
Semi-Supervised Domain Adaptation with CycleGAN Guided by
Downstream Task Awareness
Annika M
¨
utze
1
, Matthias Rottmann
1,2
and Hanno Gottschalk
1
1
IZMD & School of Mathematics and Natural Sciences, University of Wuppertal, Wuppertal, Germany
2
School of Computer and Communication Sciences, EPFL, Lausanne, Switzerland
Keywords:
Domain Adaptation, Image-to-Image Translation, Generative Adversarial Networks, Semantic Segmentation,
Semi-Supervised Learning, Real2Sim.
Abstract:
Domain adaptation is of huge interest as labeling is an expensive and error-prone task, especially on pixel-
level like for semantic segmentation. Therefore, one would like to train neural networks on synthetic domains,
where data is abundant. However, these models often perform poorly on out-of-domain images. Image-to-
image approaches can bridge domains on input level. Nevertheless, standard image-to-image approaches do
not focus on the downstream task but rather on the visual inspection level. We therefore propose a “task aware”
generative adversarial network in an image-to-image domain adaptation approach. Assisted by some labeled
data, we guide the image-to-image translation to a more suitable input for a semantic segmentation network
trained on synthetic data. This constitutes a modular semi-supervised domain adaptation method for semantic
segmentation based on CycleGAN where we refrain from adapting the semantic segmentation expert. Our
experiments involve evaluations on complex domain adaptation tasks and refined domain gap analyses using
from-scratch-trained networks. We demonstrate that our method outperforms CycleGAN by 7 percent points
in accuracy in image classification using only 70 (10%) labeled images. For semantic segmentation we show
an improvement of up to 12.5 percent points in mean intersection over union on Cityscapes using up to 148
labeled images.
1 INTRODUCTION
For automatically understanding complex visual
scenes from RGB images, semantic segmentation
(pixel-wise classification) is a common but challeng-
ing task. The state-of-the-art results are achieved by
deep neural networks (Chen et al., 2019; Tao et al.,
2020; Liu et al., 2021). These models need plenty of
labeled images to generalize. However, a manual la-
bel process on pixel level detail is time and cost con-
suming and usually error-prone (Cordts et al., 2016;
Rottmann and Reese, 2022). To reduce the label-
ing cost, weakly- and semi-supervised methods were
proposed (Dai et al., 2015; van Engelen and Hoos,
2020). These methods use weak labels like bound-
ing boxes for segmentation tasks or fewer labels as
they can benefit from a pool of unlabeled data. How-
ever, they are limited to scenarios captured in the
real world and the annotation cost of weak labels still
might be intractable (Tsai et al., 2018). On the other
hand, in recent years simulations, especially of urban
street scenes, were significantly improved (Dosovit-
skiy et al., 2017; Wrenninge and Unger, 2018). The
advantage of synthetic data is that images generated
by a computer simulation often come with labels for
the semantic content for free. Training on synthetic
data has the potential to build a well-performing net-
work as plenty of data is available and diverse scenar-
ios can be generated which are rare or life-threatening
in the real world. However, neural networks do not
generalize well to unseen domains (Hoffman et al.,
2016). Even if the model learns to generalize well on
one domain (e.g., real world) it can fail completely on
a different domain (e.g., synthetic) (Wrenninge and
Unger, 2018) or vice versa. Domain adaptation (DA)
is used to mitigate the so-called domain shift (Csurka,
2017) between one domain and another. DA aims at
improving the model’s performance on a target do-
main by transferring knowledge learned from a la-
beled source domain. It has become an active area of
research in the context of deep learning (Toldo et al.,
2020) ranging from adaptation on feature level (Tsai
et al., 2018), adaptation on input level (Hoffman et al.,
2018; Dundar et al., 2018; Brehm et al., 2022), self-
80
Mütze, A., Rottmann, M. and Gottschalk, H.
Semi-Supervised Domain Adaptation with CycleGAN Guided by Downstream Task Awareness.
DOI: 10.5220/0011630900003417
In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2023) - Volume 5: VISAPP, pages
80-90
ISBN: 978-989-758-634-7; ISSN: 2184-4321
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

training (Mei et al., 2020; Zhang et al., 2021), a
combination thereof (Kim and Byun, 2020) to semi-
supervised approaches (Chen et al., 2021). Depend-
ing on the amount of labels available in the target do-
main the DA is unsupervised (UDA; no labels avail-
able), semi-supervised (SSDA; a few labels available)
or supervised (SDA; labels exist for all training sam-
ples in the target domain) (Toldo et al., 2020). Adapt-
ing on input level to the style of the target domain dis-
regarding the downstream task at hand but preserving
the overall scene is referred to image-to-image trans-
lation (I2I) and is often realized by generative adver-
sarial networks (GANs) (Goodfellow et al., 2014).
Taking advantage of the synthetic domain we train
a downstream task expert therein. We then shift the
out-of-domain input (real world) closer to the syn-
thetic domain via a semi-supervised I2I approach
based on CycleGAN (Zhu et al., 2017) for mitigat-
ing the domain gap. We thereby refrain from chang-
ing the expert which leads to a modular DA method.
We combine the unsupervised GAN-based I2I method
from CycleGAN with a downstream task awareness
in a second stage with the help of a relatively small
contingent of ground truth (GT) in the real domain to
adapt to the needs of the downstream task network.
Our main contributions are:
• we present a novel modular SSDA method for se-
mantic segmentation guiding the generator of an
I2I domain adaptation approach to a semantic seg-
mentation task awareness. Thereby, our down-
stream task network does not need to be retrained.
• we demonstrate that our method is applicable to
multiple complex domain adaptation tasks.
• we consider a pure domain separation in our
analysis by using from-scratch-trained neural net-
works leading to a less biased domain gap.
Based on our knowledge this is the first time the gen-
erator of a GAN setup is guided with the help of a
semantic segmentation network to focus on the down-
stream task. Furthermore, the composition of genera-
tor and semantic segmentation network can be under-
stood as a method to establish an abstract intermedi-
ate representation in a data-driven manner. We study
how well the generator can adapt to its tasks of gen-
erating the abstract representation and supporting the
downstream task.
The remainder of this paper is organized as fol-
lows: In Sec. 2 we review related approaches, partic-
ularly in the context of semi-supervised domain adap-
tation. It follows a detailed description of our method
in Sec. 3. We evaluate our method on two different
tasks and three different datasets in Sec. 4, showing
considerable improvements with only a few GT data
samples. Finally, we conclude and give an outlook to
future work in Sec. 5.
