
Semantically Layered Representation for Planning Problems and Its
Usage for Heuristic Computation Using Cellular Simultaneous Recurrent
Neural Networks
Michaela Urbanovsk
´
a and Anton
´
ın Komenda
Department of Computer Science (DCS), Faculty of Electrical Engineering (FEE), Czech Technical University in Prague
(CTU), Karlovo namesti 293/13 Prague, 120 00, Czech Republic
Keywords:
Classical Planning, Cellular Simultaneous Recurrent Neural Networks, Semantically Layered Representation,
Learning Heuristic Functions.
Abstract:
Learning heuristic functions for classical planning algorithms has been a great challenge in the past years.
The biggest bottleneck of this technique is the choice of an appropriate description of the planning problem
suitable for machine learning. Various approaches were recently suggested in the literature, namely grid-
based, image-like, and graph-based. In this work, we extend the latest grid-based representation with layered
architecture capturing the semantics of the related planning problem. Such an approach can be used as a
domain-independent model for further heuristic learning. This representation keeps the advantages of the
grid-structured input and provides further semantics about the problem we can learn from. Together with the
representation, we also propose a new network architecture based on the Cellular Simultaneous Recurrent
Networks (CSRN) that is capable of learning from such data and can be used instead of a heuristic function
in the state-space search algorithms. We show how to model different problem domains using the proposed
representation as well as explain the new neural network architecture and compare its performance in the
state-space search against existing classical planning heuristics and heuristics provided by the state-of-the-art.
1 INTRODUCTION
Classical planning in conjunction with machine learn-
ing can create a powerful general problem-solving
system that can be applied to real-world problems as
well as existing classical planning benchmarks. Us-
ing machine learning to infer a heuristic and possi-
bly improve planning state-space search algorithm is
a widely discussed topic that is being tackled from
many sides. Despite many existing state-of-the-art ap-
proaches, there is not a single standard technique that
could be used for heuristic computation, as problem
representation often becomes a cornerstone. Standard
modeling languages such as PDDL (Ghallab et al.,
1998) has been used in off-shelf planners for years,
but their logic-like structure is difficult to process by
machine learning techniques such as neural networks.
That is why many existing approaches use an alter-
native problem representation to make the data better
structured for neural networks.
One of the first examples is (Groshev et al., 2018)
where authors used a 2D grid representation of the
Sokoban puzzle to compute a policy using a con-
volutional neural network (CNN). Following works
such as (Urbanovsk
´
a and Komenda, 2021) and (Ur-
banovsk
´
a and Komenda, 2022) have used 2D grid rep-
resentation for the Sokoban puzzle as well as other
different domains that natively contain a grid struc-
ture. A similar approach is used with the Cellular Si-
multaneous Recurrent network (CSRN) in (Ilin et al.,
2008) where authors use a neural network to compute
a heuristic function for a maze traversal problem.
Another alternative is using the graph representa-
tion of the problem and processing it through graph
neural networks (GNN). This approach has been used
as a domain-independent heuristic in (Shen et al.,
2020) as authors represented a relaxed version of the
planning problem by a graph to compute the heuristic
function. Another approach is (St
˚
ahlberg et al., 2022)
which uses graph representation created from PDDL
predicates to learn a policy that leads the state-space
search. A slightly different approach is proposed in
(Toyer et al., 2020) where authors use the PDDL’s
structure to build the neural network for each plan-
ning domain.
The work (Urbanovsk
´
a and Komenda, 022a) dis-
Urbanovská, M. and Komenda, A.
Semantically Layered Representation for Planning Problems and Its Usage for Heuristic Computation Using Cellular Simultaneous Recurrent Neural Networks.
DOI: 10.5220/0011691000003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 493-500
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
493

cusses different possible grid representations of plan-
ning problems suitable for machine learning. Many
classical planning benchmarks contain an underlying
grid structure and therefore problem representations
proposed in (Urbanovsk
´
a and Komenda, 022a) apply
to them.
In this work, we propose a novel semantically
layered problem representation based on principles
introduced in (Urbanovsk
´
a and Komenda, 022a) to-
gether with a modified version of the CSRN archi-
tecture suitable for processing such representation.
We model several planning domains with underlying
grids to show the advantages and limitations of this
approach. Lastly, we compare the performance of
the trained networks to the existing classical planning
heuristics in terms of performance in a search algo-
rithm.
2 SEMANTICALLY LAYERED
PLANNING PROBLEM
REPRESENTATION
Representation of the planning problems can of-
ten be a bottleneck for any machine learning algo-
rithm. Many works focus on problems that are rep-
resentable in 2D (Groshev et al., 2018), (Urbanovsk
´
a
and Komenda, 2021), (Chrestien et al., 2021), (Ilin
et al., 2008), (Urbanovsk
´
a and Komenda, 2022),
however, those are often not domain-independent.
This problem has been addressed in (Urbanovsk
´
a and
Komenda, 022a) which showed a possible extension
to the 2D grid representation that could lead to a
domain-independent representation for many existing
planning benchmark domains. It also showed that
the domains without an implicitly defined grid can be
modified using expert knowledge to fit into the 3D
grid representation and still be processable by exist-
ing grid-based approaches.
In this work, we build on the ideas proposed in
(Urbanovsk
´
a and Komenda, 022a) and show that they
are beneficial for the learning of heuristic functions
and that they allow for expressing more complex do-
mains that cannot be formulated on a 2D grid.
We propose the semantically layered grid rep-
resentation which is based on the various semantic
elements of the planning problem (a subset of ob-
jects, predicates, facts, and/or actions), which can
be expressed in STRIPS (Fikes and Nilsson, 1971)
or PDDL (Ghallab et al., 1998). Therefore, this ap-
proach could be further extended in the future to con-
tain an automatic conversion from PDDL straight to
the 3D semantically accurate grid representation. At
...
