
Data Augmentation Through Expert-Guided Symmetry Detection to
Improve Performance in Offline Reinforcement Learning
Giorgio Angelotti
1,2 a
, Nicolas Drougard
1,2 b
and Caroline P. C. Chanel
1,2 c
1
ISAE-SUPAERO, University of Toulouse, France
2
ANITI, University of Toulouse, France
Keywords:
Offline Reinforcement Learning, Batch Reinforcement Learning, Markov Decision Processes, Symmetry
Detection, Homomorphism, Density Estimation, Data Augmenting, Normalizing Flows, Deep Neural Networks.
Abstract:
Offline estimation of the dynamical model of a Markov Decision Process (MDP) is a non-trivial task that
greatly depends on the data available in the learning phase. Sometimes the dynamics of the model is invariant
with respect to some transformations of the current state and action. Recent works showed that an expert-
guided pipeline relying on Density Estimation methods as Deep Neural Network based Normalizing Flows
effectively detects this structure in deterministic environments, both categorical and continuous-valued. The
acquired knowledge can be exploited to augment the original data set, leading eventually to a reduction in the
distributional shift between the true and the learned model. Such data augmentation technique can be exploited
as a preliminary process to be executed before adopting an Offline Reinforcement Learning architecture,
increasing its performance. In this work we extend the paradigm to also tackle non-deterministic MDPs, in
particular, 1) we propose a detection threshold in categorical environments based on statistical distances, and 2)
we show that the former results lead to a performance improvement when solving the learned MDP and then
applying the optimized policy in the real environment.
1 INTRODUCTION
In Offline Reinforcement Learning (ORL) and Of-
fline Learning for Planning the environment dynamics
and/or value functions are inferred from a batch of
already pre-collected experiences. Wrong previsions
lead to bad decisions. The distributional shift, defined
as the discrepancy between the learnt model and real-
ity, is the main responsible for the performance deficit
of the (sub)optimal policy obtained in the offline set-
ting compared to the true optimal policy (Levine et al.,
2020; Angelotti et al., 2020). Is there a way to exploit
expert knowledge or intuition about the environment
to limit the distributional shift? Several models ben-
efit from a dynamics that is invariant with respect to
some transformations of the system of reference. In
physics, such a property of a system is called a symme-
try (Gross, 1996). In the context of Markov Decision
Processes (MDPs) (Bellman, 1966) a symmetry can
be defined as a particular case of an MDP’s homomor-
a
https://orcid.org/0000-0002-1878-5833
b
https://orcid.org/0000-0003-0002-9973
c
https://orcid.org/0000-0003-3578-4186
phism (Angelotti et al., 2022). Knowing that a system
to be learned is endowed with a symmetry or of a ho-
momorphic structure can lead to more data-efficient
solutions of an MDP.
The automatic discovery of homomorphic struc-
tures in MDPs has a long story (Dean and Givan, 1997;
Ravindran and Barto, 2001; Ravindran and Barto,
2004). In (Li et al., 2006) a theoretical analysis of
the possible types of MDPs state abstractions proved
which properties of the original MDP would be in-
variant under the transformation: the optimal value
function, the optimal policy, etc. Eventually, the full
automatic discovery of a factored MDP representation
was proven to be as hard as verifying whether two
graphs are isomorphic (Narayanamurthy and Ravin-
dran, 2008). In recent years (van der Pol et al., 2020a;
van der Pol et al., 2020b; Angelotti et al., 2022) rekin-
dled the topic.
In (van der Pol et al., 2020a) a contrastive loss
function that enforces action equivariance on a to-
be-learned representation of an MDP was adopted to
learn a structured latent space that was then exploited
to increase the data efficiency of a data-driven plan-
ner. (van der Pol et al., 2020b) introduced peculiar
Angelotti, G., Drougard, N. and Chanel, C.
Data Augmentation Through Expert-Guided Symmetry Detection to Improve Performance in Offline Reinforcement Learning.
DOI: 10.5220/0011633400003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 2, pages 115-124
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
115

classes of Deep Neural Network (DNN) architectures
that by construction enforce the invariance of the op-
timal MDP policy under some set of transformations
obtained through other Deep RL paradigms. The lat-
ter also provided an increase in data efficiency. In
(Angelotti et al., 2022) an expert-guided detection of
alleged symmetries based on Density Estimation sta-
tistical techniques in the context of the offline learning
of both continuous and categorical environments was
proposed in order to eventually augment the starting
data set. The authors showed that correctly detecting
a symmetry (based on the computation of a symme-
try confidence value
ν
k
> ν
) and data augmenting the
starting data set exploiting this information led to a
decrease in the distributional shift. Unfortunately, the
said work concerned only deterministic MDPs and
did not include an analysis of the performance of the
policy obtained in the end. In other fields of Machine
Learning data augmentation has been extensively ex-
ploited to boost the efficiency of the algorithms in data-
limited setups (van Dyk and Meng, 2001; Shorten and
Khoshgoftaar, 2019; Park et al., 2019).
Recently (Yarats et al., 2022) showed the impor-
tance of large and diverse datasets for ORL by demon-
strating empirically that offline learning using a vanilla
online RL algorithm over a batch that is diverse enough
can lead to performances that are comparable to, or
even better than, pure ORL approaches.
In this context, the present work addresses the fol-
lowing research questions: Is it possible to develop
a method for expert-guided detection of alleged sym-
metries based on Density Estimation statistical tech-
niques in the context of offline learning that also works
for stochastic MDPs? The main idea is to extend previ-
ous works (van der Pol et al., 2020a; van der Pol et al.,
2020b; Angelotti et al., 2022) to deal with stochastic
MDPs; and, Is Data Augmentation exploiting a de-
tected symmetry really beneficial to the learning of an
MDP policy in the offline context? We would like to
empirically demonstrate (O)RL policy improvement
when enriching the batch as proposed by (Yarats et al.,
2022).
Contributions. In this work, we take over and ex-
tend the state-of-the-art with the aim of providing an
answer to the listed research questions. More specifi-
cally, the contributions of this paper are the followings:
1.
Algorithmic Contribution. A refinement of the de-
cision threshold, based on statistical distances, is
defined for categorical MDPs. This new decision
threshold is valid also in both stochastic and de-
terministic environments, improving hence over
the state-of-the-art that only tackled deterministic
scenarios;
2.
Experimental Contribution. The improvement of
the policy performance obtained by augmenting
the data with the symmetric images of the transi-
tions is demonstrated experimentally in an offline
learning context. The good quality of the method is
clear in the categorical setting while it is fuzzier in
the continuous setting since offline methods with
Deep Neural Networks are affected by the (non-
trivial) choice of the hyperparameters.
It is worth saying that the presented work aim is not
to be a competitor to the ORL algorithms, but a way
to augment the batch by validating expert intuition.
Once the batch has been augmented one could use any
offline RL method.
