
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based
Epidemic Simulations
Sapana Kale
1 a
, Shabbir Bawaji
1
, Akshay Dewan
1
, Meenakshi Dhanani
1
, Kritika Gupta
1
,
Harshal Hayatnagarkar
1 b
, Swapnil Khandekar
1
, Jayanta Kshirsagar
1 c
, Gautam Menon
2 d
and Saurabh Mookherjee
1
1
Engineering for Research (e4r), Thoughtworks Technologies, Yerwada, Pune, 411 006, India
2
Ashoka University, Sonipat, Haryana, 131029, India
Keywords:
Epidemiology, Epidemic Simulations, Agent-Based Simulations, Large-Scale Simulations, Agent-Based
Modeling, Parallel Computing, Distributed Computing.
Abstract:
EpiRust is an open source, large-scale agent-based epidemiological simulation framework developed using
Rust language. It has been developed with three key factors in mind namely 1. Robustness, 2. Flexibility, and
3. Performance. We could demonstrate EpiRust scaling up to a few millions of agents, for example a COVID-
19 infection spreading through Pune city with its 3.2 million population. Our goal is to simulate larger cities
like Mumbai (with 12 million population) first, and then entire India with its 1+ billion population. However,
the current implementation is not scalable for this purpose, since it has a well-tuned serial implementation
at its core. In this paper, we share our ongoing journey of developing it as a highly scalable cloud ready
parallel and distributed implementation to simulate up to 100 million agents. We demonstrate performance
improvement for Pune and Mumbai cities with 3.2 and 12 million populations respectively. In addition, we
discuss challenges in simulating 100 million agents.
1 INTRODUCTION
EpiRust
1
is an open source, large-scale agent-based
epidemic simulator written in the Rust programming
language. It has been developed to balance three key
factors for epidemic simulations namely 1. Robust-
ness 2. Flexibility, and 3. Performance. Rust offers
memory safety of managed run-times without their
overheads (Matsakis and Klock, 2014).
The earlier EpiRust version was developed as a
serial implementation using only single CPU core.
The implementation was sufficient to simulate a large
city like Pune with approximately 3 million popula-
tion. However, it was not enough for running sim-
ulations with larger agent populations, such as for
cities like Mumbai with more than 10 million pop-
ulation. We found that EpiRust runs slower for larger
populations following a linear characteristic in a log-
a
https://orcid.org/0000-0002-7582-865X
b
https://orcid.org/0000-0002-2300-5539
c
https://orcid.org/0000-0002-0581-7218
d
https://orcid.org/0000-0001-5528-4002
1
https://github.com/thoughtworks/epirust/
log scale as lower performance caused by total higher
lookups (see Figure 2). Thus, it was imperative to de-
velop concurrent implementations to take advantage
of multicore processors and multiple networked com-
puters. Here, the Rust language offered benefits via
the concurrency constructs either built into it or in the
ecosystem. In the rest of this paper, we describe our
journey of implementing parallel and distributed im-
plementations of EpiRust. In the next section, we dis-
cuss the related work in this ecosystem, followed by
the EpiRust model. Thereafter we explain our par-
allel and distributed implementations covering archi-
tecture, design, and cloud-readiness. Later, we share
the details about large-scale experiments which we
have run for Mumbai and Pune with their represen-
tative populations and discuss the performance num-
bers. Finally, we conclude with their limitations and
our plans.
Kale, S., Bawaji, S., Dewan, A., Dhanani, M., Gupta, K., Hayatnagarkar, H., Khandekar, S., Kshirsagar, J., Menon, G. and Mookherjee, S.
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based Epidemic Simulations.
DOI: 10.5220/0011717000003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 1, pages 297-307
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
297

2 PAST WORK
Traditionally, epidemiologists relied upon calculus-
based models for their simplicity and lower resources
required for simulations. However, these models suf-
fer with many significant downsides, such as aggre-
gating dynamics at the population level, ignoring in-
dividuals’ decision making, and assumption of ho-
mogeneous population (Kermack and McKendrick,
1927).
To rescue from this situation, agent-based models
can simulate bottom-up social dynamics (Gilbert and
Terna, 2000) such as epidemic spread (Patlolla et al.,
2004). Here, an agent represents a person in a virtual
society, and collectively their synthetic population is
a simplified representation of the real target popula-
tion with their demographic heterogeneity (Chapuis
et al., 2022). This heterogeneity plays a crucial role
in modeling of agent interactions and decisions (Dias
et al., 2013; Wildt, 2015; Klabunde and Willekens,
2016; Hessary and Hadzikadic, 2017). In addition to
this heterogeneity, the population size is another fac-
tor. The insights vary for different population sizes,
and hence it is imperative to run the simulations as
close to the real population size as possible (Jaffry and
Treur, 2008; Kagho et al., 2022).
To develop agent-based epidemic simulations, one
could consider from the available frameworks or li-
braries including Repast (Collier, 2003), NetLogo
(Tisue and Wilensky, 2004), MASON (Luke et al.,
2005), EpiFast (Bisset et al., 2009), GAMA (Tail-
landier et al., 2010), GSAM (Parker and Epstein,
2011), D-MASON (Cordasco et al., 2013), and Open-
ABL (Cosenza et al., 2018a).
A survey of agent-based simulation software
(Abar et al., 2017) found that it is harder to develop
and run models for extreme-scale simulations for it re-
quires a huge amount of compute resources and their
management.
One approach is to develop simplified models. For
example, GSAM (Global Scale Agent Model) which
observes that “to track a contagion, simulating ev-
eryone’s entire day-to-day schedule may not be nec-
essary” (Parker and Epstein, 2011). The alternative
approach is to leverage the computer hardware and
software solutions for scaling without sacrificing de-
tails (Parker and Epstein, 2011; Parry and Bithell,
2012). A few frameworks emphasize on addressing
the needs for developing large-scale models, mainly
because such models are inherently detail-oriented,
complex, and resource-intensive (Eubank et al., 2004;
Bisset et al., 2009; Parker and Epstein, 2011; Abar
et al., 2017; Antelmi et al., 2019; Kshirsagar et al.,
2021; Kerr et al., 2021). This pursuit requires over-
coming several challenges in improving scalability by
combining proven and novel techniques.
A common technique is to split a large simula-
tion model into multiple models and then to simu-
late them using multiple compute instances. This ap-
proach needs to take care of initialization, communi-
cation, and coordination as required. All these aspects
are studied in a sub-discipline of simulation engineer-
ing namely Co-simulation (Gomes et al., 2018).
With multicore CPUs and GPUs becoming main-
stream, it is imperative to harness such resources as
demonstrated by OpenABL for GPUs and FPGAs
(Cosenza et al., 2018a; Xiao et al., 2020). In addition,
some of these resources can be better managed via a
cloud computing environment, and thus it is highly
desired to have a framework which could be cloud
ready. An example is HASH Platform (Hash, 2022),
an open-source platform which allows users to spec-
ify a model and execute it on its own cloud infrastruc-
ture. However, scalability of OpenABL and HASH
does not exceed a few million agents.
Choosing a programming language for develop-
ment also plays an important role, as it directly affects
resource utilization for large simulations. For exam-
ple, the work (Pereira et al., 2017) ranks program-
ming languages for their use of CPU, memory, and
energy consumption across different algorithms. In
the context of agent-based simulations, these insights
are corroborated in the work (Antelmi et al., 2019)
which compares performance of Java-based MASON
against a Rust-based framework for up to a million
agents. The comparison confirms that Rust performs
better for large-scale simulations consuming lower re-
sources like CPU and memory.
Thus, it is imperative to combine these techniques
together to achieve necessary performance and scal-
ability for large-scale simulations. EpiRust is an at-
tempt in this direction to develop an open-source per-
formant, flexible, and most importantly robust agent-
based simulation framework which could scale up to
a billion agents towards mimicking the population of
entire India.
