
An Improved Diagonal Loading-Based Minimum Variance Distortionless
Response Beamformer
Quan Trong The
a
Digital Agriculture Cooperative, No. 15 Lane 2, Tho Thap, Dich Vong, Cau Giay, Hanoi, Viet Nam
Keywords:
Microphone Array, Speech Enhancement, Minimum Variance Distortionless Response, Diagonal Loading,
Desired Target Speaker, Dual-Microphone System, the Signal-to-Noise Ratio.
Abstract:
The MVDR beamformer has more prominent solution and much better noise reduction and interference sup-
pression capability than the conventional beamforming method, which required that the associated microphone
array steering vector to sound source is accurately known. However, whenever the a priori information about
the direction of arrival of the interest signal is not imprecise, microphone mismatch or different microphone
sensitivities; the evaluation of MVDR beamformer is often degraded, thus speech distortion, which decreases
the speech quality, is unavoidable. For mitigating the drawbacks, diagonal loading has been imposed to en-
hance MVDR’s performance in terms of improving the signal-to-noise ratio (SNR) and removing background
noise. So diagonal loading has been a common widely used method to enhance the robustness of MVDR beam-
former. The inherent problem of diagonal loading is the choice of optimal parameter λ to increase the effective
working of diagonal loading in complex acoustical situation. In this correspondence, the author presented a
method for calculating the necessary parameter λ to improve the speech enhancement in dual-microphone sys-
tem. The illustrated experiment has proven the capability of considered technique via a numerical example.
1 INTRODUCTION
Separation and speech enhancement are the most pop-
ular challenging task in digital signal processing. In
real environment, target speech signal is often dis-
torted, cause: third-party speaker, noise, transport ve-
hicle, interference. Separation speech refers to the
task of saving the target speech speaker and suppress-
ing the unwanted different noisy environment. In
this context, speech enhancement is extracting one or
more target speakers, and mitigate the effect of an-
noying noise, interfering environment or reduce some
types of speech distortions due to reverberation, the
complex surrounding recording scenario. So that, the
terms of “signal enhancement” and “source separa-
tion” are very necessary in almost industry applica-
tion. Audio device, hearing aid, teleconference, com-
munication.
Conference has several speakers, which can be
considered as target source speech, that requires sep-
arating each component from a complicated mixture.
Moreover, speech enhancement is the most crucial
pre-processing for further speech application, such as:
a
https://orcid.org/0000-0002-2456-9598
Figure 1: Extracting the desired speech is an essential task
in speech enhancement.
dialogue, speech recognition, distant remote, GPS,
surveillance device, video game. For dealing these
problems, the microphone array (MA) (Benesty et al.,
2008, 2016, 2017; Lockwood et al., 2004; Brandstein
and Ward, 2001) is used for using the advantage of
microphone array geometry, the spatial information
of direction-of-arrival (DOA), the coherence between
microphones, the characteristics of environment to
alleviate the effect of noise while saving the target
speaker. MA allows more input signals are multi-
The, Q.
An Improved Diagonal Loading-Based Minimum Variance Distortionless Response Beamformer.
DOI: 10.5220/0012009100003561
In Proceedings of the 5th Workshop for Young Scientists in Computer Science and Software Engineering (CSSE@SW 2022), pages 19-26
ISBN: 978-989-758-653-8; ISSN: 2975-9471
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
19

channel. The number of microphones has increased
in many applications in the last few years. Most of
telephone, tablets or hearing-aid require 2-3 micro-
phones.
Figure 2: The using of microphone array technology.
The enhancement capabilities of MA are often
higher than single-channel method. Because of the
designed spatial filter to extract the target directional
source speaker while eliminating all interference and
noise. MA exploit the spatial a priori information
about position, configuration user-defined of MA, dif-
ference of phase, more general the different acoustic
properties between MA to achieve the better noise re-
duction while keeping the target speech. In contrast,
the single – channel approach doesn’t have knowl-
edge of source or noise, so in results, the smaller qual-
ity obtained signal.
Minimum Variance Distortionless Response
(MVDR) (Pan et al., 2014; Ba et al., 2007; Erdogan
et al., 2016; Xiao et al., 2017a,b) has an attractive
performance, which is the most widely studied
and the basic to some commerce available acoustic
devices. MVDR utilizes the information of DOA of
target desired speaker for forming beampattern to-
ward this direction while minimizing the output noise
power. Based on the precise knowledge of interest
signal’s DOA, MVDR has ability of extracting the
only target directional useful speech component. In
practice, the DOA of target speaker if usually is not
determined exactly, due to many reasons: position of
MA, influence of interference or noisy environment,
that degrades seriously performance of MVDR
beamformer. A lot of research has been developed
to overcome this problem, by extending the region
where the target directional sound source can be
determined. In this paper, the author proposed the
using of diagonal method for solving the problem of
imprecise DOA of interest signal to improve speech
enhancement.