2 BACKGROUND
Definition 1 (Markov Decision Process). An MDP
(Bellman, 1966) is a tuple
M = (S,A,R,T,γ)
.
S
and
A
are the sets of states and actions, R : S × A → R is the
reward function,
T : S ×A → Dist(S)
is the transition
function, where
Dist(S)
is the set of probability distri-
butions on
S
, and
γ ∈ [0,1)
is the discount factor. Time
is discretized and at each step
t ∈ N
the agent observes
a system state
s = s
t
∈ S
, acts with
a = a
t
∈ A
drawn
from a policy
π : S → Dist(A)
, and with probability
T (s,a,s
′
)
transits to a next state
s
′
= s
t+1
, earning a
reward
R(s,a)
. The value function of
π
and
s
is defined
as the expected total discounted reward using
π
and
starting with
s
:
V
π
(s) = E
π
∑
∞
t=0
γ
t
R(s
t
,a
t
)|s
0
= s
.
The optimal value function
V
∗
is the maximum of the
latter over every policy π.
Definition 2 (MDP Symmetry). Given an MDP
M
,
let
k
be a surjection on
S ×A ×S
such that
k(s, a, s
′
) =
k
σ
(s,a,s
′
),k
α
(s,a,s
′
),k
σ
′
(s,a,s
′
)
∈ S × A × S
. Let
(T ◦ k)(s,a,s
′
= T (k(s, a, s
′
))
.
k
is a symmetry if
∀(s,s
′
) ∈ S
2
,
a ∈ A
both
T
and
R
are invariant with
respect to the image of k:
(T ◦ k)(s, a, s
′
= T (s,a,s
′
), (1)
R
k
σ
(s,a,s
′
),k
α
(s,a,s
′
)
= R(s,a). (2)
As (Angelotti et al., 2022), in this paper we will
focus only on the invariance of
T
, therefore we will
only demand for the validity of Equation 1. Problems
with a known reward function as well as model-based
approaches can thus benefit directly from the method.
Probability Mass Function Estimation for Dis-
crete MDPs. Let
D = {(s
i
,a
i
,s
′
i
)}
n
i=1
be a batch of
recorded transitions. Performing mass estimation over
D
amounts to compute the probabilities that define the
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
116

categorical distribution
T
by estimating the frequen-
cies of transition in D. In other words:
ˆ
T (s,a,s
′
) =
n
s,a,s
′
∑
s
′
n
s,a,s
′
if
∑
s
′
n
s,a,s
′
> 0,
|S|
−1
otherwise.
(3)
where
n
s,a,s
′
is the number of times the transition
(s
t
=
s,a
t
= a,s
t+1
= s
′
) appears in D.
Probability Density Function Estimation for Con-
tinuous MDPs. Performing density estimation over
D
means obtaining an analytical expression for
the probability density function (pdf) of transitions
(s,a,s
′
)
given
D
:
L(s,a, s
′
|D)
. Normalizing flows
(Dinh et al., 2015; Kobyzev et al., 2020) allow defin-
ing a parametric flow of continuous transformations
that reshapes a known initial pdf to one that best fits
the data.
Expert-Guided Detection of Symmetries. The
paradigm described in (Angelotti et al., 2022) can be
resumed as follows:
1.
An expert presumes that a to be learned model is
endowed with the invariance of
T
with respect to
a transformation k;
2.
She/He computes the probability function estima-
tion based on the batch D:
(a)
(categorical case) She/He computes
ˆ
T
, an esti-
mate of
T
, using the transitions in a batch
D
by
applying Equation 3;
(b)
(continuous case) She/He performs Density Es-
timation over D using Normalizing Flows;
3.
She/He applies
k
to all transitions
(s,a, s
′
) ∈ D
and then checks whether the symmetry confidence
value ν
k
;
(a)
(categorical case) of samples
k(s, a, s
′
) =
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),k
σ
′
(s,a, s
′
)
∈ k(D)
s.t.
T (s,a,s
′
) = (T ◦ k)(s,a,s
′
)
exceeds an expert
given threshold ν;
(b)
(continuous case) of probability values
L
eval-
uated on
k(D)
exceeds a threshold
θ
that cor-
responds to the
q−
order quantile of the distri-
bution of probability values evaluated on the
original batch. The quantile order
q
is given
as an input to the procedure by an expert (see
Algorithm 2);
4.
If the last condition is fulfilled then
D
is aug-
mented with k(D).
Note that once a transformation
k
is detected as a
symmetry the dataset is potentially augmented with
transitions that are not present in the original batch,
injecting hence unseen and totally novel information
into the dataset.
3 ALGORITHMIC
CONTRIBUTION
Our algorithmic contribution consists in the improve-
ment of the calculation of
ν
k
in part (3.a) of the previ-
ous list (Angelotti et al., 2022). Indeed, that approach
does not yield valid results when applied to stochas-
tic environments. In order for the method to work in
stochastic environments we need to measure a distance
in distribution. The latter somehow was considered
in the version of the approach that took care of con-
tinuous deterministic environments since learning a
distribution over transitions represented by their fea-
tures is independent of the nature of the dynamics.
However, when dealing with categorical states the no-
tion of distance between features can’t be exploited.
We propose to compute the percentage
ν
k
relying
on a distance between categorical distributions. Since
the transformation
k
is a surjection on transition tuples,
we do not know a-priori which will be the correct
mapping
k
σ
′
(s,a, s
′
) ∀s
′
∈ S
. In other words, we can
compute
k
σ
′
, the symmetric image of
s
′
, only when we
receive as an input the whole tuple
(s,a, s
′
)
since an
inverse mapping might not exist.
Therefore we will resort to computing a pes-
simistic approximation of the Total Variational Dis-
tance (proportional to the
L
1
-norm). In particu-
lar, given
(s,a, s
′
)
, we aim to calculate the Cheby-
shev distance (the
L
∞
-norm) between
T (s,a,·)
and
T
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),·
. Recall that given two vec-
tors of dimension
d
,
x
and
y
both
∈ R
d
,
||x − y||
∞
≤
||x − y||
1
.
Let us then define the following four functions:
m(s,a, s
′
) = min
s∈S\{s
′
}:
ˆ
T ̸=0
ˆ
T (s,a,s) (4)
M(s,a,s
′
) = max
s∈S\{s
′
}
ˆ
T (s,a,s), (5)
m
k
(s,a, s
′
) = min
s∈S s.t.
s̸=k
σ
′
(s,a,s
′
)
and
ˆ
T ◦k̸=0
ˆ
T
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),s
,
(6)
M
k
(s,a, s
′
) = max
s∈S s.t.
s̸=k
σ
′
(s,a,s
′
)
ˆ
T
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),s
(7)
where
m
(
M
) and
m
k
(
M
k
) are the minimum (maxi-
mum) of the probability mass function (pmf)
ˆ
T
when
evaluated respectively on an initial state and action
(s,a)
and
k
σ
(s,a, s
′
),k
α
(s,a, s
′
)
for which
ˆ
T ̸= 0
.
