
Bottom-up Japanese Word Ordering Using BERT
Masato Yamazoe
1
, Tomohiro Ohno
1,2 a
and Shigeki Matsubara
3 b
1
Graduate School of Science and Technology for Future Life, Tokyo Denki University, Tokyo, Japan
2
Graduate School of Advanced Science and Technology, Tokyo Denki University, Tokyo, Japan
3
Information & Communications, Nagoya University, Nagoya, Japan
Keywords:
Sentence Generation, Paraphrasing, Readability, Dependency Structure.
Abstract:
Although Japanese is widely regarded as a relatively free word order language, word order in Japanese is
not entirely arbitrary and has some sort of preference. As a result, it is an important technique to produce a
sentence that is not only grammatically correct but also easy to read. This paper proposes a method for the
word ordering of a whole Japanese sentence when the dependency relations between words are given. Using
BERT, the method identifies the easy-to-read word order for a syntactic tree based on bottom-up processing.
We confirmed the effectiveness of our method through an experiment on word ordering using newspaper
articles.
1 INTRODUCTION
Although Japanese has a relatively free word order,
the word order is not completely arbitrary and has
some sort of preference for readability (Nihongo Ki-
jutsu Bunpo Kenkyukai, 2009). If a sentence is gener-
ated without taking such preferences into account, the
generated sentence’s word order becomes grammati-
cally correct but difficult to read in Japanese. Unless
the generator improves its word order, such a sentence
is frequently generated, even if the generator is a na-
tive Japanese speaker. As a result, it is an important
technique to generate a sentence whose word order is
not only grammatically correct but also easy to read.
Several studies on word ordering have been per-
formed for sentence elaboration support and sentence
generation. Uchimoto et al. (Uchimoto et al., 2000)
proposed a method for statistically ordering words
based on different factors involved in determining
word order in Japanese to learn Japanese word order
trends from a corpus. Takasu et al. (Takasu et al.,
2020) proposed a method of ordering for a set of bun-
setsus
1
which are directly dependent on the same bun-
a
https://orcid.org/0000-0001-7015-7714
b
https://orcid.org/0000-0003-0416-3635
1
Bunsetsu is a linguistic unit in Japanese that roughly
corresponds to a basic phrase in English. A bunsetsu is
made up of one independent word and zero or more ancil-
lary words. In Japanese, a dependency relation is a modifi-
cation relation in which a modifier bunsetsu is dependent on
setsu, for the purpose of applying it to sentence gen-
eration. Both studies by Takasu et al. and Uchimoto
et al. have the same problem setting about the input
and output. Because the bunsetsus input set is a sub-
set of all bunsetsus in a sentence, neither study per-
forms word ordering for the entire sentence. Kurib-
ayashi et al. (Kuribayashi et al., 2020) proposed to
use Japanese Language Models as a tool for exam-
ining canonical word order in Japanese, and verified
the validity of using LMs for the analysis. How-
ever, they limited the number of verbs and bunsetsus
in a sentence for simplicity, and thus did not target
complex sentences. Although there have been also
several studies on estimating appropriate word order
in monolingual languages other than Japanese (Filip-
pova and Strube, 2007; Harbusch et al., 2006; Kruijff
et al., 2001; Ringger et al., 2004; Shaw and Hatzivas-
siloglou, 1999; Schmaltz et al., 2016), it is not clear
that their studies can apply to Japanese.
As an elemental technique for sentence genera-
tion, we propose a method for ordering all bunset-
sus constituting a whole sentence so that the word
order becomes easy to read. Specifically, our method
identifies the appropriate order by conducting bottom-
up processing for a tree representing the dependency
structure of a whole sentence (hereafter, dependency
tree) and by using a model of BERT (Devlin et al.,
a modified bunsetsu. That is, the modifier bunsetsu and the
modified bunsetsu work as modifier and modifiee, respec-
tively.
Yamazoe, M., Ohno, T. and Matsubara, S.
Bottom-up Japanese Word Ordering Using BERT.
DOI: 10.5220/0011743600003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 673-681
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
673

2019), given a set of all bunsetsus in the sentence and
the dependency relations between their bunsetsus as
the input. We performed word ordering experiments
using newspaper article sentences, and our results out-
performed previous methods.
The contributions of this paper are as follows: 1.
We demonstrated the utility of BERT in determining
the appropriate order of two bunsetsus in Japanese.
2. We demonstrated the effectiveness of bottom-up
processing in word ordering a complete Japanese sen-
tence.
2 WORD ORDERING IN
SENTENCE GENERATION
In this study, we assume that a set of bunsetsus con-
stituting a complete sentence, as well as the depen-
dency relations between those bunsetsus, is provided
as input, and we attempt to arrange all bunsetsus in
the input set in an order that is easy to read. With
the applications of sentence generation and machine
translation in mind, the assumption that these inputs
are provided is made. When creating a sentence, it is
assumed that the content to be expressed is fixed.
