
Upper Bound Tracker: A Multi-Animal Tracking Solution for Closed
Laboratory Settings
Alexander Dolokov
1,∗
a
, Niek Andresen
1,3,∗ b
, Katharina Hohlbaum
4 c
,
Christa Th¨one-Reineke
2,3
d
, Lars Lewejohann
2,3,4 e
and Olaf Hellwich
1,3 f
1
Department of Computer Vision & Remote Sensing, Technische Universit¨at Berlin, 10587 Berlin, Germany
2
Institute of Animal Welfare, Animal Behavior, and Laboratory Animal Science, Department of Veterinary Medicine,
Freie Universit¨at Berlin, 14163 Berlin, Germany
3
Science of Intelligence, Research Cluster of Excellence, Marchstr. 23, 10587 Berlin, Germany
4
German Federal Institute for Risk Assessment (BfR ), German Centre for the Protection of Laboratory Animals (Bf3R),
https://ww w.scienceofintelligence.de
Keywords:
Multiple Object Tracking, Upper Bound Tracker, Identity Switches, Mouse Home Cage Surveillance.
Abstract:
When tracking multiple identical objects or animals in video, many erroneous results are implausible right
away, because they ignore a fundamental truth about the scene. Often the number of visible targets is bounded.
This work i ntroduces a multiple object pose estimation solution for the case that this upper bound is known.
It dismisses all detections that would exceed the maximally permitted number and is able t o re-identify an
individual after an extended period of occlusion including the re-appearance in a different place. An example
dataset wi th four f r eely interacting laboratory mice is additionally introduced and the tracker’s performance
demonstrated on it. The dataset contains various conditions ranging from almost no opportunity to hide for
the mice to a fairly cluttered environment. The approach is able to significantly reduce the occurrences of
identity switches - the error when a known individual is suddenly identified as a different one - compared to
other current solutions.
1 INTRODUCTION
Automatic video analysis often requires tracking of
specific objects in the scene. That means a comp uter
system has to be able to re cognize and localize some-
thing, whic h it has been told to follow, in every frame
of a video. In the application to observing animals
there can be th e additional requirement to track not
only one individual and its body parts, but multiple si-
multaneously. To the human ob server individuals ca n
appear identical, while - throu gh the utilization of vi-
sual appearanc e and the time compon ent - the system
has to be able to distinguish and identify them.
a
https://orcid.org/0000-0003-0207-4372
b
https://orcid.org/0000-0002-3596-0795
c
https://orcid.org/0000-0001-6681-9367
d
https://orcid.org/0000-0003-0782-2755
e
https://orcid.org/0000-0002-0202-4351
f
https://orcid.org/0000-0002-2871-9266
∗
These authors contributed equally to this work
1.1 Multiple Object Tracking and Pose
Estimation
Multiple Object Tracking (MOT) is challenging and
solutions ar e often not good enough without human
correction of error. In this work, we consider the
case, where a numbe r of near ly identical individ-
uals and their pre-defined (body) parts should be
tracked across all frames (Multi-Obje ct Po se Estima-
tion). Our c ontribution is not limited to the task of
pose estimation, but can also be used for situations
where no keypoints play a role. Since it is most use-
ful in laboratory animal settings, in which pose is of-
ten necessary, we present it in the Multi-Obje ct Pose
Estimation context.
1.2 Typical Frameworks
A typical Multi-Object Po se Estimation framework
performs three steps (top-down, Figure 1 (a)): 1) Ob-
ject Detection, 2) Body Part Detection and 3) Track-
Dolokov, A., Andresen, N., Hohlbaum, K., Thöne-Reineke, C., Lewejohann, L. and Hellwich, O.
Upper Bound Tracker: A Multi-Animal Tracking Solution for Closed Laboratory Settings.
DOI: 10.5220/0011609500003417
In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2023) - Volume 5: VISAPP, pages
945-952
ISBN: 978-989-758-634-7; ISSN: 2184-4321
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
945

(a)
(b)
Figure 1: (a) Top-down processing: An object detector
finds the individuals. Another detector finds the body parts
around the location of the detected objects. (b) Bottom-up
processing: All body parts on the whole image are detected.
As a separate step they have to be assembled and thereby as-
signed to individuals.
ing. Object Detection finds the individuals, Body Part
Detection finds the bo dy parts of each individual and
Tracking assigns every detection to a n individual. In
contrast to de te c ting all occurring body parts on the
whole image (bottom-up, Figure 1 (b)), the top-down
structure allows a better resolution when detecting
body parts, because the detection is run on a c rop of
the original image. On the other ha nd it n ecessitates
the training of two separate networks: the object de-
tector and th e body part detector.
