yinlong Liu
2
, Zhenshan Bing
2
, Fabian Schreier
1,3
, Jan Seyler
3
and Shahram Eivazi
1,3
1
University of T
¨
ubingen, T
¨
ubingen, Germany
2
Technical University of Munich, Munich, Germany
3
Festo, Esslingen, Germany
Keywords:
Q-function Targets Via Optimization, Data Efficiency, Hindsight Goals Techniques, Offline Data Collection,
Dynamic Buffer.
Abstract:
In this paper, we examine three extensions to the Q-function Targets via Optimization (QT-Opt) algorithm and
empirically studies their effects on training time over complex robotic tasks. The vanilla QT-Opt algorithm
requires lots of offline data (several months with multiple robots) for training which is hard to collect in
practice. To bridge the gap between basic reinforcement learning research and real world robotic applications,
first we propose to use hindsight goals techniques (Hindsight Experience Replay, Hindsight Goal Generation)
and Energy-Based Prioritization (EBP) to increase data efficiency in reinforcement learning. Then, an efficient
offline data collection method using PD control method and dynamic buffer are proposed. Our experiments
show that both data collection and training the agent for a robotic grasping task takes about one day only,
besides, the learning performance maintains high level (80% successful rate). This work serves as a step
towards accelerating the training of reinforcement learning for complex real world robotics tasks.
1 INTRODUCTION
In recent years, reinforcement learning (RL) algo-
rithm become one of the most popular artificial in-
telligence techniques. In various famous human-
machine competitions such as StarCraft competitions
between AlphaStar and MaNa (Vinyals et al., 2019),
the machine behaviours performed very well with
help of RL. As a general learning method, it can
be used for different tasks and the agent learns the
policy via exploring action space on its own simu-
lator (Zhang et al., 2015) not like hard coded con-
trol methods where any change to environment may
lead to error states such as it could make the robot be
stuck in some poses without adaptive control design.
Normally RL performs well more on low dimension
space, for continuous tasks such as robotics manipu-
lation, however, a long training time is necessary to
reach reliable learning level (Sutton and Barto, 2018).
To provide reliable performance under environment
changes, the mapping from inputs to outputs in RL
can be substituted with a neural network for updating
(Li, 2017). Based on this mapping suppose, several
techniques in RL are proposed to improve the learn-
ing performance of agent such as Deep Q-learning
(DQN) (Szepesv
´
ari, 2010), Double Q-learning (Has-
selt, 2010) and (Van Hasselt et al., 2016) and Deep
Deterministic Policy Gradient (DDPG) (Wiering and
Van Otterlo, 2012). Apart from that, Hindsight Ex-
perience Replay (HER) (Andrychowicz et al., 2017),
Hindsight Goal Generation (HGG) (Ren et al., 2019)
and Energy-Based Prioritization (EBP) (Zhao and
Tresp, 2018) are proposed by researchers previously
to address the problems of efficient data sampling for
real world application.
Google X team proposed Q-function Targets via
Optimization (QT-Opt) as a scalable deep reinforce-
ment learning algorithm for vision-based robotic
tasks (Kalashnikov et al., 2018). It can deal with
the actions which contain continuous and discrete ac-
tion space based on the Clipped Double Q-learning
(Fujimoto et al., 2018) with cross-entropy method
(CEM) that can avoid direct max operation over Q-
values. Besides, it can overcome the notoriously un-
stable problem caused by policy network and Qt-opt
combines both advantages of on-policy learning and
off-policy learning (Bodnar et al., 2019). In prac-
tice, QT-Opt needs numerous computing resources
as well as time and hardware to collect offline data
such as Google had used 7 robots over the course
698
Li, C., Liu, Y., Bing, Z., Schreier, F., Seyler, J. and Eivazi, S.
Accelerate Training of Reinforcement Learning Agent by Utilization of Current and Previous Experience.
DOI: 10.5220/0011745600003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 698-705
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

(a) The robot arm first moved behind the object in
Pushing task.
(b) The robot arm finally pushed the object to the
desired position successfully.
Figure 1: The original QT-Opt methods are already im-
plemented in real world tasks. The left scenarios of both
figures are the real world Pushing task showing that the
robot arm is pushing the object to the desired position. The
right scenes of both figures are synchronous to the left real
world motions and show the trajectory of the robot arm end-
effector from the starting point (blue sphere) to the final po-
sition. The light blue sphere presents the original object po-
sition, the pink one is the current object position, the small
yellow sphere shows the current position of end-effector
and the green one is the desired goal position. The robot
arm first moved behind the object, then pushed the object to
desired goal position successfully.
of several weeks to collect the offline data. With a
distributed robotic grasping experiment they needed
to keep the environment information same across all
robots which make it unpractical. Here we aim to
use relatively much less resources (e.g. 14k CPU
core vs. 32 CPU core) while achieving a competi-
tive learning performance. As such, we proposed sev-
eral techniques to improve the learning performance
and tested them in simulation using 7 degrees of free-
dom robotic arm (Franka Emika robot arm). Our pa-
per makes the following contributions:
• An PD control data generation is proposed to
make the offline data collection simple and effi-
cient.
• HER, HGG and EBP are adapted to the QT-opt
structure for efficient data sampling.
• A dynamic buffer mechanism is proposed to re-
duce the size of offline data as well as generation
of sub-optimal trajectories in offline data.
