
Emotions Relationship Modeling in the Conversation-Level Sentiment
Analysis
Jieying Xue, Minh-Phuong Nguyen and Le-Minh Nguyen
Japan Advanced Institute of Science and Technology, 923-1292, 1-8 Asahidai, Nomi, Ishikawa, Japan
Keywords:
Sentiment Analysis, Emotion Recognition in Conversation, COSMIC, Emotion Dependencies, Transformer.
Abstract:
Sentiment analysis, also called opinion mining, is a task of Natural Language Processing (NLP) that aims
to extract sentiments and opinions from texts. Among them, emotion recognition in conversation (ERC) is
becoming increasingly popular as a new research topic in natural language processing (NLP). The current
state-of-the-art models focus on injecting prior knowledge via an external commonsense extractor or applying
pre-trained language models to construct the utterance vector representation that is fused with the surrounding
context in a conversation. However, these architectures treat the emotional states as sequential inputs, thus
omitting the strong relationship between emotional states of discontinuous utterances, especially in long con-
versations. To solve this problem, we propose a new architecture, Long-range dependencY emotionS Model
(LYSM) to generalize the dependencies between emotional states using the self-attention mechanism, which
reinforces the emotion vector representations in the conversational encoder. Our intuition is that the emo-
tional states in a conversation can be influenced or transferred across speakers and sentences, independent
of the length of the conversation. Our experimental results show that our proposed architecture improves
the baseline model and achieves competitive performance with state-of-the-art methods on four well-known
benchmark datasets in this domain: IEMOCAP, DailyDialog, Emory NLP, and MELD. Our code is available
at https://github.com/phuongnm94/erc-sentiment.
1 INTRODUCTION
Emotion recognition in conversation, as a crucial re-
search topic in natural language processing (NLP), it
has received increasing attention (Poria et al., 2017;
Zhang et al., 2019; Ghosal et al., 2020a; Guibon et al.,
2021; Song et al., 2022). Unlike ordinary sentence or
utterance emotion recognition, ERC ideally requires
context modeling of individual utterance. This con-
text can be attributed to the preceding utterances and
relies on the temporal sequence of utterances.
Since ERC relies heavily on temporal order-based
context, therefore, previous works (Poria et al., 2017;
Majumder et al., 2019; Ghosal et al., 2019; Zhang
et al., 2019) applied recurrent neural network (RNN)
to process the constituent utterances of a conversation
in sequence. Besides, with the success of pre-trained
language models (Devlin et al., 2019; Liu et al.,
2019), recent works (Guibon et al., 2021; Lee and
Choi, 2021; Song et al., 2022) integrate contextual
information by connecting surrounding utterances for
the current utterance encoding process. Furthermore,
many works (Ghosal et al., 2019; Lee and Choi, 2021)
tend to leverage the relationships between speakers in
a conversation and apply the graph neural network to
improve the performance. In another aspect, a pro-
posed framework, COSMIC (Ghosal et al., 2020a),
applies a commonsense knowledge extractor to col-
lect additional useful features of utterance representa-
tions, such as the intent or reaction of speaker, etc.
This work explores the contribution of dependen-
cies between emotional states among utterances in
a conversation. The intuition is that the emotional
states can be affected or transferred between speak-
ers in a conversation, regardless of the length of the
conversation. The relationship among the emotional
states is an essential aspect of the ERC system (Song
et al., 2022; Guibon et al., 2021; Kim and Vossen,
2021). However, these previous approaches only con-
sider the transfer of emotion between the adjacent ut-
terances in a conversation and thus omit the depen-
dencies of emotion states in long-range utterances. In
another aspect, the emotional states in conversations
are typically transferred between speakers. For exam-
ple, funny people usually have positive emotions in
their sentences and could transmit that to those who
276
Xue, J., Nguyen, M. and Nguyen, L.
Emotions Relationship Modeling in the Conversation-Level Sentiment Analysis.
DOI: 10.5220/0011658200003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 276-284
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

I did it, I asked her to marry me.
excited
Yes, I did it.
excited
When?
excited
Where is she right now?
happy
She--,well, she said yes, first of all,
let me say that right off the bat. ...
happy
u3
u4
u5
u8
u33
...
...
Figure 1: Example of the long-range emotions dependen-
cies in a conversation (IEMOCAP dataset). The blue words
following the template u<id> with <id> is the index of
utterance in the conversation.
talk to them (Figure 1). The emotional states can be
transferred between speakers in a conversation via ad-
jacent utterances (e.g. u3, u4, u5) or long-range
distance utterances (e.g. u3, u8, u33). The ques-
tions of the right speaker (u5, u33) are normal emo-
tions if stand-alone, however, in particular contexts,
these utterances are affected by the feelings of the
other speaker regardless of their position in the con-
versation. Accordingly, our model can enhance the
performance of the ERC system by learning the atten-
tion between the pairs of emotions in a conversation
and achieving rich transcription.
Therefore, we propose a new architecture LYSM,
to model the dependencies between the emotional
states applying the self-attention mechanism to boost
the robust baseline model based on the COSMIC
framework. We also conducted experiments to evalu-
ate the performance of our proposed model compared
with previous methods on four popular benchmark
datasets: IEMOCAP, DailyDialog, Emory NLP, and
MELD. Experimental results showed that our pro-
posed model works effectively and achieves competi-
tive results with the current SOTA results, and outper-
form the baseline models on all experimental datasets.