1.3 Other Tracking Solutions
There are two rec ent tra cking solutions attacking the
problem from slightly different an gles. DeepLabCut
(DLC) by Mathis et al. (Mathis et al., 2018) is an
accurate tracker being used in many applications on
animal videos. It is based on the first step of Deep-
erCut (Insafutdinov et al., 2016) - a model for hu-
man pose estimation. DLC uses a pre-trained ResNet
(He et al., 2016) ar chitecture for feature extraction
followed by deconvolutions outputting a heatmap lo-
cating the specific body part. It is able to reliably
find arbitrary ima ge features based on just a few hun-
dred training examples usually. With the recent re-
lease of version 2.2 it is also able to track multiple
individuals at a time (La uer et al., 2 021). Here the
authors use a different orde r of the steps sketche d in
subsection 1. 2. They first perform body part detection
and then assemble all the individuals (i.e. bottom-up)
claiming, that the object detection as the first step of-
ten fails, when multiple individuals interact. At the
end of tracking in DLC a stitching operation is per-
formed, that optimizes the tracks globally. Each pair
of consecutive track lets gives an affinity value and the
merging of tracklets is chosen such that the total a ffin-
ity is minimal. Here the optimal choice is found by a
min-cost flow algorithm. In contrast to the proposed
method, DLC internally crea te s a model of how the
individual bodyparts compose the whole, such that
the detected part can be attributed to the right individ-
ual, even if other individuals are close by. The false
detection of only one body par t can trigger th e cre-
ation of a new individual track - an event the propo sed
approa c h tries to prevent. SLEAP is an other open-
source tracking framework (Pereira et al., 2022). It
includes both bottom-up and top-down approac hes
also for multiple individuals and their bo dy parts. It
relies on an interactive lea rning process with a human
in the loop. The user lab els some data, lets the method
predict and then fixes erroneous detections, which are
then used for fu rther training and so on. For step 3)
Tracking two options are offered: Optical Flow or
Kalman Filter. Both try to generate a pred ic tion of
where a track will continue in a new frame. Those
predictions are then match e d to the detections min-
imizing the matching cost. Both DLC an d SLEAP
allow a manual repair of switch e d identities during
tracking. False detections have to be removed manu-
ally, since no fixed upper bound is employed.
1.4 Multitracker Features
The Multitracker fra mework introduced in this work
utilizes currently successful deep learning methods
for all steps and introduces a novel approach to step
3) Tracking, that leverages the knowledge of the max-
imum number of individuals present, which is avail-
able in many laboratory animal applications.
For Step 1) Object Detection. the here imple-
mented method is YOLOX (Ge e t al., 2021). The
YOLO approa c h handles the detection and clas-
sification of objects in an ima ge in one deep
network, while outper forming alternative meth-
ods (Redmon et al., 2016) such as Faster R-CNN
(Ren et al., 2016). We chose YOLOX, because it
combines high quality predictions with high effi-
ciency. It allows d ifferently scale d models, which e n-
ables users to tune the tr ade-off between speed and ac-
curacy themselves. SSD (Liu et al., 2016) is another
successful method, but it did not perform a s well as
YOLOX on the mouse data while being comparable
in speed. SSD is thus not included in the Multitracker
framework.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
946

For Step 2) Keypoint Detection. the here imple-
mented especially successful and frequently used op-
tions are Efficient U-Net (Ronneberger et al., 2015),
Stacked Hourglass Network (Newell et al., 2016)
and Pyramid Scene Parsing Network (PSP)
(Zhao et al., 2017). These methods are available
in the provided framework, but are no t elaborated or
evaluated in this work.
For Step 3) Tracking. four methods are of-
fered. The two widely adopted MOT algorithms
SORT (Bewley et al., 2016) and the V-IoU Tracker
(Bochinski et al., 2018), the curr ent state-of-the- art
OC-SORT (Cao e t al., 2022) as well as the novel Up-
per Bound Tracker introdu ced in this work. All four
perform track assignment, estimation, and ma nage-
ment based on bounding boxes created by an object
detector. A motion model or the curr ent frame is
used to estimate the current location using the past
track data. These estimated tracks are then m atched
with the new detections. Afterwards the creation and
deletion of tracks is managed based on simple rules.
The different approaches in each of these steps dis-
tinguish the m ethods. SORT (Bewley et al., 2016)
is a tracking method , that utilizes a Kalman Fil-
ter (Kalman, 1960) to estimate the next position in
a track. Afterwards it maxim iz es the intersection
over union (IoU) between tracks and detec tions with
the help of the Hungarian algorithm. SORT creates
new tracks after an unmatched detection and deletes
them if they could not be matched with a detection
too many time steps in a row. This sophisticated
method is able to co pe with inconsistent detections
through the Kalman filter. Observaion-Centric SORT
(OC-SORT) (Cao et al., 2022) is based on SORT,
but introduces improvements to the Kalman Filter
step. There the prediction s for the next step are not
assumed linear, which leads to large improvements
over SORT in situations of oc clusions and non-linear
movement. The Visual-I ntersection-over-Union (V-
IoU) tracker (Bochinski et al., 2018) relies on more
consistent detections. A new detectio n is matched to
a track by computing the IoU between it and the previ-
ous d e te ctions. If the intersection is high, the new de-
tection likely belongs to that track. Unmatched tracks
are continued with a visual tracker to fill detections
gaps at least for some number of time steps. The same
is done backwards in time with unmatched detections.
The fourth and final tracking method is designed for
a slightly less general setting, that is introduc e d in the
next section.
