
An Experimental Consideration on Gait Spoofing
Yuki Hirose
1
a
, Kazuaki Nakamura
2 b
, Naoko Nitta
3
and Noboru Babaguchi
4
1
Graduate School of Engineering, Osaka University, Suita, Osaka, 565-0871, Japan
2
Faculty of Engineering, Tokyo University of Science, Tokyo, 125-8585, Japan
3
School of Human Environmental Sciences, Mukogawa Women’s University, Nishinomiya, Hyogo, 663-8558, Japan
4
Institute for Datability Science, Osaka University, Suita, Osaka, 565-0871, Japan
Keywords:
Gait Recognition, Spoofing Attacks, Master Gait, Masterization, G ait Spoofing, Fake Gait Silhouettes,
Multimedia Generation.
Abstract:
Deep learning technologies have improved the performance of biometric systems as w el l as increased the
risk of spoofing attacks against them. So far, lots of spoofing and anti-spoofing methods were proposed
for face and voice. However, for gait, there are a limited number of studies focusing on the spoofing risk.
To examine the executability of gait spoofing, in this paper, we attempt to generate a sequence of fake gait
silhouettes that mimics a certain target person’s walking style only from his/her single photo. A feature vector
extracted from such a single photo does not have full information about the target person’s gait characteristics.
To complement the information, we update the extracted feature so that it simultaneously contains various
people’s characteristics like a wolf sample. Inspired by a wolf sample or also called “master” sample, which
can simultaneously pass two or more verification systems like a master key, we call the proposed process
“masterization”. After the masterization, we decode its resultant feature vector to a gait silhouette sequence.
In our experiment, the gait recognition accuracy with t he generated fake silhouette sequences is increased from
69% to 78% by the masterization, which indicates an unignorable risk of gait spoofing.
1 INTRODUCTION
Recently, deep neural networks (D NN s) have been
introdu ced in a wide range of research fields and
achieved great success. One of the most DNN-
benefitted research fields is biometrics such as face
identification, voice au thentication, gait recognition,
and so on, whose pe rformance has been d rastically
improved by DNNs. On the o ther hand, DNNs have
also accelerated the performance of multimedia gen-
eration techniques. D N Ns, or more specifically gen-
erative adversarial networks (GANs), can generate
highly realistic facial images, speech data, and so on
that mimics an actual person’s biometric characte ris-
tics (Kammoun et al. , 2022; Toshpulatov et al., 2021;
Tu et al., 2019). These tec hniques are useful in some
aspects (e.g., content c reation and movie production),
but they b ring a risk of spoofing attacks against bio-
metrics.
The risk of spoofing attacks against face identifi-
cation and voice authentication has been widely dis-
a
https://orcid.org/0000-0003-3370-0372
b
https://orcid.org/0000-0002-4859-4624
cussed in the literatu re (Conotter et al., 2014; Nguye n
et al., 2015; Chen et al., 2022; Shiota et al., 2015;
Wang et al., 2019). There a re a lot of existing studies
proposing anti-spoofing methods for face and voice.
However, for gait, which is a re la tively novel biomet-
ric clue for human identification, the risk of spoof-
ing attacks ha s not been well-analyzed yet. Although
the development of gait r ecognition is still halfway,
it is advantageous in that it can be applied to low-
resolution videos where facial textures a re not clearly
observed. Hence, gait recognition will be more
widely a nd complementarily used with face identifi-
cation in the near future society. This means that ex-
ploring the (fu ture) risk of gait spoofing is an impor-
tant issue even if the performance and the spread of
gait recognition are still limited at present.
So far, a few existing studies focus on the risk of
gait spoofing (Gafur ov et al., 2007; Hadid et al., 201 2;
Hadid et al., 2013). However, they do not assume
fake gait generated by multimedia genera tion tech-
niques; they only assume th e ca ses where an attacker
physically mimics the target person’s walking style or
physically wears the same clothes as th e target person.
Unlike them, in this paper, we focus o n the risk of
Hirose, Y., Nakamura, K., Nitta, N. and Babaguchi, N.
An Experimental Consideration on Gait Spoofing.