Those zero values are excluded because, in the context
of a small dataset, many transitions are unexplored,
and including values
= 0
would often lead to over-
pessimistic estimates.
In order to approximate the Chebyshev distance
between
ˆ
T (s,a,·)
and
ˆ
T (k
σ
(s,a, s
′
),k
α
(s,a, s
′
),·)
we
Data Augmentation Through Expert-Guided Symmetry Detection to Improve Performance in Offline Reinforcement Learning
117

define a pessimistic approximation d
k
as follows:
d
k
(s,a, s
′
) = max
n
M(s,a,s
′
) − m
k
(s,a, s
′
)
| {z }
(I)
,
M
k
(s,a, s
′
) − m(s,a,s
′
)
| {z }
(II)
, (8)
ˆ
T (s,a,s
′
) − (
ˆ
T ◦ k)(s, a, s
′
)
| {z }
(III)
o
.
For the moment consider
ˆ
T (s,a,·)
and
ˆ
T
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),·
just as two sets of
numbers. Remove the value corresponding to
s
′
from
the first set, the one corresponding to
k
σ
′
(s,a, s
′
)
from
the second set, and any remaining zeros from both.
Taking the max between (I) and (II) just equates to
selecting the maximum possible difference between
any two values of these modified sets. Equation 8 sim-
ply tells us to select the worst possible case since we
do not know which permutations of states we should
compare when computing the Chebyshev distance.
s
′
is removed from
ˆ
T (s,a,·)
and
k
σ
′
(s,a, s
′
)
is removed
from
ˆ
T
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),·
since we know that
k
maps
(s,a, s
′
)
to
k
σ
(s,a, s
′
),k
α
(s,a, s
′
),k
σ
′
(s,a, s
′
)
and hence we can compare those values directly (III).
Notice that
0 < d
k
(s,a, s
′
) ≤ 1 ∀(s,a,s
′
) ∈ S × A × S. (9)
In the following, we propose to improve the algorithms
proposed in (Angelotti et al., 2022). In detail, we rede-
fine the symmetry confidence value
ν
k
. We propose to
estimate ν
k
as in Line 2 of Algorithm 1 as:
ν
k
(D) = 1 −
1
|D|
∑
(s,a,s
′
)∈D
d
k
(s,a, s
′
). (10)
From equations 8 and 9, it follows that: (i) in deter-
ministic environments
ν
k
(Eq. 10) coincides with the
one prescribed in (Angelotti et al., 2022); and, (ii)
1 > ν
k
≥ 0
, so
ν
k
can be interpreted as a percentage.
This last allows us to suppose that
ν
k
is an estimate of
the probability of
k
being a symmetry of the dynamics,
and therefore we can relax the necessity of defining an
expert-given threshold
ν
(cf. (Angelotti et al., 2022)
Alg. 1). We then set
ν = 0.5
as an input in Algorithm
1 and eventually augment the batch if
ν
k
> 0.5
(Lines
3-5).
Remark (Extreme Case Scenario). Is Equation 8
too pessimistic? Consider that for a given state ac-
tion couple
(s,a)
we have a transition distributed
over 3 states
s ∈ S = {One,Two,Three}
with proba-
bilities
T (s,a,One) = 0.01
,
T (s,a,Two) = 0.01
and
T (s,a,T hree) = 0.98
. Now, assume the estimate of
Algorithm 1: Symmetry detection and data augmenting in a
categorical MDP.
Input: Batch of transitions D , k alleged
symmetry
Output: Possibly augmented batch D ∪ D
k
1
ˆ
T ← Most Likely Categorical pmf from D
2 ν
k
= 1 −
1
|D|
∑
(s,a,s
′
)∈D
d
k
(s,a, s
′
) (where
d
k
is defined in Equation 8)
3 if ν
k
> 0.5 then
4 D
k
= k(D) (alleged symm. transitions)
5
return
D ∪ D
k
(the augmented batch)
6 else
7 return D (the original batch)
8 end
the transition function is perfect. Does the dis-
tance in Equation 8 converge to
0
? Not always,
but what matters for the detection of symmetries is
the average of the distances over the whole batch
(Eq. 10). Suppose that these probabilities were in-
ferred from a batch with the transition
(s,a, One)
once,
(s,a, Two)
once and
(s,a, Three)
ninety-eight
times. Consider
(s,a, Three)
.
M(s,a,Three) =
M
k
(s,a, Three) = m(s,a,Three) = m
k
(s,a, Three) =
0.01
. Following Eq. 8,
d
k
(s,a, Three) = 0
. How-
ever,
d
k
(s,a, One) = d
k
(s,a, Two) = 0.97
, which is
a too pessimistic estimate. Nevertheless let’s calcu-
late
ν
k
(Eq.10). For this state-action pair
(s,a)
, the
average over the batch is therefore:
(d
k
(s,a, One) +
d
k
(s,a, Two) + 98d
k
(s,a, Three))/100 = 0.0194
. If
the estimation is the same for other pairs
(s,a)
, then
ν
k
= 1 − 0.0194 = 0.9806
. This is a value close to 1
suggesting k is a symmetry.
4 EXPERIMENTS
In order to show the improvements provided by our
contribution we tested the algorithms in a stochas-
tic version of the toroidal Grid environment and two
continuous state environments of the OpenAI’s Gym
Learning Suite: CartPole and Acrobot. We have cho-
sen the same scenarios as (Angelotti et al., 2022) in
order to demonstrate that our approach generalizes
well to the stochastic case contrary to the approach
proposed in (Angelotti et al., 2022).
4.1 Setup
We collect a batch of transitions
D
using a uniform
random policy. An expert alleges the presence of a
symmetry k and we proceed to its detection using
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
118

Algorithm 2: Symmetry detection and data augmenting in a
continuous MDP with detection threshold
ν = 0.5
(Angelotti
et al., 2022).
Input:
Batch of transitions
D
,
q ∈ [0,1)
order
of the quantile, k alleged symmetry
Output: Possibly augmented batch D ∪ D
k
1 L ← Density Estimate (D) (e.g. with
Normalizing Flows)
2 Λ ←
Distribution
L(D)
(
L
evaluated over
D
)
3 θ = q-order quantile of Λ
4 D
k
= k(D) (alleged symmetric transitions)
5 ν
k
=
1
|D
k
|
∑
(s,a,s
′
)∈D
k
1
{L(s,a,s
′
|D)>θ}
6 if ν
k
> 0.5 then
7
return
D ∪ D
k
(the augmented batch)
8 else
9 return D (the original batch)
10 end
Algorithm 1 (categorical case) or Algorithm 2 (contin-
uous case). In the continuous case, Density Estimation
is performed by a Masked Autoregressive Flow archi-
tecture (Papamakarios et al., 2017) with
3
layers of
bijectors.