Besides, Reaching task and Pushing task are al-
ready implemented in the real world based on the
original ideas with QT-Opt while Google X team did
not present them. Like Figure 1 shown, the robot arm
pushed the object to desired goal position success-
fully. The aim of implementing them is to extend the
Google work and verifies the feasibility of our pro-
posed methods so as to build the theoretical and ex-
perimental fundamentals for complex tasks. The fo-
cus of this paper is the grasping task (PickAndPlace
task). In this paper, we adapted the QT-Opt to non-
distributed QT-Opt for quick comparison. Based on
own version of QT-Opt, the performance comparison
over grasping task are given in simulation. In the fu-
ture, the grasping task in the real world can be im-
plemented like the accomplished tasks. The paper
presents the introduction and preliminaries containing
the contributions and the fundamentals of RL tech-
niques. Then the methods that used in the research are
discussed in the section methodology. Section results
and discussion analyse the results. Finally, conclu-
sions and future work plan are given in the following
sections.
2 PRELIMINARIES
Reinforcement learning is one of main learning
branches of machine learning (Hammersley, 2013).
The mechanism of RL is based on Markov decision
processes (MDP) (Garcia and Rachelson, 2013) and
pursue an optimal policy (Puterman, 1990). In this
process, at each time step t, the agent in one state s
t
performs an action a
t
. Criteria to generate the action
is based on the policy π(a
t
| s
t
). In every step, agent
receives a reward r
t
according to the reward function
r(r
t
| s
t
,a
t
) and then transitions to the next state s
t+1
according to the transition function p(s
t+1
| s
t
,a
t
). An
optimal policy π
?
can be derived by maximizing the
expected discounted sum of the rewards like Equa-
tion 1. The discounting factor γ is limited in the [0, 1]
for avoiding the infinity rewards for the environments
without final states (Bennett and Hauser, 2013).
π
?
= argmax
π
E
r∼p(τ|π)
[
∑
t≥0
γ
t
r
t
] (1)
Based on that, Q-function can be used to find the
optimal policy. After setting environments based on
consecutive states, the Q-function is written as Bell-
man equation as followed (Barron and Ishii, 1989):
Q
π
(s
t
,a
t
) = E
r∼p(τ|π)
[r
t
+ γQ
π
(s
t+1
,a
t+1
)] (2)
Further, neural network can be integrated with re-
inforcement learning (DQN). The responding target
value is:
Q
t
= r(s, a, s
t+1
) + γmax
a
t+1
Q(s
t+1
,a
t+1
) (3)
Accelerate Training of Reinforcement Learning Agent by Utilization of Current and Previous Experience
699
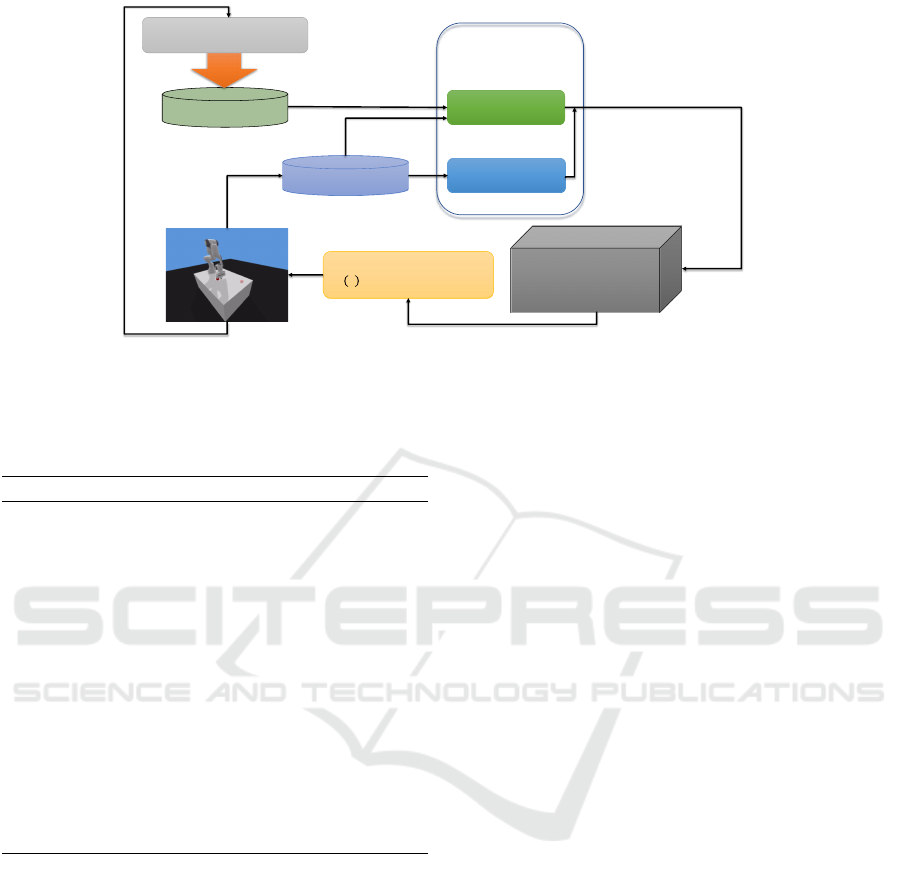
Offline Data
Cross Entropy Method
Online Data
Model Weight
(, )
Dynamic Replay Buffer
PD Generation Techniques
Off-policy
On-policy
Train
Generate at the Beginning
=
�
(, )
Figure 2: Modified method structure. The offline data can be generated via PD controller mode, then the online data are
collected. A dynamic buffer is used to choose the data for updating. Finally, CEM chooses the responding policy based on
the neural network weights. Rather than original QT-Opt, Bellman updater is substituted with the new buffer mechanism and
the offline data is collected by PD generation techniques.