This assumption is also discovered in the prob-
lem setting of the previous studies by Uchimoto et
al. (Uchimoto et al., 2000) and Takasu et al (Takasu
et al., 2020). In the following, we discuss the above
two previous studies.
2.1 Word Ordering by Using Syntactic
Information (Uchimoto et al., 2000)
The word order in a sentence is related to the sen-
tence’s dependencies. Uchimoto et al. (Uchimoto
et al., 2000) performed word ordering using syn-
tactic information under the assumption that depen-
dency parsing had already been performed. They
defined word ordering task as identifying the order
of bunsetsus in a set of all modifier bunsetsus B
r
=
{b
r
1
, b
r
2
, ··· , b
r
n
}(n ≥ 2) which depend on the same
modifiee bunsetus b
r
. They made all possible permu-
tations {b
k
|1 ≤ k ≤ n!} from B
r
and found the easiest-
to-read one among {b
k
|1 ≤ k ≤ n!}. Here b
k
is the k-
th permutation. They proposed a method of word or-
dering based on syntactic information using a model
trained by the Maximum Entropy Method. However,
they focused on the word ordering of B
r
, which is a
subset of all bunsetsus in a sentence, so they did not
identify the order of bunsetsus in a whole sentence
and did not evaluate their results in a sentence unit.
2.2 Word Ordering by Using RNNLM
and SVM (Takasu et al., 2020)
Takasu et al. (Takasu et al., 2020) inherited the prob-
lem setting of Utimoto et al. (Uchimoto et al., 2000),
and used not only an SVM model trained based on
the main features
2
selected from those of Uchimoto
et al., but also the Recurrent Neural Network Lan-
guage Model(RNNLM), which is expected to capture
natural word ordering. In particular, among {b
k
|1 ≤
k ≤ n!} which means all permutations created by B
r
,
they identified the permutation b
k
which maximize
Score(b
k
) defined by Formula (1) as the most read-
able one.
Score(b
k
) = αS
RNNLM
(b
k
) + (1 − α)S
SV M
(b
k
), (1)
where S
RNNLM
(b
k
) and S
SV M
(b
k
) mean the score for
a b
k
by the RNNLM and by the SVM model, respec-
tively.
S
SV M
(b
k
) is defined by Formula (2). Here, a per-
mutation b
k
is expressed by b
k
= b
k
1
b
k
2
···b
k
n
, where b
k
i
is the i-th bunsetsu in the k-th permutation b
k
.
S
SV M
(b
k
) =
n−1
∏
i=1
n−i
∏
j=1
P
SV M
(o
k
i,i+ j
|b
r
) (2)
Here, o
k
i,i+ j
means an order relation that the bunsetsu
b
k
i
is located before b
k
i+ j
, and P
SV M
(o
k
i,i+ j
|b
r
) means
the probability predicted
3
by the SVM model, which
expresses how appropriate the order relation o
k
i,i+ j
is in readability given the bunsetsu b
r
which is de-
pended by the two bunsetsu b
k
i
and b
k
i+ j
. Takasu et
al.’s SVM model is thought to be a re-implementation
of the Maximum Entropy Method used in Utimoto et
al. (Uchimoto et al., 2000) to capture the word order
tendency based on syntactic information.
S
RNNLM
(b
k
) is defined by Formula (3).
Here, a permutation b
k
is expressed by
b
k
= w
k
1,1
, w
k
1,2
···w
k
1,m
1
···w
k
n,1
···w
k
n,m
n
, where
w
k
i, j
is the j-th word
4
in the i-th bunsetsu in the k-th
permutation b
k
.
S
RNNLM
(b
k
) =
n
∏
i=1
m
i
∏
j=1
P
RNNLM
(w
k
i, j
|w
k
1,1
, w
k
1,2
, ···w
k
i, j−1
),
(3)
where P
RNNLM
(w
k
i, j
|w
k
1,1
, w
k
1,2
, ···w
k
i, j−1
) means the
probability that w
k
i, j
comes just after the word se-
quence w
k
1,1
, w
k
1,2
, ···w
k
i, j−1
, which is predicted by
2
As the main features, morpheme information of each
bunsetsu connected by dependency relations is used.
3
The probability is calculated by Platt’s scaling (Platt,
2000).