3 EpiRust MODEL
For simulating epidemics, EpiRust follows a mini-
malist approach based on cellular automata (Gilbert
and Terna, 2000). It models a virtual city with pri-
mary aspects of geography, heterogeneous population
of agents, and disease dynamics. Geography is mod-
eled as a grid which is divided into functional ar-
eas namely residential, transport, work, and hospital.
Agents occupy these functional areas during the sim-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
298
ulation according to their attributes and schedules.
The agent heterogeneity emerges from their de-
mographic and professional attributes such as status
of employment, nature of work (essential or non-
essential), and preferred mode of transport (between
public and private transport). Each agent lives in a
dedicated home, and if employed, works in a work
area. Agents move across different areas based on
their respective schedules.
During these movements, agents come in close
contact with each other spreading infection with cer-
tain probability. To evaluate this infection spread, the
EpiRust model uses Moore neighborhood for eight
neighboring cells (White et al., 2007). The disease
dynamics is implemented as per the Mordecai SEIR
compartmental model (Childs et al., 2020), which
captures various disease states such as catching an in-
fection, being infected, recovering and so on. As per
the paper, we have specialized the model for COVID-
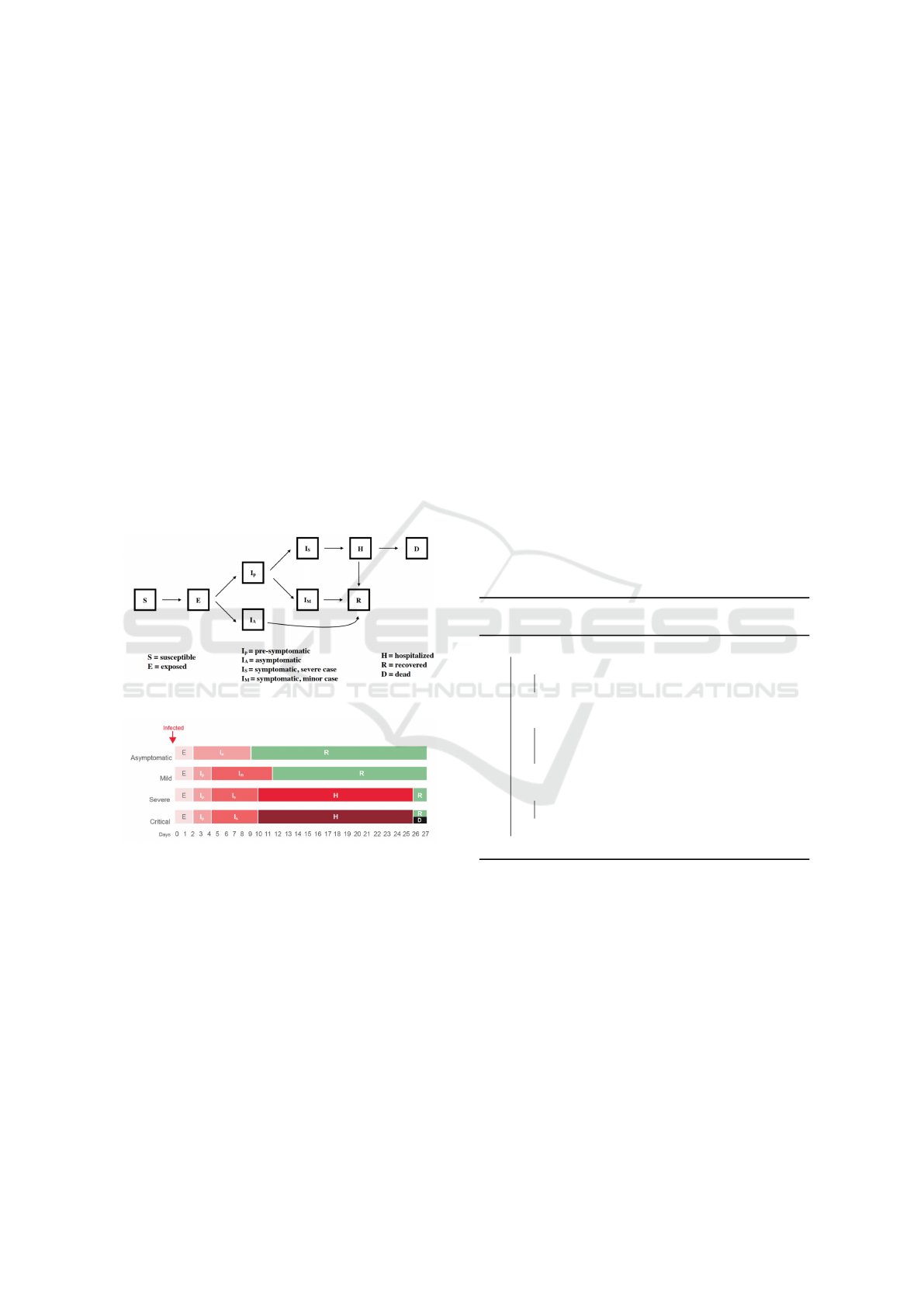
19 (see figures 1a and 1b) as per the paper (Snehal
Shekatkar et al., 2020).
(a) The Mordecai SEIR Model for COVID-19.
(b) COVID-19 Disease Dynamics over Time.
Figure 1: Disease Dynamics of COVID-19 (Snehal
Shekatkar et al., 2020).
Compartmental models in epidemiology represent
disease propagation via compartments like suscepti-
ble (S), exposed (E), infectious (I), and removed (R);
removed translates to recovered or dead. These can be
modeled mathematically or using agent-based mod-
els (for more details on mathematical models for epi-
demiology, please refer to the work (Brauer, 2008)).
EpiRust can be configured to simulate general com-
partmental models like SEIR and SIR.
To contain a rapidly spreading infection in a simu-
lation run, EpiRust supports three intervention strate-
gies namely lockdown, isolation via hospitalization,
and vaccination. These intervention strategies can be
configured before running the simulation.
A simulation progresses in discrete time steps (or
ticks), and typically each step is mapped to an hour.
Thus, twenty-four steps represent a day in the simula-
tion. For each time step, the simulation iterates over
all the agents, and computes their next disease state as
per the disease dynamics model. This is the core al-
gorithm for executing simulations which are depicted
in Algorithm 1. The outer loop iterates over discrete
time steps, whereas the inner loop iterates over agents.
Thus, the set of rules and behaviors are executed for
every agent during each time step. However, the or-
der in which these behaviors are executed, and their
internal states are updated, significantly alters the out-
come of the overall simulation. It happens because
an agent could refer to other agents’ states such as
their location on the grid which are no more original
rather updated during their evaluation. This problem
is known as Path Dependence (Gulyás, 2005). Path
dependence is not desired within a time-step for its
side-effects, but is desired across time steps for that it
enables emergence in simulations.
Algorithm 1: Simplified Simulation Loop (Iterative
Map-Reduce).
for each step in 1..n do
if can_intervene then
Apply intervention;
end
for each agent do
Move agent on the grid;
Update infection state;
end
if number_of_infected == 0 then
Stop simulation;
end
end
To counter this problem, EpiRust uses a double-
buffering technique (Gulyás, 2005; Cosenza et al.,
2018b; de Aledo Marugán et al., 2018) which main-
tains two separate buffers of agents’ states for re-
ferring and updating each. These two buffers are
swapped after each time step. Solving this problem
also helps in writing a parallel version of the agents’
loop which is described further in the following sec-
tion along with the distributed architecture and imple-
mentation.