Algorithm 1: Cross Entropy Method (CEM).
Inputs: Neural network outputs and Gaussian pa-
rameters
Outputs: Actions and Q-values
1: Initialize standard error and mean based on a
Gaussian distribution
2: for i = 1, 2, ..., until the iteration you choose do
3: Generate N actions based on a Gaussian dis-
tribution
4: Obtain the Q-values in neural networks
5: Choose the best M samples from N actions
6: Update the CEM parameters with the M sam-
ples
7: end for
8: return maximum actions and the responding Q-
values
However, if the target is susceptible to error, then
the maximum that we get is generally larger than the
true maximum and it can lead to overestimation bias.
Then the values continue to propagate through the
Bellman equation. Finally, the agent may learn in
the wrong direction. The max operation is the main
reason of overoptimistic value estimates. To solve
this, one can decouple the selection from the evalu-
ation. The Clipped Double Q-learning is based on
this idea to update the policy, while two independent
estimates of the true Q value are included. To avoid
the overestimation of Q-values, the minimum of the
two next-state action values produced by two Q neu-
ral networks is used to compute the updated targets
(Hasselt, 2010).
The traditional policy can be updated by getting
the maximum of Q value, then its responding action in
robotic environments is the policy in each steps. Nor-
mally, a second network for updating Q-values or ac-
tions is needed. Thus, a cross-entropy method (CEM)
is proposed to perform the optimization avoiding the
need for a second maximizer network. The Algorithm
1 shows the process of CEM (Kalashnikov et al.,
2018). With CEM and clipped Double Q-learning,
the Q-values can be updated as:
Q
?
(s
t
,a
t
) = r
t+1
+ γmin
i=1,2,...
Q
θ
i
(s
t+1
,a
CEM
) (4)
The above equation is the core of pure QT-Opt al-
gorithm which is an on-policy training algorithm. It
is meaningful to extend this algorithm to a structure
which combines both advantages of on-policy and
off-policy learning. The agent can learn fast in the
right direction when it explores enough behaviours
like Figure 2 shown. Apart from that, how to gen-
erate a good offline data is vital concern for the QT-
Opt algorithm. From the paper (Kalashnikov et al.,
2018), offline data can be obtained by adopting the
previous online data. The difference of on-policy and
off-policy learning is whether updating based on the
current strategy. In this status, the online data in cur-
rent updating is on-policy, while for the next updating,
these data is off-policy. Besides, the data that we ob-
tained need to include enough successful data, other-
wise, it always learns the bad behaviour which is not
wanted. Thus, they first bootstrapped the data with
QT-Opt, then they saved all data and constructed the
data with enough successful data and relative com-
plete action space.
Another well-known problem with RL is data ef-
ficiency. The reinforcement learning can generate
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
700
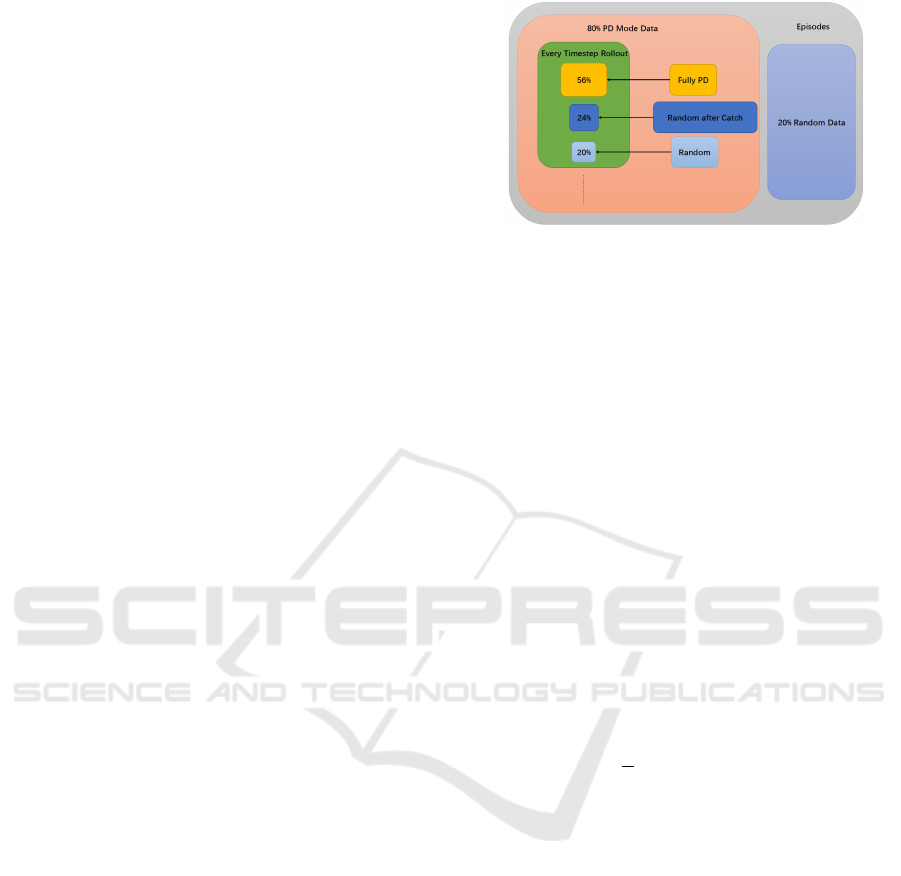
the data via the simulator on its own not like deep
learning, while at the beginning, the generated data
is not so efficient as to the agent to learn the cor-
rect behaviour. Hindsight Experience Replay (HER)
and Hindsight Goal Generation (HGG) are the meth-
ods proposed to improve the task performance via in-
creasing the data efficiency. HER can replay each
episode with a different goal which the agent achieved
and it can construct a number of achieved hindsight
goals based on the intermediate states (Andrychow-
icz et al., 2017). Apart from that, HGG generates
valuable hindsight goals which are easy for an agent
to achieve in the short term and are also potential for
guiding the agent to reach the actual goal in the long
term (Ren et al., 2019).