There are some research directions for enhanc-
ing the evaluation of MVDR beamformer. One of
the most important parameters is a steering vector,
which present the acoustic of sound propagation in
environment from the desired source to all element of
MA. More generally, a normalized of relative transfer
function (RTFs) (Gannot et al., 2001b,a) is used for
further signal processing. To improve performance
of MVDR beamformer, RTF may be measured a pri-
ori or based on knowledge of microphone properties,
room acoustic, speaker location, position.
However, in complex situation with presence of
microphone mismatches or error of preferred DOA,
the diagonal loading (DL) (Wu and Zhang, 1999;
Vorobyov et al., 2003; Lorenz and Boyd, 2005; Shah-
bazpanahi et al., 2003; Chen and Vaidyanathan, 2007)
technique is developed to address the problem of de-
graded performance of MVDR beamformer. DL tech-
nology is not only known provides the robustness,
which against the DOA mismatch but also to the im-
precise steering vector. Several research of DL have
been proposed to force the magnitude of final signal
in complex recording environment to exceed or equal
to the original microphone array signal. The one well-
known disadvantage of DL is the way of choosing the
exact parameters is still lacking.
In this contribution, the author introduces an im-
provement of MVDR beamformer (imMVDR) that
can be integrated into multi-microphone system for
extracting the target directional speaker while elimi-
nating all non-target directional noise or interference.
The rest of this paper is organized as: The next
section is the model signal of MVDR beamformer.
The proposed method, which use the diagonal tech-
nique is presented in section 3. The enhanced evalu-
ation of the suggested method is illustrated in section
4, a comparison the quality output signal between the
traditional MVDR beamformer (traMVDR) and im-
MVDR provides the robustness for separating inter-
ested speech source signal. Finally, concluding re-
marks and the future research of this approach are
conducted.
Hundreds of microphone phones have been used
for acoustic acquisition sound source from distance.
However, dual-microphone array (DMA2) is more
popular widely applied in almost speech application,
due to it’s simplicity, low computational load, com-
pact, and easily installed in almost audio equipment.
In experiment, DMA2 is used for verifying and illus-
trating the effectiveness of suggested method in term
of increasing the signal-to-noise ratio (SNR) in real
environment.
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
20
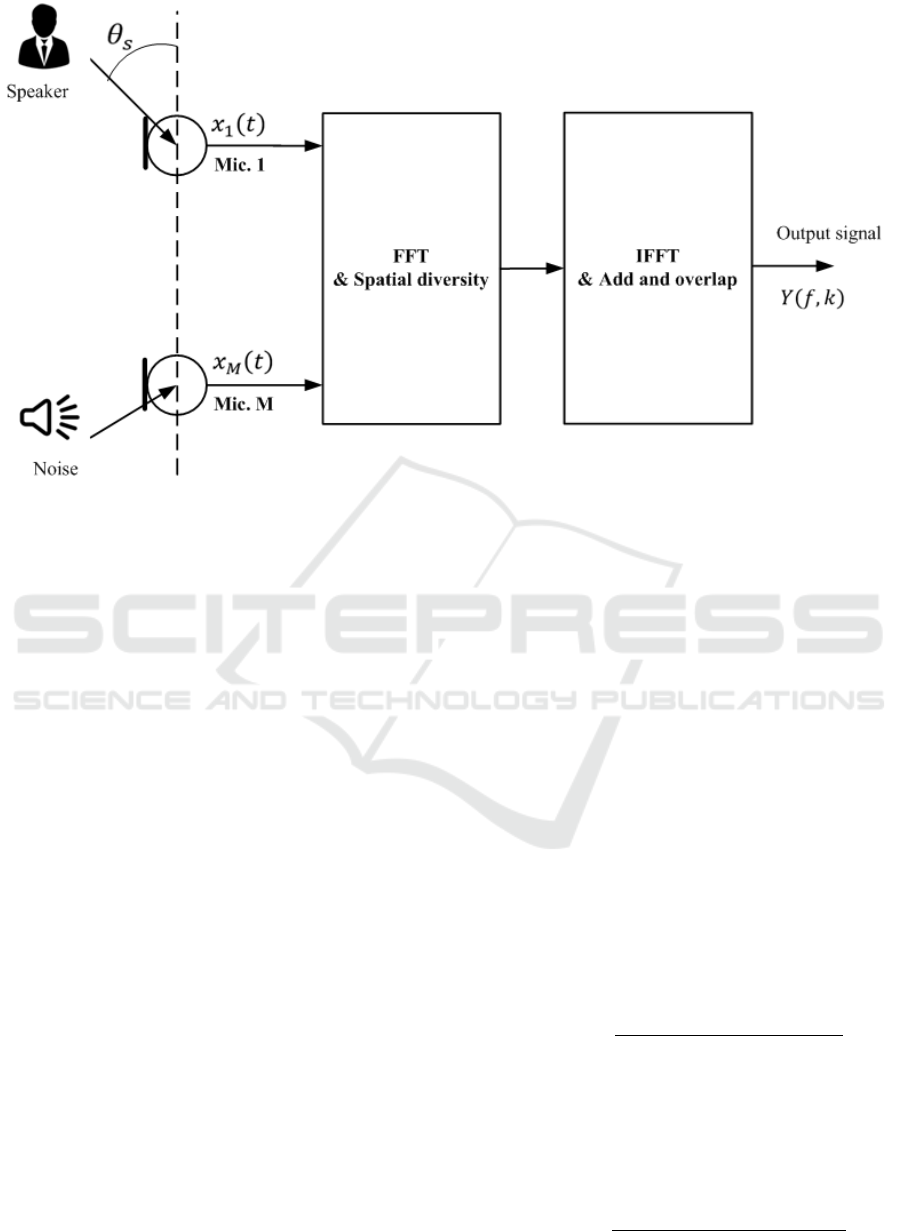
Figure 3: The scheme of beamforming in the frequency domain.