DOI: 10.5220/0011661200003417
In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2023) - Volume 5: VISAPP, pages
559-566
ISBN: 978-989-758-634-7; ISSN: 2184-4321
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
559
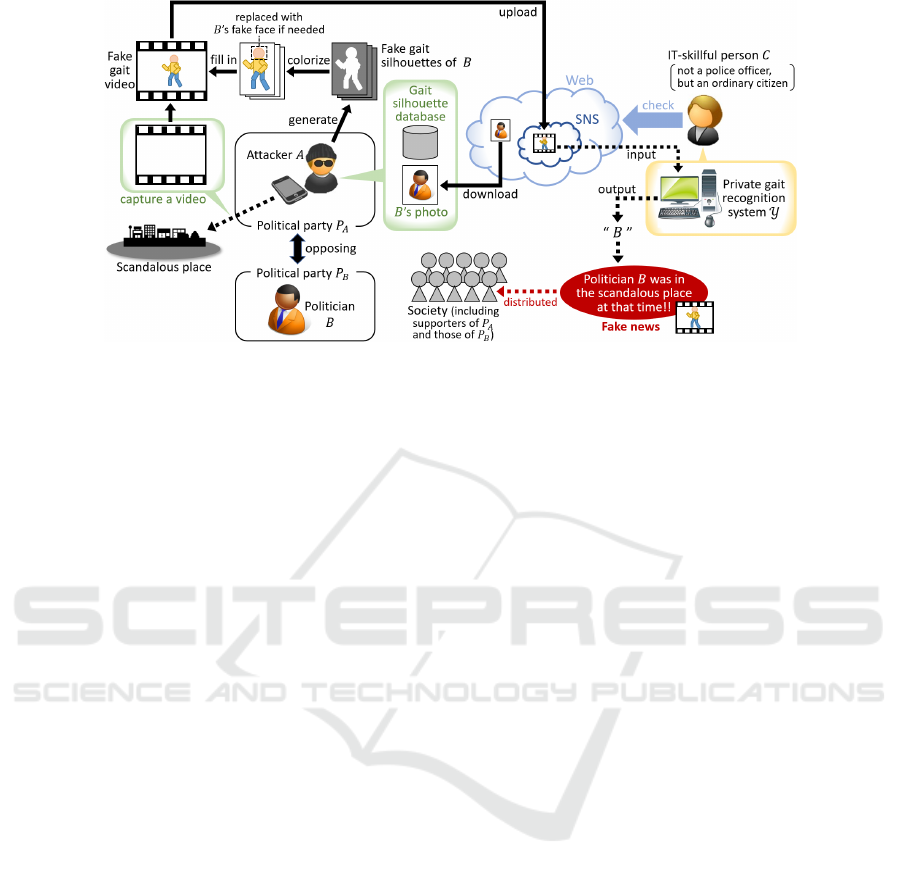
Figure 1: Assumed scenario of gait spoofing.
gait spoofing caused by DNN-based multimedia g en-
eration tec hniques. Specifically, in order to analyze
whether a spoofing attack a gainst gait recognition is
practically possible or not, we propose a metho d for
generating a seq uence of a target individual’s fake gait
silhouettes using DNNs.
Figure 1 depicts a possible scenario o f spoofin g at-
tacks against gait analysis. Suppose that there are two
political parties P
A
and P
B
opposing each other. An
attacker A joining the party P
A
attempts to injure the
reputation of a politician B in the party P
B
by making
his fake video. First, the attacker A capture s a video
of a certain scandalous place using his own device. In
parallel, he generates a sequence of fake gait silhou-
ettes that mimic or spoof B’s walking style. Then, he
colorizes the generated silhouettes and fills in them to
the video captured above, which results in a fake gait
video of B. In this step, he also generates a fake face
of B and inserts it into the fake ga it video if needed.
This increases the reality of the fake video but is not
necessarily needed when the video resolution is low.
Note that the colorization process itself is not so im-
portant bec ause human eyes cannot identify peop le b y
their b ody textures whereas automa te d systems just
use silhouette information. At last, the attac ker up-
loads the fake gait video onto the Web, particularly
SNS. Nowadays, there ar e a lot of IT-skillful people
who want to ch e ck the social behavior of politicians.
For them , a gait recognition system can be a useful
tool. O ne such person C, who is not a police officer
but an ordinary citizen, checks the SNS and inputs the
fake video into her private gait recognition system Y .
As a result, the politician B’s behavior is fabricated
and distributed as fake news even th ough the checker
C has no malicious intent, as shown in Figure 1. The
fake gait video may pass the mod e rn deep fake detec -
tion systems because most of them are focu sin g only
on faces. In other words, fake news fabricated with
a fake face becom es more difficult to detect by com-
bined with fake gait.
In the above scenario , we assume tha t the attacker
A can use a single photo of the politician B as well as
a large database of gait silhouettes tha t are not related
to B no r Y . Under this assumption, targets of th e gait
spoofing are not limited to politicians; not only other
famous people such as celebrities and sports players
but even o rdinary citizens whose photo is on the Web
or SNS could be a victim of this attack. The goal
of the attacker is to generate a sequence of fake gait
silhouettes that can be recognized as the vic tim by an
unknown gait recognition system Y .
The contributions of this paper are summarized as
follows. Fir st, this is the fir st work focusing on the
method of DNN-based gait spoofing and an a lyzing its
risk, to the best of our knowledge. Second, to achieve
gait spoofing, we introduce the novel concept named
“master gait”, which is a master key-like gait data that
can be accepted by multiple gait verification systems.
The concept of master gait is utilized to complement
the limited information of a single photo. We will
explain its details in Section 3.
2 RELATED WORK
2.1 Spoofing Attacks Against
Biometrics
Methods of spoo fing attacks against face recognition
and voice authentication have been actively stu died
for m ore than fifteen years. On e of the simplest at-
tack ways is a presentation attack. For a face reco gni-
tion system equipped with a camera, an attacker can
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
560

fool it by presenting a photo or a video of some valid
user (Patel et al., 2016; Anjos et al., 20 14). Similarly,
for a voice authentication system equipped with a mi-
crophone, the attacker can fool it by replaying pre-
recorde d voice of some valid user (Cheng and Roedig,
2022).