EBP is a method to choose valuable data in buffer
considering energy changes. In robot grasping task,
the object kinematic and potential energies changes
in trajectory are considered as the criteria of valu-
able data which means that the object was caught
and moved to other place. If the energy changes of
the trajectory are higher, the replay buffer has higher
chance to choose this trajectory for updating (Zhao
and Tresp, 2018). Then the agent can use less time
to fully learn the behaviour based on valuable data in
buffer.
3 METHODOLOGY
In this paper, we focus on how to use relatively
less resources (a day of training and a gaming PC
with RTX2070) to accomplish the competitive learn-
ing performance like Google X team did in 2018
when they used QT-Opt to accomplish 96% over robot
grasping task which took several months for training
and collecting data. To avoid the need for large scale
cluster we use the physical information as observa-
tion in this paper rather than images. Our methods
can be be formed with three perspectives. The Figure
2 shows the method structure and contains the follow-
ing points.
• Adapting HER, HGG, and EBP to the QT-Opt
structure.
• A PD control data generation method.
• A dynamic buffer mechanism.
First, HER and HGG can help learning with in-
creasing data efficiency. How to use HER with QT-
Opt has been proposed before (Fujita et al., 2020) in
large scale cluster (not the focus of this paper) but the
combination of QT-Opt and HGG which has not been
studied yet. In this paper, EBP is used to increase
the data efficiency and can be combined with HER
Figure 3: PD Method to Generate Offline Data.
and HGG. HER needs to replay the episode with the
hindsight goals, so many successful trajectories can
be created in learning. As such, there is no need to
change the QT-Opt structure.
HGG needs to choose the goal and initial state be-
fore each rollout. The fundamental of HGG is based
on the following suppose:
|V
π
(s,g) −V
π
(s
0
,g
0
)| ≤ L · d((s,g),(s
0
,g
0
)) (5)
Here, V
π
shows the responding policy, the func-
tion d(·) is a metric that d = c||φ(s) − φ(s
0
)||
2
+ ||g −
g
0
||
2
. c is the hyperparameter which is larger than zero
to make sure trade-off between the distances between
the initial states and the final states. φ(·) is a state
abstraction to map from state space to goal space.
Based on Equation 5, we can rewrite the equation
via (s,g) ∼ T , (s
0
,g
0
) ∼ T and solve the optimization
problem:
min
π,T
[L · D(T,T
?
) −V
π
(T )] = min
π,T
[c||φ(s) − φ(s
0
)||
2
+||g −g
0
||
2
−
1
L
V
π
(T )]
(6)
Where D(·) is the Wasserstein distance based on
d(·). We assume that T is hindsight. Then K parti-
cles will be adopted from T
?
, instead of dealing with
T
?
, the approximation method is used to simplify the
tasks, hence, for every task ( ˆs
i
0
, ˆg
i
) ∈
ˆ
T
?
, the hindsight
trajectory T should minimize the following sum:
∑
ω(( ˆs
i
0
, ˆg
i
),τ
i
) (7)
where we define ω((ˆs
i
0
, ˆg
i
),τ
i
) is transformed
based on Equation 7. Then the corresponding
achieved state will construct the hindsight goals in T .