2 THE MVDR BEAMFORMER
In a noisy acoustic recording situation, it is very im-
portance to capture the speech signal from target di-
rectional talker, therefore the only capable method is
using MA beamforming to acquire the desired sig-
nal. It is assumed that a DMA2 is used to record
speaker and acoustic environment. With f , k index
frequency and frame, a target speaker S( f ,k) from
a certain direction θ
s
, an unwanted noise V ( f ,k) are
captured by DMA2, the observed microphone signals
X
1
( f ,k),X
2
( f ,k) can be written by in the frequency
domain as:
X
1
( f ,k) = S( f ,k)e
jΦ
s
+V
1
( f ,k) (1)
X
2
( f ,k) = S( f ,k)e
− jΦ
s
+V
2
( f ,k) (2)
where e
jΦ
s
,e
− jΦ
s
is the transfer function of target
talker relative to microphone 1,2 respectively. Φ
s
=
π f τ
0
cos(θ
s
),τ
0
= d/c,d distance between two micro-
phones, c = 343(m/s) speed of sound propagation in
the air, τ
0
is the time delay.
We denote X
X
X( f ,k) = [X
1
( f ,k) X
2
( f ,k)]
T
,
D
D
D( f ,θ
s
) = [e
jΦ
s
e
− jΦ
s
]
T
, V
V
V ( f ,k) =
[V
1
( f ,k) V
2
( f ,k)]
T
with ()
T
indicates transpose
operator, equation (1-2) can be rewritten by:
X
X
X( f ,k) = S( f , k)D
D
D( f ,θ
s
) +V
V
V ( f ,k) (3)
The steering vector D
D
D( f ,θ
s
) play a major role in
all MA algorithm. Due to, D
D
D( f ,θ
s
) contains the in-
formation of DOA desired talker.
The digital signal processing is necessary to find
an optimum weight vector W
W
W ( f ,k), which ensures the
final output signal Y ( f ,k) approximate the original
signal S( f ,k):
Y ( f ,k) = W
W
W
H
( f ,k)X
X
X( f ,k) (4)
where ()
H
is the symbol of Hermitian conjugation.
MVDR beamformer is aiming to minimizing the
power of noise at the output without speech distortion,
therefore, the optimum problem is described by the
following equation:
min
W
W
W (
(
( f
f
f ,
,
,k
k
k)
)
)
W
W
W (
(
( f
f
f ,
,
,k
k
k)
)
)
H
Φ
Φ
Φ
VV
( f ,k)W
W
W (
(
( f
f
f ,
,