4
To be more accurate, a symbol showing a boundary be-
tween bunsetsus is placed after the final word of each bun-
setsu.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
674
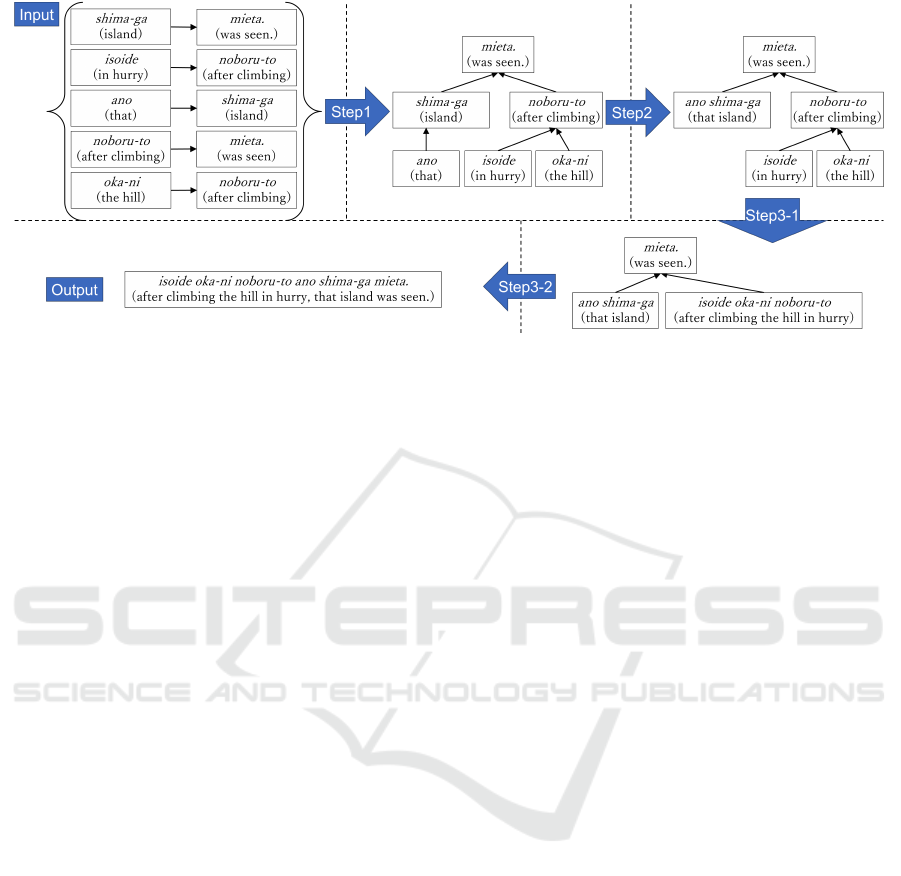
Figure 1: Example of word ordering by the bottom-up processing.
RNN having two hidden layers of LSTM (Sunder-
meyer et al., 2012). Since the number of factors in
Formula (2) is different from that of Formula (3),
Score(b
k
) in Formula (1) is calculated after the nor-
malization of S
RNNLM
(b
k
) and S
SV M
(b
k
).
However, like Uchimoto et al., they focused on the
word ordering of B
r
, which is a subset of all bunset-
sus in a sentence, and thus did not identify the order of
bunsetsus in a whole sentence or evaluate their results
in a sentence unit. Furthermore, when RNNLM cal-
culated the score, they did not take into account the
modifier bunsetsus, which depend on each bunsetsu
in a set B
r
. That is, because they only targeted child
nodes in the dependency tree and ignored descendant
nodes, the string generated by ordering the target bun-
setsus did not always appear in actual texts.
3 BOTTOM-UP WORD
ORDERING USING BERT
All bunsetsus that compose a complete sentence, as
well as their dependency relations, are considered in-
put in our method. Our method outputs a sentence
in which the input bunsetsus are arranged so that the
word order is easy to read. At that point, our method
determines the appropriate word order among the in-
put bunsetsus using bottom-up processing for a de-
pendency tree constructed from the input bunsetsus
and their dependency relations, as well as a BERT
model to judge the word order between two bunset-
sus.
3.1 Bottom-Up Processing
Our approach conducts word ordering by the follow-
ing bottom-up processing.
1. A dependency tree is created from all input bun-
setsus and dependency relations. Each bunsetsu is
placed as a node, and the nodes are connected via
edges that express dependency relations. Here, in
the following steps 2 and 3, multiple nodes are
merged into one node. As a result, strictly speak-
ing, a node is a sequence of bunsetsus, including
a sequence of length one, and an edge is a depen-
dency relationship in which the final bunsetsu of
a bunsetsu sequence constituting a child node de-
pends on the final bunsetsu of a bunsetsu sequence
constituting a parent node.
2. A parent node which has only one leaf child node
and the child node are merged into one node. The
merge process is performed by concatenating the
child node’s bunsetsu sequence before the par-
ent node’s bunsetsu sequence, while keeping in
mind the Japanese syntactic constraints that no de-
pendency relations are directed from right to left.
This step is repeated until no parent node has only
one leaf child node.
3. For a parent node which has multiple leaf child
nodes, a parent node and the child nodes are
merged into one node. First, a BERT model is
used to determine the correct order of the child
nodes in the merge process. Second, the calcu-
lated order is used to concatenate the bunsetsu se-
quences of each child node. Finally, the bunsetsu
sequence of the parent node is concatenated after
the above-created bunsetsu sequence.
4. Step 2 and step 3 are repeated until the depen-
dency tree has only one root node.