From the above deduction (Ren et al., 2019), we
can find that HGG needs to make several changes
to adjust QT-Opt structure. The hindsight goals T
are stored in a pool mechanism. The updated Q-
values for HGG need to obtained by the inputs com-
puting in pool which we called AchievedPool via neu-
ral network. Normally, algorithms like DDPG have a
Accelerate Training of Reinforcement Learning Agent by Utilization of Current and Previous Experience
701
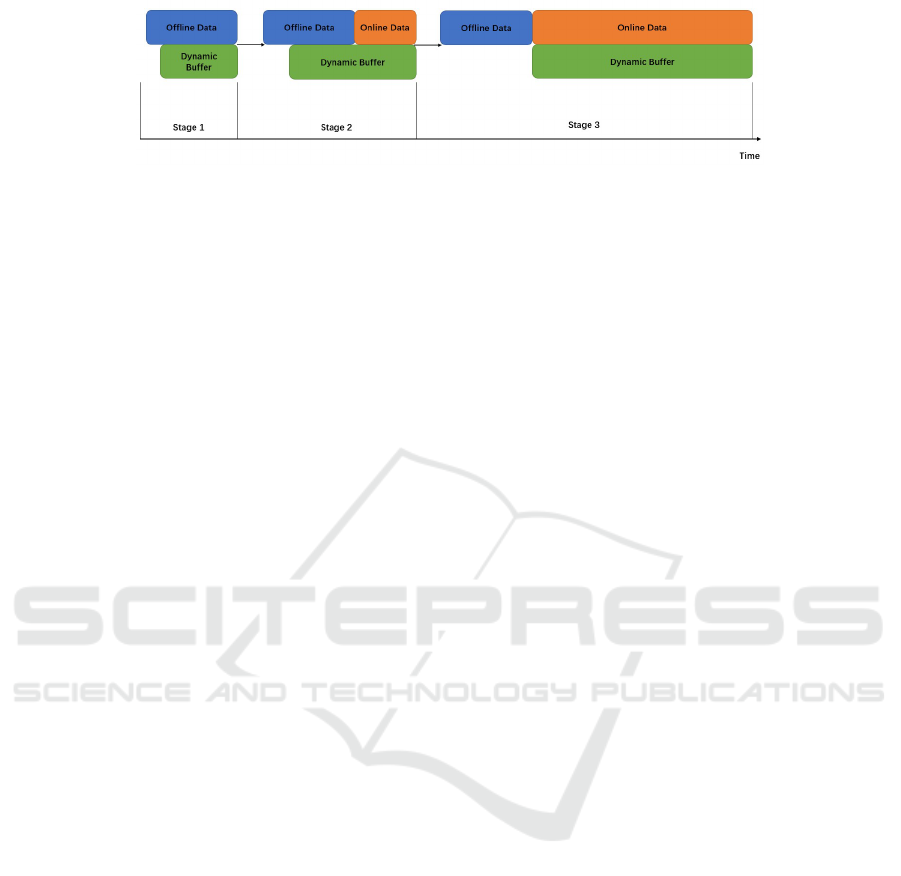
Figure 4: Dynamic Buffer Mechanism. At the beginning, the rest 3/4 data are considered as offline data in QT-Opt. With
online data adding, the offline data buffer contains both offline data and online data for off-policy updating. Finally, the buffer
will be full of online data. In this period, the buffer is dynamic with the online data adding.
specific network to generate these Q-values. How-
ever, QT-Opt uses CEM algorithm which will gen-
erate actions and Q-values in same networks. The
achieved Q-value will be obtained by CEM with cur-
rent weights from V
π
(T ), CEM is also the mecha-
nism of actions generation in Qt-opt, so we use the
responding Q-values outputs of CEM to Equation 6.
Second, a new offline data bootstrapping tech-
nique is proposed. It is known that QT-Opt can take
advantages of off-policy and on-policy learning when
training more complex tasks. Simple randomly gen-
erated data can not directly be used as the offline data
in QT-Opt structure as proposed by authors (Kalash-
nikov et al., 2018) and the QT-Opt need at least 30
percents successful data. It is difficult to make sure
that the random data can have at least 30 percents
successful samples even if we get the data from on-
policy training. Thus, an efficient method to generate
enough valuable data is our concern.
We propose to use PD control method to generate
offline data. PD control method is a simple method to
control the agent to move fast and stable to our desired
goal. P is proportional parameter and D is derivative
coefficient, while P can help fast achieving goal and
D can make the response stable. When we use the
PD control method, for example in the PickAndPlace
task, we design the robot arm first moves about the
object and finger is open, the end-effector goes down
to contain the object and further closes the finger to
catch the object, finally, it catches the object to the
goal area.
Our successful samples index among all samples
can be reached. However, it is also not helpful to set
all the offline data as successful data because then
the agent can not learn which behaviour is not cor-
rect. For example, in grasping task, if the offline data
is always successful, the finger could close when it
is near the threshold of the object and catch the ob-
ject, but the agent can never learn how to react if
the finger is open in the above circumstance. To in-
clude unsuccessful examples, a random policy needs
to combine with the PD control data. Besides, the
random actions in PickAndPlace task are not often to
present the finger with grasping the object and in this
transport, the design to show that it drops the object
or it starts fully random motions to test which angle
is best to catch the object need to be also included.
For the trajectories generated by our method, they are
not fully from the PD control mode while they need
some bad behaviours to let the agent learn not to be-
have that. Thus, bootstrapping in PickAndPlace task,
we set at each time-step, there exists 56% probabili-
ties where trajectories are fully PD control generated,
20% probabilities where trajectories are fully random
mode without any control, the rest 24% probabilities
where trajectories are integrated in PD control mode
but with random motion in several steps as Figure 3
shown.
Third, we propose a dynamic buffer mechanism
to further increase the learning performance (Fig-
ure 4). The PD generated data can be considered
as ScriptedTra jectories which are the trajectories
which use successful policy to generate. Apart from
PD control data generation, it also needs to add more
explored policies in QT-Opt structure. The others are
the trajectories which are based on exploration to gen-
erate which is the ExploredTra jectories. They also
need to have at least 30% successful data (Kalash-
nikov et al., 2018) which can not be certain via fully
random sampling.
Our PD controller method has the enough success-
ful data while it does not explore all the policies. It
has more data directly towards to the goal even with
random scripted data. The explored policies that we
need are sub-optimal policies. We can use the pre-
vious on-policy data as ExploreTra jectories but it
needs to satisfy the rate of successful trajectories, thus
the robot needs to explore almost all action space to
collect the data from Google X team.
To solve this problem, we propose to first use PD
offline data for training while saving the transitions in
each time step so we can add them to our database
later. In our experiment, our data use the combination
of these two policies, they are PD control data as of-
fline data and following explored data as online data.