,k
k
k)
)
)
s.t. W
W
W (
(
( f
f
f ,
,
,k
k
k)
)
)
H
D
D
D( f ,θ
s
) = 1
(5)
where Φ
Φ
Φ
VV
( f ,k) = E{V
V
V
H
( f ,k)V
V
V ( f ,k)} is the covari-
ance matrix of noise. The optimum criteria of pre-
serving the target directional speech signal leads to
the solution:
W
W
W ( f ,k) =
Φ
Φ
Φ
−1
VV
( f ,k)D
D
D( f ,θ
s
)
D
D
D
H
( f ,θ
s
)Φ
Φ
Φ
−1
VV
( f ,k)D
D
D( f ,θ
s
)
(6)
In realistic speech application, due to not avail-
able information about noise, the covariance matrix
of observed microphone array signals is used instead
of noise Φ
Φ
Φ
XX
( f ,k) = E{X
X
X
H
( f ,k)X
X
X( f ,k)}. So, the fi-
nal optimum weight vector is:
W
W
W ( f ,k) =
Φ
Φ
Φ
−1
XX
( f ,k)D
D
D
s
( f ,θ
s
)
D
D
D
H
s
( f ,θ
s
)Φ
Φ
Φ
−1
XX
( f ,k)D
D
D
s
( f ,θ
s
)
(7)
An Improved Diagonal Loading-Based Minimum Variance Distortionless Response Beamformer
21
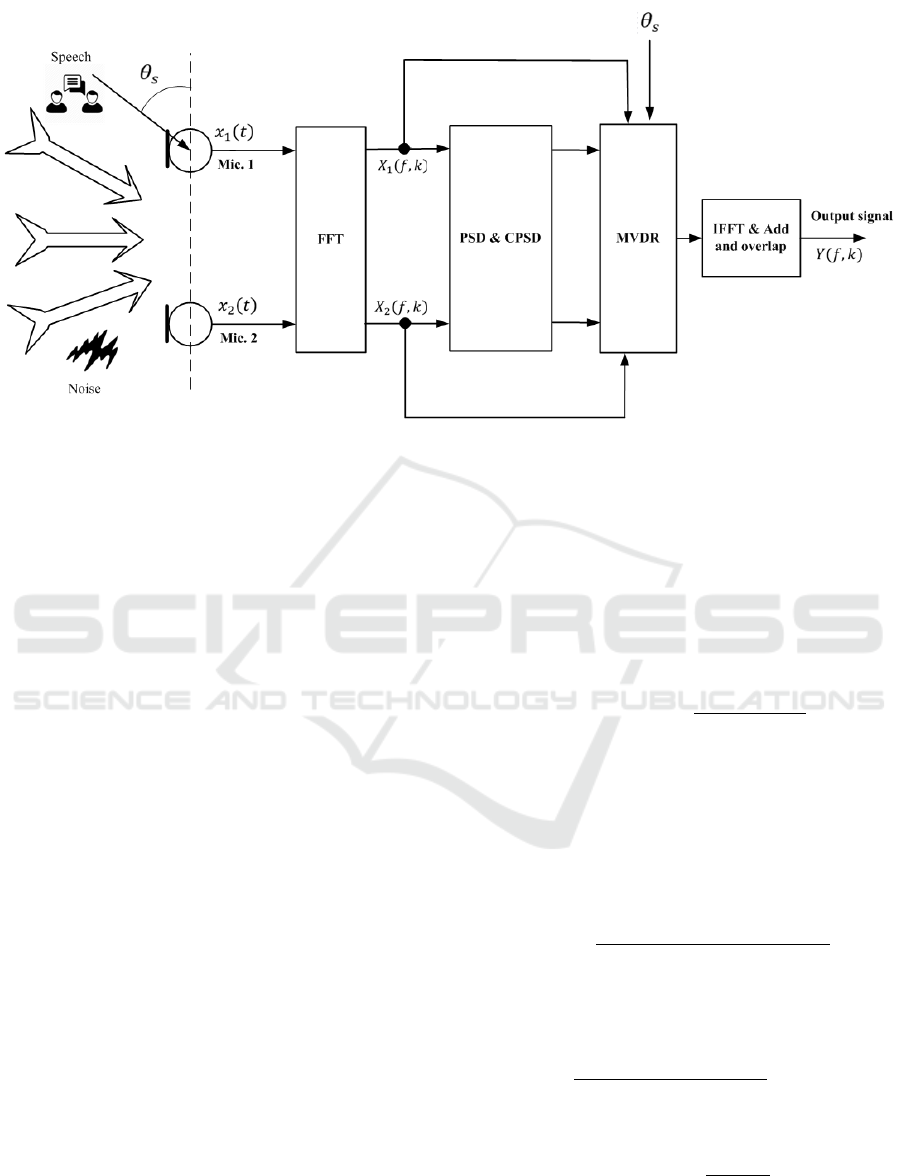
Figure 4: The scheme of MVDR beamformer.
Φ
Φ
Φ
XX
( f ,k) =
E{X
1
∗
( f ,k)X
1
( f ,k)} ∗ 1.001 E{X
1
∗
( f ,k)X
2
( f ,k)}
E{X
2
∗
( f ,k)X
1
( f ,k)} E{X
2
∗
( f ,k)X
2
( f ,k)} ∗ 1.001
(8)
P
X
i
X
j
( f ,k) = (1 − α)P
X
i
X
j
( f ,k − 1) + αX
∗
i
( f ,k)X
j
( f ,k) (9)
where Φ
Φ
Φ
XX
( f ,k) is denoted by equation (8).
With the power spectral density,
E{X
i
∗
( f ,k)X
j
( f ,k)} = P
X
i
X
i
( f ,k) is calculated
as (9), where α is the smoothing parameter.
3 THE DIAGONAL
LOADING-BASED PROPOSED
METHOD
The matrix covariance Φ
XX
( f ,k) is one of the most
common enhanced for enhancing MVDR beam-
former. Diagonal loading technique is an efficient
method for increasing the robustness of signal pro-
cessing and speech quality of the output beamformer,
while alleviating all surrounding background noise.
Matrix covariance
Φ
XX
( f ,k)
is added λI
I
I, where λ is unknown parameter in range
{0..1}, I
I
I is the unity matrix. The problem of de-
termining λ still the most challenging in speech en-
hancement.