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based Epidemic Simulations
299
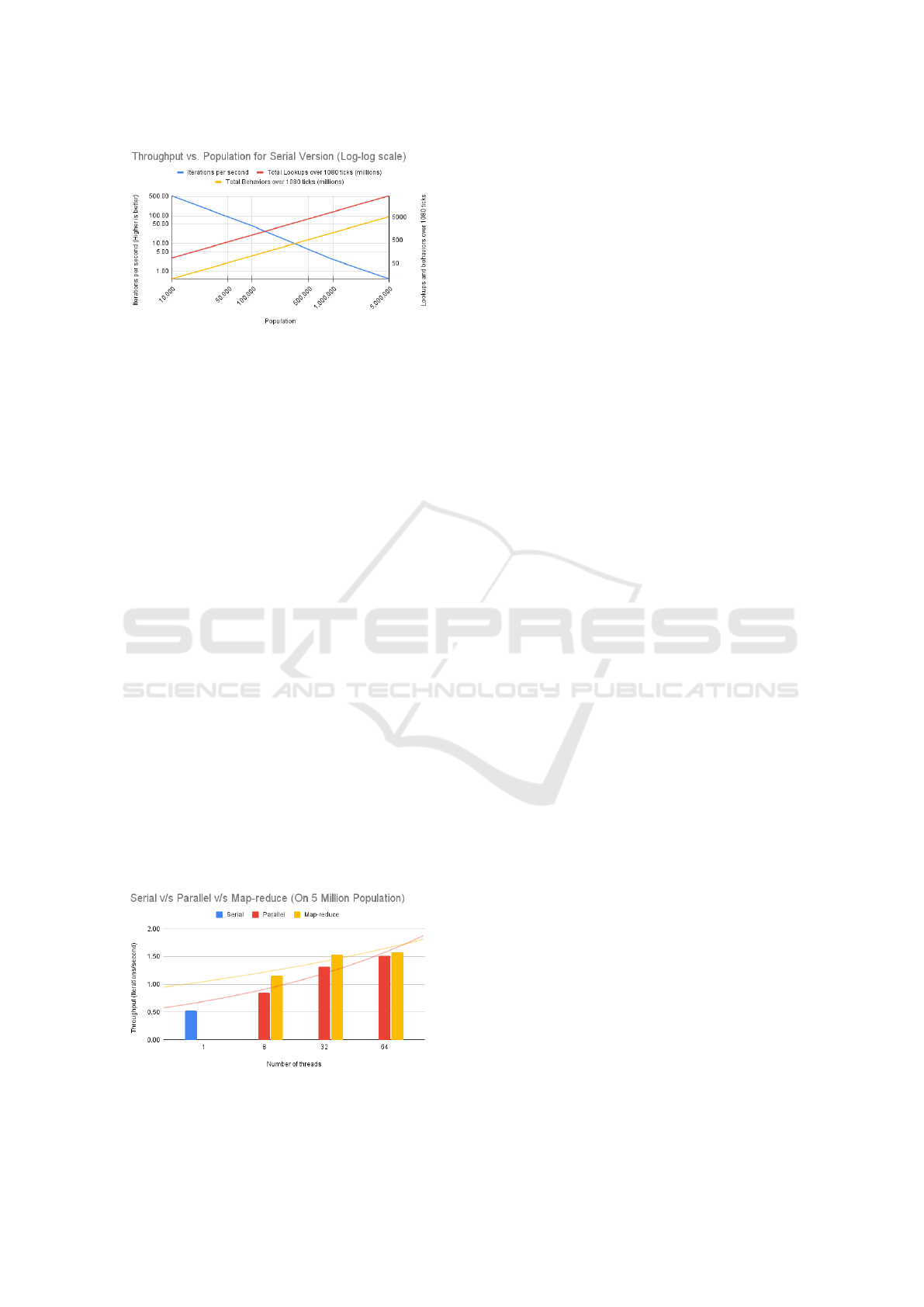
Figure 2: Throughput vs. Population for Serial Version
(Log-log scale).
4 PARALLEL
IMPLEMENTATION
EpiRust has a goal of simulating over a billion agents
closer to the population of India. However, the se-
rial, single-threaded implementation could not scale
beyond 10 million agents and therefore the perfor-
mance was sub-linearly slower for larger populations
(see Figure 2 showing linear characteristics in a log-
log scale). Thus, it was imperative to explore op-
portunities to harness modern multi-core processors,
clusters of computers, and cloud environments via
parallel and distributed implementation. Rest of this
section describes approaches for parallel implementa-
tions whereas the following section continues for the
distributed implementation.
To harness multi-core processors, we needed data
and/or task parallelism opportunities. Agent itera-
tions in Algorithm 1 offer data parallelism. A couple
of caveats are around path dependency and collisions
in agent placements. As discussed in the earlier sec-
tion, the solution based on double-buffering addresses
the path dependency problem enabling parallel eval-
uation of agent states except in case of collisions in
agent placements. The agent collisions impose syn-
chronization penalties which we decided to ignore for
now.
Figure 3: Serial v/s Parallel v/s Map-reduce (for 5 million
population).
The Rust language promotes what is called ‘fear-
less concurrency’ by virtue of its distinctive mem-
ory management approach which guarantees mem-
ory safety especially for concurrent accesses (Klab-
nik and Nichols, 2019). The Rust ecosystem pro-
vides many libraries (crates as they are called) to
harness parallelism. To represent the grid, we are
using concurrent hashmap implementation supported
by dashmap crate (Dashmap, 2023). Another such
crate is Rayon (Rayon, 2022) which provides a data-
parallelism library for data-race free computations.
Using these libraries, we evaluated two different ways
for harnessing multi-core computers namely parallel
iteration, and map-reduce implementation.
4.1 Parallel Iteration
Rayon has a module called as par_iter to help us
achieve the results. The par_iter module spawns
multiple threads and then executes different data seg-
ments on different CPU cores using these threads for
getting higher throughput. Rayon makes it easy con-
verting a sequential iterative computation into parallel
iterative one, just by substituting iter module with
par_iter module.
4.2 Map-Reduce Implementation
Map-reduce is a dual-operation data-parallel tech-
nique used for processing large collection data. The
map operation assigns data elements to available com-
pute elements in batches and waits till all data ele-
ments are processed. The reduce operation collects
these results and summarizes (or reduces) them into a
desired form. Rayon provides map-reduce operation
on collections (Dean and Ghemawat, 2008). EpiRust
employs a map function on each agent such that the
agent goes through evaluation and state update. The
reduce operation collects older and newer locations
of each agent along with few other details.