2 RELATED WORK
Overview of ERC Task. Currently, most dialogue
emotion recognition tasks are based on three major
innovations: recurrent neural networks-based (RNNs)
(Hochreiter and Schmidhuber, 1997), graph convolu-
tion network-based (GCN) (Defferrard et al., 2016)
and self-attention-based (Devlin et al., 2019). There
is a fact that contextual information plays an im-
portant role in understanding the meaning of utter-
ances in a conversation, and RNNs architecture (like
LSTMs and GRUs) have achieved great improve-
ments in ERC (Poria et al., 2017; Ghosal et al., 2020a)
because it can capture context as sequential infor-
mation. Besides, in some works, the utterance con-
tent and speaker identity are encoded to capture sen-
tence semantics better. On the other hand, GCNs has
also attracted many recent works (Ghosal et al., 2019;
Zhang et al., 2019; Lee and Choi, 2021) to accom-
plish this task by capturing the relationships between
interlocutors and the dependence of utterance on the
speakers and the listeners. However, these works have
not considered the emotional dependencies between
utterances, while this feature plays an important role
in conversational sentiment detection.
Lastly, with the success of the pre-trained mod-
els in many NLP tasks (Vaswani et al., 2017; Devlin
et al., 2019), the ERC tasks have also been applied
widely in many recent works (Kim and Vossen, 2021;
Ghosal et al., 2020a; Lee and Choi, 2021; Song et al.,
2022). Most of these works use the self-attention
mechanism at words-level to utterance encoding (Kim
and Vossen, 2021; Song et al., 2022; Ghosal et al.,
2020a) and capture the information in the whole con-
text or localize context of each sentence in a conver-
sation. Compared with these works, our work ap-
plies a self-attention mechanism over emotional states
throughout a whole conversation to learn the strong
effect of emotions between inter-speakers.
[Object Promise]. There have been a number of re-
cently proposed models showing improvements in af-
fective dependence in ERC tasks (Guibon et al., 2021;
Lee and Choi, 2021; Song et al., 2022). Most of these
works apply a CRF layer on the top of the deep learn-
ing model, which is typically applied to sequence la-
beling tasks in NLP. In another aspect, these works
(Kim and Vossen, 2021; Lee and Choi, 2021; Song
et al., 2022) use the self-attention mechanism to en-
code the dependencies between words in the limited
context of current utterance, while our LYSM apply
the self-attention mechanism to model the emotional
states in the whole conversation. The closest model
to our LYSM is the EmotionFlow model (Song et al.,
2022). However, the EmotionFlow only considers the
emotional relations of adjacent utterances, while our
LYSM model can capture the dependencies among
the emotional state of all utterances in a conversation.
To this end, we also conduct experiments to compare
with the approaches using the CRF to demonstrate the
effectiveness of our proposed model.
3 METHODOLOGY
In this section, we detail our proposed model archi-
tecture, LYSM, based on the COSMIC framework.
To model the strong relationship between emotions in
the conversation, we proposed to use the self-attention
Emotions Relationship Modeling in the Conversation-Level Sentiment Analysis
277
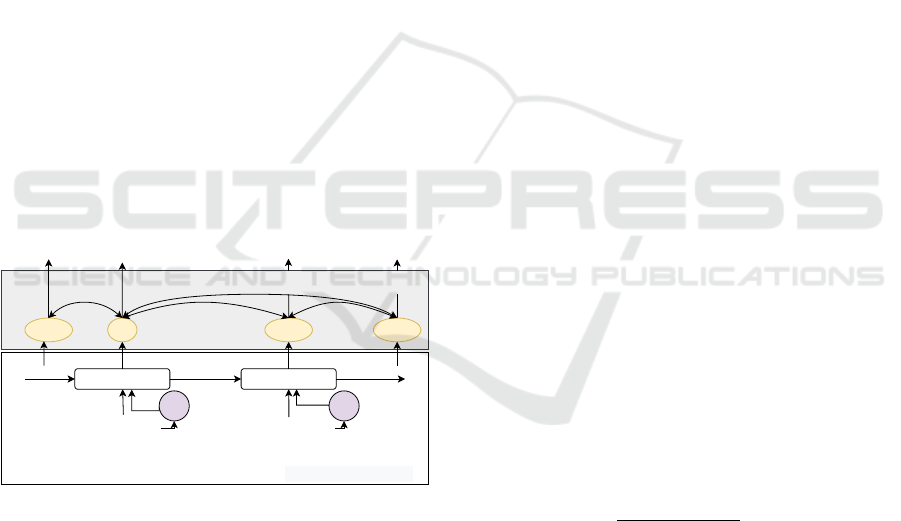
mechanism (Vaswani et al., 2017) and contrast it with
the Conditional Random Field (CRF), which adapted
from the idea of previous works (Song et al., 2022)
on the top of the COSMIC framework. The whole
system contains two main components: (1) the con-
versational encoding component to transform the ut-
terances in conversation into the hidden vector repre-
sentation, and (2) the emotional dependency encoding
component to learn the effect of emotional relation-
ships in conversation.