2 RELATED WORK
Our work is based on two main concepts: DA with
I2I, and semi-supervised learning in the context of
GANs and DA. For I2I, GANs have shown excel-
lent performance. Formerly, paired data was needed
to adapt to the new style (Isola et al., 2017). But as
paired data is sparse, unsupervised methods were de-
veloped like CycleGAN (Zhu et al., 2017), where a
composition of GANs and a cycle consistency loss
leads to a consistent mapping between the domains.
Depending on whether and how much data is avail-
able in a paired manner, I2I is called supervised, semi-
supervised or unsupervised. For example, (Shukla
et al., 2019) propose a semi-supervised I2I approach
in the context of semantic segmentation via image to
label transformation. When using I2I in the context
of domain adaptation this taxonomy is used for the
amount of labeled data in the target domain as ex-
plained in the introduction. In the following we will
always refer to the latter taxonomy. Independent of
the label amount, for I2I in DA, a semantic consis-
tency is pursued, and the performance is measured via
the downstream task performance. To this aim (Hoff-
man et al., 2018) and (Brehm et al., 2022) make use
of the task loss in an unsupervised manner to adapt
the task network to the real domain. In addition, there
are several SSDA approaches in the context of clas-
sification (Wu et al., 2018; Saito et al., 2019; Kim
and Kim, 2020; Jiang et al., 2020; Mabu et al., 2021).
SSDA for semantic segmentation tasks is considered
less. (Wang et al., 2020) propose to adapt simulta-
neously on a semantic and global level using adver-
sarial training. A student-teacher approach aligning
the cross-domain features with the help of the intra-
domain discrepancy of the target domain, firstly con-
sidered in the context of DA by (Kim and Kim, 2020),
is proposed by (Chen et al., 2021).
Training in a two stage manner where the first
stage (pre-training) aims to initialize good network
parameters for the second stage is a common semi-
supervised learning technique. We transfer this con-
cept to GANs of an I2I method. In the context of
general GANs, using pre-training is not new. (Wang
et al., 2018) for example, analyzed pre-training for
Wasserstein GANs with gradient penalty((Gulrajani
et al., 2017)) in the context of image generation.
An overview over when, why and which pre-trained
GANs are useful is given by (Grigoryev et al., 2022).
We follow their suggestion of pre-training both the
Semi-Supervised Domain Adaptation with CycleGAN Guided by Downstream Task Awareness
81

generator and the discriminator but refrain from the
suggestion of using ImageNet pre-trained GANs to
not distort the domain gap analysis.
In general, UDA methods tend to lack important
information of the target domain compared to their
counterparts trained in a supervised manner (Chen
et al., 2021). On the other hand for I2I it is unlikely
to have paired data between real world images and
the abstract (e.g., synthetic) domain like assumed in
(Shukla et al., 2019). Furthermore, pure I2I meth-
ods are task agnostic and therefore may lack semantic
consistency (Toldo et al., 2020). For this reason we
propose a SSDA method with a task aware I2I com-
ponent. Independently of our approach, recently a
similar approach was published based on classifica-
tion in a medical context with domain gaps primarily
in image intensity and contrast (Mabu et al., 2021).
Unlike this publication, we aim at more demanding
tasks such as semantic segmentation on much broader
domain gaps like realistic to abstract domains lead-
ing to potentially broader applications. Furthermore,
our method allows an analysis of the influence of the
task awareness compared to the standard loss. In con-
trast to other above-mentioned approaches which use
ImageNet pre-trained networks, we train completely
from scratch for a pure domain separation. Further-
more, they adapt the downstream task network to mit-
igate the domain gap, whereas we keep the task net-
work fixed. This leads to a modular approach where
the real world domain can be exchanged without the
need of retraining the synthetic expert. Besides, we
consider I2I from real images to the synthetic domain
to retain the benefits of a synthetic expert. This in-
cludes the possibility to train and test on a variety of
scenarios which are rare and life-threatening in the
real world. Testing is more challenging for the other
approaches as they consider the opposite direction. In
the following we explain our method in more detail.
3 METHODOLOGY
Our method consists of three stages which are de-
picted in Fig. 1 and explained in detail in this section.
a) Training of Downstream Task Network:We assume
that we have full and inexhaustible access to labeled
data in the synthetic domain S . Based on a training set
(X, y) with X ⊂ S , we train a neural network f in a su-
pervised manner on the synthetic domain solving the
desired task (e.g., semantic segmentation or classifi-
cation). In contrast to the “common practice” (Kang
et al., 2020), we do not use ImageNet (Deng et al.,
2009) pre-trained weights for the downstream task
(Cycle)
GAN
real
world
labels
(synthetic world)
semantic segmentation
network
predicted
semantic
segmentation
mask
subset of
real world
ground truth
stage a) – Supervised training on simulated data
stage c) – Task awareness with a subset of labeled data
synthetic
world
stage b) – Unsupervised image-to-image translation
Figure 1: Concept of our method: Stage a) – Training of
a downstream task model (e.g., semantic segmentation net-
work) on the abstract/synthetic domain. Stage b) – Training
a CycleGAN based on unpaired data to transfer real data
into the synthetic domain. Stage c) – We freeze the down-
stream task network and tune the generator with the help of
a few labeled data points by guiding it based on the loss of
the downstream task network.
network backbone. To ensure a pure domain sepa-
ration and a non-biased downstream task network, we
train f completely from scratch. This ensures that the
network learns only based on the synthetic data, and
we prevent a bias towards the real world. As a con-
sequence, we accept a reduction of the total accuracy
when evaluating the model on the real domain (out-
domain accuracy). However, with the help of an inde-
pendent validation set, we measure our in-domain ac-
curacy to ensure appropriate performance in the syn-
thetic domain. After the model has reached the de-
sired performance, we freeze all parameters and keep
our synthetic domain expert fixed.
b) Unsupervised Image-to-Image Translation: To mit-
igate the domain gap between real (R ) and synthetic
(S) data, we build on the established I2I method Cy-
cleGAN (Zhu et al., 2017) – a GAN approach which
can deal with unpaired data by enforcing a cycle con-
sistency between two generators (G
S→R
and G
R →S
).
The domain discriminators to classify whether the
sample is generated or an in-domain sample are de-
noted with D
S
and D
R
. The generator loss consists of
four loss components (L
G
R →S
, L
G
S→R
, L
cyc
, L
identity
)
which are described in detail in (Zhu et al., 2017).