...
slice encoding
goal condition
neighbors' values
hidden states
}
}
}
...
Figure 1: General structure of the vector representation cre-
ated for every grid cell in the semantically layered represen-
tation.
this time, we are using a handcrafted representation
reflecting the problem’s semantics.
The semantically layered representation has three
dimensions. The first two copy the size of the grid on
the input, and the third dimension contains semanti-
cally different layers, where each layer corresponds to
a different element in the problem instance. The num-
ber of layers can be constructed in two ways. The first
one is layer per object type which creates one seman-
tic layer for one type of object. This way of generat-
ing the layers creates a smaller representation in terms
of the number of layers, but it can also lead to prob-
lems with the encoding of certain problem domains.
A good example is the Tetris domain, where we can
have multiple blocks of the same type that would be
impossible to tell apart in this representation.
The second one is the layer per object instance
that creates one semantic layer for every instance of
every type. One disadvantage of this representation
is the high number of layers it can possibly generate.
Therefore, it slows down the computation of the net-
work as it enlarges the input data. One great advan-
tage is the amount of information it can represent. Let
us take the Tetris example again, where we can repre-
sent every Tetris block within its own layer. That pro-
vides us with complete information about the problem
instance and its objects.
To differentiate between these two representa-
tions, we address the layer per object type input rep-
resentation as one-layer representation and the layer
per object instance input representation as multi-layer
representation.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
494

2.1 Example Problem Formulations
Let us start with the simplest domain originally used
with CSRN, which is the maze domain. One instance
of the maze problem contains walls and free cells and
an agent which is supposed to get to a certain goal
location in the maze. This problem can be represented
by a 2D grid. We can also model it in the semantically
layered representation. Since the maze has only one
agent and one goal position, the one-layer and multi-
layer representations are identical.
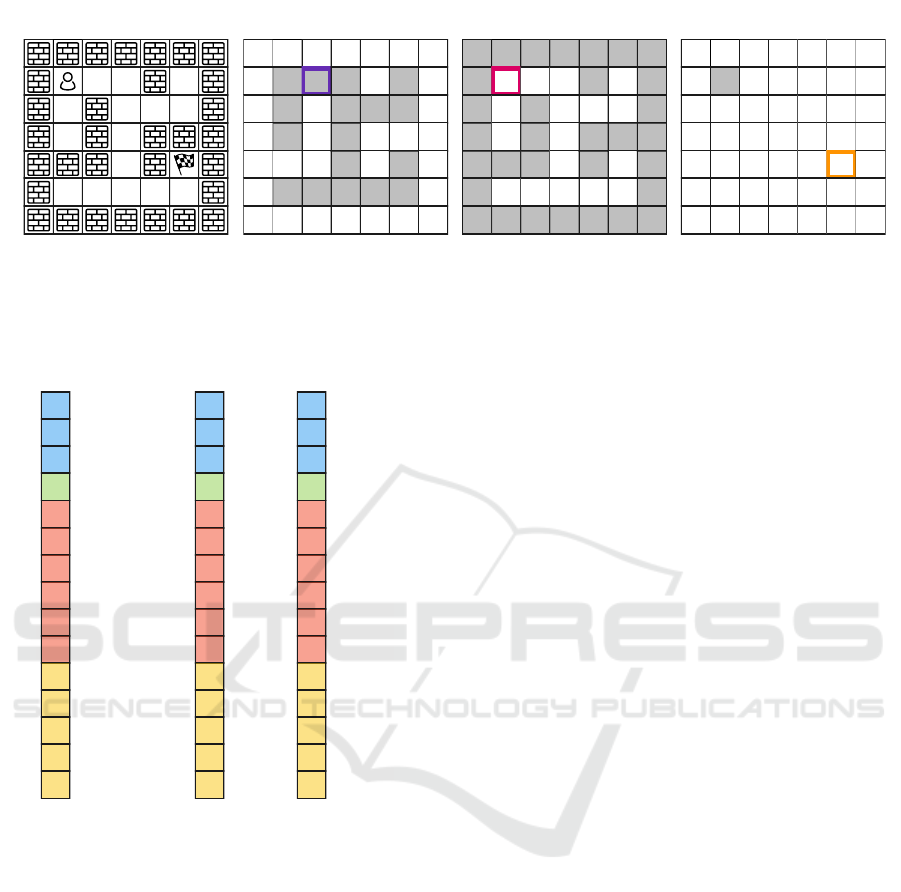
Figure 2 shows how to create such a representa-
tion. We create one layer for the free cells, one layer
for the walls, and one layer for the agent. Each layer
has binary values based on the objects’ positions in
the grid. Next, we create the vector representation
for each grid cell in every layer as displayed in Fig-
ure 1. First, we have n + 1 values, where n = num-
ber of slices present in the representation and the last
binary value represents a goal condition. Goal con-
dition means that the object represented by the slice
at that grid cell should appear in a goal state. For ex-
ample, the maze would have that value equal to one
at the agent slice on the grid cell that corresponds to
the goal’s location. Next, there are m values that are
received from the neighboring grid cells every iter-
ation, and lastly, we have h hidden states produced
by the cell network in the last iteration. Examples of
the vectors representations for the maze domains are
shown in Figure 3.
Now, let us take the Sokoban puzzle as an exam-
ple of a more complex domain. A Sokoban instance
has walls, free tiles, boxes, an agent, and goal posi-
tions which have to have boxes on them to reach the
goal. Different entities can overlap each other, there-
fore using a 2D grid by itself can be limiting for the
neural network to express that a box is standing on a
goal cell or that an agent is standing on a goal cell.