Conducting a presentation attack needs some
“spoof data”, i.e ., a photo or pre-recorded voice of
a valid user. For the face, spoof data can be retrieved
from social networking services such a s Facebook or
Instagram in so me cases (Kuma r et a l., 2017). In con-
trast, for the voice, spoof data cannot always be easily
obtained. Hence, speech synthesis techniques are of-
ten exploited to make spoof data . A voice spoofing
attack using such sy nthetic data is called a voice syn-
thesis attack . The speech synthesis techniques used
for this attack are divided into two categories: voice
conversion (VC) (Liu et al., 2018) and text-to-speech
(TTS) (Tu et al., 2019). VC is a technique to convert
a so urce speaker’s voice to a target speaker’s voice
without changing its linguistic information. TTS is
a technique to c onvert an arbitral plaintext to spoken
words with a certain target speaker’s voice. Applying
these techniques to the attacker’s own voice or plain-
text da ta to co nvert it to a valid user’s voice, h e can
obtain spoof data (Kreuk et a l., 2018; Zhang et al.,
2021). Multimedia generation techniques are also ex-
ploited for face spoofing. Nowadays, no t on ly 2D im-
ages/video but also 3D volume data of faces can be
generated by GANs (Toshpulatov et al., 2021), which
are at risk of being exploited for face spoofing (Gal-
bally and Satta, 2015).
To defeat the above spoofing methods, anti-
spoofing methods for face and voice authentication
have also be en a c tively studied. For instance, the re
is some previous work that tried to discriminate
computer-generated or GAN-generated face images
from real face images (Conotter et al., 2014; Nguyen
et al., 2015). Recently, CNNs are often used for face
anti-spoofing. For instance, Chen et al. found that
the luminance component of face images is helpful
to detect GAN-generated faces and proposed to use
YCbCr images in addition to RGB imag e s as input
of a CNN (Chen et al., 2022). For voice, pop noise-
based anti-spoofing methods are well-studied (Shiota
et al., 2015; Wang et al., 2019). When a hu man speaks
into a microphone, his/her breath sometimes reaches
the microphone, which yields a pop noise. This is
difficult to be naturally generated eve n with GANs.
Therefore pop noises become a good clue for voice
anti-spoofing.
As discussed above, a lot of spoofing and anti-
spoofing methods have been studied for face recog-
nition and voice au thentication. In contrast, for gait
recogn ition systems, spoofing attacks with synth e tic
data have not been studied yet. T hus, in this paper,
we focus on gait spoofing utilizing CNN-b a sed mul-
timedia generation techniques.
2.2 Wolf Attacks by “Master” Samples
The purpose of spoofing attacks is to create a fake
biometric sample (e.g. face) that is similar to a target
person and dissimilar to all other people. However,
researchers in the field of biom etrics found that it is
possible to create a single fake sam ple that is similar
to two or more people . This is called a “wolf sample”,
and the attacks against biometric verification system s
based on a wolf sample ar e called “wolf attacks” (Une
et al., 2007). Suppose that th ere are two or more peo-
ple who have th e ir own biometric verification system.
Each verification system is a two-class classifier th at
predicts whether an input biom etric sample is from
its owner or not. An attacker can simultaneously fool
many of these systems by using a sin gle wolf sam-
ple, where the wolf sample plays the role of a master
key. Since this is a serious problem, methods of wolf
attacks and their countermeasures have been stud ie d.
For instance, Ohki et al. evaluated the executabil-
ity of wolf attacks against voice verification systems
(Ohki e t a l., 2012). Nguyen et al. proposed a GAN-
based method for generating a wolf sample against
face recognition systems (Nguyen et al., 2020). They
refer to the wolf samples generated by their method
as “master faces”.
Although there is no previous work focusing on
wolf attacks against gait recognition systems, we be-
lieve that the characteristics of wolf samples are help-
ful to conduct gait spoofing. Thus, we introduce
the concep t of “master gait” in the proposed method,
which is explained in the next section.