The code is publicly available on GitHu b
1
.
1
https://github.com/dolokov/upper
bound tracking
2 UPPER BOUND TRACKING
Most MOT benchmarks (Dendorfer et al., 2020) track
objects in open world settings, e.g. public surveil-
lance cameras in public spaces. Video sequences and
their corresponding trac ks are relatively short. No
prior information about the total number of individual
objects is known. In some behavioural observation
experiments however, c ameras film animals w ithin a
cage. In this closed world setting, a small number of
subjects is filmed for a lon g time. For eac h video, the
total number of participating animals is known. We
call this setting ”Upper Bound Tracking” as it con-
tains a strict upper bound for the number of visible
subjects a t any time. Utilizing this knowledge can
improve tracking significantly and is at the center of
the proposed Upper Bound Tracker (UBT). By careful
design, tracking rules ca n be derived that guaran te e to
never violate the upper bound while at the same time
increase global track consistency.
3 METHOD
The Upper Bound Tracker (UBT) is based on OC-
SORT (Cao et al., 2022) and contains adjustme nts to
the creation of new tracks and to the reconnection of
lost tracks. It is designed to reduce identity switches
compare d to other tr ackers by preventing spurious
detections to create new tra cks. Like SORT a nd
OC-SORT, the UBT is similar to the V-IoU Tracker
(Bochinski et al., 2018) by assigning a new detection
to a track if they have a large IoU. But it never cre-
ates new tracks if the upper bound for the number of
individuals is already reached. Additionally a novel
reidentification step is introduced, that connects a pre-
viously lost track to a new appearing one. In conju nc-
tion with the strict upper bound this reidentification
takes effect, when an animal was occluded for an ex-
tended period o f time - leading to less than the maxi-
mum amount of individuals visible - and reappears at
a later point. This way the correct identity is assigned
again given that in the meantime the other individuals
were n ot also lost f rom sight.
The frame update step is presented in Algorithm
1. It describes the steps, that are performed after the
detections have been made on the new frame and the
Kalman Filter has predicted the next bounding boxes.
In the frame update step an unmatch ed track is set to
inactive a fter it has not been matched with a detection
for a set nu mber of time steps (∗
1
in Algorithm 1). An
unmatched detection is matched with the clo sest inac-
tive track, w hen it is stable (∗
2
). We call a detection
stable, when in e ach of the last three time steps the re
Upper Bound Tracker: A Multi-Animal Tracking Solution for Closed Laboratory Settings
947

was a detection close by it (IoU >
1
2
) - i.e. it is stable,
when it did n ot appear far away from all other rec e nt
tracks.
The described approach results in all additional
detections being discarded when the upper bound is
already reached. This is only correct if the exist-
ing tracks are all following the actual individuals an d
are not due to some spurious detections. The chance
of such a fault happening are reduced by the need
for detections to be stable before being attac hed to a
track, as well as the required small distance to the last
known trac k position. On ly close-by and very contin-
uous false detections could cause an issue, that - given
the current framework and data - is only prevented by
using a good object detector for step 1). When false
detection occur on ly briefly for a few frames, they
are unlikely to cause any problem for the proposed
method, while other methods will create new tracks
for them.
4 DATASET AND EVALUATION
We created video s to test the tracker’s performance in
a setting, where the Up per Bound Tracker approach
might be useful in the future: videos o f a fixed number
of animals moving in a closed cage. In the videos four
mice are freely m oving through a 425 x 276 mm (type
III) polyc a rbonate cage, that is filmed from above
such that the whole cage is in the frame. The filter
top as well as g rid of the cage were removed and re-
placed by a custom-mad e transparent lid of the same
size, which prevented the mice from climbing onto
and walking along the edge of the cage walls. Dur-
ing video recording, food pellets normally supplied as
diet (LASvendi, LAS Q CDiet, Rod 16, auto clavable)
were placed on the floor. Water was provided in a bot-
tle attached to the external wall of the cage; the drink-
ing nip ple was put through a hole in the cage wall so
that the mice had free access to water during the vide o
recording. The video dataset is publicly available
2
.
The mice were vid eo-recorded under ten different
environmental enrichment conditions; i.e., for e ach
video segment different enrichment items were pro-
vided to th e mice - from here on called o c clusion
conditions or just conditions (see Table 1). The m ore
objects were present, the more occlusions could oc-
cur. In all occlusion conditions, the cage floor was
covered with wooden bedding material (JRS Ligno-
cel FS14, spruce/ fir, 2,5-4 mm) and 5 g sh redded co t-
ton cocoons (UNIGLOVES Dental Watterollen Gr.3).