This can be easily solved by the semantically layered
representation. We create a layer for walls, spaces we
can step on, the agent, boxes, and goal positions. This
would be when using the one-layer representation. In
the bottom row, we can see the difference when us-
ing the multi-layer representation, where we have a
separate slice for every box and every goal position.
Since boxes and goal positions are represented by a
one grid cell and not multiple grid cells, we can tell
them apart even in the one-layer representation. Also
in Sokoban, the boxes and goals are homogeneous,
meaning there is no difference in what box ends up on
what goal position, which allows for the more concise
one-layer representation.
3 SEMANTICALLY LAYERED
CSRN
Since we proposed a new semantically layered rep-
resentation of the grid-based planning problems, we
have to create a new architecture that can process
it. Therefore, we propose the semantically layered
CSRN (slCSRN). This architecture is scale-free and
holds the original CSRN’s principles and extends
them to the semantically layered representation with
the same goals—to compute heuristic values usable
in the state space search algorithms with grid-based
planning problems.
Neighborhood Function. Originally, the CSRN
architecture used the 4-neighborhood of every grid
cell for sending and receiving information from other
cells. By adding a third dimension to the input, we
have to communicate across the layers as well. Since
we want this neighborhood function to stay domain-
independent, we replaced it with the 6-neighborhood
function that communicates with all surrounding grid
cells and also wraps in all 3 dimensions. The original
4-neighborhood was corresponding to the available
actions in the maze domain. Therefore, we hypothe-
size that this can cause worse results as the neighbor-
hood no longer correspond to actual planning actions.
Vector Representation of Grid Tiles. The cell
networks process each grid cell’s vector representa-
tion that is based on the information about the cell,
values sent by neighboring cells, and hidden states
produced by the cell network in the previous recurrent
iteration. In (Ilin et al., 2008), the vector representa-
tion included information about the grid cell being a
wall or a goal that was caused by the usage on one do-
main. In different domains, we need to express more
than that, and extending to the 3D also calls for encod-
ing the identity of the grid layer we are processing.
Therefore, the first n values in the vector represen-
tation include one binary value for every layer type,
therefore every layer’s grid cells know their seman-
tics. The general schema for the vector representation
is shown in Figure 1.
Goal Condition. Another change to the vector
representation of the grid cells is also the goal condi-
tion binary value that is placed after the layer encod-
ing. The goal condition is equal to one in layers that
have an effect on the goal at the position that is sup-
posed to be present in the goal state. That means that
we no longer just have a grid cell equal to a goal (po-
sition) like we had in the maze domain. Now we can
express more complex goal conditions similar to how
we express them in STRIPS, using a set of facts that
have to be true in a goal state. For example, in the
Tetris domain, we can now express in every block’s
Semantically Layered Representation for Planning Problems and Its Usage for Heuristic Computation Using Cellular Simultaneous
Recurrent Neural Networks
495
0 0 0
0 1 1
0 1 0
0
1
1
0
0
1
0 1 0
0 0 0
1
1
0
0
0
1
1
0
0
0
0
1
0
0
0 1 1
0 0 0
1
0
1
0
1
0
0
0
1 1 1
1 0 0
1 0 1
1
0
0
1
1
0
1 0 1
1 1 1
0
0
1
1
1
0
0
1
1
1
1
0
1
1
1 0 0
1 1 1
0
1
0
1
0
1
1
1
0 0 0
0 1 0
0 0 0
0
0
0
0
0
0
0 0 0
0 0 0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0 0 0
0 0 0
0
0
0
0
0
0
0
0
Maze in 2D
Free space layer
Wall layer
Agent layer
1
2
3
4
5
6
7
1 2 3 4 5 6 7
Figure 2: One-layer representation of an instance of the maze problem. Maze in 2D represents the maze on the input Next we
see three semantic layers and their binary encoding on the input.
1
0
0
0
0
0
1
1
0
0
-1
-1
-1
-1
-1
[2,3]
Free space layer
0
1
0
0
1
0
1
0
1
1
-1
-1
-1
-1
-1
[2,2]
Wall layer
0
0
1
1
0
0
0
0
0
1
-1
-1
-1
-1
-1
[5,6]
Agent layer
Figure 3: Vector representations of selected color-coded
grid cells from the semantic layers of a maze instance shown
in Figure 2 created based on the general vector representa-
tion template shown in Figure 1.
layer that its position is required in the bottom half of
the grid to meet its goal condition.