The next task was to evaluate throughput of these
two implementations. The Figure 3 shows results of
running parallel and map-reduce based simulations
for a hypothetical society of 5 million agent popu-
lation. Based on these results, the map-reduce im-
plementation performs slightly better than the paral-
lel implementation, especially for the lower number
of cores. With higher cores, the throughput becomes
plateaued. This observation became a challenge for
our next goal to run simulations for large cities like
Mumbai (with 12+ million population), and sug-
gested looking for approaches like a distributed im-
plementation. A stable, performant, and flexible dis-
tributed implementation could scale from tens of mil-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
300
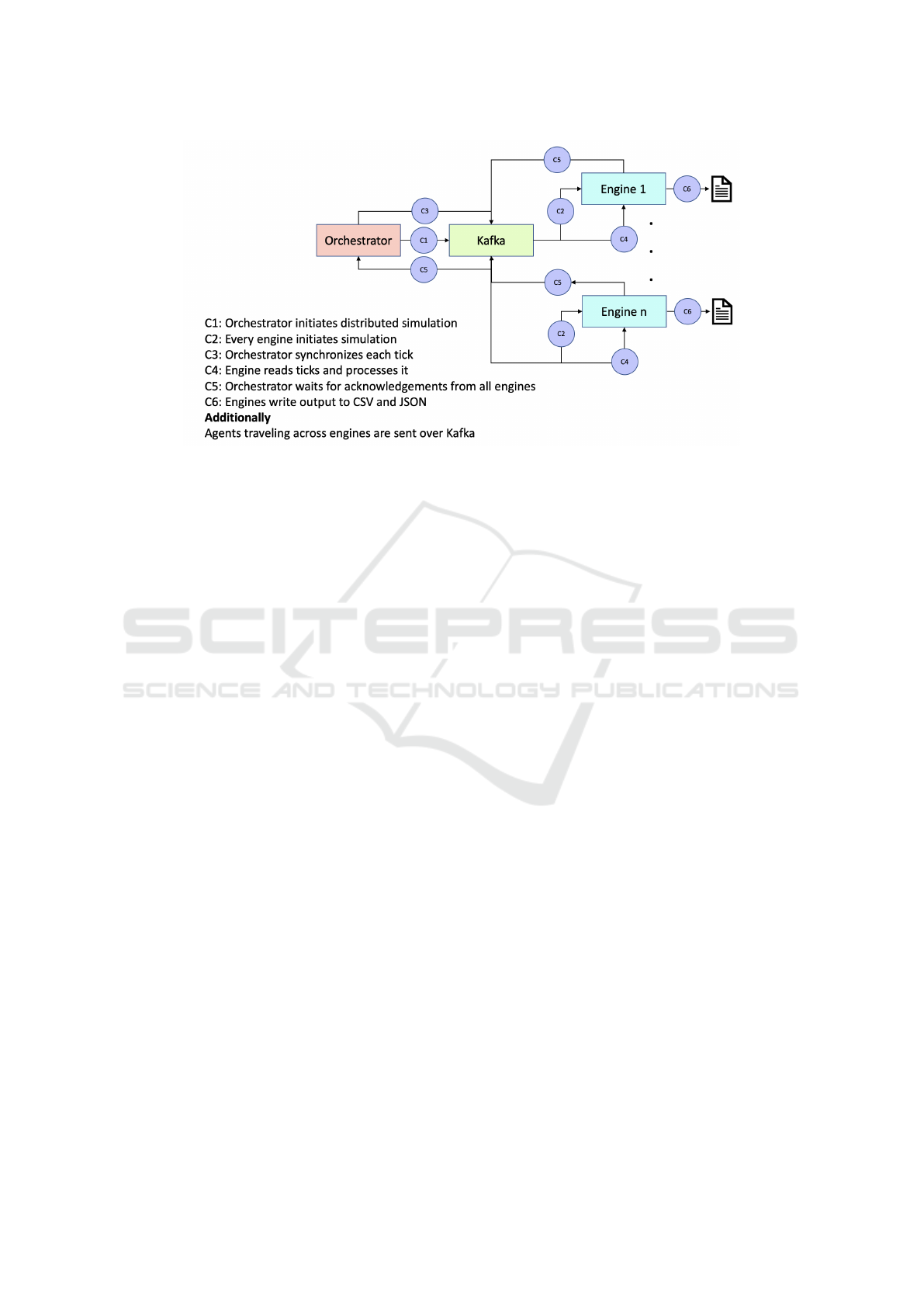
Figure 4: System Architecture.
lions to hundreds of millions.
5 DISTRIBUTED
IMPLEMENTATION
Simulating large cities as a serial and single process
has been a challenge due to steeper memory and pro-
cessor requirements. On the CPU front, combining
insights from Figures 2 and 3 tells that the throughput
would drop substantially for large cities like Mum-
bai. In addition, the throughput per core is far better
for smaller agent populations. In addition, EpiRust
consumes more memory for the traditional double-
buffering approach.
These observations prompted us to organize a
large virtual society into smaller hierarchical units,
and then running simulations for these smaller units
becomes an attractive possibility for scaling, in par-
ticular scaling out.
In India, cities have smaller administrative units
called ‘wards’. Wards have diverse population den-
sity, public transport facilities, initial number of in-
fections, and so on. EpiRust configuration accepts
these parameters. Thus, a monolithic EpiRust pro-
cess instance is broken into multiple instances called
EpiRust Engines as depicted in Figure 4. Usually, one
engine is assigned per administrative unit. Each of
these engines can now use multiple CPU cores in par-
allel.
Once generalized, the approach could be applied
upwardly from cities to states to an entire country. For
such larger experiments, the computing infrastructure
also needs to scale beyond a single powerful computer
to a cluster of computers, which suggests the need for
a distributed implementation of EpiRust.
5.1 Traveling and Commuting Across
Engine Instances
In the previous EpiRust model, a city was a mono-
lithic representation such that agents would live en-
tirely in that city. Agents would commute between
home and work as per their schedules. With multiple
engine instances, each engine instance would have a
separate grid with its own residential, transport, work
areas and hospitals. In addition, for large cities like
Mumbai, an agent could live in an engine representing
the ward, and could commute to another ward. Hence
modeling of commute in EpiRust is an important part
of simulating urban scenarios.
5.2 Using Apache Kafka as a
Distributed Event Store
To implement commuting, an engine needs to com-
municate and coordinate with other engines (please
see C2 and C4 in Figure 4). We see this communi-
cation as an event publish-subscribe based approach,
for which we use Apache Kafka, an open source, dis-
tributed event store and stream processing platform.
An agent or set of agents leaving the engine can be
seen as an event or message over a Kafka instance.
For load distribution, we have assigned a topic per en-
gine which that engine listens to. Each engine sends
messages describing the leaving agents to the topics
of destination engines. Engines receiving the mes-
sages would spawn agents with specified details.
During the COVID-19 epidemic, many Indian
cities witnessed unfortunate migrant workers en
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based Epidemic Simulations
301
masse going back to their hometowns. EpiRust can
simulate such travel and/or migration with appropri-
ate configuration.
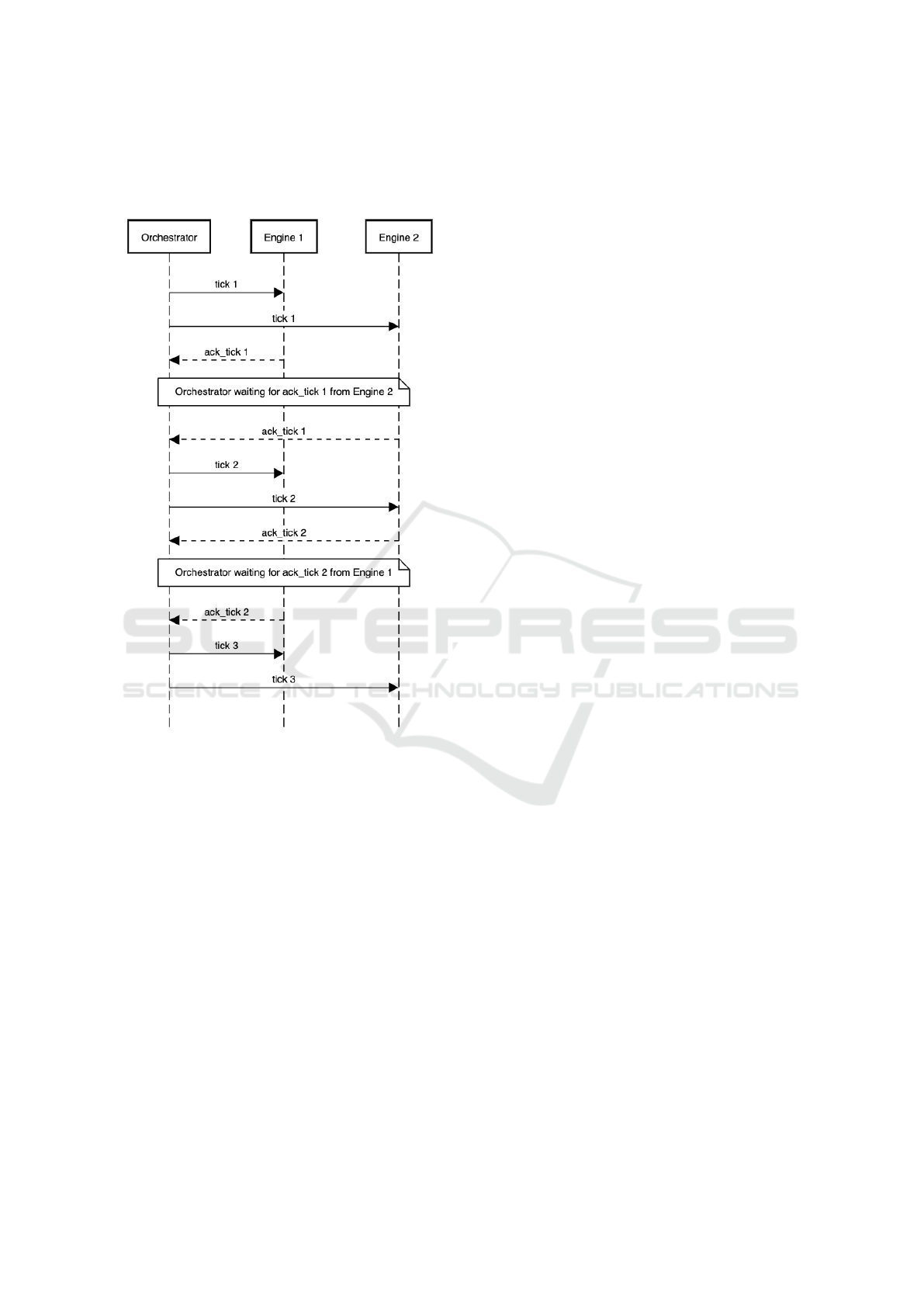
Figure 5: Barriers to synchronize commuter population
across engines in a 24-hours (or ticks) day.