3 GAIT SPOOFING METHOD
3.1 Concept Definitions
In this p a per, the term “gait verification” means
a two-class classification task. A gait verification
system only focuses on a single individual and pre-
dicts whether an input gait silhouette sequence S =
{s
1
, ··· , s
m
} is genuinely captured from the indi-
vidual or no t. s
i
is the i-th fra me in S. Generally,
a verification system first compresses S into a single
feature map f = F(S) by a compressor F, whose typ-
ical example s a re Gait Energy Im a ge (GEI) (Man and
Bhanu, 2006) and Frequency Domain Feature (FDF)
An Experimental Consideration on Gait Spoofing
561
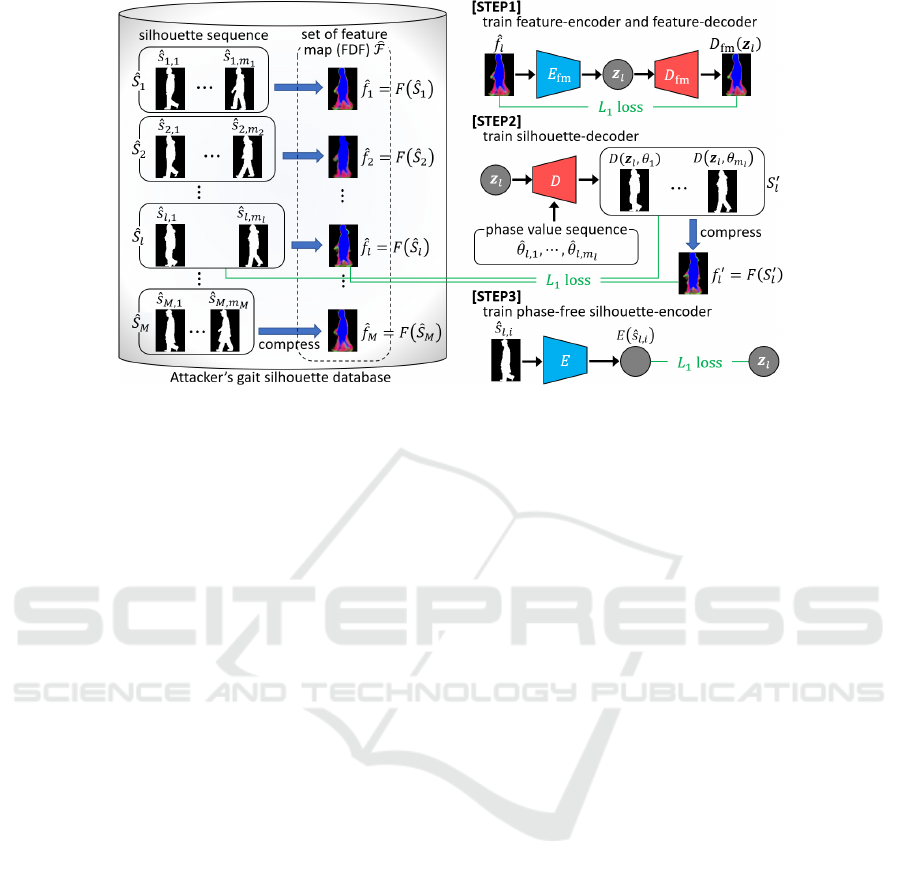
Figure 2: Procedure for training gait silhouette decoder D and encoder E.
(Makihara et al., 2006). GEI is the pixel-wise aver-
age of {s
i
} while FDF is the pixel-wise Fourier co-
efficients calculated for {s
i
}. For the feature map f ,
the verification system outputs a single score ω( f ) =
ω(F(S)) ∈ [0, 1], where the input S is classified as
“genuin e” if and only if ω( f ) ≥ 0.5. Based on the
above, we define a “master gait” as a feature map
that ha s a score higher than 0.5 for two or more dif-
ferent individuals’ gait verification systems.
In contrast, the term “gait recognition” means a
multi-class classification task. A gait recog nition sys-
tem focuses on K different individuals (K ≥ 2) and
predicts which of them an input sequence S is cap-
tured from. A recognition system generally ou tputs
K-dimensional sco re vector η( f ) = η(F(S)) ∈ [0, 1]
K
.
If the j-th element in η( f ) is larger than all the other
elements, the system judge s S is captured from the j -
th individual.
3.2 Overview of the Proposed Method
The sh a pe of a single gait silhou e tte s is determined
by two factors: body shape (including the shape of
clothes) and posture. Since walking is a periodic ac-
tion, a human’s posture in h is/h e r one cycle of gait
can be represented by a phase value θ ∈ [0, 2π]. A
human’s body shape can be represented by a certain
shape vector z ∈ R
d
, where d is its dimensionality.
Thus, a gait silhouette s can be determined by z and
θ. Let D be a decoder that ge nerates a silhouette im-
age s = D(z, θ) from z and θ.
The goal of gait spoofing is to obtain th e opti-
mal shape vector z
∗
that maximizes η
b
( f (z)), where
f (z) = F(S(z)) is a f eature map of a fake silhou-
ette sequence S(z) = {D(z, θ
i
)|i = 1, ··· , n} gener-
ated by D. η is the score vector outputted by the
checker C’s gait recognition system Y , and b is the
ID of the spoofing target B. The phase sequence
Θ = {θ
1
, ··· , θ
n
} can be arbitrarily given. Note that
attacker A does not know the network structure and
the parameters of Y but he can guess F beca use th ere
are only a few kinds of feature maps wid ely used for
gait recognition. In this paper, we assume FDF as the
feature map extrac tor F.
To obtain z
∗
, the attacker can use a single photo
of the target B, as we assumed in Sec tion 1. Let p be
the silhouette extracted from the photo. The simplest
way to find z
∗
is train ing a phase-free shap e encoder
E that can extract z from D(z, θ) as z = E(D(z, θ)),
by which we can get z
∗
as z
∗
= E(p). However,
this strategy can hardly provide a good z
∗
in prac-
tice. This is bec a use a single silhouette p does not
have full information about B’s gait characteristics.