As adversarial losses L
G
∗
we use the least-squares
loss (Mao et al., 2017) which has already been used
for CycleGAN and leads to a more stable training ac-
cording to (Zhu et al., 2017). Let x
r
∼ p
data
denote the
data distribution in the real domain then the loss for
G
R →S
is given by
L
G
R →S
= E
x
r
∼p
data
(x
r
)
h
D
S
G
R →S
(x
r
)
− 1
2
i
(1)
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
82

The overall generator loss is defined as the weighted
sum:
L
Gen
= L
G
R →S
+ L
G
S→R
+ λ
cyc
L
cyc
+ λ
cyc
λ
id
L
identity
,
with weighting factors λ
cyc
> 0 and λ
id
> 0. This
leads to a solid image-to-image translation. However,
this translation is still task agnostic and therefore po-
tentially misses important features when transferring
the style from one domain to another.
c) Downstream Task Awareness: We use the unsuper-
vised models from stage b) as initialization for stage
c) where we extend the model training and guide the
generator with the help of a small amount of labeled
data to the downstream task. Let T
R
= {(x
r
i
, y
r
i
) ∈
R × Y : i = 1, . . . , N
L
} be a labeled subset from do-
main R with a label set Y , where N
L
denotes the
number of labeled samples. We achieve the down-
stream task awareness by extending the adversarial
loss in Eq. (1) for the generator G
R →S
based on the
loss of the downstream task network f . As task loss
we consider the (pixel-wise) cross entropy (CE) be-
tween the prediction f (x) and the label y denoted by
L
task
(x, y) = L
CE
( f (x), y).
For a labeled training sample t
i
= (x
r
i
, y
r
i
) ∈ T
R
we define the extended generator loss
ˆ
L
G
R →S
with the
help of a weighting factor α ∈ [0, 1] as follows:
ˆ
L
G
R →S
(t
i
) =(1 − α)
D
S
G
R →S
(x
r
i
)
− 1
2
|
{z }
adversarial loss as in Eq. (1)
+ α
L
CE
f (G
R →S
(x
r
i
)), y
r
i
| {z }
task loss
. (2)
We use α for a linear interpolation between the two
loss components to control the influence of one or the
other loss during training. The overall generator loss
therefore becomes:
ˆ
L
Gen
=
ˆ
L
G
R →S
+ L
G
S→R
+ λ
cyc
L
cyc
+ λ
cyc
λ
id
L
identity
The discriminator losses are kept identically.
The combination of stage b) and c) leads to our
semi-supervised learning strategy for the GAN train-
ing. For the DA the images generated by G
R →S
are
fed to f . In principle our approach is independent
of the chosen architecture as the general concept is
transferable, and we make no restriction to the under-
lying domain expert as long as a task loss can be de-
fined. Furthermore, due to our modular composition,
the intermediate representation generated by G
R →S
could also be used for additional tasks/analyses and
could be evaluated with respect to other metrics such
as those described by (Pang et al., 2021).
Figure 2: Examples of the Sketchy dataset. Top row: real
photos. Bottom row: one of the corresponding sketches.
4 NUMERICAL EXPERIMENTS
We evaluate our method on two different downstream
tasks: classification and semantic segmentation. For
the first one mentioned we consider the domain shift
between real objects and their sketches and for the se-
mantic segmentation we examine experiments on real
world urban street scenes transferred to two different
simulations. As evaluation metrics we use the well es-
tablished mean Intersection over Union (mIoU) (Jac-
card, 1912) for semantic segmentation and report ac-
curacy for classification experiments.
4.1 Classification on Real and Sketch
Data
For the classification experiments we choose sketches
as abstract representation of real world objects.
Therefore, we consider a subset of the Sketchy
dataset (Sangkloy et al., 2016). The original dataset
comprises 125 categories – a subset of the ImageNet
classes – and consists of 12,500 unique photographs
of objects as well as 75,471 sketches drawn by dif-
ferent humans. Figure 2 shows examples from the
dataset. A detailed description of the dataset gen-
eration process is given in (Sangkloy et al., 2016).
For our experiments we limit our dataset to the 10
classes alarm clock, apple, cat, chair, cup, elephant,
hedgehog, horse, shoe and teapot. As the origi-
nal dataset includes sketches which are “incorrect
in some way” (Sangkloy et al., 2016), we removed
sketches which we could not identify as the labeled
class. For validation, we randomly chose 50 sketches
per class. As the number of real photos is more lim-
ited we chose 10 random photos per class for valida-
tion. This results in a remaining training set of 4,633
sketch images and 700 real photos.
For the stage a) training we use as classifier a
ResNet18 (He et al., 2016) which is our downstream
task network. For the I2I approach based on Cycle-
GAN (stage b) and c)) we used the implementation
of (Zhu et al., 2017) and extended it according to our
method described in Sec. 3. We fix the amount of GT
data used in stage c) to 70 images (10% of the data)
Semi-Supervised Domain Adaptation with CycleGAN Guided by Downstream Task Awareness
83

real
stage b)
α = 0.1
α = 0.2
α = 0.3
α = 0.4
α = 0.5
α = 0.6
α = 0.7
α = 0.8
α = 0.9
α = 1.0
0.085
0.135
0.185
0.235
0.285
0.335
0.385
0.435
accuracy
Figure 3: Classification results of the sketch expert with dif-
ferent types of input. The performance when an RGB pho-
tograph is given as input, is indicated by “real”. CycleGAN-
only performance is denoted with “stage b)” (our method
when no task awareness is added). With increasing weight-
ing factor α the generator which generates the inputs was
trained with more emphasis on the task loss L
task
. The re-
sults are based on 70 GT (10%) images during stage c) train-
ing.
for our experiment and use the categorical cross en-
tropy loss as task loss.
After stage a) training on sketches, the classifi-
cation network f achieves an in-domain accuracy of
94.11%. When evaluating f on the real domain we
see a drop to 9% accuracy. For a 10-class prob-
lem, this performance is slightly below the perfor-
mance when predicting the classes uniformly at ran-
dom. This confirms that the domain gap between gray
scale sketches and RGB photographs is notably big-
ger than the domain gap considered in (Mabu et al.,
2021).
Feeding f with images generated by G
R →S
after
stage b) training, already improves the accuracy sub-
stantially by 27 percent points (pp) reaching an ab-
solute accuracy of 36%. When continuing training
G
R →S
with stage c), we achieve up to 43% accuracy
of f depending on how much we weight the task loss
component in Eq. (2). A quantitative comparison of
the network performance with respect to different in-
puts is shown in Fig. 3. For values of α ≤ 0.5, we ob-
serve no clear trend compared to a CycleGAN-only
training (i.e., task agnostic). Whereas, we improve
the accuracy using our method when L
task
dominates
(α > 0.5) the adversarial loss yielding a relative in-
crease of up to 7 pp.