Figure 1 shows an example of the bottom-up pro-
cessing above. In step 1, the six input bunsetsus and
the five dependency relations between the six input
bunsetsus are used to create the dependency tree in the
Bottom-up Japanese Word Ordering Using BERT
675

Figure 2: Differences between the bottom-up processing
and non-bottom-up processing.
top center of Figure 1. In step 2, “shima-ga (island),”
which is a parent node having only one leaf child
node, and the child node “ano (that)” are merged into
one node “ano shima-ga (that island).” In step 3-1,
the appropriate word order among the leaf child nodes
“isoide (in hurry)” and “oka-ni (the hill),” which de-
pend on their parent node “noboru-to (after climb-
ing),” are calculated and the child nodes and parent
node are merged into one child node “isoide oka-ni
noboru-to (after climbing the hill in hurry)” accord-
ing to the calculated order. In step 3-2, the correct
word order among the leaf child nodes “ano shima-
ga (that island)” and “isoide oka-ni noboru-to (after
climbing the hill in hurry),” which depend on “mieta.
(was seen.),” are calculated and the three bunsetsus
are merged into one node “isoide oka-ni noboru-to
ano shima-ga mieta. (after climbing the hill in hurry,
that island was seen.).” Since there is now only one
root node in the tree, the word ordering is complete.
Based on Figure 2, we outline the differences
between the bottom-up processing employed by our
method and the non-bottom-up one employed by
Takasu et al.’s method (Takasu et al., 2020). In the
non-bottom-up processing, when calculating the ap-
propriate word order among the leaf child nodes of
the root node “mieta. (was seen.),” the child nodes
“shima-ga (island)” and “noboru-to (after climbing,)”
remain composed of one bunsetsu because those
nodes are not created by their descendant nodes being
merged into. As a result, the non-bottom-up process-
ing judges which of two bunsetsu sequences ”shima-
ga noboru-to (island after climbing)” and ”noboru-to
shima-ga (after climbing, island),” which are respec-
tively composed of two bunsetsus, is easier to read by
using a machine learning model.
However, in the bottom-up processing, when de-
termining the correct word order among the leaf child
nodes of the root node, the child nodes “ano shima-
ga (that island)” and “isoide oka-ni noboru-to (af-
ter climbing the hill in hurry)” have been created
by their descendant nodes being merged into during
the bottom-up processing. Therefore, ”ano shima-
ga isoide oka-ni noboru-to (that island after climbing
the hill in hurry)” and ”isoide oka-ni noboru-to ano
shima-ga (after climbing the hill in hurry, that island)”
are the focus of the judgment by a machine learning
model.
3.2 Identification of Child Node Order
Using BERT
As explained in Section 3.1, a model based on BERT
(Devlin et al., 2019) is used when determining the
appropriate order among leaf child nodes of a parent
node. Hereinafter, we explain the calculation in case
of ordering the leaf child nodes V
r
= {v
r
1
, v
r
2
, ··· , v
r
n
}
of a parent node v
r
. When the leaf child nodes V
r
=
{v
r
1
, v
r
2
, ··· , v
r
n
} is provided, among {v
k
|1 ≤ k ≤ n!}
which means all permutations
5
created by V
r
, our
method identifies the permutation v
k
which maximize
S(v
k
) defined by Formula (4) as the most readable
one. Concretely speaking, when a permutation v
k
is
a sequence of nodes v
k
1
v
k
2
···v
k
n
, where v
k
i
means the
i-th node in a permutation v
k
, S(v
k
) is calculated as
follows.
S(v
k
) =
n−1
∏
i=1
n−i
∏
j=1
P
BERT
(o
k
i,i+ j
|v
r
) (4)
Here, o
k
i
,
i
+
j
means an order relation that the node v
k
i
is located before v
k
i+ j
, instead of an order relation be-
tween two bunsetus in Section 2.2. P
BERT
(o
k
i,i+ j
|v
r
)
means the probability predicted by our BERT model,
which expresses how appropriate the order relation
o
k
i,i+ j
is in readability when the two nodes v
k
i
and v
k
i+ j
depend on a parent node v
r
.
Figure 3 shows the outline of our BERT model.
The input to BERT is the subword sequence of the
concatenation of the two leaf child nodes v
k
i
and v
k
i+ j
and the parent node v
r
in this order with [CLS] at the
beginning and [SEP] after each of the three nodes.
Our approach takes only the output of BERT corre-
sponding to [CLS], which is the representation of the
totality of the input token sequence, and via the two
Linear layers and Sigmoid, outputs the probability
that the order relation that v
k
i
is located before v
k
i+ j
is easy to read. Each sequence length of the leaf child
nodes is altered when the input sequence length sur-
passes the BERT upper limit. To adjust, some sub-
words are removed from the front of each node while
ensuring that the ratio of the two nodes’ sequence
length is maintained, while each sequence length is
not shorter than the length of the longest bunsetsu
measured in training data.