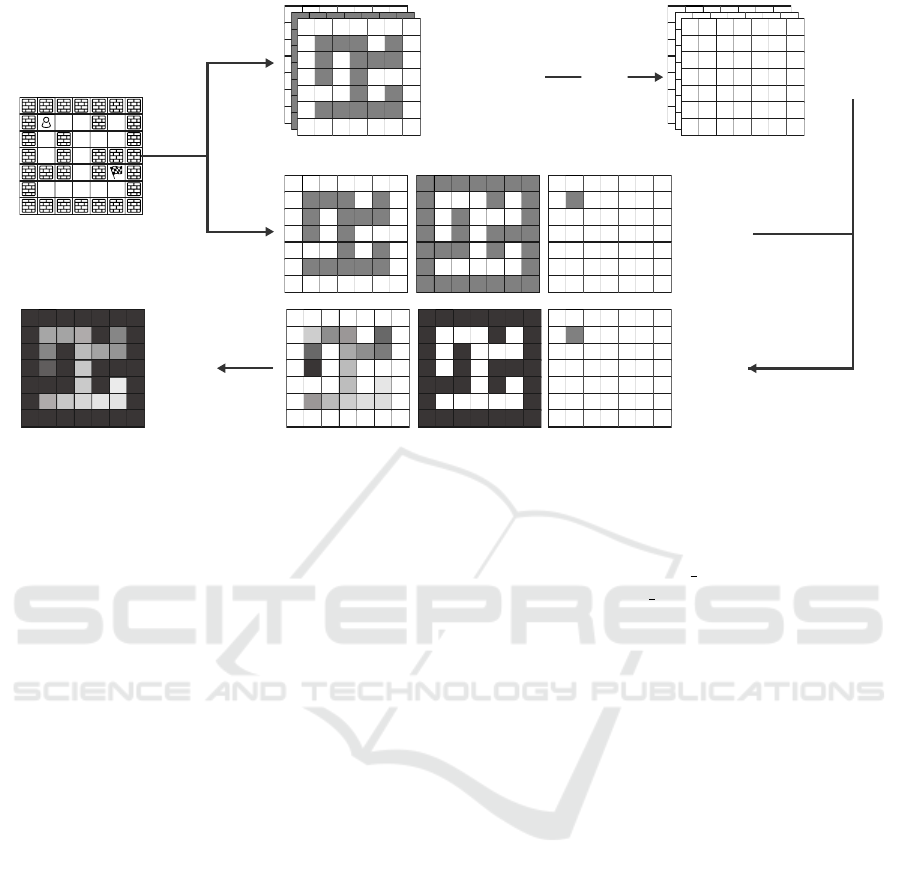
Output Interpretation. Interpreting the output of
the CSRN architecture is a challenge for every do-
main that is not fully representable in 2D. Since we
are using 3D input representation, but we still need
the heuristic represented on a 2D grid, we had to cre-
ate a new computation of the output values that can be
further used as a heuristic. The process of interpreting
the heuristic is displayed in Figure 4.
At the beginning of the computation, we take the
2D input grid and create the semantically layered rep-
resentation and binary masks that show the positions
of each object in its respective semantical layer. We
then process the semantically layered representation
through our architecture and receive the output which
has one layer corresponding to each input layer. By
masking every output layer with the binary masks we
created at the beginning, we have a masked input that
only highlights values relevant to the position of the
object in the current state that is on the input. We
then flatten the masked output layers and obtain a 2D
heuristic projection we can use in the search. This
approach is inspired by the potential heuristic (Pom-
merening et al., 2015) from Classical Planning, where
we sum the potentials of facts that are present in the
state despite computing the potentials for all of them.
3.1 Unfolded-slCSRN
The new input representation provides us with more
expressivity and information about the problem’s se-
mantics. However, it also requires more communica-
tion across the semantically layered grid to propagate
any information. The capacity of a CSRN network
where all cell networks share weights is relatively
small, and we hypothesized that a very low number of
parameters might be limiting to learning the heuris-
tic function. Therefore, we created an alternative to
the slCSRN with more trainable parameters, but the
same scalability. We call it the unfolded-slCSRN. The
structure of the network is the same as slCSRN, but
every recurrent iteration has its own trainable set of
weights that are shared among all cell networks.
3.2 Training
Training of the slCSNR and unfolded-slCSRN is done
in the same manner as in (Urbanovsk
´
a and Komenda,
2022). We use ADAM optimizer (Kingma and Ba,
2015) together with the monotonicity measuring loss
function as described in (Urbanovsk
´
a and Komenda,
2021).
As a side metric, we use the error function de-
scribed in (Urbanovsk
´
a and Komenda, 2022) that
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
496
0 0 0
0 1 0
0 0 0
0
0
0
0
0
0
0 0 0
0 0 0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0 0 0
0 0 0
0
0
0
0
0
0
0
0
0 0 0
0 1 1
0 1 0
0
1
1
0
0
1
0 1 0
0 0 0
1
1
0
0
0
1
1
0
0
0
0
1
0
0
0 1 1
0 0 0
1
0
1
0
1
0
0
0
1 1 1
1 0 0
1 0 1
1
0
0
1
1
0
1 0 1
1 1 1
0
0
1
1
1
0
0
1
1
1
1
0
1
1
1 0 0
1 1 1
0
1
0
1
0
1
1
1
0 0 0
0 1 0
0 0 0
0
0
0
0
0
0
0 0 0
0 0 0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0 0 0
0 0 0
0
0
0
0
0
0
0
0
Current state - maze
Free space layer mask
Wall layer mask
Agent layer mask
1
2
3
4
5
6
7
1 2 3 4 5 6 7
Semantically layered
representation
Binary masks
for the
current state
1 1 1
1 0 0
1 0 1
1
0
0
1
1
0
1 0 1
1 1 1
0
0
1
1
1
0
0
1
1
1
1
0
1
1
1 0 0
1 1 1
0
1
0
1
0
1
1
1
0 0 0
0 1 1
0 1 0
0
1
1
0
0
1
0 1 0
0 0 0
1
1
0
0
0
1
1
0
0
0
0
1
0
0
0 1 1
0 0 0
1
0
1
0
1
0
0
0
slCSRN
slCSRN output
for every layer
Masked
slCSRN
output for
every layer
Masked
slCSRN
output
summer over
third
dimension
Figure 4: Example of the heuristic interpretation for an instance from the maze domain.
measures the number of erroneous decisions in the
search that are not present in any plan that solves the
problem.