The experiments were performed using 2 Dodeca-
core Skylake Intel® Xeon® Gold 6126 @ 2.6 GHz
and 96 GB of RAM and 2 GPU NVIDIA® V100 @
192GB of RAM. The code to run the experiments is
available at https://github.com/giorgioangel/dsym.
Computation of
ν
k
and Batch Augmentation. We
report the
ν
k
obtained with an ensemble of
N
different
iterations of the procedure: we generate
z ∈ N
sets of
N
different batches
D
of increasing size.Remember that
since
ν
k
∈ [0,1)
we can interpret it as the probability
of the presence of a symmetry and select a detection
threshold
ν = 0.5
or higher, while in (Angelotti et al.,
2022) the threshold
ν
was expert-given. We calculate
ν
k
with both the (Angelotti et al., 2022) method and
the approach here presented.
Evaluation of the Performance (Categorical Case).
In the end, let
ρ
be the distribution of initial states
s
0
∈ S
and let the performance
U
π
of a policy
π
be
U
π
= E
s∼ρ
[V
π
(s)].
Our experimental contribution is
the comparison between the performances obtained
by acting in the real environment with
ˆ
π
(the optimal
policy solving the MDP defined with
ˆ
T
) and
ˆ
π
k
(the
optimal policy obtained with
ˆ
T
k
). In particular we
consider the quantity
∆U = U
ˆ
π
k
−U
ˆ
π
. (11)
∆U > 0
means that data augmenting leads to better
policies.
In categorical environments the policies are ob-
tained with Policy Iteration and evaluated with Policy
Evaluation.
Evaluation of the Performance (Continuous Case).
In continuous environments Offline Learning is not
trivial. We use the implementation of two Model-
Free Deep RL architectures: Deep Q-Network (DQN)
(Mnih et al., 2015) and Conservative Q-Learning
(CQL) (Kumar et al., 2020) of the d3rlpy learning
suite (Seno and Imai, 2021) to obtain a policy start-
ing from the batches. The first method is the one that
originally established the validity of Deep RL and it
is used in online RL while the second was specifically
developed to tackle offline RL problems. Since the
convergence of the training of Deep RL baselines is
greatly dependent of hyperparameter tuning that itself
depends on both the environment and the batch (Paine
et al., 2020), we will apply DQN and CQL with the
default parameters provided by d3rlpy, abiding hence
more faithfully to an offline learning duty. This means
that sometimes the learning might not converge to a
good policy. We find this philosophy more honest
than showing the results obtained with the best seed or
the finest-tuned hyperparameters. Each architecture is
trained for a number of steps equal to fifty times the
number of transitions present in the batch.
4.2 Environments
Stochastic Grid (Categorical). In this environment,
the agent can move along fixed directions over a torus
by acting with any
a ∈ A = {↑,↓,←,→}
(see Figure
1). The grid meshing the torus has size l = 10.
Figure 1: Representation of the Grid Environment (Angelotti
et al., 2022). The red dot is the position of a state
s
on the
torus. A possible displacement obtained by acting with
action a =↑ is shown as a red arrow.
The agent can spawn everywhere on the torus with
a uniform probability and must reach a fixed goal. At
every time step, the agent receives a reward
r = −1
if
it does not reach the goal and a reward
r = 1
once the
goal has been reached, terminating the episode. When
performing an action the agent has
60%
chances of
moving to the intended direction,
20%
to the opposite
Data Augmentation Through Expert-Guided Symmetry Detection to Improve Performance in Offline Reinforcement Learning
119
one, and
10%
along an orthogonal direction. We col-
lect
z = 10
sets of
M = 100
batches with respectively
N = 1000 × i
z
steps in each batch (
i
z
going from
1
to
z).
Table 1: Toroidal Grid: proposed transformations and label.
k Label
k
σ
(s,a,s
′
) = s
′
k
α
s,a = (↑,↓,←,→),s
′
= (↓, ↑, →, ←)
TRSAI
k
σ
′
(s,a,s
′
) = s
k
σ
(s,a,s
′
) = s
k
α
s,a = (↑,↓,←,→),s
′
= (↓, ↑, →, ←) SDAI
k
σ
′
(s,a,s
′
) = s
′
k
σ
(s,a,s
′
) = s
k
α
s,a = (↑,↓,←,→),s
′
= (↓, ↑, →, ←) ODAI
k
σ
′
(s,a = (↑,↓,←,→),s
′
) =
s
′
− (0,2), s
′
+ (0,2), s
′
+ (2,0), s
′
− (2,0)
k
σ
(s,a,s
′
) = s
k
α
(s,a = (↑,↓,←,→),s
′
) = (→, ←, ↑, ↓) ODWA
k
σ
′
(s,a = (↑,↓,←,→),s
′
) =
s
′
− (0,2), s
′
+ (0,2), s
′
+ (2,0), s
′
− (2,0)
k
σ
(s,a,s
′
) = s
′
k
α
(s,a,s
′
) = a TI
k
σ
′
s,a = (↑,↓,←,→),s
′
=
s
′
+ (0,1), s
′
− (0,1), s
′
− (1,0), s
′
+ (1,0)
k
σ
(s,a,s
′
) = s
′
k
α
(s,a,s
′
) = a TIOD
k
σ
′
(s,a,s
′
) = s
The proposed symmetries for this environment are
outlined in Table 1. We check for the invariant of
the dynamics with respect to the following six trans-
formations (the valid symmetries are displayed in
bold): (1) Time reversal symmetry with action in-
version (TRSAI); (2) Same dynamics with action in-
version (SDAI); (3) Opposite dynamics and action
inversion (ODAI); (4) Opposite dynamics but wrong
action (ODWA); (5) Translation invariance (TI); (6)
Translation invariance with opposite dynamics (TIOD).