In the most crowded occlusion condition, there are a
2
https://www.scienceofintelligence.de/research/data/
four-mice-from-above-dataset/
Input: u, T , D, n
ia
, d
cl
, d
reid
, n
misses
Result: new Tracks T
′
Match tr a cks T to detections D with Linear
Programming with IoU criterion;
/* Update tracks for good matches
*/
foreach matched pair of track and detection
(t,d) do
update trac k attributes t
′
←
1
2
(t + d);
n
t
misses
← 0;
set t to active;
end
/* Set lost tracks to inactive */
foreach un m atched track t do
n
t
misses
← n
t
misses
+ 1;
if n
t
misses
≥ n
ia
then Set t inactive;
//
∗
1
end
foreach un m atched sta ble detection d do
/* If there are too few tracks
add a new one */
if |T | < u then
d
min
← min
t∈T
dist(d,t);
if d
min
> d
cl
then
add new track at position d to T
end
end
/* Otherwise add detection to
closest inactive track */
else
t
closest
← argmin
t∈T
inactive
dist(d,t);
if dist(t
closest
, d) < d
reid
then
interpolate between the last
matched location of t
closest
and
d;
//
∗
2
set t
closest
to active;
end
end
end
Algorithm 1: The frame update step. Inputs are: u - the
upper bound, T - the current Kalman Filter predicted loca-
tions and sizes of the tracks, D - the new detections, n
ia
-
the number of time steps after a lost track is set to inactive,
d
cl
- the minimum clearance distance, d
reid
- the maximum
reidentification distance. Detections d and tracks t consist
of location (x,y), width and height.
transparent tunnel, a house with a running plate, some
paper strips, and paper towel, which offered the mice
lots of options to hide from the camera and should
be challenging for any tracker. Sample frames from
those two most extreme conditions can be found in
Figure 2. For more information on the camera setup
see section 7. This kind of data can be found in ex-
periments observin g the social life of mice. The in-
dividual has to be recognized in order to judge e. g.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
948

Figure 2: E xample frames of the least and the most oc-
cluded conditions.
each mouse’s activity level or the number of inter a c-
tions with other m ic e. Tra cking can help to do this
automatically, but a h igh number of identity switches
will dampen its usefulness. They have to be corrected
manually forcing a researcher to watch the whole se-
quence again. Thus the number of switches has to be
minimal in such an application.
For training the metho d the YOLOX-M
(Ge et al., 2021) object detection model was trained
on frames taken from four different occlusion con-
ditions including the least and the most occluded
conditions. 300 frames were taken from the be-
ginning of each of the four video segments with a
distance of 50 frames (or 1.67 seco nds) between
each other. The resulting 1200 frames were labeled
with bound ing boxes around the mic e. 10% or 120
frames were taken as validation set. Training was
performed until convergence (about 300 epochs).
Afterwards the three tracking methods were run and
their performance evaluated. For evaluation a number
of video snippets were annotated manually. Every
50th f rame was shown to the annotator, who then
drew bounding boxes around each visible mouse and
assigned the boxes to an individual. Individuals are
recogn izable in the videos th rough the markings on
their tail. For the gaps of 49 frames (o r 1. 6 seconds)
between bounding-bo x an notated fram es the bo und-
ing boxes were interpolated. This was done for the
first minute of six videos with different occlusion
conditions. Note, that localization performance was
not evaluated here.
These obtained ground truth tracks were used
for evaluation with the HOTA metric (Higher Or-
der Tracking Accura cy) (Luiten et al., 2021). This
recently published metric balances the measure-
ment of performance o f a tra cker in correct de-
tection and correct association, while eliminating a
number of shortcomings, that common metrics like
MOTA (Bernardin and Stiefelhagen, 2008) and IDF1
(Ristani e t al., 2016) have. For these metrics a higher
value is better.
Since a good tracker in applications to laboratory
animals science and elsewhere has to follow each in-
dividual reliably the number of ide ntity switches were
separately counted. Here ’iden tity switch’ refers to
the event, that an animal is assigne d to a track, that
was previously associated with a different animal.
A comparison is also made to the complete
multiple-object pose estimation solution DeepLabCut
(DLC) in version 2.2. DLC does not output bound-
ing boxes, but the metrics HOTA and MOTA are
(partially) c omputed with a similarity score between
bounding b oxes. To be able to consider these met-
rics as well, we determined the bounding boxes of the
keypoints, that DLC outputs and increased their width
and height by 10%. On those metrics the comparison
is not fair, because the bounding boxes stem from an
approximate heuristic, so the values ar e not important
to consid e r. The other metrics are more meaningful
here. We used the same training data as for the o ther
methods and tr ained a multi-animal DLC model using
default paramete rs.
The final experiment presented here delivers evi-
dence that the introduction of the upper bound leads
to better results. To this end the method is applied
to the same data, but with an upper bound that is too
high.
5 RESULTS
In the following comparisons between the UBT and
the a forementioned approac hes for step 3) Tracking
(V-IoU, SORT and O C-SORT trackers) are presente d.
On all video s regardless of occluding objects in
the scene th e UBT outperforms OC-SORT, SORT
and V-IoU on the metric counting the number of ID
switches (IDSW). Here the difference in performance
to the second best, OC-SORT, is rather small, while
the difference to the other methods is substantial, cut-
ting th e number of switches in half at least.
On the other metrics it shows good performance
as well. Table 2 (upper panel) shows results for the
easiest condition, in which no obstacles obscure the
mice. UBT performs slightly better than OC-SORT in
all metrics. Th e HOTA, IDF1 and IDSW pe rformance
sees a big gab between the two on one side and SORT
and V-IoU on the other. The MOTA score is similar
for all four.