To be able to compare the results with the exist-
ing state of the art, we train slCSRN and unfolded-
slCSRN for the maze and the Sokoban puzzle do-
mains. The training data set for the maze domain
contains 10 samples of size 5 × 5. The base for the
Sokoban puzzle training sets contains 100 fully evalu-
ated 3x3 maps with one box and 28 3x3 maps with two
boxes. Every batch is constructed so it contains sam-
ples from only one problem instance, which leaves us
with 128 batches to train with. We trained the archi-
tectures on the whole training set as well as only 10
randomly selected batches to see how the selection of
training data influences the performance of the trained
networks.
The parameters of the architecture were selected
from the following
• number of recurrent iterations = [10, 20, 30]
• number of hidden states = [5, 15, 30]
We also used both one-layer and multi-layer rep-
resentations to see if they have any impact on the abil-
ities of the trained networks.
4 EXPERIMENTS
The experimental evaluation is comparing the re-
sults with versions of CSRN from (Urbanovsk
´
a and
Komenda, 2022) and state-of-the-art classical plan-
ning heuristics. We take the selected trained networks
and plug them into a search algorithm as a heuristic
function. We measure three metrics in total to de-
termine the performance of the trained networks—
average path length (avg pl), average number of
expanded states (avg ex), and coverage (cvg). Cov-
erage is the most important of these as it shows the
percentage of solved problems in the provided set.
4.1 Comparison of Trained Networks
We trained both slCSRN and unfolded-slCSRN with
the one-layer and multi-layer representation to see
how the performance changes and if there is a trade-
off between the complexity of the input, training time,
and final performance.
Of the two selected problem domains, Sokoban is
the more complex one, and therefore we choose it as
the main indicator of the performance of the individ-
ual architecture versions and input format combina-
tions. Each slCSRN and unfolded-CSRN was trained
on the full training data set (128 batches) and 10 ran-
domly selected batches as described in Section 3.2.
We can see that training on the whole available
training set produces consistently better errors on both
train and validation sets. In general, the unfolded ver-
sion of the slCSRN showed better results in both one-
layer and multi-layer representations, so we assume
that the higher number of trainable parameters posi-
tively influences the ability of the network to learn.
The configuration with the best error values overall
is the unfolded-slCSRN trained on the whole training
set. To be precise, it is its parametrization with 10
recurrent iterations and 15 hidden states. Its conver-
Semantically Layered Representation for Planning Problems and Its Usage for Heuristic Computation Using Cellular Simultaneous
Recurrent Neural Networks
497
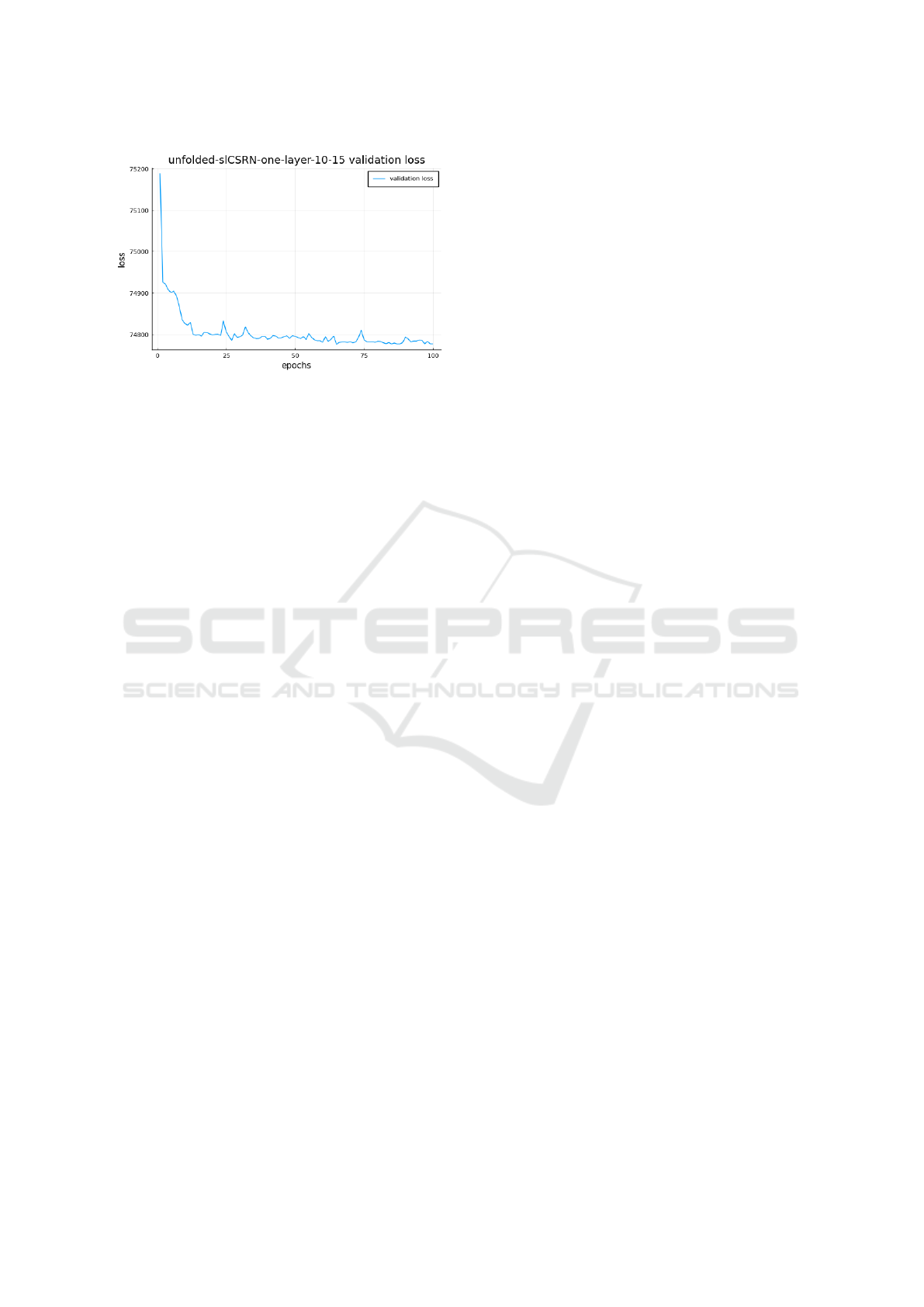
Figure 5: Convergence graph of the validation error for
the unfolded-slCSRN architecture trained on Sokoban 128
batches with one-slice representation.
gence of the validation error is shown in Figure 5.