5.3 Orchestration
In a distributed setup, engines could run at differential
throughput depending upon their population sizes as
seen in Figure 3. However, if the engines are required
to support commute, travel, and migration, then the
engines need to synchronize at each time step or tick
for transferring agents amongst themselves. For ex-
ample, if an agent were to leave a source engine at
time t, and to reach its destination engine at time t+k,
assuming the travel takes k units of time, then the
destination engine needs to be synchronized at t+k
time. However, if the destination engine has fewer
agents and hence higher throughput, then it must wait
for other engines to join it at the tick t+k. For en-
suring this barrier, EpiRust has a component namely
Orchestrator, and it is commonly required in a dis-
tributed simulation setup as discussed in a survey pa-
per on co-simulation (Gomes et al., 2018).
The orchestrator is a process doing multiple jobs.
First, it sends the initialization configuration to all en-
gines to instantiate their geographies and disease dy-
namics (please refer to C1 in Figure 4). Second, it
synchronizes all the engines twice in 24 ticks, when
agents travel to-and-fro engines using kafka. It sends
a vector tick over Kafka (please refer to C3 in Figure
4), and then on receiving this tick, each engine starts
its execution. During this tick, each engine executes
routine for all its agents, sends an acknowledgement
after completion, and waits for the next tick from the
orchestrator (please refer to C4 in Figure 4). The or-
chestrator waits for acknowledgements, and once re-
ceived from all engines, only then it sends the next
tick (please refer to C5 in Figure 4).
Here, the slowest engine determines the overall
throughput of the distributed setup. Hence, it is im-
portant to balance throughput of all engines by ad-
justing their parameters and by assigning appropriate
compute resources. In this way, each engine could
finish a time step or tick roughly in the same duration,
thereby the time spent in synchronization or barrier at
the end of that tick could be minimized.
In our earlier distributed EpiRust implementation,
we faced multiple challenges to simulate populations
beyond 10 million. Here, we discuss two critical
challenges related to communication and coordina-
tion across engines as shown in Figure 5.
The first challenge was about varying engine
throughput caused by different agent populations as-
signed to them. This variation made faster engines
with lower populations to wait for slower engines
with higher populations, at the commute barrier 5.
The second challenge was related to the synchro-
nization bottleneck while using kafka. The root cause
of this problem was that all engines were simultane-
ously publishing and receiving all the messages over a
shared kafka topic. Each engine had to scan through
all messages to identify those meant for it, and this
approach added overheads and thereby wait-times for
the engines. These wait-times not only degraded the
performance of engines but also introduced reliability
issues due to intermittent broker connection failures.
We fixed these failures by increasing the polling
interval and session timeout duration for consumers.
To improve the performance, scaling of Kafka be-
came necessary. As every engine is in a separate
consumer group, we could not increase the number
of consumers (or partitions). So, we created sepa-
rate topics, one for every engine to consume the com-
muters’ information. With this change, an engine
now receives the relevant messages meant only for it-
self instead of all the messages meant for all the en-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
302

gines. Thereafter, to improve load balancing, we dis-
tributed these topics across multiple brokers. This ap-
proach helped in reducing the message consumption
overhead, thereby yielding approximately 50% per-
formance improvement for large populations as dis-
cussed in the results section 6.2.
5.4 Cloud-Ready Deployment Setup
Depending upon the size of simulation, deploying and
managing a large-scale distributed EpiRust on a clus-
ter of workstations or a cloud service could be a non-
trivial task. The recent advancements in virtualization
technologies such as containers and Kubernetes take
away much of the complexity on the user-side for ef-
ficient use and management of computing resources.
Containers are execution environments, used for
packaging and running applications in isolation. A
container wraps all the application dependencies such
as application binaries, configuration files, third party
libraries, and operating system required for its exe-
cution. Being an isolated environment, a container-
ized application is abstracted from the underneath in-
frastructure and operating system making containers
portable across platforms. With these features, con-
tainers aid in handling fluctuations in workload and
help in scaling the application. These containers need
to be managed for scaling and resilience and that is
where Kubernetes comes into picture.
Kubernetes is ‘an open-source system for manag-
ing containerized applications across multiple hosts’
(kubernetes.io, 2022). It provides basic mechanisms
for deployment, maintenance, and scaling of appli-
cations. It helps in running distributed systems re-
siliently. EpiRust can be deployed on any infrastruc-
ture with a Kubernetes service which includes all ma-
jor cloud providers as well as any locally set up Ku-
bernetes clusters. Each EpiRust engine instance can
be configured to represent a different geographical re-
gion. These instances generate output files during the
simulation runs. For storage of these configuration
and output files, Volumes are used. Volumes allow
us to store files and share them across containers. To
install the engine instances and the orchestrator, we
use Helm. The application is packaged using Helm
Chart to start/stop simulation with a single command,
and provide a way of pre-processing, post-processing,
and cleanup of data via hooks. Logging and mon-
itoring are essential aspects for observability of the
deployed software. We use other open-source soft-
ware like Prometheus, Grafana, ELK stack for log-
ging and monitoring purposes for resource optimiza-
tion, automated alerts and debugging. With contain-
ers and Kubernetes support, efforts for a large-scale
EpiRust deployment are reduced. This substantially
eases scheduling of simulation experiments.
In the following section, we discuss a few large-
scale experiments and their results.
6 EXPERIMENTS AND RESULTS
In this section, we describe how the experiments can
now be run in parallel and distributed modes for large
cities, and that too at higher throughput. We begin
by sharing the compute infrastructure used for these
experiments. It is followed by the details of baseline
and intervention scenarios for simulation experiments
for Pune and Mumbai cities. Finally, we discuss the
results of these experiments and compare them with
the results from earlier EpiRust paper.
6.1 Experiment Infrastructure
As discussed in an earlier section 5.4, the contain-
ers and Kubernetes pods have made EpiRust a cloud-
ready application. Our experiments were scheduled
on an in-house or local computing infrastructure and
on a public cloud infrastructure.
Local Infrastructure: The in-house infrastruc-
ture was configured as a local Kubernetes cluster.