When we only use the task loss in the genera-
tor training (α = 1.0), the performance of f drops
again. This is expected as we remove the adversar-
ial loss completely and therefore do not get notable
feedback from the discriminator. We also investigate
the change of the performance with respect to α in
our semantic segmentation experiments where we ob-
serve this trend more clearly in the CARLA setup (cf.
Fig. 8).
Exemplary, we show the results of different gen-
erators trained with different α weighting in Fig. 4.
RGB photo
one GT sketch
CycleGAN only
α = 0.2 α = 0.4 α = 0.6 α = 0.8 α = 0.9
L
task
only
cup cup
cat
shoe shoe shoe
cat
Figure 4: Qualitative results of the output of the generators
trained with different weighting (α) of the downstream task
loss. Top row: Real domain RGB photo (input of genera-
tor) and one of the ground truth sketches of the RGB photo.
Bottom row: Generated sketches and the prediction results
of the downstream task network.
The classification results of the network trained on
sketches are reported underneath the images. Even
though f classifies the shoe correctly for α = 0.6,
α = 0.8 and α = 0.9, we as human can barely see a
difference between the generated images. Neverthe-
less, these results show that with emphasis on the task
loss the generator learned to support the downstream
task.
In the next paragraph we consider semantic seg-
mentation – a distinct more challenging task – on the
domain gap between real and simulated street scenes.
4.2 Semantic Segmentation on
Simulated Street Scenes
a) Dataset: For the semantic segmentation task we
use the established dataset Cityscapes (Cordts et al.,
2016) for the real domain. The dataset contains im-
ages which were taken in multiple cities and have a
resolution of 2,048 × 1,024 pixels. For our experi-
ments we use the 2,975 images of the train split as
well as the 500 validation images where the fine an-
notations are publicly available.
For the synthetic domain we conduct our ex-
periments on two different datasets. In the first
experiment we use one of the standard dataset in
domain adaptation experiments: SYNTHIA-RAND-
CITYSCAPES (Synthia) (Ros et al., 2016). It con-
sists of 9,000 images with a resolution of 1,280×760,
randomly taken in a virtual town from multiple view
points. To have coincided classes in both domains,
we restrict the classes to the commonly used 16 for
domain adaptation which are the Cityscapes training
IDs except for train, truck and terrain (Brehm et al.,
2022). As no fixed validation set is given, we leave
out the last 1400 images during training. Using the
first 700 thereof for validation.
As a second setup we generated a dataset with the
help of the open-source simulator CARLA (Dosovit-
skiy et al., 2017) which allows for the extraction of a
strongly controlled dataset to realize our hypothesis of
unlimited data in the synthetic domain. To showcase
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
84
this we restrict our data to town 1 of CARLA with
fixed environmental settings like weather, wind etc.
We generated 3,900 images for training and 1,200 im-
ages for validation with a resolution of 1,920 × 1,080
by randomly spawning the ego vehicle on the map.
Furthermore, we spawned each time a random num-
ber of road users for a diverse scenery. Similar to
Synthia not all Cityscapes training classes exist in
CARLA. In particular, there is no distinction between
different vehicle and pedestrian types. To this end, we
fuse them into a vehicle and a pedestrian metaclass.
Therefore, we consider only 13 classes: road, side-
walk, building, wall, fence, pole, traffic light, traffic
sign, vegetation, terrain, sky, pedestrian, vehicles.
In contrast to manually labeling, the segmenta-
tion mask of CARLA is comparably fine detailed. To
adapt the more coarse labeling of a human annota-
tor and therefore generate more comparable seman-
tic segmentation masks we smooth the label and the
RGB images in a post-processing step according to
the method from (Rottmann and Reese, 2022).
b) Implementation & Results – Synthetic Domain Ex-
pert: For the semantic segmentation network f , we
use a DeepLabv3 with ResNet101 backbone (Chen
et al., 2017) ranging under the top third of seman-
tic segmentation models on Cityscapes with respect
to the comparison of (Minaee et al., 2021). We train
with Adam (Kingma and Ba, 2014) with class weight-
ing, polynomial learning rate and from scratch with-
out pre-training to evaluate the domain gap accu-
rately. To range the results, we trained and evaluated
f once on Cityscapes to state the oracle performance
of the from-scratch-trained network independently of
our experiments. This led to a mIoU of 62.74% on
the validation set. This model is only used as refer-
ence and therefore we refrained from hyperparameter
tuning.
For the experiments with Synthia as synthetic do-
main, we trained f for 3 days with a batch size of 2
due to GPU memory capacity which led to 107 epochs
of training on the training dataset. During training, we
crop patches of size 1,024 × 512 and flip horizontally
with a chance of 50%. On the in-domain validation
set we achieve a mIoU of 64.83%.
For the experiments with CARLA as synthetic
domain, we trained our network for 200 epochs
with random quadratic crops of size 512. The best
mIoU achieved on the validation set during training
is 91.89%. Benefiting from the simulation we con-
structed a meaningful in-domain expert with this. As
the image resolution of Synthia and CARLA images,
differ from the resolution of Cityscapes, a resizing is
necessary. Depending on the scaling and aspect ra-
tio the network’s prediction performance differs. We
0 0.2 0.4 0.6 0.8 1
0.21
0.23
0.25
0.27
0.29
0.31
0.33
0.35
loss weight α
mIoU
segmentation performance of our method
Figure 5: Influence of the task loss based on the Synthia
experiment setup. The weighting represents a linear inter-
polation between the adversarial generator loss and the task
loss (cf. Eq. (2)), resulting in the original CycleGAN imple-
mentation for α = 0 and the pixel-wise cross entropy loss
for α = 1.
chose the scaling with the best performance, which
we found for 1,024 × 512. For a fair comparison we
let the GANs generate the same resolution.
c) Implementation Details – Domain Shift: When not
denoted otherwise we used 175 epochs for the stage
b) training (task agnostic training) and additionally 50
epochs for the stage c) training where labeled data is
available. We use the pixel-wise cross entropy as task
loss. To balance the scale of the task loss L
task
with
respect to the adversarial generator loss L
G
R →S
we in-
clude an additional scaling factor γ. Multiplying the
task loss with γ leads to more balanced loss compo-
nents and therefore a better interpretability.
d) Experiment Setup and Results: First experiments
were done on a mixture of labeled and unlabeled data,
but we experienced an unstable training when alter-
nating between the corresponding loss functions
ˆ
L
Gen
and L
Gen
. Splitting the generator training into two
stages as described in Sec. 3, led to a more stable
training and therefore better results.