Based on these results, we selected the unfolded-
slCSRN architecture as one of our heuristic functions
for the following experiments. The unfolded-slCSRN
trained on the maze domain achieved zero error on
the configuration with 10 recurrent iterations and 30
hidden states so it is selected for the planning experi-
ments as well.
4.2 Planning Experiments
We have selected one network for the maze domain
and four networks for the Sokoban puzzle domain
to run in the planning experiments and be used as a
heuristic function during the search. Since we are try-
ing to learn the monotonicity property of the heuristic
function, we are using the Greedy Best First Search
algorithm as the state space search algorithm, as it is
guided solely by the heuristic values.
Although it is not our goal in this work to outper-
form the existing approaches, we seek to see how the
performance changes. The unfolded-slCSRN has to
deal with a much larger input and also contains more
data processing when converting the 2D representa-
tion of problems to the one-layer semantically layered
representation. All these actions may impact the per-
formance in search as they slow down the network’s
evaluation.
The maze domain is evaluated on four data sets
of sizes 8 × 8, 16 × 16, 32 × 32, and 64 × 64 where
each one contains 50 unseen maze instances. The
time limit for one instance is 10 minutes.
The Sokoban domain is evaluated on three data
sets, 8 ×8 with two boxes, 10 ×10 from the Boxoban
data set (Guez et al., 2018), 16 × 16 with two boxes
where each set contains 50 unseen samples. The time
limit for one instance is 10 minutes.
For both domains, we compare the results with
the state-of-the-art planning heuristics LM-Cut (Pom-
merening and Helmert, 2013) and h
FF
(Hoffmann,
2001) as well as with the blind heuristic and Eu-
clidean distance as baselines. We also included the
results from (Urbanovsk
´
a and Komenda, 2022) that
achieved the best performance so far, to see the influ-
ence of the semantically layered representation on the
performance compared to the CSRN that uses the flat
2D representation.
4.3 Discussion
The results for the maze domain are presented in Ta-
ble 1. We compare the results with both state-of-the-
art heuristics and the best CSRN network from (Ur-
banovsk
´
a and Komenda, 2022). The coverage on all
four data sets is equal to one, which means that all
problems were solved. That is by itself a success,
as the larger input for the network and its extended
structure do not negatively influence the evaluation
time such that the search would be excessively slowed
down and unable to find the solutions in time.
The smallest 8 × 8 data set is the only one that
does not have an average path length equal to the op-
timal value. The average number of expanded states is
larger than in the case of the CSRN. The maze domain
does not benefit from the multidimensional represen-
tation due to its low complexity. Therefore, we were
not expecting a great impact on the results when using
the semantically layered representation. This hypoth-
esis showed to be true, as the results of the unfolded-
slCSRN are on par with the CSRN.
The results for the Sokoban domains are in Ta-
ble 2. Since Sokoban is a PSPACE-complete problem
(Culberson, 1997), the performance difference is ex-
pected to be a lot more prominent. We can see this
on coverage, where the maximum amount of solved
problems is equal to 96%. The best coverage achieved
on the 10 × 10 data set is 10%.
A possible cause, in this case, could be the evalua-
tion time of the new architectures. Especially the ones
using the multi-layer representation which is more
costly to evaluate as the input’s size increases with the
number of objects in the problem instance. That pro-
longs the runtime of the whole algorithm. This can be
seen at the unfolded-slCSRN-multi-layer as it reaches
the lowest coverage on the 10 × 10 data set and also at
the slCSRN-multi-slice as it has the lowest coverage
at the 8 × 8 data set.
The overall best results from the proposed archi-
tectures are the unfolded-slCSRN-one-layer results.