The cluster had 5 compute nodes, each with an AMD
Ryzen 2700X microprocessor providing 8-cores and
16-threads, and 64 gigabytes of memory. The ex-
periments using parallel and map-reduce versions of
EpiRust could run on multiple CPU cores. In a dis-
tributed setup managed by Kubernetes, each engine
was run in a Kubernetes pod and got a CPU core as
per the job configuration. An upper bound for mem-
ory consumption could be specified, and in its ab-
sence, an engine could consume up to the entire avail-
able memory. Three brokers each for Apache Kafka
and Apache Zookeeper were run in the same cluster
with their own Kubernetes pods.
Cloud Infrastructure: We had set up a fifteen-
node Kubernetes cluster on Elastic Kubernetes Ser-
vice (EKS) of Amazon Cloud Services (AWS). These
nodes were based on the AWS’ c5a.4xlarge in-
stances, each equipped with 16 vCPUs and 32 giga-
bytes of memory. The reason for choosing this in-
stance type was that EpiRust is compute-intensive and
not memory or I/O intensive. AWS Elastic File Sys-
tem (EFS) was used for storage. Three brokers each
for Apache Kafka and Apache Zookeeper were de-
ployed in the same cluster with their own Kubernetes
pods.
All the simulations for Mumbai and Pune in the
parallel mode were run with eight CPU cores.
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based Epidemic Simulations
303
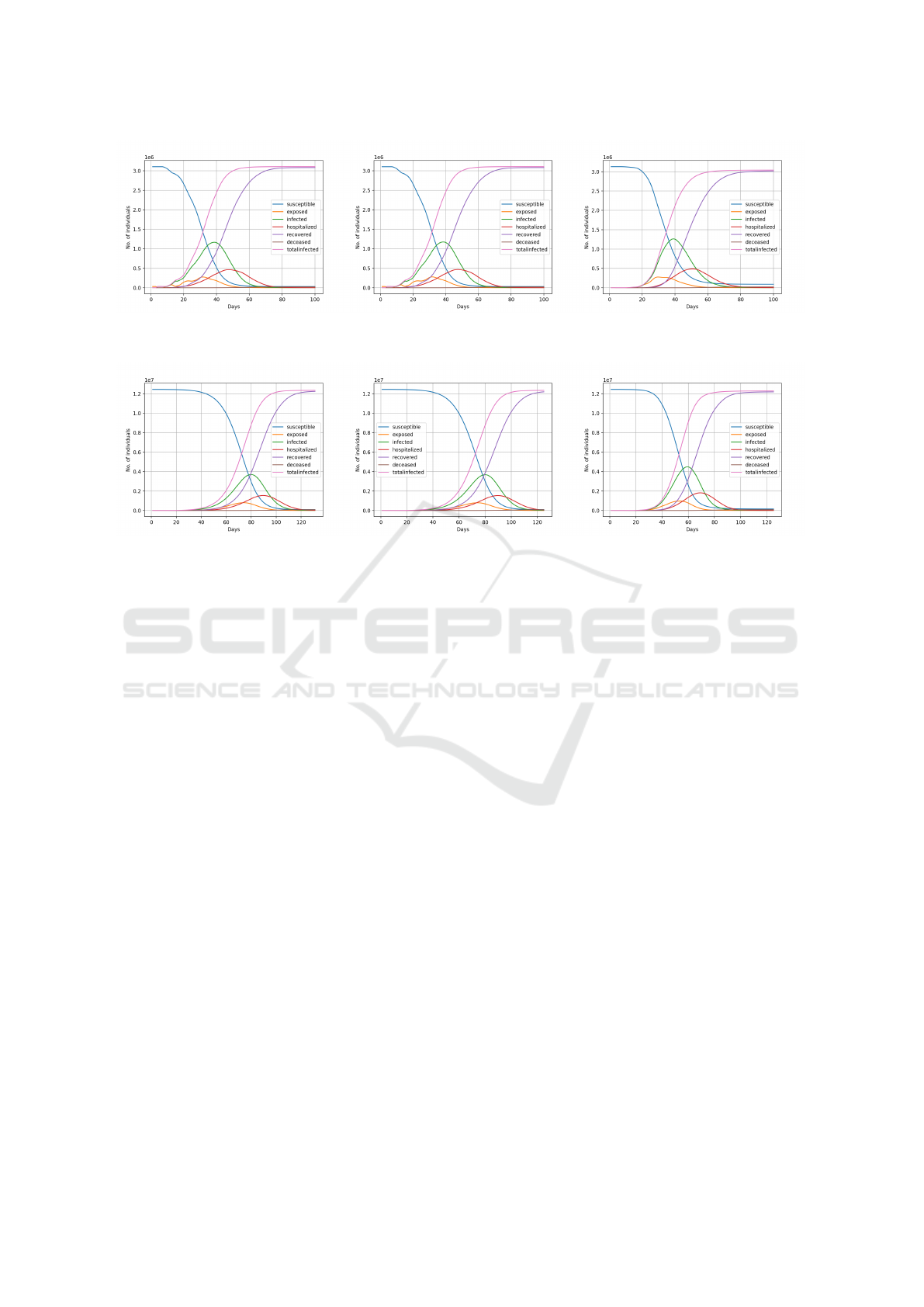
(a) Serial. (b) Parallel. (c) Distributed.
Figure 6: Epidemic Curves of Serial, Parallel, and Distributed Stochastic Simulations of Pune City.
(a) Serial. (b) Parallel. (c) Distributed.
Figure 7: Epidemic Curves of Serial, Parallel, and Distributed Simulations of Mumbai City.
6.2 Experiments
Here, we discuss the experiments for simulating an
unchecked COVID-19 infection spreading through
two large cities, Pune and Mumbai. In addition, we
have an experiment for a hypothetical large society of
100 million population, mainly to test scalability of
EpiRust.
6.2.1 Pune
To run simulations for Pune city in distributed mode,
we created 15 engine instances, one for each ward
(administrative unit) in the city. These wards have
populations varying within a smaller range between
146,333 and 253,778 with mean at 208,809. We
have modeled commutation within and across wards.
Within a ward, approximately 80% of the working
agents use public transport and the rest use private
transport. Across wards, all agents use public trans-
port. The model assumes that 100 agents from every
ward commute to every other ward, making it 1400
agents per ward and 21000 total across the city.
6.2.2 Mumbai
Mumbai has 24 administrative wards according to the
government health department (Mumbai, 2011). The
population across wards ranges between 127,290 and
941,366 with an average of 518,432. The model as-
sumes agent commuting patterns like Pune.
6.2.3 A Hypothetical Society of 100-million
Population
This section describes our experiments to stress-test
the setup for a hypothetical society of 100 million
population. To test the scalability limits of distributed
EpiRust, we ran the simulation with 100 million pop-
ulation spread over 100 EpiRust engines each with a
population of 1 million agents on the AWS infrastruc-
ture. We spawned 15 nodes with c5a.4xlarge with
100 engine instances. Each engine was equipped with
2 CPU cores and 2 GB of maximum memory.
6.3 Results
The results of the serial, parallel, and distributed setup
are discussed below. For validation, we compared
the Mumbai and Pune results with respective serial
runs. The shapes of epidemic curves (epi-curves) are
as seen in Figures 6 and 7. However, the distributed
simulation of Pune shows an altered shape and left
shifted exposed curve in Figure 6c than in Figures 6a
and 6b. Like Pune, we can observe a leftward shift
in all curves, and taller and steeper infected peak in
Figures 7c. Our explanation is that the agents form
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
304
denser and localized contact networks in a distributed
setup, which alters the nature of disease contagion.