5
Since the number of bunsetsus which depend on a
modifiee is at most 7, the number of all possible permu-
tations is within computable range.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
676

Figure 3: Our BERT model to predict P
BERT
(o
k
i,i+ j
|v
r
) based on BERT.
4 EXPERIMENT
We conducted an experiment using newspaper articles
to gauge the effectiveness of our word ordering strat-
egy. The word order in newspaper articles is consid-
ered to be readable in this paper.
4.1 Outline of Experiment
In our experiment, we utilized the Kyoto University
text corpus Ver. 4.0 (Kawahara et al., 2002), which
is annotated with information on morphological anal-
ysis, bunsetsu segmentation, and dependency analy-
sis. We used 25,388 sentences from newspaper arti-
cles published in 1995 between January 1st and Jan-
uary 8th and from January 10th to June 9th for train-
ing purposes
6
. Among the 2,368 sentences from ar-
ticles appearing on January 9th and from June 10th
to June 30th, 1,050 sentences were used for develop-
ment data, and 1,164 sentences for test data. Because
the order of a complete sentence could be determined
solely by syntactic information by simply repeating
step 2 in Section 3.1, the remaining 154 sentences
were not used in this instance.
We obtained the following two measurements to
assess word ordering. The first is sentence agree-
ment: the percentage of the sentences whose whole
word order agrees with that in the original sentence.
The second is pair agreement: the percentage of the
pairs of bunsetsus whose word order agrees with that
in the original sentence
7
. For each agreement, we cal-
culated the mean of the five models made with the
same hyperparameters.
6
In creating training data, we extracted all pairs of two
nodes from the set of multiple nodes which depends on the
same bunsetsu, and then, we made two order relations for
each pair and labeled an order relation same as the correct
one as a positive and the other incorrect one as a negative.
7
To avoid counting redundant pairs, the pairs whose or-
der relation is fixed by that of each bunsetsu’s ancestor are
not measured.
We prepared the following four methods for com-
parison.
• [BERT
−
]: is as same as our method except us-
ing non-bottom-up processing instead of bottom-
up processing.
• [RNNLM
−
+SVM
−
]: is the method proposed by
Takasu et al (Takasu et al., 2020), which employs
the non-bottom-up processing. This is built on
setting α = 0.15 of Formula (1).
• [RNNLM+SVM]: is as same as the above
method [RNNLM
−
+SVM
−
] except utilizing the
bottom-up processing instead of the non-bottom-
up processing. This is built on setting α = 0.19 of
Formula (1).
• [SVM
−
]: is the method which singly uses SVM
in [RNNLM
−
+SVM
−
], that is, which is built on
setting α =0 in Formula (1). We assume that
this method is equivalent to the Uchimoto et al.
method that has been re-implemented (Uchimoto
et al., 2000).
We implemented our model in Figure 3 using Py-
Torch
8
. For the Japanese pre-trained model of BERT,
we used the model published by Kyoto University
(BASE WWM ver.)
9
. The two Linear layers’ re-
spective unit counts were set at 768 and 200, and
their respective drop-out rates were set at 0.1. An
optimizer named AdamW was employed. Parame-
ters were updated using mini-batch learning (learning
rate 1e-6, batch size 16). BCELoss was used as the
loss function. The sentence agreement for each epoch
was measured using the development data, and thus,
epoch 6 was found to be the best epoch.
4.2 Experimental Results
Table 1 shows the experimental results. Our method
[BERT] significantly outperformed all other methods
8
https://pytorch.org/
9
https://nlp.ist.i.kyoto-u.ac.jp/?ku bert japanese/
Bottom-up Japanese Word Ordering Using BERT
677

Figure 4: Example of sentences correctly ordered by [BERT] but incorrectly by [RNNLM+SVM].
Figure 5: Example of sentences incorrectly ordered by [BERT] but correctly by [RNNLM+SVM].
Table 1: Experimental results (pair and sentence agree-
ment).
pair sentence
[BERT] 92.01% 71.53%
[BERT
−
] 89.48% 65.36%
[RNNLM+SVM] 85.56% 58.68%
[RNNLM
−
+SVM
−
] 85.84% 58.59%
[SVM
−
] 85.49% 57.47%
in terms of both pair agreement and sentence agree-
ment (p < 0.01). As a result, we confirmed the effec-
tiveness of bottom-up word ordering using BERT in
word ordering.
5 DISCUSSION
5.1 Effects of Using BERT
We compare our method [BERT] with
[RNNLM+SVM], which employs the same bottom-
up processing as [BERT] but uses the different
machine learning RNNLM and SVM from BERT, to
analyze the outcomes of using BERT.