With online data adding, the offline data buffer con-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
702
tains both offline data and online data for off-policy
updating. Finally, the agent can sample data fully on
explored data. This is the method we called the dy-
namic buffer. Besides, this mechanism also avoids the
Bellman updater in original QT-Opt structure for dy-
namic buffer not only generates ExploreTra jectories
but also provides the agent which data need to be
trained for updating network weights.
This technique can certain that the agent is
able to explore the policies, and also have ac-
ceptable successful rate. In details like Figure 4
shown, for a buffer data with offline data and on-
line data, first with one probability α we used en-
ergy sampling method, and with 1 − α percentage
the data is sampled from the rest 3/4 trajectories
randomly. 3/4 trajectories can be updated when
adding more new data. At the beginning, these tra-
jectories contain the enough offline data, and the
offline data let the agent learn in the right way.
Then the online data can be further included as
ExploredTra jectories based on neural networks up-
dating. This innovative technique makes sure the of-
fline data is made of the ScriptedTra jectories and
ExploredTra jectories, besides, the at least 30% suc-
cessful data can also be certain. As such, the rely on
offline data can be less because the more online data
with the help of hindsight goals techniques like HER
and HGG are more available to use. Furthermore,
HGG technique can also generate more couples in-
cluding the initial states and goals which are easy to
reach. Then more virtual goals can be among the real
goals, these new generated online data therefore be-
come more potentials.
4 RESULTS AND DISCUSSION
The experiment environment (Gallou
´
edec et al.,
2021) is based on Pybullet engine (Coumans and Bai,
2021) and Gym (Brockman et al., 2016) with Panda
robot from Franka Emika company. Before com-
plex tasks, Reaching task and Pushing task are imple-
mented to prove the feasibility of original QT-Opt in
fully continuous space. In our simulation task, a con-
tinuous action space is used which means both robot
joint control, as well as the gripper finger open and
close operations are continuous. The non-distributed
QT-Opt is implemented under the mentioned setup.
For the typical robot PickAndPlace task, several com-
parison experiments are implemented. To evaluate the
performance of our algorithm, we adopt the following
measures. First, the successful rate is our main crite-
ria to judge whether the method that we propose is
effective or not. Normally, the x-axis is the episode
information. One episode in our experiment is one
complete test that the robot arm starts from the ini-
tial state and implements to reach goal position under
maximum steps. The responding y-axis presents the
information of successful rate. The successful rate is
obtained after training one episode via implementing
50 tests without updating based on current neural net-
work weights. Second, for several new methods that
we proposed, one curve to present the efficiency is
not persuasive. Hence, it is necessary to have a num-
ber of tests over this new method based on the same
environment, then the mean value can be considered
as the rational value for comparisons.
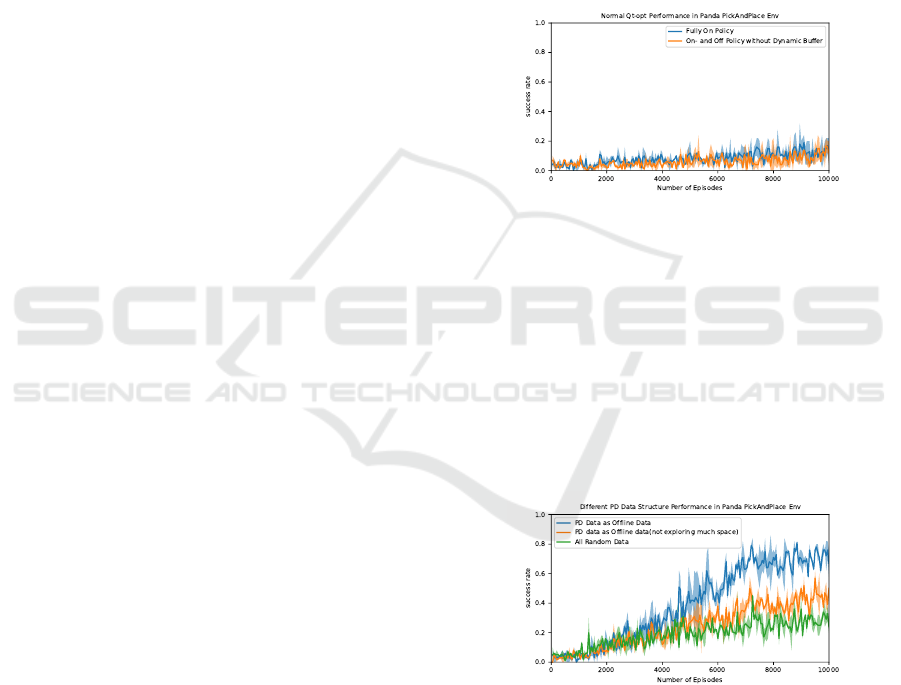
Figure 5: Normal QT-Opt Learning Performance. The blue
curve shows the fully online Qt-opt learning while the or-
ange one shows the Qt-opt combining with normal buffer
using on-and offline data.
First, pure on-policy QT-Opt and QT-Opt with
normal replay buffer (our baseline) are implemented
over PickAndPlace task. The results can be seen in
Figure 5. With normal buffer, or fully online data, QT-
Opt performs bad learning performance over robot
PickAndPlace task. Therefore, it is necessary to ex-
plore how to use the offline data to update the target
value and improve the data efficiency.