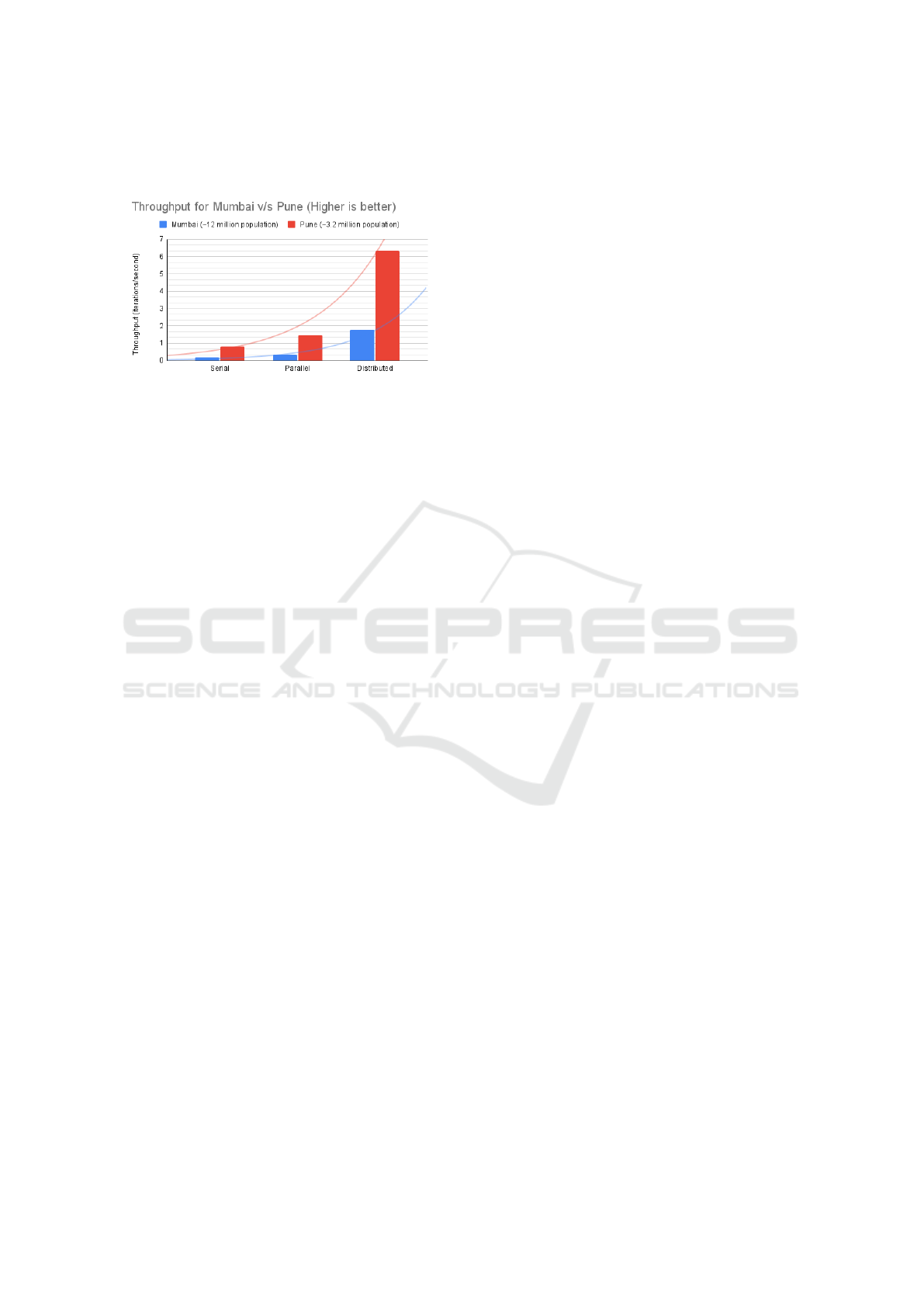
Figure 8: Comparison of Throughput of Serial, Parallel,
Distributed Simulations of Mumbai and Pune Cities on
AWS Cloud Infrastructure.
To understand the throughput of this implemen-
tation, Figure 8 compares the throughput numbers
of simulations for Mumbai and Pune cities in serial,
parallel, and distributed modes. The Mumbai sim-
ulation in the parallel mode is approximately three
times faster than in the serial mode, and more than
ten times faster in distributed mode. Improvements
for Pune simulations are in the similar order, which
is two times and eight times faster in parallel and dis-
tributed modes respectively than the serial mode.
Earlier for a 100 million population, a 45-day sim-
ulation (1080 ticks) had finished within 10920 sec-
onds (approximately 3 hours), with throughput of
0.09 iterations per second. This implementation how-
ever had suffered a communication bottleneck dis-
cussed in section 5.3. After fixing this bottleneck, the
same simulation finished in 3960 seconds (approxi-
mately 1 hour 6 minutes) with throughput close to
0.27 iterations per second, which is roughly 2.7 times
higher than the earlier implementation.
7 CONCLUSION AND FUTURE
WORK
With parallel and distributed implementations of
EpiRust, we could transition to a faster policy eval-
uation regime for large cities like Mumbai and
Pune. The speedup from the serial to distributed
has improved between 8x and 10x. This transition
should help us in moving towards even larger ex-
periments along the geographical hierarchy of cities,
districts/counties, states, and the country. In our
plans, we intend to identify and fix computation and
communication bottlenecks of the current version.
We hope that widening these bottlenecks could help
EpiRust scale to the population of a billion agents.
Finally, we would like to understand the stability of
these experiments using statistical methods.
8 REPRODUCIBILITY
In order to repeat the experiments described in
this paper, one can refer to the source code of
EpiRust which is available at https://github.com/
thoughtworks/epirust/tree/icaart2023. Details about
the experiments, their setup and configurations can be
found here: https://github.com/thoughtworks/epirust/
tree/icaart2023/experiments.
ACKNOWLEDGEMENTS
The authors would like to thank Dhananjay Kha-
parkhuntikar for his contributions in development,
and Shivir Chordia (Azure Business Lead of Mi-
crosoft India) for his support of cloud compute re-
sources during the prototyping phase of EpiRust.
REFERENCES
Abar, S., Theodoropoulos, G. K., Lemarinier, P., and
O’Hare, G. M. (2017). Agent Based Modelling and
Simulation tools: A review of the state-of-art soft-
ware. Computer Science Review, 24:13–33.
Antelmi, A., Cordasco, G., D’Auria, M., Vinco, D. D., Ne-
gro, A., and Spagnuolo, C. (2019). On evaluating rust
as a programming language for the future of massive
agent-based simulations. In Asian Simulation Confer-
ence, pages 15–28. Springer.
Bisset, K. R., Chen, J., Feng, X., Kumar, V. A., and
Marathe, M. V. (2009). Epifast: a fast algorithm
for large scale realistic epidemic simulations on dis-
tributed memory systems. In Proceedings of the 23rd
international conference on Supercomputing, pages
430–439.
Brauer, F. (2008). Compartmental models in epidemiol-
ogy. In Mathematical epidemiology, pages 19–79.
Springer.
Chapuis, K., Taillandier, P., and Drogoul, A. (2022). Gener-
ation of synthetic populations in social simulations: A
review of methods and practices. Journal of Artificial
Societies and Social Simulation, 25(2):6.
Childs, M. L., Kain, M., Kirk, D., Harris, M., Couper, L.,
Nova, N., Delwel, I., Ritchie, J., and Mordecai, E.
(2020). The impact of long-term non-pharmaceutical
interventions on covid-19 epidemic dynamics and
control. medRxiv.
Collier, N. (2003). Repast: An extensible framework for
agent simulation. The University of Chicago’s Social
Science Research, 36:2003.
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based Epidemic Simulations
305

Cordasco, G., De Chiara, R., Mancuso, A., Mazzeo, D.,
Scarano, V., and Spagnuolo, C. (2013). Bringing to-
gether efficiency and effectiveness in distributed sim-
ulations: the experience with d-mason. Simulation,
89(10):1236–1253.