Upper Bound Tracker: A Multi-Animal Tracking Solution for Closed Laboratory Settings
949
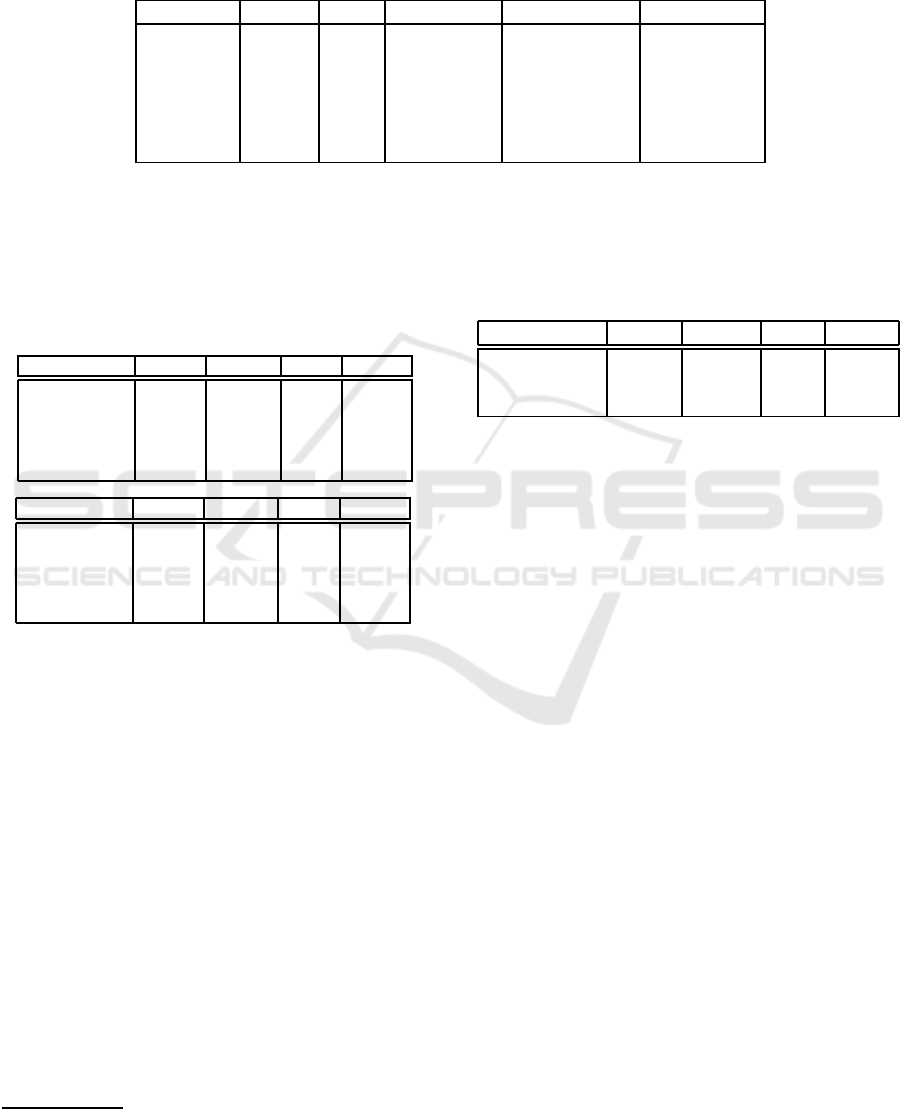
Table 1: Objects in the cage in each of t he six occlusion conditions. A n ’X’ marks the presence of the object. E ach condition
has wooden bedding material and shredded cotton and can also have: tunnel (tr ansparent, 11,5 cm x 3,5 cm, custom-made),
one or two grams of white paper strips (LILLICO, Biotechnology Paper Wool), thin paper towels (cellulose, unbleached,
layers, 20x20cm, Lohmann & Rauscher), Mouse igloo with or wi thout running plate (ZOONLAB GmbH, Castrop-Rauxel,
Germany; round house: 105 mm in diameter, 55 mm in height; round plate: 150 mm in diameter).
Condition Tunnel Igloo Paper strips Running Plate Paper towels
1
2 X
3 X X
4 X X 1g
5 X X 2g X
6 X X 2g X X
Table 2: MOT performance of the five compared methods
on the easiest and on the most difficult occlusion condi-
tion. HOTA: area under the curve for HOTA
α
for α ranging
from 0.05 to 0.95 in st eps of 0.05; IDSW: number of iden-
tity switches; bolt: best value for each column; *: DLC
could not be fairly evaluated with HOTA and MOTA (see
section 4).
Easiest Occlusion Condition
HOTA MOTA IDF1 IDSW
SORT 0.39 0.86 0.42 25
OC-SORT 0.56 0.85 0.74 5
V-IoU 0.33 0.84 0.33 42
UpperBound 0.58 0.88 0.77 4
DLC 0.54* 0.42* 0.71 0
Most Difficult Occlusion Condition
HOTA MOTA IDF1 IDSW
SORT 0.30 0.73 0.31 57
OC-SORT 0.34 0.69 0.41 25
V-IoU 0.30 0.71 0.30 71
UpperBound 0.33 0.54 0.48 22
DLC 0.19* -0.06* 0.27 66
The most difficult occlusion cond ition (Table 2
lower panel) sees OC-SORT slightly ahead of UBT
in the HOTA and SORT ahead in the MOTA score.