Figure 6: Different PD data learning performance with dy-
namic buffer. The blue curve is combined with HER, EBP
and dynamic buffer based on PD offline data generated from
our method. The orange curve in this figure shows the
similar PD mechanism without sampling at each time-step
rather maintain the responding fraction in whole episodes.
The green curve is fully random bootstrapping to collect the
offline data with dynamic buffer.
Further, a PD offline data generation compari-
son is implemented in PickAndPlace task (Figure 6).
The blue curve is combined with HER, EBP and dy-
Accelerate Training of Reinforcement Learning Agent by Utilization of Current and Previous Experience
703
namic buffer based on PD offline data generated from
our method. The orange curve in this figure shows
the similar bootstrapping mechanism. However, this
mechanism is not generating the data with the pro-
posed percentages in each time step rather distribute
in whole episodes. Besides, it contains only grasp-
ing status without opening fingers in PD episodes.
This method can obtain good and fast successful data
in buffer, but not explore the enough action space.
And the green curve is fully random bootstrapping
to collect the offline data with dynamic buffer. From
that, we can conclude that our PD offline data gener-
ation can explore much action space and achieve bet-
ter learning performance than other techniques. Our
method can reach about 80% successful rate while the
other two perform under 60% successful rate finally.
Besides, it is necessary to include dropping the object
circumstances when grasping successfully based on
the comparison between orange curve and blue curve
so that the agent can deal with the behaviours.
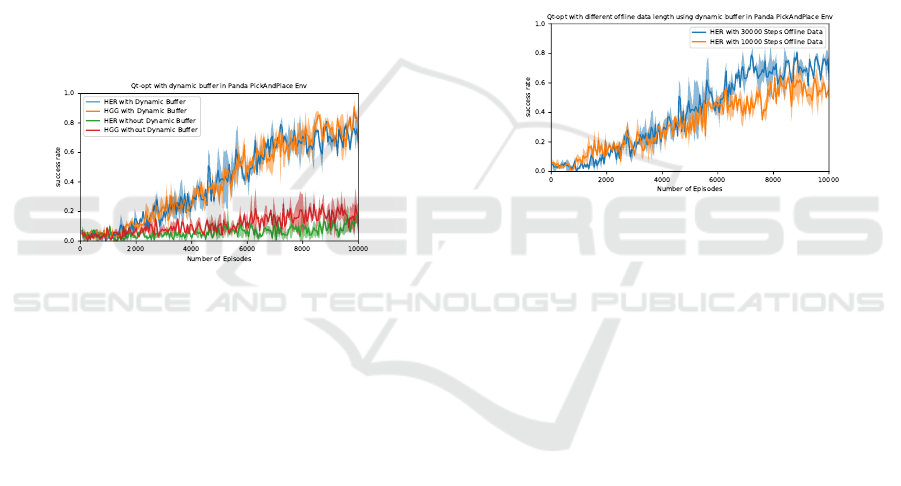
Figure 7: QT-Opt with hindsight goal techniques and dy-
namic buffer. The blue curve shows the performance of
mixed-policy QT-Opt with HER and dynamic buffer, the
orange curve presents how the mixed-policy QT-Opt with
HGG and dynamic buffer performs. The red curve shows
the circumstance of mixed-policy QT-Opt with HGG and
normal buffer. While the green one shows the performance
of mixed-policy QT-Opt with HER and normal buffer. All
offline data length is 30000 steps, the sampling rate among
the online data and offline data is 80%.
From the curves over QT-Opt with normal of-
fline data in PickAndPlace task in Figure 5 which
means that ScriptedTra jectories, the learning suc-
cessful rate is limited, the data does not explore all
behaviours in action space. As discussed in last sec-
tion, ExploredTra jectories are needed. Hence, dy-
namic buffer is implemented and compared with the
full PD control method generation data as offline data
in the Figure 6 and 7. Comparing to the orange curve
in Figure 5 as our baseline with normal buffer, the dy-
namic buffer version like the blue curve shown in the
Figure 6 and 7 performs much better.
Apart from that, HGG and HER can be combined
with QT-Opt and improve dynamic buffer learning ef-
fect for they can generate better data for next replay in
replay buffer and make more midpoints to final suc-
cess. Besides, HGG combination can achieve more
successful rate and perform more stable than HER
with QT-Opt in the final stage as Figure 7 shown,
though the difference is not so significant (5% - 10%).
Further, different length of offline data learning
performance are implemented as Figure 8. With more
offline data, the learning performance shows faster
and better learning over robot grasping task. With
30000 steps offline data, the learning successful rate
reaches 75% while with 10000 steps offline data, the
performance is about 55%.
With the help of dynamic buffer mechanism and
hindsight goals techniques, the offline data size is
around 30000 steps data which occupy less than 1k
memories in PC. The vanilla QT-Opt on the other
hand needed 580k memories data (Kalashnikov et al.,
2018).
Figure 8: The learning performance with different number
of offline data. The blue one shows the learning perfor-
mance of mixed-policy Qt-opt with 30000 steps offline data.
The orange curve has only 10000 steps offline data. The al-
gorithm is based on HER and dynamic buffer. The sampling
rate among the online data and offline data is 80%.