First, we investigate the positive effect of using
BERT. There were 231 sentences in which all bunset-
sus were correctly ordered by our method [BERT]
10
,
but incorrectly ordered by [RNNLM+SVM]. A typi-
cal example is depicted in Figure 4, where a box ex-
10
We analyzed the experimental results using the model
with the highest sentence agreement among the five models
created as our method.
presses a bunsetsu. In this example, our method suc-
cessfully concatenated two bunsetsus which tend to
be continuous and expressed as a single phrase like
an idiom, such as “genkai-ga aru (and are limited)”
and “saisyo-ni subeku (to minimize)”, without inter-
rupting other bunsetsus between the two ones.
Next, we analyzed the negative effect of us-
ing BERT. There were 78 sentences in which
all of the bunsetsus were correctly arranged by
[RNNLM+SVM] but were arranged improperly by
our method [BERT]. A typical example is shown in
Figure 5, where a box expresses a bunsetsu. In this ex-
ample, [BERT] made a mistake by placing “samitto-
syuryo-go (After the summit)” before “Murayama-
Tomiichi-syusyo-wa (Prime Minister Tomiichi Mu-
rayama).” However, the [BERT] output sentence is
thought to be just as readable as the gold sentence,
which is a sentence from a newspaper article. Al-
though many of the sentences produced by [BERT]
were found to be incorrect, they were considered to be
as readable as the gold sentence. Note that this anal-
ysis was performed without context. Future research
will need to examine the relationships between word
order and context.
5.2 Effects of Bottom-up Processing
By contrasting [BERT] and [BERT
−
], which em-
ploys the same machine learning BERT as [BERT]
but non-bottom-up processing, we can describe the
outcomes of using the bottom-up processing in our
method [BERT].
First, we examine the positive effect of employ-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
678
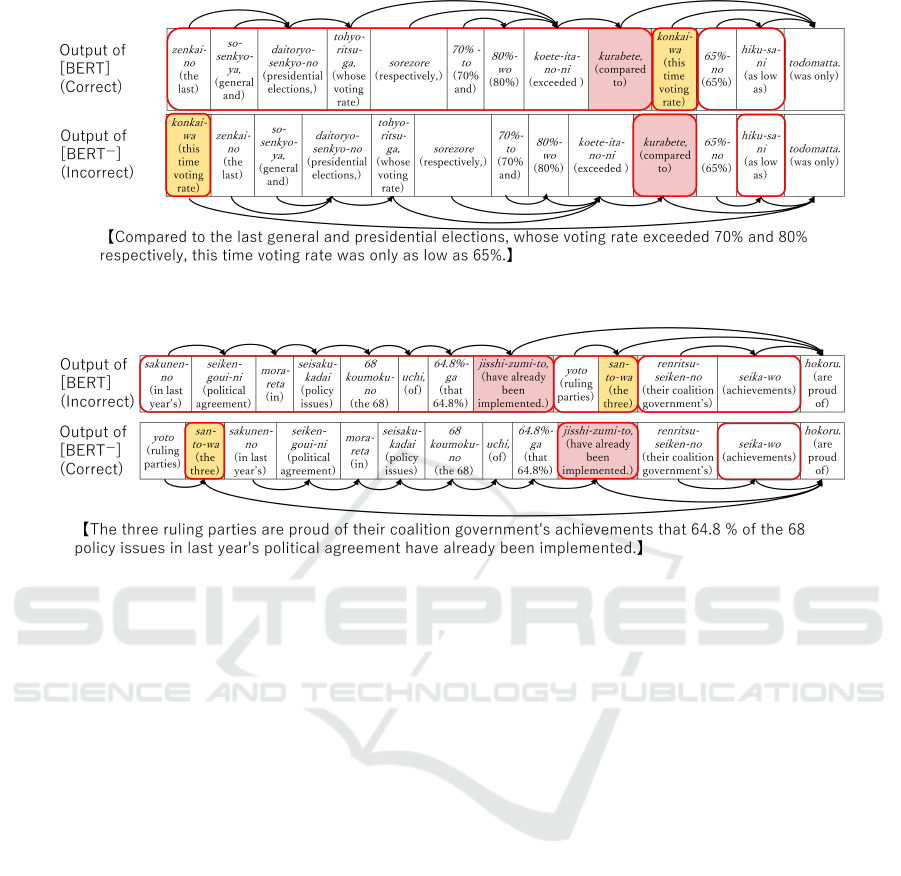
Figure 6: Example of sentences correctly ordered by [BERT] but incorrectly by [BERT
−
].