As explained in Sec. 2, due to the pure domain
separation we are considering, a direct comparison to
other DA methods is barely meaningful. Hence, for
evaluation we compare our approach with the same
types of methods as done in (Mabu et al., 2021):
M1. Synthetic domain expert f fed with images gen-
erated by G
R →S
based on CycleGAN-only train-
ing (stage b) only; equaling α = 0.0)
M2. Synthetic domain expert f fed with real im-
ages without domain transformation (original
Cityscapes images)
M3. Semantic segmentation network f
R
trained from
scratch in a supervised manner on the same
amount of labeled real-world images as available
at stage c).
During the GAN-training we evaluate f on the (GAN-
transformed) Cityscapes validation set and report the
best mIoU during training.
Semi-Supervised Domain Adaptation with CycleGAN Guided by Downstream Task Awareness
85

Table 1: Domain gap comparison of networks trained from
scratch vs. ImageNet pre-trained (Dundar et al., 2018) with
Cityscapes as out-of-domain (ood) evaluation.
Synthia → Cityscapes (mIoU in %)
method ood oracle gap
ImageNet pre-trained 31.8 75.6 43.8
from scratch (ours) 9.9 62.7 52.8
To analyze the impact of the different loss compo-
nents in the Synthia setup, we set the scaling parame-
ter γ empirically to 0.25, we fix the GT amount to 5%
(148 labeled training images) and vary the weighting
parameter α between 0 and 1. The corresponding re-
sults are shown in Fig. 5. We see the positive impact
of the task awareness in the growing mIoU values.
Using a weighting of α = 0.9 for L
task
, we achieve
34.75% mIoU which is a performance increase of
13.41 pp compared to M1 (task agnostic training).
In Fig. 6 we show for one example the differ-
ently generated images as well as their predictions
by the synthetic expert. The column “Cityscapes”
in Fig. 6 illustrates the low prediction performance
of a synthetic domain expert when never having seen
real-world images (M2). The network’s performance
drops to roughly 10% when real world images are
used as input for the domain expert. Here we see a
significant difference to results reported by other do-
main adaptation methods which use ImageNet pre-
trained networks, e.g., (Dundar et al., 2018). The do-
main gap is summarized in Tab. 1 where we com-
pare ImageNet pre-trained network performance to
ours evaluated on Cityscapes. We state out-of-domain
performance (i.e., trained on Synthia; second col-
umn), oracle performance (i.e., trained on the full
Cityscapes training dataset; third column), and the
domain gap between them, measured as difference
in performance (last column). The results indi-
cate that the ImageNet pre-training already induces
a bias towards the real domain distorting a pure do-
main separation which should be avoided when an-
alyzing domain gaps. Based on our training-from-
scratch setup, using task agnostic generated images
(M1) improves already significantly the performance
(11.44 pp) whereas our approach (task aware GAN)
can lead to a relative improvement of up to 24.85 pp
when 5% GT images are available.
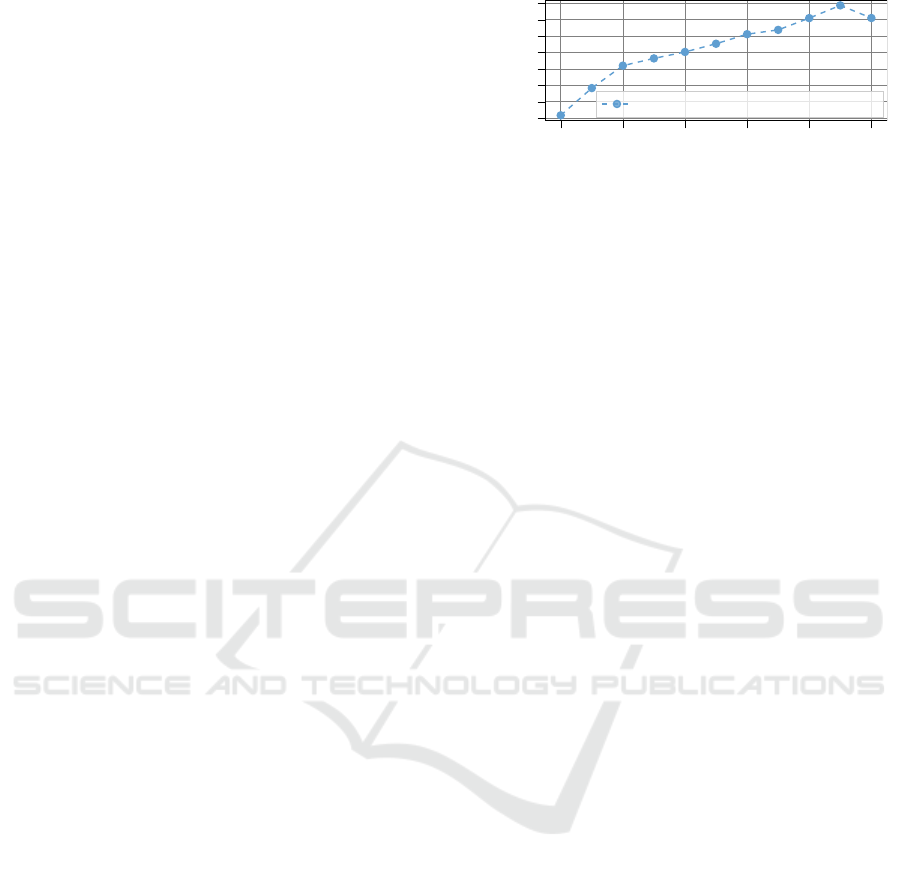
Moreover, we analyze the capacity of the method
based on the amount of GT available. Therefore, we
fix α = 0.8 and vary the GT amount for the stage
c) training. We randomly sample images from the
Cityscapes training dataset for each percentage but
fix the set of labeled data for the experiments with
CARLA and “Cityscapes-only” training (M3) for the
sake of comparison. Results are shown in Fig. 7
(blue curve). The dotted horizontal line is the mIoU
achieved by f when exclusively feeding images gen-
erated by the task agnostic GAN after finishing stage
b) training. For a fair comparison we trained the task
agnostic GAN for another 125 epochs which results
in a better mIoU of 21.34% which we use as result
for GT = 0 (equaling α = 0.0). For our experiment
we compare 0.5% (14 images), 1% (29 images), 2%
(59 images), 5% (148 images) and 10% (297 images)
of GT data for the stage c) training. Triggering the
task awareness with only 14 images already improves
the network accuracy by 6.75 pp. The results show
that training G
R →S
with the task loss on negligible
few GT data, improves the network’s understanding
of the scene without retraining the network itself.