The
N
dependent average results for symmetry detec-
tion using the method from (Angelotti et al., 2022) are
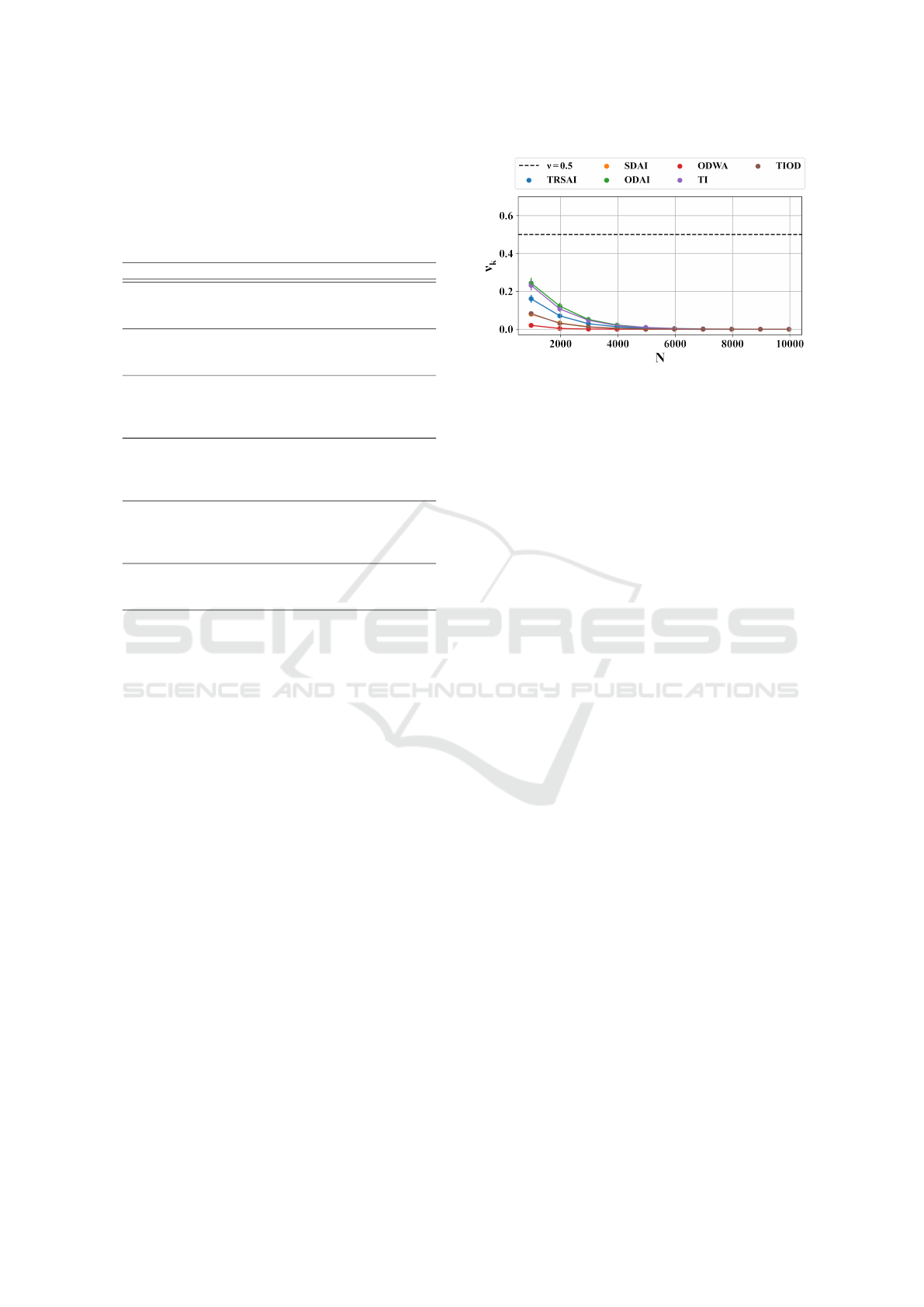
reported in Figure 2, and results using our method are
displayed in Figure 3a. Figure 3b presents the perfor-
mance improvement
∆U
, with its standard deviation
being represented by a vertical error bar.
Stochastic CartPole (Continuous). A pole is pre-
cariously balanced on a cart and an agent can push
the whole system left or right to prevent the pole from
falling.
The dynamics is similar to that of CartPole (Brock-
man et al., 2016) (see Figure 5), however the force that
the agent uses to push the cart is sampled from a nor-
mal distribution with mean
f
(the force defined in the
deterministic version) and standard deviation
˜
σ = 2
.
Recall that the state is represented by the features
(x,θ,v,ω)
and
A = {←, →}
. For the evaluation of
ν
k
Figure 2: Stochastic toroidal Grid Environment. Probability
of symmetry
ν
k
calculated with the method proposed by (An-
gelotti et al., 2022).The threshold at
ν = 0.5
is displayed as a
dashed line. Since all
ν
k
< 0.5
means that no transformation
is detected as a symmetry.
we set the quantile
q = 0.1
and we collect
z = 10
sets
of
M = 100
batches with respectively
N = 1000 × i
z
steps in each batch (and
i
z
going from
1
to
10
). We
evaluate
∆U
by training the agent on single batches
of
N = 5000 × i
z
(and
i
z
going from
1
to
6
) both aug-
mented and not augmented with
k
. The acronyms of
the valid symmetric transformations are displayed in
bold: (1) State and action reflection with respect to an
axis in
x = 0
(SAR); (2) Initial state reflection (ISR);
(3) Action inversion (AI); (4) Single feature inversion
(SFI); (5) Translation invariance (TI). Their effects on
the transition
(s,a, s
′
)
are listed in Table 2. Average re-
sults and errors are displayed in Figure 4a. The results
considering the evaluation of performance gain (
∆U
)
are shown in Table 4.
Stochastic Acrobot (Continuous). The Acrobot is
a planar two-link robotic arm working against gravity,
the agent can decide whether to swing or not the elbow
left or right to balance the arm straightened up (see
Figure 6). It is the very same Acrobot of (Brockman
et al., 2016) but at every time step a noise
ε
is sampled
from a uniform distribution on the interval
[−0.5,0.5]
and added to the torque. A state is represented by
the features
(s
1
,c
1
,s
2
,c
2
,ω
1
,ω
2
)
where
s
i
and
c
i
are
respectively
sin(α
i
)
and
cos(α
i
)
in shorthand notation.
The action set
A = {−1, 0,1}
. For the evaluation of
ν
k
we set
q = 0.1
. For the detection case, we collected
z = 5
sets of
M = 100
batches with
N = 1000 × i
z
steps within each one (
i
z
going from
1
to
z
). The
evaluation of the performance was carried out on single
batches, with and without data augmentation, with
N = 10000 × i
z
steps and
i
z
going from
1
to
4
. For the
evaluation of
∆ z = 5
due to computational necessities.