Figure 7: Example of sentences incorrectly ordered by [BERT] but correctly by [BERT
−
].
ing bottom-up processing. There existed 134 sen-
tences in which all bunsetsus were appropriately or-
dered by our method [BERT], but incorrectly ordered
by [BERT
−
]. A typical example is shown in Fig-
ure 6, where a box and an arrow express a bunsetsu
and a dependency relation between bunsetsus respec-
tively. In Japanese, it is known that a long modi-
fier phrase has a strong preference to be located at
the beginning of a sentence (Nihongo Kijutsu Bunpo
Kenkyukai, 2009). In this example, according to the
preference, our method arranged suitably three nodes
expressed by red rounded rectangles at the top of Fig-
ure 6 by placing the longest modifier phrase “zenkai-
no ··· kurabete (last ··· Compared to)” at the begin-
ning of a sentence. It is conceivable that the BERT
model in our method can take the information into
account because each node targeted by our method is
composed of multiple bunsetsus by being combined
during bottom-up processing. In contrast, [BERT
−
]
made a mistake by placing the same longest modifier
phrase in the middle of the sentence. This is because
each node targeted by [BERT
−
] only contains one
bunsetsu, as indicated by the red rounded rectangle at
the bottom of Figure 6. As a result, the BERT model
is unable to take into account the information of the
other bunsetsus that make up the modifier phrase.
Next, we analyzed the negative effect of employ-
ing bottom-up processing. There existed 59 sen-
tences in which all bunsetsus were correctly ordered
by [BERT
−
], but incorrectly ordered by [BERT]. A
typical example is depicted in Figure 7, where a box,
an arrow and a red rounded rectangle express the same
as those of Figure 6. In this example, our method
made a mistake by placing the longest modifier phrase
“sakunen-no ··· jisshi-zumi-to (in last year’s ··· have
already been implemented.) before “yoto san-to-ha
(The three ruling parties)” when ordering the three
child nodes of “hokoru. (are proud of)”. Although
our method could have arranged the nodes so that a
long modifier phrase would preferably appear on the
front side of a sentence, this was a relatively uncom-
mon word order in the gold sentence, where the long
modifier phrase would appear in the middle. How-
ever, [BERT
−
] could arrange the three phrases in the
same order as that of the gold sentence because of
not being influenced by the information of the other
bunsetsus composing the modifier phrase. The output
sentence by [BERT] in this example is also consid-
ered to be just as readable as the gold sentence. The
subjective evaluation is an issue for the future.
5.3 Analysis on Sentence Length
The increased number of bunsetsus in a sentence as
well as the permutations are thought to be the main
reasons why word ordering generally has lower ac-
Bottom-up Japanese Word Ordering Using BERT
679
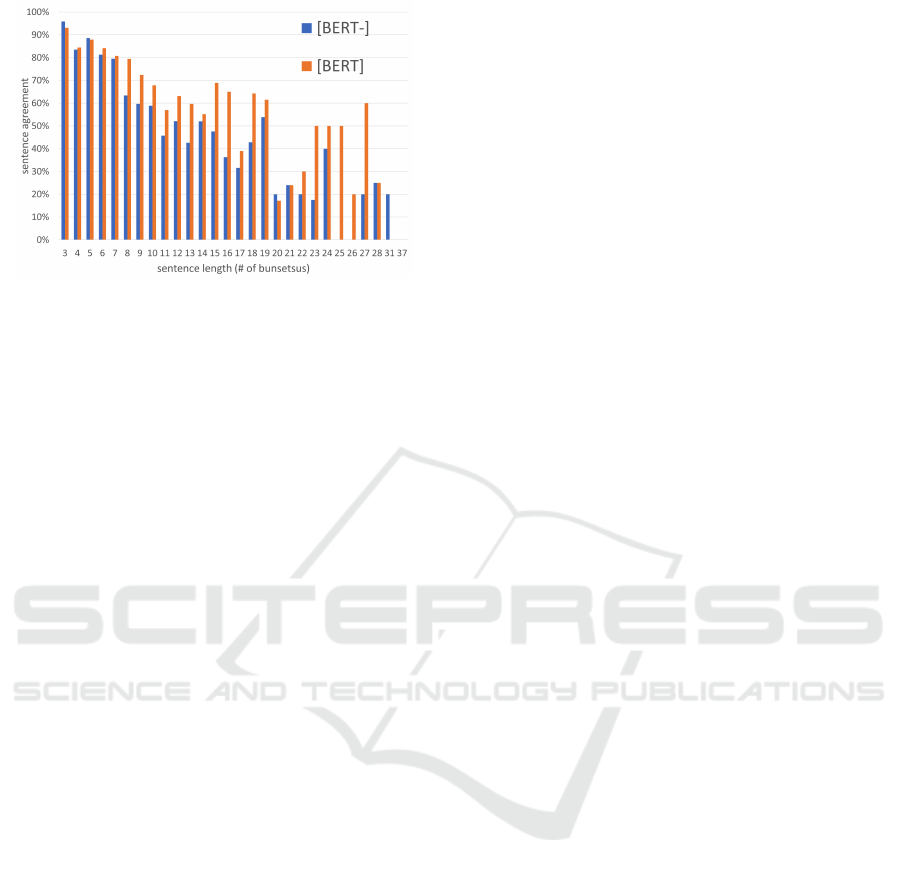
Figure 8: Sentence agreement relative to sentence length.
curacy for longer sentences. It is assumed that the
bottom-up processing of our method, which takes into
account all modifiers (descendant bunsetsus) of each
bunsetsu, is effective for the word ordering of long
sentences, in which each bunsetsu tends to have more
modifiers. In this section, we explain the analysis of
sentence length in terms of whether the bottom-up or
non-bottom-up processing is carried out.