3.1 Task Definition
Given a conversation containing the sequence of ut-
terances and corresponding speakers [(u
t
, p
t
)]
N
t=1
with
N utterances, the target is to identify the emotion of
each utterance (y
t
) from the pre-defined set of emo-
tions, such as happy, sad, etc. To represent the hidden
vectors of each input sentences of speakers and their
corresponding emotions simultaneously, and improve
the sentiment analysis system based on the aforemen-
tioned information, we propose LYSM architecture
to learn the dependencies between the utterances of
the speakers in a conversation. Specifically, we lever-
age the current state-of-the-art model in this area as a
strong baseline, COSMIC (Ghosal et al., 2020a), and
build on it to model the layer relationships between
emotion vectors via attention mechanism (Figure 2).
COSMIC framework
GRU GRU
step (t) step (t+1)
uterance (x
t
)
uterance (x
t+1
)
CSK CSK
person A: I dont think
I can do this anymore
e
t e
t+1
e
t+2
e
t-1
emotion dependencies
y
t
y
t-1
y
t+1
y
t+2
......
person B: Well I guess you
aren’t trying hard enough.
Figure 2: The architecture of the Long-range dependencY
emotionS Model (LYSM) based on COSMIC framework in
the conversation-level emotion recognition task. The CSK
components indicate the external CommonSense Knowl-
edge extractor module.
3.2 COSMIC Framework
This framework (Ghosal et al., 2020a) aims to in-
ject prior commonsense knowledge into the emotion
recognition process. The knowledge features were ex-
tracted by an external tool based on the commonsense
knowledge graph, COMET (Bosselut et al., 2019).
The main important part of this framework is that the
authors reveal the contribution of special common-
sense features to the emotion recognition task, which
contains the intent of speaker I S
cs
(u
t
), the effect of
speaker ES
cs
(u
t
), the reaction of speaker R S
cs
(u
t
),
the effect of listeners E L
cs
(u
t
), and the reaction of lis-
teners R L
cs
(u
t
). Furthermore, they also proposed a
novel architecture using these features to identify the
emotion of utterances effectively.
For representing sentences in the conversation,
(Ghosal et al., 2020a) firstly fine-tune a pre-trained
language model (e.g. RoBERTa) on the emotion clas-
sification task without considering the context. Then
they use the fine-tuned model to generate the con-
tinuous vector of utterances. Similar to the conven-
tional BERT architecture (Devlin et al., 2019), a to-
ken [CLS] is added at the beginning of the sentence to
represent the meaning of the whole natural sentence.
In addition, the authors use the average of four [CLS]
hidden vectors in the last layers to get the final repre-
sentation for an utterance (x
t
).
For modeling the sequential features in the con-
versation, this framework uses the GRU cells (Chung
et al., 2014) to represent hidden states that affect the
emotion of human sentences. There are five differ-
ent features are constructed sequentially along with
utterances in the conversation: context state, internal
state, external state, intent state, and emotion state;
these states are encoded by five separated GRU cells,
GRU
C
, GRU
Q
, GRU
R
, GRU
I
, and GRU
E
respectively.
For mathematical operation, firstly, the context vector
(c
t
) is computed based on sentence vector (x
t
), pre-
vious internal state (q
s(u
t
),t−1
) and previous external
state (r
s(u
t
),t−1
):
c
t
= GRU
C
(c
t−1
, (x
t
⊕q
s(u
t
),t−1
⊕r
s(u
t
),t−1
)) (1)
where ⊕ is the concatenation function. Then, a soft
attention vector (a
t
) is introduced to update the inter-
nal and external hidden vectors:
u
i
= tanh(W
s
c
i
+ b
s
), i ∈ [1, t −1] (2)
α
i
=
t−1
∑
i=1
(
exp(u
|
i
x
i
)
∑
t−1
j
exp(u
|
j
x
j
)
)c
i
(3)
where W
s
, b
s
are learnable parameters. Then, the in-
ternal (q
s(u
t
),t
), external (r
s(u
t
),t
) intent (i
s(u
t
),t
) and
emotion (e
t
) states are computed based on the pre-
vious states incorporating with the commonsense
knowledge and soft attention vectors:
q
s(u
t
),t
= GRU
Q
(q
s(u
t
),t−1
, (a
t
⊕ES
cs
(u
t
))) (4)
r
s(u
t
),t
= GRU
R
(r
s(u
t
),t−1
, (a
t
⊕R S
cs
(u
t
))) (5)
i
s(u
t
),t
= GRU
I
(i
s(u
t
),t−1
, (I S
cs
(u
t
) ⊕q
s(u
t
),t
)) (6)
e
t
= GRU
E
(e
t−1
, x
t
⊕q
s(u
t
),t
⊕r
s(u
t
),t
⊕i
s(u
t
),t
)
(7)
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
278

In addition, the states of listeners also are updated for
each utterance (u
t
) with the replacement of E S
cs
(u
t
),
R S
cs
(u
t
) by EL
cs
(u
t
), R L
cs
(u
t
) in Equations 4, 5,
respectively. Then, the emotion label probabilities of
the current utterance are calculated via a softmax layer
based on the emotion vector e
t
:
p
t
= softmax(W
e
e
t
+ b
e
) (8)
where W
e
, b
e
are learnable parameters. Finally, the
probabilities (p
t
) of all sentences in the conversation
are forwarded to compute the negative log likelihood
loss, and the model is trained based on the back-
propagation algorithm.