As a result, the speech distortion often occurs in
frame, where the signal-to-noise ratio (SNR) high.
Due to, the necessary information of noise is more re-
quired than target directional speech, the author uses
the information the speech presence probability (SPP)
(Gerkmann and Hendriks, 2012a,b) and SNR to form
an appropriate value of λ.
λ = SPP( f ,k) ∗
1
1 + SNR( f , k)
(10)
where SPP( f ,k) was calculated from (Gerkmann and
Hendriks, 2012a,b).
In the scenario with these criteria: the speech
component of target speaker and noise are uncorre-
lated, the noise is the same and uncorrelated between
two microphones. An estimation of speech covari-
ance σ
2
s
( f ,k) (Zelinski, 1988) can be expressed as:
σ
2
s
( f ,k) =
Re{P
X
1
X
2
( f ,k) + P
X
2
X
1
( f ,k)}
2
(11)
where Re{.} is the mathematical operator, which gets
the real part.
And an estimation of noise covariance:
σ
2
n
( f ,k) =
P
X
1
X
1
( f ,k) + P
X
2
X
2
( f ,k)
2
− σ
2
s
( f ,k) (12)
The temporal SNR( f , k) is computed by:
SNR( f , k) =
σ
2
s
( f ,k)
σ
2
n
( f ,k)
(13)
From the equation (7), the denominator plays a
role as equalizer for MVDR beamformer. Therefore,
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
22

the author proposed the modified MVDR beamformer
as the following equation:
W
W
W ( f ,k) =
(Φ
Φ
Φ
XX
+ λI
I
I)
−1
( f ,k)D
D
D
s
( f ,θ
s
)
D
D
D
H
s
( f ,θ
s
)(Φ
Φ
Φ
XX
+ λI
I
I)
−1
( f ,k)D
D
D
s
( f ,θ
s
)
(14)
The diagonal loading technique is suitable with
complex recording scenarios in presence of diffuse,
coherent, incoherent noise field or interference. With
an adaptive determined addition to covariance matrix
of observed data, the performance of beamformer will
rapidly adapt to the change of considered environ-
ment.
The next section will analyze the improvement of
the proposed technique for reducing speech distortion
and enhance speech quality.
4 EXPERIMENTS AND
DISCUSSION
In experiment, a DMA2 is used for recording the tar-
get directional speech talker in presence of surround-
ing noise, interference of real situation. The pur-
pose of this experiment is verifying the capability of
saving target directional speech in comparison with
the conventional MVDR. The distance between two
microphones d = 5(cm). The model of experiment
is illustrated in figure 5. The desired speaker stand
at the direction θ
s
= 90(deg) relative to the axis of
DMA2. For further digital signal processing, the au-
thor used Hamming window, α = 0.1, FFT = 512,
overlap 50%, the sampling frequency Fs = 16kHz. A
measurement SNR (Ellis, 2011) is used for estimating
the speech quality of obtained signal. The configura-
tion of experiment is shown in figure 5.
Figure 5: The scheme of experiment.
The author will compare the waveform and energy
of microphone array signal and processed signals by
traMVDR, imMVDR to realize the effectiveness of
the proposed method. The observed microphone sig-
nal is shown in figure 6.
The obtained signal by traMVDR and imMVDR
are presented in figure 7, 8. The effectiveness of
the proposed method is preserving the original speech
component while mitigating all background noise. In
comparison with the convention MVDR, as we can
see, traMVDR removes noise, but the it’s weakness is
speech distortion due to several reasons. imMVDR
has deal it perfectly, and help keeping the original
speech signal. With an appropriate addition, which
has the information of speech presence probability
and the SNR, MVDR beamformer has achieved a bet-
ter result in extracting the target directional useful
speech signal while removing the background noise
or coherence noise. MVDR beamformer has the ca-
pability of minimizing the noise at the beamformer’s
output, but because of some reasons, such as the er-
ror of direction of arrival (DOA) of target speaker, the
microphone mismatches, the different sensitivities of
microphones, that degrade the performance of MVDR
beamformer. In figure 7, all of surrounding noise are
suppressed, but the beamformer has cancelled origi-
nal signal.
Therefore, as the following of diagonal loading
technique, the author has expropriated a small value,
which depends on the speech presence probability and
temporal SNR. The effectiveness of the proposed has
increased the amplitude of received signal. Figure 9
presents the energy of microphone array, traMVDR
and imMVDR. imMVDR reduces speech distortion
to 3.5 (dB).
The comparison in term of speech quality between
two output signals depicted in table 1. The speech
quality is increased from 1.8 to 5.4 (dB).
Table 1: The signal-to-noise ratio (dB)
Method Microphone traMVDR imMVDR
Estimation array signal
NIST STNR 9.5 24.0 25.8
WADA SNR 6.8 20.4 25.8
So, in the complicated environment, the suggested
diagonal loading technique has improved the per-
formance of MVDR beamformer and enhanced the
speech quality and intelligibility. The effectiveness
of imMVDR was verified and numerical result con-
firmed the capability of this approach, which uses
the information of speech presence probability and
instantaneous SNR. The obtained numerical results
have satisfied the aim of evaluated experiment.