We allege the following transformations
k
, as always
the valid ones are bolded: (1) Angles and angular
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
120
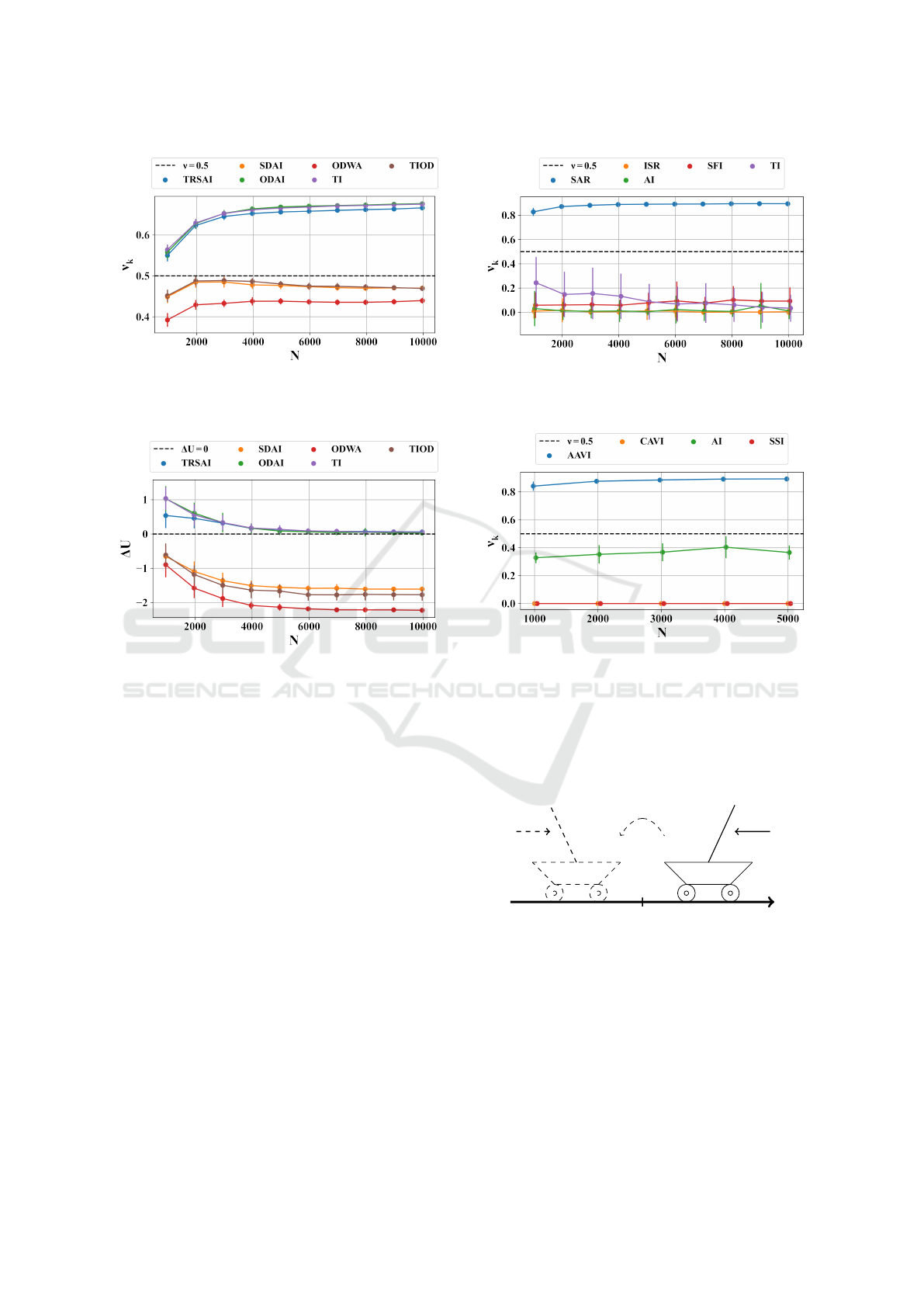
(a) Probability of symmetry
ν
k
with our approach. The
threshold at
ν = 0.5
is displayed as a dashed line.
ν
k
> 0.5
means that the transformation is detected as a symmetry.
(b) Performance difference
∆U
(Eq. 11). The threshold at
∆U = 0
is displayed as a dashed line.
∆U > 0
means that
data augmenting leads to better policies.
Figure 3: Stochastic Toroidal Grid Environment.
ν
k
and
∆U
for the transformations
k
computed over sets of
100
different
batches of size
N
. Points are mean values and bars standard
deviations.
velocities inversion (AAVI); (2) Cosines and angular
velocities inversion (CAVI); (3) Action inversion (AI);
(4) Starting state inversion (SSI).
The images of the transformations are reported in
Table 3. The
N
dependent average results and standard
deviations are reported in Figure 4b. The results con-
sidering the evaluation of performance gain (
∆U
) are
shown in Table 5.
5 DISCUSSION
Stochastic Grid (Categorical). Detection phase
(
ν
k
). We see from Figure 2 that using the state-of-
the-art approach no transformation is detected as a
symmetry because
ν
k
< 0.5
,
∀k
in the proposed set of
transformations. This result highlights the inadequacy
(a) Stochastic CartPole. Probability of symmetry
ν
k
. The
threshold at
ν = 0.5
is displayed as a dashed line.
ν
k
> 0.5
means that the transformation is detected as a symmetry.
(b) Stochastic Acrobot. Probability of symmetry
ν
k
. The
threshold at
ν = 0.5
is displayed as a dashed line.
ν
k
> 0
means that the transformation is detected as a symmetry.
Figure 4:
ν
k
, for the transformations
k
computed over sets of
different batches of size
N
in Stochastic CartPole (left) and
Stochastic Acrobot (right). Points are mean values and are
a bit shifted horizontally for the sake of display. Standard
deviation is displayed as a vertical error bar.
x
x = 0
a
h
g(a)
Figure 5: The cart in the right is a representation of a Cart-
Pole’s state
s
t
with
x
t
> 0
and action
a
t
=←
(Angelotti et al.,
2022). The dashed cart in the left is the image of
(s
t
,a
t
)
under the transformation
h
which inverses state
f (s) = −s
and action g(a) = −a.
of the state-of-the-art method to deal with stochas-
tic environments. On the contrary, our novel algo-
rithm perfectly manages to identify the real symme-
tries of the environment (see Figure 3a):
ν
k
> 0.5
,
k ∈ {TRSAI,ODAI,TI}
. Moreover, there are no false
positives:
ν
k
< 0.5
,
k ∈ {SDAI,ODWA,TIOD}
. We
Data Augmentation Through Expert-Guided Symmetry Detection to Improve Performance in Offline Reinforcement Learning
121

α
1
> 0
α
2
< 0
Figure 6: Representation of a state of the Acrobot environ-
ment (Angelotti et al., 2022).
Table 2: Proposed transformations and labels for Stochastic
CartPole.
k Label
k
σ
(s,a, s
′
) = −s
k
α
s,a = (←,→), s
′
= (→, ←) SAR
k
σ
′
(s,a, s
′
) = −s
′
k
σ
(s,a, s
′
) = −s
k
α
(s,a, s
′
) = a ISR
k
σ
′
(s,a, s
′
) = s
′
k
σ
(s,a, s
′
) = s
k
α
s,a = (←,→), s
′
= (→, ←) AI
k
σ
′
(s,a, s
′
) = s
′
k
σ
s = (x,...), a,s
′
= (−x, ...)
k
α
(s,a, s
′
) = a SFI
k
σ
′
(s,a, s
′
) = s
′
k
σ
s = (x,...), a,s
′
= (x + 0.3,...)
k
α
(s,a, s
′
) = a TI
k
σ
′
s,a, s
′
= (x
′
,...)