This can be due to the increased information capacity
that comes with the unfolded version and also with
the relatively small input size. This suggests that the
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
498
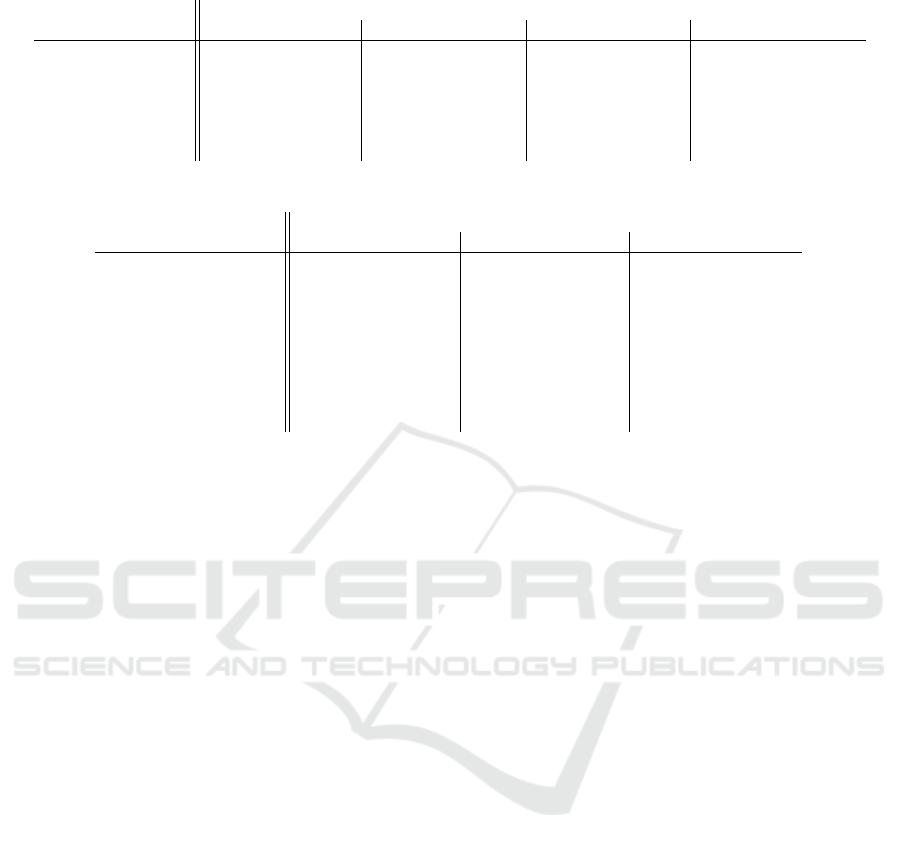
Table 1: Planning experiments for the maze domain. All best results are in bold lettering.
8x8 16x16 32x32 64x64
avg pl avg ex cvg avg pl avg ex cvg avg pl avg ex cvg avg pl avg ex cvg
blind 11.64 27.42 1 23.36 96.82 1 46.2 267.28 1 104.72 1085.66 1
ED 10.76 14.58 1 23.36 48.14 1 46.2 129.7 1 104.72 561.44 1
h
FF
10.76 10.76 1 23.36 23.36 1 46.2 46.2 1 104.72 104.72 1
LM-cut 10.76 10.76 1 23.36 23.36 1 - - 0 - - 0
CSRN-ADAM-20-5 10.76 17.28 1 23.36 77.48 1 46.2 305.52 1 104.72 1292.78 1
unfolded-slCSRN-10-30 10.80 21.66 1 23.36 100.20 1 46.2 392.38 1 104.72 1391.12 1
Table 2: Planning experiments for the Sokoban domain. All best results are in bold lettering.
8x8 10x10 - Boxoban 16x16
avg pl avg ex cvg avg pl avg ex cvg avg pl avg ex cvg
blind 111.24 3.5k 1 1.2k 66k 1 30k 52k 0.54
ED 31.10 0.5k 1 45.64 8.2k 1 115.33 12.6k 0.54
h
FF
- - 0.04 - - 0 - - 0
LM-cut - - 0 - - 0 - - 0
CSRN-ADAM-10-15 51.44 7.3k 1 58.33 51.5k 0.36 224.93 263.4k 0.28
sl-CSRN-one-layer 34.52 1.1k 0.96 37.5 1.1k 0.08 - - 0
sl-CSRN-multi-layer 35.0 1.3k 0.92 29.5 378.75 0.08 - - 0
unfolded-slCSRN-one-layer 37.67 1.0k 0.96 37.8 1.7k 0.1 - - 0
unfolded-slCSRN-multi-layer
34.04 1.2k 0.96 29.0 452.5 0.04 - - 0
Sokoban puzzle might require the level of semantics
provided by the one-layer representation and it does
not benefit from a further extension of the information
on the input by using the multi-layer representation.
Another reason could be the output interpretation
described in Section 3. By getting rid of the third
dimension of the output due to practical reasons, we
might be losing a certain amount of information that
might improve the heuristic estimate. In the future,
we would like to focus on different ways of interpret-
ing the heuristic that would avoid this issue and might
provide even better information on how to guide the
state space search.
Even though we did not outperform the state-of-
the-art results of the CSRN architecture in the plan-
ning experiments, we have shown that the semanti-
cally layered representation can be used in the search,
in the maze domain even without significantly slow-
ing down the algorithm and compromising the results.
In the Sokoban domain, we showed how the amount
of training data influences the learning as the net-
works trained on the full available data set performed
the best. The results encourage us to implement more
domains into this representation and look for ones that
are possibly going to benefit from the multi-layer rep-
resentation and the extended information it provides.
5 CONCLUSIONS
We have proposed two novel representations for
grid-based planning problems that can be used as a
domain-independent representations. Both the one-
layer and the multi-layer representation provide addi-
tional semantics to the planning problem, in opposi-
tion to the 2D grid representation used in the previous
state of the art.
To process this new representation, we proposed
two versions of the CSRN architecture. The slCSRN
with similar principles and weights shared among the
cell networks. And the unfolded-slCSRN provides a
larger information capacity as it shares a different set
of weights among the cell networks in every recurrent
iteration.
We trained the slCSRN and unfolded-slCSRN
with both one-layer and multi-layer representations
and compared the performance of the trained net-
works to classical planning heuristics and the CSRN
architecture.
The results for the maze domain were on par be-
tween the CSRN and unfolded-slCSRN. The main
difference was seen in the Sokoban domain. Its per-
formance is influenced by the complexity and runtime
of the newly introduced unfolded-slCSRN network,
as well as by the exponential state space the Sokoban
puzzle has.
This representation may be a great step in the
possible domain-independent heuristic computation
for planning problems on grids. As proposed in
(Urbanovsk
´
a and Komenda, 022a), many planning
benchmarks can be modeled on grids even without
the necessary underlying structure. This representa-
tion allows us to use graph-based methods as well as
image-based methods to analyze heuristic computa-
tion for planning problems using neural networks.