3.3 LYSM Architecture
In this work, we proposed a variant Long-range
dependencY emotionS Model (LYSM) architecture
based on COSMIC framework, which can learn the
strong dependencies between emotional states in a
conversation. We surmise that the emotional states
in the conversation strongly affect each other. For
example, the emotion of some certain utterances in
the head conversation can affect the utterances in the
middle or last position of the conversation. However,
in the COSMIC framework, the emotional states in
the long conversation are encoded by recurrent archi-
tecture that is not directly connected to each other.
Therefore, in our proposed architecture, LYSM, we
utilize the power of the COSMIC framework to get
the utterance vector representation fused by common-
sense knowledge and construct a new component to
explore the strong relations between emotional states
(e
t
) via the Transformer Encoder layer with the Self-
Attention mechanism (Vaswani et al., 2017).
For mathematical, the sequence of emotional
states (e = [e
t
]
N
t=1
) taken from Equation 7 is fed to the
Transformer Encoder layer to get new representation
fused by emotion context dependencies.
g
q
j
, g
k
j
, g
v
j
= eW
q
j
, eW
k
j
, eW
v
j
, j ∈ [1, #heads]
head
j
= softmax(
g
q
j
·(g
k
j
)
|
√
d
h
)g
v
j
(9)
g
mul
= (head
1
⊕head
2
⊕... ⊕head
#heads
)W
o
g
norm
= LayerNorm(g
mul
+ e)
e
0
= LayerNorm(FFW(g
norm
) + g
norm
)
where #heads is the number of heads in Multi-
head layer, d
h
is the dimension size of per head,
LayerNorm and FeedForward(FFW ) are the func-
tions that are used similarly to (Vaswani et al., 2017).
Finally, the new emotional state vector e
0
= [e
0
t
]
N
t=1
is
used to compute the probabilities of emotion label by
softmax layer, similar to Equation 8:
p
t
= softmax(W
e
e
0
t
+ b
e
) (10)
3.4 Conditional Random Field
This architecture is typically applied for sequence
labeling tasks such as POS tagging, Named Entity
Recognition (Ma and Hovy, 2016). To model the de-
pendencies between emotions in a conversation, pre-
vious works (Song et al., 2022; Guibon et al., 2021)
built a CRF layer as the last layer of the Neural Net-
work model. Therefore, it is potential to adapt this ar-
chitecture to the COSMIC framework for comparison
with our proposed model LYSM. In detail, we treat
the sentiment vector representation (e
t
) as the emis-
sion score of each utterance for all emotional labels,
and the transmission score that is considered as the
influence between emotions is random initial values.
After that, these weights are learned end-to-end in the
training process.
score(e, y) =
N
∑
t=1
(W
em
e
t
+ b
em
)[y
t
] +
N
∑
t=0
(W
tr
[y
t
, y
t+1
])
p(y|e) =
exp(score(e, y))
∑
y
0
exp(score(e, y
0
))
(11)
where y
0
, y
N+1
is additional start and end of emotional
labels; [·] is the matrix selection operator given row
and column indexes; W
em
, b
em
, W
tr
are the learnable
weights for emission and transmission scores; y
0
is a
candidate of emotion flow in the set of possible emo-
tion flows. By using CRF layer, the model is trained
to maximize the log-probability of gold emotion se-
quence labels.
4 EXPERIMENT
In this section, we describe the detail of the experi-
ments to evaluate the performance of our LYSM.
Dataset. We conducted experiments to evaluate the
performance of our proposed architecture, LYSM on
four benchmark datasets (Table 1):
• IEMOCAP: (Busso et al., 2008) is the dataset
of six different emotion categories collected from
conversations of ten different speakers, each con-
versation contains utterances of two persons.
• DailyDialog: (Li et al., 2017) is the largest multi-
utterance dialogue dataset collected in daily life
conversations, including seven different emotion
categories. Following the previous work exper-
imental setup, we ignore the label neutral when
Emotions Relationship Modeling in the Conversation-Level Sentiment Analysis
279

compute the evaluation score because this label is
highly imbalanced in 83% of utterances across the
whole dataset.
• MELD: (Poria et al., 2019) and EmoryNLP (Za-
hiri and Choi, 2018) are the datasets of seven dif-
ferent types of emotions scraped from TV shows.
The IEMOCAP is the dataset that contains long dia-
logues with an average of around 50 utterances per
conversation, while DailyDialog is the dataset that
contains many topics in conversation. By conduct-
ing experiments on these various kinds of datasets,
we can evaluate the generalization ability and mea-
sure the improvement of our proposed model com-
pared with the baseline COSMIC framework.
Table 1: Statistics information on all ERC datasets. The
character # denote the size of the set.
Dataset
# dialogues # utterances
train dev test train dev test
IEMOCAP 108 12 31 5,163 647 1,623
DailyDialog 11,118 1,000 1,000 87,823 7,912 7,836
MELD 1,039 114 280 9,989 1,109 2,610
EmoryNLP 659 89 79 7,551 954 984
Experimental Setup. Since our proposed model is
constructed based on COSMIC model, therefore, we
conducted experiments using the results of the COS-
MIC framework with the following steps: fine-tune
the pre-trained language model for utterance repre-
sentation and commonsense knowledge feature ex-
traction. We use these continuous feature vectors
which are equal to input features of the COSMIC
framework, as the input to our LYSM architecture.