= (x
′
+ 0.3,...)
notice that while in a deterministic environment
ν
k
= 0
∀k
which is not a symmetry, here the stochasticity
makes the detection more complicated since
ν
k
≈ 0.5
−
for N = 2000.
Evaluation of performance gain (
∆U
). The dif-
ference in the performance of the deployed policies
Table 3: Proposed transformations and labels for Stochastic
Acrobot.
k Label
k
σ
s = (s
1
,s
2
,ω
1
,ω
2
,. .. ),a, s
′
= (−s
1
,−s
2
,−ω
1
,−ω
2
,. . . )
k
α
(s,a = (−1,0, 1),s
′
= (1, 0,−1) AAVI
k
σ
′
s,a, s
′
= (s
′
1
,s
′
2
,ω
′
1
,ω
′
2
,. .. )
= (−s
′
1
,−s
′
2
,−ω
′
1
,−ω
′
2
,. . . )
k
σ
s = (c
1
,c
2
,ω
1
,ω
2
,. .. ),a, s
′
= (−c
1
,−c
2
,−ω
1
,−ω
2
,. . . )
k
α
s,a = (−1,0, 1),s
′
= (1, 0,−1) CAVI
k
σ
′
s,a, s
′
= (c
′
1
,c
′
2
,ω
′
1
,ω
′
2
,. .. )
= (−c
′
1
,−c
′
2
,−ω
′
1
,−ω
′
2
,. . . )
k
σ
(s,a, s
′
) = s
k
α
s,a = (−1,0, 1),s
′
= (1, 0,−1) AI
k
σ
′
(s,a, s
′
) = s
′
k
σ
(s,a, s
′
) = −s
k
α
s,a, s
′
) = a SSI
k
σ
′
(s,a, s
′
) = s
′
∆U
perfectly fits the expected behavior. When
k
is a
symmetry
∆U > 0
and saturates to
0
with
N
increas-
ing. When
k
is not a symmetric transformation of the
dynamics
∆U < 0
and keeps decreasing with
N
(see
Figure 3b).
Stochastic CartPole (Continuous). Detection
phase (
ν
k
) In Stochastic CartPole the algorithm fails
to detect the symmetry
k = TI
. This could be due
to the fact that the translation invariance symmetry
in this case is fixed for a specific value (see TI in
Table 2 where the translation is set at
0.3
). If the
translation is too small the neural network fails
to discern the transformation from the noise. The
algorithm classifies correctly as a symmetry
k = SAR
and the remaining transformations as non-symmetries
(see Figure 4a).
Evaluation of performance gain (
∆U
). Results are dis-
played in Table 4. ORL is very unstable and sensitive
to the choice of hyperparameters. On top of that, the
training is carried out for a fixed number of epochs.
We notice that, on average over different batch sizes,
∆U > 0
for DQN and SAR, and SFI transformations.
While SAR is a valid symmetry, SFI it’s not. A more
conservative algorithm like CQL only detects SAR as
a valid symmetry. The performance difference for TI
both for DQN and CQL is so close to zero that we
think that augmenting the dataset with this symmetry
might not be a substantial power-up over using just the
information contained in the original batch.
Stochastic Acrobot (Continuous). Detection phase
(
ν
k
). In this environment the only real symmetry of
the dynamics,
AAVI
, gets successfully detected by the
algorithm with
q = 0.1
. Non symmetries yield a
ν
k
<
0.5 (Figure 4b).
Evaluation of performance gain (
∆U
). Results
are displayed in Table 5 and show that the training in
Stochastic Acrobot is harder than in Stochastic Cart-
Pole since, even with a large dataset, sometimes the
algorithms do not manage to learn a good policy. In
particular, while CQL manages to learn how to behave
in the environment exploiting the AAVI symmetry (av-
erage
∆U = 52.9
), DQN still struggles with every
k
,
good and wrong. Nevertheless, CQL apparently bene-
fits from augmenting the dataset also with wrong sym-
metries even though to a smaller extent. We suppose
this effect is due to the instability in ORL training.
6 CONCLUSIONS
Data efficiency in the offline learning of MDPs is
highly coveted. Exploiting the intuition of an expert
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
122

Table 4: ∆U for every alleged symmetry in Stochastic CartPole with two baselines and different batch sizes N.
N (number of transitions in the original batch)
k Baseline 5000 10000 15000 20000 25000 30000 Average ∆U
SAR
DQN -7.3 25.4 41.8 7.2 9.0 3.4 13.3
CQL 37.4 -2.5 -4.1 20.1 17.9 -9.0 10.0
ISR
DQN -1.3 -48.5 -29.9 -78.7 -107.8 -29.1 -49.2
CQL 6.4 1.6 -2.2 -22.3 -10.3 -25.9 -8.8
AI
DQN 26.9 -48.5 -43.7 -74.6 -41.3 -84.6 -44.3
CQL -13.1 -7.6 -29.8 -6.5 -22.3 -15.3 -15.8
SFI
DQN -33.4 17.9 21.4 45.4 -6.9 -0.1 7.4
CQL -5.5 -2.1 7.4 -3.9 -3.6 -18.5 -4.4
TI
DQN 36.9 -28.1 34.5 15.7 6.1 -9.1 -0.2
CQL 7.6 -1.3 -2.1 11.8 -16.5 5.2 0.8
Table 5: ∆U for every alleged symmetry in Stochastic Acrobot with two baselines and different batch sizes N.
N
k Baseline 10000 20000 30000 40000 Average ∆U
AAVI
DQN 24.7 -17.5 -63.4 -10.6 -16.7
CQL -2.8 10.5 -9.5 213.3 52.9
CAVI
DQN 8.9 -9.3 -24.6 -48.0 -12.2
CQL -8.8 0.5 4.4 1.1 -0.7
AI
DQN -377.3 -399.3 -386.8 -388.5 -388.0
CQL -25.6 235.3 -88.2 -49.9 17.9
SSI
DQN 265.7 -408.2 -334.9 -396.3 -218.4
CQL 35.8 4.0 11.9 -22.8 7.2
about the nature of the model can help to learn dynam-
ics that better represent reality.
In this work, we built a semi-automated tool that
can aid an expert in providing a statistical data-driven
validation of her/his intuition about some properties of
the environment. Correct deployment of the tool could
improve the performance of the optimal policy ob-
tained by solving the learned MDP. Indeed, our results
suggest that the proposed algorithm can effectively
detect a symmetry of the dynamics of an MDP with
high accuracy and that exploiting this knowledge can
not only reduce the distributional shift but also pro-
vide performance gain in an envisaged optimal control
of the system. However, when applied to ORL envi-
ronments with DNN, all the prescriptions (and issues)
about hyperparameter fine-tuning well known to ORL
practitioners persist.