5 CONCLUSIONS
In this paper, modified QT-Opt as the basic method
for efficient learning in robotics tasks is used to avoid
overestimation of Q-values and be stable. PD con-
trol data generation with several random steps in
data structure can construct offline data to accom-
plish better training in QT-Opt structure instead of
collecting the large amount of previous data as of-
fline data which needs more time and real world
robots. Further, the agent can inspire from the
limited numbers of control behaviours, imitate and
explore the whole policy. The dynamic buffer
mechanism combines the ScriptedTra jectories with
ExploredTra jectories without manual insertion.
Thus, the complexity of the collection data can be
reduced significantly and the learning performance
can be improved with hindsight goals techniques fur-
ther. This novel combination shows competitive per-
formance for efficient reinforcement learning and pro-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
704

vides new research direction for QT-Opt learning over
real world robot tasks.
6 FUTURE WORK
In the future, we plan to use a hybrid action space in-
cluding both continuous joint control and discrete fin-
ger move. Based on current results, we expect to have
the significant improvement in hybrid action space as
well. In engineering, we also plan to mix simulation
and real robot, then the neural networks weight can be
transferred to real robot using transfer learning tech-
niques (Torrey and Shavlik, 2010). We expect that
the agent learn faster in further training in real world
compare to start training without simulation data.
REFERENCES
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong,
R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P.,
and Zaremba, W. (2017). Hindsight experience replay.
arXiv preprint arXiv:1707.01495.
Barron, E. and Ishii, H. (1989). The bellman equation for
minimizing the maximum cost. Nonlinear Analysis:
Theory, Methods & Applications, 13(9):1067–1090.
Bennett, C. C. and Hauser, K. (2013). Artificial intelligence
framework for simulating clinical decision-making: A
markov decision process approach. Artificial intelli-
gence in medicine, 57(1):9–19.
Bodnar, C., Li, A., Hausman, K., Pastor, P., and
Kalakrishnan, M. (2019). Quantile qt-opt for risk-
aware vision-based robotic grasping. arXiv preprint
arXiv:1910.02787.
Brockman, G., Cheung, V., Pettersson, L., Schneider, J.,
Schulman, J., Tang, J., and Zaremba, W. (2016). Ope-
nai gym. arXiv preprint arXiv:1606.01540.
Coumans, E. and Bai, Y. (2016–2021). Pybullet, a python
module for physics simulation for games, robotics and
machine learning. http://pybullet.org .
Fujimoto, S., van Hoof, H., and Meger, D. (2018). Ad-
dressing function approximation error in actor-critic
methods. CoRR, abs/1802.09477.
Fujita, Y., Uenishi, K., Ummadisingu, A., Nagarajan, P.,
Masuda, S., and Castro, M. Y. (2020). Distributed
reinforcement learning of targeted grasping with ac-
tive vision for mobile manipulators. arXiv preprint
arXiv:2007.08082.
Gallou
´
edec, Q., Cazin, N., Dellandr
´
ea, E., and Chen, L.
(2021). Multi-goal reinforcement learning environ-
ments for simulated franka emika panda robot.
Garcia, F. and Rachelson, E. (2013). Markov decision pro-
cesses. Markov Decision Processes in Artificial Intel-
ligence, pages 1–38.
Hammersley, J. (2013). Monte carlo methods. Springer
Science & Business Media.
Hasselt, H. (2010). Double q-learning. Advances in neural
information processing systems, 23:2613–2621.
Kalashnikov, D., Irpan, A., Pastor, P., Ibarz, J., Herzog, A.,
Jang, E., Quillen, D., Holly, E., Kalakrishnan, M.,
Vanhoucke, V., et al. (2018). Qt-opt: Scalable deep
reinforcement learning for vision-based robotic ma-
nipulation. arXiv preprint arXiv:1806.10293.
Li, Y. (2017). Deep reinforcement learning: An overview.
arXiv preprint arXiv:1701.07274.
Puterman, M. L. (1990). Markov decision processes. Hand-
books in operations research and management sci-
ence, 2:331–434.
Ren, Z., Dong, K., Zhou, Y., Liu, Q., and Peng, J. (2019).
Exploration via hindsight goal generation. arXiv
preprint arXiv:1906.04279.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT press.
Szepesv
´
ari, C. (2010). Algorithms for reinforcement learn-
ing. Synthesis lectures on artificial intelligence and
machine learning, 4(1):1–103.
Torrey, L. and Shavlik, J. (2010). Transfer learning. In
Handbook of research on machine learning appli-
cations and trends: algorithms, methods, and tech-
niques, pages 242–264. IGI global.
Van Hasselt, H., Guez, A., and Silver, D. (2016). Deep re-
inforcement learning with double q-learning. In Pro-
ceedings of the AAAI conference on artificial intelli-
gence, volume 30.
Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu,
M., Dudzik, A., Chung, J., Choi, D. H., Powell, R.,
Ewalds, T., Georgiev, P., et al. (2019). Grandmas-
ter level in starcraft ii using multi-agent reinforcement
learning. Nature, 575(7782):350–354.
Wiering, M. A. and Van Otterlo, M. (2012). Reinforce-
ment learning. Adaptation, learning, and optimiza-
tion, 12(3).
Zhang, F., Leitner, J., Milford, M., Upcroft, B., and Corke,
P. (2015). Towards vision-based deep reinforcement
learning for robotic motion control. arXiv preprint
arXiv:1511.03791.
Zhao, R. and Tresp, V. (2018). Energy-based hindsight
experience prioritization. In Conference on Robot
Learning, pages 113–122. PMLR.
Accelerate Training of Reinforcement Learning Agent by Utilization of Current and Previous Experience
705