Hence, there is a certain extraction error ∆z between
˜z = E(p) and z
∗
, i.e., ˜z = z
∗
+ ∆z. This ∆z needs to
be estimated f or gait spoofing.
In summa ry, the process of gait spoo fing is as fo l-
lows, where we d escribe the ways to a chieve steps (1)
and (3 ) in Subsections 3.3 and 3.4, respectively.
(1) The attacker first trains D and E using his own gait
silhouette database.
(2) With the trained E, he gets ˜z = E(p) using a photo
of the target pe rson B.
(3) Next, he optimizes the ˜z to z
∗
= ˜z − ∆z by esti-
mating ∆z.
(4) Finally, he gene rates a fake silhouette sequence
{D(z
∗
, θ
i
)|i = 1, ··· , n} by the trained D and arbi-
trarily given Θ = {θ
1
, ·· · , θ
n
}.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
562

3.3 Training Process of Gait Silhouette
Encoder and Decoder
Figure 2 depicts the proposed pro c edure for training
D and E, which c onsists of three steps.
It is difficult to direc tly train the phase-free silhou-
ette encoder E. Hence, we first train a f e ature map-
leve l encoder E
fm
and dec oder D
fm
as STEP1. To this
end, for each sequence
ˆ
S
l
= { ˆs
l,1
, · ·· , ˆs
l,m
l
} in the
attacker’s database, we compress it by F and ob tain a
feature map
ˆ
f
l
= F(
ˆ
S
l
). Let
ˆ
F = {
ˆ
f
l
|l = 1, · · · , M}
be a set of th e obtained feature maps. Using
ˆ
F ,
we train an autoencoder, whose encoder and decoder
parts are E
fm
and D
fm
, respectively. T he lo ss function
for STEP1 is
Loss
1
=
∑
l
ˆ
f
l
− D
fm
(z
l
)
=
∑
l
ˆ
f
l
− D
fm
(E
fm
(
ˆ
f
l
))
. (1)
Since z
l
= E
fm
(
ˆ
f
l
) extracted from
ˆ
f
l
by E
fm
is phase-indepen dent, it can be used as a phase-
free shape vector of the silhouette image ˆs
l,i
for all
i ∈ {1, · · · , m
l
}. Using them, we next train the
silhouette-level decoder D as STEP2. The loss func-
tion for STEP2 is
Loss
2
=
∑
l
ˆ
f
l
− F(S
′
l
)
+
1
m
l
m
l
∑
i=1
ˆs
l,i
− D(z
l
,
ˆ
θ
l,i
)
, (2)
where S
′
l
= {D(z
l
,
ˆ
θ
l,i
)|i = 1, ··· , m
l
}. The phase
value
ˆ
θ
l,i
for each image ˆs
l,i
is calcu la te d by our pre-
vious method (Hirose et al., 201 9). Finally, we train
the phase-free silhouette encoder E as STEP3, whose
loss function is
Loss
3
=
∑
l
E( ˆs
l,i
) − z
l
. (3)
3.4 Optimization of G ait Shape Vector
Using Master Gait
Shape vector ˜z = E(p) obtained by the encoder E in-
cludes an extraction error ∆z. Due to the error, ˜z does
not keep enough level of characteristics of the spoof-
ing target B. Hence, the attacker has to emphasize the
characteristics.
Here, suppose that th e attacker trains a gait ver-
ification system f or each individual in his database.
Let X
j
( j = 1, ··· , K) be the j-th individual’s veri-
fication system and let ω
j
be the output score of X
j
,
where K is the number of in dividuals in the attacker’s
database. By inpu tting a feature map
˜
f = D
fm
( ˜z) into
X
j
for a ll j, the attacker can obtain a set of scores
{ω
j
(D
fm
( ˜z))| j = 1, ··· , K}. Sin c e the target B is
not any individual in the attacker’s da ta base, all of the
scores are less than 0.5. However, if the d a ta base is
large enough, it has some individuals somewhat sim-
ilar to B. Hence, some elements in the score set are
relatively larger than the other elements. This repre-
sents th e target B’s gait characteristics. In the pro-
posed method, we em phasize the characteristics by
perturbing ˜z so that the relatively large elements be-
come further larger and the other elements become
smaller. The perturbation result is u sed as z
∗
, which
satisfies ω
j
(D
fm
(z
∗
)) > 0.5 for two or more elements.
This means D
fm
(z
∗
) behaves as a master gait, thus we
refer to the above process as “masterizat ion” of ˜z.
The co ncrete process of the masteriza tion is as fol-
lows (see also Figu re 3). First, the attacker trains X
1
,
X
2
, · · · , and X
K
using his own database. Next, he in-
puts the shape vector ˜z = E(p) into each X
j
and ob-
tains a score vector
ω( ˜z) =
ω
1
(D
fm
( ˜z))
.
.
.