Figure 8 demonstrates the sentence agreement of
our method [BERT] and the method [BERT
−
], which
uses non-bottom-up processing, relative to sentence
length. At almost every length, [BERT] outperformed
[BERT
−
]. Particularly, the agreement of [BERT
−
]
decreases as the number of bunsetsus in a sentence
rises, whereas [BERT] maintains a relatively high
agreement no matter how many bunsetsus are present.
In our method, the input to BERT includes the
modifiers (descendant bunsetsus) of each bunsetsu be-
cause of conducting the bottom-up processing. There-
fore, it is conceivable that our method could prop-
erly consider the information included in the modi-
fiers, and thus could perform word ordering with a
high agreement for long sentences also.
6 CONCLUSION
In this paper, we propose a method for Japanese word
ordering. By processing the dependency tree from the
bottom up and utilizing BERT, our method can deter-
mine the appropriate order for a set of bunsetsus that
make up a sentence. The experimental results verified
the effectiveness of the BERT model and bottom-up
word ordering. In the future, we would like to en-
hance the evaluation including the use of operators’
subjective judgments.
ACKNOWLEDGEMENTS
This work was partially supported by JSPS KAK-
ENHI Grand Number JP19K12127.
REFERENCES
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2019). BERT: Pre-training of deep bidirectional
transformers for language understanding. In Proceed-
ings of the 2019 Conference of the North American
Chapter of the Association for Computational Lin-
guistics: Human Language Technologies, Volume 1
(Long and Short Papers), pages 4171–4186.
Filippova, K. and Strube, M. (2007). Generating constituent
order in German clauses. In Proceedings of the 45th
Annual Meeting of the Association of Computational
Linguistics, pages 320–327.
Harbusch, K., Kempen, G., van Breugel, C., and Koch, U.
(2006). A generation-oriented workbench for perfor-
mance grammar: Capturing linear order variability in
German and Dutch. In Proceedings of the 4th Inter-
national Natural Language Generation Conference,
pages 9–11.
Kawahara, D., Kurohashi, S., and Hasida, K. (2002). Con-
struction of a Japanese relevance-tagged corpus. In
Proceedings of the 3rd International Conference on
Language Resources and Evaluation, pages 2008–
2013.
Kruijff, G.-J. M., Kruijff-Korbayov
`
a, I., Bateman, J., and
Teich, E. (2001). Linear order as higher-level deci-
sion: Information structure in strategic and tactical
generation. In Proceedings of the 8th European Work-
shop on Natural Language Generation, pages 74–83.
Kuribayashi, T., Ito, T., Suzuki, J., and Inui, K. (2020). Lan-
guage models as an alternative evaluator of word order
hypotheses: A case study in Japanese. In Proceed-
ings of the 58th Annual Meeting of the Association for
Computational Linguistics, pages 488–504.
Nihongo Kijutsu Bunpo Kenkyukai (2009). Gendai ni-
hongo bunpo 7(Contemporary Japanese Grammer 7).
Kuroshio Shuppan. (In Japanese).
Platt, J. (2000). Probabilistic outputs for support vec-
tor machines and comparisons to regularized likeli-
hood methods. Advances in Large Margin Classifiers,
10(3):61–74.
Ringger, E., Gamon, M., Moore, R. C., Rojas, D., Smets,
M., and Corston-Oliver, S. (2004). Linguistically in-
formed statistical models of constituent structure for
ordering in sentence realization. In Proceedings of the
20th International Conference on Computational Lin-
guistics, pages 673–679.
Schmaltz, A., Rush, A. M., and Shieber, S. (2016). Word
ordering without syntax. In Proceedings of the 2016
Conference on Empirical Methods in Natural Lan-
guage Processing, pages 2319–2324.
Shaw, J. and Hatzivassiloglou, V. (1999). Ordering among
premodifiers. In Proceedings of the 37th Annual Meet-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
680

ing of the Association for Computational Linguistics,
pages 135–143.
Sundermeyer, M., Schl
¨
uter, R., and Ney, H. (2012). LSTM
neural networks for language modeling. In Proceed-
ings of Interspeech 2012, pages 194–197.
Takasu, M., Ohno, T., and Matsubara, S. (2020). Japanese
word ordering using RNNLM and SVM. In In Pro-
ceedings of the 82nd National Convention of IPSJ,
Volume 2020(1), pages 453–454. (In Japanese).
Uchimoto, K., Murata, M., Ma, Q., Sekine, S., and Isahara,
H. (2000). Word order acquisition from corpora. In
Proceedings of the 18th International Conference on
Computational Linguistics, Volume 2, pages 871–877.
Bottom-up Japanese Word Ordering Using BERT
681