Additionally, we compare our method with results
of f
R
(M3). Having no labeled data, a supervised
method can barely learn anything. Therefore, we set
the value to the same as for 0.5% GT which most
likely overestimates the performance. The results are
visualized by the orange curve in Fig. 7. The results
show that our method outperforms M3 by a distinct
margin when only a few labels are available. How-
ever, when we have access to more than 297 (10%)
fine labeled images of Cityscapes, a direct supervised
training should be taken into consideration.
For the CARLA experiments we set γ = 1, as the
losses are already in the same scale. We repeat the
three experiments on our CARLA dataset. The results
of varying α are visualized by the blue curve in Fig. 8.
Also, on the CARLA dataset our method shows a
notable improvement over CycleGAN-only training
(M1; α = 0) when choosing a balanced weighting be-
tween the adversarial and the task loss. These exper-
iments confirm that the task awareness improves the
performance, but the task loss should be used in addi-
tion and not as a stand-alone concept.
The results of the GT amount variation are shown
in Fig. 9 for α = 0.4 where the blue curve represents
the best mIoU results achieved with our method and
the orange curve shows the results of f
R
(M3) given
different amount of GT. As before our method out-
performs M1 as well as M3 when less than 5% GT
is available. Above that, the supervised method is
superior. The distinct improved semantic segmenta-
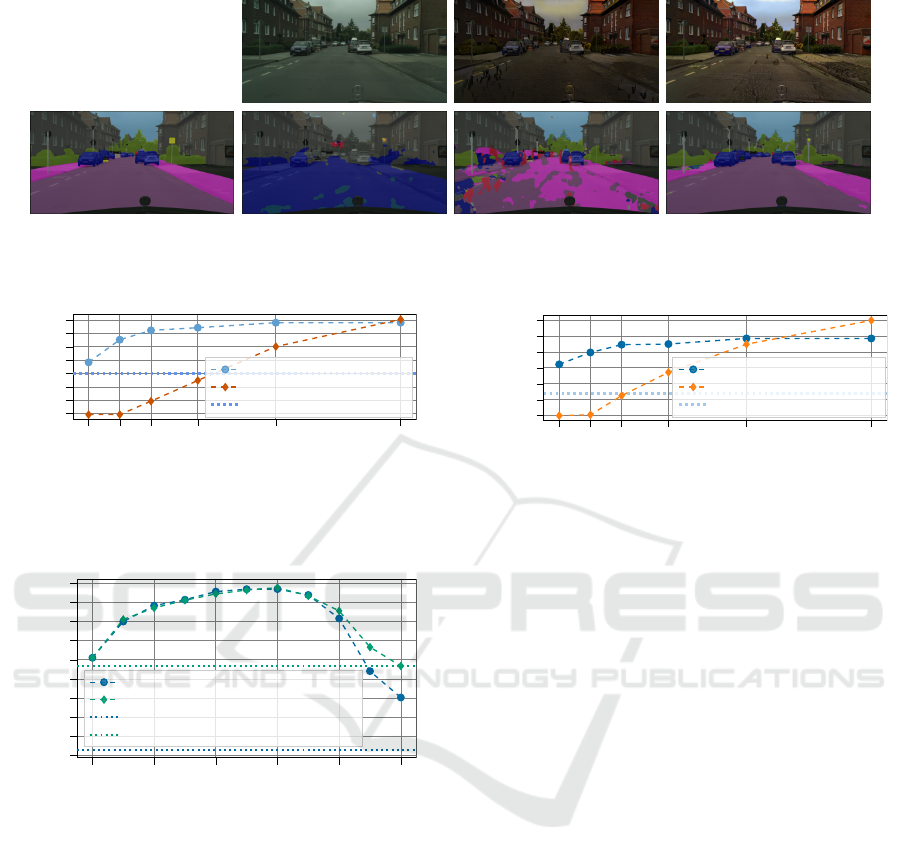
tion of the street scene can also be seen in the qualita-
tive results shown in Fig. 10 (bottom row). As in the
previous experiment visual differences recognizable
by humans of the generated images with CycleGAN
(top row mid) and our method (top row right) are lim-
ited. Furthermore, we see again the low performance
caused by the domain gap when feeding real images
to our from-scratch-trained synthetic expert f . On the
untranslated images (M3), f yields an mIoU of 9%.
Hence, the observed results achieved by our method
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
86
Cityscapes ground truth
Cityscapes
prediction of Cityscapes
CycleGAN
prediction of transf. image
Task aware GAN (ours)
prediction of transf. image
Figure 6: Comparison of prediction results of an untranslated Cityscapes image (left), task agnostic I2I (mid) and our approach
(right) based on a semantic segmentation network trained on Synthia.
0 0.5 1 2 5 10
0.06
0.10
0.14
0.18
0.22
0.26
0.30
0.34
GT amount used for training (%)
mIoU
our method based on Synthia
Cityscapes (16 classes)
start point stage c)
Figure 7: Performance comparison of our method based on
Synthia setup with different amount of ground truth (blue)
and a from scratch supervised training on Cityscapes with
the same amount of data (orange).
0 0.2 0.4 0.6 0.8 1
0.175
0.200
0.225
0.250
0.275
0.300
0.325
0.350
0.375
0.400
loss weight α
mIoU
complete method with 175 epochs stage b)
complete method with 285 epochs stage b)
start point stage c) (175 epochs)
start point stage c) (285 epochs)
Figure 8: Influence of the task loss for the CARLA exper-
iment setup. The weighting represents a linear interpola-
tion between the adversarial generator loss and the task loss
Eq. (2). Results after stage c) based on a 175 epochs unsu-
pervised GAN-training are shown in blue. The green graph
shows the method performance when trained with a longer
amount of stage b) steps.
demonstrate a significant reduction of the domain gap
via generating more downstream task relevant visual
features.
Lastly, we consider a longer stage b) training to
find out whether a longer training further improves
the results. We train in total 285 epochs in stage b)
and show the results of the complete method with 5%
GT in Fig. 8 visualized by the green curve. The ex-
periments reveal that a moderate number of epochs
for stage b) is already enough for a good initialization
of stage c). Although we start the stage c) training
0 0.5 1 2 5 10
0.10
0.16
0.22
0.28
0.34
0.40
0.46
GT amount used for training (%)
mIoU
our method based on CARLA
Cityscapes (13 classes)
start point stage c)
Figure 9: Performance comparison of our method based on
CARLA setup with different amount of GT (blue) and of
f
R
which is trained from scratch in a supervised manner on
Cityscapes with the same amount of data (orange).
with a higher mIoU (dotted lines) when trained with
stage b) for more steps, the experiments show that we
achieve nearly the same absolute mIoU values.