ω
K
(D
fm
( ˜z))
∈ [0, 1]
K
. (4)
Then, he finds top -N large elements in ω( ˜z) and
makes a N-hot vector h
N
= (h
N,1
··· h
N,K
)
⊤
∈
{0, 1}
K
. Each element of h
N
is set as 1 if and only if
its correspon ding elements in ω( ˜z) is included in the
top-N ones. Other elements in h
N
are set as 0. After
that, he calculates the binary cross entropy between
ω( ˜z) and h
N
, i.e.,
−
K
∑
j=1
h
N, j
log{ω
j
(D
fm
( ˜z))}
+(1 − h
N, j
)log{1 − ω
j
(D
fm
( ˜z))}
, (5)
and min imizes it with respe ct to ˜z to find the optimal
z
∗
. The minimizatio n process is performed by a gra-
dient descent algo rithm. This process is equiva lent to
estimating ∆z as ∆z = ˜z − z
∗
.
4 EXPERIMENTS
4.1 Experimental Setup
To examin e the performance of the proposed method,
we conducted an experimen t, w here we used the
OU-ISIR Gait Database (Makihara et al., 2012) as a
dataset. This d ataset has several different subsets, two
of which called “treadmill-(A)” and “treadmill-(B)”
An Experimental Consideration on Gait Spoofing
563
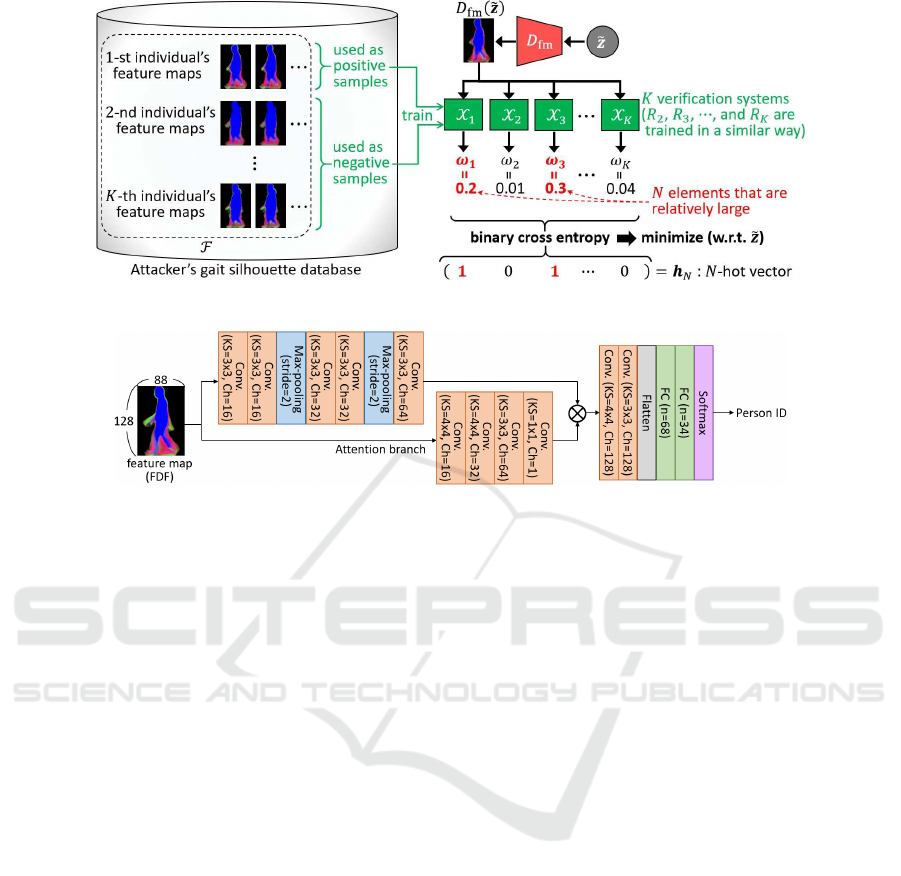
Figure 3: Updating procedure of ˜z by masterization.
Figure 4: Network structure of gait recognition system Y . “Conv” means a convolutional layer, where “KS” and “Ch” are its
kernel size and num. of channels. “FC” means a fully-connected layer, where “n” is num. of units in it. “⊗” is pixel-wise
multiplication.
were used. The treadmill-(A) consists of 612 ga it sil-
houette sequences of 34 individuals ( 18 sequences per
individual), while the treadmill-(B) consists of 2176
sequences of 68 individuals ( 32 sequ ences per indi-
vidual). In our experiment, we used the treadmill-(A)
to construct the checker C’s gait recognition system
Y as well as treated the tr eadmill-(B) as the a ttacker
A’s datab a se.
We trained Y as a DNN, whose network structure
is shown in Figure 4. After training Y , we selected
a single frame from each sequence in the treadmill-
(A) an d used it as the photo of the spo ofing target B.
From the photo, we generated a fake gait silhouette
sequence and fed it into Y to check whether it is cor-
rectly recognized or not. We repeated this process for
every frame in the tr eadmill-(A), and finally evaluated
the recognition accuracy. High e r accuracy is de sira ble
for the attacker since it means a high success rate of
gait spoofin g.