In these experiments, we aim to evaluate the effec-
tiveness of our LYSM architecture compared with the
original COSMIC framework. In addition, to com-
pare with the EmotionFlow model (Song et al., 2022)
related to emotional transference, we also conducted
experiments incorporating the CRF layer on our pro-
posed model.
For each dataset mentioned above, we run it ten
times with different random seeds and compute our
proposed model performance using the Weighted Av-
erage F1 score (Ghosal et al., 2020a). The best model
is selected based on the dev set of each dataset and
used to get the evaluation score on the test set. Then,
we report the mean value of performance compared
with the previous works on these datasets.
5 RESULT ANALYSIS
5.1 Main Results
We conducted experiments on four aforementioned
datasets and show the results in Table 2. Our proposed
model improved the performance of the COSMIC
framework on all datasets. On the IEMOCAP dataset,
the LYSM architecture improved the F1 score by 0.19
compared to the COSMIC framework. On the Daily-
Dialog dataset, our proposed model improved Macro
F1 score by 0.27 and Micro F1 score by 0.21 com-
pared with the baseline model. On the EmoryNLP
and MELD datasets, we only conducted experiments
on the setting of emotion recognition tasks with seven
different emotion classes, and the result shows an im-
provement of 0.23 F1 score and 0.19 on F1 score, re-
spectively. These results show that our LYSM archi-
tecture is generalized and the emotion dependencies
component can works effectively when incorporated
into the COSMIC framework.
Compared with EmotionFlow, which uses CRF to
learn emotion transfer, our model has more advan-
tages because it is supported by the commonsense
knowledge information based on the COSMIC frame-
work. However, for a fair comparison between the
CRF layer and the self-attention mechanism, and we
showed the ablation study in section 5.2. Compared
with the EmoBerta, our LYSM architecture achieved
competitive results on the MELD dataset, but lower
than the results on the IEMOCAP dataset. We ar-
gue that the reason comes from the model size of
EmoBerta. While EmoBerta fine-tuning on Roberta
large (Liu et al., 2019) contains 355 million param-
eters with 9 minutes training per epoch (Kim and
Vossen, 2021), our LYSM used a fixed fine-tuned
Roberta to get an utterance encoding vector that only
contains 17 million parameters for the training pro-
cess with 30 seconds per epoch.
5.2 Ablation Study
In this experiment, we inspect the effectiveness of the
component learning emotional dependencies. In our
LYSM architecture, we used the self-attention mech-
anism whereas the previous works (Song et al., 2022;
Guibon et al., 2021) suggest using the CRF layer to
model the emotion transfer between sequences of ut-
terances in a conversation. Therefore, we conducted
additional experiments by applying the CRF layer
(+CRF) on both COSMIC and our model (Table 3). In
Table 3, although we used the same setting as (Ghosal
et al., 2020a), the different results of our re-produced
COSMIC framework with them because of the ex-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
280
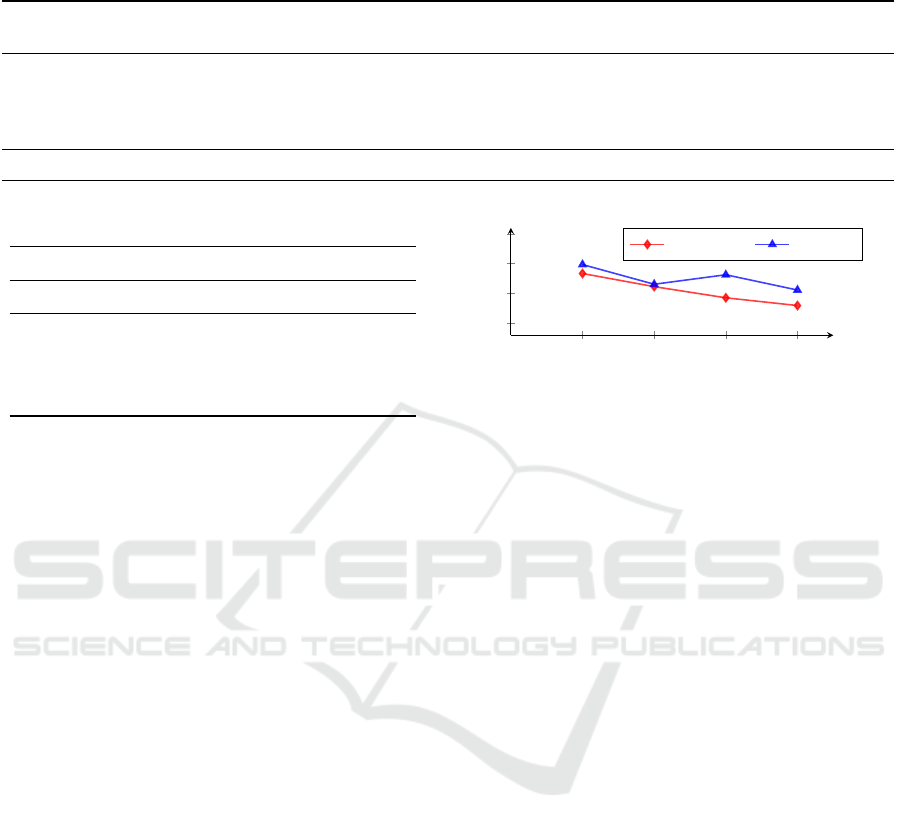
Table 2: Performance comparison between methods. This table contains two parts: previous works and our results. The
values in the below part refer to the results of the experiments implemented in this work.