5 CONCLUSION AND OUTLOOK
In this paper, we presented a modular semi-supervised
domain adaptation method based on CycleGAN
where we guide the generator of the image-to-image
approach towards downstream task awareness with-
out retraining the downstream task network itself. In
our experiments we showed on a “real to sketch” do-
main adaptation classification task that the method
can cope with large domain gaps. Furthermore, we
showed that our method can be applied to more com-
plex downstream tasks like semantic segmentation
yielding significant improvements compared to a pure
I2I approach and from scratch training when a lim-
ited amount of GT is available. Besides, we analyzed
the impact of the task awareness and the GT. Con-
trary to the common practice, all results were pro-
duced based on a non-biased domain gap. To this end,
we trained all components from scratch. Our achieved
results suggest that the commonly used ImageNet pre-
trained backbone already incorporates real world do-
main information and therefore distorts the gap analy-
sis. Additionally, we showed that we can achieve very
Semi-Supervised Domain Adaptation with CycleGAN Guided by Downstream Task Awareness
87

Cityscapes ground truth
Cityscapes
prediction of Cityscapes
CycleGAN
prediction of transf. image
Task aware GAN (ours)
prediction of transf. image
Figure 10: Comparison of prediction results of an untranslated Cityscapes image (left), task agnostic style transfer (mid) and
our approach (right) based on a semantic segmentation network trained on our CARLA dataset.
strong models when considering abstract representa-
tions (like sketches or modifiable simulations).
For future work, we are interested in elaborat-
ing more on the (intermediate) abstract representa-
tion, e.g., investigating if the robustness of the model
can benefit from it. Additionally, it has potential to
help us better understand which visual features are
important for a downstream task network. Generat-
ing more informative images for a downstream task
network might give insights into the network behav-
ior and help generate datasets which are cut down to
the most important aspects of the scene for a neu-
ral network which is not necessarily what a human
would describe as meaningful. Moreover, an uncer-
tainty based data selection strategy for stage c) train-
ing, could further improve the method. In addition,
the method could be combined with self-training as
these models need a good initialization to generate
reasonable pseudo labels (Mei et al., 2020). Never-
theless, when training the downstream task network
completely from scratch, we have shown that the net-
work performance is questionably low. Therefore, our
method can be seen as complementary to the self-
training approaches to ensure a reasonable prediction
of the network in early stages.
ACKNOWLEDGMENT
This work is funded by the German Federal Ministry
for Economic Affairs and Climate Action within the
project “KI Delta Learning”, grant no. 19A19013Q.
We thank the consortium for the successful coop-
eration. Moreover, the authors gratefully acknowl-
edge the Gauss Centre for Supercomputing e.V.
(www.gauss-centre.eu) for funding this project by
providing computing time through the John von Neu-
mann Institute for Computing (NIC) on the GCS Su-
percomputer JUWELS (J
¨
ulich Supercomputing Cen-
tre, 2019) at J
¨
ulich Supercomputing Centre (JSC).
Furthermore, we thank Hannah L
¨
orcks for assisting
in setting up the classification experiments.
REFERENCES
Brehm, S., Scherer, S., and Lienhart, R. (2022). Semanti-
cally consistent image-to-image translation for unsu-
pervised domain adaptation. ICAART, 2:131–141.
Chen, L.-C., Papandreou, G., Schroff, F., and Adam, H.
(2017). Rethinking Atrous Convolution for Semantic
Image Segmentation. arXiv:1706.05587.
Chen, Y., Li, W., Chen, X., and Van Gool, L. (2019). Learn-
ing Semantic Segmentation From Synthetic Data: A
Geometrically Guided Input-Output Adaptation Ap-
proach. In 2019 IEEE/CVF Conference on Computer
Vision and Pattern Recognition, pages 1841–1850.
Chen, Y., Ouyang, X., Zhu, K., and Agam, G. (2021). Semi-
supervised Domain Adaptation for Semantic Segmen-
tation. arXiv:2110.10639.
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler,
M., Benenson, R., Franke, U., Roth, S., and Schiele,
B. (2016). The Cityscapes Dataset for Semantic Ur-
ban Scene Understanding. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 3213–3223.
Csurka, G. (2017). Domain Adaptation for Visual Applica-
tions: A Comprehensive Survey. arXiv:1702.05374.
Dai, J., He, K., and Sun, J. (2015). Boxsup: Exploit-
ing bounding boxes to supervise convolutional net-
works for semantic segmentation. In Proceedings of
the IEEE international conference on computer vi-
sion, pages 1635–1643.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei,
L. (2009). ImageNet: A Large-Scale Hierarchical Im-
age Database. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
Workshops.
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., and
Koltun, V. (2017). CARLA: An Open Urban Driving
Simulator. In Conference on Robot Learning, pages
1–16. PMLR.
Dundar, A., Liu, M.-Y., Wang, T.-C., Zedlewski, J., and
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
88

Kautz, J. (2018). Domain stylization: A strong, sim-
ple baseline for synthetic to real image domain adap-
tation. arXiv:1807.09384.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A., and Ben-
gio, Y. (2014). Generative adversarial nets. In
Proceedings of the 27th International Conference on
Neural Information Processing Systems - Volume 2,
NIPS’14, pages 2672–2680, Cambridge, MA, USA.
MIT Press.
Grigoryev, T., Voynov, A., and Babenko, A. (2022).
When, Why, and Which Pretrained GANs Are Use-
ful? arXiv:2202.08937.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and
Courville, A. (2017). Improved Training of Wasser-
stein GANs. arXiv:1704.00028.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep Resid-
ual Learning for Image Recognition. In Proceedings
of the IEEE Conference on Computer Vision and Pat-
tern Recognition, pages 770–778.
Hoffman, J., Tzeng, E., Park, T., Zhu, J.-Y., Isola, P.,
Saenko, K., Efros, A., and Darrell, T. (2018). Cy-
CADA: Cycle-Consistent Adversarial Domain Adap-
tation. In International Conference on Machine
Learning, pages 1989–1998. PMLR.
Hoffman, J., Wang, D., Yu, F., and Darrell, T. (2016). FCNs
in the Wild: Pixel-level Adversarial and Constraint-
based Adaptation. arXiv:1612.02649.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017).
Image-to-Image Translation with Conditional Adver-
sarial Networks. In 2017 IEEE Conference on Com-
puter Vision and Pattern Recognition, pages 5967–
5976.
Jaccard, P. (1912). The Distribution of the Flora in the
Alpine Zone. New Phytologist, 11(2):37–50.
Jiang, P., Wu, A., Han, Y., Shao, Y., Qi, M., and Li, B.