Cosenza, B., Popov, N., Juurlink, B., Richmond, P.,
Chimeh, M. K., Spagnuolo, C., Cordasco, G., and
Scarano, V. (2018a). Openabl: a domain-specific lan-
guage for parallel and distributed agent-based simula-
tions. In European Conference on Parallel Process-
ing, pages 505–518. Springer.
Cosenza, B., Popov, N., Juurlink, B. H. H., Richmond, P.,
Chimeh, M. K., Spagnuolo, C., Cordasco, G., and
Scarano, V. (2018b). Openabl: A domain-specific lan-
guage for parallel and distributed agent-based simula-
tions. In Euro-Par.
Dashmap (2023). Dashmap: Blazingly fast concurrent map
in rust.
de Aledo Marugán, P. G., Vladimirov, A., Manca, M.,
Baugh, J., Asai, R., Kaiser, M., and Bauer, R. (2018).
An optimization approach for agent-based computa-
tional models of biological development. Adv. Eng.
Softw., 121:262–275.
Dean, J. and Ghemawat, S. (2008). Mapreduce: Simpli-
fied data processing on large clusters. Commun. ACM,
51(1):107–113.
Dias, S., Sutton, A. J., Welton, N. J., and Ades, A. E.
(2013). Evidence Synthesis for Decision Making 3:
Heterogeneity—Subgroups, Meta-Regression, Bias,
and Bias-Adjustment. Medical Decision Making,
33(5):618–640.
Eubank, S., Guclu, H., Anil Kumar, V., Marathe, M. V.,
Srinivasan, A., Toroczkai, Z., and Wang, N. (2004).
Modelling disease outbreaks in realistic urban social
networks. Nature, 429(6988):180–184.
Gilbert, N. and Terna, P. (2000). How to build and use
agent-based models in social science. Mind & Soci-
ety, 1(1):57–72.
Gomes, C., Thule, C., Broman, D., Larsen, P. G., and
Vangheluwe, H. (2018). Co-simulation: a survey.
ACM Computing Surveys (CSUR), 51(3):1–33.
Gulyás, L. (2005). Understanding Emergent Social Phe-
nomena. PhD thesis, Computer and Automation Re-
search Institute, Budapest.
Hash (2022). hash.ai. https://hash.ai/.
Hessary, Y. K. and Hadzikadic, M. (2017). Role of Be-
havioral Heterogeneity in Aggregate Financial Mar-
ket Behavior: An Agent-Based Approach. Procedia
Computer Science, 108:978–987.
Jaffry, S. W. and Treur, J. (2008). Agent-based and
population-based simulation: A comparative case
study for epidemics. In Proceedings of the 22nd Euro-
pean Conference on Modelling and Simulation, pages
123–130. Citeseer.
Kagho, G. O., Meli, J., Walser, D., and Balac, M. (2022).
Effects of population sampling on agent-based trans-
port simulation of on-demand services. Procedia
Computer Science, 201:305–312.
Kermack, W. O. and McKendrick, A. G. (1927). A contri-
bution to the mathematical theory of epidemics. Pro-
ceedings of the royal society of london. Series A, Con-
taining papers of a mathematical and physical char-
acter, 115(772):700–721.
Kerr, C. C., Stuart, R. M., Mistry, D., Abeysuriya, R. G.,
Rosenfeld, K., Hart, G. R., Núñez, R. C., Cohen, J. A.,
Selvaraj, P., Hagedorn, B., George, L., Jastrz˛ebski,
M., Izzo, A. S., Fowler, G., Palmer, A., Delport, D.,
Scott, N., Kelly, S. L., Bennette, C. S., Wagner, B. G.,
Chang, S. T., Oron, A. P., Wenger, E. A., Panovska-
Griffiths, J., Famulare, M., and Klein, D. J. (2021).
Covasim: An agent-based model of covid-19 dynam-
ics and interventions. PLOS Computational Biology,
17(7):1–32.
Klabnik, S. and Nichols, C. (2019). The Rust Programming
Language (Covers Rust 2018). No Starch Press.
Klabunde, A. and Willekens, F. (2016). Decision-Making
in Agent-Based Models of Migration: State of the
Art and Challenges. European Journal of Population,
32(1):73–97.
Kshirsagar, J. K., Dewan, A., and Hayatnagarkar, H. G.
(2021). EpiRust: Towards a framework for large-
scale agent-based epidemiological simulations using
rust language. In Linköping Electronic Conference
Proceedings. Linköping University Electronic Press.
kubernetes.io (2022). Kubernetes (k8s).
Luke, S., Cioffi-Revilla, C., Panait, L., Sullivan, K., and
Balan, G. (2005). Mason: A multiagent simulation
environment. Simulation, 81(7):517–527.
Matsakis, N. D. and Klock, F. S. (2014). The rust language.
ACM SIGAda Ada Letters, 34(3):103–104.
Mumbai, M. C. O. G. (2011). Mumbai population breakup
by administrative wards.
Parker, J. and Epstein, J. M. (2011). A Distributed Plat-
form for Global-Scale Agent-Based Models of Dis-
ease Transmission. ACM Transactions on Modeling
and Computer Simulation, 22(1):1–25.
Parry, H. R. and Bithell, M. (2012). Large scale agent-based
modelling: A review and guidelines for model scaling.
Agent-based models of geographical systems, pages
271–308.
Patlolla, P., Gunupudi, V., Mikler, A. R., and Jacob, R. T.
(2004). Agent-based simulation tools in computa-
tional epidemiology. In International workshop on in-
novative internet community systems, pages 212–223.
Springer.
Pereira, R., Couto, M., Ribeiro, F., Rua, R., Cunha, J., Fer-
nandes, J. P., and Saraiva, J. (2017). Energy efficiency
across programming languages: how do energy, time,
and memory relate? In Proceedings of the 10th ACM
SIGPLAN International Conference on Software Lan-
guage Engineering, pages 256–267, Vancouver BC
Canada. ACM.
Rayon (2022). Rayon: Simple work-stealing parallelism for
rust.
Snehal Shekatkar, Bhalchandra Pujari, Mihir Arjunwad-
kar, Dhiraj Kumar Hazra, Pinaki Chaudhuri, Sitabhra
Sinha, Gautam I Menon, Anupama Sharma, and Vish-
wesha Guttal (2020). Indsci-sim a state-level epidemi-
ological model for india. Ongoing Study at https:
//indscicov.in/indscisim.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
306

Taillandier, P., Vo, D.-A., Amouroux, E., and Drogoul, A.
(2010). Gama: a simulation platform that integrates
geographical information data, agent-based modeling
and multi-scale control. In International Conference
on Principles and Practice of Multi-Agent Systems,
pages 242–258. Springer.
Tisue, S. and Wilensky, U. (2004). Netlogo: A simple en-
vironment for modeling complexity. In International
conference on complex systems, volume 21, pages 16–
21. Boston, MA.
White, S. H., Del Rey, A. M., and Sánchez, G. R. (2007).
Modeling epidemics using cellular automata. Applied
mathematics and computation, 186(1):193–202.
Wildt, T. (2015). Heterogeneity, agent-based modelling and
system dynamics - A study about the effects of includ-
ing adopter heterogeneity in diffusion of innovations
models and the consequences on paradigm choice.
Unpublished. Publisher: Unpublished.
Xiao, J., Andelfinger, P., Cai, W., Richmond, P., Knoll, A.,
and Eckhoff, D. (2020). Openablext: An automatic
code generation framework for agent-based simula-
tions on cpu-gpu-fpga heterogeneous platforms. Con-
currency and Computation: Practice and Experience,
32(21):e5807.
Parallel and Distributed Epirust: Towards Billion-Scale Agent-Based Epidemic Simulations
307