Here the OBT performs best o nly in IDF1 and ID SW.
Performance on the other conditions can be found
in section 7 in th e appendix.
DLC perfor ms as well as OC-SORT and UBT on
the least occluded condition
3
. On the most difficult
condition its performance falls o ff, however. Here it
is similar to SORT and V-IoU again.
When setting the upper boun d too high perfor-
mance on all metrics drops (Table 3).
6 DISCUSSION
The HOTA and IDF1 metrics have a range be tween 0
(nothin g was done right) to 1 (perfect performance).
MOTA is unbounded in the negative direction and
3
Only considering IDF1 and IDSW - see section 4
Table 3: MOT performance of the U BT when setting the up-
per bound incorrectly. The correct upper bound for the data
is 4. Evaluation was done on the easiest occlusion condi-
tion. HOTA: area under the curve for HOTA
α
for α ranging
from 0.05 to 0.95 in st eps of 0.05; IDSW: number of iden-
tity swi tches.
Upper Boun d HOTA MOTA IDF1 IDSW
4 0.58 0.88 0.77 4
5 0.51 0.64 0.68 5
10 0.38 -0.41 0.46 9
also has an upper bound of 1. The number of ID
switches can of course be any non- negative integer.
This metric is dominated by the UBT with OC-SORT
closely following. The good performance of it in
the domain of gettin g the identity of the ind ividu-
als right is still visible in the IDF1 metric , which
has a bias towards that component to MOT perfor-
mance (Luiten et al., 2021). Here the UBT a gain out-
performs othe r methods by a good margin. This in-
dicates, that the impr ovements, that OC-SORT and
UBT brought, were mainly to the consistency of indi-
vidual identification, and less to the localization accu-
racy. The poorer performance of UBT in the MOTA
metric on the most c hallenging condition points to-
wards a weakness in correctly drawing bo unding
boxes around individuals, that are only partially vis-
ible. The other occlusion conditions paint a similar
picture. The effect of the introduction of the upper
bound on th e number of spurious detections becomes
obvious in the ablation experiment. When setting the
upper bound to ten instead of the co rrect four, the
MOTA score even be comes n egative, which happens,
when often more false positives occur than there are
ground truth tracks.
7 CONCLUSION
The UpperBound Tracker shows great improvements
on existing baseline methods for MOT. It is also able
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
950

to out-perform the recent state-of-the- art tracker OC-
SORT by a small margin. The most balanced metric
HOTA, which gives ap propriate weight to both sub-
tasks: finding the individuals and consistently identi-
fying th em, still shows ro om for impr ovement under
challengin g conditions. The other metrics give evi-
dence, in which sub-task the contribution of the UBT
idea lies. The number of ide ntity switches is much
lower. This is indicating, that the correct and c onsis-
tent identification of tracked individuals benefits fr om
the re-connection to the closest inactive track, that is
introdu ces in the UBT in this work. Further research
should address the case when more than one indi-
vidual is gone from view. The reidentification cou ld
take into account past trajectories and appearances of
missing tracks to connect them once they reappear.
In the MOT sub-task of f ollowing and re-identifying
individuals in videos, that fulfill the requirement of
a known maximum number of individuals, U BT is a
good choice.
ACKNOWLEDGEMENTS
Funded by the Deutsche Forschungsgemeinschaft
(DFG, German Research Foundation) under Ger-
many’s E xcellence Strategy – EXC 2002/1 “Science
of I ntelligence” – project number 390523135.
We thank Clara Bekemeier and Sophia Meier for
manual data annotatio n and Benjamin Lan g for build-
ing the transparent cage lid.
REFERENCES
Bernardin, K. and Stiefelhagen, R. (2008). Evaluating mul-
tiple object tracking performance: the clear mot met-
rics. EURASIP Journal on Image and Video Process-
ing, 2008:1–10.
Bewley, A., Ge, Z., Ott, L., Ramos, F., and Upcroft, B.
(2016). Simple online and r ealt ime tracking. In 2016
IEEE international conference on image processing
(ICIP), pages 3464–3468. IE EE.
Bochinski, E., Senst, T., and Sikora, T. (2018). Extending
iou based multi-object tracking by visual information.
In 2018 15th IEEE International Conference on Ad-
vanced Video and Signal Based Surveillance (AVSS),
pages 1–6. IEEE.
Cao, J., Weng, X., Khirodkar, R., Pang, J., and Kitani,
K. (2022). Observation-centric sort: Rethinking
sort for robust multi-object tracking. arXiv preprint
arXiv:2203.14360.
Dendorfer, P., Rezatofighi, H ., Milan, A., Shi, J., Cremers,
D., Reid, I., Roth, S., Schindler, K., and Leal-Taix´e, L.