Besides its pros, the current work is still con-
strained by several limitations. We note that the quality
of the approach in continuous MDPs is greatly affected
by the architecture of the Normalizing Flow used for
Density Estimation and, more generally, by the state-
action space preprocessing. In detail, sometimes an
environment is endowed by symmetries that an expert
can not straightforwardly perceive in the default repre-
sentation of the state-action space and a transformation
would be required (imagine the very same CartPole,
but with also the linear speed and position of the car
expressed in polar coordinates).
In the future we plan: (i) to expand this approach by
trying out more recent Normalizing Flow architectures
like FFJORD (Grathwohl et al., 2019); (ii) to consider
combinations of multiple symmetries; (iii) after the
offline detection of a symmetry, to exploit the data
augmentation to improve the learning phase of online
agents.
Data Augmentation Through Expert-Guided Symmetry Detection to Improve Performance in Offline Reinforcement Learning
123

ACKNOWLEDGEMENTS
This work was funded by the Artificial and Natural
Intelligence Toulouse Institute (ANITI) - Institut 3iA
(ANR-19-PI3A-0004).
REFERENCES
Angelotti, G., Drougard, N., and Chanel, C. P. C. (2020).
Offline learning for planning: A summary. In Proceed-
ings of the 1st Workshop on Bridging the Gap Between
AI Planning and Reinforcement Learning (PRL) at the
30th International Conference on Automated Planning
and Scheduling, pages 153–161.
Angelotti, G., Drougard, N., and Chanel, C. P. C. (2022).
Expert-guided symmetry detection in markov decision
processes. In Proceedings of the 14th International
Conference on Agents and Artificial Intelligence - Vol-
ume 2: ICAART,, pages 88–98. INSTICC, SciTePress.
Bellman, R. (1966). Dynamic Programming. Science,
153(3731):34–37.
Brockman, G., Cheung, V., Pettersson, L., Schneider, J.,
Schulman, J., Tang, J., and Zaremba, W. (2016). Ope-
nAI Gym. arXiv preprint arXiv:1606.01540.
Dean, T. and Givan, R. (1997). Model Minimization in
Markov Decision Processes. In AAAI/IAAI, pages 106–
111.
Dinh, L., Krueger, D., and Bengio, Y. (2015). NICE: Non-
linear Independent Components Estimation. In Bengio,
Y. and LeCun, Y., editors, 3rd International Confer-
ence on Learning Representations, ICLR 2015, San
Diego, CA, USA, May 7-9, 2015, Workshop Track Pro-
ceedings.
Grathwohl, W., Chen, R. T. Q., Bettencourt, J., Sutskever, I.,
and Duvenaud, D. (2019). FFJORD: Free-Form Con-
tinuous Dynamics for Scalable Reversible Generative
Models. In 7th International Conference on Learning
Representations, ICLR 2019, New Orleans, LA, USA,
May 6-9, 2019. OpenReview.net.
Gross, D. J. (1996). The role of symmetry in fundamen-
tal physics. Proceedings of the National Academy of
Sciences, 93(25):14256–14259.
Kobyzev, I., Prince, S., and Brubaker, M. (2020). Normal-
izing Flows: An Introduction and Review of Current
Methods. IEEE Transactions on Pattern Analysis and
Machine Intelligence.
Kumar, A., Zhou, A., Tucker, G., and Levine, S. (2020). Con-
servative q-learning for offline reinforcement learning.
Advances in Neural Information Processing Systems,
33:1179–1191.
Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline
reinforcement learning: Tutorial, review, and perspec-
tives on open problems. ArXiv, abs/2005.01643.
Li, L., Walsh, T. J., and Littman, M. L. (2006). Towards a
Unified Theory of State Abstraction for MDPs. ISAIM,
4:5.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness,
J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidje-
land, A. K., Ostrovski, G., et al. (2015). Human-level
control through deep reinforcement learning. Nature,
518(7540):529–533.
Narayanamurthy, S. M. and Ravindran, B. (2008). On the
Hardness of Finding Symmetries in Markov Decision
Processes. In Proceedings of the 25th international
conference on Machine learning, pages 688–695.
Paine, T. L., Paduraru, C., Michi, A., Gulcehre, C., Zolna, K.,
Novikov, A., Wang, Z., and de Freitas, N. (2020). Hy-
perparameter selection for offline reinforcement learn-
ing. arXiv preprint arXiv:2007.09055.
Papamakarios, G., Pavlakou, T., and Murray, I. (2017).
Masked autoregressive flow for density estimation.
In Proceedings of the 31st International Conference
on Neural Information Processing Systems, NIPS’17,
page 2335–2344, Red Hook, NY, USA. Curran Asso-
ciates Inc.
Park, D. S., Chan, W., Zhang, Y., Chiu, C.-C., Zoph, B.,
Cubuk, E. D., and Le, Q. V. (2019). Specaugment: A
simple data augmentation method for automatic speech
recognition. In Proc. Interspeech 2019, pages 2613–
2617.
Ravindran, B. and Barto, A. G. (2001). Symmetries and
Model Minimization in Markov Decision Processes.
Technical report, USA.
Ravindran, B. and Barto, A. G. (2004). Approximate Homo-
morphisms: A Framework for Non-exact Minimization
in Markov Decision Processes.
Seno, T. and Imai, M. (2021). d3rlpy: An offline deep
reinforcement library. In NeurIPS 2021 Offline Rein-
forcement Learning Workshop.
Shorten, C. and Khoshgoftaar, T. M. (2019). A survey on
Image Data Augmentation for Deep Learning. Journal
of Big Data, 6(1):1–48.
van der Pol, E., Kipf, T., Oliehoek, F. A., and Welling,
M. (2020a). Plannable Approximations to MDP Ho-
momorphisms: Equivariance under Actions. In Pro-
ceedings of the 19th International Conference on Au-
tonomous Agents and MultiAgent Systems, AAMAS
’20, page 1431–1439, Richland, SC. International
Foundation for Autonomous Agents and Multiagent
Systems.
van der Pol, E., Worrall, D., van Hoof, H., Oliehoek, F.,
and Welling, M. (2020b). MDP Homomorphic Net-
works: Group Symmetries in Reinforcement Learning.
In Larochelle, H., Ranzato, M., Hadsell, R., Balcan,
M. F., and Lin, H., editors, Advances in Neural Infor-
mation Processing Systems, volume 33, pages 4199–
4210. Curran Associates, Inc.
van Dyk, D. A. and Meng, X.-L. (2001). The art of data aug-
mentation. Journal of Computational and Graphical
Statistics, 10(1):1–50.
Yarats, D., Brandfonbrener, D., Liu, H., Laskin, M., Abbeel,
P., Lazaric, A., and Pinto, L. (2022). Don’t change the
algorithm, change the data: Exploratory data for offline
reinforcement learning. In ICLR 2022 Workshop on
Generalizable Policy Learning in Physical World.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
124