Methods
IEMOCAP DailyDialog MELD EmoryNLP
W-Avg F1 Macro F1 Micro F1 W-Avg F1 W-Avg F1
DialogueRNN re-product (Ghosal et al., 2020b) 62.57 41.80 55.95 57.03 31.70
EmoBerta (Kim and Vossen, 2021) 67.42 - - 65.61 -
EmotionFlow (Song et al., 2022) 65.05 - - - -
COSMIC (Ghosal et al., 2020a) 65.28 51.05 58.48 65.21 38.11
LYSM (ours) 65.47 51.32 58.69 65.40 38.34
Table 3: Ablation study on the IEMOCAP dataset.
Methods IEMOCAP
EmotionFlow (Song et al., 2022) 65.05
COSMIC 64.50
COSMIC +CRF 64.82
LYSM 65.47
LYSM +CRF 65.43
perimental environment such as libraries or comput-
ing servers. Similar to previous works, our experi-
mental results confirmed the CRF layer also supports
the COSMIC model with 0.32 F1 score improvement.
However, when compared with our proposed model
using the self-attention layer, the performance im-
provement is larger than with a 0.97 F1 score. We
argue that self-attention can learn the influence be-
tween pairs of discontinuous utterances in a conver-
sation, not just adjacent utterances like the CRF layer.
In addition, we also apply the CRF layer to the LYSM
architecture, but the results did not improve because
the emotional dependencies information was already
captured by the self-attention layer. These results
demonstrated the effectiveness of our LYSM architec-
ture and the importance of emotional dependencies in
a conversation.
5.3 Result Analysis
Conversation Length. We conducted an analytica
experiment to inspect the effect of the conversation
length on the performance of the ERC system (Fig-
ure 3). We found that the performance of both the
COSMIC framework and our LYSM tends to decrease
as conversation length increases. In addition, these re-
sults also show that our LYSM obviously outperforms
the baseline model across all groups of conversation
length, which prove the generalization of our model.
In particular,the improvement was noticeable during
the long conversations. This result is the evidence
for the effectiveness of our LYSM in capturing long-
range emotion dependencies.
(-40]
(40-50]
(50-60]
(60-)
60
65
70
75
#conversation
W-Avg F1
COSMIC LYSM
Figure 3: Performance comparison between our LYSM and
COSMIC on IEMOCAP dataset with respect to the number
of utterances in a conversation (#conversation) .
Improvement Example. Based on our observa-
tions on the output prediction results of the IEMO-
CAP dataset, we found that LYSM architecture gener-
ally works more effectively in strong emotional con-
versations. For better understanding the improvement
of LYSM architecture, we present examples in Table 4
of different predictions on our LYSM architecture and
the COSMIC model. In this conversation, there are
two speakers who are in a negative mood with many
angry labels in their sentences. We found that in the
sentences containing strongly emotional words (hell
in utterance u30), both LYSM architecture and COS-
MIC showed the correct predictions. However, the
COSMIC framework can predict the utterances con-
taining normal words (u23, u24, u26) as slight nega-
tive emotion (frustrated), but our LYSM based on
the strong context relationships is more accurate for
sentiment label prediction.
Learning Process. We reproduced the COSMIC
framework and conducted experiments to inspect the
weighted average F1 values of this model compared
with our LYSM architecture on IEMOCAP dataset
(Figure 5).
The weighted average F1 values of our proposed
architecture on the development set are higher than
the COSMIC framework in most epochs. These re-
sults demonstrated the generality and effectiveness of
the LYSM architecture.
Emotions Relationship Modeling in the Conversation-Level Sentiment Analysis
281
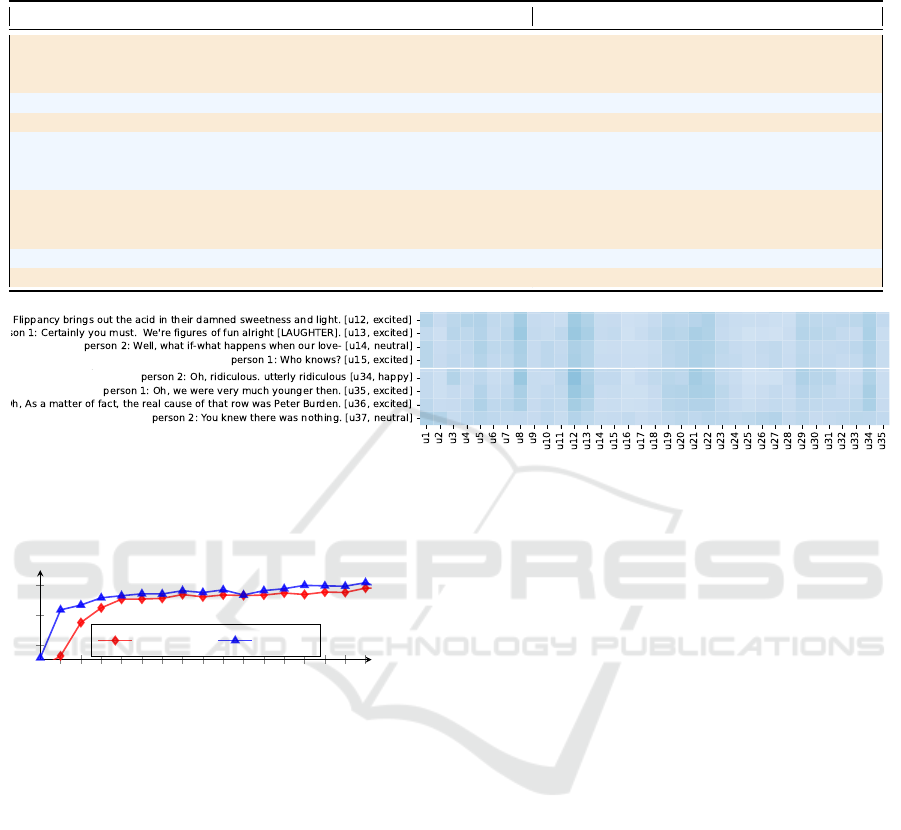
Table 4: Improvement example collected in IEMOCAP dataset. The green and red labels indicate the correct and incorrect
prediction of the models, respectively.