(2020). Mot20: A benchmark for multi object track-
ing in crowded scenes. arXiv:2003.09003[cs]. arXiv:
2003.09003.
FELASA Working Group on Revision of Guidelines for
Health Monitoring of Rodents and Rabbits, M¨ahler,
M., Berard, M., Feinstein, R. , Gallagher, A ., Illgen-
Wilcke, B., Pritchett-Corning, K., and Raspa, M.
(2014). Felasa recommendations for the health mon-
itoring of mouse, rat, hamster, guinea pig and rabbit
colonies in breeding and experimental units. Labora-
tory animals, 48(3):178–192.
Ge, Z., Liu, S., Wang, F., Li, Z., and Sun, J. (2021).
Yolox: Exceeding yolo series in 2021. arXiv preprint
arXiv:2107.08430.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Insafutdinov, E., Pishchulin, L., Andres, B., Andriluka, M.,
and Schiele, B. (2016). Deepercut: A deeper, stronger,
and faster multi-person pose estimation model. In Eu-
ropean Conference on Computer Vision, pages 34–50.
Springer.
Kalman, R. E. ( 1960). A New Approach to Linear Filtering
and Prediction Problems. Journal of Basic Engineer-
ing, 82(1):35–45.
Lauer, J., Zhou, M., Ye, S., Menegas, W., Nath, T., Rahman,
M. M., Di Santo, V., Soberanes, D., Feng, G. , Murthy,
V. N., et al. (2021). Multi-animal pose estimation and
tracking with deeplabcut. bioRxiv.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.,
Fu, C.-Y., and Berg, A. C. (2016). Ssd: Single shot
multibox detector. In European conference on com-
puter vision, pages 21–37. Springer.
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-
Taix´e, L., and Leibe, B. (2021). Hota: A higher order
metric for evaluating multi-object tracking. Interna-
tional journal of computer vision, 129(2):548–578.
Mathis, A., Mamidanna, P., Cury, K. M., Abe, T., Murthy,
V. N., Mathis, M. W., and Bethge, M. (2018).
Deeplabcut: markerless pose estimation of user-
defined body parts with deep learning. Nature Neu-
roscience, 21(9):1281–1289.
Newell, A., Yang, K., and Deng, J. (2016). Stacked hour-
glass networks for human pose estimation. In Euro-
pean conference on computer vision, pages 483–499.
Springer.
Pereira, T. D., Tabris, N., Matsliah, A., Turner, D. M., Li, J.,
Ravindranath, S., Papadoyannis, E. S., Normand, E.,
Deutsch, D. S., Wang, Z. Y., McKenzie-Smith, G. C.,
Mitelut, C. C., Castro, M. D., D’Uva, J., Kislin, M.,
Sanes, D. H., Kocher, S. D., Wang, S. S.-H., Falkner,
A. L., Shaevitz, J. W., and Murthy, M. (2022). Sleap:
A deep learning system for multi-animal pose track-
ing. Nature Methods.
Redmon, J., Divval a, S., Girshick, R., and Farhadi, A.
(2016). You only look once: Unified, real-time object
detection. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 779–
788.
Upper Bound Tracker: A Multi-Animal Tracking Solution for Closed Laboratory Settings
951
Ren, S., He, K., Girshick, R., and Sun, J. (2016). Faster
r-cnn: towards real-time object detection with region
proposal networks. IE EE transactions on pattern
analysis and machine intelligence, 39(6):1137–1149.
Ristani, E., Solera, F., Zou, R., Cucchiara, R., and Tomasi,
C. (2016). Performance measures and a data set for
multi-target, multi-camera tracking. In European con-
ference on computer vision, pages 17–35. Springer.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net:
Convolutional networks for biomedical image seg-
mentation. In International Conference on Medical
image computing and computer-assisted intervention,
pages 234–241. S pringer.
Zhao, H., Shi, J., Qi, X., Wang, X., and Jia, J. (2017).
Pyramid scene parsing network. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 2881–2890.
APPENDIX
Ethics Statement
Maintenance of mice and all animal experimentation
was approved by the Berlin State Authority and the
Ethics committee (“Landesamt f¨ur Gesun dheit und
Soziales”, permit num ber: G0249/19). The study was
performed accordin g to the German Animal Welfare
Act, and the Direc tive 2010/63 /EU for the protection
of animals used for scientific pu rposes.
Animals
Four female C57BL/6J mice obtained from Charles
River Laboratories (Sulzfeld, Germ any) were used at
an age of approximately 10 months. The animals
were group-housed in two polycarbonate type 3 cages
(425 x 276 mm each) with filter tops, which were con-
nected with each other via a tube. The cages con-
tained wooden bedding material (JRS Lignoc e l FS14,
spruce/ fir, 2,5-4 mm), a triangular plastic house (140
mm long side, 100 mm short sides, 50 mm in height;
Tecniplast, Italy), a transparent tunnel (11 mm x 40
mm , custom -made), an d five pieces of paper towel (2
x Paper Towels 23x24,8c m folded, Essity ZZ Towel;
3 x cellulose, un bleached, layers, 20x20c m, Lohmann
& Rauscher). The animals were maintained under
standard conditio ns (room temperature: 22 ± 2 °C;
relative humidity: 55 ± 10 %) on a light:dark cycle
of 12:12 h of artificial light (lights on from 7AM to
7PM in the winter and 8AM to 8PM in the summer)
with a 30 min twilight transition pha se. They had
free access to water and were fed pelleted m ouse die t
ad libitum (LASvendi, LAS QCDiet, Rod 16, auto-
clava ble). Cages were clean ed once a week and the
mice were handled using a tunnel. The experimenter
was female. The mice were free of all vir al, bacterial,
and parasitic pathogen s listed in the FELASA re com-
mendations (FELASA Working Group on Revision
of Guidelines for Health Monitoring of Rodents and
Rabbits).