An Improved Diagonal Loading-Based Minimum Variance Distortionless Response Beamformer
23
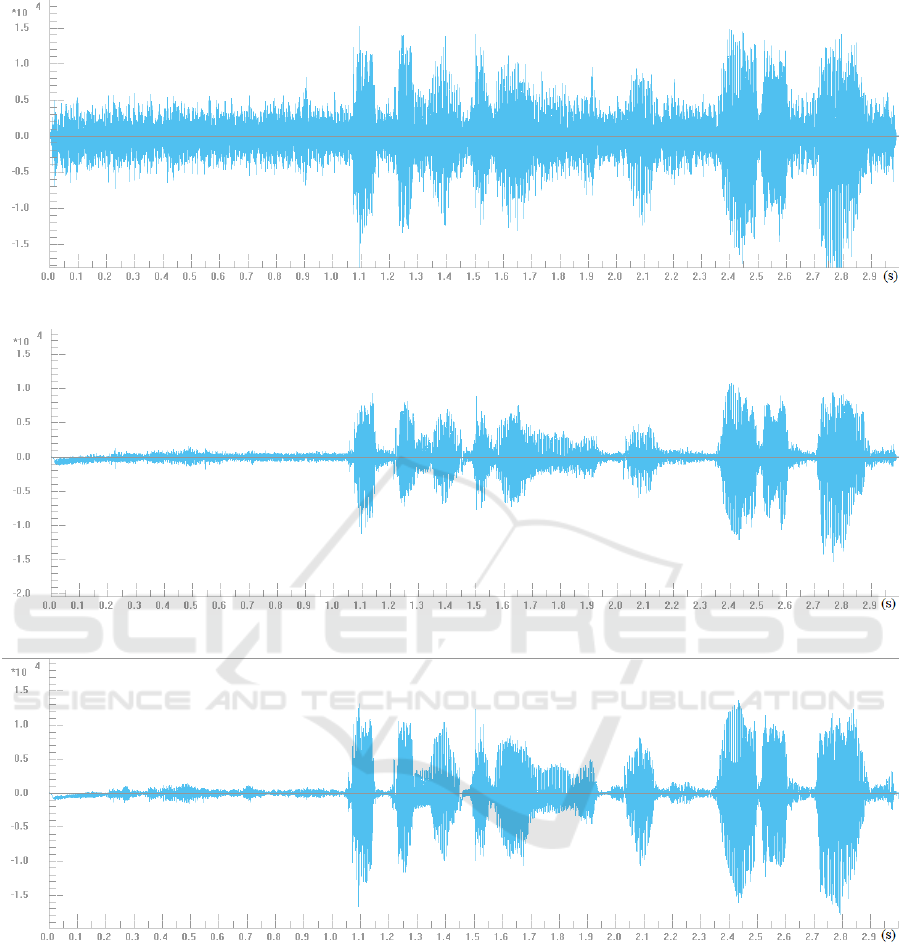
Figure 6: The waveform of the observed microphone array signal.
Figure 7: The obtained signal by traMVDR.
Figure 8: The obtained signal by imMVDR.
5 CONCLUSION
In many speech applications, such as hearing aids, au-
dio devices; extracting of desired speech signal is a
challenging problem from a mixture of corrupted sig-
nal with surrounding interference and different noise
at low SNR. The performance of microphone array
signal processing usually significantly deteriorated in
the presence of unwanted noise, different speaker or
complex recording scenario. Therefore, improvement
of diagonal loading is a promising method for enhanc-
ing MVDR beamformer to extract useful target signal.