Semantically Layered Representation for Planning Problems and Its Usage for Heuristic Computation Using Cellular Simultaneous
Recurrent Neural Networks
499

In the future, we would like to focus on modeling
more problem domains and extending the results to
a more domain-independent setting. We would also
like to create a system that would be able to create
the semantically layered representation solely from
the PDDL as its structure copies the structure of the
planning problem.
ACKNOWLEDGEMENTS
The work of Michaela Urbanovsk
´
a was
supported by the OP VVV funded project
CZ.02.1.01/0.0/0.0/16019/0000765 “Research
Center for Informatics” and by the Grant Agency
of the Czech Technical University in Prague, grant
No. SGS22/168/OHK3/3T/13. The work of Anton
´
ın
Komenda was supported by the Czech Science
Foundation (grant no. 22-30043S).
REFERENCES
Chrestien, L., Pevn
´
y, T., Komenda, A., and Edelkamp, S.
(2021). Heuristic search planning with deep neu-
ral networks using imitation, attention and curriculum
learning. CoRR, abs/2112.01918.
Culberson, J. (1997). Sokoban is pspace-complete.
Fikes, R. E. and Nilsson, N. J. (1971). Strips: A new ap-
proach to the application of theorem proving to prob-
lem solving. Artificial intelligence, 2(3-4):189–208.
Ghallab, M., Knoblock, C., Wilkins, D., Barrett, A., Chris-
tianson, D., Friedman, M., Kwok, C., Golden, K.,
Penberthy, S., Smith, D., Sun, Y., and Weld, D.
(1998). Pddl - the planning domain definition lan-
guage.
Groshev, E., Tamar, A., Goldstein, M., Srivastava, S., and
Abbeel, P. (2018). Learning generalized reactive poli-
cies using deep neural networks. In 2018 AAAI Spring
Symposium Series.
Guez, A., Mirza, M., Gregor, K., Kabra, R., Racaniere,
S., Weber, T., Raposo, D., Santoro, A., Orseau, L.,
Eccles, T., Wayne, G., Silver, D., Lillicrap, T., and
Valdes, V. (2018). An investigation of model-free
planning: boxoban levels.
https://github.com/deepmind/boxoban-levels/.
Hoffmann, J. (2001). Ff: The fast-forward planning system.
AI magazine, 22(3):57–57.
Ilin, R., Kozma, R., and Werbos, P. J. (2008). Beyond feed-
forward models trained by backpropagation: A prac-
tical training tool for a more efficient universal ap-
proximator. IEEE Transactions on Neural Networks,
19(6):929–937.
Kingma, D. P. and Ba, J. (2015). Adam: A method for
stochastic optimization. In Bengio, Y. and LeCun,
Y., editors, 3rd International Conference on Learn-
ing Representations, ICLR 2015, San Diego, CA, USA,
May 7-9, 2015, Conference Track Proceedings.
Pommerening, F. and Helmert, M. (2013). Incremental lm-
cut. In Twenty-Third International Conference on Au-
tomated Planning and Scheduling.
Pommerening, F., Helmert, M., R
¨
oger, G., and Seipp, J.
(2015). From non-negative to general operator cost
partitioning. In Bonet, B. and Koenig, S., editors,
Proceedings of the Twenty-Ninth AAAI Conference on
Artificial Intelligence, January 25-30, 2015, Austin,
Texas, USA, pages 3335–3341. AAAI Press.
Shen, W., Trevizan, F. W., and Thi
´
ebaux, S. (2020). Learn-
ing domain-independent planning heuristics with hy-
pergraph networks. In Beck, J. C., Buffet, O., Hoff-
mann, J., Karpas, E., and Sohrabi, S., editors, Pro-
ceedings of the Thirtieth International Conference on
Automated Planning and Scheduling, Nancy, France,
October 26-30, 2020, pages 574–584. AAAI Press.
St
˚
ahlberg, S., Bonet, B., and Geffner, H. (2022). Learning
general optimal policies with graph neural networks:
Expressive power, transparency, and limits. In Kumar,
A., Thi
´
ebaux, S., Varakantham, P., and Yeoh, W., ed-
itors, Proceedings of the Thirty-Second International
Conference on Automated Planning and Scheduling,
ICAPS 2022, Singapore (virtual), June 13-24, 2022,
pages 629–637. AAAI Press.
Toyer, S., Thi
´
ebaux, S., Trevizan, F. W., and Xie, L. (2020).
Asnets: Deep learning for generalised planning. J.
Artif. Intell. Res., 68:1–68.
Urbanovsk
´
a, M. and Komenda, A. (2021). Neural net-
works for model-free and scale-free automated plan-
ning. Knowledge and Information Systems, pages 1–
36.
Urbanovsk
´
a, M. and Komenda, A. (2022). Learning heuris-
tic estimates for planning in grid domains by cellu-
lar simultaneous recurrent networks. In Rocha, A. P.,
Steels, L., and van den Herik, H. J., editors, Proceed-
ings of the 14th International Conference on Agents
and Artificial Intelligence, ICAART 2022, Volume 2,
Online Streaming, February 3-5, 2022, pages 203–
213. SCITEPRESS.
Urbanovsk
´
a, M. and Komenda, A. (2022a). Grid represen-
tation in neural networks for automated planning. In
Rocha, A. P., Steels, L., and van den Herik, H. J., edi-
tors, Proceedings of the 14th International Conference
on Agents and Artificial Intelligence, ICAART 2022,
Volume 3, Online Streaming, February 3-5, 2022,
pages 871–880. SCITEPRESS.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
500