Camera Setup
The video r ecording was don e with a Basler acA1920-
40um camera (Lens LM25HC F1 .4 f25mm, Kowa,
Nagoya, Japa n) mo unted on a tripod pointing down at
the type III cage (425 mm × 276 mm × 150 mm) with
transparent lid. The camera has a resolution of 1920
x 1200 pixels and was set to record 30 monochrome
frames per second with a pixel bit dep th of 8 bit.
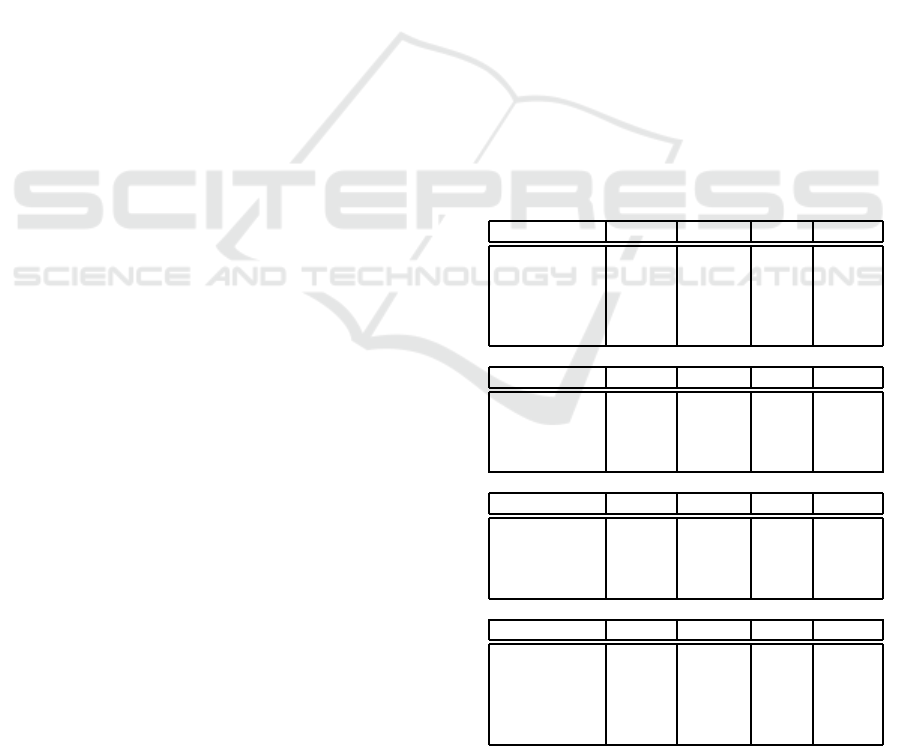
Performance on Other Occlusion
Conditions
Table 4: MOT performance of the five compared methods
on different occlusion conditions. HOTA: area under the
curve for HOTA
α
for α ranging from 0.05 to 0.95 in steps of
0.05; IDS W: number of identity switches; bolt: best value
for each column; *: DL C could not be fairly evaluated with
HOTA and MOTA (see section 4) and was not evaluated for
all conidtions.
Occlusion Condition Difficulty 2/6
HOTA MOTA IDF1 IDSW
SORT 0.43 0.77 0.52 15
OC-SORT 0.52 0.72 0.67 9
V-IoU 0.40 0.74 0.48 27
UpperBound 0.52 0.73 0.72 5
DLC 0.46* 0.41* 0.66 19
Occlusion Condition Difficulty 3/6
HOTA MOTA IDF1 IDSW
SORT 0.26 0.62 0.24 83
OC-SORT 0.25 0.46 0.27 55
V-IoU 0.22 0.57 0.21 118
UpperBound 0.38 0.53 0.54 30
Occlusion Condition Difficulty 4/6
HOTA MOTA IDF1 IDSW
SORT 0.45 0.84 0.49 23
OC-SORT 0.59 0.79 0.71 3
V-IoU 0.42 0.82 0.45 33
UpperBound 0.70 0.85 0.92 0
Occlusion Condition Difficulty 5/6
HOTA MOTA IDF1 IDSW
SORT 0.40 0.61 0.48 35
OC-SORT 0.43 0.52 0.56 36
V-IoU 0.38 0.57 0.45 53
UpperBound 0.54 0.57 0.78 17
DLC 0.37* 0.24* 0.51 20
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
952