The silhouette-level encoder E and de c oder D, the
feature map-level encoder E
fm
and decoder D
fm
, and
gait verification system s {X
j
} were trained as a DNN
with the attacker’s data base, namely the treadmill-
(B). The network structures of the se DNNs are shown
in Figure 5, where we set the dimensionality of the
shape vector z ∈ R
d
as 16, i.e., d = 16.
4.2 Results and Discussions
Figure 6 shows the result of the experiment under var-
ious settings of N. The red solid line indicates the
recogn ition accuracy of Y w hen we fed it with the
fake gait silhouette sequences generated by the pr o-
posed method. Th e blue da shed line indicates the
recogn ition accuracy without the masterization. Com-
pared to the dashed line, we obtained better ac curacy
when N = 1 and N = 3. This result demon strates the
effectiveness of the masterization as a technique for
gait spoofing attacks. On the other hand, when N ≥ 5 ,
the gait recognition accuracy is seriously degraded by
the masterization. The purp ose of the masterization is
to e nlarge the relatively large elements in the score set
{ω
j
(D
fm
( ˜z))| j = 1, ··· , K}. However, most of these
scores are small since the spoofing target person is not
any individual in the attacker’s database. Therefore,
even the fourth or fifth largest value in the score set
is q uite small, at least in this experiment. Enlarging
such values is not effective for gait spoofing. Based
on the ab ove consideration, the best setting of N de-
pends on the size of the attacker’s database. We will
try to find the relationship between them in our future
work.
Figure 7 shows some examples of fake gait sil-
houettes generated by the pr oposed method as well
as those without masterization. We ca n see that the
generated silhouettes lose their shape when N = 20.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
564
Figure 5: Network structure of E, D, E
fm
, D
fm
, and X
j
. “Deconv” means a transposed convolutional layer. “⊕” means
concatenation operator.
Figure 6: Recognition accuracy of gait recognition system
Y under various settings of N.
Figure 7: Examples of fake gait silhouettes generated by the
proposed method.
On the other hand, the silhouettes gen erated with rela-
tively small N (e.g. , N = 3) can keep a natur al appear-
ance. These results indicate that the proposed method
does not give any serious distortion to the generated
fake gait silho uettes when N is appropriately set. In
the case of “without ma sterization”, arm regions in
the silho uettes are not generated well. This is be-
cause the input photo does not have the information
of the arm shape. Nevertheless, the pr oposed method
with N = 3 can generate the arm regions more nat-
urally. This is a rea son why the pro posed method
achieves higher accuracy than th at without masteri-
zation in Fig ure 6.
5 CONCLUSION
In this paper, we focused on the risk of gait spoofing
and pro posed a method for generatin g a fake gait sil-
houette seq uence of a target person only from his/he r
single photo. In general, a single photo does not have
full information about the gait c haracteristics of its
owner. Hen c e, it is not e nough for the attacker to
just extract a feature vector from the photo. To solve
this prob le m, we proposed to emp hasize the gait char-
acteristics of the target person by the m a sterization
of the feature vector, before decoding it to a silhou-
ette sequence. In ou r experiment, we found that the
gait recognition accuracy with the gene rated fake se-
quences was increased from 69% to 78% by the mas-
terization. This means the unignorable risk of ga it
spoofing. We will further investigate the possibility
of gait spoofing as well as try to propose its counter-
measure in our future work.
This work was supported by JSPS KAKENHI u n-
der Grant JP21J11069 and JST CREST under Grant
JPMJCR20D3.
An Experimental Consideration on Gait Spoofing
565

REFERENCES
Anjos, A ., Chakka, M. M., and Marcel, S. (2014). Motion-
based counter-measures to photo attacks in face recog-
nition. IET Biometrics, 3(3):147–158.
Chen, B., Liu, X., Zheng, Y., Zhao, G., and Shi, Y. (2022).
A robust gan-generated face detection method based
on dual-color spaces and an improved xception. IEEE
Trans. on Circuits and Systems for Video Technology,
32(6):3527–3538.
Cheng, P. and Roedig, U. (2022). Personal voice assistant
security and privacy — a survey. Proceedings of the
IEEE, 110(4):476–507.
Conotter, V., Bodnari, E., Boato, G., and Farid, H. (2014).
Physiologically-based detection of computer gener-
ated faces in video. In Proc. 21st IEEE Int’l Conf.
on Image Processing, pages 248–252.
Gafurov, D., Snekkenes, E., and Bours, P. (2007). Spoof
attacks on gait authentication system. IEEE Trans. on
Information Forensics and Security, 2(3):491–502.
Galbally, J. and Satta, R. (2015). Three-dimensional and
two-and-a-half-dimensional face recognition spoofing
using three-dimensional printed models. IET Biomet-
rics, 5(2):83–91.
Hadid, A. , Ghahramani, M., Bustard, J. , and Nixon, M.
(2013). Improving gait biometrics under spoofing at-
tacks. In Proc. 17th IAPR Int’l Conf. on Image Analy-
sis and Processing, pages 1–10.