This contribution presents an improved of diagonal
loading that takes into account the calculation of nec-
essary parameter. Objective experiment was carried
out to confirm the ability of suggested technique in
increasing of speech quality, noise reduction and the
signal-to-noise ratio from 1.8 to 5.4 (dB). The numer-
ical result has ensured that the proposed method can
be integrated into multi-microphone system. The es-
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
24
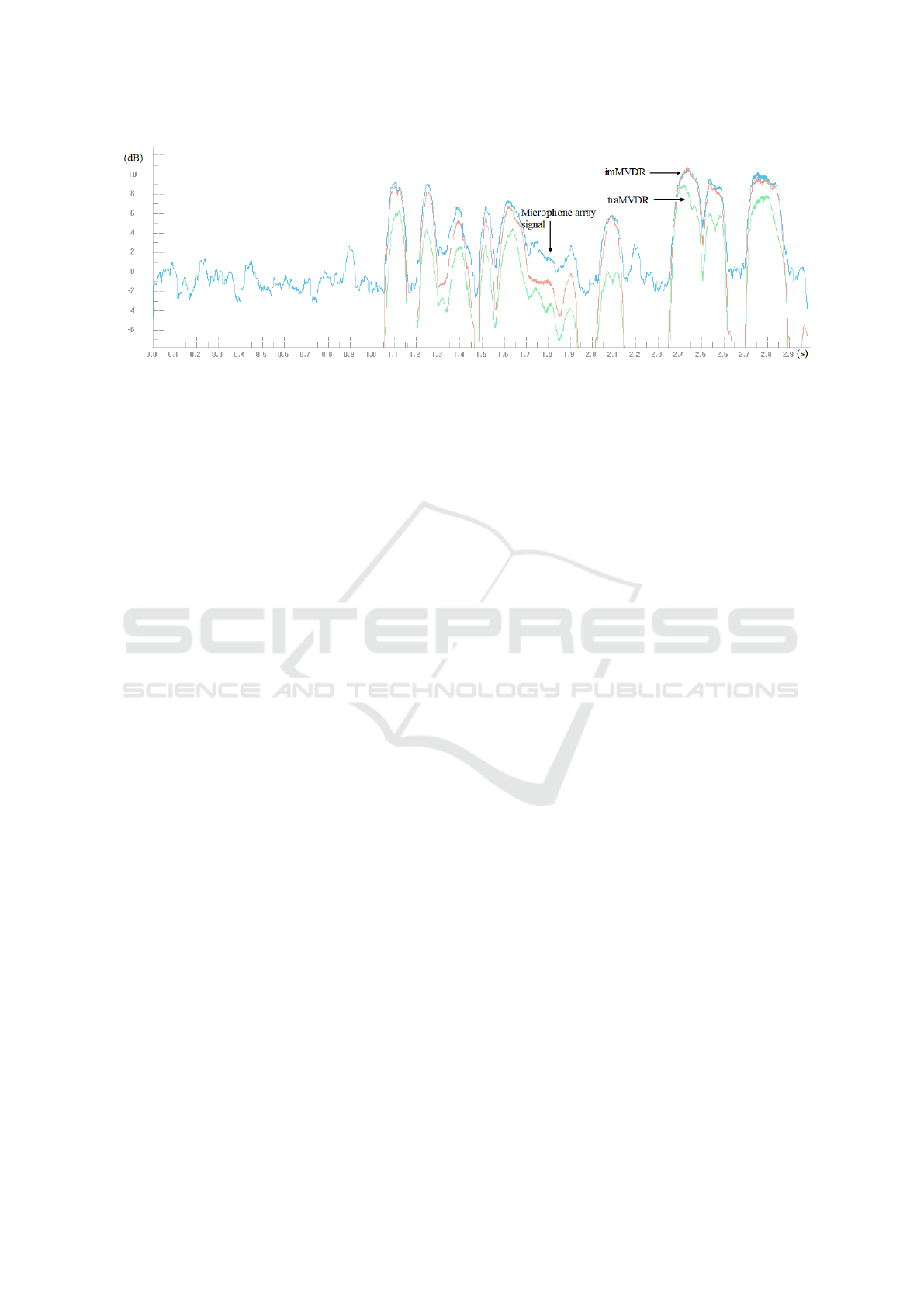
Figure 9: The illustrated energy of microphone array signal and traMVDR, imMVDR.
timation of speech presence probability can be more
applied into several approaches to enhance the perfor-
mance of speech enhancement system.
ACKNOWLEDGEMENTS
This research was supported supported by Digital
Agriculture Cooperative. The author thank our col-
leagues from Digital Agriculture Cooperative, who
provided insight and expertise that greatly assisted the
research.
REFERENCES
Ba, D. E., Florencio, D., and Zhang, C. (2007). Enhanced
MVDR Beamforming for Arrays of Directional Mi-
crophones. In 2007 IEEE International Conference
on Multimedia and Expo, pages 1307–1310. https:
//doi.org/10.1109/ICME.2007.4284898.
Benesty, J., Chen, J., and Huang, Y. (2008). Microphone
Array Signal Processing, volume 1 of Springer Top-
ics in Signal Processing. Springer Berlin, Heidelberg.
https://doi.org/10.1007/978-3-540-78612-2.
Benesty, J., Chen, J., and Pan, C. (2016). Fundamentals
of Differential Beamforming. SpringerBriefs in Elec-
trical and Computer Engineering. Springer Singapore.
https://doi.org/10.1007/978-981-10-1046-0.
Benesty, J., Cohen, I., and Chen, J. (2017). Fundamen-
tals of Signal Enhancement and Array Signal Process-
ing. John Wiley & Sons Singapore. https://doi.org/10.
1002/9781119293132.
Brandstein, M. and Ward, D., editors (2001). Microphone
Arrays: Signal Processing Techniques and Applica-
tions. Digital Signal Processing. Springer Berlin, Hei-
delberg. https://doi.org/10.1007/978-3-662-04619-7.