(2020). Bidirectional Adversarial Training for Semi-
Supervised Domain Adaptation. In Twenty-Ninth In-
ternational Joint Conference on Artificial Intelligence,
volume 1, pages 934–940.
J
¨
ulich Supercomputing Centre (2019). JUWELS: Modu-
lar Tier-0/1 Supercomputer at the J
¨
ulich Supercom-
puting Centre. Journal of large-scale research facili-
ties, 5(A135).
Kang, G., Wei, Y., Yang, Y., Zhuang, Y., and Hauptmann,
A. (2020). Pixel-Level Cycle Association: A New
Perspective for Domain Adaptive Semantic Segmen-
tation. In Advances in Neural Information Processing
Systems, volume 33, pages 3569–3580. Curran Asso-
ciates, Inc.
Kim, M. and Byun, H. (2020). Learning Texture Invari-
ant Representation for Domain Adaptation of Seman-
tic Segmentation. In Proceedings of the IEEE/CVF
conference on computer vision and pattern recogni-
tion, pages 12975–12984.
Kim, T. and Kim, C. (2020). Attract, Perturb, and Ex-
plore: Learning a Feature Alignment Network for
Semi-supervised Domain Adaptation. In European
conference on computer vision – ECCV 2020, pages
591–607, Cham. Springer International Publishing.
Kingma, D. P. and Ba, J. (2014). Adam: A method for
stochastic optimization. arXiv:1412.6980.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin,
S., and Guo, B. (2021). Swin transformer: Hierarchi-
cal vision transformer using shifted windows. In Pro-
ceedings of the IEEE/CVF International Conference
on Computer Vision, pages 10012–10022.
Mabu, S., Miyake, M., Kuremoto, T., and Kido, S. (2021).
Semi-supervised CycleGAN for domain transforma-
tion of chest CT images and its application to opacity
classification of diffuse lung diseases. International
Journal of Computer Assisted Radiology and Surgery,
16(11):1925–1935.
Mao, X., Li, Q., Xie, H., Lau, R. Y. K., Wang, Z., and
Paul Smolley, S. (2017). Least Squares Generative
Adversarial Networks. In Proceedings of the IEEE
International Conference on Computer Vision, pages
2794–2802.
Mei, K., Zhu, C., Zou, J., and Zhang, S. (2020). In-
stance Adaptive Self-Training for Unsupervised Do-
main Adaptation. arXiv:2008.12197.
Minaee, S., Boykov, Y. Y., Porikli, F., Plaza, A. J., Kehtar-
navaz, N., and Terzopoulos, D. (2021). Image Seg-
mentation Using Deep Learning: A Survey. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence.
Pang, Y., Lin, J., Qin, T., and Chen, Z. (2021). Image-to-
Image Translation: Methods and Applications. IEEE
Transactions on Multimedia.
Ros, G., Sellart, L., Materzynska, J., V
´
azquez, D., and
L
´
opez, A. M. (2016). The SYNTHIA Dataset: A
Large Collection of Synthetic Images for Semantic
Segmentation of Urban Scenes. In The IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 3234–3243.
Rottmann, M. and Reese, M. (2022). Automated Detection
of Label Errors in Semantic Segmentation Datasets
via Deep Learning and Uncertainty Quantification.
arXiv:2207.06104.
Saito, K., Kim, D., Sclaroff, S., Darrell, T., and Saenko,
K. (2019). Semi-supervised domain adaptation via
minimax entropy. In Proceedings of the IEEE/CVF
International Conference on Computer Vision, pages
8050–8058.
Sangkloy, P., Burnell, N., Ham, C., and Hays, J. (2016).
The sketchy database: learning to retrieve badly
drawn bunnies. ACM Transactions on Graphics,
35(4):119:1–119:12.
Shukla, S., Van Gool, L., and Timofte, R. (2019). Extremely
Weak Supervised Image-to-Image Translation for Se-
mantic Segmentation. In 2019 IEEE/CVF Interna-
tional Conference on Computer Vision Workshop (IC-
CVW), pages 3368–3377. ISSN: 2473-9944.
Tao, A., Sapra, K., and Catanzaro, B. (2020). Hierarchi-
cal multi-scale attention for semantic segmentation.
arXiv:2005.10821.
Toldo, M., Maracani, A., Michieli, U., and Zanuttigh, P.
(2020). Unsupervised Domain Adaptation in Seman-
tic Segmentation: A Review. Technologies, 8(2):35.
Semi-Supervised Domain Adaptation with CycleGAN Guided by Downstream Task Awareness
89

Tsai, Y.-H., Hung, W.-C., Schulter, S., Sohn, K., Yang, M.-
H., and Chandraker, M. (2018). Learning to Adapt
Structured Output Space for Semantic Segmentation.
In 2018 IEEE/CVF Conference on Computer Vision
and Pattern Recognition, pages 7472–7481.
van Engelen, J. E. and Hoos, H. H. (2020). A sur-
vey on semi-supervised learning. Machine Learning,
109(2):373–440.
Wang, Y., Wu, C., Herranz, L., van de Weijer, J., Gonzalez-
Garcia, A., and Raducanu, B. (2018). Transferring
GANs: generating images from limited data. In Pro-
ceedings of the European Conference on Computer Vi-
sion, pages 218–234.
Wang, Z., Wei, Y., Feris, R., Xiong, J., Hwu, W.-M., Huang,
T. S., and Shi, H. (2020). Alleviating Semantic-
Level Shift: A Semi-Supervised Domain Adaptation
Method for Semantic Segmentation. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition Workshops, pages 936–937.
Wrenninge, M. and Unger, J. (2018). Synscapes: A Pho-
torealistic Synthetic Dataset for Street Scene Parsing.
arXiv:1810.08705.
Wu, Z., Han, X., Lin, Y.-L., Uzunbas, M. G., Goldstein,
T., Lim, S. N., and Davis, L. S. (2018). Dcan:
Dual channel-wise alignment networks for unsuper-
vised scene adaptation. In Proceedings of the Euro-
pean Conference on Computer Vision, pages 518–534.
Zhang, P., Zhang, B., Zhang, T., Chen, D., Wang, Y., and
Wen, F. (2021). Prototypical pseudo label denois-
ing and target structure learning for domain adap-
tive semantic segmentation. In Proceedings of the
IEEE/CVF conference on computer vision and pattern
recognition, pages 12414–12424.
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. (2017).
Unpaired Image-to-Image Translation using Cycle-
Consistent Adversarial Networks. In IEEE Interna-
tional Conference on Computer Vision (ICCV).
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
90