Id Utterance Label LYSM COSMIC
u23 S1: You infuriate me sometimes. Do you know that? God. angry angry frustrated
u24 S1: Isn’t it your business, too, if dad – if I tell dad and he throws a
fit about it? I mean, you have such a talent for ignoring things.
angry angry frustrated
u25 S2: I ignore what I got to ignore. I mean, the girl is Larry’s girl. angry frustrated frustrated
u26 S1: She is not Larry’s girl! angry angry frustrated
u27 S2: From your father’s point of view he’s not dead and she’s still
his girl. Now, you can go on from there if you know where to go,
Chris, but I don’t know. So what can I do for you?
angry frustrated frustrated
u28 S1: I don’t know why it is but everytime I reach out for something
I- that I want, I have to pull back because I might hurt somebody
else. My whole bloody life; time after time after time.
frustrated frustrated angry
u29 S2: Well, you’re a considerate fella, there’s nothing wrong in that neutral neutral neutral
u30 S1: To hell with that! angry angry angry
Figure 4: Heatmap visualization of dependencies between pairs of emotional states in a conversation. This figure shows the
scaled Self-Attention in the LYSM architecture, computed in Equation 9. The title each row or column of this heatmap is an
utterance (u
i
) in a conversation. The bolder colors show higher attention scores.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
20
40
60
Epochs
W-avg F1
COSMIC LYSM
Figure 5: Weighted average F1 values of COSMIC and our
LYSM architecture on IEMOCAP development set .
Emotional Dependency. In our LYSM architec-
ture, we aim to model the dependencies between pairs
of the emotional state of utterances to improve the
performance of sentiment analysis system. There-
fore, in this experiment, we depict the dependencies
of emotional states pairs constructed by utterances in
a conversation (Figure 4). We found that the depen-
dencies among emotional states affect not only the ad-
jacent sentences but also the remote sentences. For
example, the emotion happy in utterance 34 (column
u34) is affected by the utterances in the whole con-
versation including the beginning sentences. Besides,
the special emotional states which are different from
others in a conversation typically get more attention
than the remainder, such as utterances u12, u13, u34.
This clearly evidences emotion dependencies are im-
portant for emotion recognition systems.
6 CONCLUSION
In this work, we explore the importance of emo-
tion dependency features in conversation-level emo-
tion recognition tasks. We also proposed an effective
model, LYSM, which incorporates a self-attention
mechanism into the COSMIC framework to improve
performance and achieve competitive results with the
SOTA on four benchmark datasets IEMOCAP, Daily-
Dialog, EmornyNLP, and MELD. Our model is sim-
ple yet effective that can be widely applied to other
architectures in the sentiment recognition domain. In
future work, we would like to apply the self-attention
mechanism to model the emotional dependencies of
each individual speaker in the conversation and ex-
plore the contribution of personality features in senti-
ment analysis.
ACKNOWLEDGEMENT
This work was supported by JSPS Kakenhi Grant
Number 20H04295, 20K20406, and 20K20625.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
282

REFERENCES
Bosselut, A., Rashkin, H., Sap, M., Malaviya, C., Celikyil-
maz, A., and Choi, Y. (2019). COMET: Common-
sense transformers for automatic knowledge graph
construction. In Proceedings of the 57th Annual Meet-
ing of the Association for Computational Linguis-
tics, pages 4762–4779, Florence, Italy. Association
for Computational Linguistics.
Busso, C., Bulut, M., Lee, C.-C., Kazemzadeh, A., Mower,
E., Kim, S., Chang, J. N., Lee, S., and Narayanan,
S. S. (2008). Iemocap: interactive emotional dyadic
motion capture database. Language Resources and
Evaluation, 42(4):335–359.
Chung, J., Gulcehre, C., Cho, K., and Bengio, Y. (2014).
Empirical evaluation of gated recurrent neural net-
works on sequence modeling. In NIPS 2014 Workshop
on Deep Learning, December 2014.
Defferrard, M., Bresson, X., and Vandergheynst, P. (2016).