Hadid, A., Ghahramani, M., Kellokumpu, V., Pi et ik¨ainen,
M., Bustard, J., and Nixon, M. (2012). Can gait bio-
metrics be spoofed? In P roc. 21st IAPR Int’l Conf. on
Pattern Recognition, pages 3280–3283.
He, Z., Wang, W., D ong, J., and Tan, T. (2020). Tempo-
ral sparse adversarial attack on sequence-based gait
recognition. arXiv:2002.09674.
Hirose, Y., Nakamura, K., Nitta, N., and Babaguchi, N.
(2019). Anonymization of gait silhouette video by
perturbing its phase and shape components. In Proc.
11th Asia-Pacific Signal and Information Processing
Association Annual Summit and Conference, pages
1679–1685.
Kammoun, A., Slama, R., Tabia, H., Ouni, T., and Abid,
M. (2022). Generative adversarial networks for face
generation: A survey. ACM Computing Surveys, page
37 pages.
Kreuk, F., Adi, Y., Cisse, M., and Keshet, J. (2018). Fooling
end-to-end speaker verification with adversarial ex-
amples. In Proc. 2018 IEEE Int’l Conf. on Acoustics,
Speech and Signal Processing, pages 1962–1966.
Kumar, S., Singh, S., and Kumar, J. (2017). A compar-
ative study on face spoofing attacks. In Proc. 2017
Int’l Conf. on Computing, Communication and Au-
tomation, pages 1104–1108.
Liu, L., Ling, Z., Jiang, Y., Zhou, M., and Dai, L. ( 2018).
Wavenet vocoder with limited t raining data for voice
conversion. In Proc. INTERSPEECH 2018, pages
1983–1987.
Makihara, Y., Mannami, H., Tsuji, A., Hossain, M. A., Sug-
iura, K., Mori, A., and Yagi, Y. (2012). The ou-isir gait
database comprising the treadmill dataset. IPSJ Trans.
on Computer Vision and Applications, 4:53–62.
Makihara, Y., Sagawa, R., Mukaigawa, Y., Echigo, T., and
Yagi, Y. (2006). Gait recognition using a view trans-
formation model in t he frequency domain. In Proc.
European C onf. on Computer Vision, pages 151–163.
Man, J. and Bhanu, B . (2006). Individual recognition using
gait energy image. IEEE Trans. on Pattern Analysis
and Machine Intelligence, 28(2):316–322.
Maqsood, M., Ghazanfar, M. A., Mehmood, I., Hwang,
E., and Rho, S. (2022). A meta-heuristic optimiza-
tion based less imperceptible adversarial attack on gait
based surveillance systems. Journal of Signal Pro-
cessing Systems, page 23 pages.
Nguyen, H., Nguyen-Son, H., Nguyen, T., and Echizen, I.
(2015). Discriminating between computer-generated
facial images and natural ones using smoothness prop-
erty and local entropy. In Proc. 14th Int’l Workshop
on Di git al Forensics and Watermarking, pages 39–50.
Nguyen, H. H., Yamagishi, J., Echizen, I., and Marcel,
S. (2020). Generating master faces for use in per-
forming wolf attacks on face recognition systems. In
Proc. 2020 IEEE Int’l Joint Conf. on Biometrics, page
10 pages.
Ohki, T., Hidano, S., and Takehisa, T. (2012). Evaluation
of wolf attack for classified target on speaker verifi-
cation systems. In Proc. 12th Int’l Conf. on Control
Automation Robotics and Vision, pages 182–187.
Patel, K., Han, H., and Jain, A. K. (2016). Secure face
unlock: Spoof detection on smartphones. IEEE Trans.
on Information Forensics and Security, 11(10):2268–
2283.
Shiota, S., Villavicencio, F., Yamagishi, J., Ono, N.,
Echizen, I. , and Matsui, T. (2015). Voice liveness
detection algorithms based on pop noise caused by
human breath for automatic speaker verification. In
Proc. of 16th Annual Conf. of the Int’l Speech Com-
munication Association, pages 239–243.
Toshpulatov, M., Lee, W., and Lee, S. (2021). Generative
adversarial networks and their application to 3d face
generation: A survey. Image and Vision Computing,
108:18 pages.
Tu, T., Chen, Y., Yeh, C., and Lee, H. (2019). End-to-end
text-to-speech for low-resource languages by cross-
lingual transfer learning. In Proc. INTERSPEE CH
2019, page 5 pages.
Une, M., Otsuka, A., and Imai, H. (2007). Wolf attack prob-
ability: A new security measure in biometric authen-
tication systems. In Proc. Int’l Conf. on Biometrics,
pages 396–406.
Wang, Q., Lin, X., Zhou, M., Chen, Y., Wang, C., Li,
Q., and Luo, X. (2019). Voicepop: A pop noise
based anti-spoofing system for voice authentication on
smartphones. In Proc. IEEE Conf. on Computer Com-
munications, pages 2062–2070.
Zhang, Y., Jiang, F., and Duan, Z. (2021). One-class learn-
ing towards synthetic voice spoofing detection. IEEE
Signal Processing Letters, 28:937–941.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
566