Chen, C.-Y. and Vaidyanathan, P. P. (2007). Quadratically
Constrained Beamforming Robust Against Direction-
of-Arrival Mismatch. IEEE Transactions on Sig-
nal Processing, 55(8):4139–4150. https://doi.org/10.
1109/TSP.2007.894402.
Ellis, D. (2011). Objective measures of speech qual-
ity/SNR. https://labrosa.ee.columbia.edu/projects/
snreval/.
Erdogan, H., Hershey, J. R., Watanabe, S., Mandel, M. I.,
and Roux, J. L. (2016). Improved MVDR Beam-
forming Using Single-Channel Mask Prediction Net-
works. In Proc. Interspeech 2016, pages 1981–1985.
https://doi.org/10.21437/Interspeech.2016-552.
Gannot, S., Burshtein, D., and Weinstein, E. (2001a). Signal
enhancement using beamforming and nonstationarity
with applications to speech. IEEE Transactions on
Signal Processing, 49(8):1614–1626. https://doi.org/
10.1109/78.934132.
Gannot, S., Burshtein, D., and Weinstein, E. (2001b). The-
oretical Performance Analysis of the General Trans-
fer Function GSC. In Proc. Int. Workshop Acous-
tic Echo Noise Control. https://www.eng.biu.ac.il/
∼
gannot/articles/Perf.pdf.
Gerkmann, T. and Hendriks, R. C. (2012a). Unbiased
MMSE-Based Noise Power Estimation With Low
Complexity and Low Tracking Delay. IEEE Trans-
actions on Audio, Speech, and Language Process-
ing, 20(4):1383–1393. https://doi.org/10.1109/TASL.
2011.2180896.
Gerkmann, T. and Hendriks, R. C. (2012b). Unbiased
MMSE-Based Noise Power Estimation With Low
Complexity and Low Tracking Delay. IEEE Trans-
actions on Audio, Speech, and Language Process-
ing, 20(4):1383–1393. https://doi.org/10.1109/TASL.
2011.2180896.
Lockwood, M. E., Jones, D. L., Bilger, R. C., Lansing,
C. R., O’Brien, W. D., Wheeler, B. C., and Feng, A. S.
(2004). Performance of time- and frequency-domain
binaural beamformers based on recorded signals from
real rooms. The Journal of the Acoustical Society of
America, 115(1):379–391. https://doi.org/10.1121/1.
1624064.
Lorenz, R. G. and Boyd, S. P. (2005). Robust minimum
variance beamforming. IEEE Transactions on Sig-
nal Processing, 53(5):1684–1696. https://doi.org/10.
1109/TSP.2005.845436.
Pan, C., Chen, J., and Benesty, J. (2014). On the noisere-
duction performance of the MVDR beamformer in-
noisy and reverberant environments. In 2014 IEEE
International Conference on Acoustics, Speech and
An Improved Diagonal Loading-Based Minimum Variance Distortionless Response Beamformer
25

Signal Processing (ICASSP), pages 815–819. https:
//doi.org/10.1109/ICASSP.2014.6853710.
Shahbazpanahi, S., Gershman, A., Luo, Z.-Q., and Wong,
K. M. (2003). Robust adaptive beamforming for
general-rank signal models. IEEE Transactions on
Signal Processing, 51(9):2257–2269. https://doi.org/
10.1109/TSP.2003.815395.
Vorobyov, S. A., Gershman, A. B., and Luo, Z.-Q. (2003).
Robust adaptive beamforming using worst-case per-
formance optimization: a solution to the signal mis-
match problem. IEEE Transactions on Signal Pro-
cessing, 51(2):313–324. https://doi.org/10.1109/TSP.
2002.806865.
Wu, S. Q. and Zhang, J. Y. (1999). A new robust beam-
forming method with antennae calibration errors. In
WCNC. 1999 IEEE Wireless Communications and
Networking Conference (Cat. No.99TH8466), vol-
ume 2, pages 869–872 vol.2. https://doi.org/10.1109/
WCNC.1999.796795.
Xiao, X., Zhao, S., Jones, D. L., Chng, E. S., and Li,
H. (2017a). On time-frequency mask estimation
for MVDR beamforming with application in robust
speech recognition. In 2017 IEEE International Con-
ference on Acoustics, Speech and Signal Processing
(ICASSP), pages 3246–3250. https://doi.org/10.1109/
ICASSP.2017.7952756.
Xiao, Y., Yin, J., Qi, H., Yin, H., and Hua, G. (2017b).
MVDR Algorithm Based on Estimated Diagonal
Loading for Beamforming. Mathematical Problems in
Engineering, 2017:7904356. https://doi.org/10.1155/
2017/7904356.
Zelinski, R. (1988). A microphone array with adaptive
post-filtering for noise reduction in reverberant rooms.
In ICASSP-88., International Conference on Acous-
tics, Speech, and Signal Processing, pages 2578–2581
vol.5. https://doi.org/10.1109/ICASSP.1988.197172.
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
26