Convolutional neural networks on graphs with fast
localized spectral filtering. In Lee, D., Sugiyama,
M., Luxburg, U., Guyon, I., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 29. Curran Associates, Inc.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2019). BERT: Pre-training of deep bidirectional
transformers for language understanding. In Pro-
ceedings of the 2019 Conference of the North Amer-
ican Chapter of the Association for Computational
Linguistics: Human Language Technologies, Volume
1 (Long and Short Papers), pages 4171–4186, Min-
neapolis, Minnesota. Association for Computational
Linguistics.
Ghosal, D., Majumder, N., Gelbukh, A., Mihalcea, R., and
Poria, S. (2020a). COSMIC: COmmonSense knowl-
edge for eMotion identification in conversations. In
Findings of the Association for Computational Lin-
guistics: EMNLP 2020, pages 2470–2481, Online.
Association for Computational Linguistics.
Ghosal, D., Majumder, N., Mihalcea, R., and Poria, S.
(2020b). Utterance-level dialogue understanding: An
empirical study. CoRR, abs/2009.13902.
Ghosal, D., Majumder, N., Poria, S., Chhaya, N., and Gel-
bukh, A. (2019). DialogueGCN: A graph convolu-
tional neural network for emotion recognition in con-
versation. In Proceedings of the 2019 Conference on
Empirical Methods in Natural Language Processing
and the 9th International Joint Conference on Nat-
ural Language Processing (EMNLP-IJCNLP), pages
154–164, Hong Kong, China. Association for Com-
putational Linguistics.
Guibon, G., Labeau, M., Flamein, H., Lefeuvre, L., and
Clavel, C. (2021). Few-shot emotion recognition in
conversation with sequential prototypical networks.
In Proceedings of the 2021 Conference on Empiri-
cal Methods in Natural Language Processing, pages
6858–6870, Online and Punta Cana, Dominican Re-
public. Association for Computational Linguistics.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural Comput., 9(8):1735–1780.
Kim, T. and Vossen, P. (2021). Emoberta: Speaker-aware
emotion recognition in conversation with roberta.
CoRR, abs/2108.12009.
Lee, B. and Choi, Y. S. (2021). Graph based network with
contextualized representations of turns in dialogue.
In Proceedings of the 2021 Conference on Empiri-
cal Methods in Natural Language Processing, pages
443–455, Online and Punta Cana, Dominican Repub-
lic. Association for Computational Linguistics.
Li, Y., Su, H., Shen, X., Li, W., Cao, Z., and Niu, S.
(2017). DailyDialog: A manually labelled multi-turn
dialogue dataset. In Proceedings of the Eighth Inter-
national Joint Conference on Natural Language Pro-
cessing (Volume 1: Long Papers), pages 986–995,
Taipei, Taiwan. Asian Federation of Natural Language
Processing.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D.,
Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov,
V. (2019). Roberta: A robustly optimized bert pre-
training approach.
Ma, X. and Hovy, E. (2016). End-to-end sequence label-
ing via bi-directional LSTM-CNNs-CRF. In Proceed-
ings of the 54th Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers),
pages 1064–1074, Berlin, Germany. Association for
Computational Linguistics.
Majumder, N., Poria, S., Hazarika, D., Mihalcea, R., Gel-
bukh, A., and Cambria, E. (2019). Dialoguernn: An
attentive rnn for emotion detection in conversations.
Proceedings of the AAAI Conference on Artificial In-
telligence, 33(01):6818–6825.
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh,
A., and Morency, L.-P. (2017). Context-dependent
sentiment analysis in user-generated videos. In Pro-
ceedings of the 55th Annual Meeting of the Associa-
tion for Computational Linguistics (Volume 1: Long
Papers), pages 873–883, Vancouver, Canada. Associ-
ation for Computational Linguistics.
Poria, S., Hazarika, D., Majumder, N., Naik, G., Cambria,
E., and Mihalcea, R. (2019). MELD: A multimodal
multi-party dataset for emotion recognition in conver-
sations. In Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics, pages
527–536, Florence, Italy. Association for Computa-
tional Linguistics.
Song, X., Zang, L., Zhang, R., Hu, S., and Huang, L.
(2022). Emotionflow: Capture the dialogue level emo-
tion transitions. In ICASSP 2022 - 2022 IEEE Inter-
national Conference on Acoustics, Speech and Signal
Processing (ICASSP), pages 8542–8546.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I.
(2017). Attention is all you need. In Guyon, I.,
Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R.,
Vishwanathan, S., and Garnett, R., editors, Advances
in Neural Information Processing Systems 30, pages
5998–6008. Curran Associates, Inc.
Zahiri, S. and Choi, J. D. (2018). Emotion Detection
on TV Show Transcripts with Sequence-based Con-
volutional Neural Networks. In Proceedings of the
Emotions Relationship Modeling in the Conversation-Level Sentiment Analysis
283

AAAI Workshop on Affective Content Analysis, AF-
FCON’18, pages 44–51, New Orleans, LA.
Zhang, D., Wu, L., Sun, C., Li, S., Zhu, Q., and Zhou, G.
(2019). Modeling both context- and speaker-sensitive
dependence for emotion detection in multi-speaker
conversations. In Proceedings of the Twenty-Eighth
International Joint Conference on Artificial Intelli-
gence. International Joint Conferences on Artificial
Intelligence Organization.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
284
